 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Phyton para todos: 5 formas de detectar "missing values"
En este nuevo post de la serie Phyton para todos, vamos a ver un ejemplo práctico sobre cómo detectar "missing values", o campos vacíos en nuestros datos de trabajo.
Los pasos que vamos a dar son los siguientes:
- Localizar los datos de trabajo en Google Dataset Search y descargarlos (en este ejemplo desde Kaggle)
- Cargar los datos en un dataframe
- Renombrar columnas
- Investigar si faltan datos: ¿hay missing values? -- lo veremos de 5 formas distintas
Localizar los datos de trabajo
En este ejemplo, vamos a utilizar el buscador de datasets de Google. Vamos a trabajar con dos datasets diferentes: el del Titanic y el de clasificación de chocolates. Tan sencillo como poner las palabras "chocolate" y "Titanic" para acceder los datos que haya publicados sobre estos temas.
 Figura 1: Google Dataset Search
Figura 1: Google Dataset Search
En ambos casos, nos interesan los datasets de Kaggle, así que los descargaremos desde ahí mismo en formato csv.
 Figura 2: Localizamos los datos que nos interesan en Kaggle
Figura 2: Localizamos los datos que nos interesan en Kaggle
Abrimos un Jupyter notebook para trabajar con ellos.
A continuación, abrimos un Jupyter notebook para empezar a trabajar. Si no habéis trabajado nunca con esta herramienta, en este post os explicamos cómo hacerlo de forma muy sencilla.
: ¿Qué son los Jupyter Notebooks?")
(Por supuesto que podéis trabajar con el editor Python que os resulte más cómodo).
Iremos paso a paso explicando cada sección, y al final incluiremos el Jupyter notebook completo.
Importación de librerías y carga de datos
El primer paso, como siempre, es cargar las librerías,
Importaciones import os import pandas as pd import seaborn as sns import missingno as msno
Comprobar el directorio de trabajo donde deben estar los csv que hemos descargado
os.getcwd()
Como queremos ver las gráficas en el propio notebook, añadimos:
%matplotlib inline
Cargamos los datos en un dataframe y echamos un vistazo a las cabeceras de las columnas:
choco_data = pd.read_csv('flavors_of_cacao.csv')
print(choco_data.columns)
titanic_data = pd.read_csv('train.csv')
