 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

El increíble mundo interior de los modelos de lenguaje LLM (II)
Radiografía de un modelo
Vamos a ver un modelo por dentro, físicamente. Para ello, nos valdremos de este:
 https://huggingface.co/distilbert/distilbert-base-uncased
https://huggingface.co/distilbert/distilbert-base-uncased
Es un modelo (versión destilada de BERT) de unos escasos 67 millones de parámetros. Algo ya antiguo (en términos de internet), pero nos servirá para ilustrar el ejemplo.
Con un pequeño código que hace uso de la librería 'transformers' (también de HuggingFace) nos descarga el modelo y lo deja en el mismo directorio:
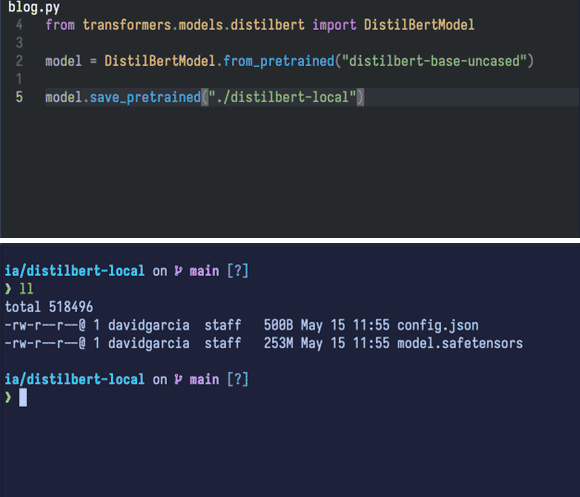
Nos ha descargado dos archivos:
- Uno de ellos es el modelo en sí,
model.safetensors(253 megabytes). - El otro es
config.json, que contiene la arquitectura del modelo, necesario cuando lo carguemos puesto que la librería que usaremos (PyTorch) lo necesita para ajustarse a éste.
Ese config.json nos da mucha información también a nosotros.
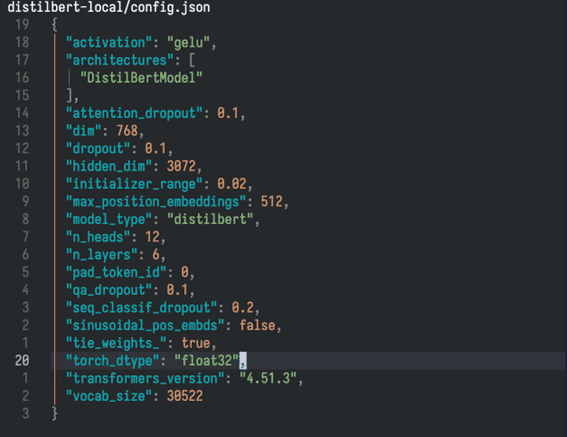
Vamos a fijarnos en unos cuantos datos de ese archivo.
El espacio en disco del espacio vectorial del modelo
El tamaño del vocabulario (vocab_size) que 'entiende' el modelo es de 30.522 tokens (buen momento para hacer referencia a nuestro artículo acerca de la tokenización y el caballero Don Quijote:)
Cada uno de esos tokens tiene asociado un vector (dim) con 768 'casillas' o valores. Este vector asociado al token es nuestro vector del principio del artículo, recordemos:
- Modelo TEF: [1,1,1,1,1]
- El piano: [0, 0.2, 0.8, 0, 1]
Es decir, una posición de un espacio vectorial de 768 dimensiones (recordemos que el plano cartesiano solo tiene dos)
Bien, pues además tenemos otro valor, cada uno de esos 768 puntitos del espacio vectorial tiene unas coordenadas o precisión del tipo float32 (torch_dtype) que definen a un único token de los 30.522.
Ese formato, float32, son 4 bytes (o 32 bits). Por lo tanto, en espacio de disco, solo los tokens ocupan:
30.522 * 768 * 4 bytes = 90 megabytes aproximadamente.
Por cierto, si queréis ver el vocabulario de este modelo (los tokens) está disponible aquí.
Capas y parámetros
No nos olvidemos que las redes neuronales poseen una característica típica: las capas.
