 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

IA al alcance de todos: proyectos que nos permiten ejecutar modelos LLM en máquinas modestas
Trabajar con la IA generativa forma parte de nuestros quehaceres desde que comenzó a vislumbrarse como una de las nuevas revoluciones que va a cambiarlo todo y... ya habrás oído muchas veces el resto. Lo cierto es que disponer de un modelo de red neuronal profunda que machaque cientos de gigas y aprenda a hacer cosas que antes nos llevaban un buen puñado de horas en un trabajo determinado y nos echen una mano, resulta en un empujón a la productividad.
Al fin y al cabo, la programación y los ordenadores en general no dejaron de ser nunca un acelerador para tareas que podríamos hacer "a mano". De hecho, los primeros ordenadores se crearon precisamente para acelerar cálculos que se hacían y revisaban por personas en el contexto de la Segunda Guerra Mundial.
Algo que quedó clara desde un momento es que para usar la IA se necesitaba una buena potencia computacional. Para ello, se ofrecen servicios online para utilizarla. Desde uso gratuito a subscripción, la oferta de servicios basados en IA ha producido un auténtico campo de abono cuyo ritmo de aparición hace imposible estar al día (perceptiblemente mayor incluso que el ritmo de aparición de los frameworks para Javascript).
Los LLM se han democratizado hasta proveer de modelos para dispositivos móviles e incluso mucho más modestos respecto a las características hardware.
Pero ¿Realmente hace falta una máquina de alto nivel para echar a andar un modelo para charlar o generar imágenes? Nada más lejos de la realidad. Los LLM se han democratizado hasta proveer de modelos para dispositivos móviles e incluso mucho más modestos respecto a las características hardware.
Además de bajar el listón de requerimientos, el despliegue (instalación) es cada vez más sencillo y su interfaz más agradable para la persona con escasos conocimientos técnicos.
Vamos a presentar varias alternativas tanto privativas como open source de aplicaciones que podemos instalar en nuestros ordenadores (ojo, evidentemente no nos va a servir aquel portátil que tenemos hace 12 años en el trastero) y experimentar con IA generativa y "on premise", sin recurrir a servicios online.
LM-Studio, fácil y rápido
El primero de todos, el más "amigable" es LM-Studio. Extremadamente fácil de instalar y se nos presente con una interfaz de usuario relativamente intuitiva.
 Enlace: https://lmstudio.ai/
Enlace: https://lmstudio.ai/
Una vez instala lo primero que nos pregunta es elegir y descargar un modelo para su uso local:
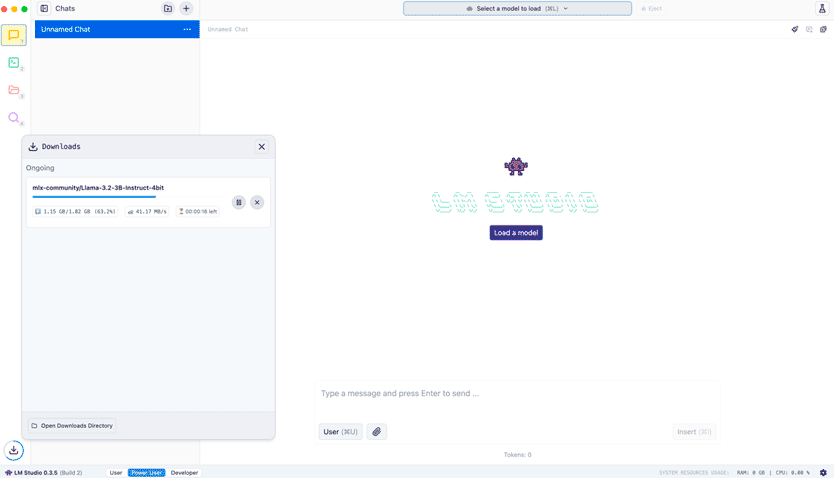
Elegimos el que viene por defecto: Llama 3.2 de 3 billones de parámetros (alrededor de 2Gb). Un modelo nada exigente, aunque por supuesto, tendrá sus limitaciones dando a la vez mucho juego.
En la máquina que hemos usado para las pruebas (Apple M1 Pro), Llama 3.2 3B daba un ratio de casi 60 tokens por segundo. Unos números muy buenos para una ejecución local. Además, la respuesta en todo momento es coherente:
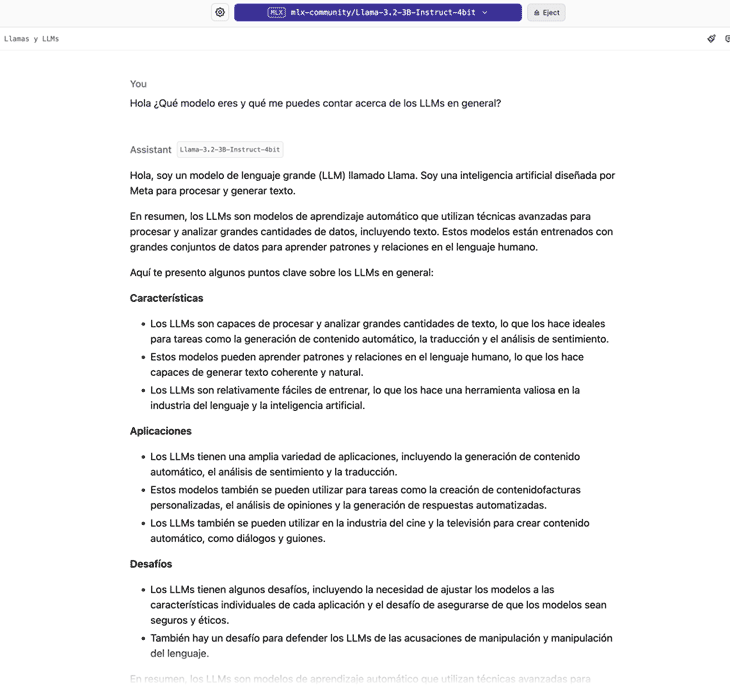
En definitiva, es una opción para experimentar de forma rápida y sin complicaciones los LLM en tu máquina y sin requerir de grandes requerimientos que es el objetivo de este artículo.

