 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

De los silos a los espacios de datos: cómo está cambiando la interoperabilidad sanitaria
Vivimos en la era del dato. Las empresas tecnológicas mueven millones de registros cada día con una fluidez que parece magia. Y sin embargo, cuando un médico necesita acceder al historial completo de un paciente que ha sido atendido en otro hospital, el proceso puede llegar a ser tan rudimentario como una llamada por teléfono o esperar un fax dependiendo del hospital.
Estamos en un momento paradójico, ya que nunca hemos generado tantos datos de salud, pero aprovecharlos sigue siendo complejo: están fragmentados entre sistemas que no se comunican, codificados en formatos heterogéneos y sujetos a una regulación estricta que limita su uso. Sin embargo, algo está cambiando, especialmente en los últimos años. Para entenderlo hay que empezar por el principio: ¿por qué es tan difícil compartir datos sanitarios?
La dificultad de compartir datos entre hospitales tiene varios motivos: los hospitales tienen una elevada (y justificada) cautela a la hora de permitir el acceso a sus datos debido al carácter sensible de estos. Esto, sumado a que históricamente muchos hospitales han construido o adquirido su infraestructura tecnológica de forma independiente y, en numerosas ocasiones, sin coordinación entre ellos, ha derivado en sistemas cerrados de los que es técnica y legalmente complicado extraer datos, lo que les da el nombre de silos.
El resultado es que la investigación clínica es más lenta y cara de lo necesario, la atención al paciente se resiente por falta de contexto clínico y el potencial de la Inteligencia Artificial, ya demostrado en ámbitos concretos como el análisis de imagen clínica o la detección temprana de patologías, se ve mermado ya que sigue dependiendo en gran medida de una mejor interoperabilidad de los datos.
Nunca hemos generado tantos datos de salud y, sin embargo, sigue siendo difícil compartirlos.
Cómo hablar el mismo idioma: ontologías, codificación semántica y OMOP
Hoy en día ya hay muchos hospitales que tienen sus datos estructurados en tablas, pero parece que sigue sin ser suficiente, ¿por qué? Uno de los mayores obstáculos para la investigación multicéntrica es que cada hospital codifica sus datos de forma diferente:
- Un mismo medicamento puede aparecer bajo nombres distintos.
- Pueden utilizar distintas unidades de medida.
- O directamente tener estructuras de datos distintas.
Todo esto hace que comparar datos entre instituciones sea, en la práctica, rehacer el trabajo de integración desde cero con cada una.
El primer paso para resolver esto es conceptual: necesitamos acordar qué significa cada cosa. Ahí es donde entran las ontologías de conocimiento, vocabularios controlados que asignan un identificador único y universal a cada concepto. Algunas de las más extendidas en clínica son:
- SNOMED-CT: diagnósticos, síntomas y procedimientos clínicos
- LOINC: pruebas de laboratorio y observaciones
- RxNorm: medicamentos y tratamientos
- ICD-10/CIE-10: clasificación de diagnósticos y causas de mortalidad
Con estas herramientas, el asma no es 'cuadro asmático' ni 'asma': es el concepto 195967001, igual en cualquier sistema del mundo que use SNOMED.
■ Las ontologías nos permiten utilizar un idioma interoperable, pero sigue quedando un problema: cada institución usa ontologías distintas, versiones distintas, o las aplica de forma inconsistente.
¿Cómo se orquesta todo esto?
Aquí es donde el Common Data Model de OMOP da un paso más, ya que incorpora un vocabulario unificado que mapea todas estas ontologías entre sí. Cuando un hospital transforma sus datos a OMOP, ese proceso de transformación resuelve también la codificación: el Espidifen local se convierte en el concepto RxNorm correspondiente, un texto libre del diagnóstico se mapea a SNOMED, la analítica de glucosa adopta su código LOINC.
El resultado es que cualquier análisis diseñado para OMOP puede ejecutarse en cualquier institución participante sin modificaciones, porque todos los datos ya hablan el mismo idioma, hasta el nivel del concepto individual.
