 Cloud y Business Apps
Cloud y Business Apps Ciberseguridad
Ciberseguridad Data & AI
Data & AI IoT y Conectividad
IoT y Conectividad Industria
Industria Salud
Salud Banca y Finanzas
Banca y Finanzas Sector Público
Sector Público Retail
Retail Turismo y Ocio
Turismo y Ocio Transporte y Logística
Transporte y Logística Energía y Utilities
Energía y Utilities Ciudades Inteligentes
Ciudades Inteligentes
AI of Things
Desde la unidad de negocio de AI of Things, Telefonica Tech ayuda a sus clientes en su proceso de transformación digital unificando las capacidades de IoT, Inteligencia Artificial, Big Data y Blockchain.
.jpg)
El potencial de la Inteligencia Artificial de las Cosas para transformar todo tipo de sectores
El concepto AI of Things (Inteligencia Artificial de las Cosas) que engloba las tecnologías digitales IoT, conectividad, Big Data e Inteligencia Artificial, entre otras, demuestra cada vez más su potencial para transformar todo tipo de sectores: agroalimentario, logístico, turístico, industrial… Los objetos físicos, provistos de sensores IoT y conectividad, junto con el análisis de grandes volúmenes de datos y la aplicación del aprendizaje automático y la Inteligencia Artificial permiten extraer conocimientos valiosos. También reconocer patrones, automatizar tareas, optimizar procesos y tomar decisiones basadas en datos. Esta capacidad multiplica el valor de las cosas conectadas y desbloquea nuevas oportunidades de negocio. En este post hemos reunido una selección de contenidos que exploran algunas de las tecnologías y aplicaciones de AI of Things que desarrollamos, utilizamos e implementamos en Telefónica Tech. Conectividad e IoT IA & Data Automatización, Conectividad e Inteligencia Aumentada al servicio de una reindustrialización competitiva, disruptiva y sostenible 18 de mayo de 2023 Conectividad e IoT Satélites con tecnología 5G para dar cobertura IoT en todo el planeta 10 de abril de 2023 AI of Things Estadios de fútbol inteligentes: el mayor espectáculo del mundo, aún más espectacular 25 de mayo de 2022 AI of Things Alumbrado público inteligente: oportunidades de negocio y beneficios 25 de enero de 2023 AI of Things Visualización de datos para una gestión óptima de flotas de vehículos 13 de diciembre de 2022 AI of Things Nuevas oportunidades empresariales con IoT (Internet de las Cosas) 29 de noviembre de 2022 AI of Things Cómo la digitalización permite conocer y atender con precisión las necesidades de un cultivo ecológico de cerezas 3 de octubre de 2022 AI of Things Tiendas phygital: qué son y cómo están cambiando la experiencia de compra 19 de julio de 2023 Conectividad e IoT IA & Data Digitalización industrial: revelamos las claves en Advanced Factories 2023 20 de abril de 2023 Conectividad e IoT IA & Data La evolución definitiva hacia la digitalización de la industria 22 de septiembre de 2022 AI of Things Entrega en 10 minutos: cómo la Inteligencia Artificial optimiza las rutas de reparto 26 de septiembre de 2022 AI of Things Las redes LPWA y 5G habilitan nuevas soluciones IoT 30 de noviembre de 2022 AI of Things Soluciones OEM para el coche conectado 15 de noviembre de 2022 AI & Data Edge AI: Inteligencia Artificial fuera de la nube 13 de abril de 2023 AI of Things Mantenimiento preventivo en sensores: anticipación de fallos en sensores, predicción de cambio de baterías 17 de octubre de 2022 AI of Things Soluciones de Big Data e Inteligencia Artificial para la industria del turismo 27 de septiembre de 2022 IA & Data AI of Things para una gestión eficiente y sostenible del agua 21 de agosto de 2023 IA & Data Ingredientes para las Ciudades Inteligentes del presente 16 de noviembre de 2023 Conectividad e IoT 5G: cuatro casos de uso reales y prácticos 22 de marzo de 2023 AI of Things How can we bring Internet of Things to the rural world? October 13, 2022 AI of Things Pódcast Latencia Cero: La inesperada relación entre Smart Cities y Agricultura Inteligente 5 de octubre de 2022 Imagen: rawpixel.com en Freepik.
26 de julio de 2023

Wifi 7: te damos las claves de la nueva generación
La conectividad wifi 7, la nueva versión del estándar de conectividad, va a llevar la velocidad de Internet a un nivel completamente nuevo. En comparación con su predecesor, wifi 6, esta nueva generación contempla mejoras en aspectos como la estabilidad, la eficiencia y la capacidad de respuesta. Pero, ¿qué efectos tendrá esto en la experiencia general del usuario? Hoy conocerás de cerca las novedades que trae la red wifi en su séptima versión (wifi 7) y los cambios que esto le depara al futuro de la conectividad. Un tráfico de datos más fluido con wifi 7 El nuevo wifi 7 permitirá una mejor experiencia de conexión, especialmente en contextos en los que es indispensable contar con una latencia óptima para manejar grandes cantidades de datos, como el streaming en 4K y 8K. A su vez, la llegada de wifi 7 es una buena noticia para los usuarios que requieren una conexión estable de cara al intercambio de datos en tiempo real, como las compañías con un alto volumen de dispositivos IoT (Internet de las Cosas). Esto es posible gracias a que el ancho de banda se duplica, pasando de 160 MHz a los 320 MHz. Por otro lado, con la duplicación MIMO (enlaces de entradas y salidas múltiples), se hace más eficiente la transmisión inalámbrica y se extiende la capacidad de acceso a flujos de servicios. Esto significa que el usuario podrá ejecutar múltiples aplicaciones al mismo tiempo con una baja incidencia de interrupción. La explicación está en una mayor capacidad de respuesta simultánea en bandas altas, incluso en áreas congestionadas. Un router de sexta generación, por ejemplo, puede conectarse a una sola banda de 2,4 GHz, 5 GHz y 6 GHz. En cambio, un router de la nueva generación admite múltiples bandas dentro de este espectro. También se espera una mejora notable en la conexión de múltiples dispositivos dentro de la misma red wifi, con lo cual habría grandes beneficios para las empresas que dependen de la interoperabilidad de equipos conectados a Internet (como los sistemas de vigilancia). Esta capacidad de conectar más dispositivos y mantener un tráfico de datos fluido también beneficia la conectividad en el hogar, mejorando la experiencia en videojuegos, streaming, manejo de plataformas online (teletrabajo), etc. Se estima que, en un hogar promedio, el nuevo wifi permitirá mantener entre 6 y 8 dispositivos conectados al mismo tiempo sin afectar la estabilidad o velocidad de transmisión. AI OF THINGS Las redes LPWA y 5G habilitan nuevas soluciones IoT 30 de noviembre de 2022 La nueva generación wifi 7 podrá alcanzar velocidades de más de 30 gigabits por segundo A grandes rasgos, se habla de una velocidad promedio cuatro veces superior a wifi 6, lo que abrirá un mundo de posibilidades a la retransmisión de contenido en 8K, los juegos multijugador en línea, las aplicaciones de realidad aumentada y otros servicios en la nube. Aunque el consenso general es que wifi 7 alcance velocidades de hasta 30 Gbps, Intel afirma que el nuevo estándar puede llegar a los 48 Gbps. Wifi 7 también será compatible con los routers wifi existentes, por lo que no hace falta preocuparse por sustituir los equipos actuales cuando se masifique el nuevo estándar. No obstante, en el futuro es posible que sea inevitable hacer la transición a un router de última generación para aumentar la cobertura wifiy mejorar la seguridad de las redes, tanto empresariales como domésticas. Se espera que la nueva generación wifi llegue al mercado a mediados de 2024, aunque el próximo año ya podríamos ver sus primeras aplicaciones. El nuevo estándar wifi 7 será más rápido que el actual, y podrá alimentar a más dispositivos simultáneamente, por lo que será clave para mejorar procesos industriales, flujos de trabajo y, desde luego, la experiencia de navegación.
7 de diciembre de 2022

Todo lo que debes saber sobre deep learning
Gracias al enorme desarrollo tecnológico de los últimos años, hoy existen soluciones de gran impacto para el entorno empresarial. Un claro ejemplo de ello es el deep learning, un concepto que cada vez adquiere mayor relevancia en las estrategias digitales gracias a las posibilidades que otorga. ¿Qué es deep learning? Se trata de un campo de la inteligencia artificial (IA) en el que algoritmos imitan la manera en que el cerebro humano procesa datos. Esto ocurre gracias a redes neuronales artificiales que buscan emular la manera en que el cerebro humano opera, para identificar patrones y generar predicciones a partir de grandes volúmenes de datos. Todo, sin la necesidad de supervisión, por lo que se trata de un tipo de machine learning, pero mucho más avanzado que el tradicional. Dado el potencial de esta tecnología para extraer información de valor -por ejemplo, para identificar oportunidades de negocio o mejorar procesos-, diversas industrias están invirtiendo en desarrollos relacionados con el deep learning. Se estima que este mercado pasará de 6.850 millones en 2020 a 179.960 millones en 2030, dando cuenta de la importancia que tiene para las estrategias empresariales. ¿Qué papel cumplen las redes neuronales artificiales? Como vimos anteriormente, el deep learning busca imitar el funcionamiento del cerebro humano, utilizando estructuras lógicas que se asemejan al sistema nervioso, con un sistema de “neuronas artificiales” capaz de percibir diferentes características de los objetos analizados. Para procesar la data, estas redes neuronales se organizan en capas que integran múltiples unidades de procesamiento interconectadas, las cuales trabajan simultáneamente, emulando la forma en que el cerebro procesa la información. Estas capas están organizadas de la siguiente manera: Capa de entrada: representa los campos de entrada para los datos que ingresarán al sistema. Capas ocultas: pueden ser varias. Simbolizan el puente entre la entrada y salida de la red neuronal. Los datos pasarán por todas las unidades de procesamiento que integran estas capas. Capa de salida: representa el destino final de los datos y el lugar en donde se generará el resultado del modelo. Mediante continuo entrenamiento, la red neuronal artificial irá mejorando el desempeño de sus predicciones al comparar las respuestas con los resultados esperados. Estas redes neuronales artificiales representan algoritmos capaces de reconocer patrones y distinguir, por ejemplo, imágenes o sonidos específicos en cosa de segundos. Y aunque inicialmente su capacidad predictiva será muy limitada, tras muchas repeticiones el algoritmo será capaz de replicar con exactitud el resultado conocido en función de los datos utilizados, adquiriendo mayor autonomía y precisión. Usos del deep learning Habiendo aclarado qué es deep learning y cómo funciona, veamos algunos de sus principales usos en la actualidad son: Reconocimiento de voz y traducción automática en plataformas como YouTube y Skype, o en asistentes digitales como Siri y Alexa. Reconocimiento facial en Google Fotos. Métodos antifraudes que se ocupan de analizar los detalles de las transacciones (hora en que son ejecutadas, destinatarios, montos, entre otra información de relevancia) para detectar acciones sospechosas que puedan afectar a las cuentas bancarias. En el sector agrícola, se puede apreciar en sistemas de riego inteligentes que consideran factores como el nivel de agua en el suelo o de humedad en el aire. Beneficios del aprendizaje profundo Dadas las aplicaciones que tiene, el deep learning se posiciona como una de las tecnologías de mayor impacto para el entorno empresarial, generando beneficios como: Automatización de procesos: la capacidad de trabajo autónomo del aprendizaje profundo permite que diferentes procesos se puedan automatizar, logrando mayor eficiencia y calidad. Capacidad para trabajar con datos no estructurados: el deep learning logra identificar patrones y realizar predicciones de gran manera aun cuando los datos no se encuentren organizados. Rentabilidad a largo plazo: el deep learning puede ayudar a las organizaciones a detectar oportunidades de negocio o mejoras en diversas áreas. Sistema escalable: esta tecnología trabaja sin problemas con grandes volúmenes de datos, por lo que puede adaptarse fácilmente a mayores niveles de información que vayan en sintonía con el crecimiento de una organización. El deep learning está marcando la pauta en la transformación digital de las organizaciones, impactando en áreas como flujos de trabajo, servicio al cliente y optimización de procesos. Dar el salto hacia esta tecnología es determinante para potenciar la competitividad y, con ello, fortalecer el posicionamiento de las empresas en un mercado cada vez más digitalizado.
6 de septiembre de 2022

Digital twin: ¿qué es y para qué sirve?
Una de las claves del éxito empresarial es tener la capacidad de anticipar el impacto que eventuales cambios pueden tener en un producto o servicio. Eso es, básicamente, lo que permite un digital twin, un concepto de suma relevancia para organizaciones tanto privadas como públicas. Gracias a los digital twins, las empresas pueden mejorar el desempeño de productos, servicios o estrategias determinadas, anticipando resultados gracias a datos actualizados y precisos. Gemelos digitales: el espejo del mundo físico En concreto, los digital twins o gemelos digitales son representaciones virtuales que reflejan el comportamiento de un producto o servicio físico. Usualmente, este modelo se nutre de datos provistos por sensores IoT conectados a los objetos físicos, información que alimenta el modelo virtual creado para replicar y simular su conducta. Todo, con el objetivo de mejorar su rendimiento y anticipar el impacto de posibles cambios. La información obtenida es procesada a través de tecnologías como el machine learning para simular el comportamiento que presentaría un objeto al integrar nuevas funcionalidades o sufrir modificaciones en su diseño, identificando eventuales virtudes y defectos para realizar los ajustes necesarios antes de implementarse en la realidad. Los digital twins están siendo utilizados en diferentes áreas dadas las posibilidades que otorgan: Por ejemplo, en el sector salud, hoy permiten a los profesionales diseñar una representación virtual de un paciente u órgano en concreto, para estudiar los impactos de determinados procedimientos. En la industria automotriz también están marcando la pauta, siendo de gran ayuda en el diseño y construcción de diversos modelos, tal como lo hace Ford. Dado su impacto en las cadenas de producción, se estima que el mercado de los gemelos digitales presentará una tasa de crecimiento anual compuesta (CAGR) de 38% entre 2019 y 2025, año en que alcanzaría los US$ 35.8 billones, de acuerdo con Deloitte. Principales características de los gemelos digitales Para entender mejor cómo funcionan los digital twins, revisemos algunas de sus principales características: Mientras más información se recopile del producto, servicio o proceso en estudio (ciclo de vida, especificaciones de diseño, detalles de funcionamiento, etc.), el modelo de simulación será capaz de entregar predicciones más confiables. Todo, gracias a la inteligencia artificial (IA) y machine learning. Tiene un carácter predictivo, siendo ideal para anticipar fallas y, así, realizar las correcciones pertinentes para que no ocurran en la realidad. Su funcionamiento incorpora el uso de diferentes tecnologías para analizar y simular el comportamiento de los objetos, como el Internet de las Cosas (IoT), cloud computing y machine learning. Es importante aclarar que un gemelo digital no es lo mismo que un programa de simulación: mientras este último estudia elementos en particular, un digital twin opera a mayor escala -como cadenas logísticas o procesos industriales- gracias a que genera todo un entorno virtual. Ventajas de usar un gemelo digital Entre los principales beneficios que se pueden obtener del uso de los gemelos digitales, vale la pena destacar los siguientes: Mayor rendimiento. El monitoreo y simulación virtual de un proceso o sistema permite tomar decisiones y ejecutar acciones que impliquen mayor eficiencia y mejoras en su rendimiento. Mejor I+D. Utilizar gemelos digitales facilita un diseño de productos y procesos más eficaz, a raíz de la gran recolección y procesamiento de datos por medio de tecnologías como cloud computing, IoT, Big Data e IA. Anticipar posibles fallas. La capacidad predictiva de los digital twins permite reducir riesgos en el plano real. Mejor procesamiento de los productos y materias. Gracias a estas representaciones virtuales, es posible optimizar el ciclo de vida de los elementos, pudiendo ampliarlo o, incluso, potenciar las acciones de reciclaje al identificar elementos que pueden reutilizarse. AI OF THINGS La digitalización de la tecnología predictiva: gemelos digitales 10 de enero de 2022 Principales industrias que usan los digital twins De acuerdo con el Foro Económico Mundial, se espera que para el año 2025 la inversión en digital twins se potencie en áreas como: Manufactura: USD$ 6,7 mil millones. Automotriz: USD$ 5,1 mil millones. Aviación: USD$ 5,1 mil millones. Energía y servicios: USD$ 3,8 mil millones. Salud: USD$ 3,8 mil millones. Logística y comercio minorista: USD$ 2,3 mil millones. El futuro de los digital twins Las posibilidades que otorgan los digital twins son tan amplias como las necesidades de las organizaciones, y se incrementan conforme evoluciona la tecnología, especialmente en lo que a conectividad e inteligencia artificial respecta. El proyecto Hexa-X es un claro ejemplo de lo anterior, del cual forman parte grandes empresas del sector de la comunicación -como Telefónica- y reconocidos centros de investigación europeos. Esta iniciativa busca dar una visión de los futuros sistemas 6G al conectar el mundo físico con el virtual, con lo que se espera -entre otras cosas- replicar digitalmente ciudades enteras para estudiar su comportamiento. En la actualidad, los digital twins tiene un rol estratégico en los procesos organizacionales al permitir simular y predecir el comportamiento de productos, servicios o procesos físicos, siendo de gran valor para apoyar la toma de decisiones respecto a las innovaciones que están cambiando el mundo.
11 de agosto de 2022

Descubre lo que tienes que saber sobre 6G
Promete aterrizar en 2030 y tener pruebas piloto en 2026. Pero sobre todo, promete múltiples mejoras en términos de conectividad. Nos referimos al 6G, la sexta generación de redes móviles que ya genera expectativas dadas sus características. El nuevo estándar ofrecerá una latencia mínima, mejorando la experiencia en las transmisiones en vivo. Además, esto es clave para potenciar campos como los de la realidad extendida y la inteligencia artificial (IA), optimizando el rendimiento de los sistemas gracias a un tráfico de datos más rápido y fluido En este artículo, exploraremos las principales características y beneficios de la próxima era en conectividad móvil, y sus principales diferencias con el actual estándar. 6G: así es el futuro móvil La sexta generación de redes móviles promete mejoras en cuanto a la tasa de transmisión. Pero eso no es todo: la latencia también se verá reducida (0,1 milisegundos), lo que permitirá que, por ejemplo, las transmisiones estarán cerca de ser en tiempo real. Promete significativas ventajas para diversos sectores industriales, y potenciando el desarrollo de tecnologías como la realidad extendida, dando paso a experiencias realmente inmersivas. Se estima que el 6G puede crear experiencias que hasta hoy solo vimos en ciencia ficción, haciendo viables las interfaces sensoriales. Por ejemplo, a través de lentes inteligentes o de contacto, podremos sentir y ver como si estuviéramos en la realidad. De esta manera, el 6G permitirá mejorar la experiencia en industrias como la salud, potenciando la telemedicina gracias a la realidad extendida. Esta mayor velocidad en la transmisión de datos y la prácticamente nula latencia hará posible una mejor experiencia audiovisual y en lo que a videojuegos respecta, entre otras aplicaciones ligadas a la vida cotidiana. Así, gracias a la próxima generación en conectividad móvil será posible reforzar o mejorar procesos como: Detección de amenazas Reconocimiento facial Medición de la calidad del aire Automatización de tareas. ¿En qué se diferencia de 5G? La principal diferencia radica en que la sexta generación de conectividad móvil multiplicará hasta por 10 las tasas de transmisión de datos. Y aunque el 5G llegó para mejorar en temas como la velocidad y latencia, el 6G promete grandes mejoras en ambos aspectos: Latencia: pasará de 1 ms a 0,1 ms. Velocidad: el aumento será considerable, pasando de los 20 Gbps actuales 1 Tbps. Se espera que 6G sea 100 veces más rápido que 5G. Además, como tiene una mayor capacidad, permite que se conecten más dispositivos a un mismo router, algo que impactará tanto la experiencia en el hogar como en entornos productivos. Lo anterior se apreciará en el fortalecimiento del ecosistema IoT, facilitando el intercambio de datos prácticamente en tiempo real, agilizando las operaciones y, con ello, la toma de decisiones. Los beneficios de esta nueva generación también se relacionan con el cuidado del medioambiente, ya que esta nueva generación de conectividad móvil tiene un menor consumo de energía. Esto, pues mientras el 5G se enfocó en rendimiento, el 6G apunta a la sustentabilidad. Hacia una nueva era en conectividad móvil Se estima que en España existen más de 54 millones de conexiones móviles. Considerando que la población es de poco más de 47 millones de personas, es evidente el impacto positivo que traerá el 6G cuando aterrice en nuestro país. Por un lado, millones de personas podrán disfrutar de una conexión de alta velocidad y rendimiento, mejorando experiencias cotidianas como disfrutar de contenido online o trabajar desde casa sin problemas de navegación. Por otro, las empresas podrán potenciar sus entornos digitales, impulsando la automatización y el fortalecimiento de nuevos flujos de trabajo. Y aunque todavía nos estamos acostumbrando a la llegada del 5G, ya es posible anticipar las ventajas que se desprenden de la próxima generación de conectividad móvil.
28 de junio de 2022

Conoce la diferencia entre machine learning y deep learning
Durante los últimos años, la inteligencia artificial (IA) ha generado una revolución en el entorno empresarial, dando paso a soluciones enfocadas en la automatización y agilidad en los procesos. Ahora bien, ¿cuál es la diferencia entre machine learning y deep learning, dos de los principales conceptos ligados a la IA? Sin embargo, para diferenciar claramente machine learning vs deep learning, lo primero es entender en qué consisten cada una de estas ramas de la IA. ¿Qué es Machine Learning? El aprendizaje automático en la capacidad de las máquinas o equipos computaciones de aprender por sí solos a partir del análisis de datos e identificación de patrones, lo que les permite realizar predicciones de manera autónoma, es decir, sin la necesidad de la supervisión humana. Esta tecnología -parte de la IA- está presente en diversas áreas, por lo que sus aplicaciones son bastante amplias. Por ejemplo, es una herramienta de gran utilidad en el mundo del marketing, facilitando el análisis del comportamiento y necesidades de clientes para potenciar las ventas y mejorar la experiencia del cliente. Y también está presente en tu día a día, por ejemplo, cuando tu plataforma de streaming te recomienda contenidos en particular; o cuando te aparecen sugerencias de amistad en redes sociales. Es tal el impacto de esta tecnología en el contexto global, que se estima que el mercado del machine learning pasará de USD$ 8.000 millones en 2021 a USD$ 117.000 millones para 2027. ¿En qué consiste Deep Learning? Se trata de un subconjunto de machine learning que busca replicar la forma en que el cerebro humano procesa la información. Esto, mediante el uso de redes neuronales artificiales que se organizan en diferentes capas y procesan los datos, permitiendo realizar predicciones. Al igual que en el machine learning, los algoritmos que componen la red neuronal de un sistema de aprendizaje profundo pasan por un entrenamiento con grandes volúmenes de datos, lo que les permite mejorar su capacidad predictiva hasta alcanzar altos niveles de precisión. Desde luego, el aprendizaje profundo está presente en diversas industrias. Por ejemplo, el sector automotriz destina cerca de USD$ 32.000 millones en la materia para optimizar sus productos y flujos de trabajo. En lo que a salud respecta, gracias al deep learning es posible hacer diagnósticos médicos con mayor precisión y antelación, algo de gran ayuda en enfermedades de gran complejidad, como el cáncer. Dada su relevancia para en entorno empresarial, se estima que el mercado del deep learning superará los USD$ 44.000 millones para 2027. Machine Learning vs Deep Learning: ¿en qué se diferencian? Al comprender cómo funcionan estos dos campos de la inteligencia artificial (machine learning y deep learning), es posible identificar sus principales diferencias: 1. Intervención humana Si bien ambas disciplinas logran llegar a trabajar de forma autónoma, lo cierto es que el machine learning requiere de una mayor intervención humana para lograr los resultados esperados; mientras que el deep learning puede lograr la autonomía. 2. Nivel de complejidad Otra diferencia entre machine learning y deep learning se vincula con la complejidad de sus algoritmos y los recursos que requieren para funcionar. Por un lado, los sistemas de aprendizaje automático resultan más simples y pueden llegar a funcionar en equipos convencionales, a diferencia del aprendizaje profundo que requiere de software más robustos y potentes para procesar sus intrincados modelos de redes neuronales. 3. Tiempo y precisión El tiempo necesario para que una máquina logre trabajar con autonomía en la identificación de patrones y la realización de predicciones es menor en el machine learning. Sin embargo, sus resultados no llegan a tener el grado de precisión que ofrece el deep learning. 4. Características de los datos Una gran diferencia entre machine learning y deep learning es la organización de la data: Para que el aprendizaje automático otorgue su máximo potencial requiere que los datos hayan sido previamente estructurados. Por otro lado, el aprendizaje profundo puede trabajar sin inconvenientes con grandes volúmenes de datos no estructurados, siendo de gran valor cuando se trata de identificar tendencias o patrones. Tecnologías como la inteligencia artificial, machine learning o deep learning son una muestra evidente de la transformación digital que experimentan las sociedades actualmente. Si bien aún es complejo visualizar los límites de estos campos tecnológicos, lo que sí está claro es que vienen a mejorar los sistemas y herramientas que se utilizan en el presente para ir en beneficio de las personas y organizaciones.
8 de junio de 2022

¿Qué es y cómo funciona Machine Learning?
El machine learning es, sin duda, uno de los conceptos que está marcando pauta en lo que a desarrollo tecnológico respecta, siendo determinante para potenciar la automatización de procesos y mejorar los flujos de trabajo. De hecho, se espera que este mercado presente un CAGR (tasa de crecimiento anual compuesta) de un 38,8% entre 2022 y 2029, un dato que permite dimensionar la importancia de esta tecnología para el desarrollo empresarial. Machine Learning: potenciando la inteligencia de sistemas informáticos En otras palabras, machine learning o aprendizaje automático es una rama de la inteligencia artificial (IA) entendida como la capacidad que tiene un programa de reconocer patrones en grandes volúmenes de datos, lo que les permite realizar predicciones. De esta forma, mediante el procesamiento de la información, las máquinas pueden llegar a trabajar de forma autónoma al aprender por sí mismas, sin la necesidad de ser programadas previamente. Esto permite al programa aprender, identificar patrones y generar predicciones, gracias al entrenamiento del algoritmo a partir de una base de datos para analizar. El objetivo es que, al repetir este proceso, cada vez los algoritmos logren entregar resultados más confiables y precisos. ¿Para qué sirve Machine Learning? El también llamado aprendizaje automático ha pasado a formar parte del día a día de miles de personas y organizaciones. De hecho, puede que no lo notes, pero el machine learning está presente en instancia como: Recibir recomendaciones en plataformas como Spotify, Netflix o YouTube, sobre listas de reproducción o contenido que pueda ser del agrado de una persona en particular. Ver anuncios en redes sociales como Instagram o Facebook sobre productos o servicios que te sean de interés. Al utilizar aplicaciones como Waze para trasladarte en vehículo a algún destino en específico. Obtener mejores resultados en Google. Optimización de la gestión documental. Cuando recibes correos, Gmail filtra aquellos que representan spam. Tipos de aprendizaje automático Se pueden identificar diferentes tipos de machine learning en función de cómo aprenden las máquinas a reconocer patrones y realizar predicciones. A continuación, se mencionan los más destacados: 1. Aprendizaje supervisado Los algoritmos integran datos etiquetados que contienen información previa sobre qué es lo que se quiere que aprenda un equipo para tomar decisiones y hacer predicciones. Por ejemplo, un negocio de paraguas puede predecir su nivel de venta al haber registrado en los últimos años las ventas de cada día y el contexto en el que se realizaban (mes, temperatura, clima, entre otros). 2. Aprendizaje no supervisado La base de datos para analizar ha sido ordenada en torno a etiquetas, por lo que los algoritmos buscan reconocer patrones en esta data desorganizada para obtener nuevos conocimientos y agrupar registros por afinidad. En particular, este tipo de aprendizaje cobra mucho valor para las empresas cuando se planean campañas de marketing al servir como identificador de nichos de mercado. 3. Aprendizaje por refuerzo Bajo este método, el algoritmo aprende por experiencia en base a ejercicios de prueba y error, recompensando los aciertos y castigando los errores. El objetivo es que, al adquirir mayor práctica, los algoritmos logren predecir de forma adecuada los eventos en estudio. Principales beneficios del aprendizaje automático Son diversas las ventajas que entrega este campo de la inteligencia artificial a nivel organizacional, entre las que destacan: Predecir tendencias en el mercado a partir del comportamiento de los consumidores, optimizando estrategias de marketing o determinando el nivel de producción que demanda un bien en una temporada específica. Optimizar los procesos de segmentación de público objetivo y anuncios, al identificar los hábitos de consumo de las personas y sus preferencias. Reducir el alto número de vulneraciones de seguridad, identificando las anomalías que suelen presentarse ante ataques, por ejemplo, de malware. Esto es de suma importancia en la actualidad, considerando que durante 2021 hubo 40.000 ciberataques cada día en España. Mejorar la relación con el cliente al brindar una atención más cercana y personalizada. Un gran ejemplo de esto lo constituyen los chatbots, herramientas para automatizar la interacción con clientes que han logrado un enorme desarrollo en la actualidad. Incentivar la apuesta por la innovación y búsqueda de soluciones tecnológicas más eficaces para resolver fallas e inconvenientes en las organizaciones. El aprendizaje automático ofrece múltiples beneficios para compañías de diversos sectores, como salud, alimentación, educación, transporte y publicidad, entre otras. Por eso, se espera que siga creciendo su implementación en el ecosistema empresarial. Además, se trata de una tecnología clave para potenciar la productividad y mejorar los flujos de trabajo a nivel general, facilitando el crecimiento de las organizaciones en medio de un entorno cada vez más digital y dinámico, siendo determinante para anticiparse a las variables del mercado.
2 de junio de 2022

