Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Deep Learning vs Atari: entrena tu IA para dominar videojuegos clásicos (Parte I)
18 de abril de 2018
Hace unos meses, comenzamos una serie de posts en este mismo blog donde explicamos cómo entrenar una Inteligencia Artificial ( IA ) para que lograra superar algunos juegos. Si este tema te interesa, te invitamos a registrarte al webinar "Domina los videojuegos clásicos con OpenAI y Machine Learning" donde explicaremos en directo todo sobre el OpenAI Gym, desde su instalación hasta su funcionamiento, y también mostrando ejemplos con Python y técnicas sencillas de Aprendizaje Reforzado (RL). Será una serie de dos capítulos, que se estrenará el 24 de abril a las 16:00 CET. Registrate aquí.
 Figura 1. Atari 2600 lanzada al mercado en septiembre de 1977
Figura 1. Atari 2600 lanzada al mercado en septiembre de 1977
Antes de continuar con estos nuevos capítulos, te animamos a que leas los artículos:
- Parte 1. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos, preparando la “rejilla de juegos”.
- Parte 2. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos, observando el entorno.
- Parte 3. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos, resolviendo CartPole con Random Search.
- Parte 4. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos. Aprende Q-Learning con el juego “Taxi”, parte 1 de 2.
- Parte 5. Cómo entrenar a tu Inteligencia Artificial jugando videojuegos. Aprende Q-Learning con el juego “Taxi”, parte 2 de 2.
En los cuales podrás encontrar una introducción a OpenAI y sus librerías Universe y Gym para luego continuar desarrollando algunas soluciones simples de aprendizaje para entornos sencillos y bien conocidos como CartPole o el juego Taxi. Estos artículos te ayudarán a instalar el entorno y las librerías necesarias, así como a sentar las bases necesarias para afrontar los próximos posts.
En esta nueva serie continuaremos con OpenAI pero esta vez nos enfrentaremos a retos mayores, tanto en la complejidad de los juegos (entorno a resolver) como en el diseño del agente de IA (técnicas de Aprendizaje Reforzado). El objetivo final será ofrecer una introducción al entrenamiento de una Inteligencia Artificial el cual se sea capaz de superar estos entornos de videojuegos con más dificultad siguiendo la estrategia de prueba y error.
La base del entrenamiento se realizará sobre el clásico videojuego Breakout de Atari, aunque las soluciones que propondremos se podrán extrapolar a otros con más o menos las mismas características. Aunque hemos aumentado la dificultad de los entorno, para la solución que vamos a ofrecer necesitaremos juegos en los que el escenario no sea demasiado complejo, sin demasiados objetos en movimiento que analizar y que la secuencia de movimientos sea sencilla, por ejemplo: izquierda, derecha y disparo. Dentro de este límite de complejidad podemos encontrar clásicos como Space Invaders o Ms. Pac-Man.
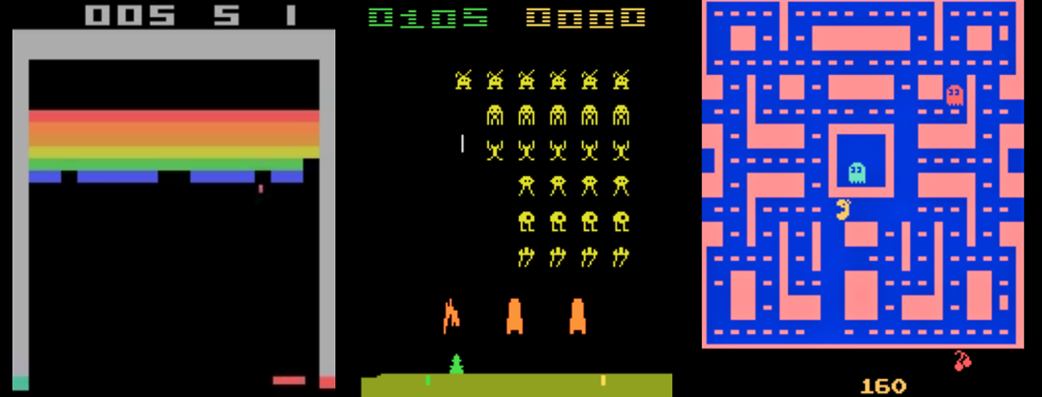 Figura 2. Captura de ejecución de los entornos OpenAI Gym de los juegos Breakout, SpaceInvaders y MsPacMan.
Figura 2. Captura de ejecución de los entornos OpenAI Gym de los juegos Breakout, SpaceInvaders y MsPacMan.