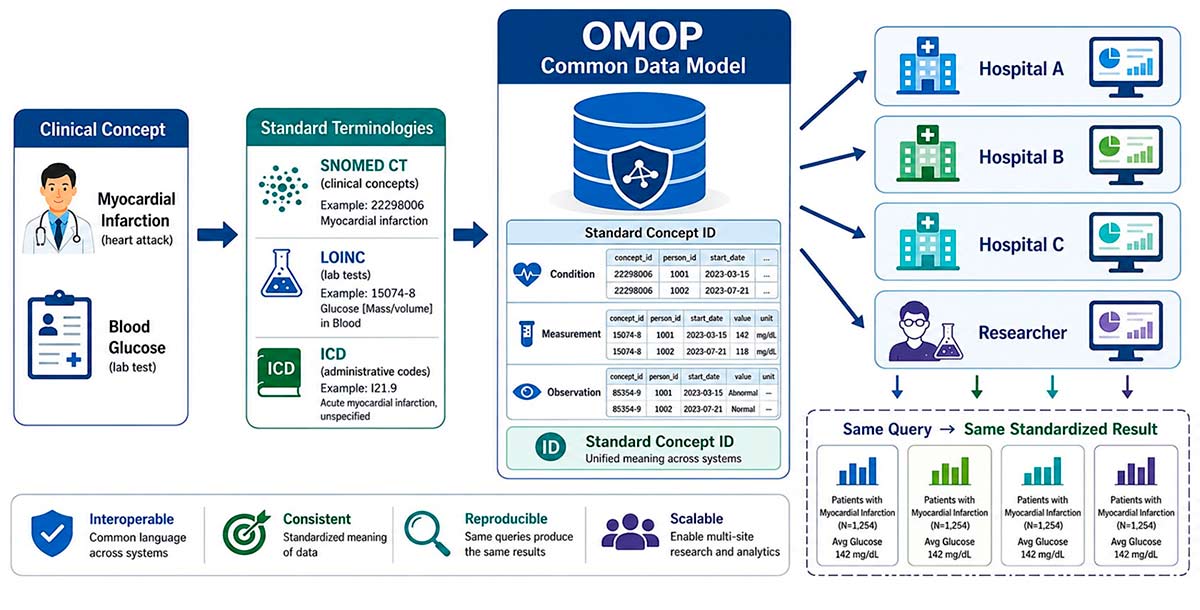 Fig 1. Flujo de estandarización de datos clínicos hacia el modelo común OMOP
Fig 1. Flujo de estandarización de datos clínicos hacia el modelo común OMOP
HL7-FHIR: Una solución para conectarlo todo.
Si OMOP es el idioma común para el análisis, FHIR es el protocolo para la conversación en tiempo real entre sistemas. Desarrollado por HL7 International, define un conjunto de recursos clínicos estándar (paciente, medicamento, diagnóstico, observación…) y una herramienta API REST1 para leerlos y escribirlos. La idea es tan sencilla como poderosa: si tu sistema habla FHIR y el mío habla FHIR, intercambiar un historial clínico deja de ser un proyecto de meses (extraer, enviar por correo, procesar e introducir al nuevo sistema) para convertirse en una llamada a una API.