NFT y su relación con Blockchain
Los NFT se han vuelto cada vez más relevantes en el entorno digital, abarcando sectores como arte, la moda, el metaverso y los play-to-earn (juegos en los que las recompensas son activos digitales). Este escenario no sería posible sin el desarrollo de las tecnologías Blockchain, que constituyen la base de todo el entorno de las finanzas descentralizadas y de criptomonedas como Bitcoin y Ethereum. Se trata de un conjunto de tecnologías que están replanteando la forma en que desarrollan diversos procesos, desde finanzas hasta medicina, y que actualmente cobija grandes proyectos a nivel global en múltiples áreas. ¿Qué es Blockchain? Blockchain, o cadena de bloques, es una tecnología computacional que permite llevar un registro descentralizado de las operaciones digitales. Es algo así como un libro de registros público en el que queda asentado cada movimiento, sin posibilidad de alterar el historial. Su creación se le atribuye a Satoshi Nakamoto, una persona o colectivo responsable del Bitcoin y de la tecnología que lo sustenta, es decir, blockchain. Hablamos de una base de datos descentralizada, sustentada en una red de nodos que representan puntos de conexión a la red. La información es estructurada en bloques encriptados que deben validarse antes de ser incluidos en la cadena de bloques. Algunas de sus particularidades son: Los bloques validados siguen una secuencia histórica. La red no es controlada por individuos o instituciones, por el contrario, es descentralizada Una vez añadidos a la cadena de bloques, los registros no pueden ser modificados. Lo anterior se traduce en una estructura que otorga total transparencia a las operaciones, con plena independencia. Esto ha ampliado las aplicaciones del blockchain, las cuales van desde finanzas hasta registros de identidad descentralizados, entre muchas otras. Ethereum: la base de los NFT A partir del blockchain surge Ethereum, una plataforma de código abierto que permite la creación de smart contracts o contratos inteligentes, piezas de código creadas en lenguaje de programación en donde se expresarían instrucciones específicas que serían ejecutados por la máquina virtual de Ethereum. Como vimos en un artículo anterior, Ethereum es la plataforma en la que se sustentan los tokens no fungibles (NFT), activos digitales únicos e irremplazables que operan en blockchain, lo que les otorga un valor único. Lo anterior ha permitido a empresas monetizar sus operaciones digitales, así como abrir un mundo de oportunidades para artistas, ya que los NFTs pueden ser obras de arte digital, sonidos, textos o cualquier archivo respaldado por un certificado digital generado en blockchain. NFT: elementos únicos e irremplazables Un NFT solo puede ser alojado en una dirección de la red, no podrá ser duplicado y solo podrá ser transferido usando una llave privada. Puesto que las transacciones quedan registradas en la cadena de bloques, podemos acceder al registro histórico y confirmar la procedencia de las obras de arte digital del mercado. Para hacer esto, solo debemos ingresar la llave pública de la NFT en Etherscan, un explorador de blockchain de uso gratuito que permite acceder a información como direcciones de wallets, smart contracts y transacciones plasmadas en bloques. De esta manera, podemos navegar por la cadena de bloques y acceder a información de valor para comprobar, por ejemplo, la autenticidad de obras de arte digital o cualquier otro NFT. Una tecnología con diversas aplicaciones Blockchain no se limita al mundo de las criptomonedas y de los NFT, sino que se extiende a metodologías y protocolos que están siendo implementados en distintas industrias, debido a su eficiencia y transparencia. Como infraestructura de base de datos, ofrece grandes ventajas en servicios de validación, almacenamiento y seguridad tanto a entidades gubernamentales como privadas. De igual forma, gracias al Blockchain as a Service (BaaS), empresas de diversos sectores pueden aprovechar los beneficios que otorga este conjunto de tecnologías. Sin duda, la cadena de bloques está reconfigurando el mercado, y entender su funcionamiento y aplicaciones es clave para adaptarse a las nuevas tendencias y, con ello, optimizar diversos procesos.
5 de mayo de 2022

Wallet o monederos digitales: ¿en qué consisten?
En un mercado cada vez más digital, conceptos como criptomonedas, blockchain y economía descentralizada son parte de una nueva manera de entender las transacciones. Para comprar, vender o almacenar diversos activos digitales, necesitas una wallet y, a continuación, te contamos todo sobre esta solución. Las criptomonedas se consolidan en los mercados como los activos predilectos para acceder a servicios digitales y a mercados como el metaverso y los NFTs. Todo, con el blockchain como eje de las operaciones, garantizando la integridad de las transacciones y sentando las bases de una economía descentralizada en la que las wallets son fundamentales. ¿Qué es un monedero digital o digital wallet? Gracias a una wallet, criptomonedas, tokens y NFTs pueden ser administrados por su dueño, por lo que representan un elemento clave en la gestión de activos digitales. Con un monedero digital podemos firmar smart contracts, confirmar o denegar transacciones, hacer movimientos entre servicios de blockchain e, incluso, tomar decisiones de gobernanza en algunos proyectos de finanzas descentralizadas. ¿Cómo funcionan? Los monederos digitales habilitan determinadas operaciones gracias a dos llaves: clave pública y privada. La pública consiste en una dirección única, codificada dependiendo del entorno blockchain en el que opere la red. Esta dirección no puede ser duplicada ni modificada. Para enviarla a terceros, lo que realmente se envía es un certificado de clave pública, que permite identificar el destinatario de una transacción. En la misma línea, la clave privada hace las veces de contraseña y es la que permite validar las transacciones en la cadena de bloques. Al perder esta llave, perderíamos acceso, control y propiedad sobre los activos digitales registrados en la dirección. Tipos de wallets Como hemos señalado, para gestionar un monedero digital necesitamos clave pública y privada. Pero para entender mejor su funcionamiento, y alternativas disponibles a la hora de gestionar activos digitales, es conveniente conocer los tipos de wallet que existen: Para móviles En este tipo de wallet, criptomonedas y otros activos digitales son gestionados desde un smartphone, por lo que se trata de monederos digitales que operan como cualquier otra app. Online Como su nombre lo indica, este tipo de wallet operan en la Web, por lo que no es necesario descargar archivos para gestionar activos como criptomonedas o NFTs, solo se requieren la clave pública y privada. En este caso, la llave privada es resguardada por la plataforma, a la que accedemos por medio de los protocolos de seguridad establecidos por el sitio. De escritorio En este caso, el wallet se descarga en un computador y, como el resto de los monederos digitales, también precisa de un certificado de clave pública para direccionar transacciones, así como de la clave privada para autorizarlas. Uno de sus grandes beneficios es que no está permanentemente conectada a Internet (a diferencia de las anteriores), lo que se traduce en menos riesgos de vulneraciones de seguridad. Wallet en hardware Se trata de dispositivos físicos -como un pendrive- en los que se almacenan la información asociada a sus activos digitales. Ledger es uno de los sistemas más populares en este formato, el cual permite almacenar diversos activos digitales y gestionarlos con total seguridad. ¿Cómo se utilizan? Desde luego, cada wallet tiene características propias. Sin embargo, todas operan de la misma forma: almacenando la clave pública y privada que sustenta las transacciones en blockchain. Las funciones más comunes de un monedero digital de criptomonedas son: firmar, transferir, depositar, aprobar cambios o ajustes en nuestra cuenta. Cada interacción realizada a través de nuestro wallet se registra en la cadena de bloques, certificando la integridad del proceso. Accesibilidad a entornos financieros El uso de blockchain sigue en aumento, y diversas organizaciones en el mundo están desarrollando aplicaciones en la cadena de bloques debido a las ventajas en términos de velocidad, privacidad y seguridad que ofrecen. Por otra parte, esta tecnología sienta las bases para un entorno de finanzas descentralizadas, brindando mayor transparencia y agilidad a las operaciones gracias a soluciones como las wallets. Por eso, son esenciales para operar en el mundo de las criptomonedas y de los activos digitales en general.
4 de mayo de 2022

GOOD TECH TIMES: Reinventando el turismo. Claves para acelerar la recuperación.
FORMATO: Charla de 30 minutos + Q&A de 10 minutos CUÁNDO: 16 de junio, 16:00 h (CET) CÓMO: Inscripción gratuita en eventbrite SOBRE QUÉ: La digitalización es una pieza clave en el plan de modernización y competitividad del sector turístico. Tecnologías como IoT, Big Data, 5G, edge computing, la nube y la ciberseguridad son las grandes protagonistas de la transformación digital de este sector, que permitirán afrontar los retos a los que se enfrenta para reactivar la demanda y restablecer la confianza, a través de un modelo sostenible. Descubre las soluciones tecnológicas para el turismo del futuro y conoce todas las claves para acelerar su recuperación el próximo 16 de junio a las 16:00h CET de la mano de: Natalia Bayona, Director Innovation, Education and Investments - World Tourism Organization UNWTO, Gema Igual, Alcaldesa de Santander, Chris Palomino - Global IT Vice President - Meliá Hotels International y Javier Lorente, Director de Business Development e Ingeniería España - Telefónica Tech. ¡Regístrate ya! Miércoles, 16 de junio, 16:00 h CET. ¿Te lo vas a perder? ¡Inscríbete ya en este enlace! GOOD TECH TIMES Bienvenidos a esta nueva serie de webinars divulgativos en los que hablaremos de temas de interés general sobre IoT, Big Data, Inteligencia Artificial y Blockchain, entre otros. ¿Te lo vas a perder? ¡Regístrate ya!
8 de junio de 2021

LINKEDIN LIVE: Hacia una Agricultura más sostenible e inteligente: Vertical Farming
QUÉ: Directo en la company page de LinkedIn de AI of Things FORMATO: Charla de 30 minutos + Q&A de 10 minutos CUÁNDO: 20 de mayo, 16:00 h (CET) CÓMO: Inscripción gratuita en eventbrite SOBRE QUÉ: La agricultura de precisión nos permitió dar un primer paso hacia la gestión eficiente en la productividad, sostenibilidad y rentabilidad en la producción agrícola. Después de la pandemia, se ha hecho evidente que la independencia alimenticia, la producción sostenible y el cuidado del medio ambiente cobran aún más sentido. La agricultura 4.0 es sinónimo de explotación agrícola eficiente coexistiendo sensorización, conectividad, análisis de datos y trazabilidad, pero también cambiando la forma de cómo cultivamos físicamente. Dentro de Smart Agro en Telefónica Tech, incorporamos soluciones de Vertical Greende cultivos verticales de alta densidad basados en tecnología de aeroponia RHPA permitiendo una nueva dimensión de cultivos “indoor” digitalmente controlados y con acceso remoto. Soluciones altamente eficientes en producción agrícola sin interacción con el medio ambiente. Para entender todos los puntos de vista de los beneficios de la Agricultura 4.0, el próximo 20 de mayo contaremos con: • Paco Sánchez, Gerente de Onubafruit • Hugo Scagnetti, Fundador y CEO Vertical Green • Paz Revuelta, Product Manager en New Business en Telefonica Tech ¿Quieres volver a verlo? https://www.youtube.com/watch?v=qnVZ00wZsGU&list=PLi4tp-TF_qjMFph5Xhd-k4WR_sa_Pq8nA&index=2
18 de mayo de 2021

Reconocidos como uno de los Líderes por Gartner en ‘Managed IoT Connectivity Services, Worldwide’
Gartner, la firma líder y más influyente en consultoría y research tecnológico a nivel global, ha publicado recientemente una nueva edición de su “Cuadrante Mágico en Servicios de IoT Gestionados a nivel mundial”, donde Telefónica se posiciona, por séptima vez, como una de las compañías líderes en este mercado. Se trata del benchmark más importante sobre IoT a escala global, siendo una de las referencias principales en el mercado utilizada por las empresas a la hora de decidir qué compañías son las mejor posicionadas para prestarles servicios de IoT. Por ello, el aparecer como líderes nos da una excelente visibilidad y puede ayudarnos a ganar nuevos clientes. Asimismo, este informe es muy útil para comprender mejor hacía dónde está yendo el mercado IoT y cuáles son las tendencias clave que se vislumbran. El famoso gráfico del “Magic Quadrant” consta de dos ejes: El eje horizontal o X alude a la visión estratégica y mide el conocimiento que los proveedores analizados tienen acerca de cómo se puede aprovechar, a través del diseño de estrategias, el momento actual del mercado para la generación de valor. El eje vertical o Y, pone foco en las capacidades del proveedor para ejecutar con éxito su propia visión del mercado. Cada año Gartner invita a participar a multitud de potenciales proveedores de servicios IoT y solo aquellos que superan unos criterios de inclusión serán seleccionados para ser evaluados en el cuadrante. A partir de ahí se inicia proceso largo y complejo en el que Gartner examina minuciosamente la visión y la capacidad de ejecución de los diferentes candidatos en base, sobre todo, a un extenso y detallado cuestionario, una presentación, referencias de clientes aportadas y toda la información que le haya llegado directa o indirectamente de cómo ha evolucionado cada proveedor. El resultado de este análisis determina la posición de cada empresa en el cuadrante como “Leader”, “Challenger”, “Visionnaire” o “Niche” En el ámbito de los negocios tecnológicos, ambos, empresas y clientes, somos conscientes de la importancia de aparecer “arriba y a la derecha” como líderes en un cuadrante mágico de Gartner. Pero, ¿qué significa que Telefónica aparezca como uno de los líderes? Pues bien, más allá de suponer que la compañía haya alcanzado una alta puntuación en este ejercicio, los líderes ejecutan con una “visión clara sobre la dirección del mercado y desarrollan competencias para mantener su liderazgo”, según afirma Gartner. Además, son compañías apreciadas como innovadoras, son líderes de opinión, están preparadas para el futuro y, no menos importante, “dan forma al mercado, en lugar de seguirlo”. Pero no solo es Gartner quién reconoce nuestro liderazgo en IoT, ahí están también los reconocimientos de otras casas de analistas muy influyentes en IoT como IDC, GlobalData o Transforma. Estos logros suceden tras un año difícil aunque, bueno, califiquémoslo mejor como “muy retador”, por aquello de que siempre es mejor adornar los desafíos con una buena carga de optimismo. Un año cargado de incertidumbre y marcado por los efectos de una pandemia mundial cuyo impacto en todos los sectores está siendo aun de gran envergadura. Es en este contexto donde Telefónica compite en este cuadrante con un número cada vez mayor de participantes (18 vs 13 en 2014), donde no solo competimos las telcos, sino también otros “players” como operadores virtuales móviles, fabricantes de hardware o compañías puras de IoT. Sucede, además, en plena consolidación de la compañía que ha fusionado los negocios del IoT y Big Data en Telefónica Tech y que, recientemente, con el inspirador nombre de “Artificial Intelligence of Things”, es ya la unidad de negocio que basa su propuesta en la combinación natural de tecnologías basadas en Inteligencia Artificial, IoT, Big Data y Blockchain, con el objetivo de acompañar a los clientes en el viaje de su transformación digital. Muchas veces me preguntan cuál es el toque mágico de la varita para conseguir que una compañía como Telefónica sea valorada positivamente por los analistas de la industria. Mi respuesta es, simplemente, que no lo hay. Y esto lo digo porque este “mundo” no basa su ejercicio en el puro azar o casualidades. Más allá de tener una visión clara y una ejecución extraordinaria, esto va de trabajar en equipo, construyendo relaciones sólidas y de confianza con los analistas en un escenario con recorrido continuo, donde la credibilidad no surge en unos pocos meses ni en un acto transaccional ocasional. Requiere de una dedicación diaria, mucho esfuerzo y compromiso para llegar ahí “arriba a la derecha”. Bajo nuestro punto de vista, el éxito en las relaciones con los analistas dependerá por lo tanto de conocerlos y que nos conozcan bien, de saber qué es lo que hacen y qué es lo que esperan de nuestra compañía, de conocer lo que están diciendo en sus informes. También de escucharlos, entender lo que pretenden explicar, capturar toda esa información de gran valor que nos servirá para progresar y mejorar. De sentarnos junto a ellos en el momento adecuado y dejar que entren en acción los mensajes y el contenido. En Telefónica creemos en ello y contamos con el mejor equipo de expertos, convencidos de la importante labor que resulta el contar las maravillosas cosas que esta casi centenaria compañía está creando para enriquecer y hacer más fácil la vida de millones de personas. Escrito por José Luis Vázquez Marín, Telefónica Industry Analyst Office. Para mantenerte al día con el área de Internet of Things de Telefónica visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube
5 de mayo de 2021

LinkedIn Live - Las dos caras de Blockchain: garantías adicionales y nuevos modelos de negocio
El peso creciente del mundo online en el consumo y las relaciones comerciales hacen cada día más necesario construir relaciones de confianza donde tanto los consumidores tengan absolutas garantías de calidad del producto que consumen, como las empresas puedan confiar ciegamente en los datos y la información que utilizan para tomar decisiones. Blockchain es la tecnología perfecta que permite crear esa confianza. En el directo del próximo 29 de abril, hablaremos con los representantes de dos empresas diferentes (Szentia y Castillo de Canena) que nos ayudarán a entender cómo puedes beneficiarte de esta tecnología en las operaciones y cómo adoptar Blockchain de una manera fácil y rápida con nuestro producto TrustOS, un servicio gestionado que simplifica enormemente la utilización de esta tecnología en tus sistemas de información. ¡Conoce todo sobre la solución Blockchain! Además, te invitamos a asistir al directo que haremos a través de LinkedIn el próximo 29 de abril a las 16:00 h CET, para que conozcas la solución en más detalle, así como varios casos de éxito de la mano de los responsables de producto. Regístrate aquí para poder verlo ¡Te esperamos!
23 de abril de 2021

GOOD TECH TIMES
El Centro Comercial del futuro: un espacio repleto de experiencias. FORMATO: Charla de 30 minutos + Q&A de 10 minutos CUÁNDO: 25 de marzo, 16:00 h (CET) CÓMO: Inscripción gratuita en eventbrite SOBRE QUÉ: El mundo del Retail vive hoy una revolución en la que la sostenibilidad y la tecnología juegan un papel fundamental para la experiencia de los clientes. En concreto, el concepto de los Centros Comerciales está evolucionando hacia una experiencia sensorial y comercial para el visitante. Un concepto que busca ofrecer al comprador diversos elementos que atraigan su atención con el fin último de que disfruten de su estancia en el Centro Comercial. En este sentido, la tecnología IoT y Big Data se convierten en necesarias para poder construir las soluciones de Smart Retail que permiten la creación de estas experiencias. Además, gracias a la tecnología se alcanza un conocimiento mayor del consumo energético de los espacios físicos y permite a los retails ahorrar y cuidar del Medio Ambiente. En este directo contaremos con dos gurús de la industria del Retail: Ian Sandford, Presidente de Eurofund David Pérez Balaguer, CEO del grupo NO-GROUP ...que, junto a Fernando Piquer, CEO de Movistar Riders y nuestra experta Paula Alamán Herbera, Industry Lead en Telefónica Tech – AI of Things, mantendrán una conversación interesante sobre el rumbo que toma la evolución de los Centros Comerciales y qué papel juega la tecnología en la transformación digital para ofrecer la mejor experiencia de cliente. GOOD TECH TIMES Bienvenidos a esta nueva serie de webinars divulgativos en los que hablaremos de temas de interés general sobre IoT, Big Data, Inteligencia Artificial y Blockchain, entre otros. ¿Te lo vas a perder? ¿Quieres volver a ver el webinar? Pincha aquí: https://www.youtube.com/watch?v=g7qavay3ers&list=PLi4tp-TF_qjOIngr_7ilEHR_XueGYuRwN&index=54
18 de marzo de 2021

Data Driven Advertising: la solución publicitaria que habla con tus clientes
Ya es un hecho que nos encontramos ante una situación única en la historia debido a la COVID-19, pero no es ni mucho menos el primer hito al que nos hemos tenido que enfrentar. En épocas de crisis se ha demostrado que aquellas marcas y anunciantes que no dejan de invertir son los que mejor parados salen cuando los tiempos son tan inciertos. Cada vez son más los profesionales de marketing que se oponen a una desinversión publicitaria en periodos tan complicados, ya que, de darse el caso, la marca dejará de inmediato de estar presente en la mente del consumidor y tendrá que asumir las consecuencias de lo que este hecho conlleva. Por ejemplo, disminución de la intención de compra, aumento de la presencia de competidores, etc. Es el momento donde debemos estar más presentes que nunca El consumo de información y entretenimiento, además de haber alcanzado récords históricos, está cambiando – el 9’6% de los españoles ha comprado por primera vez de manera online bebidas y comida según el barómetro de Kantar -. Es crucial, debido a este nuevo ecosistema, conocer y dirigirse a una audiencia específica en función de las características y de los mensajes que quieran transmitir la marca y el anunciante. De la misma manera, creemos en la necesidad de realizar inversiones publicitarias con un objetivo y sobre todo que apunten a un segmento que encaje con la audiencia que se demanda. Es necesario comprender a los potenciales clientes, conocer sus hábitos e interpretarlos para comunicarnos con ellos a través de mensajes que encajen con sus rutinas. En Telefónica Tech estamos convencidos del gran valor de nuestros datos en el mercado de la publicidad, por eso ponemos a disposición de nuestros clientes soluciones basadas en analítica Big Data que cuentan con una amplia cantidad de información y una rigurosa recolección. Esto es crucial para cualquier profesional de marketing ya que ayuda a la optimización de sus inversiones publicitarias y de sus presupuestos en campañas. La solución abarca tres procesos que consideramos que conforman la cadena de realización de una buena campaña de publicidad, que son: la planificación, la ejecución y por último la medición. Data Driven Advertising permite a las marcas y anunciantes identificar sus segmentos objetivos e impactar a los perfiles deseados con una publicidad segmentada, proporcionando a posteriori datos agregados de conversiones de campañas a través de una solución completa e integral. Planificación La planificación es, en nuestra opinión, una de las fases más importantes de todo el proceso que supone una campaña de marketing, ya que hay que saber leer muy bien la información de la que disponemos para luego seleccionar correctamente el objetivo de la campaña, el canal de ejecución y el público al que hay que dirigir la publicidad que la marca y anunciante desea comunicar. Además, para este proceso, podemos calcular la visibilidad de los establecimientos para los principales términos de búsqueda, identificado los puntos de venta que tienen una visibilidad positiva, para de esta manera optimizar los presupuestos. En Telefónica guiamos y acompañamos a las marcas y anunciantes durante todo este proceso, mediante el análisis de toda la información disponible, agregada y anonimizada de nuestros clientes y de su movilidad, siendo capaces de identificar el target a impactar y dirigirlo hacia el objetivo de la campaña. Ejecución Una vez que tenemos claro a quién vamos a impactar pasamos a estudiar el cómo, y para ello ponemos a disposición de nuestros clientes la posibilidad de impactar a su público objetivo desde diferentes canales de ejecución como son: las redes sociales, el entorno de display programático o en las búsquedas. Asimismo, basándonos en la movilidad de los individuos ofrecemos diferentes tipos de campaña como pueden ser las campañas “drive to store” cuyo objetivo es llevar público de calidad a la tienda o campañas que llamamos “geolocated” que buscan impactar a perfiles que se mueven en una determinada ubicación. Medición Por último, la solución Data Driven Adverting ofrece una medición muy completa que permite a las marcas y anunciantes saber en todo momento los cambios de comportamiento de sus usuarios en cuanto a su movilidad y la eficiencia de las campañas publicitarias. Esta solución pone en valor uno de los activos más importantes para Telefónica y para el mundo de la publicidad, a través de unos datos determinísticos y verificados que pueden ayudar al entendimiento del comportamiento del consumidor para que este luego pueda ser impactado publicitariamente. Escrito por Sandra Alonso, Product Lead
9 de marzo de 2021

Planificando la ubicación de un site de retail con los datos
Una de las decisiones de negocio clave para cualquier marca es decidir dónde “establecer su tienda”. Esto implica la necesidad de conocer muy bien a los consumidores y su target, y aún más cuando una marca quiere dar el salto de un modelo de negocio totalmente online a tener un establecimiento físico. En este post, analizamos el caso de éxito de la marca de cosméticos Natura, y cómo gracias a la tecnología LUCA Store la empresa ha aumentado su presencia en Brasil. Natura Cosméticos S.A o simplemente Natura fabrica y comercializa una gran variedad de productos cosméticos para el mercado enfocado en el cuidado de la piel, belleza, perfume y cuidados capilares. La compañía da especial importancia a la innovación y sostenibilidad. En total la empresa tiene más de 3200 establecimientos a nivel internacional, además de comercializar sus productos a través de representantes. Natura es según ingresos, actualmente, la mayor compañía de cosméticos en Brasil y en julio de este año compró la marca The Body Shop de la empresa L’Oréal. En sus comienzos, Natura operaba a través de un modelo de ventas directo con sus consumidores, basado en sus representantes. Hasta que, satisfactoriamente, tomaron la decisión de abrir un establecimiento retail y quisieron identificar los lugares con mayor potencial de ventas. Este potencial de ventas se mide dependiendo del número de usuarios que pasan ese lugar y el grupo demográfico al que pertenecen. El proyecto con LUCA implica la combinacíon de VIVO Big Data, los indicadores de clientes internos de Natura y el conocimiento sobre el sector, además de la tecnología LUCA Store. La solución LUCA Store analiza millones de puntos de datos móviles con el fin de proporcionar información muy valiosa para los retailers que aportan información sobre quién, qué, cuándo, por qué y cómo actúa un cliente. El resultado de esta combinación de datos y tecnologías junto con los KPI’s de Natura es la habilidad de sugerir con mayor precisión el lugar más adecuado para abrir un establecimiento. Estas sugerencias, además, también tendrán en cuenta, incluso, qué días y a qué horas debería abrir un establecimiento al público. En el vídeo a continuación se puede ver aquí la demo de la tecnología LUCA Store: https://www.youtube.com/watch?v=pgBn4W62fzQ&feature=youtu.be La información proporcionada por LUCA Store proporcionó a LUCA información valiosa sobre más de 40 millones de personas de cinco países brasileñas. Descubre los casos de éxito destacados en todos los sectores en nuestra web
17 de febrero de 2021

