 Cloud Híbrida
Cloud Híbrida Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes

Humanity's Last Exam para una evaluación rigurosa del progreso de la IA
En anteriores artículos hemos hablado sobre la importancia de evaluar el progreso de los modelos de lenguaje para comprender sus capacidades y sus limitaciones, y para orientar de forma adecuada su desarrollo. No se trata solo de medir su rendimiento en tareas específicas, sino también la profundidad de lo que llamamos su conocimiento y razonamiento.
Como vimos entonces, los modelos de lenguaje ya comienzan a superar muchos de los benchmarks tradicionales, como MMLU y GPQA, alcanzando en algunos casos niveles de rendimiento que llegan al 90% de la escala de medición.
Esto ha generado la necesidad de desarrollar nuevos enfoques de evaluación, más exigentes y representativos.
Más allá de los benchmarks convencionales
Hoy no existe un marco universal para evaluar modelos de IA. Mientras que organismos como NIST e ISO trabajan en la definición de estándares, en la práctica la industria se basa en un conjunto de benchmarks de facto, como MMLU, GSM8K (para matemáticas) y HumanEval (para generación de código).
Sin embargo, cada desarrollador combina métricas y pruebas de manera particular, lo que dificulta la comparación directa entre modelos.
■ Uno de los desafíos en la evaluación de la IA es el fenómeno de ‘entrenamiento para test’, cuando los modelos se optimizan para destacar en pruebas de evaluación sin que esto implique un verdadero desarrollo en su capacidad de razonamiento, como en el caso Dieselgate.
Humanity’s Last Exam
De esta necesidad surge la propuesta de Humanity’s Last Exam (HLE), un método de evaluación diseñado para escudriñar en el conocimiento académico de la IA desde una perspectiva más profunda; midiendo habilidades como el razonamiento avanzado, la comprensión temática y la calibración de confianza.
En lugar de enfocarse en preguntas de opción múltiple o en la mera recuperación de información, HLE evalúa el conocimiento a través de 3.000 preguntas cerradas de respuesta abierta que abarcan más de cien disciplinas académicas. Su objetivo es reflejar mejor las habilidades cognitivas de los LLM en contextos académicos expertos, incluyendo:
- Humanidades y Clásicos: Historia, literatura, filosofía y lenguas de civilizaciones antiguas, como Grecia y Roma.
- Ciencias naturales: Física, biología y química, con problemas que exigen un análisis detallado.
- Matemáticas y lógica: Preguntas que ponen a prueba la capacidad de razonamiento formal y resolución de problemas abstractos.
- Ecología y ciencias de la vida: Evaluaciones sobre las interacciones biológicas y adaptaciones de los organismos a su entorno.
—Por ejemplo, una pregunta en en la temática de Clásicos podría requerir la traducción de una inscripción romana en escritura palmirena, siempre y cuando el modelo evaluado sea multimodal.
 Imagen: Humanity's Last Exam.
Imagen: Humanity's Last Exam.
Un aspecto relevante en el desarrollo de HLE es que en él participan un millar de expertos de más de 500 instituciones en 50 países, incluyendo profesores, investigadores y titulados de posgrado. Esta variedad de perspectivas busca que las preguntas formuladas sean de alta calidad y profundidad, reflejando fielmente los desafíos académicos a la vez que incorpora diferentes perspectivas científicas y culturales.
Las preguntas de HLE buscan evaluar la comprensión profunda de los LLM más allá de la simple generación de texto.
La calibración de confianza como pilar de la evaluación
Los LLM a veces generan respuestas incorrectas, y es importante que sean capaces de reconocer cuándo sucede y ellos mismo no están seguros de su respuesta.
HLE enfatiza la necesidad de que los modelos reconozcan su propia incertidumbre en lugar de dar por buenas sus alucinaciones: respuestas que son incorrectas o inventadas generadas con exceso de seguridad. Un modelo bien calibrado debería indicar una menor confianza en su respuesta cuando hay una alta probabilidad de que sea incorrecta.
Para evaluar esto, HLE requiere que cada respuesta generada vaya acompañada de un indicador de su nivel de confianza expresado en una escala del 0% al 100%.