Desde la capa de entrada, pasando por las capas ocultas y saliendo por la capa de salida, los datos van rebotando y pasando por todas las capas hasta componer el resultado final.
Nuestro modelo en estudio posee 67 millones de parámetros, aproximadamente.
Solo la capa de embeddings (la que ocupan los tokens y sus vectores asociados) posee:
30.522 * 768 = 23.440.896, unos 23 millones de parámetros.
Debemos sumar los parámetros de cada capa que posee el modelo y gracias al archivo "config.json" sabemos que este modelo posee seis capas internas (el modelo transformer); indicado por el campo "n_layers".
Además de los parámetros de esas capas tendrá otros que nos permiten modelar sesgos, normalizar valores y distintos trucos para proyectar el resultado final que le llegará al usuario: la respuesta del modelo.
Todos los parámetros sumados nos dejarán con esa cifra de 67 millones.
¿Cómo es un modelo por dentro?
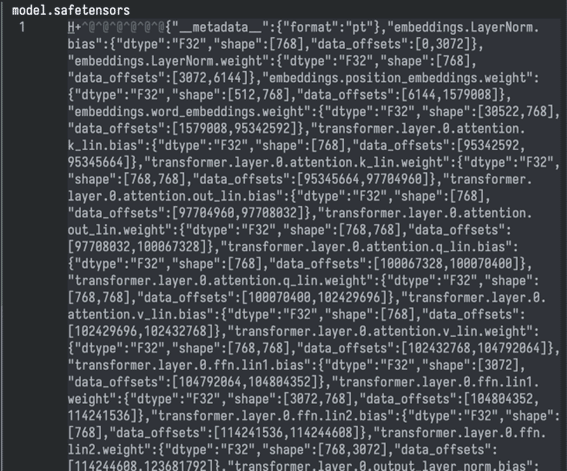
Es un archivo (o a veces conjunto de archivos) físico. Posee un campo de metadatos que describe la estructura interna y el resto son datos binarios.
Observemos, la cabecera con los metadatos:
A continuación, la mayor parte del archivo son los pesos de las distintas capas, que están en formato binario; naturalmente, ininteligibles:
Mediante un pequeño script, usando la librería safetensors (también de HuggingFace) podemos ver aquello que habíamos comentado respecto de las capas:
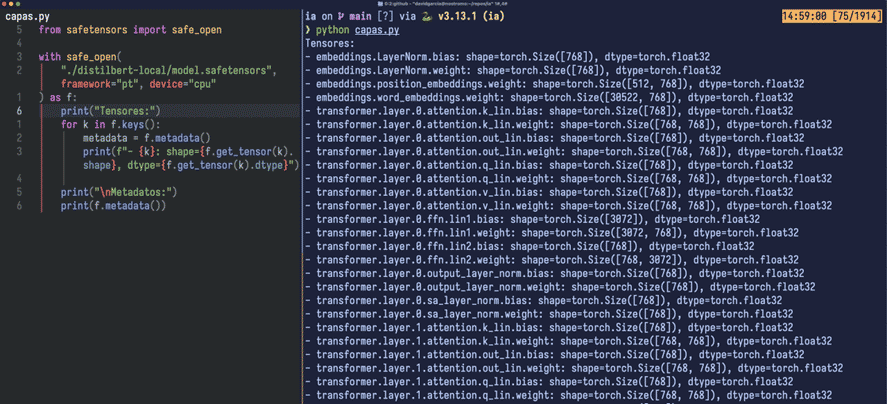

- word_embeddings, es fácil de detectar por esos (30.522, 768) y es una matriz (o tensor 2D) de 30.522 filas que se corresponden con los tokens, cada fila posee un vector de 768 floats32; indicados como vemos en 'dtype'.
- position_embeddings es otra matriz, dimensionada con (512, 768). Atentos a esto que es interesante. Cuando una frase o párrafo llega al modelo en forma de tokens, el modelo no tiene 'conciencia' del orden en el que están los tokens que le llegan. Es por ello por lo que se usa este espacio para organizar la entrada.
Ese valor, 512, no está ahí por capricho: es el contexto máximo del modelo. Más allá de 512 tokens de entrada 'cortará' la entrada y no la procesará. Es como si el modelo no nos escuchase a partir de 512 tokens. Naturalmente, puede procesarlo por lotes (chunking), pero... hmm... ya no es lo mismo.