RFID: La solución para digitalizar tu tienda
La transformación digital es un concepto que lleva muchos años en boca de mucha gente y se ha ido desarrollando en diferentes líneas de acción; ahora, en tiempos de pandemia, ha cobrado incluso más relevancia como catalizador del cambio para la evolución de las empresas. La digitalización afecta en dos vertientes, la primera es lo que vamos a llamar el “backoffice” de la empresa incluyendo los procesos internos y de gestión de forma que puedan encontrarse eficiencias, mejoras operativas, etc. La segunda vertiente de la digitalización afecta a lo que vamos a llamar el “frontoffice” de la empresa, modificando la experiencia final de sus clientes. Hoy vamos a hablar de un producto que afecta tanto al “backoffice” como al “frontoffice” de las empresas, centrándonos en las empresas del mundo del retail. Este producto es RFID for Retail. El RFID (identificación por radio frecuencia) es una tecnología que lleva tiempo acompañándonos y en los últimos años se han producido eficiencias en el precio de implementación de la tecnología consiguiendo llegar a un mayor número de empresas. ¿En qué consiste esta solución? Por si alguien no conoce la tecnología vamos a explicar de forma muy breve y sencilla en qué consiste. Por una parte, tenemos una etiqueta RFID en la que grabamos información. La etiqueta puede estar construida con diferentes materiales o formatos para, por ejemplo, hacerla resistente al agua, a bajas temperaturas, etc. El sistema cuenta con antenas para poder leer las etiquetas, las cuales se colocan estratégicamente en función del caso de uso que se quiera resolver. Y por último contamos con un SW de gestión para dar de alta o baja etiquetas, modificarlas o visualizar las lecturas. En el mundo del retail, afecta directamente a la parte de “backoffice” de las tiendas y a todo lo relativo de la cadena de suministro, stock de productos, espacio de almacenamiento o tiempos de reposición. Desde hace años los retailers más potentes han ido trabajando para evolucionar sus sistemas logísticos, fabricando y distribuyendo prácticamente bajo demanda, reduciendo o eliminando los almacenes centrales o regionales y minimizando el espacio necesario en tienda para almacenar producto; gestionando al cabo del día decenas de miles de prendas y complementos. Esta forma de trabajar es la base ideal para la implementación de un sistema de RFID, de tal manera que los productos se etiquetarían en origen en la factoría con la etiqueta RFID y se darían de alta en el sistema. En función de las necesidades se controlaría la mercancía de forma unitaria desde la salida del almacén, la carga en el medio de transporte, posibles puntos intermedios hasta su llegada al almacén final de la tienda. Control total sobre la cadena de suministro En cada punto donde se instalen las antenas lectoras se podrán obtener las mediciones en tiempo real de todos los productos que pasen por allí. Esto nos va a ofrecer un control total sobre la cadena de suministro, pudiendo reconocer puntos que no son eficientes o posibles mermas de stock antes de su llegada al almacén. Una cantidad ingente de datos que el retailer podrá usar para hacer más eficiente su cadena de suministro y procesos de carga y descarga, controlando en todo momento la integridad del producto enviado. Una vez llega a la tienda, con antenas instaladas tanto en el almacén como en la propia tienda se va a tener el control del stock de la tienda en tiempo real de todas las prendas, sabiendo qué prenda es, talla, color, etc. De esta forma, se podrán diseñar estrategias de reposición de producto basadas en datos en tiempo real. Como punto extra, cada etiqueta RFID también sirve de trigger para la alarma del establecimiento, por ejemplo, si se intenta sacar del establecimiento sin haber sido pagado. Esta función de alarma también nos va a ayudar a tener controlados los probadores, pudiendo tener antenas configuradas y definiendo una operativa que permita conocer en cada momento qué prendas están en cada probador, si alguna queda abandonada o si el cliente devuelve menos. El potencial transformador del RFID en el core de una empresa de retail es enorme Hasta ahora nos hemos centrado en hablar de la transformación sobre el “backoffice” de la empresa, pero habíamos indicado que el producto RFID for Retail tiene la capacidad de transformar también el “frontoffice”. En este caso, desde la unidad de IoT&Big Data de Telefónica Tech, hemos implementado varios casos de uso que van a generar una experiencia de cliente mejor. Contenidos audiovisuales Gracias a las soluciones de Digital Signage y Spotsign podemos tener una playlist de contenidos audiovisuales. Además, si integramos el sistema de RFID y un lector situado junto a una pantalla, el cliente puede acercar un producto y conocer contenidos informativos sobre este. Mejorar la experiencia en los probadores Los probadores también son un punto interesante para ofrecer experiencias diferentes. Las prendas están etiquetadas para que, una vez las metes en probador, una pantalla las identifique. De tal forma que el cliente tiene la posibilidad de pedir otro color, otra talla…incluso si no hay stock en ese momento, el cliente lo podrá comprar a través de la app o web y recibirlo en su casa. Cajas de autopago Para cerrar el journey dentro de la tienda, el sistema RFID permite implementar cajas de autopago sin contacto donde el cliente no tiene necesidad de sacar las prendas individualmente para su lectura, solo tiene que colocar las prendas en una zona designada y se leerán todas indicando en la pantalla las prendas que son y pudiendo pagar por diferentes medios digitales. Una vez el pago se ha realizado con éxito el sistema desalarma los productos para que el cliente pueda salir del comercio. Como hemos ido desgranando en el post, el potencial transformador del RFID es enorme, permitiendo a los retailers dar un salto en la evolución de su funcionamiento interno y además ofreciendo mejores experiencias y más seguras a sus clientes. Escrito por: Mariano Banzo – Product Manager Retail, Telefónica Tech
15 de febrero de 2021

Una solución para adaptar la flota de vehículos frente a la COVID-19 y la tormenta Filomena
La movilidad es un aspecto clave tanto en el día a día de las ciudades como en las situaciones excepcionales que hemos experimentado en el último año por la COVID-19 o el reciente temporal “Filomena”. En ambos escenarios hemos comprobado que saber adaptarse y anticiparse nos pueden evitar muchos problemas y que la tecnología cumple una función esencial para mejorar la prestación de servicios esenciales en las ciudades. Entonces, ¿Cómo nos adaptamos y anticipamos? Desde mi punto de vista, la respuesta es clara: transformación digital de la mano de tecnologías como IoT y Big Data. Y esto precisamente es en lo que Ferrovial Servicios llevamos trabajando desde hace años. Estas tecnologías nos permitieron ofrecer servicios eficientes durante el confinamiento general en marzo de 2020. Durante este periodo, gracias a la digitalización de nuestros procesos, nuestra actividad no paró y pudimos prestar servicios esenciales en más de 600 municipios a más de 25 millones de ciudadanos en España. También ha ocurrido algo parecido con el temporal Filomena. Gracias a la solución tecnológica 'Fleet Optimise' de gestión inteligente de flota de vehículos hemos podido continuar, a pesar de todas las adversidades, prestando servicios críticos como son la recogida de residuos y limpieza viaria. Esta tecnología nos ha permitido organizar en ciertos contratos rutas dinámicas de recogida de residuos en función de los acuerdos con los clientes y saber en qué calles teníamos que ir a recoger los residuos. La plataforma IoT de Telefónica y las capacidades de big data nos han ofrecido flexibilidad y rapidez para adaptarnos a cada situación. Y todo esto ¿Cómo lo conseguimos? Contamos con una flota de más de 4.000 vehículos sensorizados de los cuales se recoge información en tiempo real. A través de un dispositivo que se conecta a la electrónica del vehículo, conseguimos extraer este tipo de información: conocer en tiempo real dónde está cada camión, lo que está haciendo, a qué velocidad va o dónde para. Toda esta información se procesa para poder predecir qué va a pasar. De tal forma que conseguimos ofrecer a los ayuntamientos y administraciones públicas la información que nos demandan en cada momento y dar una solución en tiempo real a nuestros clientes. En definitiva, las tecnologías IoT & Big Data permiten capturar en tiempo real toda la información, procesarla y a partir de ahí tomar las mejores decisiones. ¿En qué ha beneficiado a nuestro negocio? Gracias a 'Fleet Optimise' hemos conseguido ofrecer un servicio de mayor calidad a los ciudadanos. También nos ha impactado en la eficiencia y sostenibilidad, puesto que ahora utilizamos los recursos adecuadamente de tal manera que hacemos más eficiente el proceso y reducimos desplazamientos lo que impacta en el medioambiente por la reducción de la huella de carbono. Además, podemos guiar al conductor al punto de recogida para reducir distancias a la hora de recolectar los residuos, de tal forma que impacta en el ahorro de tiempo y combustible. El poder agregar y comparar nos proporciona información clave para los planes de mejora continua de la compañía. Todo esto se traduce en una gran ayuda al conductor que al fin y al cabo es el eje del que pilota toda la flota. Y, por último, en el aumento de la seguridad en todas nuestras operaciones. Por ejemplo, en caso de accidente proporciona información para analizar mejor lo que ha ocurrido. En definitiva, conseguimos información para mejorar nuestros patrones de comportamiento. Nadie cuestiona hoy en día que las plataformas de IoT y Big Data formen parte de nuestro catálogo de servicios, igual que nadie se cuestiona que tengamos un PC o un teléfono móvil. Nuestros clientes dan por hecho que lo tenemos. Las plataformas digitales son esenciales para prestar los servicios. Escrito por Paco Gimeno, Director de Transformación Digital y Sistemas de Ferrovial Servicios.
20 de enero de 2021

Optimización de flotas en la era post-Covid
La llegada de la COVID-19 ha alterado el mundo tal y como lo conocíamos y está obligando a muchas empresas a evolucionar digitalmente para adaptarse a las nuevas necesidades del mercado, dónde la movilidad de sus clientes y empleados se ha visto reducida drásticamente. Esto no está haciendo más que afianzar algunas tendencias que veníamos observando en los últimos años, como puede ser la compra online con envío a domicilio o el teletrabajo, a la vez que pone de manifiesto nuevas necesidades como es el disponer de datos para adaptarnos rápidamente a acontecimientos inesperados. En esta línea, observamos que uno de los entornos dónde mayor impacto puede tener el disponer de estos datos es en la movilidad, ya que existe una necesidad creciente de controlar y gestionar de forma más eficiente los activos, las personas y por supuesto los vehículos. Un ejemplo que tenemos todos muy reciente en nuestras cabezas es la distribución de las vacunas contra la COVID-19, que requiere de un control absoluto por el alto valor de los bienes y sus difíciles condiciones de conservación. Garantizar que estas vacunas llegan a tiempo a sus destinos manteniendo en todo momento la cadena de frío es crítico para la recuperación de la sociedad actual y por ello, se hace imprescindible el uso de soluciones que nos ayuden en esta tarea. En Telefónica llevamos años ayudando a nuestros clientes con un amplio porfolio de soluciones para la gestión de sus diferentes activos móviles, y es hoy más que nunca cuando toman especial relevancia soluciones como Fleet Optimise que permite, mediante tecnologías como IOT, Big Data y la Inteligencia Artificial, gestionar su flota de vehículos de forma eficiente y ayudarles en la toma de decisiones estratégicas de negocio. Gracias a la instalación de dispositivos IoT en los vehículos podemos recoger una gran cantidad de información en tiempo real, como su posición GPS, odómetro, consumo de combustible, hábitos de conducción o averías; y volcar toda esa información en nuestras plataformas para poder digerirla y sacarle el máximo partido. Tras muchos años de experiencia, entendemos el negocio de nuestros clientes diferenciándolo en 2 planos independientes: el plano operativo y el plano estratégico: En el plano operativo les entregamos a nuestros clientes las herramientas para poder gestionar la operativa diaria de su flota: conocer dónde se encuentran sus vehículos en tiempo real, sus alertas, que trayectos han realizado o cuándo tienen que pasar una revisión. En el plano estratégico adicionalmente les damos las herramientas para entender realmente cómo funciona su flota de vehículos y tomar las decisiones adecuadas. Para ello nos apoyamos en tecnologías como el Big Data y la Inteligencia Artificial que nos permiten procesar infinidad de datos, disponer de una visión agregada de todos los vehículos e incluso desarrollar modelos predictivos, lo que supone un salto cualitativo para nuestros clientes. Volviendo al ejemplo del traslado de las vacunas, la parte operativa nos permite saber dónde se encuentra el vehículo y si existe algún problema durante el traslado como pudiera ser una avería en el camión. La parte estratégica nos permite analizar todos los trayectos de forma conjunta, entender qué incidencias son las más frecuentes, dónde ocurren y en última instancia, cómo evitarlas. Gracias a Fleet Optimise, nuestros clientes están consiguiendo: Aumentar la productividad de su flota haciendo un uso más eficiente de los vehículos Reducir los costes operativos derivados del alto gasto en combustible, mantenimientos y reparaciones Asegurar el correcto uso de sus vehículos reduciendo la siniestralidad, fraude e infracciones de sus conductores Garantizar la seguridad de sus empleados, vehículos y mercancía Además, estamos poniendo foco en 3 nuevas funcionalidades que nos van a ayudar a adaptarnos a la nueva realidad que nos estamos encontrando con la pandemia: Descarga remota de tacógrafo: Permite disponer de la información en tiempo real y así poder maximizar el uso de los vehículos pesados Apertura remota de puertas: Evita el uso de llaves, minimizando así la interacción humana y maximizando el uso de los vehículos Transición a vehículo eléctrico: Ayuda a definir la mejor estrategia para evolucionar la flota actual hacia vehículos eléctricos más eficientes y ecológicos Si bien podemos pensar en empresas de distribución y logística como los principales clientes de esta solución, la realidad nos demuestra que cualquier empresa con flota de vehículos, independientemente de su sector de actividad y del tipo de vehículo, puede beneficiarse de Fleet Optimise ya que es una solución extremo a extremo que está disponible a escala global, dónde ofrecemos todos los elementos de forma integrada (dispositivo, comunicaciones, instalación, plataforma, mantenimiento, atención al cliente y servicios de valor añadido) para que el cliente pueda centrarse exclusivamente en el core de su negocio que es la gestión de sus activos. Las circunstancias de este nuevo entorno cambiante que nos ha tocado vivir, nos exige ser capaces de adaptarnos y tomar decisiones de forma rápida para poder avanzar en un marco empresarial cada vez más exigente, y para ello, la transformación digital de la mano de la tecnología IOT y Big Data está demostrando ser clave para el éxito de nuestros clientes. Escrito por Fernando García Gómez, IoT Smart Mobility - Telefónica
11 de enero de 2021

Cómo transformar una compañía(XII): la transformación del talento interno
El cambio de paradigma que conlleva el uso de grandes volúmenes de datos (internos, de sensores, públicos…) y la aplicación de la Inteligencia Artificial en los negocios es imparable. La digitalización de nuestro día a día, junto con la democratización de la tecnología empujan a las empresas muy rápidamente hacia el cambio. Y prioriza la creación de una estrategia para que todos los empleados evolucionen hacia nuevos perfiles en los que cambian las funciones, los conocimientos, los roles y las herramientas a utilizar. En este post de la nuestra serie “Cómo transformar una compañía” abordaremos una de las partes fundamentales del cambio, la transformación de las personas que forman parte de una compañía: el talento interno. El activo más preciado en una organización Se suele decir que el activo más preciado en una organización es su equipo humano. En éste se deben concentrar gran parte de los esfuerzos, apoyando la incorporación de las nuevas habilidades y adoptar una “cultura del dato” en toda la organización. Todas las áreas deben tener nuevas habilidades para poder ser autónomas en su parcela, no sólo las capas técnicas. Cuando una empresa vira su estrategia hacia el dato, una de las primeras cosas que debería plantearse es llevar a cabo un diagnóstico del talento interno basado en 2 preguntas básicas (aunque normalmente nada fáciles de contestar): ¿Qué habilidades tienen mis equipos? ¿Qué habilidades necesito que tengan mis equipos? Cómo definir un plan de transformación Una vez evaluada la diferencia entre los conocimientos actuales (habilidades, metodologías, uso de tecnología, etc..) y los que queremos tener en la compañía obtenemos el punto de partida para crear la estrategia, definir la ruta y desarrollar el plan transformacional adecuado: Diseño de itinerarios de desarrollo específico para los diferentes perfiles y necesidades detectadas: Syllabus y contenidos Formatos y metodologías Casos de uso y prácticas afines Disponibilizar la plataforma de práctica Elección de herramientas Proceso de selección de los candidatos idóneos para cada programa/itinerario Diseño del sistema de medición de indicadores de seguimiento (KPIS) Cronograma de despliegue Despliegue del plan global (selección alumnos, impartición de programas, acciones de acompañamiento, comunicación interna, etc…). Coordinación y Monitorización de todas las fases. Plan de comunicación interna que permita alinear las necesidades de la empresa con el crecimiento de los empleados, y generar comunidades. De la urgencia, al plan global Algunas empresas no parten de un plan tan global sino que van abordándolo por fases y urgencia, basándose en necesidades concretas detectadas. Es habitual por ejemplo empezar por las capas más técnicas, transformando perfiles de analistas de datos tradicionales hacia el Data Science y el análisis de datos a gran escala en sistemas distribuidos. O, por ejemplo, seleccionando perfiles de IT o de sistemas para formaciones en habilidades de Data Engineering o de arquitectura Big Data. Puede ser un buen primer paso, pero no necesariamente suficiente: urge incorporar el vocabulario del dato en todas las capas de la empresa. En particular, es importante no descuidar la transformación de las capas directivas. Éstas, necesitan conocer todos los procesos para tomar las decisiones estratégicas correctas, tanto de dimensionamiento, como de activación de planes concretos. El cambio real se alcanza cuando es transversal y a todos los niveles, cuando conseguimos cambiar la cultura de la compañía, y no siempre es fácil de conseguir. La importancia de tener un plan estratégico Desde mi experiencia, uno de los aspectos claves para el éxito de un plan global que logre la adopción real de estos modelos de upskilling y reskilling interno, es que estén totalmente apoyadas desde las áreas directivas y de recursos humanos. Es crucial para el éxito de este tipo de iniciativas que se perciba como una inversión para el crecimiento de la empresa y del negocio, y no como un gasto en el empleado. Si las áreas de dirección no acompañan claramente este plan, es probable que fracase y que en poco tiempo se vuelva a trabajar con métodos y procesos antiguos. Si nos centramos en ofrecer una formación concreta a nuestros empleados, sin seguimiento y sin una vinculación directa con la actividad real a desempeñar, no alcanzaremos la transformación completa. La oferta de formación en el mercado es amplísima y puede fácilmente cubrir conceptos concretos y algunas partes del recorrido transformacional. Ahora bien, si lo que se pretende es tener una CULTURA DEL DATO no vale con aprender conceptos: el proceso de alineación del talento con las necesidades y procesos clave de la compañía va mucho más allá y conviene darle la importancia que merece, desde fomentar la mentalidad “experimental” y de trabajo en equipo, a aprovechar el potencial de los datos disponibles o aprender a trabajar con la tecnología de la compañía. Para ello es necesario diseñar concienzudamente el plan estratégico y desarrollar un modelo que se vaya adaptando a los resultados y a las necesidades que vayan surgiendo. Escrito por Natàlia Mata. Lee todos los posts de la serie “Cómo transformar una compañía” aquí. Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.
7 de enero de 2021

Caso de éxito: Departamento de Transporte de UK
El Departamento de Transporte es el organismo gubernamental responsable de la mayor parte de la red de transporte del Reino Unido. Nuestro cliente necesitaba entender rápidamente los patrones de movilidad pública en todo el Reino Unido durante la primera ola de COVID-19 para poder entender mejor el movimiento del país y tomares decisiones basadas en datos. ¿Cuál era el desafío? El mayor reto era entregar informes diarios casi en tiempo real para hacer frente a la comprensión de una situación pandémica que está en constante movimiento. Además, otro de los desafíos era la comunicación de los patrones de datos al cliente de una manera oportuna y la adhesión a las normas éticas requeridas, asegurándose de que los datos son anónimos y agregados. ¿Y qué hay de los beneficios? Gracias a Luca Transit, se obtuvieron conocimientos de movilidad casi en tiempo real, lo que permitió al gobierno actuar de manera considerada y dar forma a la política en respuesta al comportamiento de la población. "Hemos estado apoyando al Departamento de Transporte (DfT) con información diaria desde el comienzo de la pandemia y nos complace continuar apoyándolos hasta el 2021", Ant Morse, Jefe de Digital, O2. Con esta solución el cliente consigue ver los datos del día anterior en un formato de fácil acceso, cubriendo los movimientos de las personas en el Reino Unido, y con datos agregados totalmente anónimos. Además, pueden solicitar datos a medida que ayuden a mejorar la comprensión y el análisis de los datos, con soluciones proactivas, sugeridas y demostradas por O2. Los insights se recogen a través de las redes de O2, que lo utiliza más de un 35% de la población de Reino Unido. Gracias a O2, los datos reunidos sobre la movilidad fueron muy representativos y obtuvimos gran conocimiento gracias a diversos grupos sociales y demográficos. La solución En definitiva, los datos reunidos permitieron comprender el cumplimiento público en respuesta a las restricciones de movilidad impuestas. Además, permitió al gobierno calcular los próximos pasos a seguir para ayudar a frenar la propagación de COVID-19 en el Reino Unido. AI OF THINGS Así se mueve Alemania: datos móviles para mejorar planes de transporte 20 de octubre de 2020 AI OF THINGS Caso de éxito: Mejora de los servicios de transporte en Bristol 26 de agosto de 2020 Las ciudades también pueden sacar partido de las nuevas tecnologías como IoT, Big Data o Inteligencia Artificial. ¿Quieres ser la próxima? Descubre los casos de éxito destacados en todos los sectores en la web de LUCA.
17 de diciembre de 2020

Internet de las Cosas (IoT) aplicado al desarrollo de la agricultura familiar en Perú
La costa del Perú, se caracteriza por ser un ambiente desértico, con lluvia escasa, por lo que la agricultura costera depende exclusivamente del agua de riego, que puede obtenerse de los ríos que se forman por las lluvias en la parte alta o del agua del subsuelo. En estas condiciones, la eficiencia del uso del recurso hídrico, más que una estrategia productiva es una necesidad, para hacer más competitiva la producción agrícola. Y es precisamente por ello que el interés por la gestión del recurso hídrico a través de las nuevas tecnologías se ha hecho más necesario y notorio. Figura 1: Cultivo de algodón Proyecto Algodón Smart Agro 4.0 En febrero de 2018, FAO y Telefónica SA firmaron un acuerdo para impulsar el uso de tecnología de punta en el sector agro, con la finalidad de mejorar la vida de los pequeños y medianos agricultores en América Latina. En Perú, se desarrolló el proyecto piloto “Algodón SMART AGRO 4.0” de eficiencia hídrica conducido por el Proyecto +Algodón, de la Organización de las Naciones Unidas para la Alimentación y la Agricultura (FAO) y la Agencia Brasileña de Cooperación (ABC), en alianza con Telefónica. Su finalidad era mejorar los cultivos de algodón de pequeños agricultores familiares de las regiones de Ica y Lambayeque, a través del incremento de la productividad y promoción del uso eficiente del agua para el riego, todo ello mediante el uso de tecnología. Modelo de intervención La participación de Telefónica consistió en brindar asesoría especializada, conectividad e instalar un kit de tensiómetros digitales de tres (3) profundidades, conectados al terreno de cultivo de cada agricultor. Esta propuesta, a través del análisis de Big Data, uso de IoT y la sistematización recibida de los equipos en una plataforma digital, permitieron generar las recomendaciones de riego para la optimización del recurso hídrico. Figura 2: Tensiómetros instalados en terreno de cultivo El proyecto piloto tuvo una duración de año y medio, en la que se obtuvieron dos cosechas del cultivo de algodón y un cultivo intermedio de frejol entre cada período de algodón. Participaron en el proyecto en total cinco (5) pequeños agricultores, tres (3) de la región Ica y dos (2) de la región Lambayeque. Asimismo, en 2019 se recibió la visita de la Viceministra de Políticas Agrarias del MINAGRI, a quien se le presentó los primeros resultados y el funcionamiento de la tecnología dentro de uno de los pilotos. Figura 3: Presentación de primeros resultados del proyecto piloto. Resultados de la intervención Los rendimientos obtenidos en las parcelas intervenidas fueron superiores a los obtenidos por productores aledaños. En el primer cultivo de algodón se observó un incremento del 10 al 77%. En el cultivo intermedio, la productividad aumentó de un 18 a un 29%. Lamentablemente, los resultados del segundo cultivo de algodón se vieron afectados por las restricciones generadas por la pandemia del COVID-19. En cuanto a la eficiencia hídrica, en una de las parcelas de la región Ica que tuvo cultivo de algodón y cultivo intermedio, se obtuvo un ahorro de agua del 20%. El piloto Algodón SMART AGRO 4.0 fue un proceso de aprendizaje que permitió la validación de la solución tecnológica sobre el terreno. Los resultados positivos logrados, demuestran la importancia de la agricultura digital para un desarrollo rural sostenible en pequeñas fincas. La iniciativa se realizó en el marco de un trabajo colaborativo entre sector privado, organismo internacional y sector público. Es un claro ejemplo de cómo las soluciones tecnológicas pueden potenciar y favorecer la economía de los pequeños agricultores. A la vez, puso de relieve los interesantes retos que requieren ser abordados en el sector agricultura en Perú.
16 de diciembre de 2020

Caso de éxito ONS: datos para la gestión de movilidad en el Reino Unido
En la "historia con datos" de hoy mostramos, una vez más, cómo soluciones basadas en tecnologías Big Data, IoT e Inteligencia Artificial ofrecen un mundo infinito de posibilidades y ayuda con mayor precisión en la toma de decisiones que respondan a las necesidades de cada organización y su realidad. En este año marcado por la pandemia de la COVID-19 los departamentos gubernamentales y las organizaciones nacionales han necesitado con urgencia comprender los patrones de movilidad a diario, para desarrollar nuevos conjuntos de datos, analizar los datos existentes y extraer nuevos insights , información de valor, que fueran relevantes para su toma de decisiones.Así es como, junto con el equipo de O2 hemos apoyado a los departamentos gubernamentales del Reino Unido durante 2020, gracias al proyecto realizado con la Oficina de Estadísticas Nacionales (ONS). La ONS (Office for National Statistics) ofrece estadísticas e insights muy valiosos sobre economía, sociedad y ciudadanía de Reino Unido tanto para el gobierno británico, como empresas y sociedad, en general. El uso de la movilidad ha demostrado ser un importante caso de uso para el cual los datos y análisis de tendencias han sido fundamentales para la respuesta colectiva a la pandemia. A medida que la pandemia de la COVID-19 comenzó a afianzarse, la ONS buscaba conjuntos de datos confiables y en tiempo real que los ayudaran a establecer tendencias de movimiento entre la población, que luego podrían usarse para obtener insights relevantes e informar de la respuesta del país. Gracias a estos insights extraídos del análisis avanzado de datos de movilidad, la ONS ha podido proporcionar una imagen precisa de cómo los grupos de personas se mueven en el país. Los insights extraídos de estos data sets origen – destino están totalmente anonimizados y agregados, mostrando el comportamiento y tendencias de grupos de personas, como pueden ser los viajes de diferentes grupos demográficos, así como grupos de ingresos, duración del viaje y tiempo de permanencia, por ejemplo. Además, estos data sets se han adaptado según las necesidades y requerimientos para poder extraer insights adicionales que necesitara la ONS como, por ejemplo, el análisis enfocado en la populación de tercera edad o grupos de personas vulnerables, para comprender cuáles eran sus patrones de comportamiento y movilidad en zonas concretas, y poder identificar estos espacios e informar del riesgo. “La ONS ha sido muy claro sobre cuáles son los requerimientos y data sets que necesitan, y estamos trabajando exhaustivamente para ofrecerles lo que precisan. Además, ofrecemos insights sobre cómo estos análisis de datos aportan valor para la toma de decisiones y resultados que buscan” Ian Burrows, Digital Insights Director, O2 Así, nuestro equipo de O2 en el Reino Unido sigue desarrollando nuevos data sets y aportando análisis e insights enriquecidos para acompañar a la ONS en sus tomas de decisión en este contexto y realidad actual. El sector público y las ciudades también pueden sacar partido de las nuevas tecnologías como IoT, Big Data o Inteligencia Artificial. ¿Quieres ser la próxima? Descubre los casos de éxito destacados en todos los sectores en la web de LUCA.
9 de diciembre de 2020

