 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

La tokenización y el caballero andante Don Quijote
Seguramente, desde la irrupción de lo que denominamos IA generativa habrás escuchado la palabra 'tokens' o 'tokenización'. Por ejemplo, en términos de rendimiento de un modelo te hablan de 'tokens por segundos' o cuando usas la api de un LLM en nube te cobran en términos de 'x dólares por (millones de) tokens'. Es decir, se usa como medida de cuantificación de rendimiento y costes.
En realidad el término ya estaba presente en el vocabulario de la informática desde muchas décadas atrás (como la gran mayoría de conceptos hoy día, solo que bastante más evolucionados, por supuesto).
Hoy vamos a tratar de explicar qué son los tokens y la tokenización, dentro del concepto de los LLM, de forma comprensible. Manos a la obra.
¿Qué significa (originalmente) un 'token'?
¿Alguna vez has ido a la feria y te has montado en un coche de choques? ¿Introducías monedas en el coche de choques? No, ¿verdad' Lo que metías en el monedero del coche era una ficha cuyo valor se traducía en un tiempo de uso limitado de ese cochecito, y el valor monetario (su precio) era lo que pagabas en monedas en la caseta.
Como curiosidad, el coste del viaje en cochecito se eleva por la inflación, pero el token siempre es el mismo. De hecho, muchas fichas (tokens) pueden tener décadas de antigüedad y su función sigue siendo la misma mientras que su valor significativo es el que se altera.
Bien, pues esa ficha es un token. Se capta la idea, ¿verdad?
¿Qué significa token en el contexto de la informática?
Pues tiene muchos significados distintos y muy diversos usos, que incluso no tienen nada que ver unos con otros, pero curiosamente... al final no dejan de ser fichas de feria: representan a 'algo'.
Por ejemplo, en ciberseguridad, un token es una cadena hexadecimal con una longitud prefijada que te da un sistema de autenticación. O también es ese número que se genera de manera pseudo-aleatoria como segundo factor de autenticación.
En criptomonedas, un token representa un activo digital o un derecho asociado a un sistema blockchain. Por ejemplo, en el caso de los NFT, la posesión de un token implica la propiedad digital del activo que representa.
Ahora, vamos a aproximarnos a un uso más cercano al de los LLMs: los compiladores. Imagina un pequeño fragmento de código fuente, por ejemplo, en JavaScript:
console.log("hola mundo");
Un compilador o intérprete verá el código fuente en forma de ‘tokens’, es decir, unidades mínimas de significado, como las palabras o símbolos que componen este código: console (objeto), . (operador), log (método), "hola mundo" (cadena de texto) y ; (terminador).
console.log ( "hola mundo" ) ;
Estos ‘trozos’ permiten que el compilador entienda y analice el código. En los modelos de lenguaje, el concepto es similar, pero aplicado al texto en lenguaje natural: los tokens representan palabras o partes de palabras para que el modelo pueda analizar su significado y contexto.
En resumen, tanto en el mundo analógico como el digital, podríamos deducir que un token es una entidad mínima y única que posee representa un valor y objeto en un sistema. Sí, correcto, cuándo estudiábamos Lengua en el colegio los profes nos hablaban de 'unidad mínima con significado en el lenguaje': ¡los morfemas y lexemas!
¿Qué es la 'tokenización' en el contexto de los LLM?