Estos juegos arcade se podían jugar en la consola Atari 2600, desarrollada en 1977, la cual resultó ser un éxito de ventas durante más de una década y, sin duda, marcaron la infancia y adolescencia de muchos de nosotros. La simplicidad de los entornos de juego desarrollados para esta consola, ha permitido que estos “mundos” se conviertan en plataformas para estudio y aplicación de la teoría de IA y técnicas de aprendizaje automático. Esta sencillez permite que cada frame de un juego se pueda definir por estado en un espacio de observaciones relativamente manejable y un conjunto de acciones reducido.
Como hemos comentado antes, el videojuego que hemos elegido para realizar nuestra PoC es Breakout. Este videojuego arcade clásico fue creado en 1976 por Nolan Bushnell y Steve Bristow pero implementado inicialmente por Steve Wozniak (no os perdáis la fantástica historia detrás del diseño de Breakout que implica a Steve Jobs y Steve Wozniak) que tiene como finalidad romper todos los ladrillos que ocupan la mitad superior de la pantalla con una pelota la cual rebota, utilizando para ello una especie de pala o raqueta. La pala, controlada por el jugador, puede moverse tanto a la derecha como a la izquierda de la pantalla dentro de los límites del juego.
 Figura 3. Captura de ejecución del entrenamiento en el entorno Breakout en OpenAI Gym.
Figura 3. Captura de ejecución del entrenamiento en el entorno Breakout en OpenAI Gym.
El objetivo del jugador es devolver la pelota hacia los ladrillos para irlos destruyendo uno a uno, evitando que la pelota se pierda por la parte inferior de la pantalla, lo cual provocaría la pérdida de una vida. El juego se reanuda cuando todos los ladrillos se han golpeado o cuando el jugador ha perdido las cinco vidas de las que nos ofrece el juego al inicio de la partida.
Gracias al gran número de entornos soportados ( aquí podéis ver la lista de todos ellos), volvemos a usar OpenAI y Gym el cual esta vez se encargará de suministrar las capturas de los fotogramas del juego para posteriormente poder identificar y ubicar los pixeles en la pantalla los cuales corresponderán a los diferentes elementos del juego (como por ejemplo la posición de la pelota, de la pala, etc).
El entorno Gym que hemos utilizado se llama Breakout-v0 y presenta las siguientes características:
