 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

From silos to data spaces: how healthcare interoperability is changing
We live in the age of data. Technology companies move millions of records every day with a level of fluidity that seems almost magical. And yet, when a doctor needs access to the complete medical history of a patient who has been treated at another hospital, the process can still be as rudimentary as making a phone call or waiting for a fax, depending on the hospital.
We are living through a paradoxical moment because never before have we generated so much healthcare data, yet making effective use of it remains complex: it is fragmented across systems that cannot communicate with one another, encoded in heterogeneous formats and subject to strict regulation that limits its use. However, something is changing, especially over the last few years. To understand it, we need to start at the beginning: why is it so difficult to share healthcare data?
There are several reasons why sharing data between hospitals is so difficult: hospitals are highly cautious, and understandably so, when it comes to granting access to their data because of its sensitive nature. Combined with the fact that many hospitals have historically built or acquired their technological infrastructure independently and, in many cases, without coordination with one another, this has resulted in closed systems from which extracting data is technically and legally complex, giving rise to what are known as data silos.
The result is that clinical research is slower and more expensive than necessary, patient care suffers from a lack of clinical context and the potential of artificial intelligence, already proven in specific fields such as clinical image analysis or the early detection of diseases, is diminished because it still depends heavily on improved data interoperability.
Never before have we generated so much healthcare data and yet sharing it remains difficult.
Speaking the same language: ontologies, semantic coding and OMOP
Today, many hospitals already have their data structured in tables, but that still does not seem to be enough. Why? One of the biggest obstacles to multicentre research is that each hospital encodes its data differently:
- The same medication may appear under different names.
- Different units of measurement may be used.
- Or they may simply use different data structures.
All of this means that comparing data between institutions effectively involves rebuilding the integration work from scratch every single time.
The first step towards solving this problem is conceptual: we need to agree on what each thing means. This is where knowledge ontologies come into play, controlled vocabularies that assign a unique and universal identifier to each concept. Some of the most widely used in healthcare are:
- SNOMED-CT: diagnoses, symptoms and clinical procedures
- LOINC: laboratory tests and observations
- RxNorm: medications and treatments
- ICD-10/CIE-10: classification of diagnoses and causes of mortality
With these tools, asthma is no longer described as ‘asthmatic episode’ or ‘asthma’: it becomes concept 195967001, identical in any system in the world using SNOMED.
■ Ontologies allow us to use an interoperable language, but one problem still remains: each institution uses different ontologies, different versions or applies them inconsistently.
How is all of this orchestrated?
This is where the OMOP Common Data Model goes one step further, as it incorporates a unified vocabulary that maps all these ontologies to one another. When a hospital transforms its data into OMOP format, that transformation process also resolves the coding: the local Espidifen becomes the corresponding RxNorm concept, free-text diagnosis entries are mapped to SNOMED and glucose test results adopt their corresponding LOINC code.
The result is that any analysis designed for OMOP can be run in any participating institution without modifications, because all data already speaks the same language, right down to the individual concept level.
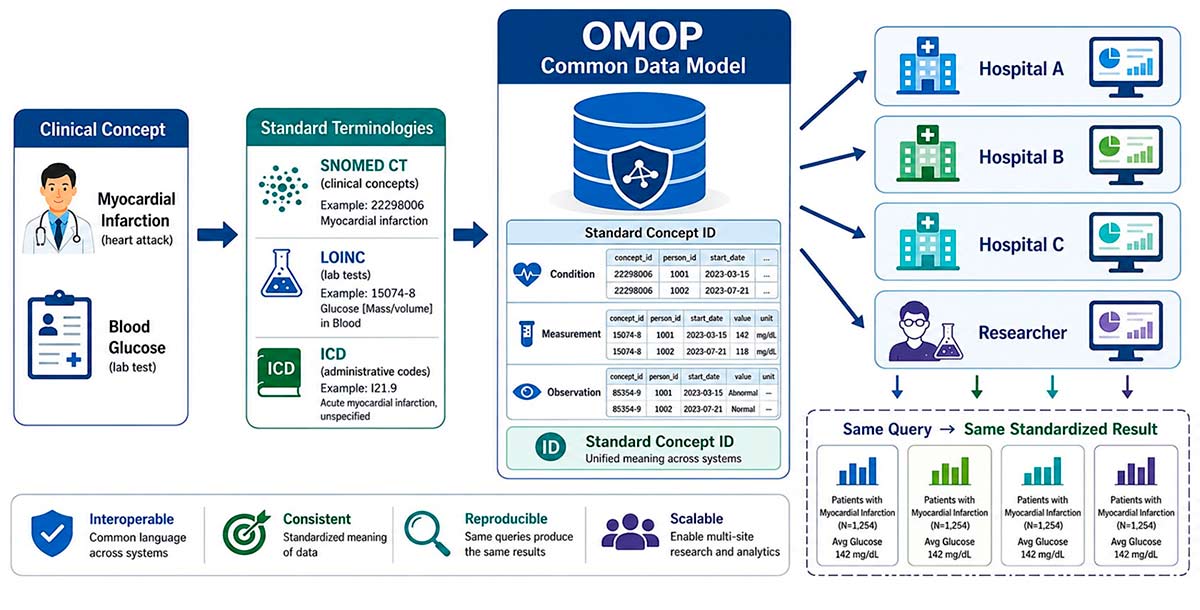 Fig. 1. Clinical data standardisation workflow towards the common OMOP model
Fig. 1. Clinical data standardisation workflow towards the common OMOP model
HL7-FHIR: a solution for connecting everything
If OMOP is the common language for analysis, FHIR is the protocol for real-time communication between systems. Developed by HL7 International, it defines a set of standard clinical resources (patient, medication, diagnosis, observation…) and a REST API1 for reading and writing them. The idea is as simple as it is powerful: if your system speaks FHIR and mine speaks FHIR, exchanging a medical record no longer becomes a months-long project (extracting, emailing, processing and importing into the new system) but instead a simple API call.
