Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Python para todos (4): Carga de datos, análisis exploratorio y visualización
Ya tenemos el entorno instalado, hemos practicado un poco con algunos comandos, y hemos aprendido qué son las librerías y cuáles son las más importantes. Ha llegado el momento de empezar nuestro experimento predictivo. Trabajaremos sobre uno de los datasets más recomendados para principiantes, el de clasificación de lirios (iris dataset). Este conjunto de datos es muy práctico porque tiene un tamaño muy manejable (sólo tiene 4 atributos y 150 filas), los atributos son numéricos, no es preciso hacer ningún cambio de escala o de unidades, y permite una aproximación sencilla (como problema de clasificación), y otra más avanzada (como problema clasificación multi-clase). Este dataset es un buen ejemplo para explicar la diferencia entre aprendizaje supervisado y no supervisado.
Los pasos que vamos a dar a partir de ahora son los siguientes:
- Carga de los datos y módulos/librerías necesarias para este ejemplo.
- Exploración de los datos .
- Evaluación de diferentes algoritmos para seleccionar el modelos más adecuado a este caso.
- Aplicación del modelo para hacer predicciones a partir de lo "aprendido".
Para que no sea demasiado largo, en este 4º post realizaremos los dos primeros pasos y, en el siguiente y último (¡todo llega!), el tercero y el cuarto.
1. Carga de los datos/librerías/módulos.
Ya vimos en el post anterior la gran variedad de librerías que tenemos disponibles. En cada una de ellas, a su vez, hay módulos distintos. Pero para poder utilizar, tanto las librerías como los módulos, hay que importarlos explícitamente (salvo la librería estándar). En el ejemplo anterior importamos algunas librerías de ejemplo para comprobar las versiones. Ahora, importaremos unos módulos que necesitamos para este experimento en particular. Crea un nuevo Jupyter Notebook para el experimento. Podemos llamarle "Clasificación de Lirios". Para cargar las librerías y módulos que necesitamos, teclea o, copia y pega este código:
https://gist.github.com/PalomaRS/cc3ca3c0e8a4a9949a4db5403cde9bd3#file-cargamodulos-ipynb
A continuación, cargaremos los datos. Lo vamos a hacer directamente desde el repositorio de Machine Learning UCI . Para ello usamos la librería pandas, que acabamos de cargar, y que también nos será útil para el análisis exploratorio de los datos, porque dispone de herramientas de visualización de datos y de estadística descriptiva. Tan sólo necesitamos conocer la URL del dataset y especificar los nombres de cada columna al cargar los datos ('sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'). Para cargar los datos, teclea o, copia y pega este código:
https://gist.github.com/PalomaRS/b5f2ad393bea0e438a60ad9d6340d71b#file-cargadataset-ipynb
También puedes descargar el csv del dataset a tu directorio de trabajo y sustituir la URL por el nombre del fichero local.
2. Exploración de los datos
En esta fase vamos a fijarnos en temas como la dimensión de los datos, qué aspecto tienen, vamos a hacer un pequeño análisis estadístico de sus atributos y vamos a agruparlos por clases. Cada una de estas acciones no reviste mayor dificultad que la ejecución de un comando que, además podrás reutilizar una y otra vez en proyectos futuros. En particular, trabajaremos con la función shape, que nos dará las dimensiones del dataset, la función head, que nos mostrará los datos (le indicaremos el número de registros que queremos que nos muestre), y la función describe, que nos dará valores estadísticos sobre el dataset.
Nuestra recomendación es ir probando uno a uno cada uno de los comandos que encontraréis a continuación. Podéis teclearlos directamente o copiarlos y pegarlos en vuestro Jupyter Notebook. (Usad la barra de desplazamiento vertical para llegar al final de la celda). Cada vez que agreguéis una función, ejecutad la celda usando (Menú Cell/Run Cells).
https://gist.github.com/PalomaRS/28bc5f7faf918ac7924ef23bc47e6561#file-exploracion-ipynb
Como resultado, obtendréis algo parecido a esto:
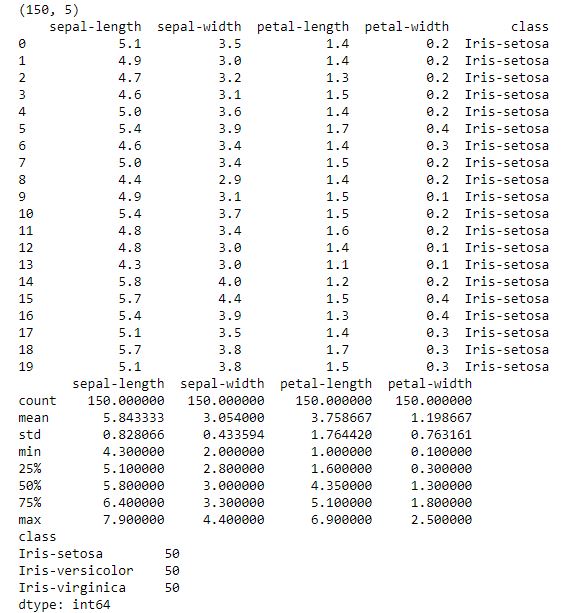
Figura 2: Resultados de aplicar los comandos de exploración del dataset.