- Si predice una respuesta con un 90% de confianza y esa respuesta es incorrecta, el modelo tiene un problema de calibración y sobreestima su certeza.
- Si un modelo está bien calibrado, cuando indique que tiene un 80% de confianza en su respuesta entonces sus respuestas serán correctas, de promedio, el 80% de las veces.
Con esto se busca detectar cuándo un modelo realmente comprende una respuesta y cuándo solo está generando una predicción sin fundamento. Conocer este parámetro de fiabilidad es fundamental también para conocer sus limitaciones. Sobre todo si el modelo se va a implementar en ámbitos críticos como el diagnóstico médico.
HLE enfatiza la necesidad de que los modelos reconozcan su incertidumbre en lugar de generar respuestas incorrectas con excesiva confianza.
Limitaciones y oportunidades de mejora
Los primeros resultados obtenidos con HLE muestran que modelos avanzados y muy utilizados, como GPT-4o y Grok-2, tienen dificultades para responder correctamente a preguntas muy especializadas. En HLE alcanzan tasas de acierto y puntuaciones significativamente más bajas (menos del 4%) que en pruebas anteriores.
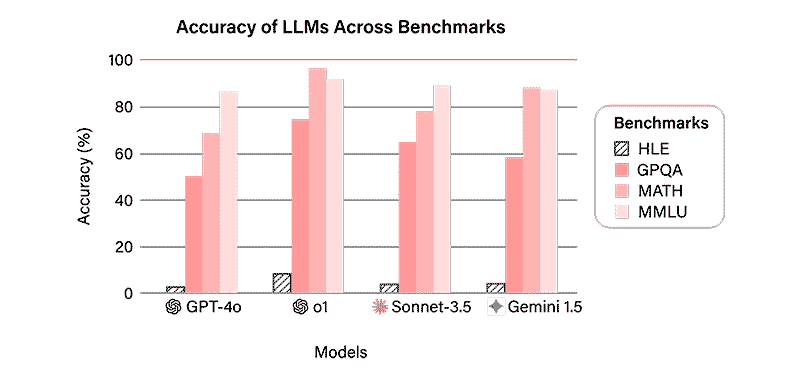 Imagen: Humanity's Last Exam.
Imagen: Humanity's Last Exam.
Además, HLE ha identificado problemas en la resolución de problemas matemáticos y en la capacidad para manejar conceptos abstractos. Estas deficiencias reflejan que muchos modelos están más optimizados para la predicción secuencial de palabras que para una comprensión estructural profunda.
Estos hallazgos certifican la necesidad de desarrollar métodos de evaluación rigurosos. Que no solo midan la capacidad de generación de texto, sino también la habilidad de razonamiento y generalización.
■ Calibración e interpretabilidad: un modelo bien calibrado revela mejor sus propias limitaciones y grados de incertidumbre, lo que permite comprender mejor cómo y por qué genera ciertos resultados o toma determinadas decisiones. Un mayor transparencia mejora si utilidad y fiabilidad en aplicaciones prácticas.
Conclusión
El desarrollo de nuevas métricas de evaluación refleja tanto la acelerada evolución de los modelos de lenguaje como la necesidad de mejorar la forma en que se mide su progreso. HLE, con su enfoque en dificultad, diversidad temática, calibración y colaboración global, aspira a ir un paso más allá en la evaluación del conocimiento académico de los LLM.
Los resultados de HLE revelan deficiencias persistentes en el razonamiento matemático y la comprensión conceptual de los LLM.
A pesar de los avances en el rendimiento, tamaño y eficiencia de los modelos LLM, sus tasas de acierto modestas, incluso en las versiones más avanzadas, indican que todavía queda un amplio margen de mejora para que la IA satisfaga las demandas de rigor y exactitud que exige el campo académico y profesional.
La propuesta de HLE reafirma la necesidad de adoptar pruebas que evalúen la capacidad de los modelos de manera holística y rigurosa, para garantizar que el desarrollo de los modelos está alineado con las necesidades humanas.




