Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

¿Están los LLM revolucionando el futuro y nos superarán? Métodos clave para medir su poder (Parte 1)
En los últimos años los Large Language Models (LLM) han transformado significativamente la forma en que interactuamos con la inteligencia artificial, revolucionando sectores que van desde la atención al cliente hasta la investigación científica.
Sin embargo, el rápido avance de estos modelos plantea una pregunta crítica: ¿cómo medimos de manera efectiva su rendimiento? Dado que los LLM no solo deben generar texto coherente, sino también responder con precisión, adaptarse a diversos contextos y manejar tareas cada vez más complejas, la evaluación de su calidad es un desafío multidimensional.
En este artículo veremos algunos de los métodos más utilizados para medir el rendimiento de estos modelos. Con una comprensión clara de estas herramientas de evaluación podremos analizar de manera más rigurosa la capacidad de los LLM para resolver problemas reales y su potencial para seguir avanzando en la IA conversacional.
Métodos de evaluación de rendimiento
Cuando se anuncia el lanzamiento de un LLM se suele mostrar una tabla como la siguiente. En este caso estamos mostrando la tabla del performance del modelo Llama 3, de Meta. Aquí se pueden ver las evaluaciones del modelo en distintas pruebas. Hoy, en este artículo, exploraremos en qué consisten las dos primeras, MMLU y GPQA.
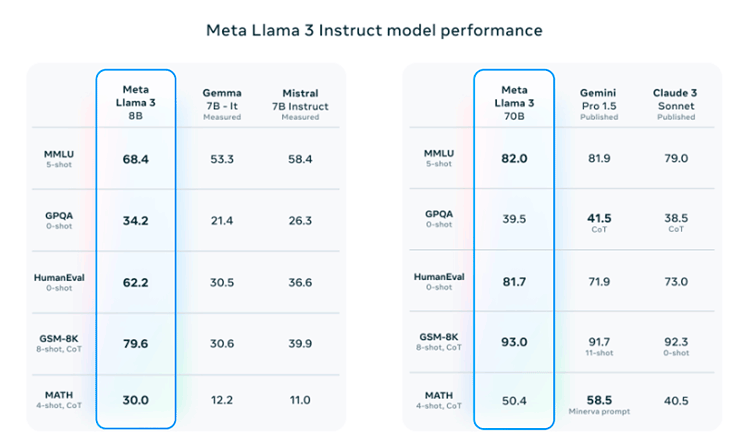
Undergraduate level knowledge (MMLU)
La prueba de comprensión lingüística multitarea masiva (MMLU) dijo “Hola mundo” a raiz del paper Measuring Massive Multitask Language Understanding, publicado en 2020 por Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, Jacob Steinhardt.
En el paper se propuso una prueba para medir la precisión multitarea de modelos textuales de la época, que no estaban muy de moda por aquel entonces, pero ya existían.
- La prueba abarca 57 tareas, entre ellas matemáticas elementales, historia de Estados Unidos, informática y derecho.
- Para obtener una alta nota en esta prueba, los modelos deben poseer un amplio conocimiento del mundo y capacidad para resolver problemas.
En la publicación del paper se observó que, si bien la mayoría de los modelos del momento tenían una precisión cercana a la del azar, el modelo GPT-3 más grande mejoraba al azar en casi 20 puntos porcentuales de media. Recordemos que ha llovido desde entonces, el modelo disponibilizado en la aplicación ChatGPT es GPT-3.5 y existen versiones más avanzadas como el 4o, 4, etc.
Sin embargo, en 2020, en cada una de las 57 tareas, los mejores modelos seguían necesitando mejoras sustanciales antes de alcanzar la precisión de un experto. Los modelos también tenían un rendimiento desigual y a menudo no saben cuándo se equivocan. Peor aún, seguían teniendo una precisión casi aleatoria en algunos temas socialmente importantes, como la moral y el derecho.
✅ Al evaluar de forma exhaustiva la amplitud y profundidad de los conocimientos académicos y profesionales de un modelo, la prueba puede utilizarse para analizar modelos en muchas tareas e identificar deficiencias importantes.
En 2024 todas esas brechas y distancias máquina-humano se han reducido notablemente, llegando la máquina, en algunas áreas de conocimiento, a ser capaz de tratar de tú a tú a personal experto en ciertas materias.
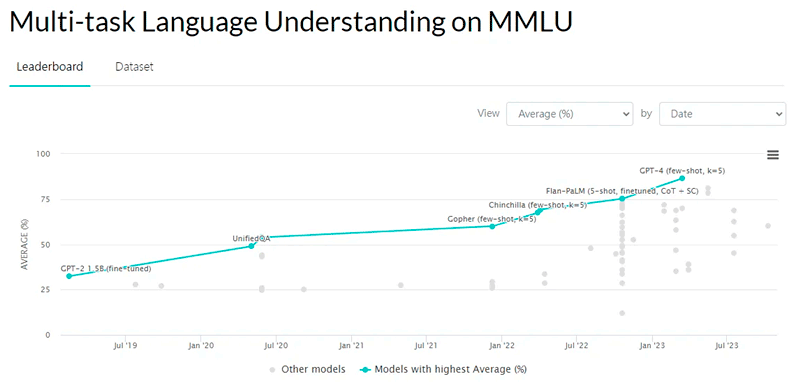
Observa cómo ha ido evolucionando la nota de la prueba MMLU para diversos LLM a lo largo de los años. Desde los aproximadamente 30 puntos de GPT-2 a los 86 de GPT-4, en apenas ¡4 años!
Y ahora veamos el estado del arte en 2024.