Hemos dado tantas pistas e información que posiblemente ya podrías escribir el párrafo. Aun así, todavía nos quedan unos trucos en la manga. Tenemos bastante acorralado el término pero nos quedan unos retoques.
Como hemos visto, tanto en los lenguajes de programación como en el lenguaje humano, hay unidades mínimas. Al final, se separan en 'trozos' (tokens) con significado para analizar el significado de la sentencia, frase o palabra.
Es lo que el Procesamiento del Lenguaje Natural (NLP, en sus siglas en inglés) hace. Técnicas que se llevan usando desde el nacimiento de esta rama de la inteligencia artificial (década de los 50).
Para que un ordenador 'entienda' el lenguaje humano se debe hacer una traducción de palabras a números. Porque esto último es lo único que puede hacer realmente una máquina: operar con números. Ese es el verdadero poder detrás de las bambalinas: operar con números y guardar o manipular valores en una memoria.
Lo abordaremos en otra publicación más adelante, pero adelantamos que la 'magia' detrás de los LLM está en la transformación a vectores de las palabras (tokenizadas) y las relaciones entre ellas. Vamos a quedarnos con: tokens -> números.
Pues bien, la 'tokenización' es el proceso de convertir texto a tokens, pequeños 'trozos' de palabras que existen en forma de vectores dentro del LLM. Además, no solo hay una tokenización canónica sino que existen varias técnicas o procesos que se adaptan al tipo de texto que le proporcionemos en la entrada.
La tokenización, un ejemplo práctico
Hay tantas técnicas de tokenización como situaciones diversas que dependen, como hemos comentado, de la entrada a procesar. Existen tokenizadores que se especializan en detectar y separar caracteres sueltos (ideales para lenguajes humanos basados en ideogramas: chino, coreano, japones...), el denominado Unigram.
Tenemos los algoritmos de tokenización por palabras, adecuados para ciertos idiomas, pero con sus limitaciones: no reconocen palabras que no hayan visto antes y pueden ser ineficientes en el almacenamiento: (coche, coches, cochecito, cochazo...).
Con un buen equilibrio tenemos los basados en sub-palabras: BPE (Byte Pair Encoding) y WordPiece, entre otros. Muy cerca de estos están los que operan a nivel de byte, que es el usado, por ejemplo, por ChatGPT.
Para facilitar la comprensión usaremos la tokenización por palabras, de la librería open-source 'tokenizers' del proyecto HuggingFace.
Tokenización por palabras
El método más básico para la tokenización es aquel que divide la entrada en palabras. Vamos a ver un ejemplo básico:
Antes de nada, debemos preguntarnos una cosa: damos por hecho que sabemos qué es una palabra, al menos en nuestro idioma. ¿Pero sabemos qué es una palabra en otros idiomas? ¿Estamos seguros?
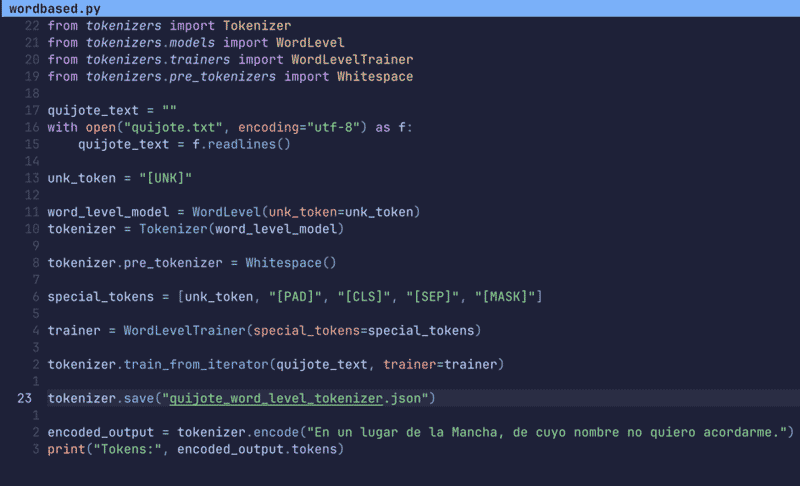
Tampoco lo sabe el algoritmo que tokeniza un texto delimitando los tokens a palabras completas. Para ello, necesita un vocabulario donde se encuentren las palabras, asignarles un identificador numérico y entrenar a dicho tokenizador para que 'aprenda' a separar un texto en palabras. Para la tarea, hemos entrenado al modelo del tokenizador con el texto de nuestro querido El Quijote de la Mancha. Sí, el texto completo del siglo XVII y veremos bastantes curiosidades respecto de la fecha...
Cargamos el texto del Quijote línea por línea:

Entrenando el tokenizador
Instanciamos el tokenizador por palabras, WordLevel:

Es la clase principal que vamos a utilizar, pero ese tokenizador implementa un algoritmo genérico al que debemos entrenar para que aprenda a tokenizar textos en español.
Eso lo podemos hacer instanciando un entrenador específico para WordLevel:

Lo que veis es una lista de tokens especiales: separadores, padding (relleno), máscaras y el token especial más importante: "[UNK]" que sirve para marcar aquellas palabras que no conoce.
Le pasamos el texto del Quijote (no tarda prácticamente nada en realizar el entrenamiento) y guardamos nuestro 'vocabulario' (luego veremos cómo está formado por dentro) para usarlo posteriormente si queremos, ahorrándonos el entrenamiento.
Usando el tokenizador
Esto ya es bastante simple. Además, en la misma secuencia hemos acoplado su entrenamiento, directamente pasamos a la fase de tokenización.

Ejecutamos:

Como vemos, obtenemos los tokens del texto que le hemos pasado (última línea), es la línea inicial del Quijote, por supuesto, ya tokenizada.
Vemos como reconoce todas las palabras, signos de puntuación y no hace uso de ningún token especial para indicar separaciones, rellenos o palabras desconocidas por el modelo de tokenización.
Probemos con una frase que no tenga relación alguna con el Quijote:

y su salida:

Todo bien, ¿verdad? Pero tenemos un problema. El Quijote es un texto del siglo XVII, ¿Qué pasaría si... introducimos una frase con palabras de nuestro contexto?
Probemos:

la salida:

Desconoce las palabras: 'artificial' y curiosamente, también 'caluroso'. Nos aseguramos de que no aparecen en todo el texto del Quijote:

Con 'caluroso' tenemos un caso digno de comentar:

Sí está 'calurosos' pero no exactamente 'caluroso', el singular. Como nuestro tokenizar aprende por palabras completas para él, 'caluroso', es una nueva palabra y no contempla que sean ni tan siquiera similares para la tokenización. Es decir, o está o no está.
Estas ausencias en el texto de entrenamiento provocan que aquellas palabras que no estén en su vocabulario sean desconocidas; de ahí que le atribuya el token especial "[UNK]" en la salida de la tokenización.
El vocabulario del tokenizador WordLevel
Lo que hace el entrenador es crear un vocabulario para que el tokenizador lo use posteriormente. Si echamos un vistazo al vocabulario, veremos que es extremadamente sencillo, al final crea un diccionario clave-valor, donde a cada palabra vista se le asigna un identificador numérico.
Observemos la palabra 'calurosos' que vimos antes:
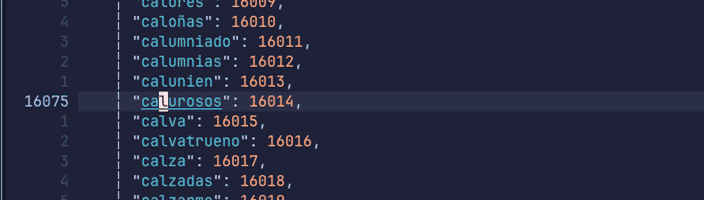
Esto hace un mapeo directo con la salida, vamos a verlo:

Cada token tiene su entrada en dicho diccionario, incluyendo el token especial.
Si buscamos a la inversa, por ejemplo, el token con el identificador 2116, veremos dónde se encuentra en nuestro vocabulario:
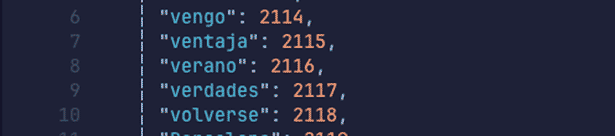
Ahí lo tenemos.
De hecho, podemos hacer justo lo contrario y reconstruir el texto (con la salvedad de las palabras desconocidas) desde una lista de identificadores:

y su salida:

Observemos que no está 'artificial' ni 'caluroso'.
BPE, un tokenizador más avanzado
Es un problema que nuestro tokenizador marque como desconocidas palabras que sabemos que existen pero por no estar en el conjunto de entrenamiento las pasa por alto. Esto es porque el tokenizador por palabras posee una rigidez en ese aspecto. Es bueno... pero solo en aquello que ha visto y conoce.
Veamos un ejemplo con BPE, un tokenizador más flexible usado originalmente para algoritmos de compresión. BPE funciona a nivel de bytes, que es al final en lo que está compuesta una palabra desde el punto de vista del ordenador.
Es bastante intuitivo. Crea subconjuntos de bytes y les asigna un reemplazo en base a la frecuencia de aparición de dichos subconjuntos. Un ejemplo:
"desencriptar encriptación encriptador"
Si hacemos un análisis veremos que hay subconjuntos que se repiten con más frecuencia:
"en", "cr", "pt"...
Pequeños átomos capaces de reconstruir el texto original pero con un espacio de vocabulario mucho menor y que permite ser adaptado para codificar palabras que no hayan sido vistas antes (con excepciones).
Si volvemos a nuestro Quijote, vamos a emplear BPE para tokenizar de nuevo nuestra frase actual y ver que ocurre:
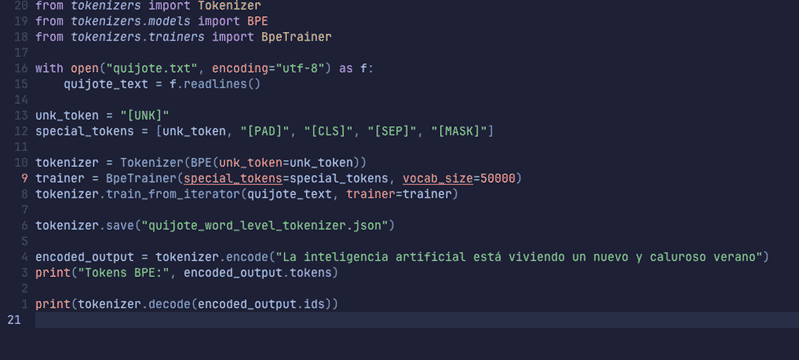
Ejecutamos y observemos la salida:

Ya lo tenemos. Aunque en nuestro diccionario no estén las palabras 'artificial' y 'caluroso' no hemos tenido problemas en tokenizarlas, no hay un token especial [UNK] indicando que no las entiende.
¿Por qué ahora sí?
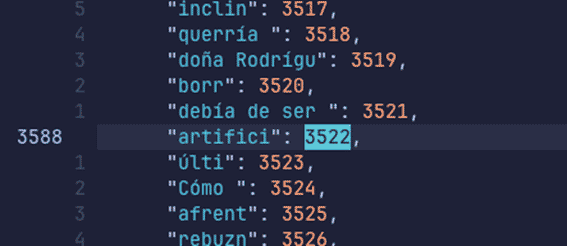
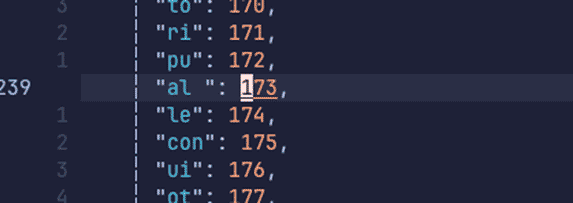
Veamos el mapeo de los tokens (su identificador) de la palabra que no encontraba 'artificial'. Esta palabra está compuesta por 'artifici' y la muy común partícula 'al'.
artifici: 3522
al: 173
Como podemos observar incidentalmente, nuestro vocabulario ya no tiene palabras completas, sino partículas que luego formarán palabras.
Curiosamente, 'artifici' es encontrada con estos usos en el Quijote:

Qué es, naturalmente, el uso que el gran maestro Cervantes otorgaba en su tiempo: 'artificio':
 captura tomada de la web de la RAE en referencia a las acepciones de artificio
captura tomada de la web de la RAE en referencia a las acepciones de artificio
Conclusiones
Y nada más tengo para vuesas mercedes que ofrecer en este humilde escrito, salvo el ruego de que estas letras les sirvan para entender los artificios y maravillas de la tokenización, arte en el que las máquinas, cual modernos encantadores, desmenuzan las palabras como quien desbroza caminos en tierras ignotas. Si os place, tomad este conocimiento y haced buen uso de él, que así lo encomiendo a vuestra razón y prudencia.
Como hemos visto, antes de que el modelo produzca una salida de texto generado han de pasar muchas más cosas. La primera de las etapas es preparar la entrada, que normalmente será texto en un lenguaje humano, para que pueda ser procesada de forma correcta.
Hemos aprendido que es un token y como se produce durante la tokenización. Los tipos que existen y ejemplos prácticos para observar su comportamiento real, fortalezas y debilidades. También la producción de un 'vocabulario' fruto del entrenamiento y su uso para mapear los tokens con identificadores y recorrer el camino a la inversa.
■ En próximos artículos profundizaremos en nuevos conceptos que nos ayuden a entender que hay detrás de los LLM y la IA Generativa en general.



