 Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Project Zero, descubrimiento de vulnerabilidades usando modelos LLM
Introducción
Que la inteligencia artificial generativa revolucionará el descubrimiento de vulnerabilidades en el software es algo que poca gente duda, lo que no está claro aun, simplemente es el cuándo.
Para los que no lo conozcan, Project Zero es una iniciativa de Google creada en 2014 cuyo objetivo es estudiar y mitigar el potencial impacto de las vulnerabilidades de día cero (una vulnerabilidad de día cero (ZeroDay en inglés) es una vulnerabilidad que los atacantes conocen y para la cual no hay un parche disponible por parte del proveedor) en los sistemas de hardware y software de los que dependen los usuarios de todo el mundo.
Tradicionalmente, la identificación de fallos en el software es un proceso laborioso y propenso a errores humanos. Sin embargo, la IA generativa, particularmente aquella cuya arquitectura ha sido diseñada como un agente capaz de razonar y con herramientas auxiliares que le permitan simular a un investigador humano especializado, puede analizar grandes volúmenes de código de manera eficiente y precisa, identificando patrones y anomalías que de otra forma podrían pasar desapercibidos.
En este contexto en este artículo revisaremos los avances de los investigadores de seguridad de Project Zero en el diseño y uso de sistemas basados en las capacidades de la inteligencia artificial generativa que sirva de catalizador en la búsqueda, verificación y remediación de vulnerabilidades.
Orígenes: Proyecto Naptime
Desde mediados de 2023, estos investigadores de seguridad de Google comenzaron a diseñar y probar una arquitectura basada en LLM (Large Language Model) para el descubrimiento y verificación de vulnerabilidades. El detalle de este proyecto está perfectamente detallado en un artículo de mediados de 2024 en su blog, del que recomendamos fervientemente su lectura a los interesados.
Nosotros aquí nos centraremos en detallar sus principios de diseño y arquitectura ya que es interesante entender los componentes clave para que un LLM pueda trabajar de forma efectiva en la búsqueda de vulnerabilidades.
Principios de diseño
Basados en la amplia experiencia del equipo de Project Zero en la búsqueda de vulnerabilidades, estos han establecido un conjunto de principios de diseño para mejorar el rendimiento de los LLM aprovechando sus fortalezas mientras se abordan sus limitaciones actuales para la búsqueda de vulnerabilidades. Los resumimos a continuación:
- Espacio para el razonamiento: Es crucial permitir que los LLM participen en procesos de razonamiento profundos. Este método ha demostrado ser efectivo en diversas tareas, y en el contexto de la investigación de vulnerabilidades, fomentar respuestas detalladas y explicativas ha llevado a resultados más precisos.
- Entorno interactivo: La interactividad dentro del entorno del programa es esencial, ya que permite a los modelos ajustar y corregir sus errores, mejorando la efectividad en tareas como el desarrollo de software. Este principio es igualmente importante en la investigación de seguridad.
- Herramientas especializadas: Equipar a los LLM con herramientas especializadas, como un depurador y un entorno de scripting, es esencial para reflejar el entorno operativo de los investigadores de seguridad humanos.
Por ejemplo, el acceso a un intérprete de Python mejora la capacidad de un LLM para realizar cálculos precisos, como convertir enteros a sus representaciones binarias de 32 bits. Un depurador permite a los LLM inspeccionar con precisión los estados del programa en tiempo de ejecución y abordar errores de manera efectiva. - Verificación perfecta: A diferencia de muchas tareas relacionadas con el razonamiento, donde la verificación de una solución puede introducir ambigüedades, las tareas de descubrimiento de vulnerabilidades pueden estructurarse de manera que las soluciones potenciales puedan verificarse automáticamente con absoluta certeza. Esto es clave para obtener resultados de referencia fiables y reproducibles.
- Estrategia de muestreo: La investigación efectiva de vulnerabilidades a menudo implica explorar múltiples hipótesis. En lugar de considerar múltiples hipótesis en una sola trayectoria, se aboga por una estrategia de muestreo que permita a los modelos explorar múltiples hipótesis a través de trayectorias independientes, habilitada mediante la integración de la verificación dentro del sistema de extremo a extremo.
Arquitectura de Naptime
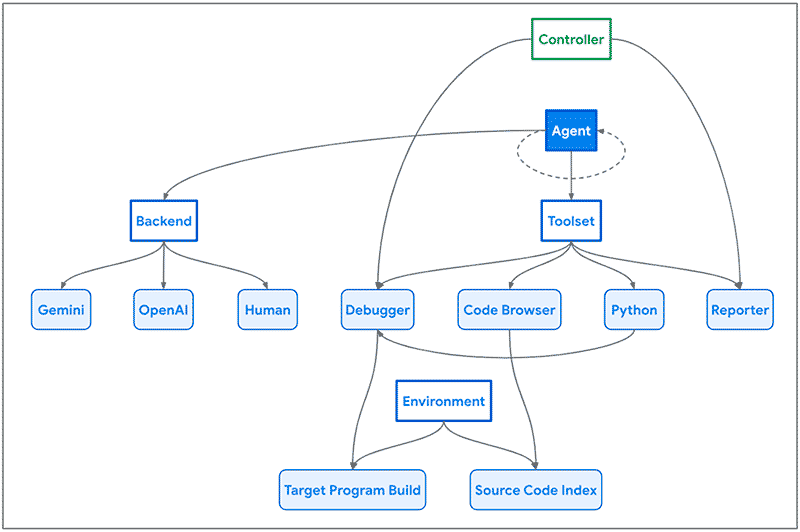 Arquitectura de NapTime – Imagen extraída del artículo de Project Zero.
