Cloud & Business Apps
Cloud & Business Apps Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Surviving FOMO in the age of Generative AI
The FOMO ('fear of missing out') or anxiety you are feeling with Generative AI...it's not just you: LinkedIn is daily flooded with new content, every week the best LLM in the world is launched, all hyperscalars seem to be the only sensible option for what you want to do...
In this hypersonic flight of Generative AI (GAI), it is difficult to distinguish the disruptive from the distracting, but we must not forget that technology is nothing but a tool, and that the focus of this revolution is what you can do and what you can solve, no what you use for it.
FOMO and speed of information
GAI has been around for less than two years, since the launch of ChatGPT at the end of 2022. Far from having had its hype peak and starting to wane, interest in the subject is growing, and seems far from reaching its peak.
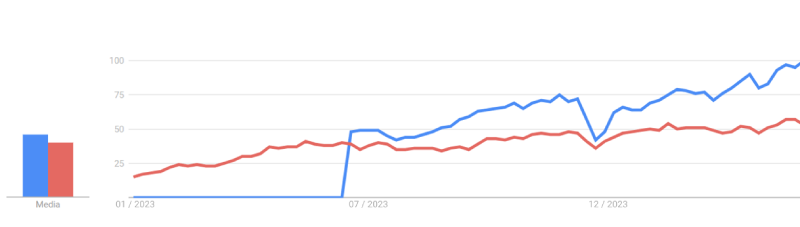 Figure 1: Interest from January 1, 2023 Google searches for “Artificial Intelligence” (red line) and “ChatGPT” (blue line). Source: Google Trends.
Figure 1: Interest from January 1, 2023 Google searches for “Artificial Intelligence” (red line) and “ChatGPT” (blue line). Source: Google Trends.
So far in 2024, there has not been a week without a “bombshell” about GAI, whether it's a new model, a new platform feature, merger or acquisition moves, unexpected discoveries... for example, HuggingFace, the main public repository for GAI, has now over 700,000 models, with more than 40,000 new ones being added every month.
It is exhausting for anyone working in this field to keep up with it. In fact, it's very common to feel what's known as FOMO, a type of social anxiety characterized by a desire to be continually connected to what others are doing.
However, in order to develop GAI use cases, is it really necessary to be hyperconnected, always on the lookout for the latest news from all GAI players? Can we be left behind? More importantly, can we fail in our use case by not keeping up with the latest trend?
The short answer is NO. We should not be obsessed with all these innovations, because no matter how fast the field evolves (still incipient and in its early stages), the development of an GAI use case is complex and time-consuming, so it is important to focus on other aspects. In other words, we must ensure we see the wood for the trees. To this end, we have four tips.
Tip 1: Some use cases are not GAI, but 'classic' AI
When the machine learning wave emerged, many companies and organizations wanted to develop AI use cases. The problem is that, thinking they were going to be left behind, it seemed more important the function than the tool; they were more concerned about being able to say that the use case used AI than the use case itself. And this led to many proposals not really needing AI, but other, more established tools. In many situations, a statistical and detailed analysis of the data, with a dashboard to be able to consume the results, covered the needs perfectly and, in many cases, was the first step to mature in the discipline and tackle an AI use case from the knowledge obtained.
Something similar is happening now: we must understand that GAI does not replace classical (non-generative) AI, but complements it, allowing us to do things that were not possible with a classical model. What's more, there are use cases common to both possibilities, such as a text classification, where classical AI may have some advantages even if it does not offer such a good performance. Dimensions such as the need for explainability, the computational resources required or the hallucinations of language models (LLM) can influence the development of a use case with AI or GAI..
✅ Bottom line: Not all that glitters is gold.
Tip 2: Do not take the biggest and newest model, but the most suitable one
As we have mentioned before with the example of the volume of models in HuggingFace, nowadays there are models for all tastes. But here size matters, and generally the larger a model is (being neural networks, the number of network parameters), the better generic performance it has.
But this performance is generic because it is evaluated against known tests of general knowledge, such as general culture questions, specialized topics, logical reasoning... and all this is fine, but when we are going to develop a specific use case, we will need to adapt the LLM to our own data, where we do not really know how well each model works.