Los datos como aliados para definir nuevos modelos de trabajo ante la COVID19
La necesidad de evolucionar los modelos de trabajo tradicionales ya venía siendo una tendencia desde los últimos años. Sin embargo, los últimos acontecimientos surgidos por la pandemia mundial han obligado a las corporaciones a acelerar este proceso de transformación. Podríamos decir entonces que el paradigma que engloba la definición de las nuevas formas de trabajo es ya un concepto con el que, cualquier responsable de RRHH de una gran organización, responsable de seguridad o responsable de operaciones de los espacios físicos, seguro que ya está familiarizado con él. https://www.youtube.com/watch?v=fCrPB1wSdzU Llegados a este punto cobra especial importancia que los equipos que hemos mencionado anteriormente cuenten con los recursos necesarios para facilitar su toma de decisiones. Como ya hemos introducido en otros blogs, los datos son nuestro gran aliado como recurso para la toma de decisiones y nos pueden ayudar a aprovechar las bondades de la transformación data driven desde su eje de organización. Siendo conocedores de esta nueva necesidad, desde Telefónica IoT & Big Data, venimos trabajando en el diseño de una solución basada en las capacidades que nos ofrece la tecnología Big data, que permita integrar y analizar toda la información de valor respecto a las dimensiones que engloban la forma en la que ejecutamos los modelos de trabajo. “Desde nuestra perspectiva entendemos los nuevos modelos de trabajo como un paradigma que engloba dos dimensiones principalmente, la dimensión del entorno físico o trabajo presencial y la dimensión del entorno digital o trabajo en remoto” Con todo ello, nace la solución Adapting to new ways of Working, un producto multisectorial, modular y escalable, cuyo propósito es convertirse en una solución de monitorización de los entornos y las nuevas formas de trabajo, adaptada al contexto y peculiaridades de cada organización. Con este propósito, esta herramienta ha sido diseñada con funcionalidades específicas para conseguir nuevos modelos de trabajo, permitiendo a las organizaciones garantizar la seguridad y bienestar de los empleados en el proceso de retorno a la oficina. “Adapting to new ways of working” permite analizar la información disponible para garantizar la premisa de conseguir la máxima productividad teniendo en cuenta la flexibilidad” ¿Qué hace diferencial nuestro producto? Proporciona instrumentos enfocados a optimizar los protocolos y tomar decisiones en cualquier momento, gracias a la utilización de diferentes fuentes de datos internas y acceso a fuentes de datos externas, adecuadamente explotadas con técnicas de inteligencia artificial. Disponemos de un equipo de servicios profesionales expertos en el desarrollo de soluciones de analítica e integración de datos, así como perfiles especializados en iniciativas de People Analytics. ¿Cuáles son los principales retos que ayuda a resolver Adapting to new ways of working? Seguimiento de métricas y KPI’s clave para garantizar el bienestar de los empleados en el centro de trabajo. Identificación de insights en todo el journey del empleado (viaje hacia/desde la oficina). Descubrimiento de evidencias que permitan optimizar el rediseño de los espacios de trabajo. Obtención de insights para la gestión ágil de los protocolos de seguridad y limpieza de edificios. Seguimiento de métricas y kpis clave para optimizar la gestión del trabajo en remoto. Obtención de insights encaminados a facilitar la conciliación laboral y la desconexión digital. Identificación de métricas que permitan conocer las principales relaciones entre la fuerza de trabajo. ¿Cómo te podemos ayudar desde Telefónica? Nuestros servicios permiten cubrir el end to end del desarrollo de la herramienta, fundamentando el mismo en 4 pilares principales. Figura 1: Adapting to new ways of working (click para ampliar) “Un optimista ve una oportunidad en toda calamidad, un pesimista ve una calamidad en toda oportunidad”. Winston Churchill. Sigamos el consejo de Winston Churchill y seamos optimistas, de tal forma que, ante este nuevo reto planteado para todas las organizaciones, veamos la oportunidad y no solo la calamidad. Veamos la oportunidad de mejorar y optimizar la forma en la que veníamos trabajando, pudiendo así adelantar la implementación de nuevos modelos de trabajo más adecuados para garantizar la seguridad en las empresas y en los empleados. Escrito por Sergio Mayor Martín ¿Necesitas info sobre Adapting to new ways of working? ¡Contáctanos en nuestra web!. No te pierdas nuestro evento en directo del próximo 3 de diciembre en Linkedin. Inscripción gratuita en este enlace. QUÉ: Directo en la company page de LUCA en LinkedIn FORMATO: Charla y demo de 30 minutos + Q&A de 10 minutos CUÁNDO: 3 de diciembre, 09:30 h (CET)
30 de noviembre de 2020
Blockchain para garantizar la trazabilidad de la vacuna del COVID19
Cuando hablamos de blockchain pensamos en dos casos de uso, las criptomonedas y la trazabilidad en las cadenas de suministro. Trazabilidad es de hecho una de las características que vienen a nuestra mente cuando pensamos en blockchain. La industria alimentaria, textil o farmacéutica son algunos de los ejemplos más claros de trazabilidad en cadena de suministro. Pero cada vez son más los sectores en los que se supone un valor añadido. Sin embargo, ¿por qué es importante la trazabilidad y qué convierte a blockchain en una tecnología clave para suministrarla? Si te preguntas por qué, te animo a que sigas leyendo este artículo para entenderlo. Blockchain como tecnología clave para soluciones de trazabilidad Cualquier proceso podemos descomponerlo en pequeñas piezas para detallar con precisión el origen, manipulación y movimiento de cualquier activo. En cada paso recolectamos el máximo de información posible para saber qué ha pasado. Cuanto más información, más control tenemos sobre el proceso. Cualquier empresa quiere conocer el máximo detalle con respecto al proceso o producto. Controlar el proceso permite garantizar la calidad y seguridad de los productos. Pero para garantizar la trazabilidad del proceso, una empresa debe asegurar la veracidad e integridad de la información. Es decir, necesita garantizar que: La información no se haya alterado partidaria o involuntariamente desde que se registró. Blockchain crea ecosistemas de confianza donde la información está replicada masivamente. No hay una única entidad central que gestione, custodie o controle la información. Por tanto, nadie puede manipularla en su beneficio sin que la red se entere y la información podemos considerarla inmutable. La fuente de la información sea fiable. Si la información registrada no se puede modificar, no podemos permitirnos introducir errores. Aquí es donde la combinación de blockchain con dispositivos IoT se hace vital. Cuanto más cerca de la generación del dato lo registremos en la cadena más confianza tendremos en su calidad. Además, podemos auditar los dispositivos IoT y garantizar que no se han alterado para incrementar la confianza. La información es fácilmente verificable. Cuando hablamos de Blockchain hablamos de una red. La información la comparten todos los participantes de la red. A través de contratos inteligentes, se establecen las reglas que todos los actores previamente han acordado. Estas reglas aplican y están consensuadas tanto para registrar como para verificar información. Como vemos, Blockchain juega un papel relevante a la hora de garantizar estos tres requisitos sobre la información de un proceso. Un caso concreto: industria farmacéutica Debido a las circunstancias excepcionales que estamos viviendo, un ejemplo muy actual de trazabilidad lo encontramos en la industria farmacéutica. Oímos en los medios sobre las condiciones especiales de distribución y fabricación que se exigen para la vacuna del COVID-19. En este caso estamos viendo como las diferentes compañías se empeñan en transmitir confianza en su vacuna. Para construir esa confianza es crítico dotar de trazabilidad y trasparencia a todo el proceso de elaboración, distribución y comercialización. Controlar las condiciones de conservación es crítico para garantizar su eficacia y la seguridad con las que han sido elaboradas. Cada lote de vacunas se puede rastrear fácilmente a partir de un identificador único e irrevocable. Y a cada lote le asignamos su histórico de circunstancias y actividad (condiciones y fechas de fabricación, traslados, almacenaje, etc.). Esto permite trazar todo el ciclo de vida de las vacunas. Conociendo el histórico podemos garantizar la eficacia y prevenir posibles riesgos. Pero también erradicar las copias ilegítimas que pudieran incorporarse al mercado. En este contexto hablar de bloques, transacciones, redes y contratos inteligentes puede parecer muy lejano a la realidad. Sin embargo, todos estos elementos propios de Blockchain nos permiten construir soluciones a este tipo de retos cotidianos. Trazabilidad con TrustOS Precisamente el módulo de trazabilidad es el más utilizado por los clientes de TrustOS, la plataforma de Blockchain de Telefónica. Este módulo ofrece todas las funcionalidades necesarias para la creación, gestión y seguimiento de activos digitales. De forma muy sencilla podemos crear representaciones digitales de cualquier proceso o ciclo de vida de un producto. Cada paso o modificación del producto es registrado en blockchain. Un tercero puede así verificar cualquier información recogida durante su fabricación o distribución. Por ejemplo, podemos crear un activo en blockchain que represente un lote de vacunas. Eso es lo que hemos hecho en el demostrador del video. Modelización del traslado de un lote de vacunas Hemos modelado el traslado de un lote de vacunas. En cada paso, simulamos como un dispositivo IoT interactúa con Blockchain a través de TrustOS. El dispositivo, actualiza la posición y toma medidas de las condiciones de conservación (temperatura y humedad). Para cada activo se establecen alarmas o reglas dinámicas que permiten monitorizar que los valores respetan unos umbrales. Por ejemplo, para el transporte de la vacuna del COVID19, exigimos que la temperatura sea constante (-80ºC). En el momento que alguna medidas supera los umbrales, el contrato inteligente encargado emitirá una alarma. Además la alarma se registra en la cadena para que nadie pueda ponerlo en duda. Toda la información de trazabilidad está disponible para ser verificada. Tanto en tiempo real, según se está registrando y produciendo las alarmas, como finalizado el transporte. Podemos también utilizar blockchain para emitir un certificado digital. Este certificado es firmado por los actores involucrados, por ejemplo, la empresa de transportes y el destinatario. Una vez firmado, el propio certificado como toda la información es verificable e irrefutable. Se convierte en una herramienta muy poderosa para eliminar las posibles disputas entre las partes en este tipo de procesos. Escrito por Diego Escalona Rodriguez Para mantenerte al día con el área de Internet of Things de Telefónica visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube.
25 de noviembre de 2020

Alcalá de Henares: un ejemplo sobre cómo el Big Data ayuda a la movilidad de las ciudades
Gracias al Big Data, el Ayuntamiento de Alcalá de Henares puede entender el comportamiento real de los desplazamientos de los visitantes y ciudadanos en la región para ayudar en la toma de decisiones en relación al turismo y la movilidad de la ciudad. Esta es la conclusión a la que ha llegado un equipo de expertos del Grupo Internacional AUTELSI que ha estudiado el turismo de esta localidad y ha incluido servicios de Big Data como necesarios para poder analizar la presencia y movilidad de los turistas y visitantes en la ciudad. Crowd analytics para detectar patrones y tendencias Para este proyecto, utilizamos nuestra plataforma tecnológica Smart Steps para extraer conocimiento sobre las tendencias globales de conglomerados de personas, ayudando así a las organizaciones a optimizar su propuesta de valor. Estos productos de Crowd Analytics están orientados a analizar el volumen de personas que visitan una o varias zonas específicas, permitiendo conocer ciertos patrones de comportamiento. Los datos se tratan de manera anonimizada y agregada para proporcionar mayor conocimiento sobre el sector de estudio. También ayudamos a nuestros clientes a obtener valor a través de análisis a medida y APIs que permiten el consumo de estos insights. Para ofrecer este servicio “se tienen en cuenta las fuentes de información y todo lo relacionado al tratamiento de éstas. Por supuesto, garantizando un proceso anónimo y seguro. Todos los eventos generados en la red móvil están georreferenciados, y tienen asociado una marca temporal, lo que permite analizar la actividad de manera anónima, en diferentes localizaciones geográficas y a lo largo de diferentes ventanas temporales”, explica El concejal de Innovación Tecnológica, Miguel Castillejo. Los resultados Gracias al Big Data se pueden sacar muchos datos que, de manera debidamente analizada, puede ayudar en la toma de decisiones para que ayudes a tus visitantes a encontrar justo lo que están buscando: Datos reales mediante la extracción y anonimización de los datos procedentes de la red móvil. Análisis aplicando modelos matemáticos se obtienen perfiles y patrones de comportamiento de los turistas. El conocimiento que se obtiene mediante LUCA Tourism, se generan a través de la implementación de complejos algoritmos y modelos matemáticos. Informes de resultados generados en función de la información necesaria, por ejemplo: volumen de turistas, lugares más visitados por día y franja horaria, clasificación entre extranjeros y nacionales etc. Análisis personalizados realizados por nuestro equipo de científicos según las necesidades de los clientes Beneficios para tu empresa Detección de necesidades específicas de negocio: gracias al análisis del comportamiento de los viajeros podemos identificar posibles casos de negocio. Oferta personalizada: productos y servicios adaptados a las necesidades de los turistas. Análisis y seguimiento: posibilidad de comparar resultados actuales con anteriores para identificar los puntos de mejora y definir planes de acción. AI OF THINGS Un nuevo concepto de Turismo 4 de octubre de 2019 AI OF THINGS ¿Cómo se reinventan las diferentes industrias tras la COVID 19? 2 de noviembre de 2020 Las ciudades también pueden sacar partido de las nuevas tecnologías como IoT, Big Data o Inteligencia Artificial. ¿Quieres ser la próxima? Descubre los casos de éxito destacados en todos los sectores en la web de LUCA.
19 de noviembre de 2020

Deep Learning e imágenes por satélite para estimar el impacto de la COVID19
Motivados por el hecho de que la pandemia de COVID-19 ha causado conmoción mundial en un corto periodo de tiempo desde diciembre de 2019, estimamos el impacto negativo del confinamiento a causa de la COVID-19 en la capital de España, Madrid, utilizando imágenes de satélite comerciales cortesía de Maxar Technologies©. Las autoridades en España están adoptando todas las medidas necesarias, incluyendo ciertas restricciones a la movilidad urbana, para contener la propagación del virus y mitigar su impacto en la economía nacional. Dichas restricciones dejan señales en las imágenes de satélite que se pueden detectar y clasificar automáticamente. Detección de vehículos. Nuestra idea es desarrollar una solución que permita el conteo de automóviles estimando la presencia de coches visibles en imágenes satelitales de alta resolución. Estudios recientes revelan un incremento de hasta un 90% cuando se compara el tráfico de coches entre otoño de 2018 y 2019 en varios hospitales de Wuhan, China. Esta observación parece indicar que una infección estaba creciendo en la comunidad y ciertas personas requerían atención médica. De igual manera, partimos de la hipótesis de que el número de coches disminuyó drásticamente durante el confinamiento debido a la COVID-19 en Madrid, para investigar más a fondo cómo detectar con precisión estos automóviles utilizando técnicas de visión por computador. Figura 1: Imágenes satelitales cortesía de RSMetrics© sugieren que la COVID-19 podría haber estado circulando por China mucho antes de que se conociera el primer caso. Deep Learning. Por esta razón, investigamos cómo detectar con precisión dichos coches usando técnicas de visión por computador. Recientemente, impulsados por el éxito de los algoritmos basados en deep learning, la mayor parte de la literatura ha buscado enfoques inspirados en redes neuronales convolucionales (CNNs). La principal razón de su popularidad es que las CNNs aprenden a extraer características de la imagen de manera automática, de modo que no hay necesidad de seleccionarlas manualmente. Como resultado, las CNNs atraen un gran interés debido a que son más robustas frente a los múltiples cambios de apariencia que presentan las imágenes adquiridas en escenarios “sin restricciones”. Las aproximaciones actuales que detectan objetos generalmente fallan o pierden precisión debido al tamaño relativamente pequeño de los objetos de interés y la gran cantidad de datos a procesar en imágenes “sin restricciones” con la presencia de factores adversos como son, diferentes ciudades/países, cambios en la perspectiva, oclusiones, iluminación, borrosidad, etc. F igura 2: Variabilidad hostil en apariencia debido a diferentes factores que incluyen cambios de punto de vista (ángulo nadir), sombras, cambios de luz marcados por el clima y las estaciones, etc. Datos etiquetados. Hemos organizado los métodos existentes en dos categorías en función de si directamente estiman la cantidad de coches a partir de la imagen (conteo por regresión) o si primero aprenden a detectar coches individualmente y luego cuentan las ocurrencias para establecer la cantidad total de automóviles en la imagen (conteo por detección). Así, llegamos a la conclusión de que este último enfoque logra un rendimiento superior. Figura 3: Ambos enfoques supervisados necesitan un conjunto de imágenes de entrenamiento etiquetadas. Conteo por regresión requiere del número total de coches anotados. Conteo por detección requiere la posición de cada vehículo definiendo las coordenadas del rectángulo que delimita su superficie Además de por las dificultades anteriormente mencionadas, la detección de automóviles en imágenes satelitales también se ve afectada por el problema del sesgo en el conjunto de datos, lo que significa que los modelos aprendidos habitualmente solo funcionan bien en la misma escena en la que fueron entrenados. Para aliviar tales sesgos, entrenamos nuestro modelo utilizando diferentes imágenes anotadas con automóviles capturados a diferentes resoluciones espaciales de las bases de datos COWC y DOTA, reflejando las necesidades de las aplicaciones del mundo real. Hasta donde sabemos, esta es la primera vez que un algoritmo combina con éxito imágenes a diferentes resoluciones para hacer frente a la falta de datos satelitales debidamente anotados. Conjunto de datos de Madrid. Como era de esperar, necesitamos la resolución más alta comercialmente disponible para poder detectar vehículos pequeños. Por esta razón, descargamos 153 imágenes de satélite de 22 regiones de interés alrededor de la comunidad autónoma de Madrid con una resolución espacial de 30 cm (datos del satélite WorldView-4 accesibles mediante la plataforma SecureWatch©). Seleccionamos áreas concretas de Madrid donde el conteo de coches sea un proxy de actividad como son, centros comerciales, nudos en las carreteras, hospitales, zonas industriales y universidades, entre otros. En el siguiente vídeo podemos observar visualmente la reducción en el número total de coches antes y durante las restricciones de movilidad a causa de la COVID-19. Por tanto, parece razonable estudiar el impacto global del confinamiento en el volumen de tráfico. https://www.youtube.com/watch?v=iJq0BnK9upQ Recorrido por algunas imágenes procesadas para percibir visualmente la dramática reducción en la presencia de vehículos sobre Madrid (audio en español con subtítulos en inglés). Resultados En los experimentos medimos el rendimiento de nuestra propuesta y calculamos estadísticas de recuento de automóviles para cuantificar la dramática caída en la cantidad de vehículos durante el confinamiento. Como resultado, corroboramos estas estadísticas utilizando indicadores adicionales como puedan ser los datos de telecomunicaciones y los sensores de tráfico respectivamente. Llegamos a la conclusión de que todos estos indicadores también se correlacionan con las estadísticas oficiales de actividad económica, por lo que el recuento de automóviles puede complementar las medidas tradicionales de actividad económica ayudando a los responsables políticos a adaptar sus propuestas para aplanar la curva de recesión. Figura 4: Curvas que indican cómo está evolucionando el brote COVID-19 en Madrid desde 2020. Los colores rojo, amarillo y azul comparan las curvas obtenidas con datos de telecomunicaciones anonimizados y agregados de las antenas de Telefónica Movistar, estadísticas de tráfico adquiridas de los sensores del Ayuntamiento de Madrid, y estimando la presencia de coches visibles con nuestra tecnología satelital respectivamente. Información adicional sobre la tecnología de detección de vehículos, las imágenes satelitales de alta resolución descargadas, un análisis de mercado, y resultados comparativos para cada región de interés también son presentados en el material complementario. Escrito por Roberto Valle Fernández. No te pierdas el próximo webinar "Deep Learning e IA para mejorar el tráfico en tiempos de Covid19" que tendrá lugar el próximo 25 de noviembre. Para agendarte este evento pincha aquí. (Recuerda seguir los pasos de registro para poder verlo en directo) Otros post sobre aplicaciones del Deep Learning relacionadas con el COVID19: Para mantenerte al día con LUCA visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube.
4 de noviembre de 2020

¿Cómo se reinventan las diferentes industrias tras la COVID 19?
La COVID19 nos ha obligado a cambiar la perspectiva. Ha creado nuevas necesidades, ha introducido nuevos “productos de primera necesidad” en nuestra lista de la compra, nos ha obligado a cambiar muchos hábitos en nuestra vida personal y también en la profesional. Y una cosa está clara: el virus “ha venido para quedarse”, al menos una buena temporada, entre nosotros. Por este motivo, no podemos quedarnos de brazos cruzados. Tenemos que aprender a vivir con él, a seguir adelante en nuestras vidas y en nuestros negocios. La capacidad de adaptación a una realidad cambiante siempre ha sido clave, pero en los últimos tiempos, se ha vuelto imprescindible. No solo por la gran velocidad a la que se producen éstos cambios, sino también, por su calado. Sin embargo, esa adaptación a las circunstancias del presente, no nos debe hacer olvidar hacia dónde debemos ir. Tener claras las metas que van a permitir superar esta situación y seguir creciendo cuando todo vuelva a la normalidad. Puede haber más o menos discusión sobre cuáles han de ser estas metas. Pero una de ellas resulta incuestionable: la transformación digital. La importancia de la transformación digital en era Covid Hace unos meses, desde el área de Telefónica IoT&BD, ya nos planteamos cómo asumir el reto que suponía la nueva realidad. Imaginamos posibles escenarios e identificamos necesidades comunes. Nuevas necesidades surgidas de la coyuntura del momento, pero también orientadas a las circunstancias futuras, a dar soporte a una de las claves más claras de la recuperación: la transformación digital. AI OF THINGS Soluciones de Telefónica IoT, Big Data e IA para la era post Covid19 6 de julio de 2020 Así revisitamos nuestro portfolio para ver cómo nuestras herramientas podían reorientarse para dar respuesta también a las nuevas necesidades surgidas a raíz de la pandemia. En ese momento, definimos un primer paquete de soluciones post Covid, con herramientas como Covid Compliance, Retail Recovery, Workforce Optimise, Customer Discovery, Mobility for Public Admin y IA & Big Data Assessment. Las nuevas soluciones del catálogo de productos post-covid19 En el tiempo transcurrido desde el lanzamiento de estas primeras soluciones, en la unidad de IoT & Big Data de Telefónica Tech, hemos seguido trabajando en identificar qué otras soluciones se podían sumar a las anteriores, para ayudar a nuestros clientes a consolidar su transformación digital. No sólo para superar con éxito la difícil situación actual, sino para hacer de manera consciente esta inversión en el futuro digital de sus negocios. Por tanto, la inversión en cubrir una necesidad del momento se convierte también en una inversión de futuro. Los nuevos productos incluidos en esta segunda campaña cubren también distintas necesidades y escenarios de negocio multisectoriales. ¿Controlar de forma remota la infraestructura desplegada en los distintos sistemas de gestión del agua, realizar en remoto lecturas o monitorización de contadores inteligentes…? Tu solución es Smart Water Solution, una solución integral para el ciclo del agua. ¿Definir un lenguaje común para toda la compañía, crear un modelo organizativo orientado al dato, alinearse con políticas nacionales, europeas o de un sector concreto? En este caso, los servicios de consultoría de Data Governance pueden ser tu solución. Esta solución multisectorial es diferencial ya que aúna todas las capacidades de Telefónica, de forma modular y escalable permitiendo adaptar el producto a la necesidad particular de cada cliente. ¿Localizar vehículos en tiempo real por GPS, ahorrar costes gracias a políticas de mantenimiento preventivo y control del consumo de combustible, mejorar hábitos de conducción de los empleados, disponer de datos agregados para tomar mejores decisiones estratégicas...? Fleet Optimise es un producto pensado para empresas que cuenten con flota de vehículos independientemente de su sector de actividad. ¿Identificar tu segmento objetivo basándonos en analítica de datos, planificar las mejores campañas “drive to store” o “media at location, medir su impacto tanto online como offline…? Tu respuesta es Data Driven Advertising, que te permitirá identificar la forma óptima de dirigirte a tu audiencia deseada. ¿Conocer el stock en tiempo real, hacer inventario de productos, habilitar cajas de auto check-out, controlar probadores, habilitar pantallas de información, prevenir mermas, reponer con mayor eficiencia... etc mediante tags RFID? En este caso, RFID for Retail es tu solución. Por último, si lo que te preocupa es cómo analizar el impacto de la desescalada en los espacios de trabajo y en el uso de las herramientas digitales y el teletrabajo, tenemos la solución de Adapting new ways of working. Esta combina las diversas fuentes de datos junto con nuestros servicios profesionales especializados para monitorizar la desescalada en tu negocio. Aportamos nuestra propia experiencia Aún a riesgo de resultar repetitivos, no queremos dejar de recordar un aspecto clave de nuestra propuesta. En Telefónica, no sólo ofrecemos un conjunto de herramientas y servicios orientados a cubrir las necesidades presentes y futuras de nuestros clientes. También, ponemos a su disposición las buenas prácticas aprendidas en nuestro propio proceso de digitalización interno, como compañía y de adaptación a esta nueva realidad. Escrito por María Muñoz Ferrer Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube
2 de noviembre de 2020

