Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

La evolución del Big Data hacia el modelo lakehouse: ventajas, retos y casos de uso
Hoy en día, vivimos en un mundo en el que los datos uno de los activos más valiosos para las empresas. La llegada de la Inteligencia Artificial en los últimos años ha incrementado todavía más su relevancia, puesto que los datos son la materia prima fundamental para su desarrollo.
El Big Data no es algo nuevo ni mucho menos. Lleva con nosotros más de dos décadas y con el paso del tiempo han ido evolucionando las arquitecturas en la que almacenamos y explotamos estos datos para mejorar el rendimiento y costes de nuestros sistemas.
En los últimos años, la arquitectura lakehouse se ha consolidado como un nuevo enfoque para almacenar y explotar datos, prometiendo optimizar costes, mejorar la consistencia y la calidad de los datos, y ofrecer un alto rendimiento. ¿Es esta la solución definitiva para nuestros sistemas?
Los datos se han convertido en un activo empresarial muy valioso.
Evolución de las arquitecturas de datos
Para comprender el concepto de arquitectura data lakehouse, es imprescindible abordar previamente las arquitecturas de data warehouse y data lake.
Lo primero que debemos entender es que estas tres arquitecturas son formas de almacenar grandes cantidades de datos para poder ser explotados.
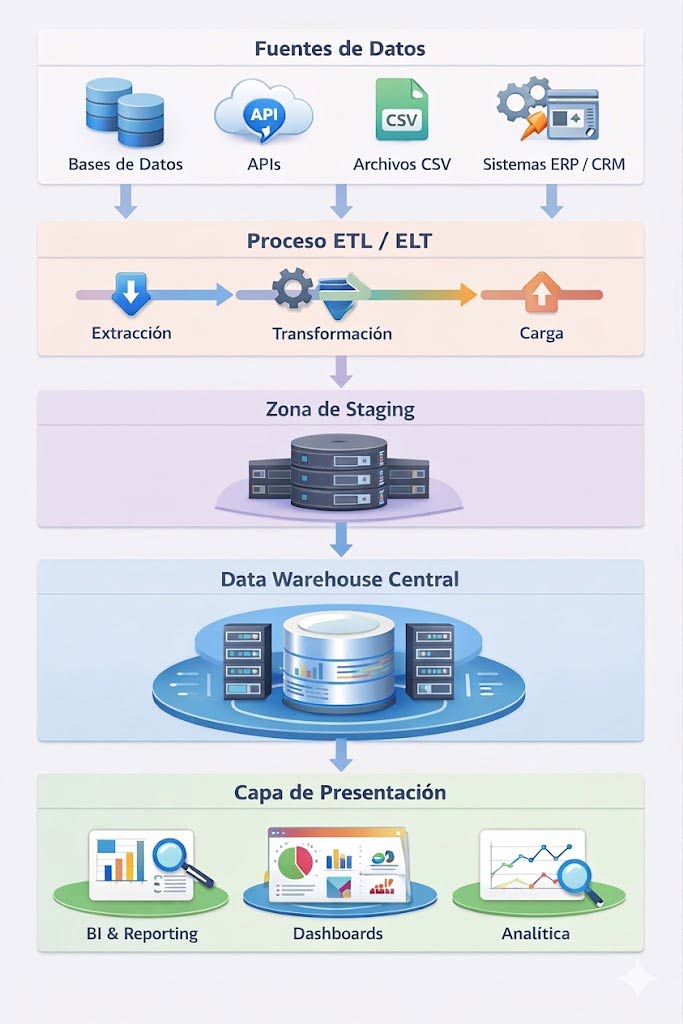
La idea de los data warehouse surgió entre los años 80-90 del siglo pasado cuando las empresas empezaron a almacenar datos de sus procesos y con ello surgió la necesidad de explotarlos. Esta arquitectura está formada normalmente por varias capas:
- Fuentes de datos: sistemas transaccionales, aplicaciones y otras fuentes que generan datos.
- Proceso de extracción y transformación de los datos: proceso en el que los datos se extraen, se limpian, se transforman y se preparan para su almacenamiento.
- Almacenamiento de los datos: repositorio central de datos estructurados y modelados para análisis, generalmente mediante modelos tipo estrella o copo de nieve. A día de hoy algunas herramientas muy utilizadas son Snowflake, BigQuery, Redshift y Synapse.
