Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Redes neuronales: una perspectiva histórica y práctica (II)
En la anterior entrega introducimos las redes neuronales en su marco histórico. En esta entrega lo haremos desde la perspectiva práctica, con código que podamos 'tocar'.
Vamos a empezar por el Perceptron simple, el que nos proporcionó Frank Rosenblatt y lo utilizaremos para que aprenda a resolver funciones lógicas sencillas como AND u OR.
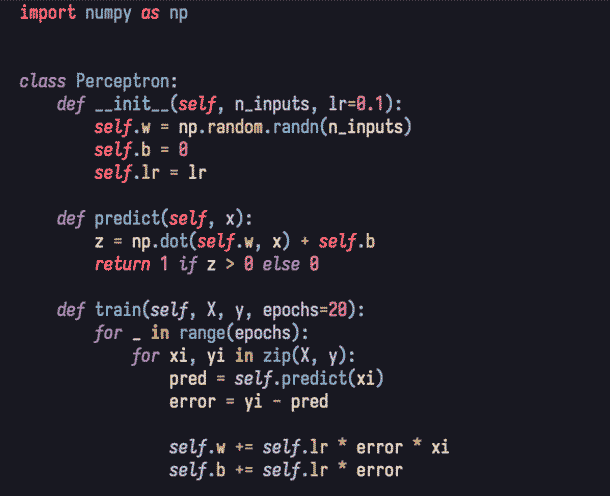
Como vemos, tenemos una clase Perceptron que posee un constructor y dos métodos, uno para entrenar (train) y otro para hacer las predicciones (predict).
Las funciones lógicas AND y OR poseen dos entradas (pueden ser más) y una salida. Estas son las tablas de verdad que mapean dos valores (las entradas) a un resultado:
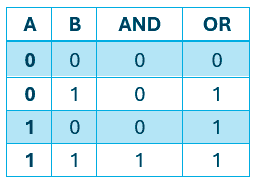
Por lo tanto, el objetivo de nuestro perceptrón será que aprenda cómo funcionan y sepa resolver el mismo problema por sí solo.
El objetivo: aprender y generalizar por sí mismo.
El valor de los pesos es generado aleatoriamente, como puede verse en el constructor (__init__) cuando se usa numpy.random.randn. Si os fijáis bien, el parámetro n_inputs lo indicamos nosotros al instanciar la clase.
Aquí la idea principal es: ¿Que tenemos dos entradas? Pues entonces tendremos dos pesos inicializados de forma aleatoria.
Si los pesos no tuvieran un valor aleatorio las neuronas de una red aprenderían exactamente lo mismo, sin aportar riqueza al aprendizaje.
El 'bias' y la tasa de aprendizaje
Las otras dos variables son el 'bias' o sesgo (self.b) y la tasa de aprendizaje (self.lr). El bias añade múltiples características positivas al perceptrón, entre ellas: adaptarse mejor a los datos de entrada, evitar la no-activación cuando las entradas se anulan (ceros) y sobre todo, algo muy interesante, evitan o ayudan a paliar el overfitting y underfitting.
El 'bias' mejora la adaptación y estabilidad del modelo
Como podemos ver, también se va actualizando con el entrenamiento. El bias puede ser un cero, un valor arbitrario o incluso, como los pesos, aleatorio, lo importante es que se ajuste durante el entrenamiento como un peso más.
Por otro lado, ese 'lr' (learning rate) es la tasa de aprendizaje. Es una medida de 'cuánto' va a variar el ajuste de los pesos durante el entrenamiento. Es decir, la cantidad que se añadirá o restará (dependiendo del signo del error) al peso.
Es mejor imaginarlo como el mando de temperatura de un horno. Si la tasa de aprendizaje fuese de 0.1 es como si cada posición del mando subiese solo 0.1º y si la tasa de aprendizaje fuese de 0.001, el mando de temperatura solo subiría por cada posición una milésima de grado.
Esto afecta muchísimo al resultado del entrenamiento puesto que con una tasa de aprendizaje pequeña se necesitarán muchas iteraciones para llegar a un ajuste fino, mientras que una grande puede que no llegue nunca a un ajuste cercano al ideal al ser más grueso.
La neurona (artificial) y su activación
Si no lo has visto antes y te has imaginado miles de millones de puntos interconectados con lucecitas brillando en un hipercubo dentro de una realidad virtual... siento decepcionarte.
Esto es una neurona artificial:

