 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Gonzalo Álvarez Marañón
Escritor, científico y conferenciante. Exembajador del Área de Innovación y Laboratorio de Telefónica Tech.
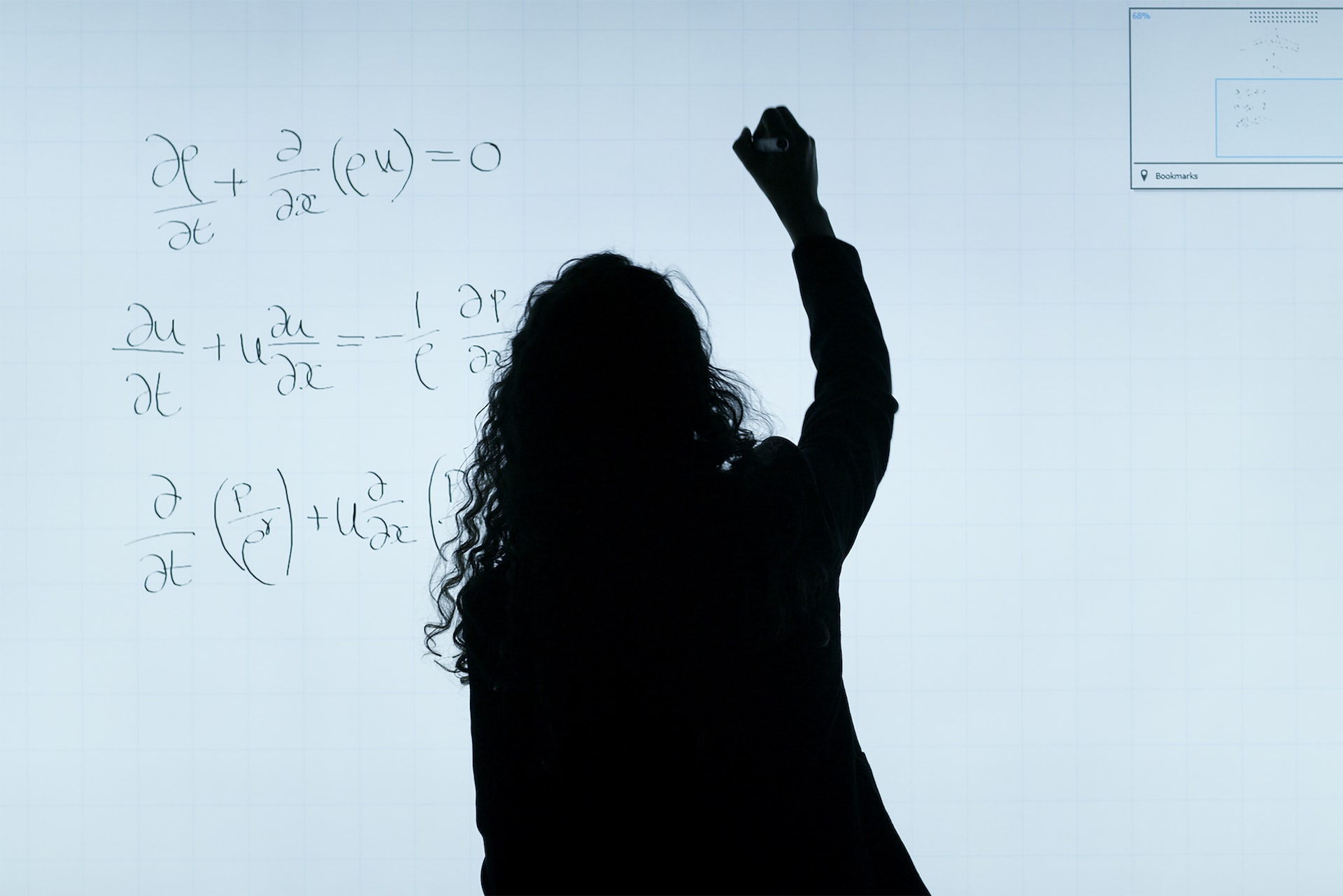
Matemáticas contra el cibercrimen: cómo detectar fraude, manipulaciones y ataques aplicando la Ley de Benford
A principios del siglo XX, cuando todavía no existían las calculadoras ni los ordenadores ni los móviles, los científicos e ingenieros recurrían para sus cálculos a tablas de logaritmos recopiladas en gruesos volúmenes. Por ejemplo, un atajo para multiplicar dos números grandes consiste en buscar sus logaritmos en las tablas, sumarlos (sumar es más fácil que multiplicar, ¿verdad?) y buscar finalmente en las tablas el antilogaritmo del resultado. En los años 30, el físico Frank Benford trabajaba como investigador en General Electric. Un buen día, Benford se percató de que las primeras páginas de los libros de logaritmos estaban más gastadas que las últimas. Este misterio sólo podía tener una explicación: sus colegas buscaban números que empezaban con dígitos pequeños con más frecuencia que los que empezaban con dígitos más grandes. [1] Como buen científico, se preguntó: ¿por qué sus compañeros y él mismo encontraban en su trabajo esa distribución de números? Intuitivamente pensamos que el primer dígito de cualquier número debería seguir una distribución uniforme, es decir, la probabilidad de que un número cualquiera empiece por 1, 2, 3, … Hasta el 9 debería ser la misma e igual a 1/9 = 11,111…%. ¡Pues no! La frecuencia de ocurrencia de dígitos Benford comprobó desconcertado cómo la frecuencia de ocurrencia de dígitos en los números de muchos fenómenos naturales sigue una distribución logarítmica. Intrigado por este descubrimiento, Benford tomó muestras de datos de varias fuentes (desde las longitudes de los ríos, hasta los censos de población) y observó que la probabilidad de que el primer dígito de un número cualquiera sea igual a d viene dada por la siguiente ley logarítmica: Pr( d ) = log( d + 1 ) – log( d ) = log ( ( d + 1 ) / d ) = log( 1 + 1 / d ) La siguiente tabla recoge todos los valores de P( d ) desde 1 hasta 9. Probabilidades (en porcentaje) del primer dígito significativo de números que siguen la Ley de Benford. En la página Testing Benford's Law encontrarás numerosos ejemplos de conjuntos de datos que siguen esta ley, como los números de seguidores en Twitter o la reputación de usuario en Stack Overflow. Captura de la página Testing Benford's Law. Por qué los dígitos forman esta distribución La explicación de por qué forman esta distribución es (relativamente) sencilla. Fíjate en la siguiente barra de escala logarítmica. Si escoges puntos aleatoriamente en esta barra, el 30,1% de los valores caerán entre 1 y 2; el 17,6% caerán entre 2 y 3; y así sucesivamente, hasta encontrar que sólo el 4,6% de los valores caerán entre 9 y 10. Por consiguiente, en una serie numérica que siga una distribución logarítmica, habrá más números que empiecen por 1 que por otro dígito mayor (2, 3, …), habrá más números que empiecen por 2 que por otro dígito mayor (3,4, …), y así sucesivamente. Barra de escala logarítmica. Pero no vamos a detenernos aquí, ¿verdad? La siguiente pregunta interesante que surge es: ¿cómo se pueden identificar los conjuntos de datos que normalmente se ajustan a la Ley de Benford? Para entender la respuesta, necesitamos viajar con la imaginación a dos países bien distintos: Mediocristán y Extremistán. AI OF THINGS Mujeres que cambiaron las Matemáticas 9 de marzo de 2023 En Extremistán, la ley de Benford 'rules' Si pones en fila a todos los empleados de tu organización y mides sus alturas, obtendrás una distribución normal: la mayoría de la gente tendrá una altura media; algunos pocos serán más bien altos y otros, más bien bajos; y un par de personas serán altísimas y otro par, bajísimas. Si un empleado llega tarde a la sesión de medición, cuando sumemos su altura al resto no alterará significativamente la media del grupo, con independencia de lo alto o bajo que sea. Si en vez de medir la altura registras el peso o las calorías consumidas cada día o el número de calzado, obtendrás resultados similares. En todos los casos, obtendrás una curva similar a la siguiente. Distribución normal Aprovechando que los tienes a todos reunidos, podrías anotar a continuación el patrimonio de cada uno. ¡Qué diferencia! Ahora la mayoría poseerá un capital total más bien exiguo, un grupo mucho menor habrá acumulado un capital decente, un pequeño grupo poseerá una pequeña fortuna y unos poquísimos disfrutarán de fortunas escandalosas. Y si el consejero delegado llega tarde y añadimos su patrimonio al del grupo, su impacto posiblemente será brutal en la media. Ya puestos, si mides el número de seguidores en Instagram de tus compañeros y hay alguna celebrity entre ellos, obtendrás resultados similares. Representados gráficamente, todos estos resultados tendrán una forma similar a la siguiente. Distribución potencial Como ves, no todas las distribuciones aleatorias son iguales. De hecho, existe una gran variedad entre ellas. Podríamos agruparlas en dos grandes categorías: las que siguen distribuciones (aproximadamente) normales y las que siguen distribuciones (aproximadamente) potenciales. Nicholas Nassim Taleb las describe muy gráficamente en su famoso libro El cisne negro como dos países: Mediocristán, donde los sucesos individuales no aportan mucho considerados de uno en uno, sino solo de forma colectiva; Extremistán, donde las desigualdades son tales que una única observación puede influir de forma desproporcionada en el total. Así que respondiendo a la pregunta de qué conjuntos de datos se ajustan a la Ley de Benford, claramente hablamos de datos en el país de Extremistán: grandes conjuntos de datos que comprenden múltiples órdenes de magnitud en los valores y que presentan invariancia de escala. Este último concepto significa que puedes medir tus datos usando un rango de diferentes escalas: pies/metros, euros/dólares, galones/mililitros, etc. Si la Ley de frecuencia de dígitos es verdadera, debe serlo para todas las escalas. No hay ninguna razón por la que sólo una escala de medición, la que eliges por casualidad, debería ser la correcta. Un par de restricciones adicionales para que un conjunto de datos siga la Ley de Benford son que estén constituidos por números positivos, que estén libres de valores mínimos o máximos, que no estén compuestos de números asignados (como los números de teléfono o los códigos postales) y que los datos sean transaccionales (ventas, reembolsos, etc.). En estas condiciones, es posible, aunque no necesario, que el conjunto de datos siga esta ley. Vale, tienes un conjunto de datos que se ajusta perfectamente a la ley de Benford. ¿Y de qué te sirve? Pues te sirve por ejemplo para detectar fraudes, manipulaciones y ataques de red. Veamos cómo. CYBER SECURITY Inteligencia Artificial, ChatGPT y Ciberseguridad 15 de febrero de 2023 Cómo aplicar la Ley de Benford contra el cibercrimen El pionero de la aplicación de la Ley de Benford para la lucha contra el fraude fue Mark Nigrini, quien relata en su libro Benford's Law: Applications for Forensic Accounting, Auditing, and Fraud Detection multitud de ejemplos fascinantes de cómo pilló a los defraudadores y timadores. Nigrini explica, por ejemplo, que muchos aspectos de las cuentas financieras siguen la Ley de Benford, como por ejemplo: Reclamaciones de gastos Transacciones con tarjeta de crédito Pedidos Préstamos Saldos de clientes Asientos de diario Precios de las acciones Precios de inventario Reembolsos de clientes Etc. Propone tests especiales, que llama análisis digital, para detectar datos fraudulentos o erróneos que se desvían de la ley cuando han sido fabricados. Encontré especialmente revelador cómo desenmascara esquemas Ponzi como el timo Madoff por culpa de los resultados financieros que, al ser inventados, no seguían la Ley de Benford y hacían saltar todas las alarmas. El método no es infalible, pero funciona tan bien que estos tests han sido integrados en los programas de auditoría utilizados por los auditores de cuentas, como Caseware IDEA o ACL. Pantallazo del análisis de Benford del programa Caseware IDEA. En otro trabajo, los autores demostraron que las imágenes en el dominio de la Transformada Coseno Discreta (DCT) siguen de cerca una generalización de la Ley de Benford y usaron esta propiedad para el estegoanálisis de imágenes, es decir, para detectar si una imagen dada lleva un mensaje oculto. La Ley de Benford también puede usarse para detectar anomalías en: Datos económicos y sociales recogidos en encuestas. Datos de procesos electorales. Transacciones de divisas con criptomonedas. Dinámica de pulsaciones de teclado de diferentes usuarios. Detectar errores o manipulaciones de datos de descubrimiento de fármacos. En Benford Online Bibliography encontrarás una base de datos no comercial de acceso abierto de artículos, libros y otros recursos relacionados con la Ley de Benford. Otro caso de uso de la ley de Benford es la detección de anomalías de tráfico de Internet, como ataques DDoS. Se sabe desde hace muchos años que los tiempos entre llegadas de paquetes exhiben una distribución potencial, que sigue la ley de Benford. Por el contrario, los ataques DDoS, por el hecho de ser ataques de inundación, rompen cualquier normalidad de comportamiento de tráfico en una red. En concreto, los tiempos entre llegadas de paquetes no son lo suficientemente largos y aparecen como desviaciones notables de la Ley de Benford, como puede apreciarse en la siguiente figura: Análisis de Benford de los tiempos entre llegadas de paquetes que revela cuatro ataques de DoS. Lo mejor de este método de detección de ataques DDoS basado en anomalías es que, a diferencia de otros enfoques, «no requiere ningún aprendizaje, ninguna inspección profunda de paquetes, es difícil de engañar y funciona incluso aunque el contenido de los paquetes esté cifrado». El futuro de la ley de Benford en la Ciberseguridad Biometría, estegoanálisis, fraude, ataques de red,… El mundo de la Ciberseguridad está empezando a incorporar el análisis de distribución de probabilidad de leyes logarítmicas con resultados muy prometedores. Se trata de una técnica flexible, no consume apenas recursos, rapidísima y no requiere ningún tipo de entrenamiento. Exige, eso sí, que el conjunto de datos normal cumpla las condiciones suficientes para ajustarse a la Ley de Benford. La próxima vez que te enfrentes a un conjunto de datos, pregúntate si el primer dígito de cada número sigue la Ley de Benford. Tal vez encuentres anomalías inesperadas. ______ [1] En realidad, esta misma observación fue realizada en 1881 por el astrónomo y matemático Simon Newcomb. Publicó un artículo al respecto, pero pasó desapercibido. Foto de apertura: This is Engineering RAEng / Unsplash
16 de marzo de 2023

Recupera el control de tus datos personales gracias a la Identidad Descentralizada sobre Blockchain
Apuesto a que, cuando tenías 18 años, en alguna ocasión te pidieron el carné de identidad en una discoteca o despacho de alcohol para verificar si eras mayor de edad. ¿Te paraste a pensar en la cantidad desmesurada de información que revelabas solo por mostrar tu DNI? Tu fecha de nacimiento, no solo si eres mayor de edad. Tu lugar de nacimiento. Tu lugar de residencia. Tu nombre y apellidos. El nombre de tus padres. Tu número de DNI. No está mal para responder a una sencilla pregunta binaria: ¿eres o no mayor de edad? El problema es que en pleno siglo XXI arrastramos un sistema de identidad del siglo XIX. La presentación de las credenciales y su verificación se realiza en el mismo documento: el DNI, el título universitario, la nómina… Y cuando presentas este documento a un tercero para que verifique alguna de tus afirmaciones ("soy mayor de edad", "tengo el título de ingeniero", "gano suficiente para pagarte la renta"), puede hacerse con toda la información del documento y guardarla para siempre. ¡Pierdes el control de tu información personal! Hoy nuestra vida es digital. En nuestras interacciones en el mundo físico y online vamos dejando un reguero de datos personales. Cada vez que nos registramos en todo tipo de servicios introducimos una y otra vez los mismos datos. Y una vez cedidos, ya no hay marcha atrás. Los sistemas de identidad actuales están centralizados, no son portables ni confiables y te arrebatan el control de tus propios datos. Como consecuencia, nuestra identidad digital en Internet aparece fragmentada en multitud de apps y servicios y totalmente fuera de nuestro control. ¿Y si se produce una brecha de datos tras un ciberataque con éxito a uno de la infinidad de servidores que los almacena? Tus datos personales acabarán en las garras de cualquier cibercriminal, quien los venderá al mejor postor. En los últimos años están ganando tracción las credenciales verificables y los identificadores descentralizados para compartir tus datos personales sin renunciar a tu privacidad. Gracias a las soluciones de "Identidad Descentralizada! (o "Identidad Auto-Soberana"), ninguna empresa ni institución controla o almacena tu información de forma centralizada: puedes revocar tus credenciales verificables en cualquier momento, manteniendo tus datos siempre bajo tu control. Tú decides quién y cómo usa tus datos. En este artículo te explicaré cómo funcionan y qué pasos se están dando para acelerar la adopción de la identidad descentralizada en el mundo. ¿Qué es la identidad digital? Sin ponernos muy filosóficos, lo cierto es que en primer lugar debemos abordar esta espinosa cuestión: ¿qué es la identidad digital? En 2005, en un trabajo pionero y de absoluta vigencia, el ingeniero de Microsoft Kim Cameron la definió de la siguiente manera: Un conjunto de afirmaciones realizadas por un sujeto digital sobre sí mismo o sobre otro sujeto digital. ¿Y qué es un sujeto digital? Según Cameron, es "una persona o cosa representada o existente en el ámbito digital que se describe o trata". De manera que, además de a nosotros los humanos, esta definición comprende a todo tipo de máquinas y dispositivos, recursos digitales e incluso políticas y relaciones entre todos ellos. ¿Y una afirmación? Se trata de "una declaración sobre la verdad de algo, típicamente discutida o en duda". Por ejemplo, que una persona es mayor de edad, que posee el título de ingeniero, que ingresa más de una cierta cantidad de dinero o que conoce la contraseña para autenticarse ante un servicio remoto. Esta definición de identidad digital separa limpiamente la presentación de afirmaciones de la verificación de su vínculo con un objeto del mundo real. ¿Y qué características debe poseer un sistema de identidad digital para llegar a ser universalmente aceptable y duradero? Según el propio Kim Cameron, debería cumplir las siguientes Siete Leyes de la Identidad Digital: Control y consentimiento del usuario: los sistemas técnicos de identidad sólo deben revelar la información que identifica a un usuario con el consentimiento de éste. Divulgación mínima para un uso restringido: la solución que revela la menor cantidad de información identificable y limita mejor su uso es la más estable a largo plazo. Partes justificadas: la divulgación de información identificable debe limitarse a las partes que ocupan un lugar necesario y justificable en una determinada relación de identidad. Identidad dirigida: un sistema de identidad universal debe admitir tanto identificadores «omnidireccionales» para su uso por parte de entidades públicas (p.e. un servidor web) como identificadores «unidireccionales» para su uso por parte de entidades privadas (p.e. un token de sesión entre un visitante y ese sitio web), facilitando así el descubrimiento y evitando la liberación innecesaria de información correlacionable. Pluralismo de operadores y tecnologías: un sistema de identidad universal debe canalizar y permitir la interoperación de múltiples tecnologías de identidad gestionadas por múltiples proveedores de identidad. Integración humana: el metasistema de identidad universal debe definir al usuario humano como un componente del sistema distribuido integrado a través de mecanismos de comunicación hombre-máquina sin ambigüedad que ofrezcan protección contra los ataques a la identidad. Experiencia coherente en todos los contextos: el metasistema de identidad unificador debe garantizar a sus usuarios una experiencia sencilla y coherente, al tiempo que permite la separación de contextos a través de múltiples operadores y tecnologías. Los sistemas actuales de identidad no cumplen estas leyes. Pero se está trabajando en nuevas propuestas de identidad digital, basadas en Credenciales Verificables, en Blockchain y en algunas tecnologías más. Repasémoslas. Las Credenciales Verificables En primer lugar, para operar una identidad digital según las leyes de Cameron, se requiere un sistema de almacenamiento e intercambio de credenciales estandarizado, que permita portar al mundo online las credenciales tradicionalmente usadas en el mundo offline: DNI, pasaporte, titulaciones, licencias, títulos de propiedad, información médica, datos fiscales, etc. El W3C lleva trabajando desde 2017 en el Modelo de Datos de Credenciales Verificables. Esta especificación proporciona «un mecanismo para expresar este tipo de credenciales en la web de manera criptográficamente segura, respetando la privacidad y verificable por máquinas». En el mundo físico, una credencial contiene como mínimo: Información que identifica al sujeto de la credencial: foto, nombre, número de DNI, etc. Información que identifica a su emisor: estado, universidad, banco, etc. Información sobre el tipo de credencial: pasaporte, carné de conducir, tarjeta sanitaria, diploma, etc. Los atributos o las propiedades específicas que se afirman: lugar de nacimiento, tipo de vehículo que puede conducir, titulación expedida, etc. Evidencia sobre cómo se derivó la credencial. Información sobre las restricciones de la identidad: fecha de caducidad, términos de uso, etc. Una credencial verificable no solo puede representar la misma información que una credencial física, sino que, además, gracias a la adición de tecnologías como las firmas digitales, los intentos de manipulación se vuelven más evidentes, por lo que resultan más fiables que sus homólogas físicas. Si necesitas compartir información con otra identidad digital, puedes generar una presentación verificable solamente de los datos personales que tú elijas. Luego muestras esta presentación verificable al verificador para demostrar que posees credenciales verificables con las características que afirmas poseer. Tanto las credenciales verificables como las presentaciones verificables pueden transmitirse rápidamente, lo que las hace más convenientes que sus homólogas físicas cuando se trata de establecer la confianza a través de Internet. Un elemento clave de este sistema son los Identificadores Descentralizados (DID): un nuevo tipo de identificador único global, diseñados para que personas y organizaciones puedan generar sus propios identificadores utilizando sistemas en los que confían. Estos nuevos identificadores permiten a las entidades demostrar el control sobre ellos mediante la autenticación con pruebas criptográficas como las firmas digitales. Sus objetivos de diseño son: descentralizados, controlados por el usuario, privados, seguros, basados en pruebas criptográficas, descubribles, interoperables, portables, simples y extensibles. La cuestión que surge a continuación es: ¿cómo se almacenan de forma segura? Identidad descentralizada sobre Blockchain Actualmente, tu información personal está desperdigada por miles de servidores, fuera de tu control: pueden desaparecer y llevarse con ellos tu información; pueden ser atacados y tu información, divulgada; pueden comerciar con tus datos sin tu consentimiento; pueden negarte el acceso futuro o cambiar los términos de uso. Tus datos ya no te pertenecen. El objetivo fundamental de la Identidad Auto-Soberana es que tú poseas y controles toda la información sobre ti, garantizando tu privacidad. Es decir, buscamos un sistema descentralizado (no está controlado por ninguna organización ni oligopolio), transparente (toda la información está visible por todo el mundo) e inmutable (nadie puede alterar la información almacenada). Estos requisitos te habrán hecho pensar inmediatamente en Blockchain: actúa como un libro de contabilidad distribuido y abierto a cualquiera para leer y escribir con la propiedad de que una vez que un bloque se ha añadido a la cadena de bloques es muy difícil (idealmente imposible) cambiarlo. La identidad descentralizada funciona de forma similar a una criptodivisa: creas una pareja de claves pública y privada en una cartera de identidad (identity wallet). Tu cartera calcula el hash de tu clave pública (tu identificador) y lo almacena de forma inmutable en una cadena de bloques. Tú creas, posees y controlas estos identificadores descentralizados, independientemente de cualquier organización o gobierno. Además, tu cartera actúa como interfaz con la cadena de bloques y con otros actores, de manera que te resulte tan sencillo trabajar con tus identidades como usar Instagram. Mientras controles las claves criptográficas vinculadas a tu identidad descentralizada, conservarás el control. ¿Y qué pasa con tus datos? ¿Se almacenan en la cadena de bloques, a la vista de todo el mundo? ¡No! Tus credenciales con sus afirmaciones se guardan en un Hub de Identidad: una red de almacenes de datos distribuidos y replicados, por la nube (cloud) y por el borde (edge), en smartphones, laptops, altavoces inteligentes, … donde tú elijas. Por ejemplo, si completas tus estudios en una Universidad, ésta te emitirá un diploma asociado a tu identidad, con toda su información cumpliendo con el estándar de las credenciales verificables. Puedes almacenar esta información en tu Hub de Identidad. Si más adelante necesitas probar ante un empleador que posees el título, bastará con que crees una presentación verificable de tus credenciales, la cual podrá ser independientemente verificada por el empleador. Ilustración 1. Funcionamiento esquemático de un sistema de identidad descentralizada. ¿Quién está trabajando en la Identidad Descentralizada? El grupo de trabajo más activo sobre identidad auto-soberana es la Decentralized Identity Foundation (DIF). Aglutina a los principales actores del panorama actual y a sus iniciativas más destacadas. Si quieres aprender más sobre este tema, sin duda es tu primer destino. Uno de estos actores es Microsoft, quien sorprendió a propios y ajenos cuando en 2017 anunció ION (Identity Overlay Network: una red de Identificadores Descentralizados que se ejecuta sobre la blockchain de Bitcoin. Está trabajando muy duramente por hacer penetrar en el mercado la identidad descentralizada, tal y como relatan en su sitio web sobre identidad. Otra compañía muy relevante que ha apostado por la identidad descentralizada es IBM, con su iniciativa llamada Verify Credentials. En Europa, el trabajo de referencia es el European Self-Sovereign Identity Framework (ESSIF), uno de los casos de uso más destacados de la European Blockchain Services Infrastructure (EBSI). Por supuesto, otras muchas iniciativas públicas y privadas se están sumando a este movimiento por todo el mundo: Hyperledger Indy/Aries, ID2020, Sovrin, Civic, Serto o Bloom, por citar algunas. El futuro de la Identidad Descentralizada Nuestras identidades no son algo que deba gestionar un intermediario. Deberían ser gestionadas por cada uno de nosotros, bajo nuestro completo control, preservando por defecto nuestra privacidad y nuestra seguridad. Gracias a la identidad digital descentralizada, los usuarios podremos controlar nuestra identidad digital online por primera vez desde el nacimiento de Internet. Más aún, millones de personas, hoy carentes de identidad digital debido a las limitaciones de nuestras infraestructuras de autenticación, podrán acceder mediante la identidad auto-soberana a servicios financieros, educativos y sociales y disfrutar de derechos que hasta ahora les son inaccesibles. La historia sobre la Identidad Descentralizada aún se está escribiendo. Te he presentado a varios protagonistas y las primeras escenas del drama, pero el desenlace aún queda lejos. En un mundo cada vez más descentralizado, encaminado hacia la confianza cero, la identidad es el último reto por superar.
18 de mayo de 2021

El futuro de las credenciales universitarias apunta hacia Blockchain y Open Badges
¿Quieres un título universitario en 48 h y sin abrir un libro, por menos de 1.000€? No hay problema. No hace falta ni acudir a la Darknet. Busca en Google “comprar título universitario falso” o “fake diplomas market” y encontrarás docenas de proveedores que te garantizan una réplica del título de la carrera y universidad que elijas, por un módico precio, variable en función del prestigio buscado. Incluso pueden falsificarte títulos expedidos por universidades ficticias, algunas tan ilustres como la de Miskatonic. Todo vale porque su vocación de servicio es “ayudarte a encontrar un empleo de más calidad y más rápido”. ¿Y por qué no las cierra la Policía? Porque no es delito venderlos, sino utilizarlos. Así las cosas, la falsedad documental en el ámbito educativo se está convirtiendo en una verdadera lacra social y económica. Es trivial poner cualquier cosa en un CV y muy barato respaldarlo con un título falso, pero muy costoso verificarlo. Por eso, la mayoría de los reclutadores de talento ni se molestan en intentarlo y se lo tragan todo. ¡Necesitamos algo mejor que los títulos y diplomas en papel! Las credenciales digitales representan la evolución natural de las credenciales tradicionales para eliminar el fraude. Pero no vale un PDF con una firma digital. Permitir un intercambio ágil y seguro de credenciales que facilite el proceso de verificación y contratación exige protección criptográfica mucho más sofisticada. Se necesita reconciliar dos tecnologías: Credenciales más allá de los títulos académicos expedidos por instituciones educativas tradicionales: contemplarán todo tipo de conocimientos, habilidades y capacidades que reflejen los logros de aprendizaje de un individuo a lo largo de su vida. Además, todo ello irá encapsulado digitalmente usando un vocabulario estándar para describir dichos logros académicos, universalmente reconocido y fácilmente intercambiable. Un sistema de almacenamiento de las credenciales digitales que sea transparente, inmutable, infalsificable y públicamente accesible, para contar la historia académica de forma segura y verificable por cualquiera. Hmmmm, ¿a qué huelen estos dos requisitos? Cada vez más gente cree que a Open Badges y Blockchain. ¿Qué son y cómo resolverían juntas las limitaciones de los títulos actuales? Open Badges, un formato de credencial digital verificable, portátil y repleto de información sobre habilidades y logros Para entender la razón de ser de Open Badges, primero es importante comprender las limitaciones de los títulos, diplomas y certificaciones actuales: Los títulos tradicionales, como el de “Ingeniero Superior de Telecomunicación”, no dicen mucho acerca de los conocimientos, habilidades y capacidades específicas de su propietario. “Vale, sí, Fulanito tiene el título de ingeniero pero ¿posee habilidades avanzadas de programación en Python?, ¿posee la capacidad de dirigir un proyecto de securización de una red corporativa?, ¿posee algún conocimiento práctico sobre la ISO 27001?”. Los títulos carecen de la granularidad requerida por el mercado laboral actual. Cuentan una historia incompleta sobre quien los ostenta, sin mencionar que muchas carreras y programas están claramente obsoletos. Hay educación fuera del jardín amurallado de la Universidad. Existe una descomunal oferta de formación no reglada servida actualmente por una miríada de plataformas de e-learning, con propuestas de verdadera calidad, pero no es fácil validar los conocimientos y habilidades adquiridos, lo que dificulta su reconocimiento y comparación. Existen otros muchos lugares donde aprender más allá de la universidad y de las escuelas de negocio y de los cursos online: talleres, autoaprendizaje, proyectos personales o comunitarios, el puesto de trabajo… ¿Cómo hacer visibles y relevantes los conocimientos y habilidades así adquiridos en términos que sean reconocidos por las instituciones educativas formales y por los ecosistemas de formación y carreras profesionales? El mercado actual requiere un sistema de credenciales capaz de capturar conocimientos, habilidades y competencias de forma granular, en muchos contextos diferentes, y asociarlos con tu identidad digital, y que puedan mostrarse a las partes interesadas para demostrar tus capacidades. Estas credenciales deberían permitir conectar el aprendizaje a través de contextos de aprendizaje formales e informales, permitiendo a cada persona elaborar sus propios itinerarios de aprendizaje, a su propio ritmo, basándose en sus propios intereses y estilos de aprendizaje. Las insignias (badges) son la solución propuesta para responder a todos estos requisitos. Una insignia puede representar una microcredencial, pero también cualquier otro tipo de credencial, incluyendo títulos oficiales y certificaciones de fabricantes. Sin duda, la iniciativa más avanzada y prometedora en esta línea es el proyecto Open Badges, impulsado inicialmente por la Fundación Mozilla y actualmente bajo el liderazgo de IMS Global Learning Consortium. En esencia, una Insignia Abierta ("open badge") es un formato estandarizado y abierto para representar credenciales educativas, verificables y compartibles, con información detallada sobre el logro y lo que el propietario hizo para obtenerla. Muchos sistemas de gestión de aprendizaje (Learning Management System, LMS) ya las incorporan de forma nativa. De hecho, las insignias abiertas pueden coexistir a la perfección con las cualificaciones tradicionales y la acreditación profesional, ya que los complementan (o pueden llegar a reemplazarlos), con la ventaja de permitir la portabilidad de habilidades y conocimientos. Cada Insignia Abierta podrá comunicar una cualificación, habilidad o logro proporcionando un símbolo visual con datos y pruebas verificables que pueden compartirse digitalmente para facilitar el acceso al empleo y a nuevos ciclos de aprendizaje. Para salvaguardar el valor de cada Insignia Abierta, deberán cumplirse una serie de criterios: nombre de la organización emisora, requisitos para obtenerla, criterios de evaluación, fecha de emisión, etc. Ilustración 1. Ejemplo de Insignia Abierta. Las Insignias Abiertas pueden ser emitidas, obtenidas y gestionadas utilizando una de las muchas plataformas certificadas de Insignias Abiertas. Las partes interesadas pueden confiar en que una Insignia Abierta representa un logro legítimo y autenticado, cuya naturaleza se describe en la propia insignia, que también está vinculada a la organización emisora. Las Insignias Abiertas son verificables, de modo que un empleador puede confirmar el emisor de la credencial y su caducidad, si procede. En resumen, las Insignias Abiertas proporcionan las siguientes ventajas frente al sistema tradicional de credenciales: Menor fraude. Mayor facilidad para listar y encontrar competencias. Registro permanente sin temor a la pérdida o dependencia del emisor. Una imagen más detallada y dinámica que un CV tradicional. Sin embargo, un escollo que se encontraron las Insignias Abiertas en sus inicios fue cómo almacenarlas y compartirlas de manera segura. Y aquí es donde entra en escena el segundo protagonista de esta historia. Cuando Open Badges y Blockchain se unen son como la leche y el cacao en polvo En pocas palabras, una cadena de bloques actúa como un libro de contabilidad distribuido y abierto a cualquiera para leer y escribir con la propiedad de que una vez que un bloque se ha añadido a la cadena de bloques es muy difícil (idealmente imposible) cambiarlo. Para más información sobre Blockchain, te recomiendo leer The CIO’s Guide to Blockchain. Almacenar las insignias en una Blockchain presenta numerosas ventajas: El estudiante toma el control de sus logros académicos oficiales (titulaciones y diplomas), en lugar de recaer exclusivamente en las manos de las instituciones expendedoras. La educación no termina con la formación reglada. Las insignias en una blockchain permiten al estudiante añadir todo tipo de credenciales fuera de los muros académicos, algunas que nada tienen que ver con la formación propiamente dicha, como experiencia laboral validada por el empleador. Open Badges + Blockchain = Credenciales de Confianza. Se eliminan todos los intermediarios, ya que las credenciales están firmadas por la institución que las expide y cualquiera puede verificar su validez. A diferencia de una página web alojada en algún servidor institucional, Blockchian ofrece permanencia e inmutabilidad: tienes la garantía de que los datos ni desaparecerán (mientras quede un nodo en la red P2P) ni serán modificados, pase lo que pase con la entidad que los expidió. Desaparece el fraude. En Telefónica ya contamos con un producto propio que ofrece Open Badges sobre Blockchain como parte de su solución. Se trata de TrustOS, el sistema operativo de la confianza y facilitador de Blockchain para empresas. A través de la plataforma de certificación de TrustOS, se puede registrar cualquier hecho, acción o documento como un certificado digital verificable, de una manera rápida y sencilla. Más allá de logros académicos, se está utilizando para garantizar condiciones de calidad y seguridad en procesos empresariales, acuerdos de confidencialidad firmados entre varias partes, o el origen y autenticidad de un producto, entre otros muchos casos de uso Encontramos también otros proyectos que ofrecen servicios similares, entre los que destacan: Blockcerts: en 2016, el Media Lab del MIT propuso un estándar abierto a prueba de manipulaciones para la escritura de credenciales en Blockchain, llamado Blockcerts, que permite comprobar y verificar las credenciales y su interoperabilidad con otros sistemas. Como no podía ser menos, el MIT lo ha incorporado a sus diplomas digitales. EKO: la plataforma EKO Blockchain es un servicio público de cadena de bloques construido sobre Ethereum. Es totalmente compatible con los contratos inteligentes Solidity basados en EVM y ofrece algunas características innovadoras, como los contratos confidenciales. Accredible: si prefieres que te lo den todo hecho, Accredible se ofrece como SaaS, incluyendo funciones como creación y gestión de credenciales, potenciación de marca, integración con los principales LMS, analítica completa y herramientas nativas para incluir las credenciales fácilmente en cualquier canal. OpenBlockchain: se trata de una iniciativa del Knowledge Media Institute (KMI) de la Open University del Reino Unido, con varias experiencias realizadas con credenciales digitales. Bestr: es la plataforma italiana de credenciales digitales, implementada sobre Blockcerts. Hacia un sistema de credenciales abierto, transparente, descentralizado, permanente, inmutable y verificable El mercado de las credenciales digitales está en plena efervescencia: se están explorando nuevas tecnologías y estándares, aparecen nuevas propuestas comerciales o abiertas, muchas instituciones educativas experimentan con distintas alternativas. La combinación de insignias abiertas y Blockchain permite sistemas de credenciales digitales que podrían evitar el fraude, abrir nuevas perspectivas sobre el modo en que se utilizan las credenciales y ofrecer nuevos mecanismos para que las comunidades compartan conocimientos. Pero el verdadero desafío no es tecnológico sino político. Será necesario un esfuerzo concertado para garantizar que los estándares de los sistemas de credenciales digitales sean abiertos y atiendan a las necesidades de todos los implicados (alumnos, instituciones educativas, empleadores y gobiernos), sin priorizar los intereses de unas organizaciones sobre otras. El futuro de las credenciales digitales verificables está por escribir. Estos son solo los primeros renglones.
4 de mayo de 2021

Desenmarañando el enredo cuántico de la ciberseguridad: ordenadores cuánticos, criptografía cuántica y post-cuántica
¿Sabes cuál es la diferencia entre la computación cuántica, la criptografía cuántica y la criptografía post-cuántica? Porque la verdad, no tienen (casi) nada que ver entre ellas. Son términos que aparecen continuamente enredados en conversaciones sobre ciberseguridad. En este artículo te contaré lo que todo CIO/CISO debería saber sobre estos tres términos para participar en la conversación sin meter la pata ni que le cuelen goles. ¡Vamos a desenmarañar este enredo cuántico! Ordenadores cuánticos y el poder del paralelismo masivo Empecemos con la computación cuántica. Como todos sabemos, los ordenadores clásicos utilizan fenómenos físicos clásicos para representar bits: una corriente eléctrica que pasa o que no pasa por un transistor, un dipolo magnético orientado hacia arriba o hacia abajo, un disco de plástico con agujeritos o sin agujeritos al alcance de un haz láser, y así sucesivamente. Son estados bien definidos, que permiten representar sin ambigüedad unos y ceros: un uno es un uno y un cero es un cero. Por el contrario, los ordenadores cuánticos utilizan partículas cuánticas, como fotones o electrones, para representar bits cuánticos o qubits. Y aquí irrumpe el asombro: un qubit puede encontrarse a la vez en estado cero o en estado uno o en todos los estados intermedios entre cero y uno. Esta sorprendente propiedad de la física cuántica, conocida como superposición de estados, permite realizar cálculos masivos en paralelo. Por ejemplo, imagina que quieres calcular los resultados de una función f (x) para todos los posibles valores de x. Si la entrada x posee una longitud de dos bits, en un ordenador clásico tendrás que probar secuencialmente los cuatro posibles valores: primero 00, luego 01, después 10 y finalmente 11. En cambio, un ordenador cuántico realizará los cuatro cálculos simultáneamente. Pero hay truco: los dos qubits almacenan los cuatro posibles resultados a la vez, pero la lectura solo devuelve uno de esos cuatro valores y tú no puedes elegir cuál, sucede aleatoriamente. Por consiguiente, los algoritmos cuánticos deben explotar con mucha inteligencia y maña esta característica para que la probabilidad de que leas aleatoriamente el resultado que buscas sea lo más cercana posible al 100%. Y esto no es fácil. Por eso existen tan pocos algoritmos cuánticos. Los dos más conocidos en el ámbito de la ciberseguridad son el de Shor, capaz de arrasar la criptografía de clave pública en uso hoy, y el de Grover, que simplemente debilita la criptografía de clave secreta y los hashes, con la sencilla solución de doblar el tamaño de la clave o del hash. Además de para romper la criptografía actual, los ordenadores cuánticos tendrán otros muchos usos más constructivos, como, por ejemplo, los siguientes reseñados por Gartner en su más que recomendable informe The CIO’s Guide to Quantum Computing: Aprendizaje automático: mejora del ML mediante una predicción estructurada más rápida. Inteligencia Artificial: cálculos más rápidos para mejorar la percepción, la comprensión y el diagnóstico de fallos de circuitos/clasificadores binarios. Química: nuevos fertilizantes, catalizadores y química de las baterías para impulsar mejoras en la utilización de los recursos. Bioquímica: nuevos fármacos, medicamentos a medida y, tal vez, incluso restauradores de cabello. Finanzas: simulaciones Monte Carlo más rápidas y complejas; por ejemplo, comercio, optimización de trayectorias, inestabilidad del mercado, optimización de precios y estrategias de cobertura. Salud: secuenciación genética del ADN, optimización del tratamiento de radioterapia/detección de tumores cerebrales, en segundos en lugar de horas o semanas. Materiales: materiales superresistentes; pinturas anticorrosivas; lubricantes; semiconductores. Computación: funciones de búsqueda multidimensional más rápidas; por ejemplo, optimización de consultas, matemáticas y simulaciones. De criptografía cuántica, nada; mejor, distribución cuántica de claves La criptografía cuántica no existe. Lo que sí que existe desde el año 1984 es la "distribución cuántica de claves" (Quantum Key Distribution, QKD). Es decir, la (mal llamada) criptografía cuántica no tiene nada que ver con la computación cuántica, sino que se trata en realidad de un ejercicio brillante de comunicación cuántica, aplicado a la distribución de claves aleatorias. Históricamente, el mayor obstáculo de la criptografía ha sido el problema de la distribución de claves: si el canal es inseguro y necesitas cifrar la información, ¿por qué canal envías la clave de cifrado? En 1984, los investigadores C. Bennett y G. Brassard idearon el primer método para compartir claves a través de un canal cuántico de comunicaciones utilizando fotones individuales convenientemente polarizados, bautizado como BB84. Este protocolo posee la interesante propiedad de que, si un atacante intercepta bits de la clave, será detectado necesariamente, ya que, en el mundo cuántico, no se puede observar sin dejar huella. Posteriormente, se han presentado otros protocolos de QKD, como el E91, propuesto por el investigador A. Ekert en 1991, basado en el "entrelazamiento" o "enredo cuántico" entre dos partículas (quantum entanglement); y muchos otros más. Tampoco vayas a creer que la QKD es el Santo Grial de la criptografía. De hecho, algunas de las agencias de inteligencia más grandes del mundo han señalado que dista mucho de solucionar nuestros problemas de confidencialidad. Una cosa es lo que la física teórica puede proponer y otra bien distinta lo que los ingenieros pueden construir. Aunque la brecha entre teoría y práctica se está cerrando a pasos agigantados desde aquella humilde PoC de 1984, la implementación de QKD aún no es todo lo segura que sin duda llegará a ser con los avances tecnológicos. Criptografía post-cuántica o cómo resistir a un futuro dominado por los ordenadores cuánticos Por último, llegamos a la criptografía post-cuántica, que poco o nada tiene que ver con las dos anteriores. La "criptografía post-cuántica" (Post-Quantum Cryptography, PQC) o "criptografía resistente a la computación cuántica" (Quantum-Safe Cryptography) aglutina aquellos algoritmos criptográficos capaces de resistir a los algoritmos de Shor y de Grover, antes mencionados. Se trata de algoritmos matemáticos clásicos, algunos con más de 40 años de vida. Las tres alternativas mejor estudiadas hasta la fecha son la criptografía basada en hashes, la criptografía basada en códigos y la criptografía basada en celosías. De acuerdo con el reciente informe Post-Quantum Cryptography (PQC): A Revenue Assessment, el mercado de software y chips de criptografía post-cuántica se disparará hasta los 9.500 millones de dólares para 2029. Aunque las capacidades de la PQC se incorporarán en numerosos dispositivos y entornos, según el informe, los ingresos de PQC se concentrarán en los navegadores web, la Internet de las Cosas (IoT), 5G, las fuerzas de seguridad (policía, ejército, inteligencia), servicios financieros, servicios de salud y la propia industria de la ciberseguridad. El NIST ha iniciado un proceso para solicitar, evaluar y normalizar uno o más algoritmos de PQC para firma digital, cifrado de clave pública y establecimiento de claves de sesión. Tras tres años de análisis de los candidatos propuestos, el NIST anunció en julio los ganadores de la segunda ronda para la selección del nuevo estándar de criptografía post-cuántica. En la tercera y última ronda, el NIST especificará uno o más algoritmos resistentes a la computación cuántica para 1) firma digital, 2) cifrado de clave pública y 3) generación de claves criptográficas. Los algoritmos que pasan a la tercera ronda son Classic McEliece, CRYSTALS-KYBER, NTRU y SABER, en las categorías de cifrado de clave pública y gestión de claves; y CRYSTALS-DILITHIUM, FALCON y Rainbow, en la categoría de firma digital. Que no te enreden con la cuántica Hoy solo el 1% de las organizaciones están invirtiendo en computación y ordenadores cuánticos. Se trata de un área en plena efervescencia, que consume presupuestos billonarios, al alcance solo de los equipos de I+D más sofisticados. Europa está navegado la segunda revolución cuántica mediante su programa europeo Quantum Flagship, si bien nadie duda que China ha tomado la delantera. Se espera que en una o dos décadas llegaremos a disfrutar de ordenadores cuánticos de miles de qubits libres de errores. Cuando llegue ese día, si llega, se producirá un profundo cambio en la tecnología tal y como la conocemos ahora. Por otro lado, el área de las comunicaciones cuánticas se encuentra mucho más madura, con multitud de propuestas plenamente operativas, disponible en un amplio abanico de precios y prestaciones. En 3 años, se espera el desarrollo y certificación de dispositivos y sistemas de generación cuántica de números aleatorios (QRNG) y de distribución de claves (QKD), abordando la alta velocidad, el alto TRL, los bajos costes de despliegue, los protocolos novedosos y las aplicaciones para el funcionamiento de la red, así como el desarrollo de sistemas y protocolos para repetidores cuánticos, memorias cuánticas y comunicación a larga distancia. Todo ello conduciría en 10 años a una "Internet Cuántica". En cuanto a la criptografía post-cuántica (PQC), no es más que criptografía de toda la vida, basada en algoritmos matemáticos clásicos, pero con la peculiaridad de resistir a la computación cuántica. Si ahora mismo tu organización maneja información cifrada cuya confidencialidad necesita garantizarse durante más de 10 años, más vale que vayas analizando la oferta de productos PQC en el mercado para iniciar la transición. El futuro será cuántico o no será o será algo intermedio o será y no será a la vez o... ¡Que no te enreden con la cuántica!
20 de abril de 2021

El puzle por el que ofrecen un trillón de dólares a quien lo resuelva
¿Eres aficionado a los puzles matemáticos? Pues aquí tienes uno muy lucrativo… ¡pero duro de roer! Si descubres un método para romper los hashes utilizados en Blockchain, ¡podrías hacerte con todos los futuros Bitcoins aún por minar! El criptominado se basa en un concepto llamado “prueba de trabajo” (y en el azar). Los mineros con mayores recursos computacionales a su alcance (y a quienes más favorece el azar) son recompensados con nuevos bitcoins. En este artículo explicaremos el origen de las pruebas de trabajo, ligado a la batalla contra el spam, y cómo se utilizan hoy en Bitcoin. Si los spammers tuvieran que pagar por cada correo que envían, otro gallo cantaría Eso mismo pensó Adam Back en 1997. Reputado criptógrafo y hacker, había leído un artículo publicado en 1992 por Cynthia Dwork y Moni Naor sobre cómo combatir el spam obligando a realizar costosos cálculos matemáticos. Este artículo le inspiró para diseñar su propuesta de pago por envío de correo: si quieres enviar spam, vas a tener que pagar, pero no con dinero, pagarás con sudor de computación (si te recordaba a “Fama”, eres muy mayor). El spammer tendrá que resolver un puzle criptográfico de dificultad variable y no enviará su correo hasta que dé con la solución. Resolver el puzle será muy complicado, pero verificar la solución, muy sencillo. En otras palabras, o pruebas que has trabajado duro, o no hay spam que valga. Y así nació Hashcash. La propuesta de Back exige añadir la cabecera X-Hashcash: al protocolo SMTP, de manera que, si un mensaje llega a una pasarela de correo o a un cliente de correo sin dicha cabecera, será rechazado inmediatamente. ¿Y con qué token hay que rellenar esta cabecera? En primer lugar, se requiere una función de hash segura. Aunque Hashcash proponía SHA-1, hoy se utilizaría otro algoritmo, como por ejemplo SHA-256 o SHA-3. En segundo lugar, Hashcash usa los siguientes parámetros: Un factor de trabajo w, tal que 0 <= w <= L, siendo L el tamaño de la salida de la función de hash (en bits). Se utiliza para modular la dificultad del puzle. Un número de versión, ver. Un parámetro de marca de tiempo: time. Un identificador de recurso: resource. Un número de como mínimo 64 bits elegido aleatoriamente: trial. El token de Hashcash se compone uniendo dichos campos por el carácter ':', de la siguiente forma: token = ver:time:resource:trial El puzle consiste en calcular repetidamente el hash del token hasta que los w bits más significativos sean 0, incrementando en uno el valor de trial cada vez que no se acierte. Evidentemente, cuanto mayor sea el valor de w, más difícil será el puzle. Por fortuna para el receptor, verificar que la solución al puzle es correcta es tan trivial como calcular el hash del token. Además, no importa cuántos puzles resuelvas, resolver uno nuevo siempre te llevará en promedio el mismo tiempo: la dificultad se mantiene constante para un valor dado de w. Y si la potencia de cómputo mejora con el tiempo, basta con incrementar w y otra vez a sudar. Por supuesto, los tokens solo se consideran válidos si no se repiten, porque entonces, resuelto uno, bastaría con anexionarlo a todos los mensajes de spam. Una forma económica de resolver el problema de cómo almacenar un histórico de los tokens consiste en configurar un período de expiración, calculado gracias al parámetro time. Aunque esta idea no llegó a cuajar para luchar contra el spam, terminó inspirando a Satoshi Nakamoto para diseñar la prueba de trabajo de Bitcoin. Los criptomineros acuñarán bitcoins con el sudor de sus ASICs En la mina se excava la tierra en busca de un recurso escaso y muy valioso. En Bitcoin, el recurso escaso es la capacidad de cómputo. Los nodos de la red de Bitcoin compiten unos contra otros en una carrera frenética por ser el primero en resolver un puzle criptográfico, llamado "prueba de trabajo", basado en Hashcash. Explicado de forma muy simplificada, se toma el hash del nuevo bloque, c, que se desea incorporar a la cadena de bloques, se concatena con un nonce, x, y se calcula el hash del conjunto. Si el valor del hash resultante comienza por un número predeterminado de ceros, es decir, es menor que un cierto target, entonces ¡has ganado la carrera! En caso contrario, súmale uno al nonce y vuelta a empezar. La función de hash utilizada en Bitcoin es SHA256, pasada dos veces consecutivas. Expresado matemáticamente: SHA256( SHA256( c | x ) ) < target( d ) La dificultad de este puzle puede adaptarse dinámicamente, variando el número d de ceros iniciales que debe tener el hash. Así, una dificultad de 1 significa que el hash debe tener (al menos) un cero a la izquierda, mientras que una dificultad de 10 significa que el valor hash tendrá al menos 10 ceros a la izquierda. Cuanto más alto sea el nivel de dificultad, más ceros a la izquierda serán necesarios y más complicado será el puzle, ya que la dificultad crece exponencialmente con el número de ceros. Obviamente, cuanto más complicado sea el rompecabezas de hash, más potencia de cálculo o tiempo se necesita para resolverlo. Bitcoin establece la dificultad de manera que globalmente se cree un nuevo bloque cada 10 minutos en promedio. El primer minero en resolver el puzle recibe una recompensa en forma de bitcoins y cobra las tasas aplicadas a las transacciones contenidas en el bloque. La recompensa para el ganador está programada desde el principio. Inicialmente se recompensaba al criptominero ganador con 50 bitcoins por cada nuevo bloque. Esta recompensa se reduce a la mitad cada 210.000 bloques, es decir, aproximadamente cada 4 años. Debido a la reducción a la mitad de la recompensa por bloque, la cantidad total de bitcoins en circulación nunca superará los 21 millones de bitcoins. Estos incentivos económicos deben compensar el gasto de recursos computacionales o nadie minaría bitcoins. ¡¡¡Soy mineroooooo!!! En sus inicios, para minar bitcoins bastaba con un ordenador con una CPU decente. Pero los jugosos incentivos hicieron aumentar rápidamente la dificultad del mecanismo de prueba de trabajo. Las CPUs fueron pronto sustituidas por GPUs, éstas a su vez por FPGAs y, a medida que los bitcoins se revalorizaban, pasaron a utilizarse circuitos integrados de aplicación específica (ASICs). No sé si todos los criptomineros que adquieren estos equipos se hacen de oro, pero sus fabricantes ciertamente sí que han encontrado su particular filón. La barrera de entrada para minar es hoy tan elevada, que desde hace muchos años la comunidad de mineros está dominada por un pequeño número de grupos de minería de “grandes jugadores”. Como resultado, el grupo supuestamente grande y diverso de pares que colectivamente mantiene la integridad del sistema se convierte a la postre en un grupo muy pequeño de entidades, cada una de las cuales posee un enorme poder computacional en forma de hardware especializado, albergado en gigantescas granjas, repartidas las mayores por China, Rusia, Islandia, Suiza y EEUU. Estos grupos exclusivos forman una suerte de oligopolio que divide entre ellos la responsabilidad de mantener la integridad del sistema. Queda abierta la puerta a abusos de poder, como, por ejemplo, omitir transacciones específicas o discriminar a usuarios específicos. Al final, Bitcoin y Blockchain no son tan descentralizados como se esperaba en su concepción original porque la integridad del sistema no está distribuida entre un número enorme de entidades, sino que se concentra en unas pocas entidades muy poderosas, estableciéndose una especie de centralidad oculta que socava la naturaleza distribuida de todo el sistema. El reverso tenebroso de las pruebas de trabajo Y no olvidemos un problemilla asociado a las pruebas de trabajo. Dado que resolver los puzles criptográficos requiere un gasto inmenso de potencia computacional, el proceso de minería/validación resulta prohibitivamente caro, tanto en términos de electricidad como de disipación de calor. Este consumo tiene un impacto increíblemente perjudicial para el medio ambiente. En un trabajo publicado en 2019, The Carbon Footprint of Bitcoin, sus autores afirman que la minería de Bitcoin representa el 0,2% de todo el consumo de electricidad en el mundo y que produce tanto dióxido de carbono como una metrópolis del tamaño de Kansas City (unos 500.000 habitantes). Otra investigación publicada en Nature en 2018, Quantification of energy and carbon costs for mining cryptocurrencies, calculó que la minería de Bitcoin, Ethereum, Litecoin y Monero combinadas produjo durante un período de 30 meses el equivalente a entre 3 y 13 millones de toneladas de dióxido de carbono. Y viendo el precio al alza de todas estas criptomonedas, a pesar de su volatilidad, todo apunta a que el consumo de energía (y de emisiones) seguirá creciendo. Una vez más se demuestra que cuando la criptografía salta de las pizarras de los criptógrafos al mundo real, las cosas se complican. A fin de cuentas, Bitcoin no se ejecuta sobre papel, sino sobre procesadores. Y a más trabajo, mayor consumo.
22 de marzo de 2021

En Internet nadie sabe que eres un perro ni aunque uses certificados TLS
Te habrás fijado en que la mayoría de las páginas web llevan un candadito. Si haces clic en él, aparecerá una ventana que afirma que “la conexión es segura”. ¿Segura? ¿Qué clase de seguridad? ¿Cómo de segura? En este artículo tumbaremos a los certificados digitales sobre la mesa de operaciones y los diseccionaremos exhaustivamente para llegar al fondo del asunto: ¿qué seguridad aporta TLS? TLS, el protocolo de seguridad detrás de las páginas web seguras con HTTPS Una página web protegida por Transport Layer Security (TLS), el protocolo detrás del candadito, ofrece tres garantías o servicios de seguridad: Confidencialidad: la comunicación entre tu navegador y el servidor web está cifrada, de manera que, si un atacante intercepta los datos, no podrá enterarse de su contenido. Integridad: si se produce un error fortuito en la transmisión o un adversario intenta manipular la comunicación, se detectará la modificación. Autenticación: un certificado digital te contará quién es la (supuesta) empresa dueña de la página web que estás visitando. En resumen, si una página está protegida con TLS, tienes la garantía (casi) absoluta de que nadie salvo el servidor web destino podrá ver los datos que os intercambiáis. Vamos, que la confidencialidad está garantizada. El problema que queda sin resolver del todo es: ¿quién hay de verdad detrás de ese servidor? En otras palabras, ¿a quién le estás enviando tus datos cifrados? En Internet nadie sabe que eres un perro Ilustración por Peter Steiner. The New Yorker, número del 5 de julio de 1993 (Vol.69 (LXIX) no. 20), página 61. Este chiste data de 1993 y no podía ser más actual porque en 30 años ¡no hemos avanzado gran cosa! Si estás leyendo este artículo en la página web de empresas.blogthinkbig.com, ¿cómo sabes que es la página de blogthinkbig.com de Telefónica y no es una falsificación? Solo tienes un recurso: hacer clic en el candadito y abrir el certificado. ¿Y qué te encuentras? Que el certificado ha sido emitido por la empresa GlobalSign a nombre de *.blogthinkbig.com. ¿Te quedas ahora tranquilo con respecto a la identidad del propietario de la página web? Pues la verdad que no ayuda mucho, ¿verdad? Pero un certificado contiene mucha más información que ese resumen inicial. Selecciona la pestaña Detalles y verás muchísimos campos. En concreto, el campo Sujeto te revela que, en este ejemplo, la empresa detrás de *.blogthinkbig.com es Telefónica S.A. Pero no vayas a creer que todos los certificados ofrecen esa información: unos ofrecen menos, no revelan la entidad detrás del sitio web; otros proporcionan más. Vamos a diseccionarlos para que entiendas qué representa cada campo. Disección de un certificado TLS Los certificados digitales son documentos electrónicos que garantizan (hasta cierto punto) la identidad de una persona física o jurídica y que ésta posee una determinada clave pública. Una tercera parte de confianza, llamada la Autoridad de Certificación (AC), se ocupa de validar esta identidad y de emitir los certificados que ligan identidad con clave pública. Un certificado TLS contiene la siguiente información: Versión del estándar X509, actualmente se utiliza la 3. Número de serie usado por la autoridad de certificación. Hoy se exige que sean aleatorios, no secuenciales, con una entropía mínima de 20 bits. Identificador del algoritmo, que debe ser el mismo que el "Algoritmo de firma del certificado", descrito más abajo. Se ubica en esta posición para ser protegido por la firma. Identificación de la autoridad de certificación, mediante un nombre distinguido (Distinguished Name, DN) único: CN – CommonName L – LocalityName ST – StateOrProvinceName O – OrganizationName OU – OrganizationalUnitName C – CountryName El periodo de validez del certificado: desde cuándo hasta cuándo es válido. El nombre distinguido único del titular del certificado. Puede tratarse de una persona física o jurídica. La autoridad verifica esta identidad de forma más o menos fehaciente, como se verá. Información de la clave pública del titular, especificada por: Algoritmo Tamaño de la clave Exponente Módulo Extensiones (opcional): se introdujeron en la versión 3 para flexibilizar la rígida estructura anterior. Una AC puede utilizar extensiones para emitir un certificado solo para un propósito específico, por ejemplo, solo para servidores web. Las extensiones pueden ser "críticas" o "no críticas". Las no críticas pueden ignorarse, mientras que las críticas deben aplicarse y un certificado será rechazado si el sistema no reconoce una extensión crítica. Algoritmo de firma del certificado. Existen multitud de algoritmos seguros en uso: RSA, DSA, ECC, etc. Firma del certificado: el valor de la firma. Para los versados en criptografía, este valor corresponde al resultado de cifrar con la clave privada de la AC el hash de la información del certificado. Esta firma permite verificar que la clave pública que aparece en el certificado efectivamente pertenece al titular del certificado, porque así lo certifica la autoridad de certificación. En resumen, un certificado digital recoge la garantía de una autoridad que da fe de que una clave pública pertenece a una persona (física o jurídica) dada. ¿Cuánto puedes fiarte de su palabra? Veámoslo. No todos los certificados fueron creados con el mismo nivel de confianza La misión principal de una autoridad de certificación es validar la identidad de la entidad que solicita un certificado. Y no todos los certificados ofrecen el mismo grado de confianza en la identidad del titular, porque el proceso de validación puede variar enormemente de unos tipos de certificado a otros. Existen tres niveles de validación para sitios web: Validación de dominio: los certificados de validación de dominio (DV) representan el nivel más bajo de validación, ya que la AC solo verifica que quien solicita el certificado posee el dominio para el que lo pide y que dicho dominio está registrado en Whois. La propiedad del dominio se comprueba típicamente a través de un correo electrónico de confirmación enviado a una dirección en dicho dominio. Si el destinatario sigue el enlace del correo electrónico, se emite el certificado. La emisión de certificados DV está totalmente automatizada y puede ser muy rápida. La duración depende en gran medida de la rapidez con la que se responda al correo electrónico de confirmación. No incluyen el nombre de la entidad poseedora del dominio, solo el nombre de dominio. Por ejemplo, los certificados de Let’s Encrypt pertenecen a esta categoría. ¿Qué garantías aportan sobre la identidad del titular del dominio? ¡Ninguna! Un sitio web con un certificado DV es seguro en el sentido de proteger la confidencialidad, pero no garantiza en absoluto la identidad del sitio. Sabes que tus datos viajan cifrados, pero no tienes ni idea de a quién se los envías. Son ideales para sitios web de particulares, pymes, blogs, foros, sin pretensión de ofrecer servicios de pago y sin tratar datos personales. Validación de organización: los certificados de organización validada (OV) requieren verificar la identidad del titular del dominio. Las prácticas de validación de la identidad del solicitante varían drásticamente de unas autoridades de certificación a otras, existiendo una gran inconsistencia y diversidad de garantías, aunque todas exigen el envío de algún documento oficial para verificar el dominio, el CIF, el teléfono, la dirección física y algún otro requisito. El proceso puede tardar de uno a tres días laborables. Incluyen el nombre de la organización en el contenido del certificado. Estos certificados resultan indicados para instituciones y empresas que desean una presencia sólida en Internet, pero sin ofrecer servicios transaccionales a través de la web. Validación extendida: los certificados de validación extendida (EV) ofrecen el mayor grado de confianza. También requieren la verificación de la identidad y la autenticidad, pero con requisitos muy estrictos. Se introdujeron para solucionar la falta de coherencia de los certificados OV. Exigen incluso más documentación que los certificados OV para verificar fehacientemente la identidad del solicitante y sus operaciones de negocio. También incluyen en el certificado el nombre de la organización a la que se le ha emitido e incluso se ve la organización al hacer clic sobre el candadito, sin necesidad de hurgar en los detalles del certificado, facilitando así la verificación de su identidad por parte de los visitantes a su sitio web. Es el más indicado para aquellos sitios web que ofrecen servicios que involucren transacciones financieras. Normalmente lo utilizan los bancos, grandes organizaciones y tiendas online de renombre. Debido a los controles implantados, la obtención de un certificado EV suele llevar de 5 a 15 días. Es importante resaltar que todos ellos ofrecen la misma fortaleza criptográfica: 256 bits de cifrado simétrico y 2.048 bits de cifrado de clave pública. La diferencia entre unos y otros no reside en la criptografía, idéntica para todos ellos, sino en los procesos de validación, más o menos estrictos, lo que ofrece más o menos garantías sobre la identidad de la persona (física o jurídica) detrás de un sitio web. La criptografía funciona de cine, lo que falla son los procesos En resumen, para que una infraestructura de clave pública (PKI) funcione, las autoridades de certificación tienen que hacer bien su trabajo, entre otras tareas críticas, verificar la identidad de los solicitantes de certificados. Si esta validación no se ejecuta correctamente, la criptografía solo sirve para asegurar la confidencialidad: los datos comunicados entre el servidor web y tu navegador viajan cifrados, sí, ningún atacante podrá hacerse con ellos, pero ¿a quién se los estás enviando, de quién los estás recibiendo? Esa incógnita solo la resuelve la información del certificado del sitio web. Y ahí, por desgracia, las matemáticas tienen poco que añadir: es misión de las AC. Por eso se producen incidentes como el reciente con Camerfirma: Google dudó de las buenas prácticas de esa autoridad de certificación. No se cuestiona la criptografía, sino los procesos de validación de la identidad. Al final, la ciberseguridad es una combinación equilibrada de tecnología, procesos y personas. En la criptografía puedes confiar, en el resto… Si quieres saber cómo actualizar tus certificados TLS/SSL puedes consultar a nuestros expertos. MÁS INFORMACIÓN
22 de febrero de 2021

Criptografía funcional: la alternativa al cifrado homomórfico para realizar cálculos sobre datos cifrados
—Te ofrezco las coordenadas exactas de cada operativo desplegado en la zona de combate. —¿Por cuánto? —100.000. —Es mucho. —Y un código que muestra en pantalla la posición actualizada de todos y cada uno de los soldados enemigos. —¡Trato hecho! Los videojuegos son un negocio muy serio. Mueven un mercado de muchos miles de millones de euros en todo el mundo y atraen a todo tipo de delincuentes. Por ejemplo, en un videojuego multijugador online, cada dispositivo debe conocer la posición de todos los objetos sobre el terreno para poder renderizarlos correctamente en 3D. Además, necesita conocer las posiciones de otros jugadores, para representarlos si están a la vista del jugador local o no representarlos si se ocultan tras muros o rocas. El servidor se enfrenta a un dilema clásico: si proporciona las posiciones de los jugadores a los demás jugadores, podrán hacer trampas; pero si no las proporciona, el juego no sabrá cuándo mostrar a los jugadores ocultos. En lugar de proporcionar las coordenadas exactas, lo ideal sería poder proporcionar la información de si un objetivo está o no a la vista del jugador local, pero sin filtrar su posición. Algo difícilmente posible hasta la invención de la criptografía funcional. La criptografía funcional, un paso más allá de la criptografía convencional de clave pública Con todos sus beneficios y maravillas, la criptografía de clave pública presenta algunas limitaciones prácticas: Proporciona acceso todo-o-nada a los datos cifrados: o descifras el texto claro completo o no obtienes ninguna información sobre el texto claro. Una vez cifrados los datos con la clave pública, solo existe una única clave privada capaz de descifrarlos. En 2011, D. Boneh, A. Sahai y B. Waters propusieron ir más allá del cifrado asimétrico convencional con su criptografía funcional: una nueva propuesta de cifrado de clave pública en la que diferentes claves de descifrado permiten acceder a funciones sobre los datos en claro. En otras palabras, la criptografía funcional permite filtrar deliberadamente información sobre los datos cifrados a usuarios determinados. En un esquema de cifrado funcional, se genera una clave pública, pk, con la que cualquier usuario puede cifrar un mensaje secreto, m, de manera que c = E(pk, m). Y aquí viene la vuelta de tuerca: en lugar de utilizar una clave de descifrado convencional, se crea una clave secreta maestra, msk, solo conocida por una autoridad central. Cuando esta autoridad recibe la descripción de una función, f, deriva a partir de msk una clave de descifrado funcional, dk[f], asociada con f. Cualquiera que use dk[f] para descifrar los datos cifrados, c, obtendrá en cambio el resultado de aplicar la función f a los datos en claro, f(m), pero ninguna información adicional sobre m. Es decir, D(dk[f], c) = f(m). La criptografía de clave pública convencional es un caso particular de criptografía funcional en el que f es la función identidad: f(m) = m. Aplicaciones del cifrado funcional Se pueden idear multitud de casos de uso para el cifrado funcional, allí donde se requiera operar sobre datos cifrados, pero sin verlos: Filtrado de spam: un usuario no confía en su proveedor de correo, pero quiere que limpie sus mensajes de spam. El usuario puede implantar un sistema de cifrado funcional: cifra todos sus mensajes con pk y proporciona al servidor una clave de descifrado funcional, dk[f], donde f es una función de filtrado de spam que devuelve 1 si un mensaje m es spam y 0 en caso contrario. El servidor usará dk[f] para comprobar si un mensaje cifrado es spam, pero sin obtener ninguna información adicional sobre el mensaje en claro. Búsquedas en bases de datos: un servicio en la nube almacena miles de millones de imágenes cifradas. La Policía quiere encontrar todas las imágenes que contengan la cara de un sospechoso. El servidor le proporciona una clave de descifrado funcional con la que descifra las imágenes que contienen la cara objetivo, pero que no revela nada sobre otras imágenes. Análisis de grandes volúmenes de datos: considera un hospital que registra los datos médicos de sus pacientes y quiere ponerlos a disposición de la comunidad científica con fines de investigación. El hospital puede delegar en una nube pública el almacenamiento cifrado de los datos sensibles de sus pacientes. A continuación, puede generar claves de descifrado funcional que reparte a los investigadores, gracias a las cuales pueden calcular diferentes funciones estadísticas sobre los datos, sin revelar nunca los registros individuales de cada paciente. Machine Learning sobre datos cifrados: después de entrenar un clasificador sobre un conjunto de datos en claro, se puede generar una clave de descifrado funcional asociada a este clasificador y con ella clasificar un conjunto de datos cifrados, de manera que al final solo se revela el resultado de la clasificación, sin filtrarse nada sobre los datos del conjunto. Control de acceso: en una gran organización se desea compartir datos entre los usuarios de acuerdo con diferentes políticas de acceso. Cada usuario puede cifrar x = (P, m), donde m son los datos que el usuario desea compartir y P es la política de acceso que describe cómo el usuario quiere compartirlos. La clave de descifrado funcional dk[f] comprobará si las credenciales o los atributos del usuario coinciden con la política y revelará m solo en tal caso. Por ejemplo, la política P = ("CONTABILIDAD" O "TI") Y "EDIFICIO PRINCIPAL" devolvería m a un departamento de contabilidad o un departamento de TI con una oficina en el edificio principal de la organización. Diferencias con respecto al cifrado totalmente homomórfico (FHE) Si estás familiarizado con el concepto del cifrado totalmente homomórfico (FHE), posiblemente habrás pensado en él al leer sobre cifrado funcional. La diferencia entre ambos es crucial: el cifrado totalmente homomórfico (FHE) realiza operaciones sobre los datos cifrados y el resultado sigue estando cifrado. Para acceder al resultado de los cálculos sobre los datos cifrados se necesita descifrarlo, lo cual puede resultar un inconveniente en según qué casos de uso. La siguiente representación esquemática ayudará a visualizar la diferencia entre ambos esquemas de cifrado. En el caso del cifrado totalmente homomórfico (FHE), la función f se calcula sobre los datos cifrados y el resultado queda cifrado: E(m1), E(m2), …, E(mn) --> E(f(m1, m2, …, mn)) Mientras que con el cifrado funcional, el resultado queda directamente accesible tras el cálculo de f: E(m1), E(m2), …, E(mn) --> f(m1, m2, …, mn) Otra importante diferencia es que, en el caso de FHE, cualquiera puede realizar los cálculos sobre los datos cifrados, por lo que, dado el texto cifrado del resultado, no existen garantías de que los cálculos se hayan llevado a cabo correctamente. FHE exige el uso de protocolos de conocimiento nulo para verificar que se evaluó la función correcta. En cambio, en la criptografía funcional, solamente el poseedor de la clave de descifrado funcional puede realizar los cálculos, lo que aporta mayores garantías de corrección. Seguridad del cifrado funcional Existe una gran variedad de esquenas de cifrado funcional, basados en diferentes artificios matemáticos muy complejos. Por simplificar mucho, un cifrado funcional se considera seguro si un adversario no puede obtener más información sobre m que f(m). Incluso si n partes en posesión de las claves dk[f1], dk[f2], …, dk[fn], se ponen de acuerdo para atacar m en un ataque de colusión, no obtendrán más información que f1(m), f2(m), …, fn(m). El nivel de información sobre m revelado está totalmente controlado por quienquiera que genere las claves de descifrado funcional. Criptografía de clave pública supervitaminada y supermineralizada para un futuro en la nube El cifrado funcional es una disciplina aún muy joven, que está recibiendo un fuerte impulso investigador por sus infinitas aplicaciones en servicios en la nube y en IoT. Una aplicación especialmente interesante potenciada por el proyecto europeo FENTEC es la posibilidad de trasladar el proceso de toma de decisiones basado en datos cifrados de extremo a extremo desde los sistemas back-end a algunas pasarelas en redes complejas, lo que se llama toma de decisiones local. Poder habilitar las pasarelas para que realicen dicha toma de decisiones local es un gran paso adelante para asegurar las redes IoT y otras redes altamente descentralizadas que podrían querer implementar el cifrado de extremo a extremo, sin perder demasiadas capacidades de decisión a nivel de las pasarelas. Si quieres probar la criptografía funcional, puedes hacerlo gracias a varias bibliotecas publicadas por los investigadores del proyecto FENTEC. Puedes ir directamente a Github y empezar a jugar con CiFEr, una implementación en C, y con GoFE, implementada en Go. Incluso puedes probarlo en tu navegador usando WASM. El cifrado funcional representa un paso más hacia una criptografía más potente y versátil, capaz de proteger la privacidad de los usuarios en casos de uso que hasta ahora resultaban impensables con la criptografía convencional.
8 de febrero de 2021