print(titanic_data.columns)
Vemos que los nombres de las columnas del primer dataset son demasiado largos, los vamos a acortar un poco.
 Figura 3: Nombres de columnas de ambos datasets
Figura 3: Nombres de columnas de ambos datasets
También, echamos un vistazo a la información de contexto de los datos: Número de registros, significado de cada columna, escala de valoración etc.
Para la valoración de chocolates, la podemos encontrar en este enlace.
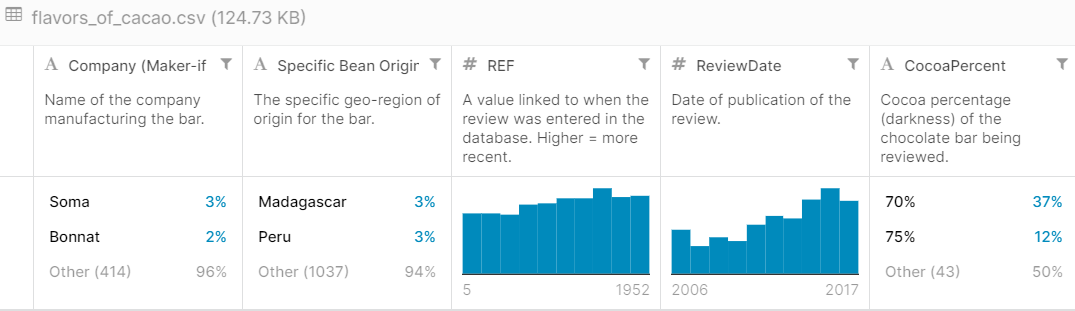 Figura 5: Imagen (parcial) de la información sobre el dataset flavors_of_cacao.csv
Figura 5: Imagen (parcial) de la información sobre el dataset flavors_of_cacao.csv
La información sobre el dataset del Titanic la podemos ver en este otro enlace:
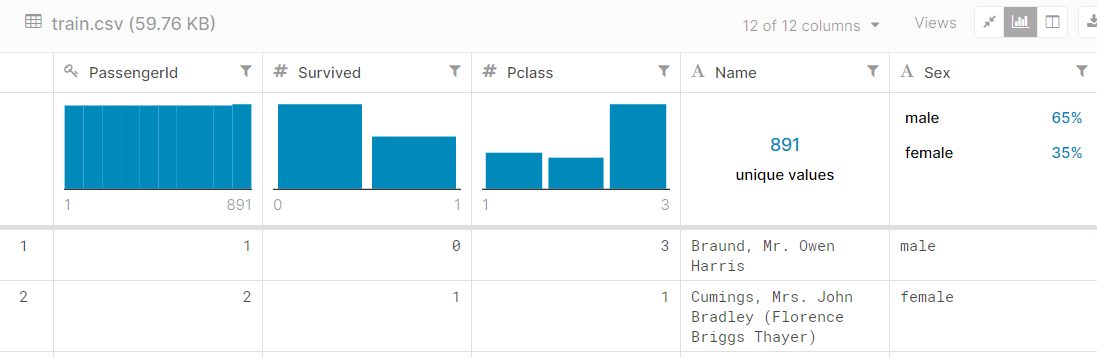 Figura 6: Imagen (parcial) de la información sobre el dataset train.csv
Figura 6: Imagen (parcial) de la información sobre el dataset train.csv
Modificación columnas
Renombramos las columnas del dataset flavors usando columns. Con columns, cambiamos todas. Si queremos cambiar sólo una,es mejor usar la función rename.
choco_data.columns = ['Company','Bar name','REF',
'Date','Cooa percent','C Location','Rating','Bean','Origin',]
Para ver los 5 primeros registros:
choco_data.head(5).T titanic_data.head(5)
En el primero, observamos que la fila "Bean" aparece en blanco. ¿Faltarán valores?
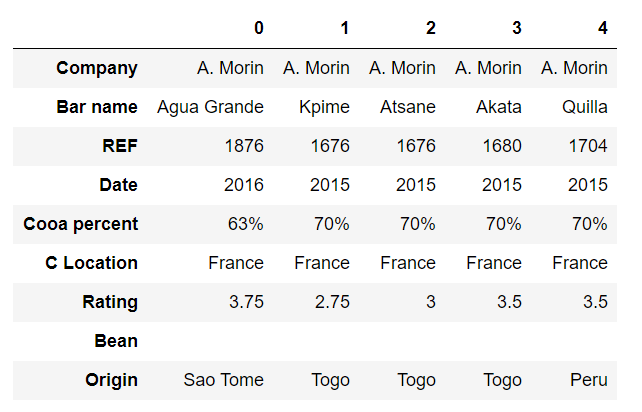 Figura 7: Primeros 5 valores del dataset flavours_of_cacao
Figura 7: Primeros 5 valores del dataset flavours_of_cacao
En este otro dataset observamos valores "NaN"="not a number", por tanto, si hay valores faltantes.
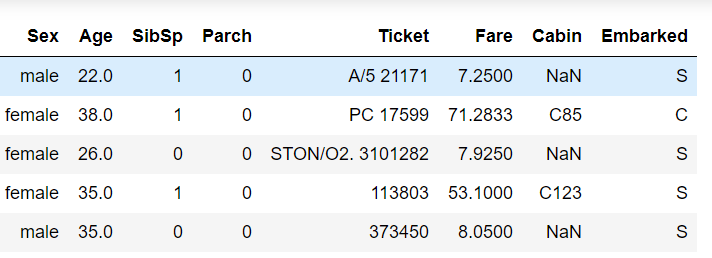 Figura 8: Primeros 5 valores del dataset titanic_data.csv
Figura 8: Primeros 5 valores del dataset titanic_data.csv
Detección de valores que faltan: "missing values"
Vamos a tratar de identificar los valores que faltan de 5 formas distintas:
- Con la función isnull de pandas
- Con el método info de pandas
- Con un mapa de calor seaborn
- Con la librería missingno
- Con un gráfico de barras
1. Con la función isnull de pandas
La función isnull de pandas, da como resultado "True" cuando falta un dato. Veamos qué ocurre al aplicarla a estos conjuntos de datos.
