Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Redes neuronales (I): una perspectiva histórica y práctica
Las redes neuronales (artificiales). ¿Qué decir de ellas? No es algo nuevo y sin embargo son el corazón de toda esta revolución y verano de la IA. No es un concepto nuevo porque ya se descubrió y desarrolló durante los años 40.
Su evolución hasta día de hoy es digna y merecedora de un par de párrafos. Así que, ponte un café y una silla cómoda y prepárate para conocer...
El origen de las Redes Neuronales
Podríamos decir que la llama inicial llega de Warren S. McCulloch. Neurólogo estadounidense que se propuso, entre otras investigaciones, crear un modelo matemático del funcionamiento del cerebro. Sí o sí, esto le llevaría a trasladar el concepto de neurona biológica al modelo lógico.
No estaba solo en esa guerra. Le acompañó un matemático experto en lógica: Walter Pitts. De esa colaboración nació un paper considerado el detonante de las redes neuronales: "A Logical Calculus of Ideas Immanent in Nervous Activity", publicado en 1943.
¿Cuál fue el paso dado en este punto?
Modelo matemático de una neurona biológica y sobre todo: cómo la suma de las entradas de la neurona activan la salida... si se supera un umbral determinado. Esto es la "activación" (quédate con esto).
A este paso podemos añadir el planteamiento que en 1949 realizó el fisiólogo canadiense, Donald Hebb: las neuronas no trabajan aisladas, sino que poseen un comportamiento "asambleario" (así fue como lo denominó). Propuso que las neuronas que se activan al mismo tiempo tienden a asociar ese comportamiento e inversamente en la desactivación.
Esto es la puerta al concepto de "red", pero es que además, dado que la asociación se asienta con el tiempo o repetición de la activación, lo que tenemos es un "aprendizaje". Es decir, si una acción se repite con el tiempo y sobre un grupo determinado de neuronas, éstas terminarán por asociarse entre ellas y "reforzar" ese "aprendizaje": una respuesta afinada.
La clave del aprendizaje en redes neuronales reside en la repetición: cuanto más practicas, más se refuerzan las conexiones y se optimiza la respuesta.
Este concepto es, nada más y menos, el origen de lo que hoy conocemos como "pesos" de la red neuronal. Todavía no hemos llegado a los años 50 y ya se hablaba de redes, aprendizaje y refuerzo.
Eddie Van Halen no era científico, pero dejó tres reglas muy sencillas para dominar un instrumento musical como la guitarra eléctrica: "practicar, practicar y practicar". Y tenía razón.
A base de repetir movimientos, el cerebro los "optimiza" reforzando las conexiones neuronales que disparan esas neuronas: plasticidad sináptica: te vuelves ágil y diestro porque tu cerebro ve que repites algo. Y como máquina que optimiza procesos biológicos que es, accede a mejorar tus conexiones para ello. El parangón con la IA es obvio ¿verdad?
El perceptrón de Frank Rosenblatt
Vamos a situar nuestra máquina del tiempo en 1958. Recordemos que dos años atrás nació la Inteligencia Artificial en la conferencia del colegio Dartmouth. Célebre reunión estival propiciada por el padre de la IA (y de LISP, pero eso es otra historia): John McCarthy.
Frank Rosenblatt, investigador de Cornell, desarrolla el Perceptrón. Sintetiza las ideas anteriores (de las que hemos hablado) y crea un modelo inspirado en neuronas que aprenden ajustando pesos. Una revolución.
El perceptrón original, además de ser un modelo matemático, no era un programa (software) sino una máquina, hardware real, que imitaba el proceso neuronal biológico modelado en la pizarra. La imagen del Perceptron Mark I es icónica:
 Foto: National Museum of the U.S. Navy - 330-PSA-80-60 (USN 710739)
Foto: National Museum of the U.S. Navy - 330-PSA-80-60 (USN 710739)
El perceptrón fue la primera máquina capaz de aprender ajustando sus propios pesos, revolucionando el campo de la Inteligencia Artificial.
Se trataba de una rejilla de 20x20 fotocélulas como entrada, una capa oculta de 512 "neuronas" (los perceptrones) y una capa de salida de ocho. En la foto podemos ver como la máquina "aprendía" a detectar la letra "C".
Esto levantó muchas expectativas, la tecnología de redes neuronales era prometedora y se invirtieron fondos y esperanzas en ella hasta que en 1969 se publica el libro "mazazo"...
Perceptrones, una introducción a la geometría computacional (1969)
Dos de los asistentes a la conferencia de Dartmouth: Seymour Papert (padre también del lenguaje Logo y la famosa tortuga) y Marvin Minsky, dieron luz a un libro polémico en varios sentidos.
