 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Pensando en ataques a WAFs basados en Machine Learning
Una de las piezas fundamentales para la correcta implementación de machine y deep learning son los datos. Este tipo de algoritmos necesitan consumir, en algunos casos, una gran cantidad de datos para lograr dar con una combinación de “parámetros” internos que le permitan generalizar o aprender, con el fin de predecir nuevas entradas. Si estas familiarizado con la seguridad informática, probablemente lo que hayas notado es que datos es lo que sobra, la seguridad se trata de datos, y los encontramos representados en distintas formas: files, logs, network packets, etc.
Típicamente, estos datos se analizan de una forma manual, por ejemplo, utilizando file hashes, reglas personalizadas como las firmas y heurísticas definidas manualmente. Este tipo de técnicas requieren demasiado trabajo manual para mantenerse al día con el panorama cambiante de las amenazas cibernéticas, que tiene un crecimiento diario dramáticamente exponencial. En 2016, hubo alrededor de 597 millones de ejecutables de malware únicos conocidos por la comunidad de seguridad según AVTEST, y en lo que va del 2020 ya vamos mas de mil millones.
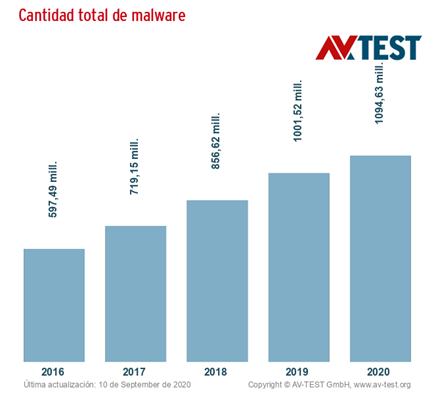 Imagen 1: fuente https://www.av-test.org/es/estadisticas/software-malicioso/
Imagen 1: fuente https://www.av-test.org/es/estadisticas/software-malicioso/
Para este volumen de datos, un análisis manual de todos los ataques es humanamente imposible. Por este motivo, los algoritmos de deep y machine learning son ampliamente utilizados en la seguridad, por ejemplo: antivirus para detectar malware, firewall detectando actividad sospechosa en la red, SIEMs para identificar tendencias sospechosas en los datos, entre otros.
Al igual que un ciberdelincuente podría aprovechar una vulnerabilidad de un cortafuegos para obtener acceso a un web server, los algoritmos de machine learning también son susceptibles a un posible ataque como vimos en estas dos entregas anteriores: Adversarial Attacks, el enemigo de la inteligencia artificial 1 y Adversarial Attacks, el enemigo de la inteligencia artificial 2. Por lo tanto, antes de poner tales soluciones en la línea de fuego, es crucial considerar sus debilidades y comprender cuán maleables son bajo estrés.
Ejemplos de ataques a WAF
Veamos un par de ejemplos de ataque a dos WAFs, donde cada uno cumple con un simple objetivo: detectar XSS y sitios maliciosos analizando el texto de una URL específica. A partir de grandes sets de datos, donde estaban correctamente etiquetados XSS y sitios maliciosos, se entrenó un algoritmo del tipo logistic regression con el cual poder predecir si es malicioso o no.
Los sets de datos para XSS y para sitios maliciosos utilizados para entrenar estos dos algoritmos de logistic regression, básicamente, son una recopilación de URLs clasificadas en “buenas” y “malas”:
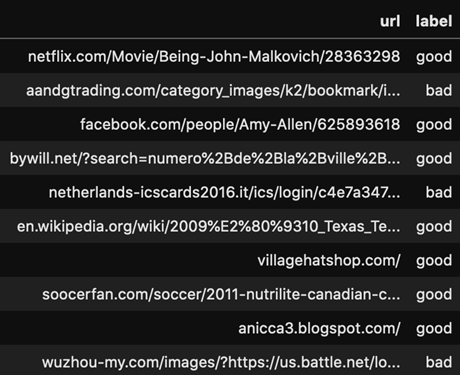 Imagen 2: URLs maliciosas
Imagen 2: URLs maliciosas
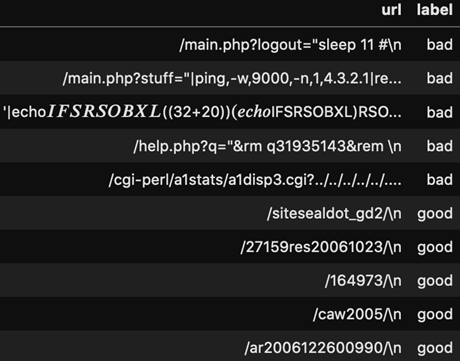 Imagen 3: XSS
Imagen 3: XSS
Donde el set de datos de sitios maliciosos contiene unos 420.000 URLs entre buenas y malas y, por el lado de XSS, hay 1.310.000.