choco_data .isnull()
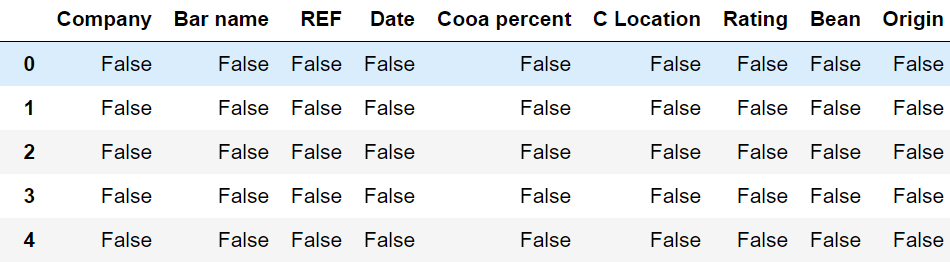 Figura 9: Resultado de aplicar isnull sobre flavours_of_cacao
Figura 9: Resultado de aplicar isnull sobre flavours_of_cacao
Nos llama la atención que, aparentemente, no faltan datos. Todos los valores, incluso en la columna Bean, son "False".
En el otro dataset si podemos apreciar algunos valores "True". En la columna "Cabin" vemos unos cuantos. (Recordemos que en esta columna había valores "NaN").
titanic_data .isnull()
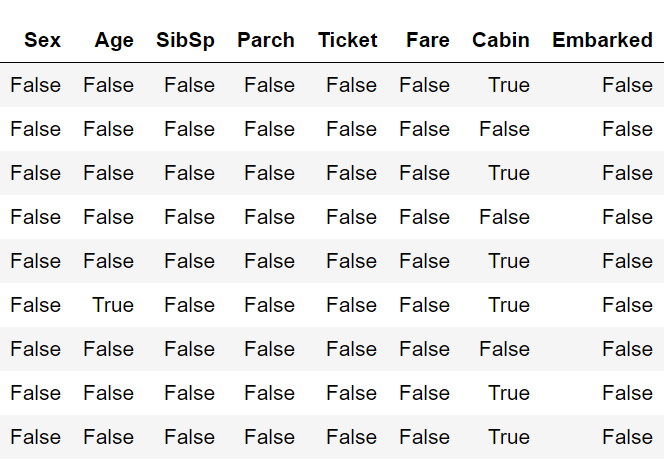 Figura 10: Resultado (parcial) de aplicar isnull sobre titanic_data.csv
Figura 10: Resultado (parcial) de aplicar isnull sobre titanic_data.csv
2. Con el método info de pandas
Éste método nos da una información más resumida. En el resumen obtenido para el dataset, vemos que de 891 entradas, hay campos para los que el número de valores es menor. Por ejemplo, 204 para "Cabin", 714 para "Age", 889 para "Embarked".
titanic_data.info(verbose=True,null_counts=True)
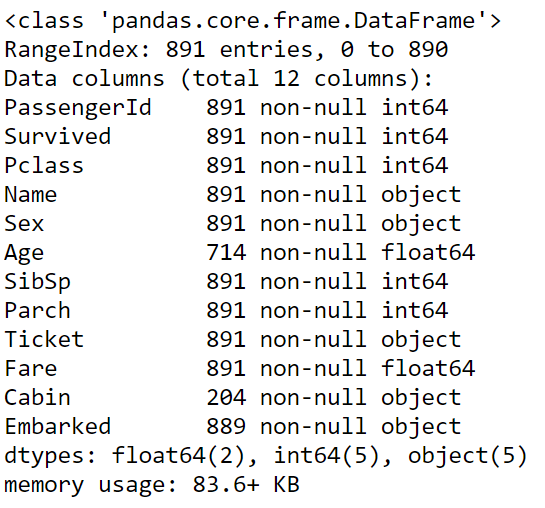 Figura 11: Información resumida del dataset titanic_data
Figura 11: Información resumida del dataset titanic_data
Para el otro dataset:
choco_data.info(verbose=True,null_counts=True)
Nuevamente, parece que no faltan datos, ya que de 1795 entradas, hay 1795 valores no nulos para cada columna.
