Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Cómo sobrevivir al FOMO en la era de la IA Generativa
El FOMO ('fear of missing out', 'temor a perderse algo') o la ansiedad que sientes con la IA Generativa no es solo cosa tuya: LinkedIn está diariamente inundado de nuevo contenido, cada semana se lanza el mejor LLM del mundo, todos los hiperescalares parecen ser la única opción sensata para lo que quieres hacer...
En este vuelo hipersónico de la IA Generativa (IAG), es difícil distinguir lo disruptivo de lo distractivo, pero no debemos olvidar que la tecnología no es más que una herramienta, y que el centro de esta revolución es lo que se puede hacer y lo que puede resolver, no con qué
El FOMO y la velocidad de la información
La IAG lleva menos de dos años entre nosotros, desde el lanzamiento de ChatGPT a finales de 2022. Lejos de haber tenido su pico de hype y empezar a decaer, el interés que suscita el tema es cada vez mayor, y parece lejos de tocar techo.
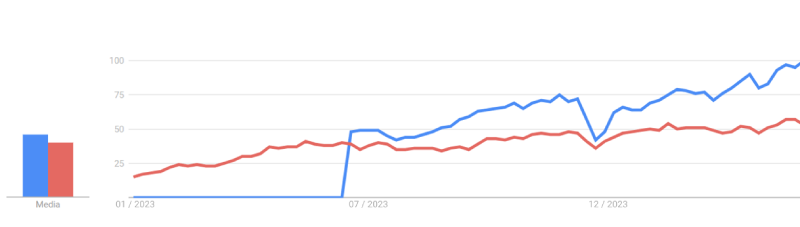 Figura 1: Interés desde el 1 de enero de 2023 de búsquedas en Google de “Inteligencia Artificial” (línea roja) y “ChatGPT” (línea azul). Fuente: Google Trends.
Figura 1: Interés desde el 1 de enero de 2023 de búsquedas en Google de “Inteligencia Artificial” (línea roja) y “ChatGPT” (línea azul). Fuente: Google Trends.
En lo que llevamos de 2024, es rara la semana en la que no hay un “bombazo” sobre la IAG, ya sea un nuevo modelo, una nueva función de una plataforma, movimientos de fusiones o adquisiciones, descubrimientos inesperados… por ejemplo, en HuggingFace, el principal repositorio público de IAG, tiene ya más de 700.000 modelos, y se añaden más de 40.000 cada mes.
Para cualquiera que trabaje en esto, resulta agotador estar al día. De hecho, es muy habitual sentir eso que se conoce como FOMO, un tipo de ansiedad social caracterizado por un deseo de estar continuamente conectado con lo que otros están haciendo.
Pero, para desarrollar casos de uso de IAG, ¿es realmente necesario estar hiperconectados, siempre pendientes de la última novedad de todos los actores de la IAG? ¿Acaso podemos quedarnos atrás? Y lo más importante, ¿podemos fracasar en nuestro caso de uso por no haber estado al loro del último grito?
La respuesta corta es NO. No debemos obsesionarnos con todas estas novedades, ya que, por muy deprisa que evolucione el campo (aún incipiente y en sus primeros estadios), el desarrollo de un caso de uso de IAG es complejo y requiere tiempo, por lo que es importante centrarse en otros aspectos. Es decir, debemos evitar que el bosque nos impida ver los árboles. Para ello, podemos proponer cuatro consejos.
Consejo 1: Algunos casos no son IAG, sino IA 'clásica'
Cuando surgió la ola del machine learning, muchas empresas y organizaciones querían desarrollar casos de uso de IA. El problema es que, pensando que se iban a quedar atrás, parecía más importante la función que la herramienta; estaban más preocupadas por poder decir que el caso de uso utilizaba IA que por el caso de uso en sí. Y esto hizo que muchas propuestas realmente no necesitaran IA, sino otras herramientas más establecidas. En muchas situaciones, un análisis estadístico y detallado de los datos, con un cuadro de mando para poder consumir los resultados, cubría perfectamente las necesidades y, en muchos casos, era el primer paso para madurar en la disciplina y afrontar un caso de uso de IA a partir del conocimiento obtenido.