Criptografía chivata: cómo crackear dispositivos inviolables
La llave de seguridad Titan de Google o la YubiKey de Yubico son el último grito en seguridad de autenticación multifactor. Según la propia página de Google: «Las llaves cuentan con un chip de hardware dotado de firmware diseñado por Google para verificar que nadie las ha manipulado. Estos chips se han diseñado para resistir los ataques físicos que buscan extraer el firmware y el material secreto de la llave». En otras palabras, una llave Titan o YubiKey almacena tu clave privada y debería ser imposible extraerla del dispositivo. Debería. Porque poderse, se puede, tal y como demostraron en enero varios investigadores del NinjaLab en un trabajo titánico (vale, sí, era un chiste malo). ¿Cómo lo consiguieron? Usando un ataque de canal lateral. Cómo funcionan los ataques de canal lateral ¿Qué pasa cuando los algoritmos matemáticos abandonan las pizarras de los criptógrafos y se programan dentro de chips del Mundo Real™? En el burdo mundo físico, alejado de los ideales cuerpos platónicos, a un bit no le queda más remedio que ser representado como una corriente eléctrica que pasa (“1”) o no pasa (“0”) por un transistor. Y, por sutilmente que circule, una corriente eléctrica inevitablemente produce efectos a su alrededor: una pequeña radiación electromagnética, una pequeña variación de temperatura, una pequeña subida en el consumo de energía, un pequeño desplazamiento de aire, un sonido imperceptible, … Si eres capaz de medir esos efectos, eres capaz de leer claves, estados intermedios, memoria, en fin, de extraer información suficiente como para sortear el algoritmo matemático. Da igual lo segura que sea tu criptografía, si la implementación en hardware permite un ataque de canal lateral, quedará en nada. Ilustración 1. Modelo criptográfico tradicional (ideal), frente al modelo criptográfico de canal lateral (real) Los criptoanalistas descubrieron desde los albores de la criptografía mecánica que todo dispositivo criptográfico se “chiva” de lo que está pasando en su interior. En lugar de atacar los algoritmos, los ataques de canal lateral atacan la implementación de los algoritmos. Resumiendo: si hay hardware implicado, habrá un canal lateral filtrando información. Es pura física. Veámoslo con un ejemplo. El ataque por análisis de potencia contra RSA En un artículo anterior, expliqué los ataques matemáticos contra el popular algoritmo de cifrado de clave pública RSA, aunque solo mencioné de pasada la posibilidad de los ataques de canal lateral. Como bien sabes, para cifrar con RSA se realiza la siguiente operación con la clave pública, e y n: c = me mod n mientras que para descifrar se utiliza la clave privada, d: m = cd mod n El objetivo del atacante es extraer del dispositivo esta clave privada, d. Como ves, el funcionamiento de RSA se basa en la operación de exponenciación. Dado que RSA utiliza números enteros muy, muy grandes, los matemáticos buscaron atajos para que el cálculo de estas operaciones fuese rápido. Concretamente, suele utilizarse el algoritmo de exponenciación binaria, también conocido como cuadrado y multiplica. Es muy sencillo de entender. Para calcular 34 = 11100 puedes hacer las siguientes operaciones: 32 = 9 (cuadrado) 92 = 81 (cuadrado) Para calcular este resultado ha bastado con elevar al cuadrado dos veces seguidas. Veamos qué pasa con otro exponente. Para 35 = 11101 el algoritmo funciona así: 32 = 9 (cuadrado) 92 = 81 (cuadrado) 81 × 3 = 243 (multiplicación) En este caso, se han realizado dos cuadrados y una multiplicación. Finalmente, considera 312 = 111100: 32 = 9 (cuadrado) 9 × 3 = 27 (multiplicación) 272 = 729 (cuadrado) 2792 = 531.441 (cuadrado) A estas alturas, te habrás percatado de cómo funciona el algoritmo: tras ignorar el primer “1” del exponente, si te encuentras con un “1”, haz una cuadrado y una multiplicación; si te encuentras con un “0”, haz solo un cuadrado. Da igual lo grandes que sean la base y el exponente, siempre se puede exponenciar mediante estas dos operaciones de manera extraordinariamente eficiente. En resumen, siempre se eleva al cuadrado y sólo se multiplica si el bit de exponente que se procesa es 1. Ahora bien, como puedes imaginar, cuadrado y multiplicación son dos operaciones que se tomarán mucho más tiempo que solo cuadrado. Si pudieras ver el tiempo que está tardando un circuito en operar, deducirías qué operación está realizando y, por tanto, cuál es el exponente privado, d. Y la realidad es que es tan sencillo como observar el consumo del dispositivo, tal y como se muestra en la siguiente figura: Figura 1. Análisis de consumo de un chip operando con RSA (fuente: Understanding Cryptography: A textbook for students). De la observación de la traza, se deduce que la clave secreta es: operaciones: S SM SM S SM S S SM SM SM S SM … clave privada: 0 1 1 0 1 0 0 1 1 1 0 1 … Por supuesto, este ataque funciona para claves de cualquier longitud. Del mismo modo, otros algoritmos de cifrado filtran información de otras formas, pero, por desgracia, todos filtran algo. Y cuando el análisis de potencia no filtra la información buscada, existen otros muchos ataques. Tipos de ataques de canal lateral Además del ataque de canal lateral basado en consumo de potencia, los investigadores han ido descubriendo otras muchas formas de obtener información de un dispositivo hardware en operación: Ataque a la caché: la caché es una memoria de acceso directo casi instantáneo, usada para almacenar datos e instrucciones muy utilizados. Cuando los datos se cargan en caché por primera vez (cache miss) se produce un retardo, al contrario de cuando los datos ya están en cache (cache hit), cuyo acceso es instantáneo. Esta diferencia en los tiempos de acceso filtra valiosa información que puede ser utilizada por un adversario para obtener datos confidenciales de la memoria. Los devastadores Meltdown y Spectre son ejemplos de este tipo de ataque. Ataque de tiempo: se lleva a cabo mediante la medición del tiempo que tardan distintas instrucciones de un algoritmo criptográfico en ejecutarse según diversos parámetros. Las variaciones de tiempo permiten extraer información de la clave. Ataque de monitorización de consumo: no todas las operaciones que realiza un algoritmo son igual de complejas. En general, a mayor complejidad, mayor consumo. Midiendo estas variaciones de consumo se puede extraer información sobre los argumentos del algoritmo, como en el ejemplo visto para RSA. Ataque electromagnético: todo dispositivo electrónico filtra radiación electromagnética, que puede proporcionar directamente el contenido de la información confidencial. Estas mediciones pueden utilizarse para inferir claves criptográficas utilizando técnicas equivalentes a las del análisis de potencia o pueden utilizarse en ataques no criptográficos, como, por ejemplo, TEMPEST, que permiten reproducir la información de un monitor desde otra habitación. Ataque de sonido: se puede deducir el funcionamiento del procesador de un dispositivo y romper su criptografía escuchando con un smartphone convencional el sonido de sus condensadores y bobinas al operar. También existen ataques no criptográficos que explotan el sonido emitido por las teclas de un teclado al introducir una contraseña o el ruido de las cabezas de una impresora de chorro de tinta al imprimir. Análisis diferencial de fallos: cuando se induce al hardware a fallar de manera intencionada, las respuestas inesperadas que arroja la ejecución de un algoritmo pueden utilizarse para obtener información sobre sus datos. Son muy famosos los ataques padding oracle contra RSA o el ataque de extensión de longitud, basados en esta técnica. La criptografía no se ejecuta sobre papel, sino sobre hardware Por muy seguro que sea un algoritmo sobre el papel, cuando se ejecuta en hardware se abre la puerta a los ataques de canal lateral. Aunque se conocen desde principios del siglo XX, habían pasado relativamente desapercibidos porque exigen la proximidad física del atacante para realizarlos. Pero gracias a smartphones y drones es sencillo hoy implantar micrófonos y sensores en cualquier lugar para lanzar ataques de canal lateral contra las víctimas. Con el tiempo, estos ataques serán cada vez más fáciles y baratos. Ni siquiera la distribución cuántica de claves se libra de los ataques de canal lateral. Además de los mencionados, continuamente se descubren nuevos ataques: arranque en frío, basados en software, en mensajes de error, ópticos, etc. Existen muchas contramedidas que pueden añadirse a los diseños hardware para contrarrestar estos ataques: inyectar aleatoriedad, añadir ruido, borrar datos, etc. Se trata de una carrera en la que los atacantes van siempre un paso por delante de los ingenieros y que, por desgracia, no tiene final a la vista.
25 de enero de 2021

El cifrado plausiblemente negable o cómo revelar una clave sin revelarla
Cuando la policía secreta detuvo a Andrea en el control del aeropuerto, ella pensó que era un mero trámite reservado a todos los ciudadanos extranjeros. Cuando registraron su equipaje y encontraron el disco USB con todos los nombres y direcciones de los disidentes políticos a los que estaba ayudando a huir del país, se sintió tranquila: el disco estaba cifrado con una clave AES de 256 bits, ni con un supercomputador lo descifrarían en mil millones de años. Cuando la sujetaron desnuda a una parrilla y recibió la primera descarga de 1.000 voltios, sus nervios y músculos se convulsionaron en un estallido de pánico. ¿Cuánto tiempo podría aguantar antes de revelar la clave secreta? Si ella hablaba, ¿cuántas personas más serían torturadas y asesinadas? ¿De qué sirve la criptografía si pueden hacerte revelar la clave? Efectivamente, ni el mejor algoritmo de cifrado del mundo resistirá al criptoanálisis de manguera de goma: ¿para qué molestarse en atacar matemáticamente un algoritmo de cifrado, cuando mediante extorsión, soborno o tortura pueden extraerse las claves de las personas que lo utilizan o administran? Sería maravilloso poder cifrar la información de manera que, si revelas bajo coacción la clave de cifrado, no se descifre con ella la información sensible original, sino un señuelo. Por fortuna, esta asombrosa forma de criptografía existe: se trata del cifrado plausiblemente negable (plausibly deniable encryption). El cifrado plausiblemente negable para descifrar un mensaje u otro en función del escenario Como bien sabes, un algoritmo de cifrado (E) recibe como entradas un mensaje sensible a proteger (el texto claro, m) y una corta ristra aleatoria de bits (la clave, k) y produce como salida un conjunto de bits de aspecto aleatorio (el texto cifrado, c) de aproximadamente la misma longitud que el mensaje: c = Ek( m ) El mismo mensaje m cifrado con la misma clave k produce el mismo texto cifrado c. Por simplificar, en este artículo dejaremos de lado el cifrado con relleno aleatorio que evita precisamente este determinismo. Recíprocamente, el mismo texto cifrado c descifrado con la misma clave k, produce el mismo texto claro m usando el correspondiente algoritmo de descifrado (D): m = Dk( Ek( m ) ) Es en este sentido que se afirma que el cifrado compromete: una vez que has cifrado un texto m con una clave k y compartido el texto cifrado c, los tres valores quedan indisolublemente ligados. Si bajo coacción revelas k, a partir de c se obtendrá el texto original m, perfectamente legible por todos. Si en vez de revelar la clave verdadera k, te inventas cualquier valor k’, entonces el resultado de descifrar c con ella será un texto aleatorio y, por tanto, ilegible, por lo que todos sabrán que no confesaste la auténtica clave: k. De manera que podrán seguir coaccionándote hasta que reveles la verdadera k. Es más, el mero hecho de almacenar o transmitir mensajes cifrados ya es de por sí incriminatorio en según qué escenarios. A un gobierno represivo, a un criminal sanguinario o a una pareja celosa, poseer o enviar información cifrada le hará sospechar que algo tienes que ocultar. El cifrado protege la confidencialidad del mensaje, pero no oculta su existencia. ¿Cómo salir del paso si un adversario intercepta tu información cifrada y exige que la descifres? Ni quieres revelar la información cifrada, ni puedes descifrarlo con una clave errónea que devuelva un texto ilegible. El objetivo del cifrado plausiblemente negable es que el mismo texto cifrado c pueda descifrarse con dos claves distintas, k1 y k2, resultando en dos textos claros diferentes, m1 y m2, ambos perfectamente legibles, pero con un giro fascinante: m1 es el texto sensible cuya confidencialidad realmente deseas proteger, mientras que m2 es un texto legible y plausible, que actúa como señuelo, y que puedes mostrar alegremente para satisfacción del adversario. ¡Ambos creados a partir del mismo c! Cómo conseguir un cifrado negable rudimentario mediante el cifrado XOR Si crees que el cifrado plausiblemente negable es cosa de magia, verás cómo puede lograrse una versión rudimentaria mediante un sencillo ejemplo basado en la libreta de un solo uso. Basta con utilizar la operación XOR, también conocida como suma módulo 2, que representaremos por (+). En este algoritmo, se cifra y descifra de la siguiente manera: Cifrado à c = m (+) k Descifrado à m = c (+) k = m (+) k (+) k = m ya que el XOR de un valor consigo mismo es igual a 0. Partimos de dos mensajes, el sensible m1 y el señuelo m2, y de una clave secreta, k1, tan larga como el mensaje más largo. El texto cifrado c se calcula como: c = m1 (+) k1 La clave k2 se calcula como k2 = c (+) m2 Si c se descifra con k1 se obtiene m1: c (+) k1 = m1 (+) k1 (+) k1 = m1 Mientras que si c se descifra con k2 se obtiene m2: c (+) k2 = c (+) c (+) m2 = m2 ¡El cifrado negable funciona! El adversario no tiene forma de saber si m2 era el mensaje auténtico o una falsificación. Con suerte, quedará satisfecho y dejará en paz a la víctima. Obviamente, se pueden calcular tantas claves y mensajes alternativos a partir de c como se desee. Otro escenario de uso del cifrado negable que nada tiene que ver con la protección ante la coacción es enviar diferentes instrucciones a destinatarios distintos, pero ¡todas ellas contenidas en el mismo texto cifrado! Todos los destinatarios reciben abiertamente el mismo texto cifrado c. Sin embargo, a cada destinatario se entrega una clave ki distinta que descifrará un mensaje mi distinto a partir del mismo c. El destinatario 1 obtendrá el mensaje m1 si descifra c con la clave k1, el destinatario 2 obtendrá el mensaje m2 si descifra c con la clave k2 y así sucesivamente. Ninguno podrá leer el mensaje del otro. Es más, ni sospechará de su existencia. Por supuesto, esta versión resultaría impráctica, ya que requiere claves tan largas como los propios mensajes. Así que los criptógrafos tuvieron que idear algoritmos más eficientes. La mejora incremental del cifrado negable a lo largo de los años El primer algoritmo operativo de cifrado negable fue propuesto en 1997 por R. Canetti, C. Dwork, M. Naor y R. Ostrovsky, basado en la siguiente ingeniosa idea: imagina que el emisor (Alice) y el receptor (Bob) han acordado un cierto método que permite a Alice elegir en algún dominio un elemento o bien de forma totalmente aleatoria o bien de forma pseudoaleatoria, de manera que Bob pueda distinguir la elección aleatoria de la pseudoaleatoria. Cuando Alice quiere transmitir un 1, envía una cadena pseudoaleatoria; mientras que para transmitir un 0, envía una cadena verdaderamente aleatoria. Dado que el adversario no puede distinguir el elemento pseudoaleatorio del aleatorio, Alice puede fingir haber enviado cualquier mensaje. Con los años, se han ido proponiendo numerosos esquemas de cifrado negable, tanto de clave pública como de clave secreta. Estos últimos pueden usarse para cifrar grandes volúmenes de datos, como por ejemplo discos duros completos. Un buen exponente de estos sistemas de cifrado negable aplicado a discos es la herramienta multiplataforma Truecrypt, con sus volúmenes ocultos dentro de volúmenes cifrados. Se basó en el trabajo pionero desarrollado en 1997 por los criptopunks Julian Assange (sí, el de Wikileaks) y Ralf Weinmann, bautizado precisamente Rubberhose File System (sistema de archivos de manguera de goma), en referencia al mencionado método de criptoanálisis. Se han lanzado también herramientas para cifrado negable del contenido de smartphones con Android, como por ejemplo Mobiflage o MobiCeal. La app BestCrypt proporciona la mayor cobertura, ya que funciona en Windows, macOS, Linux y Android. Cuidado con el cifrado negable, que puede delatarte Con todo, el cifrado negable no está exento de riesgos muy serios. Si el adversario está suficientemente versado en criptografía, la mera sospecha de que estés usando un sistema de cifrado negable le motivará a seguir extrayéndote claves. Supón que has usado Truecrypt para cifrar la información de tu disco, dato que no puedes ocultar a una investigación forense digital básica. ¿Se contentará tu adversario con la primera clave que le reveles? Posiblemente te seguirá coaccionando, con manguera de goma u otros medios, para que reveles una segunda clave. Y una tercera. Y una cuarta... ¿Cómo sabrá el adversario que te ha extraído la última clave y no ocultas aún otra más? El cifrado negable puede volverse contra ti en un escenario de criptoanálisis de manguera de goma, porque podría incitar a no parar nunca. En definitiva, el cifrado plausiblemente negable es otra herramienta más que la criptografía pone al servicio de las libertades y derechos civiles. Eso sí, en circunstancias de peligro real de coacción, debe usarse con precaución.
11 de enero de 2021

Escondiendo las claves debajo del felpudo: los Gobiernos podrían garantizar la inseguridad universal
Sonó el timbre de la puerta. "¿Quién llamará a estas horas?", se preguntó Brittney Mills, mientras se levantaba con dificultad del sofá. Sus ocho meses de embarazo empezaban a entorpecer sus movimientos. "Tú no te muevas", le dijo al pasar a su hija de 10 años sentada delante de la TV. Cuando Brittney abrió la puerta, dos balazos la dejaron seca en el suelo. Su hija corrió a esconderse en el baño al oír los disparos. Su bebé murió unas horas más tarde,nunca se encontró al asesino. Las autoridades recurrieron a su iPhone en busca de evidencias incriminatorias, pero no pudieron desbloquearlo. Acudieron a Apple, pero la compañía alegó que no podía entrar en su smartphone porque su contenido estaba cifrado y sin su código de desbloqueo era imposible recuperar las claves. Este caso real, acaecido en abril de 2015 en Baton Rouge, Louisiana, junto a otros muchos, como el del tiroteador Syed Farook, quien asesinó a 14 personas y dejó heridas a 22 en San Bernardino, han enfrentado a las autoridades contra Apple y reabierto un viejo debate: ¿debe la tecnología de cifrado estar disponible para todo el mundo, con el consiguiente riesgo de entorpecer las investigaciones criminales? Puede que no seas consciente de ello, pero usas a todas horas la criptografía más robusta que jamás haya existido Cuando usas apps de mensajería, como Whatsapp, iMessage o Telegram; o aplicaciones de videoconferencia, como Facetime o Zoom; o algunos servicios de correo electrónico, como ProtonMail u OpenPGP; estás usando cifrado de extremo a extremo: la comunicación entre tu dispositivo y el de la otra persona está totalmente cifrada y nadie, ni siquiera el proveedor del servicio, puede enterarse del contenido. Es más, tu información dentro del smartphone está cifrada mediante una clave maestra generada dentro del dispositivo a partir de tu código de desbloqueo y que nunca lo abandona. Igualmente, puedes cifrar tu portátil con una clave maestra derivada de tu contraseña. Al final, resulta que productos de consumo cotidianos incorporan una criptografía tan potente que ya nadie puede romperla. Y claro está, no solo tú usas un smartphone o un portátil, también criminales, terroristas y asesinos. Las autoridades contemplan impotentes cómo en las salas de los tribunales se apilan montañas de smartphones, tablets y ordenadores con evidencia inestimable en su interior… ¡a la que nadie puede acceder! ¿Debería prohibirse la criptografía? ¿Deberían relajarse las medidas de seguridad de los dispositivos tecnológicos actuales? Algunos gobiernos están proponiendo una vía intermedia: custodiar una copia de las claves (key escrow). La idea detrás de la custodia de claves En apariencia, el concepto es bien sencillo: una autoridad de confianza custodia una copia de las claves de cifrado usadas por todos los dispositivos existentes en el país. Es decir, se busca que los malos no tengan acceso a la información de los ciudadanos, pero que los buenos sí la tengan, por supuesto solo en caso excepcional. Existen precedentes ya desde los 90. En aquella época, el gobierno de EEUU aún consideraba la criptografía como munición y, por tanto, su exportación estaba prohibida, salvo que se debilitase a claves de 80 bits. Para la potencia de cálculo de la época no estaba ni tan mal, porque se suponía que nadie más que la NSA podría romperlas. ¿Qué podía salir mal? No hace falta buscar muy lejos. Consideremos el protocolo SSL/TLS. Los navegadores y sitios web se vieron obligados a incluir suites de cifrado con 80 bits de clave. Ya conoces el famoso adagio informático: "si funciona, no lo toques". Así que, 20 años después, TLS seguía soportando las suites debilitadas a pesar de que la restricción de exportación había desaparecido en 2000. Y en 2015 llegaron los ataques FREAK y LogJam, que permitían degradar la seguridad de un sitio web a las suites de cifrado de exportación, volviendo su criptografía tan débil que se rompía en segundos. Irónicamente, los sitios web del FBI y de la NSA también cayeron afectados. Allá por los 90, la NSA también intentó restringir las capacidades criptográficas de los dispositivos de comunicaciones mediante otra vía: el chip Clipper. La idea detrás de Clipper era que cualquier dispositivo telefónico o aparato de comunicaciones que fuese a usar criptografía incorporase el chip Clipper con una clave criptográfica preasignada que luego se entregaría al gobierno bajo custodia. Si alguna agencia gubernamental estimaba necesario intervenir una comunicación, desbloquearía la clave y descifraría la comunicación. Por fortuna, nunca llegó a ver la luz, ya que no fue capaz de cumplir los requisitos exigidos y resultó ser hackeable. Si te pica la curiosidad por la historia de este chip, te recomiendo el capítulo dedicado a su auge y deceso en el libro Cripto, de Stephen Levy. Otra cuestión que surge es: ¿quién custodia la clave? El servidor de claves constituye un punto único de fallo. Si un atacante consigue irrumpir en él, se haría con las claves de toda la población y podría descifrar las comunicaciones de todos los ciudadanos. Obviamente, no parece una buena idea almacenarlas todas en el mismo sitio. Podría obligarse a que cada proveedor de servicio almacenase la de sus clientes, pero ¿cuántos lo harían con seguridad? O podrían repartirse las claves entre varias agencias gubernamentales, de manera que tendrían que aportar cada una su parte de la clave en caso de necesitarse. Por supuesto, implementar un sistema tal de reparto de claves no es para nada sencillo y la clave maestra sigue siendo vulnerable una vez recompuesta. Otra opción sería recurrir a la criptografía con umbral, pero aún está muy verde, lejos de llegar a algoritmos robustos universalmente aceptados. Más aún, aunque existieran dichos algoritmos, la solución elegida obligaría a importantes cambios en los protocolos y aplicaciones criptográficas de todos los productos y servicios. Habría que rescribirlos, con la consiguiente aparición de vulnerabilidades y errores. Además, quedan muchas preguntas en el aire: ¿estos cambios deberán implantarse a nivel de sistema operativo en iOS, Android, Linux, Windows, MacOS, etc.?, ¿todo creador de aplicaciones que usen cifrado estaría obligado a entregar claves bajo custodia?, ¿estarían todos los usuarios obligados a usar estas puertas traseras?, ¿cuánto tiempo tardaría en hacerse la migración?, ¿qué pasaría con las aplicaciones legadas?… Hasta ahora estamos hablando de custodiar la clave como si existiera una única clave por usuario o por dispositivo. La realidad es bien distinta, tanto para cifrado en reposo como para cifrado en tránsito se utilizan multitud de claves que van rotando constantemente, derivadas a partir de claves maestras, que también pueden rotar. No se cifran dos mensajes de WhatsApp con la misma clave. Cada vez que cambias la contraseña o código de acceso a tu dispositivo se actualiza una cadena de claves. En fin, ni siquiera está claro qué clave o claves habría que custodiar ni cómo podrían actualizarse las claves custodiadas para servir de algo en caso de necesitarse. En resumen, citando el completo trabajo de un grupo de criptógrafos de los 90, la custodia de claves impactaría en al menos tres dimensiones: Riesgo: el fallo de los mecanismos de recuperación de claves puede poner en peligro la seguridad de los sistemas actuales de cifrado. Complejidad: aunque sería posible hacer la recuperación de claves razonablemente transparente para los usuarios finales, una infraestructura de recuperación de claves plenamente funcional es un sistema extraordinariamente complejo, con numerosas entidades, claves, requisitos operativos e interacciones nuevas. Costo económico: nadie ha descrito aún, y mucho menos demostrado, un modelo económico viable para dar cuenta de los verdaderos costos de la recuperación de claves. Hasta ahora hemos asumido que el Gobierno solo haría uso de las claves bajo custodia para investigaciones criminales. ¿Qué garantía tienes de que no las usarán contra sus propios ciudadanos? La cosa se complica aún más. ¿Y qué hay de los criminales? Para ellos sería tan sencillo como crear sus propias apps de mensajería o de cifrado de datos con criptografía segura sin revelar a nadie sus claves y santas pascuas. Si obligas a custodiar las claves, solo los criminales usarán claves sin custodiar. En fin, los sistemas de custodia de claves resultan intrínsecamente menos seguros, más costosos y difíciles de usar que los sistemas similares sin una función de recuperación. El despliegue masivo de infraestructuras basadas en la custodia de claves para cumplir las especificaciones de las fuerzas del orden requeriría importantes sacrificios en materia de seguridad y comodidad y un aumento sustancial de los costes para todos los usuarios. Además, la creación de una infraestructura segura de la magnitud y complejidad descomunales que se requerirían para un sistema de esa índole va más allá de la experiencia y la competencia actual en la materia, por lo que bien podría introducir en última instancia riesgos y costes inaceptables. Bastantes fallos de seguridad tienen ya productos y servicios actuales que buscan ser seguros, como para introducir la vulnerabilidad criptográfica por diseño en nuestros futuros productos y servicios. Hasta ahora todos los intentos han fallado miserablemente. Y todo apunta a que seguirían fallando en el futuro.
14 de diciembre de 2020

Qué tendrá de malo la criptografía cuántica que las mayores agencias de inteligencia del mundo desaconsejan su uso
La criptografía cuántica no existe. Lo que todo el mundo entiende cuando se menciona el término "criptografía cuántica" es en realidad la distribución cuántica de claves (Quantum Key Distributrion, QKD). Y de este tema precisamente quiero hablarte hoy: en qué consiste y por qué algunas de las agencias de inteligencia más grandes del mundo han señalado que dista mucho de solucionar nuestros problemas de confidencialidad. La clave de la seguridad perfecta se esconde en la mecánica cuántica La distribución cuántica de claves persigue solucionar todos los problemas del cifrado de Vernam: crear claves aleatorias tan largas como el mensaje a cifrar sin que ningún atacante pueda interceptarlas. Veamos cómo. Recordarás de las lecciones de física del colegio que la luz es una radiación electromagnética compuesta por un chorro de fotones. Estos fotones viajan vibrando con cierta intensidad, longitud de onda y una o muchas direcciones de polarización. Si eres aficionado a la fotografía, habrás oído hablar de los filtros polarizadores. Su función es eliminar todas las direcciones de oscilación de la luz salvo una, como se explica en la siguiente figura. Ahora entras en el laboratorio de física y envías uno a uno fotones que pueden estar polarizados en una de cuatro direcciones distintas: vertical (|), horizontal (–), diagonal a la izquierda (\) o diagonal a la derecha (/). Estas cuatro polarizaciones forman dos bases ortogonales: por un lado, | y –, a la que llamaremos base (+); y, por otro, / y \, a la que llamaremos (×). El receptor de tus fotones utiliza un filtro, por ejemplo, vertical (|). Es evidente que los fotones con polarización vertical pasarán tal cual, mientras que los polarizados horizontalmente y, por lo tanto, perpendiculares al filtro, no pasarán. Sorprendentemente, ¡la mitad de los polarizados diagonalmente atravesarán el filtro vertical y serán reorientados verticalmente! Por lo tanto, si se envía un fotón y pasa a través del filtro, no puede saberse si poseía polarización vertical o diagonal. Igualmente, si no pasa, no puede afirmarse que estuviera polarizado horizontal o diagonalmente. En ambos casos, un fotón con polarización diagonal podría pasar o no con igual probabilidad. Ya tenemos los mimbres para armar un sistema de distribución cuántica de claves, eso sí, sin ordenadores ni algoritmos cuánticos. Recuerda: la criptografía cuántica no existe. Distribución cuántica de claves usando fotones polarizados Supongamos que Alice y Bob quieren acordar una clave de cifrado aleatoria tan larga como el mensaje, de longitud n bits. Primero necesitan acordar una convención para representar los unos y ceros de la clave usando las direcciones de polarización de los fotones, por ejemplo: En 1984 Charles Bennet y Gilles Brassard idearon el siguiente método para hacer llegar la clave totalmente aleatoria de n bits al destinatario sin necesidad de recurrir a otros canales de distribución: Alice le envía a Bob una secuencia aleatoria de 1's y 0's, utilizando una elección aleatoria entre las bases + y ×. Bob mide la polarización de estos fotones utilizando aleatoriamente las bases + y ×. Claro está, como no tiene ni idea de qué bases utilizó Alice, la mitad de las veces estará eligiendo mal la base. Además, algunos fotones no le habrán llegado por errores en la línea. Alice utiliza cualquier canal de comunicaciones inseguro y le cuenta qué base de polarización utilizó para cada fotón que envió, + o ×, aunque no le dice qué polarización concreta. En respuesta, Bob le cuenta a Alice en qué casos ha acertado con la polarización correcta y por lo tanto recibió el 1 ó 0 sin error. Ambos eliminan los bits que Bob recibió con las bases erróneas, quedando una secuencia en promedio un 50% menor que la original, que constituye la clave de una cinta aleatoria 100% segura. ¿Y cómo detectar si un intruso está haciendo de las suyas? Alice y Bob seleccionan al azar la mitad de los bits de la clave obtenida y públicamente los comparan. Si coinciden, entonces saben que no ha habido ningún error. Descartan esos bits y se asume que el resto de los bits obtenidos son válidos, lo que significa que se habrá acordado una clave final de n/4 bits de longitud. Si una parte considerable no coincide, entonces o bien había demasiados errores fortuitos de transmisión o bien un atacante interceptó los fotones y los midió por su cuenta. En cualquier caso, se descarta la secuencia completa y se vuelve a empezar. Como se ha observado, si el mensaje tiene n bits de longitud, en promedio habrá que generar y enviar 4n fotones entrelazados. ¿Y no podría un atacante medir un fotón y reenviarlo sin que se note? ¡Imposible! Según el teorema de no clonación, no puede crearse una copia idéntica de un estado cuántico desconocido arbitrario. Si el atacante mide el estado de un fotón, ya no será un objeto cuántico, sino un objeto clásico de estado definido. Si lo reenvía una vez medido, el receptor medirá correctamente el valor de ese estado solo el 50% de las veces. Gracias al mecanismo de conciliación de claves recién descrito, se puede detectar la presencia de un atacante en el canal. En el mundo cuántico, no se puede observar sin dejar huella. Todo pinta muy bien sobre el papel, pero no convence a las agencias de inteligencia Ya has visto de forma muy, muy simplificada cómo funciona la (mal llamada) criptografía cuántica. Lamentablemente, se anuncia a menudo como la panacea de la criptografía: "el cifrado seguro que las leyes de la Física vuelven irrompible" o "el cifrado que los hackers nunca podrán romper". Sí, sí, con las ecuaciones en la mano, todo pinta muy bonito. El problema es que esas ecuaciones tienen que saltar desde la pizarra al Mundo Real™. Y aquí, señoras y señores, es donde empiezan los problemas. Recientemente, algunas de las mayores Agencias de Inteligencia del mundo han manifestado sus dudas sobre la QKD y desaconsejado su uso. Veamos por qué. Por ejemplo, en EEUU la NSA identificó los siguientes inconvenientes de índole práctica: La distribución cuántica de claves es sólo una solución parcial a nuestros problemas de criptografía. No olvides que la QKD genera material de clave para usar como secuencia cifrante con el cifrado de Vernam o como clave para algoritmos de cifrado clásicos, como AES. Como bien sabes, una cosa es la confidencialidad y otra la autenticación. ¿Cómo sabes que el material de clave que te está llegando procede de la fuente legítima y no de un impostor? La QKD no proporciona un medio para autenticar la fuente de la transmisión QKD, por lo que no queda más remedio que acudir a la criptografía asimétrica o a claves precargadas para proporcionar esa autenticación. Es decir, la criptografía cuántica requiere la criptografía asimétrica que supuestamente la computación cuántica iba a machacar. La distribución cuántica de claves requiere un equipo de propósito especial. Para desplegarla, se necesita equipamiento óptico especial para comunicaciones ya sea de fibra óptica o a través del espacio libre. En la pila de protocolos, la QKD es un servicio de la capa de enlace, lo que significa que no puede implementarse en software ni como un servicio en una red. Y no puede integrarse fácilmente en el equipamiento de la red existente. Dado que la QKD está basada en hardware, también carece de flexibilidad para actualizaciones o parches de seguridad. La distribución cuántica de claves dispara los costos de infraestructura y los riesgos de amenazas internas. Las redes QKD a menudo necesitan el uso de repetidores de confianza, lo que supone un coste adicional para las instalaciones seguras y un riesgo de seguridad adicional por las amenazas internas. Estas limitaciones eliminan de un plumazo muchos casos de uso. Asegurar y validar la distribución cuántica de claves representa un reto importante. A diferencia del hype proclamado por el marketing, la seguridad real que proporciona un sistema de QKD no es ni de lejos la seguridad incondicional teórica de las leyes de la física, sino más bien la seguridad más limitada que puede lograrse mediante diseños de hardware e ingeniería. Sin embargo, la tolerancia al error en la seguridad criptográfica es muchos órdenes de magnitud más pequeña que en la mayoría de los escenarios de ingeniería física, lo que hace muy difícil su validación. El hardware específico utilizado para realizar QKD puede introducir vulnerabilidades, lo que da lugar a varios ataques bien publicitados contra sistemas QKD comerciales. Recomiendo encarecidamente la lectura del artículo negro sobre la criptografía cuántica, breve y bastante asequible, para entender sus problemas reales de implementación. La distribución cuántica de claves aumenta el riesgo de denegación de servicio. ¿Te acuerdas cómo podía detectarse la presencia de un intruso porque crecía el número de errores en la clave y terminaba descartándose? La sensibilidad a una escucha clandestina como base teórica de las afirmaciones de seguridad de la QKD puede convertirse en su propia perdición: la denegación de servicio es un riesgo significativo para la QKD. Y si piensas que la NSA se ha vuelto paranoica, lee lo que opinan en UK: Dado que los protocolos QKD no proporcionan autenticación, son vulnerables a los ataques de intermediario en los que un adversario puede acordar claves secretas individuales compartidas con dos partes que creen que se están comunicando entre sí. La QKD requiere hardware especializado y extremadamente caro. Más que caro. ¡Carísimo! Las distancias a las que QKD puede transmitir claves son hoy por hoy modestas, del orden de unos pocos miles de Km con prototipos experimentales muy delicados, muy lejos de su viabilidad comercial. QKD sirve para acordar claves, pero no para firmar digitalmente información. La criptografía va mucho más allá del cifrado simétrico. Si no usamos criptografía cuántica, ¿cómo nos protegemos de los ordenadores cuánticos? Para la mayoría de los sistemas de comunicaciones del Mundo Real™, la criptografía post-cuántica (PQC) ofrecerá un antídoto contra la computación cuántica más efectivo y eficiente que la QKD. Si bien todavía es pronto para que la mayoría de las organizaciones se pongan a desplegar PQC, hay una cosa que todo el mundo debería hacer: facilitar la transición de su infraestructura criptográfica a una que sea ágil, es decir, una que permita cambiar con relativa facilidad los algoritmos, las longitudes de las claves, etc. Cuando el algoritmo y las longitudes están cableados en el código, el costo y la complejidad del cambio en caso de incidente pueden resultar abrumadores. Resumiendo, si quieres invertir en criptografía, olvídate de la cuántica y empieza a ser cripto-ágil. Lleguen o no lleguen los ordenadores, si eres cripto-ágil estarás preparado para problemas clásicos, cuánticos y los que te echen.
30 de noviembre de 2020

Nonces, salts, paddings y otras hierbas aleatorias para aderezar ensaladas criptográficas
Cuentan las crónicas de los reyes de Noruega que el rey Olaf Haraldsson el Santo disputaba con el vecino rey de Suecia la posesión de la isla de Hísing. Decidieron resolver la disputa pacíficamente con un juego de dados. Tras acordar que la ganaría quien obtuviera la puntuación más alta, lanzó los dados en primer lugar el rey de Suecia. –¡Doce! ¡He ganado! No hace falta que arrojéis los dados, rey Olaf. Mientras agitaba los dados entre sus manos, Olaf el Santo replicó: –Todavía quedan dos seises en los dados y no le será difícil a Dios, mi Señor, hacer que vuelvan a aparecer en mi favor. Volaron los dados y volvieron a salir dos seises. De nuevo lazó los dados el rey de Suecia y de nuevo sacó dos seises. Cuando le llegó el turno a Olaf el Santo, uno de los dados arrojados se partió en dos, mostrando una mitad un 6 y la otra, un 1, sumando un total de 13. Como consecuencia, la titularidad de la isla le fue adjudicada a Noruega y ambos reyes se despidieron como amigos. La aleatoriedad juega un papel fundamental en todos los juegos de azar. Y lo que tal vez te sorprenda más: la criptografía no podría existir sin la aleatoriedad. En este artículo descubrirás cómo se usa la aleatoriedad en criptografía y cómo obtener números aleatorios, tarea, como verás, nada sencilla. ¿Qué es la aleatoriedad? Existen tantas definiciones sobre aleatoriedad que podríamos llenar un libro con ellas. En criptografía es común la siguiente interpretación, que cito de Bruce Scheneier: La aleatoriedad se refiere al resultado de un proceso probabilístico que produce valores independientes, uniformemente distribuidos e impredecibles que no pueden ser reproducidos de manera fiable. Quiero destacar los siguientes tres ingredientes que debe exhibir todo generador de aleatoriedad para usarse con garantías en "ensaladas criptográficas": Independencia de valores: no existe ninguna correlación entre los valores generados. Por ejemplo, si lanzas una moneda (sin trucar) al aire y sale cara nueve veces seguidas, ¿qué es más probable? ¿Cara o cruz en el décimo lanzamiento? Pues la probabilidad sigue siendo 1/2, porque el resultado de un lanzamiento es independiente de los lanzamientos precedentes. Impredecibilidad: aunque te aburras observando valores y más valores, no puedes predecir con probabilidad superior al azar el próximo valor, sin importar lo larga que haya sido la secuencia precedente. Nuevamente, monedas, dados y ruletas constituyen excelentes generadores aleatorios porque, por muchas teorías que elabores, no sabrás qué saldrá a continuación (asumiendo que no están trucados). Distribución uniforme: seguro que mientras leías la crónica del rey Olaf el Santo habrás pensado: «¡Imposible! ¿Cómo van a salir dos seises cuatro veces seguidas?». Y haces bien en dudar, porque la probabilidad de esta secuencia es (1/36)·(1/36)·(1/36)·(1/36) = (1/36)4 = 0,00000059537… o 1 entre 1,67 millones. No es probable que se dé esa secuencia, pero sí es posible. De hecho, si se tiran los dados mil millones de veces aparecería en promedio unas 600 veces. La aleatoriedad tal y como la imaginamos se manifiesta en los grandes números, no en los pequeños números. Cuantos más valores se generen, esperaremos ver todas las secuencias posibles, distribuidas uniformemente, sin ningún tipo de sesgo. El problema con la aleatoriedad es que nunca estás seguro. ¿Estaban trucados los dados de los reyes nórdicos? ¿Coincidió que, mira tú por dónde qué casualidad, esa secuencia improbable se dio ese día? Existen pruebas de aleatoriedad que dictaminan con una confianza muy elevada si un generador es o no aleatorio, pero nunca se puede estar absolutamente seguro. De hecho, existe una amplia gama de conjuntos de pruebas estadísticas (NIST, Test01, Diehard, ENT, etc.) que tratan de descartar las secuencias que no verifican ciertas propiedades estadísticas, aunque no pueden garantizar la perfecta aleatoriedad. Cómo se generan los números aleatorios Sí, pero ¿cómo se generan números aleatorios en un ordenador? Para no complicar las cosas, limitémonos a dos enfoques: Generadores de bits verdaderamente aleatorios (TRNG): requieren una fuente natural de aleatoriedad. Diseñar un dispositivo de hardware o un programa de software para explotar esta aleatoriedad y producir una secuencia de bits libre de sesgos y correlaciones es una tarea difícil. Por ejemplo, se sabe que el ruido térmico de una resistencia es una buena fuente de aleatoriedad. Los TRNGs también pueden recolectar entropía en un sistema operativo en ejecución mediante el uso de sensores conectados, dispositivos de E/S, actividad de la red o del disco, registros del sistema, procesos en ejecución y actividades del usuario como pulsaciones de teclas y movimientos del ratón. Estas actividades generadas por el sistema y por el humano pueden funcionar como una buena fuente de entropía, pero pueden ser frágiles y ser manipuladas por un atacante. Además, son lentas para producir bits aleatorios. Generadores de números pseudoaleatorios (PRNG): por desgracia, la mayoría de las fuentes naturales no son prácticas debido a la lentitud inherente al muestreo del proceso y a la dificultad de asegurar que un adversario no observe el proceso. Además, sería imposible de reproducir, lo que exigiría dos copias de la misma secuencia: una para Alice y otra para Bob, lo que entraña la dificultad casi insalvable de hacérselas llegar a ambos. Por lo tanto, se requiere un método para generar aleatoriedad que se pueda implementar en software y que sea fácilmente reproducible, tantas veces como sea necesario. La respuesta está en los generadores de números pseudoaleatorios: un algoritmo matemático eficiente y determinístico para transformar una cadena corta y uniforme de longitud k, llamada la semilla, en una cadena de salida más larga, de aspecto uniforme (o pseudoaleatorio), de longitud l >> k. Dicho de otra manera: "Un generador pseudoaleatorio utiliza una pequeña cantidad de verdadera aleatoriedad para generar una gran cantidad de pseudoaleatoriedad". Para qué sirve la aleatoriedad en criptografía La aleatoriedad es difícil de generar y difícil de medir. A pesar de todo, es un ingrediente clave para el éxito de cualquier algoritmo criptográfico. Fíjate los diferentes papeles que puede llegar a jugar la aleatoriedad para hacer segura la criptografía. Claves de cifrado: para cifrar un mensaje se necesita una clave de cifrado, tanto para algoritmos de clave secreta como algoritmos de clave pública. Si esta clave es fácil de adivinar, ¡vaya timo! Un requisito fundamental para el uso seguro de todo algoritmo de cifrado es que la clave se seleccione de manera aleatoria (o lo más aleatoriamente posible). De hecho, un problema al que se enfrenta el ransomware es cómo generar claves aleatorias para cifrar los archivos de las víctimas. El mejor algoritmo de cifrado del mundo no vale nada si se desvela la clave. Se recomienda usar un dispositivo hardware para generarlas, como el TPM de los sistemas Windows o un HSM. Vectores de inicialización: los algoritmos de cifrado en bloque se sirven de un valor inicial aleatorio, llamado vector de inicialización (IV), para arrancar el cifrado del primer bloque y garantizar que el mismo mensaje cifrado con la misma clave nunca arrojará el mismo valor, siempre que se use un IV distinto. Este valor puede ser conocido, pero no predecible. Nuevamente, resulta crítico por tanto usar valores aleatorios (e impredecibles) para evitar repeticiones. Una vez más, se recomienda acudir a dispositivos hardware para generarlos. Nonces: un nonce es un número que solo puede usarse una vez (number used once) en un protocolo seguro de comunicación. ¿Y qué utilidad pueden tener estos fugaces nonces? De forma parecida a lo explicado con los vectores de inicialización, los nonces aseguran que aunque se transmitan los mismos mensajes durante una comunicación, se cifrarán de forma completamente diferente, lo que evita los ataques de reproducción o de reinyección. De hecho, los nonces suelen funcionar como IVs: se genera un nonce y se cifra con la clave secreta para crear el IV. Se utilizan además en protocolos de autenticación, como en HTTPS, o para los sistemas de prueba de trabajo, como en Bitcoin. Salts: la sal es otro valor aleatorio usado comúnmente a la hora de almacenar contraseñas en una base de datos. Como sabrás, nunca deben almacenarse las contraseñas en claro: ¡cualquier atacante que accediera a la tabla de usuarios vería las contraseñas! En su lugar podría almacenarse el hash de la contraseña. Pero ¿qué pasará si dos contraseñas son iguales? ¡Darán el mismo hash! Si un atacante roba la base de datos y ve muchos hashes de contraseñas idénticos, ¡bingo! Sabe que son contraseñas facilonas, de las que todo el mundo elige cuando no se esmera. Por otro lado, se pueden precomputar gigantescas tablas de hashes de contraseñas conocidas y buscar esos hashes en la base de datos robada. Para evitar estos problemas, se añade un valor aleatorio: la sal. En adelante, no se guardará el hash de la contraseña, sino la sal y el hash de la contraseña concatenada con la sal: H( contraseña || sal). Por consiguiente, dos contraseñas idénticas darán como resultado dos hashes diferentes siempre que la sal sea aleatoria. Igualmente, ya no sirven de nada los ataques que precalculaban hashes de contraseñas conocidas. Como los nonces, las sales no tienen que ser secretas, pero sí aleatorias. Otra aplicación típica de sales es en funciones de derivación de claves a partir de contraseñas (KDF). Un esquema muy sencillo consiste en repetir n veces el hash de una contraseña y una sal: clave = Hn( contraseña || salt ) Relleno: el famoso algoritmo de cifrado de clave pública RSA es determinista, es decir, el mismo mensaje cifrado con la misma clave arrojará siempre el mismo texto cifrado. ¡Eso no puede ser! Hace falta aleatorizar el mensaje en claro. ¿Cómo? Añadiendo bits aleatorios de manera muy cuidadosa, en lo que se conoce como el esquema OAEP, lo que transforma al RSA tradicional en un esquema probabilístico. Igualmente, para evitar la maleabilidad del cifrado con RSA en las firmas digitales, el esquema PSS añade aleatoriedad. Firmas ciegas: para conseguir que una persona firme digitalmente un documento, pero sin que pueda ver el contenido del documento firmado, se utilizan igualmente valores aleatorios que "ciegan" al firmante, ocultando el contenido del mensaje a firmar. Posteriormente, conocido el valor aleatorio, puede verificarse el valor de la firma. Es el equivalente digital a firmar un documento poniendo encima un papel de calco: impide ver el documento a firmar, pero transfiere perfectamente la firma al documento. ¿Y quién querría firmar algo sin verlo antes? Estos protocolos de firma ciega su utilizan, por ejemplo, en aplicaciones de voto electrónico y de dinero digital. Sin aleatoriedad no hay seguridad Los números aleatorios tienen una importancia capital en criptografía: constituyen la base misma de la seguridad. La criptografía no puede incorporarse a los productos y servicios sin números aleatorios. Un generador de números aleatorios inadecuado puede comprometer fácilmente la seguridad de todo el sistema, como confirma la larga lista de vulnerabilidades debidas a una pobre aleatoriedad. Por tanto, la elección del generador aleatorio debe tomarse cuidadosamente al diseñar cualquier solución de seguridad. Sin buena aleatoriedad no hay seguridad.
17 de noviembre de 2020

Piedra, papel o tijera y otras formas de comprometerte ahora y revelar el compromiso luego
¿Alguna vez has jugado a piedra, papel o tijera? Apuesto a que sí. Bien, vamos a rizar el rizo: ¿cómo jugarías a través del teléfono? Una cosa está clara: el primero en revelar su elección pierde seguro. Si tú gritas «¡piedra!», el otro dirá «papel» y así perderás una y otra vez. La cuestión es: ¿cómo conseguir que los dos os comprometáis a un valor sin revelárselo a la otra parte? En la vida real se usan sobres de papel y cajas para comprometerse con un valor sin revelarlo. Por ejemplo, un juez de un jurado escribe su veredicto en un papel y lo mete en un sobre cerrado. Cuando se abren los sobres, ya no puede echarse atrás. ¿Podrá la criptografía crear un sobre o caja digital, incluso más seguro? ¡Qué pregunta, por supuesto que sí! Veamos cómo jugar a piedra, papel o tijera por teléfono gracias a la criptografía. Creando esquemas de compromiso mediante protocolos criptográficos En criptografía, un esquema de compromiso permite comprometerse a un valor que permanecerá oculto hasta el momento en que deba revelarse y ya no habrá marcha atrás. Usando la analogía de la caja: guardas tu mensaje en una caja cerrada con llave y le entregas la caja a otra persona. Sin la llave, no puede leer tu mensaje. Ni tú puedes cambiarlo, porque la caja está en su poder. Cuando le entregues la llave, abrirá la caja y, entonces sí, podrá leer el mensaje. Como ves con este sencillo ejemplo, un esquema de compromiso consta de dos fases: La fase de compromiso: guardas el mensaje bajo llave en una caja y envías la caja. La fase de revelación: el destinatario de la caja la abre con tu llave y lee el mensaje. Matemáticamente, este esquema puede representarse de la siguiente manera: c = C (r, m) Es decir, el compromiso c es el resultado de aplicar una función C pública a un valor aleatorio r y a un mensaje m. Cuando posteriormente el emisor revele los valores de r y m, el receptor podrá recalcular c y, si coincide con el original, sabrá que no ha habido trampa ni cartón. Para considerarlo seguro, todo esquema de compromiso deberá satisfacer las siguientes dos propiedades: Secreto (u ocultación): al final de la primera fase, el receptor no obtiene ninguna información sobre el valor comprometido. Este requisito debe satisfacerse incluso si el receptor hace trampas. La ocultación protege los intereses del emisor. Sin ambigüedad (o vinculación): dado el mensaje comprometido en la primera fase, el receptor encontrará ese mismo valor en la segunda fase tras la «apertura» legal del compromiso. Este requisito debe cumplirse incluso si el emisor hace trampas. La vinculación protege los intereses del receptor. Una forma sencilla de realizar este esquema digitalmente es usando funciones hash criptográficamente seguras como función de compromiso C. Imagina que nuestros viejos amigos Alice y Bob quieren jugar a piedra, papel o tijera por teléfono. Pueden enviarse la siguiente información usando la función hash genérica H y un valor aleatorio rA, como se muestra en la figura: Al final del protocolo, Bob necesita verificar que el valor del hash hA enviado por Alice es igual al valor H ( rA || «piedra» ) calculado por él mismo. Si ambos valores concuerdan, sabe que Alice no ha hecho trampa. El resultado de este protocolo es que Alice pierde el juego porque el papel envuelve a la piedra. Sigamos el protocolo anterior desde la perspectiva de Alice. Ella primero se compromete con el valor «piedra» enviando a Bob el valor del hash hA. Por su parte, Bob no podrá determinar todavía que Alice se ha comprometido con dicho valor, ya que Bob no conoce el valor aleatorio rA utilizado y Bob es incapaz de invertir la función hash. El hecho de que Bob no pueda determinar qué valor ha sido comprometido es la propiedad de "secreto" (u "ocultación") del esquema de compromiso. Tan pronto como Bob envía su propio valor «papel» a Alice, ella sabe que ha perdido, pero es incapaz de hacer trampa, ya que para engañar a Bob tendría que inventar un valor diferente para el valor aleatorio rA, digamos rA’, que cumpla H( rA’ || «tijera» ) = H( rA || «piedra» ). Pero este fraude implicaría que Alice puede encontrar colisiones en la función hash, lo cual se considera (computacionalmente) imposible (técnicamente, se requiere que la función hash sea resistente a la segunda preimagen). Esta es la propiedad de "sin ambigüedad" (o "vinculación") del esquema de compromiso: que Alice no pueda cambiar de opinión después de la fase de revelación. El uso de hashes como función de compromiso constituye la forma más sencilla de implementar un esquema de compromiso. Sin embargo, en aplicaciones reales, puede requerirse que el compromiso exhiba algunas propiedades especiales, como el homomorfismo, que exigen funciones matemáticas más sofisticadas, basadas en variantes de Diffie-Hellman, ElGamal o Schnorr. Uno de los ejemplos más conocidos es el compromiso de Pedersen, muy simple y con la siguiente propiedad de gran utilidad en muchas situaciones: si has comprometido dos mensajes m1 y m2 a los valores c1 y c2, respectivamente, entonces el producto de los dos compromisos, c1 × c2, es igual al compromiso de la suma de los mensaje m1 + m2. Aplicaciones de los esquemas de compromiso Los esquemas de compromiso están viendo nuevas aplicaciones gracias al desarrollo reciente de novedosos protocolos criptográficos: Al igual que hemos empezado el artículo jugando a piedra, papel o tijera por teléfono, podríamos utilizar versiones de los esquemas de compromiso para cualquier otro juego de azar jugado remotamente: desde tirar una moneda al aire hasta jugar al póker mental y otros juegos de azar. Otra aplicación de los esquemas de compromiso junto con las pruebas de conocimiento nulo es la construcción de bases de datos de conocimiento nulo, en las que se pueden hacer consultas que solo revelan si una propiedad consultada es o no verdadera, como, por ejemplo, si una persona es mayor de edad o si tiene saldo suficiente en su cuenta, pero sin revelar ni su edad ni su saldo. En esta aplicación se utiliza un esquema especial bautizado como compromiso mercurial. Los esquemas de compromiso constituyen asimismo una pieza clave de un esquema de reparto de secretos verificable: la distribución del secreto entre varios individuos va acompañada de compromisos de las partes del secreto que posee cada uno. Los compromisos no revelan nada que pueda ayudar a una parte deshonesta, pero tras la revelación de los compromisos de las partes cada individuo puede verificar si las partes son correctas. Los esquemas de compromiso también se están utilizando en las subastas óptimas y creíbles, en las que el pujador debe comprometerse con el valor de una puja sin posibilidad de echarse hacia atrás. Polyswarm utiliza esquemas de compromiso junto con contratos inteligentes en Ethereum. Polyswarm es un mercado descentralizado de inteligencia de amenazas en el que se incentiva la detección de amenazas poniendo dinero en juego: la moneda virtual Nectar (NCT). Los motores de los distintos fabricantes pueden apostar dinero en función de la confianza en sus propias detecciones. Comprometen su veredicto calculando el hash Keccak sobre la muestra de potencial malware junto con un número aleatorio. Este hash representa su compromiso sobre el artefacto. Después de que un motor se haya pronunciado, ya no hay marcha atrás. Una vez se ha cerrado la ventana de compromiso, durante la cual los motores podían hacer sus predicciones, éstos revelan su veredicto original y su número aleatorio. Los que hicieron evaluaciones correctas son recompensados, mientras que los que fallaron en su predicción pierden sus apuestas. De esta manera, Polyswarm recompensa la participación honesta en el mercado, incentivando la calidad y la detección de malware único. Subastas en línea, juegos de azar por Internet, firma de contratos inteligentes, búsqueda segura en bases de datos, computación multiparte segura, pruebas de conocimiento nulo, … existen multitud de aplicaciones que requieren que la información se oculte de forma segura hasta el momento en que puede ser revelada. A medida que crezca el interés por los entornos de computación pública, como blockchain, los esquemas de compromiso seguirán aportando confianza e impulsarán el florecimiento de nuevas tecnologías seguras.
10 de noviembre de 2020

¿Eres cripto-ágil para responder con rapidez a ciberamenazas cambiantes?
Un negocio se considera ágil si es capaz de responder rápidamente a los cambios del mercado, adaptándose para conservar la estabilidad. Ahora bien, sin criptografía no hay seguridad y sin seguridad no hay negocio. Así que, en última instancia, la agilidad de un negocio vendrá condicionada por su cripto-agilidad. ¿Y qué necesita un negocio para ser cripto-ágil? Ser capaz de adoptar una alternativa al método de cifrado en uso cuando éste se demuestra vulnerable, con el mínimo impacto en la infraestructura de la organización. Cuanto más rápido y automatizado sea el proceso de reemplazo de un algoritmo criptográfico (o de sus parámetros), mayor será la cripto-agilidad del sistema. En criptografía ningún algoritmo es totalmente «seguro», como mucho es «aceptable» La definición de seguridad en criptografía es contingente. Cuando se afirma que un algoritmo se considera seguro, en realidad, lo que se quiere decir es que actualmente no se conoce ningún riesgo de seguridad cuando se utiliza de acuerdo con las directrices adecuadas. La palabra clave aquí es "actualmente", porque lo que se considera seguro hoy, con toda probabilidad, dejará de serlo mañana, debido a avances en computación (¿ordenador cuántico a la vista?), avances en criptoanálisis, avances en hardware y avances en matemáticas. En otras palabras, un algoritmo se considera seguro si computacionalmente resulta inviable romperlo hoy. El descubrimiento de vulnerabilidades en criptosistemas y la retirada de los algoritmos afectados resulta inevitable con el tiempo. Por eso necesitas ser cripto-ágil: para poder actualizar los métodos de cifrado utilizados dentro de los protocolos, sistemas y tecnologías que usas tan pronto se descubran las nuevas vulnerabilidades… ¡o incluso antes de que aparezcan! Y no solo hay que pensar en vulnerabilidades. En el Mundo Real™, la criptografía debe cumplir regulaciones y estándares, lo que en muchos casos exigirá cambios en algoritmos de cifrado y protocolos de comunicaciones. Cómo encontrar la cripto-agilidad El peor momento para evaluar tu criptografía es después de que se haya producido un compromiso con todo el mundo corriendo como pollo sin cabeza. Ser cripto-ágil implica un control completo sobre los mecanismos y procesos criptográficos de tu organización. Ganar este control no es tarea fácil porque, como señala Gartner en su informe Better Safe Than Sorry: Preparing for Crypto-Agility: Los algoritmos criptográficos se rompen «repentinamente», al menos desde el punto de vista del usuario final. A pesar de que se producen crónicas de muertes anunciadas, como la de SHA-1, hay organizaciones que ni se enteran hasta que se produce el incidente, cuando ya es tarde para cambiar el algoritmo por otro sin impacto en la organización. La mayoría de las organizaciones desconocen su criptografía: el tipo de cifrado que utilizan, qué aplicaciones lo utilizan o cómo se utiliza. Los desarrolladores suelen permanecer ciegos a los detalles de las bibliotecas de funciones criptográficas, por lo que programan dependencias criptográficas ignorando la flexibilidad de las bibliotecas. Esto puede hacer que, en caso de incidente, la aplicación de parches o la respuesta sea difícil o impredecible. Los algoritmos de código abierto suelen considerarse seguros debido a que cualquiera puede auditarlo, pero las revisiones de su aplicación real son poco frecuentes. En este contexto, toda organización debería prepararse para lo peor. ¿Cómo? Según Gartner, esta preparación implica: Incluir por diseño la cripto-agilidad en el desarrollo de aplicaciones o en el flujo de trabajo de adquisición de aplicaciones a terceros. Todo software creado internamente deberá cumplir con los estándares de seguridad criptográfica aceptados por la industria, como por ejemplo, la Suite B o FIPS 140-3; o con la regulaciones y normativas vigentes, como el RGPD. Conviene utilizar frameworks de desarrollo, como JCA o .NET, que abstraen la criptografía facilitando la sustitución de unos algoritmos por otros sin alterar el código. Igualmente, existen otros lenguajes y bibliotecas que favorecen la reutilización y sustitución rápida de código criptográfico, los cuales deberían priorizarse frente a alternativas menos flexibles. A la hora de adquirir aplicaciones de terceros, asegúrate de que el proveedor sigue las directrices anteriores. Todo software y firmware debería incluir los algoritmos y técnicas criptográficas más recientes consideradas seguras. Inventariar las aplicaciones que utilizan criptografía e identificar y evaluar su dependencia de los algoritmos. Presta especial atención a los sistemas de gestión de identidad y accesos, a las infraestructuras de clave pública (PKI) en uso en tu organización y a cómo se gestionan las claves. Este trabajo te facilitará evaluar el impacto de una brecha criptográfica y te permitirá determinar el riesgo para aplicaciones específicas y priorizar los planes de respuesta a incidentes. Incluir alternativas criptográficas y un procedimiento de intercambio de algoritmos en tus planes de respuesta a incidentes: por ejemplo, la identificación y sustitución de algoritmos, la ampliación o modificación de las longitudes de las claves y la recertificación de algunos tipos de aplicaciones. En el caso de dispositivos hardware, pregunta al fabricante cómo gestionan los cambios de claves y de algoritmos. Estate preparado por si, en caso de compromiso, necesitas descifrar datos privados con una clave o algoritmo obsoletos para volverlos a cifrar con una nueva clave o algoritmo. Y no olvides incluir a los dispositivos IoT en tu inventario, porque algunos vienen con las claves precargadas y poca flexibilidad criptográfica y se despliegan en campo por muchos años. Vulnerabilidades, regulaciones, ordenadores cuánticos, … El cambio criptográfico acecha desde todas las esquinas. Aplicar estas mejores prácticas aumentará tu cripto-agilidad para reaccionar con rapidez a las ciberamenazas.
20 de octubre de 2020

Cifrado que preserva el formato para garantizar la privacidad de datos financieros y personales
Tu información personal pulula por miles de bases de datos de organizaciones públicas y privadas. ¿Cómo proteger su confidencialidad para que no caiga en las manos equivocadas? A primera vista, la solución parece obvia: cífrala. Por desgracia, en criptografía las cosas nunca son sencillas, cifrar la información así sin más plantea numerosos inconvenientes. Veámoslo con un ejemplo. Inconvenientes del cifrado de datos confidenciales Imagina que un comercio online o tu entidad financiera quieren cifrar tu número de tarjeta de crédito que guardan en su base de datos. Podrían recurrir a la solución estándar de cifrado: usar AES, por ejemplo, en modo CTR con una clave de 128 bits y con un vector de inicialización aleatorio. Si tu número de tarjeta es 4444 5555 1111 0000, el resultado de cifrarlo con AES-128-CTR se muestra en la siguiente tabla, codificado de diferentes maneras habituales: Texto claro4444 5555 1111 0000Texto cifrado en Base64U2FsdGVkX1/Kgcb0V8G++1DWcwyu47pWXflP2CiVda51Ew==Texto cifrado en hexadecimal53616c7465645f5f3601f1e979348111d342c038e9275492a1966fd8659f61a89869Texto cifrado sin codificarSalted__ݺ▒Ii<½║'{☺Éqc»▬@Çþ¶ÔÈ×C♂♦ Como ves, el formato del texto cifrado nada tiene que ver con el formato del texto claro original: Cambia la longitud: el texto cifrado es mucho más largo que el texto claro. Violaría los límites de longitud estándar para tarjetas de crédito impuestos por la base de datos. Cambia el formato: nadie reconocería ese chorizo como un número de tarjeta de crédito. Si un ciberatacante roba la base de datos, no tiene que ser muy avispado para darse cuenta de que lo que está robando no es una tarjeta de crédito lista para usar. Cambia el conjunto de caracteres: no pasaría ninguna validación para el contenido del registro porque contiene caracteres que no son números y no digamos ya en su forma sin codificar, que parece el WhatsApp de un adolescente. El texto cifrado causaría problemas en el esquema de datos. Esta transformación del texto claro en una cadena monstruosa romperá muchos sistemas: No podrás almacenarlo en bases de datos que no estén preparadas para aceptar ese nuevo formato. No podrás transmitirlo por las pasarelas de pago al uso. Tendrás que descifrarlo cada vez que lo usas. No podrás buscar un número de tarjeta determinado en la base de datos para consultar sus operaciones. ¿Te parece poco? Pues no acaban ahí los problemas. Si durante una consulta a la base de datos el valor cifrado se descifra para leerlo y luego se vuelve a cifrar, AES en modo CTR utilizará un nuevo vector de inicialización aleatorio, por lo que el cifrado final no se parecerá en nada al valor cifrado anterior. Como prueba, en esta nueva tabla tienes el mismo valor de tarjeta cifrado con la misma clave, pero con otro vector de inicialización: Texto claro4444 5555 1111 0000Texto cifrado en Base64U2FsdGVkX18OyY1wEH1Co2mFw3nXazm9e6yCGqLLAyTbug==Texto cifrado en hexadecimal53616c7465645f5f09c2cb2e14abda1d21bea9d22e3653e8310e6e8551a94bbf1467Texto cifrado sin codificarSalted__Ñ╬T7¶Í«é¿r═§yG»¬³hºƒð7→{╩e Nada que ver, ¿verdad? Como consecuencia, olvídate de utilizar los datos cifrados como una clave única para identificar una fila en una base de datos porque cambiarán de cifrado a cifrado. En resumen: cifrar los datos que tienen formato muy estricto, como una tarjeta de crédito, plantea una serie de limitaciones prácticas aparentemente insalvables. Pero entonces, si el cambio de formato impide su cifrado, ¿cómo cumplir con las últimas regulaciones, como la GDPR, la PCI DSS o la PSD2? ¿Cómo conservar la confidencialidad de los datos sin perjudicar a la funcionalidad de las bases de datos? ¿Qué solución proporciona la criptografía? La respuesta que han dado los criptógrafos a este dilema se conoce como cifrado de datos con preservación del formato (Format-Preserving Encryption, FPE). FPE extiende los algoritmos de cifrado clásicos, como AES, de manera que los textos cifrados conservan la longitud y el formato originales. Es más, en el caso particular de una tarjeta de crédito, incluso puede hacerse que el valor cifrado pase la comprobación de Luhn. Mira cómo quedaría cifrado el número de tarjeta de crédito anterior usando FPE: Texto claro4444 5555 1111 0000Texto cifrado con FPE1234 8765 0246 9753 Con FPE, una tarjeta de crédito se cifra en una cadena que sigue pareciendo una tarjeta de crédito y pasa todos los controles. Gracias a FPE, los datos ya no causan errores en las bases de datos, ni en los formatos de mensajes, ni en las aplicaciones legadas. ¿Y cuál es la gran ventaja de FPE? Puedes procesar y analizar los datos mientras están cifrados porque seguirán cumpliendo las reglas de validación. Por supuesto, existen numerosos datos muy formateados más allá de los números de tarjeta de crédito que pueden protegerse con éxito mediante FPE: Número IMEI Número de cuenta bancaria Número de teléfono Número de la seguridad social Código postal DNI Dirección de correo electrónico Etc. Estos identificadores los usan rutinariamente todo tipo de industrias: comercio electrónico, financiera, salud, etc. La cuestión es: ¿hasta qué punto resultan seguros estos métodos de cifrado? FPE en el mundo real En 2013 el NIST adoptó en su recomendación SP 800-38G tres algoritmos para cifrar los datos preservando el formato, llamados, respectivamente, FF1, FF2 y FF3. Si tienes curiosidad por el nombre, deriva de usar un esquema de cifrado con mucha solera: el cifrado de Feistel; de ahí que los algoritmos basados en él se llamen Feistel-based Format-preserving encryption o FF. FF2 ni siquiera llegó a ver la luz, ya que fue roto durante el proceso de aprobación. En cuanto a FF3, en 2017 ya le encontraron debilidades, que han sido fortalecidas en su posterior versión FF3-1. De momento, FF1 y FF3-1 aguantan el tipo. A pesar de todo, los algoritmos de FPE aún presentan limitaciones: Los algoritmos de FPE son deterministas: textos claros idénticos darán como resultado textos cifrados idénticos cuando se cifran con la misma clave, a diferencia de lo que ocurre con el cifrado convencional, que suele estar aleatorizado. No obstante, para datos con formatos no tan exigentes, como una dirección de email, sí que puede añadirse fácilmente aleatoriedad, ya que una dirección de correo puede tener cualquier longitud, a diferencia de, por ejemplo, un número de teléfono que siempre tendrá 9 dígitos. Los esquemas de FPE no proporcionan integridad de datos (no tienes garantía de si el dato cifrado ha sido alterado) ni autenticación del emisor (no tienes garantía de quién cifró el dato). En definitiva, FPE continúa como un problema de investigación abierto, en el que veremos aún muchos avances tanto en criptoanálisis (romper algoritmos) como en la creación de otros nuevos más potentes.
6 de octubre de 2020

El futuro de las firmas digitales para proteger tu dinero está en la criptografía con umbral
Imagina que fueras una persona tan moderna, tan moderna, que todo tu dinero lo tuvieras en criptodivisas en lugar de en un banco tradicional. Si has manejado criptodivisas, sabrás que suelen gestionarse a través de apps de criptomonedero. Su misión es facilitar las operaciones típicas de realizar transacciones y consultar saldos, pero no almacenan criptodivisas. Por encima de todo, poseen la misión crucial de firmar con tu clave privada. En esencia, ¿qué es un criptomonedero? ¡Un interfaz para tu clave privada! Sí, esa clave privada es como las llaves del reino: da acceso a todo tu dinero. Cualquiera que la conozca, podrá limpiarte los bolsillos. Si la pierdes, no podrás recuperar tu capital. Por consiguiente, tendrás que protegerla muy bien. ¡Y no es tarea fácil! En este artículo, pasaré revista a las alternativas tradicionales y las nuevas que están emergiendo para garantizar la seguridad de las firmas digitales. Eso sí, para evitar entrar en detalles matemáticos, a lo largo del artículo usaré una sencilla analogía. Imagina que cada unidad de criptomoneda está protegida dentro de una caja fuerte con un candado que solo puede abrirse con la llave del propietario de esa criptomoneda. Las criptomonedas no se mueven realmente entre cajas, sino que siempre están en su propia caja fuerte. Cuando transfieres monedas de una a otra, en lugar de enviarlas, en realidad es como si solo cambiaras los candados de una caja a otra. Por ejemplo, cuando Alice le transfiere dinero a Bob, en realidad sólo quita su candado de la caja abriéndolo con su llave y le pone en su lugar el candado de Bob. Bob puede quitarlo más tarde con su llave y así sucesivamente. Imagina que cada persona tiene infinitos candados, de manera que cualquiera puede ponerle a una caja cualquiera el candado de otra persona, pero solo el dueño del candado puede abrirlo con su llave. ¿Entendido? ¡Vamos allá! Yo me lo guiso, yo me lo como: duplicado de claves La solución más sencilla y extendida actualmente para asegurar tu llave consiste en hacer muchas copias de tu llave y guardarlas en muchos sitios distintos, así te aseguras de que no la perderás. El problema evidente es que cuantas más copias hagas de tu llave, mayor será la oportunidad de que un atacante se haga con una de ellas. Podrías confiar copias de tu llave a otras personas, seguro que tu cuñado se ofrece a guardártela. Pero si lo piensas bien, lo único que consigues es cambiar de sitio el problema. Primero, ¿hasta qué punto te puedes fiar de su honestidad? Segundo, por muy buenas intenciones que tenga, ¿hasta qué punto puedes confiar en sus buenas prácticas? No, el duplicado no parece una buena idea. Ilustración 1. Caja fuerte tradicional: un candado, una llave. Lo bien repartido, bien sabe: multifirmas (multisig) Otro enfoque más prometedor consiste en repartir entre varias personas la responsabilidad de custodiar la llave y abrir el candado. En vez de que la caja tenga un único candado, la nueva caja tendrá varios candados y cada persona autorizada recibirá una llave distinta, cada una para su candado. A partir ahora, harán falta varias llaves para abrir los varios candados de la caja. Es lo que se conoce como multifirma o Multisig. Multisig evita el punto único de fallo anterior porque, al protegerse la caja con varios candados, será más difícil que se vea comprometida: ya no basta con una llave, se necesitan varias para abrir la caja. Para flexibilizar las operaciones, se suelen emplear esquemas M-de-N: se le ponen N candados a la caja con la peculiaridad de que para desbloquearla solo hace falta abrir M, donde M es menor o igual que N. Parece magia, ¿verdad? Por ejemplo: Con tu pareja podéis usar una multifirma 1-de-2 para que cualquiera de los dos pueda abrir la caja. Si uno pierde la llave, el otro aún podrá abrir la caja. Pero si un atacante roba cualquiera de las dos llaves, también podrá abrirla. Y si tu pareja es una persona manirrota, ¡nada impide que vacíe la cuenta! Con una multifirma 2-de-2, ahora los dos tenéis que abrir la caja. Así os protegéis el uno del otro y un atacante tendrá que robar ambas llaves, ya que una sola no abrirá la caja. Estas multifirmas también sirven para autenticación multifactor: podrías tener una llave en tu ordenador y otra en tu smartphone. Sin acceso a ambos dispositivos, la caja no se abre. Con multifirma 2-de-3, si tenéis un hijo, podríais entregarle una llave y los padres os quedáis con las otras dos. El chaval os necesitará a cualquiera de los dos para abrir la caja, ya que solo con su llave no podrá. Con un esquema 4-de-7, varias personas en un equipo o en un comité tendrán que cooperar para abrir la caja. Resultan muy apropiados para desplegar políticas corporativas. Y todos los escenarios que puedas imaginar. El problema de Multisig es que requiere una caja más grande para poder acomodar varios candados y además cualquiera que pase por delante notará una medida de protección inusual: "Hmm, ¿qué tendrá dentro? Vamos a seguirle la pista". Por otro lado, el coste de las transacciones también se incrementa porque hay que añadir la información de cada firmante a la cadena de bloques. Ilustración 2. Caja fuerte Multisig: dos candados, dos llaves. Tacita a tacita: esquema de reparto de secretos de Shamir (SSSS) Aquí también se reparte la responsabilidad de la custodia de las llaves y de abrir las cajas, pero en lugar de crear varios candados que se abren cada uno con su llave, se crea un solo candado de aspecto normal y es la llave la que se divide en partes que son entregadas a cada uno de los participantes. Además, el candado tiene una peculiaridad: puede abrirse con un número M de partes de la llave inferior al número total N de partes en que se dividió al forjarla. Técnicamente, se utiliza lo que se conoce como esquema de reparto de secretos de Shamir (Shamir's Secret Sharing Scheme, SSSS). El reparto de Shamir también permite operar con esquemas M-de-N, para flexibilizar el acceso, al igual que con Multisig. Ahora la caja parece normal desde fuera, ya que se protege con un único candado. Su problema es que, antes de abrir la caja, los participantes reconstruyen la llave juntando cada uno su parte. En este instante, justo cuando acaba de reconstruirse la llave, se vuelve vulnerable al robo. Por otro lado, en SSSS alguien tiene que crear la llave en primer lugar para luego hacerla trocitos y repartirlos. Ahí aparece otra ventana de oportunidad para que un atacante robe la llave antes de que sea dividida. Más aún, hay que fiarse de esta tercera parte, pues ¿quién garantiza que no conserva una copia de la llave completa? Ilustración 3. Caja fuerte SSSS: un candado, una llave dividida en dos. Firmando desde el umbral ¿Y no se podría tener varias llaves distintas y un solo candado? Es decir, ¿no existirá algún método que combine lo mejor de Multisig con las bondades de SSSS? Sí, existe. Se llaman esquemas de firma con umbral (Threshold Signature Scheme, TSS), basados en la criptografía con umbral, una subdisciplina de la computación multi-parte segura. En el esquema de firmas con umbral, cada usuario crea su propia llave (que nadie más conoce) y luego se juntan para forjar entre todos un candado de apariencia completamente normal. El truco está en que este candado especial puede abrirse cuando cada una de las N llaves (o un subconjunto M de ellas) van haciendo girar por turno un poco la cerradura, hasta que entre todas consiguen darle la vuelta completa. Una gran ventaja de TSS es que las llaves no se juntan nunca, por lo que se evitan las ventanas de oportunidad de SSSS. Otra característica de seguridad adicional es el "refresco": cada cierto tiempo preestablecido, las llaves se refrescan para evitar que un atacante vaya robando una por una M de las N llaves creadas y con las M abrir el candado. Otra ventaja de las firmas con umbral es que se pueden revocar llaves o crear otras nuevas sin cambiar el candado, para aquellas situaciones en las que entren nuevos participantes o salgan del grupo, situación típica en entornos corporativos. Como contrapartida, TSS exige que todas las partes estén presentes al forjar el candado y al abrirlo, por lo que este protocolo no puede ejecutarse asíncronamente. Además, aún está muy verde, todavía se están haciendo propuestas criptográficas y ha habido hasta un ataque con éxito contra una de las propuestas. Ilustración 4. Caja fuerte TSS: un candado, dos llaves. El futuro de las firmas digitales ya está aquí La disciplina de las firmas con umbral es un campo reciente, con numerosas propuestas, aún lejos de alcanzar la madurez de los esquemas de firma convencionales, como ECDSA. De momento, TSS está aportando a los usuarios seguridad de doble factor para el acceso a las claves privadas o el reparto de la capacidad de firmar entre varios dispositivos para que un solo dispositivo comprometido no ponga en riesgo todo tu dinero. En el caso de empresas, TSS permite implantar políticas de control de acceso que impiden tanto a los que están dentro como a los que están fuera robar fondos corporativos. Gracias a las firmas con umbral, la clave privada dejará de ser un único punto de fallo.
22 de septiembre de 2020

Blockchain, criptomonedas, zkSTARKs y el futuro de la privacidad en un mundo descentralizado
En la Italia renacentista eran comunes los duelos entre matemáticos, pero no cruzando aceros, sino problemas de difícil resolución. Uno de los huesos más duros de roer en la época fueron las ecuaciones cúbicas. Conocer el método para su resolución confería una ventaja enorme en estos duelos, en los que los dos matemáticos duelistas se jugaban no solo su prestigio sino jugosas recompensas y a veces hasta la cátedra. Uno de los enfrentamientos más famosos fue protagonizado por los matemáticos Niccolo Fontana, apodado Tartaglia por su tartamudez, y Girolamo Cardano. En 1535, en un duelo contra otro matemático, Antonio Maria del Fiore, Tartaglia aplastó a su rival tras resolver 30 cuestiones relacionadas con ecuaciones cúbicas, mientras que del Fiore no resolvió ni uno solo de sus 30 problemas. Había quedado demostrado, más allá de toda duda razonable, que Tartaglia conocía un método para resolver cúbicas, sin que hubiera revelado el método en sí. Impresionado por su victoria, Cardano le ofreció a Tartaglia encontrarle mecenas si le revelaba el codiciado método de resolución de ecuaciones cúbicas. Tartaglia accedió en 1539, bajo promesa de que no lo publicara jamás. Seis años después, Cardano lo publicó en su obra Ars Magna, alegando que lo había aprendido de otro matemático, Scipione del Ferro, y desatando la ira de Tartaglia. Éste retó a Cardano a un duelo matemático, al que acudió su discípulo, Lodovico Ferrari, quien derrotó a Tartaglia. Como resultado, Tartaglia acabó sin prestigio y sin blanca. En el mundo de la seguridad de la información surgen multitud de escenarios similares en los que una entidad conoce un secreto y necesita probar a otra entidad que lo conoce, pero no es conveniente que le revele el secreto ni ninguna información parcial sobre el secreto: ¿Quién gana más dinero, tu cuñado o tú? ¿Cómo podéis demostrarlo para satisfacción de toda la familia, pero sin que ninguno de los dos revele la cifra? ¿Cómo demostrar la legitimidad de una transacción en una Blockchain pública, pero sin revelar ni emisor, ni receptor, ni valor transferido? ¿Cómo demostrarle a una app instalada en tu smartphone que conoces la contraseña para autenticarte ante un sitio web, pero sin proporcionarle la contraseña a esa app, ni a tu smartphone, ni, incluso, al sitio web? ¿Cómo puedes probar que eres mayor de edad para acceder a un servicio para adultos, pero sin revelar tu edad? ¿Cómo puedes demostrar que eres ciudadano de la Unión Europea para acceder a un servicio de salud comunitario, pero sin que se sepa de qué nacionalidad? ¿Cómo puedes convencer a una app de pagos de que tienes fondos suficientes en tu cuenta para una transacción, pero sin divulgar tu saldo? ¿Cómo puede convencer un estado a otros de que ha destruido su arsenal militar nuclear sin dejar que inspectores neutrales entren en sus instalaciones? ¿Cómo votar electrónicamente de manera que se recuente tu voto, pero sin saber a quién has votado? ¿Cómo demostrar que un teorema es correcto sin proporcionar su prueba matemática? ¿Cómo demostrar que conoces la solución al sudoku más complicado del mundo, sin desvelarla? Afortunadamente, la criptografía aporta una respuesta para estos y otros muchos dilemas parecidos: las pruebas de conocimiento nulo (Zero Knowledge Proof, ZKP). Veamos con dos ejemplos mundanos cómo funcionan estas pruebas. Pruebas de conocimiento nulo interactivas y no interactivas Tu cuñado asegura ser capaz de distinguir a simple vista el agua bendita de Lourdes del agua del grifo, pero la verdad es que tú no te fías mucho de sus poderes místicos. Imagina que tenéis dos vasos llenos de agua, uno de Lourdes y el otro del grifo. ¿Cómo puede probarte tu cuñado que sabe cuál es cuál sin ni siquiera revelarte cuál es cuál? ¡Muy fácil! Basta con seguir los siguientes pasos: Le vendas los ojos y lanzas una moneda al aire. Si sale cara, intercambias la posición de los vasos; si sale cruz, los dejas como están. Le quitas la venda y le preguntas si los vasos han sido intercambiados o siguen en el mismo lugar. Obviamente, no basta con desafiar a tu cuñado una sola vez, ya que podría acertar por pura casualidad el 50% de las veces. En cambio, si de verdad posee clarividencia, acertará el 100% de las veces. Por tanto, si repetís los dos pasos de la prueba n veces, la probabilidad de que tu cuñado siempre acierte por puro azar se reduce a p = (1/2)n. Por ejemplo, si es Nochevieja y no echan nada en la TV, podríais repetir la prueba 100 veces, con lo que p = 7,38×10‒31, o sea, prácticamente nula. Este protocolo para la identificación de los vasos es un ejemplo de sistema de prueba interactivo: un probador (tu cuñado) y un verificador (tú) intercambian múltiples mensajes (retos y respuestas), típicamente dependientes de números aleatorios (idealmente, los resultados de lanzamientos de monedas no trucadas), hasta que el probador convence (prueba al verificador) la verdad de una afirmación, con una probabilidad abrumadora. Un problema (o ventaja, según se mire) de estas pruebas interactivas es que solo el verificador queda convencido por la prueba. Tu hermana podría pensar que tu cuñado y tú os habéis conchabado para animar la cena de Nochevieja y habéis acordado de antemano los intercambios de vasos. La única forma de que el probador probara a otra persona que conoce el secreto es que esa otra persona actuara a su vez como verificador, proponiendo intercambios de vasos al azar. Y así con todas y cada una de las personas a las que tu cuñado quiera convencer de que conoce el secreto. ¡Qué agotador! ¿Cómo convencer a todos a la vez en un solo paso? Existen otros protocolos más eficientes que permiten probar el conocimiento del secreto en un solo paso y para satisfacción de un número arbitrario de observadores. Se conocen como pruebas de conocimiento nulo no interactivas. Por ejemplo, imagina que se ofrece un premio millonario por resolver un sudoku y ¡tú lo has resuelto! Pero tu cuñado, quien persigue la gloria más que el dinero, está dispuesto a pagarte el doble por su solución. ¿Cómo puedes probarles a la vez a él y a todos sus parientes que conoces la solución, pero sin que la vean antes de pagar por ella? ¿Tienes a mano unas cuantas barajas de cartas? ¡Entonces será fácil! En un sudoku hay nueve filas, nueve columnas y nueve cajas. En cada una de estas agrupaciones tienen que aparecer los nueve valores del 1 al 9. En total, cada número aparece 9 veces. Si dispones de siete barajas idénticas puedes seleccionar 27 cartas para cada número, sin importar el palo: 27 ases, 27 doses, …, 27 nueves, un total de 243 cartas. Dibujas con rotulador indeleble sobre el mantel del ajuar de la abuela el sudoku del concurso, de manera que sobre cada número dado (son las pistas o números conocidos) colocas tres cartas boca arriba del valor correspondiente. Pides a todos que salgan de la sala y colocas en secreto boca abajo tres cartas con el valor adecuado sobre cada casilla por resolver. Una vez colocados todos los montoncitos de tres cartas, pides que entren todos de nuevo y ¡empieza la magia! Primero, retiras una carta de cada fila y haces nueve montones con las nueve cartas de cada fila. A continuación, retiras una carta de cada columna y haces nueve montones con las nueve cartas de cada columna. Por último, haces nueve montones con las nueve cartas de cada caja. Barajas bien por separado cada uno de los 27 montones y extiendes boca arriba las cartas de cada montón sobre la mesa. Si conocías la solución al sudoku, ¡cada uno de los 27 montones contendrá nueve cartas del 1 al 9! Arrebatados por el júbilo, tu cuñado te hace un bizum y la abuela olvida el disgusto del mantel. Este ejemplo demuestra cómo funciona en la práctica una prueba de conocimiento nulo no interactiva. Resultan cruciales cuando se busca que un gran número de verificadores verifiquen eficientemente una prueba. Todo esto está muy bien para entretener a la familia en Nochevieja, pero ¿para qué sirven en el mundo real? La idea de ZKP fue propuesta hace más de 30 años por los criptógrafos Goldwasser, Micali y Rackoff del MIT. Se consideró tan revolucionaria que mereció el primer Premio Gödel en 1993 y el Premio Turing en 2012. Sin embargo, no vio ninguna aplicación práctica en la industria… ¡hasta hoy! ZKP fue durante décadas un poderoso martillo en busca de clavos y por fin los clavos están apareciendo con la progresiva descentralización de servicios gracias a las cadenas de bloques (blockchain). Cadenas de bloques y pruebas de conocimiento nulo en el mundo real No, Bitcoin, Litecoin, Ethereum, incluso Monero, no son anónimos como el dinero contante y sonante, sino pseudoanónimos, o sea, que las transacciones dejan rastro en la cadena de bloques pública. Sin embargo, no todas las criptomonedas son pseudoanónimas: el uso más prominente de las ZKP hasta ahora es ZCash, una de las criptodivisas más populares, que permite transacciones anónimas. Concretamente, ZCash utiliza pruebas de conocimiento nulo no interactivas sucintas (Zero-Knowledge Succinct Non-interactive ARgument of Knowledge, zkSNARK), que permiten probar el conocimiento de un secreto en milisegundos mediante un único mensaje enviado por el probador al verificador. Gracias a las zkSNARK, en ZCash la única información registrada tras un pago es que se ha realizado una transacción válida: no queda información sobre el remitente, el destinatario o el importe. Ethereum también ha comenzado a integrar las zkSNARK, concretamente en forma de contratos precompilados. Un contrato inteligente es básicamente un depósito de fondos que se activa una vez que se realiza una tarea determinada. Por ejemplo, tu cuñado pone 100 ETH en un contrato inteligente contigo, de manera que cuando completes la tarea acordada, obtendrás los 100 ETH del contrato inteligente. ¿Y si la tarea que tienes que hacer es confidencial y no quieres revelarle sus detalles a tu cuñado? Gracias a zkSNARK, Ethereum prueba que la tarea del contrato inteligente se ha completado sin revelar cuáles son sus detalles. En principio, las zkSNARK pueden aplicarse a cualquier tipo de blockchain, en una capa de seguridad de conocimiento nulo (Zero-knowledge Security Layer, ZSL), útil en multitud de casos de uso en cualquier empresa. Uno de los más interesantes es la identidad descentralizada. Blockchain, identidad descentralizada y pruebas de conocimiento nulo Nuestros datos personales se han convertido en la mercancía con la que comercian los gigantes tecnológicos para manipular nuestro comportamiento a través de la publicidad y de las redes sociales. Las zkSNARK y Blockchain pueden trabajar muy bien en conjunto, aportando privacidad, seguridad y transparencia a la hora de intercambiar y verificar información, en áreas como el cuidado de la salud, las comunicaciones y las finanzas. El truco reside en las soluciones de identidad basadas en cadenas de bloques. Tradicionalmente, una miríada de servidores pertenecientes a organizaciones públicas o privadas almacenan y comparten datos sobre tu persona, como DNI, fecha de nacimiento, saldo en la cuenta bancaria, contraseña (o su hash), grado de discapacidad, nacionalidad, contactos, número de teléfono, etc. En cambio, en una solución descentralizada se almacenan credenciales verificables: permiten realizar sencillas operaciones sobre ellas, pero sin ver su valor. Por ejemplo: ¿eres mayor de edad?, ¿puedes aparcar en la plaza para discapacitados?, ¿tienes fondos para este pago?, ¿puedes volar a este país?, ¿conoces la contraseña para iniciar sesión?, etc. De esta forma, el servicio no obtiene ningún conocimiento sobre tu persona, ¡porque tu información personal no se envía en ningún momento! Por consiguiente, no puede robarse, no puede compartirse ilícitamente, no puede comerciarse con ella. Tú eres dueño y señor de tus datos. Corda de R3 es un buen ejemplo del trabajo que se está haciendo en esta línea. Afianzando el futuro de las ZKP No creas que es oro todo lo que reluce. Las zkSNARK también presentan sus puntos débiles, entre ellos, los tres mayores son: Dependen de una configuración inicial de confianza entre probador y verificador: se requiere un conjunto de parámetros públicos para construir las pruebas de conocimiento nulo y, por lo tanto, transacciones privadas. Estos parámetros son tan críticos que suelen generarse por un grupo muy pequeño en el que se deposita confianza absoluta, lo que crea un posible problema de centralización. Por ejemplo, en Zcash esta fase inicial de configuración se conoce como la Ceremonia de Generación de Parámetros. La escalabilidad de las zkSNARK puede mejorarse: a medida que aumenta el tiempo de ejecución, aumenta el tiempo necesario para generar y especialmente verificar las pruebas. La criptografía subyacente está basada en curvas elípticas, lo que las vuelve vulnerables a la computación cuántica. La superación de estas debilidades llegó en 2018 de la mano del criptógrafo Eli-Ben Sasson, inventor de las pruebas de conocimiento nulo no interacticas transparentes y escalables (Zero-Knowledge Scalable Transparent ARguments of Knowledge, zkSTARK). Estas pruebas son transparentes en el sentido de no requerir una configuración inicial de confianza porque se basan en una criptografía más sencilla a través de funciones de hash resistentes a colisiones. Este enfoque también resulta computacionalmente menos costoso y, por tanto, más escalable. Y además es resistente a los ataques de los futuros ordenadores cuánticos por apoyarse en criptografía post-cuántica. Uno de sus inconvenientes es que el tamaño de la prueba es mayor, lo que podría resultar limitante en según qué aplicaciones. Sasson ha fundado una empresa alrededor de las zkSTARK, STARKWARE, para mejorar la escalabilidad y privacidad de las tecnologías de cadena de bloques. Por supuesto, las cadenas de bloques no son el único ámbito de aplicación de las pruebas de conocimiento nulo. Recientemente se constituyó ZKProof, una iniciativa abierta que aúna a la academia y la industria, para promover el uso seguro, eficiente e interoperable de las tecnologías de prueba de conocimiento nulo. Su misión principal es estandarizar protocolos para facilitar su adopción por la industria. El dato por fin bajo control del usuario Las pruebas de conocimiento nulo albergan un inmenso potencial para devolver a la gente el control de sus datos, permitiendo a otros verificar ciertos atributos de esos datos sin revelarles los datos mismos. Sin duda, las ZKP presentes y las que están por venir causarán un enorme impacto en las finanzas, el cuidado de la salud y otras industrias, al permitir todo tipo de transacciones al mismo tiempo que se salvaguarda la privacidad de los datos.
7 de septiembre de 2020

Cómo seguir contagios de la COVID-19, descubrir contactos en WhatsApp o compartir tus genes respetando tu privacidad
Cuando te das de alta en una nueva red social, como WhatsApp, se te suele preguntar si quieres averiguar quiénes de entre tus contactos ya forman parte de dicha red social (contact discovery). Pero si tú no quieres proporcionar tu lista completa de contactos, ¿cómo saber si alguno está en la red social sin compartir tu agenda? Los países de medio mundo están desarrollando apps de seguimiento de contagios de la COVID-19. En España, por ejemplo, se puso en marcha el piloto Radar COVID en la isla de La Gomera a finales de junio. Estas apps despiertan muchos recelos en cuanto a la privacidad. ¿Sería posible descubrir si has estado en contacto con alguna persona contagiada sin que ni tú ni el servidor sepáis quién es exactamente? O imagina que un laboratorio ha descubierto un fármaco contra la COVID-19 que funciona solamente con las personas que poseen unos determinados genes. ¿Cómo puede saber el laboratorio si posees esos genes sin que tú le reveles todo tu genoma ni el laboratorio te revele cuáles son esos genes específicos? ¿Qué está pasando? El Big Data y la computación en la nube están dando origen a multitud de situaciones en las que dos partes poseen cada una un conjunto de datos que desea compartir con la otra para encontrar la intersección entre ambos conjuntos. Eso sí, sólo revelando los datos en común. Se trata de un viejo problema de la criptografía conocido como Intersección Privada de Conjuntos (Private Set Intersection, PSI) que está experimentando un fuerte resurgimiento. Además de los tres escenarios ya mencionados, existen muchos otros casos de uso: Una empresa desarrolla una app de diagnóstico remoto de la COVID-19 con una precisión extraordinaria a partir de una lista de síntomas proporcionada por el paciente. El paciente no desea revelar sus síntomas a la empresa ni la empresa desea revelar a nadie qué síntomas usa para el diagnóstico. La misma persona recibe atención médica en distintas localidades. Las distintas administraciones desean saber qué pacientes han visitado centros de salud de otras comunidades sin revelar una a otra su lista de pacientes. Con el fin de llevar a cabo una operación internacional, varios organismos de ciberseguridad nacionales desean encontrar la intersección entre sus bases de datos de IPs delictivas sin revelarse unos a otros sus listas completas de IPs. Una agencia de publicidad envía un anuncio online a un grupo de usuarios. Algunos de estos usuarios posteriormente compran el producto en una tienda física. La agencia desea encontrar la intersección entre el conjunto de los usuarios que vieron el anuncio del producto y los que lo compraron en tiendas físicas (online-to-offline ad conversions). Una empresa de comida sana sirve comidas a muchos empleados de otra empresa, la cual les realiza pruebas médicas dos veces al año. La empresa de restauración desea saber si los empleados que han bajado el colesterol en el último año consumieron su comida, pero la otra empresa no quiere (ni debe) revelar los datos de salud de sus empleados. Cuanta más tracción ganan la nube y el Big Data, más casos de uso nuevos surgen cada día: detección de botnets, identificación de tramposos en juegos online, compartición de ubicaciones, descubrimiento de credenciales comprometidas, etc. La necesidad de realizar esta intersección de conjuntos de forma privada ha quedado clara, pero la cuestión es: ¿cómo lograrlo? La criptografía ofreció numerosas técnicas de PSI, desde la solución naive con funciones de hash a los protocolos con terceras partes semiconfiables y los protocolos que sólo involucran a dos partes. Veamos someramente cómo funcionan. La solución naive con funciones de hash Consiste en comparar los hashes de cada elemento de ambos conjuntos. Si dos hashes coinciden, entonces se ha producido un ajuste. Este enfoque, que fue usado por WhatsApp en su día, es sencillo y rápido, pero no es seguro porque con un conjunto de datos pequeño o con una baja entropía, como por ejemplo números de teléfono, es perfectamente factible realizar un ataque de fuerza bruta, calculando los hashes de todos los posibles elementos. De esta forma, armado con la lista de hashes de todos los teléfonos, WhastApp no sólo sabría los contactos que compartís, ¡sino los números de teléfono de todos tus contactos! Igualmente, este enfoque tampoco sirve para comparar DNIs, identificadores sencillos, nombres, etc. Sólo aporta seguridad cuando los datos a comparar son aleatorios o poseen una alta entropía. PSI basado en terceras partes semiconfiables Otro enfoque más robusto consiste en hacer pasar cada uno de los elementos de los conjuntos por la misma función HMAC con una clave secreta que las dos partes, Alice y Bob, han acordado previamente. Envían sus datos aleatorizados a la tercera parte, Trent, quien les devuelve a cada uno el conjunto intersección. Como Alice y Bob han conservado cada uno una tabla privada con las salidas de la función HMAC para cada dato de sus conjuntos respectivos, pueden buscar en esta tabla los ajustes y determinar qué elementos comparten. La máxima información filtrada a Trent es la cardinalidad del conjunto intersección, es decir, cuántos elementos poseen en común Alice y Bob; y la cardinalidad de los conjuntos de Alice y Bob, ya que Trent sabrá si alice tiene más elementos en su conjunto que Bob o viceversa. Por supuesto, Trent podría resultar ser malicioso e intentar engañar a Alice y Bob, por ejemplo, devolviendo un conjunto intersección diferente al real. Por fortuna, existen sencillos ajustes a este protocolo para evitar este tipo de manipulaciones por parte de Trent. Lo que nunca descubrirá son los datos de Alice y Bob. PSI basado en dos partes ¿Qué pasa si no quieres depender de una tercera parte? No hay problema. Existen multitud de enfoques alternativos en los cuales sólo interactúan las dos partes implicadas que quieren encontrar la intersección entre sus conjuntos. Uno de los primeros enfoques propuestos y conceptualmente más sencillos se basa en las premisas criptográficas del famoso protocolo de Diffie-Hellman para acordar claves de sesión entre dos partes a través de un canal inseguro. En este caso, Alice y Bob aplican el protocolo DH para compartir una clave de sesión por cada dato en sus respectivos conjuntos. Cualquier clave compartida que se encuentre en ambos conjuntos indica que el elemento correspondiente es un miembro de los conjuntos originales de ambas partes. Veamos con más detalle su funcionamiento: Alice y Bob acuerdan un número primo de gran tamaño, p, usando un canal público. Alice genera al azar una clave privada, a. Alice calcula el hash, gi, de cada uno de los valores de su conjunto original. En realidad, este paso es algo más complicado, ya que hay que repetir el hash hasta que g sea una raíz primitiva módulo p, pero no entraremos en los pormenores matemáticos. Para cada uno de estos valores gi, Alice calcula el valor gia mod p. Alice envía estos valores a Bob. Bob genera aleatoriamente una clave privada, b. Bob calcula repetidamente el hash, hi, de cada uno de los valores de su conjunto original, hasta que sean raíces primitivas módulo p. Para cada uno de estos valores de hash, Bob calcula hib mod p. Bob calcula las claves compartidas correspondientes a cada elemento del conjunto original de Alice, elevando los valores recibidos de Alice a la potencia de su clave privada, es decir, giab mod p. Bob envía sus valores calculados, hib mod p, a Alice, así como las claves compartidas calculadas correspondientes a los elementos del conjunto original de Alice, giab mod p. Alice calcula las claves compartidas correspondientes a cada elemento del conjunto original de Bob elevando los valores recibidos de Bob a la potencia de su clave privada, es decir, hiba = hiab mod p, para cada uno de los valores recibidos de Bob. Alice compara las claves compartidas calculadas a partir de los elementos de su propio conjunto original, giab, con las claves compartidas calculadas con los elementos de Bob, hiab. La intersección consiste en aquellos elementos del conjunto original de Alice cuya clave compartida también se puede encontrar en el conjunto de claves compartidas calculadas a partir de los elementos del conjunto original de Bob, giab = hiab. Desde la publicación de este protocolo han aparecido docenas de alternativas que utilizan primitivas criptográficas cada vez más sofisticadas. Se han propuesto protocolos muy elaborados basados en otros algoritmos de clave pública, como operaciones con RSA ciego; basados en filtros de Bloom; en cifrado totalmente homomórfico; en la transferencia inconsciente (OT) para transmitir los datos de los conjuntos; o en variantes del Circuito Confuso de Yao, capaz de simular cualquier función matemática con un circuito booleano utilizando exclusivamente puertas lógicas AND y XOR. Retos de seguridad y escalabilidad de PSI Los retos de seguridad y escalabilidad a los que se enfrentan todos estos protocolos para calcular la intersección privada de conjuntos son muy variados: Los protocolos más eficientes funcionan para conjuntos pequeños de unos pocos cientos o miles de elementos. Sin embargo, en muchas aplicaciones reales se necesitan comparar conjuntos de miles de millones de datos, lo que exige encontrar alternativas más rápidas. Además de exigir pocas operaciones para su funcionamiento, es importante minimizar las comunicaciones para intercambio de datos entre las partes. No todos los agentes implicados van a jugar según las normas. En computación segura multipartita se consideran dos tipos de adversario: semihonesto (o pasivo) y malicioso (o activo). El adversario semihonesto trata de obtener la mayor cantidad de información posible de la ejecución de un determinado protocolo, sin desviarse de los pasos del protocolo. Más peligroso y realista es el adversario malicioso, porque se desvía arbitrariamente de los pasos del protocolo para jugar con ventaja y obtener más información que los demás. Los protocolos PSI robustos ante adversarios maliciosos son considerablemente más pesados y menos eficientes que los protocolos resistentes a adversarios semihonestos. Los enfoques de PSI más sencillos filtran información: como mínimo, el número de elementos en cada conjunto y el número de elementos en el conjunto intersección. En las aplicaciones en las que ni siquiera es aceptable filtrar esta información, se requieren protocolos más seguros, que por desgracia requieren mayor número de operaciones y mayor ancho de banda. Cuanto más avancen la nube y el Big Data, mayor será la demanda de PSI A medida que las leyes y normativas de protección de datos evolucionan en un esfuerzo por salvaguardar la esfera privada de la vida de los ciudadanos, la intersección privada de conjuntos hará posible que las organizaciones públicas y privadas continúen generando conocimientos a partir del Big Data que beneficien al ciudadano, a la vez que se satisfacen las regulaciones de privacidad. En junio de 2019 Google anunció una herramienta para realizar operaciones sobre la intersección de conjuntos bautizada como Private Join and Compute. Según la nota de prensa: «Utilizando este protocolo criptográfico, dos partes pueden cifrar sus identificadores y datos asociados y luego unirlos en una consulta. Pueden entonces hacer ciertos tipos de cálculos sobre el conjunto de datos solapados para obtener información útil de ambos conjuntos de datos en conjunto. Todas las entradas (identificadores y sus datos asociados) permanecen totalmente cifradas y son ilegibles durante todo el proceso. Ninguna de las partes revela nunca sus datos en bruto, pero pueden seguir respondiendo a las preguntas que se les plantean utilizando la salida del cálculo. Este resultado final es lo único que se descifra y se comparte en forma de estadísticas agregadas como, por ejemplo, un recuento, una suma o un promedio de los datos de ambos conjuntos. Private Join and Compute combina la intersección privada de conjuntos con el cifrado totalmente homomórfico para proteger los datos individuales. El siguiente vídeo ofrece una idea de su funcionamiento: PSI supone la intersección entre la voracidad de datos de las grandes organizaciones y el derecho a la privacidad de los ciudadanos. Gigantes tecnológicos como Google, Microsoft o Baidu están invirtiendo enormes sumas de dinero y de neuronas criptográficas en estas tecnologías. En los próximos meses veremos hacia donde viran las aplicaciones de análisis masivo de datos, si a favorecer al ciudadano con mejores servicios o a erosionar aún más su maltrecha privacidad. Porque, como sentenció el criptógrafo Phil Rogaway: La vigilancia que preserva la privacidad no deja de ser vigilancia.
21 de julio de 2020

Retos y oportunidades de negocio de la criptografía poscuántica
Si estás leyendo este artículo desde un navegador, mira detenidamente el candadito arriba en la barra de direcciones. Haz clic en él. Ahora haz clic en «Certificados». Por último, selecciona la pestaña «Detalles del certificado». Observa el valor «Clave pública», ¿qué ves? RSA, tal vez DSA, o incluso ECDSA. Pues dentro de unos años, dejarás de ver esos algoritmos. ¿Por qué? Porque los ordenadores cuánticos los habrán borrado del mapa. Observa ahora otros protocolos de comunicación segura: TLS, responsable del candadito que protege las páginas web y prácticamente de protegerlo todo; el cifrado extremo a extremo de Whatsapp o el de Zoom, etc. Piensa en las firmas digitales: validación de contratos, identificación de la autoría de software, verificación de identidad, garantía de la propiedad en blockchain, etc. Esos mismos algoritmos (RSA, DSA, ECDSA) están por todas partes, pero tienen los días contados: 10 o 15 años, como mucho. ¿Será el fin de la privacidad? ¿No más secretos? Por suerte, no. Hay vida criptográfica más allá de RSA y de DSA y de ECDSA. ¡Bienvenido al futuro postcuántico! Hola, ordenadores cuánticos. Adiós, criptografía clásica La computación cuántica es más eficiente que la clásica en algunas tareas como, por ejemplo, resolver los problemas matemáticos sobre los que descansa la seguridad de los algoritmos de clave pública que hoy usamos para cifrado y firma digital: RSA, DSA, ECDSA, ECC, DH, etc. En un mundo de ordenadores cuánticos, la criptografía requiere algoritmos basados en problemas matemáticos impermeables a los avances de la computación cuántica. Por fortuna, esos algoritmos criptográficos existen desde hace décadas. Se los conoce colectivamente como criptografía postcuántica (post-quantum cryptography, PQC). Las tres alternativas mejor estudiadas hasta la fecha son: Criptografía basada en hashes: como su nombre indica, utilizan funciones hash seguras, que resisten a los algoritmos cuánticos. Su desventaja es que generan firmas relativamente largas, lo que limita sus escenarios de uso. Leighton-Micali Signature Scheme (LMSS) o los esquemas de firma de Merkle se cuentan entre los candidatos más sólidos para reemplazar a RSA y ECDSA. Criptografía basada en códigos: la teoría de códigos es una especialidad matemática que trata de las leyes de la codificación de la información. Algunos sistemas de codificación son muy difíciles de decodificar, llegando a requerir tiempo exponencial, incluso para un ordenador cuántico. El criptosistema mejor estudiado hasta la fecha es el de McEliece, otro prometedor candidato para intercambio de claves. Su inconveniente: claves de millones de bits de longitud. Criptografía basada en celosías: posiblemente se trate del campo más activo de investigación en criptografía postcuántica. Una celosía es un conjunto discreto de puntos en el espacio con la propiedad de que la suma de dos puntos de la celosía está también en la celosía. Un problema difícil es encontrar el vector más corto en una celosía dada. Todos los algoritmos clásicos requieren para su resolución un tiempo que crece exponencialmente con el tamaño de la celosía y se cree que lo mismo ocurrirá con los algoritmos cuánticos. Actualmente existen numerosos criptosistemas basados en el Problema del Vector más Corto. El ejemplo que tal vez haya suscitado más interés es el sistema de cifrado de clave pública NTRU. Entonces, si ya tenemos sustitutos para RSA, DSA, ECDSA, ¿por qué no seguir con los algoritmos de toda la vida hasta que aparezcan los primeros ordenadores cuánticos capaces de romperlos y en ese momento cambiar con un clic a los postcuánticos? En criptografía, los partos son largos y dolorosos Existen cuatro poderosas razones para empezar a trabajar ya en la transición hacia la criptografía postcuántica: Necesitamos tiempo para mejorar la eficiencia de la criptografía postcuántica: para que te hagas una idea, para alcanzar la seguridad proporcionada por claves de b bits en ECC, los algoritmos postcuánticos pueden requerir claves de entre b2 y b3 bits, así que echa cuentas. La mejora de eficiencia resulta especialmente crítica pensando en dispositivos constreñidos, de uso extendido en aplicaciones IoT, y principales destinatarios de la PQC. Necesitamos tiempo para crear confianza en la criptografía postcuántica: el NIST ha iniciado un proceso para solicitar, evaluar y normalizar uno o más algoritmos de PQC para firma digital, cifrado de clave pública y establecimiento de claves de sesión. Por su lado, el IRTF Crypto Forum Research Group ha terminado de estandarizar dos algoritmos de firma basados en hash de estado, XMSS y LMS, que también se espera que sean estandarizados por el NIST. Necesitamos tiempo para mejorar la usabilidad de la criptografía postcuántica: Después, estos estándares deben incorporarse a las bibliotecas criptográficas en uso por los lenguajes de programación más populares y por los chips criptográficos y por los módulos hardware. El proyecto Open Quantum Safe (OQS) está trabajando en liboqs, una biblioteca C de código abierto para algoritmos PQC. A continuación, deberán integrarse dentro de los estándares y protocolos criptográficos, tales como TLS, X.509, IKEv2, JOSE, etc. OQS también está trabajando en las integraciones de liboqs en OpenSSL y en OpenSSH. Luego, estos estándares y protocolos deberán ser incluidos por todos los vendedores en sus productos: desde los fabricantes de hardware, hasta los de software. Necesitamos proteger algunos secretos por mucho tiempo: existen datos muy valiosos y que tienen una larga vida útil: registros de empleados, registros de salud, registros financieros, etc. En el ámbito militar e industrial la necesidad de asegurar secretos por mucho tiempo es incluso mayor. Por ejemplo, podrían robarse hoy los planes de diseño de nuevas armas militares o de aeronaves comerciales, cifrados con algoritmos clásicos, a la espera de los ordenadores cuánticos para descifrarlos incluso décadas después del robo. En resumen, aún no estamos preparados para que el mundo cambie a la criptografía postcuántica con sólo apretar un botón. ¿Será la criptografía cuántica la mejor arma contra los ordenadores cuánticos? La criptografía cuántica se reduce hoy a la distribución cuántica de claves (QKD): intercambiar una clave aleatoria entre dos extremos no autenticados con la certeza de que cualquier intento de intercepción será detectado. Esta clave puede usarse posteriormente para cifrar la información confidencial usando el algoritmo de Vernam y así garantizar el secreto perfecto, incluso ante el ataque de un ordenador cuántico. ¡No tan rápido! Por desgracia, la QKD presenta muchos inconvenientes de índole práctica que desaconsejan su adopción, al menos en el futuro próximo: Dado que los protocolos QKD no proporcionan autenticación, son vulnerables a los ataques de intermediario en los que un adversario puede acordar claves secretas individuales compartidas con dos partes que creen que se están comunicando entre sí. La QKD requiere hardware especializado y extremadamente caro. Las distancias a las que QKD puede transmitir claves son hoy por hoy modestas, del orden de unos pocos miles de kilómetros con prototipos experimentales muy delicados, muy lejos de su viabilidad comercial. QKD sirve para acordar claves, pero no para firmar digitalmente información. La criptografía va mucho más allá del cifrado simétrico. Resumiendo, para la mayoría de los sistemas de comunicaciones del mundo real de ahí afuera, la PQC ofrecerá un antídoto contra la computación cuántica más efectivo y eficiente que la QKD. ¿Dónde veremos próximamente aplicaciones de la PQC? De acuerdo con el informe Post-Quantum Cryptography (PQC): A Revenue Assessment publicado el 25 de junio por la firma de analistas de tecnología cuántica Inside Quantum Technology, el mercado de software y chips de criptografía postcuántica se disparará hasta los 9.500 millones de dólares para 2029. Aunque las capacidades de la PQC se incorporarán en numerosos dispositivos y entornos, según el informe, los ingresos de PQC se concentrarán en los navegadores web, IoT, 5G, las fuerzas de seguridad (policía, ejército, inteligencia), servicios financieros, servicios de salud y la propia industria de la ciberseguridad. Si todos son conscientes de la sombra de la computación cuántica sobre la criptografía clásica, ¿por qué no están invirtiendo más recursos ahora mismo en PQC? Porque todos los actores están aguardando a que el NIST (National Institute of Standards and Technology) complete la Ronda 3 de sus normas de PQC, que sucederá en 2023. A partir de esa fecha, los servicios ofrecidos por la industria de la ciberseguridad incluirán los algoritmos de PQC estandarizados por el NIST. Por ejemplo, Inside Quantum Technology considera que los fabricantes proporcionarán ofertas de PQC como servicio para el correo electrónico y las VPN. Además, la industria de la ciberseguridad recomendará, desarrollará e implementará software de PQC para sus clientes. Según su predicción, en 2029 los ingresos de las ofertas de ciberseguridad relacionadas con PQC probablemente alcanzarán los 1.600 millones de dólares. Da el salto a PQC antes de que sea demasiado tarde Si ahora mismo tu organización maneja información cifrada cuya confidencialidad necesita garantizarse durante más de 10 años, más vale que vayas analizando la oferta de productos PQC. Y mientras tanto, sin pausa pero prisa, te convendría ir haciendo un piloto para evaluar si sería posible salir a producción con las soluciones comerciales disponibles. Dado que antes o después habrá que dar el salto a PQC, es mejor examinar ahora con calma las estrategias para reducir los costos de cambio de tecnología e ir preparando la transición. Porque de una cosa puedes estar seguro: el día de la PQC llegará.
7 de julio de 2020

China encabeza la carrera hacia una Internet cuántica impermeable a los ataques
¿Sabías que existe un algoritmo de cifrado 100% seguro? Se conoce como cifrado de Vernam (o libreta de un solo uso). En 1949, Claude Shannon demostró matemáticamente que dicho algoritmo consigue el secreto perfecto. ¿Y sabías que no se usa (casi) nunca? Pues tal vez las cosas cambien después de que un grupo de investigadores chinos haya batido el récord de transmisión cuántica de claves entre dos estaciones separadas por 1120 km. Estamos un paso más cerca de alcanzar el Santo Grial de la criptografía. La paradoja del cifrado perfecto que no puede usarse en la práctica ¿Cómo es posible que el único cifrado 100% seguro no se use? En criptografía las cosas nunca son sencillas. Para empezar, el cifrado de Vernam es 100% seguro siempre y cuando se cumplan estas cuatro condiciones: La clave de cifrado se genera de forma verdaderamente aleatoria. La clave es tan larga como el mensaje a cifrar. La clave nunca se reutiliza. La clave se mantiene en secreto, siendo conocida sólo por el emisor y receptor. Veamos la primera condición. Un generador de bits verdaderamente aleatorios requiere una fuente natural de aleatoriedad. El problema es que diseñar un dispositivo hardware para explotar esta aleatoriedad y producir una secuencia de bits libre de sesgos y correlaciones es una tarea muy difícil. Aun así, imagina que contamos con un generador perfecto de claves, capaz de crear secuencias aleatorias de cualquier longitud. Ahora surge otro reto incluso más formidable: ¿cómo compartir de forma segura claves tan largas como el propio mensaje a cifrar? Piénsalo, si necesitas cifrar la información es porque no te fías del canal de comunicación. Entonces, ¿en qué canal confiar para enviar la clave de cifrado? Podrías cifrarla a su vez, pero ¿con qué clave? ¿Y cómo la compartes? Entramos en un bucle infinito sin escapatoria. La clave de la seguridad perfecta se esconde en la mecánica cuántica La distribución cuántica de claves soluciona de una tacada y con brillantez todos los problemas del cifrado de Vernam: permite crear claves aleatorias de la longitud deseada sin que ningún atacante pueda interceptarlas. Veamos cómo lo hace. Como recordarás de las lecciones de física del colegio, la luz es una radiación electromagnética compuesta por fotones. Estos fotones viajan vibrando con cierta intensidad, longitud de onda y una o muchas direcciones de polarización. Si eres aficionado a la fotografía, habrás oído hablar de los filtros polarizadores. Su función es eliminar todas las direcciones de oscilación de la luz salvo una, como se explica en la siguiente figura: Ahora entras en el laboratorio de física y envías uno a uno fotones que pueden estar polarizados en una de cuatro direcciones distintas: vertical (|), horizontal (–), diagonal a la izquierda (\) o diagonal a la derecha (/). Estas cuatro polarizaciones forman dos bases ortogonales: por un lado, | y –, a la que llamaremos base (+); y, por otro, / y \, a la que llamaremos (×). El receptor de tus fotones utiliza un filtro, por ejemplo, vertical (|). Es evidente que los fotones con polarización vertical pasarán tal cual, mientras que los polarizados horizontalmente y, por lo tanto, perpendiculares al filtro, no pasarán. Sorprendentemente, la mitad de los polarizados diagonalmente pasarán por el filtro vertical y serán reorientados verticalmente! Por lo tanto, si se envía un fotón y pasa a través del filtro, no puede saberse si poseía polarización vertical o diagonal, tanto \ como /. Igualmente, si no pasa, no puede afirmarse que estuviera polarizado horizontal o diagonalmente. En ambos casos, un fotón con polarización diagonal podría pasar o no con igual probabilidad. Y no acaban aquí las paradojas del mundo cuántico. La acción fantasmal a distancia que Einstein aborrecía El entrelazamiento cuántico se produce cuando un par de partículas, como dos fotones, interactúan físicamente. Un rayo láser disparado a través de un cierto tipo de cristal puede hacer que los fotones individuales A y B se dividan en pares de fotones entrelazados. Ambos fotones pueden separarse por una gran distancia, tan grande como se quiera. Y aquí viene lo bueno: cuando el fotón A adopta una dirección de polarización, el fotón B entrelazado con A adopta el mismo estado que el fotón A, sin importar a la distancia a la que se encuentre de A. Se trata del fenómeno que Albert Einstein escépticamente denominó "acción fantasmal a distancia." En 1991 al físico Artur Ekert se le ocurrió aprovechar esta propiedad cuántica del entrelazamiento para idear un sistema de transmisión de claves aleatorias e imposibles de interceptar por un atacante sin que se le detecte. Distribución cuántica de claves usando el entrelazamiento cuántico Supongamos que Alice y Bob quieren acordar una clave de cifrado aleatoria tan larga como el mensaje, de longitud n bits. Primero necesitan acordar una convención para representar los unos y ceros de la clave usando las direcciones de polarización de los fotones, por ejemplo: Estado/Base + x0–/1|\ Paso 1: se genera y envía una secuencia de fotones entrelazados, de manera que Alice y Bob van recibiendo uno a uno los fotones de cada par. Cualquiera puede generar esta secuencia: Alice, Bob o incluso una tercera parte (en la que se confía o no). Paso 2: Alice y Bob eligen una secuencia aleatoria de bases de medida, + o x, y van midiendo el estado de polarización de los fotones que les van llegando, sin importar quién mide primero. Cuando Alice o Bob miden el estado de polarización de un fotón, su estado se correlaciona perfectamente con el de su pareja entrelazada. A partir de este momento, ambos están observando el mismo fotón. Paso 3: Alice y Bob comparan públicamente qué bases han usado y mantienen solamente aquellos bits que fueron medidos en la misma base. Si todo ha funcionado bien, Alice y Bob comparten exactamente la misma clave: como cada par de fotones medidos están entrelazados, necesariamente han de obtener el mismo resultado si ambos miden con la misma base. En promedio, las bases de medida habrán coincidido el 50% de las veces. Por tanto, la clave obtenida será de longitud n/2. Este sería un ejemplo del esquema del procedimiento: Paso 1Posición en la secuencia123456789101112 Paso 2Bases aleatorias de AliceXX++X+X++X+XObservaciones de Alice/\||/–\|–\–/Bases aleatorias de BobX++XX++++XX+Observaciones de Bob/–|//–||–\\– Paso 3Coincidencia de basesSíNo SíNo SíSí NoSíSíSíNo No Clave obtenida0 1 00 101 Pero ¿y si algún atacante estuviera interceptando estos fotones? ¿No conocería también la clave secreta generada y distribuida? ¿Y si hay errores de transmisión y los fotones se desentrelazan por el camino? Para resolver estos problemas, Alice y Bob seleccionan al azar la mitad de los bits de la clave obtenida y públicamente los comparan. Si coinciden, entonces saben que no ha habido ningún error. Descartan esos bits y se asume que el resto de los bits obtenidos son válidos, lo que significa que se habrá acordado una clave final de n/4 bits de longitud. Si una parte considerable no coincide, entonces o bien había demasiados errores fortuitos de transmisión o bien un atacante interceptó los fotones y los midió por su cuenta. En cualquier caso, se descarta la secuencia completa y se vuelve a empezar. Como se ha observado, si el mensaje tiene n bits de longitud, en promedio habrá que generar y enviar 4n fotones entrelazados para que la clave tenga la misma longitud. ¿Y no podría un atacante medir un fotón y reenviarlo sin que se note? Imposible, porque una vez medido, se encuentra en un estado definido, no en una superposición de estados. Si lo envía tras observarlo, ya no será un objeto cuántico, sino un objeto clásico de estado definido. Como consecuencia, el receptor medirá correctamente el valor del estado sólo el 50% de las veces. Gracias al mecanismo de conciliación de claves recién descrito, se puede detectar la presencia de un atacante en el canal. En el mundo cuántico, no se puede observar sin dejar huella. Ni que decir tiene que el protocolo original de Ekert es más sofisticado, pero con esta descripción simplificada puede entenderse el experimento realizado por los investigadores chinos en colaboración con el mismo Ekert. China bate el récord de distribución cuántica de claves El equipo de investigación chino liderado por Jian-Wei Pan logró distribuir claves a 1120 km de distancia usando fotones entrelazados. Esta hazaña representa otro gran paso en la carrera hacia una Internet cuántica totalmente segura para largas distancias. Hasta ahora, los experimentos de distribución cuántica de claves se han realizado a través de fibra óptica a distancias de poco más de 100 km. La alternativa más obvia, es decir, enviarlos a través del aire desde un satélite, no es tarea sencilla, ya que las partículas de agua y polvo de la atmósfera desentralazan los fotones con rapidez. Los métodos convencionales no conseguían que llegase desde el satélite al telescopio sobre el suelo más de uno de cada 6 millones de fotones, a todas luces insuficiente para transmitir claves. En cambio, el sistema creado por el equipo de investigadores chinos de la Universidad de Ciencia y Tecnología de Hefei consiguió transmitir una clave a velocidad de 0,12 bits por segundo entre dos estaciones separadas 1120 km. Dado que el satélite llega a ver ambas estaciones simultáneamente durante 285 segundos al día, puede transmitirles claves mediante el método de entrelazamiento cuántico a una velocidad de 34 bits/día y una tasa de error de 0,045. Es una cifra modesta, pero un avance prometedor, teniendo en cuenta que mejora en 11 órdenes de magnitud la eficiencia previa. En palabras del propio Ekert, «el entrelazamiento proporciona la seguridad suprema». Ahora solo falta superar todas las barreras tecnológicas. La carrera para construir una Internet de información cuántica impermeable a los ataques no ha hecho más que empezar, con China a la cabeza y a gran distancia del pelotón.
23 de junio de 2020

Criptografía contra el coronavirus
Gobiernos y autoridades sanitarias de todo el mundo están lanzando apps de seguimiento de contagios. Por otra parte, en una alianza sin precedentes, Apple y Google unieron fuerzas para crear una API que facilita su desarrollo. Los científicos coinciden en que la adopción de este tipo de apps por el mayor número posible de ciudadanos ayudará a desacelerar la expansión de la Covid-19. Según un cálculo aproximado, si el 80% de los usuarios de terminales móviles con iOS o Android las instalan, esto equivaldría al 56% de la población total, una cifra suficiente para contribuir significativamente a frenar la pandemia. Por desgracia, desde el anuncio de la puesta en marcha de estas apps han circulado todo tipo de bulos y fake news difundiendo mentiras sobre escenarios conspiranoicos de espionaje masivo. Este miedo infundado puede llevar a muchas personas a no utilizar la app cuando esté disponible en su país, por eso en este artículo vamos a explicar cómo funciona su criptografía para garantizar la privacidad de los usuarios. La criptografía de las apps basadas en la API de Apple y Google Si las autoridades sanitarias de tu país o región han creado una app, puedes acudir a Apple Store o a Play Store a descargártela, dependiendo de si tu dispositivo es iOS o Android, respectivamente. Aunque puedes tener instalada en tu dispositivo más de una app que use las notificaciones de exposición, sólo puede haber una activa al mismo tiempo. Si decides instalar voluntariamente la app autorizada en tu región o país, ésta te solicitará permiso para recopilar y compartir identificadores aleatorios. Para proteger tu privacidad, la app usa un Generador de Números Aleatorios Critptográficamente Seguro para generar aleatoria e independientemente una clave temporal de exposición (Temporal Exposure Key o ExpKey) cada 24 horas. A partir de ella se derivan, mediante una función HDKF, una clave de cifrado para generar los identificadores temporales de proximidad (Rolling Proximity Key o RPIKey) y una clave de cifrado de metadatos asociados (Associated Encrypted Metadata Key o AEMKey) para cifrar metadatos adicionales en caso de que posteriormente des positivo en un test. RPIKey = HKDF(ExpKey, NULL, UTF8(“EN-RPIK”), 16) AEMKey = HKDF(ExpKey, NULL, UTF8(“EN-AEMK”), 16) Las especificaciones de Bluetooth de Baja Energía (Bluetooth Low Energy o BLE) asumen que la dirección MAC de tu dispositivo cambia cada 15-20 minutos para evitar el rastreo del dispositivo. Cada vez que cambia tu dirección MAC, la app genera un nuevo identificador rotativo de proximidad (Rolling Proximity ID o RPID) obtenido cifrando, mediante AES-128 con la clave RPIKey anterior, el valor de la nueva ventana de tiempo de 10 minutos, Ti. RPID = AES128(RPIKey, UTF8(“EN-RPI”) || 0x000000000000 || Ti) Por otro lado, los metadatos asociados se cifran con AES128-CTR usando como clave la AEMKey anterior y como IV, el RPID. AEM = AES128−CTR(AEMKey, RPID, Metadata) Ilustración 1. Esquema de Claves para Notificación de Exposiciones (fuente: Exposure Notification Cryptography Specification) Estos metadatos comprenden la fecha, la duración estimada de la exposición y la intensidad de la señal Bluetooth. Para proteger aún más tu privacidad, la duración estimada máxima que se registra es de 30 minutos. La intensidad de la señal Bluetooth ayuda a comprender la proximidad de los dispositivos. Por lo general, cuanto más cerca estén los dispositivos, mayor será la intensidad de la señal registrada. Asimismo, otros dispositivos que reciban tus identificadores Bluetooth los registrarán de un modo similar y los almacenarán junto con los metadatos asociados. Como puedes ver, ni los identificadores Bluetooth ni las claves aleatorias del dispositivo incluyen información sobre tu ubicación ni sobre tu identidad. Tampoco aparece GPS por ningún lado, por lo que no hay forma de rastrear tus movimientos. Tu terminal y los terminales que te rodean funcionan en segundo plano intercambiando constantemente esta información sobre RPID y metadatos cifrados a través de BLE sin necesidad de tener la aplicación abierta para que este proceso se lleve a cabo. ¿Qué sucede si doy positivo en Covid-19? Si posteriormente se te diagnostica la Covid-19, tu terminal publica tus últimas 14 claves de exposición temporal (ExpKey) en un servidor de las autoridades sanitarias de tu región o país denominado Servidor de Diagnóstico. Su misión es agregar las claves de diagnóstico de todos los usuarios que han dado positivo y distribuirlas a todos los demás usuarios que participan en la notificación de la exposición. Todos los demás dispositivos del sistema descargan estas 14 claves, regeneran los identificadores RPID para los 14 últimos días y los comparan con los identificadores almacenados localmente. Si existe alguna coincidencia, la app tendrá acceso a los metadatos asociados (pero no al identificador coincidente), de modo que podrá notificarte que se ha producido una posible exposición y te orientará sobre qué medidas adoptar en función de las instrucciones dictadas por las autoridades sanitarias. En función de su diseño, es posible que la app genere un valor de riesgo de exposición que el Gobierno o las autoridades sanitarias podrían utilizar para adaptar las directrices específicamente para ti y así controlar mejor la pandemia. El valor de riesgo de exposición se define y se calcula en función de los metadatos asociados, así como el valor de riesgo de transmisión que el Gobierno o las autoridades sanitarias pueden definir para las claves aleatorias del dispositivo coincidentes. En ningún caso se compartirá el valor de riesgo de exposición ni el valor de riesgo de transmisión con Apple ni Google. Los parámetros usados para este valor de riesgo de transmisión podrían incluir información que les has proporcionado (como los síntomas de los que informes o si tu diagnóstico ha sido confirmado mediante una prueba) u otra información que el Gobierno o las autoridades sanitarias consideren que podría afectar a tu riesgo de transmisión, como tu profesión. La información que decidas proporcionar al Gobierno o a las autoridades sanitarias se recopila de conformidad con los términos de la política de privacidad de la app y sus obligaciones legales. Por el contrario, si permaneces sano y no das positivo, tus Claves de Exposición Temporal no abandonarán tu dispositivo. Algunas reflexiones finales sobre la API de Apple y Google y tu privacidad Dada la imagen de Gran Hermano de Google y Apple en nuestro imaginario colectivo, a mucha gente le dará igual la criptografía de esta API y no se fiará de estas dos empresas. Para darte más seguridad, ten en cuenta que: Tú decides si recibes o no las notificaciones de exposición: esta tecnología sólo funciona si decides optar por ella. Si cambias de opinión, puedes apagarla en cualquier momento. El Sistema de Notificaciones de Exposición no rastrea tu ubicación: no recoge ni utiliza la ubicación de su dispositivo mediante GPS u otros medios. Utiliza Bluetooth para detectar si dos dispositivos están cerca uno del otro, sin revelar su ubicación. Ni Google ni Apple ni otros usuarios pueden ver tu identidad: todas las coincidencias del sistema de Notificaciones de Exposición se procesan en tu dispositivo. Las autoridades sanitarias pueden pedirte información adicional, como un número de teléfono para ponerse en contacto contigo y proporcionarte orientación adicional. Sólo las autoridades sanitarias pueden utilizar este sistema: el acceso a la tecnología se concederá únicamente a las aplicaciones de las autoridades sanitarias. Sus aplicaciones deben cumplir con criterios específicos sobre privacidad, seguridad y uso de datos. Apple y Google desactivarán el sistema de notificaciones de exposición en cada región cuando ya no sea necesario. El éxito está en la masa crítica Recuerda que estas apps sólo surtirán efecto si al menos el 80% de los usuarios de iOS y Android las instalan y mantienen el Bluetooth encendido cuando salen de sus casas. Si desactivas la conexión Bluetooth de tu dispositivo, también dejarán de recopilarse y compartirse los identificadores Bluetooth aleatorios con otros dispositivos. Esto significa que la app no podrá notificarte si te has expuesto a alguna persona con Covid-19. Por lo tanto, cada ciudadano equilibrará en su conciencia el bien público con la salvaguarda de la privacidad para tomar la decisión de si utilizar estas apps o no.
9 de junio de 2020

Zoom busca ser más segura gracias a la compra de Keybase
El confinamiento decretado como medida excepcional para frenar la expansión del COVID-19 ha forzado a millones de personas en empresas, centros educativos y hogares a interactuar virtualmente. Empujados a usar apps de videollamada grupal para el trabajo, para las clases o simplemente para estar en contacto con familiares y amigos, los usuarios se enfrentaron al difícil reto de elegir qué app utilizar. Típicamente, el criterio imperante a la hora de decantarse por una u otra es la popularidad o la gratuidad, sin pensar dos veces en la seguridad o la privacidad. A fin de cuentas, si es gratis y "la usa todo el mundo", ¿para qué darle más vueltas? Para bien o para mal, la app más favorecida por el público resultó ser Zoom. Semanas después de iniciarse la cuarentena, sigue a la cabeza de la lista de las apps gratuitas más descargadas tanto para iOS como para Android, con la fabulosa cifra de 300 millones de usuarios diarios. Como es bien sabido, cuanto más popular se vuelve un programa o aplicación, más atrae a los cibercriminales. Tal vez su éxito arrollador no se lo imaginaba ni la propia empresa Zoom o tal vez no se tomaron la seguridad en serio desde sus inicios, pero lo cierto es que llegaron a la graduación con los deberes sin hacer. Los tres grandes golpes a la seguridad de Zoom Entre los numerosos problemas y escándalos de seguridad y privacidad, destacaron tres en especial: Zoombombing: Este ataque consiste en irrumpir en una sala de Zoom y compartir la pantalla con imágenes de violencia extrema, pornografía o cualquier otra forma de troleo. El zoombombing se popularizó en escuelas y universidades, lo que obligaba a suspender las clases. Muchas instituciones educativas llegaron a prohibir el uso de Zoom en favor de otras aplicaciones. Zoom aprendió la dura lección e implantó numerosas medidas para combatir el zoombombing: contraseñas obligatorias, bloqueo de sesiones, expulsión de participantes, funcionamiento restringido de la pantalla compartida y del chat, icono de seguridad más visible, etc. También publicó una guía de buenas prácticas para proteger las aulas virtuales. Compartir datos con Facebook: Al igual que otro millón de apps, Zoom en iOS utiliza un SDK de Facebook para permitir a sus usuarios iniciar sesión mediante su cuenta de Facebook, lo que se conoce como login social. Este SDK recopila algunos datos sobre los usuarios, como modelo de dispositivo, versión de la app u operadora de telefonía, y los envía a los servidores de Facebook, incluso aunque no tengan cuenta en Facebook y, por tanto, no lo usen para iniciar sesión. No se sabe qué hace Facebook con esta información, pero en respuesta a las numerosas quejas, Zoom eliminó por completo el SDK de Facebook. Falsas alegaciones sobre el cifrado de extremo a extremo seguro: Zoom aseguraba en su página web estar usando cifrado de extremo a extremo en sus conexiones, pero resultó que en realidad usaban cifrado TLS para cifrar las comunicaciones entre los clientes y los servidores, lo que implica que los servidores de Zoom tienen acceso a todas las videollamadas. La empresa no tuvo más remedio que retractarse: «A la vista del reciente interés en nuestras prácticas de cifrado, para empezar, queremos pedir disculpas por la confusión que hemos causado al dar a entender erróneamente que las reuniones de Zoom eran capaces de usar cifrado de extremo a extremo». Plan de seguridad de 90 días Con el ánimo de recuperar su imagen y su base de usuarios, el 1 de abril Zoom sorprendió con un plan de seguridad de 90 días. Como parte de este plan, el 8 de abril, Zoom creó un comité de seguridad integrado por algunos CISOs muy destacados. El mismo día contrató al conocido experto en ciberseguridad de Stanford Alex Stamos, ex-CISO de Facebook, como asesor de seguridad para revisar su plataforma. El 27 de abril lanzó Zoom 5.0, con soporte para cifrado con AES-GCM con claves de 256 bits. Pero (y este es un gran "pero") las claves de cifrado para cada reunión las generan los servidores de Zoom. Es decir, un cibercriminal no puede espiar una conversación entre dos usuarios, pero Zoom sí, si así lo quisiera. En cambio, otros servicios como Facetime, Signal o WhatsApp sí que utilizan cifrado de extremo a extremo verdadero: nadie más que los dos usuarios a ambos extremos de la comunicación pueden ver su contenido porque son ellos mismos quienes generan las claves de cifrado. En consecuencia, ni los cibercriminales ni los servidores de la empresa proveedora del servicio pueden espiar las conversaciones. Sin el cifrado de extremo a extremo, Zoom podría verse obligada a entregar registros de las reuniones a un gobierno en respuesta a solicitudes legales. Estas peticiones ocurren todo el tiempo en todo el mundo. De hecho, empresas como Apple, Google, Facebook y Microsoft publican informes de transparencia detallando cuántas solicitudes de datos de usuarios reciben de qué países y cuántas de ellas atienden. Sin embargo, Zoom no publica semejantes informes de transparencia. El cifrado extremo a extremo de Keybase que Zoom busca para sus videollamadas Sobre el papel, el cifrado extremo a extremo parece sencillo: los clientes generan las claves efímeras de sesión y se las intercambian cifrándolas con la clave pública del destinatario. Por desgracia, generar y gestionar todas estas claves para ofrecer cifrado de extremo a extremo escalable en videollamadas de alta calidad con docenas de participantes y más de 300 millones de usuarios conectándose diariamente a sus servidores constituye un reto tecnológico formidable. Por eso Zoom acudió a Keybase. El 7 de mayo, compró la empresa de mensajería y transferencia de archivos con protección criptográfica extremo a extremo, Keybase.io, por una cantidad no revelada. Con su ayuda, Zoom espera ofrecer un modo de reunión cifrado de extremo a extremo. Eso sí, sólo para las cuentas de pago. Además, como declaran en su comunicado: Seguirán colaborando con los usuarios para mejorar los mecanismos de información de que disponen los anfitriones de las reuniones para informar sobre los asistentes no deseados y problemáticos. Zoom no supervisa ni supervisará proactivamente el contenido de las reuniones, pero su equipo de seguridad seguirá utilizando herramientas automatizadas para buscar pruebas de usuarios abusivos basándose en otros datos disponibles. Zoom no ha construido ni construirá un mecanismo para descifrar las reuniones en vivo con fines de interceptación legal. Tampoco tienen un medio para insertar a sus empleados u otras personas en las reuniones sin que aparezcan reflejadas en la lista de participantes. No construirán ninguna puerta trasera criptográfica para permitir la vigilancia secreta de las reuniones. En definitiva, Zoom se compromete a permanecer transparente y abierta mientras construye su solución de cifrado de extremo a extremo. De hecho, planea publicar un borrador detallado del diseño criptográfico el viernes 22 de mayo. Cómo queda Zoom tras la compra de Keybase La reacción de Zoom ha sido admirable. Lejos de negar las críticas o demandar a los investigadores que hallaran sus vulnerabilidades, Zoom respondió con un ambicioso plan de seguridad de 90 días cuyo Santo Grial será el cifrado de extremo a extremo provisto por Keybase. Zoom tomó decisiones de seguridad equivocadas en el pasado, pero parece claramente resuelta a convertirse en la app de videollamadas más potente y segura del mercado. Está demostrando cómo con autocrítica y transparencia resulta posible salir fortalecido de una grave crisis de seguridad.
12 de mayo de 2020