¿Qué son los Kite Cloud Connectors?
Los Cloud Connectors son una de las capacidades Cloud Ready que nos ofrece Kite, desarrollada por nuestro grupo de Tecnología IoT. En este post os explicaremos en qué consiste. ¿ Qué son los Cloud Connectors? En esencia, son un servicio mediante el cual podemos disponer de todos los datos de conectividad de nuestras SIMs volcados en los brokers IoT de los principales hyperscalers de IoT: Azure y AWS. Figura 1: Modelo de arquitectura La principal ventaja que podemos conseguir con ellos es incluir los datos de conectividad dentro de la lógica de negocio de la solución del cliente. Por ejemplo, se pueden disparar acciones bajo ciertas circunstancias identificadas por la red de Telefónica desde la propia infraestructura del cliente, lo que ahorra tiempo de implementación o de gestión: Cuando el IMEI cambia, Cuando el consumo de voz o datos alcanza un umbral o cuando se detecta una alteración en la localización basada en red de una SIM Además, estas reglas de negocio pueden usar los datos combinados de la red, los dispositivos, y otros datos que el cliente disponga previamente en su infraestructura. Integración de Kite con el IoT Core de AWS mediante Cloud Connectors A modo de ejemplo, vamos a mostrar los datos de conectividad en un dashboard generado en Grafana, de una serie de SIMS que tenemos distribuidas en el mundo. La arquitectura desplegada es la siguiente: Figura 2: Arquitectura para visualización de los datos de conectividad de las SIMS en un dashboard de Grafana Como podemos apreciar en el diagrama anterior, los dispositivos del cliente, usando las SIMs de Kite, se conectan a través de nuestra red con el broker MQTT de AWS IoT Core, donde vuelcan los datos propios de telemetría del dispositivo. De manera paralela, se envían desde Kite en tiempo real las modificaciones o eventos que hay sobre la información de la SIM: estado de la SIM, estado de la conexión, APN utilizado, alias, consumo de datos/voz/SMS, IMEI del dispositivo conectado, etc., aglutinando todos esos datos en el mismo componente. Figura 3: Datos de estado de las SIMS aglutinados en un componente ¿Qué podemos hacer con estos datos? Como ejemplo de una de la multitud de opciones que se pueden realizar con estos datos, hemos optado por integrarlos en un dashboard de Grafana. Una vez los datos han sido registrados en el IoT Core, hemos configurado una regla que envía todos estos datos a un microservicio que se encarga de parsear la información y enviarla a una base de datos. Figura 4: Regla para disparar la función Lambda Para el despliegue del anterior microservicio, hemos utilizado una herramienta de AWS llamada AWS Lambda. Este permite ejecutar código sin provisionar ni administrar servidores, y se paga sólo por el tiempo de cómputo que se utiliza. Lambda puede ejecutar código en una gran cantidad de lenguajes de programación, sin tener que realizar tareas de administración. Sólo hay que cargar el código y automáticamente se desencadena todo lo necesario para ejecutar y escalar la función con alta disponibilidad. Figura 5: Función Lambda Las funciones lambda pueden realizar multitud de tareas: desde enviar los datos a un backend on premise del cliente, como republicar la información en otros servicios de AWS como el SNS o incluso enviarlo a otras nubes públicas como Azure o GCP. En nuestro caso, para realizar este demostrador, hemos decidido enviar esta información a una base de datos MySQL, también hosteada y gestionada dentro AWS . Esto nos permite tener un histórico de todas las modificaciones que se han producido en las SIMs que tenemos monitorizadas. Figura 6: Información registrada en un MySQL Visualización en EC2 Como la visión de la base de datos puede ser un tanto árida optamos por desplegar un Grafana en una máquina del ec2 y así mostrar esta información de una manera más amigable. Grafana es una herramienta para visualizar datos de serie temporales. A partir de una serie de datos recolectados se puede obtener un panorama gráfico de la situación de una empresa, organización o servicio. Desplegar un servicio como este es algo muy sencillo, y muy bien documentado en la red. Una vez desplegado en EC2, lo único que resta es configurar como fuente de datos de Grafana la base de datos MySQL que hemos utilizado anteriormente y … ¡Ya podemos empezar a agregar los widgets que más nos interesen, para mostrar los datos que queremos representar! Y como muestra dejamos el siguiente Dashboard Figura 7: Dashboard Escrito por Luis Peña, IoT & Cloud Solutions Architect. Para mantenerte al día con el área de Internet of Things de Telefónica visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube
27 de octubre de 2020

Repasamos con Richard Benjamins las novedades sobre Inteligencia Artificial, Living Apps y el Hogar Digital
¿Las máquinas nos brindarán un futuro mejor o peor? Cuando escuchamos el término Inteligencia Artificial (IA), surgen miedos e incertidumbres al igual que conceptos futuristas abstractos. Pensamos en coches autónomos, chatbots, reconocimiento facial e IoT, pero también existe el temor de que la IA nos supere un día en inteligencia. Cuando entramos más en materia, vemos que hay un sinfín de interrogantes en referencia a la IA. Por ello, hemos tenido la suerte de contar con Richard Benjamins, Chief AI & Data Strategist en Telefónica, para que nos cuente más sobre las novedades, riesgos y usos de la IA, así como su aplicación en los hogares. ECAI y las políticas europeas en referencia a la Inteligencia Artificial Hace poco tuvo lugar la ECAI, la conferencia europea de IA, que este año se organizó en Santiago de Compostela de forma online, y en la que Benjamins participó. Como en cada edición, en la conferencia se habló de los avances en los campos del procesamiento de lenguaje natural, representación de conocimiento y razonamiento, aprendizaje automático, planificación y robótica. Un punto central del debate fue el uso responsable de la IA, en el que Benjamins contribuyó con un artículo sobre este tema. Como la conferencia se celebró entre expertos europeos, nos interesaba mucho saber si Europa tiene un enfoque diferente a otros países con relación a la IA. Benjamins dice al respecto que “Europa tiene una aproximación única, muy enfocada en el uso responsable de la IA”, y nos presenta las diferentes aproximaciones en el mundo. Según el experto hemos de distinguir entre distintos enfoques. Por un lado, el americano, “donde casi toda la actividad de IA está en manos de cinco grandes empresas, los GAFAM – Google, Amazon, Facebook, Apple y Microsoft” y el gobierno interviene muy poco. Por otro lado, la aproximación china, “donde el gobierno impulsó muchísimo el desarrollo de la IA en sus empresas y donde hay mucha intervención gubernamental”. Por último, tenemos el enfoque de Europa que busca encontrar un término medio con un mercado libre, pero con posible regulación en los ámbitos de alto riesgo. También es interesante tener en cuenta qué políticas prevé Europa para proteger a las personas y asegurar que los avances de la IA sean en beneficio de todos. Sobre ello, Richard afirma que “Europa ha definido unos principios de IA que recomienda que usen todas las organizaciones”. Estos principios están pensados para ayudar a “que la IA tenga un efecto positivo en la sociedad”, evitando así “consecuencias negativas o un impacto negativo en los derechos humanos”. “¿Las máquinas nos quitarán el trabajo? “Es solo uno de los miedos que las personas pueden tener al pensar en los avances de la IA. Para aclarar si este tipo de miedo es justificado o no, comenta que lo que sabemos -como en cada revolución tecnológica- es que desaparecerán trabajos, se crearán trabajos nuevos y cambiará la naturaleza de los trabajos actuales. Pero no sabemos en qué proporción y con qué rapidez se harán estos tres cambios. A día de hoy, nadie puede pretender saber si -por la IA- el futuro del trabajo está en peligro o no. Mitos, cuentos, y miedos innecesarios acerca de la Inteligencia Artificial Temer a la IA y las consecuencias que conlleva su aplicación es un sentimiento generalizado, tanto en las personas que conocen en profundidad el tema como en las que no. De hecho, en el año 2015 varios expertos en IA y otros científicos como Stephen Hawking firmaron una carta abierta para advertir de los peligros de la Inteligencia Artificial, y recalcar la necesidad de estudiar a fondo los posibles riesgos que conlleva su aplicación. ¿Firmaría Richard Benjamins, como experto en el campo de la Inteligencia Artificial una carta similar? “Es bueno que un grupo pequeño de expertos investigue estos peligros por si seamos capaces de dar unos cuantos saltos cuánticos en el desarrollo de la IA. Sin embargo, veo este punto muy lejano”. Afirma que “hoy en día estamos muy, pero muy lejos de que la IA -con intención propia – nos pueda hacer daño. Si nos hace daño es porque hay personas detrás.” Por ello, Benjamins no firmaría esa carta, porque tiene una versión racional y objetiva. Él sabe que “una IA basada en aprendizaje profundo no entiende, no tiene sentido común, no sabe razonar y no comprende la causalidad. Y ni estoy hablando de conciencia y consciencia.” No hay que temer la IA, sino advertir -según él -de sus riesgos en “manos de personas”. Consciente de esos miedos, mitos y cuentos, Benjamins escribió junto a Idoia Salazar el libro: “El mito del algoritmo, Cuentos y cuentas de la inteligencia artificial”, que se publicó el 3 de septiembre de 2020. El libro tiene el objetivo de acabar con las confusiones sobre lo qué puede y qué no puede hacer la IA, y de “equipar a todos los lectores con el bagaje suficiente para que puedan formar su propia opinión sobre la IA”. Cuando conocemos la realidad, a menudo, los miedos desvanecen ante los hechos. Telefónica y el papel del experto en IA responsable Otro tema que está surgiendo en Europa, especialmente para Gobiernos y grandes empresas, es el papel de un experto en IA responsable “todas las empresas que hagan uso intensivo de la IA o el Big Data, deberían tener un experto en IA responsable”, afirma Benjamins. También nos cuenta cómo se aplica el concepto de la IA responsable en el caso de Telefónica. Por un lado, la compañía publicó sus Principios de IA hace dos años donde manifestó su compromiso “al desarrollo, uso o compra de la IA de una manera justa, transparente y explicable, basada en el humano y con privacidad y seguridad.” Por otro lado, Telefónica está implementando una metodología para aplicar estos principios en los procesos de trabajo. Hay cursos de IA y ética para los empleados, un cuestionario online con preguntas y recomendaciones sobre el uso responsable, privacidad, derechos humanos, etc. que han de ser consideradas cuando se desarrollen productos y servicios nuevos. Además, dice que existe “un modelo de gobernanza para el uso de la IA.” Vemos que Telefónica es pionera en aplicar el uso responsable de IA. Esto también se refleja en las interacciones con Aura, la Inteligencia Artificial de Telefónica. https://www.youtube.com/watch?v=bjvbiY0mbFk&t=1125s El Hogar Digital y las Living Apps Pedimos a Benjamins que nos definiera lo que significa un hogar inteligente para él. Y lo definía así: “un hogar que sirva a todos sus habitantes (no sólo a uno), donde todos los dispositivos se pueden comunicar entre sí, y, muy importante, que respeta la privacidad y sea transparente sobre los datos que usa, además de dar control sobre los datos a los habitantes del hogar”. Aunque es especialista en tecnología, nos dice que su propio hogar solo tiene un 5% de inteligencia o menos. Y le permite “encender la calefacción a distancia”, y “hablar con la tele a través de Movistar Home”. En Telefónica hemos trabajado durante muchos años para poder poner a disposición de nuestros clientes un hogar cada vez más inteligente, en el que ya son capaces de interactuar con Aura, su Inteligencia Artificial. La Compañía cuenta con un ecosistema propio, que consiste en productos, servicios y experiencias, que forman el Hogar Digital. Las Living Apps representan la parte de las experiencias de entretenimiento, deporte, e-commerce o cultura, que Movistar ofrece a sus clientes a través de la televisión.
22 de octubre de 2020

Así se mueve Alemania: datos móviles para mejorar planes de transporte
Nuestros compañeros de Telefónica NEXT diseñaron, a través de los datos móviles, análisis de datos y big data, un mapa interactivo que permite visualizar flujos de movilidad nacionales. Ciudades, compañías de transporte y demás grupos de interés pueden obtener insights verdaderamente interesantes en temas como patrones de comportamiento, como horas pico, a través de datos móviles anonimizados y agregados. Conoce más sobre cómo el resultado del análisis de datos inteligente realizado en las ciudades de Hamburgo, Berlín y Munich. Gracias a “ So bewegt sich Deutschland” ("Así se mueve Alemania" en alemán), Telefónica NEXT ha creado un mapa interactivo que utiliza los datos móviles y el análisis inteligente de estos para visualizar los tráficos de flujo a nivel nacional. El objetivo de esta visualización es ofrecer un análisis más preciso a compañías de transporte y aquellas entidades interesadas, para diseñar nuevos planes de movilidad y transporte en ciudades de Alemania. La visualización ofrece además insights regionales y patrones de comportamiento, por ejemplo horas pico, en ciudades como Hamburgo, Berlin y Munich. Figura 1: Mapa interactivo "Cómo se mueve Alemania - So bewegt sich Deutschland" Telefónica Deutschland genera los datos de la red móvil en más de 48 millones de accesos, cuando los teléfonos móviles usan conexión a Internet o realizan llamadas, siempre anonimizándolos a través de un proceso certificado de TÜV de tres niveles para que ya no puedan asignarse a personas individuales. Así, el análisis de estos datos ofrecen patrones de movimiento en Alemania, aportando un valor añadido muy significativo para áreas de gran afluencia. "Gracias al proyecto So bewegt sich Deutschland hemos dado vida a nuestros flujos de datos anónimos obteniendo insights muy valiosos" La filial de Telefónica Deutschland analiza estos datos para conocer los patrones de movimiento en Alemania, lo que aporta un valor agregado significativo para áreas como la planificación del transporte. “El Big data es un tema abstracto. Con ‘Cómo se mueve Alemania', hemos dado a nuestros flujos de datos anónimos”, explica Jens Lappoehn, director general de Análisis Avanzado de Datos en Telefónica NEXT. “La visualización de datos ilustra lo que el Instituto Fraunhofer de Ingeniería Industrial confirmaba: Los datos de redes móviles anónimos representan un valioso recurso para la planificación de la movilidad". "Los datos móviles anonimizados ofrecen insights de gran valor para diseñar nuevos planes de movilidad" Viajeros diarios y madrugadores en Alemania Según los cálculos, en Alemania se realizan de media 161 millones de desplazamientos de más de dos kilómetros a la semana. En la página web, pueden consultarse estos flujos de movimiento a través de un gráfico interactivo con los promedios semanales. Cada una de las gotitas móviles representa un grupo suficientemente grande de viajeros, algo que es importante tanto para la protección de datos como para fines estadísticos. Telefónica NEXT identifica igualmente el inicio del día de cada una de las regiones alemanas. El horario de salida medio en el conjunto de Alemania son las 7:30 h de la mañana. Los datos muestran que los ciudadanos de la mitad oriental del país hasta Baviera salen de sus casas antes que los ciudadanos del oeste del país. Por estados federales o lander, Brandenburgo y Sajonia-Anhalt presentan la hora de salida más temprana del país, las 6:56 h. Figura 2: Datos de móvilidad de Munich Los residentes en Mecklemburgo-Pomerania Occidental realizan el trayecto matinal más largo, con una media de 29,6 km. El trayecto más corto de media se registra en Berlín (6,7 km). En la página web, el usuario puede introducir su propio código postal y comprobar a qué hora se comienza el día en su barrio. También pueden compararse diferentes códigos postales. Otro aspecto interesante que puede verse en la web son los diferentes tamaños de las áreas de captación para las principales ciudades alemanas. Mientras en Múnich los ciudadanos se mueven por una zona claramente definida, los desplazamientos en Hamburgo abarcan distancias mucho mayores, incluyendo regiones como Prignitz, Mecklemburgo y Pomerania Occidental. Los viajeros diarios en Hamburgo recorren una distancia media de 28,9 km hasta llegar a su lugar de trabajo. Figura 3: Datos de zonas de captación Estos son solo algunos ejemplos de cómo los datos anónimos de la red móvil pueden utilizarse en la planificación del transporte, beneficiando así a los responsables del transporte público y la planificación urbana así como a los desarrolladores de nuevas formas de movilidad. Los datos recogidos por Telefónica NEXT ya se están utilizando en numerosos proyectos. Entre estos proyectos encontramos, por ejemplo, el proyecto "ProTrain" para la optimización de la capacidad del transporte regional en Berlín-Brandenburgo, con el apoyo del Ministerio Federal de Transporte e Infraestructura Digital alemán. ¿Cómo se crean los datos? En base a los datos anónimos de la red móvil de Telefónica Deutschland, Telefónica NEXT elabora una completa matriz origen-destino para toda Alemania. La información sobre el origen y el destino de los desplazamientos de más de dos kilómetros dentro de Alemania fue registrada en marzo de 2017. Telefónica NEXT evaluó posteriormente los datos anonimizados por hora y código postal. Todos los datos consisten en valores extrapolados, es decir, se proyectan a toda la población alemana. Telefónica NEXT también ha elaborado la misma información para cada medio de transporte individual. Se ha discriminado por transporte aéreo y transporte terrestre (carretera y ferrocarril). El algoritmo que subyace puede identificar vuelos entre valores como la velocidad del trayecto o la duración del mismo. Puede consultarse también más información sobre la metodología de trabajo. El análisis de datos inteligente ayuda a optimizar el tráfico urbano. ¿Quieres que tu ciudad sea la siguiente? Descubre los casos de éxito destacados en el sector de movilidad y muchos otros en la web de LUCA.
20 de octubre de 2020

Modelado de datos: lo bien hecho bien parece
En ocasiones lo que nos parece evidente pensamos que se consigue sin esfuerzo y que cae llovido del cielo. Nada más lejos de la realidad; a menudo conseguir que las cosas parezcan simples es fruto del trabajo realizado por grandes profesionales. Cuando hablamos de datos, nos parece intuitivo que el mismo dato se llame igual en todos los puntos del sistema, y que mantenga siempre el mismo tipo de dato. Tampoco entenderíamos que el mismo nombre designase cosas distintas en diferentes puntos. Sin embargo, esto no se consigue porque sí. Necesitamos invertir mucho esfuerzo para conseguir estos resultados En ocasiones los jefes de proyecto se quejan por el tiempo que tiene que invertir su equipo para elaborar el modelo de datos. Y es que a veces cuesta ver todos los beneficios que nos aporta el modelado de los datos. Pero, ¿Qué es modelar datos?, ¿para qué sirve?, ¿por qué debo hacerlo? ¿Qué es un modelo de datos? Dicho de una forma muy concisa, el modelado de datos es el proceso por el que se toman los requisitos de negocio y se diseñan las mejores estructuras de datos para soportarlos. El modelo de datos es el equivalente al plano de nuestra casa, que es una representación conceptual de lo que queremos edificar y sirve como herramienta de comunicación entre el cliente, el arquitecto que diseña la vivienda y la cuadrilla que la construye. De una forma totalmente paralela, disponer del modelo de datos le permite al cliente comprobar que sus requisitos de negocio se han tomado en consideración (el qué implementar) y también le permite al arquitecto de datos aportar su conocimiento para crear las estructuras de BBDD para que todo funcione de una forma fluida (el cómo implementar) y, finalmente, podremos generar las instrucciones de creación de los objetos en la BBDD (la implementación). Figura 1: Tipos de modelos de datos ¿Para qué sirve? Sabiendo que en la actualidad los sistemas de información de una gran corporación acostumbran a tener cientos de miles si no millones de elementos de datos, el modelo de datos permite dividir un problema complejo en piezas menores y de una escala mucho más abordable. Igual que los escritores se enfrentan al miedo al folio en blanco, empezar a crear las tablas de un sistema desde cero puede ser una tarea intimidante. El disponer de los modelos de datos de los sistemas de los que nos alimentamos es un fuerte empujón a nuestro proyecto. Reaprovechar piezas que ya están creadas es una forma de evitar silos de información. Los datos se comparten entre aplicaciones y se evitan duplicidades innecesarias. Al reutilizar elementos creados con un estándar nos ayuda a la aplicación del mismo estándar en los nuevos desarrollos, lo que además redunda en otros beneficios como el evitar problemas por los tipos de dato de los campos y en especial nos protege de problemas con la precisión de los cálculos. Por los mismos motivos, también facilita la integración entre aplicaciones. El modelo de datos constituye una poderosa herramienta de comunicación entre los diferentes participantes en el desarrollo de un proyecto. Su lenguaje gráfico es fácilmente entendible por todos, a la vez que refleja con precisión los matices de los requisitos de negocio. Cuando se dispone de un modelo de datos todo el mundo entiende lo mismo sobre el contenido de un campo: contiene lo que está escrito en la descripción y si se debe corregir se hará tanto en el modelo como en el proceso que lo utiliza, siendo siempre la referencia en la que comprobar. La creación de modelos de datos siempre es beneficiosa, pero cuando desarrolla todo su potencial es cuando se realiza de forma corporativa. Si el modelado es a nivel de proyecto (táctico) nos servirá para guiar la colaboración de un equipo, pero si se hace a nivel corporativo (estratégico) nos ayuda a que TODOS los equipos trabajen de forma integrada. Figura 2: Proyectos transformadores ¿Por qué debo hacerlo? En estos tiempos en los que todo el mundo habla de la gobernanza de los datos, quizás la herramienta más veterana para hacerlo sea el modelo de datos. Es de destacar que DAMA cita la disciplina de modelado como una de las troncales para conseguir un buen gobierno, y que sobre ella se apoyan, en mayor o menor grado, la mayoría del resto de disciplinas de su guía (arquitectura, datos maestros, data warehouse, seguridad, integración, calidad de datos, metadatos, almacenamiento, ...) A lo largo de décadas ha demostrado su solvencia para conseguir: Mayor calidad de las aplicaciones Durante el proceso de modelado se revisan de forma exhaustiva los requisitos y se plantean todo tipo de dudas a resolver con negocio y además su naturaleza visual es un gran facilitador para la comunicación entre los diferentes grupos implicados. Adicionalmente el modelado de datos incluye una fase de optimización de rendimientos que asegura sistemas más rápidos y fiables Desarrollos más rápidos Al haberse trabajado en detalle los requisitos de negocio durante la elaboración del modelo de datos, el desarrollo se hace de una forma mucho más ágil. Se evitan así los retrabajos que se suelen dar cuando los requisitos no están claros. Menores costes de desarrollo y de mantenimiento de aplicaciones Por los mismos motivos del punto anterior, se reducen tanto los costes de desarrollo como de mantenimiento de las aplicaciones. Menores costes de almacenamiento y de procesamiento de datos Al eliminarse duplicidades se eliminan los costes asociados, tanto de almacenamiento como de procesamiento para crear ineficaces copias de los datos. Mayor facilidad para la adaptación al equipo de trabajo Al disponer de una herramienta que transmite con precisión el comportamiento esperado del sistema, el conocimiento acumulado por los miembros del equipo queda mejor documentado. De esta forma es posible formar a las nuevas incorporaciones con mayor facilidad. Mejor comprensión del contenido de los datos Será de la máxima utilidad disponer del modelo de datos a la vez que se estén consumiendo los propios datos, ya que nos ayudará a comprender su significado. Para garantizar un máximo aprovechamiento será importante estudiar la mejor forma de publicarlo, incluso por medio de la creación de alguna visualización a la medida del negocio. Figura 3: Gestión de Cambios/Control de la base de datos Desafíos de la tecnología Si bien, como se menciona más arriba, el modelado ha sido durante décadas una potente herramienta de Gobierno del Dato, la irrupción de nuevas tecnologías supone un gran reto, ya que es una técnica muy orientada a los gestores de BBDD relacionales. En ocasiones se ha dado la sensación de que la utilización de tecnologías schemaless, schema on read y otros NoSQL con datos semiestructurados, hace innecesaria la creación de un modelo de datos, cuando es exactamente lo opuesto: la flexibilidad de la que nos dotan estas tecnologías supone un esfuerzo extra para gobernar los datos que se utilicen en ellas. Por ejemplo, será más sencillo tener marcada una columna como “dato sensible según GDPR” en una BBDD cuyo esquema esté documentado en una herramienta de modelado de datos que hacerlo en una tecnología en la que cada nueva ingesta de un fichero pueda contener nuevas etiquetas en su interior. Todos hemos oído hablar del riesgo que supone que, por falta de gobierno, un Data Lake se convierta en un Data Swamp. Si no conseguimos que los datos semiestructurados sigan unas buenas pautas de gobierno, tenemos la certeza de que nuestro lago de datos se convertirá en una ciénaga. Por tanto, supone un desafío adaptar unas técnicas de modelado muy arraigadas y que no se adecuan completamente a las nuevas tecnologías, intentando, además, que sigan siendo de utilidad para nuevos tipos de gestores de BBDD aún por venir. Hay un buen número de empresas que han querido lanzarse a realizar su transformación digital y sacar beneficio de los datos de que disponen y se han dado cuenta de que no se encuentran preparadas. Para poder extraer valor es necesario tenerlos con un mínimo de gobierno y, sobre todo, conocer el significado de cada dato. Escrito por Juan Ignacio Ayala Noticias Serie <Cómo transformar una compañía> Priorizar casos de uso Conectar la tecnología con el negocio Profundizando en la arquitectura de referencia Desarrollar una metodología de ingestión de datos Complementar las fuentes internas con datos externos Las POC o como un proyecto pequeño puede salvar uno grande Noticias Serie <Gobierno del Dato> El arte de comunicar en tiempos de cambio Transformación Digital y Gobierno del Dato tras el COVID-19 Cómo convertir el dato en un activo corporativo: Gobierno del dato La calidad del dato como marca personal Para mantenerte al día con LUCA visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube.
18 de octubre de 2020

