Cloud & Business Apps
Cloud & Business Apps Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Are LLMs transforming the future? Will they overtake us? Key methods to measure their power (Part 1)
Large Language Models (LLMs) have significantly transformed the way we interact with artificial intelligence in recent years, revolutionizing industries ranging from customer service to scientific research.
The rapid advancement of these models, however, raises a critical question: how do we effectively measure their performance? Since LLMs must not only generate coherent text, but also respond accurately, adapt to diverse contexts, and handle increasingly complex tasks, assessing their quality is a multidimensional challenge.
In this article we will look at some of the most commonly used methods for measuring the performance of these models. We will have a clear understanding of these evaluation tools and will be able to more rigorously analyze the ability of LLMs to solve real problems and their potential for further advancement in conversational AI.
Performance evaluation methods
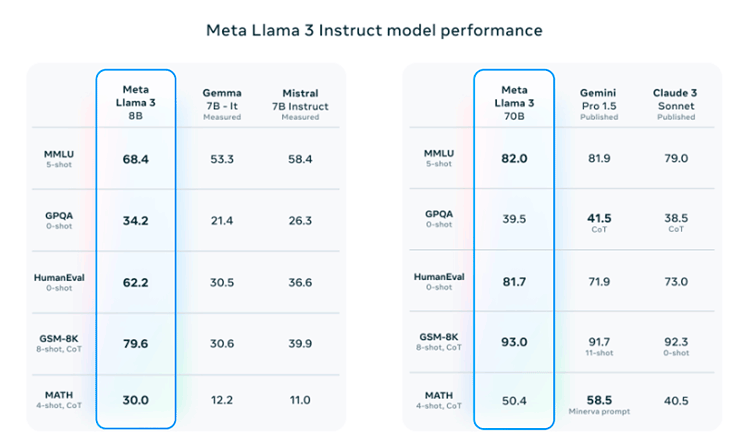
When the launch of an LLM is announced, a table like the one below is usually displayed. In this case we are showing the performance table of Meta's Llama 3 model. Here you can see the evaluations of the model in different tests. In this article, we will explore what the first two, MMLU and GPQA, are all about.
Undergraduate level knowledge (MMLU)
The Massive Multitask Language Understanding (MMLU) test said “Hello world” following the paper Measuring Massive Multitask Language Understanding, published in 2020 by Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, Jacob Steinhardt.
The paper proposed a test to measure the multitask accuracy of textual models of the time, which were not very fashionable at the time, but already existed.
- The test covers 57 tasks, including elementary mathematics, U.S. history, computer science, and law.
- Models must have a broad knowledge of the world and problem-solving skills to score high on this test.
The paper's publication noted that while most models at the time were close to randomly accurate, the largest GPT-3 model improved randomly by nearly 20 percentage points on average. Recall that it has rained since then, the model available in the ChatGPT application is GPT-3.5 and there are more advanced versions such as 4o, 4, etc.
However, in 2020, in each of the 57 tasks, the best models still needed substantial improvement before reaching expert accuracy. The models also had uneven performance and often do not know when they are wrong. Even worse, they continued to have near-random accuracy on some socially important topics, such as morality and law.
✅ By comprehensively assessing the breadth and depth of a model's academic and professional knowledge, the test can be used to analyze models on many tasks and identify important gaps.
In 2024 all of these gaps and machine-human distances have narrowed significantly, with the machine, in some knowledge areas, being able to deal one-on-one with expert personnel in certain subjects.
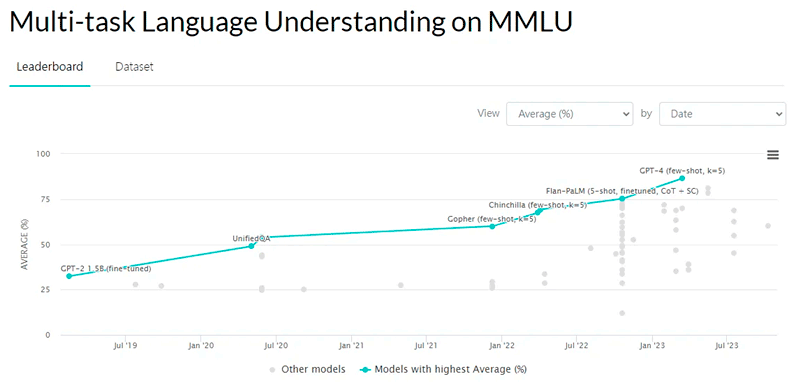
Look at how the MMLU test score for various LLMs has evolved over the years. From around 30 points in GPT-2 to 86 points in GPT-4, in just 4 years!!
And now let's look at the state of the art in 2024.