Algo similar está pasando ahora: debemos entender que la IAG no sustituye a la IA clásica (no generativa), sino que la complementa, permite hacer cosas que con un modelo clásico no eran posibles. Y es más, existen casos de uso comunes a ambas posibilidades, como puede ser una clasificación de textos, en los que la IA clásica puede tener algunas ventajas aunque no ofrezca un rendimiento tan bueno. Dimensiones como la necesidad de explicabilidad, los recursos computacionales necesarios o las alucinaciones de los modelos de lenguaje (LLM) pueden influir a la hora de desarrollar un caso de uso con IA o IAG.
✅ Conclusión: No todo lo que reluce es oro.
Consejo 2: No hay que coger el modelo más grande y nuevo, sino el más adecuado
Como hemos comentado antes con el ejemplo del volumen de modelos que hay en HuggingFace, hoy en día hay modelos para todos los gustos. Pero aquí el tamaño importa, y generalmente cuanto más grande es un modelo (al ser redes neuronales, el número de parámetros de la red), mejor rendimiento genérico tiene.
Pero este rendimiento es genérico porque se evalúa contra tests conocidos de conocimiento general, como pueden ser preguntas de cultura general, temas especializados, razonamiento lógico… y todo esto está muy bien, pero cuando vamos a desarrollar un caso de uso concreto, necesitaremos adaptar el LLM a nuestros propios datos, donde desconocemos realmente cómo de bien funciona cada modelo.
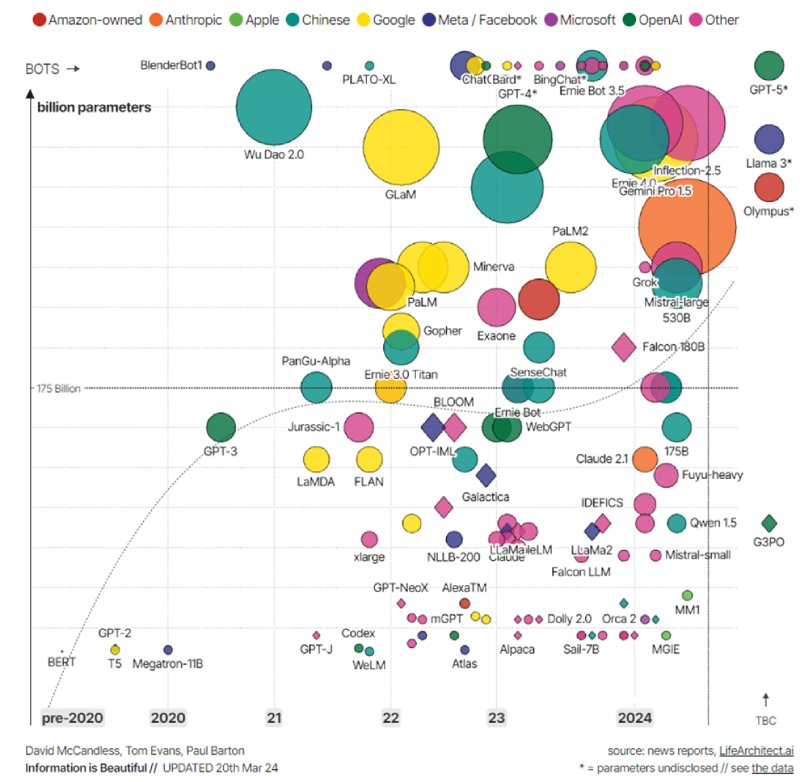 Figura 2: mapa de LLM por tamaño (número de parámetros), reflejando su desarrollador y año. Fuente: Information is Beautiful.
Figura 2: mapa de LLM por tamaño (número de parámetros), reflejando su desarrollador y año. Fuente: Information is Beautiful.
Y en este sentido, depende mucho (muchísimo) de lo que queramos hacer. Por ejemplo, los LLM más grandes son más imaginativos y creativos, pero eso los hace más propensos a alucinar. Además, como sugiere la lógica, cuantos más parámetros tenga el modelo, más recursos computacionales serán necesarios, tanto para el entrenamiento (o reentrenamiento) como para la inferencia.
De un tiempo a esta parte, se están intentando crear SLM (Small Language Models), es decir, modelos más pequeños. Esto permite un grandísimo abaratamiento en los costes de operación, y posibilita cosas tan interesantes como meterlos en dispositivos como smartphones. Para tareas sencillas, este tipo de modelos es muchísimo más adecuado que un enorme LLM.
Decía Alain Prost, 4 veces campeón del mundo de F1, que el objetivo era ganar una carrera a la menor velocidad posible. Adaptando su cita, aquí el objetivo es que el caso de uso funcione con el modelo más pequeño posible.
✅ Conclusión: Más vale maña que fuerza
Consejo 3: Lo importante es la metodología, no la tecnología
Hemos visto que no hace falta coger el modelo más grande y puntero para que nuestro caso de uso llegue a buen puerto. Pero aún así, con el vastísimo panorama de modelos que hay, ¿cuál debería coger? Y encima, si voy a desarrollar en cloud, ¿qué proveedor escojo? ¿Azure, Google, AWS, IBM…? De nuevo, no debemos obsesionarnos con ninguna de ambas preguntas.
Todos los hiperescalares ofrecen soluciones muy similares (y todos presumen de ser los únicos en ofrecerlas), y habrá aspectos no técnicos —financieros, legales, corporativos…— que determinen la mejor elección. En cuanto al modelo, ocurre un poco lo mismo: siempre que sale una nueva versión de GPT, Claude, Llama, Gemini, Mistral… presumen de ser el mejor modelo hasta ahora. Pero ya hemos visto que esa evaluación (incluso aunque nos la creamos) se hace sobre tests genéricos, y pueden no reflejar el rendimiento real para nuestro caso de uso. Así que el modelo concreto que usemos puede ser algo a explorar, pero nunca va a ser crítico.
Es mucho más importante centrarse en la metodología: entender bien qué necesidades tiene el caso de uso, qué herramientas podemos usar, qué requisitos de negocio y técnicos existen… y lo demás caerá por su propio peso. Si tenemos un caso de uso difuso, una anarquía del dato, falta de formación, una mala gestión de los recursos…, no importa el modelo o plataforma que usemos, no llegaremos a ningún sitio.
✅ Conclusión: El hábito no hace al monje
Consejo 4: Los modelos open source muchas veces son los más adecuados
Generalmente, los modelos de pago son mejores que los open source, pero una vez más, esta afirmación es un poco capciosa, ya que “mejor” es difícil de cuantificar. En un caso de uso real, hay que adaptar, integrar y desplegar una solución completa, lo cual puede cambiar el panorama. Cuando nos tocan el bolsillo la cosa se pone seria, y la estimación de costes operacionales puede dispararse con modelos de pago.
Por ejemplo, si tenemos una aplicación de IAG sirviendo a miles de usuarios, un modelo de pago cobrará por tokens de entrada y salida. En un modelo open source, solo necesitamos la infraestructura (on premise o cloud), pero no habrá costes asociados por inferencia.
Por último, los aspectos éticos, regulatorios y de privacidad son cada vez más importantes. Un modelo open source nos permite tanto el despliegue on premise como realizar fine tunings transparentes. Hiperescalares como Microsoft o IBM ofrecen modelos propios open source, aparte de sus modelos de pago.
La mitigación de posibles sesgos es mucho más fácil con modelos open source, ya que controlamos cada etapa de vida del algoritmo; de cara a auditorías y con la aplicación del Reglamento de Inteligencia Artificial (RIA), la transparencia y trazabilidad de los modelos es fundamental.
✅ Conclusión: Compartir es vivir
Mi participación en OpenExpo 2024
Como parte de la participación de Telefónica Tech en OpenExpo 2024 tuve ocasión de compartir mi experiencia y conocimiento sobre algunas de las tecnologías de IA que estamos desarrollando e implementando en Telefónica Tech, incluyendo la charla que recojo en este artículo que también puedes ver en este vídeo:
Imagen: vecstock / Freepik.