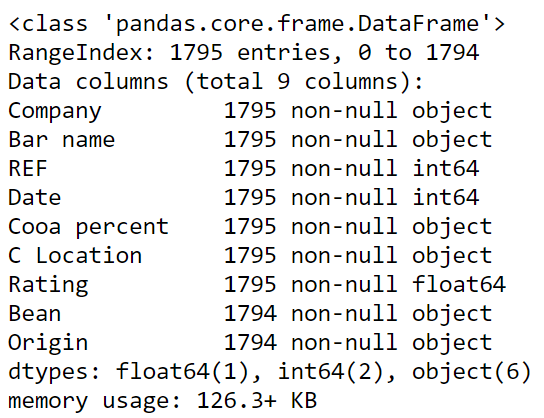 Figura 12: Información resumida del dataset flavours_of_cacao.csv
Figura 12: Información resumida del dataset flavours_of_cacao.csv
Está claro que con este dataset para algo raro, ya que los resultados no son consistentes. Antes de seguir probando métodos para ver qué pasa volvemos sobre nuestros pasos y abrimos con excel el fichero original.
Enseguida vemos que en la columna correspondiente a "Bean" aparece el carácter "Â".
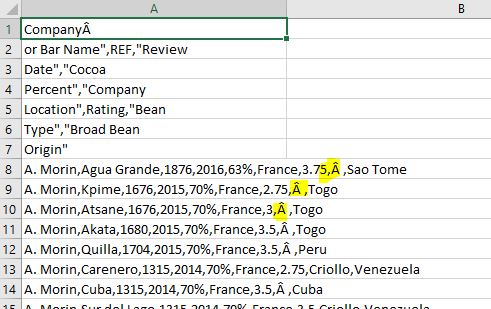 Figura 12: Abrimos el csv en excel y vemos un carácter extraño
Figura 12: Abrimos el csv en excel y vemos un carácter extraño
Puede tratarse de un error de codificación. Si este mismo csv lo abrimos con el bloc de notas, vemos que, efectivamente, ese carácter está enmascarando un espacio en blanco, por tanto, datos que faltan.
 Figura 13: Al abrirlo en el bloc de notas, vemos que se trata de un espacio en blanco
Figura 13: Al abrirlo en el bloc de notas, vemos que se trata de un espacio en blanco
Para resolver este problema, podemos abrir el csv con el bloc de notas, sustituir ", ," por "NULL" y volver a cargar el fichero. Si volvemos a aplicar la función isnull, vemos que ahora sí que identifica correctamente los campos vacíos como nulos: BeanType True
choco_data.isnull()
 Figura 14: Ahora la función isnull si detecta correctamente los valores que faltan
Figura 14: Ahora la función isnull si detecta correctamente los valores que faltan
3. Con un mapa de calor seaborn
Una vez "resuelto el misterio" del dataset del cacao, vamos a seguir viendo otras formas de detectar "missing values".
