Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Data spaces: what’s behind the name
In recent years, multiple technologies have entered the global technology ecosystem. One of the most ambitious lies behind a simple name: data spaces.
A term that, at first glance, seems to refer to some kind of Cloud storage for sharing files securely. A sort of European Cloud with more governance. When we look up its definition, we find a collection of well-meaning adjectives: trusted federated environments for sharing information and extracting value from data, providing sovereignty, security and governance.
It is not exactly the kind of definition that sparks curiosity on first reading.
And yet, behind that understated name and that accumulation of concepts lies one of the most important initiatives for European digital competitiveness. The aim of these lines is to try to explain the idea behind this apparently modest name, and why it should matter to us regardless of our role in the digital ecosystem.
■ Data spaces represent one of Europe’s most ambitious commitments to building a digital economy based on sovereignty, interoperability and trust.
Data spaces: a practical vision of European digital sovereignty
Let us start at the end. It is March 2029.
A woman from Gijón is travelling in Vienna. One afternoon, she suffers a cardiac emergency. The ambulance takes her to the city’s general hospital. The Austrian doctor needs her medical history. Today, that would mean calls to Spain, faxes, emails to a hospital that would probably not reply in time. At best, a PDF with an incomplete summary that nobody could verify.
In 2029, the patient unlocks her mobile phone and authorises access with a gesture. Her European Digital Identity Wallet —which all Member States must offer to their citizens before the end of 2026— verifies who she is, grants specific, traceable and revocable consent, and opens the door.
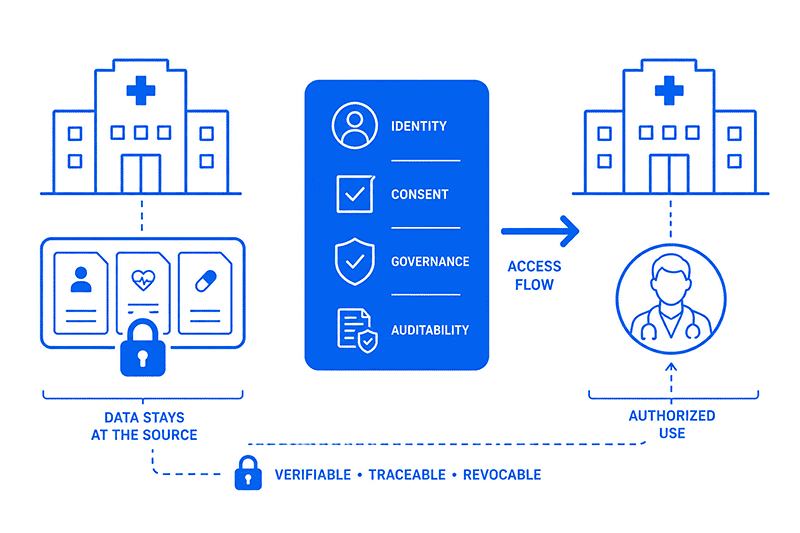
The hospital in Vienna and the hospital in Gijón do not know each other. They do not have a bilateral agreement. They do not need one. The MyHealth@EU network has already established a framework of common rules and interoperability. Standardised format. European authentication. Legal conditions predefined by an EU Regulation. All the negotiation work has already been done.
In seconds, the doctor has medications, allergies and chronic conditions on screen. The data has not travelled. Access has.
* * *
Meanwhile, a few kilometres away, an oncology research team needs to validate a predictive biomarker for pancreatic cancer. Five years ago, a study like this would have required negotiating data transfers with each hospital one by one, going through ethics committees in every country, and arming themselves with a kind of patience measured in years.
 Now they request access through the Health Data Access Body, the body created by the Regulation itself for this purpose. The terms of use are written in a language machines can understand —a W3C standard called ODRL— and the data space connector reads them, interprets them and, if the request meets the requirements, enables access.
Now they request access through the Health Data Access Body, the body created by the Regulation itself for this purpose. The terms of use are written in a language machines can understand —a W3C standard called ODRL— and the data space connector reads them, interprets them and, if the request meets the requirements, enables access.
The process that today takes years —bilateral negotiation, ethics committees in each country, case-by-case transfer— is channelled through a single point with predefined rules. Timelines are reduced from years to weeks.
Through techniques such as federated learning, an artificial intelligence model travels to each hospital, learns from local data without that data moving, and only the model weights return.
In a timeframe that used to be measured in years, they obtain results from millions of medical records. Without the original clinical data having left each hospital.
Data spaces make it possible to extract collective value from information without having to centralise it.
* * *
In another corner of the continent, a consortium of European logistics companies wants to train an artificial intelligence model that optimises multimodal transport routes (lorry, train, ship) by combining traffic, weather, energy consumption and real-time demand data.
Each company has valuable data, but none has enough on its own, and they all share the same concern: losing control over that data during the model training process.
The mobility data space offers them an alternative: each organisation publishes its data assets under conditions it defines itself, the model is trained in a distributed way, and the result is a model trained with data under European control, without any intermediary having accessed the full dataset.
■ In the global race for Artificial Intelligence, data is the scarce resource. Data spaces allow Europe to compete in AI without having to centralise its information assets in the hands of others.
In a factory in Munich, an engineer needs to verify the carbon footprint of a component manufactured in the Czech Republic. He does not send an email. He does not wait for a report. His system queries the supplier’s data catalogue, automatically negotiates the access conditions and obtains the information in real time.
The digital product passport makes it possible to trace the production chain and certify the environmental footprint of each component.
In Asturias, a cheesemaking cooperative wants to sell to a German supermarket chain that requires it to certify the traceability and environmental footprint of the product. If the European agri-food data space progresses as planned, the cooperative will be able to connect its system and make origin, pasteurisation and cold chain data verifiable in real time.
What today requires multiple validation processes and audits is resolved with a digital connection.
What sets these scenarios apart is not the technical ability to exchange information. That has existed for some time. What sets them apart is the trust framework that makes it possible to do so at scale: machine-readable contracts that eliminate months of negotiation, a European digital identity that allows authentication without prior knowledge of one another, common protocols that ensure interoperability, and regulatory backing that provides legal certainty for all participants.
These frameworks are not only roads for sharing data, but also the highway code that allows millions of different vehicles to travel along them without crashing.
Although what is described is a prospective scenario, none of this is science fiction. The regulation has been approved. The connectors work. The pilots exist.
■ The 2029 horizon is not a futuristic hypothesis: it is based on European regulations already approved, operational pilots and technologies that are available today.
But to understand how we got here, we need to go back fifteen years.
The origin of data spaces: from Fraunhofer to the European Data Strategy
In 2014, a group of researchers from the Fraunhofer Society in Germany asked themselves a question: is it possible to share data between organisations without losing control over it?
The question was not academic. For years, Europe had been watching as major technology platforms —mainly American and Chinese— built empires based on a simple model: centralising data from millions of people and companies, extracting value from it and returning services.
Organisations and citizens generate much of the data, while platforms have the ability to extract value from aggregated and processed data. An extraordinarily effective model from a business perspective, but one that raised an asymmetry that was hard to accept: whoever controls the data controls the game.
For years sharing data meant creating value for third parties while losing control over it.
Germany, with its powerful industrial fabric, felt this particularly strongly. Its car manufacturers, component suppliers and Mittelstand companies needed to share information across increasingly complex supply chains.
But, in practice, doing so meant handing data over to platforms they did not control. Sharing was, paradoxically, losing.
Out of that tension came the concept we now know as data sovereignty: the principle that whoever generates data retains control over who can access it, under what conditions and for what purpose. Even after sharing it.
It is the difference between lending a book and photocopying it. In the first case, you decide to whom, when and how. In the second, you lose control forever.
■ Data sovereignty starts from a simple idea: sharing information should not mean giving up control over it.
That project was called Industrial Data Space. A year later, it was renamed International Data Spaces, because its ambition went beyond both industrial and German borders.
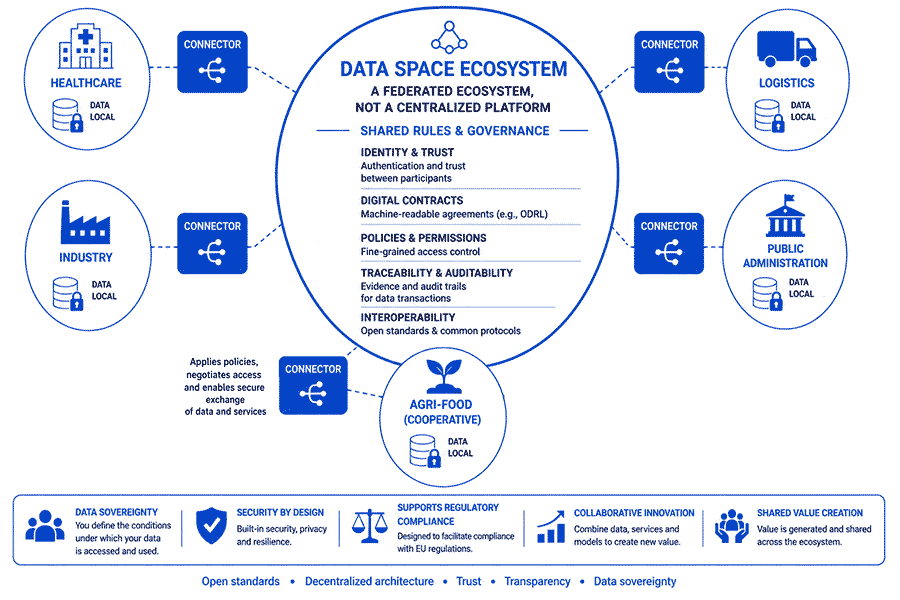
In 2016, the International Data Spaces Association (IDSA) was founded, the guardian of a standard —the IDS Reference Architecture Model— that details how participants identify themselves, negotiate usage contracts and exchange information securely and traceably.
And the truly transformative leap came on 19 February 2020, when the European Commission published the European Data Strategy and turned a concept born in a laboratory into continental policy, proposing the creation of common European data spaces in more than fourteen strategic sectors: health, agriculture, mobility, energy, manufacturing, finance, public administration, tourism, languages, cultural heritage and more.
What began as a research question in Germany ended up becoming a strategy for the whole of Europe.
The third way: the European data model
To understand data spaces, we need to understand the playing field they operate on. Today, there are three major data governance models in the world:
- The American model has tended to rely on market initiative and the leadership of large technology platforms, which collect, store and exploit data under more flexible regulation. Innovation comes first. The result is an extraordinarily dynamic ecosystem, often concentrated in few hands.
- The Chinese model, by contrast, is characterised by more intensive state supervision of data flows. The government imposes strict localisation rules and uses information in a structured way as a tool for governance and strategic competitiveness.
- Europe, traditionally distant from both models, opted for a third way: an ecosystem where data flows securely and in a regulated way between organisations, without centralisation in dominant platforms and without state control of data. A model based on rights, privacy, fair competition and, above all, sovereignty.
Data spaces do not try to replace one platform with another. They try to make possible an ecosystem where no platform is indispensable.
Data spaces are the technical materialisation of that philosophy. While other models were built on platforms (whoever has the best platform wins), Europe decided to build on shared protocols and rules.
It is the difference between a lingua franca imposed from a position of dominance and one that emerges by consensus. Slower to adopt, but potentially fairer and more durable.
■ Data spaces are the technological translation of a political decision: allowing data to generate value without that value depending on a dominant platform.
What is a data space really and how does it work?
A data space is not a centralised repository where everyone uploads their files. It is not European Cloud storage, nor a shared data lake, nor a simple collection of public APIs.
A data space is closer to a circulatory system. The blood (information) flows through veins and arteries (protocols and connectors) between organs (public and private organisations), each with its own function, but all connected and governed by a shared set of rules that ensure the system works.
A data space is not a place to store information. It is a mechanism for sharing it while retaining control over it.
Each organ retains its autonomy. The heart does not tell the liver what to do, but both share vital resources through a common system.
Data never 'leaves' its source: it remains in each organisation’s infrastructure. What travels is controlled access — under digital contracts that specify who can access what, for how long and for what purpose.
■ One of the most important ideas behind data spaces is that data stays where it is. What is shared is access, always under conditions defined by whoever generates or safeguards the data.
The key piece that makes all this possible is the connector: a software component that acts as an organisation’s gateway to the data space.
The connector is responsible for authenticating participants, negotiating usage contracts, transferring information securely and, crucially, enforcing the policies established by the data owner.
There are several reference implementations, such as Eclipse Dataspace Components or the FIWARE Data Space Connector, all based on open source code and on a common protocol — the Dataspace Protocol — that allows different implementations to communicate with each other.
Connectors are the equivalent of an organisation’s entry and exit gates within a data space.
In addition, the European Commission is developing SIMPL (Smart Middleware Platform), an open software distribution —as Ubuntu is for Linux— that provides the components needed for any organisation to deploy and operate a data space.
All of this is supported by a highly ambitious regulatory architecture.
The Data Governance Act establishes the rules for governance and trust; the Data Act clarifies access and usage rights, especially for data generated by connected devices.
And above them, the GDPR, the AI Act and the rest of the European regulatory framework which, whether we like it or not, constitutes one of the most ambitious digital protection frameworks in the world.
■ Data spaces are not only a technological architecture. They are also a regulatory architecture that combines interoperability, governance and legal certainty.
Technology makes it possible to share data. Regulation makes it possible to do so with trust.
Much more than shared files: services, AI and real-time data
An important point to clarify. When we talk about 'data' or even 'datasets', most people imagine files: Excel tables, CSVs, datasets that are downloaded and processed in batches.
And yes, a data space can do that. But reducing it to that is like describing the Internet as 'a system for sending emails'. Technically correct, radically incomplete.
Describing a data space as a file repository is as limited as describing the Internet as a network for sending emails.
Data space connectors support multiple exchange paradigms.
An organisation can expose a real-time REST service that others query on demand — no file is downloaded, a question is asked and an answer is obtained.
It can offer subscriptions and notifications: instead of repeatedly asking 'is there anything new?', a participant subscribes to an event and receives automatic alerts when a condition is met.
And in advanced scenarios, as we saw with oncology research, it can send artificial intelligence models that travel to the data — the data never moves, the algorithm does.
In other words, we can talk about data assets of all kinds:
- Static data.
- Real-time data.
- APIs.
- Machine learning models.
- Inference services.
- Query services.
- Notification services.
- ...
■ A data space does not only exchange files. It can exchange services, events, AI models, APIs and any other digital asset capable of generating value.
The architecture reflects this versatility.
Connectors separate a control plane (where permissions, contracts and policies are negotiated) from a data plane (where the actual information travels, whether a file, an API response or the weights of a model). The control plane is always the same; the data plane adapts to whatever you need to exchange.
The control plane defines the rules of the game. The data plane executes the exchange.
What is shared in a data space is not data in the flat sense of the word. It is information services: capabilities that others can invoke, query or consume, always under the conditions established by the owner.
■ The true value of data spaces is enabling different organisations to collaborate using data, services and algorithms without losing control over them.
Challenges for data spaces: interoperability, regulation and business models
It would be naive not to recognise that there are significant obstacles. And it is worth being honest about their scale.
- To build data spaces, organisations have to agree on rules, contracts, policies, standardised semantics… a necessary coordination effort to build an interoperable system that forms a value chain.
- Regulatory complexity is high. Building value chains that comply with the GDPR, the Data Governance Act, the Data Act, the AI Act and specific sector regulation requires legal and technical effort.
- Business models are uncertain. Most current projects depend on European public funding. For data spaces to survive beyond grant programmes, the value of participating has to be tangible and measurable for each individual organisation — not only for the ecosystem in the abstract.
- Technical fragmentation. The interoperability promised in architecture documents must be materialised in practice.
The vision is clear. The challenge now is to turn promised interoperability into real interoperability.

And while Europe designs and certifies, the major Cloud platforms offer data exchange solutions that work today. Proprietary, yes. Centralising, yes. But they work.
Data spaces compete from a position of open source, transparency and absence of lock-in — long-term strategic advantages that do not always win the short-term battle.
■ Data spaces compete with solutions that are already deployed and generating value today. Their differentiating commitment is based on sovereignty, transparency and the absence of technological dependencies.
Probably one of the biggest obstacles is that companies themselves may not fully identify the true purpose of data spaces.
They may see them as yet another European compliance project, another regulatory obligation rather than a strategic opportunity. They may stay on the surface of the name and never truly understand the depth of what they enable.
If this article serves any purpose, I hope it is to dismantle that misunderstanding.
The greatest risk is not technological. It is that organisations interpret data spaces as a regulatory obligation rather than a strategic opportunity.
These challenges are typical of any transformative infrastructure in its early stages. The European SEPA payments system required more than a decade of work — from the creation of the European Payments Council in 2002 to mandatory migration in 2014 — and today nobody questions its value.
What matters is that the design is solid, regulation is moving forward, and the first real use cases are beginning to show that the vision is viable.
But the difference between a vision that comes true and one that remains on paper is the speed of execution. And that is where all of us working on this have a responsibility.
The difference between a vision that transforms a continent and one that ends up forgotten in a report is the speed with which it is executed.
Epilogue: data spaces as infrastructure for European digital sovereignty
Data spaces are the infrastructure on which Europe is building its digital sovereignty. They are the circulatory system of an economy that aspires to be intelligent while remaining fair. They are the belief that it is possible to share without losing, collaborate without giving up control, and innovate without centralising.
And they reflect a way of understanding technology that is more open, federated, collaborative, fair and sovereign.
Sharing without losing. Collaborating without giving up control. Innovating without centralising. That is the promise behind data spaces.
At Telefónica, we have been contributing to building these spaces for years —in healthcare, public administration, media, the language industry– understanding them as a shared infrastructure built by everyone.
Because no single company can build a data space alone, just as no single company built the network that allows you to read this article today.
■ Data spaces are, by definition, a collective construction. Their value does not depend on one specific organisation, but on the ability of the entire ecosystem to collaborate under common rules.
The outcome has not been written. It depends on regulators, technologists, companies and citizens understanding that what is at stake is not just another technology, but the architecture of how we will live with data over the coming decades.
And that, however little the name may suggest it, is probably the most important technological decision Europe is going to make this decade.
What is at stake is not a specific technology, but the rules under which we will share, use and govern data over the coming decades.
: A guide for companies")