 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Deep Learning vs Atari: entrena tu IA para dominar videojuegos clásicos (Parte II)
 En este artículo, el segundo de nuestro experimento de Aprendizaje Reforzado (RL) y Deep Learning en entornos generados por OpenAI, continuamos el post del blog de LUCA
Deep Learning vs Atari: entrena tu IA para dominar videojuegos clásicos (Parte I), donde se ofrecen los resultados obtenidos tras el entrenamiento de un agente en los entornos
Breakout-v0 y
SpaceInvaders-v0.
En este artículo, el segundo de nuestro experimento de Aprendizaje Reforzado (RL) y Deep Learning en entornos generados por OpenAI, continuamos el post del blog de LUCA
Deep Learning vs Atari: entrena tu IA para dominar videojuegos clásicos (Parte I), donde se ofrecen los resultados obtenidos tras el entrenamiento de un agente en los entornos
Breakout-v0 y
SpaceInvaders-v0.
Introducción
- Entorno: se refiere al juego en el que el agente debe actuar y aprender a desenvolverse.
- Recompensa: incentivo que obtiene el agente tras realizar una determinada acción. en el caso del Breakout-v0, el agente conseguirá una recompensa positiva en el caso de que consiga devolver la pelota y destruir uno de los ladrillos.
- Estado: es generalmente un tensor obtenido del espacio de observaciones del entorno. En este caso, los estados consisten en un conjunto de imágenes pre-procesadas con la función de facilitar el entrenamiento del modelo.
- Acción es el conjunto posible de respuestas dentro del espacio de acciones que el agente puede realizar en función del estado o histórico de estados que ha observado. Por ejemplo, en el caso que nos ocupa sería moverse a izquierda, derecha o quedarse quieto en función de la dirección y velocidad de la pelota observada.
- Política de control (control policy) determina la elección de la acción que debe hacer el agente. Esta política de elección es determinada por el programador. Normalmente, se suele elegir una acción aleatoria al principio y, una vez el modelo está lo suficientemente entrenado, se toma la acción en función de qué valor máximo ha obtenido el modelo en el espacio de acciones.
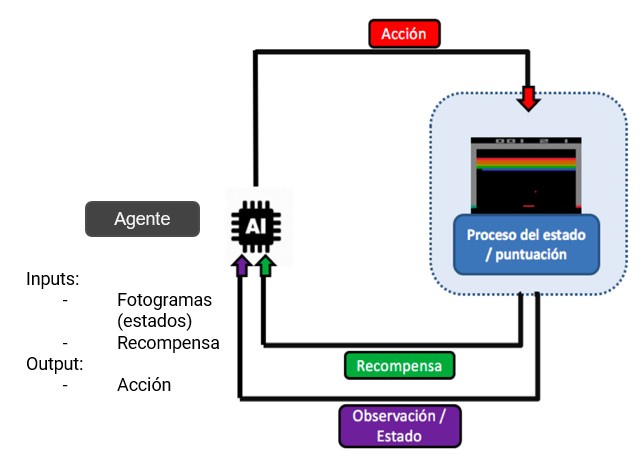 Figura 1: diagrama del proceso de aprendizaje de un agente durante el entrenamiento
Figura 1: diagrama del proceso de aprendizaje de un agente durante el entrenamiento
Inicialización del entrenamiento
El algoritmo implementado busca maximizar la recompensa en cada episodio. El agente recoge imágenes del entorno del juego para ser inyectadas en una red neuronal, lo cual le permitirá estimar qué acción elegir dado el input al modelo. Tanto para construir la arquitectura de la red profunda como para hacer los cálculos pertinentes, haremos uso de la librería TensorFlow. También recomendamos leer los posts Deep Learning con Python: Introducción a TensorFlow (Parte I y Parte II) en el caso de que queráis una introducción al funcionamiento de esta librería.
Política de toma de acciones
En un principio, los valores de las acciones se inicializan en torno a cero, dejando al agente tomar acciones aleatorias en el juego. Cada vez que el agente obtiene una recompensa positiva (i.e., destruye un ladrillo o mata a un marciano), los pesos y bias de las capas de la arquitectura se actualizan, lo que permitirá que la estimación de los Q-values sea cada vez más refinada.
