 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos. Parte 4. Aprende Q-Learning con el juego "Taxi", parte 1 de 2
2 de noviembre de 2017

Escrito por Fran Ramírez, Investigador en Eleven Paths y escritor del libro "Microhistorias: anecdotas y curiosidades de la historia de la informática".
Ahora que hemos resuelto un entorno de juegos como CartPole, vamos a dar un paso más para aprender técnicas un poco más avanzadas de aprendizaje. Uno de los métodos de RL más utilizados el llamado Q-Learning, válido siempre y cuando tengamos un número no muy grande de acciones y estados
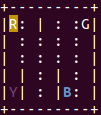 Figura 1. Renderización del juego Taxi de OpenAI Gym
Figura 1. Renderización del juego Taxi de OpenAI Gym
. Para resolver juegos más complejos como MsPacman o similares, se utilizan técnicas como DQN, Deep Q-Network, pero para poder comprenderlas mejor, es necesario aprender previamente algunos conceptos de Q-Learning. Sea cual sea la técnica que utilicemos, a partir de ahora comprobaremos que la clave de aprendizaje será el análisis de los estados anteriores.
Ahora que hemos resuelto un entorno de juegos como CartPole, vamos a dar un paso más para aprender técnicas un poco más avanzadas de aprendizaje. Uno de los métodos de RL más utilizados el llamado Q-Learning, válido siempre y cuando tengamos un número no muy grande de acciones y estados
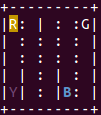 Figura 1. Renderización del juego Taxi de OpenAI Gym
Figura 1. Renderización del juego Taxi de OpenAI Gym
. Para resolver juegos más complejos como MsPacman o similares, se utilizan técnicas como DQN, Deep Q-Network, pero para poder comprenderlas mejor, es necesario aprender previamente algunos conceptos de Q-Learning. Sea cual sea la técnica que utilicemos, a partir de ahora comprobaremos que la clave de aprendizaje será el análisis de los estados anteriores.
Volviendo a Q-Learning, esta técnica se basa en las llamadas Q-Tables, las cuales almacenan valores llamados Q-Values y las recompensas obtenidas al ejecutar el par estado/acción:
Q(s , a )
s = estado
a = acción
El valor inicial de esta función será cero para todos los estados y acciones. Cuando comienza el proceso de aprendizaje, el agente recibirá una recompensa “ reward” en el estado “ state”. El objetivo final es maximizar en lo posible la recompensa total aprendiendo qué acción es la óptima para cada estado, es decir, la acción con la cual se obtiene mayor recompensa. Vamos a intentar explicarlo paso a paso y luego implementarlo. En el inicio del proceso, estado 0, Q devolverá un valor aleatorio. Este valor irá cambiando a medida que en cada paso ( t) el agente ( a) realice una acción dentro de este periodo ( at), obtenga una recompensa ( r t) y se añada a la fórmula el valor del estado anterior y la acción realizada. Podemos verlo mejor en esta fórmula en la definición de Q-Learning de la WikiPedia:

Hay varias formas de implementar este algoritmo que variará fundamentalmente en el tipo de datos que vamos a utilizar, como por ejemplo matrices, listas, etc. Utilizaremos como base la siguiente implementación de esta fórmula (es la más aceptada, como se puede ver también en este enlace), ya que es bastante sencilla de programar en Python:
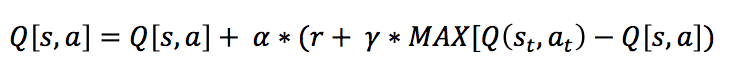
Donde:
- α es la media de aprendizaje
- γ cuantifica la importancia que le daremos a las futuras recompensas el cual varía entre 1 y 0. Si el valor es cercano a 1 las futuras recompensas tendrán más peso.
- MAX[Q(st,at) calcula el valor máximo de Q dentro de todas las posibles acciones que aparecen en el siguiente estado, se resta con los valores del estado actual y se calcula el máximo.
