 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Ataques a la Inteligencia Artificial (III): Data Poisoning
Introducción
Este artículo se engloba en una serie de artículos sobre ataques a Inteligencia Artificial de la que ya hemos publicado varios artículos:
- Un primer artículo con una introducción a la serie y enfocado en el ataque conocido como jailbreak.
- Un segundo artículo, primo de este que hoy publicamos, donde se trata el poisoning de forma general para, posteriormente, hacer foco en un tipo de ataque conocido como model poisoning.
Recordemos del ya publicado artículo sobre poisoning, que los ataques de envenenamiento se pueden clasificar en ataques a los datos de entrenamiento del modelo de IA o ataques directos al propio modelo y sus parámetros. En esta ocasión, analizaremos el otro tipo de ataque de data poisoning que es el principal referente de ataques de envenenamiento a nivel global.
✅ Os invitamos, de nuevo, a consultar el post de la semana pasada sobre envenenamiento para entender mejor el contexto general de este artículo.
¿En qué consiste un ataque de data poisoning?
En un ataque de data poisoning los atacantes manipulan los datos de entrenamiento de un modelo de IA para introducir vulnerabilidades, puertas traseras o sesgos que podrían comprometer la seguridad, eficacia o comportamiento ético del modelo. Esto conlleva riesgos de degradación del rendimiento, explotación del software subyacente y daño a la reputación.
El envenenamiento a sistemas de aprendizaje automático no es algo novedoso, sino que tiene casi 20 años de historia.
Sin embargo, con la proliferación del uso de sistemas de inteligencia artificial, y en particular, el uso de modelos generativos como los LLM que conlleva a una necesidad de volumen de datos de entrenamiento sin precedentes, el data poisoning ha tomado más relevancia.
Podemos pensar en el entrenamiento de los modelos fundacionales de Inteligencia Artificial generativa como una compresión de una buena porción de internet. Siguiendo el símil de la compresión, se trata de una compresión con pérdidas, es decir, no podremos recuperar la información original de los parámetros del modelo, sino que es transformada en un aprendizaje cuya explicabilidad es, hoy en día, lamentablemente, bastante baja.
¿Son posibles los ataques de data poisoning a gran escala?
Hablamos anteriormente de que el entrenamiento de un modelo fundacional, requiere un “trozo” significativo de internet. La intuición nos dice que el atacante necesitaría un esfuerzo ímprobo para obtener el control de un volumen significativo de los datos de entrenamiento de cara a poder tener influencia sobre el sistema final.
Pues como se ha demostrado en la siguiente investigación, se puede ver que no es tan difícil tener capacidad de influir en modelos como los grandes modelos de lenguaje (LLM) o modelos generativos de texto a imagen, si los atacantes juegan bien sus cartas.
Los investigadores describen dos tipos de ataque que pueden ser efectivos a gran escala:
Split-view data poisoning
Se basa en que la información recopilada y etiquetada por los creadores del índice de datasets populares, como LAION-400M, no tiene por qué ser válida en el momento del entrenamiento real.
La compra de dominios obsoletos por parte de atacantes como parte de sus cadenas de ataque es conocida. En este caso los atacantes comprarían un dominio presente en dichos datasets y modificarían sus datos para manipular el proceso de aprendizaje del sistema final.
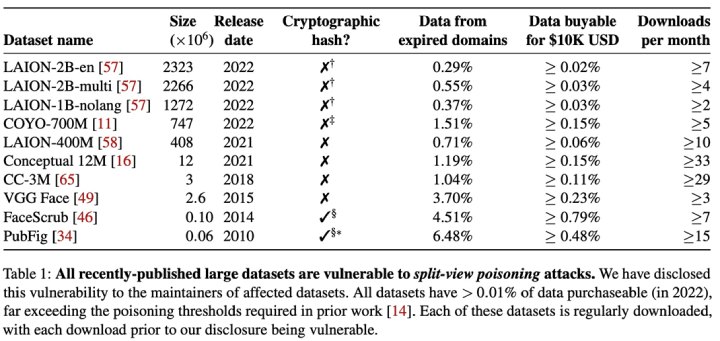
En la tabla anterior, que forma parte de la investigación, podemos ver la cantidad de datos que puede ser adquirida por diez mil dólares de inversión, para todos los datasets analizados se supera el umbral del 0,01% que otras investigaciones estiman necesario para poder impactar en las prestaciones del modelo.
Frontrunning data poisoning
Muchos datasets populares para el entrenamiento de modelos de IA se basan en una captura puntual (snapshot) de contenido generado por usuarios (crowdsourced) y moderado por algunos usuarios con mayores permisos de edición, pensemos por ejemplo en snapshots de la wikipedia.
Si el atacante conoce el momento y periodicidad de dichas capturas de información, podría aprovecharse de ello e introducir manipulaciones maliciosas. Aunque posteriormente un moderador pudiese rectificar la manipulación, el snapshot ya estaría contaminado y generaría potenciales problemas de envenenamiento en los sistemas que los utilizasen para su entrenamiento.