El primero de ellos es porque tenían, técnica y matemáticamente, razón: un perceptrón simple como el propuesto por Rosenblantt (una sola capa) era incapaz de resolver una función tan sencilla como XOR (función lógica que es verdad solo si A o B está activado, pero no los dos a la vez). Daba igual que aprendiera o no, no iba a poder porque matemáticamente se probaba que no podía hacerlo.
Sin ponernos pedantes con las matemáticas: un perceptrón de una capa no puede resolver funciones más allá de las lineales. Funciones simples como XOR no son lineales y ahí encalla.
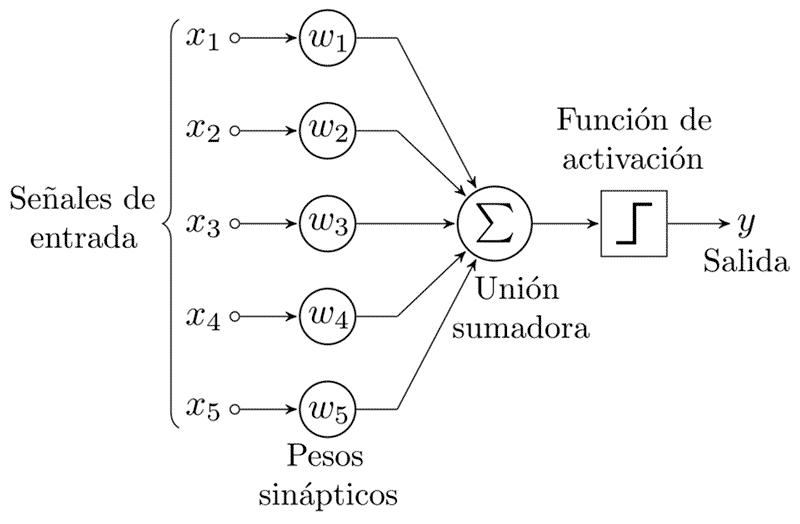 Esquema de Perceptrón de cinco entradas. Imagen: Alejandro Cartas, (CC)
Esquema de Perceptrón de cinco entradas. Imagen: Alejandro Cartas, (CC)
El segundo motivo es que, como efecto del primero, dio paso a uno de los inviernos de la IA. Se cortó el grifo de las subvenciones e inversiones con lo cual tanto Frank Rosenblantt, (cuyo trabajo se vio minusvalorado) como el resto de la comunidad temprana de la IA... no estaban muy contentos con esta publicación a pesar de ser un trabajo sólido y contundente.
Curiosamente, el libro dejaba una perla que no se había explorado, una hipótesis o pregunta al aire que tardó una década sin su respuesta: ¿Podría un perceptrón multicapa resolver el problema que no lograba el de una sola capa?
Un perceptrón de una sola capa no puede resolver funciones no lineales como XOR; la clave está en explorar modelos multicapa.
Backpropagation (Retropropagación)
El crudo y frio invierno de la IA duró bastantes años (spoiler: no fue el primero ni sería el último). Estamos ya en los años 80 y la informática estaba en pleno apogeo, los ordenadores estaban a punto de convertirse en una commodity debido al interés de los fabricantes en ofrecer equipos a muy reducido precio y prestaciones a las familias.
No obstante, la investigación, a pesar de los duros recortes y desconfianza, no se detenía. Año 1986, Hinton, Rumelhart y Williams, publican un artículo que recoge el guante dejado en los 70: "Learning representations by back-propagating errors".
Una bomba. Es posible que una red neuronal aprenda representaciones internas complejas. La función XOR (que no es más que un ejemplo) y cualquier otra no lineal deja de ser un problema. La redes neuronales, cual pantalones de campana, vuelven a estar de moda, aunque todavía les quedaba un largo y gélido recorrido.
¿Y cuál era el ingrediente secreto? Más capas y un importante hallazgo: la red neuronal era capaz de corregirse a sí misma.
Imaginad un arquero que está aprendiendo a usar el arco. El primer disparo rebasa la diana y deja la flecha 2 metros más lejos y hacia el flanco izquierdo. El arquero toma otra flecha de su carcaj, baja levemente los brazos al apuntar, tensa el arco y dispara. La flecha da en la diana, no en el centro pero al menos ha llegado. Sabe que debe recomponer su postura, girar un poco más el cuerpo hacia su derecha y acertará en el centro del objetivo.
La retropropagación permite que una red neuronal se corrija a sí misma, aprendiendo de sus errores hasta alcanzar el objetivo.