Una representación gráfica del proceso estado/acción/recompensa podría ser la siguiente:
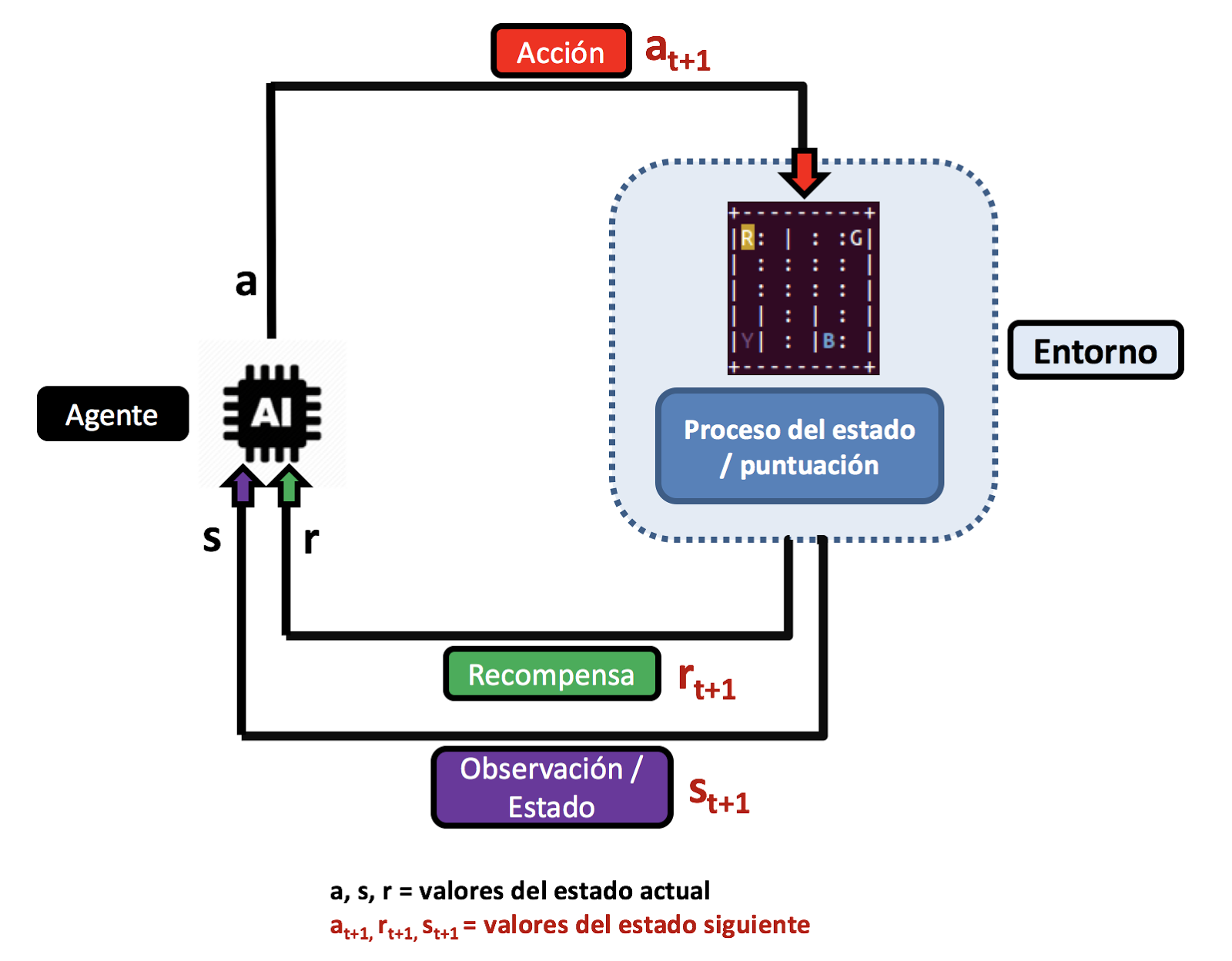 Figura 2. Esquema simple de funcionamiento de Q-Learning y sus estados
Figura 2. Esquema simple de funcionamiento de Q-Learning y sus estados
La mejor forma de ver cómo funciona este algoritmo es implementándolo. Para probarlo, utilizaremos otro entorno, un poco más complejo que CartPole llamado Taxi (v2). Este entorno consiste en 4 localizaciones, etiquetadas con diferentes letras y colores. Nuestra misión es recoger a un pasajero de nuestro taxi en una ubicación y dejarlo en otra. Cada vez que lo consigamos obtendremos una recompensa de 20 puntos por cada pasajero que logremos llevar a su destino, y -1 por cada paso que damos durante el trayecto. También existe una penalización de -10 puntos si se recoge o se deja a un pasajero de forma ilegal.