20 preguntas sobre las apps de rastreo de contagios del Covid-19
Los gobiernos de todo el mundo están lanzando apps de rastreo de contagios del Covid-19. A pesar de su loable objetivo de frenar la expansión de la pandemia y acelerar la vuelta a la normalidad, como era de esperar, llegan envueltas en la polémica. Como su propio nombre indica, una app de "rastreo" plantea dudas sobre la amenaza a la privacidad y seguridad de los ciudadanos. En este artículo listamos 20 de las preguntas más frecuentes que nos surgen a todos sobre el uso de estas apps. 1. ¿Cuál es el objetivo de estas apps? El objetivo de estas apps es frenar la propagación del virus. En el pasado, el procedimiento era diferente: a través de entrevistas a los individuos contagiados, se les preguntaba por las personas con quienes habían estado en contacto. Una vez identificadas, se notificaba a estas personas para que se pusiesen en cuarentena o para darles prioridad en las pruebas de diagnóstico. Este método manual plantea también problemas de privacidad, se presta al error, resulta tremendamente costoso en tiempo y personal y, además, se limita a los contactos que pueden ser identificados por la persona infectada. 2. ¿Cómo funcionan las apps de rastreo de contagios? Depende de cada app en particular, pero en general todas funcionan emitiendo constantemente códigos Bluetooth únicos y cambiantes. Al mismo tiempo, monitorizan constantemente los teléfonos a su alrededor, registrando los códigos de cualquier otro teléfono que encuentren dentro de un cierto rango y por cuánto tiempo. Por ejemplo, dentro de un radio de 2 metros durante 10 minutos. Cuando una autoridad sanitaria confirma que un usuario está infectado, su app sube a un servidor los códigos anónimos generados durante las últimas dos semanas. Si la app de otro usuario encuentra una coincidencia con uno de sus códigos almacenados, le notifica que puede haber estado expuesto y le informa de los pasos a seguir: cuarentena o prueba de diagnóstico o lo que decida la autoridad sanitaria. El sistema utiliza Bluetooth LE, no GPS, es totalmente opcional, no recopila datos de localización de los usuarios y no carga ningún código de nadie sin un diagnóstico positivo de Covid-19. 3. ¿Qué tienen que ver Apple y Google en todo esto? El 10 de abril, Apple y Google sorprendieron con el anuncio de su alianza para crear una tecnología basada en Bluetooth LE (Low Energy) para el rastreo de contactos integrada en los sistemas operativos iOS y Android. Los distintos países podrán desarrollar sus aplicaciones de seguimiento de contactos sobre las funciones proporcionadas por las APIs y la plataforma de Apple y Google. Ambas empresas han creado esta tecnología para facilitar a los gobiernos de todo el mundo la creación de apps de seguimiento de contagios si así lo desean. 4. ¿Por qué estas apps utilizan Bluetooth LE y no GPS? La tecnología GPS permite ubicar en todo momento a una persona, lo que supondría una grave amenaza a la privacidad. Por el contrario, la comunicación Bluetooth se produce directamente entre dispositivos móviles, sin que se registre la ubicación donde se produjo la proximidad, lo que facilita la creación de un sistema descentralizado. Por otro lado, Bluetooth LE permite estimar con mayor precisión la proximidad funcional en entornos de alto riesgo para la proximidad: dentro de edificios, en vehículos y aviones, en el tránsito subterráneo, etc. Incluso podría saberse si dos personas a menos de 2 m entre sí están separadas por un tabique midiendo la potencia de la señal Bluetooth y con información complementaria de los sensores del terminal: si está dentro o fuera de un bolso o bolsillo, si está quieto o en movimiento, etc. 5. ¿Hasta qué punto mi privacidad y seguridad se verán amenazadas si instalo estas apps? Es difícil de saber porque cada país desarrollará su propia app, e incluso cada región dentro de cada país, basada o no en la plataforma de Apple y Google. Alrededor de 300 científicos e investigadores de todo el mundo han firmado un manifiesto donde proponen los siguientes principios que deberían ser adoptados por cualquier app: Las aplicaciones de rastreo de contactos sólo deben utilizarse para apoyar las medidas de salud pública para la contención del Covid-19. El sistema no debe ser capaz de recopilar, procesar o transmitir más datos de los necesarios para lograr este propósito. Cualquier solución considerada debe ser totalmente transparente. Los protocolos y su implantación, incluidos los subcomponentes proporcionados por las posibles empresas colaboradoras, deben estar disponibles para su análisis público. Debe documentarse sin ambigüedades cómo, dónde y para qué se almacenan los datos procesados. Los datos recopilados deben ser mínimos para el propósito dado. Cuando existan múltiples opciones posibles para implementar un determinado componente o función de la aplicación existe, se debe elegir la opción que mejor preserve la privacidad. Desviaciones de este principio sólo son permisibles en caso necesario para lograr el propósito de la aplicación con mayor eficacia, y debe justificarse claramente. El uso de las aplicaciones de rastreo de contactos y los sistemas que las soportan debe ser voluntario, utilizado con el consentimiento explícito del usuario y los sistemas deben ser diseñados para poder ser apagados, y todos los datos borrados, cuando la crisis actual llegue a su fin. Por su lado, Apple y Google aseguran que la privacidad del usuario es un requisito esencial en el desarrollo de su propia especificación: No se requiere la posición del usuario: cualquier uso de ubicación será opcional. En caso de que sea necesario acceder a la geolocalización del dispositivo, se exigirá consentimiento expreso. Los identificadores únicos de proximidad cambiarán cada 15 minutos, de tal forma que sea inútil rastrear a una persona usando Bluetooth. Los identificadores únicos de proximidad se intercambiarán únicamente entre dispositivos y no se subirán a la nube. El usuario debe decidir si quiere participar en la iniciativa. El usuario debe consentir si quiere ser identificado —de forma anónima, siempre— como una persona que tiene Covid-19. Habrá que esperar a las apps desplegadas por los distintos gobiernos para evaluar hasta qué punto cumplen o no con estas directrices. 6. ¿Cómo de eficaces resultarán estas apps para frenar la pandemia? Según un análisis realizado por investigadores del proyecto Covid-Watch, las aplicaciones de rastreo de contactos necesitan que entre el 50 y el 70 por ciento de la población las utilice. De lo contrario, las personas sintomáticas no sabrían dónde contrajeron el virus y las personas asintomáticas seguirían propagándolo sin saberlo. Como referencia, en Corea del Sur sólo llegó a usar la app oficial un 10% de la población. Por mucho que Apple y Google respalden estas aplicaciones, su grado de penetración será menor del esperado. De acuerdo con analistas de Counterpoint Research, alrededor de 1.500 millones de usuarios utilizan teléfonos básicos que no operan bajo Android ni iOS y que carecen de chips Bluetooth LE. Igualmente, quienes utilizan smartphones con más de cinco años de antigüedad no podrán instalar esta aplicación por restricciones de tecnología o del sistema operativo. Por su lado, Bill Gates señala acertadamente en una reciente entrada de su blog que: «una limitación es que no tienes que estar necesariamente en el mismo lugar al mismo tiempo para infectar a alguien, puedes dejar el virus sobre una superficie. Este sistema se perdería este tipo de transmisión». Por último, cualquier rastreo de contacto efectivo carece de utilidad sin pruebas masivas de diagnóstico, que hoy todavía son pocas, caras y lentas. Además, los individuos diagnosticados necesitan la libertad económica y el espacio para recluirse en cuarentena. Y muchas personas mayores o de bajos ingresos, las que pueden estar en mayor riesgo, son precisamente las menos propensas a tener teléfonos inteligentes capaces de albergar estas apps. 7. Cuando la app me avisa de que alguien que estuvo en mi proximidad ha sido contagiado, ¿qué garantías tengo de ello? Está claro que cualquiera no podrá notificar que está contagiado porque entonces el sistema se prestaría a todo tipo de errores y abusos: desde usuarios que se auto-diagnostican incorrectamente, hasta trolls que inundan el sistema con falsos positivos. La solución exige que el diagnóstico positivo sea aprobado por una autoridad médica o de salud pública competente. Otros falsos positivos pueden provenir simplemente de errores en los cálculos de proximidad por Bluetooth LE, en especial porque falle al detectar paneles, tabiques o paredes. Como cualquier sistema de detección, las apps de rastreo tendrán su tasa de falsos positivos, así como de falsos negativos: desde virus depositados sobre superficies hasta contactos con personas sin smartphone o que optan por no activar el rastreo. 8. Si la app me avisa de que he próximo a una persona contagiada, ¿qué tengo que hacer? Cada país decidirá cómo se te avisa, ya sea por medio de una llamada, un mensaje o una notificación en el smartphone. A partir de ahí, puede que se te recomiende la cuarentena, la visita a un centro de salud o un hospital para hacerte el test, u otras opciones según tu territorio. 9. ¿Qué datos personales compartirán las apps y con quién? Estos esquemas están diseñados para no cargar ningún dato de la mayoría de los usuarios (los no contagiados) y sólo códigos Bluetooth anónimos de personas infectadas. Aun así, a la hora de notificar el contagio, un usuario tiene que subir necesariamente algunos datos al servidor, que por muy anónimos que sean pueden dejar un rastro, como la dirección IP de su terminal. Quien gestione ese servidor, probablemente una institución pública de salud, podría llegar a identificar los teléfonos de las personas que se reportan como positivas y, por lo tanto, sus ubicaciones e identidades. Asímismo, se proponen tiempos prudenciales para albergar dicha información y se aconseja no almacenar metadatos de las comunicaciones pero, de nuevo, no parece estar implementado de forma intrínseca en el código, sino que se apela a las buenas prácticas de los gestores de los servidores. 10. ¿Quién sabrá si he sido contagiado? Cuando un individuo comparte voluntariamente su diagnóstico, su app subirá a un servidor los códigos que ha ido generando durante los 14 días previos. Todas las apps están descargando del mismo servidor estos listados de códigos para comprobar si alguno coincide con los almacenadas localmente. Por tanto, nadie sabrá si te has contagiado, salvo obviamente la autoridad sanitaria que te diagnosticó en primer lugar. 11. ¿Qué app nos propondrán usar previsiblemente en España? Aparentemente, la Secretaría de Digitalización e Inteligencia Artificial apuesta por un sistema descentralizado como el recomendado por la UE. Inicialmente España se adhirió al Pepp-PT, pero éste ha modificado parte de su compromiso inicial y actualmente aboga por un sistema centralizado. 12. ¿Cuándo empezará su uso? Depende de cada país. En España, se espera su puesta en marcha es el martes 28 de abril. 13. ¿Estoy obligado a usar estas apps? De momento, no. Como hemos visto, la eficacia del sistema se basa en su uso masivo, por lo que, como mínimo, el 60% de la población debería usarlas para que el sistema resulte efectivo. Cada ciudadano equilibrará en su conciencia el bien público con la salvaguarda de la privacidad para tomar la decisión de si usarlas o no. 14. Si tengo la app instalada, ¿alguien podrá rastrear mis movimientos? En principio, no, ya que las apps de seguimiento de contactos se basan en Bluetooth LE y no en GPS. Y digo en principio porque el creador de la app podría querer activar el uso de GPS, pero esa opción ya no depende de la plataforma de rastreo proporcionada por Apple y Google o por otras iniciativas, como DP3T. En cualquier caso, salvo ciberataque a sus servidores, el seguimiento sólo estará disponible para las autoridades de salud pública. 15. Está surgiendo una gran cantidad de apps de rastreo de contagios por todo el mundo, ¿son todas iguales? No. Aunque todas se basan en Bluetooth siguiendo un esquema más o menos como el descrito, difieren en quién controla la información de los servidores y en cuánta información personal se almacena en dichos servidores. Las versiones que más celosamente protegen la privacidad sólo cargan las claves generadas por los dispositivos, que no son personalmente identificables (salvo complicados ataques descritos más adelante). En otras versiones, las apps suben además el perfil personal completo de los usuarios: nombre, edad, domicilio, código de identificación, etc. Recientemente se ha creado la Coalición TCN, una coalición mundial para establecer los protocolos de rastreo de los primeros contactos digitales para luchar contra Covid-19. Esta coalición tiene por objeto aunar esfuerzos para desarrollar un protocolo abierto y compartido que pueda ser utilizado por múltiples aplicaciones para frenar la pandemia preservando la privacidad. 16. ¿Violan estas apps las leyes de protección de datos? Según el comunicado de prensa de la Comisión Europea, «deberán ser plenamente conformes con las normas de protección de datos y de la intimidad de la UE, expuestas en las directrices presentadas hoy tras la consulta al Comité Europeo de Protección de Datos.» 17. Cuando pase la pandemia, ¿podrán rastrearme? Esta pregunta difícil de contestar. Jaap-Henk Hoepman, profesor de Seguridad Digital en la Radboud University Nijmegen, en Holanda, y responsable del Privacy & Identity Lab, no lo tiene claro, como denuncia en su blog. Para él los peligros de un sistema de este tipo no están en que pudiera efectivamente ayudar a esa futura fase de retorno a la normalidad, sino a todo lo que podría venir después tras implantar este tipo de sistema en nuestros móviles: La policía podría ver rápidamente quién ha estado cerca de la víctima de un crimen activando el teléfono de la víctima como «infectado». Lo mismo podría aplicarse para encontrar a las fuentes de los periodistas o a los «soplones» que filtran información. Una empresa podría instalar balizas Bluetooth equipadas con este software en puntos de interés para marcar ciertas balizas como «infectadas» y así localizar a quienes pasaron cerca. Si tienes Google Home en casa, Google podría usar este sistema para identificar a todos los que visitaron tu hogar. Si tu pareja es celosa, podría instalar una aplicación secreta en tu móvil para seguirte y comprobar con quién has estado en contacto; o padres para espiar a sus hijos. 18. ¿Cómo funciona la criptografía detrás de estas apps? Situándonos en una perspectiva más técnica, la criptografía varía de unas apps a otras, pero todas siguen unos pasos semejantes: Al instalar la aplicación, se genera una clave única asociada al dispositivo en cuestión, tomando en cuenta componentes del sistema. Se persigue así la impredictibilidad e imposibilidad de replicación para asegurar la privacidad y el anonimato. Además, se almacena localmente en el dispositivo de forma segura. De esa primera clave, se deriva una segunda clave, que se regenerará diariamente. Mientras el Bluetooth está activado, se aprovecha la comunicación para enviar, en los paquetes asociados al protocolo, un identificador de proximidad. Los terminales con Bluetooth activado se intercambian entre sí estos identificadores de proximidad cuando entran dentro del radio de alcance mutuo predefinido. Estas claves cambian cada 15 minutos y se derivan a partir de las claves diarias anteriores. Los identificadores de proximidad enviados y recibidos son procesados y almacenados exclusivamente de forma local. Si uno de los dueños del teléfono es diagnosticado como positivo, las autoridades sanitarias le asignan un número de permiso. Esta persona envía una solicitud a la base de datos pública con el número de permiso y su historial de números de eventos de contacto transmitidos. Si el número de permiso es válido, los números de eventos de contacto se almacenan en la base de datos y se transmiten a todos los demás teléfonos. Cada teléfono compara los números de eventos de contacto publicados públicamente con su propia historia. Si hay alguna coincidencia, significa que estaban cerca de un individuo infectado y se les da instrucciones sobre qué hacer a continuación. 19. ¿Qué escenarios de ataque pueden diseñarse para saltarse las medidas de protección? Se barajan diferentes ataques para revelar la identidad de los usuarios diagnosticados como positivos. Por fortuna, las arquitecturas descentralizadas exigen rastrear individualmente a los usuarios, lo que implica muchísimo tiempo y reduce drásticamente la escala del ataque. Por ejemplo, un atacante podría grabar con una cámara la cara de todo el que pasa por delante mientras registra las señales Bluetooth de sus apps. En el futuro, si uno de esos transeúntes informa de que es positivo, la app del atacante recibirá como cualquier otra todas sus claves del servidor y será capaz de hacer coincidir los códigos que el usuario emitió en el momento de pasar por delante de la cámara, identificando así a un extraño como positivo. Otra versión de este ataque de correlación permitiría el rastreo comercial: una empresa de publicidad podría ubicar en comercios a pie de calle balizas Bluetooth que recojan los códigos de rastreo de contactos emitidos por los clientes que las visitan. La empresa podría entonces utilizar la aplicación de salud pública para descargar todas las claves de las personas que luego son diagnosticadas con Covid-19 y generar todos sus códigos de las últimas dos semanas. Ese método podría determinar hipotéticamente qué rastro de códigos representaba a una sola persona y seguirlos de tienda en tienda. Dado que el sistema toma no sólo como variable el tiempo de exposición sino también la cercanía de los dispositivos, un atacante podría generar falsos positivos amplificando su señal vía hardware de modo que usuarios que se encuentran a una gran distancia seguirían siendo igualmente notificados, pese a ser físicamente imposible que se hayan contagiado de ese usuario. Tal vez el problema más grave resida en el propio diseño de las apps más que en los potenciales ataques. Como argumenta en Twitter tras el anuncio de Apple y Google el criptógrafo Moxie Marlinspike, creador de la popular aplicación de comunicaciones cifradas Signal, según la descripción inicial de la API de Apple y Google, el teléfono de cada usuario de la aplicación tendría que descargar cada día las claves de cada persona recién diagnosticada con Covid-19, lo que rápidamente se traduciría en una importante carga de datos: «Si un número moderado de usuarios de teléfonos inteligentes se infectan en una semana determinada, eso es 100s de [megabytes] por cada teléfono a descargar». Un argumento a favor del sistema centralizado es que las apps podrían determinar mejor quién necesita descargar qué claves recogiendo datos de localización GPS, enviando a los usuarios sólo las claves relevantes para su área de movimiento. En tal caso, Google y Apple señalan que si una aplicación de rastreo de ubicación desea utilizar el GPS, primero deberá pedir permiso al usuario, como lo hace cualquier aplicación. 20. ¿Por qué Apple y Google cambiaron el nombre a su propuesta? En su nuevo comunicado del 24 de abril, Apple y Google ya no se refieren a su sistema como «rastreo de contactos» sino como «notificación de exposición» por considerar que esta expresión explica mejor el valor de su propuesta. Según dicen, la finalidad de la herramienta no es «rastrear» usuarios, sino «notificarlos» cuando existe una posible exposición a una persona con coronavirus. Para determinar el nivel de exposición, el software será capaz de calcular la proximidad entre dispositivos y el tiempo de exposición, limitado a 30 minutos.
28 de abril de 2020

Las 10 mejores charlas TED para aprender sobre ciberseguridad
El nivel medio de las presentaciones profesionales suele ser tan bajo que la gente prefiere trabajar a escucharlas. Lo verás en todo tipo de reuniones: a la segunda diapositiva, los asistentes ya están respondiendo al correo o terminando un informe. Por fortuna, no todas las presentaciones son iguales: desde hace más de 20 años, las charlas TED arrojan un rayo de esperanza sobre este desolador panorama. En esta entrada te traemos las 10 mejores charlas para aprender sobre ciberseguridad y, a la vez, para conocer pautas y trucos sobre cómo mejorar tus propias presentaciones. 1. Bruce Schneier: El espejismo de la seguridad La seguridad es tanto un sentimiento como una realidad. El sentimiento y la realidad de la seguridad están ciertamente relacionados entre sí, pero también es cierto que no son iguales. La mayoría de las veces, cuando la percepción de la seguridad no coincide con la realidad de la seguridad, es porque la percepción del riesgo no coincide con la realidad del riesgo. No evaluamos los compromisos en seguridad matemáticamente, examinando las probabilidades relativas de los diferentes eventos. En su lugar, tenemos atajos, reglas generales, estereotipos y sesgos, generalmente conocidos como "heurísticas". Estas heurísticas afectan a la forma en que pensamos sobre los riesgos, cómo evaluamos la probabilidad de los eventos futuros, cómo consideramos los costos y cómo realizamos los compromisos. Y cuando esas heurísticas fallan, nuestro sentimiento de seguridad se aleja de la realidad de seguridad. En esta charla, el gurú de la criptografía, Bruce Schneier, explica cuáles son algunos de los sesgos cognitivos detrás de nuestra mala evaluación del riesgo en ciberseguridad y cómo superarlos. 2. Marta Peirano: ¿Por qué me vigilan, si no soy nadie? Escritora, periodista y activista, Marta Peirano revela en esta charla la escalofriante realidad de la vigilancia a la que vivimos sometidos sin nuestro conocimiento y, por supuesto, sin nuestro consentimiento. Peirano derriba estrepitosamente ese ingenuo mito de “yo no tengo nada que ocultar”. Tu vida en la red debe permanecer protegida por el anonimato no porque tengas algo que ocultar sino porque tu privacidad es un derecho fundamental. Si no haces nada por protegerlos, tus datos dejarán de ser tuyos. 3. Caleb Barlow: ¿De dónde viene realmente el ciberdelito? El exvicepresidente de seguridad de IBM propone responder al ciberdelito con el mismo esfuerzo colectivo que aplicamos a una crisis sanitaria como el Covid-19: compartiendo información oportuna sobre quién está infectado y cómo se está propagando la enfermedad. Según Barlow, tenemos que democratizar los datos de inteligencia de riesgos. Hay que conseguir que organizaciones públicas y privadas se abran y compartan lo que está en su arsenal privado de información. Los ciberatacantes se mueven rápidamente; tenemos que avanzar más rápido. Y la mejor manera de hacerlo es abrir y compartir datos sobre lo que está sucediendo. Si no compartes, entonces eres parte del problema. 4. Mikko Hypponen: Luchando contra virus, defendiendo Internet Han pasado 25 años desde el primer virus para PC (Brain A), propagado de disquete a disquete. Lo que una vez fue un fastidio, hoy se ha convertido en una herramienta sofisticada de espionaje y crimen. En esta charla Hypponen explica cómo funciona la economía del cibercrimen. 5. Ralph Langnet: Crackeando Stuxnet, un arma cibernética del siglo XXI Cuando fue descubierto por primera vez en 2010, el gusano informático Stuxnet planteó un desconcertante acertijo. Más allá de su nivel de sofisticación inusualmente alto, asomaba un misterio aún más problemático: su propósito. Con la ayuda de su equipo identificó que Stuxnet era un ataque ciberfísico dirigido a un objetivo específico y único, identificó que este objetivo era el programa nuclear iraní (algo que nadie quiso creer durante meses) y analizó los detalles exactos de cómo este ataque, o más exactamente, estos dos ataques, estaban destinados a funcionar. En esta charla aprenderás cómo funcionan los ataques dirigidos contra las infraestructuras críticas. 6. Mikko Hypponen: Tres tipos de ciberataques Existen tres grandes grupos de ciberatacantes: los cibercriminales, que buscan enriquecerse a traés de negocios online ilegales; los hacktivistas, que buscan protestar y cambiar situaciones políticas; y los gobiernos de las naciones, que buscan espiar y controlar a los ciudadanos, sí, incluso en las democracias occidentales. Tu gobierno te espía. 7. Avi Rubin: Todos sus dispositivos pueden ser hackeados Los ciberataques van más allá del daño a ordenadores y del robo de datos. También pueden matar. Esta charla explica cómo funciona el hacking de dispositivos con un impacto real en las vidas humanas: dispositivos médicos, vehículos, etc. Cualquier dispositivo con software puede ser vulnerable. Tendrá fallos. Y si tiene fallos, serán explotados. No podemos olvidar que toda tecnología debe incorporar seguridad. 8. James Lyne: Ciberdelincuencia cotidiana y qué hacer al respecto ¿Eres consciente de lo que tus dispositivos revelan sobre ti? ¿Cuánta seguridad y privacidad regalas a cambio de comodidad y utilidad? El malware funciona porque el 99% de las víctimas no toman las medidas más básicas de precaución. ¿Cómo ataca el malware? ¿Qué puede pasarte? Y ¿cómo puedes protegerte? James Lyne te pondrá al corriente en esta charla. 9. Lorrie Faith Cranor: ¿Qué hay de malo en su c0ntr@señ@? Para combatir las debilidades de las contraseñas basadas en texto, tanto inherentes como inducidas por el usuario, los administradores y las organizaciones suelen instituir una serie de reglas -una política de contraseñas- a las que los usuarios deben atenerse al elegir una contraseña. ¿Cómo debería ser una buena contraseña? Tras estudiar miles de contraseñas reales para averiguar los errores más sorprendentes y comunes de los usuarios, Lorrie Cranor tiene algunas respuestas. 10. Finn Myrstad: Cómo las compañías de tecnología te decepcionan brindando tu información y privacidad ¿De qué sirve proteger tu casa con una cerradura si cualquiera puede entrar a través de un dispositivo conectado? A pesar de no leer jamás los términos y condiciones, empeño inútil, marcas la casilla afirmando que sí lo has hecho y, ¡boom!, estás de acuerdo en que tu información personal se recopile y use. Las empresas depositan toda la carga sobre el consumidor. La tecnología solo beneficiará a la sociedad si respeta los derechos humanos más básicos, como la privacidad.
31 de marzo de 2020

Criptografía Ligera para un mundo doblegado bajo el peso del IoT
No te creas que todos los dispositivos IoT son tan potentes como los asistentes inteligentes controlados por voz del salón o como las pulseras de actividad. De hecho, la inmensa mayoría de dispositivos IoT desplegados por el mundo apenas poseen memoria, ni CPU, ni energía. Y tampoco entienden de seguridad: carecen de los recursos necesarios para conectarse a Internet cifrando el tráfico, para gestionar certificados digitales o para calcular hashes. La preocupación surge cuando estos "dispositivos constreñidos" gestionan información potencialmente sensible. ¿Cómo protegerlos si la criptografía convencional les está vetada? Usando Criptografía Ligera (Lightweight Cryptography). La criptografía tradicional no sirve de mucho en el mundo IoT Los "dispositivos constreñidos" son aquellos que ven seriamente limitados su conectividad, memoria, CPU, latencia, throughput y suministro de energía. Entre los más comunes te sonarán las etiquetas RFID, las redes de sensores inalámbricos, los controladores industriales y los dispositivos embebidos. Se trata de dispositivos sencillos, baratos y poco glamurosos. Utilizan microcontroladores de 4, 8 o 16 bits. Sus memorias RAM rondan los 64 bytes o incluso tan solo los 16 bytes. Sus conjuntos de instrucciones son también muy reducidos. Algunos, como las etiquetas RFID, no tienen ni batería y se alimentan de la energía electromagnética transmitida por el propio lector al acercarlo. O bien sus baterías no pueden reemplazarse con facilidad, como en un marcapasos. Nombre RAM ROM Clase 0 (C0) << 10 KB << 100 KB Clase 1 (C1) ≈ 10 KB ≈ 100 KB Clase 2 (C2) ≈ 50 KB ≈ 250 KB Tabla 1. Clases de dispositivos constreñidos En estas condiciones, como puedes imaginar, tratar de implantar un AES o un RSA sería imposible. Hay que entender que los estándares y protocolos criptográficos convencionales fueron diseñados para servidores y equipos de escritorio, incluso para tablets y smartphones, pero no aplican en este mundo caracterizado por la escasez de energía, de CPU y de memoria. Tabla 2. Tipos de criptografía en función del tipo de dispositivo Si el dispositivo constreñido no almacena ni transmite información, como por ejemplo un termómetro que mide la temperatura corporal y la muestra en un display, entonces no existe verdadera necesidad de criptografía. Pero si el termómetro comunica estos datos a otro dispositivo, como un smartphone, la película cambia, al igual que con otros dispositivos IoT en medicina, como glucómetros, bombas de insulina, cápsulas endoscópicas, marcapasos, etc. Además de en medicina, en otros ámbitos de IoT se da la misma situación: sensores de vehículos, carreteras inteligentes, microcontroladores en procesos industriales (IIoT), tecnologías vestibles, ciudades inteligentes, agricultura de precisión y un largo etcétera. No todos ellos necesitan protección criptográfica, ni mucho menos, pero en algunas aplicaciones se requerirá proteger los datos en reposo o en tránsito, y aquí es donde aparece en escena la Criptografía Ligera. No se puede tener todo: el despiadado compromiso de seguridad en IoT La criptografía en IoT exige un compromiso entre seguridad, rendimiento y coste. El rendimiento se refiere al consumo de energía, latencia y throughput; el coste, a memoria y CPU. Cuanto más seguro sea un algoritmo o protocolo, mayor impacto negativo ejercerá sobre el coste y sobre el rendimiento. Del mismo modo, si se quiere mejorar el rendimiento o bajar el coste, se impactará negativamente en la seguridad. Como todo compromiso, no tiene respuesta sencilla. Puedes llegar a alcanzar dos objetivos simultáneamente, pero no los tres: si quieres que el dispositivo sea barato y rápido, no resultará seguro; si lo quieres seguro y barato, no funcionará rápido; y si lo quieres seguro y rápido, no te saldrá barato. Con dispositivos IoT constreñidos, los criptógrafos tienen que apañárselas para conseguir la máxima seguridad posible partiendo de severas restricciones de rendimiento y de coste. Figura 1. Compromiso entre seguridad, rendimiento y coste en IoT Criptografía Ligera no es sinónimo de criptografía débil, sino de eficiencia y robustez En el último decenio los criptógrafos han propuesto diversas primitivas criptográficas ligeras que ofrecen un compromiso razonable entre seguridad, rendimiento y coste con respecto a la criptografía convencional: Cifradores en bloque: son algoritmos utilizados para cifrar los datos en un intento de reemplazar a AES, aunque obteniendo niveles de seguridad comparables. Existen docenas de propuestas, que trabajan con tamaños de bloque más reducidos, por ejemplo, 64 bits en lugar de 128; claves más pequeñas, por ejemplo, 80 bits en lugar de 128 o 256; menor número de vueltas y diseño de vueltas más sencillo; programación de claves más simple e implementaciones mínimas, que no soportan complejos modos de operación. Destacan los algoritmos PRESENT, CLEFIA y SIMON. Funciones hash: son algoritmos utilizados para crear resúmenes criptográficamente seguros de los datos. Igualmente, se han propuesto numerosas funciones ligeras de hash, como PHOTON y SPONGENT, caracterizadas por tamaños más reducidos tanto de salida como de estado interno. Eso sí, con el riesgo de sufrir colisiones y tamaños de mensaje también menores, por ejemplo, de hasta 256 bits. Códigos de autenticación de mensajes (MAC): generan un código a partir de un mensaje y de una clave secreta que se utiliza para verificar la autenticidad y la integridad del mensaje. Se recomienda que el tamaño del código sea de al menos 64 bits para las aplicaciones típicas. También se han realizado algunas propuestas para estas funciones, como Chaskey, TuLP o LightMAC. Cifradores en flujo: se cuentan entre las primitivas más prometedoras para entornos constreñidos, ya que desde siempre los cifradores en flujo se han orientado a la eficiencia: elevados niveles de seguridad con alto rendimiento y bajo coste. Existen numerosas propuestas, entre las que destacan Grain, Trivium y Mickey. ¿Y qué pasa con la criptografía de clave pública para intercambiar claves? Pues lo cierto es que todavía no ha surgido ninguna propuesta apropiada para entornos altamente constreñidos, como los dispositivos de Clase 0. Aparte de variantes algo más ligeras de ECC, se barajan opciones totalmente diferentes, como fabricar los dispositivos constreñidos con claves precargadas que solo conocerán los dispositivos pesados con los que interactúen. ¿Cómo conciliar todo esto? Por supuesto, los dispositivos más potentes tendrán que implantar estos algoritmos de Criptografía Ligera, para poder comunicarse de forma segura con los constreñidos. Puede utilizarse una pasarela intermedia o un agregador, que se comunica con dispositivos constreñidos usando sus algoritmos y protocolos ligeros, y que luego reenvía a los dispositivos más pesados, como servidores en la nube, la información procedente del dispositivo debidamente protegida usando la criptografía convencional. Como puedes imaginar, ante el crecimiento explosivo de dispositivos IoT e IIoT, el interés por esta criptografía no ha parado de aumentar en los últimos años. De hecho, tanto el Instituto de Estándares y Tecnología Americano (NIST) como la Organización Internacional de Estándares (ISO/CEI) están trabajando intensamente en la búsqueda, prueba y estandarización de métodos que puedan utilizarse con garantías para la Criptografía Ligera. Todo sea por un futuro con dispositivos IoT interconectados, ¡pero con seguridad!
16 de marzo de 2020

Qué es la privacidad diferencial y por qué Google y Apple la usan con tus datos
Para poder personalizar sus productos y servicios y ofrecer cada vez mejores características que los hagan más valiosos y útiles, las empresas necesitan conocer información sobre sus usuarios. Cuanto más sepan sobre ellos, mejor para ellas y mejor, supuestamente, para sus usuarios. Pero claro, mucha de esta información es de carácter sensible o confidencial, lo cual representa una seria amenaza a su privacidad. Entonces, ¿cómo puede hacer una empresa para saberlo todo sobre sus clientes y a la vez no saber nada sobre ningún cliente en particular? ¿Cómo pueden sus productos proporcionar grandes características y gran privacidad a la vez? La respuesta a esta paradoja reside en la "privacidad diferencial": aprender tanto como sea posible sobre un grupo mientras se aprende lo menos posible sobre cualquier individuo en él. La privacidad diferencial permite obtener conocimientos de grandes conjuntos de datos, pero con una prueba matemática de que nadie puede obtener información sobre un solo individuo del conjunto. Gracias a la privacidad diferencial puedes conocer a tus usuarios sin violar su privacidad. Veamos, en primer lugar, la amenaza a la privacidad de los grandes conjuntos de datos. Ni el anonimato ni las grandes consultas garantizan la privacidad Imagina que un hospital mantiene registros de sus pacientes y que los cede a una empresa para que pueda hacer un análisis estadístico de ellos. Por supuesto, elimina la información personalmente identificable, como nombre y apellidos, DNI, dirección, etc. y sólo mantiene su fecha de nacimiento, sexo y código postal. ¿Qué podría salir mal? En 2015, la investigadora Latanya Sweeney armó un ataque de reidentificación sobre un conjunto de datos de registros hospitalarios. Agárrate, porque a partir de historias en los periódicos fue capaz de identificar personalmente (con nombres y apellidos) al 43% de los pacientes de la base de datos anonimizada. De hecho, llegó a afirmar que el 87% de la población de EEUU se identifica de manera única por la fecha de nacimiento, el género y el código postal. Como ves, las técnicas de anonimización de las bases de datos fracasan miserablemente. Además, cuanto más anonimizada está una base de datos (cuanta más información personalmente identificable se ha eliminado), menos útil resulta. ¿Y si sólo se permiten consultas sobre grandes volúmenes de datos y no sobre individuos concretos? El "ataque diferenciador" se ocupa de este caso: supongamos que se sabe que el sr. X aparece en cierta base de datos médicos. Lanzamos las siguientes dos consultas: "¿cuántas personas padecen anemia drepanocítica?" y "¿cuántas personas sin el nombre de X padecen anemia drepanocítica?" En conjunto, las respuestas a las dos consultas arrojan el estado drepanocítico del sr. X. Según la Ley Fundamental de Recuperación de Información: "Las respuestas demasiado exactas a demasiadas preguntas destruirán la privacidad de manera espectacular." Y no creas que prohibir estos pares de preguntas evita los ataques diferenciadores, el mero hecho de rechazar una doble consulta ya podría filtrar información. Hace falta algo más para conseguir garantizar la privacidad y, a la vez, poder hacer algo útil con las bases de datos. Existen diferentes propuestas para alcanzar privacidad diferencial. Empecemos por una técnica muy sencilla empleada por los psicólogos desde hace más de 50 años. Si quieres privacidad, añade ruido Imagina que quiero obtener respuesta a una pregunta embarazosa: ¿alguna vez te has zampado una lata de comida para perros? Como el tema es delicado, te propongo que respondas de la siguiente manera: Lanza una moneda (sin trucar) al aire. Si sale cara, vuelve a lanzarla al aire y, salga lo que salga, tú responde la verdad. Si sale cruz, entonces lánzala de nuevo y responde "sí" si sale cara y "no" si sale cruz. Ahora tu confidencialidad queda a salvo porque nadie puede saber si respondiste la verdad o si seleccionaste un resultado aleatorio. Gracias a este mecanismo de aleatorización se ha alcanzado negación plausible: aunque vean tu respuesta, puedes negarla y no podrán demostrar lo contrario. De hecho, si te preguntaste para qué se hace un lanzamiento extra en el primer caso si luego no se tiene en cuenta, es para protegerte en situaciones en las que puedan observarte lanzar la moneda. ¿Y qué pasa con la precisión del estudio? ¿Sirve para algo con tanto dato aleatorio? La verdad es que sí. Como la distribución estadística de los resultados de lanzar al aire una moneda es perfectamente conocida, puede eliminarse sin problema de los datos. ¡Atención, matemáticas! No sigas leyendo si no toleras las ecuaciones. La cuarta parte de respuestas positivas son dadas por personas que no se comen la comida de su perro y por tres cuartas partes de las que sí. Por lo tanto, si p representa la proporción de personas que zampan latas de comida para perros, entonces esperamos obtener (1/4)(1- p) + (3/4) p respuestas positivas. Por lo tanto, sí es posible estimar p. Y cuantas más personas sean consultadas, más se aproximará el valor calculado de p al valor real. Sin ir más lejos, esta idea (con alguna complicación adicional) fue adoptada por Google en 2014 para su proyecto RAPPOR (Randomized Aggregatable Privacy-Preserving Ordinal Response). Según Google, "RAPPOR proporciona una nueva y moderna manera de aprender estadísticas de software que podemos utilizar para salvaguardar mejor la seguridad de nuestros usuarios, encontrar errores y mejorar la experiencia general del usuario». Por supuesto, protegiendo la privacidad de los usuarios. O eso dicen. Lo bueno es que puedes examinar el código de RAPPOR por ti mismo para verificarlo. Privacidad diferencial más allá de las respuestas aleatorizadas Las respuestas aleatorizadas son una forma simplificada de alcanzar la privacidad diferencial. Los algoritmos más potentes utilizan la distribución de Laplace para extender el ruido por todos los datos y aumentar así el nivel de privacidad. Y existen otros muchos, recogidos en el libro de descarga gratuita The Algorithmic Foundations of Differential Privacy. Lo que todos tienen en común, eso sí, es la necesidad de introducir el azar de una forma u otra, típicamente medida por un parámetro ε, que puede ser tan pequeño como se quiera. Cuanto más pequeño sea ε, mayor la privacidad del análisis y menor precisión en los resultados, ya que cuanta más información intentes consultar a tu base de datos, más ruido necesitas inyectar para minimizar la fuga de privacidad. Te enfrentas inevitablemente a un compromiso fundamental entre la precisión y la privacidad, lo cual puede ser un gran problema cuando se entrenan modelos complejos de Machine Learning. Y lo que es aún peor: por pequeño que sea ε, toda consulta fuga información, y con cada nueva consulta, la fuga se incrementa. Una vez traspasado el umbral del nivel de privacidad que has predeterminado, no puedes seguir adelante o empezarás a fugar información personal. En ese punto, la mejor solución puede ser simplemente destruir la base de datos y empezar de nuevo, lo cual parece poco viable. Por tanto, el precio a pagar por la privacidad es que el resultado de un análisis diferencialmente privado nunca será exacto, sino una aproximación con fecha de caducidad. ¡No se puede tener todo! ¿O sí? El cifrado totalmente homomórfico y la computación multiparte segura permiten el análisis 100% privado y 100% preciso. Por desgracia, estas técnicas son hoy por hoy demasiado ineficientes para aplicaciones reales de la magnitud que manejan Google o Apple. Demasiado bonito para ser verdad, ¿dónde está la trampa? Desde que en 2016 Apple anunció que iOS 10 incorporaría privacidad diferencial, el concepto ha saltado de las pizarras de los criptógrafos a los bolsillos de los usuarios. A diferencia de Google, Apple no ha liberado su código, por lo que no puede saberse con exactitud qué tipo de algoritmo utiliza ni si lo utiliza con garantías. En cualquier caso, parece buena señal que gigantes como Google y Apple den pasos, aunque sea tímidos, en la dirección correcta. La criptografía pone a su alcance recursos para conocer a sus usuarios y a la vez salvaguardar su privacidad. Esperemos que el uso de estos algoritmos se popularice y otros gigantes, como Amazon o Facebook, comiencen también a implantarlos.
3 de marzo de 2020

Criptografía eterna: cómo cifrar los datos hasta el final de los tiempos
Se cree que Julio César, en el período entre el 58 y el 51 a.C., envió mensajes cifrados a su abogado Marco Tulio Cicerón y a otros senadores romanos usando una sustitución mono-alfabética. En el cifrado de César, cada letra del mensaje original se reemplaza por la letra situada tres lugares a su derecha en el alfabeto. De modo que sus famosas palabras: VINI VIDI VINCI se cifran como YLQL YLGL YLQFL Seguro durante siglos, hoy este cifrado es tan trivial que se enseña a los niños para introducirlos a la criptografía. Los secretos más íntimos de Julio César habrían resistido por pocos siglos así cifrados. ¿Y los secretos actuales? Regresando a nuestros tiempos, resulta ilustrativo revisar el auge y caída de DES (Data Encryption Standard), el algoritmo de cifrado que marcó el inicio de la época moderna de la criptografía de uso público. Aprobado como estándar en el año 1976, proporcionó confidencialidad al mundo civilizado hasta que fue reemplazado por el nuevo estándar AES en 2002. ¿Qué motivó el cambio? Hoy DES puede romperse en unos pocos segundos con un ataque de fuerza bruta. Si alguien cifró información con DES esperando que el secreto se mantuviera por muchos años, se habrá llevado un gran chasco. Surge por tanto una pregunta fundamental: ¿cómo puede protegerse un secreto a largo plazo, preservándose su confidencialidad a lo largo de los años? El Santo Grial de la criptografía: el cifrado eterno que nunca se rompe, pero que resulta práctico ¿Qué se entiende por "secreto perfecto"? Un adversario tiene un acceso completo y perfecto al canal (autenticado o no). Dado cualquier texto cifrado, un adversario no obtiene ninguna información sobre el texto claro correspondiente por muchos recursos computacionales que posea. ¿Existe el secreto perfecto? Sí, el cifrado de Vernam o libreta de un solo uso, pero nunca se utiliza. ¿Cómo es posible? ¡Porque resulta impráctico! El cifrado de Vernam mezcla los bits del mensaje original con una secuencia de bits verdaderamente aleatoria tan larga como el mensaje y que nunca se repite. El resultado es un cifrado inatacable por ningún método actual ni futuro. Aunque se puede demostrar matemáticamente que Vernam es 100% seguro, plantea numerosos inconvenientes de orden práctico, siendo los dos principales: La generación de la clave: generar bits aleatorios no es tarea fácil, y menos aún hacerlo en cualquier tipo de dispositivo de uso cotidiano, ya que se debe recurrir a procesos físicos aleatorios. A la mente te vendrá lanzar al aire una moneda o un dado. Otros métodos más sofisticados se basan en el decaimiento de la actividad radiactiva de partículas, en el ruido térmico en una resistencia o en las turbulencias generadas por la rotación de un disco duro. El único método moderno que parece estar ganando tracción es el uso de generadores cuánticos de aleatoriedad, como los de las empresas QuSide, ID Quantique o Qrypt. La distribución de la clave: por mucho que tengas una clave aleatoria para cifrar usando el cifrado de Vernam, si no puedes almacenarla y hacérsela llegar de forma segura al destinatario, no te servirá de nada. ¡El mayor obstáculo es que la clave es tan larga como el mensaje! Si estás cifrando comunicaciones a Gbits/s, ¡necesitas transportar la clave a la misma velocidad! Y si quieres guardar un secreto para siempre, necesitas igualmente guardar la clave para siempre tan larga como el propio secreto, tirando por tierra así la ventaja del cifrado. Además, no puedes reutilizarla, ni siquiera un fragmento diminuto. Por fortuna, una vez más, la física llega al rescate: la distribución cuántica de claves solventa el problema, aunque no está exenta a su vez de dificultades y obstáculos, que aún están en fase de investigación. Una vez más, la empresa ID Quantique se ha posicionado como pionera en este mercado. En resumen, el cifrado de Vernam constituye el Santo Grial de la criptografía: el algoritmo irrompible que protege los secretos para siempre. Por desgracia, salvo en contadísimas ocasiones, no puede usarse en la práctica, así que habrá que buscar enfoques menos perfectos pero más prácticos y que envejezcan con lentitud. Los demás algoritmos de cifrado envejecen... y mueren ¿Cómo es que un algoritmo envejezca y deje de ser seguro con los años? Existen varios avances que debilitan a todo algoritmo criptográfico con el paso del tiempo: Avances en computación: todo algoritmo de cifrado depende de una clave. Un ataque de "búsqueda exhaustiva" prueba todos sus posibles valores hasta dar con el correcto. Para llevarlo a cabo solo hace falta potencia bruta de cómputo, no fineza matemática. De ahí que se llame también ataque de "fuerza bruta". No importa lo bien diseñado que esté un algoritmo ni lo inteligentes que sean sus operaciones, el avance inexorable de la capacidad de cómputo va erosionando lentamente su seguridad, hasta que finalmente puede realizarse la búsqueda exhaustiva en tiempo y coste razonables. Por mucho que aumentes la longitud de la clave, ¿cómo preservar la confidencialidad ante un atacante armado con recursos computacionales infinitos? Salvo con Vernam, no parece posible con ningún otro algoritmo. Avances en criptoanálisis: todos los algoritmos criptográficos de dominio público se someten al escrutinio despiadado de toda la comunidad científica. Con los años, terminan descubriéndose debilidades que disminuyen la complejidad de los ataques. Recordemos al pobre César. Si la clave tiene una longitud n, cualquier vía de ataque que reduzca el número necesario de pruebas por debajo de 2n supone un avance. Cuando la reducción es tan drástica que con la potencia de cómputo del momento un ataque se vuelve factible, entonces el algoritmo se considera roto. Un algoritmo bien diseñado podría no tener ningún resquicio. Avances en matemáticas: las matemáticas no son inmutables. Se producen avances que permiten resolver problemas antes insolubles. Muchos algoritmos criptográficos se basan en la asunción de que P ≠ NP: hasta ahora nadie ha podido demostrar que "si resulta fácil de comprobar que la solución de un problema es correcta, entonces debe ser igualmente fácil de resolver". No se descarta que se produzcan avances en matemáticas que permitan resolver en tiempo polinómico problemas como el del viajante, el de la factorización, el del logaritmo discreto o el de la búsqueda de los vectores más cortos en una celosía. Avances en computación: problemas considerados hoy NP podrían ser de tipo P bajo paradigmas computacionales radicalmente diferentes del Silicio. El ejemplo más claro surgió con la computación cuántica y sus algoritmos de Shor, para factorizar números; y de Grover, para acelerar búsquedas en listas. Su consecuencia más devastadora para la criptografía es que arrasará con los algoritmos de cifrado de clave pública RSA, DSA, ECDSA, Diffie-Hellman y ECC, los estándares de facto actuales. Existen por supuesto otras formas de computación no convencional, como la computación biológica basada en ADN y su capacidad de paralelización masiva, o la basada en nanohilos, o en nanotubos de carbono, o en moléculas orgánicas, o en óptica, o en micro/nanofluidos, o incluso en amebas caóticas, y muchas más que se están investigando. ¿Aparecerán entre ellas algoritmos eficientes para resolver otros problemas matemáticos centrales en tiempo polinómico? Nadie lo sabe aún. El futuro está lleno de posibilidades. Todo algoritmo conocido ha sucumbido o se cree que sucumbirá ante uno o más de los avances anteriores. Y ninguno resistiría a una infinita potencia de cómputo. Con la excepción del cifrado de Vernam, claro. Entonces, si Vernam es impráctico, ¿qué se puede hacer? El futuro ya no es lo que era: cómo prepararse para nuevos futuros Veamos cómo prepararnos para los ataques inesperados que nos depare el futuro: Algoritmos capaces de resistir las amenazas conocidas: ya desde mediados de los 80 existen algoritmos criptográficos basados en la dificultad de resolver problemas matemáticos distintos de la factorización de enteros y del logaritmo discreto. Las tres alternativas resistentes mejor estudiadas (por ahora) ante los ordenadores cuánticos son: Criptografía basada en hashes: como su nombre indica, utilizan funciones hash seguras, que resisten a los algoritmos cuánticos. Su desventaja es que generan firmas relativamente largas, lo que limita sus escenarios de uso. Leighton-Micali Signature Scheme (LMSS) constituye uno de los candidatos más sólidos para reemplazar a RSA y ECDSA. Criptografía basada en códigos: la teoría de códigos es una especialidad matemática que trata de las leyes de la codificación de la información. Algunos sistemas de codificación son muy difíciles de decodificar, llegando a requerir tiempo exponencial, incluso para un ordenador cuántico. El criptosistema mejor estudiado hasta la fecha es el de McEliece, otro prometedor candidato para intercambio de claves. Criptografía basada en celosías: posiblemente se trate del campo más activo de investigación en criptografía post-cuántica. Una "celosía" es un conjunto discreto de puntos en el espacio con la propiedad de que la suma de dos puntos de la celosía está también en la celosía. Un problema difícil es encontrar el vector más corto en una celosía dada. Todos los algoritmos clásicos requieren para su resolución un tiempo que crece exponencialmente con el tamaño de la celosía y se cree que lo mismo ocurrirá con los algoritmos cuánticos. Actualmente existen numerosos criptosistemas basados en el Problema del Vector más Corto. Por otro lado, los nuevos paradigmas de computación proponen a su vez algoritmos criptográficos, que podrían resistir a los avances en otros paradigmas. Uno de los campos de investigación más intensos es el de la criptografía basada en DNA. Otro enfoque radicalmente distinto en el que yo mismo trabajé durante años es el de la criptografía basada en caos (el estudio de los sistemas dinámicos no lineales). Su mayor inconveniente radica en que típicamente opera con números reales, que se llevan fatal con los ordenadores. Y aunque existen propuestas interesantes para proteger la transmisión de datos, en cuanto a cifrar datos en reposo no aportan grandes ventajas frente a otros esquemas más convencionales. Hasta el presente, estos sistemas han disfrutado de una atención marginal y nunca han llegado a entrar en el mainstream criptográfico. No obstante, no está de más mantener un ojo en su evolución. Cifrado múltiple: se define como cifrado múltiple el proceso de tomar un mensaje ya cifrado y volverlo a cifrar una o más veces utilizando uno o más algoritmos diferentes, a poder ser basados en problemas o paradigmas muy distintos entre sí, con la esperanza de que, si uno cae, el resto siga resistiendo. Reparto proactivo de secretos: esta técnica permite el almacenamiento seguro de la información en un entorno distribuido: el secreto se divide en partes que se distribuyen a diferentes entidades, como por ejemplo servidores de almacenamiento, de tal manera que cualquier subconjunto no cualificado de participantes no obtiene ninguna información sobre el secreto. Por lo tanto, la seguridad de la información se mantiene mientras un adversario no comprometa a un subconjunto cualificado de participantes. Una vez completado el reparto, sería necesario renovar las muestras cada cierto tiempo para que, si un atacante ha comprometido alguna, ya no resulte válida al juntarla con las partes renovadas. Presentan muchos inconvenientes prácticos: requisitos excesivos de almacenamiento, mucho tráfico generado durante las renovaciones, asunción de "servidores seguros", complicados protocolos de verificación, etc. Reemplazo al vuelo: otro enfoque propone la sustitución eficiente de la criptografía insegura por otra que no haya sido rota. Este enfoque requiere que todas las aplicaciones que usen criptografía la importen desde una API de criptografía dedicada: la Java Cryptographic Extensions (JCE), las clases del espacio de nombres System.Security.Cryptography en .NET o bibliotecas criptográficas independientes, como OpenSSL, Bouncy Castle, o NaCl, entre las más populares y robustas. Además, se necesitan protocolos que ejecuten rápidamente la sustitución de la criptografía obsoleta ante algún avance por otra aún resistente. Tales protocolos no sólo deben sustituir a las primitivas de la criptografía, también tienen que reemplazar las claves, certificados, etc. Cuando la eternidad no es posible, el tiempo necesario es más que suficiente En la práctica, tampoco es que sea necesario proteger la información por tiempo ilimitado. La sensibilidad de la información decae con el tiempo. Algunos datos deben mantenerse secretos hasta su publicación o desclasificación, como en el caso de patentes o informes gubernamentales, plazos que pueden oscilar entre unos pocos meses y unas docenas de años, pero no siglos. Otros deben protegerse durante un número de años estipulado por la Ley, como información privada de usuarios. Según algunas legislaciones, como la alemana, la confidencialidad de los datos de los pacientes debe preservarse incluso después de su muerte. En definitiva, el concepto de "largo plazo" es muy relativo, dependiente del contexto. En definitiva, no hay que obsesionarse con una "seguridad eterna" y buscar en cambio una seguridad por el "tiempo necesario". A pesar de los impresionantes avances en criptografía, la solución práctica para la confidencialidad a largo plazo sigue siendo un objetivo difícil de alcanzar. Tal vez, inalcanzable.
4 de febrero de 2020

SHA-1 no celebrará más cumpleaños, ha muerto
Gracias al auge de las criptomonedas, los hashes se han convertido en la operación matemática más veces calculada a lo largo de la historia. Mientras lees estas líneas, millones de GPUs en gigantescas granjas de criptominado están calculando trillones de hashes por segundo. ¿Qué hace que los hashes sean tan valiosos y qué tiene de especial SHA-1? ¿¡Hashes, para qué os quiero!? Simplificando al máximo, puede decirse que una función de hash calcula resúmenes de datos: recibe como entrada datos de cualquier tamaño y devuelve un valor de longitud fija. h = H( x ) Es decir, da igual el tamaño de la entrada x, 100 bits, mil megas o un millón de gigas, el valor devuelto h siempre tendrá la misma longitud. Distintas funciones de hash devuelven resúmenes de longitudes distintas, como se muestra en la tabla siguiente. Pero eso sí, la misma función de hash devolverá resúmenes siempre de la misma longitud. Algoritmo Tamaño de la salida Uso legado Uso futuro SHA-2 256, 384, 512, 512/256 P P SHA-3 256, 384, 512 P P SHA-3 SHAKE128, SHAKE256 P P Whirlpool 512 P P BLAKE 256, 384, 512 P P RIPEMD-160 160 P O SHA-2 224, 512/224 P O SHA-3 224 P O MD5 128 O O RIPEMD-128 128 O O SHA-1 160 O O Además, las funciones de hash son unidireccionales: es imposible conjeturar los datos originales a partir del resumen obtenido. Vamos, que no hay marcha atrás. Técnicamente, se dice que son funciones no invertibles. ¿Y para qué sirve calcular resúmenes de longitud fija a partir de datos de tamaño arbitrario? ¡Para todo! Se utilizan para las firmas digitales, para crear cadenas de bloques, para almacenar contraseñas, para autenticar mensajes, para derivar claves a partir de contraseñas, para cifrar los datos con algoritmos impenetrables por los ordenadores cuánticos, para verificar la integridad de archivos, para resolver puzles criptográficos, para organizar estructuras de datos como los árboles de Merkle, para identificar archivos en grandes repositorios, para construir generadores de números pseudoaleatorios, ¡y sigue y sigue! Como ves, los hashes constituyen un pilar de la criptografía. Eso sí, para considerarse criptográficamente seguros se les exige una serie de requisitos. Cuándo una función de hash es criptográficamente segura y cuándo no Para su uso en aplicaciones criptográficas, una función de hash debe poseer una serie de propiedades: Resistencia a la preimagen: dado un hash, es imposible encontrar un mensaje cualquiera que produzca el mismo hash. Resistencia a la segunda preimagen: dados un mensaje y su hash, es imposible encontrar otro mensaje que produzca el mismo hash. Resistencia a colisiones: es imposible encontrar dos mensajes cualesquiera que produzcan el mismo hash. En la siguiente tabla se resumen los requisitos generalmente aceptados para una función de hash criptográfica. Las tres primeras propiedades son requisitos para su aplicación práctica. Las siguientes garantizan su aplicación segura en criptografía. Requisitos Descripción Tamaño de entrada variable H puede aplicarse a un bloque de datos de cualquier tamaño. Tamaño de salida fijo H produce una salida de longitud fija. Eficiencia H( x ) es relativamente fácil de calcular para cualquier x dada, permitiendo que tanto las implementaciones de hardware como de software sean prácticas. Resistente a preimágenes (propiedad de unidireccionalidad) Para cualquier valor hash dado h, es computablemente inviable encontrar x tal que H( x ) = h. Resistente a la segunda preimagen (resistencia débil a colisiones) Para cualquier x dado, es computacionalmente inviable encontrar y ≠ x con H( y ) = H( x ). Resistente a las colisiones (resistencia fuerte a colisiones) Es computacionalmente inviable encontrar cualquier par ( x, y) con x ≠ y, tal que H( y ) = H( x ). Pseudoaleatoriedad La salida de H supera las pruebas estándar de pseudoaleatoriedad. El ataque del cumpleaños ¿Cuántas personas crees que hace falta meter en una sala para que la probabilidad de que dos de ellas cumplan años el mismo día sea superior al 50%? Intuitivamente, pensamos que hará falta un número muy grande: cincuenta, cien personas, mil. ¡Pues no! Basta con 23 personas. Es lo que se conoce como la paradoja del cumpleaños: no porque contradiga la lógica, sino nuestra intuición. ¿Y qué tienen que ver los cumpleaños con los hashes? La paradoja anterior en realidad plantea un problema de colisiones, en este caso, la probabilidad de que en un grupo de t personas dos cumplan años el mismo día de entre N días. Matemáticamente, esta probabilidad se calcula como: Puede comprobarse fácilmente que para N = 365 y t = 23, dicha probabilidad es 50,7%. Ahora bien, si N es muy grande, entonces la probabilidad de que haya una repetición en el conjunto puede aproximarse como la raíz cuadrada de N. Por lo tanto, para un hash de n bits, si seleccionamos bloques de datos al azar, podemos esperar encontrar dos bloques de datos con el mismo valor hash con probabilidad superior al 50% en un número de intentos igual a √(2n) = 2n/2. Por consiguiente, si el hash tiene una longitud de 160 bits, un ataque de fuerza bruta o de búsqueda exhaustiva exige probar en promedio 280 posibles valores de hash para encontrar una colisión. Es como reducir la longitud efectiva del hash a la mitad. Estos ataques siempre son posibles y su complejidad computacional depende del número de bits del hash. Por esta razón, normalmente necesitamos duplicar la longitud de salida de las funciones hash en comparación con el tamaño de la clave de otras primitivas criptográficas. Por ejemplo, si AES se considera seguro hoy con 128 bits, una función de hash necesitará el doble: 256 bits. De hecho, por culpa del ataque del cumpleaños 256 bits es la longitud mínima recomendada hoy para hashes. Sin embargo, si la función de hash es débil, existen otros mecanismos para encontrar colisiones distintos a la fuerza bruta. Y eso, queridos amigos, es lo que le pasó a SHA-1. Crónica de la muerte anunciada de SHA-1 Las siglas SHA provienen de Secure Hash Algorithm. SHA constituye toda una familia de hashes. En 1993, el NIST americano creó SHA, el primer miembro de la familia, hoy llamado SHA-0 para distinguirlo de los siguientes: SHA-1, del que luego hablaremos; SHA-2, que a su vez comprende SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224 y SHA-512/256; y SHA-3, en sus versiones de 224, 256, 384 y 512 bits, así como las versiones de tamaño arbitrario de salida SHAKE128 y SHAKE256. En concreto, SHA-1 fue diseñado por la NSA en 1996 como parte de su Algoritmo de Firma Digital (DSA). Durante prácticamente dos décadas SHA-1 ha sido el algoritmo de hash más popular, presente de forma predeterminada o como opción en todas las aplicaciones criptográficas habidas y por haber, incluyendo TLS y SSL, OpenSSL, PGP, SSH, S/MIME, Ipsec, sistemas de control de revisiones como Git, todas las bibliotecas criptográficas y, en general, todas aquellas aplicaciones en las que se usan hashes. Por desgracia, se le fueron descubriendo diferentes vulnerabilidades con los años. De hecho, ya desde 2010 se desaconsejó su uso y se fue eliminando paulatinamente de protocolos y estándares. El golpe más duro lo recibió en 2017 cuando Google encontró una colisión para SHA-1 completamente documentada en SHAttered, implementando por primera vez, gracias a la evolución de la capacidad de cómputo, un ataque puramente teórico publicado en 2005, con complejidad de 269 en lugar de 280. El último clavo en el ataúd se lo pusieron dos investigadores en 2020 implementando otro ataque teórico propuesto en 2019 por ellos mismos. Su ataque permite encontrar colisiones con una complejidad de 261,2, en dos meses de cálculos, con un coste de computación de 11.000 dólares: tan asequible que SHA-1 se considera muerto y enterrado. Para demostrar la viabilidad del ataque, crearon dos peticiones de firma de certificados PGP/GnuPG: uno con el nombre de la víctima y otro con el nombre y la foto del atacante, de forma que ambos originaban el mismo hash SHA-1. El atacante podía solicitar una firma de su clave y su imagen a un tercero (de la Web of Trust o de una CA) y transferir la firma a su certificado. A partir de ahí, el atacante podía hacerse pasar por la víctima y firmar cualquier documento en su nombre. Tras este ataque devastador, SHA-1 se considera completamente inseguro, al mismo nivel que MD5, por lo que se deberían reemplazar inmediatamente por alternativas más seguras como SHA-256 o SHA-3. Revisa las especificaciones de todos tus productos y programas y asegúrate de que ninguno continúa usando SHA-1.
21 de enero de 2020

Fiat Cryptography, el sistema del MIT para generar código criptográfico optimizado para todo tipo de hardware
Fiat Cryptography es el nombre que recibe un sistema desarrollado por investigadores del MIT para generar automáticamente y verificar simultáneamente algoritmos criptográficos optimizados en todas las plataformas de hardware. De esta manera, se evitan los errores de implementarlos a mano y resultan mucho más eficientes. Google usa implementaciones de esa biblioteca en BoringSSL para reemplazar el código especializado existente en Chrome, Android y CloudFlare. ¿Qué tiene de especial este sistema y por qué es tan importante? Toda conexión TLS comienza con un apretón de manos La criptografía está por todas partes. Por ejemplo, cada vez que te conectas con el navegador a una página a través del protocolo HTTPS, tu dispositivo y el servidor web ejecutan un establecimiento de comunicación (handshake) para negociar una sesión de TLS: Intercambian los algoritmos de cifrado soportados junto con sus fortalezas y acuerdan los parámetros de conexión deseados. Validan los certificados presentados o se autentican utilizando otros medios. Hoy RSA sigue siendo el algoritmo de clave pública más utilizado, aunque perdiendo terreno rápidamente ante ECC, debido a que ECC utiliza claves mucho más cortas y previene algunos problemas de RSA. Acuerdan una clave secreta compartida para cifrar con un algoritmo simétrico tipo AES los datos intercambiados durante la sesión. Comprueban que los mensajes anteriores no han sido modificados por un tercero. A partir de este momento, todos los datos viajarán cifrados. Todas estas operaciones consumen muchos recursos, especialmente el uso de algoritmos de clave asimétrica, y en particular el uso de RSA. De ahí la importancia de codificar los algoritmos de forma totalmente correcta, para evitar brechas de seguridad, y de forma tan optimizada como sea posible, para agilizar las transacciones con potencialmente miles de clientes. En pos de la máxima eficiencia, los algoritmos criptográficos se codifican por lo general en lenguajes de bajo nivel, como C a pelo e incluso ensamblador, independientemente para cada tipo de hardware. Hay que tener en cuenta que la criptografía de clave pública como ECC o RSA opera con enteros muy grandes. La mayoría de los chips no pueden almacenar números tan grandes en un solo registro, por lo que los dividen en números más pequeños que puedan almacenarse en un registro. Pero el número de registros y su tamaño varían de un chip a otro con consecuencias de rendimiento diferentes. Y, para colmo, si se cambia el tamaño del módulo primo bajo el que se realizan las operaciones matemáticas al cifrar y descifrar, entonces ¡hay que recodificar a mano todo el algoritmo! ¿Buscas codificar criptografía? ¡Pues vas a sufrir! ¿Por qué codificar algoritmos criptográficos es fuente de tanto sufrimiento? La mala programación vuelve insegura la mejor criptografía. La implementación a mano de bajo nivel ha sido la única manera de lograr un buen rendimiento, asegurar que el tiempo de ejecución no filtre información secreta y permitir que el código sea llamado desde cualquier lenguaje de programación. Para que te hagas una idea de la complejidad de esta tarea, aquí tienes el código en C solamente para la operación elevar un número al cuadrado módulo un primo en una arquitectura de 64 bits. Figura 1. Codificación en C de la función elevar al cuadrado módulo un primo (Fuente: https://www.youtube.com/watch?v=PVHDIiqvBaU). Recapitulando: cada algoritmo criptográfico debe programarse cuidadosamente para cada longitud de módulo para cada arquitectura y para cada longitud de palabra. Y todo ello a mano. Cambia cualquiera de esos elementos y ¡vuelta a empezar desde cero! Como puedes imaginar, surgen muchas oportunidades para cometer errores por el camino. Y así ha sido, como listan con paciencia los autores del trabajo Fiat Cryptography en su apéndice. ¡Hágase la criptografía! Y los algoritmos fueron creados. Y los criptógrafos vieron que eran buenos Los autores de Fiat Cryptography muestran que su compilador automático puede producir este código especializado en aritmética modular, a través de versiones formalizadas de las optimizaciones basadas en teoría de números que antes sólo se aplicaban a mano. En su trabajo, presentan experimentos para una amplia gama de longitudes de módulo, compilados para procesadores x86 de 64 bits y ARM de 32 bits, demostrando velocidades desde cinco hasta diez veces superiores en comparación con bibliotecas tradicionales de grandes enteros. Además, al implementar su compilador en el asistente de pruebas Coq, genera pruebas de corrección funcional. Estas ventajas combinadas con las garantías rigurosas de corrección/seguridad y ahorro de mano de obra bastaron para convencer a Google de que adoptara el compilador para partes de su implementación de TLS en su biblioteca de código abierto BoringSSL, utilizada para generar claves y certificados para Chrome, apps de Android y otros programas. Al automatizar la escritura de algoritmos criptográficos, la Fiat Cryptography puede eliminar errores, producir código más seguro y aumentar el rendimiento. Tras el éxito obtenido en BoringSSL, muy pronto la veremos en otras bibliotecas criptográficas.
20 de enero de 2020

