 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Sinfonier Community and beyond!
18 de marzo de 2016
When we show Sinfonier and I mention its benefits, people always do the simple same question: So, we can do anything with it? The simple answer is yes, if you know the sources you want to monitor, what you are looking for and if the necessary APIs are in place to use the existing modules offered by Sinfonier or to create the new modules you require.
This time, instead of showing a security example, I would like to propose in this technical community to monitor the sentiment in Twitter about and event that happened in December 1916 in Verdun in WWI where about 700.000 French and German soldiers died during a ten months battle.

To achieve this task I have followed the next steps:
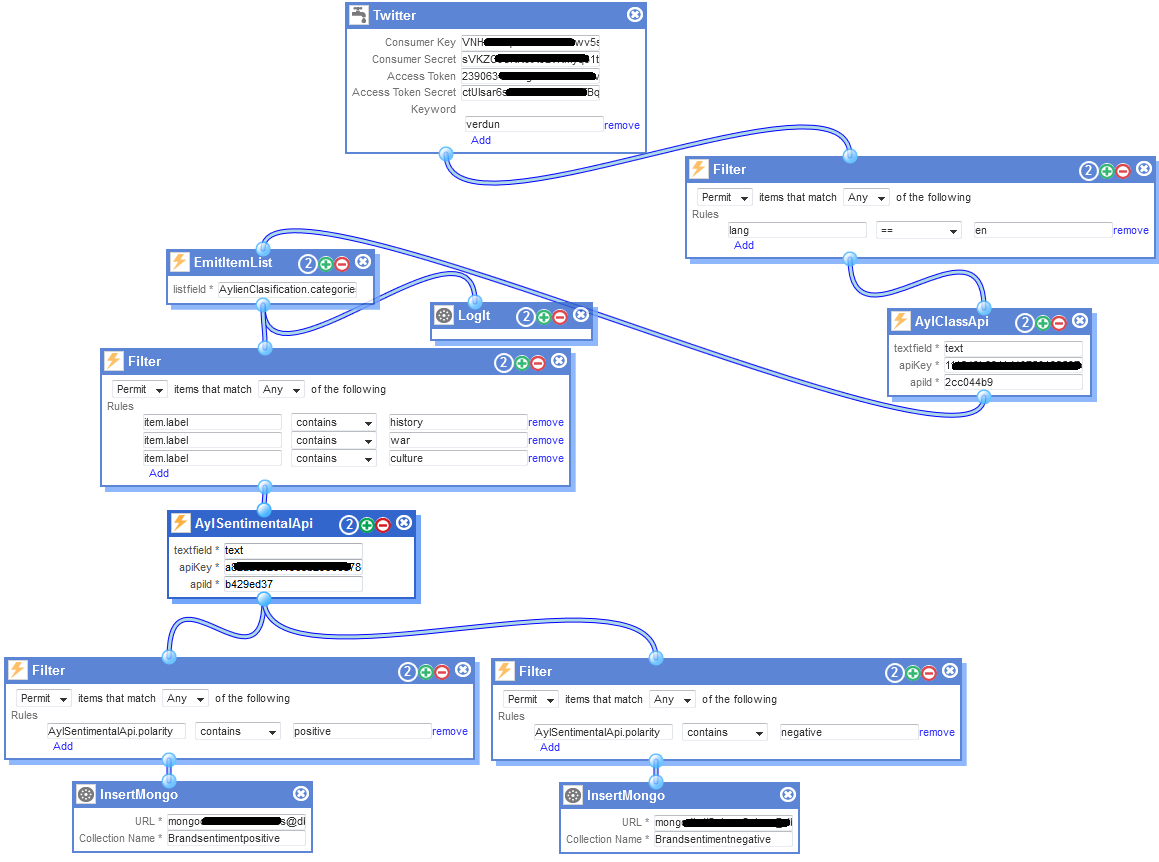
- ACCESS DATA: Twitter. I have created an account in this social media network which delivers real-time stream of semi-structured data (loosely formatted characters inside a field but with little structure within it). The information is delivered in a JSON format which is what I will need to process. For example, word to search in the tweets: Verdun.

-
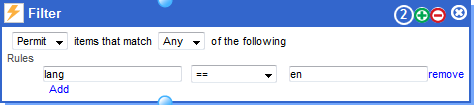
PREPARE AND CLEANSE DATA: Filter. I just want to keep those tweets written in a specific language, in this case English. In the field “lang” belonging to each tweet, I search for those tweets written in “ en”.
-
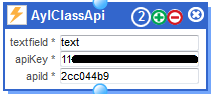
APPLY ADVANCED ANALYTICS: Now I add to my topology the module named “ AlyClassApi” which sends the text, in English and mentioning the word Verdun, to a sentiment analysis cloud service called Aylien (after creating a free user account – 2000 queries per day) which will classify the text in the tweet according to some predefined categories.
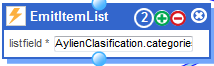
- As this module delivers a JSON array, I need to use the module called “EmitItemList” which will create simple JSONs for those elements present in the array (in this case the array is called categories).
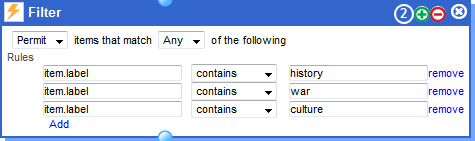
- Having simple JSONs, I use a second filter module in order keep those tweets that I presume they are mentioning the battle of Verdun, so I search for the categories having the words history, war and culture. The results are then analysed by a second Aylien sentiment module that simply categorises the filtered texts as “positive or negative” (another category that is not considered is the category called “neutral”).
-
OUTPUT RESULTS: The final tweets are sent to two MongoDBs (after creating a free user account) where I can finally read those tweets which have gone through all the steps. The final topology looks like the following diagram:
The logical results show that the battle of Verdun still suggests a negative sentiment and mainly those which have been categorised as positive, are those people who like to know about what happened during that time in the WWI.

If this example does not suit your needs, you can also try to find out if that brand you like, it is perceived positively or negatively (for example, those local popular chocolate drinks such as ColaCao in Spain, Poulain in France or Vanhouten in the Netherlands).
Or maybe to gain insights rapidly about what tourists think about your town/city recently visited, by simply changing the word to search in Twitter, using the word of your town/city and in the second filter to filter by tourism, culture and entertainment. This may assist some town/city councils to evaluate their activities promoting tourism.

Sebastian García de Saint-Léger
sebastian.garciadesaintleger@telefonica.com
Thanks to Fran and Alberto.
Thanks to Fran and Alberto.