Arquitectura de NapTime – Imagen extraída del artículo de Project Zero.
Como vemos en la imagen anterior, la arquitectura de Naptime se centra en la interacción entre un agente de IA y una base de código objetivo. Al agente se le proporciona un conjunto de herramientas especializadas diseñadas para imitar el flujo de trabajo de un investigador de seguridad humano.
Estas herramientas incluyen un navegador de código, un intérprete de Python, un depurador y una herramienta de informes, que permiten al agente navegar por la base de código, ejecutar scripts de Python, interactuar con el programa y observar su comportamiento, y comunicar su progreso de manera estructurada.
Orígenes: Benchmark – CyberSecEval 2
Otro hito importante, para la evolución y medición del valor de estos sistemas inteligentes para la búsqueda de vulnerabilidades, se produjo en abril de 2024 con la publicación y presentación por parte de investigadores de Meta de un banco de pruebas diseñado para evaluar las capacidades de seguridad de los LLM, llamado CyberSecEval 2, ampliando una propuesta anterior de los mismos autores, para incluir pruebas adicionales para la inyección de prompts y el abuso del intérprete de código, así como la identificación y explotación de vulnerabilidades.
Esto es crucial, ya que, con ese marco se permite una medición estándar de las capacidades de los sistemas conforme vayan generándose mejoras, siguiendo el principio de sabiduría popular empresarial:
Lo que no se mide no se puede evaluar.
Evolución hacia Big Sleep
Un factor clave de motivación para Naptime y posteriormente de Big Sleep, fue el continuo descubrimiento en la naturaleza de exploits para variantes de vulnerabilidades previamente encontradas y parcheadas.
Los investigadores detallan que, la tarea de análisis de variantes es más adecuada para los LLM actuales, que el problema más general de la investigación de vulnerabilidades de código abierto.
Al proporcionar un punto de partida concreto, como los detalles de una vulnerabilidad previamente solucionada, eliminamos mucha ambigüedad de la investigación de vulnerabilidades y comenzamos con una teoría bien fundamentada:
Este fue un error anterior; probablemente haya otro similar en algún lugar.
- Con estas premisas, Naptime ha evolucionado hasta convertirse en Big Sleep, una colaboración entre Google Project Zero y Google DeepMind.
- Se ha usado Big Sleep equipado con el modelo Gemini 1.5 Pro para la obtención del resultado que a continuación se presenta.
Primeros resultados reales obtenidos
Poniendo a prueba BigSleep, los investigadores trasladan en un artículo, del que de nuevo invitamos encarecidamente a su lectura, han logrado descubrir la primera vulnerabilidad real en el conocido y popular proyecto de base de datos de código abierto SQLite.
De forma muy resumida: recopilaron una serie de commits recientes en el repositorio de SQLite. Ajustaron el prompt para proporcionar al agente tanto el mensaje del commit como un diff del cambio, y solicitaron al agente que revisara el repositorio actual en busca de problemas relacionados que podrían no haber sido solucionados.
Big Sleep encontró y verificó una vulnerabilidad de manejo incorrecto de memoria (Stack Buffer Underflow) en SQLite.
¡Eureka! Big Sleep encontró y verificó una vulnerabilidad de manejo incorrecto de memoria (Stack Buffer Underflow) que fue reportada a los autores de SQLite y que, debido a su remediación en el mismo día, no afectó a usuarios de dicha popular base de datos ya que no llegó a ser publicada en ninguna distribución oficial.
Conclusiones
Encontrar vulnerabilidades en el software antes de que se lance significa que no hay margen para que los atacantes compitan: las vulnerabilidades se solucionan antes de que los atacantes tengan la oportunidad de usarlas. Estos primeros resultados apoyan la esperanza de que la IA pueda ser clave en este paso para finalmente cambiar las tornas y lograr una ventaja asimétrica para los defensores.
Los primeros resultados apoyan la esperanza de que la IA pueda proporcionar una ventaja asimétrica para los defensores de ciberseguridad.
Bajo nuestro punto de vista, las líneas actuales de generar modelos con mayor capacidad de razonamiento (Por ejemplo el anunciado modelo o1 por parte de OpenAI) y la irrupción de los agentes que dotan de una mayor autonomía al sistema para interactuar con su entorno (por ejemplo, computer use de Anthropic) resultará clave, en un futuro cercano, para cerrar el gap de este tipo de sistemas para el descubrimiento de vulnerabilidades con capacidades iguales o incluso superiores (o más bien complementarias) a las de los investigadores humanos.
Aún queda mucho trabajo por delante, para que estos sistemas sean una ayuda efectiva para el descubrimiento y remediación de vulnerabilidades, en particular para casos complejos, pero sin duda la arquitectura diseñada y la natural evolución de los LLM permiten atisbar un futuro cercano donde su uso será predominante y clave para mejorar la seguridad global del Software mundial.
Finalizamos con una adaptación de las famosas palabras del astronauta Neil Amstrong:
Un pequeño paso para los LLM, un gran salto para las capacidades de defensa en ciberseguridad.
⚠️ Para recibir alertas de nuestros expertos en Ciberseguridad, suscríbete a nuestro canal en Telegram: https://t.me/cybersecuritypulse
Imagen: Freepik.



