 Hybrid Cloud
Hybrid Cloud Cybersecurity
Cybersecurity Data & AI
Data & AI IoT & Connectivity
IoT & Connectivity Industry
Industry Health
Health Banking and Finance
Banking and Finance Public Sector
Public Sector Retail
Retail Tourism and Leisure
Tourism and Leisure Transport & Logistics
Transport & Logistics Energy & Utilities
Energy & Utilities Smart Cities
Smart Cities

Biases in AI (II): Classifying biases
We have already seen in the first chapter of this series the concept of biases and other related concepts, such as a particularly relevant one: discrimination. Once these concepts have been analyzed, it is essential to identify and classify them in order to be able to deal with the risks involved. Let's start with biases.
The National Institute of Standards and Technology (NIST)—the U.S. government agency in charge of promoting innovation and industrial competition—published NIST Special Publication 1270 in March 2022, entitled Towards a Standard for Identifying and Managing Bias in Artificial Intelligence, which aims to provide guidance for future standards in identifying and managing biases.
This document:
- On the one hand it describes the stakes and challenge of bias in AI and provides examples of how and why it can undermine public trust.
- On the other hand, it identifies three categories of bias in AI (systemic, statistical, and human) and describes how and where they contribute to harm.
- And finally, it describes three major challenges to mitigating bias: datasets, testing and evaluation, and human factors, and introduces preliminary guidance for addressing them.
As we were saying and according to NIST, there are three types of biases that affect AI-based systems: computational or statistical biases, human biases, and systemic biases.

We are going to develop these three types of biases indicated by NIST, complementing this classification with more detail and our own points of view.
1. Computational biases
These are the ones that we can measure from a trained Artificial Intelligence model. They are the tip of the iceberg and, although measures can be taken to correct them, they do not constitute all the sources of possible biases involved.
Statistical or computational biases arise from errors that result when the sample is not representative of the population. These biases arise from systematic rather than random factors.
The error can occur without prejudice, bias, or discriminatory intent.
These biases are present in AI systems in the data sets and algorithmic processes used in the development of AI applications and often arise when algorithms are trained on one type of data and cannot extrapolate beyond that data.
Here we can find several types in turn
- a. Data Selection Bias: occurs when the data used to train a model does not fairly represent reality.
—For example, if a hiring algorithm is trained primarily on male resumes, it could bias decisions toward male candidates. - b. Algorithmic Bias: occurs when algorithms favor certain outcomes or certain groups.
—For example, a credit system that automatically penalizes low-income people because of their financial history could have an algorithmic bias.
2. Human biases
These are those we each have implicitly that affect how we perceive and interpret the information we receive.
Human biases reflect systematic errors in human thinking based on a limited number of heuristic principles and value prediction to simpler judgmental operations. They are also known as cognitive biases as they are related to the way in which human beings process information and how we make decisions based on it.
Within human bias we can find several categories:
- a. Confirmation Bias: occurs when the AI system relies on pre-existing beliefs or assumptions in the data, as there is a tendency to search for, interpret and remember data that reinforces those pre-existing beliefs or opinions.
—For example, if a movie recommendation algorithm only suggests specific genres to a user, it might reinforce their previous preferences. - b. Anchoring Bias: occurs when there is an over-reliance on the first piece of information or anchor.
—For example, if an online pricing system displays a high initial price, users may perceive any price below that initial anchor as a 'bargain' or cheap price. - c. Halo effect: valuing a person or thing in terms of a salient characteristic. — For example, assuming that a candidate with a prestigious university on his or her resume is automatically more competent. d. Negativity Bias: occurs when more weight is given to negative information than to positive information.
—For example, imagine a fraud detection system might be more likely to identify false positives due to this bias derived from being trained with 'negative' information.
These human biases are introduced into AI systems in several ways:
- During their development (e.g., by programming a credit system by introducing existing human biases).
- In training (e.g., by using male training data in a selection process).
- In labeling (if there are errors or biases in human labeling that introduce such bias into the data).