Protegiendo los derechos de autores de imágenes ante la ingesta por LLM
Conocidas compañías de Inteligencia Artificial como OpenAI, Meta, Google y Stability AI se enfrentan a una serie de demandas por parte de artistas que afirman que su material con derechos de autor e información personal fue recopilado sin su consentimiento ni ningún tipo de compensación.
Recientemente la Universidad de Chicago ha publicado una herramienta, llamada NightShade, que permite a los artistas añadir pequeños cambios imperceptibles a los píxeles en su arte antes de subirlo en línea, de modo que, si es incorporado en un conjunto de entrenamiento de IA, puede causar que el modelo resultante de texto a imagen sea envenenado y se desvíe de su comportamiento esperado.
Tras el uso de la herramienta, las muestras de datos envenenadas pueden manipular a los modelos para que aprendan, por ejemplo, que imágenes de sombreros son pasteles, e imágenes de perros son gatos.
Los datos envenenados son muy difíciles de eliminar, ya que requiere que las compañías tecnológicas encuentren y eliminen cada muestra corrupta minuciosamente.
 Imagen de los efectos de envenenamiento de NightShade sobre Stable Diffusion
Imagen de los efectos de envenenamiento de NightShade sobre Stable Diffusion
Como podemos apreciar en la imagen anterior, los investigadores probaron el ataque en los modelos más recientes de Stable Diffusion. Cuando alimentaron a Stable Diffusion con solo 50 imágenes envenenadas de perros y luego le solicitaron que creara imágenes de perros por sí mismo, el resultado comenzó a verse extraño: criaturas con demasiadas extremidades y caras caricaturescas.
Con 300 muestras envenenadas, un atacante puede manipular a Stable Diffusion para generar imágenes de perros que parezcan gatos.
Posibles mitigaciones
En el primer escenario planteado en el artículo, sobre envenenamiento a gran escala, los propios autores proponen en su investigación, dos medidas de mitigación bastante sencillas y no costosas de implementar.
- Split-view data poisoning → Prevenir el envenenamiento mediante la verificación de integridad, como, por ejemplo, con la distribución de hashes criptográficos para todo el contenido indexado, asegurando así que los creadores de modelos obtengan los mismos datos que cuando los mantenedores del dataset los indexaron y etiquetaron.
- Frontrunning data poisoning → Introducir una aleatoriedad en la planificación de los snapshots o retrasar su congelación durante un breve periodo de verificación antes de su inclusión en una captura, aplicando correcciones de moderadores de confianza.
Respecto a las mitigaciones sobre envenenamiento de imágenes realizadas por herramientas como NightShade, las alternativas son menos halagüeñas. Quizá la más evidente sería llegar a un acuerdo de atribución y económico con los artistas. Otra posible mitigación sería el empleo de técnicas de robust training.
Se trata de un enfoque alternativo para mitigar ataques de envenenamiento y consiste en modificar el algoritmo de entrenamiento de aprendizaje y realizar un entrenamiento robusto en lugar de un entrenamiento regular. El defensor puede entrenar un conjunto de múltiples modelos y generar predicciones mediante votación de modelos para detectar anomalías.
El problema es que el entrenamiento de multiples modelos implicaría un coste practicamente inasumible para grandes modelos como los LLM que nutren la Inteligencia Artificial Generativa.
Conclusiones
Nos hacemos eco de algunos de los retos inlcuidos en la taxonomía sobre ataques a IA publicada por el NIST y añadimos nuestras conclusiones.
Los datos son cruciales para entrenar modelos. A medida que los modelos crecen, la cantidad de datos de entrenamiento crece proporcionalmente. Esta tendencia es claramente visible en la evolución de los LLM.
La reciente aparición de sistemas de IA Generativa multimodales intensifican aún más la demanda de datos al requerir grandes cantidades de datos para cada modalidad.
Hasta ahora, internet era un campo “virgen” de contenido sintético a gran escala, sin embargo, la disponibilidad de potentes modelos abiertos crea oportunidades para generar cantidades masivas de contenido sintético que pueden tener un impacto negativo en las capacidades de los LLM entrenados a posteriori, llevando al colapso del modelo… Algo similar a la degeneración fruto de la endogamia en las antiguas monarquías.
Por otro lado, las herramientas de envenenamiento de datos de código abierto publicadas recientemente como NightShade aumentan el riesgo de ataques a gran escala sobre datos de entrenamiento de imágenes. Aunque han sido creadas con nobles intenciones, que sin duda compartimos, estas herramientas se pueden volver muy dañinas si caen en manos de personas con intenciones maliciosas.
◾ MÁS DE ESTA SERIE
: Jailbreak")
: Model Poisoning")
⚠️ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse