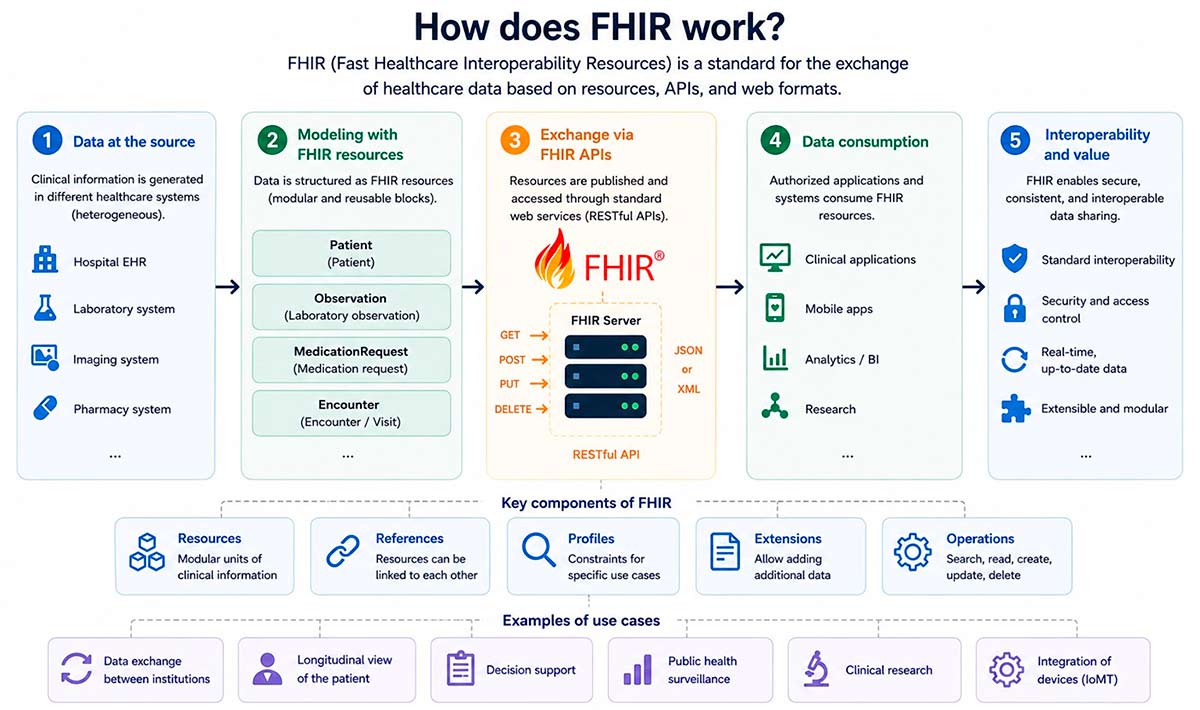 Fig. 2. Standardised data exchange using the FHIR protocol
Fig. 2. Standardised data exchange using the FHIR protocol
Final destination: healthcare data spaces
If the goal is not only for each patient to access their own medical history, but also for that data to be reused for research and improving care, there is little value in every hospital using FHIR if legal restrictions prevent the data from leaving the hospital. What is therefore needed is a governance layer: institutional agreements, consent mechanisms and legal structures that make it possible to share data without exposing the patient.
