 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Humanity's Last Exam for a rigorous assessment of AI progress
In previous articles, we discussed the importance of evaluating language models' progress to understand their capabilities and limitations and to guide their development appropriately. It is not just about measuring their performance in specific tasks, but also the depth of what we call their knowledge and reasoning.
As we saw then, language models are already beginning to surpass many traditional benchmarks, such as MMLU and GPQA, reaching performance levels that hit 90% on the measurement scale in some cases.
This has generated the need to develop enhanced, more demanding and representative assessment approaches.
Beyond conventional benchmarks
Today there is no universal framework for evaluating AI models. While organizations like NIST and ISO work on defining standards, the industry relies in practice on a set of de facto benchmarks, such as MMLU, GSM8K (for mathematics), and HumanEval (for code generation).
However, each developer combines metrics and tests in a particular way, making direct comparisons between models difficult.
■ One of the challenges in evaluating AI is the phenomenon of ‘test training’, where models are optimized to excel in evaluation tests without this implying a true development in their reasoning capacity, as in the Dieselgate case.
Humanity’s Last Exam
From this need arises the proposal for Humanity’s Last Exam (HLE), a method designed to scrutinize AI academic knowledge from a deeper perspective; measuring skills such as advanced reasoning, thematic understanding, and confidence calibration.
Instead of focusing on multiple-choice questions or mere information retrieval, HLE evaluates knowledge through 3,000 closed-ended questions spanning over a hundred academic disciplines. Its goal is to better reflect LLM cognitive abilities in expert academic contexts, including:
- Humanities and Classics: History, literature, philosophy, and languages of ancient civilizations, such as Greece and Rome.
- Natural sciences: Physics, biology, and chemistry, with detailed analysis problems.
- Mathematics and logic: Questions that test formal reasoning and abstract problem-solving abilities.
- Ecology and cife sciences: Assessments of biological interactions and organism adaptations to their environment.
—For example, a question in the Classics theme might require the translation of a Roman inscription in Palmyrene writing, provided the evaluated model is multimodal.
 Image: Humanity's Last Exam.
Image: Humanity's Last Exam.
A relevant aspect of HLE development is the participation of a thousand experts from over 500 institutions in 50 countries. These experts include professors, researchers, and postgraduate degree holders. This variety of perspectives aims for high quality and depth questions, faithfully reflecting academic challenges while incorporating different scientific and cultural perspectives.
HLE questions seek to assess LLMs' deep understanding beyond mere text generation.
Calibration confidence as the cornerstone of assessment
LLMs sometimes generate incorrect answers, and it is important that they recognize when this happens and they are not sure of their own answer.
HLE emphasizes the need for models to recognize their own uncertainty instead of confidently generating hallucinations: answers that are incorrect or invented generated with excessive confidence. A well-calibrated model should indicate lower confidence in its response when there is a high probability of it being incorrect.
To evaluate this, HLE requires that each generated response be accompanied by an indicator of its confidence level expressed on a scale from 0% to 100%.
- If it predicts a response with 90% confidence and that answer is incorrect, the model has a calibration problem and overestimates its certainty.
- If a model is well calibrated, when it indicates it has 80% confidence in its response, then its answers will be correct, on average, 80% of the time.
This seeks to detect when a model truly understands an answer and when it is just generating a prediction without foundation. Knowing this reliability parameter is also fundamental to understanding its limitations, especially if the model is to be implemented in critical areas such as medical diagnosis.
HLE emphasizes the need for models to recognize uncertainty instead of generating incorrect answers with excessive confidence.
Limitations and improvement opportunities
The first results obtained with HLE show that advanced and widely used models, such as GPT-4o and Grok-2, have difficulties correctly answering very specialized questions. In HLE they achieve significantly lower success rates and scores (less than 4%) than in previous tests.
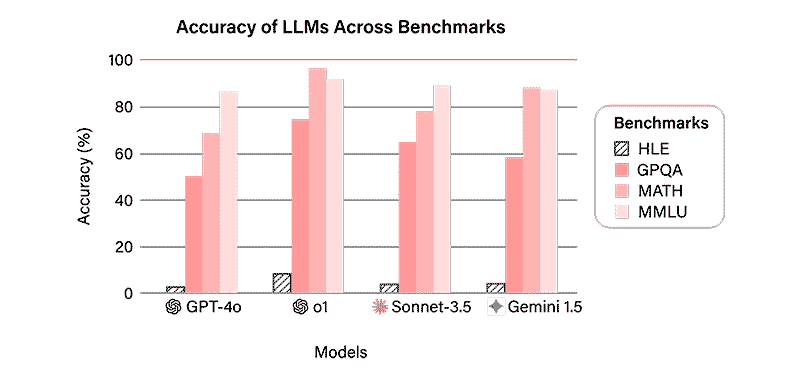 Image: Humanity's Last Exam.
Image: Humanity's Last Exam.
Additionally, HLE has identified issues with solving mathematical problems and handling abstract concepts. These deficiencies reflect that many models are better optimized for sequential word prediction than for deep structural understanding.
These findings confirm the need to develop rigorous evaluation methods. Tests that measure not only text generation abilities but also reasoning and generalization abilities as well.
■ Calibration and interpretability: A well-calibrated model better reveals its own limitations and degrees of uncertainty, allowing for a better understanding of how and why it generates certain results or makes certain decisions. Greater transparency improves practical utility and reliability.
Conclusion
The development of revised evaluation metrics reflects both the accelerated evolution of language models and the need to improve how their progress is measured. HLE, with its focus on difficulty, thematic diversity, calibration, and global collaboration, aims to take a step further in assessing LLM academic knowledge.
HLE results reveal persistent deficiencies in LLM mathematical reasoning and conceptual understanding.
Despite advances in LLM performance, size, and efficiency, their modest success rates, even in the most advanced versions, indicate that AI still has ample room for improvement to meet the rigorous and precise demands of the academic and professional fields.
The HLE proposal reaffirms the need for tests that holistically and rigorously evaluate models' capacity, to ensure model development aligns with human needs.




