 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Análisis de la fuga de información de la plataforma Trello
Introducción
En ocasiones no se requiere ser receptor de un ataque complejo para que la reputación de una organización se vea afectada por su aparición en los medios de comunicación. Así le ha sucedido este enero a Trello, la conocida plataforma de gestión de proyectos y tareas propiedad de Atlassian.
Un actor, con el seudónimo de emo, puso a la venta en un conocido foro de hacking, datos de 15 millones de usuarios de Trello con información pública y privada de los mismos: nombre de usuario, nombres completos y correos electrónicos asociados.
Como suele suceder, Trello al ser contactada para obtener información de la fuga de información, sugirió que no se trataba de un ataque sino de información recolectada mediante el escaneo de información pública (scraping) de los perfiles de su plataforma partiendo de un listado de potenciales usuarios.
Si bien es cierto que estas técnicas de scraping se pueden utilizar para estos fines, en un principio, el correo electrónico asociado a una cuenta de Trello es una información privada a la que solamente el usuario en cuestión debe tener acceso y ahí es donde radica lo relevante de esta fuga de información.
Configuración de las API
La mayoría de las plataformas SaaS (Software as a Service) emplean interfaces de programación llamadas API (Application Programming Interface) para ofrecer información a usuarios y desarrolladores de sus características, funcionalidades, estadísticas y uso.
Habitualmente las organizaciones protegen el abuso de estas APIs principalmente mediante dos técnicas que pueden o no usarse de forma coordinada:
- La autenticación: solamente aquellos usuarios con unas credenciales de acceso pueden obtener información del servicio y muchas veces limitando a su propio uso.
- Límites de uso de la API (rate limiting): La definición de límites de uso temporales de la interfaz por parte de un usuario en los términos y condiciones del servicio. Normalmente esta limitación se realiza por IP u otros datos que permitan determinar un origen de las solicitudes.
La ausencia de unas adecuadas medidas antiabuso en la API de Trello están en la causa raíz de la fuga de información detectada.
¿Qué ocurrió en el incidente de Trello?
El actor bajo el seudónimo de emo descubrió que un punto de acceso (endpoint) de la API pública de Trello, que no requería autenticación, permitía obtener información de los perfiles de los usuarios no solamente a través de su nombre de usuario o id de Trello sino también a través de un correo electrónico.
El atacante se construyó un listado de más de 500 millones de correos electrónicos potenciales, basado en información pública o disponible de anteriores fugas de información y comenzó a solicitar los datos de perfil asociados a la API de Trello.
Para no ser detectado y excluido del acceso a la API, el atacante utilizó uno de los múltiples servicios de proxy disponibles en internet para lanzar las consultas desde diferentes IPs y no ser afectado por protecciones de rate limiting que comentamos anteriormente.
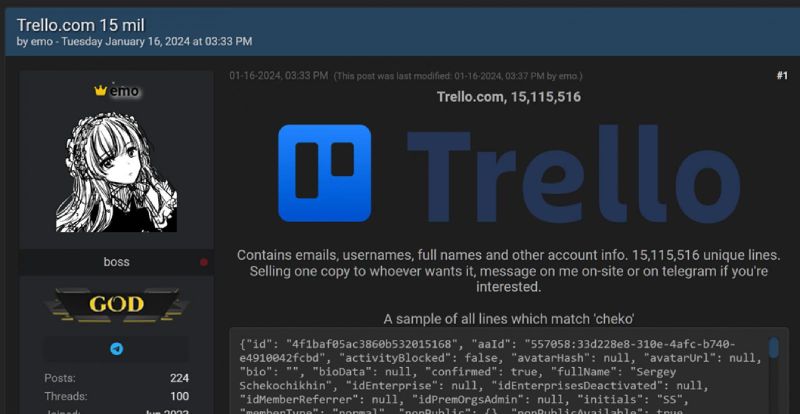 Captura de pantalla de la información publicada por emo en el foro
Captura de pantalla de la información publicada por emo en el foro
Tras pasar todos los correos electrónicos por la API de X (Twitter), el atacante terminó obteniendo los datos de perfil y correo electrónico de más de 15 millones de usuarios y los puso a la venta el 16 de enero de 2024. Simple pero efectivo.
La información relativa a este ataque ha sido reflejada en el conocido portal de brechas de seguridad HaveIBeenPwned.
Impacto
No es la primera vez que un endpoint de una API pública haya sido utilizado para la construcción de un conjunto de datos de un determinado servicio. Twitter tuvo un problema similar en 2021, cuando atacantes explotaron un error en su API que permitía a los usuarios ver si un determinado correo electrónico o número de teléfono estaba asociado con esta red social. Twitter corrigió ese fallo en enero de 2022, pero para entonces, ya era demasiado tarde, y se produjo una filtración de datos de más de 200 millones de perfiles.
Podríamos argumentar que el impacto del incidente es bajo, ya que no se han filtrado contraseñas, ni datos relativamente sensibles de usuarios, pero, aunque se pueda ver desde esa perspectiva, en muchas ocasiones estas bases de datos de servicios asociados a un determinado usuario se utilizan en campañas de mayor complejidad partiendo de la información de OSINT (Inteligencia de fuentes abiertas) disponible.
Un correo electrónico, por ejemplo, se puede usar en futuras campañas de credential stuffing como la que se usó en un inicio en el ataque contra 23andme sobre el que escribimos recientemente en este mismo blog.
Otro potencial riesgo de este tipo de recopilación de información privada es su uso para campañas de phishing por email a los usuarios que se han detectado que tienen cuenta en Trello. Este tipo de campañas suelen tener un porcentaje de éxito bastante más alto debido a que el usuario recibe un correo de un servicio que utiliza lo que le hace menos proclive a la desconfianza.
Conclusiones
Antes de la publicación de una API por parte de un proveedor de servicios en la nube es importante realizar un bastionado de la misma, o incluso ejercicios de hacking para que se detecten las deficiencias de esta y los potenciales casos de mal uso o abuso de dicha interfaz.
Proveer información, relativamente sensible como el correo electrónico, de la asociación de un usuario con un servicio de forma pública o sin autenticación debe evitarse, ya que esos datos pueden ser usados para recopilar información en fases de descubrimiento por parte de un atacante.
Un ejemplo clásico de esto es la interfaz de recuperación de contraseñas, a veces los servicios cambian el mensaje dependiendo de si el usuario existe:“un mensaje con la información para la recuperación de contraseña ha sido enviado a su correo electrónico” o no existe: “el usuario no está registrado”, esto permite la construcción de una base de datos de usuario a través de simple fuerza bruta.
La reputación de una organización expuesta a internet es un valor alto y sensible.
Felizmente, este tipo de errores son cada vez menos frecuente y los servicios optan por mensajes genéricos para la recuperación de contraseñas del estilo de: “En caso de que el correo conste en nuestros sistemas, recibirá un enlace para reestablecer su contraseña.”
En resumen, la reputación de una organización expuesta a internet es un valor alto y sensible. Es muy difícil de construir y, como hemos visto en este artículo, muy fácil de erosionar incluso sin ser objeto de un ataque complejo. Por ello, las organizaciones deben tratar de llevar a cabo ciclos de desarrollo seguro y realizar pruebas de seguridad previas a la salida de una API a producción.
⚠️ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse
: Jailbreak")



