Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

¿Qué es overfitting y cómo evitarlo?
9 de abril de 2019
En Machine Learning, describimos el aprendizaje de la función objetivo a partir de los datos de entrenamiento como aprendizaje inductivo. Entendemos que la inducción se refiere al aprendizaje de conceptos generales a partir de ejemplos etiquetados específicos, que es exactamente el problema que los algoritmos de Machine Learning supervisado pretenden resolver. La capacidad de inducción de un modelo se refiere a cómo de preciso es un modelo de ML en entender ejemplos específicos que el mismo no vio cuando el algoritmo del que partía estaba siendo entrenado. El objetivo de un buen modelo de aprendizaje automático es generalizar bien los datos de entrenamiento a cualquier dato del dominio del problema. Esto nos permite hacer predicciones en el futuro sobre los datos que el modelo nunca ha visto.
Las principales causas cuando se obtienen malos resultados al entrenar diferentes modelos de Machine Learning son el overfitting o el underfitting de los datos. Cuando entrenamos nuestro modelo intentamos ajustar los datos de entrada entre ellos y con la salida. En función de las características de nuestro dataset y de la elección de las muestras, se puede producir overfitting o “sobreajuste” y underfitting o “subajuste”. Estas dos casuísticas no dejan de ser más que la incapacidad de nuestro modelo de generalizar el dataset provisto.
Es muy común que, al comenzar a entrenar el modelo, se caiga en el problema del underfitting. Lo que ocurrirá es que nuestro modelo sólo se ajustará a aprender los casos particulares que le enseñamos y será incapaz de reconocer nuevos datos de entrada. En nuestro conjunto de datos de entrada muchas veces introducimos muestras atípicas (o anómalas) o con ruido en alguna de sus dimensiones, o muestras que pueden no ser del todo representativas. Cuando sobre-entrenamos nuestro modelo y caemos en el overfitting, nuestro algoritmo estará considerando como válidos sólo los datos idénticos a los de nuestro conjunto de entrenamiento y siendo incapaz de distinguir entradas buenas como fiables si se salen un poco de los rangos ya preestablecidos. En la siguiente imagen vemos una simplificación a un ejemplo de regresión que nos permite visualizar el problema del underfitting y el overfitting. Encontrar un equilibrio para una correcta generalización se convierte en necesario. 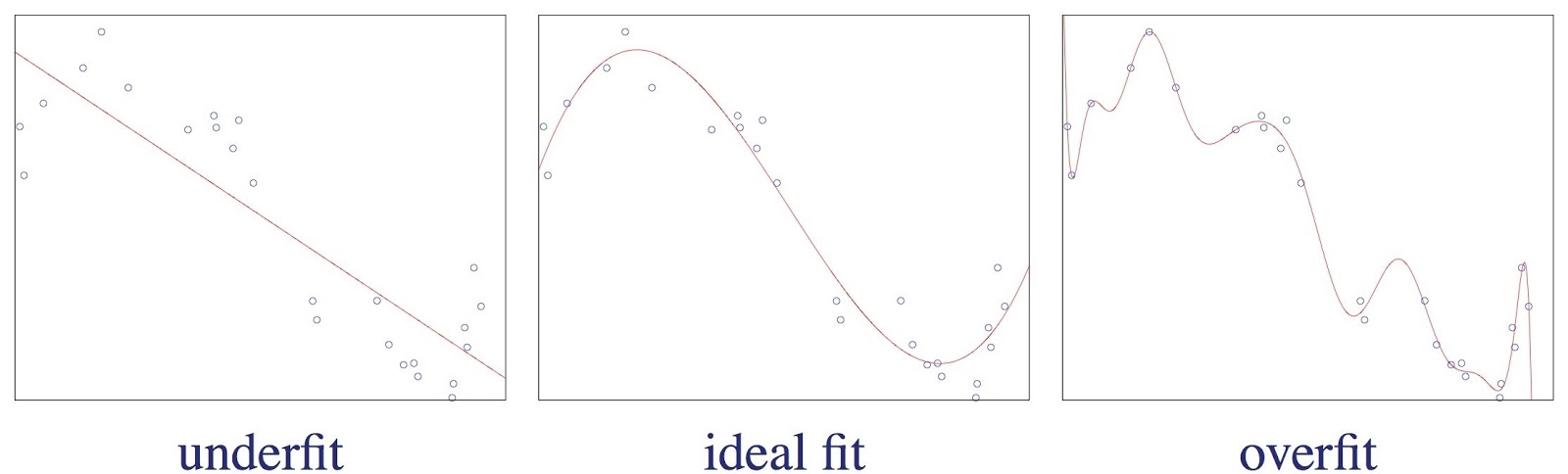 Fig. 1: Over-fitting vs Under-fitting vs ideal fit a model. Fuente
Fig. 1: Over-fitting vs Under-fitting vs ideal fit a model. Fuente
Fig. 1: Over-fitting vs Under-fitting vs ideal fit a model. Fuente
Se debe encontrar un punto medio ( sweet spot) en el aprendizaje de nuestro modelo en el que nos aseguremos de que no estamos incurriendo en underfitting u overfitting, lo cual a veces puede resultar una complicada tarea.