RSA contra las cuerdas: 1.001 razones por las que está cayendo en desgracia (I)
Muchos medios han anunciado en las últimas semanas que se ha encontrado una vulnerabilidad en RSA que permite atacar uno de cada 172 certificados. Pues no, como explicábamos hace poco, no ha sido así. Es cierto que RSA está moribundo, pero poco tiene que ver la causa de su muerte con el supuesto ataque. En esta primera parte del artículo repasaremos los problemas de seguridad y las dificultades de implementación de RSA, que lo convierten en una elección cada día menos recomendable, hasta el extremo de que ha sido abandonado por TLS 1.3 como algoritmo de intercambio de claves. RSA para dummies El algoritmo RSA sirve tanto para cifrar usando una clave pública como para firmar digitalmente usando una clave privada. Su funcionamiento resulta sorprendentemente sencillo: Se generan aleatoriamente dos números enteros primos, p y q, cuyo producto es n = p·q. Se elige un número entero e cualquiera que sea coprimo con respecto a ϕ(n) = (p−1)·(q−1). Ambos números, (n, e), constituyen la clave pública. Se calcula d, el inverso multiplicativo de e módulo ϕ(n), tal que e·d = 1. Este número (d) constituye la clave privada. Y ya está todo listo para empezar a operar. Por ejemplo, para cifrar un mensaje m (consistente en un número entero menor que n): c = me mod n. La operación de descifrado es tan sencilla como: m = cd mod n = (me)d mod n = med mod n = m, ya que e·d = 1. Cualquiera que conozca la clave pública (n, e) puede cifrar, pero solamente el legítimo propietario de la clave privada (d) podrá descifrar. En la práctica, los mensajes a cifrar suelen ser claves secretas de sesión, como ocurre por ejemplo en el protocolo criptográfico TLS. Para firmar se realizan exactamente las mismas operaciones, pero en orden inverso. Solo el legítimo propietario de la clave privada (d) podrá firmar un mensaje m: s = md mod n. Mientras que cualquiera que conozca la clave pública correspondiente (n, e) podrá verificar la firma, dados m y s: m = se mod n = (md)e mod n = mde mod n = m, ya que d·e = 1. Y así, sobre el papel, todo parece sencillo. ¡Pues no lo es! Multiplicar es fácil, factorizar es difícil La seguridad de RSA se basa en la dificultad de factorizar grandes números, es decir, de encontrar sus factores primos. Considerando la potencia de cómputo actual, para que RSA sea seguro en la práctica, se recomiendan longitudes para el módulo n de 2048 bits o más. De hecho, para 2020 ya se prescribe una longitud de 4096 bits. La penalización de pago es que las operaciones matemáticas con números tan grandes se ralentizan considerablemente, especialmente en dispositivos con potencia limitada. ¡RSA es dolorosamente lento! Encontrar el número primo de gran tamaño no es tarea fácil Para una longitud n de 2048 bits se necesitan primos de aproximadamente 1024 bits. El enfoque típico consiste en seleccionar al azar un número impar de unos 1024 bits y pasarle un test de primalidad. En función del tamaño de los números buscados, este proceso puede llegar a ser computacionalmente prohibitivo, lo que impulsa a muchos desarrolladores a buscar atajos con consecuencias devastadoras. El generador de números debe ser aleatorio e impredecible. Si existe algún tipo de sesgo o defecto en el generador, pueden ocurrir todo tipo de desastres. Por ejemplo, podrían ser predecibles, como ocurrió con el error de la distribución de OpenSSL de Debian, que redujo las semillas de inicialización del generador a tan solo 32.768 valores. O podría suceder que en algún momento se repitan dos primos, de modo que dos módulos n compartan el mismo número p o q, en cuyo caso mediante el ataque Batch-GCD se pueden recuperar los primos compartidos calculando el mayor divisor común entre todos los pares de n. En 2012, dos grupos de investigación, constataron independientemente que en torno al 0,75% de certificados TLS de Internet compartía factores primos debido a una entropía insuficiente durante la generación de los primos. En 2016, otro trabajo mostró que el 0,4% continuaba vulnerable. Este es el problema denunciado en 2019 por los autores del estudio sobre la supuesta vulnerabilidad de RSA que tanto ruido ha hecho. No es una vulnerabilidad como tal de RSA, sino un fallo de implementación. En algunos casos, incluso si dos valores de n no tienen exactamente el mismo factor, pero están muy próximos, ambos n pueden factorizarse. p y q deben ser independientes. Si comparten aproximadamente la primera mitad de sus dígitos, podría factorizarse n mediante el método de factorización de Fermat. Algunos programadores buscan atajar generando primos buscando a partir del valor objetivo: por ejemplo, arrancan desde 21024 y van iterando de dos en dos comprobando si el número es primo. ¡¡¡Desastre!!! Los tests de primalidad son probabilísticos. Deciden con una probabilidad muy alta que el número es primo, pero no pueden asegurarlo. Para aumentar la seguridad, se pasan repetidas veces. Los más usados son el test de Miller-Rabin y el test de Solovay-Strassen. No es tanto un problema de seguridad, como de eficiencia. Aunque eso sí, sería desastroso que p o q no fueran primos. Conclusión: no solo RSA es dolorosamente lento, ¡buscar sus claves también lo es! Puedes encontrar instrucciones, explicaciones, ejemplos y código sobre este asunto en la completísima página de FactHacks. La versión "libro de texto" de RSA es para la escuela, no para la vida real Nunca, bajo ningún pretexto, debe utilizarse en aplicaciones reales lo que se conoce como la versión «libro de texto» de RSA, es decir, tal cual la he explicado, ya que sería susceptible a todo tipo de ataques: Al ser determinista, dado un mensaje cifrado, podría buscarse exhaustivamente el correspondiente mensaje claro. O se podría construir un diccionario de parejas de textos claro/cifrado. Por el mismo motivo, es susceptible a ataques de reinyección: si un atacante intercepta paquetes cifrados con RSA, podría reutilizarlos inyectándolos en otra comunicación. Sucumbe a los ataques de encuentro en el medio (a no confundir con ataques de hombre en el medio), que funcionan precalculando listas de mensaje cifrados con (n, e) y mensajes cifrados con (n, e−1) y buscando colisiones entre las listas. En resumen, para evitar estos problemas, en lugar de usar RSA tal cual resulta crítico utilizar relleno (padding), tal como explicaré algo más adelante. En la segunda parte de este artículo veremos otros problemas de la RSA: CYBER SECURITY RSA contra las cuerdas: 1.001 razones por las que está cayendo en desgracia (II) 13 de enero de 2020
7 de enero de 2020

Los programadores saludables desayunan cereales criptográficos todas las mañanas
¿Cuál es la peor pesadilla de un programador? La criptografía. Según los autores del estudio Why does cryptographic software fail?: «Nuestro estudio cubre 269 vulnerabilidades criptográficas reportadas en la base de datos CVE desde enero de 2011 hasta mayo de 2014. Los resultados muestran que sólo el 17% de los errores se encuentran en bibliotecas criptográficas (que a menudo tienen consecuencias devastadoras), y el 83% restante son usos indebidos de bibliotecas criptográficas por parte de aplicaciones individuales. Observamos que la prevención de errores en diferentes partes de un sistema requiere técnicas diferentes, y que no existen técnicas efectivas para tratar ciertas clases de errores, como la generación de claves débiles.» Por otro lado, ¿y si nos adentramos en el mundo Android? En An Empirical Study of Cryptographic Misuse in Android Applications los autores nos cuentan: «Desarrollamos técnicas de análisis de programas para comprobar automáticamente los programas en el mercado de Google Play, y encontramos que 10.327 de las 11.748 aplicaciones que utilizan APIs criptográficas, 88% en total, cometen al menos un error.» Lo que vienen a confirmar estos estudios es que rara vez la criptografía es el eslabón débil de la seguridad. La criptografía no solo existe en los libros de matemáticas. Ha de corporeizarse, para que la criptografía funcione, necesita estar escrita en software, integrada en un sistema de software más grande, administrada por un sistema operativo, ejecutada en hardware, conectada a una red y configurada y operada por los usuarios. Cada uno de estos pasos trae consigo dificultades y vulnerabilidades. Son los fallos cometidos por los desarrolladores al implementar la criptografía los que abren la puerta al desastre. Este artículo recoge los errores más típicos que todo desarrollador debe evitar para crear aplicaciones criptográficamente sólidas. Si reinventar la rueda ya es mala idea, en criptografía es el caos Resulta edificante la lectura del artículo Great Crypto Failures, firmado por dos investigadores de Check Point Software Technologies, donde reseñan varios fallos épicos de implementaciones criptográficas en ransomware. Si quieren que su código sea ligero y único, los creadores de ransomware se enfrentan a la necesidad de escribir sus propias implementaciones de los algoritmos criptográficos como AES o RSA, en lugar de recurrir a bibliotecas criptográficas establecidas. Pero tú no compartes ninguna de sus restricciones, en lugar de escribir tu propia versión de un algoritmo, deberías recurrir a bibliotecas criptográficas creadas por expertos en criptografía que saben muy bien lo que se traen entre manos. Muchos lenguajes de programación cuentan con una o varias APIs para criptografía. Por ejemplo, Java ofrece la Java Cryptographic Extensions (JCE), mientras que .NET proporciona las clases del espacio de nombres System.Security.Cryptography. Además de las primitivas criptográficas ofrecidas por los propios lenguajes de programación, existen bibliotecas criptográficas independientes, como OpenSSL, Bouncy Castle, o NaCl, entre las más populares y robustas. Todas estas APIs criptográficas proporcionan servicios criptográficos como cifrado, generación de claves secretas, código de autenticación de mensajes, acuerdo de claves, gestión de certificados, firma digital, etc. ¡Bingo! Usas una biblioteca y ¡problema resuelto! No tan rápido. En realidad, tus problemas no han hecho más que empezar. Es cierto que estas APIs están concebidas para permitir a los desarrolladores de aplicaciones aplicar fácilmente la criptografía. Aíslan al desarrollador de los arcanos detalles criptográficos necesarios para implementar los distintos algoritmos. Así, el programador se dedica a escribir su código y se olvida de los herméticos entresijos de la criptografía. La codificación de los algoritmos se delega en los proveedores de las APIs, los auténticos expertos, de manera que al desarrollador le basta con invocar a las funciones expuestas por las APIs. ¿Qué podría salir mal? Ay, la criptografía es más difícil de lo que parece. Para confusión de desarrolladores, las APIs ofrecen una amplia variedad de algoritmos diferentes que, a su vez, admiten una multitud de modos y opciones de configuración. Además, cada proveedor puede admitir algoritmos adicionales o, peor aún, proporcionar diferentes valores predeterminados para la misma llamada a la API. Como resultado, los desarrolladores se enfrentan a la tarea de utilizar y orquestar correctamente todos estos componentes de la API, a menudo sin entender a fondo su funcionamiento. Hmmmm. A mí ya me está llegando el aroma de una suculenta receta para el desastre. Entren si se atreven en el túnel del terror criptográfico Imagina que eres un programador de Android. Sí, eres el Rey de la Programación, pero nunca te enseñaron criptografía en la escuela. Un día, necesitas algo aparentemente tan trivial como cifrar una cadena de texto. ¿Cómo lo harías? El primer paso consiste en consultar al oráculo de Google para ver si ya hay algo por ahí que puedas reutilizar. Después de todo, no necesitas más que cifrar una triste cadena de texto. En una reciente charla, Maximilian Blochberger, creador de la biblioteca criptográfica Tafelsalz, buscó en Google: "Android encryption example" Y este es el resultado que apareció en primer lugar y que a mí también me sigue apareciendo a día de hoy: private static byte[] encrypt(byte[] raw, byte[] clear) throws Exception { SecretKeySpec skeySpec = new SecretKeySpec(raw, ”AES”); Cipher cipher = Cipher.getInstance(”AES”); cipher.init(Cipher.ENCRYPT_MODE, skeySpec); byte[] encrypted = cipher.doFinal(clear); return encrypted; } […] byte[] keyStart = ”this is a key”.getBytes(); KeyGenerator kgen = KeyGenerator.getInstance(”AES”); SecureRandom sr = SecureRandom.getInstance(”SHA1PRNG”); sr.setSeed(keyStart); kgen.init(128, sr); // 192 and 256 bits may not be available SecretKey skey = kgen.generateKey(); byte[] key = skey.getEncoded(); byte[] encryptedData = encrypt(key,b); byte[] decryptedData = decrypt(key,encryptedData); Vamos a diseccionar el código anterior, línea por línea: encrypt(byte[] raw, byte[] clear) No se valida la longitud de la entrada ni de salida. Todos sabemos lo peligroso que resulta trabajar con buffers sin ningún tipo de validación. Entre otros problemas, pueden producirse desbordamientos, leer más allá del tamaño del array, y esos problemillas. SecretKeySpec skeySpec = new SecretKeySpec(raw,
”AES”); Un desarrollador no tiene por qué saber de criptografía. Él solo quiere cifrar una cadena de texto. ¿Con qué algoritmo? ¡Pues ni idea! Mientras sea seguro, le vale. Todas las bibliotecas ofrecen una gran variedad de algoritmos. ¿Son todos seguros? Tristemente, no. En un artículo previo listé los algoritmos que deben dejar de usarse. Si lo consultas, encontrarás a AES entre los seguros. Entonces, todo bien, ¿no? Pues no, porque en JCE, “AES” es la abreviatura de “AES/ECB/PKCS5PADDING”, que significa que se utilizará AES en modo ECB de encadenamiento de bloques y con el algoritmo de relleno descrito en PKCS#5. Si te has leído el artículo sobre criptografía insegura, recordarás que el modo ECB es inseguro. Por desgracia, las propias bibliotecas criptográficas pueden no estar proporcionando opciones seguras por defecto o pueden proporcionar algoritmos obsoletos por cuestiones de compatibilidad con aplicaciones legadas. SecureRandom sr = SecureRandom.getInstance(”SHA1PRNG”); Se utiliza el algoritmo SHA1, hoy considerado inseguro. byte[] keyStart = ”this is a key”.getBytes(); Inicializa la clave de cifrado con una contraseña leída de un parámetro estático. Es una idea mala, mala, mala. Tan mala, que a nadie que copie este código se le ocurrirá hacerlo así, ¿verdad? ¿O no tan verdad? De hecho, todo el asunto de la derivación de la clave de cifrado AES a partir de una contraseña está mal hecho. Existen protocolos mucho más seguros, como PBKDF2. byte[] encryptedData = encrypt(key,b); Se cifran los datos de entrada con la clave recién generada. Si se cifran los mismos datos con la misma clave, se obtendrá el mismo resultado. ¡Falta diversificación! En un buen protocolo criptográfico, por muchas veces que cifres un mismo mensaje con la misma clave, siempre obtendrás un resultado distinto. Puede conseguirse gracias a añadir aleatoriedad cada vez, como un vector de inicialización aleatorio, o bien añadiendo un contador, como en el caso del modo CTR. Técnicamente, se busca que el cifrado posea la propiedad IND-CPA. byte[] decryptedData = decrypt(key,encryptedData); Y ya, para terminar, redoble de tambores…, el cifrado no está autenticado, por lo que se garantiza la confidencialidad, pero no la autenticidad. Por ejemplo, AES-GCM proporciona ambos atributos. No está mal para un pequeño código de ejemplo que aparece en primer lugar en la página de resultados de Google cuando se busca Android encryption example. ¡Menudo ejemplo! No es de extrañar que el 88% de las apps de Android tuvieran errores criptográficos. Pero los problemas no acaban aquí. Incluso si resuelves todos los inconvenientes que he señalado, empiezan tus problemas verdaderamente gordos. ¿De dónde leerá el código la contraseña del usuario? ¿Dónde guardará la clave de cifrado recién derivada? ¿Cómo se gestiona la clave en memoria durante el cifrado? ¿De qué manera se cifrará a su vez para que esté protegida? ¿Quién tiene acceso a esas claves? ¿Cuántas veces se reutilizan por el mismo usuario o para el mismo fin? ¿Por cuánto tiempo se almacenan? Si pueden salir del sistema, ¿cómo se protegen? Y una larga ristra de preguntas similares, que obtienen respuesta en lo que se conoce como gestión de claves, una disciplina complicada de la criptografía. Así que, ¿qué puedes hacer? Algunos mandamientos cuando uses cripto en tus programas Seguir las siguientes reglas no te garantizará la seguridad total. Pero no seguirlas te conducirá al desastre. 1) Nunca te inventes algoritmos criptográficos. Usa los existentes considerados seguros. En el artículo "La criptografía insegura que deberías dejar de usar" encontrarás un listado de algoritmos considerados hoy inseguros y cuáles usar en su lugar. Por fácil que parezca inventar un algoritmo criptográfico, ¡no lo es! Las raras veces en que se ha podido vulnerar un sistema por culpa de un algoritmo débil, la causa fue: Se usó un algoritmo obsoleto. Se usó un algoritmo cocinado en casa. ¡No lo hagas! 2) Nunca codifiques algoritmos criptográficos. Usa bibliotecas de confianza. Hay tantos detalles sutiles, que si no has entendido perfectamente el funcionamiento del algoritmo y no usas bibliotecas de enteros grandes cuyo funcionamiento entiendas también perfectamente, lo más probable es que algo salga mal. Personas con más conocimiento ya se han pegado con esos detalles. ¡Aprovéchate! Utiliza una API criptográfica de confianza. 3) Entiende cómo funcionan todas las funciones y parámetros de la biblioteca criptográfica que elijas. Ni la mejor biblioteca servirá de nada si no sabes usarla. Necesitarás tomar decisiones como: El tipo de encadenamiento de bloques: nunca uses ECB. Usa otros modos con vectores de inicialización aleatorios y distintos cada vez. La longitud de la clave: 128 bits o más para algoritmos de cifrado simétrico, 3072 bits o más para RSA y 256 bits o más para ECC. Utilizar o no salts: desde luego, y que sean aleatorios y distintos en cada llamada. Qué tipo de padding utilizar. Etc. Existen multitud de bibliotecas. Algunas, como OpenSSL, son muy crípticas y cuesta usarlas incluso a quienes comprenden la criptografía. Dan acceso a primitivas criptográficas de bajo nivel, por lo que para hacer tareas complejas, como por ejemplo autenticar y cifrar un mensaje, es necesario invocar a cerca de una docena de funciones. ¡Cuántas oportunidades para cometer algún error! Por este motivo, criptógrafos benévolos que aman a la Humanidad se han esforzado en crear bibliotecas intuitivas y fáciles de usar, con funciones del nivel más alto posible. En lugar de exponer funciones básicas, estas bibliotecas dan acceso a tareas, como por ejemplo “autenticar y cifrar un mensaje” o “firmar un documento”. Es la propia API la que se encarga de los detalles farragosos implicados en las tareas. Algunas bibliotecas a considerar creadas con esta filosofía son NaCl, Tafelsalz o Libsodium. Su objetivo es que te resulte casi imposible cometer errores de seguridad al usarlas. 4) Gestiona tus claves. Utiliza claves generadas aleatoriamente. No uses semillas estáticas ni fácilmente adivinables, como la hora. Necesitas funciones criptográficamente seguras. No te preocupes, tu API las tendrá. Y recuerda: la función random()no sirve. No uses contraseñas como claves. Usa funciones de derivación de claves a partir de contraseñas. No sufras, tu API las tendrá. Nunca uses claves constantes. Si usas criptografía asimétrica: No copies las claves privadas, ni las almacenes en claro, ni las escribas (hard-code) en tus programas. Evita usar la misma clave pública para operaciones diferentes: cifrado, autenticación, firma, etc. La mala programación vuelve insegura la mejor criptogrfía Por muy a prueba de fallos que esté diseñada una biblioteca criptográfica, tendrás que comprender, aunque sea superficialmente, lo que estás haciendo. La realidad es que muchos desarrolladores carecen de una comprensión formal de la aplicación de la criptografía en su software, a pesar de que son expertos en el desarrollo de software en sí mismo. A ver, no necesitas convertirte en un Caballero Criptógrafo de la Orden de la Cifra, pero tampoco te hará daño leer algún buen tutorial sobre criptografía o hacerte algún curso online de calidad. Y si quieres poner a prueba tus conocimientos sobre criptografía desarrollando código, atrévete con los Cryptopals challenges. ¡Desayuna tus cereales criptográficos todas las mañanas!
26 de noviembre de 2019

La criptografía insegura que deberías dejar de usar
DES es inseguro, pero ¿y TripleDES? Sí, MD5 ya está roto, pero ¿qué pasa con SHA256? ¿Puedo seguir usando RSA con 2048 bits de clave o debería pasarme a ECC? ¿El modo de encadenamiento ECB es inseguro siempre, incluso con AES? ¿Son de fiar algoritmos nuevos con nombres molones como Salsa y ChaCha? La cuestión es: ¿qué algoritmos han quedado obsoletos con el paso del tiempo y habría que dejar de utilizar? Este artículo te ayudará a orientarte en esta espesa sopa criptográfica. Los dos motivos fundamentales por los que un algoritmo cae en desgracia Hay dos formas de atacar un algoritmo criptográfico: La bestia: se trata de probar todas las combinaciones posibles. Se lo denomina "ataque de fuerza bruta" o de "búsqueda exhaustiva". Para llevarlo a cabo solo hace falta potencia de cómputo. Con los años, a medida que la potencia aumenta, la longitud de la clave o del hash se va quedando corta. La sutil: se buscan debilidades matemáticas en el algoritmo en sí, independientemente de la longitud de sus claves o tamaños de bloque. Para llevarlo a cabo se requiere un profundo conocimiento del algoritmo y de las matemáticas implicadas. Este estudio recibe el nombre de "criptoanálisis". Con el paso del tiempo, los criptógrafos van encontrando debilidades en algunos algoritmos. Por lo tanto, debes evitar a toda costa los algoritmos débiles y también los algoritmos robustos con claves cortas. Además, deberás evitar usos inseguros de algoritmos robustos, como por ejemplo el encadenamiento de bloques AES en modo ECB, o RSA sin relleno. Quién es quién en criptografía La siguiente tabla recoge los algoritmos que deberías dejar de usar y por qué otros deberías reemplazarlos. * Pruebas de seguridad débiles, pueden seguir usándose, aunque sin garantías. Pero vayamos viendo los detalles poco a poco, para entender mejor las recomendaciones de la tabla anterior. Algoritmos de generación de números pseudoaleatorios La criptografía y la aleatoriedad forman una de esas parejas inseparables, como Ramón y Cajal o como Ortega y Gasset. En criptografía necesitas números aleatorios para generar claves secretas y públicas/privadas, vectores de inicialización, salts, nonces, identificadores de sesión, etc. Un generador pseudoaleatorio de números (GPAN) se considera criptográficamente seguro (GPANCS) si es imposible predecir el siguiente valor de una secuencia por muchos valores anteriores que se conozcan (en realidad, es mucho más complicado, pero dejémoslo ahí). Obviamente, para uso criptográfico, sólo se recomiendan algoritmos GPANCS. Los lenguajes de programación suelen venir equipados con una función rand() o random(), que genera secuencias pseudoaleatorias, que pasan muchas pruebas de aleatoriedad, pero que no son criptográficamente seguras. Dependiendo de su implementación, usarán Generadores Lineales Congruenciales o Mersenne twisters. Evita siempre utilizar estas funciones rand() o random() con fines criptográficos. Figura 1. Resultados de apariencia poco aleatoria del generador lineal congruencial para distintos parámetros de entrada. Algoritmos de hash Los algoritmos de hash producen un resumen de longitud fija a partir de una entrada de longitud arbitraria. Se utilizan para generar códigos de autenticación de mensajes (MAC) en servicios de integridad, para comprimir mensajes antes de su firma, para derivar claves a partir de contraseñas, para generar números pseudoaleatorios, para cifrar, y mucho más. Para considerarse criptográficamente seguras, las funciones de hash deben satisfacer al menos tres propiedades: Resistencia a la preimagen: dado un hash, es imposible encontrar un mensaje cualquiera que produzca el mismo hash. Resistencia a la segunda preimagen: dados un mensaje y su hash, es imposible encontrar otro mensaje que produzca el mismo hash. Resistencia a colisiones: es imposible encontrar dos mensajes cualesquiera que produzcan el mismo hash. Además, la longitud del hash debe ser suficientemente larga como para prevenir los ataques de fuerza bruta. Teniendo en cuenta la potencia de cómputo actual y el hipotético futuro post-cuántico, se recomiendan longitudes de hash de al menos 256 bits. Por otro lado, los ataques de extensión de longitud funcionan contra los algoritmos de hash basados en la construcción de Merkle–Damgård, comoMD5, SHA-1 y SHA-2, cuando se usan a modo de MAC. Se puede seguir utilizando la familia SHA-2, siempre que se trunquen las salidas a una longitud menor, como por ejemplo SHA-512/256. Algoritmos de cifrado simétrico o de clave secreta Los algoritmos de criptografía simétrica se utilizan fundamental para proteger la confidencialidad de la información. Emplean la misma clave secreta tanto para cifrar como para descifrar, esta clave debe tener una longitud mínima de 128 bits para considerarse segura hoy y en el futuro próximo. Pero hay un asunto más, los algoritmos de cifrado en bloque dividen la información a cifrar en bloques de una longitud determinada, por ejemplo, 256 bits. Cada bloque se va cifrando uno por uno, usando la misma función de cifrado con la misma clave. Esta forma de encadenar los bloques así sin más se conoce como ECB y resulta vulnerable ya que bloques idénticos darán como resultado bloques cifrados idénticos. Figura 2. La vulnerabilidad del modo de encadenamiento de bloques ECB: a la izquierda, la imagen original; a la derecha, la misma imagen cifrada en modo ECB (Imágenes de Wikipedia). Para evitarlo, se utilizan distintos modos de encadenamiento, los cuales no están exentos de problemas. Por ejemplo, el encadenamiento CBC es susceptible a un ataque de oráculo de relleno. La recomendación actual es utilizar AES-GCM. Algoritmos de cifrado asimétrico o de clave pública En cambio, la criptografía asimétrica utiliza una pareja de claves pública y privada para cifrar y descifrar. Su uso principal es la creación de firmas digitales y el establecimiento de claves de sesión. Los algoritmos más usados hoy en día tanto para cifrar como para firmar son RSA, basado en el problema de la factorización, y la criptografía de curva elíptica (ECC), basada en el problema del logaritmo discreto. En RSA es especialmente importante resaltar que nunca bajo ningún concepto debe utilizarse directamente en lo que se conoce como su versión "libro de texto", ya que sería susceptible a todo tipo de ataques: Al ser determinista, dado un cifrado, podría buscarse exhaustivamente el texto claro. Por el mismo motivo, es susceptible a ataques de reinyección. Sucumbe a los ataques de encuentro en el medio (a no confundir con ataques de hombre en el medio). Para mensajes cortos y exponente e pequeño, se pueden realizar ataques extrayendo la raíz e-ésima del cifrado, ataques de broadcast de Håstad, ataques de Coppersmith, ataques de Franklin-Reiter. Y eso por no mencionar los ataques contra implementaciones deficientes, como los ataques de temporización, los ataques de canal lateral o, ya puestos, el ataque de Bleichenbacher contra RSA PKCS#1 v1.5, tristemente de moda tras el reciente ataque ROBOT. En implementaciones reales en protocolos resulta necesario utilizar relleno y otros mecanismos de protección, como RSA-OAEP, así como claves equivalentes a una seguridad de algoritmo simétrico de al menos 128 bits. Para RSA, supone claves públicas de 3072 y para ECC, de 256 bits. Dependiendo del tipo de algoritmo, la longitud de clave requerida puede variar sustancialmente, como puede apreciarse en la siguiente tabla y en el gráfico que la acompaña. Se puede encontrar una exhaustiva recomendación de longitudes de clave en la página de BlueKrypt. Figura 3. Equivalencia entre las distintas longitudes de claves para AES, RSA y ECC ( a partir de las recomendaciones del NIST de 2019 para gestión de claves). Algoritmos de firma digital La firma digital permite verificar que un mensaje no ha sido manipulado y además ha sido firmado por una persona determinada. Es más, el firmante no podrá echarse atrás y afirmar que no firmó el documento. Para firmar digitalmente se utiliza una combinación de hashes y criptografía asimétrica: el mensaje a firmar primero se resume mediante una función de hash, el cual se cifra por el signatario con su clave privada, operación que nadie más en el mundo puede realizar, ya que se supone que él es la única persona que conoce esta clave privada. En cambio, cualquiera que conozca su clave pública puede verificar esta firma. Al igual que al hablar de la criptografía asimétrica, en la firma se utilizan los mismos algoritmos RSA o ECC. Y también deben ser implementados cuidadosamente o se cometerán errores épicos. Se recurre por tanto a RSA-PSS y, aunque ECDSA se usa ampliamente, lo cierto es que no existen pruebas sólidas de su seguridad y sí algunos problemas menores. Como ves, la criptografía es extremadamente compleja. Ante la duda, déjate guiar por la tabla. Y si quieres profundizar en el tema, puedes leer el informe Algorithms, Key Size and Protocols Report (2018) publicado por la iniciativa europea ECRYPT-CSA, en el cual me he basado libremente para elaborar este artículo.
12 de noviembre de 2019

Criptovirología: la criptografía canalla detrás de los secuestros de datos del Ransomware
Durante siglos, la criptografía ha evocado imágenes de protección, privacidad y seguridad. Hasta que, en 1996, dos investigadores de la Universidad de Columbia en EEUU, Adam Young y Moti Yung, concibieron el primer criptovirus de la Historia: «En este trabajo presentamos la idea de la Criptovirología, demostrando que la criptografía también puede ser utilizada ofensivamente. Por ofensivo queremos decir que puede ser utilizada para montar ataques basados en la extorsión que causan pérdida de acceso a la información, pérdida de confidencialidad y fuga de información.» En su artículo seminal, Young y Yung sentaron las bases teóricas de lo que sería el ransomware que hoy todos aborrecemos: la intersección entre la criptografía y el malware. CRIPTOGRAFÍA + MALWARE = RANSOMWARE En su momento, el trabajo de Young y Yung no recibió atención por considerarse poco realista: Su propuesta requería el uso de criptografía asimétrica. Ni todo el hardware de la época poseía la capacidad computacional para trabajar con RSA, ni las restricciones de exportación de criptografía permitían el uso de longitudes de clave suficientemente robustas. No se vislumbraba medio impune de cobrar el rescate. Por supuesto, con el aumento de la capacidad de cómputo y con el auge de las criptomonedas, el escenario cambió. A partir de mediados del 2000, el ransomware criptográfico experimentó un crecimiento sin precedentes. Su efecto ha sido, y sigue siendo, devastador. Cuando la criptografía se vuelve canalla A grandes rasgos, el proceso de ataque de los criptovirus bosquejado por Young y Yung atraviesa tres fases: Infectar a la víctima. Cifrar todos los archivos de ciertas extensiones a los que tenga acceso. Pedir el rescate. Para ser invulnerable, el ransomware criptográfico necesita dos elementos: Criptografía robusta: algoritmos de cifrado simétricos y asimétricos a prueba de balas. Claves fuertes: suficientemente largas y totalmente aleatorias. El resto del artículo examina las fases que sigue un ransomware criptográfico bien diseñado para cifrar todos los archivos a los que tenga acceso: Generar de manera totalmente aleatoria claves secretas de algoritmos simétricos robustos para cifrar los archivos. Cifrar con estas claves los archivos de la víctima. Cifrar dichas claves con claves públicas de algoritmos asimétricos. Proceso seguido por el ransomware para extorsionar a sus víctimas. 1) No random, no ransom Para cifrar un archivo se requiere una clave de cifrado aleatoria. Si te parece trivial, ponte en el lugar del creador del malware: una vez desplegado en un dispositivo infectado, cuyas especificaciones técnicas desconoces por completo, ¿cómo obtiene tu programa esa clave para cifrar con ella los archivos de la víctima? Tienes varias opciones: Codificarla directamente en el malware: hmm, mala idea. El análisis de código binario mediante reversing del ejecutable dará con las claves. Por ejemplo, DMA Locker v1 incluía la clave de cifrado en el propio código, lo que permitía su fácil recuperación. Solicitarla a un servidor C&C: es una solución aceptable, aunque plantea sus propios inconvenientes: la víctima debe estar conectada a Internet; el acceso a ese servidor no puede estar bloqueado por un cortafuegos; el tráfico debe cifrarse, lo que añade nuevas complejidades; el sitio se aloja en la red Tor; suelen necesitar Algoritmos de Generación de Dominio para evitar el cierre de servidores por las autoridades; etc. Por ejemplo, CryptoWall utilizaba este enfoque, con grandes réditos. Cada copia genera su propia clave de cifrado: para ser robustas, las claves criptográficas necesitan generarse de forma verdaderamente aleatoria. En caso contrario, podrían adivinarse o regenerarse. La cuestión es: ¿dónde encuentras en el dispositivo infectado la entropía necesaria para crear claves robustas? Y no, no se te ocurra recurrir a la típica función rand() de los lenguajes de programación, porque fallará miserablemente, como DMA Locker v2. La forma más segura es utilizar funciones robustas y bien testadas llamadas Generadores de Números Pseudo-Aleatorios Criptográficamente Seguros (Cryptographically Secure Pseudo Random Number Generator, CSPRNG). En los sistemas operativos de la familia Windows, las funciones CSPRNG están disponibles a través de APIs dedicadas, como CryptGenRandom(), vía la Cryptographic API (CAPI), ahora obsoleta; la posterior RtlGenRandom(), llamada también SystemFunction036; o, la más reciente, BCryptGenRandom(), proporcionada por la Cryptography API: Next Generation (CNG). Por supuesto, existen soluciones análogas en otras familias de sistemas operativos, aunque con otros nombres. Así pues, la mejor opción será que el malware invoque al ejecutarse a una función CSPRNG para generar la clave aleatoria. De hecho, este paso resulta tan crucial para el éxito del ataque, que algunas propuestas anti-ransomware, como USHALLNOTPASS, Redemption, PayBreak o DRBG, proponen controlar el acceso a estas funciones mediante hooks o instalar en ellas puertas traseras para coartar así la capacidad del ransomware de generar claves robustas. Algunos ransomware crean una misma clave para cifrar todos los archivos de la víctima, mientras que otros, más paranoicos, crean una clave diferente para cada extensión de archivo o incluso para cada archivo individual a cifrar. En todos los casos, quedan por resolver otros dos retos: ¿Cómo se cifran los archivos con esa(s) clave(s)? ¿Cómo se protege(n) esa(s) clave(s)? 2) Cifra, cifra, cifra sin parar El ransomware recurre a la criptografía simétrica para cifrar los archivos de la víctima. Algunos ejemplos de ransomware, como Nemucod, 7ev3n, XORist o Bart, recurrieron a algoritmos de cifrado basados en hacer XOR entre el archivo y diversas variantes de claves, desde las que se rompían trivialmente hasta las que suponían un bonito ejercicio para una asignatura de Criptografía 101. Así que mejor no reinventar la rueda, sino recurrir a algoritmos de cifrado bien estudiados y de seguridad demostrada, como el AES. Estos algoritmos se caracterizan por: Ser muy rápidos, pudiendo alcanzar velocidades de hasta 1 GB/s, dependiendo de la implementación en software y del procesador del dispositivo. Requerir claves cortas, por ejemplo, de 128 ó 256 bits. Pero una cosa es proponerse utilizar un algoritmo robusto de cifrado y otra muy distinta es utilizarlo bien. En primer lugar, con el fin de ser muy compactos y evitar la compilación con bibliotecas criptográficas, muchos autores de ransomware programan ellos mismos los algoritmos criptográficos. Cualquiera que haya tratado de codificar AES o RC5 habrá comprobado que se trata de una pesadilla. Por ejemplo, los autores de Petya, al codificar ellos mismos el algoritmo de cifrado en flujo Salsa20, cometieron varios errores sutiles, pero decisivos, a la hora de programar los buffers y variables de 16, 32 y 64 bits. Debido a estos errores, las claves generadas de 512 bits de longitud poseían en realidad 256 bits efectivos. En segundo lugar, como su propio nombre indica, los algoritmos de cifrado en bloque operan cifrando bloques de uno en uno. Como consecuencia, bloques en claro idénticos darán como resultado bloques cifrados idénticos. ¿Qué tiene eso de malo? Echa un vistazo a la legendaria foto del pingüino de Linux cifrada encadenando los bloques sin más: Imágenes de la Wikipedia. Esta debilidad exige que los bloques se encadenen de forma que bloques idénticos se cifren de manera diferente. Si el malware no usa un modo de encadenamiento apropiado, existe la posibilidad de recuperar parte de los archivos cifrados. Muchas muestras de ransomware, como DMA Locker, han venido utilizando el modo ECB de encadenamiento de bloques. Otro fallo tremendo ha sido la utilización de algoritmos de cifrado en flujo reutilizando la misma clave para todos los archivos. Por ejemplo, TorrentLocker o DirCrypt cometieron este fallo de principiante. En la práctica, teniendo acceso a un único archivo sin cifrar y su correspondiente archivo cifrado de más de 2 MB, se podía recuperar la clave usada mediante un ataque trivial de texto claro conocido y, con ella, descifrar todos los demás archivos cifrados. Y no basta con cifrar a conciencia. Además, los archivos de la víctima deben destruirse, ya que, en caso contrario, sería posible su recuperación mediante herramientas de disco, como con ciertas versiones de Gpcode.ak. Normalmente, el malware sobrescribe los archivos en claro con su versión cifrada o bien los borra de manera irreversible. Por ejemplo, cosa curiosa, LeChiffre sólo cifraba los primeros y los últimos 8.192 bytes de cada archivo. ¡Y aún hay más! El ransomware no sólo necesita destruir por completo los archivos cifrados, sino también sobrescribir la memoria para borrar todo rastro de las claves usadas. En el caso de WannaCry, por ejemplo, los analistas pudieron recuperar los números primos p y q utilizados para generar las claves públicas. Con Bad Rabbit, las claves quedaban en memoria y se podían leer siempre que no se reiniciara la máquina. CryptoDefense también dejaba rastro de las claves de cifrado usadas. La conclusión es clara: la criptografía es más compleja y traicionera de lo que parece. 3) Mi clave, dónde estará mi clave Ya solo queda un pequeño detalle: ¿cómo proteger la clave usada para cifrar los archivos? Si está en el código, será recuperada mediante reversing. Si se destruye sin más, luego no será posible descifrar los archivos y nadie pagaría el rescate. Si se envía desde el servidor C&C podría ser interceptada. Tal y como sugirieron Young y Yung, nada como cifrarla a su vez mediante un algoritmo de cifrado asimétrico, como RSA o ECC. Normalmente, se despliega la copia de malware junto con su propia clave pública o bien ésta se solicita al servidor C&C, como en el caso de DMA Locker v4. Además, si la clave es de longitud suficiente, no existe ningún peligro en escribirla en el código a la vista de los analistas. En cambio, si es corta, como ocurrió con TeslaCrypt, el valor de la clave pública podría factorizarse y obtenerse la clave privada para descifrar con ella las claves de cifrado de los archivos. Eso sí, la pareja de claves pública y privada debe ser única para cada copia del malware. En caso contrario, si se usa la misma pareja durante toda una campaña, pagado el rescate una sola vez por una víctima y obtenida entonces la clave privada, se podrán descifrar las claves de cifrado de archivos de todas las demás víctimas, como ocurrió con DMA Locker v3. El futuro del Ransomware Por mucha cripto que usen, no hay que perder de vista el hecho de que el ransomware no es más que un virus. Antes de cifrar nada, necesita infectar a la víctima. Los malos están haciendo sus deberes: las sucesivas versiones de ransomware usan la criptografía de manera cada vez más sofisticada. Bien implementada, la criptografía de un ransomware es inatacable. Con el tiempo no habrá manera de crear “descifradores”. Sólo quedará la prevención.
29 de octubre de 2019

Cómo el marmitako de bonito te ayudará a interpretar los resultados de pruebas, tests y evaluaciones
El 15 de agosto se celebra en España la fiesta de la Asunción. Ese día, en la villa costera de Castro Urdiales se convoca un concurso de marmitako de bonito. Más de 160 cuadrillas acuden temprano con sus mesas, cazuelas y fogones y se van desplegando a lo largo del puerto. Pasan la mañana cocinando, entre música, vino, cerveza y pintxos. Al mediodía aparecen los jueces, pasean entre los grupos, charlan con los concursantes y prueban las distintas marmitas. Cuando los veo cuchara en mano, me pregunto: ¿qué cantidad mínima deben probar de cada marmita para hacerse una idea justa del sabor de toda la marmita y no morir de empacho en el intento? ¿Una cucharada? ¿Dos? ¿Todo un plato? En el ámbito de la ciberseguridad, todos los días nos encontramos con nuevos estudios, encuestas e informes que nos ilustran sobre el coste del cibercrimen, el volumen de ataques, la inversión en ciberseguridad, el número de organizaciones con programas de protección y así una lista inacabable. Los creadores de estos estudios se enfrentan al mismo dilema que los jueces de las marmitas: ¿a cuántas empresas hay que encuestar? ¿Qué empresas son las más representativas? ¿Qué preguntas son las más adecuadas? En este artículo exploraremos cómo debes leer un estudio (report, survey, study) para discernir si su metodología arroja resultados dignos de confianza. Antes de empezar: las tres reglas básicas del muestreo Si quieres conocer una propiedad de una población, lo ideal sería preguntar a toda la población. Por desgracia, no suele ser posible encuestar a todos los individuos. Surge la necesidad de tomar una o varias muestras más pequeñas y manejables y preguntar solo a esos individuos. El problema de una muestra es que puede estar sesgada. Por ejemplo, si quieres conocer el grado de madurez en ciberseguridad de las empresas de tu país y sólo preguntas a empresas financieras, posiblemente obtendrás un resultado muy diferente que si preguntas solo a empresas de marketing. Del mismo modo, posiblemente encontrarás resultados bien diferentes si encuestas a empresas de menos de 10 trabajadores que a las de más de 10.000. La mejor manera de superar este tipo de sesgos consiste en seleccionar la muestra completamente al azar de entre toda la población. De esta manera, te aseguras de que en promedio aparecerán en la muestra empresas de todos los sectores, tamaños y demás características imaginables. Por último, ¿cómo de grande debería ser la muestra para representar al total de la población? Un error muy común consiste en pensar que se requiere una fracción muy grande de la población total. En realidad, a partir de una población de unos 20.000 individuos, da igual. Lo que importa es el número de individuos en la muestra, no qué fracción del total suponen. Los jueces del marmitako prueban la misma cantidad de cada marmita, con independencia del tamaño de la marmita. Piénsalo: te basta con una sola cucharada para probar lo mismo un plato que toda una cazuela. Veamos cómo calcular el tamaño de una muestra representativa. El tamaño de la muestra importa ¿Te has topado con datos como los siguientes? Según Accenture, en 2018 las empresas han sufrido un promedio de 145 brechas de seguridad con un impacto medio de 13,0 millones de dólares por empresa. Según EY, en 2018 el 8% de las organizaciones dice que los smartphones son los que más han aumentado su debilidad, mientras que el 4% está más preocupado por la seguridad de IoT. Según PwC, en 2018 han caído los ataques externos (hackers, competidores, outsiders) y aumentado los internos (empleados, proveedores, consultores, contratistas), atribuyéndose a empleados un 30% de los ataques sufridos. El día a día del profesional de la ciberseguridad rebosa con datos publicados en estos informes y copiados y repetidos hasta la saciedad en blogs, presentaciones y tuits. Estos números suelen aceptarse sin cuestionarlos. Pero ¿cuán exactos son los resultados de la muestra de la encuesta? Los informes típicos de los fabricantes y consultoras suelen omitir elementos extremadamente importantes de información: el nivel (o grado) de confianza y el margen de error (o intervalo de confianza) y, a veces, hasta el tamaño de la muestra. Además de otros asuntos que iremos mencionando. En las encuestas se busca estimar una proporción determinada de la población. Por ejemplo, qué proporción (o porcentaje) de empresas usan la nube o qué proporción externaliza la seguridad. La proporción real de toda la población se denota con p, mientras que la estimación de p a partir de la proporción de la muestra se denota con p’. Cuando la encuesta sobre una muestra revela que el 48% de las empresas piensa aumentar su presupuesto en ciberseguridad, lo que nos están diciendo es que p’ = 0,48 es la mejor estimación a partir de la muestra empleada para el valor real p de toda la población. La mejor estimación, sí, pero ¿cómo de buena? Me fío, no me fío: intervalos de confianza y grado de confianza Imagina que en tu país hay 1 millón de empresas y quieres conocer cuántas revisan sus logs de seguridad al menos diariamente. Como no puedes preguntar a todas y cada una de ellas, realizas una encuesta a un grupo de 100 empresas seleccionadas al azar, de manera que las hay grandes, pequeñas y medianas; de todos los sectores; recién creadas y longevas; vamos, de todo. 78 de esas 100 empresas dicen revisar los logs al menos una vez al día. En otras palabras, p’ = 0,78. ¿Puedes afirmar entonces que el 78% de las empresas de tu país revisa diariamente sus logs (o, lo que es lo mismo, que p = 0,78)? ¡Ni de lejos! Supón que tienes un superpoder que te permite saber que el valor real es p = 0,75. Si repites la encuesta con otras 100 empresas distintas seleccionadas igualmente al azar, con toda seguridad obtendrás un resultado distinto, por ejemplo, p’ = 0,72. ¿Y si repites la encuesta con otras 100 nuevas empresas? Sin duda, obtendrás un nuevo valor para la estimación, por ejemplo, p’ = 0,80. Y así sucesivamente. Si repites numerosas veces la encuesta con grupos de 100 empresas distintas, obtendrás valores distintos, aunque posiblemente todos ellos alrededor del valor real, p = 0,75. De hecho, se asume que la estimación, p’, de la proporción real sigue una distribución normal (en realidad deben cumplirse ciertas condiciones, pero no entraremos en detalle en este artículo) y que la media de esa distribución es el valor buscado de la proporción real, p. Por supuesto, no conoces el valor real de p, sino el valor de una de las encuestas. Al no conocerse el valor de p, no puede calcularse su desviación estándar. Lo máximo que puede hacerse es calcular la desviación estándar de la estimación de la distribución, p’, a la que se conoce como error estándar (SE) y se calcula como donde q’ = 1 − p’. Siguiendo con el ejemplo, ¿qué nos dice entonces una encuesta cuando afirma que el 78% de las empresas revisa sus logs diariamente? Si introducimos en la fórmula del error estándar (SE) los siguientes valores, p’ = 0,78, q’ = 1 − p’ = 0,22, y tamaño de la muestra n = 100, se obtiene que el error estándar es SE = 0,0414 = 4,14%. Como la distribución es normal, lo que nos indica este valor es que existe una probabilidad del 68% de que el valor real de p esté dentro del intervalo [p’ – SE, p’ + SE] = [0,73, 0,82]. Y que hay una probabilidad del 95% de que p esté dentro del intervalo [p’ – 2xSE, p’ + 2xSE] = [0,69, 0,86]. Figura 1. El error sigue una distribución normal En otras palabras. Si yo soy p’, existe una probabilidad del 95% de que el valor de p esté como mucho a dos errores estándar de mí, a un lado u otro. Eso sí, no tenemos ni idea del valor de p, solo sabemos que probablemente estará en ese intervalo. Es muy fácil de ver gráficamente. Supón que has repetido la encuesta 20 veces con 100 empresas distintas seleccionadas aleatoriamente cada vez. La siguiente figura muestra cómo en 19 ocasiones los intervalos de confianza contuvieron el valor real de p. Solo en una ocasión el intervalo de confianza no contuvo a p. El valor medio de todos esos intervalos se acerca mucho a p. Figura 2. Intervalos de confianza de 20 muestras diferentes para un grado de confianza del 95%. Por lo tanto, si al entrevistar a 100 empresas hemos obtenido como respuesta que el 78% leen sus logs diariamente, podemos afirmar que no sabemos exactamente qué proporción real p de empresas revisan sus logs diariamente, pero que el intervalo del 69% al 86% contiene con un 95% de probabilidad la proporción real. ¡Qué diferente! Por lo tanto, con humildad estadística, hemos admitido que no estamos seguros de dos cosas: Necesitamos un intervalo, no sólo un valor, para tratar de capturar la proporción real p. Ni siquiera estamos seguros de que la verdadera proporción p esté en ese intervalo, pero estamos "bastante seguros" de que lo está. ¿Cómo de seguros? Al 95%. O al grado de confianza que queramos, a sabiendas de que, a mayor confianza, mayor margen de error. Como recordarás, el error estándar es inversamente proporcional al tamaño de la muestra. Por consiguiente, para estrechar el intervalo de confianza basta con aumentar el tamaño de la muestra. En el ejemplo anterior, si en vez de a 100 se interroga a 200 empresas y se obtiene que 77 leen sus logs diariamente (p’ = 0,77) el valor de SE pasaría a ser 0,03, lo que significa que ahora tenemos una confianza del 95% en que el valor real de p se encuentra en el intervalo entre el 71% y 83%. Lo hemos acotado aún más. Y cuanto mayor sea la muestra, más estrecho será el intervalo donde reside el valor real. Obviamente, en el límite, cuando el tamaño de la muestra es igual al tamaño de la población, llegaremos al valor exacto. No es oro todo lo que reluce en los informes y estudios El investigador Josiah Dykstra publicó recientemente el libro Essential Cybersecurity Science: Build, Test, and Evaluate Secure Systems, con el que pretende acercar el método científico a la práctica de la ciberseguridad. Como no podía ser menos, dedica un capítulo a destapar la mala ciencia, las afirmaciones pseudo-científicas y el hype marketiniano. Con más razón que un santo denuncia cómo los vendedores, publicistas e incluso investigadores tratan de convencerte de algo en presentaciones, revistas, convenciones y foros, a menudo sin mucho fundamento. Nos propone tener a mano algunas preguntas aclaratorias para sondear más a fondo al interlocutor (si lo tienes delante) y decidir por uno mismo si el producto o los resultados experimentales son válidos. Duda en especial de los informes patrocinados por un fabricante. Las reproduzco textualmente, marcando en negrita las directamente relacionadas con el tema de este artículo: ¿Quién hizo el trabajo? ¿Existen conflictos de intereses? ¿Quién pagó por el trabajo y por qué se hizo? ¿La experimentación o investigación siguió el método científico? ¿Es repetible? ¿El resultado ha sido confirmado o replicado por múltiples fuentes independientes? ¿Cómo se eligió el conjunto de datos experimentales o de evaluación o a los sujetos de prueba? ¿Qué tan grande era el tamaño de la muestra? ¿Fue realmente representativa? ¿Cuál es la precisión asociada con los resultados? ¿Y el grado de confianza en los mismos? ¿Cuáles son las conclusiones basadas en hechos y cuáles son meras especulaciones? ¿Cuál es el error de muestreo? ¿Qué estaba buscando el desarrollador o investigador cuando se encontró el resultado? ¿Estaba sesgado por las expectativas? ¿Qué otros estudios se han realizado sobre este tema? ¿Dicen lo mismo? Si son diferentes, ¿por qué son diferentes? ¿Ayudan los gráficos y las visualizaciones a transmitir información significativa sin manipular al espectador? ¿Adverbios del tipo «significativamente» y «sustancialmente» usados al describir el producto o investigación están suficientemente apoyados por la evidencia? Si el producto parece estar apoyado principalmente por anécdotas y testimonios, ¿cuál es la evidencia que lo sustenta? ¿Cómo se estableció la causalidad a partir de la correlación entre datos/eventos? ¿Los resultados dependen de datos raros o extremos que podrían atribuirse a anomalías o condiciones no normales? ¿Cuál es el intervalo de confianza del resultado? ¿Las conclusiones se basan en predicciones extrapoladas a partir de datos diferentes de los reales? ¿Los resultados se basan en sucesos raros? ¿Cuál es la probabilidad de que se dé la condición? Incluso si los resultados son estadísticamente significativos, ¿el tamaño del efecto es tan pequeño que los resultados se vuelven irrelevantes? Por supuesto, no estás obligado a hacerte todas esas preguntas. Pero al menos te harás alguna, ¿verdad? Después de todo, a nadie le gusta encontrarse un pelo flotando en su marmitako.
15 de octubre de 2019

Señor Jobs, la reproducción aleatoria de su iPod a mí no me parece aleatoria
En su libro The Perfect Thing, Steven Levy (el famoso autor de Hackers: Heroes of the Computer Revolution y Crypto: Secrecy And Privacy In The New Cold War) nos cuenta cómo empezó a darse cuenta de que había canciones, e incluso artistas, que a su iPod no le gustaban. Investigando el asunto comprobó que no era el único que creía que su iPod tenía preferencias propias. Daba la impresión de que casi todos los iPods parecían tener un artista favorito, o dos, o tres, ya que cuando reproducía de forma aleatoria (en modo shuffle), su iPod decidía qué artista le apetecía y luego se dedicaba a poner los trabajos de ese intérprete. Rápidamente, la gente saltó a dar explicaciones parapsicológicas ("pienso en una canción o en un grupo y mi iPod lo reproduce") y hasta conspiranoicas ("Apple prohíbe al iPod reproducir canciones de este grupo porque es de derechas"). En cambio, Levy intentó analizar racionalmente lo que podría estar pasando: ¿por qué los ingenieros de iPod afirman que el modo shuffle es "absolutamente, inequívocamente aleatorio", pero se comporta como si tuviera voluntad propia y estados de ánimo? ¿Hay un fantasma en la máquina? Levy consultó a John Allen Paulos, un matemático de la Universidad Temple de Filadelfia, quien le explicó cómo "a menudo interpretamos e imponemos patrones a eventos que son aleatorios. Especialmente con algo como canciones. Las canciones evocan emociones y algunas se quedan en nuestras mentes más que otras. (...) Nuestros cerebros no están diseñados para comprender la aleatoriedad". Levy concluyó que cuando pensamos que el modo shuffle del iPod no es aleatorio, el problema está en nuestras percepciones. Nuestras mentes perciben patrones y tendencias que realmente no existen. A menudo escuchamos series de canciones consecutivas del mismo artista y pensamos que no es aleatorio, aunque, de hecho, con verdadera aleatoriedad, tales secuencias consecutivas son mucho más probables de lo que cabría esperar. La percepción incorrecta de la aleatoriedad empujó a Apple a introducir la función Smart Shuffle en una nueva versión de iTunes. Con esta característica, se evitan las secuencias consecutivas del mismo artista. Según declaró Steve Jobs en su día: Lo hacemos menos aleatorio para que se perciba como más aleatorio. La noche en el casino de Montecarlo en la que cientos perdieron millones La noche del 18 de agosto de 1913, algo inusual ocurrió en una mesa de ruleta del casino de Montecarlo. Algunos jugadores notaron que la bolita había aterrizado en negro durante 10 giros seguidos de la rueda. La gente comenzó a congregarse alrededor de la mesa. Diez negros seguidos es una secuencia excesivamente larga. Necesariamente, debería caer en rojo en la próxima ronda. Así que los jugadores comenzaron a apostar agresivamente al rojo. La rueda giró de nuevo… ¡Y la bolita cayó en negro por undécima vez consecutiva! Al igual que en la duodécima… Y decimotercera... Y decimocuarta… Y cuanto más duraba la racha de negros, más convencidos estaban los jugadores de que la próxima vuelta produciría necesariamente un rojo. El valor de sus apuestas al rojo se incrementó. Sus pérdidas se dispararon. ¡La bolita aterrizó 26 veces consecutivas en negro! La probabilidad de ocurrencia de tal secuencia es (18/37)26 o alrededor de 1 en 66,6 millones, suponiendo que el mecanismo no esté trucado. Para cuando cayó finalmente en rojo en la ocasión vigesimoséptima, la mayoría de los jugadores estaban completamente arruinados. Pero ¿qué crees que hicieron los que aún conservaban capital? Pues apostar una y otra vez al rojo, persuadidos de que a una racha tan larga de negros necesariamente habría de seguirle una racha igualmente larga de rojos para compensar. Por supuesto, no fue así. Los pocos que no lo habían perdido todo en la racha de negros, lo perdieron en la inexistencia de racha de rojos. Aquella noche tal vez fue la más rentable en la historia del casino: se perdieron fortunas y nació la "falacia de Montecarlo". La "falacia de Montecarlo", también conocida como "falacia del jugador", recoge la idea de que el comportamiento pasado influye en el comportamiento futuro. Puede comprender las siguientes ideas equivocadas: Un suceso aleatorio tiene más probabilidad de ocurrir porque no ha ocurrido durante cierto período. Un suceso aleatorio tiene menos probabilidad de ocurrir porque ha ocurrido durante cierto período. Un suceso aleatorio tiene más probabilidad de ocurrir si no ocurrió recientemente. Un suceso aleatorio tiene menos probabilidad de ocurrir si ocurrió recientemente. Este error de juicio se produce porque por algún extraño mecanismo inconsciente atribuimos memoria a los objetos. Si lanzas una moneda al aire y salen 10 caras seguidas, la probabilidad de que salga cara la próxima vez sigue siendo 1/2, por mucho que haya salido cara las 10, 100 o 1.000 veces anteriores. Pero nos resistimos a creer que siga siendo 1/2 porque pensamos: "¿Cuál es la probabilidad de que salga cara 10 veces seguidas? Es bajísima (concretamente, de 1/1024). Por lo tanto, la próxima tiene que salir cruz". Por desgracia, el azar no es un proceso justo que se corrige a sí mismo para compensar rachas largas. Ni la ruleta ni la moneda guardan memoria. Cuando observamos una serie corta de eventos aleatorios independientes, cualquier secuencia puede producirse, por desviada de la media que esté. Se puede culpar a la heurística de representatividad como responsable de esta distorsión cognitiva: la gente cree que las secuencias cortas de eventos aleatorios deberían ser representativas de eventos más largos. Como explicamos al hablar sobre la regresión a la media, la realidad no funciona así. Los dioses hablan, los espíritus hablan, los ordenadores hablan Sucumbimos a esta falacia allí donde el azar esté involucrado. Leí en la revista Nautilus la curiosa historia de Sid Meier, el diseñador del popular juego Civilization. Cuenta cómo las pruebas de validación del juego revelaron el siguiente hecho paradójico: si a un jugador se le dice que tiene una probabilidad de éxito del 33% en una batalla, pero luego no puede derrotar a su oponente tres veces seguidas, se vuelve furioso e incrédulo. Así que Meier alteró el juego para sintonizarlo con los sesgos cognitivos humanos: si tu probabilidad de ganar una batalla es de 1/3, el juego te garantiza que ganarás como tarde en el tercer intento. ¡Ah, qué paradoja! Una tergiversación de la probabilidad real que, sin embargo, ofrece la ilusión de justicia divina. La profesora de matemáticas Deborah Bennet, autora de Randomness, cierra su obra con estas palabras que resumen a la perfección nuestra incapacidad de manejar la aleatoriedad: A corto plazo, el azar puede parecer volátil e injusto. Y aunque la experiencia con largas series puede ayudar a modificar algunos de nuestros sesgos cognitivos basados en un malentendido de la aleatoriedad y la probabilidad, puede requerirse una secuencia muy larga. Teniendo en cuenta los conceptos erróneos, las inconsistencias, las paradojas y los aspectos contraintuitivos de la probabilidad, no debería sorprendernos que, como civilización, tardamos largos años en desarrollar intuiciones correctas. De hecho, todos los días podemos ver evidencia de que la especie humana aún no tiene un sentido probabilístico muy desarrollado. Quizás todos deberíamos abordar los encuentros casuales con precaución, a corto plazo. La aleatoriedad tal y como la imaginamos se manifiesta en los grandes números, no en los pequeños números Para el ojo no entrenado la aleatoriedad aparece como regularidad o tendencia a la agrupación Si disparas dardos con los ojos cerrados a una diana cuadrada dividida en una cuadrícula de 10x10, ¿cómo se distribuirán esos impactos aleatorios? He realizado el experimento programando 10 disparos al azar. El resultado se muestra en la siguiente figura: Figura 1. Lanzamiento aleatorio de 10 dardos Un tanto sospechoso, ¿no? Todos los dardos menos uno se encuentran por debajo de la línea 40. Además, una casilla ha recibido tres disparos y otra, dos. ¿Seguro que será aleatorio? En nuestra imaginación, confundimos "aleatorio" con "uniformemente distribuido". Pasemos de los dardos a las monedas. Si se lanza al aire una moneda sin trucar seis veces seguidas, representando «cara» con un 1 y «cruz» con un 0, aparecerán secuencias de lo más variado, como por ejemplo las siguientes: 1 0 1 0 1 0 1 1 1 1 1 1 1 0 1 1 0 1 Reconócelo. ¿No te parece más aleatoria la tercera secuencia, 1 0 1 1 0 1? Las dos primeras parecen demasiado ordenadas, ¿verdad? No coinciden con nuestra idea intuitiva de aleatoriedad. En realidad, las tres secuencias son equiprobables, con una probabilidad de (1/2)6 = 1/64. Pero como estamos más acostumbrados a ver secuencias desordenadas que ordenadas (porque de hecho hay más), de alguna manera la tercera secuencia es la que mejor representa nuestra imagen preconcebida de cómo debe ser la aleatoriedad. Sin embargo, para que una secuencia aleatoria nos parezca aleatoria no podemos observar unas pocas instancias, sino muchas. Así que volvamos a la diana. ¿Qué pasa si lanzamos 100 dardos? Poniendo a trabajar al ordenador ofrece este nuevo resultado. ¿Parece más aleatorio ahora? Figura 2. Lanzamiento aleatorio de 100 dardos Aquí ya hay quien empieza a ponerse nervioso. ¡Hay 33 recuadros no visitados! En otras palabras: no ha caído ni un solo dardo en un tercio de la diana. Es más, en un recuadro han aterrizado nada menos que 4 dardos. "Hmmm, aquí pasa algo raro. Si los disparos son aleatorios, ¿no deberían haberse distribuido por todo el tablero?" De nuevo, confundimos aleatoriedad con uniformidad. Sí, efectivamente, se distribuirán por todo el tablero… ¡Cuando el número de disparos sea suficientemente alto! ¿Serán 1.000 dardos un número suficientemente alto? Veámoslo. Figura 3. Lanzamiento aleatorio de 1.000 dardos Nos vamos acercando. Por puro azar, un recuadro (señalado en la imagen) solo ha recibido un dardo, mientras que otros han recibido incluso más de 10. Por supuesto, cada vez que se repita el experimento se obtendrá una distribución diferente, pero estadísticamente similar. Es más, repítelo un número suficientemente alto de veces y hasta terminará apareciendo la cara de Mona Lisa o del mismísimo pato Donald. La pareidolia no es más que eso: ver figuras antropomorfas en las nubes, vírgenes en las manchas de humedad de la pared o rostros humanos en las formaciones geológicas de Marte. Nuestro cerebro detecta orden donde no existe. Si la Naturaleza aborrece el vacío, los seres humanos aborrecemos el desorden. Durante miles de años hemos conectado con la imaginación las estrellas del cielo para recrear todo tipo de constelaciones. La mente humana es una fabulosa herramienta de búsqueda de sentido. Somos extraordinarios reconociendo patrones, viendo caras en cualquier disposición aleatoria de objetos o dando sentido a distribuciones aleatorias que no lo tienen. Volvamos a la diana anterior. Imagínate que en realidad es el plano de una ciudad y los diez puntos de la Figura 1 representan casos de un raro cáncer registrado en los últimos cinco años. Claramente, están concentrados en un barrio, ya que afecta a un área muy restringida del mapa. Si quiere la casualidad que en ese barrio se haya levantado una antena de telefonía móvil o cualquier construcción "sospechosa", ¡la polémica está servida! Sin embargo, toda inferencia carece de relevancia estadística. Esta tendencia a considerar erróneamente como no aleatorias las inevitables "rayas" o "grupos" que surgen en pequeñas muestras de distribuciones aleatorias se conoce como la "ilusión de agrupamiento". La ilusión es causada por nuestra tendencia a subestimar la cantidad de variabilidad que probablemente aparezca en una pequeña muestra de datos aleatorios o semialeatorios. Ignorar el papel del azar puede conducir a decisiones desastrosas "Durante el intenso bombardeo de Londres en la Segunda Guerra Mundial, generalmente se creyó que los bombardeos podrían no ser aleatorios porque un mapa de los impactos revelaba la existencia de llamativas zonas indemnes. Algunos sospecharon que en estas zonas no afectadas había espías alemanes. Un cuidadoso análisis estadístico reveló que la distribución de los impactos era la habitual de un proceso aleatorio, y la habitual también en provocar una fuerte impresión de que no se producía al azar»" Esta historia narrada por el famoso psicólogo Daniel Kahneman en su libro Pensar rápido, pensar despacio viene a ilustrar nuestra necesidad de imponer orden a nuestro alrededor y de buscar explicaciones causales para todo, incluso para fenómenos de naturaleza aleatoria. En el fondo, es como aquel pistolero que disparaba a la pared del granero y después dibujaba la diana alrededor de los disparos. Examina de nuevo la Figura 2. Si correspondiera al mapa de los bombardeos, ¿qué pensarías de las zonas marcadas en azul? ¿Serían nidos de espías? No. Como ya hicieron nuestros antepasados observando el cielo nocturno, nuestra necesidad de dotar de sentido a la realidad nos ciega al razonamiento estadístico y nos impulsa también a conectar los puntos aleatorios con una buena historia. Por desgracia, las explicaciones causales de acontecimientos aleatorios son inevitablemente falsas. Buscamos patrones. Creemos en un mundo coherente en el que las regularidades aparecen no por accidente, sino como resultado de la causalidad mecánica o de la intención de alguien. No esperamos ver la regularidad producida por un proceso aleatorio. Y cuando detectamos lo que parece ser una regla, rápidamente rechazamos la idea de que el proceso es verdaderamente aleatorio. Los procesos aleatorios producen muchas secuencias que convencen a las personas de que el proceso no es aleatorio, después de todo. Y si no, que se lo pregunten al Sr. Jobs y a su modo Smart Shuffle.
24 de septiembre de 2019