Así, vemos que este dataset tiene 150 instancias con 5 atributos, vemos la lista de los 20 primeros registros, y vemos distintos valores de longitud y anchura de los pétalos y sépalos de la flor que, en este caso, corresponden a la clase Iris-setosa. Por último, podemos ver el número de registros que hay en el dataset, la media, la desviación estándar, los valores máximo y mínimo de cada atributo y algunos porcentajes.
Pasamos a visualizar los datos. Podemos realizar gráficos de una variable, que nos ayudarán a entender mejor cada atributo individual, o gráficos multivariable, que permiten analizar las relaciones entre atributos. Es nuestro primer experimento, y no nos queremos complicar demasiado, así que probaremos únicamente los primeros.
Como las variables de entrada son numéricas, podemos crear un diagrama de caja y bigotes (box and whisker plot), que nos dará una idea mucho más clara de la distribución de los atributos de entrada (longitud y anchura de pétalos y sépalos). Para ello, tan sólo tenemos que teclear o copiar y pegar este código.
https://gist.github.com/PalomaRS/6a9702ce4cc13f28c49a1e41508af73a#file-caja_bigotes-ipynb
Al ejecutar esta celda, obtenemos este resultado.
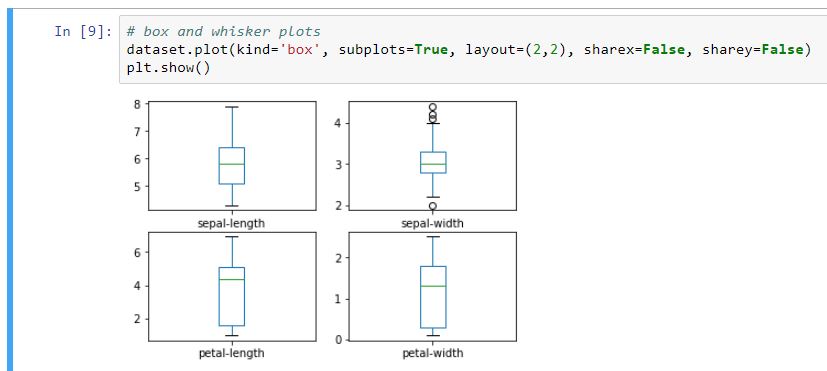
Figura 3: Box yWhisker plots.
También podemos crear un histograma de cada atributo o variable para hacernos una idea de qué tipo de distribución siguen. Para ello, no tenemos más que agregar en nuestro Jupyther Notebook (como en el ejemplo anterior, mejor de uno en uno, para ver mejor la ejecución) los siguientes comandos.
https://gist.github.com/PalomaRS/35e187ab4aeb40be83f462183bf2d663#file-histograma-ipynb
Ejecutamos la celda, y obtenemos este resultado. A primera vista, podemos ver que las variables relacionadas con los sépalos, parecen seguir una distribución Gaussiana. Esto es muy útil porque podemos usar algoritmos que saquen partido de las propiedades de este grupo de distribuciones.
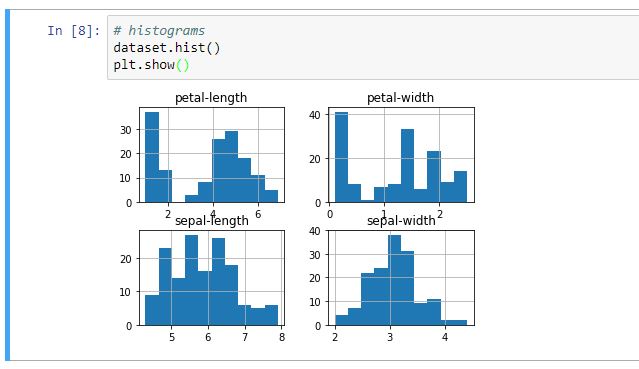
Figura 4: Histogramas.
Ya casi estamos terminado. En el siguiente post finalizaremos nuestro primer experimento en Machine Learning con Python. Evaluaremos diferentes algoritmos sobre un conjunto de datos de validación, y elegiremos el que nos ofrezca mejores métricas de precisión para elaborar nuestro modelo predictivo. Y, por último, usaremos el modelo.
Todos los post de este tutorial, aquí:
- Introducción: Machine Learning con Python para todos los públicos.
- Python para todos (1): Instalación del entorno Anaconda.
- Python para todos (2): ¿Qué son los Jupiter Notebook?. Creamos nuestro primer notebook y practicamos algunos comandos fáciles.
- Python para todos (3): ¿Qué son las librerías?. Preparamos el entorno.
- Python para todos (4): Empezamos el experimento propiamente. Carga de datos, análisis exploratorio (dimensiones del dataset, estadísticas, visualización etc)
- Python para todos (5) Final: Creación de los modelos y estimación de su precisión