Al ser un ataque del tipo white box, tenemos acceso a todo el proceso y manipulación de datos para el entrenamiento de los algoritmos. Por lo tanto, podemos apreciar que el primer paso en los dos escenarios es aplicar una técnica llamada TF-IDF (Term frecuency – Inverse document frecuency), que nos va a brindar una importancia a cada uno de los términos dada su frecuencia de aparición en cada una de las URLs en nuestros sets de datos.
A partir de nuestro objeto TF-IDF podemos obtener el vocabulario generado para ambos casos, y una vez entrenado el algoritmo podríamos fácilmente acceder y ver a cuáles de estos términos le dio mayor peso. A su vez, a partir de estos términos podemos fácilmente manipular el output del algoritmo. Veamos el caso de clasificación de sitios maliciosos.
Clasificación de sitios maliciosos
Según el algoritmo, si alguno de estos términos aparece en una URL hay una alta probabilidad de que sea un sitio no malicioso:
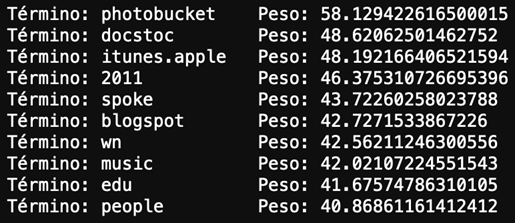 Imagen 4: peso de los términos para considerarlos NO maliciosos.
Imagen 4: peso de los términos para considerarlos NO maliciosos.
Esto quiere decir que, simplemente añadiendo alguno de estos términos a mi URL maliciosa, voy a poder influenciar al máximo al algoritmo a mi merced. Tengo mi URL maliciosa que el algoritmo detecta con bastante certeza que, efectivamente, es un sitio malicioso:
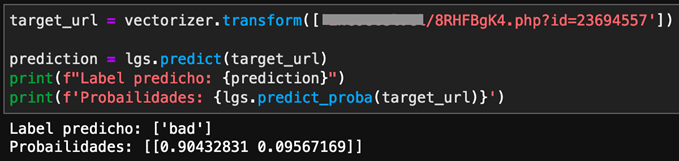 Imagen 5: URL maliciosa
Imagen 5: URL maliciosa
Con un 90% de confianza, clasifica la URL como maliciosa. Pero si le añadimos el término ‘photobucket’ a la URL, el algoritmo ya la clasifica como “bueno”:
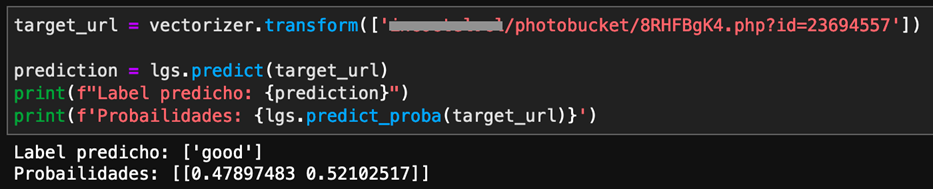 Imagen 6: URL maliciosa con un término que da “confianza”.
Imagen 6: URL maliciosa con un término que da “confianza”.