- Explotación de los datos: herramientas de inteligencia de negocio (BI, business intelligence) que permiten la generación de informes, cuadros de mando y análisis.
El reto actual ya no es solo almacenar datos, sino explotarlos de forma eficiente y sostenible.
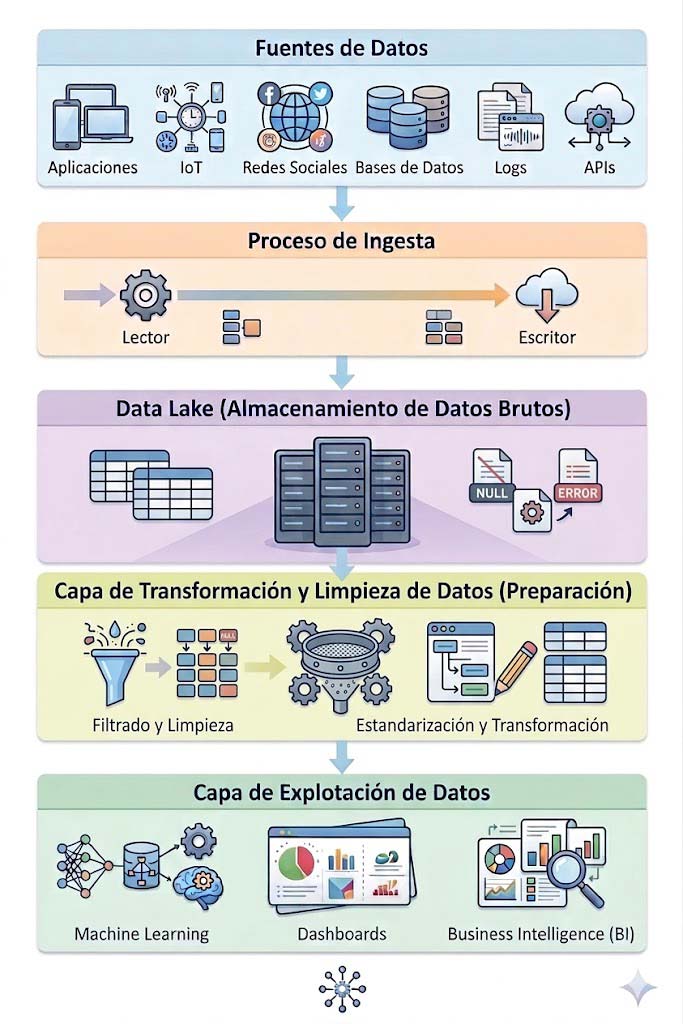
Con el paso del tiempo aumentó el volumen, la variedad y la velocidad de los datos (Big Data, IoT, redes sociales, etc.) y de esta forma surgió la necesidad de una nueva arquitectura que fuera capaz de almacenar una gran cantidad de datos en cualquier forma, estructurados, semiestructurados y no estructurados. Esta arquitectura es conocida como data lake y sus capas habituales son:
- Fuentes de datos: esta primera capa es el origen de los datos que alimentarán nuestro sistema.
- Ingesta de datos: se ingestan los datos de las fuentes origen en crudo en nuestro almacenamiento.
- Almacenamiento: se tienen todos los datos Almacenados en crudo y sin organizar. Algunas de las herramientas más utilizadas son Amazon S3, Azure Data Lake Storage Gen2 y Google Cloud Storage.
- Transformación y limpieza: se limpian y se transforman los datos para enviarlos a las herramientas de explotación.
- Explotación de los datos: se utilizan herramientas de business inteligence y machine learning.
Ventajas y desventajas de estas arquitecturas
Gracias a disponer de datos limpios, consistentes y estructurados, los data warehouse permiten garantizar una alta calidad de los datos, una gobernanza sólida y consultas rápidas y eficientes. No obstante, presentan menor flexibilidad, los cambios en el esquema pueden ser lentos y los costes de almacenamiento y procesamiento suelen ser altos.
En cambio, los data lakes permiten almacenar grandes volúmenes de datos en su formato original, lo que aporta una gran flexibilidad y facilita la ingesta rápida de información sin necesidad de transformarla previamente. Además, suele ser más escalable y económico, y resulta ideal para análisis avanzados, ciencia de datos y machine learning.