■ Para que entendamos las cifras actuales que se manejan respecto del contexto: Un modelo como Llama 3.2 1B o 3B posee una ventana de contexto de 128.000 tokens. E incluso Llama 4 Scout (aunque con requerimientos que se nos escapan) posee un contexto de 10 millones.
El contexto es vital para un modelo y su comprensión de aquello que le estamos pidiendo, por ello, cuanto más grande la ventana de contexto mayor será la fidelidad y calidad de la respuesta.
Lo que vemos como LayerNorm bias y weight son dos vectores (tensores 1D) cuyos valores aprendidos durante el entrenamiento permiten ajustar (escalar y desplazar) el resultado de la normalización de la combinación entre los tensores word_embeddings y position_embeddings, justo antes de que esa información entre en las capas de la red.
A continuación, vemos las capas en sí, son seis, indexadas desde el cero al cinco, sus tensores son iguales en todas:
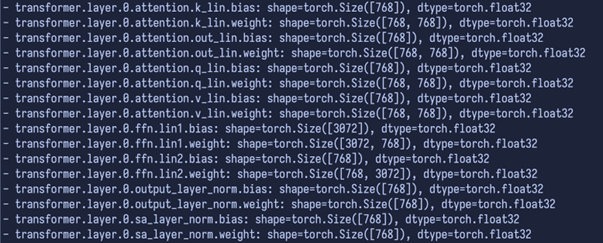
Lo primero que hay que entender es que todos los tensores que vemos en el modelo son, en esencia, o bien pesos (weight) o sesgos (bias).
- Los pesos son los grandes parámetros que la red aprende durante el entrenamiento: son los 'cableados' que determinan cómo se transforma la información de una capa a la siguiente.
- El bias, o desplazamiento, es una especie de 'ajuste fino' que permite a la red ajustar el resultado de cada capa, asegurando que incluso para entradas particulares (por ejemplo, todas en cero) la salida pueda ser diferente de cero si el modelo lo necesita. Es algo sutil, pero sin estos bias, habría situaciones en las que la red no produciría salidas adecuadas para ciertos patrones de entrada.
Así, cada capa del modelo suele venir en 'parejas': una matriz de pesos y un vector de bias que garantice un comportamiento adecuado en todas las situaciones.
Respecto a la distinción entre ellas, no vamos a detenernos con precisión, pero resalta sobre ellas el nombre de 'attention'. Seguramente te habrás topado con la frase Attention is all you need. Esas son las partes de la capa que pertenecen a la subcapa o módulo de atención.
En vez de procesar el texto de forma lineal (o secuencial), el modelo de atención, actor principal del modelo Transformer, le permite al modelo procesar la entrada (lo que le decimos) de forma que interrelaciona todas las palabras entre ellas a la vez, otorgándoles una 'puntuación', que determina el enfoque en unas más que en otras, dependiendo del contexto. Una revolución.
■ FFN es un modelo de red neuronal ya conocido: "Feed-Forward Network" y que complementa al mecanismo de atención. Gracias a esta red neuronal, el modelo puede centrarse (esta vez sí) en un solo token y afinar aún más el resultado que procede de attention.
De hecho, si observamos la mítica imagen del famoso paper veremos que la FFN cobra una gran importancia como componente del modelo:
Sin esta red, el modelo no podría detectar relaciones complejas o matices.
El resto, capas de normalización para terminar de darle forma a la salida de cada capa.
Bonus track: ¿Qué ocurre si a un modelo le quitamos progresivamente sus capas?
Venga, vamos a probarlo. Es un modelo que sustituye [MASK] por una palabra adecuada al texto.
Le preguntamos:
> Madrid is located in:
Lo primero de todo es verlo en acción con todas sus seis capas:
Funciona correctamente, adivina que es 'spain'.
Ahora creamos una función que invoque al modelo de la misma forma, pero progresivamente le irá quitando capas...
■ Como vemos va desvariando bastante, dado que, al ir quitando capas, a su vez vamos restando precisión en la respuesta. En próximos artículos veremos más temas en profundidad técnica y de forma práctica acerca de los modelos grandes de lenguaje.
■ PARTE I
")



