 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos. Parte 2, observando el entorno
6 de julio de 2017
Escrito por Fran Ramírez, Investigador en Eleven Paths y escritor del libro "Microhistorias: anecdotas y curiosidades de la historia de la informática".
Ahora que ya tenemos preparada nuestra rejilla de juegos, vamos a ver de una forma sencilla cómo funciona el proceso de aprendizaje del algunas IA observando el entorno que les rodea. Nuestro objetivo no es entrar en profundidad en los aspectos teóricos, sino intentar aprender de la forma más práctica posible con ejemplos.
 Figura 1: Fotograma de la película Tron
Figura 1: Fotograma de la película Tron
El área de Machine Learning que se utiliza en OpenAI para entrenar los agentes a jugar videojuegos es la llamada Reinforcement Learning (RL) o Aprendizaje Reforzado. Otras áreas dentro de Machine Learning son también el Aprendizaje Supervisado ( Supervised ) y Aprendizaje no Supervisado ( Unsupervised ), los cuales trataremos más adelante con otros ejemplos.
RL es capaz de dotar a los agentes de algoritmos que le permitan examinar y aprender del entorno en el cual se están ejecutando para conseguir un objetivo a cambio de recompensas (luego lo veremos con más detalle, pero básicamente es un indicador que informa al agente si se han tomado correctamente las decisiones). Estos algoritmos no tienen un objetivo concreto, simplemente ayudan al agente a aprender con pruebas de ensayo y error como obtener la mayor recompensa posible.
Estos son algunos conceptos que debemos conocer en RL:
- Estado (state): describe la situación actual del entorno. Por ejemplo, en el juego Breakout de Atari, un posible estado sería la situación de la raqueta, la posición de la bola, su trayectoria, etc.
- Política (policy): reglas que utiliza un agente en base a las entradas de un estado para llegar a obtener una recompensa. Dicho de otra forma, las reglas que utiliza para ejecutar una acción y se suele representar por un mapa de estados.
- Acción (action): son los pasos que realiza el agente basándose en las entradas definidas por el estado y las políticas. En el caso de Breakout una acción podría ser moverse a izquierda o derecha después de analizar la posición y trayectoria de la bola en la pantalla.
- Recompensa (reward): se obtiene una vez se ha ejecutado una acción. Esta recompensa puede ser positiva (recompensa) o negativa (castigo).
Para conseguir los mejores resultados durante el proceso de aprendizaje, es muy importante obtener toda la información posible del entorno que vamos a intentar resolver. De esa forma sabremos qué consecuencias han tenido nuestras acciones y así poder avanzar en su resolución. En OpenAI existe una función llamada step (la veremos más adelante) la cual devuelve cuatro variables relacionadas con datos obtenidos del entorno:
- observation (tipo “objeto”): es un elemento representado en el entorno que estamos analizando. Por ejemplo, puede ser el tablero de un juego de mesa o la velocidad y ángulo de la bola del juego BreakOut.
- reward (tipo “float”): indicará el valor (la escala de este valor depende del entorno) de la recompensa obtenida en la acción previa que hemos realizado.
- done (tipo “boolean”): cuando una tarea del proceso de aprendizaje a terminado (también llamados “episodios”) esta variable toma el valor “True”. Una vez llegado a este punto el entorno se reinicializará.
- info (tipo “info”): información para depuración.