¿A qué hace referencia el 5-shot que aparece bajo los resultados de cada LLM?
Los modelos de lenguaje pueden ser evaluados en diferentes modalidades según el número de ejemplos que se les proporciona antes de responder. Esto es lo que se conoce como "few-shot", "zero-shot" o "one-shot".
- Zero-shot: El modelo responde directamente sin haber visto ningún ejemplo previo.
- One-shot: El modelo recibe un ejemplo antes de ser evaluado.
- Few-shot (n-shot): El modelo recibe varios ejemplos antes de responder a la nueva pregunta.
El término 5-shot significa que el modelo recibe 5 ejemplos de cómo se debe responder a una pregunta antes de ser evaluado en una nueva pregunta similar.
Y ahora lo interesante, ¡veamos algunas preguntillas que se le hacen a los LLM! En este caso, extraídas del paper, pregunta de macroeconomía, física, matemáticas y medicina. ¿Conoces la respuesta de alguna? 😊

✅¿Te interesa leer el paper donde se presenta este modelo de evaluación? Lo tienes aquí: Measuring Massive Multitask Language Understanding →
GPQA
GPQA es un desafiante conjunto de datos de 448 preguntas de opción múltiple escritas por expertos en biología, física y química.
En este caso las preguntas son de alta calidad y extremadamente difíciles: los expertos que tienen o están haciendo doctorados en los dominios correspondientes alcanzan una precisión del 65%, mientras que los validadores no expertos altamente cualificados sólo alcanzan una precisión del 34%. Todo ello a pesar de pasar una media de más de 30 minutos con acceso ilimitado a la web (es decir, las preguntas son “a prueba de Google”).
Y como no podía ser menos, las preguntas también son difíciles para los sistemas de inteligencia artificial más avanzados, ¡GPT-4, alcanza una precisión de menos del 40%!
Esta prueba no tiene como objetivo frustrar por placer a los doctores, futuros doctores y a los LLM; se desea ir más allá: si queremos que los futuros sistemas de IA nos ayuden a responder a preguntas muy difíciles, por ejemplo, a la hora de desarrollar nuevos conocimientos científicos, se tienen que desarrollar métodos de supervisión escalables que permitan a los humanos supervisar sus resultados, lo que puede resultar difícil incluso si los supervisores son expertos y tienen conocimientos.
La dificultad de GPQA tanto para los no expertos como para los sistemas de IA de vanguardia debería permitir experimentos de supervisión escalables y realistas, que esperamos puedan ayudar a idear formas de que los expertos humanos obtengan información veraz de sistemas de IA que superan las capacidades humanas.
Estas son las métricas de algunos de los LLM más fuertes del mercado.

Recordemos, por insistir, que Zero-shot significa que el modelo responde directamente una pregunta sin haber visto ningún ejemplo previo.
✅ Y como intuyo que también tienes mucha curiosidad, te dejo el paper por aquí: A Graduate-Level Google-Proof Q&A Benchmark →
Conclusiones
Los LLM más avanzados del mercado, como GPT-4 de OpenAI, PaLM de Google, LLaMA de Meta y otros, se entrenan con volúmenes de datos extremadamente grandes y diversos, que abarcan una amplia variedad de fuentes. Dentro de la vasta cantidad de datos con los que se han entrenado ya existe información que puede resolver las cuestiones a las que se enfrentan en las pruebas anteriormente mencionadas.
Consecuentemente es obligatorio hacerse la siguiente pregunta, ¿más datos mejorarían el rendimiento de estos modelos? ¿más cómputo, más billones (americanos) de parámetros? o en una línea de trabajo paralela, ¿habría que hacer más hincapié en la calidad del dato, su tratamiento, etc.?
Para cerrar este primer capítulo, podemos llegar a la conclusión de que medir el rendimiento de los LLM es una tarea compleja que requiere de la utilización de diversos métodos para capturar sus capacidades y limitaciones.
A través de pruebas cualitativas, como MMLU, es posible evaluar con mayor precisión el nivel de comprensión, adaptabilidad y eficiencia de estos modelos en una amplia gama de tareas.
Sin embargo, a medida que los LLM continúan evolucionando, es fundamental que los métodos de evaluación también se adapten para reflejar su creciente sofisticación y su impacto en el mundo real.
En última instancia, un enfoque riguroso y diversificado para medir su rendimiento permitirá que estas herramientas sigan impulsando avances en la inteligencia artificial y en diversas disciplinas.
La imagen de apertura está, por supuesto, sacada con una inteligencia artificial generativa, en este caso se usa Dall-E. Prompt: picture of a mad scientist working with an AI to solve complex problems.
■ MÁS DE ESTA SERIE
")