Q-function
La misión del agente es interactuar con el emulador con la intención de aprender qué acción tomar dado un cierto estado o subconjunto de estados con la misión de maximizar la recompensa a obtener derivada de esa acción.
Función de pérdida y optimizador
Dada la gran cantidad de frames por segundo a procesar y la elevada dimensionalidad de los estados a manejar, un mapeo directo de la causalidad estado-acción resulta impracticable. Por ello, nos vemos obligados a aproximar la función Q mediante el muestreo aleatorio de un elevado número de estados, recompensas y acciones recogidos por el agente. Generalmente la función de pérdida (loss-function) elegida y que se busca minimizar es el error cuadrático medio (Root Mean-Squared Error) entre los Q-values obtenidos como resultado de aplicar nuestro modelo y los Q-values esperados.
sqrt(loss) = Q(s’, a’) - Q(s, a) = reward(s, a) + gamma · max(Q(s’, a’) - Q(s, a))
Para encontrar el mínimo de la función anterior se hace uso del algoritmo de optimización iterativo Gradient Descent. A través de este algoritmo se calculan los gradientes de la función de pérdida para cada peso y desplaza los mismos en la dirección que minimice la función. Sin embargo, encontrar los mínimos de una función no lineal puede resultar complicado, especialmente por la posibilidad de quedarnos estancados en un mínimo local lejos del mínimo global que se quiere conseguir o pasar múltiples iteraciones en una parte plana o cuasi plana de la función. Optimizar una red neuronal es una tarea complicada, altamente dependiente de la calidad y cantidad de los datos con los que se entrene el modelo. La complicación de optimizar la red también vendrá dada por la arquitectura de la misma, entendiendo que a mayor número de capas y mayor dimensionalidad de las mismas, se tendrá que abordar la optimización de un mayor número de pesos y biases.
Preprocesado de los inputs
Uno de los factores más importantes para garantizar un buen entrenamiento del modelo, dado los largos tiempos de computación requeridos, reside en el pre-procesado de la imagen y en la naturaleza del input a la red neuronal. Esto también afectará directamente a las rutinas a desarrollar de cara a la interacción con el entorno. Por lo general, es recomendable que la imagen generada por el entorno de OpenAI Gym sea procesada antes de ser incluida en el modelo, generalmente con la intención de reducir su dimensionalidad, eliminando aquella información de la imagen que no sea de utilidad a la hora de entrenar la red neuronal. Hay que hacer hincapié en que, por lo general, la información relativa al color apilada por OpenaAI Gym en los 3 canales de color que se nos facilitan no contiene información valiosa para el entrenamiento del modelo, por lo que será obviada antes de introducir los estados en el modelo.
Las imágenes devueltas por el entorno OpenAI Gym son arrays de 210 x 160 píxeles agrupadas en 3 capas RGB. Esto hace que el uso de memoria sea elevado. Por ello, se hace imprescindible abordar un pre-procesado de las imágenes para disminuir la dimensión de los inputs, eliminando información innecesaria para entrenar el modelo y disminuir el uso de memoria. Las pruebas realizadas en este proyecto se han fundamentado en dos aproximaciones con respecto al procesado de imágenes:
- Como primera aproximación, se toman imágenes del entorno de juego y se procesan, convirtiéndose a escala de grises haciéndose un resizing, eliminando el fondo y usando un filtrado de imágenes sencillo para poder detectar movimiento. El estado resultante de ese procesado se compone de la última imagen del entorno de juego junto con una traza de movimiento de las trayectorias más recientes de los objetos.
- En la segunda alternativa de procesado, se ha optado por dar como input al modelo un conjunto de 4 capturas con la intención de que pueda aprender a detectar el movimiento. Esto es necesario, pues un único estado como input no nos aporta apenas información sobre la velocidad, dirección y aceleración de la pelota y la pala.
Únicamente nos interesa el área de juego por donde se mueven la pelota y la pala y donde se encuentran los ladrillos; por ello, los bordes de las capturas no aportan información valiosa al modelo, por lo que esta zona se elimina. Además, a cada imagen se le disminuye la resolución a la mitad y se pasa a blanco y negro, pues los canales RGB de la imagen original tampoco aportan información al entrenamiento del modelo.



