 Cloud & Business Apps
Cloud & Business Apps Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities
Javier Coronado Blazquez
Doctor en Física Teórica por la Universidad Autónoma de Madrid especializado en Data Science y Machine Learning. Pasé de investigar materia oscura y rayos gamma a ser un adicto a los datos y su visualización. Actualmente, soy parte del equipo de AI & Analytics de Telefónica Tech, trabajando como Data Scientist y formador en transformación digital de empresas.

Quantum Machine Learning: the next revolution in AI?
AI and Machine Learning were, for decades, the ‘ugly ducklings’ of computer science due to hardware limitations, which kept methods like neural networks confined to academic books and theoretical papers. There was no real guarantee they would actually work, yet today neural networks run the world, even if we still don’t fully understand them. Applications like classifiers, recommendation systems, computer vision, or LLMs (ChatGPT and its peers) are now part of our daily lives. There are quite a few parallels with quantum computing, the eternal promise that is gradually approaching a practical horizon; uncertain, yes, but already attracting billions in investment. So let’s combine the two most hyped fields today: AI and quantum computing. What could possibly go wrong? The playing field: classical vs quantum First, a quick disclaimer: we’ll focus on Quantum Machine Learning (QML), which assumes at least a basic understanding of quantum computing. To get up to speed (and see Telefónica Tech’s role in this space), check out our previous blog posts series. If we’re talking about AI and Machine Learning, we first need to define what we’re cooking (the data) and what oven we’re using (the processing). This gives rise to four core paradigms: CC (Classical data, classical processing): traditional ML. Logistic regression, facial recognition networks, or ChatGPT. QC (Quantum data, classical processing): classical ML used to analyze quantum states from experiments or detectors, applied mainly in basic science. CQ (Classical data, quantum processing): The current Holy Grail: using classical data (images, text, etc.) on a quantum computer to harness its vastly superior computational power. QQ (Quantum data, quantum processing): The pure vision—Feynman’s dream. A quantum computer learning from quantum nature (e.g., molecular simulation). Right now, more science fiction than Star Wars. Classical/Quantum ML matrix. If we’re talking about AI and machine learning, we need to define what we’re cooking and in what oven. Let’s focus on that ‘holy grail’: using a quantum computer to make machine learning faster and more accurate. Training complex neural networks is essentially an optimization problem: we’re trying to find the lowest point on a mountain range we’ve never seen before (the loss function). Which direction do we move in? How fast? How do we know the minimum we’ve found is the lowest possible? Should the landscape around us influence our next move? Training a large neural network is a very hard problem, so any extra computing power is welcome (hence the Nvidia GPU craze and megadata centers). In today’s quantum computing (known as NISQ, or Noisy Intermediate-Scale Quantum), we don’t have perfect machines. Due to the delicate nature of quantum chips, they produce many errors that are hard to correct. That’s why the dominant approach is the use of Variational Quantum Circuits (VQC). The challenge of encoding classical data into quantum systems It works as a hybrid system, where the (classical) CPU tells the (quantum) QPU: "Try rotating your qubits with these parameters" (something you can't do with traditional bits). The QPU runs the circuit and measures the outcome. The CPU checks the result and says: "Slight improvement, now tweak the parameters like this instead". And so on, iteratively, until the best possible outcome is reached. A quantum computer doesn’t understand JPEGs or Excel files. It’s essentially the same kind of optimization problem as before. The theoretical advantage lies in the fact that the ‘mountain map’ in Hilbert space (the mathematical space qubits live in) is vastly richer and more dimensional than classical space. This, in theory, allows shortcuts to the global minimum that a classical computer would never see. So, is it that simple? If someone handed us a quantum computer, would it be plug-and-play? Unfortunately, no. A quantum computer doesn’t understand JPEGs or Excel. Its language is based on wave amplitudes and spin states. Encoding is the process of translating classical data (your usual x values) into a quantum state. But if you have a dataset with one million entries, and it takes a million steps just to load them into the quantum computer, you’ve already lost your exponential advantage before even starting. It’s like having a Ferrari, but having to push it by hand to the highway. ■ There are encoding techniques like amplitude, basis, or phase encoding, but preparing these states in real-world problems is extremely expensive and requires very deep circuits that, as of today, generate too much noise. Without a working QRAM (quantum RAM), which doesn't physically exist yet, this remains the first bottleneck, but certainly not the last. In search of the missing algorithm The legendary Shor’s algorithm from 1995 mathematically proved that a quantum computer can factor numbers exponentially faster than any known classical algorithm, breaking RSA encryption (based on factoring huge numbers), which secures most of our digital information. While today's best supercomputers would need billions of years to crack it, a practical quantum computer with thousands of qubits could do it in a matter of hours. Machine Learning hasn’t had its 'Shor moment' yet. There’s no definitive proof that a QML algorithm offers a generalizable exponential advantage for classical data problems. There are algorithms like HHL to solve linear equation systems (a foundation of many ML techniques). It’s exponentially fast, but comes with so many input/output constraints that it’s nearly unusable in practice. Machine Learning hasn’t had its 'Shor moment' yet. Hope lies not in brute force, but in the quantum kernel trick (the quantum version of a classical ML technique used in Support Vector Machines). Quantum computers can naturally compute distances between data in infinitely dimensional spaces. If we can show that certain patterns are only separable in that space, we will have achieved real-world advantage. Technical and theoretical challenges in Quantum Machine Learning Today, we’re still in the ‘scientific playground’ phase. Maybe one day we’ll train an LLM far more efficiently with fewer parameters using quantum computing. For now, so-called quantum-inspired algorithms have already shown that techniques from quantum mechanics and complex systems like tensor networks can compress neural network models, from CNNs to LLMs, proving that quantum and AI are destined to converge. Quantum Neural Networks (QNNs) exist and run on simulators and small chips. But they face a problem known as the barren plateau. A similar issue once plagued classical ML under the name vanishing gradient. Think back to our mountain map: imagine you’re in a shallow valley. The slope is gentle and the terrain bumpy, you struggle to tell which direction leads down, but with patience and precise steps, you’ll find the bottom. Solutions like new activation functions, residual connections, or forget gates in LSTMs helped address that. Quantum Machine Learning is still in the ‘scientific playground’ phase. But quantum barren plateaus are far worse. It’s like being dropped in the middle of the Sahara and told there’s a hole one meter wide and 10 km deep somewhere nearby (the optimal solution). The terrain is flat, and no matter how much you feel around with your foot or look around, you have no idea whether the hole is 1 km or 1,000 km away. The algorithm gets lost in the vastness of Hilbert space and stops learning. So, if current quantum hardware (NISQ) is noisy and limited, and classical computers are robust but blind to certain correlations, why choose just one? Quantum Boosting: combining classical and quantum to enhance learning One of the most promising and pragmatic paths is using ensemble techniques. In classical ML, we know that combining several ‘weak’ models (as in Random Forests) reduces variance and improves generalization. The idea is to create a heterogeneous ‘committee of experts’, and this has benefits. For example, error orthogonality: ensemble theory says that combining models works better when their errors are uncorrelated. Say you train a powerful classical model that achieves, say, 85% accuracy. You then take the remaining 15% of misclassified cases (the residuals). Now you train a small quantum model specifically to tackle those residuals. Because this quantum model focuses on a data subset with 'hard' structures, its usefulness is maximized without having to load the entire dataset into the QPU. This is known as Quantum Boosting, using the quantum kernel only where its dimensional advantage truly matters. Combining models works better when their errors are uncorrelated. Conclusion: optimism or realism? Quantum Machine Learning isn’t just ‘faster ML’, but a paradigm shift. We might never use quantum computers to classify cat photos or predict ad clicks (classical ML already excels at that), but if we’re still figuring out what LLMs are capable of, any forecast about quantum computing’s future is bold, to say the least. Where QML will certainly prove valuable is in the QQ quadrant: discovering new materials, developing drugs, or unlocking fundamental physics, problems that are inherently quantum. That’s where QML plays at home. As Richard Feynman said at the end of his famous 1981 lecture: “Nature isn’t classical, dammit. And if you want to make a simulation of nature, you’d better make it quantum.” For everything else, we’re still searching for that elusive algorithm that proves encoding our classical world into atoms is worth the effort. Quantum Machine Learning isn’t just ‘faster ML’, it’s a paradigm shift. References: What is Quantum Machine Learning (QML)? | by Be Tech! with Santander | Medium Overview | IBM Quantum Learning Understanding quantum computing’s most troubling problem—the barren plateau Telefónica Tech AI & Data Surviving FOMO in the age of Generative AI June 25, 2024
December 10, 2025

Creative AI in business: how to adapt ChatGPT (and similar) to my customer's needs
Generative Artificial Intelligence (GenAI) has gone from being of purely academic interest in the last year to making the front pages of world news, thanks to the democratization of tools like ChatGPT or Stable Diffusion, capable of reaching the general public with free use and a very simple interface. However, from a business point of view, is this wave of attention pure hype, or are we in the early stages of a major revolution? Is GenAI capable of generating new and innovative use cases? The LLM (Large Language Models) era The GenAI is a branch of AI focused on creating new content. We can consider IAG as a new stage of AI: with traditional statistics you can only have descriptive and diagnostic analysis. We can move on to predictive and prescriptive analytics with AI (especially with machine learning techniques), which is able to foresee patterns or situations and offer recommendations or alternatives to deal with them. By using GenAI, we have creative analytics, capable not only of studying existing data but also of generating new information. Although GenAI is applied to all forms of human creativity (text, audio, image, video...), possibly its best-known aspect are the so-called Large Language Models (LLM), especially OpenAI's ChatGPT, which has the honor of being the fastest growing App in history. Rather than using machines' language, we can speak our own natural language with them. 'Traditional' AI (in this field anything more than 5 years old is already traditional) undoubtedly meant a change of mentality for companies, equivalent to the democratization of computing in the 80s and the internet in the 90s. This digital transformation makes it possible to optimize processes to make them more efficient and secure, and to make data-driven decisions, to mention two of the main applications. Do we have equivalent use cases with GenAI? Some of them, proposed in these early stages of GenAI, include: Internal searches for documentation: having large volumes of unstructured information (text), specific information on concepts, strategies or doubts can be consulted in natural language. Until now, we did not have much more than Ctrl+F to search for exact correspondences, which is not very efficient, very error-prone, and only provides fragmentary information. Chatbots: with the precision and versatility achieved by the latest LLMs, chatbots are able to respond much more fully to user questions. This allows the vast majority of problems that customers may have to be solved with great agility, requiring human intervention only in the most complex ones. It is even possible to perform feelings analysis on past responses, to understand which strategies and solutions have been the most satisfactory. Synthetic data generation: from a private dataset, we can swell its volume to provide a larger sample. This is especially useful when obtaining real data requires a lot of time or resources. With IAG, it is not necessary to have advanced knowledge of statistical techniques to do this. Proposal writing: using existing documents, we can generate new value proposals aligned with the company's strategy, according to the type of client, team, type of use case, deadlines, etc. Executive summaries: also from documents, or voice transcriptions (another use of GAI), we can summarize long and complex texts, often of a technical or legal nature, even adapting the style of the summary to our needs. Thus, if we do not have time to attend an important committee, to read 120 pages of a proposal or to understand a new European legislation, the GAI can summarize the most relevant points in a clear and concise way. Personalized marketing: 'Traditional' AI enables customer profiling and segmentation, which facilitates the design of personalized campaigns. Using GAI, marketing can be created on an individual level, so that no two interactions with each customer are the same, and always in line with the company's existing values and campaign style. This opens the door to creating content on a scale that would be impossible to create manually, as with automatically generated YouTube captions. Retraining or adapting... or both It all sounds great, but how can we have an LLM for our company? The most obvious option is brute force: we train one of our own. Unfortunately, it is no coincidence that the best LLMs come from the so-called hyperscalers: OpenAI, Google, Meta, Amazon... training one of these models requires an exorbitant amount of data, time, and resources. ◾ As an example, the training of GPT-4 cost about 100 million dollars, a figure within the reach of very few pockets. On the other hand, as ChatGPT-3 reminds us every time we ask it about something current, its training was done with data up to September 2021, so it does not know anything later. However, its successor GPT-4 did incorporate conversations with GPT-3 as part of the training. This meant that, if a user in one company had revealed secrets to it in the chat of the previous version, another user in GPT-4 could access that information simply by asking for it. As a result of these incidents, many companies have banned its use to prevent leaks of confidential data. Therefore, if we cannot train our own model natively, we have to adopt other strategies to make the LLM work with our data and company casuistry. There are two strategies, fine tuning, and retrieval-augmented generation (RAG). There is no one better than the other, but it depends on many factors. Fine tuning: as its name suggests, the idea is to refine the model, but keeping its base. That is, take an existing LLM like ChatGPT, and train it by incorporating all the data from my company. Whilst it can be somewhat costly, we are talking about orders of magnitude less than the millions of dollars involved in doing it natively, as it is a small training set compared to all the information that the base model has gobbled up. RAG: In this case, all we do is create a database of information relevant to the customer, so that they can ask the LLM questions about it. When faced with a query, the LLM will search through all these documents for pieces of information that seem relevant to what has been asked, will make a ranking of the most similar ones, and will generate an answer from them. Its main advantage is that it will not only tell us the answer, but it can also indicate which documents and which parts are used to create it, so that the information can be traced and verified. Which of the two is more suitable for my use case or customer? As we have said, it depends. We must take into account the volume of data available, for example. If our customer is a small company and is only going to have a few hundred or a few thousand documents, it is difficult to do a satisfactory fine tuning (we will probably have overfitting), and the RAG approach will be much more appropriate. Privacy is also fundamental If we need to restrict the information that employees at different levels or departments can access, we will have to make a RAG, in which different documents are available depending on the type of access. The fine-tuning approach is not suitable, as there would be a potential data leakage similar to the one discussed in GPT. How versatile and interpretable should our model be? This point is crucial, because choosing the wrong strategy depending on the use case can ruin it. If we want our LLM to summarize a document for us, for instance, or to make a mix of several documents to explain something to us, we want it to be literal and traceable. LLMs are very prone to hallucinate, especially when we ask them something they don't know. Thus, if we use a fine tuning strategy and ask them to explain something that is not in any document, they may pull a fast one and start making things up. However, if we have a chatbot for customer service, we need it to be very flexible and versatile, because it must deal with many different casuistries. In this case, fine tuning would be much more suitable than RAG. The refresh rate of our data is also important If we are mainly interested in taking into account past data, knowing that the rate of new data will be very low, it may be interesting to adopt a fine tuning, but if we want to incorporate information with a high frequency (hours, days), it is much better to go for a RAG. The problem is that fine tuning "freezes" the incoming data, so that every time we would like to incorporate new information we would have to re-train it, being very inefficient (and expensive). A compromise between the two approaches There is a compromise between the two approaches, consisting of fine tuning to incorporate a large corpus of past information from the company or customer, and using a RAG on top of this more versatile and adapted model, to consider recent data. ◾ Following the chatbot example, this would allow us to have a virtual assistant capable of dealing with a range of situations based on the history of resolved incidents, and at the same time have updated information on the status of open incidents. Once we have all these factors in mind, we can choose one of the strategies, or combine them, in order to create a customized ChatGPT for different customers, thus generating an attractive value proposition with different use cases. References: https://www.linkedin.com/pulse/rag-vs-finetuning-your-best-approach-boost-llm-application-saha/ https://rito.hashnode.dev/fine-tuning-vs-rag-retrieval-augmented-generation https://neo4j.com/developer-blog/fine-tuning-retrieval-augmented-generation/ https://towardsdatascience.com/rag-vs-finetuning-which-is-the-best-tool-to-boost-your-llm-application-94654b1eaba7 Cyber Security AI of Things Generative AI as part of business strategy and leadership September 20, 2023
August 14, 2024

Surviving FOMO in the age of Generative AI
The FOMO ('fear of missing out') or anxiety you are feeling with Generative AI...it's not just you: LinkedIn is daily flooded with new content, every week the best LLM in the world is launched, all hyperscalars seem to be the only sensible option for what you want to do... In this hypersonic flight of Generative AI (GAI), it is difficult to distinguish the disruptive from the distracting, but we must not forget that technology is nothing but a tool, and that the focus of this revolution is what you can do and what you can solve, no what you use for it. FOMO and speed of information GAI has been around for less than two years, since the launch of ChatGPT at the end of 2022. Far from having had its hype peak and starting to wane, interest in the subject is growing, and seems far from reaching its peak. Figure 1: Interest from January 1, 2023 Google searches for “Artificial Intelligence” (red line) and “ChatGPT” (blue line). Source: Google Trends. So far in 2024, there has not been a week without a “bombshell” about GAI, whether it's a new model, a new platform feature, merger or acquisition moves, unexpected discoveries... for example, HuggingFace, the main public repository for GAI, has now over 700,000 models, with more than 40,000 new ones being added every month. It is exhausting for anyone working in this field to keep up with it. In fact, it's very common to feel what's known as FOMO, a type of social anxiety characterized by a desire to be continually connected to what others are doing. However, in order to develop GAI use cases, is it really necessary to be hyperconnected, always on the lookout for the latest news from all GAI players? Can we be left behind? More importantly, can we fail in our use case by not keeping up with the latest trend? The short answer is NO. We should not be obsessed with all these innovations, because no matter how fast the field evolves (still incipient and in its early stages), the development of an GAI use case is complex and time-consuming, so it is important to focus on other aspects. In other words, we must ensure we see the wood for the trees. To this end, we have four tips. Tip 1: Some use cases are not GAI, but 'classic' AI When the machine learning wave emerged, many companies and organizations wanted to develop AI use cases. The problem is that, thinking they were going to be left behind, it seemed more important the function than the tool; they were more concerned about being able to say that the use case used AI than the use case itself. And this led to many proposals not really needing AI, but other, more established tools. In many situations, a statistical and detailed analysis of the data, with a dashboard to be able to consume the results, covered the needs perfectly and, in many cases, was the first step to mature in the discipline and tackle an AI use case from the knowledge obtained. Something similar is happening now: we must understand that GAI does not replace classical (non-generative) AI, but complements it, allowing us to do things that were not possible with a classical model. What's more, there are use cases common to both possibilities, such as a text classification, where classical AI may have some advantages even if it does not offer such a good performance. Dimensions such as the need for explainability, the computational resources required or the hallucinations of language models (LLM) can influence the development of a use case with AI or GAI.. ✅ Bottom line: Not all that glitters is gold. Tip 2: Do not take the biggest and newest model, but the most suitable one As we have mentioned before with the example of the volume of models in HuggingFace, nowadays there are models for all tastes. But here size matters, and generally the larger a model is (being neural networks, the number of network parameters), the better generic performance it has. But this performance is generic because it is evaluated against known tests of general knowledge, such as general culture questions, specialized topics, logical reasoning... and all this is fine, but when we are going to develop a specific use case, we will need to adapt the LLM to our own data, where we do not really know how well each model works. Figure 2: map of LLMs by size (number of parameters), reflecting their developer and year. Source: Information is Beautiful. In this sense, it depends a lot (but a lot) on what we want to do. For example, larger LLMs are more imaginative and creative, but that makes them more prone to hallucinate. Also, as logic suggests, the more parameters the model has, the more computational resources are needed, both for training (or retraining) and for inference. Attempts have recently been made to create SLMs (Small Language Models), i.e., smaller models. This allows a huge reduction in operating costs and makes possible such interesting things as putting them in devices such as smartphones. Such models are much more suitable for simple tasks than a huge LLM. Alain Prost, 4 times F1 world champion, used to say that the goal was to win a race at the lowest possible speed. Adapting his quote, the goal here is to make the use case work with the smallest possible model. ✅ Bottom line: Brains over brawn Tip 3: The important thing is the methodology, not the technology We have seen that it is not necessary to take the biggest and leading model for our use case to come to fruition. But still, with the wide range of models out there, which one should I choose? And on top of that, if I am going to develop in the cloud, which provider should I choose: Azure, Google, AWS, IBM...? Again, we shouldn't be obsessed with none of these two questions. All the hyperscalars offer very similar solutions (and they all claim to be the only ones to offer them), and there will be non-technical aspects —financial, legal, corporate...— that will determine the best choice. As for the model, it's a bit the same thing: whenever a new version of GPT comes out, Claude, Llama, Gemini, Mistral... all claim to be the best model so far. However, we have already seen that this evaluation (even if we believe it) is done on generic tests and may not reflect the real performance for our use case. So, the particular model we use may be something to explore, but it is never going to be critical. It is much more important to focus on the methodology. Understand what the needs of the use case are, what tools we can use, what business and technical requirements exist... and the rest will fall under its own weight. If we have a fuzzy use case, data anarchy, lack of training, poor resource management..., no matter what model or platform we use, we will not get anywhere. ✅ Bottom line: Don’t judge a book by its cover Tip 4: Open-source models are often the best fit Paid models are generally better than open source, but again, this statement is a bit of a stretch, as “better” is hard to quantify. In a real use case, a complete solution has to be adapted, integrated and deployed, which can be a game changer. When it comes to our pockets, things get serious, and operational cost estimation can skyrocket with payment models. If we have a GAI application serving thousands of users, for example, a paid model will charge for inbound and outbound tokens. In an open-source model, we only need the infrastructure (on premise or cloud), but there will be no associated inference costs. Ethical, regulatory, and privacy issues are becoming more and more important. An open-source model allows both on premise deployment and transparent fine tuning. Hyperscalars such as Microsoft or IBM offer their own open-source models, in addition to their paid models. The mitigation of possible biases is much easier with open source models, since we control each stage of the algorithm's life; for audits and with the application of the Artificial Intelligence Regulation (EU AI Act), the transparency and traceability of the models is essential. ✅ Bottom line: Sharing is caring Cloud AI of Things Copilot Microsoft 365 and how it can help you in your work? June 3, 2024 Imagen: vecstock / Freepik.
June 25, 2024

Behind-the-scenes algorithms: Hollywood and the AI technology revolution
The audiovisual landscape, like so many other sectors, is transforming the industry at a dizzying speed thanks to the growing influence of Artificial Intelligence (AI). The convergence of advanced algorithms and digital film production has led to a revolution, challenging the traditional conventions of the entertainment industry. This change is not free of tensions, as evidenced by the recent actors' and screenwriters' strike that has shaken Hollywood, marking a turning point in the relationship between human creativity and automation. In this context, regulation presents itself as an inescapable necessity, a crucial measure to balance the limitless possibilities of AI with the core values of cinematic storytelling and the creative workforce. Let's delve into the intricacies of this revolution that is already a reality. Lights, camera...and strike! Hollywood and the digital transformation In 2007 the Western film (and series) hub was thrown into chaos when the WGA (Writers Guild of America, the American screenwriters' union) called a historic strike. The dispute centered on an emerging scenario: the digital consumption of content. The irruption of online platforms and streaming services (many of them new digital players on an analog board), which promised a new paradigm, sparked a crucial conflict over fair compensation for screenwriters in this new terrain. Hollywood titans found themselves caught between the pages of scripts and code lines, as screenwriters sought to adapt their contracts to the rapidly evolving digital age. This 100-day strike not only brought production to a standstill, but also exposed the cracks in the traditional business model in the face of digital transformations that would shape the future of the entertainment industry. In 2023 we experience deja vù: the breakdown of negotiations between the actors' union, SAG-AFTRA, and the Alliance of Motion Picture and Television Producers (AMPTP) triggers a new strike, the first of its kind since 1980. Tensions escalate with the simultaneous strike of screenwriters beginning in May. SAG-AFTRA president Fran Drescher accuses the AMPTP of acting in an "insulting and disrespectful" way and highlights four key factors in the strike: economic justice, regulation of the use of Artificial Intelligence, adaptation to self-recording, and residuals (additional payments received for continued use of a work after its initial release, which were a key point in the 2007 strike, to recognize that their product generates value long after its initial release). Using "digital doubles" without explicit consent is one of the main points of tension regarding AI. There were several points of tension regarding AI. One of the main ones was the use of "digital doubles," in most cases without explicit consent. Extras and extras reported that on many occasions they had been scanned as part of their contract, without specifying what for, finding that they were not rehired because they had a digital model to use for free. SAG-AFTRA demanded regulation of this technology, fairly compensating those people from whom a digital double is generated. Similarly, the WGA called for limiting the use of Large Language Models (LLMs) such as ChatGPT to dispense with real scriptwriters. It all sounds like science fiction, but it is already the daily life of tens of thousands of professionals in the audiovisual sector, who see their jobs endangered by the unregulated and improper use of AI. There is no doubt that this is only the beginning of a long road to understanding and a new production model that enables digital transformation in a humane, sustainable, and ethical way. Here are some recent examples of the use of AI in cinema and television. We’re living in the future AI has always been part of the cinematic imagination, and science fiction features hundreds of movies with this theme, from Metropolis or Blade Runner to Terminator and War Games. In recent years, movies have been becoming more realistic, as what seemed pure fantasy begins to be perceived as a reality that already exists or is very close to being so. Just look at how two of the most critically acclaimed movies in 2023, The Creator and Mission: Impossible. Dead Reckoning, have AI as a central theme (in fact, Joe Biden acknowledged that the latter motivated him to pass the new U.S. regulations on AI. Black Mirror posed a great dilemma that seemed to predict what happened later with the strike. In the small screen world, the very dark Black Mirror posed a great dilemma that seemed to predict (once again) what happened later with the strike. Spoiler alert! In its first episode of the sixth season, Joan is awful, a streaming platform -suspiciously similar to Netflix- generates with AI a series in almost real time narrating the day of a user but starring a digital double of actress Salma Hayek. Seeing her privacy exposed in this way, the only way to get the platform's attention is for the user to do extremely ridiculous and humiliating things, so that Salma Hayek herself complains about appearing on screen performing these actions with which she does not agree and for which she is not getting paid. Considering the previous section, does it sound familiar? But we don't need to talk about AI movies or series, because AI already creates them (partially, although it's a matter of time before it can do it completely), generally with some controversy. Disney has clearly taken the lead in this field, as early as 2020 with The Mandalorian and the rejuvenation of Mark Hamill through deepfake. Most recently, Marvel's Loki series has AI-generated promotional art, and Secret Invasion, also from Marvel, employs AI in its credits, with a somewhat questionable result (although defended by the showrunners). Lastly, the Disney+ film Prom Pact [Link: https://nypost.com/2023/10/15/disneys-prom-pact-has-audiences-cringing-at-ai-actors/] used AI-generated extras in one scene, with a more than objectionable finish in this case. These digital doubles were also mostly non-white ethnicities, thus eliminating job opportunities for African American or Asian people, further deepening the complex ethical aspect of unregulated AI. A less controversial application of AI in cinema is the possibility of being able to restore and even rescue virtually lost films, in particular, celluloids before 1930. While traditional techniques are insufficient, AI proves capable of going further and being able to share with the public a cinema that could not otherwise exist. For example, the mega-documentary Get Back (also from Disney+) restored footage in very poor condition, especially in terms of sound quality, using AI. In this way, it was possible to isolate each instrument separately, reaching an excellent audio standard. In the same way, these techniques have been used so that in 2023 we will experience the release of a new song by The Beatles, Now and Then, by being able to repair John Lennon's voice from a 1977 home recording, and make it sound as if it had been recorded in the studio. An inevitable revolution, an inexcusable regulation The SAG-AFTRA strike eventually came to an end with the ratification of a new agreement in December 2023. Within this, there are 5 whole pages dedicated solely to the role of AI, stipulating ethical and legal boundaries, and requiring both explicit consent and fair remuneration for people affected by the application of these tools. It is clear that AI is here to stay. If we look in the rear-view mirror, we realize that, although it may seem like ChatGPT has been with us all our lives, it was launched in November 2022. We are still in the early stages of what promises to be a new technological revolution that will completely transform the audiovisual sector. In this fascinating cross between art and algorithms, we remember the words of Arthur C. Clarke: "Any sufficiently advanced technology is indistinguishable from magic". And there is a reason why there is always talk of "the magic of cinema". Innovation will always be ahead of our inertia as human beings, so it is normal for there to be tensions at the beginning of any paradigm shift. It is only necessary to remember that the 1982 classic Tron, a pioneer in the use of CGI (Computer Generated Images), could not be nominated for an Oscar for Best Visual Effects because the Film Academy considered that “using a computer is cheating”. In a year in which we have had these historic strikes in the audiovisual sector with a great focus on the impact of AI, we have been able to witness the first commercial applications of this technology, not exempt from ethical considerations and legal problems. In this sense, a clear AI regulation positioned in favor of human workers is completely necessary, to adapt to this new paradigm just as we adapted more than 15 years ago to the arrival of streaming platforms and 100% digital content. The revolution, soon in the best cinemas. Referencias: SAG-AFTRA’s new contract hinges on studios acting responsibly with AI - The Verge Marvel’s “Secret Invasion” AI Art Sparks Controversy in Opening Credits | by Jim the AI Whisperer | The Generator | Medium AI movie restoration - Scarlett O’Hara HD - deepsense.ai Actors Approve SAG-AFTRA Deal That Ended 118-Day Strike (people.com) * * * AI of Things AI in Science Fiction Films: A Recurring Pattern of Fascination and Horror May 12, 2022
January 29, 2024
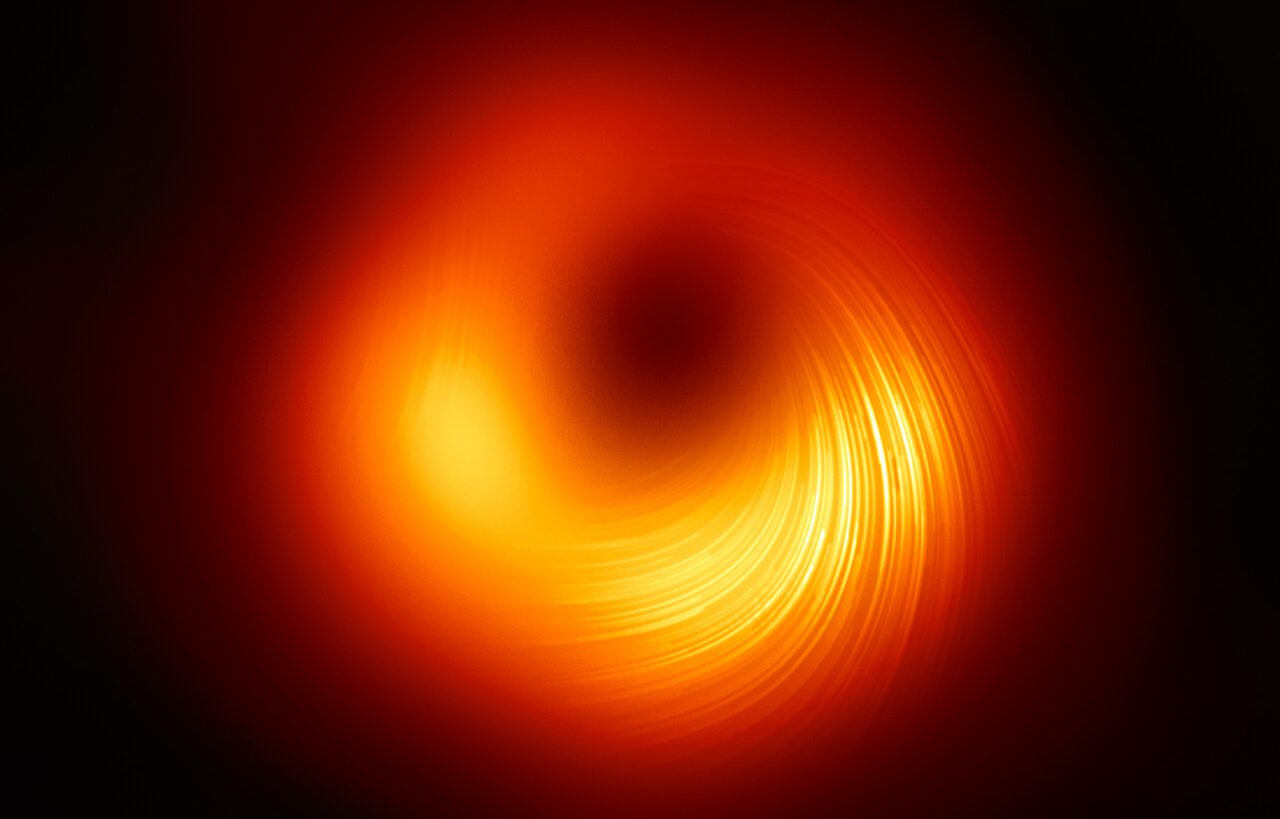
Big Data in basic research: from elementary particles to black holes
Big Data paradigm has profoundly penetrated all the layers of our society, changing the way in which we interact with each other and technological projects are carried out. Basic research, specifically in the field of physics, has not been immune to this change in the last two decades and has been able to adapt to incorporate this new model to the exploitation of data from leading experiments. We will talk here about the impact of Big Data on three of the major milestones in modern physics. (1) Large Hadron Collider: the precursor of Big Data One of the buzzwords of 2012 was the "Higgs boson", that mysterious particle that we were told was responsible for the mass of all other known particles (more or less) and that had been discovered that same year. But in terms of media hype, the focus was on the instrument that enabled the discovery, the Large Hadron Collider, or LHC, at the European Organization for Nuclear Research (CERN). The LHC is a particle accelerator and is probably the most complex machine ever built by humans, costing some €7.5 billion. A 27 km long ring buried at an average depth of 100 metres under the border between Switzerland and France, it uses superconducting electromagnets to accelerate protons to 99.9999991% of the speed of light (i.e., in one second they go around the ring more than 11,000 times). By colliding protons at these delirious speeds, we can create new particles and study their properties. One such particle was the Higgs boson. To make sure that the protons, which are elementary particles, collide with each other, instead of using them one by one, large packets are launched, resulting in about 1 billion collisions per second. All these collisions are recorded as single events. Thousands of individual particles can be produced from a single collision, which are characterised in real time (well below a millisecond) by detectors, collecting information such as trajectory, energy, momentum, etc. Massive amounts of data As we can imagine, this produces an enormous amount of data. Specifically, over 50,000-70,000 TB per year of raw data. And that's just from the main detectors, as there are other secondary experiments at the LHC. Because it doesn't operate every day of the year, it generates an average of 200-300 TB of data; a complicated - but feasible - volume to handle today. The problem is that the LHC came into operation in 2008, when Big Data was a very new concept, so there was a lot of ad hoc technology development. Not for the first time, the Internet itself was born at CERN, with the World Wide Web. The Worldwide LHC Computer Grid (WLCG), a network of 170 computing centres in 42 countries, was established in 2003, with a total of 250,000 available cores allowing more than 1 billion hours of computing per year. Each of the nodes in this network can be dedicated to data storage, processing or analysis. Depending on the technical characteristics, each of the nodes in this network can be dedicated to data storage, processing or analysis. To ensure good coordination between them, a three-tier hierarchical system was chosen: Tier 0 at CERN, Tier 1 at several regional sites, and Tier 2 at centres with very good connectivity between them. LHC control room / Brice, Maximilien, CERN Spain hosts several of these computing centres, both Tier 1 and Tier 2, located in Barcelona, Cantabria, Madrid, Santiago de Compostela and Valencia. One of the aspects that has fostered this large volume of data is the application of machine learning and artificial intelligence algorithms to search for physics beyond what is known, but that is a story for another day… AI OF THINGS Women who changed Mathematics March 9, 2023 (2) James Webb Space Telescope: the present and future of astrophysics The LHC explores the basic building blocks of our Universe: the elementary particles. Now we are going to travel to the opposite extreme, studying stars and entire galaxies. Except for the remarkable advances in neutrino and gravitational-wave astronomy in recent years, if we want to observe the Universe, we will do so with a telescope. Due to the Earth's rotation, a "traditional" telescope will only be able to observe at night. In addition, the atmospheric effect will reduce the quality of the images when we are looking for sharpness in very small or faint signals. Wouldn't it be wonderful to have a telescope in space, where these factors disappear? That was what NASA thought in the late 1980s, launching the Hubble space telescope in 1995, which has produced (and continues to produce) the most spectacular images of the cosmos. NASA considered a couple of decades ago what the next step was, and began designing its successor, the James Webb Space Telescope (JWST), launched on 25 December 2021 and currently undergoing calibration. With a large number of technical innovations and patents, it was decided to place JWST at the L2 Lagrange point, 4 times further away from us than the Moon. At such a distance, it is completely unfeasible to send a manned mission to make repairs, as was the case with Hubble, which orbits at "only" 559 km from the Earth's surface. NASA's James Webb Telescope main mirror. Image Credit: NASA/MSFC/David Higginbotham One of the biggest design challenges was data transmission. Although the JWST carries shields to thermally insulate the telescope, because it is so far from the Earth's magnetosphere, the hard disk that records the data must be an SSD (to ensure transmission speed) with high protection against solar radiation and cosmic rays, since it must be able to operate continuously for at least 10 years. This compromises the capacity of such a hard disk, which is a modest 60 GB. With the large volume of data collected in observations, after about 3 hours of measurements this capacity may be reached. The JWST is expected to perform two data downloads per day, in addition to receiving pointing instructions and sensor readings from the various components, with a transmission rate of about 30 Mbit/s. Compared to the LHC's divs this may seem insignificant, but we must not forget that JWST orbits 1.5 million kilometres from Earth, in a tremendously hostile environment, with temperatures of about 30°C on the Sun-facing side and -220°C on the shadow side. An unparalleled technical prodigy producing more than 20 TB of raw data per year, which will keep the astrophysical community busy for years to come, with robust and sophisticated machine learning algorithms already in place to exploit all this data AI of Things Endless worlds, realistic worlds: procedural generation and artificial intelligence in video games August 22, 2022 (3) Event Horizon Telescope: Lifetime Big Data Both the LHC and JWST are characterised by fast and efficient data transmission for processing. However, sometimes it is not so easy to get the "5 WiFi stripes". How many times have we been frustrated when a YouTube video would freeze and load because of our poor connection? Let's imagine that instead of a simple video we need to download 5 PB of data. This is the problem encountered by the Event Horizon Telescope (EHT), which in 2019 published the first picture of a black hole. This instrument is actually a network of seven radio telescopes around the world (one of them in Spain), which joined forces to perform a simultaneous observation of the supermassive black hole at the centre of the galaxy M87 for 4 days in 2017. Over the course of the observations, each telescope generated about 700 TB of data, resulting in a total of 5 PB of data scattered over three continents. The challenge was to combine all this information in one place for analysis, which it was decided to centralise in Germany. In contrast to the LHC, the infrastructure for data transfer at this level did not exist, nor was it worth developing as it was a one-off use case. It was therefore decided to physically transport the hard disks by air, sea and land. One of the radio telescopes was located in Antarctica, and we had to wait until the summer for the partial thaw to allow physical access to its hard disks. Researcher Katie Bouman (MIT), who led the development of the algorithm to obtain the black hole photo with the EHT, proudly poses with the project's hard disks. In total, half a tonne of storage media was transported, processed and analysed to generate the familiar sub-1 MB image. Explaining the technique required to achieve this would take several individual posts. What is important here is that sometimes it is more important to be pragmatic than hyper-technological. Although our world has changed radically in so many ways thanks to Big Data, sometimes it is worth giving a vintage touch to our project and imitate those observatories of a century ago that transported huge photographic plates from telescopes to universities to be properly studied and analysed Featured image shows the polarised view of the black hole in M87. The lines mark the orientation of polarisation, which is related to the magnetic field around the shadow of the black hole. Photo: EHT Collaboration
April 3, 2023

Ghosts in the machine: does Artificial Intelligence suffer from hallucinations?
Artificial Intelligence (AI) content generation tools such as ChatGPT or Midjourney have recently been making a lot of headlines. At first glance, it might even appear that machines “think” like humans when it comes to understanding the instructions given to them. However, details that are elementary for a human being turn out to be completely wrong in these tools. Is it possible that the algorithms are suffering from hallucinations? Science and (sometimes) fiction 2022 was the year of Artificial Intelligence: we saw, among other things, the democratisation of image generation from text, a Princess of Asturias award, and the world went crazy talking to a machine that had the power to last: OpenAI's ChatGPT. Although it is not the aim of this article to explain how this tool works, as it is outlined in Artificial Intelligence in Fiction: The Bestiary Chronicles, by Steve Coulson (spoiler: written by herself), we can say that, in short, it does try to imitate a person in any conversation. With the added bonus that she might be able to answer any question we ask her, from what the weather is like in California in October to defending or criticising dialectical materialism in an essay (and she would approach both positions with equal confidence Why browse through a few pages looking for specific information when we can simply ask questions in a natural way? The same applies to AI image generation algorithms such as Midjourney, Dall-e, Stable Diffusion or BlueWillow. These tools are similar to ChatGPT in that they take text as input, creating high quality images. Examples of the consequences of mind-blowing Artificial Intelligence Leaving aside the crucial ethical aspect of these algorithms —some of which have already been sued for using paid content without permission to be trained— the content they generate may sometimes seem real, but only in appearance For instance, We can ask you to picture The Simpsons as a sitcom from the 1980s. Indeed, it all seems disturbingly real, even if those images haunt us in our nightmares. Or to generate images of a party. At first glance we wouldn't know if they are real or not, as they look like photos with an Instagram or Polaroid filter. However, as the headline suggests, as soon as we start to look at them more closely we see details that don't quite add up: mouths with more teeth than usual, hands with 8 fingers, limbs sticking out of unexpected places... none of these fake photos pass a close visual examination. Artificial intelligence learns patterns and can reproduce them, but without understanding what it is doing. This is because, basically, all the AI does is learn patterns, but it doesn't really understand what it is seeing. So if we train it with 10 million images of people at parties, it will recognise many patterns: people are often talking, in various postures, holding glasses, posing with other people... but it is unable to understand that a human being has 5 fingers, so when it comes to creating an image with someone holding a glass or a camera, it just “messes up”. But perhaps we are asking too much of the AI with images. If you're a drawing hobbyist, you'll know how difficult it is to draw realistic hands holding objects. Photo: Ian Dooley / Unsplash What about ChatGPT? If you are able to write an article for this blog, you might not make mistakes like that. And yet ChatGPT is tremendously easy to fool, which is not particularly relevant. It is also very easy to fool us without us realising it. And if the results of a web search are going to depend on it, it is much more worrying. In fact, ChatGPT has been tested by hundreds of people all over the world in exams ranging from early childhood education tests to university exams to entrance exams. In Spain, he was subjected to the EVAU (the old university entrance exam) History test, in which he got a pass mark. “Ambiguous answers”, “overreaching to other unrelated subjects”, “circular reiterations”, “incomplete”... are some of the comments that professional correctors gave to his answers. A few examples: If we ask what is the largest country in Central America, it might credibly tell us that it is Guatemala, when in fact it is Nicaragua. It may also confuse two antagonistic concepts, so that if we wanted to understand the differences between the two, it would be confusing us. If, for example, we were to use this tool to find out whether we can eat a certain family of foods if we have diabetes and it gave us the wrong answer, we would have a very serious problem. If we ask him to generate an essay and cite papers on the subject, it is very likely that it will mix articles that exist with invented ones, with no trivial way of detecting them. Or if we ask about a scientific phenomenon that does not exist, such as “inverted cycloidal electromagnon”, it will invent a twisted explanation accompanied by completely non-existent articles that will even make us doubt whether such a concept actually exists. However, a quick Google search would have quickly revealed that the name is an invention. That is, ChatGPT is suffering from what is called "AI hallucination". A phenomenon that mimics hallucinations in humans, in which it behaves erratically and asserts as valid statements that are completely false or irrational. AI of Things Endless worlds, realistic worlds: procedural generation and artificial intelligence in video games August 22, 2022 Androids hallucinate with electric sheep? So, what is going on? As we have said before, the problem is that the AI is tremendously clever at some things, but terribly stupid at others. ChatGPT is very bad at lying, irony and other forms of language twisting. The problem then lies in having a critical spirit and distinguishing what is real from what is not (in a way, as is the case today with fakenews). In short, the AI will not give in: if the question we ask it is direct, precise, and real, it will give us a very good answer. But if not, it will make up an answer with equal confidence. When asked about the lyrics to Bob Dylan's “Like a Rolling Stone”, it will give us the full lyrics without any problem. But if we get the wrong Bob and claim that the song is by Bob Marley, it'll pull a whole new song completely out of the hat. A sane human being would reply “I don't know what song that is”, “isn't that Dylan's”, or something similar. But the AI lacks that basic understanding of the question. As language and AI expert Gary Marcus points out, “current systems suffer from compositionality problems, they are incapable of understanding a whole in terms of its parts”. Platforms such as Stack Overflow, a forum for queries about programming and technology, have already banned this tool to generate automatic answers, as in many cases its solution is incomplete, erroneous or irrelevant. And OpenAI has hundreds of programmers explaining step-by-step solutions to create a training set for the tool. The phenomenon of hallucination in Artificial Intelligence is not fully understood The hallucination in Artificial Intelligence is not fully understood at a fundamental level. This is partly because the algorithms behind it are sophisticated deep learning neural networks. Although extremely complex, at its core it is nothing more than a network of billions of individual "neurons", which are activated or not depending on input parameters, mimicking the workings of the human brain. In other words, linear algebra, but in a big way. CYBER SECURITY Artificial Intelligence, ChatGPT, and Cyber Security February 15, 2023 The idea is to break down a very complicated problem into billions of trivial problems. The big advantage is that it gives us incredible answers once the network is trained, but at the cost of having no idea what is going on internally. A Nature study, for example, showed that a neural network was able to distinguish whether an eye belonged to a male or female person, despite the fact that it is not known whether there are anatomical differences between the two.. Or