Otros conceptos con los que nos tenemos que familiarizar son los términos bias y varianza. Suelen resultar confusos para los recién llegados al Machine Learning, pero en realidad son muy intuitivos. De manera muy simple, un alto sesgo o bias indican que el modelo sufre de underfitting o subajuste y una alta varianza indica que el modelo sufre de overfitting. 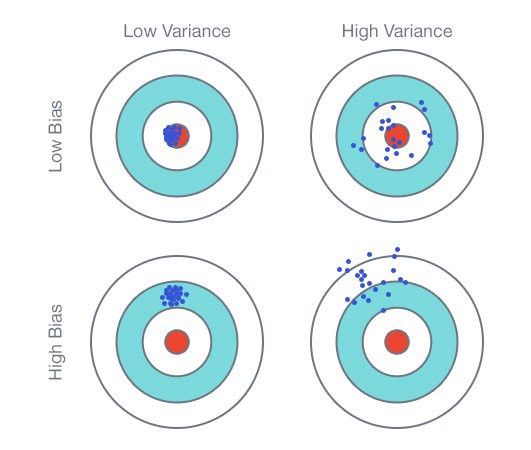 Fig. 2: Graphical Illustration of bias-variance trade-off , Source: Scott Fortmann-Roe., Understanding Bias-Variance Trade-off. Fuente En anteriores artículos, sobre todo aquellos basados en tutoriales de Python sobre aplicación de algoritmos de Machine Learning, habréis visto que uno de los pasos que siempre se dan es realizar una partición del dataset en muestras de entrenamiento y testeo. Esta práctica, muy recomendable, nos sirve para monitorizar el entrenamiento de nuestro algoritmo y para poder prevenir errores en el aprendizaje. Al monitorizar el entrenamiento de un algoritmo, siempre se suelen monitorizar los errores de entrenamiento y testeo para prevenir las condiciones de alto bias y alta varianza. Para reconocer este problema deberemos subdividir nuestro conjunto de datos de entrada para entrenamiento en dos: uno para entrenamiento y otro para la validación que el modelo no conocerá de antemano. Esta división se suele hacer del 70-80% para entrenar y 20-30% para validar. El conjunto de validación deberá tener muestras lo más diversas posibles y en cuantía suficiente.
Fig. 2: Graphical Illustration of bias-variance trade-off , Source: Scott Fortmann-Roe., Understanding Bias-Variance Trade-off. Fuente En anteriores artículos, sobre todo aquellos basados en tutoriales de Python sobre aplicación de algoritmos de Machine Learning, habréis visto que uno de los pasos que siempre se dan es realizar una partición del dataset en muestras de entrenamiento y testeo. Esta práctica, muy recomendable, nos sirve para monitorizar el entrenamiento de nuestro algoritmo y para poder prevenir errores en el aprendizaje. Al monitorizar el entrenamiento de un algoritmo, siempre se suelen monitorizar los errores de entrenamiento y testeo para prevenir las condiciones de alto bias y alta varianza. Para reconocer este problema deberemos subdividir nuestro conjunto de datos de entrada para entrenamiento en dos: uno para entrenamiento y otro para la validación que el modelo no conocerá de antemano. Esta división se suele hacer del 70-80% para entrenar y 20-30% para validar. El conjunto de validación deberá tener muestras lo más diversas posibles y en cuantía suficiente.
