 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes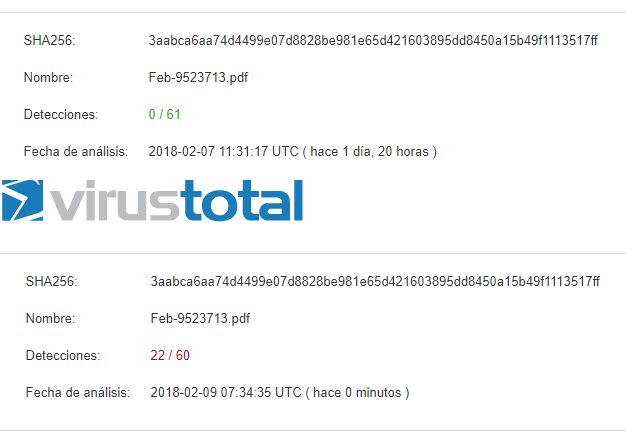

El ¿milagroso? machine learning y el malware. Claves para ejercitar el escepticismo (y II)
13 de febrero de 2018
En el principio de la detección del malware se usó la firma. Después vino la heurística, la nube, el big data y en los últimos tiempos, machine learning y la inteligencia artificial. Métodos y técnicas que, convenientemente rodeados de los "sospechosos habituales" ( holístico, sinergias, disruptivo, etc.), podemos encontrar en casi todo discurso. Pero independientemente del negocio alrededor, la tecnología es neutra y no debería ser ni mejor ni peor de por sí, sino más o menos adecuada para resolver un problema. Lo que quizás erosiona la fama de una tecnología pueden ser los titulares forzados cuando se abusa de ellos con fines no puramente tecnológicos. El machine learning aplicado al malware es infinitamente valioso. Eso sí, a veces parece fallar la ejecución del experimento que pretende ensalzarlo. Veamos por qué y ejercitemos el escepticismo.
Claves para detectar un titular con gancho ¿Cuántas muestras?
Cuantas más mejor, sin duda. Pero a veces es complicado recopilar muestras, y más aún frescas. Las casas antivirus no tienen problema para esto pero… ¿y los análisis académicos? Existen conjuntos cerrados, como " contagioDump " que se mueven a veces entre las 200 muestras de familias muy concretas, con información que se actualiza de forma casi manual y lentamente. A nuestro entender, no son suficientes ni representativas de la problemática del malware actual.
Otros estudios, por ejemplo, han basado su análisis en el éxito en la detección de 249 muestras, que no parece muy representativo del espectro del malware en general. También hay quien se queda con incluso menos: IMAD, de 2009 pretende clasificar utilizando machine learning, si un archivo binario para sistemas UNIX es malware o no. En sus experimentos, se utilizan solo 100 muestras de malware y 180 de goodware.
 Otro ejemplo de uso de machine learning realizado con 249 muestras maliciosas
Otro ejemplo de uso de machine learning realizado con 249 muestras maliciosas
Claves para detectar un titular con gancho ¿Y los falsos positivos?
Una clave para dar un buen titular si los números no acompañan, es ocultar los falsos positivos. Detectar el 100% del malware es sencillo, si te puedes permitir el lujo de equivocarte siempre. Pero, ¿y si ese "lujo" está determinado y acotado por un exiguo 2%? El juego se pone interesante. "Ahí fuera" en la industria de la detección de malware profesional es lo tolerado, alrededor del 2%. Equivocarte más a la hora de cazar malware o goodware es condenar cualquier sistema puesto que se perderá la confianza en su criterio a poco que aumente el volumen de uso.
Por ejemplo, aunque en este estudio no utiliza "machine learning" estrictamente hablando, en "Classifying Anomalous Mobile Applications Based on Data Flows”. En este documento se realiza un estudio en el que se pretende clasificar malware móvil ayudándose de algoritmos genéticos. Los resultados del artículo y experimento resultan bastante pobres. No muestra la tasa de falsos positivos que se intuye muy alta en la tabla adjunta. Además habla de la detección dentro de una misma familia y no en general, algo que resulta mucho más sencillo y con lo que la tasa de acierto se infla artificialmente.
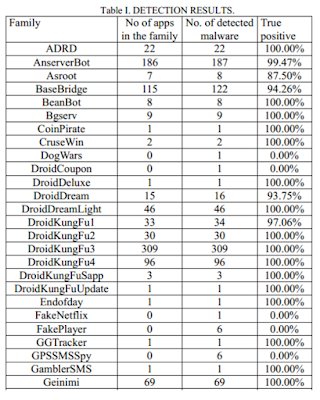 Ejemplo realizado con muy pocas muestras y bastantes falsos positivos
Ejemplo realizado con muy pocas muestras y bastantes falsos positivos
Contra los falsos positivos, se debe mostrar la tabla de confusión, donde quede claro la tasa de falsos positivos, negativos y verdaderos positivos y negativos, o valores que los relacionen como la precisión, la curva ROC, etc. Estos datos deben mostrarse claramente y con porcentajes.