a potentially very dangerous example, in which a single facial photo classified people as heterosexual or homosexual. Who watches over the watchman? Then, if we are not able to understand what is going on behind the scenes, how can we diagnose the hallucination, and how can we prevent it? The short answer is that we can't right now. And that's a problem, as AI is increasingly present in our everyday lives. Getting a job, being granted credit by a bank, verifying our identity online, or being considered a threat by the government are all increasingly automated tasks. If our lives are going to have such an intimate relationship with AI, we'd better make sure it knows what it's doing. Other algorithms for text generation and image classification had to be deactivated, as they turned out to be neo-Nazi, racist, sexist, sexist, homophobic... and they learned this from human biases. In a sort of Asimov's tale, let's imagine that, in an attempt to make politics "objective", we let an AI make government decisions. We can imagine what would happen then. Although some people point to a problem of lack of training data as the cause of hallucinations, this does not seem to be the case in many situations. Perhaps in the near future a machine will be able to really understand any question. Or not. In fact, we are reaching a point where exhausting the datasphere —the volume of relevant data available— is beginning to be on the horizon. That is, we will no longer have much to improve by increasing the training set. The solution may then have to wait for the next revolution in algorithms, a new approach to the problem that is currently unimaginable. This revolution may come in the form of quantum computing. Perhaps in the near future a machine will be able to really understand any question. Maybe not. It is very difficult and daring to make long-term technological predictions. After all, the New York Times wrote in 1936 that it would be impossible to leave the earth's atmosphere, and 33 years later, Neil Armstrong was walking on the moon. Who knows, maybe in a few decades it will be AI that diagnoses why humans “hallucinate”… Publications: https://www.unite.ai/preventing-hallucination-in-gpt-3-and-other-complex-language-models/ https://nautil.us/deep-learning-is-hitting-a-wall-238440/ https://medium.com/analytics-vidhya/what-happens-when-neural-networks-hallucinate-9bd0d4594943 Featured photo: Pier Monzon / Unsplash
February 20, 2023

10-minute delivery: how Artificial Intelligence optimises delivery routes
Nowadays, speed and immediacy is a necessity for almost any company, especially for those in the logistics sector dedicated to the transport and delivery of goods. Due to the high volume of orders, it is essential to try to optimise the entire process, including physical delivery, and even react in real time to possible unforeseen events. This is possible with the Artificial Intelligence of Things (AIoT) platform, which combines Big Data and Artificial Intelligence. Analytics as a planning tool How many times have we taken the car and found ourselves stuck in an unexpected traffic jam in the city? Especially during rush hour or if there is an event in the area, it is quite possible that a 10-minute drive can turn into a frustrating half-hour give-and-take. Now imagine that instead of going from point A to point B, we have to constantly move around the city, as would be the case for a transport company delivering goods. In this situation, possible delays would accumulate successively, seriously affecting our logistical planning. We could fantasise about imitating films such as the remake of The Italian Job (2003), where, in order to get through the city in the shortest possible time, they hack the traffic lights so that they can turn green when we need them to. The dark side of this idea is also found in cinema: in The Jungle 4.0 (2007), a cyber-terrorist paralyses several cities by turning all the traffic lights green simultaneously, creating hundreds of accidents. Optimizing delivery routes with Smart Mobility While remaining within the law, there are different ways to try to optimise our routes, both in real time and for predicting possible delays, with so-called Smart Mobility. The first step if we want to work in real time is to sensor our delivery fleet, with the so-called Internet of Things (IoT). With IoT sensors, the entire fleet status is always known and any incidents can be traced in real-time In general, these sensors are simply and non-invasively connected to the vehicle's OBD (On-Board Diagnostics) connector. In this way, we can know the status of our entire fleet at all times and have full traceability. If a delivery vehicle deviates from the route, runs out of battery, suffers a breakdown or exceeds the maximum speed, the system will send an immediate alert. In recent years the costs of this IoT infrastructure have been drastically reduced. Today, the sensors themselves, the network connection and the information processing platform are very affordable at the enterprise level, with packaged solutions from leading cloud service providers. Real-time tracking and tracing of all shipments All this, moreover, with the highest standards of security and privacy, using technologies such as Blockchain. With this, we can have real-time tracking and tracing of any goods on their route, including environmental conditions (humidity, temperature, pressure, vibrations, etc.) with alerts if certain parameters are exceeded, as well as detecting possible tampering or opening. The next challenge is to plan the route for each of these delivery vehicles. This is made possible by combining IoT and Artificial Intelligence (AI) in the Artificial Intelligence of Things (AIoT) platform. By combining IoT sensor data with advanced AI analytics, economic, operational and energy factors will be taken into account to increase operational efficiency. The optimal route (i.e., the one with the shortest time/fuel consumption) does not necessarily have to be the shortest distance. For example, if tolls exist, the route with the lowest overall cost may be one that involves taking a small detour to avoid using the toll road. When assigning deliveries to the different vehicles and determining the best route, the AI will consider parameters such as the combination of packages to be delivered, delivery or collection times, product characteristics, load volume, vehicle type and information from its sensors, etc. Since artificial intelligence makes decisions based on more information, the better predictions it can make with more quality data. All this data is internal, i.e., information generated by the company itself. However, we can enrich it by incorporating external sources. This new knowledge can be critical when planning our route. In general, the more data we have (as long as it is relevant and of good quality), both in variety and extent, the better the prediction the AI can make, as it will use more information to make its decisions. For example, we can add weather information, to predict whether there is going to be a big snowstorm or torrential rain potentially affecting the logistics chain. In such a case, the optimal route in terms of weather may be a large deviation from the base route. Another important external source is the calendar of public holidays, events or incidents (road closures due to sporting events, demonstrations, festivals, etc.). Finally, statistical traffic data can be used to predict traffic jams, according to geography, time of year, time of day, etc. Thus, the AI will design the optimal route considering all these boundary conditions. Still, this only allows us to plan our route a priori, but we will not be able to react in real time to unforeseen events. Or will we? AI reflexes Let's imagine now that we have our route perfectly designed and optimised, taking into account all relevant factors. However, if there is an accident blocking a street, or a major traffic jam that we didn't expect, we would suffer an unforeseen delay. Is there a way to react to this in real time? This is where services like Telefónica Tech's Smart Steps come into play. With this technology, it is possible to geolocate mobile devices, either by location based on the mobile network or the WiFi network. https://www.youtube.com/watch?v=RrW0c_6svJw This makes it possible, for example, to see whether a shop or a street is very busy at the moment, by analysing the movement patterns of individual devices. Always with anonymised data, as it is only relevant in aggregate, it is possible to calculate footfall, using both streaming data and historical data. This also makes it possible to estimate traffic density in real time. For example, if there is a major traffic jam, Smart Steps will detect how both devices are moving in fits and starts on the road, very slowly, generating a traffic jam alert. With all this information, the AI can update the planning in real time, i.e. it can be prescriptive. Imagine, for example, that we are in a city centre making deliveries in neighbourhood A, but in a while we will be moving to neighbourhood B. Artificial intelligence has the advantage of having all the information at its disposal, so it will make better decisions than a human. If in the optimal pre-calculated route, we will be able to plan our route in real time. If an accident has occurred on the pre-calculated optimal route that has generated a traffic jam, AI will use all this information in real time to design a new itinerary on the go, modify delivery times, prioritise the order, send a message to the end customer with possible updates, etc. The main advantage over a human reaction is that the AI has all the information available and will therefore make a better decision. In short, the AIoT platform offers a differential value to any company seeking to increase the operational efficiency of its logistics processes, with full traceability of its fleet of vehicles, optimisation of delivery routes and a system of real-time alerts in case of possible unforeseen events. AI of Things AI-based Google Green Light optimizes traffic in a dozen cities to save time and reduce emissions October 13, 2023