Antes de seguir avanzando y crear nuestra primera IA en Python, es muy importante interpretar los valores que nos devuelven los escenarios. Para nuestra primera prueba vamos a elegir un entorno llamado CartPole, el cual tiene unas acciones y reglas muy sencillas. Básicamente, el juego trata de mantener el mayor tiempo posible en equilibrio una varilla que está sujeta a una caja la cual podemos mover de izquierda a derecha. Estos son los datos de observación y acción del entorno CartPole según la Wiki de OpenAI:
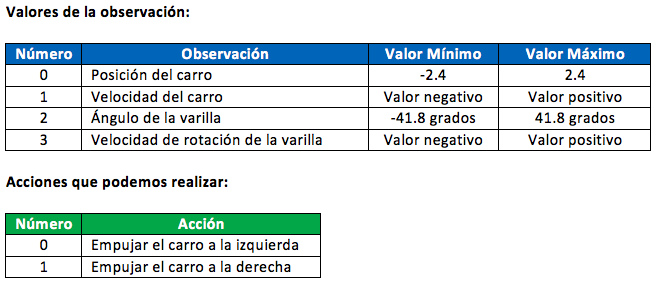
El episodio termina si la la varilla en equilibrio supera los 20.9 grados desde la vertical y a la vez no nos salgamos de la pantalla (tanto a la izquierda como a la derecha) a una distancia de 2,4 unidades desde el centro. También acabará si la duración del episodio supera los 200 intentos. En el siguiente video podemos ver un ejemplo de ejecución de este entorno:

El control sobre la caja para conseguir el equilibrio y mantener la varilla lo más recta posible, se realiza aplicando una fuerza con valor 0 para empujar el carro a la izquierda o 1 para empujarlo a la derecha. Por cada paso que damos y la vara se mantenga en equilibrio, obtenemos una recompensa de +1. Por este motivo podréis ver más adelante que la recompensa es igual que el número de intentos que hemos ejecutado durante el episodio. Finalmente, este escenario se considera resuelto si la media de recompensas en cada intento es mayor o igual a 195.0 ejecutando 100 intentos como máximo.
Es muy importante tener claro qué variables y valores obtenemos del entorno por cada paso que ejecutamos. El siguiente programa de ejemplo prepara un entorno de CartPole y ejecutará varias acciones aleatorias. Esto generará valores de observación que podremos ir viendo por la pantalla:
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
recompensa=0
for t in range(200):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
recompensa=recompensa+reward
if done:
print ("Paso final que provoca el fin del episodio:")
print(observation)
print("Episodio ",i_episode,"terminado en {} intentos".format(t+1))
recompensa=recompensa+reward
print ("Recompensa obtenida: ",recompensa)
break
input ("Fin del episodio, pulsa Enter para continuar")
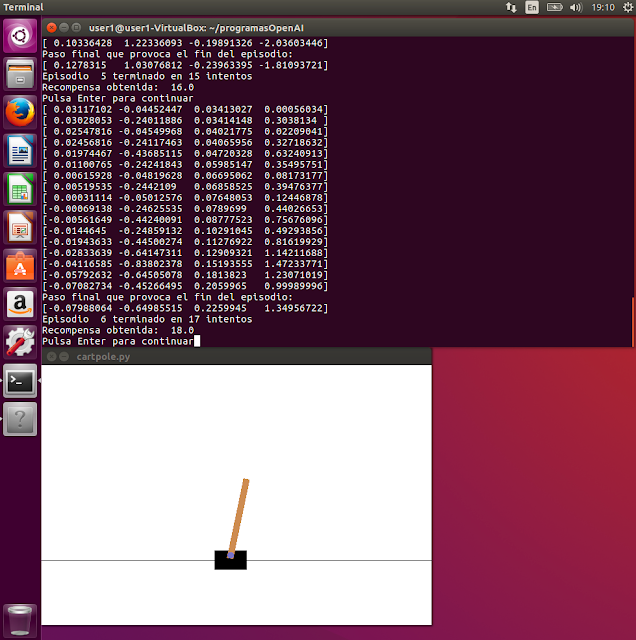
El programa ejecuta 20 episodios, dentro de los cuales realizará un máximo de 200 intentos hasta que termine. En la siguiente imagen tenemos una captura de una ejecución terminada en el episodio 6 que ha finalizado después de 17 intentos obteniendo una recompensa de 18 puntos (el paso final que provoca la parada de la ejecución también puntúa):
A continuación mostramos el último bloque de valores obtenidos al final del episodio el cual ha provocado su finalización:

Como podemos observar, el tercer valor corresponde al “ Ángulo de la varilla” y es igual a 0.2259945 (22.5 grados) siendo mayor de los 20.9 marcados como máximo provocando la finalización del episodio.