Pero no solo de las muestras de malware y su "determinación" viven los estudios. En general, dar por hecho que "cero detecciones" implica "goodware" sin incorporar la variable tiempo, redunda además en el fallo fundamental característico del antimalware tradicional (el falso negativo, o la muestra "que no se detecta"), y son problemas que si no son acometidos, hacen que cualquier sistema basado en ellos hereden sus problemas.
¿Qué otras fórmulas existen?
Por poner un ejemplo, CAMP (Content-Agnostic Malware Protection) es un sistema que presentó Google en 2013 con el que Chrome prometía detener el 99% del malware. Se integró en 200 millones de usuarios de Chrome como prueba de concepto para detectar ficheros bajados. Según un estudio que señalaba el propio documento presentado por Google, con suerte un antivirus tradicional detenía entre un 35% y un 70% del malware que se intenta descargar un usuario antes de que dañase el sistema. CAMP se basaba en la reputación en la nube. Reputación no tiene por qué ser "machine learning" exclusivamente, pero sí que necesitaban, para el experimento, conocer la eficacia de sus sistemas en base a unas muestras previamente etiquetadas.
Su método fue el siguiente: Seleccionaron 2200 binarios nuevos previamente desconocidos (muestras frescas). Lanzaron contra máquinas virtuales que juzgaron 1100 como goodware y 1100 como malware. Los enviaron todos a un sistema multimotor que analiza en estático y con buen criterio (por introducir la variable tiempo), esperaron 10 días para ver su evolución. De ahí se concluyó que el 99% de los binarios que Chrome reportó como maliciosos diez días antes, eran "confirmados" como malware por al menos un 20% de motores antivirus consultados.
Este parece un método interesante de etiquetado, donde al menos se respeta la variable "tiempo" y se añade un alto porcentaje de motores para confirmar. Por supuesto hubo fallos. Decían que un 12% de sus binarios fueron marcados como limpios por el sistema CAMP pero luego resultaron ser malware según el criterio del 20% de los motores. O sea, aun así su tasa de falso negativo fue excesivamente alta. Se defienden alegando que la mayoría resultaron ser adware, cosa que CAMP deliberadamente no clasifica como malware. Con esta "excusa" volvemos a la zona gris en la que la que diferenciar el "malware" resulta un ejercicio casi filosófico.
Y aun prestando especial cuidado a la tasa de detección, número de muestras y el tiempo, también se le podrían cuestionar ciertos aspectos. Recordemos que las propias casas antivirus suelen detectar muy poco a través de firmas estáticas (desde luego no es la estrategia que más éxito les reporta) y basarse demasiado en ellas es precisamente su "condena". También, que (aunque últimamente cada vez menos) las casas antivirus internamente usan también máquinas virtuales para análisis rápidos dinámicos (mala idea si no están convenientemente tuneadas). Con lo que, aunque más lentamente que CAMP, quizás marcaron como malware las muestras exactamente por la misma razón que lo hizo Chrome en un principio. Así, lógicamente la tendencia es a estar totalmente de acuerdo en ambos métodos y por tanto, heredar el aprendizaje con sus propias taras.
Igualmente, aunque se use el 20% como umbral, no olvidemos que algunos motores se inspiran entre sí para las firmas. Si un motor reputado afirma que una muestra el malware, otros puede que también lo hagan para ahorrarse el análisis. El hecho de fijarse, por ejemplo, en ocho motores no es tan importante como que lo afirmen algunos más importantes, reconocidos por su tecnología única o específica de detección, que debería ser tenida en cuenta más que la “popularidad”.
Conclusiones
En resumen, la conclusión es que todos los sistemas que hemos señalado, quizás sean efectivos, pero lo que no podemos llegar a saber es "cuánto". Sabemos que clasificará como malware una buena parte de las muestras antes de que lo "confirmen" los antivirus, pero tenemos que tener muy presente:
- Si es a costa de un número de falsos positivos que los sistemas de detección tradicionales no se pueden permitir
- A costa de usar y entrenar con conjuntos excesivamente idealizados, escasos o anticuados y perder la partida en la calle, donde se juega en otra liga fuera de los despachos y laboratorios, mucho más hostil.
- A costa de que precisamente, se pretenda confirmar el éxito a través de los antivirus, algo que de por sí se supone que se está cuestionado o se pretende complementar. O sea, se pretenda preguntar a la tecnología que se desea mejorar, si finalmente hemos conseguido hacerlo mejor que ella misma.
También te puede interesar:
» El ¿milagroso? machine learning y el malware. Claves para ejercitar el escepticismo (I)
Sergio de los Santos
ssantos@11paths.com



