 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

¿Cómo conseguir una Inteligencia Artificial justa?
POR Daniel Sierra Ramos, Data Science Manager.
Alfonso Ibañez Martín, Head of Big Data Analytics.
La posibilidad de acceder a numerosas fuentes de información, así como con el auge de nuevas tecnologías de computación y almacenamiento han propiciado la impulsión del Machine Learning como respuesta a muchos de los problemas de nuestra sociedad, tanto de índole pública como privada.
La disciplina del Machine Learning procede de la Inteligencia Artificial y tiene como foco estudiar cómo los sistemas pueden ser programados para aprender y mejorar con la experiencia, sin intervención humana.
Durante los últimos años se ha avanzado mucho en la resolución de problemas complejos gracias técnicas que permiten descubrir patrones ocultos en los datos. Esto nos permite automatizar muchas decisiones que hasta ahora eran impensables, pero con el inconveniente de no tener en cuenta uno de los aspectos más relevantes para la toma de decisiones: el sesgo humano.
Los inevitables sesgos humanos
Existe una falsa creencia acerca de la objetividad de las estimaciones que arrojan los algoritmos de Machine Learning. Se piensa frecuentemente que los patrones presentes en los datos muestran un fiel reflejo del contexto en el que se generan y por eso no deberían ser objeto de modificaciones o alteraciones para corregirlos. Sin embargo, la propia generación de estos datos sea cual sea el ámbito, está plagada de sesgos humanos que son inevitables.
A modo de ejemplo, consideremos el sencillo caso de una entidad financiera que tiene un modelo para la concesión de créditos. El modelo simplemente estima si una persona va a devolver el préstamo o no, y en función de esto el banco otorga el crédito correspondiente (o no).
Para realizar esta estimación se emplean variables relativas a cada cliente como la antigüedad, la nómina o el número de productos contratados, entre otros. Supongamos que la entidad financiera decide medir cómo de justo es su modelo de concesión de créditos en cuanto al género. Los resultados de este análisis podrían reflejar que la proporción de hombres que reciben un crédito es mucho mayor que la proporción de mujeres, aun sabiendo que el género no debería ser un factor determinante en el riesgo de impago.
Con el objetivo de conseguir una Inteligencia Artificial justa que no refleje diferencias en aspectos de índole política, religiosa o sociodemográfica, entre otros, existen varias técnicas y criterios a la hora de paliar el sesgo en los datos y/o en los resultados de un modelo analítico.

Elementos que intervienen en el aprendizaje supervisado
Para ponernos en contexto es necesario establecer un marco común en el que identificar los diferentes elementos que intervienen en un algoritmo de Machine Learning de aprendizaje supervisado.
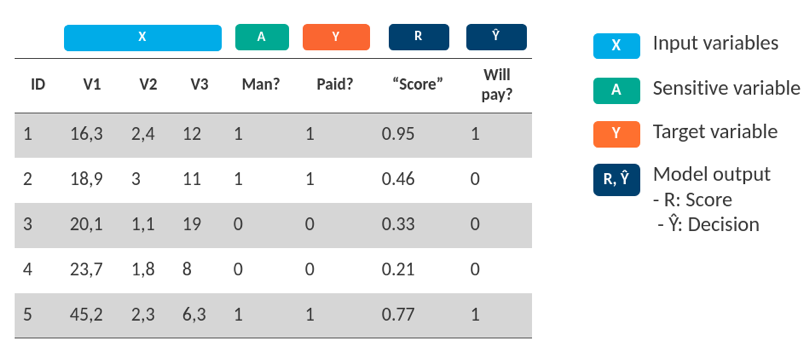
- Variables de entrada: Es el conjunto de variables predictoras empleadas en la construcción del modelo analítico. El propósito de un modelo de Machine Learning es encontrar relaciones entre este conjunto de variables y la variable objetivo.