En esta ocasión, vamos a usar los mapas de calor de seaborn, que, si recordamos, cargamos al principio, junto al resto de librerías.
sns.heatmap(titanic_data.isnull(), cbar=False)
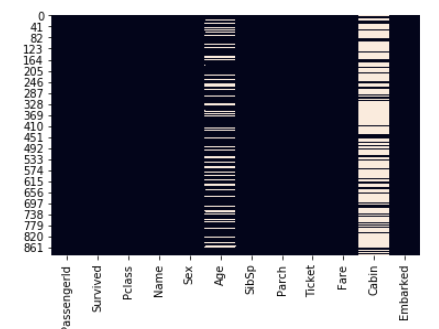 Figura 15: Vemos cómo faltan datos en Age y Cabin
Figura 15: Vemos cómo faltan datos en Age y Cabin
Para el otro dataset:
sns.heatmap(choco_data2.isnull(), cbar=False)
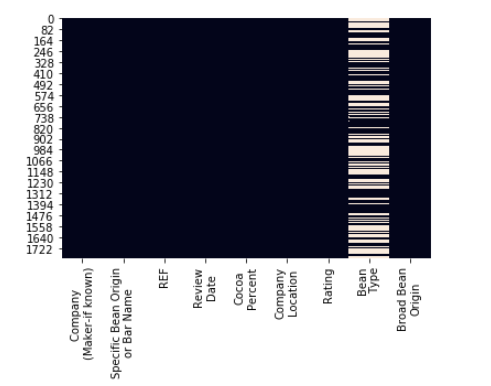 Figura 16: En este caso los datos que faltan corresponden a la variable "Bean type"
Figura 16: En este caso los datos que faltan corresponden a la variable "Bean type"
En este caso no es muy relevante, pero en ocasiones, puede ser importante saber si estos "missing values" están localizados en una parte determinada del dataset. O bien si hay alguna correlación entre los valores que faltan en una u otra variable.
4. Con la matriz de nulidad missingno
Al igual que con seaborn, importamos la librería missingno al principio del todo.
La matriz de nulidad msno.matrix los patrones de "completitud" de los datos.
A simple vista, en el dataset del Titanic, vemos cómo prácticamente todas las variables tienen valores completos, salvo "Age" y, en mayor medida, "Cabin".
La columna de la derecha resume de forma general el grado de "completitud" de los datos y señala las filas con mayor y menor número de "missing values" del conjunto de datos.
Esta visualización funciona bien con un máximo de 50 variables etiquetadas.
msno.matrix(titanic_data)
 Figura 17: Matriz de nulidad para el dataset del Titanic
Figura 17: Matriz de nulidad para el dataset del Titanic
Para el dataset de clasificación de cacao, el resultado es bien diferente.
msno.matrix(choco_data)
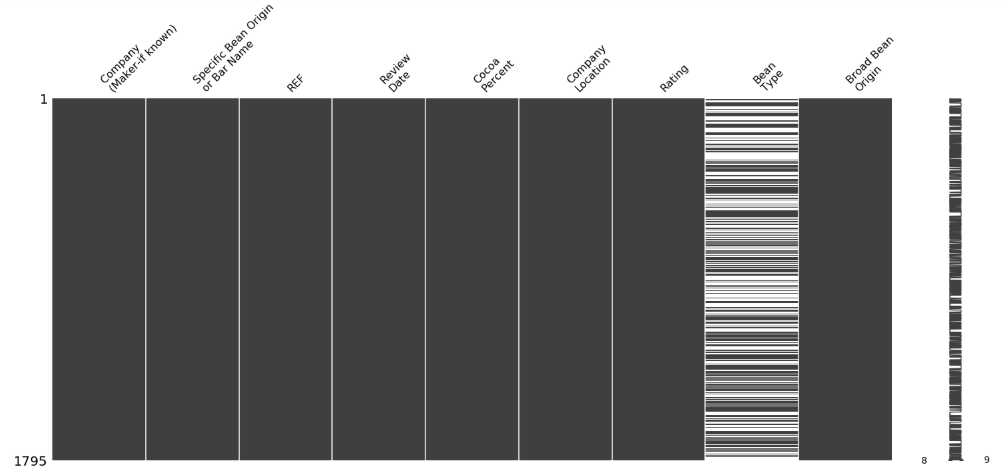 Figura 18: Matriz de nulidad para el dataset del cacao
Figura 18: Matriz de nulidad para el dataset del cacao
También podemos visualizar los valores nulos por columnas con msno.bar. Por ejemplo, para los datos del dataset del cacao se aprecia claramente qué variable es la que tiene más valores que faltan: Bean Type.
