 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Almacenamiento en AWS S3 y los ataques de Denial of Wallet. Vigila lo que haces público y tu cartera
Introducción
Normalmente cuando AWS S3 sale en las noticias de ciberseguridad es debido a malas configuraciones en los accesos a sus buckets. Podemos pensar en ellos como directorios de archivos utilizados por los servidores en la nube a los que, sin los permisos adecuados, se puede acceder y obtener información sensible.
Estos descuidos son recurrentes, con ejemplos como McGraw Hill exponiendo accidentalmente las notas de 100.000 estudiantes junto a su información personal o más de 3TB de información aeroportuaria de Perú, incluyendo la información personal identificable (PII) de los empleados, así como información sobre aviones, líneas de combustible y coordenadas de mapas GPS.
Esta innumerable serie de incidentes llevó a Amazon a añadir nuevas políticas de seguridad como el bloqueo del acceso público por defecto y deshabilitar el uso de listas de control de acceso para nuevos buckets S3 desde abril de 2023.
Sin embargo, este artículo no se trata de mala configuración de ficheros en S3, sino más bien el caso contrario. Abordamos el caso en que, de forma consciente, ciertas organizaciones hacen públicos ficheros a través de S3 y cómo los atacantes pueden repercutir importantes facturas en los costes de uso de la nube en ellas. Algo que ha sido bautizado por varios autores como un ataque de Denial of Wallet.
Uso de buckets S3 públicos
La computación en la nube permite a las organizaciones construir aplicaciones de escalado rápido. Esto ofrece nuevas formas de analizar datos, especialmente en medicina o bioinformática. Pero con la facilidad de escalar recursos hacia arriba y hacia abajo, la forma de controlar los costes cambia significativamente para los clientes de la nube.
Esto es especialmente significativo en la atención médica ya que los conjuntos de datos en esta industria suelen ser muy grandes, pensemos en proyectos de secuenciamiento de genoma donde se estima que un genoma humano completo requiere 3GB de almacenamiento.
✅ En la industria de la salud muchas grandes empresas y organizaciones usan AWS S3 y plataformas en la nube similares para almacenamiento o procesamiento de datos. Por ejemplo, hay muchos repositorios públicos de datos de bioinformática, también de agencias gubernamentales, que proporcionan archivos grandes públicamente en S3, por ejemplo, NCBI (National Center for Biotechnology Information).
¿Cómo AWS factura por sus servicios de S3?
Amazon factura a sus clientes por los servicios de S3 de dos formas principalmente: por el almacenamiento y por el volumen de datos transferido (tanto en entrada como en salida) desde ellos.
La parte más volátil de esa factura (y a la que hay que prestarle especial atención como veremos posteriormente en la sección de mitigaciones) es la de transferencia porque depende lógicamente del número de subidas o descargas de información en un determinado ciclo de facturación.
Centrándonos en la descarga de información desde S3, una suposición simple es que la descarga de datos desde S3 a través de Internet cuesta una cantidad de dinero proporcional a la cantidad de datos descargados. Con tal suposición, los que construyen el software y tiene una idea aproximada sobre los costes que un cierto servicio puede incurrir.
Como veremos a continuación a veces esa suposición puede desviarse de la realidad.
El vector de ataque descubierto
El vector de ataque explota lo que el propio Amazon publica en su página de pricing sobre cómo la transferencia de datos de salida puede ser diferente de los datos recibidos por una aplicación en caso de que la conexión se termine prematuramente.
Por ejemplo, si haces una solicitud para un fichero de 5 GB y terminas la conexión después de recibir 2 GB de datos. Amazon S3 intenta detener la transmisión de datos, pero no ocurre instantáneamente. En este ejemplo, la Transferencia de Datos de Salida puede ser de 3 GB (1 GB más de los 2 GB que recibiste). Como resultado, se te facturará por 3 GB de Transferencia de Datos de Salida.
El problema principal es la diferencia potencial entre la cantidad de datos recibidos por una entidad fuera de AWS y la cantidad de datos en la factura. En el ejemplo anterior de la documentación de AWS, la diferencia es un incremento del 50% en costes.
Sin embargo, recientemente se ha descubierto que ese incremento puede llegar a un factor de 50x en el caso de cancelar prematuramente una descarga de ficheros grandes combinado con peticiones HTTP usando Solicitudes de Rango.
Antes de analizar el impacto del ataque, entendamos qué son las peticiones con solicitud de rango y para qué son útiles.
¿Qué son las peticiones HTTP RANGE?
Las Solicitudes de Rango es un método de optimización de ancho de banda introducido en el protocolo HTTP 1.1, con la que se puede enviar solo una porción de un mensaje de un servidor a un cliente.
El proceso comienza cuando un servidor HTTP anuncia su disposición a atender solicitudes parciales utilizando el encabezado de respuesta Accept-Ranges. Un cliente luego solicita una parte específica de un archivo al servidor utilizando el encabezado de solicitud Range.
Los clientes que usan este método de optimización pueden hacerlo en casos en los que un archivo grande ha sido entregado solo parcialmente y se necesita una porción limitada del archivo en un rango específico.
✅ Una ventaja de esta capacidad es cuando se solicita un archivo multimedia grande y ese archivo multimedia está correctamente formateado, el cliente puede ser capaz de solicitar solo las porciones del archivo que se sabe que son de interés. Esto es esencial para servir por ejemplo archivos de vídeo.
Impacto potencial del ataque de denegación de cartera
Como mencionamos anteriormente la combinación de: un bucket S3 público, ficheros alojados grandes (>1GB) y peticiones con solicitudes de rango junto con una cancelación prematura de los mismos pueden generar una desviación con un factor de 50x entre lo realmente descargado y lo facturado.
Recordemos que, con las solicitudes de rango, un cliente puede solicitar recuperar una parte de un archivo, pero no el archivo completo. Al cancelar rápidamente tales solicitudes, un cliente puede solicitar partes de un archivo sin descargar todos los datos. Debido a la forma en que AWS calcula los costes de salida, se factura la transferencia del archivo completo.
Los autores pudieron reproducir un escenario donde se descargan 300MB de datos en 30 segundos de AWS S3 y se facturaron más de 6GB. Si un atacante puede inducir costes por 6GB en 30 segundos, ¿cuánto coste se pueden generar en un día, o en el fin de semana cuando se ejecutan muchos hilos en paralelo?
Hay que tener en cuenta que AWS S3 es altamente disponible, y es posible que nunca se alcance ningún límite de ancho de banda en escenarios del mundo real. Esto debería poner en guardia a cualquiera que aloje archivos grandes en un bucket S3 público, porque los costes de salida pueden dispararse.
Veamos un ejemplo de diferencia de costes usando la propia calculadora de Amazon usando ese factor x50.
Se descargan realmente 5 Terabytes que nos deberían costar aproximadamente 500 dólares.
 Costes de descarga de 5TB en AWS S3
Costes de descarga de 5TB en AWS S3
Pero se nos tarifica por 250 Terabytes que engordarían la factura hasta los 17.000 dólares.
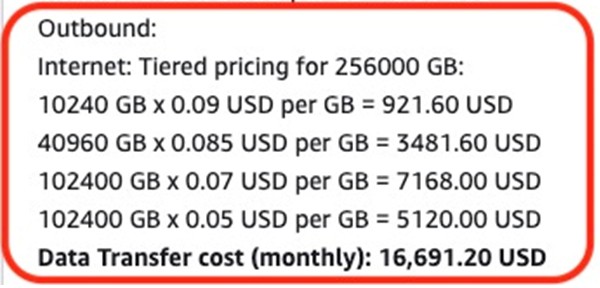 Costes de descarga de 250TB en AWS S3
Costes de descarga de 250TB en AWS S3
Mitigaciones
La primera pregunta es: ¿La organización necesita realmente usar buckets S3 públicos para almacenar ficheros de gran tamaño? En caso de poder proponer arquitecturas alternativas sería recomendable explorarlas, en profundidad, para “evitar” el riesgo.
Si se requiere el uso de buckets S3 públicos, lamentablemente debido al diseño de AWS S3 prevenir estos ataques no es una tarea sencilla.
No hay manera de decirle a AWS: “No me cobres más de X por el mes, y termina mi aplicación si excede esa cantidad.” Por lo que la mejor aproximación es la detección temprana, como primer paso y el más importante.
✅ Crear alertas de coste, activando la funcionalidad de Detección de Anomalías de Costes de AWS. Al activar esta herramienta y configurarla correctamente, serás informado sobre eventos de facturación anormales, acelerando la identificación de tales eventos adversos después de un corto plazo de tiempo y así limitar su impacto financiero.
Conclusiones
AWS S3 se ha convertido en protagonista de múltiples de fugas de información debido a la mala configuración de sus accesos, en particular habilitando el acceso universal al público desde internet.
Pero en ocasiones no se trata de incidentes de fuga de información sensible, como el caso de este artículo, en el que un atacante no busca conseguir información sensible sino que simplemente quiere ejercer un importante daño económico a una organización mediante la generación de solicitudes de acceso a grandes ficheros expuestos públicamente en el servicio de Amazon Web Services.
El daño reputacional es, en estos casos, inexistente, sin embargo, el ataque puede aumentar significativamente los costes de uso de servicios en la nube atacando donde más duele: en la propia “cartera”.
En conclusión, si una organización expone grandes ficheros en la nube, o incluso si no lo hace, es crucial implantar medidas de control de coste como las alertas para hacer un seguimiento de costes y una detección temprana de desviaciones inesperadas y actuar en consecuencia para minimizar el impacto.
La nube otorga una gran ventaja de escalabilidad sin precedentes, pero sin esas medidas de mitigación de riesgo por exceso de costes, se puede convertir, paradójicamente, en nuestra propia ruina.
⚠️ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse
.jpg "Servicios gestionados de AWS para optimizar cargas: importancia y beneficios")