Vamos primero a analizar el entorno para saber interpretarlo y ver las variables y acciones que podemos realizar. El primer paso será crearlo y ver qué valor nos devuelve al reiniciarlo:
import gym
import numpy as np
env = gym.make("Taxi-v2")
observation=env.reset()
# Visualizamos el valor devuelto al resetear el entorno
print(observation)
#Mostrar el estado actual del entorno
env.render()
Con este código, abrimos el entorno “ Taxi-v2” y lo reinicializamos, guardando el valor de salida en la variable “ observation”. Este valor devuelto está comprendido entre 0 y 499, lo cual representa todos los posibles estados del entorno y en concreto el número devuelto corresponderá con estado inicial. Además, también visualizará el estado actual con el comando env.render(). Ejecutando tres veces el programa anterior (para comparar episodios), obtendremos una salida parecida a la siguiente:
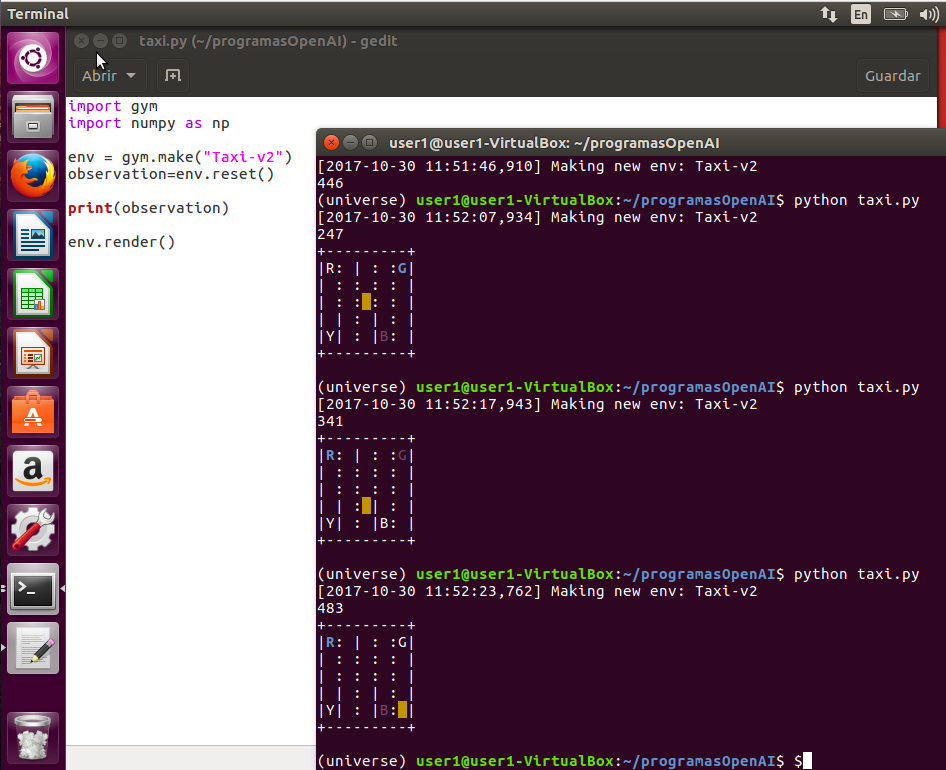 Figura 3. Salida renderizada con varios episodios
Figura 3. Salida renderizada con varios episodios
En la visualización del estado podemos ver las siguientes variables:
- El recuadro amarillo representa al taxi y su ubicación. El taxi se volverá de color verde cuando tenga a un pasajero a bordo.