Vamos a analizar el código fuente línea por línea para entender su ejecución:
import gym
Cargamos la librería gym necesaria para ejecutar los entornos de aprendizaje
env = gym.make('CartPole-v0')
Definimos una variable tipo objeto llamada “env” asignándole los valores que corresponden al entorno CartPole-v0
for i_episode in range(20):
Aquí empieza el bucle que define el número de episodios que vamos a ejecutar. En este caso serán 20 contando de 0 a 19.
observation = env.reset()
Reseteamos todos los valores del entorno actualizando la variable observation
recompensa = 0
En esta variable vamos a ir acumulando la recompensa obtenida, se reiniciará a 0 en cada episodio
for t in range(200):
Comienza el bucle que ejecuta los 200 intentos
env.render()
Este comando muestra en pantalla en cada ejecución un fotograma donde podemos ver los resultados de nuestras operaciones
print(observation)
Muestra en pantalla los cuatro valores de la variable observation que hemos comentado anteriormente. En la primera ejecución los valores serán por defecto los de un reset del entorno y en los siguientes paso mostrará en pantalla los valores actualizados según las acciones realizadas
action = env.action_space.sample()
Esta parte del código es importante ya que es donde definimos las acciones a tomar. En este caso, sólo queremos hacer movimientos de prueba, para ello utilizamos la función .sample la cual devolverá de forma aleatoria valores 0 o 1 que implican aplicar una unidad de fuerza a la izquierda o a la derecha del carro. Más adelante veremos cómo obtener la información sobre las acciones que podemos tomar desde cualquier entorno.
observation, reward, done, info = env.step(action)
Este comando devuelve los valores actualizados de las variables observation, reward, done e info que obtenemos durante la ejecución de un paso con las acciones que hemos definido env.step(action)
recompensa = recompensa + reward
96 Normal 0 false false false EN-US X-NONE X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Table Normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0in 5.4pt 0in 5.4pt; mso-para-margin:0in; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:10.0pt; font-family:Consolas; color:black; mso-themecolor:text1; mso-bidi-font-weight:bold;}
Acumulamos en la variable recompensa el valor devuelto por la variable reward
Acumulamos en la variable recompensa el valor devuelto por la variable reward
if done: print ("Paso final que provoca el fin del episodio:") print(observation) print("Episodio ",i_episode,"terminado en {} intentos".format(t+1)) recompensa=recompensa+reward print ("Recompensa obtenida: ",recompensa) break
Si la variable done es verdadera, el episodio ha terminado. El motivo de finalización en nuestro caso siempre será haber sobrepasado los 20.9 grados de inclinación (es muy improbable que el carro salga de los límites establecidos). Una vez ha terminado el episodio, enviamos por pantalla el paso final que ha provocado la parada el episodio, los valores de las observaciones, los intentos y la recompensa obtenida.
input ("Fin del episodio, pulsa Enter para continuar")
Hacemos una pausa al final del episodio para poder observar los valores devueltos
Vamos a ver un vídeo con la ejecución de este código:
Podríamos añadir una pequeña modificación para poder observar paso a paso los valores utilizados en la acción (empujar a izquierda o derecha el carro):
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
recompensa=0
for t in range(200):
env.render()
print(observation)
action = env.action_space.sample()
if action==0:
print ("Valor ",action," empuja izquierda (mueve derecha)")
else:
print ("Valor ",action," empuja derecha (mueve izquierda)")
observation, reward, done, info = env.step(action)
recompensa=recompensa+reward
input ("Fin del intento, pulsa Enter para continuar")
if done:
print ("Paso final que provoca el fin del episodio:")
print(observation)
print("Episodio ",i_episode,"terminado en {} intentos".format(t+1))
recompensa=recompensa+reward
print ("Recompensa obtenida: ",recompensa)
break
input ("Fin del episodio, pulsa Enter para continuar")
Finalmente, si queremos que se ejecute toda la operación sin pausas sólo tenemos que quitar las líneas que contengan input:
Ahora que ya sabemos cómo observar nuestro entorno de juego, en el siguiente capítulo comenzaremos a aplicar las primeras técnicas de RL para intentar resolver CartPole e incluso, si tenemos buen feedback de esta serie, llegar a enseñar a alguna IA a jugar a DOOM!.
Por si acaso te perdiste la primera parte de esta serie, aquí tienes el enlace: Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos , Parte 1, preparando la "rejilla de juegos".
Para cualquier duda, idea o comentario puedes acceder también a la comunidad de ElevenPaths donde tenemos un apartado para LUCA.
Por si acaso te perdiste la primera parte de esta serie, aquí tienes el enlace: Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos , Parte 1, preparando la "rejilla de juegos".
Para cualquier duda, idea o comentario puedes acceder también a la comunidad de ElevenPaths donde tenemos un apartado para LUCA.



