 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos. Parte 3, resolviendo CartPole con Random Search
3 de octubre de 2017

Escrito por Fran Ramírez, Investigador en Eleven Paths y escritor del libro "Microhistorias: anecdotas y curiosidades de la historia de la informática".
Ahora que ya conocemos perfectamente el entorno en el cual funciona Cartpole, vamos a empezar a utilizar algunas técnicas de IA, en concreto de RL ( Aprendizaje Reforzado , Reinforcement Learning), para que nuestro agente aprenda a resolverlo. Cartpole tiene un espacio de observación de sólo cuatro dimensiones (posición del carro, velocidad del carro, ángulo de la varilla y velocidad de rotación de la varilla) y sólo dos acciones a realizar (mover a la izquierda o a la derecha el carro). Esto hace que sea perfecto como base para probar algunas técnicas de RL y aprender cómo funcionan de la manera más sencilla posible.
Ahora que ya conocemos perfectamente el entorno en el cual funciona Cartpole, vamos a empezar a utilizar algunas técnicas de IA, en concreto de RL ( Aprendizaje Reforzado , Reinforcement Learning), para que nuestro agente aprenda a resolverlo. Cartpole tiene un espacio de observación de sólo cuatro dimensiones (posición del carro, velocidad del carro, ángulo de la varilla y velocidad de rotación de la varilla) y sólo dos acciones a realizar (mover a la izquierda o a la derecha el carro). Esto hace que sea perfecto como base para probar algunas técnicas de RL y aprender cómo funcionan de la manera más sencilla posible.

El primero de los algoritmos que vamos a ver y probar en nuestro entorno tiene una base muy simple. Básicamente se trata de ir probando movimientos aleatorios ( Random Search) y elegir aquellos en los que obtengamos los mejores resultados o recompensas . Para crear el código fuente en Python 3.0, vamos a basarnos en esta solución propuesta con algunos cambios y veremos línea por línea su funcionamiento:
import gym
from gym import wrappers
import numpy as np
def run_episode(env, parameters):
observation = env.reset()
totalreward = 0
for intento in range(200):
action = 0 if np.matmul(parameters,observation) < 0 else 1
observation, reward, done, info = env.step(action)
totalreward += reward
if done:
break
return totalreward
env = gym.make('CartPole-v0')
env = wrappers.Monitor(env, 'CartPole1', force=True)
bestparams = None
parameters = None
bestreward = 0
for episodios in range(10000):
parameters = np.random.rand(4) * 2 - 1
reward = run_episode(env,parameters)
print ("Episodio ",episodios," terminado con recompensa: ",reward)
if reward > bestreward:
bestreward = reward
bestparams = parameters
if reward == 200:
break
El primer paso será definir las librerías que vamos a utilizar. Por supuesto “ gym” es la primera y desde esta librería importamos también “ wrappers”, la cual nos permitirá monitorizar la ejecución de nuestro entorno y generar vídeos con los resultados. Por último, también importamos la librería matemática numpy (y le asignamos el alias np) para poder ejecutar operaciones matemáticas con matrices que veremos más adelante:
import gym
from gym import wrappers
import numpy as np
Antes de explicar el funcionamiento de la función run_episode vamos a analizar el cuerpo principal del programa.
Como ya hicimos anteriormente, el primer paso será crear el entorno “ CartPole-v0” asignándolo a la variable “ env”. Para poder monitorizar, grabar vídeos de la salida y ver por la pantalla la evolución del agente activamos también la opción “ wrappers”, pasando como parámetros el entorno ( env), el nombre de la carpeta donde se almacenará la información de salida (vídeos, ficheros json, etc) y la variable " force" a " true":
env = gym.make('CartPole-v0')
env = wrappers.Monitor(env, 'CartPole1', force=True)
Ahora inicializamos las variables que vamos a utilizar. La variable “ bestparam” y “ parameters” (matrices, las inicializamos ambas como vacías) almacenaremos los mejores valores obtenidos durante el aprendizaje aleatorio y las mejores recompensas en la variable " bestreward".
bestparams = None
parameters = None
bestreward = 0
La siguiente parte del código está englobada en un bucle de 10000 episodios, que son los que OpenAI propone para resolver este entorno, aunque ahora veremos que debido a la sencillez del entorno no será necesario ejecutarlos todos:
for episodios in range(10000):
La siguiente línea de código genera con cuatro valores aleatorios entre -1 y 1 que corresponderán a cada una de las observaciones que hemos mencionado al principio de artículo. Una posible salida con datos para este vector podría ser: [ 0.07956037 -0.70373308 0.81568326 -0.11323522] que serán los valores que posteriormente pasaremos al entorno:
parameters = np.random.rand(4) * 2 - 1
El siguiente paso será ejecutar el episodio pasando como parámetros en entorno que hemos creado ( env) y los parámetros generados en " parameters". Esta llamada devolverá la recompensa ( reward) obtenida y la mostraremos en pantalla con el comando print:
reward = run_episode(env,parameters)
print ("Episodio ",episodios," terminado con recompensa: ",reward)
Ahora iremos guardando las mejores recompensas a medida que ejecutamos un episodio, almacenando los mejores valores de recompensa ( bestreward) así como los parámetros que se han utilizado ( bestparams):
if reward > bestreward:
bestreward = reward
bestparams = parameters
Si la recompensa obtenida en la ejecución de uno de los episodios es 200, entonces paramos la ejecución del bucle:
if reward == 200:
break
En este punto vamos a analizar la función run_episode antes de acabar el código del programa principal. La función tiene como entrada dos parámetros, el entorno ( env) y los parámetros de entrada ( parameters):
def run_episode(env, parameters):
La variable " totalreward" almacenará la recompensa obtenida en la ejecución de un episodio y será devuelta por la función como un valor entero. La inicializamos primero:
totalreward = 0
Se inicializa el entorno de observación:
observation = env.reset()
En este punto ejecutaremos las 200 acciones como máximo para ver si conseguimos la recompensa máxima (200):
for intento in range(200):
En la siguiente línea de código vamos a definir qué hacer o que acción ( action) tomar basándonos en nuestros parámetros y las observaciones del entorno. Vamos a explicar más en detalle cómo funciona esta toma de decisión para la acción a realizar. Cada valor de los parámetros introducidos ( parameters) se multiplica por cada una de sus respectivas observaciones ( np.matmul). Este es un ejemplo de dos ejecuciones con sus respectivos datos:
parameters: [ 0.10688612 0.23223451 -0.39875783 0.88085558]
observation: [ 0.03322276 0.04032782 0.03142452 0.04958755]
mutiplicación: 0.0440652550416
action: 1
Resultado: movimiento a la derecha
parameters: [ 0.10688612 0.23223451 -0.39875783 0.88085558]
observation: [ 0.03402932 0.2349854 0.03241627 -0.23301739]
mutiplicacion: -0.159971929661
action: 0
Resultado: movimiento a la izquierda
action = 0 if np.matmul(parameters,observation) < 0 else 1
Ahora enviaremos la acción tomada al entorno para que la ejecute con el comando env.step(action) y nos devuelva nuevos valores de la observación ( observation), la recompensa( reward), si ha terminado la simulación ( done) y otros datos ( info):
observation, reward, done, info = env.step(action)
Acumulamos las recompensas obtenidas en la variable " totalreward":
totalreward += reward
Finalmente, si por cualquier circunstancia la simulación termina, paramos la ejecución del bucle de acciones y devolvemos la recompensa obtenida:
if done:
break
return totalreward
Todos estos pasos se ejecutarán cada vez que el programa principal procese un episodio el cual llama a la función run_episode. Volviendo al cuerpo principal del programa, los últimos pasos ejecutan varios escenarios utilizando los mejores valores obtenidos del entrenamiento:
input ("Pulsa Enter para probar el resultado del aprendizaje") for b in range(5000): run_episode(env,bestparams) input ("Terminado")
Los videos que se irán mostrando en pantalla durante la primera fase de aprendizaje no corresponden todas las ejecuciones, sólo pertenecen a algunas.
Vamos a ver un vídeo completo con una ejecución de aprendizaje y luego de puesta en práctica de la solución. Veremos cómo los episodios de aprendizaje terminan cuando se obtiene el valor de recompensa 200, en este caso ocurre en el episodio 5 como podemos ver en el siguiente fotograma del vídeo:
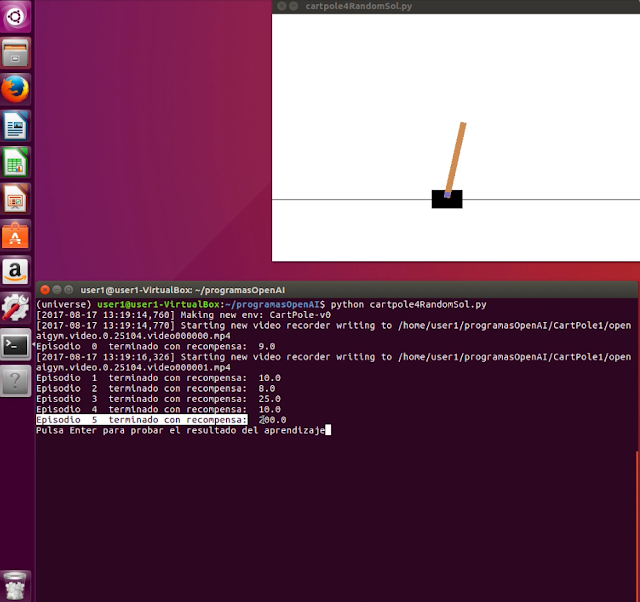
A partir de este punto se ejecutan varias simulaciones con los resultados obtenidos durante el entrenamiento:
Vamos a ver un vídeo completo con una ejecución de aprendizaje y luego de puesta en práctica de la solución. Veremos cómo los episodios de aprendizaje terminan cuando se obtiene el valor de recompensa 200, en este caso ocurre en el episodio 5 como podemos ver en el siguiente fotograma del vídeo:
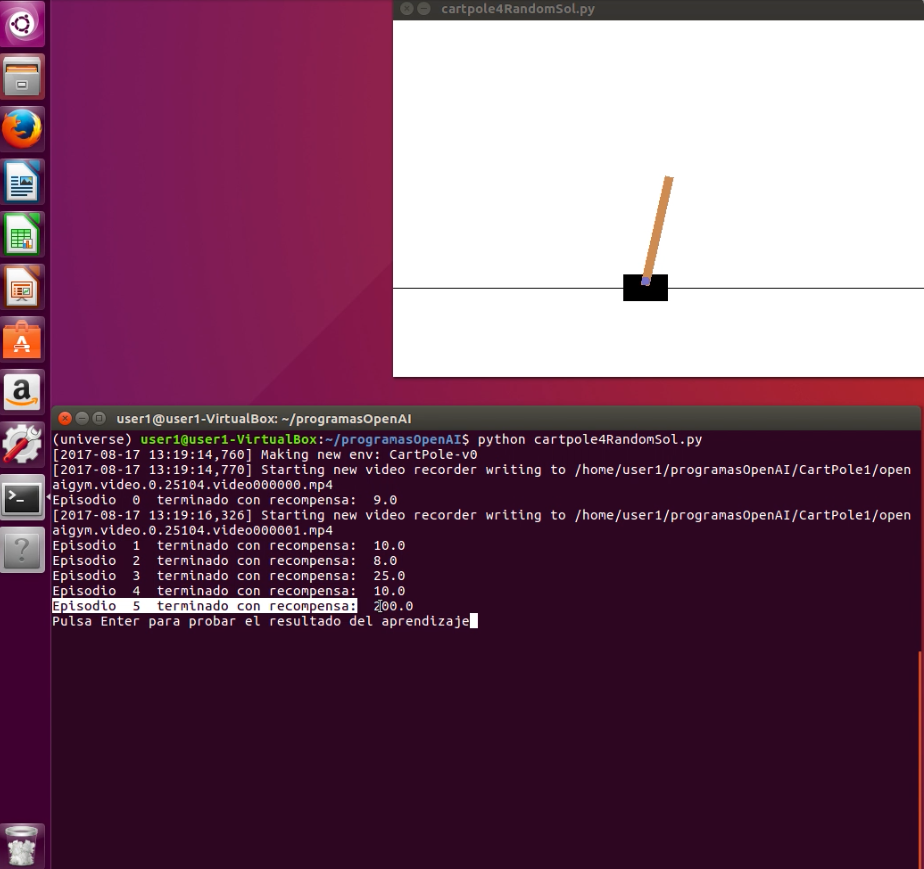
A partir de este punto se ejecutan varias simulaciones con los resultados obtenidos durante el entrenamiento:
Esta es una técnica muy sencilla y es perfecta para probar nuestra primera solución de aprendizaje y ver los resultados, pero además ofrece unos buenos resultados en este entorno del CartPole. De hecho, si ejecutamos varias veces el entrenamiento, veremos que la media de episodios para conseguir la recompensa de 200 y de esa forma finalizar el aprendizaje no son más 13 episodios. No os perdáis el siguiente artículo, vamos a empezar con técnicas y juegos más complejos.
No te olvides de consultar los otros posts que hemos publicado de esta serie:



