
Este artículo es el segundo de nuestra serie de introducción al
Deep Learning con
Python haciendo uso del framework
TensorFlow. En el artículo anterior, Deep Learning con Python: Introducción a TensorFlow (Parte I), exploramos los fundamentos de esta librería y nos familiarizamos con los conceptos y el uso de las
sesiones,
grafos, así como de las
variables y
placeholders.
En este post, y con la intención de ganar soltura en el uso de estos recursos, crearemos nuestras primeras
neuronas
y una primera
red neuronal
lo más sencilla posible dirigida a realizar
regresiones lineales
. Dado que nos vamos a poder despreocupar del aparato matemático, pues las operaciones necesarias para realizar una regresión son muy sencillas, podremos centrarnos en el manejo de los principales instrumentos de
TensorFlow
.
Para empezar, crearemos una neurona que, de manera muy sencilla, ajusta una recta a un conjunto de datos, que en este caso estarán aleatoriamente generados por nosotros. La representación de esa neurona se puede generar haciendo uso de la herramienta de visualización
TensorBoard, que abordaremos tras el primer
Jupyter Notebook.
Como pudimos ver en el anterior post, los pasos previos a realizar con TensorFlow para comenzar el entrenamiento de un modelo son:
- construir el grafo o definir la secuencia de operaciones a realizar con los datos,
- inicializar todas las variables,
- iniciar una sesión y comenzar el entrenamiento.
Antes de iniciar la sesión, que ejecutaremos dando como entrada los datos pertinentes, tendremos que definir una
función de coste y un
optimizador sobre el que entrenaremos el modelo.
En el primer notebook que se adjunta a continuación, vamos a crear nuestras primeras neuronas y vamos a aprender cómo ejecutar sesiones haciendo uso de los feed dictionaries. Una vez familiarizados con su uso, seguiremos con un ejemplo sencillo de red neuronal, veremos cómo definir una función de activación y haremos un sencillo ejemplo de regresión lineal donde deberemos definir una función de coste y un optimizador que se encargará de minimizarla.
Visualizar el
grafo
de nuestro modelo puede ayudarnos a entender las operaciones que estamos realizando. Al final de la ejecución del cuaderno anterior, tendremos en
/log/neural_network_tensorflow/
el fichero que podremos invocar con
TensorBoard
para visualizar nuestro
grafo
.
Podemos abrir un terminal y ejecutar (¡sin olvidarnos de situarnos en el entorno
Python donde está instalada la librería
TensorFlow!) lo mostrado en la captura de abajo.
 Figura 1. Comando de ejecución de TensorBoard
Figura 1. Comando de ejecución de TensorBoard
Donde el
--logdir es el path definido
/log/neural_network_tensorflow/ en el notebook. Tras ejecutar el comando de arriba, podemos clickar en
http://$localhost:6006, lo que nos permitirá acceder a la información de nuestro modelo de forma gráfica.
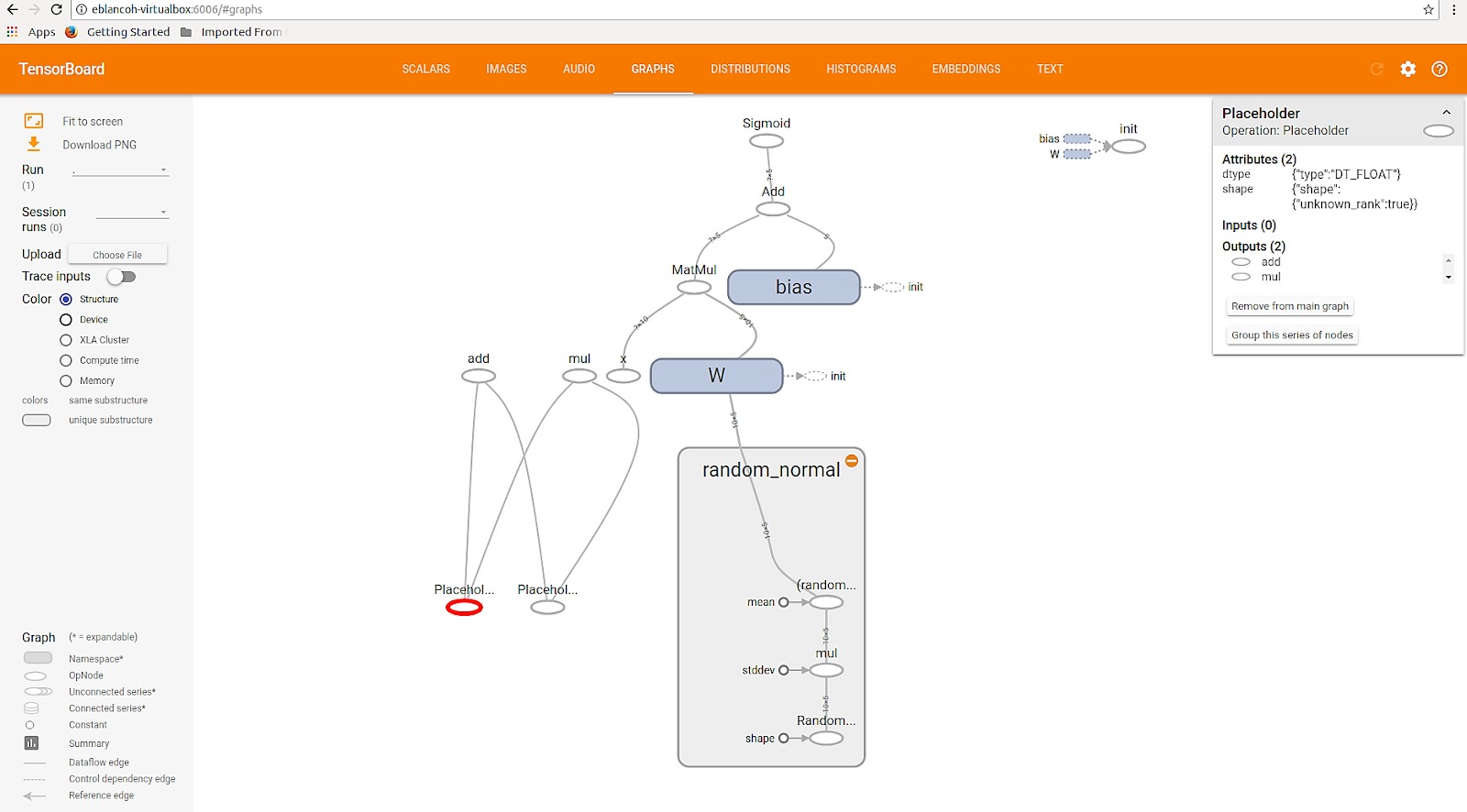 Figura 2. Ejemplo de grafo generado por TensorBoard tras la ejecución del anterior .ipynb
Figura 2. Ejemplo de grafo generado por TensorBoard tras la ejecución del anterior .ipynb
Para más información sobre las posibilidades de visualización y debugging que ofrece
TensorBoard, recomendamos leer la documentación disponible en su
página web y en su repositorio de
GitHub.
En nuestro siguiente paso, abordaremos otro ejemplo de
regresión lineal con más datos generados por nosotros mismos, con la diferencia de que el volumen del dataset va a ser mucho más grande. Dado el elevado número de variables que vamos a manejar, nos vemos obligados a dividir nuestro dataset en
batches de un cierto tamaño, de tal forma que podamos entrenar nuestro modelo de manera más eficiente. Esta estrategia es necesaria, pues tomar todos los datos de una vez resultaría inmanejable.
Para ello, iteraremos nuestro entrenamiento del modelo a lo largo de un número determinado de épocas o episodios sobre batches obtenidos de manera aleatoria, con la misión de ajustar lo mejor posible los parámetros de nuestra regresión.
También se proporciona una breve introducción al uso de los
estimadores de
TensorFlow, los cuales simplifican el código al encapsular tanto el
entrenamiento como la
evaluación y la
predicción, además de encargarse de la construcción del
grafo y de la
inicialización de variables.
En la siguiente captura podéis observar el grafo de nuestro modelo, también generado para la primera mitad del cuaderno anterior. Os animamos a explorar con
TensorBoard el grafo de la regresión lineal que acabamos de realizar. Sólo se debe modificar el comando de
--logdir , apuntando al directorio
/log/regresion_batches_tensorflow/.
 Figura 3. Grafo obtenido a partir de nuestro último modelo de regresión lineal
Figura 3. Grafo obtenido a partir de nuestro último modelo de regresión lineal
Posteriormente, hemos extendido el tamaño de nuestro set de datos para hacer uso de una estrategia de muestreo de batches y se ha introducido el uso de los Estimators, una API de TensorFlow dirigida a simplificar la simplificación en scripts creados para este tipo de análisis. En el siguiente post nos centraremos en la clasificación de datasets extensos muy conocidos. Os animamos a continuar profundizando en el mundo del cálculo numérico con TensorFlow.
 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes



