 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Attacks on Artificial Intelligence (III): Data Poisoning
Introduction
This article is part of a series of articles on Artificial Intelligence attacks, several of which have already been published:
- A first article with an introduction to the series and focused on the jailbreak attack.
- A second article, related to the one we are publishing today, where we deal with poisoning in general and then focus on a type of attack known as model poisoning.
Let us recall from the already published article on poisoning that poisoning attacks can be classified into attacks on the training data of the AI model or direct attacks on the model itself and its parameters. This time, we will analyze the other type of data poisoning attack, which is the main reference of poisoning attacks globally.
✅ Have a look at last week's post on poisoning to better understand the general context of this article.
What is a data poisoning attack?
In a data poisoning attack, attackers manipulate the training data of an AI model to introduce vulnerabilities, backdoors or biases that could compromise the security, effectiveness, or ethical behavior of the model. This carries risks of performance degradation, exploitation of the underlying software and reputational damage.
Poisoning machine learning systems is not new; it has almost 20 years of history.
However, with the proliferation of the use of artificial intelligence systems, and in particular, the use of generative models such as LLMs leading to an unprecedented need for unprecedented volume of training data, data poisoning has taken on more relevance.
We can think of the training of foundational generative AI models as a compression of a good portion of the Internet. Following the simile of compression, it is a lossy compression, i.e. we will not be able to recover the original information of the model parameters, but it is transformed into a learning process whose explainability is nowadays, unfortunately, quite low.
Are large-scale data poisoning attacks possible?
We discussed earlier that training a foundational model requires a significant "chunk" of the Internet. Intuition tells us that the attacker would need to make an enormous effort to gain control of a significant volume of the training data in order to be able to influence the final system.
As the following research has shown, it is not so difficult to influence models such as large language models (LLM) or generative text-to-image models, if the attackers play their cards right. The researchers describe two types of attack that can be effective on a large scale:
Split-view data poisoning
It is based on the fact that the information collected and tagged by the creators of the popular dataset index, such as LAION-400M, need not be valid at the time of the actual training.
The purchase of obsolete domains by attackers as part of their attack chains is known. In this case the attackers would buy a domain present in such datasets and modify its data to manipulate the learning process of the end system.
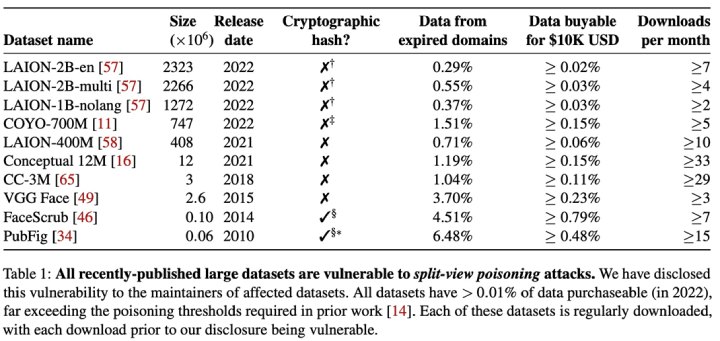
In the table above, which is part of the research, we can see the amount of data that can be acquired for ten thousand dollars of investment, for all the datasets analyzed, the threshold of 0.01% that other research estimate necessary to be able to impact the performance of the model is exceeded.
Frontrunning data poisoning
Many popular datasets for AI model training are based on a snapshot of crowdsourced content moderated by some users with higher editing permissions, such as Wikipedia snapshots.
If the attacker knows the timing and periodicity of these snapshots, he could take advantage of it and introduce malicious manipulations. Even if a moderator could later rectify the manipulation, the snapshot would already be contaminated and would generate potential poisoning problems in the systems that use them for training.
Protecting the rights of image authors from LLM ingestion
Well-known AI companies such as OpenAI, Meta, Google and Stability AI are facing a number of lawsuits from artists claiming that their copyrighted material and personal information was collected without their consent or any compensation.
Recently the University of Chicago released a tool, called NightShade, that allows artists to add small, imperceptible changes to the pixels in their art before uploading it online, so that, if incorporated into an AI training set, it can cause the resulting text-to-image model to be poisoned and deviate from its expected behavior.
Upon use of the tool, poisoned data samples can manipulate models to learn, for example, that images of hats are cakes, and images of dogs are cats.
Poisoned data is very difficult to remove, as it requires technology companies to find and remove each corrupted sample thoroughly.
 Image of NightShade's poisoning effects on Stable Diffusion
Image of NightShade's poisoning effects on Stable Diffusion
As we can see in the image above, the researchers tested the attack on Stable Diffusion's most recent models. When they fed Stable Diffusion with only 50 poisoned images of dogs and then asked it to create images of dogs on its own, the result started to look strange: creatures with too many limbs and cartoonish faces.
An attacker can manipulate Stable Diffusion to generate images of dogs that look like cats with 300 poisoned samples.
Possible mitigations
In the first scenario raised in the article, on large-scale poisoning, the authors themselves propose in their research, two mitigation measures that are fairly simple and inexpensive to implement.
- Split-view data poisoning → Prevent poisoning by integrity checking, such as distributing cryptographic hashes for all indexed content, thus ensuring that model creators get the same data as when the dataset maintainers indexed and tagged them.
- Frontrunning data poisoning → Introduce randomization in the scheduling of snapshots or delay their freezing for a short verification period before their inclusion in a snapshot, applying trust moderator corrections.
Regarding the mitigations on image poisoning made by tools such as NightShade, the alternatives are less flattering. Perhaps the most obvious would be to reach an attribution and economic agreement with the artists. Another possible mitigation would be the use of robust training techniques.
This is an alternative approach to mitigating poisoning attacks and consists of modifying the learning training algorithm and performing robust training instead of regular training. The defender can train a set of multiple models and generate predictions by voting on models to detect anomalies.
The problem is that training multiple models would imply a cost that is practically unaffordable for large models such as the LLMs that feed Generative Artificial Intelligence.
Conclusions
We echo some of the challenges included in the taxonomy on AI attacks published by NIST and add our conclusions.
Data is crucial for training models. As models grow, the amount of training data grows proportionally. This trend is clearly visible in the evolution of LLMs.
The recent emergence of multimodal Generative AI systems further intensifies the demand for data by requiring large amounts of data for each modality.
The internet was so far a "virgin" field of large-scale synthetic content; however, the availability of powerful open models creates opportunities to generate massive amounts of synthetic content that may have a negative impact on the capabilities of LLMs trained a posteriori, leading to model collapse... Something similar to the degeneration resulting from inbreeding in ancient monarchies.
Meanwhile, recently released open-source data poisoning tools such as NightShade increase the risk of large-scale attacks on image training data. Although created with noble intentions, which we certainly share, these tools can become very damaging if they fall into the hands of people with malicious intentions.
◾ CONTINUING THIS SERIES
: Jailbreak")
: Model Poisoning")



