Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities
A historical and practical perspective on neural networks (I)
Artificial neural networks. What can be said about them? They are not a new idea and yet they lie at the heart of this entire AI revolution and summer.
The concept itself dates back to the 1940s, when it was first discovered and developed. Their evolution up to the present day deserves a few paragraphs. So grab a coffee, find a comfortable chair and get ready to discover...
The origin of neural networks
We could say that the initial spark came from Warren S. McCulloch, an American neurologist who set out, among other lines of research, to create a mathematical model of how the brain works. Inevitably, this led him to translate the concept of the biological neuron into a logical model.
He was not alone in that endeavour. He was joined by Walter Pitts, a mathematician with expertise in logic. From this collaboration came a paper widely considered the starting point of neural networks: "A Logical Calculus of Ideas Immanent in Nervous Activity", published in 1943.
What was the key step at this point?
A mathematical model of a biological neuron and, above all, an explanation of how the sum of a neuron’s inputs activates the output if a certain threshold is exceeded. This is what we call activation (remember this concept).
To this we can add the proposal made in 1949 by the Canadian physiologist Donald Hebb: neurons do not work in isolation but instead exhibit what he described as "assembly behaviour". He proposed that neurons that activate at the same time tend to associate that behaviour, and the opposite occurs when they stop activating together.
This opens the door to the concept of a network. Moreover, because the association becomes established over time or through repeated activation, what we obtain is learning. In other words, if an action is repeated over time across a specific group of neurons, they will eventually associate with one another and reinforce that learning: a more refined response.
The key to learning in neural networks lies in repetition: the more you practise, the more the connections are reinforced and the more the response is optimised.
This concept is nothing less than the origin of what we now know as the weights of a neural network. We had not even reached the 1950s and researchers were already talking about networks, learning and reinforcement.
Eddie Van Halen was not a scientist, but he once summed up the path to mastering an instrument such as the electric guitar in three very simple rules: "practise, practise and practise". And he was right.
By repeatedly performing the same movements, the brain optimises them by reinforcing the neural connections that fire those neurons: synaptic plasticity. You become agile and skilful because your brain recognises that you are repeating something. And, as the biological machine that optimises processes, it improves those connections accordingly. The parallel with AI is obvious, isn’t it?
Frank Rosenblatt’s perceptron
Let us set our time machine to 1958. Remember that two years earlier Artificial Intelligence was born at the Dartmouth conference. A famous summer gathering driven by the father of AI, and of LISP too, though that is another story: John McCarthy.
Frank Rosenblatt, a researcher at Cornell, developed the Perceptron. He synthesised the earlier ideas we have discussed and created a model inspired by neurons that learn by adjusting weights. A revolution.
The original perceptron, besides being a mathematical model, was not a program or software but an actual machine: real hardware designed to imitate the biological neural process that had been modelled on the blackboard. The image of the Perceptron Mark I is iconic:
 Photo: National Museum of the U.S. Navy - 330-PSA-80-60 (USN 710739)
Photo: National Museum of the U.S. Navy - 330-PSA-80-60 (USN 710739)
(By National Museum of the U.S. Navy - 330-PSA-80-60 (USN 710739), Public Domain, https://commons.wikimedia.org/w/index.php?curid=70710209)
The perceptron was the first machine capable of learning by adjusting its own weights, revolutionising the field of Artificial Intelligence.
It consisted of a grid of 20x20 photocells as input, a hidden layer of 512 "neurons" (the perceptrons), and an output layer of eight. In the photograph we can see how the machine "learned" to detect the letter "C".
This raised enormous expectations. Neural network technology appeared promising, and funding and hopes were invested in it until, in 1969, a book landed like a hammer blow...
Perceptrons: an introduction to computational geometry (1969)
Two attendees of the Dartmouth conference, Seymour Papert, also the creator of the Logo language and its famous turtle, and Marvin Minsky, published a controversial book in several respects.
The first reason is that, technically and mathematically, they were correct: a simple perceptron such as the one proposed by Rosenblatt, consisting of a single layer, was incapable of solving a function as simple as XOR, a logical function that is true only if A or B is active, but not both at the same time. Whether it learned or not made no difference, because mathematically it could be proven that it simply could not solve it.
Without becoming overly pedantic with the mathematics: a single layer perceptron cannot solve functions beyond linear ones. Simple functions such as XOR are not linear, and that is where the limitation appears.
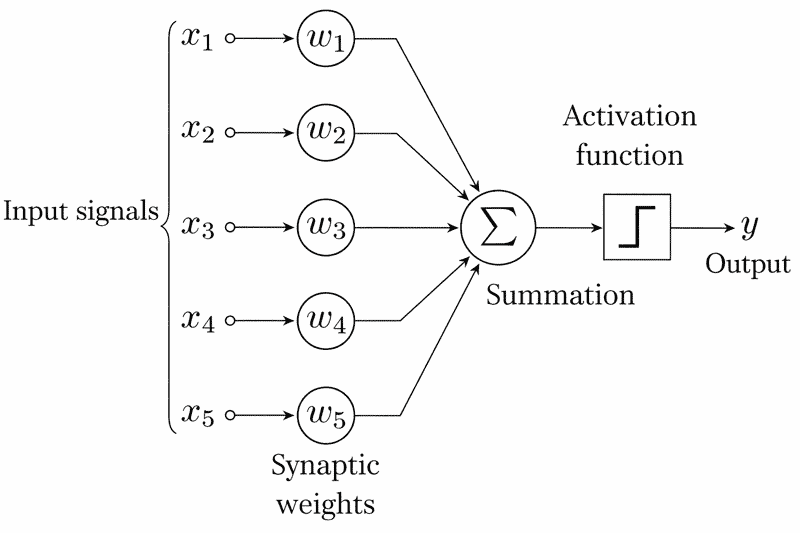 Diagram of a five input perceptron. (Alejandro Cartas, (CC)
Diagram of a five input perceptron. (Alejandro Cartas, (CC)
The second reason is that, as a consequence of the first, it triggered one of the AI winters. Funding and investment were cut off, and both Frank Rosenblatt, whose work became undervalued, and the rest of the early AI community were far from pleased with the publication, despite it being technically solid and well founded.