Un data warehouse prioriza el rendimiento; un data lake, la flexibilidad.
Por otro lado, puede volverse desorganizado si no se gestiona adecuadamente: las consultas pueden ser más complejas y lentas, y requiere que los usuarios procesen y limpien los datos antes de utilizarlos, lo que puede aumentar la dificultad de uso y reducir la calidad inicial de los datos.
Casos de uso de las arquitecturas
Partiendo de estas ventajas y desventajas que ofrecen cada una de estas arquitecturas se debe elegir cuál es la adecuada para el sistema a desarrollar. Para los casos en los que necesite presentar informes fiables, rápidos y consistentes se deberá utilizar la arquitectura data warehouse. En los casos en los que se tenga una gran cantidad de información en diferentes formatos y se quiera realizar trabajos de machine learning se deberá utilizar la arquitectura data lake.
Sin embargo, al trasladar la teoría a la práctica, los casos de uso reales suelen ser mucho más complejos. En muchos escenarios, las empresas manejan grandes volúmenes de datos procedentes de múltiples fuentes y en formatos tanto estructurados como no estructurados, mientras necesitan generar informes rápidos y fiables.
La complejidad de los datos actuales obliga a combinar rendimiento, flexibilidad y gobernanza.
Estas necesidades plantean un dilema arquitectónico: un data warehouse ofrece rendimiento y fiabilidad para el análisis, mientras que un data lake proporciona flexibilidad y escalabilidad para almacenar datos heterogéneos. Entonces, ¿qué solución resulta más adecuada en este contexto?
Ante esta tesitura las empresas han optado por combinar ambas arquitecturas de la siguiente forma:
- Fuentes de datos: sistemas transaccionales, aplicaciones y otras fuentes que generan datos.
- Ingesta de datos: se ingestan los datos de las fuentes origen en crudo en nuestro almacenamiento.
- Data lake: se tienen todos los datos Almacenados en crudo y sin organizar.
- Procesamiento de transformación y limpieza: proceso en el que los datos se extraen del Data Lake, se limpian, se transforman y se preparan para su almacenamiento.
- Data warehouse: repositorio central de datos estructurados y modelados para análisis.
- Explotación de datos: se utilizan herramientas de Business Inteligence y Machine Learning.
■ Aunque esta arquitectura resuelve gran parte de las necesidades de las empresas, también introduce una mayor complejidad operativa. La utilización de diferentes capas y herramientas incrementan los recursos necesarios para almacenamiento, procesamiento y mantenimiento, elevando así los costes asociados.
Arquitectura lakehouse
En 2019, Databricks popularizó la arquitectura data lakehouse con el objetivo de combinar las ventajas de los data lakes y los data warehouses. La idea principal consiste en almacenar los datos en un data lake y añadir una capa transaccional que permita trabajar con ellos como si fueran tablas de un data warehouse.
En Databricks esta capa se implementa mediante el formato de almacenamiento Delta Lake. Los datos se almacenan en archivos en formato Apache Parquet de bajo coste, mientras que un transaction log mantiene el registro de las operaciones realizadas sobre las tablas.
Gracias a ello, se obtienen funcionalidades como transacciones ACID, versionado de datos, control de esquemas y consultas SQL eficientes. Esto permite optimizar la gestión del almacenamiento mediante técnicas como compaction y eliminación de archivos obsoletos.
El modelo lakehouse busca combinar la escalabilidad del data lake con la fiabilidad del data warehouse.
Este enfoque introduce, sin embargo, una mayor complejidad operativa, derivada tanto del manejo de múltiples ficheros y versiones como de la necesidad de establecer políticas de gobernanza en entornos de datos heterogéneos. Asimismo, estas arquitecturas requieren un mayor grado de especialización técnica por parte de los desarrolladores.

■ Por ello, aunque la arquitectura data lakehouse permite mejorar los costes en determinados ámbitos, también introduce nuevas complejidades y costes operativos.
Conclusión
Como ocurre con el resto de las arquitecturas, el modelo lakehouse presenta ventajas y desventajas. A día de hoy, no existe una solución única que cubra todas las necesidades de una empresa. Por ello, lo más adecuado es identificar la opción más eficiente para cada caso concreto, en lugar de perseguir una solución perfecta que, en la práctica, no existe.
El aumento del volumen y variedad de datos impulsó la evolución desde el data warehouse al data lake.