- La carretera, o el camino por donde puede circular el taxi, está marcada por los “:”
- Una barrera (edificio, valla, etc.) está caracterizada por “|”
- La letra con color azul indicará la ubicación de recogida (el caso 1 será la “G”, en el dos la “R” y el tres la “R” de nuevo.
- El color magenta indicará la localización de destino (el caso 1 es la “B”, en el dos la “G” y el tercero la letra “B” de nuevo).
acciones=env.action_space
print (acciones)
Obtendremos el valor 6 de vuelta. Esto quiere decir que tenemos 6 posibles acciones a realizar. Consultando la wiki de OpenAI vemos que estos valores pueden ser:
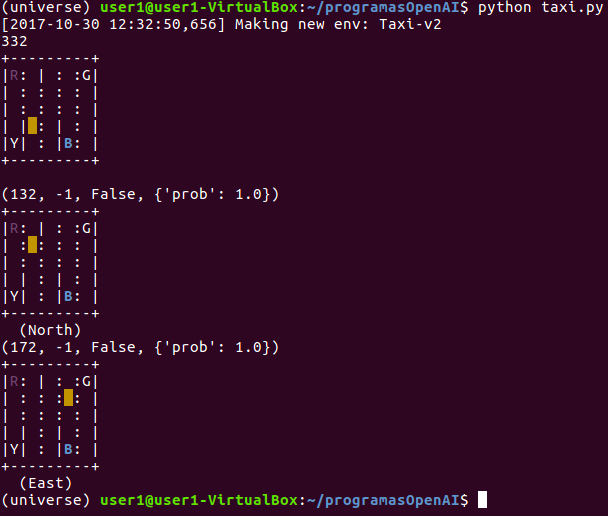 Figura 4. Renderización del entorno donde se muestran el estado inicial y los movimientos realizados.
Figura 4. Renderización del entorno donde se muestran el estado inicial y los movimientos realizados.
- (0) abajo / sur
- (1) arriba / norte
- (2) derecha / este
- (3) izquierda / oeste
- (4) recoger pasajero
- (5) dejar pasajero
Como ocurre con CartPole y con otros entornos de OpenAI Gym, cada vez que ejecutemos una acción, el entorno nos devolverá una serie de valores con los resultados de nuestra acción en cuatro variables que serán: observation, reward, done e info (podéis ver su significado en la Parte 2 de esta serie aquí).
Vamos a comprobar la salida efectuando algunos movimientos aleatorios, por ejemplo, mover arriba el taxi y luego derecha:
import gym import numpy as np env = gym.make("Taxi-v2") observation=env.reset() # Visualizamos el valor devuelto al resetear el entorno print(observation) #Mostrar el estado actual del entorno env.render() #Movimientos del taxi action=1 #mover arriba (north) el taxi observation, reward, done, info = env.step(action) print (env.step(action)) env.render() action=2 #mover derecho (east) el taxi observation, reward, done, info = env.step(action) print (env.step(action)) env.render()
En esta captura podemos ver la salida con la renderización de los tres estados, el inicial y los otros dos que muestran la evolución del taxi con las variables ( observation, reward, done e info) obtenidas:
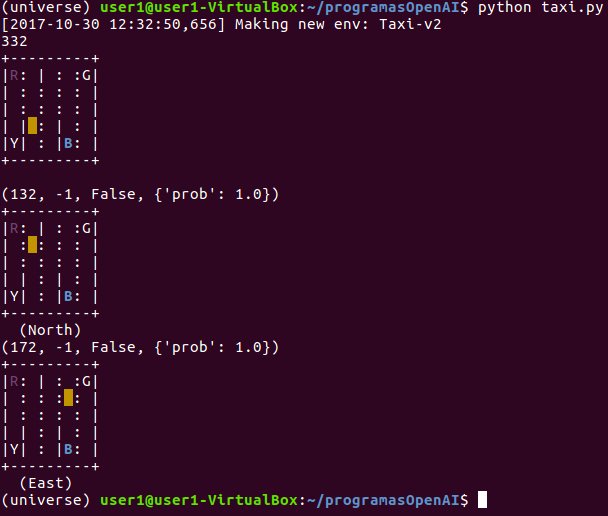 Figura 4. Renderización del entorno donde se muestran el estado inicial y los movimientos realizados.