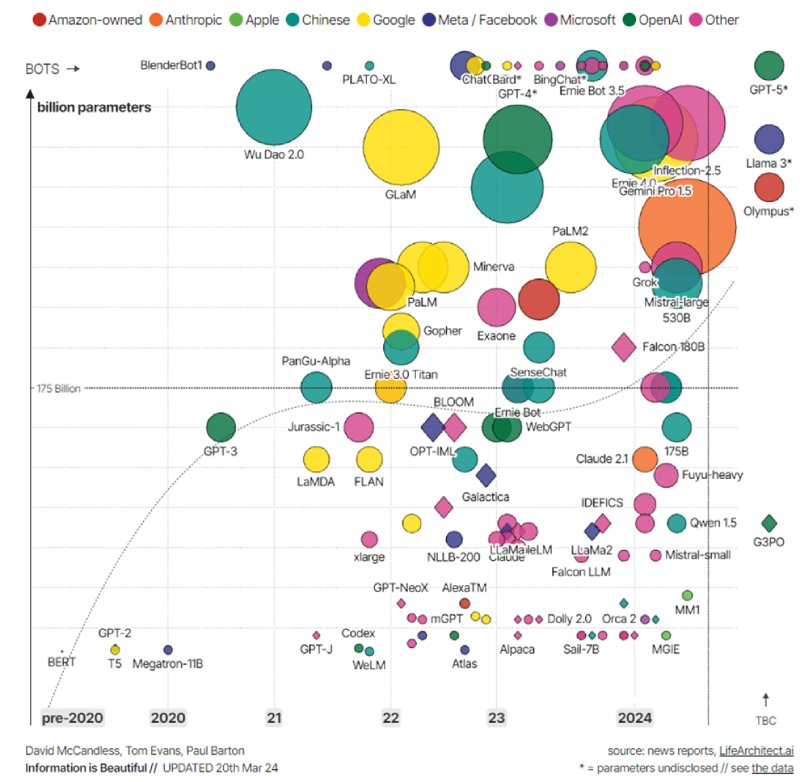 Figure 2: map of LLMs by size (number of parameters), reflecting their developer and year. Source: Information is Beautiful.
Figure 2: map of LLMs by size (number of parameters), reflecting their developer and year. Source: Information is Beautiful.
In this sense, it depends a lot (but a lot) on what we want to do. For example, larger LLMs are more imaginative and creative, but that makes them more prone to hallucinate. Also, as logic suggests, the more parameters the model has, the more computational resources are needed, both for training (or retraining) and for inference.
Attempts have recently been made to create SLMs (Small Language Models), i.e., smaller models. This allows a huge reduction in operating costs and makes possible such interesting things as putting them in devices such as smartphones. Such models are much more suitable for simple tasks than a huge LLM.
Alain Prost, 4 times F1 world champion, used to say that the goal was to win a race at the lowest possible speed. Adapting his quote, the goal here is to make the use case work with the smallest possible model.
✅ Bottom line: Brains over brawn
Tip 3: The important thing is the methodology, not the technology
We have seen that it is not necessary to take the biggest and leading model for our use case to come to fruition. But still, with the wide range of models out there, which one should I choose? And on top of that, if I am going to develop in the cloud, which provider should I choose: Azure, Google, AWS, IBM...? Again, we shouldn't be obsessed with none of these two questions.
All the hyperscalars offer very similar solutions (and they all claim to be the only ones to offer them), and there will be non-technical aspects —financial, legal, corporate...— that will determine the best choice. As for the model, it's a bit the same thing: whenever a new version of GPT comes out, Claude, Llama, Gemini, Mistral... all claim to be the best model so far. However, we have already seen that this evaluation (even if we believe it) is done on generic tests and may not reflect the real performance for our use case. So, the particular model we use may be something to explore, but it is never going to be critical.
It is much more important to focus on the methodology. Understand what the needs of the use case are, what tools we can use, what business and technical requirements exist... and the rest will fall under its own weight. If we have a fuzzy use case, data anarchy, lack of training, poor resource management..., no matter what model or platform we use, we will not get anywhere.
✅ Bottom line: Don’t judge a book by its cover
Tip 4: Open-source models are often the best fit
Paid models are generally better than open source, but again, this statement is a bit of a stretch, as “better” is hard to quantify. In a real use case, a complete solution has to be adapted, integrated and deployed, which can be a game changer. When it comes to our pockets, things get serious, and operational cost estimation can skyrocket with payment models.
If we have a GAI application serving thousands of users, for example, a paid model will charge for inbound and outbound tokens. In an open-source model, we only need the infrastructure (on premise or cloud), but there will be no associated inference costs.
Ethical, regulatory, and privacy issues are becoming more and more important. An open-source model allows both on premise deployment and transparent fine tuning. Hyperscalars such as Microsoft or IBM offer their own open-source models, in addition to their paid models.
The mitigation of possible biases is much easier with open source models, since we control each stage of the algorithm's life; for audits and with the application of the Artificial Intelligence Regulation (EU AI Act), the transparency and traceability of the models is essential.
✅ Bottom line: Sharing is caring

Imagen: vecstock / Freepik.