En la redes neuronales hay un concepto básico denominado "Forward Pass" (viene del futbol americano), es como una corriente eléctrica de señales (inputs) que va recorriendo desde la entrada a la capa de salida todas las capas intermedias. Eso es un solo pase.
La idea es que, durante la fase de entrenamiento, exista un mecanismo que compare el resultado producido con el resultado esperado y realice ajustes en los pesos de las neuronas o grupos de ellas que se han desviado en proporción al error.
Esto se realiza en tres etapas diferenciadas:
- La primera es la función de coste. Nos mide cuánto nos hemos alejado del resultado esperado. Nuestro arquero observando cuanto se ha desviado el tiro.
- La segunda es la que da nombre a la técnica. Ahora se le da la vuelta a la red y se recorre en sentido inverso, desde la salida (resultado dado y comparado) hasta la entrada.
Mediante el cálculo diferencial se extrae la derivada del error respecto a cada peso y se realiza un ajuste proporcional. Es el arquero, preguntándose qué hizo mal para que el disparo saliese tan desviado.
La tercera y última etapa es el optimizador. Ahora que sabemos qué y cuánto debemos ajustar en cada peso, se aplica la técnica conocida como descenso del gradiente para conocer la pendiente que nos dirá en qué dirección ajustar el peso: pendiente positiva → reducimos el peso; pendiente negativa → aumentamos el peso.
De nuevo, el arquero prepara un nuevo disparo corrigiendo su postura y mejorándola con las correcciones que cree oportunas respecto al tiro anterior.
Alexnet, 2012. Esta vez va en serio
¿Qué les faltaban a las redes neuronales para eclosionar?
Un caso de éxito, mucho datos y potencia de cálculo.
Hinton sabía que no se estaba equivocando, pero tuvo que esperar varias décadas de progreso para que su intuición viese la luz al final del túnel. ¿Por qué? ¿Qué tenemos hoy día que no tenían nuestros antecesores?
Potencia computacional y datos. Esa es la verdadera revolución. Richard Sutton lo describió bastante bien en un pequeño artículo de 2019: La Amarga Lección (The Bitter Lesson).
Básicamente, venía a decir que los avances en el campo habían sido más debido a un aumento de los volúmenes de datos y computación que realmente a avances en intentar "emular" los procesos biológicos del pensamiento.
Para un científico esto supone "fuerza bruta" y dejar de lado la terrible, fría pero solemne, elegante e inamovible certeza absoluta de la ciencia.
AlexNet marcó un antes y un después: la revolución de las redes neuronales llegó gracias a la potencia computacional y a la avalancha de datos.
Volvamos al camino. Hinton y su equipo presentan en 2012 AlexNet con unos resultados espectaculares usando la base de datos ImageNet, una suerte de competición en la clasificación de imágenes alrededor del conjunto de datos. Una revolución.
Hinton no se equivocaba: "Las redes neuronales son el futuro", dijo.
Debajo del capó, el modelo original de AlexNet tenía una arquitectura de 60 millones de parámetros y ocho capas (cinco de ellas convolucionales). Para que nos hagamos una idea, GPT2 (2019) tenía ya 1.500 millones de parámetros. Aunque cierto es que es otra arquitectura y orientación, nos hace recordar a Sutton y su amarga lección: fuerza bruta.
Menciones honorables en la historia de las Redes Neuronales
Hay muchos nombres, es seguro que nos olvidamos a gente importante porque esto no es el trabajo de una sola persona sino de muchas contribuciones al campo que fueron sumando y poniendo ladrillos hasta construir lo que hoy tenemos en el presente.
Paul J. Werbos, en su tesis doctoral de 1974, ya describió parte de lo que hemos contado. Es decir, la solución "estaba ahí", pero sorprendentemente... nadie le prestó atención. Básicamente, su tesis demostraba cómo entrenar un perceptrón multicapa. Es decir, la solución al problema de funciones no lineales (nuestra amiga XOR) que se resolvió más tarde.
El avance de las redes neuronales es fruto del trabajo colectivo: cada contribución suma un ladrillo en la construcción de la IA moderna.
Yann LeCun, contemporáneo y alumno de Hinton. Sin sus contribuciones las redes convolucionales (usadas sobre todo en visión artificial) hubieran tardado más en ser populares.
Yoshua Bengio, junto a LeCun y Hinton formó el "dream team" de la IA moderna (el trío fue Premio Turing 2018), además, los dos primeros junto con el británico Demis Hassabis fueron Premio Princesa de Asturias 2022 por sus contribuciones a la ciencia y tecnología.
■ MÁS DE ESTA SERIE
")