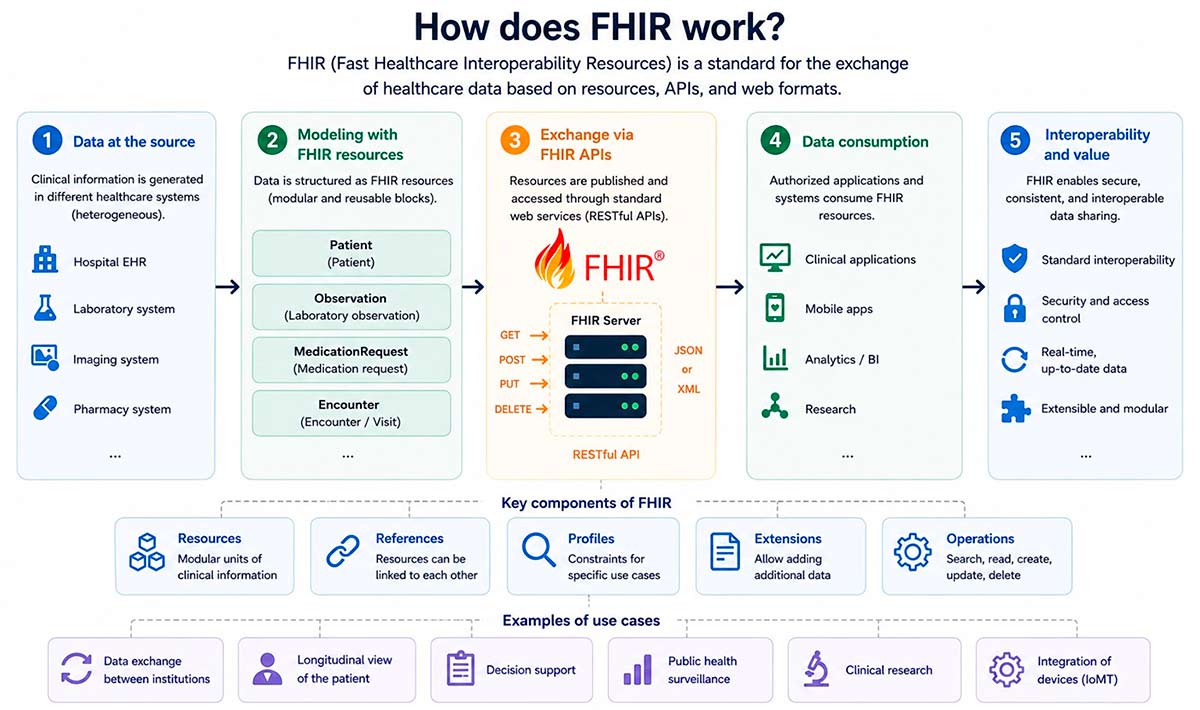 Fig 2. Intercambio estandarizado de datos mediante protocolo FHIR
Fig 2. Intercambio estandarizado de datos mediante protocolo FHIR
Destino final: los espacios de datos sanitarios
Si el objetivo no es solo que cada paciente acceda a su propio historial, sino que esos datos puedan reutilizarse para investigación y mejora de la atención, de poco sirve que todos los hospitales usen FHIR si los datos no pueden salir del hospital por limitaciones legales. Lo que hace falta, por tanto, es una capa de gobernanza: acuerdos institucionales, mecanismos de consentimiento y estructuras legales que hagan posible compartir sin exponer al paciente.
Ahí es donde encajan los espacios de datos sanitarios. Un espacio de datos no es una base de datos centralizada, sino una infraestructura distribuida que establece las normas de transferencia entre hospitales: quién puede acceder a qué datos, bajo qué condiciones y con qué garantías, sin que esos datos tengan que moverse de donde están. El mecanismo clave es la computación federada: en lugar de extraer los datos y llevarlos a un punto central, son los análisis los que viajan.
El investigador envía su consulta a cada hospital, cada hospital la ejecuta localmente sobre sus propios datos, dentro de sus propios sistemas, y devuelve únicamente el resultado agregado: "en nuestros 3.200 pacientes fumadores y menores de 30, la mortalidad fue del 4,2%". Nadie ha visto un solo registro individual y los datos sensibles no salen de la institución, pero el investigador puede combinar esos resultados para obtener evidencia a gran escala. Este es el caso más simple, pero es posible realizar consultas más complejas e incluso entrenamiento de IA predictiva de forma federada.