September 26, 2022

Endless worlds, realistic worlds: procedural generation and artificial intelligence in video games
In this post we will talk about how to automatically create realistic environments in virtual worlds. As an example, we will use the video game No Man's Sky, by Hello Games, which in 2016 created entire galaxies and planets on a real scale with a simple algorithm, all of them entirely accessible and different. As if this was not enough, we can also add artificial intelligence to the equation, which will be a revolution never seen before in the world of videogames Infinite apes, endless worlds A famous mental experiment known as the "infinite monkey theorem" says that, if we put an infinite number of monkeys to type on a computer for an infinite time, at some point one of them will write Don Quixote. By pure and simple chance. Any book, even Cervantes' opus magna, is a very long string made up of a finite number of characters, such as letters of the alphabet. In other words, in an infinite time, everything can and must happen. We can ask ourselves whether this experiment can be extrapolated to other types of content. One approach comes in the form of what is known as procedural generation. This means that, starting from a sufficiently complex algorithm, the result of this algorithm can be randomised so that each time it is executed, the result is different. This type of "unexpected result" has been applied not only in science, but also in the arts such as music or painting. However, it is in the world of video games where it has found a special appeal. A sandbox (i.e., open world) video game requires a tremendous scale of modelling. After all, we are trying to mimic an entire world in a virtual environment. Due to purely technical and developmental constraints, most sandbox games had a limited number of periodically repeated elements. Just as Neo in the Matrix would see a glitch in the form of cat-like déjà vu, we would start to see the same textures, the same trees, the same faces over and over again throughout the game. The possibility of randomising these elements, just as in real life, was all too tempting Although there are more than a few examples of these attempts at procedural generation since the 1980s, probably the prime example due to the exorbitant scale is the video game No Man's Sky, developed by Hello Games and released in 2016 for various platforms. In this game, we wake up on an unknown planet with a broken spaceship, and our first mission is to find resources to repair it. So far, so conventional. We quickly realise that, unlike in other games, if we start walking in a straight line there are no invisible barriers, insurmountable obstacles, or anything that prevents us from leaving the modelled area. In fact, we could walk all the way around the planet if we wanted to, encountering extravagant fauna and flora everywhere. When we manage to get off the planet, we see that it has a natural scale, i.e., comparable in size to Mars or Earth. In this strange Solar System, we find more planets and moons, to which we can travel by means of a fictitious warp drive (or "hyperspace", as you prefer). Landing on another of these stars, we find a new world to explore, different from the previous one in climate, landscape, fauna, flora, possible intelligent civilisations, and so on. The final twist comes when we wonder if we can also leave this Solar System, or even the galaxy. We then discover that the game contains 255 individual galaxies, with a total of 18,446,744,073,709,551,616 planets, all of them accessible and different from each other. The number, in case anyone doesn't feel like counting commas, is about 18 quintillions. If 100 people visited one planet per second, it would take about 5 billion years to visit them all. That is roughly the age of planet Earth. Hello Games managed to create an entire Universe with infinite possibilities, without having to explicitly model a single planet. It only used procedural generation to combine these individual elements in different ways. No two planets are identical, nor do they have the same fauna, flora or civilisations. In fact, by implementing online play capabilities, each player can discover planets and name them, or visit a friend in the underwater base he or she has created in a particularly peculiar Solar System. The planets are the same for everyone, as the algorithm is deterministic - it is the initial planet assignment that is completely random. As a curiosity, even the game's soundtrack is procedurally generated, based on thousands of samples from the 65daysofstatic band. Ender's (video) game No Man's Sky is an outstanding example of procedural generation in video games, but it's been 6 years since it was released. How can we go further? This is where Artificial Intelligence (AI) comes in. In video games, AI usually refers to the behaviour of NPCs (Non-Playable Characters), whether they are friends, enemies or neutrals. For example, in a racing game like Gran Turismo, the reaction of the other cars to the player's actions: does the machine have an excellent driving skill, or a mediocre one? It is interesting to see how little AI has evolved in video games. Most actions are predictable as soon as we learn the pattern. Even combat games known for their high difficulty (such as Hollow Knight, Cuphead or Dark Souls) present conceptually very simple battles, where the only real challenge lies in our ability as humans to execute a specific sequence of commands on the controller/keyboard at the exact time. The same goes for the realism of NPCs when talking to the player, as they have a limited number of lines of dialogue and animations. It is typical to burn them out in a few iterations, which would never happen in the real world. This will change radically with the application of AI, specifically Deep Learning. These algorithms will allow studios not only to have an invaluable programming tool for their works, but to autonomously generate concept art, dialogue or even entire games from scratch. In other words, procedural generation, but instead of being subject to a deterministic algorithm, it will be done organically and realistically, just as a human being would. Character behaviour will be learned from our gameplay and implemented in real time. Realism will be extreme in terms of interaction with NPCs, as there will be infinite lines of dialogue. We will not be subject to choosing from a few predefined options but will be able to engage in natural conversations with any character. In addition, software such as StyleGAN, designed by NVIDIA and released open source in 2019, allows for the creation of photorealistic faces with a Generative Adversarial Network (GAN), exponentially increasing the immersion in the proposed narrative. In a way, each person will play a different game, as the same piece of work will be condivd according to that player. Because the AI will always be learning, not only will it constantly generate new content for the game, but in a way the game will never be "finished"; only when we leave it will it stop building and updating itself. However, we must be cautious about applying Deep Learning to video games. For example, an enemy that learns from our moves could quickly become invincible, as it will quickly see the weaknesses in our strategy and adapt its style, as is the case with Sophy, the new AI in Gran Turismo, which is capable of defeating professional drivers. Only time will tell how far we can go in combining procedural generation and AI, but it's clear that the future will be very realistic.
August 22, 2022