What does the [term] 5-shot below the results of each LLM refer to?
Language models can be evaluated in different modes depending on the number of examples provided to them before responding. This is known as “few-shot”, “zero-shot” or “one-shot”.
- Zero-shot: The model responds directly without having seen any previous example.
- One-shot: The model receives one example before being evaluated.
- Few-shot (n-shot): The model receives several examples before answering the new question.
The term 5-shot means that the model receives 5 examples of how a question should be answered before being evaluated on a new similar question.
And now for the interesting part, let's take a look at some of the little questions asked to LLMs! In this case, extracted from the paper, question from macroeconomics, physics, mathematics and medicine. do you know the answer to any of them? 😊

✅Are you interested in reading the paper where this evaluation model is presented? You can read it here: Measuring Massive Multitask Language Understanding →
GPQA
GPQA is a challenging dataset of 448 multiple-choice questions written by experts in biology, physics, and chemistry.
In this case the questions are of high quality and extremely difficult: experts who have or are doing PhDs in the corresponding domains achieve an accuracy of 65%, while highly qualified non-expert validators only achieve an accuracy of 34%. All this despite spending an average of more than 30 minutes with unlimited access to the web (i.e., the questions are “Google-proof”).
And not to be outdone, the questions are also difficult for the most advanced Artificial Intelligence systems, GPT-4, reaches an accuracy of less than 40%!
This test is not intended to frustrate doctors, future doctors, and LLMs for pleasure; it is intended to go further. If we want future AI systems to help us answer very difficult questions, for example, in developing new scientific knowledge, scalable supervisory methods have to be developed that allow humans to supervise their results, which can be difficult even if the supervisors are experts and knowledgeable.
The difficulty of GPQA for both non-experts and state-of-the-art AI systems should enable scalable and realistic supervision experiments, which hopefully can help devise ways for human experts to obtain truthful information from AI systems that exceed human capabilities.
These are the metrics of some of the strongest LLMs on the market.

Let's remember, to insist, that Zero-shot means that the model directly answers a question without having seen any previous example.
✅ And as I guess you are also very curious, I leave you the paper here: A Graduate-Level Google-Proof Q&A Benchmark →
Conclusions
The most advanced LLMs on the market, such as OpenAI's GPT-4, Google's PaLM, Meta's LLaMA and others, are trained on extremely large and diverse volumes of data, spanning a wide variety of sources. Within the vast amount of data, they are trained on there already exists information that can resolve the questions they face in the above tests.
It is therefore mandatory to ask the following question, would more data improve the performance of these models, more computation, more billions (American) of parameters, or in a parallel line of work, should more emphasis be placed on the quality of the data, its treatment, etc.?
We can conclude that measuring the performance of LLMs is a complex task that requires the use of various methods to capture their capabilities and limitations.
It is possible through qualitative testing, such as MMLU, to assess more accurately the level of understanding, adaptability, and efficiency of these models across a wide range of tasks.
However, as LLMs continue to evolve, it is critical that assessment methods also adapt to reflect their increasing sophistication and real-world impact.
Ultimately, a rigorous and diversified approach to measuring their performance will enable these tools to continue to drive advances in artificial intelligence and across disciplines.
The opening image is, of course, taken with a generative artificial intelligence, in this case Dall-E is used. Prompt: picture of a mad scientist working with an AI to solve complex problems.
■ MORE OF THIS SERIES
")