Cómo transformar una compañía(IX):Conocer el significado de nuestros datos
Cuando una publicación especializada habla sobre los datos de las empresas, es muy habitual que la imagen que acompañe al artículo sea una ilustración en 3D en la que los unos y los ceros discurren frente a un observador de forma similar a como lo hacían en Matrix. Esta representación de los datos, tan cercana a cómo necesita la máquina procesar la información, no se corresponde en absoluto con las necesidades que como humanos tenemos para entender esos datos. Para nosotros es indiferente la forma en la que los datos son almacenados por el ordenador; a nosotros lo que nos importa es lo que los datos significan. Descripciones Cuentan de un CEO que pedía a sus directores el número de clientes que tenía la empresa. Entonces el Director de Marketing, sin dudarlo, sacaba una preciosa infografía, con una tipografía minimalista y colores pastel en la que aparecía la cifra solicitada. Un momento, dijo el Director de Facturación, creo que esa no es la cifra correcta. Y buscando entre sus papeles sacó un gráfico, mucho más modesto, nuevamente con la cifra, según él, solicitada. También las Directoras de Contabilidad y de Sistemas aportaron sus cifras de total de clientes de la empresa, pero ninguna coincidía. Y es que mientras Marketing conocía la cifra de clientes “prospect”, Facturación había escrito la cifra de clientes del último ciclo de facturación, Contabilidad tenía la cifra de todos aquellos que hubieran tenido algo contratado en los últimos 5 años y Sistemas el total de clientes existentes en los archivos históricos. ¿Cómo es posible, bramaba el CEO, que no me podáis responder a una pregunta tan básica para la empresa? Y la cuestión es que todos habían respondido una cifra correcta… a su manera. Al no disponer de una definición clara de lo que es un “Cliente”, cada director había buscado la respuesta de lo que se entiende por cliente dentro de su ámbito, no a nivel global. No habían utilizado una definición común para todos porque no la había. La definición de un lenguaje común para toda la corporación es un objetivo de la máxima importancia para evitar errores en la comprensión de los datos Otro aspecto en el que se debe hacer hincapié en la calidad de las descripciones. En muchas instalaciones es fácil que nos encontremos con descripciones que no aportan ninguna información, por ejemplo, “Cliente: es la tabla que tiene los datos del cliente”. Es lo que los anglosajones llaman descripciones cheeseburger (what is a cheeseburger? A burger with cheese). Si analizamos el ejemplo… … que Cliente es una tabla lo sabíamos porque estamos consultando la descripción de una tabla … que contiene datos lo sabíamos, porque todas las tablas contienen datos … y que son del cliente lo sabíamos, porque estamos en la tabla llamada “Cliente” Para evitar esto las descripciones deben definir el concepto de negocio que se almacena y no el objeto en donde está almacenado (tabla, columna, entidad, atributo, campo, fichero,…). Es una buena práctica nombrarlos siempre en singular, ya que hace más fácil centrarse en el concepto. Así, una buena descripción para el cliente podría ser “Cliente: Persona física o jurídica que tiene contratados los productos o servicios de la compañía”. Con esta descripción los directores no habrían tenido datos discrepantes; solo el de Facturación habría aportado su cifra. Nombres Recientemente, había un nombre de columna que se repetía más de 20 veces en distintas tablas de un único sistema, pero en todos los casos carecía de descripción. Al solicitar que propusieran una definición para esas columnas dijeron, ¡uy, depende! Ese nombre se utiliza unas veces para una cosa y otras veces para otra. Y es que el término “ACEITE”, vinculado a unas máquinas, a veces se refería a la cantidad en litros que se necesitaba, en otras ocasiones era la densidad, en otras un simple indicador de si llevaba o no y, finalmente, podía contener la marca comercial recomendada. Dado que todos los datos tenían el mismo nombre de columna no sería de extrañar que, para analizar el consumo de aceite de esa planta, alguien hubiera sumado los litros del depósito de una máquina con la densidad otra. Pero ¿habría pasado lo mismo si las columnas se hubieran llamado CAN_LITROS_ACEITE, DES_VISCO_ACEITE o NOM_ACEITE? Unos nombres de columna adecuados ayudan a evitar errores, ya que la utilización de nombres más descriptivos nos permite identificar correctamente el contenido de cada campo. Además, los nombres de columna deben ser coherentes en todo el sistema: un nombre de campo debe significar lo mismo en todos los sitios donde aparezca, y el mismo concepto debe aparecer siempre reflejado con idéntico nombre de campo. La utilización de estándares de nomenclatura con prefijos significativos y la utilización de nombres de campo coherentes y significativos, son buenas prácticas cuya aplicación debe ser verificada por la compañía. Disciplinas de Gobierno del Dato Vista la importancia de poder identificar con precisión el significado de nuestros datos, ¿cómo podemos mejorarlo? Hay dos disciplinas fundamentales de Gobierno del Dato en las que nos podemos apoyar para conseguirlo: el modelado de datos y la gestión de metadatos. Modelado de datos Una instalación de base de datos de una gran corporación puede tener millones de elementos de datos. El modelado de datos nos permite tener visiones con distintos niveles de abstracción, de forma que nos permita descomponer la complejidad total del sistema y buscar las mejores soluciones en cada caso. Es un proceso en el que se toman los requisitos de negocio y se diseñan las mejores estructuras de datos para soportarlos. Además: Contiene descripciones precisas, tipos de dato y valores posibles para cada campo Es una conceptualización de nuestros datos que nos permite identificar de manera rápida qué datos tenemos y cómo se relacionan. Es un mapa en el que se representan las reglas de negocio y nos permite navegar por los datos. Lo forman los conceptos de negocio, campos y relaciones. Permite centralizar la gestión y creación de estructuras de datos Con un modelo de datos obtenemosinformación sobre nuestras estructuras de datos, difusión de un lenguaje común y un mapa de relaciones. Ayuda a evitar elnacimiento de silos de información, las duplicidades de datos y los errores de integración de aplicaciones. Además, mejoramos la reusabilidad de los datos maestros, la rapidez de los desarrollos y el control sobre los datos sensibles (GDPR) El modelado de datos es una técnica sobradamente probada para gestores tradicionales de bases de datos (relacionales), pero el mayor reto al que se enfrenta en la actualidad es la aparición de multitud de nuevas tecnologías en las que es complicado aplicar una única fórmula estándar. Los metadatos Por su parte, la herramienta corporativa de metadatos es de gran ayuda para el acercamiento entre el lenguaje utilizado por los usuarios técnicos y los usuarios de negocio. Para ello, permite disponer de: Un glosario de términos de negocio que facilita el lenguaje común en la compañía Un inventario de los objetos de datos de nuestro sistema, diccionario de datos La vinculación entre los términos del glosario y los elementos del sistema con los que se ha implementado La identificación de los responsables de los datos Conclusión La utilización de un lenguaje común en toda la empresa y el conocimiento preciso del contenido de nuestros datos son dos premisas necesarias para evitar errores de cálculo, retrabajos y duplicidades (de datos y de procesos). Esto permite mejorar la integración de nuestras aplicaciones, los tiempos de desarrollo y la evolución hacia el concepto de “Data Driven”. En definitiva, hacer del dato un activo corporativo. Estas premisas son facilitadoras para multitud de procesos clave en la transformación digital de la empresa, y se usan para análisis de viabilidad técnica de casos de uso, para conectar la tecnología con el negocio, el desarrollo de los procesos de ingesta (o ETL) de los datos. En LUCA contamos con los mejores profesionales que atesoran largos años de experiencia tanto en la definición, gestión, normado y control de modelo de datos, como de herramientas de gestión de metadatos. Escrito por Juan Ignacio Ayala Todos los post de esta serie: Cómo transformar una compañía(I): Priorizar casos de uso Cómo transformar una compañía(II): conectar la tecnología con el negocio Cómo transformar una compañía(III): Profundizando en la arquitectura de referencia Cómo transformar una compañía (IV): Desarrollar una metodología de ingesta de datos Cómo transformar una compañía (V): Complementar las fuentes internas con datos externos Cómo transformar una compañía(VI):Las POC o como un proyecto pequeño puede salvar uno grande Cómo transformar una compañía(VII): Poner una PoC en producción Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.
8 de octubre de 2020

Caso de éxito: Desencadenamos la industria con Asti
ASTI es una empresa de ingeniería robótica móvil dedicada al estudio, el diseño, la fabricación, la puesta en marcha y el mantenimiento de soluciones de intralogística automatizada. Con sede en España, ofrecen sus servicios a empresas de 16 países en Europa, Norteamérica, Latinoamérica y Asia. Esta empresa está especializada en soluciones de transporte interno mediante vehículos de guiado automatizado (los llamados AGV) y sus soluciones se centran en la automatización intralogística en entornos industriales. Por eso, desde Asti, nos pidieron que transformáramos sus AGV en máquinas completamente conectadas para reducir sus costes de mantenimiento y mejorar la eficiencia. Una vez conectados los vehículos, la información y el rendimiento de estos AGV se puede recopilar de manera online. Por lo que simplifica las operaciones y las tareas posventa a la vez que minimiza las intervenciones in situ para que las máquinas no se queden paradas durante mucho tiempo. ¿Cuál fue la propuesta? Desde Telefónica ofrecimos una propuesta totalmente a medida que cubriera todas sus necesidades y la calidad garantizada: Implementamos una red lte privada/pública en planta Creamos una puerta de enlace industrial de Ethernet y conectividad IoT para volcar los indicadores clave de rendimiento de los AGVa la nube privada del cliente Hemos asignado un equipo de asistencia especializado en IoT Partners de negocio Además de ser cliente, Asti se ha convertido es nuestro Partner tecnológico. Gracias a esta asociación, ahora podemos ofrecer nuevos modelos de negocio en el sector industrial. Cada vez son mas los clientes industriales que solicitan vehículos AGV para trabajar dentro de una red de comunicación segura y fiable capaz de combinar una latencia muy baja y un alto rendimiento. Justo lo que hacen las redes privadas de Telefónica. Este caso de éxito nos ha permitido, en primer lugar, acercar las funcionalidades de la red LTE a las plantas industriales, ya que proporcionan la máxima fiabilidad, seguridad y el mejor rendimiento en entornos privados, algo de vital importancia. Y, en segundo lugar, implantar una nueva generación de redes privadas para clientes industriales, denominadas Industry Ready. De esta forma, se benefician de un mejor rendimiento de los AGV, de una inteligencia empresarial más precisa y de unos procesos de fabricación optimizados. AI OF THINGS Breve historia de Internet de las cosas (IoT) 22 de septiembre de 2020 La conectividad está ayudando a las industrias a avanzar. Y a que puedan mover cualquier cosa. ¿Te atreves a ser el siguiente? Descubre los casos de éxito destacados en el sector de movilidad y muchos otros en la web de LUCA.
6 de octubre de 2020

Lecciones aprendidas, retos y perspectivas para Blockchain en el ámbito empresarial
Durante los días 21 y 22 de Septiembre se celebró la primera edición online de la European Blockchain Convention (EBC), el congreso de negocios sobre la tecnología Blockchain más relevante de Europa, donde más de 100 ponentes repartidos en 25 sesiones debatieron sobre su aplicación en el ámbito de la empresa, tanto pública como privada, planteando los retos a los que se enfrenta y las expectativas de futuro para una de las tecnologías más disruptivas de los últimos tiempos. Por mi parte tuve el placer de representar a Telefónica en el panel “Remaining challenges of Blockchain and possible solutions” junto a Gilberto Florez de Ferrovial y Giovanni Franzese de Ericsson, donde debatimos sobre proyectos reales que hemos abordado en los últimos años, de los que hemos obtenido una experiencia que nos permite hablar con conocimiento de causa de las lecciones aprendidas, retos y perspectivas de esta tecnología en el ámbito empresarial, que resumo en este artículo (para aquellos que no tuvisteis la oportunidad de asistir al evento). El caso concreto en el que centré el análisis fue la aplicación de Blockchain en nuestra propia cadena de suministro en Brasil, el proyecto “Vicky” sobre el que ya ha comentado en este blog Fernando Valero, responsable del área de Global Supply Chain que lo hizo posible en 2018, por lo que no voy a centrarme en describir cómo se desarrolló y los beneficios obtenidos, sino las lecciones aprendidas gracias a los retos a que nos enfrentamos: En este tipo de proyectos el beneficio para el negocio viene de la transformación de los procesos y de la automatización, y aquí Blockchain es un medio, no un fin en sí mismo. Al negocio no le interesa una u otra tecnología, sólo quiere conseguir sus objetivos. Cada vez que abordamos un proyecto tenemos que responder a la pregunta “¿por qué con Blockchain?” dando una respuesta clara en el lenguaje que entiende el negocio, no desde la perspectiva tecnológica. En nuestro caso, el proyecto consiguió ROI en menos de un año, dando así sentido al uso de Blockchain. Más allá de la tecnología, es vital definir desde el principio un escenario win-win para los actores que participan en el proyecto, identificando los incentivos para todos ellos que permitan crear esa red de valor en común. Cada compañía en el proyecto Vicky (no sólo Telefónica) pudo obtener por primera vez una visión más amplia de lo que sucede en toda la cadena, pudiendo aplicar esta información en su propio beneficio. Blockchain ofrece muchas posibilidades, pero es importante priorizar estas capacidades teniendo siempre presente cuáles son los requisitos del negocio. En este caso la prioridad inicial era mejorar las operaciones, obtener visibilidad extremo a extremo en todo el ciclo de vida de los equipos para eficientar y automatizar dichas operaciones. Sólo una vez alcanzado este hito se arranca una siguiente fase para automatizar distintas actividades gracias a los smart contracts (registro documental, pagos, etc). Y más allá, la posibilidad de crear nuevas oportunidades mediante tokenización. Blockchain es la tecnología que facilita estas nuevas fases en el proyecto, una vez alcanzada la mejora operativa. Para el negocio la confianza en la información es imprescindible, por eso el objetivo es registrar los datos en Blockchain lo antes posible, con el mínimo de intermediarios, para garantizar que nadie puede alterar la información sobre la que luego se aplica la lógica de negocio. Y aquí la utilización de IoT es clave, permitiendo que los dispositivos registren automáticamente los datos que generan, en tiempo real. Porque disponer de mala información inmutable no sirve de nada. Y creedme, este tipo de proyectos genera una ingente cantidad de información valiosa, que es compleja de procesar. Por eso es imprescindible plantear en los proyectos desde el principio el uso de Bigdata y Machine Learning, que permitan obtener el máximo rendimiento de los datos existentes en beneficio del negocio. Aprendimos también que la tecnología en 2018 no era lo suficientemente madura, y además ha evolucionado a una rapidez tremenda (sólo como ejemplo: tres versiones de Hyperledger Fabric en dos años, cambiando completamente la arquitectura). Las operaciones en este entorno son muy complejas (especialmente cuando las cosas no funcionan bien), por lo que es extraordinariamente importante contar con proveedores de confianza. La experiencia en este proyecto y otros que hemos abordado en Telefónica nos ha permitido entender que siempre tendemos a repetir las mismas actividades, una y otra vez. Ese es el motivo por el que desarrollamos nuestra propuesta de valor para ayudar a las empresas a integrar sus sistemas y aplicaciones con Blockchain de forma sencilla gracias a la solución TrustOS de Telefónica, permitiendo reducir los costes, el tiempo y el riesgo de abordar proyectos con Blockchain. Porque, insisto, al negocio no le importa la tecnología de Blockchain, sino el valor que aporta a los procesos, poder incorporar esta confianza adicional en sus operaciones mediante el uso de APIs, sin la complejidad subyacente de las distintas tecnologías de Blockchain, es un valor diferencial. Y por último, el “agnosticismo tecnológico” es deseable, pero difícil de conseguir en la práctica. El uso de una solución como TrustOS, que abstrae la complejidad subyacente de las distintas tecnologías de Blockchain para facilitar el uso de los componentes que ofrecen es clave para posibilitar la evolución tecnológica sin impactar al negocio, permitiendo además interoperar entre distintas redes, públicas y privadas. Proyectos como la transformación de la cadena de suministro de Telefónica en Brasil permiten tangibilizar el valor real que aporta Blockchain para el negocio, que Gartner cuantifica en 3,1 trillones de dólares para 2030. Y Telefónica Tech con su experiencia y soluciones apuesta por facilitar el uso de esta tecnología en los próximos años, junto a otras como IoT, Bigdata, Inteligencia Artificial o Edge Computing, para responder a los retos que nos esperan en el futuro y hacer realidad esa propuesta de valor. Escrito por Jorge Ordovás. Para mantenerte al día con el área de Internet of Things de Telefónica visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube
2 de octubre de 2020

Living Apps: cómo diferenciar tu empresa a través de experiencias digitales
En un mercado donde la competencia cada vez es mayor, muchas empresas buscan la vía por la que poder diferenciarse y con la que acercarse a sus clientes. Para eso, resulta vital conocer los hábitos de los consumidores y su comportamiento en el día a día. En Telefónica, continuamos trabajando para ofrecer al cliente más servicios y comodidades dentro del hogar, en su zona de confort y, por eso, seguimos apostando por las Living Apps como el nuevo espacio que ofrece a las empresas un punto de encuentro con sus clientes. Y así también lo están haciendo terceros. Empresas como Prosegur, Iberia, Air Europa o Atlético de Madrid, ya se han unido al Hogar Digital, sumando sus valores al ecosistema de productos y servicios conectados. Ahora, nuevas compañías se han incorporado al catálogo de experiencias digitales desarrollando sus propias Living Apps, ya disponibles dentro de Movistar+. Desde casa y desde la comodidad del salón, el cliente podrá disfrutar en su televisión de aplicaciones orientadas al entretenimiento, la compra online, los viajes, el deporte, la cultura o la gestión de servicios. Y sin necesidad de descarga. Son más de un millón de hogares los que cuentan con esta funcionalidad y los que pueden acceder a estas experiencias con el mando, de forma táctil, o a través de la voz gracias a Movistar Home. Y ahora también pueden hacerlo con el Mando Vocal Movistar+, presente en miles de hogares. Quiero saber más sobre las ventajas de Living Apps Zeleris acerca sus servicios a la televisión con su Living App La compañía de paquetería ha encontrado en las Living Apps la apuesta perfecta para llevar su oferta de servicios al hogar de todos sus clientes. Zeleris ha conseguido mejorar su atención al cliente, ya que el usuario ahora puede acceder a su cuenta en la televisión para consultar todos los servicios disponibles, saber en todo momento dónde están sus pedidos de Movistar, así como conocer si este ha sufrido algún tipo de incidencia. Además, facilita una serie de “preguntas frecuentes” para que el cliente pueda resolver sus dudas con toda la comodidad desde el sofá, reduciendo los contactos al call center o los mensajes en redes sociales. Es un buen ejemplo de cómo los servicios en tiempo real también pueden ofrecer este tipo de experiencias digitales, estando muy cerca de sus clientes. Movistar Shop: un catálogo repleto de productos y servicios en la televisión Movistar continúa apostando por mejorar y enriquecer el Hogar Movistar de sus clientes, dotándolo con nuevos productos y servicios Movistar. Dentro de la Living App Movistar Shop, los usuarios pueden acercarse a ellos desde dos perspectivas. La primera, desde el desconocimiento. La aplicación permite a los usuarios descubrir nuevos servicios disponibles para incorporar a su hogar, que hagan más fácil su día a día y que les ofrezcan distintos beneficios desde el catálogo. Además, permite adquirir aquellos que les interesen sin realizar trámites extra ni complejos procedimientos, ya que el usuario no tendrá que sacar la tarjeta de crédito para realizar el pago. Con tan solo vincular su cuenta con Mi Movistar, podrán disfrutar de los servicios y adquirir los productos con un par de clics. Por otro lado, también permite a los usuarios acercarse a los productos y servicios de Movistar con los que ya cuentan para conocer en mayor detalle y sacarles el máximo partido. Desde descubrir nuevas funcionalidades hasta ver vídeos para conocer todos sus detalles y posibilidades. De esta forma, contarán con contenidos exclusivos de forma recurrente para continuar disfrutando del Hogar Movistar. Nubico Audiolibros ofrece contenidos exclusivos en su Living App Con este nuevo espacio, Nubico puede llegar de forma diferencial a un mayor número de clientes compaginando el entretenimiento con la lectura. Los clientes suscritos ya no solo pueden acceder a más de 60.000 libros y 80 revistas desde la aplicación en el dispositivo móvil, Tablet o libro electrónico, sino que se da un salto a la comodidad del hogar a través de la televisión, para estar allí donde estén sus clientes. De esta forma, Nubico ofrece como valor diferencial una serie de contenidos extra a los que suele ofrecer en su plataforma: ha puesto a disposición del cliente un catálogo de cinco audiolibros infantiles de manera gratuita e ilimitada, para que toda la familia pueda disfrutar de la literatura. Esta llega con el objetivo de transformar el hogar en un nuevo espacio en el que incentivar la lectura dentro del entorno familiar, mejorar la concentración y estimular la imaginación, ejercitando así el cerebro de los más pequeños. Accediendo con el mando a distancia a la Living App, el usuario puede navegar entre los audiolibros infantiles y seleccionar el que más le apetezca escuchar. De esta forma, el salón de casa se convierte en un nuevo espacio de consumo en el que compartir en familia historias entretenidas y divertidas. FitCo Moves ofrece entrenamientos guiados en vídeo a través de Movistar+ Si algo aprendimos a raíz del COVID19 es que nuestros hogares pueden ofrecernos mucho más de lo que pensamos. El deporte se convirtió en un pilar fundamental para muchos, quienes demandaban con mayor frecuencia distintas disciplinas para realizar en casa. Fruto de este desarrollo, llega la Living App de FitCo Moves para ofrecer sus servicios a un público mayor. Y es que, a través de la aplicación, se pueden realizar entrenamientos guiados con vídeos donde los usuarios pueden elegir qué parte del cuerpo quieren entrenar y cómo hacerlo. Además, no se queda solo en ofrecer contenido, sino que también han ideado una parte de gamificación para animar a los deportistas a no abandonar sus metas otorgándoles logros y permitiéndoles convertirlo en algo social al retar a sus amigos. Muchas empresas ya han encontrado en las Living Apps una innovadora oportunidad de negocio para llevar sus productos y servicios a los hogares de sus clientes. Además, permite la posibilidad de orientar la estrategia de cada empresa a un nuevo ecosistema: desde aportar mayor información, ofrecer servicios exclusivos. Si quieres ser la próxima, solicita información a través de este enlace.
25 de septiembre de 2020

Caso de éxito: Gestión eficiente en flotas de suministro para Cobra Group
Cobra Group es un líder mundial en ingeniería, instalación y mantenimiento industrial de infraestructuras. Cuenta con más de 28.000 empleados en 45 países en todo el mundo que ofrecen una amplia gama de servicios a todo tipo de clientes, desde particulares hasta grandes corporaciones. La compañía quería actualizar su servicio de localización que en ese momento estaba siendo proporcionado por otra compañía. Además, requería incluir características más avanzadas como la gestión remota de su flota interna de 800 vehículos, para aumentar la eficiencia y la productividad de la empresa. ¿Cuáles eran las claves para el cliente en este proceso? En primer lugar, necesitaban una solución competitiva e innovadora, que mejorara la que ya tenían implantada. El segundo reto era la optimización de los procesos de negocio. La empresa estaba rediseñando sus procesos comerciales e identificando áreas de mejora para aumentar la eficiencia y la productividad “Incremento de la eficiencia en procesos no críticos” Entonces, ¿cuáles han sido los beneficios para el negocio? La reducción de costes gracias a una buena programación y asignación de tareas. Ahora optimizan el uso del vehículo reduciendo los tiempos de viaje, kilometraje, combustible… La optimización de las operaciones de mantenimiento de la flota. Pasó de una operación de mantenimiento fija y programada a una dinámica dependiente de las horas de conducción El tamaño de la flota, ya que ahora pueden calcular el número de vehículos necesarios para el servicio Este es un ejemplo más de cómo las nuevas tecnologías como IoT o Big Data pueden ayudar a cualquier tipo de empresa a ser más eficiente y generar más ingresos. AI OF THINGS Fleet Optimise para empresas de Rent-a-car 18 de junio de 2019 AI OF THINGS Fleet Optimise y gestiona tus flotas 11 de octubre de 2019
24 de septiembre de 2020
Cómo transformar una compañía(VIII): Diseñar visualizaciones efectivas
En los artículos anteriores de esta serie, “Como transformar una empresa”, hemos comentado los distintos pasos a seguir para transformar nuestra empresa. El principio de este camino fue le selección y creación de casos de uso que facilitaran la transición desde la actual situación de la compañía hacia una compañía orientada al dato. Posteriormente, vimos los pasos necesarios para desarrollar e implementar los casos de uso. Arquitectura, ingesta de datos tanto internos como externos, pruebas y validación. Y finalmente damos el último paso de nuestro camino, la visualización de los datos. Construir una visualización efectiva. Todo el trabajo que hemos realizado hasta el momento nos ha proporcionado una gran cantidad de datos. Esto datos queremos interpretarlos, contrastarlos y compararlos entre si, u obtener insights. Para ello, deberemos crear nuestras propias visualizaciones que proporcionaran una información fácilmente compresible para el usuario. Para crear una correcta visualización de nuestros datos y que esta información sea útil para el usuario, deberemos seguir los siguientes consejos. Definir a quién va dirigido el gráfico Un gráfico lo pueden ver distintos perfiles dentro de la empresa. Cada una de estas personas tiene unas necesidades concretas. Por ello, debes conocer a quien va dirigido el gráfico para poder responder a las preguntas que les gustaría que la visualización le respondiera. Eligir el gráfico adecuado. No todos los gráficos son adecuados para representar cierta información. Cada gráfico está mostrado para mostrar un tipo de información. Figura 1: tipos de gráfico (fuente infogram.com) En esta infografía podemos ver cuál es el tipo de gráfico más adecuado para la información que queremos mostrar. Resaltar la información más importante. La idea de una visualización es facilitar la compresión e interpretación de ciertos datos. Para ello debemos facilitar la lectura de nuestro gráfico utilizando distintos colores, tamaños y fuentes de letra, que permitirán al usuario dirigir la atención a los puntos más importante o aquellos que queramos resaltar en nuestro gráfico. No usar tablas Al igual que disponemos de distintos tipos de gráficos para mostrar distintos tipos de información, también debemos hacer un uso correcto de las tablas para mostrar distintos tipos de información. Una visualización muestra relaciones, patrones o tendencias en los datos. Y para ello no es correcto usar las tablas. Las tablas se deben utilizar en los siguientes casos: Para ver y comparar datos detallados y valores exactos. Para mostrar datos en formato tabular. Para mostrar datos numéricos por categorías. Proporcionar un contexto Cuando estamos mostrando los datos es importante que el usuario posea un contexto de los datos. Dicho contexto nos permitirá ver los datos desde una perspectiva concreta y ayudará al usuario de la visualización a una mejor compresión de los datos representados. Figura 2: Contexto Como podemos observar en estos gráficos los valores de ventas de tablets y PCs en España y Francia son los mismos. Pero en el gráfico de la izquierda “Contexto Incorrecto” donde el contexto es diferente al del gráfico de la derecha “Contexto Correcto” parece que la diferencia de ventas entre las unidades de vendidas entre ambos productos es porcentualmente mayor que en el gráfico de la derecha, “Contexto Correcto”. Pero en ambos casos la variación es la misma. Alinear los gráficos. Los gráficos y demás elementos de nuestra visualización siempre deberán encontrarse en la misma escala de tamaño y alineados. Si no es posible que distintas ilusiones ópticas que nos hagan percibir la información erróneamente. Usar el color inteligentemente. El color es una poderosa herramienta en las visualizaciones. Una buena paleta de colores resaltará los datos que queremos resaltar mientras que una selección incorrecta de los colores que vamos a utilizar en nuestra visualización distraerá al usuario de los datos importantes. Dentro de las distintas paletas de colores tenemos tres grandes grupos que podemos utilizar en nuestras visualizaciones en función del tipo de la visualización. Paleta cualitativa. Seleccionaremos esta paleta cuando la variable que queramos representar sea de naturaleza categórica. Figura 3: Ejemplo de paleta cualitativa Paleta secuencial. Seleccionaremos esta paleta cuando tengamos que representar una variable numérica o tiene valores inherentemente ordenados. Los colores se asignan a los valores en una gama continua de tono o luminosidad. Figura 4: Ejemplo de paleta secuencial Paleta divergente. Al igual que la anterior paleta, esta paleta la seleccionaremos cuando tengamos que representar una variable numérica. Pero en esta ocasión dentro del rango número tenemos un punto intermedio o valor 0. Esta paleta es básicamente la combinación de dos paletas secuenciales. Figura 5: Ejemplo de paleta divergente Proporcionar información con el título Los gráficos siempre deben tener un título. Este título debe dar al usuario una visión clara de cual es la información que se está representando. Además del titulo podemos incluir un subtítulo en el cual podremos incluir la descripción de alguna tendencia o dato reseñable de nuestra representación, además también podemos incluir la unidad de medida del gráfico para una mejor compresión de este. Crear interactividad. La mayoría de las herramientas actuales de visualización te permiten crear cierta interactividad con los gráficos. Cuando sea posible utilizar esta funcionalidad para poder proporcionar al usuario una información más detallada. Formato de la página Además de los pasos que hemos visto anteriormente para construir nuestros gráficos otra parte muy importante en la visualización es el formato que demos a la página/s. La estructura de la página debe ser muy simple. En la parte superior de la página se deben situar los gráficos más importantes para posteriormente estructurar la información hacía abajo situando los gráficos menos importantes. Simplemente es representar los gráficos con una jerarquía de arriba abajo. Debemos evitar las ventanas emergentes o pop ups, que visualmente son muy atractivos pero que son una distracción para el usuario. Otro punto para considerar cuando creemos nuestra visualización es no crear muchos gráficos en única página, si incluimos mucha información en la misma pantalla distraemos al usuario. Es mejor dividir la visualización en diferentes pantallas. Y estas deberán estar ordenadas jerárquicamente mayor a menor importancia de la información. Conclusión Hacer visualizaciones puede parecer un trabajo sencillo, incluso hay software que la realiza automáticamente esta tarea. Pero si las visualizaciones no están correctamente realizadas no se está ayudando al usuario a tomas las decisiones correctas. Aplicando estas sencillas reglas en el momento de hacer nuevas visualizaciones estarás ayudando a los usuarios a tomar mejores decisiones de una forma rápida y precisa. Escrito por Victor de Andrés Pérez Todos los post de esta serie: Cómo transformar una compañía(I): Priorizar casos de uso Cómo transformar una compañía(II): conectar la tecnología con el negocio Cómo transformar una compañía(III): Profundizando en la arquitectura de referencia Cómo transformar una compañía (IV): Desarrollar una metodología de ingesta de datos Cómo transformar una compañía (V): Complementar las fuentes internas con datos externos Cómo transformar una compañía(VI):Las POC o como un proyecto pequeño puede salvar uno grande Cómo transformar una compañía(VII): Poner una PoC en producción Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.
15 de septiembre de 2020