- Un espacio de observación (env.observation_space), que puede representarse por un estado del juego, es una matriz height x width x deep = 210 x 160 x 3, representa los valores de píxel de una imagen en el juego. La tercera dimensión se reserva a los valores de rgb definidos en cada píxel para una paleta de colores de 128 bytes.
- El espacio de acciones (env.action_space.n) se define para este juego como un grupo de 4 enteros [0, 1, 2, 3]. La correspondencia de estos enteros con las acciones permitidas se puede obtener por medio de env.unwrapped.get_action_meanings(), que devuelve ['NOOP', 'FIRE', 'RIGHT', 'LEFT'].
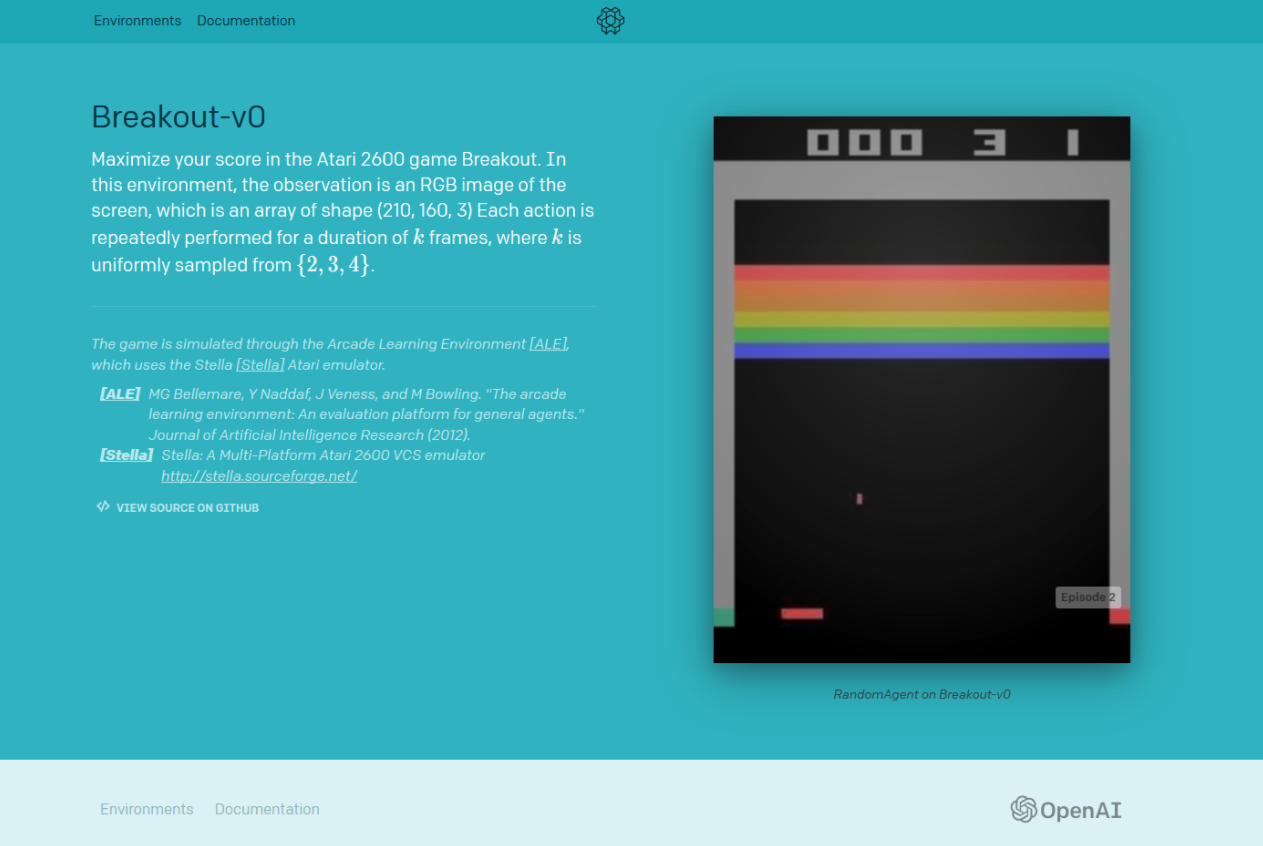 Figura 4. Información sobre el entorno Breakout-v0 en OpenAI. Fuente.
Figura 4. Información sobre el entorno Breakout-v0 en OpenAI. Fuente.
La interacción con de la herramienta OpenAI Gym se puede resumir en los siguientes pasos: cargar el entorno deseado desde la librería; obtener un estado aleatorio inicial; aplicar una cierta acción en el entorno derivada de una cierta política; esta acción derivará en un nuevo estado del juego; se obtendrá una recompensa tras aplicar la acción elegida, así como como un indicador de si la partida ha finalizado y el número de vidas restantes.
Al intentar entrenar una IA en entornos como Breakout con estrategias como, por ejemplo, random search, nos damos cuenta que es una tarea totalmente inabarcable, en especial cuando se proporcionan al agente estados o conjuntos de estados de elevado tamaño y complejidad, como en esta caso. Por lo tanto necesitamos que nuestro agente utilice una política de acciones adecuada que nos permita aproximar satisfactoriamente la función Q(s,a) que maximice la recompensa a obtenida tras la aplicación una acción a dado un estado s. Pero, ¿cómo podemos lidiar con la complejidad asociada a un conjunto de estados del entorno y aproximar esa función? Usando Deep Neural Networks dotadas de algoritmos de Q-Learning, más conocidas como Deep Q-Networks ( DQN).
Para este tipo de entrenamiento, las redes neuronales a usar son las llamadas Convolutional Neural Networks, las cuales han demostrado a lo largo de la historia del Deep Learning ser arquitecturas con un excelente comportamiento a la hora de reconocer y aprender patrones basados en imágenes. Este tipo de redes toman los valores de los píxeles de los fotogramas que se le entregan como input. Las representaciones de las entradas se irán abstrayendo en mayor medida según se profundice en la arquitectura, y terminarán reducidas a una capa densa final con un número de salidas igual al espacio de acciones del entorno (4 en el caso de Breakout-v0).
