 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

AWS S3 storage and Denial of Wallet attacks. Keep an eye on what you make public and your wallet
Introduction
It is often the case that when AWS S3 is in the cyber security news, it is due to misconfigurations in accessing its buckets. We can think of them as file directories used by cloud servers that, without proper permissions, can be accessed and sensitive information obtained.
These oversights are recurring, with examples such as McGraw Hill ccidentally exposing the grades of 100,000 students along with their personal information or more than 3TB of airport information from Peru, including employees' personally identifiable information (PII), as well as information about aircraft, fuel lines and GPS map coordinates.
This countless series of incidents led Amazon to add new security policies such as blocking public access by default and disabling the use of access control lists for new S3 buckets from April 2023.
This article, however, is not about file misconfiguration in S3, but rather the opposite case. We address the case where certain organizations knowingly make files public via S3 and how attackers can pass on significant cloud usage cost bills to them. This has been dubbed by several authors as a Denial of Wallet.
Use of public S3 buckets
Cloud computing enables organizations to build rapidly scaling applications. This offers new ways to analyze data, especially in medicine or bioinformatics. However, with the ease of scaling resources up and down, the way to control costs changes significantly for cloud customers.
This is particularly significant in healthcare as data sets in this industry are often very large - think genome sequencing projects where a complete human genome is estimated to require 3GB of storage.
✅ In the healthcare industry, many large enterprises and organizations use AWS S3 and similar cloud platforms for data storage or processing. For example, there are many public bioinformatics data repositories, also from government agencies, that provide large files publicly on S3, e.g. NCBI (National Center for Biotechnology Information).
How does AWS bill for its S3 services?
Amazon bills its customers for S3 services in two main ways: for storage and for the volume of data transferred (both inbound and outbound) from them.
The most volatile part of that bill (and the one that needs special attention as we will see later in the mitigations section) is the transfer part because it logically depends on the number of data uploads or downloads in a given billing cycle.
A simple assumption, focusing on downloading data from S3, is that downloading data from S3 over the Internet costs an amount of money proportional to the amount of data downloaded. With such an assumption, those who build the software and have a rough idea about the costs that a certain service may incur.
As we will see below, this assumption can sometimes deviate from reality.
The attack vector discovered
The attack vector exploits what Amazon itself publishes on its pricing page about how the output data transfer can be different from the data received by an application in case the connection is terminated prematurely.
For example, if you make a request for a 5 GB file and terminate the connection after receiving 2 GB of data. Amazon S3 attempts to stop the data transmission, but it does not happen instantaneously. In this example, the Outbound Data Transfer may be 3 GB (1 GB more than the 2 GB you received). As a result, you will be billed for 3 GB of Outgoing Data Transfer.
The main issue is the potential difference between the amount of data received by an entity outside of AWS and the amount of data on the invoice. In the example above from the AWS documentation, the difference is a 50% increase in costs.
It has recently been discovered, however, that this increase can reach a factor of 50x in the case of prematurely cancelling a large file download combined with HTTP requests using Range Requests.
Let's understand what range request is and what it is useful for before analyzing the impact of the attack.
What are HTTP RANGE requests?
Range Requests is a bandwidth optimization method introduced in the HTTP 1.1 protocol, with which only a portion of a message can be sent from a server to a client.
The process begins when an HTTP server announces its willingness to handle partial requests using the Accept-Ranges response header. A client then requests a specific part of a file from the server using the Range request header.
Clients using this optimization method can do so in cases where a large file has been only partially delivered and a limited portion of the file is needed in a specific range.
✅ One advantage of this capability is when a large media file is requested and that media file is correctly formatted, the client may be able to request only the portions of the file that are known to be of interest. This is essential for serving e.g. video files.
Potential impact of denial of wallet attack
As mentioned above the combination of a public S3 bucket, large, hosted files (>1GB) and requests with range requests together with a premature cancellation of the same can generate a deviation with a factor of 50x between what is actually downloaded and what is billed.
Recall that, with range requests, a customer may request to retrieve a portion of a file, but not the entire file. A customer can request parts of a file without downloading all of the data by quickly canceling such requests. The entire file transfer is billed due to the way AWS calculates the outbound costs.
The authors were able to reproduce a scenario where 300MB of data is downloaded in 30 seconds from AWS S3 and over 6GB was billed. If an attacker can induce costs for 6GB in 30 seconds, how much cost can be generated in a day, or over the weekend when many threads are running in parallel?
Keep in mind that AWS S3 is highly available, and it is possible that no bandwidth limit will ever be reached in real-world scenarios. This should put anyone hosting large files in a public S3 bucket on guard, because the outbound costs can skyrocket.
Let's look at an example of the cost difference using Amazon's own calculator using that x50 factor.
5 Terabytes are actually downloaded, which should cost us approximately 500 dollars.
 5TB offload costs on AWS S3
5TB offload costs on AWS S3
However, we are charged for 250 Terabytes, which would increase the bill to 17,000 dollars.
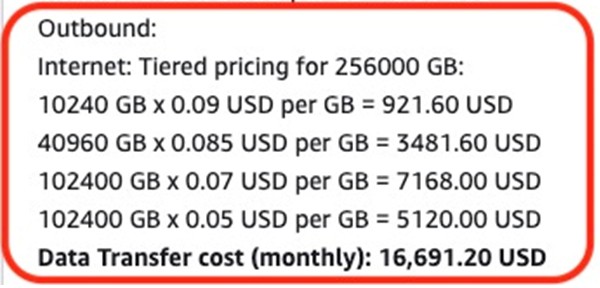 250TB offload costs on AWS S3
250TB offload costs on AWS S3
Mitigations
The first question is: Does the organization really need to use public S3 buckets to store large files? If alternative architectures can be proposed it would be advisable to explore them, in depth, to "avoid" the risk.
If the use of public S3 buckets is required, unfortunately due to the design of AWS S3 preventing these attacks is not a simple task.
There is no way to tell AWS, "Don't charge me more than X for the month and terminate my application if it exceeds that amount." So, the best approach is early detection, as the first and most important step.
✅ Create cost alerts by enabling the AWS Cost Anomaly Detection functionality. You will be informed about abnormal billing events by activating this tool and configuring it correctly, speeding up the identification of such adverse events after a short period of time and thus limiting their financial impact.
Conclusions
AWS S3 has become the target of multiple information leaks due to misconfiguration of its access, in particular enabling universal public access from the Internet.
Sometimes, however, these are not incidents of sensitive information leaks, such as the case of this article, in which an attacker is not seeking to obtain sensitive information but simply wants to inflict significant economic damage on an organization by generating requests for access to large files publicly exposed on the Amazon Web Services service.
The reputational damage is, in these cases, non-existent, however, the attack can significantly increase the costs of using cloud services by attacking where it hurts the most: in the "wallet" itself.
In conclusion, if an organization exposes large files in the cloud, or even if it does not, it is crucial to implement cost control measures such as alerts to track costs and early detection of unexpected deviations and act accordingly to minimize the impact.
The cloud provides a great advantage of unprecedented scalability, but without such cost overrun risk mitigation measures, it can become, paradoxically, our own undoing.
.jpg "AWS managed services for load optimization: importance and benefits")