Interestingly, the book left behind a gem that had not yet been explored, a hypothesis or open question that would remain unanswered for a decade: could a multilayer perceptron solve the problem that a single layer perceptron could not?
A single layer perceptron cannot solve non linear functions such as XOR; the key lies in exploring multilayer models.
Backpropagation
The harsh and cold AI winter lasted many years (spoiler: it was neither the first nor the last). By the 1980s computing was flourishing, and computers were about to become a commodity as manufacturers sought to offer capable machines at very low prices to households.
Even so, research did not stop despite severe funding cuts and widespread scepticism. In 1986, Hinton, Rumelhart and Williams published a paper that took up the question left open in the 1970s: "Learning representations by back-propagating errors".
A bombshell. A neural network could indeed learn complex internal representations. The XOR function, which is merely an example, and any other non linear function were no longer a fundamental problem. Neural networks, like flared trousers, came back into fashion, although they still had a long and cold journey ahead.
And what was the secret ingredient? More layers and a crucial discovery: the neural network was capable of correcting itself.
Imagine an archer learning to use a bow. The first shot overshoots the target and the arrow lands two metres beyond it and to the left. The archer takes another arrow from the quiver, lowers their arms slightly while aiming, draws the bow and shoots. The arrow now hits the target, not the centre but at least it reaches it. The archer knows that they need to adjust their posture, turn their body a little more to the right and they will hit the centre of the target.
Backpropagation allows a neural network to correct itself, learning from its errors until it reaches the target.
In neural networks there is a basic concept known as the Forward Pass (a term borrowed from American football). It can be thought of as a flow of signals (inputs) travelling from the input layer to the output layer through all the intermediate layers. That is a single pass.
The idea is that, during the training phase, there is a mechanism that compares the output produced with the expected result and makes adjustments to the weights of the neurons, or groups of neurons, that have deviated, in proportion to the error.
This takes place in three distinct stages:
- The first is the cost function. It measures how far we are from the expected result. Our archer observing how far the shot has deviated.
- The second is the stage that gives the technique its name. At this point the network is traversed in reverse, from the output layer, where the result has been produced and compared, back to the input layer.
Using differential calculus, the derivative of the error with respect to each weight is calculated and a proportional adjustment is made. It is the archer asking what they did wrong for the shot to go so far off course.
The third and final stage is the optimiser. Now that we know what needs to be adjusted and by how much for each weight, the technique known as gradient descent is applied to determine the slope that indicates the direction in which the weight should be adjusted: a positive slope means the weight is reduced, while a negative slope means the weight is increased.
Once again, the archer prepares another shot, correcting their posture and improving it with the adjustments they consider appropriate based on the previous attempt.
AlexNet, 2012. This time it was serious
What did neural networks lack in order to break through?
A success story, lots of data and computational power.
Hinton knew he was not wrong, but he had to wait several decades of progress for his intuition to finally see the light at the end of the tunnel. Why? What do we have today that our predecessors did not?
Computational power and data. That is the real revolution. Richard Sutton described it quite well in a short article in 2019: The Bitter Lesson.
In essence, he argued that progress in the field had come more from increasing volumes of data and computation than from attempts to "emulate" the biological processes of thought.
For a scientist, this amounts to brute force and setting aside the terrible, cold but solemn, elegant and immovable absolute certainty of science.
AlexNet marked a turning point: the neural network revolution arrived thanks to computational power and the avalanche of data.
Let us return to the path. In 2012 Hinton and his team presented AlexNet with spectacular results using the ImageNet dataset, a kind of image classification competition built around the dataset. A revolution.
Hinton was not wrong: "Neural networks are the future", he said.
Under the bonnet, the original AlexNet model had an architecture of 60 million parameters and eight layers, five of them convolutional. To put that into perspective, GPT2, in 2019, already had 1.5 billion parameters. Although it is true that it is a different architecture and serves a different purpose, it brings us back to Sutton and his bitter lesson: brute force.
Honourable mentions in the history of neural networks
There are many names, and we are bound to forget important people because this is not the work of one person alone but of many contributions to the field, each one adding and laying bricks until what we have today was built.
In his doctoral thesis in 1974, Paul J. Werbos had already described part of what we have recounted here. In other words, the solution "was already there", but surprisingly... nobody paid attention to it. In essence, his thesis showed how to train a multilayer perceptron. In other words, the solution to the problem of non linear functions, represented by our friend XOR, which would only be solved later.
The progress of neural networks is the result of collective work: every contribution adds another brick to the construction of modern AI.
Yann LeCun, a contemporary of and student under Hinton. Without his contributions, convolutional networks, used above all in computer vision, would have taken longer to become popular.
Yoshua Bengio, together with LeCun and Hinton, formed the dream team of modern AI, and the trio received the 2018 Turing Award. In addition, the first two, together with the British Demis Hassabis, received the 2022 Princess of Asturias Award for their contributions to science and technology.
■ MORE OF THIS SERIES
")