Es el resultado de una multiplicación y la suma del bias. Ese valor, que guardamos en z es la salida de la neurona.
Y la línea de abajo es su función de activación (que en ese caso ni tan siquiera es una función, es un simple if-else).
Decepcionante ¿verdad? Bueno, si agitas fuertemente tu mano y apartas todo el humo detrás de ese concepto tan simple se esconden verdaderos tesoros matemáticos. Vamos a descifrarlo.
Una neurona es simple… su combinación lo cambia todo.
Lo que hacemos es multiplicar el vector de los pesos por las entradas y agregarle el bias. Esto, nos recuerda poderosamente a un objeto matemático muy simple y familiar: la función lineal. Y es que una neurona es precisamente eso, nada más. El verdadero poder es cómo se combinan entre ellas en capas y cómo, a su vez, se combinan las capas entre sí.
Por otro lado, y con no menos protagonismo, tenemos la función de activación. Es el mecanismo que decidirá si la neurona se activa o no. Toma el valor final calculado por la neurona y decidirá si ese valor entra dentro del umbral de activación.
Existen varias funciones de activación, la más básica es la que estamos usando y se denomina función escalón:
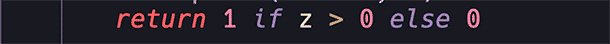
Es simple, fijamos un valor y si 'z' es mayor (supera el umbral) se activa, de lo contrario, permanece inactiva.
El problema con esta función es que es tan simple que su derivada no nos sirve para entrenar una red con backpropagation.
Para redes multicapas disponemos de funciones que sí lo permiten: ReLU, ELU o Softmax entre otras.
Entrenamiento
Como se ve en el código, hay un número de iteraciones definido por el parámetro epochs.
Ese parámetro nos permite indicar el número de generaciones o ajustes del perceptron cuando se está entrenando. Es decir, el número de veces que hará 'prueba-error' y ajuste de las variaciones.
Entrenar es iterar: prueba, error y ajuste
Si el número es muy bajo no habrá convergencia, el modelo no terminará de entrenarse y los resultados de inferencia serán muy pobres. En pocas palabras, no le hemos dado tiempo a 'entender' el problema.
Si el número es muy alto no nos servirá de mucho ya que una vez la tasa de error cae a cero, los pesos ya no se actualizarán.
Esto se ve fácilmente en el código:

Si el error es cero (observad la multiplicación), el ajuste es nulo.
Aquí debemos hacer una parada: Si los datos son separables linealmente (función OR o AND, por ejemplo) sí llegaremos a ese estado donde la tasa de error es cero.
Si por el contrario, los datos no son separables linealmente (la función XOR, por ejemplo)... el perceptron de una sola capa no llegará a converger nunca.
No todo problema puede resolverse con un perceptrón simple.
Da igual si seguimos subiendo el número de epochs o iteraciones, un perceptron de una sola capa no resolverá el problema porque su entrenamiento, matemáticamente, no puede llegar a converger.
Demostración
Vamos a entrenar nuestro perceptron para que aprenda a resolver la función AND:

Ajustamos a dos parámetros n_inputs y le enseñamos todos los resultados posibles respecto a todas las entradas n=2 posibles.
Con nuestro perceptron entrenado, hacemos que realice predicciones sobre posibles entradas:

Ejecutamos:
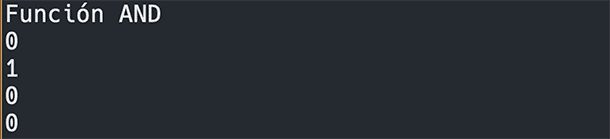
100% de resultados.
Con datos lineales, el modelo funciona perfectamente.
Ahora intentemos entrenar la red para que resuelva la función XOR, que como hemos dicho, no es lineal y por lo tanto en entrenamiento no podrá converger:

Modelo entrenado, vamos a ejecutar con:

Resultado:
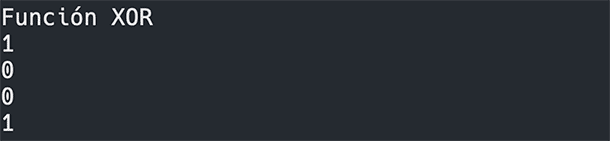
Como podemos ver, una escopeta de feria tiene una mejor tasa de resultados.
Conclusión
El despertar de las redes neuronales parece fácil desde la perspectiva del tiempo, pero no lo fue.
Lo que hoy conseguimos con unas pocas líneas de uno de los mejores lenguajes de programación, en los años 60 era una tarea ardua y compleja.
Hemos visto el funcionamiento elemental en una instancia de la red neuronal más básica: el perceptrón. El pionero que abrió el camino.
El siguiente paso es la era del perceptrón multicapa que rompió la barrera de la no-linearidad y supuso el renacimiento de las redes neuronales gracias a la backpropagation.
■ En próximas entregas veremos, de forma práctica, cómo se llegó, cómo funciona y cómo podemos implementarlo.
.jpg "Inteligencia Artificial Generativa, creando música a ritmo de perceptrón")