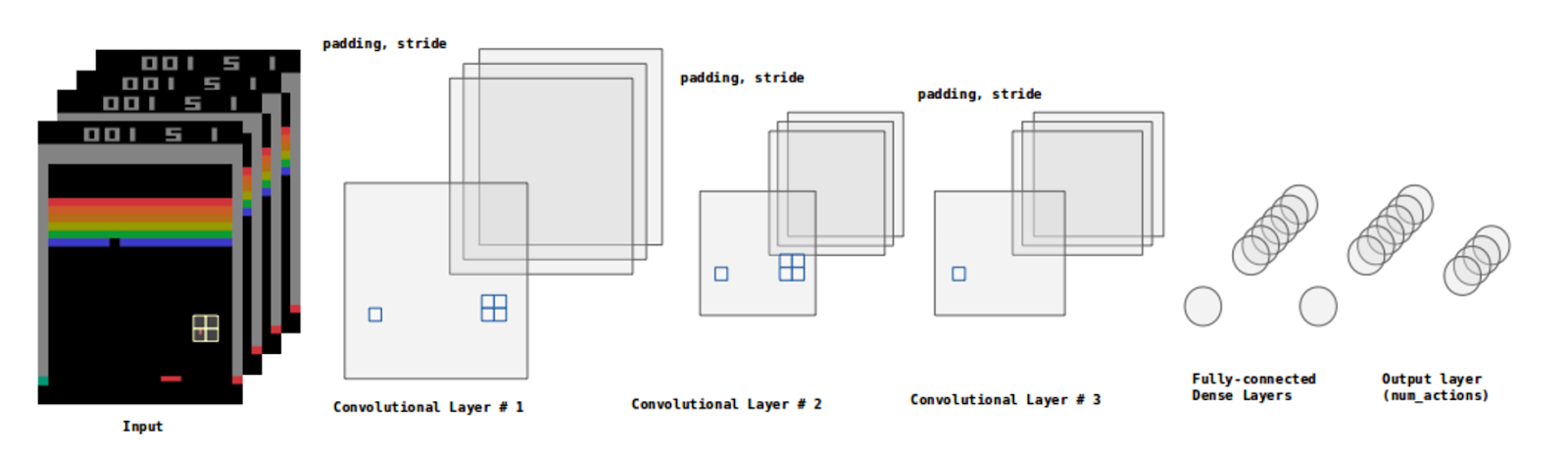 Figura 5. Detalle de las capas de la Red Neuronal Convolucional utilizada en nuestro proyecto Breakout.
Figura 5. Detalle de las capas de la Red Neuronal Convolucional utilizada en nuestro proyecto Breakout.
Optimizar una red neuronal resulta tarea complicada, altamente dependiente de la calidad y cantidad de los datos con los que se entrene el modelo. La dificultad de optimizar la red también vendrá dada por la arquitectura de la misma, entendiendo que a mayor número de capas y dimensionalidad, se tendrá que abordar la optimización de un mayor número de pesos y biases.
Como recordatorio, la función Q(s,a) se define como:

Si conociéramos perfectamente la función Q(s, a), sería inmediato conocer la acción a realizar en base a una política definida:
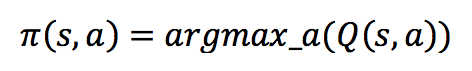
En cierto modo, la red neuronal intentará predecir su propio output a través del uso recurrente de esta fórmula dirigida a modificar la función Q(s, a). Sin embargo, ¿qué nos garantiza, mediante la toma de muestras dada una política de toma de decisiones, que logremos hacer converger nuestra función Q hacia la verdadera? Realmente ninguna, nada nos salva de que la función nunca converja hacia la solución óptima. Existen diferentes técnicas que permitirán que esa función se aproxime de manera correcta, cuya explicación dejaremos para la segunda parte de esta serie.
Durante el entrenamiento de este tipo de arquitecturas, la estrategia más conveniente es dar a nuestro algoritmo un conjunto de estados iniciales pre-procesados a partir de los cuales se obtendrá una acción beneficiosa para el agente, que recogerá la recompensa fruto de esa acción y el siguiente estado alcanzado en el entorno, con el que volverá a alimentar el modelo y así sucesivamente.
Ahora que ya tenemos una base de redes neuronales profundas y Q-learning, en el siguiente post ofreceremos el resultado del entrenamiento propio para Breakout y Space Invaders. Además, daremos más detalles sobre la implementación de la arquitectura del modelo, las estrategias usadas para hacer converger la solución y las tareas de pre-procesado de imágenes necesarias para poder entrenar la red de manera más eficiente. Nuestro modelo será una DQN construida que haga uso de la librería TensorFlow.
Ahora mismo estamos inmersos en el entrenamiento del modelo. Aquí dejamos un avance de las capacidades actuales de nuestro agente:
Como puedes ver, ¡nuestra IA ya es capaz de obtener 101 puntos en un episodio! Esto lo ha podido conseguir tras haber sido entrenada durante algo más de 1900 episodios y haber procesado casi 2.5e7 estados durante una semana de entrenamientos. Dejaremos el modelo entrenando más tiempo para poder dejaros en el próximo artículo, un vídeo en el que se muestre cómo nuestro agente es capaz de golpear todos los ladrillos antes de perder las 5 vidas de las que disponemos y además os daremos otro en el que se muestre un modelo entrenado en Space Invaders.
¡Te esperamos en la siguiente entrega de esta nueva serie!