El gran reto de la computación segura en la nube: usando datos cifrados sin descifrarlos (II)
La nube plantea grandes retos de seguridad. El más importante tal vez sea garantizar la privacidad de los datos. Es de cultura general que cifrando los datos antes de enviarlos a la nube quedan protegidos. El inconveniente es que, una vez cifrados, ya no se puede operar sobre ellos. En la primera entrega de este artículo explicamos el funcionamiento del cifrado homomórfico y sus limitaciones. En esta segunda entrega revisamos otros dos enfoques para almacenar información en la nube y realizar cálculos sobre ella sin que el proveedor tenga acceso a los datos: la computación multi-parte segura y la criptografía con umbral. La computación multi-parte segura (SMPC) Imagínate que estás charlando con otros dos compañeros de trabajo. De repente sale el tema de los bonus que cobráis. A los tres os gustaría saber quién es el que cobra el bonus más alto, pero ninguno queréis revelar el importe de vuestro bonus. ¿Cómo podéis averiguarlo? Una solución consiste en confiar en una tercera parte a quien cada uno le reveláis el importe de vuestro bonus y, una vez conocidos todos, anuncia quién gana el bonus mayor. Imagina ahora que trabajas en el servicio de inteligencia de una empresa de ciberseguridad. Se ha producido un ataque y tienes una lista de sospechosos. Los servicios de inteligencia de otras empresas también tienen sus propias listas de sospechosos. Os gustaría conocer qué sospechosos aparecen en todas las listas, pero ni tu empresa ni las demás queréis revelar vuestra lista completa. ¿Cómo podéis calcular la intersección de estas listas? Una vez más, una solución inmediata sería que cada empresa entregue su lista a una tercera parte confiable y que ésta obtenga el conjunto intersección de todas las listas de sospechosos. En ambos escenarios se recurre a una tercera parte de confianza. Pero ¿y si no te fías de esta tercera parte? Después de todo, asumir que una parte es de confianza es mucho asumir. ¿De qué otra manera podrían resolverse estos dilemas sin recurrir a terceras partes y con la misma garantía de seguridad? Precisamente, la computación multi-parte segura propone protocolos que emulan a la tercera parte de confianza. Permiten calcular una función con varios valores de entrada, de manera que sólo se revela el resultado de la evaluación de la función, manteniendo privados los valores de las entradas. Expresado matemáticamente: reunidos un número n de participantes, p1, p2, ..., pn, cada uno de los cuales posee datos privados, respectivamente d1, d2, ..., dn, desean calcular el valor de una función pública sobre esos datos privados: F(d1, d2, ..., dn), manteniendo sus propias entradas en secreto. Volvamos al ejemplo de los bonus. Si las entradas x, y, z representan vuestros bonus, queréis conocer el más alto de los tres, sin revelar el valor de ninguno. En otras palabras, queréis calcular: F(x, y, z) = max (x, y, z) Se espera que estos protocolos garanticen una serie de requisitos de seguridad: Corrección: aunque alguna de las partes engañe, el resultado final será correcto. Privacidad: solo se conoce el resultado de la evaluación de la función, pero no el valor de las entradas evaluadas (salvo la propia de cada uno, claro está). Independencia de las entradas: ninguna parte puede elegir su entrada como función de la entrada de otra parte. Justicia: si una parte conoce el resultado de la evaluación, entonces todas las partes conocerán el mismo resultado. Entrega garantizada del resultado: si una parte tiene acceso al resultado, entonces las demás partes también lo tendrán. Existen diferentes protocolos criptográficos para realizar esta computación segura distribuyéndola entre las partes. El más conocido es el protocolo de Circuito Confuso de Yao. La idea de este protocolo consiste en simular cualquier función matemática con un circuito booleano utilizando exclusivamente puertas lógicas, concretamente AND y XOR. Para funciones muy sencillas, estos circuitos pueden diseñarse incluso a mano. Obviamente, a medida que se vuelven más y más complejas, los circuitos crecen paralelamente en complejidad. Puedes imaginar que simular AES mediante puertas lógicas AND y XOR no es precisamente tarea sencilla, aunque sí posible con ¡32.000 puertas! De hecho, las implantaciones más recientes alcanzan velocidades muy eficientes, de unos pocos milisegundos. Por supuesto, la computación multi-parte segura es muchísimo más complicada. El adversario puede ser pasivo o activo, las funciones a evaluar pueden ser más o menos complicadas, pueden soportar mayor o menor número de adversarios activos, pueden imponerse mayores o menores restricciones de seguridad, pueden requerir más o menos tiempo de computación, pueden exigir que todos los nodos de la red estén conectados entre sí o basta que exista un camino cualquiera entre cualesquiera dos nodos, pueden comunicarse síncrona o asíncronamente, etc. Algunas empresas han comenzado a comercializar soluciones de SMPC en escenarios reales: aplicaciones de Datos Privados como Servicio (Private Data as a Service), tales como las bases de datos de Sharemind o de Jana; aplicaciones de gestión de claves, como los productos de Sepior o de Unbound; y aplicaciones de solución puntual, como la de Partisia. En suma, la computación multi-parte segura es un campo en continua expansión, con multitud de protocolos, escenarios y casos de uso, en el que todavía estamos muy lejos de haber escuchado la última palabra. La criptografía con umbral La criptografía se ha transformado en un estándar tecnológico para proteger la confidencialidad de los datos. En criptografía, una regla básica de diseño se conoce como Principio de Kerckhoffs: de un criptosistema se conoce todo menos la clave. La cuestión es: si guardas los datos cifrados, ¿dónde guardas la clave de cifrado? En última instancia, la seguridad de un sistema de cifrado reside en la gestión de sus claves. Las claves pasan a ser el talón de Aquiles de la criptografía. De hecho, no están seguras ni en la memoria del ordenador: Heartbleed, Spectre y Meltdown vienen a la cabeza como ejemplos recientes de vulnerabilidades que permitían leer espacios privados de la memoria y obtener, entre otros datos, claves de cifrado. A su vez, los ataques de canal lateral pueden filtrar información sobre claves gracias a variaciones electromagnéticas o de consumo de energía. Más aún, las claves pueden quedarse grabadas en una memoria DRAM incluso después de apagar el equipo. ¿No existe forma entonces de garantizar la seguridad de las claves? Una solución pasa por dividir la clave en dos o más partes, de manera que la información cifrada no pueda descifrarse a menos que se junten todas (o un número mínimo de) las partes de la clave. Por ejemplo, para dividir la clave K en tres partes, K1, K2 y K3, se seleccionan dos claves aleatoriamente, K1 y K2, de la misma longitud que K. La tercera parte de la clave se calcula como: No hay dos partes que proporcionen ninguna información sobre la clave secreta: las tres partes son necesarias para recuperar K (dejamos como ejercicio al lector comprobar que efectivamente así sucede). El esquema descrito exhibe la propiedad «3 de 3». Generalizando, un esquema de intercambio de secretos es «k de n» (siendo n ≥ k ≥ 1) si juntando k partes puede recuperarse un secreto compartido entre n partes, pero juntando k − 1 partes no se sabe nada sobre el secreto. Y así es como llegamos a la criptografía con umbral. Ya no se trata simplemente de dividir la clave en varias partes, como en el sencillo ejemplo anterior, sino de realizar operaciones criptográficas con cada parte de la clave de manera que, al juntarlas todas, el resultado sea el mismo que si se hubiera realizado con la clave completa. RSA nos ayudará nuevamente a entenderlo con mayor claridad. Hemos visto en la entrega anterior que la clave pública está formada por dos números: un exponente, e; y un módulo, n, que a su vez es el producto de dos primos, n = p · q. Por otro lado, la clave privada está formada por un número d, tal que e · d = 1 mod (p − 1) · (q − 1). Para firmar un mensaje m con RSA, se realiza el cálculo s = md mod n. Verificar la firma es muy sencillo por cualquier persona que conozca la clave pública, realizando la operación se = med = m mod n. ¿Cómo conseguir que un grupo de personas coopere para firmar un mensaje? En lugar de firmar el mensaje una sola persona con la clave privada d, se puede separar esta clave en varias, por ejemplo, en tres: d1, d2, d3, tales que d1 + d2 + d3 = d mod (p − 1) · (q − 1). Ahora, cada una de las partes puede firmar por su cuenta el mismo mensaje m: s1 = md1, s2 = md2, s3 = md3, de manera que la firma total será el producto de las tres firmas: s = s1 · s2 · s3. Es fácil verificar que s1 · s2 · s3 = md1 + d2 + d3 = md mod n. En otras palabras, sólo puede crearse una firma completa si cada una de las partes firma el mensaje con su parte de la clave privada. Así se protege la clave privada, d, ya que no se almacena completa en ningún servidor ni en ninguna memoria. Ni siquiera es necesario reunir las tres partes de la clave, ya que cada operación de cifrado de cada parte es independiente del resto. Podría comprometerse una parte de la clave o incluso dos y, aun así, la clave completa se mantendría segura. Los esquemas de criptografía con umbral más sofisticados poseen la propiedad «k de n» ya mencionada. Esta propiedad aporta tolerancia a fallos: una parte de la clave podría perderse o verse comprometida y, aun así, se podría realizar la operación criptográfica con la parte restante. Además, exige la cooperación: ninguna parte podrá realizar la operación criptográfica completa; al menos k partes han de ponerse de acuerdo. Desde la perspectiva de un atacante, comprometer una parte de la clave no le servirá de nada: necesitará comprometer al menos k partes. Como vemos, la criptografía con umbral elimina los puntos únicos de fallo en criptografía, permitiendo redistribuir la responsabilidad de la custodia de las claves. Y no vayas a creer que todo queda en ejercicios matemáticos para cursos de postgrado: los productos de gestión de claves de Sepior y de Unbound constituyen los ejemplos más avanzados de soluciones basadas en criptografía con umbral de la actualidad. Como los otros campos de estudio, está en constante expansión y veremos nuevos resultados próximamente. Después de leer estas dos entregas te habrá quedado más claro que estamos un paso más cerca de alcanzar una protección de los datos almacenados en la nube que a día de hoy solo soñamos. Consulta la primera parte de "El gran reto de la computación segura en la nube: usando datos cifrados sin descifrarlos".
25 de junio de 2019

El gran reto de la computación segura en la nube: usando datos cifrados sin descifrarlos (I)
Tomás dirige una asesoría fiscal y lleva la contabilidad de docenas de clientes. Almacena toda la información de sus clientes en la nube, de esta manera, se olvida de la gestión del espacio en disco, de la redundancia, de la escalabilidad, de las copias de seguridad, del ancho de banda para su acceso, etc. Para mantener seguros los archivos de sus clientes, Tomás los almacena cifrados en la nube. Así impide que un potencial atacante pueda robárselos a su proveedor e incluso que un administrador corrompido del propio proveedor pueda ver las cuentas de sus clientes. El problema surge cuando Tomás manipula los datos. Necesita descargarlos, descifrarlos, operar sobre ellos, volverlos a cifrar y subirlos de nuevo a la nube. La verdad es que Tomás se fía más de la seguridad proporcionada por su proveedor de servicios en la nube que de sus propios equipos. ¿Qué pasaría si el ordenador de un trabajador de Tomás resulta comprometido? ¿Cómo sabe Tomás que un ciberdelincuente no está accediendo a los datos de sus clientes en el momento más vulnerable del proceso, justo cuando está operando sobre los datos en claro? Lo que le gustaría a Tomás es que su proveedor de la nube operase directamente sobre los propios datos cifrados en la nube sin tener que descifrarlos antes: por ejemplo, sumar el IRPF de un trabajador, calcular el IVA a pagar este trimestre o realizar una búsqueda de información; y que cuando Tomás descifrase los datos, obtuviera los resultados correctos. ¿Es posible hacer realidad hoy el sueño de Tomás? Hmmm, no del todo. El reto de computar en la nube con datos cifrados sin descifrarlos Como todo en la vida, la nube tiene sus ventajas y sus inconvenientes. Las ventajas las conocemos todos: reducción de costes, nulo mantenimiento, enorme flexibilidad, total disponibilidad, alta escalabilidad, etc. Sus problemas de seguridad son igualmente evidentes: un servidor comprometido supone el compromiso de los datos alojados. La contramedida inmediata que a todos se nos ocurre para proteger los datos almacenados en la nube consiste en cifrarlos. El cifrado resulta satisfactorio siempre y cuando los datos permanezcan en reposo y no se necesite realizar operaciones sobre ellos. Pero ¿y si hay que realizar cálculos en la nube? ¿Cómo hacerlo sin descifrarlos ni revelar las claves de cifrado al software en ejecución en la nube? El reto es formidable. Se está impulsando un potente esfuerzo de investigación para desarrollar métodos criptográficos que permitan la computación con datos cifrados sin descifrarlos, como, por ejemplo: El cifrado totalmente homomórfico (FHE), que busca abordar este problema requiriendo que un cliente cifre los datos antes de enviarlos a la nube y proporcione además un código que se ejecute sobre esos datos sin descifrarlos. Los resultados se devuelven cifrados al cliente. Dado que solo el cliente controla la clave de descifrado, nadie más puede descifrar los datos originales ni los resultados, lo que garantiza la seguridad de esa información. Por desgracia, si bien el cálculo con datos cifrados es teóricamente posible, este cálculo se ralentiza en casi 10 órdenes de magnitud, lo que lo hace inviable con los algoritmos disponibles hoy. Otra estrategia consiste en la computación multi-parte segura (SMPC, Secure Multi-Party Computation), en la cual múltiples entidades pueden realizar cálculos de manera conjunta y al mismo tiempo mantener la privacidad de los datos de cada entidad. Al igual que con FHE, estos protocolos añaden una sobrecarga computacional considerable, de dos órdenes de magnitud. Por último, la criptografía con umbral exige que para descifrar un mensaje cifrado o para firmar un mensaje, varias partes (que superen un umbral predeterminado) deben cooperar en el protocolo de descifrado o firma. El mensaje se cifra mediante una clave pública y la clave privada correspondiente se comparte entre los participantes. En este artículo veremos con más detalle el funcionamiento de FHE, mientras que en un segundo artículo profundizaremos en las otras dos estrategias. El cifrado totalmente homomórfico (FHE) El cifrado homomórfico sería el «Santo Grial» de la seguridad en la nube. Se define como la capacidad de realizar operaciones sobre datos cifrados cuyo resultado, una vez descifrado, es idéntico al resultado de esas mismas operaciones sobre los datos en claro. Aunque a primera vista puede parecer mágico, lo cierto es que a nuestro alrededor abundan algoritmos criptográficos de uso cotidiano que soportan parcialmente el cifrado homomórfico, como por ejemplo los de clave pública. Se les dice «parcialmente» homomórficos porque sólo son homomórficos para una operación, como la suma o la multiplicación, pero no para cualquier otra operación algebraica. Un ejemplo con el archiconocido RSA hará que todo quede más claro. Imagina que en el servidor guardas dos cantidades, x1 y x2, cifradas con tu clave pública RSA (n y e), de manera que nadie más que el legítimo poseedor de la clave privada correspondiente, o sea, tú, podrá descifrarlas. Ahora bien, RSA (sin padding y sin las modificaciones que se le añaden para aumentar su robustez) es parcialmente homomórfico respecto de la multiplicación, ya que: Por lo tanto, el servidor podría multiplicar tus dos cantidades cifradas y entregarte el resultado cifrado sin conocer los valores de x1 ni x2. Cuando descifres el resultado devuelto obtendrás el mismo valor que si hubieras multiplicado las dos cantidades originales sin cifrar. Impresionante, ¿no? Existen otros muchos algoritmos criptográficos que al igual que RSA son parcialmente homomórficos, como ElGamal también para la multiplicación o Paillier para la suma. Las cosas se complican enormemente cuando se busca el cifrado «totalmente» homomórfico (FHE), capaz de soportar tanto la suma como el producto. Aunque existen muchas propuestas en la literatura científica sobre FHE, la más destacada es la planteada por Craig Gentry en 2009 y evolucionada por él mismo y por otros autores a lo largo de los años. Su propuesta se basa en un concepto algebraico abstracto conocido como "celosía". Seguro que has visto cientos de celosías en ventanas y balcones. Las que te venden en tiendas de bricolaje son celosías bidimensionales: listones de madera o de metal que se cruzan en ciertos puntos. Ahora imagina esa misma celosía en 3D. Y ahora añade otra dimensión. Y otra. Y otra. Y así hasta n dimensiones. Bien, ¿tienes ya una celosía n-dimensional en tu cabeza? Complicada, ¿verdad? Puedes creer que encontrar el punto más cercano a otro en esa celosía no es tarea fácil. De hecho, es tan difícil que se conoce como el Problema del Vector Más Corto (Shortest Vector Problem, SVP) y constituye precisamente el problema matemático "intratable" del cifrado basado en celosías. De hecho, este criptosistema representa una de las alternativas criptográficas más serias para la era post-cuántica. Lo mejor de todo es que, con las variantes adecuadas, las celosías también sirven para el cifrado homomórfico completo. Pero, y aquí aparece un gran, gran PERO, estos algoritmos resultan tremendamente ineficientes. Operar con los datos cifrados puede volverse hasta 10 órdenes de magnitud más lento que con los datos en claro (o sea, 1010 veces más lento o, lo que es lo mismo, un uno seguido de diez ceros: 10.000.000.000). En definitiva, son inservibles para aplicaciones prácticas reales. Hasta que no alcancen velocidades aceptables, no veremos un despliegue a gran escala en servicios en la nube. Mientras tanto, la investigación en este campo continúa intensamente. Mientras tanto, los criptógrafos no se cruzan de brazos. Si operar sobre los datos cifrados constituye un reto formidable, ¿por qué no acometer versiones más sencillas del problema? Tal vez no confíes en tu proveedor en la nube. ¿Se podría repartir la carga entre los dos? Otros esquemas criptográficos persiguen que varias partes que no confían mutuamente puedan operar sobre los datos sin tener que revelárselos unas partes a otras. Pero esa es otra historia y será contada en la segunda entrega de este artículo. Ya disponible la segunda parte de "El gran reto de la computación segura en la nube: usando datos cifrados sin descifrarlos".
24 de junio de 2019

Tus sentimientos influyen en tu percepción del riesgo y del beneficio más de lo que crees
«La seguridad es tanto un sentimiento como una realidad.» —Bruce Schneier Daniel Gardner abre su libro The Science of Fear con la estremecedora historia de los atentados del 11S en EEUU: «Y así, en los meses posteriores a los ataques del 11 de septiembre, mientras los políticos y periodistas se preocupaban sin cesar por el terrorismo, el ántrax y las bombas sucias, las personas que huían de los aeropuertos para protegerse del terrorismo se estrellaron y murieron en las carreteras de Estados Unidos. Y nadie se dio cuenta. (…) Resultó que el cambio de aviones a automóviles en Estados Unidos duró un año. Luego los patrones de tráfico volvieron a la normalidad. Gigerenzer también encontró que, exactamente como se esperaba, las muertes en las carreteras estadounidenses se dispararon después de septiembre de 2001 y volvieron a los niveles normales en septiembre de 2002. Con estos datos, Gigerenzer pudo calcular el número de estadounidenses muertos en accidentes automovilísticos como resultado directo de cambiar de aviones a coches. Fue de 1.595.» ¿Qué mató a todas estas víctimas? El miedo. Todos sabemos que volar en avión en más seguro que conducir un coche. De hecho, lo más peligroso de viajar en avión es el trayecto en coche al aeropuerto. Las estadísticas están ahí para demostrarlo. ¿Por qué entonces nos da más miedo volar en avión que montar en coche? Porque la aceptación del riesgo no sólo depende de estimaciones técnicas de riesgo y beneficio sino también de factores subjetivos, como el sentimiento. Nuestras preferencias emocionales determinan nuestras creencias sobre el mundo La heurística del afecto permite a alguien tomar una decisión basada en un afecto, es decir, en un sentimiento, en lugar de en una deliberación racional. Esta heurística funciona mediante la siguiente sustitución: Si tienes un buen presentimiento acerca de una situación, puedes percibirla como de bajo riesgo; recíprocamente, un mal presentimiento puede inducirte a una mayor percepción de riesgo. Estás usando tu respuesta afectiva a un riesgo (por ejemplo, ¿cómo me siento con respecto a los alimentos genéticamente modificados, la energía nuclear, el cáncer de mama o las armas de fuego?) para inferir cómo de grave es para ti ese riesgo (por ejemplo, ¿cuál es el número anual de muertes por cáncer de mama o por armas de fuego?). Y, a menudo, te encontrarás que existe un importante gap entre el riesgo real y el riesgo percibido. En nuestro cerebro, el riesgo lleva asociado una serie de factores psicológicos que determinan si nos sentimos más o menos asustados. ¿Y cómo pueden medirse estos factores? Uno de los investigadores más destacados sobre análisis de riesgos, Paul Slovic, propuso un modelo psicométrico para medir los niveles percibidos de riesgo en función de la respuesta afectiva ante distintas amenazas. En un primer trabajo, Slovic planteó 18 características para evaluar cuantitativamente la percepción del riesgo. Para simplificar, la siguiente tabla sólo recoge los factores de percepción de riesgo más directamente relacionados con la ciberseguridad: Las personas exageran los riesgos que: Las personas minimizan los riesgos que: Infunden miedo No infunden miedo Escapan a su control Permanecen bajo su control Resultan catastróficos, afectando a multitudes Afectan a uno o pocos individuos Afectan a otros, no al agente de la actividad (injustos) Afectan al agente de la actividad (justos) Vienen impuestos externamente Se toman voluntariamente Son desconocidos Resultan familiares No se comprenden bien Son bien comprendidos Aparecen como nuevos, infrecuentes Son viejos o comunes Tienen consecuencias inmediatas Manifiestan sus efectos a largo plazo Exploremos de nuevo el ejemplo de volar en avión o viajar en coche, desde esta nueva perspectiva. Si evalúas cada uno de los factores anteriores para ambas actividades, llegarás a un resultado similar al del gráfico siguiente: Ahora tal vez te parezca más claro por qué nos da más miedo volar en avión que montar en coche a pesar de lo que digan las estadísticas y los estudios de accidentes y mortalidad. ¡Somos seres emocionales! Revisa los artículos anteriores sobre las heurísticas de disponibilidad y de representatividad y comprobarás cómo explican la mayoría de los comportamientos listados en la tabla. Miedo y familiaridad condicionan tu percepción del riesgo ante las amenazas Posteriormente, al profundizar en el estudio de estos factores, Slovic observó cómo existen dos dimensiones dominantes entre todas ellos: miedo y familiaridad. Ambas dimensiones pueden representarse gráficamente para facilitar la clasificación de los riesgos. Limitándonos a estos dos factores, la heurística del afecto puede redefinirse como la siguiente sustitución: A la hora de evaluar dos amenazas A y B, cuanto más miedo te infunda y menos familiar te resulte una de las dos, percibirás su nivel de riesgo como más alto en comparación con la otra. Inconscientemente, realizas el juicio: volar en avión infunde más miedo y resulta menos familiar que montar en coche, luego tiene que ser más arriesgado. Así que ubicas el avión en el cuadrante inferior derecho (Alto Riesgo) y el coche, en el superior izquierdo (Bajo Riesgo). Y ni todas las estadísticas del mundo cambiarán este afecto. Puedes probarlo con tu cuñado. Esta heurística se aplica en especial cuando necesitas tomar decisiones rápidas. Cuanto te encuentras bajo presión y sin tiempo, no puedes evitar sentir reacciones afectivas o emocionales hacia la mayoría de las opciones. Por supuesto, además del afecto, también entran en acción los atajos psicológicos que te ayudan a determinar si un riesgo parece alto o bajo: son los sesgos cognitivos y heurísticas que hemos repasado en anteriores artículos. La familiaridad constituye un factor realmente determinante en la evaluación de riesgos. Cuanto más familiarizado estás con una actividad o suceso, menos atención le prestas. El cerebro se ve bombardeado por millones de datos de entrada y tiene que filtrarlos, extrayendo la información importante. Por lo general, importante es todo aquello novedoso, todo lo que supone un cambio. Con el tiempo, sometido una y otra vez al mismo estímulo, el cerebro se habitúa y termina ignorándolo. La habituación es un fenómeno maravilloso que permite que puedas desenvolverte en la vida cotidiana sin necesidad de prestar atención absolutamente a todo. El lado malo es que terminas insensibilizado hacia los estímulos frecuentes. Cuanto más familiar te resulta una actividad, menor termina pareciéndote su riesgo. De ahí que tal vez fumes, comas comida ultraprocesada, whatsappees mientras conduces y cruces la calle leyendo tu Facebook en el móvil ¡todos los días! Son actividades a las que estás tan habituado (te son tan familiares) que ya no te parecen arriesgadas. La sorprendente relación entre nuestros juicios sobre riesgo y beneficio Y no acaba aquí la historia. Paul Slovic no sólo llegó a las conclusiones descritas anteriormente en su modelo psicométrico del riesgo. Descubrió además sorprendentes relaciones entre nuestros juicios sobre riesgo y beneficio: «En el mundo, riesgo y beneficio tienden a estar positivamente correlados, mientras que en la mente (y en los juicios) de las personas resultan estar negativamente correlados. (…) Las personas basan sus juicios sobre una actividad o una tecnología no solo en su conocimiento racional y objetivo sobre ella sino también en los sentimientos suscitados. (…) Si les gusta una actividad, se sienten movidos a juzgar los riesgos como bajos y los beneficios como altos; si no les gusta, tienden a juzgar lo contrario: alto riesgo y bajo beneficio.» El ejemplo paradigmático aquí es la energía nuclear. Como todo el mundo sabe, la energía nuclear es una Cosa Mala, por lo tanto, tiene que plantear un Alto Riesgo. ¿Y cómo de beneficiosa es la energía nuclear? Pues como es una Cosa Mala, tiene que suponer un bajo beneficio. Sin embargo, los rayos X de las radiografías son una Cosa Buena, ya que las usan los médicos para salvar vidas, luego tienen que plantear Bajo Riesgo y Alto Beneficio. Así funciona nuestro cerebro. ¿Y los datos? Pues no hacen falta, la decisión ya está tomada. Solo servirían para confirmar la postura de partida. El resultado final es que sobreestimamos los riesgos de la energía nuclear y subestimamos los riesgos de los rayos X. Bajo este modelo, el afecto viene antes y dirige nuestros juicios de riesgo y beneficio. Si una visión general afectiva guía las percepciones de riesgo y beneficio, proporcionar información sobre el beneficio debería cambiar la percepción del riesgo y viceversa. Reubica el riesgo en el lugar que le corresponde en el afecto de tus empleados Todos los estudios sobre la percepción del riesgo confirman que los expertos en la materia evaluada sucumben en menor medida a la heurística del afecto. Después de todo, tienen un mayor conocimiento del campo, adquirido a través de la experiencia y del estudio. Es decir, conocen con mayor precisión las probabilidades, la naturaleza de las amenazas y el impacto de los incidentes. En definitiva, están mejor equipados para evaluar el riesgo real: su gap entre riesgo real y riesgo percibido es menor que entre los legos en la materia. La conclusión es clara: si quieres ayudar a tus empleados a tomar mejores decisiones de seguridad, necesitarás aumentar su conciencia en seguridad de la información (Information Security Awareness, ISA). Esta conclusión es tan obvia que da vergüenza ponerla por escrito. Otra cosa es que se haga. Y entre los mayores retos de esta concienciación se encuentra el reeducar al usuario sobre las tecnologías que le son muy familiares y beneficiosas, porque termina perdiendo de vista su riesgo real. Por lo tanto, uno de los puntos clave de todo programa será la deshabituación. Cuanto más familiarizados están los empleados con una tecnología y más beneficiosa la perciben, menos riesgo ven en ella. Los cibercriminales explotan precisamente esta alta familiaridad, bajo miedo y alto beneficio de ciertas tecnologías para transformarlas en vectores de entrada de ataques. Algunos ejemplos de este tipo de tecnologías familiares, agradables y beneficiosas son: El correo electrónico, tecnología con la que trabajamos todos los días a todas horas. Las memorias USB, esos pequeños dispositivos de aspecto inocente con tanta información útil. Los archivos ofimáticos de Word, Excel, PowerPoint, PDF, en los que pasamos horas diariamente y que tan alegremente compartimos. Anuncios en páginas web legítimas, que estamos hartos de ver por todas partes y son molestos, sí, pero a veces también anuncian algo valioso. Juegos y apps descargados en el smartphone, tan divertidos, tan útiles, tan monos. Fotos y vídeos intercambiados en las redes sociales. Los propios empleados de la compañía, con quienes tomamos café todas las mañanas y cuyos hijos conocemos. No viene mal de vez en cuando realizar campañas de seguridad con los empleados para recordarles que el correo electrónico, los USBs, los archivos ofimáticos, la navegación, los juegos, los materiales multimedia, los propios compañeros, etc., por muy familiares y amigables que parezcan, son la principal vía de entrada de ciberataques. Al final, tu percepción de la seguridad no solo es cuestión racional sino también emocional. No puedes combatir directamente la heurística del afecto, porque así funciona nuestro cerebro. En cambio, puedes guiar el afecto de tus empleados hacia las distintas tecnologías, elevando su nivel de conciencia.
28 de mayo de 2019

Por qué entregas tarde tus proyectos y qué puedes hacer para remediarlo
«Cualquier persona que cause daño al pronosticar debe ser tratada como un tonto o como un mentiroso. Algunos pronosticadores causan más daño a la sociedad que los criminales.» —Nassim Taleb, El cisne negro, 2007 En 1957, la Casa de la Ópera de Sydney se presupuestó por 7 millones de dólares y un plazo de ejecución de cuatro años. Finalmente, costó 102 millones de dólares y tardó 14 años en completarse. ¡Un sobrecoste del 1.400%! Posiblemente, el mayor de la historia. Los sobrecostes y retrasos son una constante en las obras de ingeniería: el canal de Panamá, la nueva Sede del Banco Central Europeo, los túneles de la M-30, el AVE Madrid-Barcelona, la variante de Pajares, la T4 de Barajas, la línea 9 del metro de Barcelona, … La lista no tiene fin. Tras estudiar cientos de obras en 20 países a lo largo de los últimos 70 años, el experto en políticas de infraestructuras y profesor de la Universidad de Oxford, Bent Flyvbjerg, llegó a la conclusión de que el 90% de los proyectos no consiguió cumplir el presupuesto. Y no sólo ocurre con las grandes obras civiles, también con los grandes proyectos de ingeniería: el Airbus A400M, los F-100 australianos o el proyecto Galileo para reemplazar a GPS, que lleva acumulados 10.000 millones de euros de sobrecoste y 15 años de retraso. Ahí es nada. ¿Y tus proyectos? ¿Cuestan más de lo que presupuestas? ¿Tardan en ejecutarse más de lo esperado? Por qué somos tan malos estimando costes y plazos: la tensión entre la visión interna y la visión externa ¡Que tire la primera piedra quien no haya sido excesivamente optimista al estimar cuánto le va a costar completar algo, en tiempo y recursos! Los psicólogos Daniel Kahneman y Amos Tversky acuñaron el término falacia de la planificación para referirse a este fenómeno paradójico: aunque todos hemos fallado miserablemente una y otra vez al estimar el plazo y presupuesto de ejecución de todo tipo de proyectos personales y profesionales en los que nos hemos visto involucrados, la siguiente vez, ¡nuestros planes siguen siendo absurdamente optimistas! En su obra "Pensar rápido, pensar despacio", Daniel Kahneman explica cómo puedes enfocar un problema utilizando una visión interna o una visión externa: Cuando usas la visión interna te centras en tus circunstancias específicas y buscas evidencias en tus experiencias similares, incluidas la evidencia anecdótica y las percepciones falaces. Imaginas escenarios idílicos donde todo sale según lo planeado. Ahora bien, además de todas las variables que barajas en tu mente, existe un volumen incalculable de variables desconocidas e indeterminables: enfermedades, accidentes, incidentes de seguridad, averías, desacuerdos entre el equipo, otros proyectos más urgentes, despidos, agotamiento imprevisto de fondos, huelgas, … ¡tantas cosas imprevisibles pueden pasar! Por desgracia resulta imposible anticiparlas todas ellas, lo que está claro es que la probabilidad de que algo salga mal aumenta cuanto más ambicioso es el proyecto. En definitiva, subestimamos lo que no sabemos. Por el contrario, cuando usas la visión externa miras más allá de ti mismo: más allá de tu experiencia pasada, más allá de los detalles de este caso particular, para prestar atención a información objetiva adicional, como por ejemplo la tasa base. En lugar de creer que tu proyecto es único, miras hacia proyectos similares en busca de datos sobre su presupuesto y duración promedios. Por desgracia, tiendes a descartar, e incluso a despreciar, la visión externa. Cuando la información estadística de casos similares entra en conflicto con tu impresión personal, desestimarás los datos. A fin de cuentas, esos proyectos duraron y costaron tanto porque los ejecutaron otros, pero tú eres diferente y a ti no puede pasarte lo que a ellos, ¿verdad? Veámoslo desde otro ángulo, gracias a este fragmento de una conversación real entre dos padres: «Voy a mandar a mi hijo a la escuela Tal.» «¿Seguro? Es muy elitista. La probabilidad de entrar en esa escuela es muy baja, tan solo del 8%.» «Bueno, bueno, la probabilidad de mi hijo será cercana al 100%, saca unas notas excelentes.» El padre, pensando en su hijo, cree que tiene una probabilidad altísima porque efectivamente el niño es muy inteligente y saca unas notas excelentes... como los cientos de otros niños que solicitan entrada en esa escuela todos los años, de los cuales solo 8 de cada 100 son admitidos. El padre utiliza solamente su visión interna para evaluar la situación. Para su pesar, la mejor estimación de la probabilidad de que su hijo entre en la escuela sigue siendo del 8%, es decir, la tasa base. En resumen, la visión externa busca situaciones similares que puedan proporcionar una base estadística para tomar una decisión: ¿otros se han enfrentado a problemas semejantes en el pasado?, ¿qué sucedió? Claro que la visión externa nos resulta una forma tan poco natural de pensar, que preferimos creer que nuestra situación es única. Como sentencia Kahneman en "Pensar rápido, pensar despacio": En la pugna entre la visión interna y la externa, la visión externa no tiene ninguna oportunidad. Bienvenido a Lago Wobegon, donde todos los niños son superiores a la medio Reconócelo, tu percepción de los acontecimientos es asimétrica. Según numerosos experimentos de psicología: Atribuyes tus éxitos a tus habilidades y tus fracasos a tu mala suerte, justo lo contrario de como entiendes los éxitos y fracasos de los demás. Te consideras más inteligente que los demás. Te crees mejor conductor que los demás. Crees que tu matrimonio durará más que los demás. En definitiva, te crees especial. Pues bien, este otro error de pensamiento se conoce como sesgo optimista. Este sesgo está a su vez íntimamente relacionado con la ilusión de superioridad. Vamos, que en nuestro fuero interno nos creemos diferentes, cuando en realidad somos muy similares. El sesgo optimista juega un papel crucial en la falacia de la planificación. Como explica el experto en obras Bent Flyvbjerg en el trabajo antes citado: "Bajo el influjo de la falacia de planificación, los directivos toman decisiones basadas en el optimismo delirante en lugar de en una ponderación racional de ganancias, pérdidas y probabilidades. Sobreestiman los beneficios y subestiman los costes. Involuntariamente tejen escenarios de éxito y pasan por alto el potencial de traspiés y errores de cálculo. Como resultado, siguen iniciativas que es poco probable que salgan dentro del presupuesto o a tiempo, o que generen los rendimientos esperados." No todo es culpa de nuestro pensamiento imperfecto El optimismo de planificadores y de quienes toman decisiones no es la única causa de esos incrementos. En "Pensar rápido, pensar despacio", Kahneman señala otros factores: "Los errores en los presupuestos iniciales no siempre son inocentes. A los autores de planes poco realistas con frecuencia los mueve el deseo de que su plan sea aprobado —por sus superiores o por un cliente—, y se amparan en el conocimiento de que los proyectos raras veces se abandonan sin terminarlos porque los costes se incrementen o los plazos venzan." Con tal de conseguir financiación a toda costa, es frecuente exagerar los beneficios del futuro proyecto y atenuar los riesgos y costes. Así, Bent Flyvbjerg aporta una fórmula que enfatiza esta espiral perniciosa en la que los proyectos que mejor se ven sobre el papel son los que obtienen mayor financiación: Costes subestimados + Beneficios sobreestimados = Financiación Al final no se están comparando proyectos reales sino versiones idealizadas de los mismos con beneficios sobredimensionados y costes y problemas barridos bajo la alfombra. Qué puedes hacer para planificar mejor tu próximo proyecto La información estadística sobre proyectos similares puede salvarnos de la falacia de la planificación. Por muy optimista que seas, puedes esperar encontrarte en promedio con dificultades similares a las enfrentadas por los equipos de otros proyectos. Bent Flyvbjerg propuso el método conocido como pronóstico por clase de referencia para eliminar el sesgo optimista al predecir la duración y el coste de proyectos. El pronóstico por clase de referencia requiere los siguientes tres pasos para tu proyecto particular: Identifica una clase de referencia relevante de proyectos pasados. La clase debe ser lo suficientemente amplia como para ser estadísticamente significativa, pero lo suficientemente restringida como para poder compararse verdaderamente con tu proyecto. Por supuesto, este paso será más difícil cuanto más raro sea el problema entre manos. En el caso de decisiones comunes (al menos para otros, aunque no para ti), identificar la clase de referencia es inmediato. Establece una distribución de probabilidad para la clase de referencia seleccionada. Esto requiere acceso a datos empíricos creíbles para un número suficiente de proyectos dentro de la clase de referencia para obtener conclusiones estadísticamente significativas. Compara tu proyecto con la distribución de la clase de referencia, para establecer el resultado más probable para tu proyecto. Al evaluar planes y pronosticar, tendemos a centrarnos en lo que es diferente, ignorando que las mejores decisiones a menudo se centran en lo que es lo mismo. Si bien esta situación que tienes entre manos parece un poco diferente, a la hora de la verdad, casi siempre es la misma. Aunque duela, admitamos que no somos tan especiales. Aprende de los antiguos filósofos estoicos a pensar sobre lo que puede salir mal: el análisis premortem de los proyectos Se atribuye a Séneca un ejercicio de meditación que los propios estoicos llamaban premeditatio malorum: algo así como una reflexión sobre lo que puede salir mal antes de acometer una empresa. Por ejemplo, antes de un viaje por mar, ¿qué podría salir mal? Podría desatarse una tormenta, el capitán podría caer enfermo, el barco podría ser atacado por piratas, etc. De esta manera, puedes prepararte para estas eventualidades. Y si nada puede hacerse ante una, si lo peor ocurre, al menos no te cogerá por sorpresa. El psicólogo estadounidense Gary Klein retoma esta vieja idea y recomienda realizar un análisis premortem del proyecto en estudio: «Un premortem en un entorno empresarial tiene lugar al principio de un proyecto y no al final, de modo que el proyecto se puede mejorar en lugar de realizar una autopsia cuando ha fracasado. A diferencia de una sesión de crítica típica, en la que a los miembros del equipo del proyecto se les pregunta qué podría salir mal, el premortem opera bajo el supuesto de que el «paciente» ha muerto y por eso pregunta qué fue lo que salió mal. La tarea de los miembros del equipo es generar razones plausibles para el fracaso del proyecto.» Si deseas aplicarlo, prueba a pronunciar este breve discurso al equipo reunido: «Imagina que ha pasado un año. Hemos seguido la planificación del proyecto al pie de la letra. El resultado ha sido un desastre. En los próximos cinco minutos escribe todas y cada una de las razones que explican el desastre, en especial, aquellas que normalmente no listarías como problemas potenciales.» Las razones apuntadas te mostrarán cómo podrían salir las cosas. Al final, un premortem puede ser la mejor manera de evitar un doloroso postmortem.
20 de mayo de 2019

Cómo predecir el futuro y reducir la incertidumbre gracias a la inferencia bayesiana (II)
En la primera parte de este artículo explicamos cómo funciona la inferencia bayesiana. En palabras de Norman Fenton, autor de Risk Assessment and Decision Analysis with Bayesian Networks: "El teorema de Bayes es adaptable y flexible porque nos permite revisar y cambiar nuestras predicciones y diagnósticos a la luz de nuevos datos e información. De esta manera, si albergamos una fuerte creencia previa de que alguna hipótesis es cierta y luego acumulamos una cantidad suficiente de datos empíricos que la contradigan o no la respalden, entonces el teorema de Bayes favorecerá la hipótesis alternativa que mejor explique los datos". En este sentido, se dice que Bayes es científico y racional, ya que obliga a nuestro modelo a "cambiar de opinión". Los siguientes estudios de caso muestran la diversidad de aplicaciones del Teorema de Bayes en ciberseguridad. Estudio de Caso 1: el triunfo de los filtros anti-spam Uno de los primeros casos de aplicación con éxito de la inferencia bayesiana en el ámbito de la ciberseguridad fueron los filtros (o clasificadores) bayesianos en la lucha contra el spam. Decidir si un mensaje es spam (correo basura, S) o ham (correo legítimo, H) es un problema clásico de clasificación para el que la inferencia bayesiana resultó especialmente apta. El método se basa en estudiar la probabilidad de aparición de determinadas palabras en mensajes de spam en comparación con los mensajes legítimos. Por ejemplo, consultando registros históricos de spam y ham puede estimarse que la probabilidad de que aparezca una palabra (P) en un mensaje de spam (S) es Pr(P|S). Sin embargo, la probabilidad de que aparezca en un mensaje legítimo es Pr(P|H). Para calcular la probabilidad de que un mensaje sea spam si contiene dicha palabra Pr(S|P) se puede utilizar una vez más la socorrida ecuación de Bayes, donde Pr(S) es la tasa base: la probabilidad de que un correo dado sea spam. Las estadísticas nos informan de que el 80% de los mensajes de correo que circulan por Internet son spam, por lo tanto, Pr(S) = 0,80 y Pr(H) = 1 – Pr(S) = 0,20. Típicamente, se elige un umbral para Pr(S|P), por ejemplo 0,95. En función de la palabra P incluida en el filtro, se obtendrá una probabilidad mayor o menor que el umbral y se clasificará consecuentemente el mensaje como spam o como ham. Una simplificación común consiste en asumir la misma probabilidad para el spam y el ham: Pr(S) = Pr(H) = 0,50. Si además cambiamos la notación para representar p = Pr(S|P), p1 = Pr(P|S) y q1 = Pr(P|H), la fórmula anterior queda: Claro, fiarse de una sola palabra para decidir si un mensaje es spam o ham puede prestarse a un elevado número de falsos positivos. Por este motivo, suelen incluirse otras muchas palabras, en lo que se conoce como un clasificador bayesiano naive. Lo de naive viene porque se asume que las palabras buscadas son independientes unas de otras, lo que constituye una idealización de los lenguajes naturales. La probabilidad de que un mensaje sea spam si contiene esas n palabras se calcula como: Así que la próxima vez que abras tu bandeja de correo y la encuentres limpia de spam, dale las gracias al señor Bayes (y a Paul Graham). Si quieres examinar el código fuente de un exitoso filtro anti spam basado en clasificadores bayesianos naive, echa un vistazo a SpamAssassin. Estudio de Caso 2: detección de malware Estudio de Caso 2: detección de malware Por supuesto, estos clasificadores pueden aplicarse no sólo a la detección de spam, sino también de otras amenazas. Por ejemplo, en los últimos años se han popularizado las soluciones de detección de malware basadas en la inferencia bayesiana: Para la detección de gusanos. Para la detección de malware para Android. Para la clasificación de malware para Android, también correlando con la petición de permisos. Estudio de Caso 3: las redes bayesianas La clasificación bayesiana naive asume que las características estudiadas son condicionalmente independientes unas de otras. A pesar de su espectacular éxito clasificando spam, malware, paquetes maliciosos, etc., lo cierto es que en modelos más realistas estas características dependen unas de otras. Para capturar esa dependencia condicional se desarrollaron las redes bayesianas, capaces de mejorar la eficiencia de los sistemas de detección (de malware, de intrusiones, etc.) basados en reglas. Las redes bayesianas constituyen una poderosa forma de machine learning para ayudar a disminuir la tasa de falsos positivos de estos modelos. Una red bayesiana de nodos (o vértices) que representan variables aleatorias y arcos (o aristas) que representan la fuerza de la dependencia entre las variables utilizando probabilidad condicional. Cada nodo calcula la probabilidad a posteriori si son ciertas las condiciones de los nodos padre. Por ejemplo, en la siguiente figura se muestra una sencilla red bayesiana: Y a continuación se muestra cuál es la probabilidad conjunta de la red: Pr(x1,x2,x3,x4,x5,x6) = Pr(x6|x5)Pr(x5|x3,x2)Pr(x4|x2,x1)Pr(x3|x1)Pr(x2|x1)Pr(x1) Los mayores desafíos para las redes bayesianas son aprender la estructura de esta red de probabilidades y entrenar la red, una vez conocida. Los autores de Data Mining and Machine Learning in Cybersecurity presentan varios ejemplos de aplicación de redes bayesianas a la ciberseguridad, como el siguiente: En esta configuración de red, un servidor de archivos, host 1, proporciona varios servicios: protocolo de transferencia de archivos (ftp), shell de seguridad (ssh) y servicios de shell remoto (rsh). El firewall permite el tráfico ftp, ssh, andrsh desde una estación de trabajo del usuario (host0) al servidor 1 (host1). Los dos números entre paréntesis indican host de origen y destino. El ejemplo aborda cuatro vulnerabilidades comunes: desbordamiento de búfer sshd (sshd_bof), ftp_rhosts, rsh login (rsh) y desbordamiento de búfer local setuid (Local_bof). La ruta de ataque se puede explicar usando secuencias de nodos. Por ejemplo, una ruta de ataque puede presentarse como ftp_rhosts (0, 1) → rsh (0, 1) → Local_bof (1, 1). Los valores de probabilidad condicional se muestran para cada variable en el gráfico de red. Por ejemplo, la variable Local_bof tiene una probabilidad condicional de desbordamiento o ningún desbordamiento en el usuario 1 con los valores combinacionales de sus padres: rsh y sshd_bof. Vemos que: Pr(Local_bof(1,1) = Yes|rsh(0,1) = Yes,sshd_bof = Yes) = 1, Pr(Local_bof (1, 1) = No|rsh(0, 1) = No,sshd_bof(0, 1) = No) = 1. Usando redes bayesianas, los expertos humanos pueden entender fácilmente la estructura de la red y la relación subyacente en los atributos de conjuntos de datos. Además, pueden modificar y mejorar el modelo. Estudio de Caso 4: el CISO ante una brecha de datos masiva En How to Measure Anything in Cybersecurity Risk, los autores presentan un ejemplo de inferencia bayesiana, aplicada por un CISO. En el escenario planteado, el CEO de una gran organización llama preocupado a su CISO porque se ha publicitado un ataque a otra gran organización de su sector. ¿Cuál es la probabilidad de que ellos sufran un ciberataque similar? El CISO se pone manos a la obra. ¿Qué puede hacer para estimar la probabilidad de ataque, más allá de consultar la tasa base: la ocurrencia de ataques a empresas similares en un año dado? Decide que un pentesting podría arrojar una buena evidencia sobre la posibilidad de una vulnerabilidad explotable remotamente, la cual a su vez influiría en la probabilidad de sufrir dicho ataque. Basándose en su larga experiencia y en su habilidad para calibrar probabilidades estima las siguientes: La probabilidad de un resultado del pentest que indique la existencia de alguna vulnerabilidad explotable remotamente, Pr(T) = 0,01 La probabilidad de que la organización esconda una vulnerabilidad explotable remotamente en el caso de que el pentest sea positivo, Pr(V|T) = 0,95; y en el caso de que sea negativo, Pr(V|¬T) = 0,0005 La probabilidad de ser atacado con éxito si esa vulnerabilidad existe, Pr(A|V) = 0,25; y si no existe, Pr(A|¬V) = 0,01 Estas probabilidades, a priori, constituyen su conocimiento previo. Armado con todas ellas y con la ecuación de Bayes, ahora puede calcular entre otras las siguientes probabilidades: La probabilidad de un ataque con éxito: Pr(A) = 1,24% La probabilidad de una vulnerabilidad explotable remotamente: Pr(V) = 1,00% La probabilidad de ser atacados con éxito si el pen test arroja resultados positivos: Pr(A|T) = 23,80%; y si arroja resultados negativos: Pr(A|¬T) = 1,01% Se aprecia cómo el resultado del pentest resulta decisivo para estimar el resto de las probabilidades, ya que Pr(A|T) > Pr(A) > Pr(A|¬T). Si una condición aumenta la probabilidad a priori, entonces su opuesto deberá reducirla. Por supuesto, la vida real del CISO es mucho más complicada. Este sencillo ejemplo nos proporciona un atisbo de cómo la inferencia bayesiana puede aplicarse para modificar los juicios en función de la evidencia acumulada en un intento de reducir la incertidumbre. Más allá de los clasificadores: el día a día en ciberseguridad de un bayesiano ¿Significa que a partir de ahora necesitas ir armado con una hoja de Excel para calcular las probabilidades a priori, a posteriori, verosimilitudes, etc.? Afortunadamente, no. Lo que importa más que el teorema de Bayes es el concepto detrás de la visión de Bayes: ir acercándonos progresivamente hacia la verdad actualizando constantemente nuestra creencia en proporción al peso de la evidencia. Bayes nos recuerda la necesidad de sentirnos a gusto con la probabilidad y con la incertidumbre. Un practicante de la ciberseguridad bayesiano: Recuerda la tasa base: la mayoría de la gente se centra en la nueva evidencia y olvida la tasa base (el conocimiento a priori). Se trata de un sesgo muy conocido, sobre el que escribimos al explicar la heurística de la representatividad: prestamos más atención a la evidencia anecdótica que a la tasa base. Este sesgo suele llamarse también falacia de la tasa base. Imagina que su modelo es erróneo y se pregunta: ¿qué puede salir mal? La confianza desmedida en el alcance de tu propio conocimiento puede llevarte a muy malas decisiones. En una entrada anterior indagamos en el sesgo de confirmación: favorecemos la información que confirma nuestras hipótesis, ideas y creencias personales, sin importar si son verdaderas o falsas. El mayor riesgo del sesgo de confirmación es que si buscas un único tipo de evidencia, con toda seguridad, la encontrarás. Necesitas buscar ambos tipos de evidencia: también la que refuta tu modelo. Actualiza incrementalmente sus creencias: la nueva evidencia afecta a la creencia inicial. Cambiar de parecer a la luz de nueva evidencia es un signo de fortaleza y no de debilidad. Estos cambios no tienen por qué ser radicales, sino incrementales, a medida que se va a acumulando evidencia en una dirección u otra. Según Riccardo Rebonato, autor de Plight of the Fortune Tellers: Why We Need to Manage Financial Risk Differently: "De acuerdo con la visión bayesiana del mundo, siempre partimos de alguna creencia previa sobre el problema en cuestión. Luego, adquirimos nuevas evidencias. Si somos bayesianos, no aceptamos en su totalidad esta nueva información, ni nos atenemos a nuestra creencia previa como si nada hubiera sucedido. En cambio, modificamos nuestra visión inicial en un grado acorde con el peso y la confiabilidad tanto de la evidencia como de nuestra creencia previa." Primera parte del artículo: » Cómo predecir el futuro y reducir la incertidumbre gracias a la inferencia bayesiana (I).
23 de abril de 2019

Cómo predecir el futuro y reducir la incertidumbre gracias a la inferencia bayesiana (I)
Imagínate que regresas a casa desde San Francisco, recién llegado de la Conferencia RSA. Estás deshaciendo la maleta, abres el cajón de tu cómoda donde guardas tu ropa interior y, ¿qué descubres? ¡Una prenda de ropa interior que no te pertenece! Lógicamente, te preguntas: ¿cuál es la probabilidad de que tu pareja te esté engañando? ¡Teorema de Bayes al rescate! El concepto tras el teorema de Bayes es sorprendentemente simple: Cuando actualizas tu creencia inicial con nueva información, obtienes una nueva creencia mejorada. Podríamos expresar este concepto, casi filosófico, con matemáticas de andar por casa de la siguiente manera: Creencia nueva y mejorada = Creencias iniciales x Nuevos datos objetivos La inferencia bayesiana te recuerda que la nueva evidencia te obligará a revisar tus viejas creencias. Los matemáticos no tardaron en asignar términos a cada elemento de este método de razonamiento: A priori es la probabilidad de la creencia inicial. La verosimilitud es la probabilidad de la nueva hipótesis basada en datos objetivos recientes. A posteriori es la probabilidad de una nueva creencia revisada. Por supuesto, si aplicas varias veces seguidas la inferencia, la nueva probabilidad a priori tomará el valor de la vieja probabilidad a posteriori. Veamos cómo funciona la inferencia bayesiana con un sencillo ejemplo, tomado del libro Investing: The Last Liberal Art. Inferencia bayesiana en acción Acabamos de terminar varias partidas a un juego de mesa con dados. Mientras guardamos el material en la caja, lanzo un dado y lo cubro con la mano. "¿Qué probabilidad hay de que haya sacado un 6?", te pregunto. "Es fácil", respondes, "la probabilidad es de 1/6". Miro debajo de mi mano y te revelo: «Es un número par. ¿Cuál es la probabilidad de que siga siendo un 6?». Ahora actualizarás tu vieja hipótesis gracias a la nueva información, de manera que responderás que la probabilidad pasa a ser 1/3. Ha aumentado. A continuación, aún te revelo más: «Y no es un 4». ¿Cuál será ahora la probabilidad de un 6? Una vez más, necesitas actualizar tu última hipótesis con la nueva información y llegarás a la conclusión de que la nueva probabilidad es 1/2, Ha vuelto a aumentar. ¡Enhorabuena! ¡Acabas de realizar un análisis de inferencia bayesiana! Cada nuevo dato objetivo te ha obligado a revisar tu probabilidad original. Analicemos, armados con esta fórmula la presunta infidelidad de tu pareja. Cómo aplicar la inferencia bayesiana para descubrir si tu pareja te es infiel Volvamos a la pregunta del inicio: ¿te engaña tu pareja? La evidencia es que has encontrado ropa interior extraña en tu cajón (RI); la hipótesis que te interesa evaluar es la probabilidad de que tu pareja te engañe (E). El teorema de Bayes podrá aclararte esta sospecha, siempre y cuando sepas (o estés dispuesto a estimar) tres cantidades: ¿Cuál es la probabilidad de que si tu pareja te engaña aparezca ropa interior en tu cajón, Pr(RI|E)? Si te está engañando, es bastante fácil imaginar cómo llegó esa ropa interior a tu cajón. Por otra parte, incluso (y quizás especialmente) si te está engañando, puedes esperar que tu pareja sea más cuidadosa. Digamos que la probabilidad de que aparezca esa prenda si te está engañando es del 50%, o sea, Pr(RI|E) = 0,50. ¿Cuál es la probabilidad de que aparezca ropa interior en tu cajón si tu pareja no te engaña, Pr(RI|¬E)? Podría ser que en secreto compra ropa del otro sexo y se la pone cuando tú no estás, cosas más raras se han visto. Podría ser que una pareja platónica suya, en quien confías plenamente, se haya quedado a dormir una noche. Podría ser un regalo para ti que se olvidó de envolver. Ninguna de estas teorías es intrínsecamente insostenible, aunque recuerdan a esas viejas excusas sobre el perro que se comió tus deberes. Colectivamente, puedes asignarles una probabilidad del 5%, o sea, Pr(RI|¬E) = 0,05. Por último y más importante, necesitas la probabilidad a priori. ¿Cuánto creías en la infidelidad de tu pareja antes de encontrar la ropa interior desconocida en tu cajón, Pr(E)? Por supuesto, ahora que has descubierto la prenda misteriosa te resultará difícil ser completamente objetivo. Idealmente, establecerás tu probabilidad a priori antes de comenzar a examinar la evidencia. Afortunadamente, a veces es posible estimar este dato empíricamente. En concreto, según las estadísticas, aproximadamente el 4% de las parejas casadas engañan a sus cónyuges en un año dado. Esta es la tasa base, así que la estableces como tu probabilidad a priori: Pr(E) = 0,04. Obviamente, la probabilidad de que no te viniera engañando será Pr(¬E) = 1 − Pr(E) = 0,96. Asumiendo un buen trabajo en la estimación de estos valores, ya solo falta aplicar el teorema de Bayes para establecer la probabilidad a posteriori. Para facilitar los cálculos, asumamos un grupo de 1.000 parejas, ilustrado como el rectángulo grande verde en la siguiente imagen. Es fácil ver que, si 40 de cada 1.000 individuos engañan a su pareja, y si de éstos, la mitad olvidan ropa interior de su amante en el cajón de su pareja, 20 personas habrán olvidado ropa interior (el grupo 4). Por otro lado, de las 960 de cada 1.000 personas que no engañan a su pareja, el 5% habrán dejado también por error una ropa interior en el cajón de su pareja, o lo que es lo mismo, 48 personas (el grupo 2). Sumando ambas cantidades resulta que habrán aparecido 68 prendas interiores misteriosas repartidas por los cajones de las parejas (grupo 2 + grupo 4). Por lo tanto, si encuentras en tu cajón una prenda interior sospechosa, ¿cuál es la probabilidad de que tu pareja te engañe? Será la proporción entre las prendas encontradas cuando las parejas son infieles (4) divididas entre las prendas totales encontradas, tanto de parejas que engañan como que no (2 + 4). Sin necesidad de hacer ningún cálculo, salta a la vista que una prenda extraña será más probable debido a una pareja fiel que a una infiel. De hecho, el valor exacto de la probabilidad a posteriori es: Pr(E|RI) = 20/68 ≈ 29%. También podemos recoger matemáticamente las proporciones de la imagen de la figura anterior en la famosa ecuación de Bayes: Sustituyendo los valores numéricos correspondientes, llegamos una vez más a la probabilidad de que tu pareja te engañe: ¡sólo del 29%! ¿Cómo obtienes este resultado sorprendentemente bajo? Porque has partido de una baja probabilidad a priori (tasa base) de infidelidad. Aunque sus explicaciones de cómo ha podido llegar esa ropa hasta tu cajón son más bien inverosímiles, partiste de la premisa de que tu pareja era fiel, lo que tiene mucho peso en la ecuación. Lo cual resulta algo contraintuitivo, pues ¿no es esa ropa interior en tu cajón prueba de su culpabilidad? Las heurísticas de nuestro Sistema I, adaptadas para los juicios rápidos e intuitivos, nos impiden llegar a las mejores conclusiones probabilísticas basadas en la evidencia disponible. En este ejemplo, prestamos una atención desmedida a la evidencia (¡ropa interior extraña!) y olvidamos la tasa base (sólo el 4% engaña). Cuando nos dejamos deslumbrar por los nuevos datos objetivos a costa del conocimiento previo, nuestras decisiones serán consistentemente subóptimas. Pero tú eres un profesional bayesiano, ¿verdad? Le concederás a tu pareja el beneficio de la duda. Eso sí, puedes advertirle de que en el futuro no se le ocurra comprarse ropa interior del otro sexo, ni regalarte ropa interior, ni invitar a pasar la noche a parejas platónicas. En estas condiciones, la probabilidad de que en el futuro vuelva a aparecer ropa interior en tu cajón si no te engaña será como mucho del 1%, o sea, Pr(RI|¬E) = 0,01. ¿Qué pasa si a los pocos meses vuelve a aparecer ropa interior extraña en tu cajón? ¿Cómo cambiará ahora tu creencia en su inocencia? A medida que va apareciendo nueva evidencia, un bayesiano actualizará su estimación inicial de la probabilidad. La probabilidad a posteriori de que te engañara la primera vez, que calculamos en un 29%, pasará a ser la probabilidad a priori de que te esté engañando esta segunda vez. Los bayesianos adaptan su evaluación de los eventos probabilísticos futuros a la luz de la nueva evidencia. Si reintroduces en la fórmula anterior las nuevas variables, Pr(E) = 0,29 y Pr(RI|¬E) = 0,01, la nueva probabilidad a posteriori de que tu pareja te la esté pegando será 95%. Ahora sí, ¡ya puedes ir pidiendo los papeles del divorcio! Este ilustrativo ejemplo, tomado de The Signal and the Noise: The Art and Science of Prediction, viene a demostrar que: Nos dejamos deslumbrar por la evidencia cuando es muy vistosa, vívida y emocional. Cuando nuestras creencias iniciales son muy robustas, pueden resultar sorprendentemente impermeables a la nueva evidencia en su contra. En la segunda parte de este artículo, exploraremos varios estudios de caso donde se aplica con éxito la inferencia bayesiana a la ciberseguridad.
9 de abril de 2019

La falacia de la tasa base o por qué los antivirus, filtros antispam y sondas de detección funcionan peor de lo que prometen
Antes de empezar la jornada, mientras saboreas tu café de la mañana, abres tu fuente favorita de información sobre noticias de ciberseguridad. Te llama la atención un anuncio de un vendedor de sistemas de detección de intrusiones: ¡NUESTRO IDS ES CAPAZ DE DETECTAR EL 99% DE LOS ATAQUES! " Hmmm, no está mal", piensas, mientras das otro sorbo a tu café. Deslizas los ojos por unas cuantas noticias más y te aparece un nuevo anuncio sobre IDSs de otro fabricante: ¡NUESTRO IDS ES CAPAZ DE DETECTAR EL 99,9% DE LOS ATAQUES! Así, a primera vista, ¿cuál de los dos IDSs es mejor? Parece una perogrullada: obviamente será mejor el que más ataques detecta, o sea, el que detecta el 99,9% de los ataques frente al 99%. ¿O no? Te lo voy a poner aún más fácil. Imagina que encuentras un tercer anuncio: ¡NUESTRO IDS ES CAPAZ DE DETECTAR EL 100% DE LOS ATAQUES! Ahora sí que sí: ¡este IDS es la bomba! ¡Lo detecta todo! Vale, sí, lo detecta todo pero, ¿a qué precio? Fíjate qué fácil es conseguir un IDS con una tasa de detección del 100%: basta con que etiquetes todos y cada uno de los paquetes de entrada como maliciosos. Conseguirás un 100% de detección a costa de un 100% de falsos positivos. Aquí acaba de entrar en escena un segundo actor a menudo ignorado cuando se proporcionan datos sobre la efectividad en la detección de ataques: ¿cuántas veces el detector hace sonar la alarma cuando no había ningún ataque? El problema de la detección Muchas aplicaciones de ciberseguridad afrontan el desafío de detectar un ataque, una anomalía o un comportamiento malicioso: Los IDSs deben detectar paquetes maliciosos entre el tráfico legítimo. Los filtros antispam deben encontrar el correo basura (spam) entre el correo convencional (ham). Los antivirus deben descubrir el malware camuflado entre los archivos inocuos. Los cortafuegos de aplicaciones deben separar las URL maliciosas de las benignas. Los detectores de metales de los aeropuertos deben señalar las armas y objetos metálicos potencialmente peligrosos y no los inofensivos. Los escaneadores de vulnerabilidades deben alertar de vulnerabilidades en servicios o códigos. Las herramientas de ciberinteligencia como Aldara deben distinguir si una conversación en redes sociales se convertirá en una crisis reputacional o si una cuenta de Twitter es un bot o si pertenece a una célula terrorista. Las herramientas de análisis de logs deben identificar los eventos correlados. Las herramientas de identificación de protocolos de red deben etiquetar correctamente los paquetes. Los detectores de mentiras deben discernir cuándo un sospechoso dice la verdad o miente. Y otros muchos más. Puedes añadir más ejemplos en los comentarios. A pesar de su disparidad, todos estos sistemas poseen una característica en común: producen alertas cuando consideran que han encontrado un verdadero positivo (True Positive o TP). Por desgracia, no son perfectos y también producen alertas ante la ausencia de actividad maliciosa o anómala, lo que se denomina falso positivo (False Positive o FP). La tabla siguiente muestra todos los posibles estados de respuesta de un detector ante un incidente. Si el sistema detecta un incidente cuando de verdad se ha producido, entonces funciona correctamente: se ha producido un verdadero positivo (TP). Por el contrario, el funcionamiento es incorrecto si realmente existe un incidente, pero el sistema no alerta del mismo: se ha producido un falso negativo (FN). Del mismo modo, si no hay incidente y el sistema identifica su presencia erróneamente, se ha producido un falso positivo (FP), mientras que se produce un verdadero negativo (TN) si el sistema no alerta en este caso. Las falsas alarmas importan tanto como las detecciones Pensemos ahora en un detector cualquiera. Por ejemplo, un IDS que detecta el 99% de los ataques: es capaz de etiquetar como malicioso el 99% de los paquetes que de hecho son maliciosos. En otras palabras, la tasa de detección (Detection Rate o DR), también llamada tasa de verdaderos positivos (True Positive Rate o TPR) es 0,99. Por otro lado, cuando llega un paquete que no es malicioso es capaz de etiquetarlo como no malicioso en el 99% de los casos o, lo que es lo mismo, la tasa de falsas alarmas (False Alert Rate o FAR), también llamada tasa de falsos positivos (False Positive Rate o FPR) es 0,01. Lo cierto es que en una red convencional la proporción de paquetes maliciosos frente a paquetes legítimos resulta extremadamente baja. En este ejemplo, supongamos que solo uno de cada 100.000 paquetes es malicioso, una cifra muy conservadora. Dadas estas condiciones, nuestro IDS alerta de que un paquete es malicioso. ¿ Cuál es la probabilidad de que de verdad sea malicioso? No te precipites a la hora de dar la respuesta. Piénsalo una segunda vez. Y ahora piénsalo aún una tercera vez. ¿Tienes ya la respuesta? Llegaremos hasta ella paso a paso. En la siguiente tabla aparecen listados los datos para un ejemplo concreto de 10.000.000 de paquetes analizados. De todos ellos, 1 de cada 100.000 son maliciosos, es decir, 100; de los cuales, el 99% habrá sido identificado correctamente como malicioso, es decir, 99 paquetes; mientras que el 1%, o sea, un solo paquete, no ha sido detectado como malicioso y no ha saltado ninguna alarma: este paquete se coló. Ya está rellena la primera columna. Por otro lado, los 9.999.900 paquetes restantes son legítimos. Ahora bien, la alarma habrá saltado erróneamente para el 1% de estos paquetes, totalizando 99.999 paquetes; mientras que para el 99% restante el detector mantuvo silencio, es decir, calló para un total de 9.899.901 paquetes. Ya está lista la segunda columna. Obviamente, filas y columnas tienen que sumar los totales mostrados en la tabla. Armados con esta tabla, ahora podemos responder con rapidez a la pregunta anterior: ¿Cuál es la probabilidad de que un paquete en verdad sea malicioso si el detector lo ha señalado como tal? La primera fila ofrece la respuesta: de las 100.098 alarmas generadas, sólo 99 se correspondieron con paquetes maliciosos, es decir, la probabilidad de que esa alerta corresponda a un paquete malicioso es bien exigua: ¡sólo un 0,0989031%! Sí, sí, puedes revisar los cálculos. No acertará ni siquiera una de cada mil veces que hace sonar la alarma. ¡Bienvenido al problema de los falsos positivos! A mucha gente le choca este resultado: ¿cómo es posible que falle tanto si la tasa de detección es del 99%? ¡Porque el volumen de tráfico legítimo es abrumadoramente mayor que el de tráfico malicioso! El siguiente diagrama de Venn ayuda a entender mejor qué está pasando. Aunque no está a escala, muestra cómo el tráfico legítimo (¬M) es muchísimo más frecuente que el malicioso (M), de hecho, es 100.000 veces más frecuente. La respuesta a nuestra pregunta se encuentra en la proporción entre el área señalado como 3) y el área completa de A. Esta área 3) es muy pequeña en comparación con A y, como consecuencia, que salte una alarma no informa mucho, en términos absolutos, respecto a la peligrosidad del paquete analizado. Lo más paradójico es que da igual cuánto mejore la tasa de detección (DR) de este hipotético IDS, no cambiarán las cosas mientras no disminuya su tasa de falsas alarmas (FAR). Incluso en el caso extremo, suponiendo que la tasa de detección es DR = 1,0; si se mantienen el resto de los parámetros intactos, cuando el IDS dispare una alarma la probabilidad de que esta alarma corresponda a un ataque real seguirá siendo nimia: ¡0,0999011%! Vemos que no llega ni siquiera al uno por mil. Por este motivo, los IDSs gozan de tan mala fama: si un IDS acierta sólo una de cada mil veces que te alerta, al final terminarás ignorando todas sus alertas. La única vía de solución pasa por mejorar la tasa de falsas alarmas, acercándola a cero tanto como sea posible. El siguiente gráfico muestra cómo evoluciona la efectividad en la detección, o lo que es lo mismo, cómo a medida que disminuye la tasa de falsas alarmas, representada como P(A|¬M), va cambiando la probabilidad P(M|A) de que exista de verdad actividad maliciosa (M) cuando el detector dispara una alerta (A). Tras examinar el gráfico, salta a la vista que por mucho que mejore la tasa de detección nunca se superará la efectividad máxima posible… a no ser que baje la tasa de falsas alarmas. De hecho, los resultados son hasta cierto punto desoladores: incluso con una tasa de detección perfecta del 100% (P(A|M) = 1,0), para alcanzar una efectividad superior al 50%, P(M|A) > 0,5, habría que bajar la tasa de falsas alarmas por debajo de 1,E-05, una proeza prácticamente inalcanzable. En resumen, está quedando claro que la efectividad de un sistema de detección (de malware, de ataques de red, de URLs maliciosas, de spam, etc.), no depende tanto de su capacidad de detectar el comportamiento intrusivo sino de su capacidad para suprimir las falsas alarmas. Por qué no puedes ignorar la tasa base cuando evalúas la efectividad de un sistema de detección de cualquier tipo de comportamiento malicioso A la hora de evaluar el comportamiento de un detector existe una interrelación entre tres variables: La tasa de detección: lo bien que el detector identifica un evento malicioso como malicioso. Idealmente, DR = 1,0. Este dato suele aparecer muy destacado por el fabricante, especialmente cuando es del 100%. La tasa de falsas alarmas: lo bien que identifica un evento legítimo como tal, sin etiquetarlo como malicioso. Idealmente, FAR = 0,0. En la práctica, este valor suele distar mucho del ideal. Es común encontrar valores entre el 1% y el 25%. La tasa base: qué porcentaje de eventos son maliciosos en el contexto estudiado. Cuanto más alto sea este valor, es decir, cuanto más "peligroso" sea el entorno, más eficiente será el detector, por el mero hecho de que hay más eventos maliciosos y, lógicamente, señalando cualquier evento como malicioso ya aumentaría el porcentaje de aciertos. El mismo detector en dos contextos distintos, uno con una elevada tasa base (muchos ataques de fondo) y otro con una baja tasa base (escasos eventos maliciosos) parecerá mágicamente mejorar su efectividad. En realidad, lo único que ocurre es que cuantos más ataques recibes, más veces acertarás etiquetando cualquier cosa como ataque. Los fabricantes suelen enfatizar el primer valor y omitir los dos segundos. Ahora bien, la tasa de falsas alarmas es tan importante como la de detección. Una organización puede malgastar miles de horas investigando falsas alarmas en malware, IDSs, logs, spam, etc. Correos importantes o archivos críticos podrían ser puestos en cuarentena o, incluso, ser borrados. En el pero caso, cuando la FAR es muy elevada, el sistema resulta tan fastidioso y consume tantos recursos para validar las alertas, que puede llegarse a desactivarlo o a ignorarlo por completo. ¡Has caído en la fatiga por alarmas! En una época en la que la mayoría de los fabricantes de este tipo de herramientas alcanzan tasas de detección cercanas al 100%, pon la vista también en los falsos positivos. Y recuerda que la tasa base condicionará totalmente la efectividad de cualquier solución. Cuanto menos prevalente sea el problema, más veces gritará en falso "¡Que viene el lobo!". Gonzalo Álvarez Marañón @gonalvmar Innovación y laboratorio en ElevenPaths www.elevenpaths.com
19 de marzo de 2019