- For loss and optimization functions (if it penalizes some errors more than others it may also penalize certain groups or certain characteristics
3. Systemic biases
And finally, systemic biases are those that are embedded in society and institutions for historical reasons. It need not be the result of any conscious bias or prejudice but rather of the majority following existing rules or norms.
These biases are present in the data sets used in AI, and institutional norms, practices and processes throughout the AI life cycle and in broader culture and society. Racism and sexism are the most common examples.
In turn, Rhite's practical guide distinguishes the two main categories of bias that exist:
- On the one hand, social bias, related to prejudices, stereotypes or inclinations rooted in a culture or society, of which historical bias is an example.
- And on the other hand, statistical bias, which involves a systematic difference between an estimated parameter in the data and its actual value in the real world and occurs when the data fail to accurately capture the expected variables or phenomena, leading to faulty AI results, such as representation bias and measurement bias.
Likewise, he adds cognitive biases that:
"They are systematic errors in thinking that can affect judgment and decision making".
Among these is the most common example of confirmation bias, in which people tend to look for or give more weight to data that confirm their pre-existing ideas or hypotheses.
In turn, the RIA in Article 14.4.b) includes the automation bias, which consists of.
"Possible tendency to rely automatically or excessively on the output results generated by an AI system (...)".
This type of bias is closely related to the confirmation and anchoring biases, categories belonging to the cognitive/human biases:
- Regarding confirmation bias, the tendency to seek information that confirms our prior beliefs may reinforce confidence in the results of AI systems, even when they make mistakes.
- Concerning the anchoring bias, over-reliance on initial information could lead to a predisposition to automatically trust the AI system's suggestions (which would function as an 'anchor').
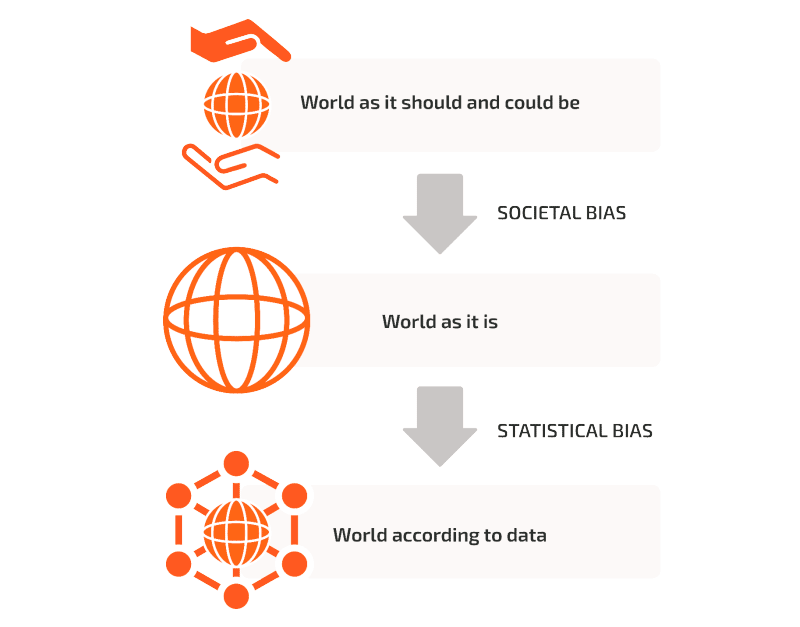 Source: Rhite.
Source: Rhite.
Conclusion
The identification and classification of the biases that affect AI is of relevant importance in order to prevent and manage the risks derived from those biases that can cause harm and violate the rights and freedoms of individuals.
In this sense, in this chapter we have identified the main categories of biases with implications in AI systems, these being: computational biases that come from errors in the results of AI systems; human biases that come from the people involved in the processes of an AI system (programming, classification, etc.); and systemic biases that affect society as a whole.
■ In the next chapter we will delve into the classification of types of discrimination.
MORE IN THIS SERIES
: The necessary distinction between biases and related concepts")



