 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

AI for everyone: projects that allow us to run LLM models on modest machines
Working with generative AI has been part of our work since it began to be seen as one of the new revolutions that is going to change everything and... You will have heard the rest many times by now. The truth is that having a deep neural network model that crunches hundreds of gigabytes and learns to do things that used to take us a good handful of hours in a given job and give us a hand, results in a boost to productivity.
After all, programming and computers in general never stopped being an accelerator for tasks that we could do “by hand”. In fact, the first computers were created precisely to speed up calculations that were done and reviewed by people in the context of World War II.
One thing that was clear from the outset was that to use AI, good computational power was needed. To this end, online services are offered to use it. From free use to subscription, the supply of AI-based services has produced a veritable compost field whose rate of emergence makes it impossible to keep up with (significantly faster even than the rate of emergence of JavaScript frameworks).
LLMs have been democratized to the point of providing models for mobile devices and even much more modest in terms of hardware features.
However, is it really necessary to have a high-end machine to run a model for chatting or generating images? Nothing could be further from the truth. LLMs have been democratized to the point of providing models for mobile devices and even much more modest in terms of hardware features.
In addition to lowering the requirements, the deployment (installation) is increasingly simple and its interface more pleasant for the person with little technical knowledge.
We are going to present several alternatives, both proprietary and open-source applications that we can install on our computers (of course, we will not use that laptop that has been in the storage room for 12 years) and experiment with generative AI and "on premise", without resorting to online services.
LM-Studio, easy and fast
The first of all, the most “user-friendly” is LM-Studio. Extremely easy to install and comes with a relatively intuitive user interface.
 Link: https://lmstudio.ai/
Link: https://lmstudio.ai/
Once installed the first thing it asks us is to choose and download a model for local use:
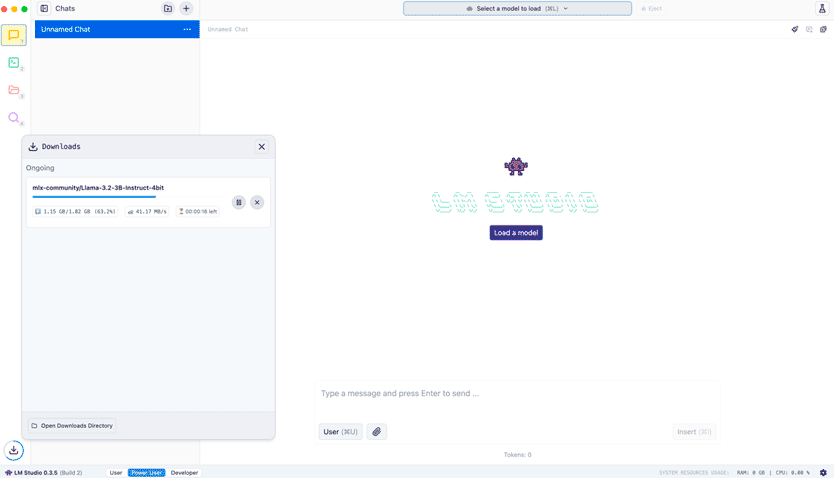
We choose the default one: Llama 3.2 of 3 billion parameters (about 2Gb). An undemanding model, although of course, will have its limitations while giving a lot of play.
On the machine we used for testing (Apple M1 Pro), Llama 3.2 3B gave a rate of almost 60 tokens per second. Very good numbers for local execution. In addition, the response at all times is consistent.
All in all, it is an option to quickly and smoothly experiment LLM on your machine without requiring large requirements, which is the aim of this article.

Ollama, open-source and with a lot of options
An open-source project made in Go that allows us to run a large number of models. You only need 8Gb of RAM to run models like Llama 3, Phi 3, Mistral or Gemma 2 among others as long as you don't use the versions with more than 7 billion parameters.
Ollama is the core, which is used from the command line. However, it has numerous options to attach a user interface if we are not used to dealing with the terminal.
Below you can see the various user interface options:
 https://github.com/ollama/ollama?tab=readme-ov-file#web--desktop
https://github.com/ollama/ollama?tab=readme-ov-file#web--desktop
Its installation leaves us with only a terminal command, 📍“ollama” and an application that raises a background service.
By doing an 📍“ollama run phi3” from the command line, the Phi3 model will be downloaded, and we can start chatting with the model.

If you are used to the terminal and don't need to attach a graphical interface, you can have it running and you can always access it quickly for any query.
We even asked it to do a simple Python function using a well-known framework for web applications. It comes out quickly, albeit with its bugs.
Ollama is flexibility and above all the confidence of being open-source. Nothing you ask or talk to the model will leave your machine.
llama.cpp, Georgi Gerganov's revolution
Open-source project started by the brilliant Bulgarian engineer Georgi Gerganov.
Inspired by previous projects (whisper.cpp) and shocked by the appearance of Meta's Llama model for free use, Georgi realized that to run the model required the use of PyTorch-type framework, which was an additional burden on the machine.
As with some of his other projects, he started an implementation in C (and C++) that had efficiency as its flagship. The challenge, which was not a small one, was to make a platform to load the model (Llama) on computers with modest specifications.
What started as a personal challenge exploded and is now surrounded by a large community that contributes to all aspects: adaptation to other models, creation of an interface, server mode, etc. and even a new model format adapted to the internal architecture of llama.cpp.
In fact, the project is used by many services that are just a mere layer on top of llama.cpp. Interestingly, although the original name is llama.cpp, as mentioned above, it currently supports numerous models.

Thanks to the contributors of the project, its installation is simple. Just download the precompiled file from the publication page.
Once installed, it presents us with a series of command line tools. Although the appearance is reminiscent of an environment exclusively for advanced users, setting up the server and its web interface is a relatively simple process.
Of course, we will have to download the model (something tremendously simple, just explore the models with format converted to GGUF.)
Once downloaded and from the installation folder where the 📍"llama-server" command is, this is all we have to do:

Once the server is up, we visit 📍“localhost:8080” in the browser and we will see an interface that will remind us of ChatGPT through which we will be able to “chat” with it.
Conclusions
LLMs are not only here to stay but to become a big part of our lives. This is just the beginning. We will foreseeably see how they will increase their context, their affinity with our questions and conversations or their knowledge of the medium and the context of the conversation.
We have not talked about models for generating media formats: photos, videos, etc. That would be something else for another article. But it is possible to load models that take care of these tasks.
The purpose of this article is simply to show that we do not need either a big machine to use models or online services to take advantage of them and start experimenting with AI at home.
Working with generative AI has been a part of our daily work since it began to emerge as one of the new revolutions.