Caso de éxito: Geolocalización para facilitar los transplantes de órganos y tejidos
El éxito de un trasplante depende, en muchos casos, de tener toda la información relativa al tejido o la muestra recibida, especialmente del momento de llegada a quirófano, para preparar al receptor con la mayor brevedad y lograr así el mayor éxito en la intervención. Por ello, Movilpack, empresa especializada en el transporte de este tipo de productos biológicos, se ha unido a Telefónica IoT para desarrollar un sistema de transporte de estos materiales totalmente geolocalizado. Esta nueva plataforma, que funciona a través de la solución tecnológica GeoGestión, permite a diferentes equipos médicos estar en contacto a través del sistema GPS de los ‘smartphone’, con el objetivo de planificar el transporte de tejidos vivos y muestras al detalle, y lograr así un mayor éxito en las intervenciones. Ya que, a través del sistema GPS de los 'smartphone' de los médicos implicados, la plataforma pone a su disposición la información exacta de los plazos y la ubicación, y asegura una repuesta rápida tanto para el receptor como para el remitente. “La geolocalización permite que los equipos médicos estén informados en todo momento de la situación del envío y se puedan tomar decisiones y buscar soluciones que pueden llevar al éxito de la entrega del producto” afirma Juan Pedro Yunta, CEO de Movilpack. De esta forma, Movilpack puede gestionar de forma más eficiente su actividad, lo que le permite agilidad, inmediatez y control sobre los envíos tan delicados que realiza. Así, la empresa consigue que entregas de tejidos vivos y muestras biológicas se lleven a cabo en plazos muy estrictos, estén monitorizadas en todo momento e incorporen información de las condiciones del tejido o la muestra, como la temperatura, la humedad o los posibles daños que sufren en el transporte. Para nuestra actividad es clave conocer la posición concreta de envío, buscar soluciones alternativas en caso de alguna modificación o retraso de un vuelo o cualquier otro transporte en el que viaje y, además, permite que el equipo médico esté informado en todo momento de la situación del envío. añade, Movilpack. Además de conocer la ubicación en tiempo real de los empleados o las flotas mediante la señal de GPS, la gestión geográfica permite la optimización de los tiempos de atención y de servicio, gestionando de forma más eficiente las distintas tareas que deben llevarse a cabo, organizándolas por ubicación y proximidad del empleado y permitiendo complementar en la misma aplicación todo el proceso administrativo derivado de la actividad de la empresa. Gracias a sus características, además de ser especialmente útil en el campo de la salud, esta tecnología tiene aplicaciones destacadas en los equipos de emergencia y en los nuevos dispositivos de movilidad urbana, por ejemplo. Apostamos por ser uno de los socios estratégicos en la aplicación de la tecnología en el sector sanitario, ¿quieres ser el siguiente? Descubre todas las soluciones de IoT y Big Data en la web.
11 de agosto de 2020

Workforce Optimise la solución para optimizar procesos, operaciones y gestión de equipos
En la oficina de algún edificio corporativo, los reunidos escuchan con complacencia el veredicto vertido por uno de ellos: “la transformación digital está a años vista; no hay motivo para que nuestra compañía cambie en el corto plazo”. Ninguno de ellos veía venir la bola de demolición con la leyenda: “COVID-19”, próxima a impactarles.1 La pandemia del COVID-19 está impulsando la transformación digital de las empresas como nunca antes lo habíamos visto. En pocas semanas, el uso de nuevas tecnologías dejó de ser un lujo para transformarse en una necesidad imperiosa. Miles de empresas comenzaron a teletrabajar por primera vez, desarrollaron nuevos canales de atención al cliente y de ventas, y redefinieron sus procesos operativos para garantizar la continuidad de sus negocios en tiempo record. Pymes y grandes empresas, distintos grados de madurez digital Ahora bien, el COVID-19 no encontró a todas las empresas en igualdad de condiciones en cuanto a digitalización: existe una brecha entre grandes empresas y Pymes. Mientras que las primeras probablemente llevaban años trabajando e invirtiendo en su transformación digital, cuando la pandemia azotó, a las pequeñas y medianas empresas la situación las tomó a contrapié. ¿A qué nos referimos, exactamente? A la escasez de datos para la toma de decisiones, a las ineficiencias en los procesos de planificación, al seguimiento descentralizado y offline de las operaciones, al uso de herramientas de comunicación inadecuadas o insuficientes y a la manualidad en los procesos de gestión de personas y el teletrabajo, entre otras. Workforce Optimise: digitalizando los procesos de las organizaciones Workforce Optimise es el producto de la unidad de IoT &Big Data de Telefónica que ayuda a las Pymes y otras empresas a cerrar la brecha digital, optimizando sus procesos de ventas, logística, operaciones y gestión de equipos. Es una solución multi-sectorial con la visión de transformar el móvil de los colaboradores en potentes herramientas de productividad. El servicio se compone de una plataforma web y una aplicación móvil que permiten: A los administradores: visualizar en tiempo real la ubicación y estado de los colaboradores, automatizar procesos manuales, reducir costes administrativos y operativos, mejorar la comunicación de la empresa y optimizar procesos internos que impactan en la satisfacción de sus clientes. Adicionalmente, digitalizar rutinas de fichaje y recursos humanos, y proveer seguridad a los colaboradores. A los colaboradores: optimizar las tareas de su día a día, administrar carteras de clientes, gestionar órdenes de trabajo y pedidos, registrar su jornada laboral, administrar itinerarios y formularios. Adicionalmente, mejorar su seguridad al disponer de un botón de eventos para gestionar situaciones que revisten atención prioritaria. Workforce Optimise, aliado de las empresas durante el confinamiento Esta solución ha permitido a cientos de clientes dar el salto al teletrabajo, digitalizando sus procesos de fichaje y gestión remota. Numerosos ayuntamientos también se han beneficiado con la implementación de la solución, que adicionalmente permite dar cumplimiento al decreto que obliga a empleadores a registrar la jornada laboral de sus colaboradores. A otras tantas empresas de servicios esenciales (agroalimentarias, salud y servicios públicos, entre otras), Workforce Optimise les ha ayudado a gestionar su continuidad operativa. 15% de reducción de gastos en combustible, 25% de ahorro en facturación de horas extras, 15% de aumento en la productividad son algunas de las mejoras reportadas para este tipo de clientes. Se trata de una solución madura, con más de 120 mil licencias desplegadas en 7 países y casos de éxito en los más diversos sectores. Es un producto en constante evolución, que se integra con facilidad a los sistemas de nuestros clientes y se adapta a sus necesidades específicas. Si te interesa conocer más sobre cómo este producto puede ayudar a tu empresa, entra en nuestra web y solicítanos más información sobre esta solución. Y si estás interesado en saber más sobre el producto y ver una demo en directo, te animamos a que te registres a nuestro próximo directo en LinkedIn el jueves 30 de julio a las 16:00 h CET. ¡Regístrate aquí! Te esperamos Escrito por Pedro Bontempi Tom Fish Burne, marketoonist.com Para mantenerte al día con el área de Internet of Things de Telefónica visita nuestra página web o síguenos en Twitter, LinkedIn y YouTube.
28 de julio de 2020

Caso de Éxito: Transformación digital de Mallorca
¿Estás de vacaciones o planeas unas próximamente? En esta nueva normalidad, las medidas de prevención para garantizar la seguridad es algo que preocupa a muchos de los turistas al planear sus vacaciones. Este ha sido el objetivo de la isla de Mallorca, donde invierten en tecnología IoT y Big Data de Telefónica para poder ofrecerles la mejor experiencia posible durante su estancia. En la actualidad, cada vez más ciudades del Mundo y, en concreto, en España buscan interactuar con sus turistas, entenderles, saber qué es lo que les gusta y lo que buscan cuando pisan un territorio específico. ¿Qué buscaba Mallorca? Esta Isla Balear necesitaba una plataforma de gestión inteligente de territorios donde se integraran múltiples servicios gestionados por el Consell de Mallorca y su adecuación del Centro de Procesamiento de Datos (CPD). Entre los servicios integrados destacan la adecuación de espacios para turistas, sistemas para eficiencia medioambiental, mejora de sistemas de tráfico o gestión de emergencias. ¿Qué han obtenido con Thinking Cities? La plataforma Thinking Cities es un modelo on-premise que se utiliza para el desarrollo en proyectos integrales. Gracias a este gestor, Mallorca ha podido conectar a sus ciudadanos con los turistas y ahora pueden tomar decisiones más precisas en base a unos datos objetivos. Ahora pueden entender y gestionar mejor todos los insights que reciben de LUCA Tourism y han podido lanzar una web de turismo local más enfocada a lo que sus visitantes necesitan. Han digitalizado también sus oficinas de turismo, han conseguido ahorros en los consumos energéticos y han adecuados las rutas y horarios de su transporte público. Un ejemplo más de cómo la administración pública y el turismo han basado su toma de decisiones en datos precisos, gracias a soluciones de IoT y Big Data, que les ha llevado al ahorro de costes y adecuación de sus medios en beneficio del turista. AI OF THINGS Caso de éxito Smart City: conectando las ciudades con sus habitantes 29 de abril de 2020 ¿Quieres ser el siguiente? Descubre los casos de éxito destacados en sector público y turismo en la web de LUCA.
23 de julio de 2020

Hacia una agricultura de datos
Sin lugar a dudas la producción de alimentos es esencial para la vida en la tierra. Lo hemos visto en los hechos durante la crisis sanitaria que vivimos en 2020 con el Covid-19, en donde fue de las pocas actividades que no se detuvieron. Todos los días el sector tiene la gran responsabilidad de alimentar a 7,8 miles de millones de personas, llueva, truene o haya una pandemia. Para 2050 se prevé no solo que esa cifra crezca a 9,8 miles de millones sino que también lo haga la cantidad de alimento consumida per cápita, requiriendo un incremento del 60% en la producción de alimentos. A este desafío, considerando la escasa superficie disponible para destinar a la agricultura, según datos de la FAO; debemos agregar otra dimensión importante: la sostenibilidad. Es en este triple desafío de: aumentar productividad reducir costos y mejorar la sostenibilidad donde entran en acción los datos. Los datos en el agro El productor agropecuario está rodeado de datos desde hace muchísimo tiempo. Como se deben imaginar, uno de los problemas que hoy en día tiene todo agricultor, es tener esa información ordenada para poder sacarle provecho. Cuando el agricultor cosecha su cultivo, no solo está obteniendo su producto final, el grano, sino que también está cosechando muchísimos bits y bytes. Literalmente, su cosechadora no solo devora plantas, sino que reporta y almacena metro a metro en su avance cuanto está cosechando, qué nivel de humedad tiene el grano o las características del fruto y todo tipo de parámetros técnicos que dan cuenta de la eficiencia de esa cosecha. Desde 1972, cuando los satélites de la primera misión de observación terrestre de la NASA fueron puestos en órbita, contamos con información periódica del estado de cada cultivo que crece en la faz de la tierra. Hoy en día la tecnología ha avanzado tanto que hay sistemas o constelaciones de satélites que pueden visitar el mismo campo varias veces por día. Por otra parte, hemos visto las resoluciones de esos satélites aumentar de decenas de metros por píxel a decenas de centímetros. Si consideramos la superficie cultivable mundial, almacenar la información que se genera para toda el área agrícola (considerando imágenes satelitales, información de sensores, maquinaria, clima, entre otros) supera los 5 Petabytes (Miles de Terabytes) cada año. Auravant: poniendo en marcha los datos Auravant es una plataforma SaaS que ayuda a los productores y asesores agropecuarios a tomar decisiones basadas en datos y producir de forma más eficiente y sostenible. Lo hacen ayudando a que el agricultor reduzca sus costos, haciendo un uso eficiente de los insumos y recursos y también ayudando a los asesores agropecuarios a que maximicen el rendimiento de los cultivos. Esta mejora en eficiencia permite a su vez aumentar la sostenibilidad de la actividad, al reducir el impacto ambiental que genera cada tonelada producida. Auravant es utilizada por más de 13.000 productores y asesores agropecuarios en 5 millones de hectáreas en todo el mundo. Con un modelo freemium busca facilitar la adopción de la agricultura digital, facilitando su acceso a pequeños productores y favoreciendo el uso de tecnologías que tienen impacto ambiental positivo. El primer punto que facilitan es almacenar y ordenar la información de cada hectárea del campo, para que pueda ser aprovechada. Ya sea obteniendo de forma automática los datos de los satélites, las cosechadoras y de estaciones meteorológicas, o de forma manual a través de su app móvil como es el caso de mediciones puntuales que hace el productor en el campo, almacenamos toda esa información y la procesamos de forma que sea accionable. El resto de las funciones que provee Auravant agregan valor sobre esos datos. Dentro de esa caja de herramientas del agricultor moderno la más fundamental es la ambientación. La importancia de una buena ambientación La ambientación o zonificación de los lotes es el primer paso para todo productor o asesor que se introduzca en el mundo de la agricultura digital. En una parcela de trigo de unas 50 hectáreas hay 80 millones de plantas. El sentido común nos dice que seguramente no debemos tratar a todas de la misma forma y de eso se trata la ambientación. Esta herramienta le permite al usuario elegir las capas preponderantes que rigen en su zona y para el cultivo que esté produciendo. En ciertas zonas por ejemplo es de vital importancia la altimetría del terreno, en otros la profundidad de compactación del suelo, mientras que, en general, siempre viene bien utilizar imágenes satelitales y mapas de rendimientos (obtenidos de cosechadoras) de campañas anteriores. Una vez hecho esto entra en acción la plataforma. Analizando las distintas capas y segmentándolas mediante algoritmos de clusterización, presenta al usuario un mapa de ambientes o zonas. De esta forma cada zona o ambiente representa una problemática distinta que requerirá un tratamiento diferenciado. Es en este tratamiento diferenciado en donde está la ganancia, permitiendo aplicar menos fertilizante en las zonas en donde no se necesita, o sembrando una densidad de semillas distinta entre las zonas que permiten más productividad de las que tienen menor potencial. Figura 1: Plataforma Auravant Tal vez lo más importante es hacer simple, para un usuario que no es científico de datos, un proceso altamente complejo. Esta accesibilidad es la que Auravant busca para favorecer la adopción de esta tecnología. Al mismo tiempo, ofrece a aquellos usuarios que quieran tener más información los controles para hacerlo. La herramienta puede funcionar de forma automática, utilizando machine learning, aunque también le permite al usuario asignar pesos manualmente, de forma que pueda ponderar la importancia de cada capa que eligió para realizar esa ambientación. Otro aspecto importante es la gran cantidad de procesamiento previo que hace la plataforma para poder hacer este proceso en tiempos récord. Según mediciones hechas por el equipo de Auravant, una ambientación realizada de forma manual por una persona con conocimiento para hacerlo lleva al menos 2 horas, mientras que en Auravant, el mismo proceso se resuelve en 30 segundos. Muchas capas requieren de pre-procesamiento como corregir deficiencias y distorsiones por la atmósfera en las imágenes satelitales, limpiar datos que no son representativos o convertir formatos y es la plataforma la que se encarga de forma transparente de estas labores. Este ahorro de tiempo es clave, por ejemplo, cuando se está en el campo con la maquinaria lista para trabajar y se debe hacer alguna modificación de último momento. Una nueva revolución agrícola En este post hemos cubierto solo un pequeño caso del potencial del uso de los datos en la agricultura. En el ciclo de vida de la producción del cultivo hay otros muchos casos de uso de datos para tomar mejores decisiones y producir de forma más sustentable. Desde una aplicación inteligente de herbicidas a una estimación del rendimiento del cultivo antes de ser cosechado, pasando por la minimización de riesgos en la planificación de la siembra, el agricultor moderno hace cada vez más uso de información para tomar la mejor decisión y depender un poco menos de la intuición. Escrito por Fernando Calo y Nicolás Larrandart , Auravant.
21 de julio de 2020

Los establecimientos físicos también se adaptan a la nueva normalidad
La tecnología se ha convertido en la herramienta necesaria sobre la que las compañías ponen foco para adaptar sus modelos de negocio ante esta crisis sin precedentes. La crisis generada por la pandemia de la COVID-19 ha supuesto cambios en los procesos, en las comunicaciones, formas de trabajo, etc en la que ha quedado patente la grandísima importancia y alcance de la transformación digital para la sociedad. Tal y como indicábamos en uno de nuestros últimos post, ninguna compañía podía prever una pandemia y menos; de estas magnitudes. Aunque muchas organizaciones ya habían puesto en marcha su proceso de transformación digital, sus propios directivos afirman que, debido a la pandemia, los procesos de transformación se han visto acelerados y de manera obligatoria han tenido que digitalizarse para poder sobrevivir y avanzar. Acelerar la transformación digital para superar la crisis Uno de los sectores que se está enfrenando a los mayores retos en esta nueva normalidad es el sector del retail. Esta crisis sanitaria global ha impactado de manera desigual en función del tipo de actividad comercial del retailer dado que algunos sectores se han visto beneficiados debido a las nuevas casuísticas y otros todavía hacen frente a una nueva realidad. Farmacias, supermercados, etc se adaptaron en tiempo récord para poder dar solución a las necesidades de consumo mientras que restaurantes, tiendas de moda, centros comerciales… todavía necesitan un pequeño empujón para atender la demanda cumpliendo con los estándares de calidad requeridos. Los consumidores han cambiado sus hábitos de consumo y el simple hecho de realizar la compra o escoger los productos por los consumidores cambian respecto a la vida antes de la pandemia. Nuestra exposición a Internet se multiplica, realizamos más compras online y en nuestra cesta de la compra incluimos productos de higiene y básicos que antes no contemplábamos. ¿Qué papel juegan ahora los establecimientos físicos? Según el informe publicado por Cushman & Wakefield, el 66% de los españoles prefiere continuar comprando en tiendas físicas tras Covid-19. Por ello, es fundamental para las compañías adaptarse y enfocarse en cumplir las normativas estipuladas para garantizar entornos seguros y confiables tanto para proveedores, como para empleados y clientes. Entre los paquetes de soluciones para esta etapa post-Covid que Telefónica ofrece, en este post, me centraré en el conjunto de soluciones IoT que permiten adaptar los establecimientos físicos a la nueva realidad: las soluciones Covid Compliance. Actualmente los espacios físicos deben garantizar las medidas de higiene y seguridad, respetar las distancias evitando masificaciones y ofrecer la mejor experiencia cliente independientemente de cuál sea el establecimiento físico en el que se encuentre el consumidor. Las oportunidades son claras para aquellos negocios que quieren reactivar su actividad. Las compañías que entiendan que este mercado es cambiante invertirán e innovarán en digitalización y procesos tecnológicos escalables para mantener una continuidad en el tiempo. ¿En qué se focalizan estas soluciones Covid Compliance? En la gestión de espacios menos masificados gracias a los medidores de aforo, indicadores de acceso, gestión de turnos cita online y conocimiento del recorrido del cliente. En la comunicación de las nuevas medidas de higiene y seguridad a través del marketing dinámico y locuciones informativas. En los servicios de automatización y venta online que se adaptan o integran en los soportes para tener un control de stock, catálogo o carta digitalizados a través de un código QR, integrando bajo una misma plataforma comercios con actividades comerciales similares, etc. En la prevención y cuidado de clientes y empleados con soluciones como dispensador de gel IoT, Health Care, sistemas de desinfección por luz ultravioleta… En las nuevas formas de trabajo en las organizaciones. De esta crisis todos saldremos diferentes, aunque mucho más fuertes en muchos aspectos, por ello, estas soluciones nacen para ayudar a las empresas a ponerse de nuevo en marcha, continuar con su actividad comercial de manera natural y hacer crecer su negocio gracias a la digitalización. Soluciones que han venido para quedarse y que sabemos que no tendrán una estacionalidad, marcarán un precedente al incluir funcionalidades que permiten conocer más sobre los clientes y su comportamiento en los establecimientos físicos. Hoteles, restaurantes, espacios corporativos y puntos de venta al público ofrecerán gracias a estas soluciones tanto a clientes como a empleados experiencias seguras y dedicadas. ¿Quieres conocer más sobre ellas? Pincha en el siguiente enlace: Covid Complince. También descubre más sbore nuestros otros productos para ayudar a empresas en el entorno post-covid, Customer Discovery y Big Data & AI Assessment. Escrito por Marina Salmeron Uribes AI OF THINGS Soluciones Big Data para afrontar con éxito la disrupción 13 de julio de 2020 AI OF THINGS Soluciones de Telefónica IoT, Big Data e IA para la era post Covid19 6 de julio de 2020
20 de julio de 2020

¿Son competitivas las estrategias basadas en datos en el sector energético? Naturgy lo demuestra
En nuestra historia con datos de hoy, os contamos el caso de éxito de una gran empresa del sector energético, Naturgy, y cómo su proceso de transformación digital en cuatro ejes hacia una compañía orientada al dato está teniendo gran impacto en el negocio y le está permitiendo posicionarse como una de las empresas líder en su sector. Dentro del marco del desarrollo de un Center Of Excellence (CoE), capaz de dar respuesta a las necesidades de centralización, tanto de todas las iniciativas de carácter analítico como de las necesidades organizativas, era necesario definir el plan estratégico de transformación en una organización orientada al dato como un primer paso esencial. Una estrategia basada en cuatro ejes Para abordar el reto, y con la ayuda Telefónica Tech se planteó un enfoque basado en la elaboración de un assessment estratégico global en cuatro ejes: Tecnología: evaluación de la plataforma actual de Big Data para definir una arquitectura de referencia sobre la que implementar casos de uso. Organización: definición de una estructura organizacional capaz de soportar el programa interno de Gobierno del dato. Personas: evaluación de las capacidades internas con el objetivo de ofrecerles un plan formativo mediante la metodología Tshape. Negocio: evaluación del nivel actual de madurez analítica e identificación y priorización de nuevos casos de uso. Esto permitió la ejecución de tres casos de uso identificados y priorizados durante el assessment, así como de un proyecto de auditoría de datos, analítica e infraestructura multipaís. ¿Y cómo impacta este despliegue en el negocio y en los beneficios de la empresa? Ramón Morote, CDO de Naturgy, confirma el potencial de uso de herramientas Big Data en una empresa como Naturgy y "su impacto directo en el negocio" en diversas áreas. El proyecto demuestra al fin el nivel de madurez de la compañía respecto a las distintas disciplinas del dato y cómo, gracias a la experiencia de Telefónica Tech ha sido posible obtener una solución táctica y estratégica en todos los ejes desarrollados en el proyecto. AI of Things AI of Things para una gestión eficiente y sostenible del agua 21 de agosto de 2023
9 de julio de 2020