This is where healthcare data spaces come into play. A data space is not a centralised database, but a distributed infrastructure that establishes the rules governing transfers between hospitals: who can access which data, under what conditions and with what guarantees, without the data needing to move from where it is stored. The key mechanism is federated computing: instead of extracting data and taking it to a central point, the analyses themselves travel.
The researcher sends their query to each hospital, each hospital runs it locally on its own data within its own systems and returns only the aggregated result: “Among our 3,200 smoking patients under the age of 30, mortality was 4.2%.” Nobody has seen a single individual record and sensitive data never leaves the institution, yet the researcher can combine those results to obtain evidence at scale. This is the simplest use case, but it is also possible to carry out more complex queries and even train predictive AI models in a federated way.
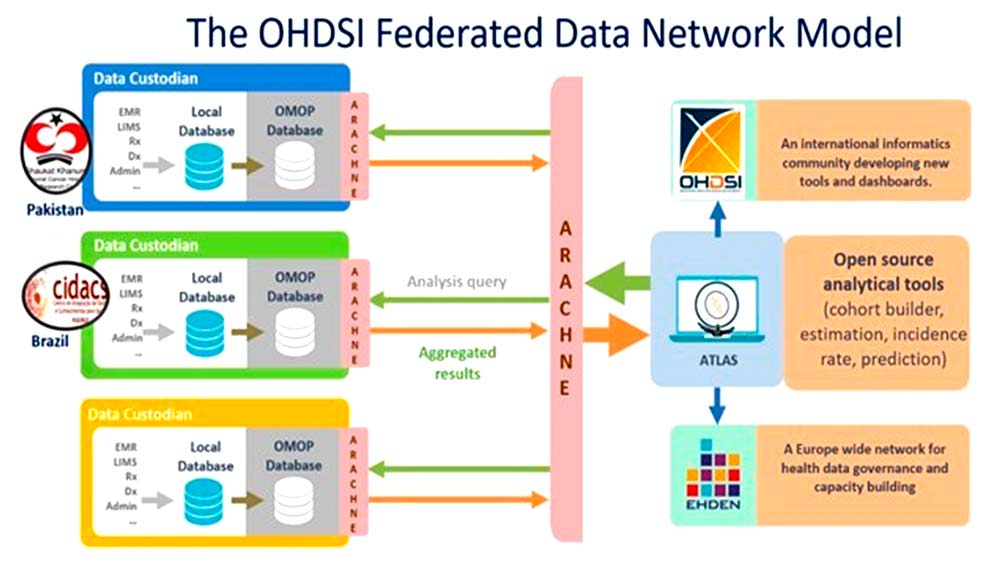 Fig. 3. Example of a federated data space architecture from the OHDSI network using ARACHNE2. Source: https://doi.org/10.1093/jamia/ocac180
Fig. 3. Example of a federated data space architecture from the OHDSI network using ARACHNE2. Source: https://doi.org/10.1093/jamia/ocac180
Because we are dealing with sensitive data, institutions need a trusted entity capable of certifying that the data space infrastructure complies with regulation. This is the context in which Gaia-X emerged, a European initiative that establishes a certification framework and common standards to ensure that all network nodes (hospitals, researchers and companies) operate under the same requirements, so that any shared service or data can be verified as secure, private and interoperable, regardless of who manages it.
■ A practical example of Gaia-X in action is the European Health Data Space (EHDS), approved by the European Parliament in 2024.
Sensitive data never leaves the healthcare institution, but knowledge can still be shared.
What is still missing
It would be naïve to present this ecosystem as the definitive solution to the problem. High-quality data does not appear by itself: it depends on healthcare professionals working under enormous clinical pressure, for whom correctly completing a record competes with caring for the next patient. The underlying issue is structural: hospital systems were historically designed for administrative management, not for analysis or research, and this is reflected in incomplete, poorly coded or inconsistent records that no formatting standard can solve on its own.
The good news is that hospital digitalisation is not only a technical requirement for making these systems work, but also a real opportunity. A hospital with well-structured data can identify patient risk patterns earlier, reduce clinical errors caused by a lack of context, optimise resources and, above all, contribute to research that improves care for future patients. Every well-coded record today is a piece of data that could save a life tomorrow.
Every advance in digitalisation brings us closer to a healthcare system capable of learning better from its data and caring better for people.

______
1. REST API: Standard web interface that allows any application to request and send data through HTTP requests, just as your browser does when loading a webpage.
2. ARACHNE: A platform within the OHDSI network that enables federated analytical studies to be run across multiple centres. It sends a query to each institution, where it is executed locally on OMOP-formatted data, and returns only aggregated results without moving sensitive data. It also manages authentication and authorisation throughout the process.