msno.bar(choco_data2)
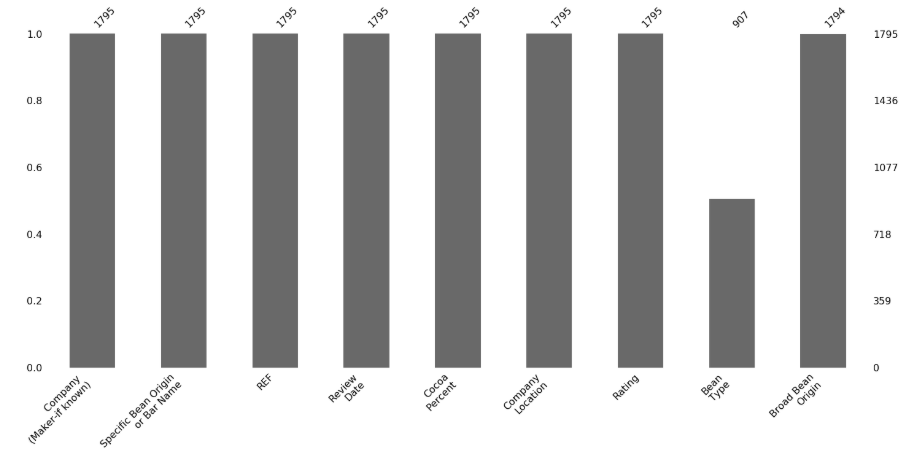 Figura 19: Valores nulos por columnas
Figura 19: Valores nulos por columnas
5. Con un mapa de calor
Por último, vamos a ver el mapa de calor de correlación de nulidad, que nos indica en qué medida la presencia o ausencia de una variable afecta a otra.
- Un valor cercano a -1 significa que si una variable aparece, es muy probable que la otra variable no aparezca
- Un valor cercano a 0 significa que no hay dependencia entre la aparición missing values de dos variables.
- Un valor cercano a 1 significa que si aparece una variable es muy probable que la otra esté presente.
msno.heatmap(titanic_data)
En este ejemplo podemos observar que la correlación entre valores que faltan para las distintas variables es prácticamente nula (valores cercanos a cero). Podría haber una ligera correlación positiva entre "Age"y "Cabin", y negativa entre "Cabin" y "Embarked". Pero, en este ejemplo, no es relevante.
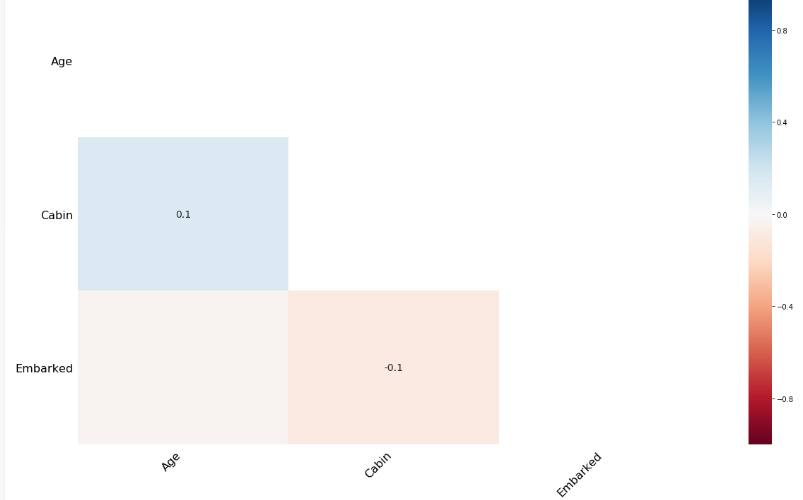 Figura 21: Mapa de calor de correlación de missing values
Figura 21: Mapa de calor de correlación de missing values
Puedes encontrar el código completo en este gist.
Una vez detectados los valores que faltan en un dataset, el siguiente paso es decidir qué hacer con ellos. Pero eso, lo dejamos para otro post.
Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.