- Variable objetivo: Es la variable sobre la que vamos a realizar estimaciones. Durante la fase de construcción del modelo, esta variable sirve para guiar el aprendizaje de los patrones históricos en los datos y que potencialmente se pueden repetir en el futuro.
- Variable sensible: Es el elemento esencial en el análisis de los sesgos en la Inteligencia Artificial justa. Esta variable, que puede encontrarse o no en el conjunto de variables de entrada, contiene la información relativa a la pertenencia o no de uno o varios grupos desfavorecidos. Un ejemplo sería la variable Género: Hombre/Mujer.
- Estimación: Son las estimaciones realizadas por el modelo, es decir, el resultado de aplicar el modelo analítico construido sobre nuevos datos. Típicamente, en un modelo de clasificación binaria, este resultado se compone de un score (puntuación de 0 a 1 de pertenecer a uno otro grupo objetivo) y una predicción (resultado binario extraído a partir del score y un umbral)
En el ejemplo de la concesión de créditos, cada uno de los elementos se puede representar en la siguiente tabla
Criterios de "fairness" en aprendizaje automático
Dentro de este contexto podemos enumerar tres criterios de análisis del fairness en machine learning. Cada uno de los siguientes criterios satisface un objetivo distinto y sólo se puede satisfacer uno a la vez. La elección del criterio de fairness estará supeditado a las necesidades de cada problema.
- Independencia: El criterio de independencia se cumple cuando la variable objetivo y la variable sensible son estadísticamente independientes. La proporción de hombres que reciben un crédito debe ser igual a la proporción de mujeres que reciben un crédito.
- Separación: También denominado equalized odds. El criterio de separación se cumple cuando la estimación y la variable sensible son condicionalmente independientes dada la variable objetivo. De la población que habría devuelto el crédito, la proporción de hombres que lo recibe debe ser igual a la proporción de mujeres que lo recibe.
- Suficiencia: También denominado predictive rate parity. El criterio de suficiencia se cumple cuando la variable objetivo y la variable sensible son condicionalmente independientes dada la estimación. De la población que recibe el crédito, la proporción de hombres que lo devuelve debe ser igual a la proporción de mujeres que lo devuelve.
Posibles técnicas correctivas
Para alcanzar dichos criterios, de forma independiente, existen numerosas técnicas correctivas que se pueden dividir en las siguientes categorías:
- Pre-Processing: Consisten en la transformación del conjunto de variables de entrada, que está sesgado, en otro conjunto no sesgado para la posterior generación del modelo analítico. Algunas de las técnicas más conocidas hacen uso de representation learning a través de Autoencoders para transformar el conjunto de variables de entrada X en un conjunto de variables de entrada Z que permita la elaboración de modelos analíticos capaces de paliar el efecto del sesgo sobre las variables sensibles.
- In-Processing: Consiste en la generación de un modelo analítico capaz de optimizar, no sólo la tasa de errores, sino también el fairness durante la fase de entrenamiento. Una de las técnicas empleadas en este contexto es la de Adversarial Debiasing, la cual consiste en la generación de un estimador capaz de maximizar la capacidad de predecir la variable objetivo a partir de las variables predictores (ML clásico) y a la vez de minimizar la capacidad de predecir la variable sensible a partir de las variables predictoras empleando GANs (Generative Adversarial Networks).
- Post-Processing: Consiste en la optimización y modificación de los resultados sesgados del modelo analítico para cumplir con alguno de los criterios del fairness. Una de las técnicas más empleadas en este contexto es la de la optimización del threshold de decisión del modelo analítico a partir de la curva ROC para lograr mitigar o eliminar los sesgos tras la obtención de los resultados.
Conclusión
En definitiva, existen numerosas herramientas que nos permiten cuantificar y corregir el sesgo humano presente en los algoritmos de Machine Learning.
Es necesario asegurar que las aplicaciones no conducen a sesgos e impactos discriminatorios por razón de la raza, el origen étnico, la religión, el sexo, la orientación sexual, la discapacidad o cualquier otra condición de las personas.