Ollama, open source y con gran cantidad de opciones
Un proyecto open source hecho en Go que nos permite correr una gran cantidad de modelos. Tan solo necesitas 8Gb de RAM para ejecutar modelos como Llama 3, Phi 3, Mistral o Gemma 2 entre otros mientras que no uses las versiones de más de 7 billones de parámetros.
Ollama es el core, el cual se usa desde línea de comandos. No obstante, posee numerosas opciones para acoplar un interfaz de usuario sino estamos acostumbrados a lidiar con la terminal.
Podemos ver en este enlace las diversas opciones de interfaz de usuario:
Su instalación nos deja tan solo con un comando de terminal, ollama y una aplicación que levanta un servicio en background.
Con hacer un ollama run phi3 desde línea de comando, se bajará el modelo Phi3 y podremos comenzar a charlar con el modelo.

Si estás acostumbrado a la terminal y no necesitas acoplar una interfaz gráfica puedes tenerlo corriendo y siempre puedes acceder a él rápidamente para cualquier consulta:

Incluso le preguntamos que hiciera una función Python simple usando un conocido framework para aplicaciones web. Lo saca rápidamente, aunque con sus fallos.
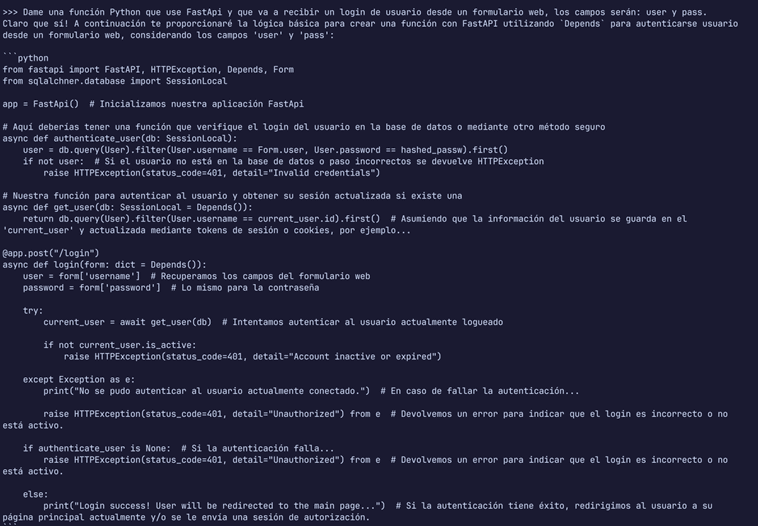
Ollama es flexibilidad y sobre todo la confianza de ser open-source. Nada de lo que preguntes o hables con el modelo saldrá de tu máquina.
llama.cpp, la revolución de Georgi Gerganov
Proyecto open source que comenzó el genial ingeniero búlgaro Georgi Gerganov.
Con la inspiración de proyectos anteriores (whisper.cpp) y la sacudida que supuso la aparición para uso libre del modelo Llama de Meta, Georgi vio que para hacer funcionar el modelo se requería del uso de framework del tipo PyTorch, lo cual suponía una carga adicional para la máquina.
Al igual que con otros de sus proyectos, comenzó una implementación en C (y C++) que tuviese la eficiencia por bandera. El reto, que no era minúsculo, era hacer una plataforma para cargar el modelo (Llama) en ordenadores con especificaciones modestas.