En busca del phishing perfecto capaz de engañarte incluso a ti
Lanzas al aire una moneda (sin trucar) seis veces seguidas: ¿cuál de las tres secuencias siguientes crees que es más probable, representando "cara" con un 1 y "cruz" con un 0? 1. 1 0 1 0 1 0 2. 1 1 1 1 1 1 3. 1 0 1 1 0 1 La mayoría de la gente elige la tercera secuencia, 1 0 1 1 0 1, porque parece más aleatoria. Las dos primeras parecen demasiado ordenadas y no coinciden con nuestra idea intuitiva de aleatoriedad. En realidad, las tres secuencias son equiprobables, con una probabilidad de (1/2)6. Pero como estamos más acostumbrados a ver secuencias desordenadas que ordenadas (porque de hecho hay más), de alguna manera la tercera secuencia es la que mejor representa nuestra imagen preconcebida de cómo debe ser la aleatoriedad. Este error de pensamiento lleva precisamente por nombre heurística de la representatividad: asumimos que un ejemplo pertenece a una clase en función de lo bien que ese ejemplo represente a nuestro estereotipo (idea preconcebida) de la clase. Por ejemplo, si ves por la calle a un joven con melena, vestido de cuero y muñequera de pinchos, te resulta más fácil imaginar que le gusta la música Heavy que si va vestido de traje y corbata con el pelo engominado. Recuerda que una heurística es un atajo de pensamiento: en lugar de responder a una pregunta complicada respondemos a otra equivalente, pero más sencilla. En el ejemplo de la moneda, en lugar de responder a la pregunta de interés, "¿cuál es la probabilidad de cada secuencia?", nos preguntamos: "¿cuál es la secuencia que parece más aleatoria?". El uso de la heurística de la representatividad refleja la presunción implícita de que lo similar va con lo similar. Pensamos erróneamente que un miembro de una categoría dada debería parecerse al estereotipo de la categoría, que un efecto debería parecerse a su causa. Como ocurre con todas las heurísticas, también la representatividad nos sirve bien en la mayoría de las situaciones: si un deportista es delgado y mide más de dos metros es más probable que juegue a baloncesto que a fútbol, si un hombre viaja con un maletín con forma de guitarra es más probable que transporte dentro una guitarra que una ametralladora y si recibes un correo de tu jefe es más probable que te lo haya enviado tu jefe a que sea un ataque de phishing. Pero por desgracia, no siempre es así. Si oyes ruidos de cascos, no esperes cebras Marcos es un joven de España de unos 30 años, con gafas, desaliñado, viste camisetas negras con dibujos de películas y series frikis y usa Linux. ¿Qué crees que es más probable? A. Trabaja como programador en ElevenPaths en Madrid B. Trabaja de reponedor en un supermercado Arrastrados por la heurística de la representatividad, muchos se sienten tentados de señalar la A como más probable. Sin embargo, en España existen muchas, muchas más personas trabajando en un supermercado que en ElevenPaths en Madrid, por lo que, aunque posiblemente haya una proporción mayor de amantes de Linux entre los empleados de ElevenPaths que entre los reponedores, su número total seguirá siendo muy inferior al de linuxeros en supermercados. El problema surge porque un fuerte estereotipo nos está cegando hacia otras fuentes de información, como por ejemplo la tasa base: el conocimiento de la frecuencia relativa de un subconjunto con respecto al total. Cuanto más se parece un individuo al estereotipo de la clase general, con mayor obstinación ignoramos la tasa base. De hecho, en las escuelas de medicina de EEUU circula el siguiente aforismo: "si oyes ruido de cascos, no esperes cebras". Lo que viene a decir que a la hora de diagnosticar una enfermedad hay que pensar primero en las causas más probables, en lugar de en las más exóticas. En otras palabras, al evaluar la probabilidad de un suceso no podemos ignorar la tasa base. Si has visto la película Moneyball recordarás cómo Billy Beane crea un equipo de baseball extraordinario reclutando a jugadores con una magnífica estadística de bateo, pero que habían sido descartados por otros ojeadores porque no poseían el aspecto estereotipado de gran bateador. Ante el asombro de los demás clubes, Beane obtuvo resultados excelentes con muy bajo coste, y todo porque fue el único que no sucumbió a la ilusión de la representatividad. Como ves, esta heurística nos hace olvidar lo (poco) que sabemos sobre probabilidad y estadística y nos apresura a tomar decisiones con consecuencias a menudo desastrosas, como en el siguiente ejemplo. Que algo sea muy plausible no implica que sea muy probable Sergio tiene 35 años, estudió informática y, desde la adolescencia, le ha gustado el hacking y la programación. Después de la carrera, trabajó dos años en una empresa de antivirus y luego tres años como pentester en una firma internacional de ciberseguridad, donde ascendió hasta jefe de departamento. A continuación, estudió un máster de Risk Fraud Management y escribió su Trabajo de Fin de Máster sobre Teoría de Juegos para detección de malware. ¿Qué crees que es más probable? A. Sergio trabaja en un gran banco. B. Sergio trabaja en un gran banco en la unidad de ciberseguridad, donde dirige un equipo de respuesta ante emergencias informáticas. He planteado este problema en docenas de cursos y la práctica totalidad de mis alumnos han elegido siempre la misma respuesta: la B. Por supuesto es la respuesta equivocada, supongo que a estas alturas del artículo lo habrás detectado con rapidez. Los empleados de la unidad de ciberseguridad de un banco suponen un pequeñísimo subconjunto de todos los empleados del banco: es matemáticamente imposible que la probabilidad de ocurrencia de un subconjunto sea mayor que la probabilidad del conjunto completo. Por ejemplo, es más probable sacar de una baraja una carta de corazones o sacar un as que sacar un as de corazones. Si tú también has elegido la B, entonces has sido víctima de otro error de pensamiento muy común conectado con el anterior: la falacia de la conjunción. Resulta obvio que la probabilidad de que dos eventos ocurran juntos (en "conjunción") es siempre menor o igual que la probabilidad de que cada uno ocurra por separado: Cuando muestro la historia de Sergio antes de hacer la pregunta, triunfa la intuición y ésta da una respuesta equivocada. En cambio, cuando lanzo la pregunta directamente, sin contar previamente la historia de Sergio, nadie elige la B, al contrario, todos eligen la A. Sin una historia plausible, gana la lógica. Si lo piensas bien, por cada nuevo detalle añadido a un escenario, la probabilidad del escenario solo puede decrecer. Por el contrario, su representatividad y, por lo tanto, su aparente probabilidad, aumentan. ¡Qué paradoja! Cuanto más plausible nos pintan un escenario y con mayor lujo de detalle, menos probable es en términos estadísticos y, sin embargo, más probable nos lo representamos. Ahora bien, las historias más coherentes no son necesariamente las más probables, pero son plausibles. Y confundimos coherencia, plausibilidad y probabilidad. Los resultados más representativos se combinan con la descripción de personalidad para producir las historias más coherentes. Este error de juicio resulta especialmente pernicioso cuando se elaboran escenarios hipotéticos para hacer pronósticos y previsiones. Considera los siguiente dos escenarios y evalúa su probabilidad: A. Durante las próximas elecciones del 28 de abril se espera un ciberataque masivo en Twitter contra políticos españoles, capaz de secuestrar más de 100 cuentas. B. Durante las próximas elecciones del 28 de abril se espera que un miembro que fue expulsado de un partido político y que posee conexiones con grupos hacktivistas orqueste como represalia un ciberataque masivo en Twitter contra los miembros de su partido, capaz de secuestrar más de 100 cuentas. El escenario B nos plantea una historia mucho más vívida y emocionante, es decir, más plausible, aunque su probabilidad es mucho menor. De hecho, el segundo escenario está contenido dentro del primero: los políticos de un partido español constituyen un subconjunto del conjunto de todos los políticos españoles. No obstante, añadir detalles a un escenario lo vuelve más persuasivo. Aunque eso sí, resulta menos probable que sea cierto. Es una trampa muy común al estimar escenarios. Aquí tienes otro ejemplo: ¿qué escenario es más probable? A. Telefónica recibirá un ataque cibernético B. Telefónica recibirá un ataque cibernético a gran escala desde Corea del Norte orientado a interrumpir las comunicaciones de gran parte de nuestro país y sembrar el caos Ahora sí, estás totalmente prevenido y sabes que el escenario A es el más probable. Te invito a que hagas esta prueba con tus amigos y verás que la mayoría elige la B. En busca del malware perfecto ¿Cómo puede un ciberdelincuente aprovecharse entonces de la heurística de la representatividad? Explotará nuestra tendencia a creernos más un escenario rico en detalles representativos que otro que posea menos detalles. Si una historia contiene detalles que "tienen que estar", tendemos a creérnosla más que si careciera de ellos, aunque, matemáticamente, cuanto más detalles incorpora una historia, con menor probabilidad será verdadera comparada con otra con menos detalles. Por ejemplo, el ciberdelincuente podría llamar a su víctima con la intención de suplantar al administrador de seguridad, explicándole que la llama desde el CPD porque ha recibido alertas de comportamiento anormal en la red originándose desde su ordenador (el de la víctima), por lo que necesita conectarse en remoto para hacer una comprobación de seguridad, para lo que requiere sus credenciales de acceso con el fin de iniciar sesión con su usuario y verificar qué está pasando. Debido a que todos estos detalles encajan con nuestra imagen estereotipada del trabajo rutinario de un administrador de seguridad, es más probable que la víctima le revele sus credenciales que si simplemente llamara diciendo que es el administrador de seguridad y que necesita su contraseña. Y fíjate cómo, de acuerdo con la teoría de la probabilidad, este segundo escenario es mucho más probable que el primero, ¡pero menos plausible! La presencia de material plausible es probable que aumente nuestra creencia en la petición implausible. En otras palabras, para explotar la representatividad y la conjunción se precede una petición implausible de tantas afirmaciones y detalles plausibles como sea posible, enriqueciendo así la historia. Cuanto más plausibles sean las primeras afirmaciones, más fácil le resultará a la víctima creer en la última petición, por implausible que resulte. Esta estrategia puede apreciarse en: Ataques de ingeniería social, por teléfono, por email e incluso en persona, que buscan suplantar a una persona de la propia organización con el fin de obtener información sensible de la víctima. Cebos que utilizan dispositivos físicos infectados, tipo unidades USB, perfectamente etiquetados y dejados adrede en lugares verosímiles, para que la víctima los encuentre y se sienta tentada de conectarlos. Mensajes de phishing con textos muy bien redactados que ofrecen varios detalles plausibles antes de solicitar que se haga clic en un enlace que típicamente conducirá a una página familiar de inicio de sesión. Estos ataques están tan dirigidos que suelen englobarse en la categoría del spear phishing. Ventanas falsas de alerta de virus simulando proceder del antivirus del equipo y que solicitan ejecutar el "antivirus" para limpiar el equipo porque supuestamente ha sido detectado algún tipo de malware. Autodefensa contra ataques a nuestra heurística de la representatividad Resumiendo, para evitar dejarte arrastrar por la heurística de la representatividad, necesitamos recordar las siguientes pautas, algunas inspiradas en la siempre estimulante obra Irracionalidad: Si un escenario requiere cumplir una condición adicional, no importa cuán plausible parezca la condición, el escenario será menos probable, no más. No juzgues únicamente por las apariencias. Si algo se parece más a una X que a una Y, sin embargo, puede ser más probable que sea una Y si hay muchas más Ys que Xs. ¡Infórmate sobre la tasa base! Siempre es menos probable que una declaración que contenga dos o más datos sea verdadera que una que contenga solo uno de los datos, por muy verosímiles que sean todos ellos. Cuídate de creer que una declaración es verdadera porque sabes que parte de ella es verdadera. Que una historia sea muy plausible no implica que sea muy probable. Cuando tengas que tomar una decisión de seguridad, rechaza los cuentos y echa cuentas.
4 de marzo de 2019

Si quieres cambiar los hábitos de seguridad de tus empleados no apeles a su voluntad, cambia su entorno
Estás en una cafetería, necesitas conectar tu smartphone a una WiFi, miras tu pantalla y ves estas opciones, supón que conoces o puedes pedir la contraseña en caso de que se te exigiera una. ¿Qué WiFi elegirías? Dependiendo de tu nivel de concienciación en seguridad, irías a por la primera: mi38, que parece tener la mejor cobertura, o a por v29o, que no está mal de cobertura, pero es segura y pide contraseña. Imagina que estás en la misma cafetería, pero en la pantalla de tu smartphone aparece esta nueva pantalla de listado de redes WiFi disponibles. ¿Cuál elegirías ahora? Tengas o no conciencia elevada en materia de seguridad, apostaría a que seleccionas 3gk6. ¿Qué ha cambiado? Son las mismas redes WiFi, pero presentadas de forma diferente. Sin que seas ni siquiera consciente, esta presentación habrá influido en tu decisión. ¡Bienvenido al poder de los "empujoncitos"! Esos pequeños "empujoncitos" que influyen en tus decisiones sin que te des cuenta de que están ahí En 2008 Richard Thaler y Cass Sunstein publicaron Un pequeño empujón: El impulso que necesitas para tomar mejores decisiones sobre salud, dinero y felicidad, un libro que ayudó a popularizar la "teoría del empujón" (nudge) y el concepto de "arquitectura de la elección". En este libro los autores proponen que diseñando cuidadosamente las opciones que se muestran al público y de qué manera se presentan o enmarcan se influirá sutilmente en la decisión tomada, sin restringir la libertad de elección. Según los autores, un empujoncito (nudge) es: "cualquier aspecto de la arquitectura de elección que altera el comportamiento de las personas de una manera predecible sin prohibir ninguna opción o cambiar significativamente sus incentivos económicos." En este libro se mencionan docenas de casos de éxito de "empujoncitos" y de arquitecturas de la elección: pegatinas con forma de mosca en urinarios que consiguen que los hombres apunten bien y manchen menos; frutas y verduras colocadas al principio del lineal de un self-service que consiguen que los usuarios coman más de estos productos que si están al final; paneles en la carretera que por el mero hecho de mostrar la velocidad de los vehículos que se aproximan consiguen una reducción de su velocidad; formularios mostrando como predeterminada la opción de ser donante de órganos al morir que consiguen diferencias abismales en el número de donantes entre unos países y otros; y un larguísimo etcétera. La lectura del libro es muy entretenida e ilustrativa. Como ya vimos en artículos pasados de esta serie, nuestra racionalidad está limitada y nuestras decisiones están sometidas sistemáticamente a sesgos y heurísticas que producen resultados indeseados en ciertas situaciones complejas. Los "empujoncitos" se apoyan en el marco teórico del sistema dual de los dos sistemas cognitivos: Sistema I y Sistema II. Lo que caracteriza a estos "empujoncitos" es el hecho de que explotan nuestra irracionalidad. Con los años, el concepto de empujoncito se ha ido refinando y han aparecido nuevas definiciones. Una particularmente útil es la del experto en ciencia de la conducta P. G. Hansen: "un empujoncito es una función de (1) cualquier intento de influir en el juicio, la elección o el comportamiento de las personas de una manera predecible, que es (2) posible debido a límites cognitivos, sesgos, rutinas y hábitos en la toma de decisiones individuales y sociales que representan barreras para que las personas se desempeñen racionalmente en sus propios intereses autodeclarados y que (3) funcione haciendo uso de esos límites, sesgos, rutinas y hábitos como parte integral de tales intentos". Esta definición sugiere las siguientes características de los "empujoncitos": Producen resultados predecibles: influyen en una dirección predecible. Combaten la irracionalidad: intervienen cuando las personas no actúan racionalmente en su propio interés debido a sus límites cognitivos, sesgos, rutinas y hábitos. Explotan la irracionalidad: explotan los límites cognitivos, las heurísticas, las rutinas y los hábitos de las personas para influir en un comportamiento mejor. Volvamos al ejemplo del principio del artículo sobre las WiFi. Atendiendo a la definición de Hansen, observamos cómo la segunda forma de presentar la lista de redes afecta de la siguiente manera: Produce resultados predecibles: más usuarios viran hacia las elecciones más seguras. Combate la irracionalidad: combate el impulso irreflexivo de conexión, que puede verse satisfecho por la primera WiFi con buena potencia que aparece listada, sin importar si está abierta o cerrada. Explota esa misma irracionalidad: juzgamos como más seguro lo que está en color verde que en rojo, favorecemos las primeras opciones de una lista frente a las últimas, hacemos más caso a pistas visuales (candados) que a textuales, primamos la (supuesta) velocidad frente a la seguridad, etc. Y todo ello mostrando las mismas redes sin prohibir ninguna opción ni cambiar los incentivos económicos de los usuarios. Es decir, se están aprovechando todos estos sesgos para mostrar la opción preferible en primer lugar en la lista, de color verde, con un candado además de texto y jerarquizando, además de por seguridad como primer criterio, también por la velocidad de conexión como segundo criterio. En definitiva, se analizan los sesgos y se diseña un pequeño empujón que los explote, respetando la libertad de elección. Varios trabajos de investigación reprodujeron este experimento de las redes WiFi , logrando modificar con éxito la conducta de los usuarios hacia elecciones más seguras. En todos los casos, los estudios llegaron a conclusiones similares: Los "empujoncitos" bien diseñados tienen el poder de influir en la decisión. Esta capacidad para modificar la conducta es mayor cuanto más probable sea que el usuario exhiba conductas inseguras. El poder de alterar la conducta aumenta si se combinan varios tipos de "empujoncitos", apelando al Sistema I y II. Cómo influir en el comportamiento de seguridad de tus empleados Cada día las personas de tu organización están enfrentándose a decisiones de seguridad de lo más variopintas además de la selección de una WiFi segura: Si descargo e instalo esta app, ¿será un riesgo para mi seguridad? Si introduzco este USB en el portátil, ¿será un vector de entrada para un virus? Si creo esta contraseña corta y fácil de recordar, ¿estaré invitando a que me la crackeen? Precisamente para eso están las políticas de seguridad: para guiar el comportamiento de los usuarios, forzándoles a actuar de la manera más segura posible dentro del contexto y objetivos de seguridad de la organización. Pero ¿existen otras alternativas? ¿Es posible guiar las decisiones de seguridad de la población respetando su autonomía sin restringir las opciones? En otras palabras, ¿se puede conseguir que actúen de forma segura, sin que sean conscientes de que se les está influyendo ni sientan coartada su libertad? Según el profesor experto en ciber leyes R. Calo existen tres tipos de intervención conductual: 1.Códigos: implican una manipulación del entorno que hace que el comportamiento indeseable (inseguro) sea (casi) imposible. Por ejemplo, si quieres que los usuarios de tu sistema creen contraseñas seguras, puedes rechazar cualquier contraseña propuesta que no cumpla con la política de seguridad de contraseñas: "12 o más caracteres con mezcla de alfanuméricos y especiales distinguiendo mayúsculas y minúsculas y no repetida en las últimas 12 ocasiones". El usuario no tiene otro remedio que pasar por el aro o no podrá iniciar sesión en el sistema. En general, todas las directivas de seguridad que no dejan opción entran dentro de esta categoría: bloquear los puertos USB para impedir conectar dispositivos potencialmente peligrosos; bloquear la instalación de software; restringir a una lista blanca los sitios a los que se puede conectar; limitar el tamaño de los adjuntos que se envían por email; y un larguísimo etcétera, contemplado típicamente en las políticas de seguridad de la organización. Los códigos resultan muy eficaces a la hora de modificar la conducta, pero no dejan elección ni explotan la racionalidad limitada, por lo que no pueden considerarse como "empujoncitos". De hecho, muchas de estas medidas resultan impopulares entre los usuarios y pueden conducir a la búsqueda de rodeos que traicionan completamente su propósito, como por ejemplo escribir las contraseñas complejas en una nota adhesiva pegada al monitor: se protege frente a ataques remotos y, en contrapartida, se facilitan e incluso fomentan los ataques internos. 2."Empujoncitos": estos sí, explotan los sesgos cognitivos y las heurísticas para influir a los usuarios hacia conductas más sabias (seguras). Por ejemplo, volviendo a las contraseñas, si quieres que los usuarios de tu sistema las creen más seguras según las directrices de tu política de seguridad mencionada anteriormente, puedes añadir un medidor de la fortaleza de la contraseña. Los usuarios sienten la necesidad de conseguir una contraseña fuerte y es más probable que sigan añadiendo caracteres y complicándola hasta que el resultado sea un flamante "contraseña robusta" en color verde. A pesar de que el sistema no prohíbe las contraseñas débiles, respetando así la autonomía de los usuarios, este sencillo empujoncito eleva drásticamente la complejidad de las contraseñas creadas. 3.Notificaciones: son intervenciones puramente informativas dirigidas a provocar la reflexión. Por ejemplo, el formulario de introducción de nuevas contraseñas puede incluir un mensaje informando de las características esperadas en las contraseñas y de la importancia de las contraseñas robustas para prevenir ataques, etc. Por desgracia, los mensajes informativos resultan muy ineficaces ya que los usuarios tienden a ignorarlos y a menudo ni siquiera les resultan inteligibles. Estas notificaciones tampoco pueden considerarse como "empujoncitos", puesto que no explotan sesgos ni límites cognitivos. No obstante, puede incrementarse notablemente su eficacia si se combinan con un pequeño empujón: por ejemplo, incluir el mensaje y el medidor de fortaleza en la misma página de creación de contraseñas. Lo que buscan estos "empujoncitos" híbridos es apelar al Sistema I, rápido y automático, y apelar con los mensajes informativos al Sistema II, lento y reflexivo. Por consiguiente, para asegurar el éxito de una intervención conductual será deseable que apele a ambos tipos de procesamiento. Los "empujoncitos" más efectivos en seguridad de la información Los "empujoncitos" híbridos resultan ser los más efectivos, combinando información que invita a la reflexión junto con algún truco cognitivo que explote sesgos o heurísticas: Opciones predeterminadas: ofrece más de una opción, pero asegurándote siempre de que la opción predeterminada sea la más segura. Aunque permitas al usuario seleccionar otra opción si así lo desea, la mayoría no lo hará. Información (subliminal):una página de creación de contraseñas induce contraseñas más robustas si aparecen imágenes de hackers, o simplemente de ojos, o incluso si se cambia el texto. Por ejemplo: “introduce tu contraseña” por "introduce tu secreto". Dianas: presenta un objetivo al usuario: por ejemplo, un medidor de fortaleza, un medidor de porcentaje completado, una barra de progreso, etc. Se esforzarán por completar la tarea. Esta intervención puede categorizarse también como feedback. Feedback: proporciona información al usuario para que comprenda si cada acción está teniendo el resultado esperado mientras se está ejecutando una tarea. Por ejemplo, informar del grado de seguridad alcanzado durante la configuración de una aplicación o servicio, o bien informar del nivel de riesgo de una acción antes de apretar el botón "enviar". Eso sí, el lenguaje debe adaptarse cuidadosamente al nivel de conocimientos del destinatario. Por ejemplo, en este estudio, el uso de metáforas conocidas como "cerrojos" y "ladrones" hizo que los usuarios entendieran mejor la información y tomaran mejores decisiones. En este otro estudio, los investigadores comprobaron cómo informar periódicamente a usuarios de Android sobre el uso de permisos que hacían las apps instaladas conseguía que revisaran los permisos concedidos. En esta otra investigación de ejemplo, los mismos investigadores informaban a los usuarios del uso que se hacía de su ubicación, lo que condujo a que restringieran el acceso que las apps hacían de su localización. En otro experimento, informar de cuánta gente puede ver tu post en redes sociales condujo a que muchos usuarios borraran el post para evitar el arrepentimiento. Comportamiento normativo: muestra el lugar que ocupa cada usuario en relación con la media de los usuarios. A nadie le gusta quedarse atrás, todo el mundo quiere estar por encima de la media. Por ejemplo, tras la selección de una contraseña, el mensaje "el 87% de tus compañeros han creado una contraseña robusta" consigue que usuarios que crearon una débil recapaciten y creen una más segura. Orden: presenta la opción más segura al principio de la lista. Tendemos a seleccionar lo primero que nos ofrecen. Convenciones: usa convenciones pictográficas: el color verde indica «seguro», el color rojo indica «peligro». Un candado representa seguridad, y así sucesivamente. Prominencia: destacar las opciones seguras atrae la atención sobre ellas y facilita su selección. Cuanto más visible sea la opción más segura, mayor será la probabilidad de que la seleccionen. Marcos: se puede presentar el resultado de una acción como obtener una ganancia o como evitar una pérdida. La aversión a la pérdida suele resultar un impulso más poderoso. Implicaciones éticas de los "empujoncitos" Como puedes imaginar, este asunto de los "empujoncitos" no está exento de implicaciones éticas, ya que estás creando intervenciones para influir en la conducta explotando agujeros en los procesos cognitivos de los usuarios. En resumen, podría decirse que estás hackeando su cerebro. Las investigadoras K. Renaud y V. Zimmermann han publicado un completo trabajo en el que exploran las ramificaciones éticas de los "empujoncitos" en su sentido más amplio en el que proponen una serie de principios generales para crear "empujoncitos" éticos. Así que antes de lanzarte a diseñar tus propios "empujoncitos" para tu organización, te recomiendo reflexionar en profundidad sobre estos cinco principios éticos: Autonomía: el usuario final debería ser libre de elegir cualquiera de las opciones ofrecidas, con independencia de la dirección hacia la que le dirija el empujoncito. En términos generales, ninguna opción será prohibida o eliminada del entorno. Si se requiere restringir las opciones por motivos de seguridad, se considera necesario añadir una explicación. Beneficio: el empujoncito solamente debería desplegarse cuando proporciona un beneficio claro y la intervención está plenamente justificada. Justicia: debería poder beneficiarse el máximo número posible de individuos, no solo el creador del empujoncito. Responsabilidad social: deben considerarse los resultados anticipados y los no anticipados del empujoncito. Deberían contemplarse siempre "empujoncitos" pro-sociales que avancen el bien común. Integridad: los "empujoncitos" deben diseñarse con un respaldo científico, en la medida de lo posible. Usa los "empujoncitos" para el bien Los "empujoncitos" están usándose cada vez más en ciberseguridad con el objetivo de influir en las personas para que elijan la opción que el diseñador del empujón considere mejor o más segura. Se están explorando nuevas arquitecturas de la elección como un medio para diseñar mejores entornos de toma de decisiones de seguridad, sin necesidad de recurrir a políticas restrictivas ni limitar opciones. Si bien el diseño neutral es una falacia, sé cauto y ético al diseñar "empujoncitos" en tu organización: que ayuden a los usuarios a vencer aquellos sesgos y heurísticas que ponen en peligro sus decisiones sobre privacidad y seguridad. Empuja tu organización hacia una mayor seguridad respetando la libertad de las personas.
19 de febrero de 2019

No confundas la frecuencia de un incidente con la facilidad con que lo recuerdas
Imagina que ha habido un par de robos con violencia en dos parques de tu ciudad y que durante días están acaparando todos los medios de comunicación. Esta tarde te gustaría salir a correr al parque junto a tu casa por lo que estos incidentes acudirán rápidamente a tu memoria, provocando que pienses en la probabilidad de ser víctima de un robo (o algo peor) en tu parque, tu mente asociará lo siguiente: ¡¡¡Parque = Peligro!!! Las imágenes que has visto en TV y en Internet harán que sobrestimes la probabilidad de que tú mismo seas la próxima víctima en otro parque cualquiera de otra ciudad. Como consecuencia, podrías evitar correr por el parque junto a tu casa (o cualquier otro parque) hasta que el eco mediático se apague. Sólo cuando dejes de pensar «¡¡¡Parque = Peligro!!», volverás a frecuentar los parques. Se trata de un comportamiento irracional a todas luces. De hecho, tu mente está usando la siguiente heurística: si me vienen con facilidad a la memoria ejemplos de algo, entonces ese algo tiene que ser común. Como al pensar en «parque» me acuden imágenes de violencia, entonces la probabilidad de que me ocurra algo violento tiene que ser muy alta. Después de todo, ¿quién se dedica a consultar las estadísticas oficiales sobre atracos en parques? Si asaltaron a dos personas en parques, eso significa que los parques son peligrosos, digan lo que digan las estadísticas, ¿no? Pues no. Los psicólogos llaman a este error de juicio el sesgo de disponibilidad: cuanto más fácil de recordar nos resulta un acontecimiento, más probable creemos que es. Tendemos a sobrestimar la frecuencia de causas sensacionales y subestimar la frecuencia de las causas mundanas Los seres humanos somos realmente malos con los números y no digamos ya calculando probabilidades. Rara vez nuestra percepción de un riesgo coincide con su realidad, tendemos a magnificar los riesgos espectaculares, novedosos, vívidos, recientes y emocionales. El resultado final es que nos preocupamos por riesgos que podríamos ignorar sin perjuicio y no atendemos lo suficiente a riesgos sobre los que la evidencia nos alerta. La siguiente tabla, adaptada por Bruce Scheneier a partir de la literatura científica sobre el tema, recoge cómo las personas percibimos los riesgos en términos generales: La heurística de disponibilidad explica la mayoría de los comportamientos listados en la tabla. Igualmente, tomamos a diario decisiones (grandes y pequeñas) con implicaciones directas en seguridad: ¿Me conecto a esta WiFi pública? ¿Introduzco este pendrive en mi puerto USB? ¿Envío este archivo confidencial adjunto por correo electrónico? Calculamos los riesgos de manera automática sin prestar demasiada atención consciente: no sacamos la calculadora ni las tablas de frecuencias de incidentes para determinar las probabilidades. Así que nos dejamos guiar por esta heurística de disponibilidad: ¿me viene a la mente rápidamente un incidente relacionado con este desafío de seguridad? ¿No? Entonces debe ser poco probable, luego el riesgo será bajo. ¿Sí? Entonces será bastante probable, por lo que el riesgo será alto. La cuestión es: ¿por qué algunos acontecimientos son más fáciles de recordar que otros? Saberlo nos ayudará a tomar mejores decisiones de seguridad y a no dejarnos influir tan fácilmente por los demás: vendedores, blogueros, prensa, amigos, etc. Las historias vívidas se graban a fuego en la memoria En concreto, los investigadores del campo han identificado algunos factores que hacen que un acontecimiento se nos grabe en la memoria más duraderamente que otros: Cualquier contenido emocional hace que el recuerdo perdure más. Una de las emociones más poderosas en este sentido es precisamente el miedo. Algo que habrás notado en muchas noticias y anuncios sensacionalistas sobre ciberseguridad. Las palabras concretas se recuerdan mejor que las abstracciones como los números. Por eso tienen mucho mayor impacto las historias anecdóticas que las estadísticas. Aunque nos duela admitirlo (¿no éramos animales racionales?), nuestras decisiones se ven más afectadas por información vívida que por información pálida, abstracta o estadística. Las caras humanas tienden a grabarse en la memoria, al menos si están expresando emociones. Por eso los anuncios y campañas más exitosos tienen protagonistas con rostro propio. Los acontecimientos más recientes se recuerdan mejor que los antiguos. La memoria se degrada con el tiempo. Si circulas por la carretera y pasas junto a un accidente, serás muy consciente del riesgo de sufrir uno tú mismo, por lo que disminuirás la velocidad y circularás con precaución durante unos pocos kilómetros... hasta que la conversación vire hacia otro tema y olvides completamente la visión del siniestro. Del mismo modo, que un acontecimiento sea novedoso también ayuda a que se fije en la memoria. Lo cotidiano pasa desapercibido; lo extraordinario, llama la atención. Y como todos los estudiantes saben bien, la concentración y la repetición ayudan a la memorización. Cuantas más veces te expones a una información, mejor se te queda. ¡Qué bien lo saben los publicistas! Todos estos efectos son acumulativos. Resumiendo, según el psicólogo social Scott Plous: En términos muy generales: (1) cuanto más disponible esté un evento, más frecuente o probable nos parecerá; (2) cuanto más vívida sea una información, más fácil de recordar y convincente resultará; y (3) cuanto más prominente (diferente al resto) es algo, más probable será que parezca causal. ¿Dónde crees que encontramos historias que cumplan todos estos requisitos? ¡En los medios! Si sale en las noticias, ¡no te preocupes! Como ocurre con otros muchos sesgos y atajos de pensamiento, en la mayoría de las situaciones de nuestra vida cotidiana la heurística de disponibilidad resulta válida: si se nos ocurren muchos ejemplos de algo es porque de verdad ha ocurrido muchas veces. Seguro que a todos nos resulta más fácil pensar en científicos hombres que en mujeres, en franquicias mundiales estadounidenses que españolas o en futbolistas en la Champions League españoles que malteses, por la sencilla razón de que hay muchísimos más ejemplos en la primera categoría que en la segunda. La heurística de disponibilidad por tanto nos sirve bien la mayor parte del tiempo, la facilidad con la que recordamos ejemplos relevantes suele ser un buen atajo para estimar su probabilidad o frecuencia. Este atajo, sin embargo, no es infalible. Algunos sucesos pueden ser simplemente más memorables que otros, por lo que su disponibilidad resulta ser un pobre indicador de su probabilidad. La información negativa que se reporta en las noticias es, en buena medida, la responsable de alimentar esta heurística. Por definición, para que algo salga en las noticias tiene que ocurrir rara vez; de hecho, tiene que ser tan prominente, que atraiga la atención. Así, las noticias informan de lo estadísticamente irrelevante, sesgando nuestra percepción sobre la frecuencia de los acontecimientos. Como resultado, si las personas evalúan su riesgo por la facilidad con que pueden recordar varios peligros, se preocuparán especialmente por los peligros a los que están expuestos en los medios de comunicación, y no tanto por los peligros que reciben menos atención, incluso si son tanto o más letales. Por este motivo tendemos a creer que es más probable morir en un accidente que de una enfermedad, debido a que el choque brutal de dos vehículos en un puente sobre un precipicio recibe mayor cobertura mediática que la muerte por asma, a pesar de que mueren 17 veces más personas por enfermedad que por accidente. Pero claro, todos los días vemos noticias de accidentes mientras que solo nos enteramos de una muerte por asma si acaece a un amigo o familiar. Más aún, algunos investigadores afirman que para que esta heurística funcione el suceso ni siquiera tiene que haber ocurrido realmente. Puede ser pura ficción: tan solo basta con que lo hayamos visto en una película o serie. Y, por supuesto, los medios audiovisuales son más vívidos que los escritos (¡y salen más caras humanas!). Con el tiempo, uno olvida dónde vio un suceso, si en el cine o en el telediario; la fuente de la información va difuminándose y sólo sobrevive el ejemplo en sí mismo, real o ficticio. ¡Como para fiarse de la disponibilidad de un ejemplo! En palabras de Daniel Kahneman: El mundo que imaginamos no es una réplica precisa de la realidad. Nuestras expectativas sobre la frecuencia de los acontecimientos están distorsionadas por la prevalencia y la intensidad emocional de los mensajes que nos llegan. Cómo sobrevivir a la heurística de disponibilidad en la ciberseguridad El primer paso para combatir un sesgo es conocer su existencia. Si has llegado hasta aquí, ya tendrás una idea clara de cómo funciona nuestra heurística de disponibilidad. A partir de ahora, ¿qué puedes hacer? Como ya sabes, bajo la influencia de la heurística de disponibilidad, los usuarios tienden a sobrestimar la probabilidad de eventos vívidos y sorprendentes y se centrarán en la información fácil de recordar. Como responsable de seguridad puedes explotar este efecto proporcionando a los usuarios historias sencillas y fáciles de recordar en lugar de citar información y datos estadísticos: por ejemplo, compartiendo con los usuarios historias sobre cómo la exfiltración de datos de un prototipo secreto condujo a un importante caso de espionaje industrial donde se robó un dispositivo USB sin cifrar, en lugar de presentar la evidencia de que «más de la mitad de los empleados reportan haber copiado información confidencial en unidades flash USB, a pesar de que el 87% de esas compañías tenían políticas que prohibían la práctica». Haz uso de la repetición: cuando más repitas un mismo mensaje, a poder ser con buenos ejemplos, más fácilmente acudirán esos ejemplos a la memoria de los usuarios y, con ellos, el propio mensaje. Aprovéchate del ruido mediático de incidentes de seguridad para utilizarlos como vectores de transmisión de tus mensajes de seguridad. Huye de las abstracciones y de los datos impersonales: ancla tus mensajes en el último ejemplo del que todo el mundo habla. Presta más atención a las estadísticas que al peligro del día. No bases tus juicios en pequeñas muestras de casos representativos, sino en los grandes números. Que algo salga últimamente mucho en los medios no significa que sea frecuente o de alto riesgo, solo que es noticioso, es decir, que constituye una buena historia. Tampoco confíes en tu memoria. Echa mano de los datos antes de decidir sobre la frecuencia o magnitud de un suceso. Bajo esta heurística, nos sentimos más impulsados a instalar contramedidas de seguridad después de haber sufrido un incidente que antes de sufrirlo. Consulta las estadísticas para entender qué riesgos reales os acechan. Y no esperes a ser golpeado para protegerte. Si el riesgo es alto, ignora la cobertura mediática que reciba el peligro. ¡Protégete ya! Recordamos más un incidente que la falta de incidentes. Al fin y al cabo, todo incidente es en sí mismo una historia, mientras que la ausencia de incidentes no construye una historia demasiado seductora. Por ejemplo, en los casinos suenan a todo volumen las músicas de las máquinas tragaperras cuando consiguen un jackpot; pero las que no ganan, no emiten sonido alguno. Esta asimetría te hará pensar que el jackpot es mucho más frecuente de lo que realmente es. Presta atención no solo a lo que ves, sino también a lo que no ves, es fácil recordar un virus con éxito; difícil, millones de virus que no tuvieron éxito. Rodéate de un equipo con diversas experiencias y puntos de vista. El mero hecho de la diversidad limitará la heurística de disponibilidad porque los miembros de tu equipo se desafiarán entre sí de forma natural. Utiliza tu red de contactos más allá de tu organización al tomar decisiones. Permite que otros te traigan perspectivas que simplemente no podrían existir dentro de tu organización. En otros grupos circularán otras historias que sesgarán sus juicios en otras direcciones. Así pues, la próxima vez que tomes una decisión, haz una pausa para preguntarte: «¿Estoy tomando esta decisión porque me viene a la mente un acontecimiento reciente o realmente estoy tomando en consideración otros factores que no puedo recordar tan fácilmente?». Cuanto mejor entendamos nuestros sesgos personales, mejores decisiones tomaremos.
5 de febrero de 2019

El futuro post-cuántico está a la vuelta de la esquina y aún no estamos preparados
Que cada año contemos con ordenadores más potentes con capacidad de cálculo cada vez mayor: ¿es bueno o malo? Piénsalo bien antes de responder. Depende, si la seguridad de la información de todo el planeta se basa en la complejidad computacional de ciertas funciones, que los ordenadores se vuelvan cada vez más rápidos será una muy, muy mala noticia. De hecho, la espada de Damocles se cierne sobre nuestros sistemas de cifrado de clave pública: RSA, DSA, ECDSA. Su seguridad depende de la dificultad de resolver ciertos problemas matemáticos considerados hoy en día intratables, como la factorización de grandes números enteros o el logaritmo discreto. La gran promesa de la computación cuántica es que dichos problemas matemáticos se resolverán con rapidez. ¿Está herida de muerte la criptografía? ¿Hay esperanza para el mundo? ¿Podremos seguir comunicándonos de manera segura tras los primeros ordenadores cuánticos? Vayamos por partes. ¿Qué queremos decir cuando afirmamos que un ordenador cuántico es más rápido que uno clásico? En las ciencias de la computación se busca encontrar el algoritmo más eficiente (es decir, el más rápido) para resolver un problema computacional dado. Con el fin de comparar la eficiencia de distintos algoritmos, se necesitan mecanismos para clasificar los problemas computacionales de acuerdo con los recursos necesarios para resolverlos. Esta clasificación debe poder medir la dificultad intrínseca del problema, con independencia de cualquier modelo computacional particular. Los recursos a medir pueden incluir tiempo, espacio de almacenamiento, número de procesadores, etc. Normalmente el enfoque principal es el tiempo y, a veces, el espacio. Por desgracia, suele ser difícil predecir el tiempo de ejecución exacto de un algoritmo ante cualquier tipo de entrada. En tales situaciones, este tiempo se aproxima. Se estudia cómo aumenta el tiempo de ejecución del algoritmo a medida que aumenta sin límite el tamaño de la entrada. Para representar estos tiempos de ejecución y facilitar su comparación, se suele utilizar la notación O grande: O(f(n)). Esta notación asintótica viene a decirnos que, para n suficientemente grande, el tiempo de ejecución crece como máximo al ritmo de la función f(n) multiplicada a lo sumo por una constante, aunque por supuesto puede crecer más lentamente. La función f(n) representa el caso peor. Para hacernos una idea más clara de eficiencia, la siguiente lista de funciones en notación asintótica está ordenada desde las que crecen más lentamente hasta las que crecen más rápidamente: El secreto de la velocidad de los futuros ordenadores cuánticos residirá en los algoritmos cuánticos, capaces de sacar partido a la superposición de los qubits. Como queda dicho, tanto en algoritmos clásicos como cuánticos, el tiempo de ejecución se mide por el número de operaciones elementales usadas por un algoritmo. En el caso de la computación cuántica, esta eficiencia puede medirse usando el modelo de circuito cuántico. Un circuito cuántico es una secuencia de operaciones cuánticas elementales llamadas puertas cuánticas, cada una aplicada a un pequeño número de qubits. La némesis de la criptografía es el famoso algoritmo de Shor: el algoritmo cuántico exponencialmente más rápido a la hora de calcular logaritmos discretos y factorizar números enteros y, por tanto, capaz de romper RSA, DSA y ECDSA. En el problema de la factorización, dado un entero n = p × q para algunos números primos p y q, la tarea del criptoanalista consiste en determinar p y q. El mejor algoritmo clásico conocido para factorizar enteros mayores de 100 dígitos es la criba general del cuerpo de números, que se ejecuta en el tiempo exp(O(ln n)1/3(ln ln n)2/3)). El algoritmo cuántico de Shor resuelve este problema a velocidad sustancialmente más rápida: en el tiempo O((log n)3). Se habla mucho también del algoritmo de Grover, capaz de agilizar las búsquedas en secuencias de datos no ordenadas de n elementos. En efecto, uno de los problemas más básicos en informática es la búsqueda no estructurada. Este problema se puede formalizar de la siguiente manera: dada la capacidad de evaluar una función f: {0, 1}n → {0, 1}, encuentra x tal que f(x) = 1, si tal x existe; de lo contrario, devuelve «no se encuentra». Es fácil ver que, sin información previa sobre f, cualquier algoritmo clásico que resuelva el problema de búsqueda no estructurada con certeza debe evaluar f un total de N = 2n veces en el peor de los casos. Incluso si buscamos un algoritmo aleatorio que tenga éxito, digamos, con probabilidad 1/2 en el peor de los casos, entonces el número de evaluaciones requeridas es de orden N. Sin embargo, el algoritmo cuántico de Grover resuelve este problema utilizando O(N1/2) evaluaciones de f en el peor de los casos. A la vista está que no es tan espectacularmente rápido como el algoritmo de Shor ni supone una amenaza tan seria, ya que se puede contrarrestar sin más que doblar la longitud de la clave. Hoy por hoy, no parece haber más algoritmos en el arsenal del criptoanalista cuántico. Así que, veamos cómo Shor y Grover afectarían a la criptografía presente si pudieran ejecutarse ya. ¿Qué pasaría de verdad si tuviéramos hoy un ordenador cuántico superpotente? En la entrada anterior vimos que se estima un mínimo de 10 años antes de que puedan construirse los primeros ordenadores cuánticos con corrección de errores y miles de qubits lógicos. ¿En qué estado quedaría la criptografía clásica ante ataques cuánticos? Criptografía de clave asimétrica Para poner los datos en contexto, romper una clave RSA de 1.024 bits exigiría un ordenador cuántico de unos 2.300 qubits lógicos y menos de 4 horas de tiempo de cómputo. El asunto es tan serio que el Instituto Nacional de Estándares y Tecnología estadounidense (NIST) ha lanzado el proyecto Post-Quantum Cryptography para buscar reemplazos a los algoritmos actuales. Se espera que el proceso de selección de los candidatos haya finalizado en 5 ó 6 años. Criptografía de clave simétrica El estándar actual para cifrado simétrico es el algoritmo AES-GCM (Advanced Encryption Standard-Galois/Counter Mode), que utiliza un tamaño de clave variable: 128, 192 ó 256 bits. Por ejemplo, para una clave de 128 bits, un ataque de fuerza bruta exige probar todos los posibles valores de la clave o, lo que es lo mismo, 2128 combinaciones. El algoritmo de Grover es capaz de acelerar esta búsqueda de forma cuadrática, es decir, necesitaría 264 operaciones. Ejecutarlo en un ordenador cuántico requeriría unos 3.000 qubits y más de 1012 años, un tiempo extremadamente largo. Incluso aunque existiera ya tal ordenador cuántico, la solución sería tan sencilla como doblar el tamaño de clave, algo que podría hacerse de forma práctica en cualquier momento. Por supuesto, alguien podría descubrir un algoritmo cuántico mucho más eficiente que el algoritmo de Grover, en cuyo caso AES-GCM habría de ser reemplazado. Hash Las funciones hash se usan en todo tipo de aplicaciones: hashes de contraseñas en bases de datos, problemas matemáticos para minar bitcoins, construcción de estructuras de datos como los árboles de Merkle, resúmenes de mensajes para firmar digitalmente, funciones de derivación de claves basadas en contraseñas, etc. El algoritmo más usado en estos momentos sigue siendo SHA256. No se espera que los algoritmos de hashing actuales se vean afectados por la computación cuántica, ya que se considera que el algoritmo de Grover no puede romper un hash como SHA256. Sin embargo, el hashing de contraseñas sí que corre mayor peligro debido al menor espacio de contraseñas. Por ejemplo, considerando un alfabeto de 100 símbolos, el conjunto de todas las posibles contraseñas de 10 caracteres de longitud tiene un tamaño de tan solo 10010 ≈ 266. Mediante Grover, el espacio de búsqueda se reduce a 233, lo que le llevaría a un hipotético ordenador cuántico unos pocos segundos. La sombra de la amenaza cuántica es otro argumento más para migrar hacia alternativas a las contraseñas, como algunos de los proyectos en los que estamos trabajando en el Laboratorio de Innovación de ElevenPaths: CapaciCard, SmartPattern, PulseID; o como Mobile Connect. Otra aplicación muy extendida de los hashes son los sistemas de prueba de trabajo, utilizados por criptomonedas como Bitcoin o Ethereum. Para validar un bloque de la cadena, los mineros deben resolver un puzle matemático que implica calcular millones de hashes. Por fortuna para Blockchain, un ordenador cuántico tardaría más de 10 minutos en resolver los retos usados en la actualidad, así que las criptomonedas seguirán a salvo, al menos por ese lado (no por el lado de la criptografía de curvas elípticas). Tabla resumen de tiempo estimado para romper criptografía clásica por medio de algoritmos cuánticos, así como contramedidas posibles (tomada de Quantum Computing: Progress and Prospects) El largo y tortuoso sendero de las migraciones criptográficas Puede decirse que la criptografía moderna nace a mediados de los 70, con algoritmos como DES, para cifrado simétrico, y Diffie-Hellman, para establecimiento de claves. Desde entonces, solo ha habido un puñado de transiciones de un algoritmo ampliamente implantado a otro. Algunas de estas migraciones han sido: desde DES y Triple-DES hasta AES; de MD5 y SHA-1 a la familia SHA-2; desde el transporte de claves RSA y el campo finito Diffie-Hellman hasta la curva elíptica de intercambio de claves Diffie-Hellman; y de los certificados RSA y DSA a los certificados ECDSA. Algunas de estas transiciones han salido bie. A AES se lo ve casi en todas partes y los protocolos de comunicación modernos utilizan predominantemente el intercambio de claves ECDH. Ahora bien, las transiciones que involucran infraestructura de clave pública han obtenido un éxito desigual: los proveedores de navegadores y las Autoridades de Certificación han tenido un largo período de transición de SHA-1 a SHA-2 en certificados, con repetidos retrasos en los plazos, la transición a los certificados de curva elíptica ha sido aún más lenta y, aun así, hoy la gran mayoría de los certificados emitidos para la web siguen utilizando RSA. En el medio plazo, es probable que nos veamos forzados a otra transición, hacia la criptografía de clave pública post-cuántica. Hay vida criptográfica más allá de RSA y de DSA y de ECDSA Antes de nada, es importante matizar que una cosa es «el fin de RSA, DSA y ECDSA» y otra bien distinta es «el fin de la criptografía». Hay vida criptográfica más allá de RSA, DSA y ECDSA. Ya desde mediados de los 80 existen algoritmos criptográficos basados en la dificultad de resolver problemas matemáticos distintos de la factorización de enteros y del logaritmo discreto. Las tres alternativas mejor estudiadas son: Criptografía basada en Hashes: como su nombre indica, utilizan funciones hash seguras, que resisten a los algoritmos cuánticos. Su desventaja es que generan firmas relativamente largas, lo que limita sus escenarios de uso. Leighton-Micali Signature Scheme (LMSS) constituye uno de los candidatos más sólidos para reemplazar a RSA y ECDSA. Criptografía basada en códigos: la teoría de códigos es una especialidad matemática que trata de las leyes de la codificación de la información. Algunos sistemas de codificación son muy difíciles de decodificar, llegando a requerir tiempo exponencial, incluso para un ordenador cuántico. El criptosistema mejor estudiado hasta la fecha es el de McEliece, otro prometedor candidato para intercambio de claves. Criptografía basada en celosías: posiblemente se trate del campo más activo de investigación en criptografía post-cuántica. Una celosía es un conjunto discreto de puntos en el espacio con la propiedad de que la suma de dos puntos de la celosía está también en la celosía. Un problema difícil es encontrar el vector más corto en una celosía dada. Todos los algoritmos clásicos requieren para su resolución un tiempo que crece exponencialmente con el tamaño de la celosía y se cree que lo mismo ocurrirá con los algoritmos cuánticos. Actualmente existen numerosos criptosistemas basados en el Problema del Vector más Corto. Por consiguiente, la gran dificultad no radica en la falta de alternativas. El doloroso problema será la transición a tiempo hacia alguna de estas alternativas anteriores: En primer lugar, los algoritmos post-cuánticos deben ser seleccionados y estandarizados por organismos como el NIST. Después, el estándar debe incorporarse a las bibliotecas criptográficas en uso por los lenguajes de programación más populares, por los chips criptográficos y por los módulos hardware. A continuación, deberán integrarse dentro de los estándares y protocolos criptográficos, tales como PKCS#1, TLS, IPSec, etc. Luego, estos estándares y protocolos deberán ser incluidos por todos los vendedores en sus productos: desde los fabricantes de hardware, hasta los de software. Una vez actualizados todos los productos software y hardware, será necesario reemitir todos los certificados, recifrar toda la información almacenada, refirmar y redistribuir todo el código, destruir todas las copias antiguas, etc. ¿Cuánto puede llevar todo este proceso? A juzgar por migraciones anteriores, como la de SHA-1 a SHA-2, y teniendo en cuenta la complejidad adicional, no menos de 20 años. ¿Y para cuándo se esperan los primeros ordenadores cuánticos capaces de atacar RSA, DSA y ECDSA? No antes de 15 años. Así está el panorama. Esperemos que el proceso de transición se acelere. Nadie sabe a ciencia cierta cuán lejos quedan los ordenadores cuánticos. Pero, por si acaso, más nos vale que nos pillen preparados.
29 de enero de 2019

No, 2019 no será el año en el que los ordenadores cuánticos acaben con la criptografía que todos usamos
¿Qué pasaría si hoy mismo entrara en funcionamiento un ordenador cuántico de varios miles de qubits lógicos y sin errores? Las infraestructuras de clave pública colapsarían. Los secretos del mundo quedarían al descubierto. Reinaría el caos. ¿Cuán lejos o cerca queda ese día? ¿Cómo afectaría a nuestra criptografía? ¿Qué hacer para proteger nuestra información confidencial ante el inminente advenimiento de los ordenadores cuánticos? Científicos, políticos y empresarios en todo el mundo están preocupados por estos mismos interrogantes. El pasado mes de diciembre, el departamento de publicaciones de las Academias de Ciencias, Ingeniería y Medicina de EE. UU. sacó a la luz un primer borrador del documento Quantum Computing: Progress and Prospects. Este documento de más de 200 páginas reúne el consenso de un Comité para la Valoración de la Viabilidad e Implicaciones de la Computación Cuántica, formado por varios científicos y expertos en el campo. El informe proporciona una prospección juiciosa y fundamentada en la evidencia científica sobre qué avances esperar en los próximos años, qué amenazas reales representarán y qué estrategia será necesario seguir para estar preparados ante la indudable llegada del primer ordenador cuántico plenamente operativo con miles de qubits. La pregunta no es si habrá o no ordenadores cuánticos. La pregunta es cuándo llegarán y si nos pillarán con los pantalones bajados. En este artículo resumo las conclusiones más relevantes a las que ha llegado el comité de expertos. Por supuesto, te animo a que leas el informe completo. Los 10 hallazgos más relevantes sobre el futuro inmediato de la Computación Cuántica Hallazgo clave 1: Dados el estado actual de la computación cuántica y su ritmo actual de avance, es altamente improbable que se construya en la próxima década un ordenador cuántico capaz de comprometer RSA 2048 o criptosistemas de cifrado de clave pública comparables basados en el logaritmo discreto. La computación clásica trabaja con bits, mientras que la cuántica trabaja con qubits. Un bit clásico posee un valor bien definido, "1" o "0", mientras que un qubit se encuentra en una superposición cuántica de estados, es decir, en una combinación de "1» y "0" a la vez. Para conseguirlo, todos los qubits necesitan estar "entrelazados", aislados del entorno exterior y bajo un control extraordinariamente preciso. ¡Todo un reto de ingeniería! La gestión del ruido resulta muy diferente en ambos modelos computacionales. Dado que un bit clásico toma los valores "1" o "0", es muy fácil eliminar el ruido que pueda producirse en las puertas lógicas. Sin embargo, como un qubit puede estar en una combinación de "1" y "0", es muy difícil eliminar el ruido de los circuitos físicos. De manera que uno de los mayores retos de diseño es la tasa de errores: en 2018, los errores en las operaciones de 2 qubits en sistemas de 5 ó más qubits son superiores al 1 %. Por consiguiente, se necesitan algoritmos Cuánticos de Corrección de Errores (Quantum Error Correction, QEC) para emular un ordenador cuántico libre de ruido (con errores totalmente corregidos). Sin QEC, un algoritmo como el de Shor para reventar RSA no podría llegar a funcionar. El problema de la QEC es que requiere: el aumento del número de qubits físicos para emular qubits más robustos y estables, llamados "qubits lógicos" y... el aumento del número de operaciones primitivas sobre los qubits físicos para emular operaciones cuánticas sobre estos qubits lógicos. En el corto plazo, la QEC es demasiado costosa, así que sólo veremos ordenadores "ruidosos". Por otro lado, no es nada sencillo convertir un gran volumen de datos clásicos en un estado cuántico de los qubits. En los problemas que requieran grandes entradas de datos, el tiempo requerido en crear la entrada cuántica bien podría superar la complejidad computacional del propio algoritmo, reduciendo o incluso eliminando la ventaja cuántica. Otro desafío al que se enfrentan es la depuración de código. La depuración en ordenadores clásicos suele basarse en examinar la memoria y en leer los estados intermedios. Ahora bien, un estado cuántico no puede copiarse (por el teorema de no clonación) para su examen. ¿Y si se leyera directamente? Entonces colapsaría a un valor concreto de bits clásicos, lo que detendría la operación de cálculo. Vamos, que aún queda mucho camino por delante para desarrollar nuevos métodos de depuración. En resumen, para construir un ordenador cuántico capaz de aplicar con éxito el algoritmo de Shor a una clave pública RSA de 2048 bits se necesita una máquina que sea cinco órdenes de magnitud más grande que las actuales, con tasas de error dos órdenes de magnitud menores y un entorno de desarrollo de software que dé soporte a estas máquinas. Hallazgo clave 2: si los ordenadores cuánticos no tienen éxito comercial a corto plazo, la financiación del gobierno podría ser esencial para evitar una disminución significativa de la investigación y del desarrollo de la computación cuántica. Desde que la computación cuántica está en boca de todos, algunas de las empresas más poderosas del mundo se han embarcado en una carrera hacia el primer ordenador cuántico de gran potencia. Pero este entusiasmo podría enfriarse si no se encuentran aplicaciones comerciales de las tecnologías en desarrollo (más allá de romper RSA en el futuro). Si se producen progresos disruptivos que posibiliten nuevos ordenadores más avanzados, los retornos financieros esperados atraerán a más grandes empresas y a más investigación en el campo. Sin embargo, si las primeras aplicaciones viables requieren un número muy elevado de qubits, solamente se mantendrá el interés si se cuenta con financiación pública. Se correría el riesgo de caer en un "valle de la muerte" y de la fuga del talento hacia otros campos más prometedores, tanto dentro del mundo académico como empresarial. Hallazgo clave 3: la investigación y el desarrollo de aplicaciones comerciales prácticas de ordenadores cuánticos de escala intermedia ruidosa (por sus siglas en inglés de noisy intermediate stage quantum o NISQ) es un problema de urgencia inmediata para el campo. Los resultados de este trabajo tendrán un profundo impacto en el ritmo de desarrollo de los ordenadores cuánticos a gran escala y en el tamaño y la solidez de un mercado comercial para los ordenadores cuánticos. Dado el coste de la QEC, los primeros ordenadores cuánticos en el corto plazo tendrán errores: serán ordenadores cuánticos de escala intermedia ruidosa (NISQ). Hoy en día no existen aplicaciones para ordenadores NISQ. Mientras no se desarrollen aplicaciones comerciales para ordenadores NISQ, no se pondrá en marcha el ciclo virtuoso de inversión. Hallazgo clave 4: dada la información disponible para el comité, aún es demasiado pronto para poder predecir el horizonte temporal de un ordenador cuántico escalable. En cambio, se puede seguir el progreso a corto plazo si se monitoriza cuál es la tasa de escalado de qubits físicos a la vez que se conserva una tasa de error promedio constante. Este progreso puede evaluarse mediante una comparativa aleatoria. A largo plazo se necesita monitorizar el número efectivo de qubits lógicos (con error corregido) que representa un sistema. El comité sugiere usar como métrica para medir el progreso en esta carrera: las tasas de errores en operaciones de 1-qubit y de 2-qubit, la conectividad interqubit y el número de qubits contenidos en un módulo hardware. Hallazgo clave 5: El estado del arte sería mucho más fácil de monitorizar si la comunidad de investigación adoptara convenciones para informes claras con el fin de permitir la comparación entre dispositivos y la traducción en métricas como las que se proponen en este informe. Un conjunto de aplicaciones de evaluación comparativa que permitieran la comparación entre diferentes máquinas ayudaría a impulsar mejoras en la eficiencia del software cuántico y en la arquitectura del hardware cuántico subyacente. El comité propone precisamente el uso de varias métricas y de varios hitos que permitan seguir el desarrollo de la computación cuántica. Estos hitos están recogidos en la siguiente figura. Hallazgo clave 6: la computación cuántica resulta valiosa para impulsar la investigación fundamental que ayudará a mejorar nuestra comprensión del universo. Al igual que con toda investigación básica, los descubrimientos en este campo podrían conducir a nuevos conocimientos y aplicaciones transformadoras. El trabajo de diseño de nuevos algoritmos cuánticos puede ayudar en el progreso de la investigación básica en computación. Es plausible esperar que la investigación en computación cuántica conducirá también al progreso de otras disciplinas, como física, química, bioquímica, ciencia de los materiales, etc. Estos avances en investigación básica podrían en el futuro revertir en nuevos avances tecnológicos. Hallazgo clave 7: Aunque aún no hay certeza de la viabilidad de un ordenador cuántico a gran escala, es probable que sean enormes los beneficios del esfuerzo para desarrollar un ordenador cuántico práctico y, a corto plazo, pueden continuar extendiéndose a otras aplicaciones de tecnología de información cuántica, como la detección basada en qubit. Se cree que los hallazgos en computación e información cuántica mejorarán otras tecnologías cuánticas. Hallazgo clave 8: si bien Estados Unidos ha desempeñado históricamente un papel importante en el desarrollo de tecnologías cuánticas, la ciencia y tecnología de la información cuántica es ahora un campo global. Dado el gran compromiso de recursos que varias naciones no estadounidenses han hecho recientemente, el apoyo continuo de los Estados Unidos es crítico si Estados Unidos quiere mantener su posición de liderazgo. Lo cierto es que EE. UU. está perdiendo este liderazgo mundial, como se aprecia en la siguiente figura, a juzgar por la inversión en I+D. Hallazgo clave 9: un ecosistema abierto que permita la polinización cruzada de ideas y grupos acelerará el rápido avance de la tecnología. Esta carrera por ser los primeros en crear el ordenador cuántico podría conducir a la opacidad en la publicación de resultados en revistas y foros científicos. Se requiere un equilibrio entre la natural protección de la propiedad intelectual y el flujo abierto de información para asegurar que el campo sigue desarrollándose. Resultado clave 10: incluso si aún quedara una década para el primer ordenador cuántico capaz de descifrar los cifrados criptográficos actuales, el riesgo de tal máquina es tan alto, y el marco de tiempo para la transición a un nuevo protocolo de seguridad es tan largo e incierto, que la priorización del desarrollo, de la estandarización y de la implementación de la criptografía post-cuántica es fundamental para minimizar la posibilidad de un posible desastre de seguridad y de privacidad. Un ordenador cuántico con alrededor de 2.500 qubits lógicos podría romper el cifrado RSA 2048 en unas horas. Los criptógrafos llevan trabajando desde hace décadas en algoritmos capaces de (supuestamente) resistir los algoritmos cuánticos. El problema no es tanto carecer de alternativas a RSA y a las curvas elípticas, sino más bien hacer la transición desde los viejos algoritmos a los nuevos. Eso sin mencionar qué pasaría con los secretos pensados para permanecer confidenciales durante muchos años. Dado que esta transición puede necesitar décadas, es prioritario empezarla ya, antes de que la amenaza se materialice. En una próxima entrada explicaremos de qué manera la computación cuántica afecta a la criptografía actual, concretamente, qué pasaría con RSA, con las curvas elípticas, con los certificados digitales, con Bitcoin y con los hashes; y veremos también qué alternativas criptográficas se están barajando para la era post-cuántica.
8 de enero de 2019

El Sesgo de Confirmación: buscamos la información que nos reasegura en nuestras decisiones descartando la evidencia en contra
Imagínate que estás en un laboratorio durante un experimento. Te piden que examines esta serie numérica: 2, 4, 6 La serie obedece una cierta regla. ¿Cuál crees que es? Puedes elegir más secuencias de tres números, decírselas al experimentador y te confirmará si obedecen o no la regla. Puedes proponerle tantas nuevas secuencias de tres números como quieras. En cuanto estés seguro, tienes que anunciarle la regla y él te dirá si la has adivinado o no. Pues bien. ¿Cuál es la primera secuencia de tres números que propondrías para deducir cuál es la regla que obedece la secuencia 2, 4, 6? Antes de seguir leyendo, por favor, piénsalo bien. ¿Qué tres números usarías? Piénsalo un poco más..., no leas aún la respuesta... Estoy seguro de que en cuanto has visto la secuencia del problema, 2, 4, 6, la primera regla que te ha venido a la cabeza es "números pares que crecen de dos en dos". He realizado este experimento docenas de veces con científicos de todas las disciplinas y también con profesionales de la seguridad. Hasta ahora, en el 100 % de los casos, me han planteado secuencias como 8, 10, 12. Es decir, me plantean tres números pares consecutivos con el objetivo de confirmar su hipótesis. ¿Me habrías planteado tú una secuencia similar? Yo les digo que, efectivamente, esas secuencias como 8, 10, 12 ó 10, 12, 14 ó similares cumplen la regla. Entonces me proponen secuencias como 100, 102, 104 ó parecidas. ¿Tú también lo habrías hecho? Y después de plantear dos o tres secuencias semejantes, quedan completamente convencidos y anuncian: "La regla es números pares que crecen de dos en dos". Naturalmente, ¡esa no es la regla! Entonces cambian de regla y me plantean series como 11, 13, 15. Y les digo que cumple la regla. Alentados, proponen 101, 103, 105. También cumple. Y entonces anuncian: "La regla es números que crecen de dos en dos". ¡Tampoco es la regla! Hay quien entonces plantea 5, 3, 1. No la cumple. Y así, poco a poco, finalmente llegan a la verdadera regla. ¿Tú la has intuido ya? La regla es cualquier serie de números en orden ascendente, sin importar la diferencia entre cada uno y el siguiente, como por ejemplo 1, 100, 1000. ¿Qué está pasando aquí? ¿Por qué resulta tan difícil encontrar una regla tan fácil? Por la sencilla razón de que la gente trata de demostrar que su hipótesis es correcta: eligen ejemplos que confirman su hipótesis en lugar de elegir aquellos que la invalidan. La realidad es que ninguna hipótesis puede ser completamente demostrada. Basta un contraejemplo para tirarla por tierra. El primer cisne negro descubierto en Australia puso fin a la hipótesis sostenida durante siglos en Europa de que "todos los cisnes son blancos". En Ciencia ocurre continuamente. Nuevos descubrimientos desplazan viejas teorías echando por tierra hipótesis sostenidas en ocasiones durante siglos. Resumiendo: si quieres demostrar que una hipótesis es probablemente cierta, tienes que fracasar en tus intentos de demostrar que es falsa. O sea, que los experimentos que diseñes no tienen que ir orientados a probar tu hipótesis sino a invalidarla. Y aquí es donde la mayoría de la gente, incluso científicos, fracasan. Porque nos aferramos con uñas y dientes a nuestras hipótesis, nos apegamos a nuestras ideas, buscamos confirmar nuestras creencias. Volviendo al experimente de la secuencia. Si tu hipótesis inicial es "números pares que crecen de dos en dos", ¿qué series de números tendrías que proponer? En lugar de aquellas que la confirman, como 10, 12, 14, aquellas que la contradicen, como 9, 15, 29. ¿Lo ves? Esta secuencia incluye números impares que no ascienden de dos en dos. Si cumple la regla, tu hipótesis queda completamente descartada. Así sí avanzas hacia la respuesta verdadera. De la otra manera, por muchas secuencias que propongas que confirmen tu hipótesis, sólo te enquistarás en tu error. Esta es la esencia del método científico: tratas de invalidar tus teorías, no de confirmarlas. Y esto, amigos, para un ser humano es una tarea titánica. Si piensas que algo es verdadero, no intentes confirmarlo, trata de refutarlo En el siguiente vídeo de Veritasium puedes seguir a varias personas durante el experimento de los números 2-4-8: ¿Te das cuenta de cómo perseveran en su hipótesis? Por mucho que sus propuestas iniciales para la regla sean rechazadas, siguen planteando secuencias de tres números que son variantes de su hipótesis inicial. Y siempre, siempre, siempre, proponen secuencias para confirmar la hipótesis, no para invalidarla. Este experimento fue diseñado y sus resultados publicados inicialmente por el psicólogo Peter Wason en los años 60. De hecho, fue él quien acuñó el término "sesgo de confirmación" para referirse a nuestra tendencia a favorecer la información que confirma nuestras hipótesis, ideas y creencias personales, sin importar si son verdaderas o falsas. Por desgracia, aunque te expliquen que estás sometido a este sesgo de confirmación, seguirás buscando la información que confirme tus hipótesis y rechazando la que la refute. Estar sobre aviso no te libera del sesgo. ¿No te lo crees? Aquí tienes otro desafío de razonamiento lógico, creado por el propio Wason: Encima de una mesa hay cuatro cartas, dos muestran una letra cada una y otras dos muestran un número cada una: A D 3 7 Cada carta tiene un número en una cara y una letra en la otra. El desafío consiste en decidir qué cartas habría que voltear para verificar la siguiente regla: Cualquier carta con una A en una cara tiene un 3 en la otra En este caso, no te daré la solución. Te invito a que dejes tu respuesta en los comentarios. Solo te doy una pista: no trates de validar tu hipótesis, trata de refutarla. Buscamos la evidencia que confirma nuestra postura Lo que vienen a mostrar estos experimentos es que una vez que te posicionas con respecto a un tema, es más probable que busques o des crédito a la evidencia que apoya tu postura, antes que a la evidencia que la desacredite. Y no vayas a pensar que funcionamos así solo para ejercicios de salón o para elaborar teorías científicas. Sucumbimos a este sesgo en nuestro día a día, a todas horas y en todo tipo de tareas e interacciones con otras personas. Cuanto más te aferras a una hipótesis, más difícil te resultará considerar otras contradictorias. La explicación es bien sencilla. Evaluar información es una actividad intelectualmente costosa. Nuestro cerebro es perezoso y prefiere los atajos de pensamiento. Así ahorra tiempo al tomar decisiones, especialmente bajo presión o ante una gran incertidumbre. Al final priorizamos la información que nos permite llegar rápidamente a la conclusión que favorecemos. Esta tendencia a buscar información confirmatoria puede conducir a todo tipo de falsas creencias y a malas decisiones, ya que siempre podrás encontrar evidencia que confirme (casi) cualquier idea. ¿Fumas y quieres creer que fumar no es tan malo para la salud? Seguro que tienes un pariente que murió a los 98 años fumando un cartón al día. ¿Eres sedentario y te resistes a creer que hacer deporte sea tan sano? Seguro que tienes otro pariente que se cuidaba todo el día y se murió de un infarto a los 38. ¿Usas la misma contraseña para todos los servicios y no crees que necesites cambiarlas? Seguro que llevas años así y nunca te ha pasado nada, así que, ¿por qué habría de pasarte mañana? Pero ya te habrás dado cuenta de que la existencia de evidencia a favor de una afirmación no basta para llegar a una conclusión firme, puesto que podría existir otra evidencia en su contra: gente que ha muerto de cáncer de pulmón como consecuencia directa del tabaco, gente que ha muerto de infarto como consecuencia de riesgo cardiovascular acumulado tras años de sedentarismo y obesidad o gente a la que le hackearon una cuenta porque obtuvieron la contraseña (idéntica) de otra. El mayor riesgo del sesgo de confirmación es que si buscas un único tipo de evidencia, con toda seguridad, la encontrarás. Necesitas buscar ambos tipos de evidencia: también la que refuta tu postura. No estás tan abierto al cambio como te gusta creer Según el profesor Stuart Sutherland, autor de Irracionalidad: El enemigo interior, cambiar nuestras ideas e hipótesis sobre la realidad resulta sumamente difícil por varios motivos: Evitamos de forma consistente exponernos a evidencia que pueda refutar nuestras hipótesis. Si recibimos evidencia contraria a nuestras creencias, tendemos a descartarla. La existencia de una creencia previa distorsiona nuestra interpretación de nueva evidencia haciéndola consistente con dicha creencia. Recordamos antes y mejor lo que está alineado con nuestras creencias. Queremos proteger nuestra autoestima, lo que nos lleva a encerrarnos en la postura adoptada para no dar el brazo a torcer. El sesgo de confirmación es omnipresente en la vida del profesional de la ciberseguridad. Lo podemos ver a diario: Si eres un tecnólogo, creerás que la tecnología es la solución a tus problemas de seguridad. Si la tecnología falla, echarás la culpa a las personas que la gestionan o usan o a los procesos implantados. Buscarás y destacarás sus éxitos e ignorarás y subestimarás sus fracasos. Inflarás así, consciente o inconscientemente, su efectividad real. En una auditoría de seguridad es muy común saltar a conclusiones nada más reunir un par de evidencias. Has encontrado algo y rápidamente te creas una explicación. Una vez formada una opinión al poco de empezar a investigar la seguridad de un sistema, pasarás más tiempo buscando evidencias que confirmen tu primera impresión que buscando las que la contradigan. Si tienes que contratar un profesional de seguridad para tu organización y crees que los que poseen certificaciones tipo CISSP, CEH, CISM, etc., están mejor preparados, entonces encontrarás todo tipo de evidencias para apoyar tu creencia. Si eres el responsable de la seguridad de la información de una empresa, en el caso en que el CEO crea en la importancia de invertir en seguridad, se enfocará en los logros de tu departamento; si cree que es un gasto innecesario, se centrará en tus errores y brechas, ignorando los éxitos pasados. Los expertos de seguridad de la organización o los contratados externamente son eso: expertos. Y es muy humano que quieran aparecer como tales ante los demás. Esta aureola de "experto" hace que todos confíen en sus juicios iniciales, lo que viene a hacer innecesario buscar soluciones alternativas. Después de todo, si el experto ha dicho que esta es la solución, ¿para qué buscar otras? El propio experto tenderá a descartar otras propuestas si siente amenazado su papel de experto. Ahondando en esta línea, no hay nada más peligroso que juntar en una sala a un grupo de expertos, porque entonces casi con total seguridad aparecerá lo que se conoce como "pensamiento grupal": cada miembro del grupo intenta conformar su opinión a la que cree que es el consenso del grupo, hasta que el grupo se pone de acuerdo en una determinada acción que cada miembro individualmente considera desaconsejable. Cuando todos piensan lo mismo, es que nadie está pensando. Relacionada con la anterior está la cuestión del "falso consenso". A veces invitamos a reuniones para tomar decisiones a personas que sabemos que opinarán como nosotros y que comparten nuestras ideas. Guía de supervivencia para el profesional de la ciberseguridad Te guste o no, tú como yo estamos sujetos al sesgo de confirmación. Aquí tienes una guía a modo de checklist que puedes usar antes de tomar decisiones importantes. Me he apoyado en algunos consejos del libro Irracionalidad de Stuart Sutherland. He buscado activamente evidencia que refute mis creencias. He buscado más de una hipótesis, de manera que he podido barajar un mínimo de dos hipótesis antagonistas. He dedicado tiempo y atención a considerar con total seriedad la información que ha entrado en conflicto con mis creencias en lugar de descartarla inmediatamente. No he distorsionado la nueva evidencia que he ido acumulando tras mi hipótesis inicial: he considerado cuidadosamente si puede interpretarse como refutación de mis creencias en lugar de como su confirmación. No me he fiado de mi memoria: soy consciente de que recordamos con mayor facilidad lo que encaja con nuestra manera de ver las cosas. Por eso he consultado con otras personas y con datos y notas de sucesos pasados. He contado con un abogado del diablo que ha cuestionado todas y cada una de mis hipótesis. Como explicamos en un artículo previo de esta serie, los sesgos son una característica inherente del pensamiento humano. Conocerlos es el primer paso para evitarlos. En concreto, el sesgo de confirmación puede llegar a ser un problema en decisiones complejas. Usa este checklist en decisiones importantes y probablemente evitarás el sesgo de confirmación. Y recuerda que cambiar de parecer a la luz de nueva evidencia es un signo de fortaleza y no de debilidad.
10 de diciembre de 2018

