Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities.jpg)

IoT anomalies: how a few wrong pieces of information can cost us dearly
When we hear the term Internet of Things - or IoT in short - we often think of internet-enabled fridges or the already famous smartwatches.
But what does it really mean? The term IoT refers to physical objects that are equipped with sensors, processors and are connected to other similar elements, allowing them to obtain certain information, process it, and collect it for later use.
It's not all fridges and overpriced digital watches: from sensors that count the number of people entering an establishment to screens with an integrated camera that can detect if someone is paying attention to its contents and record that information. Other interesting examples can be found in the first articles of this series, where we discussed several use cases of these technologies or the advantages of using smart water meters to optimise the water lifecycle.
However, sometimes the data captured deviates from the normal values. If the data received from an IoT device tells us that a person has been staring at an advertising screen for hours or that the temperature inside a building at a given moment is 60ºC, this data is dubious to say the least. These outliers must be taken into account when designing our networks and devices. The received values have to be filtered to see if they are normal values or not and act accordingly.
This is a very clear example of how Artificial Intelligence (AI) and the Internet of Things (IoT) benefit from each other. The combination of both is what we know as Artificial Intelligence of Things (AIoThings), which allows us to analyse patterns in the data within an IoT network and detect anomalous values, i.e., values that do not follow these patterns and that are usually associated with malfunctions, various problems or new behaviours, among other cases.
What is an outlier?
The first thing to ask ourselves is what anomalous values, commonly called outliers in the world of data science and Artificial Intelligence, are. If we look at the definition of anomaly in the RAE dictionary, we get two definitions that fit surprisingly well with the data domain: "deviation or discrepancy from a rule or usage" and "defect in form or operation".
The first definition refers to values that do not behave as we would expect - that is, they are far from the values we would expect. If we were to ask random people what their annual income is, we would be able to put a range of values in which the vast majority of values would lie. However, we might come across a person whose income is hundreds of millions of euros per year. This value would be an outlier, as it is far from what is expected or "normal", but it is a real value.
The second definition refers to the term "defect". This gives us a clue: it refers to values that are not correct, understanding that a data is correct when its value accurately reflects reality. Sometimes it is obvious that a value is wrong: for example, a person cannot be 350 years old and no one can have joined a social network in 1970. These values are inconsistent with the reality they represent.
What to do with outliers?
The next question to ask is what to do about these anomalies, and the answer again varies depending on their nature. In the case of inconsistent data - for which we know the values are not correct - we could remove those values, replace them with more consistent values - for example, the mean of the remaining observations - or even use more advanced AI methods to impute the value of those outliers.
The second case is more complicated. On the one hand, having such extreme data could greatly impair the capabilities of our models, and on the other hand, ignoring an outlier could have devastating consequences depending on the scenario in which we find ourselves.
To illustrate the case in which we keep outliers and they hurt us, we can imagine a scenario in which we want to predict a target variable - for example, a person's annual income - as a function of one or more predictor variables - years of experience, municipality in which he/she works, level of education, etc. If we were to use linear regression - simplistically, a method that fits a line to the data in the best possible way - we can see that an outlier could greatly impair the way that line fits the data, as shown in Figure 1.
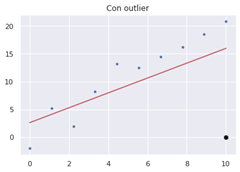
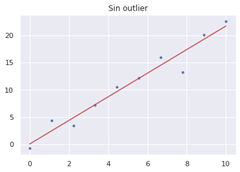 Figure 1: Comparison of results of a linear regression with and without outlier.
Figure 1: Comparison of results of a linear regression with and without outlier.
In the event that we choose to ignore these extreme values, we may have the problem of not being able to predict the consequences of such events which, although improbable, are possible. An example would be the case of the Fukushima nuclear disaster. In this case, a magnitude 9.0 earthquake was estimated to be unlikely, so the plant was not designed to withstand it (Silver, N. "The Signal and the Noise", 2012). Indeed, the probability of an earthquake of such a magnitude in that area was very small, but if the effects and damage had been analysed, it would have been possible to act differently.
Anomalies in sensors and IoT networks
It is the same in the IoT world: is the data real, or is it due to sensor error? In both cases, appropriate action needs to be taken. If the anomalous data is due to a malfunction of the sensors at specific points in time, what we will try to do is to locate those errors and predict or estimate the real value based on the rest of the data captured by the sensor. There are several AI algorithms that can be used here: based on recurrent neural networks, such as LTSMs, on time series, such as ARIMA models, and a long etcetera.
The process here would be as follows: we have a sensor inside an office building, in order to obtain the temperature over time to optimise the energy expenditure of the building and improve the comfort of the employees. When we receive the data from the sensor, it will be compared with the data predicted by an AI model. If the discrepancy is very large at a certain point - we assume that the sensor shows a temperature of 30°C at one point in time, while the rest of the day and our model show temperatures around 20-21°C - the model will detect that data as an outlier and replace it with the value predicted by our model.
In the case of receiving an anomalous data, but we do not know if it is real or not and it could be very harmful, we should act differently. It is not the same to detect a temperature in a building that is slightly higher than normal for a few moments as it is to detect very low blood sugar values in patients with diabetes - another IoT use case example.
The impact of outliers on data quality
As Clive Humby - one of the first data scientists in history - said, "data is the new oil". The value that data has taken on in our society explains the rapid development of fields such as IoT in recent years.
However, as with oil, if this data is not of the necessary quality and does not adequately reflect the information we need, it is worthless. Having the wrong data can lead to drastically different decisions that will take time and money to rectify. That's why, when capturing data in IoT environments, getting those outliers detected and corrected is a critical task.
Image: master1305 /Freepik
* * *
For more content on IoT and Artificial Intelligence, feel free to read other articles in our series:
: Multiplying the value of connected things")
: Water, a sea of data")
: You can already maximise the impact of your campaigns in the physical space")
: Recommendation and optimisation of advertising content on smart displays")