Lo que comenzó como un reto personal explotó y ahora se rodea de una gran comunidad que contribuye en todos los aspectos: adaptación a otros modelos, creación de una interfaz, modo servidor, etc e incluso un nuevo formato de modelos adaptados a la arquitectura interna de llama.cpp.
De hecho, el proyecto es usado por muchos servicios que solo son una mera capa sobre llama.cpp. Curiosamente, aunque el nombre original es llama.cpp, como hemos comentado, actualmente soporta numerosos modelos.

Gracias a los colaboradores del proyecto, su instalación es sencilla. Basta con bajar el archivo ya precompilado de la página de publicaciones.
Una vez instalado, nos presenta una serie de herramientas de línea de comandos. Si bien la apariencia nos remite a un ambiente exclusivo para usuarios avanzados, levantar el servidor y su interfaz web es un proceso relativamente sencillo.
Eso sí, deberemos encargarnos de bajar el modelo (algo tremendamente sencillo, basta con explorar los modelos con formato convertido a GGUF.)
Una vez descargado y desde la carpeta de instalación donde esté el comando llama-server, solo tenemos que hacer esto:

Una vez levantado el servidor, visitamos localhost:8080 en el navegador y veremos un interfaz que nos recordará a ChatGPT por el que podremos "charlar" con él:
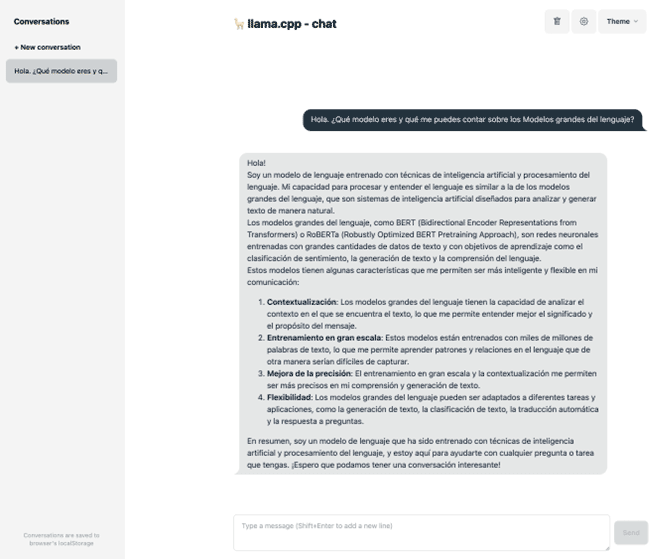
Conclusiones
Los LLM han llegado no solo para quedarse sino para formar gran parte de nuestras vidas. Esto es el principio, previsiblemente veremos cómo aumentan su contexto, su afinidad a nuestras preguntas y conversaciones o su conocimiento del medio y el contexto objeto de la conversación.
No hemos hablado de modelos de generación de formatos media: fotos, vídeos, etc. Que daría para otro artículo. Pero es posible cargar modelos que se encarguen de dichas tareas.
El objetivo del presente artículo es simplemente mostrar que ni necesitamos de una gran máquina para usar modelos ni de servicios online para sacarle partido y comenzar a experimentar con la IA en casa.
Trabajar con la IA generativa forma parte de nuestros quehaceres desde que comenzó a vislumbrarse como una de las nuevas revoluciones.




