 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Genomic Cyber Security: protecting DNA data and privacy from biological and digital threats
It was a crucial morning for an advanced biotechnology lab when something unsettling was discovered through one of its sophisticated genomic research platforms—used to design life-saving treatments based on patients' deoxyribonucleic acid (DNA). The system had been silently compromised.
No data was missing. Nothing had been deleted. While a "biological data breach" might have been suspected, instead, a few bases in a cancer genome dataset had been altered. Subtly. Intelligently. Maliciously.
The intersection between genomics and Cyber Security is not just a technical matter—it’s a human one, with implications for identity, privacy, and trust in science.
At first, the alteration went unnoticed due to limited Cyber Security capabilities and was only flagged when an anomaly emerged during a clinical trial. The implications were terrifying: someone had manipulated the genetic code—not just the data. The attacker hadn’t stolen a genome; they had corrupted it.
A few lines of synthetic DNA embedded with malware had passed through the lab’s sequencing system, enabling remote access to the research servers. The cyber threat was no longer just a virus or a data breach—it had crossed into the realm of biology.
Vulnerabilities and risks in genomic data protection
The NIST defines genomic data as being generated from the study of the structure and function of an organism’s genome, which is composed of genes and other elements that control gene activity. Examples of genomic data include DNA sequences, variants, and gene expression information.
Cyberattacks targeting genomic data can also harm individuals by enabling coercion for financial gain, discrimination based on disease risk, and loss of privacy through the exposure of kinship or hidden phenotypes including health status, emotional stability, mental ability, physical appearance, and capabilities.
In addition to privacy risks arising from cyberattacks, other privacy concerns unrelated to Cyber Security may surface when processing genomic data.
These risks may emerge when genomic data processing lacks sufficient predictability, manageability, and disassociability. Insufficient predictability can lead to privacy issues when individuals are unaware of how their genomic data is being handled. Insufficient manageability arises when there are no capabilities for granular control over genomic data.
For instance, individuals may require the option to delete part or all of their genomic data from a dataset. Allowing access to raw genomic data rather than using appropriate privacy-enhancing technologies to extract only the necessary information without revealing the raw data poses risks due to insufficient disassociability. Each of these privacy risks may impact the ability to realise the benefits of genomic data processing.
As genomic data becomes a strategic asset, it is increasingly targeted by nation-states, cybercriminals, and companies with opaque intentions.
Genomic data lifecycle
Genomic data is generated through the study of the genome’s structure and function. This data is largely immutable, associative, and contains important information about individuals’ health, phenotypes, and personalities, as well as those of their relatives—both past and future.
In some cases, small fragments of genomic data, even when stripped of identifiers, can be used to re-identify individuals, despite the fact that the vast majority of the genome is shared among humans.
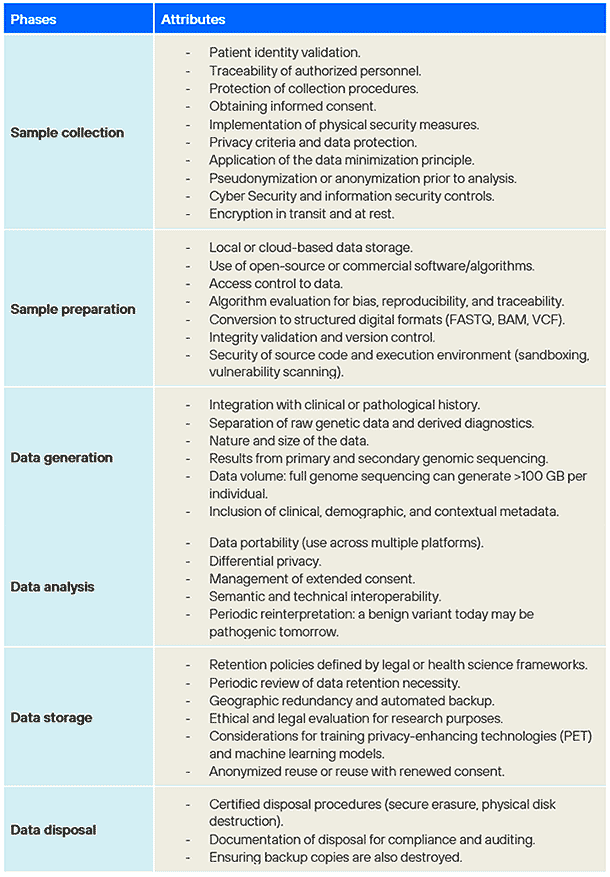
Source: Adapted and developed from NIST IR 8432 Cybersecurity of Genomic Data, outlining the attributes of each phase.
Just like other sensitive data, genomic information can be intercepted, corrupted, overwritten, or deleted at any stage of its lifecycle—from creation to storage, analysis, and dissemination.
Characteristics of genomic data
Genomic data shares characteristics with other forms of sensitive information and thus requires secure storage and transmission. However, this data possesses seven distinct attributes that, while not unique individually, form an intrinsically sensitive and valuable combination when considered together.
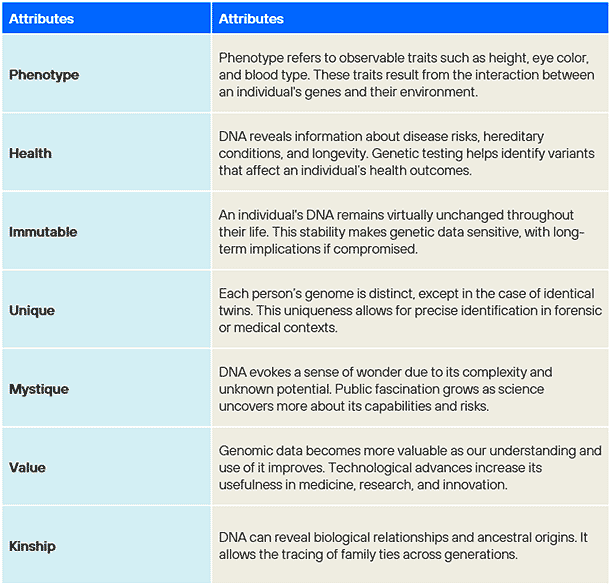
Source: Adapted and developed from NIST IR 8432 Cybersecurity of Genomic Data, detailing the attribute definitions.
As genomic technologies evolve and become more integrated into healthcare, research, and consumer services, protecting genetic data becomes an even greater challenge. Unlike other types of personal information, DNA is immutable and uniquely identifiable, containing sensitive details about a person’s health, identity, and ancestry.
A breach of genomic data not only compromises an individual’s privacy but could expose entire families to long-term risks such as discrimination, surveillance, or exploitation. The high value, uniqueness, and permanence of genomic information demand a new level of Cyber Security vigilance and ethical responsibility.
Traditional Cyber Security models are not designed to address the permanence and familial scope of genetic information, highlighting the need for new paradigms.
DNA as a challenge and responsibility in the digital age
To address these risks, robust genomic Cyber Security capabilities must be developed balancing innovation with privacy controls, consent, data sharing, and long-term storage.
Governments, healthcare providers, genetic testing companies, and researchers must collaborate to establish secure infrastructures, clear policies, and global standards for the protection of genomic data.
Ultimately, as we deepen our understanding of DNA, we must also ensure that its management is properly protected, so that advances in genomics do not jeopardize individual rights, social trust, or digital sovereignty.