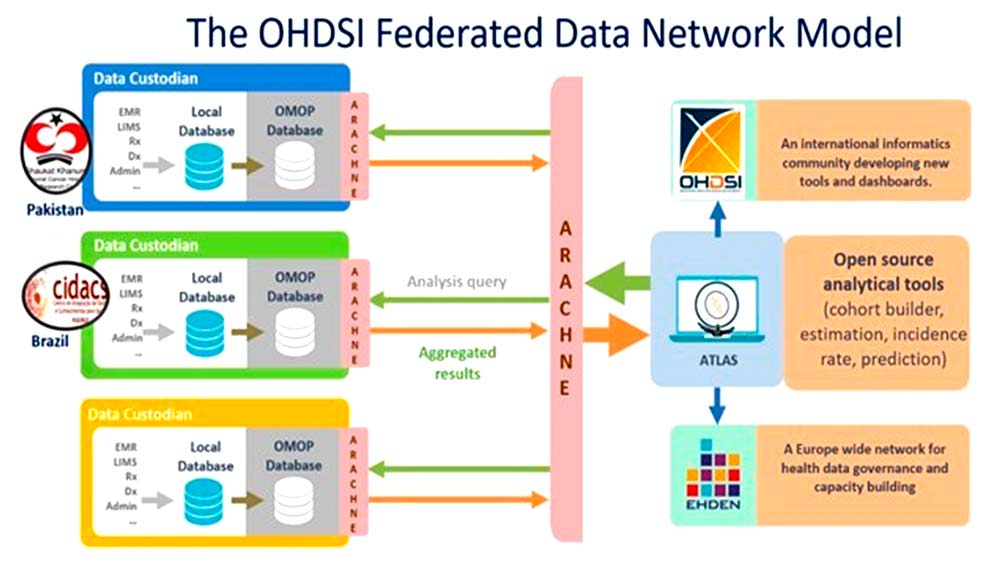 Fig 3. Ejemplo de arquitectura federada de espacio de datos de la red OHDSI utilizando ARACHNE2. Fuente: https://doi.org/10.1093/jamia/ocac180
Fig 3. Ejemplo de arquitectura federada de espacio de datos de la red OHDSI utilizando ARACHNE2. Fuente: https://doi.org/10.1093/jamia/ocac180
Como tratamos con datos sensibles, las instituciones necesitan un agente de confianza que certifique que la infraestructura del espacio de datos cumple con la regulación. En este contexto nace Gaia-X, una iniciativa europea que establece un marco de certificación y estándares comunes para garantizar que todos los nodos de la red (hospitales, investigadores, empresas) operan con los mismos requisitos, de modo que cualquier servicio o dato compartido pueda verificarse como seguro, privado e interoperable, independientemente de quién lo gestione.
■ Un ejemplo de aplicación de Gaia-X en la práctica es el European Health Data Space (EHDS), aprobado por el Parlamento Europeo en 2024.
Los datos sensibles no salen del centro sanitario, pero el conocimiento sí puede compartirse.
Lo que todavía falta
Sería ingenuo presentar este ecosistema como la solución final al problema. Los datos de calidad no surgen solos: dependen de profesionales sanitarios que trabajan bajo una presión asistencial enorme, y para quienes rellenar correctamente un registro compite con atender al siguiente paciente. El problema de fondo es estructural: los sistemas hospitalarios fueron diseñados históricamente para la gestión administrativa, no para el análisis o la investigación, y eso se refleja en registros incompletos, mal codificados o inconsistentes que ningún estándar de formato puede resolver por sí solo.
La buena noticia es que la digitalización de los hospitales no es solo un requisito técnico para hacer funcionar estos sistemas, sino una oportunidad real. Un hospital con datos bien estructurados puede detectar antes patrones de riesgo en sus pacientes, reducir errores clínicos por falta de contexto, optimizar recursos y, sobre todo, contribuir a investigaciones que mejoran la atención de futuros pacientes. Cada registro bien codificado hoy es un dato que mañana puede salvar una vida.
Cada avance en digitalización acerca una sanidad capaz de aprender mejor de sus datos y de cuidar mejor a las personas.

______
1. API-REST: Interfaz web estándar que permite a cualquier aplicación solicitar y enviar datos mediante peticiones HTTP, igual que hace tu navegador cuando carga una página.
2. ARACHNE: Plataforma de la red OHDSI que permite ejecutar estudios analíticos de forma federada en múltiples centros. Envía consulta a cada institución, donde se ejecuta localmente sobre datos en formato OMOP, y devuelve solo resultados agregados, sin mover los datos sensibles. Además, gestiona la autenticación y autorización del proceso.