El Efecto Marco: así como te presenten la información, así tomarás la decisión
Has recibido una alerta de ciberinteligencia. Se avecina un terrible ciberataque de grandes dimensiones. Eres responsable en tu organización de la protección de 600 puestos de trabajo. No tienes mucho tiempo. Puedes elegir implantar uno de entre dos programas de seguridad. ¡Necesitas tomar la decisión ya! Si eliges el programa A, podrás proteger 200 puestos de trabajo. Si eliges el programa B, existe una probabilidad de un tercio (1/3) de proteger los 600 puestos de trabajo y una probabilidad de dos tercios (2/3) de no proteger ninguno. Una cantidad sustancial de encuestados escoge el programa 1: prefieren salvar 200 puestos de trabajo sobre seguro que jugársela y no salvar ninguno. Visitemos ahora un nuevo escenario de ciberseguridad. Ante la necesidad de proteger los mismos 600 puestos de trabajo, puedes elegir entre dos nuevos programas: Si eliges el programa A’, se comprometerán 400 puestos de trabajo. Si eliges el programa B’, existe una probabilidad de un tercio (1/3) de no comprometer ningún puesto de trabajo y una probabilidad de dos tercios (2/3) de comprometer los 600 puestos de trabajo. Lee atentamente esta segunda versión. ¿Has notado que es idéntica a la primera? Al estar tan seguidas una de otra, posiblemente sí que lo hayas visto inmediatamente. Las consecuencias de A y A’ son las mismas. E igualmente ocurre para B y B’. Y, sin embargo, en el segundo escenario, la mayoría, incluso tal vez tú mismo, elige el programa B’. Este ejemplo pone de manifiesto el poder de los Marcos: el contexto de una elección afecta a la elección tomada. Cuando haces una foto de la realidad con tu smartphone, ¿es objetiva esa foto? El hecho de que lo apuntes en una dirección u otra hará que el observador contemple solamente la "ventana de realidad" que tú has elegido mostrarle. Esta ventana o "marco" no manipula necesariamente la realidad, pero la estructura de una forma sesgada. Quien observe la realidad a través de tu marco se quedará con una imagen bien distinta de la ofrecida por un marco distinto. Misma realidad, dos visiones distintas del mundo. Al igual que la fotografía puede mostrarnos distintas versiones de la "realidad objetiva ahí afuera", usamos continuamente "marcos mentales" al representarnos mentalmente la realidad. La elección consciente o inconsciente de estos marcos determinará poderosamente nuestras decisiones. Los marcos construyen la realidad que ves. Los marcos pueden crearse de formas muy variadas a la hora de plantear decisiones de seguridad: La positividad (ganancia) o negatividad (pérdida) de las opciones El orden en el que se presentan las opciones El contexto en el que se presentan las opciones El tipo de lenguaje (semántica) en el que se expresan las opciones La información adicional incluida u omitida al presentar las opciones Veámoslas de una en una. La positividad (ganancia) o negatividad (pérdida) de las opciones Este efecto fue tratado en profundidad en la entrega anterior: Eres menos racional de lo que crees cuando tomas decisiones de riesgo en condiciones inciertas. Te resumo aquí sus conclusiones: Si se enmarca la elección como una ganancia, la gente tenderá a evitar el riesgo y buscar la ganancia segura, aunque pequeña. Enmarca la elección como una pérdida, y la gente preferirá arriesgarse a una gran pérdida que perder sobre seguro, aunque sea poco. Los dos escenarios que he planteado al comienzo de este artículo son un ejemplo de este marco. Pero la vida a nuestro alrededor rebosa de ejemplos similares. ¿Cómo anunciarías un cortafuegos? Protege frente al 99,9 % de los ataques Deja pasar el 0,1 % de los ataques Obviamente, tendrás más éxito con el primer anuncio, a pesar de que ambos marcos ofrecen exactamente la misma información (lo que se conoce como «marcos puros»). Sólo cambia el foco. Por tanto, no existe en este caso un marco «correcto». Tan válido es el primero como el segundo, aunque sus efectos en la decisión tomada son predecibles. ¿Qué frase elegirías para convencer a la Dirección de invertir en tu Plan de Seguridad? Con el nuevo Plan de Seguridad ahorraremos 350.000 € el próximo año Con el nuevo Plan de Seguridad evitaremos perder 350.000 € el próximo año Siendo como somos, la segunda frase tiene mayor probabilidad de conseguir el visto bueno. El orden en el que se presentan las opciones ¿Nunca te has preguntado durante un evento qué era mejor, si ser el primero en salir o el último? En ocasiones, la información presentada en primer lugar ejerce la mayor influencia: el efecto de primacía. En otras ocasiones, la más que más impacto tiene es la información presentada al final: efecto de recencia. Por ejemplo, tienes que seleccionar un candidato como director de seguridad. En su ficha psicológica aparece descrito como: Inteligente, Trabajador, Impulsivo, Crítico, Tozudo y Envidioso. ¿Cómo lo calificarías? Lo más probable es que los dos primeros adjetivos, Inteligente y Trabajador, condicionen la interpretación que hagas de los siguientes. En principio, son rasgos positivos y hacen que te formes una impresión inicial positiva. Crean un filtro positivo que tamizarán positivamente el resto de los adjetivos. Por ejemplo, Tozudo lo interpretarás positivamente, queriendo decir que es persistente y que no se detiene ante los obstáculos. Imagina ahora que la lista de calificativos hubiera sido: Envidioso, Tozudo, Crítico, Impulsivo, Trabajador, Inteligente. En este caso, a pesar de ser los mismos adjetivos, aunque en orden inverso, posiblemente te habrías formado una peor impresión del candidato, ya que los dos primeros rasgos, Envidioso y Tozudo, son considerados como negativos. De ahí que el filtro mental que te formes será negativo y todos los demás adjetivos los interpretarás negativamente. Por ejemplo, ahora Tozudo lo entenderás más bien como cabezón y burro, impermeable a la crítica. ¡Qué diferente interpretación en función del orden! Así pues, si estás describiendo una posible solución a un cliente o a tu jefe, el orden en el que presentes la información irá condicionando su sentimiento hacia ella. Si empiezas por lo positivo, crearás un marco inicial positivo, que hará que sean más permisivos más adelante con lo negativo. Y al revés: empieza por lo negativo y crearás un marco negativo que hará que tiendan a ver bajo una luz negativa todo lo demás. El contexto en el que se presentan las opciones Un amigo muy aficionado al buen vino te ha invitado a cenar a su casa. Pongamos que no tienes ni idea de vinos. Quieres llevarle uno. Vas a la tienda y te encuentras tres botellas: una vale 1,50 €; la segunda vale 9,50 €; la tercera vale 23,50 €. ¿Cuál compras? Si eres como la mayoría de la gente, elegirás la opción en el medio. Tendemos a evitar los extremos. Esta es la técnica utilizada cuando nos quieren "colocar" algo: enmarcarlo entre extremos. Imagina ahora que necesitas que tu jefe apruebe tu presupuesto de seguridad de 1 M€ para el año que viene. ¿Cómo aumentas la probabilidad de que lo acepte? Le presentas tres presupuestos: 500 K€, 1 M€ y 2 M€ Le presentas tres presupuestos: 250 K€, 500 K€ y 1 M€ Sin duda la opción 1 te acercará al éxito. Evita los extremos. Y cuando solo tengas una opción que proponer, inventa otras dos para situarlas a uno y otro lado de la tuya. El tipo de lenguaje (semántica) en el que se expresan las opciones Existen dos formas de dar la noticia del embarazo de tu novia: ¡Mamá! ¡He dejado embarazada a mi novia! ¡Mamá! ¡Vas a ser abuela! El marco mental que elijas para tu mensaje puede determinar la reacción emocional de la audiencia: puedes decir exactamente lo mismo enmarcándolo de formas diferentes y, de este modo, conseguir evocar emociones opuestas. Lo vemos repetidamente en el mundo de la política. Es distinto debatir sobre el "matrimonio gay" que sobre la "libertad para casarse". Los políticos hablan en España de "ajustes" en lugar de "recortes" y, en la Unión Europea, de "medidas de estabilidad" en lugar de "medidas de rescate". En la guerra, se habla de "daños colaterales" en lugar de "matanza de civiles" y al «bombardeo» se lo llama "ataque de defensa reactiva". Estos marcos buscan la activación de emociones viscerales, como odio, ansiedad, miedo o euforia. Piensa en tu trabajo. Al referirte a un cortafuegos, no es igual hablar de: Una barrera de protección imprescindible Un mecanismo básico de supervivencia La segunda opción suscita una respuesta más visceral. Cuando enmarcas estás seleccionando y resaltando algunos aspectos de los acontecimientos o asuntos y estableciendo relaciones entre ellos con el fin de promover una determinada interpretación, evaluación y/o solución. La información adicional incluida u omitida al presentar las opciones En julio del 2013 se produjo un desgraciado accidente del Alvia junto a Santiago de Compostela. ¿Te parece igual proporcionar la siguiente información sobre el comportamiento del maquinista en el momento del siniestro? El maquinista hablaba por teléfono El maquinista atendía una llamada de un controlador de RENFE En el segundo caso, la información adicional cambia de raíz tu perspectiva sobre la actuación del maquinista. Añadir u omitir información puede sesgar completamente la decisión. Imagina el siguiente escenario: Eres el responsable de seguridad de una empresa multinacional con 100.000 trabajadores. Un malware se está extendiendo por los equipos de los empleados, causando estragos. La mayoría de las infecciones han tenido lugar en la unidad de un país con 5.000 personas, aunque también ha afectado a otras unidades de la organización en otros países, pero anecdóticamente. La Dirección te ha aprobado un presupuesto para atajar la infección. Tienes dos opciones para gastarlo: El Plan A salvará 1.000 equipos de la unidad de 5.000 empleados de ese país donde residen casi todas las infecciones, es decir, salvarás uno de cada cinco equipos, o sea, el 20% de los equipos de ese país, el más castigado. El Plan B salvará 2.000 equipos, pero de toda la organización de 100.000 empleados, es decir, salvarás uno de cada 50 equipos, o sea, el 2% de los equipos. ¿Qué harías? ¿Cuál de los dos planes te parece el mejor? Por favor, decídete antes de seguir leyendo. Ahora considera la misma situación, pero enmarcada de la siguiente manera: El Plan A salvará 1.000 equipos El Plan B salvará 2.000 equipos ¿Cuál elegirías ahora? Cuando se le presenta la primera versión del escenario a la gente, la mayoría elige el plan A, que permitiría salvar al 20% de los que sufren el mayor riesgo. Sin embargo, cuando se les presenta el segundo marco, se les enciende la bombilla y entonces todos eligen el Plan B. En este caso, eliminar información (los porcentajes) aclara en la mente de los encuestados la opción correcta. Por lo tanto, unas veces añadir información y otras veces eliminarla puede conducir a la decisión "correcta". Sé muy cuidadoso cuando enmarques una decisión porque del marco elegido dependerá la decisión tomada. Tu decisión dependerá de cómo te presenten la información Como ves, no somos tan libres como nos gustaría. No evaluamos todas las opciones con fría objetividad, sopesando sus impactos y probabilidades y optimizando las funciones de valor esperado. Va a ser que no. Nuestras decisiones están condicionadas por el tipo de información disponible, por cómo se expresa verbalmente, en qué contexto se proporciona y en qué orden. Somos víctimas de nuestros sesgos y heurísticas. La próxima vez que tengas que tomar una decisión de seguridad importante, párate a reflexionar y analiza el contexto de la elección. Tal vez así llegues a tomar mejores decisiones.
20 de noviembre de 2018

Eres menos racional de lo que crees cuando tomas decisiones de riesgo en condiciones inciertas
Te propongo el siguiente juego de azar: Opción A: Te doy 1.000 € con un 100 % de probabilidad Opción B: Lo echamos a suertes: si sale cara, te doy 2.000 €; si sale cruz, no te doy nada ¿Qué opción elegirías? ¿La ganancia segura o la posibilidad de ganar el doble (o nada)? Si eres como el 84 % de la población, habrás elegido la opción A, la ganancia segura. Vale, ahora te propongo un nuevo escenario. Tienes que pagar una multa y te dan a elegir cómo hacerlo: Opción A: Pagas 1.000 € de multa con un 100 % de probabilidad. Opción B: Lo echan a suertes: si sale cara, pagas 2.000 € de multa; si sale cruz, te vas de rositas sin pagar ni un euro. ¿Qué opción elegirías en este caso? ¿Pagar la multa sí o sí o jugártela a suertes, pudiendo pagar nada (o el doble)? Pues en este caso, si eres como el 70 % de la población, habrás elegido la opción B. Entonces, ¿lo estás haciendo bien? ¿Mal? Vamos a examinar ahora qué está pasando aquí desde un punto de vista puramente racional. Según la teoría de la utilidad esperada, elegirás siempre la opción que maximice la utilidad de la decisión El valor esperado de una decisión E[u(x)] (o el retorno que puedes esperar) se calcula como el producto de dos cantidades bien sencillas: la probabilidad de la ganancia p multiplicada por el valor (o utilidad) de la ganancia u(x). Es decir, cuanto más probable sea que ganes algo y mayor sea su valor, mayor será el valor esperado. Se representa matemáticamente así: Si fuéramos racionales al 100 %, haciendo uso de esta fórmula siempre sabríamos qué hacer en cada momento y cómo tomar la decisión perfecta: bastaría con calcular la probabilidad de cada decisión y su utilidad y escoger la que maximizara el valor esperado. Por desgracia, el ser humano no es una máquina racional de toma de decisiones. No somos un "homo economicus" capaz de realizar análisis de coste-beneficio perfectos y elegir resultados óptimos con total objetividad. La Teoría de la Utilidad Esperada, tan bonita sobre el papel, incurre en dos grandes fallos cuando la aplicamos al día a día más allá de los juegos matemáticos de azar: Somos muy malos estimando la probabilidad de ganar Somos muy malos estimando el valor de la ganancia Para verlo con mayor claridad, repasemos las dos propuestas del inicio del artículo a la luz de esta teoría. En el juego de azar, el valor esperado de la opción A es: E(A)=1,0∙1.000=1.000 Mientras que el valor esperado de la opción B es: E(B)=0,5∙2.000+0,5∙0,0=1.000 ¡Ambos valores son idénticos! Por tanto, desde un punto de vista estrictamente racional, tanto debería importarnos uno como otro. Y ¿qué ocurre con el segundo escenario? En este caso, el valor esperado de la opción A es: E(A)=1,0∙(-1.000)=-1.000 Y el de la opción B, en cambio: E(B)=0,5∙(-2.000)+0,5∙0,0=-1.000 Una vez más, ambas son iguales. Por lo tanto, una vez más lo mismo daría elegir una que otra. Entonces, ¿por qué más gente elige la opción A del primer escenario y la opción B del segundo en lugar de elegir cualquiera de ellas? ¡Porque no somos puramente racionales! Preferimos una pequeña ganancia segura que una gran ganancia posible. Ya lo dice el refrán: "más vale pájaro en mano que ciento volando". Sin embargo, aborrecemos una pequeña pérdida segura y preferimos una posible gran pérdida. Es decir, la pérdida segura suscita tanta aversión que, antes que perder, asumimos el riesgo. Por supuesto, el cerebro no hace ningún cálculo matemático. Simplemente aplica una heurística: si puedes ganar algo con seguridad, tómalo y no lo arriesgues por ganar más; si puedes evitar una pérdida segura, arriésgate, aunque la posible pérdida sea mayor. Cuando se ponderan ganancias y pérdidas del mismo calibre, estas últimas «pesan» más. De hecho, la satisfacción de ganar es muy inferior al dolor de la pérdida. Es muy fácil de ver. Si sales a la calle con 100 € y pierdes 50, tu valoración subjetiva de esta pérdida es mayor que si sales con los bolsillos vacíos y te encuentras 50 €, aunque se trata de una ganancia objetivamente equivalente. Sí, al final en ambos casos acabas con 50 € en el bolsillo, pero el proceso no te da igual. ¡Ni mucho menos! Según la teoría prospectiva, tu eversión a la pérdida hará que arriesgues más por no perder que por ganar ¿Recuerdas el artículo anterior, Historia de dos mentes: La abismal diferencia entre el riesgo real y el riesgo percibido? La moderna psicología de la economía del comportamiento propone un modelo del ser humano radicalmente diferente al "homo economicus": en condiciones de incertidumbre, cuando se enfrenta a una situación muy compleja, nuestro cerebro cambia el problema por otro más sencillo. Son las heurísticas o atajos de pensamiento, que nos conducen a tomar decisiones «irracionales» aunque perfectamente explicables. La siguiente curva matemática captura gráficamente la esencia de la Teoría Prospectiva, propuesta por Kahneman y Tversky: La curva recoge tres características cognitivas esenciales de la Teoría Prospectiva, propias del Sistema 1: No se trata de una línea recta (o cóncava), como cabría esperar de la teoría de utilidad. Curiosamente, tiene forma de S, lo que indica que la sensibilidad a las ganancias y a las pérdidas va disminuyendo: tendemos a sobreestimar las pequeñas probabilidades y a subestimar las grandes. También choca que las dos curvas de la S no son simétricas. La pendiente de la función cambia de manera abrupta en el punto de referencia como consecuencia de la aversión a la pérdida: tu respuesta ante una pérdida es más enérgica que ante una ganancia objetivamente equivalente. De hecho, este valor se estima entre 2 y 3 veces más fuerte. Por último, las opciones no se evalúan en función de su resultado, sino en función del punto de referencia. Si todo tu capital consiste en 1.000,00 € en el banco, que te ingresen 1.000,00 € adicionales seguro que te hace más ilusión que si tienes ya 1.000.000,00 € en el banco. Son los mismos 1.000,00 €, pero dado que el punto de referencia es diferente, no los aprecias igual. De igual modo ocurrirá para una pérdida: seguro que no te afecta lo mismo perder 1.000,00 € si tienes 2.000,00 € que si tienes 1.000.000 €, ¿a que no? Una teoría de la decisión en seguridad de la información A la luz de todo lo explicado, están quedando claras dos ideas: No evaluamos las pérdidas y ganancias de manera totalmente objetiva. Nos dejamos influir por el punto de referencia y por la aversión de la pérdida. Visto lo cual, cabe especular con las siguientes dos hipótesis sobre cómo invertirás en medidas de seguridad en función de cómo se te presente la información: Hipótesis 1: Cuando se te presentan positivamente dos opciones de inversión en medidas de seguridad de la información, preferirás la opción de mayor certidumbre Hipótesis 2: Cuando se te presentan negativamente dos opciones de inversión en medidas de seguridad de la información, preferirás la opción de menor certidumbre Veámoslo con un ejemplo. Imagínate que tu empresa te ha asignado un presupuesto para un paquete de seguridad de la información. Sin esa inversión, se estima que tu empresa experimentará pérdidas por un total de 600.000,00 € (en esta cantidad se incluyen las pérdidas financieras, físicas, datos, reputación, tiempo, etc.). ¿Cuál de los dos paquetes A o B siguientes elegirías en cada escenario? Escenario 1: Opciones presentadas positivamente: Paquete A: Conseguirás salvar con seguridad 200.000,00 € de activos. Paquete B: Existe una probabilidad de 1/3 de que salves los 600.000,00 € de activos y una probabilidad de 2/3 de que no salves nada. Escenario 2: Opciones presentadas negativamente: Paquete A: Se perderán con seguridad 400.000,00 € de activos. Paquete B: Existe una probabilidad de 1/3 de que no se pierda ningún activo y una probabilidad de 2/3 de que se pierdan los 600.000,00 € de activos. Por supuesto, se trata de los dos escenarios del inicio de este artículo, aunque replanteados en términos de decisión de seguridad. Aunque los paquetes A y B en ambos escenarios conducen a la misma utilidad esperada, según la Teoría Prospectiva, en la práctica la mayoría de directores de seguridad escogerán la A en el primer escenario (más vale salvar algo con seguridad que arriesgarse a no salvar nada) y escogerán la B en el segundo escenario. No obstante, un experimento mostró que en este segundo caso tantos eligieron uno como otro, si acaso con preferencia por la A. ¿Qué importancia tienen estos resultados para tu día a día? Resulta imposible enumerar todos los posibles ataques y calcular su probabilidad y su impacto, según la fórmula tradicional para computar el riesgo. Así que debes estar en guardia ante procesos mentales que te alejen de decisiones óptimas: Dependiendo de cuál sea tu actitud, búsqueda del riesgo o evitación del riesgo, tenderás a reaccionar de una u otra manera, puenteando así tu racionalidad. Las personas con tendencia al riesgo elegirán las opciones B. En la práctica, tendemos a la certidumbre ante la ganancia y al riesgo ante la pérdida. Por este motivo, cuando estés tomando una decisión de seguridad, detente a reflexionar: ¿Cómo me están planteando esta opción? ¿Como una ganancia o como una pérdida? ¿Cómo suelo comportarme en estos dos escenarios? ¿Tiendo a buscar la seguridad o el riesgo? ¿Quién está tomando la decisión, el Sistema 1 o el Sistema 2? Del mismo modo, cuando plantees una opción de inversión ante el comité o ante los decisores, tienes la posibilidad de hacerlo desde un marco positivo o negativo. En el primer caso, marco positivo, plantea la certeza de la ganancia y huye de las probabilidades y del riesgo. En el segundo caso, marco negativo, en lugar de plantear una pérdida segura, aunque pequeña, plantea la posibilidad de no perder (aunque te arriesgues a una gran pérdida) y enfatiza su alta probabilidad. A la hora de enmarcar una inversión en seguridad, haz uso del deseo de ganar con certeza. En lugar de plantear la inversión en seguridad como la protección esperada ante hipotéticas amenazas que podrían no materializarse, enfócate en las ganancias ciertas e indiscutibles: mejora de la reputación, confianza de los clientes, procesos y operaciones eficaces, cumplimiento normativo, etc. Trata de llevar la discusión al cuadrante de las ganancias y habla sobre cuestiones cuya evidencia sea aplastante. Busca la ganancia segura y huye de las probabilidades y los futuribles. Como ingeniero de seguridad o "Defensor", te encuentras típicamente en el cuadrante de las Pérdidas. En definitiva, hagas lo que hagas, pierdes: si los ataques tienen éxito, has fallado en su defensa: has perdido; si no queda constancia de ataques exitosos, ¿has ganado?, no, te dirán que has gastado en seguridad más de lo necesario: has perdido. Nadie dijo que el trabajo en ciberseguridad fuera fácil ni agradecido, es peor que el de portero de fútbol. Operar desde el cuadrante de las pérdidas fomenta una conducta de búsqueda de riesgo: es posible que arriesgues más en aras de una defensa total, pasando por alto soluciones seguras contra amenazas menores. Recuerda que es muy fácil sobreestimar las pequeñas probabilidades, lo que te puede llevar a invertir en soluciones para proteger ante amenazas muy llamativas, pero de muy baja prevalencia. Puedes invertir en APTs de nombres rimbombantes y olvidarte de que la mayoría de los ataques se producen a través de métodos muy pedestres y nada glamurosos: phishing, inyecciones en páginas web, malware de toda la vida recompilado y reempaquetado contra el que existen parches, … En fin, lo de siempre, que poco o nada tiene que ver con «avanzado», «inteligente» ni «sofisticado», aunque persistentes sí que son, ya que las amenazas más exitosas de hoy son las de ayer. Nihil novum sub sole. No caigas en la trampa de la sensibilidad decreciente. La curva en forma de S se va aplanando. Eso significa que un primer incidente causa mucho más impacto y revuelo que el décimo incidente de la misma magnitud. Cada ataque "dolerá" menos que el anterior a igualdad de pérdidas. La organización se va insensibilizando. Por eso es tan importante actuar desde el primer incidente, cuando la organización está «en carne viva». Cuanto más tardes en actuar, aunque el incidente se repita, se irá considerando cada vez menos y menos impactante. Después de todo, aquí seguimos, ¿no? Habrás sucumbido a «la muerte de los mil cortes». Para el defensor, un ataque tiene éxito o no lo tiene, el resultado es todo o nada. Si un ataque tiene un éxito del 1 %, no estás protegido en un 99 % porque, si te atacan con éxito, habrás sucumbido al 100 %. Un incidente exitoso y grave desplazará drásticamente tu punto de referencia hacia el abismo de las pérdidas. Ya no te sentirás tan seguro como antes del incidente. La organización invertirá posiblemente en un intento de traer de vuelta el punto de referencia a su estado inicial. Cambiar el punto de referencia hace que cambie tu sensibilidad ante los mismos incidentes: si lo has bajado, un incidente que antes te habría horrorizado ahora te dejará casi indiferente; y al revés. Conviene revisar este punto de referencia, usando todas tus métricas y medidas del riesgo a tu alcance. Por mucho que te esfuerces, tus decisiones nunca serán ideales o perfectas. Te verás sometido a innumerables restricciones y condicionantes: de recursos (económicos y personales), culturales, legislativos, etc. Y, además, tienes que añadir a la ecuación tu propio comportamiento ante el riesgo, influido a su vez por otros muchos factores de los cuales NI SIQUIERA ERES CONSCIENTE. Este artículo pretende ayudarte a aflorar a la conciencia algunos de esos factores. Tenlos en cuenta en tus próximas decisiones de seguridad. La gente tiende a aceptar una ganancia incremental en seguridad antes que la probabilidad de una ganancia mayor; del mismo modo, tiende a arriesgarse a una gran pérdida antes que aceptar la certeza de una pérdida menor. ¿Tú también?
5 de noviembre de 2018

Los seis principios de la influencia que utilizan los cibercriminales para hackear tu cerebro
" Los aficionados hackean sistemas, los profesionales hackean gente", decía Bruce Schneier. ¿Alguna vez has dicho "sí" a una petición de un desconocido a pesar de que realmente no te apetecía decir "sí"? ¿O te has sentido empujado a comprar algo que no necesitabas y te has arrepentido a los pocos instantes? ¿Te gustaría saber cómo te manipulan estas personas para que actúes como ellas quieren, incluso en tu propio perjuicio? ¿Sí? Entonces sigue leyendo y descubrirás cuáles son los seis principios de la influencia que utilizan los atacantes, el malware y los mejores timos de internet para que digas "sí" cuando deberías decir "no". Fuente:pixabay.com Personas: El eslabón más débil de la cadena de la seguridad de la organización Según escribe Kevin Mitnick, uno de los hackers más famosos de la historia, en su libro The Art of Deception: " La ingeniería social utiliza influencia y persuasión para engañar a la gente manipulándola o convenciéndola de que el ingeniero social es alguien que en realidad no es. Como resultado, el ingeniero social es capaz de aprovecharse de la gente para obtener información con o sin la ayuda de la tecnología". Como deja claro Mitnick, y él sabía mucho de eso, la ingeniería social va de "hackear personas" . ¿Por qué molestarte en hackear sistemas informáticos bien protegidos si puedes volverte contra las personas que los operan? Y si para hackear sistemas informáticos hay que saber de sistemas operativos, protocolos de comunicación y lenguajes de programación, para hackear personas habrá que saber de cómo funciona el cerebro. A pesar de que el funcionamiento del cerebro es más complejo que el de ningún ordenador, podemos atisbar en su interior y a través de experimentos conductuales tratar de inferir algunas de sus reglas de comportamiento. Precisamente eso mismo ha estado haciendo durante décadas el Dr. Robert Cialdini, el investigador más popular en el ámbito de la influencia y persuasión, autor de la biblia sobre el tema" Influence: The Psychology of Persuasion". En su libro explora en detalle cuáles son las tendencias de la naturaleza humana que explotan los atacantes para conseguir que sus víctimas acepten sus peticiones sin sospechar que están siendo engañadas. Cialdini ha identificado los siguientes seis principios: Reciprocidad Compromiso y consistencia Prueba social Preferencia Autoridad Escasez 1. Reciprocidad: Tú me rascas, yo te rasco 1.1 Principio: A cambio de un servicio, incluso no solicitado, uno siente la necesidad de devolverlo. Este sentido de la reciprocidad está inscrito en todas las sociedades. Devolver un favor constituye una regla básica de la conducta humana. Se considera de hecho la base de la civilización. Un pequeño favor inicial, aunque no lo hayas pedido, puede generar mayores favores de vuelta porque nos sentimos obligados: Aborrecemos estar en deuda: por eso solemos llevar una botella de vino cuando nos invitan a cenar o pretendemos pagar la siguiente ronda si nos invitan a la primera. Cuando nos dan muestras gratuitas de un producto en los supermercados nos sentimos más inclinados luego a comprarlo. Rechazamos socialmente la ingratitud: no gusta el que pide y no da, lo vemos como un gorrón. Cuando alguien nos ha ayudado con la maleta o nos ha limpiado el parabrisas, aun sin haberlo solicitado, tendemos a darle una propina. Si hemos disfrutado de una demo gratis, nos sentimos más inclinados a comprar el producto. Conduce fácilmente a la trampa de las pequeñas concesiones: si alguien nos invita frecuentemente a pequeñas cosas o nos hace pequeños favores, aunque nunca los hayamos solicitado ni los deseemos, no podemos evitar decir "sí" cuando más adelante nos pide a cambio un favor, por grande que éste sea. 1.2 Ataque: Un empleado recibe una llamada de alguien que se identifica del departamento de IT, informándole de que su ordenador está infectado por un virus que ha saltado todas las protecciones. Le guía a través de unos pasos para supuestamente desinfectarlo. Cuando termina, le solicita que reinicie todas sus contraseñas e incluso le sugiere cómo deben ser de complicadas y le da ideas para recordarlas. Claro, la víctima no puede negarse a compartirlas, después de todo lo que esta persona ha hecho por ella. 1.3 Defensa: Identifica siempre la intención de un favor o petición. 2. Compromiso y consistencia: Yo nunca falto a mi palabra 2.1 Principio: Tomada una decisión, se actúa de forma coherente con el compromiso contraído. La consistencia se ve como fuerza moral, como una cualidad elogiable. Cuando una persona da su palabra y se atiene a ella, la percibimos como íntegra y honesta. Una vez que nos hemos comprometido con algo, no queremos parecer inconsistentes ni indignos de confianza y tendemos a cumplir con nuestra palabra dada. De hecho, nuestro compromiso resulta más fuerte cuando es público y aparentemente de motivación interna, es decir, cuando creemos que ha salido de uno mismo sin que nadie nos haya influido en nuestra decisión. Este compromiso conduce a comportamientos absurdos como terminar de ver una película en el cine porque "he pagado la entrada", acabar un libro porque "siempre acabo lo que empiezo" o en un restaurante comerte un plato que no era de tu agrado porque "lo he pedido". 2.2 Ataque: El atacante contacta con un recién incorporado a la organización informándole de la necesidad de aceptar las directivas y procedimientos de seguridad para acceder a los sistemas de información de la compañía. Cuando la víctima se ha comprometido a cumplir con todas las normas y a hacer todo lo que se le pida, ahora el atacante puede solicitarle cualquier cosa con la excusa de seguir un procedimiento de seguridad, que seguramente la víctima se lo concederá. 2.3 Defensa: Ante nuevas peticiones, da marcha atrás y analiza las previas. 3. Prueba social: Yo como Vicente, donde vaya la gente 3.1 Principio: Uno se siente inclinado a hacer lo que todo el mundo hace. De alguna manera pensamos que, si todo el mundo lo hace, debe estar bien, especialmente si son semejantes a mí. ¿Por qué si no los libros incluyen reclamos del tipo "10 millones de lectores no pueden estar equivocados" o "150.000 ejemplares vendidos"? Esta regla de comportamiento la seguimos desde niños, imitando el comportamiento de nuestros padres, profesores y compañeros de clase y amigos. Por eso los individuos de un mismo grupo suelen comportarse de forma tan parecida. Como dice el refrán: "Dios los cría y ellos se juntan". Esta conducta emerge con mayor fuerza en situaciones inciertas, donde no está claro cómo reaccionar. En este caso, se considera como normativo el comportamiento del grupo. De ahí que, si vamos por la calle y vemos a un grupo numeroso de personas mirando hacia el cielo, nosotros también lo hagamos. O si vamos por la carretera o por una ciudad desconocida y no sabemos dónde parar a comer, lo hagamos en el local donde más clientes veamos. O que prefiramos hacer un donativo en una hucha casi llena que en otra casi vacía. Si quieres que alguien haga algo por ti, muéstrale la cantidad de gente que lo ha hecho antes. Lo usan los niños cuando presionan a sus padres para que les compren algo: "¡Soy el único de la clase que aún no lo tiene!". 3.2 Ataque: Recibes una llamada de una persona que afirma estar haciendo una encuesta y menciona el nombre de otras personas de tu departamento que ya han cooperado con él. Creyendo que la cooperación de otras personas valida la autenticidad de la petición, accedes a participar. El atacante pasa a hacer una serie de preguntas, entre las cuales puede pedirte nombres de usuario y contraseñas, direcciones internas de servidores, nombres de personas clave, etc. 3.3 Defensa: Verifica la evidencia proporcionada y no fundamentes el juicio exclusivamente en la conducta de los demás. 4. Preferencia o asociación positiva: Quién puede decirle que no 4.1 Principio: Se tiende a decir "sí" a gente que nos gusta y también a gente atractiva o similar. Nos gustan las personas a las que les gustamos. Cuanto más te parezcas a su grupo, más familiar les resultes, más fácilmente te dirán que sí. Por eso, si estás solo en un país extranjero y te encuentras con un conocido de tu ciudad con quien nunca hablas, puede que lo saludes y hasta lo abraces con efusividad. Por otro lado, cuanto más halagues a una persona, más fácilmente te dirá que sí. Incluso aunque sepa que los halagos no son sinceros. Pero es que no sabemos resistirnos a ellos. Por último, existe un efecto muy relacionado con la preferencia, bautizado como "efecto halo": asociamos todo tipo de características positivas a las personas atractivas. En otras palabras, percibimos a las personas atractivas como más inteligentes, amables y capacitadas. En definitiva, cuanto más atractivo te muestras, más persuasivo te vuelves. 4.2 Ataque: El atacante finge compartir los mismos hobbies o intereses que la víctima. O bien, finge ser de la misma universidad o ciudad. O comparte el mismo gusto en series o en comida o en vinos. O utiliza el mismo lenguaje, jerga o distintivos que lo identifican como perteneciente a la misma «tribu». Busca encontrar un vínculo de conexión emocional con la víctima y lo explota para despertar en ella sentimientos positivos, que bajen su guardia para cuando llegue la petición. 4.3 Defensa: Disocia la petición del peticionario y analiza exclusivamente la oferta. 5. Autoridad: No lo digo yo, lo dijo Einstein 5.1 Principio: Se tiende a escuchar y seguir indicaciones de alguien en una posición de autoridad. Nos fiamos de los expertos. Si está anunciado en televisión, tiene que ser bueno. Si nueve de cada diez dentistas recomiendan un chicle sin azúcar, entonces habrá que comer chicles sin azúcar. Si mi cardiólogo, que es una eminencia, me receta estatinas, ¿cómo no voy a tomarlas? Por supuesto, necesitamos delegar en expertos. El problema surge cuando un atacante explota nuestra buena fe en la autoridad, sirviéndose de sus: Títulos: Si alguien afirma poseer el título X o Y, automáticamente le conferimos todo el saber supuestamente vinculado a dicho título. Ropas: Los uniformes, insignias y otros accesorios nos hacen creer que la persona ostenta la autoridad asignada a quienes portan esa indumentaria. Vehículos: Igualmente, los vehículos oficiales, con distintivos, con instrumentos de señalización visual o acústica, nos inclinan a creer que sus ocupantes poseen la autoridad que el vehículo confiere. 5.2 Ataque: El atacante finge pertenecer al departamento de TI o ser un ejecutivo de la compañía, cualquier estratagema que lo revista de autoridad y haga bajar las defensas de la víctima. 5.3 Defensa: Pregúntate: ¿Es esta persona un experto real? ¿Puedo fiarme? 6. Escasez: Con lo que me ha costado encontrarlo 6.1 Principio: Cuanto más escasea algo, más precioso se vuelve. "¡Últimos días de función!", "¡Últimos artículos, promoción a punto de agotarse!", "Sólo tiene una hora, debe decidirse ahora mismo". Todas estas estrategias están ideadas para crear la sensación de escasez. Cuando un recurso escasea, se entiende que es valioso. Y cuanto más escaso es y por menos tiempo está disponible, más valioso se vuelve. Así se impide pensar con claridad, lo que conduce a tomar decisiones precipitadas de las que luego nos arrepentimos. El recurso escaso será más atractivo si existe competencia luchando por obtenerlo: "nos los quitan de las manos", "primera edición agotada el primer día". Así se justifican las colas para comprar el último iPhone. La raíz de este comportamiento radica en que se reacciona con mayor fuerza ante la pérdida que ante la ganancia: es más intensa la aversión a perder que el deseo de obtener una ganancia equivalente. Por eso prestamos mayor atención a un reclamo que nos promete «deja de perder 10 € en tu factura» que "gana 10 € en tu factura". 6.2 Ataque: El atacante envía mensajes de correo prometiendo que las primeras 50 personas en registrarse en el nuevo microsite de la compañía recibirán gratis entradas para el cine. Este gancho asegura que la víctima se registra inmediatamente en lugar de posponerlo. En el proceso de registro se le pide a la víctima su dirección de email y una contraseña. Como tanta gente utiliza la misma contraseña para todos los sitios de Internet, con esta argucia el atacante podrá hacerse con numerosas contraseñas válidas para sitios corporativos. 6.3 Defensa: Disocia la situación de su supuesta escasez. Conclusiones Estos comportamientos seleccionados evolutivamente para sobrevivir en grupos sociales nos aconsejan correctamente la mayor parte del tiempo: son atajos de pensamiento o heurísticas, que nos liberan de tener que procesar montañas de información antes de tomar cualquier pequeña decisión. No se trata por tanto de renunciar a ellos, sino de pararnos a pensar antes de actuar ante peticiones fuera de lo común. Defensa básica: En última instancia, la defensa se reduce a las dos siguientes reglas: Verificar la identidad: ¿es quien dice ser? Verificar la autoridad: ¿tiene necesidad de saber o está autorizada para hacer esta petición? Sólo son dos, pero nada fáciles de poner en práctica. Todos los empleados de la compañía deberían estar educados para comprender el funcionamiento de los principios de la influencia y así poder analizar peticiones y ofertas.
1 de octubre de 2018

La homeostasis del riesgo o cómo agregar medidas de seguridad puede volverte más inseguro
Un niño está jugando con su patinete. De repente, comienza a saltar desde una rampa, con peligro evidente. No lleva ni casco ni otras protecciones. Rápidamente, hace su aparición la madre: "¡Niño! ¡Ponte ahora mismo las protecciones!". El niño obedece. Se pertrecha adecuadamente bajo la mirada atenta de su madre y recibe la aprobación materna para saltar desde la rampa. Ahora sí. Ahora está "seguro". Al presenciar esta escena verídica en el parque me surgió una duda: ¿Cuándo estaba más seguro el niño? ¿Patinando sin hacer cabriolas ni llevar protecciones o bien haciendo cabriolas con todas las protecciones puestas? Esta anécdota refleja una tendencia psicológica muy humana: una vez se introduce una medida de seguridad concreta, al sentirse más seguras, las personas parecen reajustar su conducta tornándola más peligrosa. Es decir, las personas no están más “seguras”, sino que simplemente ajustan sus acciones incrementando su exposición al riesgo. Volviendo al niño del patinete. Si se siente más seguro con todas las protecciones, se atreverá a maniobras más arriesgadas que cuando no las llevaba. Puede afirmarse que en este caso aumentar la protección hace que aumente la conducta de riesgo. La cuestión es: globalmente, ¿el niño está ahora más o menos seguro? La teoría de la homeostasis del riesgo como reguladora de la conducta Todos hemos visto un termostato en operación. Se fija una temperatura, por ejemplo 25 grados. El termómetro del termostato monitoriza la temperatura de la habitación. Si cae por debajo del set point definido, entonces activa la calefacción. Pero la temperatura de la habitación seguirá cayendo durante un rato mientras la calefacción va calentando el aire. Pongamos que cae hasta los 23 grados. El aire progresivamente se calentará hasta llegar a los 25 grados preestablecidos. El termostato detiene entonces la calefacción. Pero, debido a la inercia térmica, la temperatura seguirá subiendo durante unos minutos y podría alcanzar los 27 grados, momento en el que comenzará a caer lentamente, hasta rebasar los 25 grados. Y vuelta a empezar. Curiosamente, la habitación nunca está a 25 grados. En realidad, la temperatura está oscilando continuamente entre los 23 y los 27 grados. Los 25 grados son solo la temperatura promedio. La amplitud y periodo de estas oscilaciones dependerán de factores como la sensibilidad del termómetro, la potencia calorífica de la calefacción, la inercia térmica de los materiales de la calefacción, la dimensión de la habitación, la temperatura exterior, etc. ¿Y qué tiene que ver un termostato con el riesgo? En 1982, el investigador Gerald Wilde propuso su Teoría de la Homeostasis del Riesgo (THR), equiparando con un termostato nuestra manera psicológica de afrontar el riesgo. Según Wilde, los humanos tenemos nuestro propio termostato del riesgo y cada individuo lo tiene establecido a un nivel determinado, más alto o más bajo. Intuitivamente, todos conocemos personas que adoran el riesgo y otras que huyen de él. La explicación es que sus "riesgostatos" están programados a niveles diferentes. Si las circunstancias a nuestro alrededor cambian aumentando o disminuyendo la seguridad percibida, entonces adaptamos nuestro comportamiento, haciéndolo más o menos arriesgado, hasta recobrar nuestro nivel personal de tolerancia al riesgo. En otras palabras, cuanto más seguros nos sentimos, de manera más arriesgada nos comportamos. Si esta teoría es cierta, entonces, las contramedidas de seguridad pueden surtir el efecto contrario al deseado al fomentar conductas más arriesgadas o descuidadas. Piensa en las siguientes situaciones hipotéticas: Si un programador de aplicaciones web sabe que las páginas cuyo código desarrolla serán protegidas por un WAF, ¿se volverá más despreocupado, confiado en que si comete un error de programación será compensado por el WAF? Si una empresa implanta sofisticados sistemas de seguridad física y control de acceso en sus instalaciones para impedir que personal no autorizado acceda a los despachos y praderas, ¿vigilarán menos los empleados la autorización de las personas que han entrado al edificio? Si una empresa introduce una directiva que exige cifrar todo el correo electrónico para evitar violaciones de la confidencialidad en comunicaciones con terceros, ¿incluirán los empleados más información confidencial en sus mensajes de correo, persuadidos de la inviolabilidad de sus mensajes? Si un usuario informático instala un sistema antivirus de última generación, supuestamente "infalible", ¿ejecutará alegremente cualquier archivo recibido por email, accederá a más páginas web dudosas o dejará su equipo conectado a Internet durante más tiempo? Oscilanos alrededor de nuestro nivel de riesgo tolerado La Teoría de la Homeostasis del Riesgo (THR) mantiene que en cualquier actividad, la gente acepta cierto nivel de riesgo estimado subjetivamente, para su salud, seguridad y otros bienes que valora, a cambio de los beneficios que recibe de la actividad: transporte, trabajo, comer, beber, uso de drogas, actividades recreativas, romance, deportes… lo que sea. Para Wilde, el nivel de riesgo tolerado depende de cuatro factores: El beneficio esperado del comportamiento arriesgado El coste esperado del comportamiento arriesgado El beneficio esperado del comportamiento seguro El coste esperado del comportamiento seguro ¿Por qué una persona querría descargarse un software de pago desde una red P2P sin pasar por caja, a sabiendas de que corre un riesgo al instalar un software procedente de una fuente no confiable en lugar del fabricante oficial? En la imaginación de esta persona, el beneficio de su conducta arriesgada, disfrutar del software, es idéntico tanto si paga como si no, ya que factor 1 = factor 3. Por otro lado, si no paga, el factor 2 = 0, mientras que el factor 4 >> 0. De acuerdo con la THR, siempre que la suma de los factores 1 y 4 supere con creces a la suma de los factores 2 y 3, aumentará el nivel de riesgo que un individuo está dispuesto a aceptar, como en el caso de las descargas ilegales. Wayne Kearney y Hennie Kruger hacen un buen trabajo interpretando está teoría en el contexto de la seguridad de la información. La siguiente figura recoge los principios del modelo en clave de TI: En función de sus experiencias pasadas, de su formación en seguridad, de su nivel de concienciación, de condicionantes sociales y culturales, un usuario percibe ciertos costes y beneficios asociados a su conducta (caja 1). Este análisis, más o menos consciente, le conduce a determinar un nivel de riesgo preferido o aceptado (caja 3). Ya vimos que para Wilde este nivel de riesgo tolerado dependía de cuatro factores motivadores. El usuario concluye que, si el beneficio esperado del comportamiento arriesgado (factor 1) y los costes esperados del comportamiento conservador (factor 4) son altos, el nivel objetivo de riesgo será también alto. Por el contrario, el nivel de riesgo aceptado será bajo si los costes esperados del comportamiento arriesgado (factor 2) y los beneficios esperados del comportamiento conservador (factor 3) son altos. Cualquier incidente de seguridad causará un cambio en el nivel percibido de riesgo (caja 4). Si se implantan nuevas medidas de seguridad o si aparecen nuevas amenazas, el nivel de riesgo percibido aumentará o disminuirá en consonancia. En el caso de una nueva amenaza, los usuarios tienden a cambiar su conducta de seguridad eligiendo alternativas más seguras (caja 6), lo que provocará un cambio en el estado (tasa) de brechas de seguridad (caja 7). A medida que pasa el tiempo y el usuario acumula información sobre la nueva amenaza, puede considerar que la amenaza no es tan seria o podría descubrir que la amenaza está bajo control gracias a nuevas medidas de seguridad o simplemente podría terminar por acostumbrarse a la nueva amenaza. El nivel de riesgo percibido podría caer entonces por debajo del nivel objetivo, por lo que el usuario podría empezar a comportarse con menor cautela, lo que conllevaría un aumento en el número de brechas de seguridad. El modelo de la homeostasis del riesgo es, como un termostato, un bucle de realimentación negativa en la que las variables están en permanente reajuste. Por supuesto, se trata de una teoría, capaz de explicar muchas conductas de seguridad, tanto individuales como colectivas, pero no tiene todas las respuestas para la motivación humana en relación con el riesgo. De hecho, muchos investigadores la consideran una mera hipótesis y la critican duramente, negando que los seres humanos poseamos un "termostato del riesgo" o que este termostato juegue un papel tan relevante en la toma de decisiones de seguridad. Por otro lado, los seres humanos somos excepcionalmente malos juzgando el riesgo, por lo que resulta difícil diseñar experimentos fiables para probar la teoría. Además, los seres humanos no somos puramente racionales, por lo que no actuamos movidos exclusivamente por la evaluación exhaustiva de la utilidad de nuestras acciones, sino que se entremezclan otros factores emocionales que contradicen la búsqueda de la maximización de la utilidad. Cómo fomentar comportamientos seguros a pesar de instalar contramedidas de seguridad Resumiendo lo explicado hasta ahora, las dos premisas fundamentales de la THR son: Las personas tenemos un termostato individual del riesgo establecido a un nivel determinado. Evaluamos la situación y ajustamos nuestro comportamiento para mantener este nivel. Si esta teoría es cierta, ¿cómo podemos evitar la paradoja de que a mayor número de medidas de seguridad, mayor riesgo? El experto en seguridad vial James Hedlund, propone cuatro factores a tener en cuenta para disuadir a los individuos de aumentar el riesgo de su conducta ante la adición de medidas de seguridad. Visibilidad: La medida de seguridad debe pasar desapercibida. Si no sé que está ahí, no contrarrestaré con mi comportamiento más arriesgado una medida de seguridad recién implantada. Cuanto más transparente o imperceptible sea la medida, menos afectará al comportamiento. SSL suele funcionar muy bien a nivel de usuario porque la mayoría ni sabe que existe ni que lo están utilizando. Para ellos, es una medida invisible. Efecto: La medida de seguridad no debe afectar al individuo. Cuanto más intrusiva sea una medida, más interés tendrá el individuo en desactivarla. Si el WAF tiene falsos positivos que impiden acceder a un comprador a un producto y comprarlo, el WAF será desactivado. Si el filtro antispam bloquea los mensajes de un cliente clave, el filtro será desactivado. Si el reconocimiento facial falla en momentos críticos, se volverá a la contraseña. Cuanto menos afecte la medida de seguridad al individuo, menos tratará de compensarla alterando su comportamiento. Motivación: La medida de seguridad no debe dar motivos para el cambio. Si no encuentro razón alguna para cambiar mi comportamiento, no compensaré la medida de seguridad. Cuanto menos afecte la medida a la percepción subjetiva del riesgo y menos altere la forma habitual de trabajar, menos motivación existirá para alterar la conducta. Control: La medida de seguridad debe escapar al control del individuo. Si mi comportamiento está muy controlado, no compensaré la medida de seguridad. Si tengo la libertad de desactivar el antivirus porque me da la sensación de que hace que mi compilador vaya más lento, entonces lo desactivaré. Cuanto menos margen de maniobra dejen las medidas de seguridad al usuario, menos cambiarán su comportamiento. Un ejemplo de cómo se han aplicado con éxito estos principios en la búsqueda de la seguridad del consumidor es en el caso del agua potable en las grandes ciudades. Abrimos el grifo y damos por hecho que es segura. No instalamos ni filtros ni nada adicional, no la analizamos en busca de venenos, no aprendemos sobre química antes de beberla, no nos aparecen ventanas con avisos indescifrables. No hay que tomar ninguna decisión. Simplemente, confiamos en todas las medidas de seguridad que han sido tomadas para que llegue clara y limpia a nuestro hogar. Los usuarios sueñan con acceder a la información como al agua potable. La homeostasis del riesgo en la seguridad de la información La teoría de la homeostasis del riesgo nos advierte de que cuanto más visibles son las medidas de seguridad, más pueden incitar a que la gente acepte riesgos mayores. Esta teoría, abrazada por unos y rechazada por otros, posee profundas implicaciones en la manera como debemos buscar aumentar la seguridad de nuestros usuarios. Nos invita a reflexionar a la hora de establecer estrategias de educación, formación y concienciación en seguridad de la información, a la hora de diseñar interfaces de seguridad y de implantar directivas de seguridad. La tecnología por sí misma no puede ofrecer soluciones completas a los retos de seguridad de la información. Nunca está de más introducir en el cóctel de la seguridad el comportamiento del usuario. Entender su motivación y su forma de pensar puede suponer la diferencia entre el éxito o el fracaso de una medida de seguridad. ¿Y tú qué opinas? ¿Instalar medidas de seguridad te hace ser más temerario? ¿Podremos algún día ofrecer acceso a la información tan seguro y transparente como el agua potable?
24 de septiembre de 2018

Google quiere matar la URL para salvar Internet y aún no sabe cómo
¿Cómo sabes que ahora mismo estás en el sitio web de ElevenPaths leyendo este artículo del blog? Posiblemente mirarás hacia la barra de dirección, donde aparece listada la URL: https://blog.elevenpaths.com/2018/09/informe-seguridad-navegadores-movil-ciberseguridad.htm. Sí pero, ¿estás totalmente seguro de que esa cadena alfanumérica corresponde al verdadero sitio web donde se aloja el blog de ElevenPaths y no una suplantación? Yo no estaría tan seguro. Fuente: https://en.wikipedia.org/wiki/On_the_Internet,_nobody_knows_you%27re_a_dog Este viejo chiste sigue estando de actualidad. Han pasado casi 30 años desde que Tim Berners-Lee creara la Web y aún seguimos sin un método sencillo e infalible para garantizar la identidad de un sitio web. Internet sigue sumida en una crisis de identidad Cuando visitamos nuestro banco, nuestro periódico favorito o nuestra red social principal no dedicamos una segunda mirada a la URL. La mayoría de los usuarios de navegadores estiman la identidad de un sitio por su contenido, ni siquiera por su URL, ni mucho menos por su certificado digital. Los usuarios más avanzados verifican la identidad echando un rápido vistazo a la URL. Aun así, muy pocos abren el certificado digital, verifican la ruta de certificación y demás detalles. ¿Qué tipo de validación tiene el certificado?, ¿Tiene validación de dominio (DV), de organización (OV) o extendida (EV)?, ¿Verificas estos aspectos tú mismo en cada sitio web HTTPS que te encuentras? En definitiva, vivimos sumidos en una crisis de identidad en Internet, donde nadie está seguro de quién está al otro lado de la conexión. Crisis aprovechada por los cibercriminales para montar todo tipo de ataques. Tal vez los más extendidos en este contexto sean los de phishing: El atacante crea un sitio web que es una réplica fiel del sitio web objetivo. A continuación, el atacante necesita enviar el cebo: un mensaje que incitará a las víctimas a hacer clic sobre un hiperenlace que conduce al sitio falso en lugar de al original. El vector de ataque puede ser un mensaje de correo, un mensaje en cualquier red social, un comentario en una página web, en definitiva, cualquier soporte para una URL. La víctima muerde el anzuelo: hace clic en el enlace y es conducida al sitio web del atacante, que parece el original. La réplica es tan convincente que la víctima revela confiada su información confidencial. El atacante recopila las credenciales u otra información mientras dure el ataque. En definitiva, ¿en qué se basan los ataques de phishing? En la debilidad del sistema actual de identidad, incapaz de informar con sencillez a cualquier usuario sobre qué página está visitando. Hoy la información recae sobre la URL, y es muy fácil manipularla. Entendiendo los ataques de suplantación: anatomía de una URL Estas URL son un vestigio de los primeros años heroicos de Internet. Fueron concebidas para personas acostumbradas a la línea de comando, no para el público en general, que apenas sabe distinguir entre Internet y un navegador. Las URL, como su nombre indica ( Uniform Resource Locator o localizador de recursos uniforme), suponen una manera conveniente de acceder a recursos de información alojados en servidores web. Cualquier persona que conozca la URL completa de un recurso podrá acceder a ese recurso de forma inequívoca. Toda URL se basa en la siguiente sintaxis: esquema:[//[usuario[:contraseña]@]equipo[:puerto]][/ruta][?consulta][#fragmento] Donde: Esquema: Indica el protocolo de red usado para recuperar la información del recurso identificado. El nombre de esquema va seguido por dos puntos (:) y dos barras (//). Los esquemas más habituales hoy son http, https, mailto, file o ftp. Usuario y contraseña: Contienen el nombre de usuario y la contraseña de una entidad autorizada para acceder al recurso. Están separados por dos puntos (:). Ambos datos son necesarios únicamente si el recurso exige autenticación básica. Si no se exige autenticación y están presentes, entonces se ignoran. Se utiliza el símbolo @ para separar el nombre de usuario y la contraseña del siguiente segmento. Equipo: Señala un determinado servidor donde se aloja el recurso deseado. Como se explica más adelante, puede representarse simbólica o numéricamente. Puerto: Normalmente se omite, ya que la mayoría de los esquemas ofrecen su servicio en un puerto estándar: 80 en HTTP, 443 en HTTPS o 21 en FTP. Cuando resulta necesario ofrecer el servicio en un puerto no estándar, se especifica el número de puerto, separado del host con dos puntos (:). Ruta: Especifica la ruta de acceso de archivo para el recurso. Empieza con una barra inclinada (/) y reproduce la estructura de directorios donde está alojado el recurso. Consulta: Algunos recursos web contienen elementos ejecutables y esperan, además de una ruta de archivo, una cadena de consulta. Esta consulta puede contener una o más parejas de parámetro/valor, anexadas a la URL y procesadas por las páginas dinámicas en el extremo del servidor. La cadena de consulta se inicia con un símbolo de interrogación (?) y las parejas de parámetros se separan por el símbolo &. Fragmento: Permite hacer referencia a una posición específica dentro de un recurso. Se usa típicamente en las páginas HTML, junto con las etiquetas de ancla. Para el usuario experto, la URL proporciona todo un tesoro de información acerca del recurso visitado, en especial gracias a la parametrización: tokens, enlaces de afiliados, publicidad, secuencias de navegación, etc. Por desgracia, estas largas y complicadas secuencias de letras y números resultan indescifrables para los no iniciados. Empeorando aún más las cosas, son casi imposibles de mostrar en las pequeñas pantallas de los dispositivos móviles. Esta complejidad fue rápidamente aprovechada por los ciberatacantes, en especial, para el phishing. Por increíble que nos parezca, millones de personas navegan por Internet cada día sin ser conscientes de que existe una ventanita en su navegador donde aparece la dirección de la página que están visitando. Si (casi) nadie se fija en ella, ¡qué fácil esconder ahí ataques! Estos ataques, denominados de ofuscación de URL, modifican sutilmente la dirección de manera que el usuario desprevenido no perciba nada extraño si llega a echar un vistazo superficial. A continuación, daremos un repaso a los más conocidos. Dirección del host expresada numéricamente La dirección de un host en Internet puede codificarse simbólicamente, con letras y números, fáciles de leer y recordar por los humanos, o numéricamente, con un número de 32 bits (en IPv4). Por ejemplo, Dirección simbólica: blog.elevenpaths.com Dirección numérica: 216.58.201.179 Lo que es menos conocido es que la dirección IP, expresada habitualmente como cuatro grupos de dígitos separados por punto (a.b.c.d), también puede escribirse como un único número entero, ya que: n = a x 256^3 + b x 256^2 + c x 256 + d Incluso pueden expresarse en hexadecimal y hasta en octal. De manera que: blog.elevenpaths.com = 216.58.201.179 = 3627731379 = 0xD83AC9B3 Técnicamente, lo mismo dar usar una que otra. Obviamente, las simbólicas son las que utilizamos las personas para publicar e intercambiar direcciones de equipos en Internet, por su legibilidad y facilidad para recordar. Los servidores DNS son los encargados de hacer esta traducción, lo que los convierte en blanco de ataques. Quien controla los DNS, controla hasta cierto punto la identidad de los sitios web que no usen certificado digital. Pero esa es otra guerra y no la trataremos aquí. Así pues, una ofuscación trivial consiste en dirigir a la víctima al sitio web del atacante, mostrando en la ventana de URL su dirección numérica en lugar de simbólica. Si la víctima es un usuario medio de Internet, ni se fijará en la URL, y el ataque triunfará fácilmente. Recordemos que la gente se fija en el contenido de la página para validar su identidad, no en la URL. Dominios de alto nivel con nombres similares a los originales A poco que un usuario esté atento a la barra de URL y vea una ristra de números en vez del nombre del servidor, sospechará que algo raro pasa y podría abortar la operación.Un refinamiento del ataque anterior consiste en registrar un nombre de dominio que sea muy similar al original, cambiando uno o dos caracteres. Por ejemplo cambiar carácter por número, el orden de letras, omitir una letra, una letra por otra o utilizar caracteres unicode. Las grandes instituciones suelen registrar múltiples combinaciones de su nombre de dominio, precisamente para mitigar este tipo de ataques de suplantación, dirigidos contra los Dominios de Alto Nivel (TLD). Subdominios con nombres maliciosos Este tipo de ofuscación funciona especialmente bien en dispositivos móviles, donde el ancho de la barra de dirección es fijo. El atacante registra un dominio cualquiera, con un subdominio que se corresponde con el nombre de sitio objetivo. Por ejemplo: www.elevenpaths.com.dominiodelchicomalo.com Dado que las URL no caben en la ventanita de los navegadores es necesario procesarlas de manera inteligente para hacer visible al usuario sólo su parte más significativa (eliding). Mal hecho, la víctima verá solamente la parte correspondiente al dominio objetivo y no la del dominio del atacante. En el último estudio constatamos que solo el 15 % de los indicadores de seguridad recomendados por la W3C, se encuentran en los navegadores móviles. A los navegadores aún les queda mucho camino por recorrer para identificar con seguridad a los sitios web. Comparación del sitio original de Steam Login HTTPS con certificado EV a la izquierda en ruso y sitio de phishing HTTPS ruso a la derecha, en el navegador web Opera para Android Acortadores de direcciones Desde la aparición de Twitter, se volvieron extremadamente populares y ahora se utilizan en cualquier contexto. Son en sí mismos ofuscadores de URL, ya que toman la URL original y la comprimen a un tamaño más manejable. Entre las más populares destacan bit.ly, tinyurl, goo.gl, o amzn.to, por citar solo algunas. Claro está, la mera observación de una URL acortada impide saber a dónde dirige. Sí que existen sitios web que informan de la URL sin acortar, pero ¿quién se toma las molestias de verificar una URL acortada antes de hacer clic sobre ella? ¿Lo haces tú rutinariamente? Lo cierto es que los usuarios están tan acostumbrados a toparse con este formato de URL que no suelen despertar sospechas. Autenticación básica Observa cuidadosamente esta URL. ¿A dónde te llevará? https://mibanco.com/NASApp/Net2/Gestor?PORTAL_CON_DCT=SlI&PRESTACION=login&FUNCION=directoportal&ACCION=control&destino=@3627731379 Una mirada superficial podría hacer pensar en que conduce a una página dinámica en mibanco.com. En realidad, se está haciendo uso del segmento usuario de la URL para distraer la atención del verdadero servidor al que redirige, codificado tras la arroba (@): 3627731379. Es decir, en verdad está apuntando al servidor de ElevenPaths. Afortunadamente, las últimas versiones de los navegadores son capaces de contrarrestar estas ofuscaciones. ¿Qué ha hecho Google hasta ahora? El protocolo TLS junto con los certificados digitales constituyen la mejor defensa presente contra esta crisis de identidad. En un movimiento audaz, en el Google I/O 2014 la compañía anunció su eslogan " HTTPS Everywhere", incluyendo el https como señal de ranking: penaliza con un peor posicionamiento SEO a los sitios web que carecen de certificado digital y que, por lo tanto, no soportan el esquema https://. Desde enero de 2017, además Google Chrome comenzó a indicar al navegante la seguridad de la conexión con un icono en la barra de dirección, restringiendo progresivamente sus criterios. A partir de julio de 2018, Chrome marca como "No es seguro" todos los sitios HTTP. En breve, se destacará este mismo texto, pero en color rojo parpadeante. El objetivo de Google es acostumbrar a los navegantes a una web "segura por defecto (safe by default)". Como consecuencia, resulta difícil ya encontrar sitios web "serios" sin soporte para TLS. Y, con el tiempo, todo hace pensar que la postura de Google se radicalizará aún más. ¿Llegará a bloquear el acceso con Chrome a sitios sin HTTPS? Qué duda cabe que se está perfilando una gran oportunidad para los servicios de certificación. Además, para "aligerar" las URLs, Chrome en sus últimas versiones ha decidido ocultar subdominios como "www." y "m" en su barra de navegador por considerarlos triviales, algo que no ha dejado de sembrar polémica. Cuantos más HTTPS, ¿peor seguridad? Y aquí viene la contrapartida de este movimiento de Google. Conseguir un certificado TLS es ahora más fácil (y barato) que nunca. Como consecuencia, los ciberatacantes usarán por supuesto HTTPS en sus sitios maliciosos copiados de los originales. Lo que significa que sus sitios web inseguros llevarán un flamante icono "Es seguro" de color verde, al menos hasta el momento en que caigan en las listas negras de Google. Ahora bien, cuando Chrome dice "Es seguro", ¿qué quiere decir? TLS garantiza la confidencialidad del canal. Es decir, el usuario puede tener la certeza de que sus datos no pueden ser interceptados en tránsito desde el navegador al servidor o desde el servidor al navegador. ¿Significa eso que el sitio es seguro? Obviamente no. Los datos podrían ser manipulados irresponsablemente en el servidor o caer en manos de un atacante que lo asaltase. En definitiva, "es seguro" significa canal seguro, para nada significa sitio web seguro. ¿Cuántos usuarios serán capaces de discernir estos finos detalles criptográficos? Ese indicador proporcionará una falsa sensación de seguridad: pensarán que mientras un sitio tenga el indicador verde es seguro proporcionarle los datos personales. Así que vamos a recapitular: Los usuarios de navegadores no son muy avezados en eso de leer URLs. Como declaró a la revista Wired hace poco Adrienne Porter Felt, directora de ingeniería de Chrome: "[Las URL] Son difíciles de leer, es difícil saber en qué parte de ellas se supone que debemos confiar, y en general no creo que las URL estén funcionando como una forma válida de transmitir la identidad del sitio". Los usuarios buscan formas fáciles de saber si un sitio es de fiar o no. ¿Qué mejor lugar donde mirar que el icono de Google, que informa «Es seguro» en verde o «No es seguro» en rojo? Los usuarios navegarán con mayor confianza que nunca por los sitios maliciosos, porque ahora Chrome les asegurará que «son seguros». Ya tenemos servido el cóctel para un auge en los ataques de phishing. Si no es la URL, entonces... ¿qué? En estas circunstancias, no es de extrañar que Google quiera matar la URL. Declara Porter Felt en la misma entrevista que "queremos avanzar hacia una situación en la que la identidad web sea comprensible por todos: que puedan saber con quién están hablando cuando están visitando un sitio web y puedan razonar si se puede confiar en él. Pero harán falta grandes cambios en cómo y en cuándo Chrome muestra las URL. Queremos desafiar la manera como las URL deberían mostrarse y cuestionarla mientras damos con la forma correcta de comunicar la identidad». Ahí es nada. De momento, Google tiene claro que la URL debe morir, pero aún no han encontrado la forma. Sea cual sea el mecanismo que inventen, eso sí, despertará grandes polémicas. Mientras ese día llega, seguiremos mirando la URL y viendo los detalles de los certificados. Y tú, ¿cómo crees que deberían evolucionar las URL?
17 de septiembre de 2018