Incluso podríamos empujar más esa probabilidad simplemente añadiendo otro término a la URL, por ejemplo “2011”:
 Imagen 7: URL con 2 términos que dan “confianza”
Imagen 7: URL con 2 términos que dan “confianza”
Pasemos al escenario de XSS. Tenemos un payload al cual el algoritmo lo clasifica correctamente como XSS y con una confianza del 99% (en este ejemplo el label 1 corresponde a XSS y el 0 a no XSS):
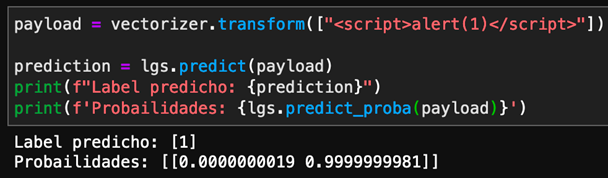 Imagen 8: Payload de XSS detectable.
Imagen 8: Payload de XSS detectable.
Veamos los términos con menor peso para invertir esa predicción:
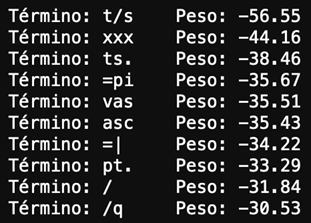 Imagen 9: peso de los términos para bajar la predicción de ataque XSS.
Imagen 9: peso de los términos para bajar la predicción de ataque XSS.
Como hicimos anteriormente, agregamos alguno de estos términos para manipular el output del algoritmo. Después de unas pruebas, damos con el payload que invierte la predicción, tuvimos que agregar el término “t/s” unas 700 veces para lograr el objetivo:
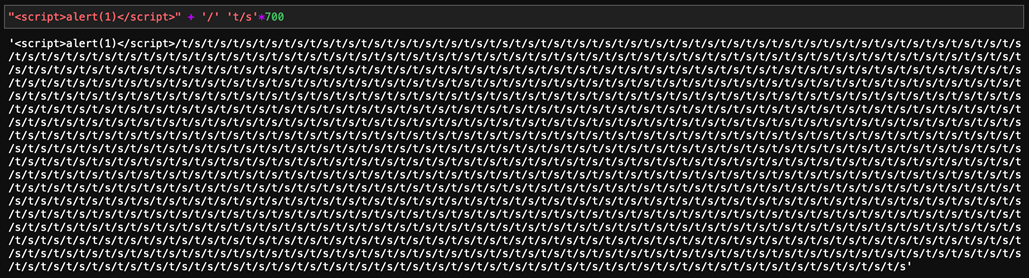 Imagen 10: payload capaz de invertir la predicción del XSS.
Imagen 10: payload capaz de invertir la predicción del XSS.
Y, efectivamente, nuestro algoritmo lo predice como NO XSS:
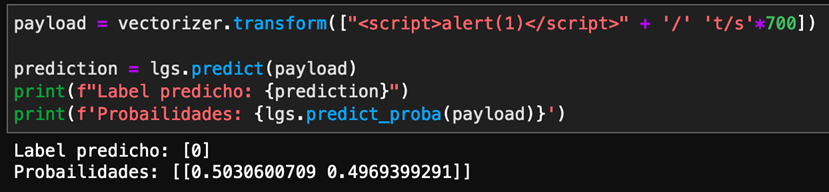 Imagen 11: No detección del XSS por el payload utilizado..
Imagen 11: No detección del XSS por el payload utilizado..
Por si alguien está interesado en el tema, les dejamos los links de los proyectos WAF de sitios maliciosos y el WAF de XSS. Algunas referencias fueron tomadas del libro Malware Data Science
Disponer de acceso a los pasos de preprocesamiento de los datos y a los modelos facilita la generación de estos tipos de ataques. Si el atacante no tuviera acceso a estos, implicaría un esfuerzo mayor para dar con el preprocesamiento justo de los datos y la arquitectura o algoritmo del modelo predictivo. Sin embargo, sigue siendo posible recrear estos ataques por medio de otras técnicas como la transferibilidad, donde muestras adversarias que están diseñadas específicamente para causar una clasificación errónea en un modelo también pueden causar clasificaciones erróneas en otros modelos entrenados de forma independiente. Incluso cuando los dos modelos están respaldados mediante algoritmos o infraestructuras claramente diferentes.