Figura 4. Renderización del entorno donde se muestran el estado inicial y los movimientos realizados.
Ahora que ya tenemos toda la información posible del entorno, vamos a intentar resolverlo utilizando Q-Tables y viendo su evolución paso a paso. Esta sería una posible implementación de una solución utilizado Q-Learning y Q-Tables aplicando la fórmula anterior basándonos en el código de este enlace:
import gym
import numpy as np
env = gym.make("Taxi-v2")
#Inicializacion de variables
Q=np.zeros([env.observation_space.n, env.action_space.n])
alpha=0.2
def run_episode(observation1, movimiento):
observation2, reward, done, info = env.step(movimiento)
Q[observation1,movimiento] += alpha * (reward + np.max(Q[observation2]) - Q[observation1,movimiento])
return done,reward, observation2
for episode in range (0,2000):
out_done=None
reward = 0
rewardstore=0
observation = env.reset()
print("Estado inicial:")
print(env.render()) # muestra estado inicial
while out_done != True:
action = np.argmax(Q[observation])
#print(env.render()) # muestra estados intermedios
out_done, out_totrwd, out_observation = run_episode(observation,action)
rewardstore += out_totrwd
observation = out_observation
print("Estado final:")
print(env.render()) # muestra estado final
print('Episodio ',episode,' Recompensa: ',rewardstore)
En el siguiente vídeo podemos ver la ejecución del programa y la salida:
Se puede observar cómo los valores de salida, la recompensa total, pasa de ser negativa en los primeros episodios a positiva en los finales. Esto quiere decir que las tablas Q se van ajustando con los valores óptimos en cada episodio realizando el mejor trayecto posible para recoger al pasajero y llevarlo al destino. En la segunda parte del vídeo, se activa la renderización para ver gráficamente los estados del episodio inicial y final, y de esa forma comprobar el recorrido realizado (lo veremos en mayor detalle en el siguiente episodio).
En el siguiente artículo analizaremos el código fuente paso a paso y veremos internamente cómo funcionan las tablas Q así como la evolución del algoritmo encontrando la solución, no te lo pierdas.
Otros episodios de esta serie:
Cómo entrenar tu IA jugando videojuegos, Parte 1
Cómo entrenar tu IA jugando videojuegos, Parte 2
Cómo entrenar tu IA jugando videojuegos, Parte 3
Se puede observar cómo los valores de salida, la recompensa total, pasa de ser negativa en los primeros episodios a positiva en los finales. Esto quiere decir que las tablas Q se van ajustando con los valores óptimos en cada episodio realizando el mejor trayecto posible para recoger al pasajero y llevarlo al destino. En la segunda parte del vídeo, se activa la renderización para ver gráficamente los estados del episodio inicial y final, y de esa forma comprobar el recorrido realizado (lo veremos en mayor detalle en el siguiente episodio).
En el siguiente artículo analizaremos el código fuente paso a paso y veremos internamente cómo funcionan las tablas Q así como la evolución del algoritmo encontrando la solución, no te lo pierdas.
Otros episodios de esta serie:
Cómo entrenar tu IA jugando videojuegos, Parte 1
Cómo entrenar tu IA jugando videojuegos, Parte 2
Cómo entrenar tu IA jugando videojuegos, Parte 3