Fig. 2: Graphical Illustration of bias-variance trade-off , Source: Scott Fortmann-Roe., Understanding Bias-Variance Trade-off. Fuente En anteriores artículos, sobre todo aquellos basados en tutoriales de Python sobre aplicación de algoritmos de Machine Learning, habréis visto que uno de los pasos que siempre se dan es realizar una partición del dataset en muestras de entrenamiento y testeo. Esta práctica, muy recomendable, nos sirve para monitorizar el entrenamiento de nuestro algoritmo y para poder prevenir errores en el aprendizaje. Al monitorizar el entrenamiento de un algoritmo, siempre se suelen monitorizar los errores de entrenamiento y testeo para prevenir las condiciones de alto bias y alta varianza. Para reconocer este problema deberemos subdividir nuestro conjunto de datos de entrada para entrenamiento en dos: uno para entrenamiento y otro para la validación que el modelo no conocerá de antemano. Esta división se suele hacer del 70-80% para entrenar y 20-30% para validar. El conjunto de validación deberá tener muestras lo más diversas posibles y en cuantía suficiente.
- Error de entrenamiento: según se incrementa la complejidad del modelo, el modelo tiende a hacer un overfitting sobre los datos del entrenamiento. El error sobre los datos de entrenamiento irá decreciendo cada vez más.
- Error de testeo: el error sobre el conjunto de validación es alto tanto en el escenario de underfitting como en el de overfitting. Nos interesa monitorizar este error para quedarnos justo en el punto de entrenamiento en el que este es menor.
La siguiente imagen ilustra perfectamente este hecho: 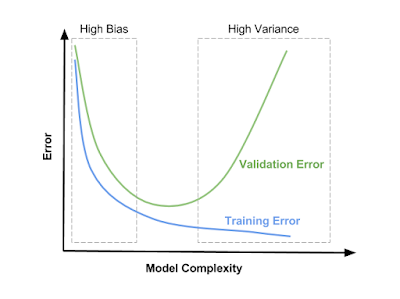 Fig. 3: Effect of model complexity on error due to bias and variance. Fuente
Fig. 3: Effect of model complexity on error due to bias and variance. Fuente
Fig. 3: Effect of model complexity on error due to bias and variance. Fuente
- Condición de alto bias: nos encontramos con underfitting en nuestro modelo. Tanto el error de entrenamiento como el de testeo son elevados. Por más que añadamos datos para que el modelo explore, no se mejora el desempeño. Como solución se podría probar aumentar el número de características a analizar o la complejidad del algoritmo.
- Condición de alta varianza: nuestro modelo está afectado por overfitting. Ajusta muy bien datos de entrenamiento, pero no es capaz de inferir correctamente los datos de validación, por lo que error de testeo es significativamente mayor que error de entrenamiento. Añadir datos variados ayuda a resolver el problema, así como la reducción de la complejidad del modelo.
Si el modelo entrenado con el conjunto de test tiene un 90% de aciertos y con el conjunto de validación tiene un porcentaje muy bajo, nos enfrentamos ante un claro caso de overfitting. Si, por el contrario, en el conjunto de validación sólo se acierta un tipo de clase o el único resultado que se obtiene es siempre el mismo, nos encontramos ante un caso de underfitting.
Para intentar que estos problemas nos afecten lo menos posible, podemos llevar a cabo diversas acciones:
- Por un lado, debemos garantizar de que tenemos una cantidad suficiente de muestras tanto para entrenar el modelo como para validarlo.
- En el caso de movernos en tareas de clasificación, deberemos contar con clases variadas y equilibradas en cantidad: por ejemplo, en caso de aprendizaje supervisado y suponiendo que tenemos que clasificar diversas clases o categorías, es importante que los datos de entrenamiento estén balanceados y sean representativos de todas las clases, para evitar sesgos innecesarios. Sobre los problemas presentados en el aprendizaje desbalanceado ya hablamos en el nuestra anterior serie Machine Learning y astrofísica: clasificando estrellas, galaxias y quasars.
- Siempre debemos subdividir nuestro conjunto de datos y mantener una porción del mismo para testar el modelo. Esto nos permitirá evaluar el desempeño del algoritmo y también nos permitirá detectar fácilmente efectos del overfitting o underfitting.
- Debemos prevenir una cantidad excesiva de dimensiones, con muchas variantes distintas, sin suficientes muestras. A veces conviene eliminar o reducir la cantidad de características que utilizaremos para entrenar el modelo. Una herramienta útil para hacerlo es Principal Component Analysis (PCA) o T-distributed Stochastic Neighbor Embedding (t-SNE).
Para mantenerte al día con LUCA visita nuestra .