Cómo transformar una compañía (V): Complementar las fuentes internas con datos externos
En artículos anteriores se ha hablado de aspectos relacionados con los datos o la empresa, o desde el punto de vista cercano a negocio . En esta entrada nos vamos a acercar un poco más a cómo piensa un área técnica a la hora de mejorar la toma de decisiones de negocio añadiendo datos de fuentes externas. ¿Cuándo es conveniente añadir fuentes de datos externas? Antes de empezar un proceso de ETL (extracción, transformación y carga, sus siglas en inglés) es común plantearse: ¿Tenemos suficientes datos? Con esta duda no hacemos referencia al volumen de los mismos, si no a la diversidad de sus orígenes. Si trabajamos en un negocio online en el que se realizan pedidos, lo habitual sería tener registrados una serie de valores como los siguientes: cuándo se realizó el pedido, cuál fue el importe, qué cliente lo hizo, desde dónde se realizó la compra. Con sólo estos cuatros datos ya nos podría surgir la duda anterior: ¿Es suficiente esta información para poder extraer insights de nuestros datos? Supongamos que analizando los datos anteriores descubrimos que tenemos varios picos de ventas. En ocasiones ocurrirá que, sobre todo si nuestras variables originales son principalmente descriptivas, no podamos explicar estos picos a partir de ninguna de ellas y tengamos que recurrir a datos externos a nuestro negocio, como podrían ser los datos meteorológicos, datos socio-demográficos o información de redes sociales. Durante muchos años, la idea tradicional de negocio en cuanto a datos se refiere, fue almacenar todo lo que la empresa tenía y hacía, guardando un histórico de estos datos. Y era sobre ese volumen de datos sobre el que las empresas realizaban las tareas analíticas. Para comprender y detectar patrones, o para intentar adelantarse a posibles aumentos en la demanda, pero sin tener en cuenta la posible influencia de factores externos. Con el abaratamiento del almacenamiento y el uso cada vez más frecuente de tecnologías Big Data se ha abierto una puerta a la posibilidad de almacenar más datos y de orígenes más diversos, lo que se puede traducir en un aumento de la calidad de los datos para nuestro negocio. Uno de los pasos necesarios en la transformación digital de una empresa consiste precisamente en la transición desde una empresa encerrada en sus propios datos, a una empresa que considera factores externos, introduciendo datos de fuera de la compañía. Tipos de fuentes de datos externos Datos de redes sociales: Las redes sociales son una de las principales fuentes de datos externos actuales, al servir tanto para entender mejor el mercado de nuestro negocio (o mejor dicho, la percepción de los usuarios del mismo), como para realizar análisis de sentimiento, con el objetivo de ver qué opinión tiene el público sobre nuestra empresa, tipo de producto, lanzamiento reciente, etc. Datos demográficos: Si vendiésemos en múltiples países al mismo tiempo, quizás observásemos distintos comportamientos en distintos países. En ocasiones la respuesta puede venir de sitios tan dispares como las edades medias de los compradores de cada país, su poder adquisitivo, o una relación más compleja de distintos datos demográficos, con lo que poder comparar el comportamiento observado con estos datos objetivos puede resultar en nuevos insights con los que tomar decisiones. Información contenida en páginas web, en los sitios que dispongan de una API que se pueda utilizar para acceder a los datos, es quizás la mejor manera de acceder a datos, al darnos datos semiestructurados que podemos automatizar y tratar de manera eficiente. Datos meteorológicos: Por ejemplo, se podría contrastar la temperatura y las precipitaciones que hay en el momento de la compra de un producto de nuestra empresa contra el histórico de pedidos, y ver si el clima influye en nuestro volumen de pedidos, o en qué tipos de clientes siguen haciendo pedido, y así hacer una categorización de los mismos más detallada. Calendario laboral y festivo. Saber cuándo tiene libre la mayoría de la gente con trabajo de una localidad puede ser útil para relacionar con nuestros propios datos, y buscar tendencias asociadas a patrones de comportamiento, ya que la gente se comporta de forma distinta en distintas épocas a lo largo del año. Valores en bolsa, ya sea porque nuestra empresa cotiza en bolsa, so porque depende o usa productos que sí lo hacen. Predecir valores futuros siempre es una tarea increíblemente ardua, pero echar la vista atrás y realizar un análisis, relacionando datos clave de nuestros propios datos, con las oscilaciones típicas de la bolsa, puede arrojar nueva luz sobre temas críticos. Iniciativas Open Data, que se podría resumir como una iniciativa para hacer accesibles al público general los datos de distintos gobiernos a distintos niveles (ayuntamientos, ministerios, gobiernos, institutos oficiales de estadística o instituciones como el Banco Mundial o la Comisión Europea). Si bien hasta ahora hemos hablado de datos de libre acceso, también hemos de mencionar datos recabados por otras empresas, y que pueden reforzar los nuestros de una manera u otra: Datos relacionados con el transporte o el alojamiento. Empresas de transporte como pueden ser empresas ferroviarias, aerolíneas, empresas especializadas en el sector hotelero o en el de alquiler y compra de inmuebles, pueden indicarnos datos tan potencialmente útiles como el potencial adquisitivo de nuestros clientes, o el tipo de perfil de los mismos (en función de si viajan mucho o no, por ejemplo). Datos relacionados con el consumo digital. En la actualidad, la mayoría de las compañías telefónica proveen internet, ya sea mediante wifi o a móvil, y recaban, de forma anonimizada y agregada (para cumplir adecuadamente con las normativas de protección de datos), datos sobre el consumo de sus clientes. Esto nos da el potencial para ayudarnos a entender el perfil de los usuarios y, por tanto, de los habitantes de una determinada zona. Datos especializados, ofrecidos por compañías como puede ser Nielsen o Bloomberg,que nos pueden servir para encontrar información muy concreta, como pueden ser precios y cotizaciones de productos financieros, tipos de cambio monedas y precios de materias primas. Conclusión En definitiva, a la hora de tomar las mejores decisiones basadas en datos, es muy posible que tengamos que usar no solamente los datos recopilados de forma interna, sino también aquellos datos externos que mejor se adecúen a nuestro caso de uso. Escrito por Guillermo Manglano Díaz. Otros post de esta serie: Cómo transformar una compañía(I): Priorizar casos de uso Cómo transformar una compañía(II): conectar la tecnología con el negocio Cómo transformar una compañía(III): Profundizando en la arquitectura de referencia Cómo transformar una compañía (IV): Desarrollar una metodología de ingesta de datos Cómo transformar una compañía (V): Complementar las fuentes internas con datos externos Cómo transformar una compañía(VI):Las POC o como un proyecto pequeño puede salvar uno grande Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.
8 de julio de 2020
Soluciones de Telefónica IoT, Big Data e IA para la era post Covid19
Estamos inmersos en una realidad que cambia continuamente. En ocasiones, lo hace de forma gradual, tan lentamente que apenas nos resulta perceptible. Otras veces, sin embargo, los cambios son tan bruscos como lo ha sido la pandemia del COVID19. Cambios que no sólo afectan a nuestro tejido empresarial, sino a nuestra salud, a nuestro entorno y modelo de vida. Reinventarse ante la adversidad Es en estos momentos cuando se hace evidente la necesidad de reinventarse para adaptarse a la nueva situación. Y emprender aquellas iniciativas, identificadas como importantes desde hace ya tiempo, pero procrastinadas/relegadas por las urgencias del día a día. ¿Cuántas empresas no eran ya conscientes de la necesidad de acometer la digitalización de su negocio? La realidad nos ha pillado desprevenidos, pero no nos ha cogido a todos igual. Porque, aunque nadie podía prever que pasara algo así, el hecho es que las empresas que ya habían puesto en marcha su proceso de transformación digital han tenido menos problemas a la hora de adaptarse a esta situación. No es momento de lamentarse, sino de ponerse manos a la obra o de acelerar si ya se había emprendido el camino de la transformación digital. De considerar nuestras opciones, qué herramientas tenemos a nuestra disposición, quiénes pueden ser nuestros aliados en esta situación. Para poder acometer de la forma más segura, fiable y en el menor tiempo lo que, en otras circunstancias hubiéramos hecho con más tiempo y más calma. Por eso es importante elegir cuidadosamente a nuestros compañeros de viaje. Telefónica IoT&BD se adapta para dar respuesta a las necesidades de sus clientes El área de Telefónica IoT&BD asumió el reto de estar a la altura de esta situación, y nos pusimos a generar ideas, diría que casi unas 50 personas, y reflexionar sobre cómo iban a impactar en nuestros clientes los cambios que estábamos viviendo y cómo debíamos adaptarnos. Empezamos analizando posibles escenarios de la recuperación o de vuelta a la normalidad, imaginando como el IoT&BD podía impulsar esa reactivación. Era imposible adivinar cuál de los escenarios se iba a producir en la realidad, incluso hoy en día tenemos incertidumbre, pero vislumbramos 4 necesidades que nos parecían comunes a los escenarios y que abarcaban tanto necesidades/casos de uso inmediatas como de medio/largo plazo: Reactivación, con foco en recuperar la movilidad y la actividad económica. “Covid compliance”, en la que adaptamos casi todos los sectores de actividad a las medidas sanitarias y de seguridad. Gestión de la movilidad de cosas, vehículos, personas como parte del cambio de paradigma de la deslocalización y dispersión de activos de las empresas Trasformación de negocio, como necesidad que sigue siendo muy relevante pues los avances en el corto plazo deben ayudar, y ser compatibles con, la transformación digital y el viaje hacia una organización data-driven. A continuación, revisitamos los discursos sectoriales adaptándolos a estas necesidades/fases de la etapa post-covid. Cada sector enfrenta retos muy concretos pues el impacto del covid afecta de forma desigual a la industria, al retail, al transporte y distribución, al sector del ocio y del turismo, a la administración pública, a las empresas energéticas... El portfolio de P&S de Telefónica IoT&BD para la era post-Covid19 Como etapa final en ese proceso de reflexión del área de Telefónica IOT&BD, nos centramos en identificar similitudes, casos de uso que se replicaban entre los distintos sectores y en las soluciones que resolvían ese “pain” del cliente. Así, terminamos seleccionando una serie de soluciones más o menos disponibles que adaptamos/tuneamos para poder acercarlas a nuestros clientes y ayudarles en esta situación tan complicada. De esta manera, destacamos estos paquetes de soluciones en esta etapa post-Covid: Covid Compliance: Es un conjunto de soluciones IoT que permiten adaptar los establecimientos y espacios corporativos de nuestros clientes a la nueva realidad tras el Covid 19. Engloba diferentes servicios, como el control de aforos, gestión de cita previa, gestión de turnos/colas…, que convierten los espacios donde compramos, comemos, disfrutamos de ocio, transitamos y trabajamos en entornos seguros y confiables. Retail Recovery: Es un paquete de insights de Big Data que ayudan al cliente a entender y comparar la movilidad y el comportamiento de los clientes potenciales antes, durante y post Covid para tomar mejores decisiones en la gestión de los puntos de venta, en las redes de transporte, o distribución. Workforce Optimise: Esta solución transforma el móvil de los colaboradores en una potente herramienta de productividad optimizando procesos de ventas, logística, operaciones, y digitalizando las interacciones al minimizar el contacto físico. Big Data Assessment: Con este estudio, la empresas pueden evaluar el estado de su compañía en términos de datos y analytics, para generar una propuesta TO BE completa y un plan de transformación asociado. Y seguimos incorporando nuevas funcionalidades y soluciones como es Customer Discovery que a través de una herramienta de Social Listening permite el acceso en tiempo real a las opiniones y percepciones de los consumidores en medios sociales, mientras se caracteriza y segmenta a los usuarios, para una toma de decisiones de negocio basadas en evidencias reales. Aportamos nuestra propia experiencia En Telefónica ponemos a disposición de nuestros clientes las buenas prácticas aprendidas en nuestro propio proceso de digitalización interno, como compañía y de adaptación a esta nueva realidad. Por ejemplo, tenemos la experiencia de desplegar las soluciones IOT&BD de Covid Compliance en nuestras tiendas Movistar que combinan innovaciones tecnológicas basadas en soluciones en la nube, Internet de las cosas (IoT) y Big Data, con elementos de seguridad física para prevenir posibles contagios del Covid-19 tanto en empleados como en clientes. De esta forma, ya desde primeros de mayo, hemos podido ofrecer a los usuarios una experiencia segura y dedicada. Escrito por Luis Jordán de Urríes Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.
6 de julio de 2020

Cómo transformar una compañía (IV): Desarrollar una metodología de ingesta de datos
En la entrada anterior profundizamos en la estructura de la arquitectura de referencia y qué aspectos técnicos se deben tener en cuenta en su definición. Siguiendo con esta serie de artículos, vamos a hablar sobre las metodologías de ingesta de datos. Los datos de una empresa son la pieza clave para el éxito futuro de una compañía. Como sabemos, estos pueden servir para predecir las ventas futuras o analizar las ventas pasadas, construir recomendadores de productos o para captación de nuevos clientes, entre otras muchas. Toda empresa debería de contar con una robusta planificación para sacarle valor a todos sus datos. Procesos ETL Para que una empresa pueda basarse en sus datos para la toma de decisiones, es importante tener los datos disponibles cuando son requeridos. Para tener buena calidad de datos y una buena base para poder explotarlos, hay que tener procesos que extraigan los datos de una o varias fuentes, los transformen y los carguen en el almacenamiento adecuado. De esto se encargan los procesos ETL (Extract, Transform, Load). En el pasado muchos de estos procesos se hacían manualmente. Sin embargo, en estos últimos años han surgido herramientas que ayudan a la automatización de estas tareas y a realizarlas de una manera más rápida y sencilla. Las principales compañías de servicios cloud disponen de estas herramientas: Amazon Glue (Amazon Web Services) Azure DataBricks (Microsoft Azure) Cloud Dataflow (Google Cloud Platform). Además, existen herramientas open source para realizar ETLs como Apache Flume, Apache NiFi y Apache Kafka entre otras. Pero esto no es todo, ya que para mantener un buen proceso ETL se debe contar con la infraestructura adecuada y necesaria en la empresa. Debido a la complejidad que conlleva la completa construcción de estos procesos, cada vez más empresas requieren la presencia de los ingenieros de datos (data engineers). ¿Qué es un Data Engineer? Muchas personas solo conocen el trabajo del científico de datos (data scientist) y el trabajo de un data engineer resulta un tanto desconocido. Pero, gracias a él, las empresas pueden tener estrategias data-driven, descubrir fallos en sus suposiciones y basar la estrategia en sus propios datos. ¿Y cuál es la tarea específica de un data engineer en este ámbito? Crear, automatizar y poner en producción la ingesta de datos, por medio de procesos ETL, donde se mueven datos de una o más fuentes de entrada a una de destino, para almacenarlos. Este proceso incluye también la transformación de los datos en el formato específico que se necesite antes de ser cargados. Estas transformaciones pueden ser múltiples y variadas: unificar varias fuentes de datos en una sola generar nuevos campos, calculados a partir de los campos originales codificar valores, facilitando los cruces de información entre diferentes fuentes transformar fechas anonimizar datos, muy importante para cumplir con las regulaciones de protección de datos El almacenamiento se puede realizar sobre bases de datos SQL (Structured Query Language) o NoSQL (not only SQL). Cuál de ellos elegir, dependerá de las necesidades concretas de cada compañía. SQL vs NoSQL Pero, ¿qué queremos decir cuando hablamos de SQL o NoSQL? Una base de datos SQL, o base de datos relacional, es un conjunto de tablas que almacena datos estructurados. Los datos estructurados son presentados como tablas con filas y columnas donde están perfectamente definidas la longitud, el tamaño y el formato de los datos. Estos sistemas son los más extendidos en las empresas y llevan muchos años de madurez, lo que hace que encontrar profesionales expertos sea relativamente fácil. Por el contrario, el término base de datos NoSQL o no relacional hace referencia a bases de datos en las cuales los datos que se almacenan son semiestructurados. Los datos semiestructurados son aquellos que siguen una estructura pero no tan definida como la de las bases de datos relacionales. Algunos ejemplos son los formatos XML (Extensible Markup Language) y JSON (JavaScript Object Notation). Estos sistemas son muy útiles en problemas Big Data porque pueden manejar grandes cantidades de información, pero llevan relativamente poco tiempo en el mercado y es por ello por lo que la búsqueda de profesionales expertos en este campo es más difícil y costosa. ETL vs ELT Además, los procesos ETLs son los encargados del control de calidad de los datos y de rechazar la ingesta si no se cumplen los requisitos de calidad. A menudo, los datos rechazados son cargados en una zona de almacenamiento diferente para su posterior diagnóstico y reintento de carga. Las ingestas en estos procesos se pueden realizar de dos formas: batch y streaming. batch: conocido como procesamiento por lotes (procesamiento batch), ya que divide los datos en lotes y los procesa por separado. Es habitual que este tipo de ingestas se realicen periódicamente una o varias veces al día o a la semana. Este tipo de procesamiento puede ser útil cuando una empresa quiere analizar las ventas en el último mes o año, puesto que no necesita la información al instante de su generación streaming: conocido como procesamiento en tiempo real (procesamiento streaming). Esta técnica procesa los datos al momento de ser generados. La latencia (tiempo que tarda en transmitir un paquete de datos) es de unos segundos o incluso milisegundos. Este tipo de procesamiento es muy útil para empresas que deben de procesar datos al instante para tomar una acción inmediata frente al usuario. Algunos ejemplos son Netflix o Uber, así como la misma Google Hemos hablado de los procesos ETL, pero existe otro paradigma más reciente denominado ELT (Extract, Load, Transform). En un proceso ELT no hay ningún requisito de transformación de los datos antes de cargarlos: los datos se ingestan en un data lake sin ninguna transformación y, una vez que los datos están cargados, se transforman solamente aquellos que se van a necesitar para un determinado análisis. ¿En qué se diferencian? Estos procesos tienen varias diferencias con respecto a ETL, las principales son: En ELT tenemos más flexibilidad a la hora de almacenar datos nuevos no estructurados, ya que son insertados sin pasar el proceso de modificación Los procesos ETL ayudan a tratar con datos sensibles, puesto que podemos anonimizar estos datos antes de cargarlos, al contrario que en ELT En un proceso ETL los datos son cargados en una base de datos o en un Data Warehouse y en un proceso ELT son cargados en un data lake Los costes de la construcción de un proceso ETL son mayores que los de un proceso ELT Conclusión Como hemos visto, existen varias formas de que una compañía tenga sus datos preparados para extraer información. La elección de usar una base de datos SQL o NoSQL en un proceso ETL, o de construir procesos ELT en lugar de ETL dependerá de las propias necesidades de la empresa, del consumidor y del problema en particular. Escrito por Ramón Casado. Todos los post de esta serie: Cómo transformar una compañía (I): Priorizar casos de uso Cómo transformar una compañía (II): conectar la tecnología con el negocio Cómo transformar una compañía (III): Profundizando en la arquitectura de referencia Cómo transformar una compañía (IV): Desarrollar una metodología de ingesta de datos Cómo transformar una compañía (V): Complementar las fuentes internas con datos externos Cómo transformar una compañía(VI): Las POC o como un proyecto pequeño puede salvar uno grande
30 de junio de 2020

Movistar Prosegur Alarmas: La nueva Living App que muestra cómo ofrecer experiencias a través de la TV
En Telefónica continuamos trabajando para ampliar la oferta de experiencias dentro del ecosistema del Hogar Digital. Siendo el salón el corazón de una casa, hemos creado un ecosistema de productos y servicios que hacen de él un espacio inteligente y conectado. En este sentido, traemos a más de un millón de hogares en España nuevas experiencias digitales impulsadas por la Inteligencia Artificial, a través de las Living Apps. Estas aplicaciones, desarrolladas internamente o por terceros, están disponibles permanentemente en la televisión de los clientes Movistar, sin necesidad de descarga. Abrimos el ecosistema a terceros para que el Hogar Digital sea un nuevo canal de llegada a los clientes. Actualmente, dentro del catálogo de Living Apps podemos encontrar diferentes propuestas de entretenimiento, cultura, deportes, viajes, e-commerce, música o gestión de servicios, liderados por empresas como Atlético de Madrid, Air Europa, Iberia o LaLiga. Todas ellas han visto en estas experiencias la posibilidad de conectar con sus clientes, de ofrecerles nuevas propuestas de entretenimiento, gestión de sus servicios e incluso un nuevo espacio en el que mostrarle los productos y servicios que todavía no conocen. A este catálogo se suma una nueva Living App bajo el marco de la seguridad del hogar y el control de dispositivos: Movistar Prosegur Alarmas. Movistar Prosegur alarmas Movistar Prosegur Alarmas da a conocer sus sistemas de seguridad desde la televisión Con esta nueva Living App, acercamos a los clientes el crecimiento en tecnología e innovación de Telefónica junto a la experiencia en seguridad y protección que ampara Prosegur Alarmas. Esta experiencia digital tiene como razón de ser dar a conocer, a través de la televisión, los dispositivos y servicios de seguridad que desde Movistar Prosegur Alarmas ponen a disposición del cliente, basadas en soluciones tecnológicas y especializadas en seguridad. La preocupación por la seguridad en los hogares españoles ha crecido en los últimos años y, por consiguiente, también el aumento de sistemas de alarmas instaladas. En este sentido, el Hogar Digital permite hacer uso de la tecnología y la innovación para obtener un mayor control de la seguridad en casa. En concreto, con la Living App Movistar Prosegur Alarmas el cliente puede acceder a un escaparate de los productos y servicios que la compañía ofrece. Alarmas para hogares Un nuevo canal de llegada al cliente A través de la televisión en Movistar+, el cliente puede acceder al catálogo de Kits de alarmas de Movistar Prosegur Alarmas, para implementarlo tanto en su lugar de residencia como en espacios de negocio. Encontrará información relacionada con el kit de alarma en cuestión, como el precio de suscripción o el equipamiento que incluye, y también podrá ponerse en contacto de forma rápida con el número que le aparecerá en la pantalla de la televisión. Además, podrá conocer los componentes de una alarma y en qué consiste cada uno de ellos, con el fin de identificar los dispositivos que mejor se adapten a sus necesidades. Accediendo a la Living App la televisión se convertirá en el centro de control de casa, donde poder gestionar la vigilancia y descubrir consejos prácticos de seguridad – aplicables, por un lado, al día a día, como a situaciones en las que los clientes se encuentren fuera del hogar o del lugar de trabajo-. En este último caso, a través de la aplicación móvil los clientes pueden controlar de forma remota la alarma que tengan instalada, con opciones de recibir imágenes en tiempo real o la posibilidad de conectar o desconectar la alarma desde el propio smartphone. Todo ello gracias a los dispositivos conectados que conforman el Hogar Digital. Recuerda que las Living Apps son oportunidades de negocio para las empresas, siendo la televisión un canal cercano y recurrente donde descubrir nuevas experiencias para los usuarios. Si quieres ampliar la información sobre ellas, puedes hacerlo a través de este enlace. https://www.youtube.com/watch?v=TOmW3F_Zlrk&feature=youtu.be
16 de junio de 2020

Reconstruyendo Mocoa a través del Big Data
Las posibilidades del Big Data para aportar al bien social son infinitas, además de consolidarse como una herramienta indispensable para alcanzar los Objetivos de Desarrollo Sostenible propuestos en la Agenda 2030. La catástrofe natural ocurrida en Mocoa, capital de Putumayo, en marzo de 2017, causó más de 22.000 damnificados, 332 muertos y 48 barrios afectados. Este acontecimiento, motivó al Centro de Pensamiento Estratégico Internacional (Cepei), a Telefónica Movistar y a LUCA a realizar una investigación, utilizando Big Data, consistente en la exploración de datos de conectividad móvil para comprender cómo se desplazó la población a raíz de lo ocurrido entre el 31 de marzo y el 1 de abril de 2017. Gracias al análisis de datos anonimizados y agregados de móviles, se comprendieron los procesos de movilización interna y externa antes, durante y después de la tragedia. Este tipo de análisis busca brindar insumos para fortalecer los procesos de planificación y toma de decisiones en el territorio respecto al manejo de desastres naturales, en especial, de la movilidad y atención de la población. La documentación y seguimiento del impacto que generó la tragedia a través de fuentes no tradicionales de datos, se convierte en una herramienta para complementar estadísticas oficiales y formular, a partir de esto, planes, programas y proyectos con enfoque de resiliencia y prevención del riesgo, tal y como lo dispone la meta 13.1 de los ODS: “Fortalecer la resiliencia y la capacidad de adaptación a los riesgos relacionados con el clima y los desastres naturales en todos los países”. Para más información sobre lo ocurrido en Mocoa, consulta la historia “Reconstruyendo a Mocoa a través de los datos”, en la plataforma Data República, auspiciada por Cepei. Los resultados de la investigación, disponibles en la plataforma permitieron identificar un descenso de hasta el 45% de la población en los días cercanos a la tragedia, siendo los principales lugares de movilización Pasto, Sibundoy, Puerto Caicedo, Orito y Bogotá. Igualmente, se encontró que la población no retornó a Mocoa como se tenía previsto, lo cual sugiere que hubo una falla en garantizar las condiciones mínimas de calidad de vida que se habían proyectado. https://www.youtube.com/watch?v=2kNdkY79quo&feature=youtu.be Proyectos como este resaltan la importancia de generar alianzas público-privadas, las cuales permitan contar con más y mejores datos para la toma de decisiones sobre problemáticas que afectan a la ciudadanía. En particular, se evidencia que los datos móviles son una fuente masiva que aporta datos de gran calidad sobre la movilidad de la población, especialmente relevante en situaciones de crisis o emergencia.
3 de abril de 2020

Caso de éxito sector público: Big Data e IA para la lucha contra la violencia de género
Desde la perspectiva de las administraciones públicas existen hoy en día multitud de retos sociales, pero la lucha contra la violencia de género es actualmente un asunto central para los Gobiernos de muchos países. Por ello, el Ministerio de Igualdad de España contactó con LUCA para explorar las posibilidades que la aplicación de Big Data e Inteligencia Artificial podía proporcionarles para mejorar sus capacidades. ¿Cuál fue el reto? El Ministerio necesitaba reforzar su plan de acción contra este tipo de violencia y decidieron que una estrategia de datos sería una buena herramienta para ello. El objetivo de este proyecto llevado a cabo por el equipo de Consultoría de LUCA, era identificar y evaluar las necesidades analíticas del organismo en este ámbito y proponer casos de uso relevantes para la prevención de la violencia de género. Para la ejecución de este proyecto, se seleccionó a LUCA por su liderazgo en el sector y por su equipo de expertos en todas las vertientes de la analítica de datos, con amplia experiencia y conocimiento en este tipo de proyectos, tanto en el sector público como en el privado. ¿Cuál fue la solución? Para dar respuesta a las necesidades del Ministerio, se lanzó un proyecto de Use Case Discovery, donde se llevaron a cabo reuniones con todas las áreas relevantes del ministerio para entender las necesidades que cada una de ellas tenía y orientar la detección de casos de uso a satisfacerlas. Desde un punto de vista, técnico también se evaluó la tecnología disponible ya internamente en la casa, así como las fuentes de información, tanto internas, como procedentes de otras áreas de las administraciones y fuentes externas. Con esta información se realizó una priorización donde se tuvo en cuenta la criticidad de las iniciativas para el Ministerio, y también la viabilidad técnica de los casos de uso en función de la complejidad tecnológica y la disponibilidad de históricos de datos suficientemente profundos. Una vez priorizados, se profundizó en las iniciativas más relevantes con un diseño detallado, donde se explicitaban los objetivos funcionales, las fuentes de información y la tecnología necesaria, los algoritmos que con mayor probabilidad deberían aplicarse para cada problema, así como una propuesta de explotación final de ese caso de uso en la operativa real. Esto ha permitido iniciar un proceso de adopción de Big Data e Inteligencia Artificial para la toma de decisiones eficiente y la optimización de las capacidades internas. A través del servicio de Consultoría de LUCA, ayudamos a todo tipo de empresas y organizaciones a extraer el valor de los datos, para que se adapten al nuevo ecosistema y saquen el máximo partido a los nuevos modelos de negocio y sistemas de toma de decisiones. Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube. AI OF THINGS Caso de éxito: proyecto pionero para el desarrollo económico y social 23 de septiembre de 2019 AI OF THINGS Incorporación de Big Data en el sector público: caso de éxito Navantia 25 de noviembre de 2019
26 de marzo de 2020

Análisis de la DANA que azotó el Levante español en 2019
En Septiembre de 2019 un fenómeno meteorológico extremo, conocido como DANA, causó graves inundaciones en el sureste español, provocando la pérdida de vidas humanas, cuantiosos daños económicos, daños en las infraestructuras y el aislamiento de numerosas poblaciones durante días. En este trabajo estudiamos el fenómeno desde la perspectiva del análisis de datos. Telefónica y Citibeats han colaborado en el uso combinado de datos anónimos y agregados provenientes de la actividad de la red móvil y de redes sociales para obtener un mayor conocimiento sobre los efectos de la DANA. El objetivo es poner en valor la aplicación del Big Data para abordar desafíos globales, como los derivados del Cambio Climático. Los principales resultados del estudio ponen de manifiesto el valor del big data móvil para detectar la ocurrencia de un desastre natural así como la respuesta de la población en términos de movilidad. Además, el uso de algoritmos avanzados de análisis de texto (extraído de miles de publicaciones en redes sociales), permiten entender de manera detallada los aspectos cualitativos relacionados con el desastre. Este trabajo es parte de la apuesta de ambas compañías por el uso de datos para el Bien Social y confiamos en inspirar a otras organizaciones del sector privado a fomentar este tipo de iniciativas. Puedes descargarte el estudio completo desde este enlace: Análisis de la DANA
2 de marzo de 2020

Caso de éxito Fundación Telefónica: Big Data para equilibrar oferta y demanda de empleo en España
En este proyecto que LUCA ha realizado junto con Fundación Telefónica se ha conseguido saltar un hueco que existía hasta ahora en España entre la oferta y la demanda de puestos digitales: los datos hablaban de que, aún con altos índices de desempleo en el país, muchas compañías no eran capaces de cubrir ciertas vacantes técnicas. Este plan se inscribe dentro de la misión de Fundación Telefónica de fomentar el desarrollo de las personas a través de planes sociales, culturales y educativos, con el foco puesto en buscar sinergias y beneficios en el mundo digital. ¿Cuáles eran los retos? Además del reto social detectado, los expertos de analítica de datos de LUCA tuvieron que asumir otro desafío importante: conseguir información útil y veraz sobre demanda y oferta laboral en España. Para ello, Fundación Telefónica acudió a importantes actores del sector, como Infojobs o Tecnoempleo. ¿Cuál fue la solución? A través de datos extraídos de fuentes externas, se ha construido un mapa interactivo de acceso gratuito en el que cualquier usuario puede encontrar respuestas a las preguntas más frecuentes sobre empleo en España: ¿Cuáles son las profesiones más demandadas en cada provincia? ¿Qué tengo que aprender para adaptarme al mercado laboral? ¿Cuál podría ser mi profesión según mis habilidades? Mapa de profesiones y habilidades digitales por provincias De esta forma, se consigue una foto muy precisa de los trabajos con más demanda y las capacidades más solicitadas a la hora de optar a estas ofertas. Estas respuestas están a su vez distribuidas por provincias, acercando aún más la información a los intereses del usuario. A través del servicio de consultoría y analítica de LUCA, ayudamos a las empresas y administraciones públicas de cualquier sector a extraer el valor de los datos en su proceso de transformación digital, para que se adapten al nuevo ecosistema y saquen el máximo partido a los nuevos procesos tecnológicos y sistemas de toma de decisiones. AI OF THINGS Caso de éxito: proyecto pionero para el desarrollo económico y social 23 de septiembre de 2019 Para mantenerte al día con LUCA visita nuestra página web, suscríbete a LUCA Data Speaks o síguenos en Twitter, LinkedIn y YouTube.
25 de febrero de 2020

Caso de éxito BCP: datos para reforzar la imagen de marca y aumentar el tráfico móvil
En esta campaña realizada por LUCA para el Banco de Crédito de Perú (BCP), uno de los bancos más importantes y el proveedor líder de servicios financieros integrados del país, se consiguió un 66% de conversiones y un VTR medio del 91% gracias a la solución de LUCA Advertising Data Rewards. En este caso, el banco tenía dos objetivos principales: generar reconocimiento de marca a la vez que construía una imagen digital sólida y, en segundo lugar, impactar a su público objetivo en el canal móvil para incentivar el tráfico hacia su app y captar leads. Esto fue posible, en primera instancia, gracias al formato Data Rewards Video, un formato que asegura altas tasas de retención de marca a través de la visualización de un vídeo publicitario a cambio de paquetes de dato; estos paquetes se consiguen tras responder correctamente a una pregunta sobre el vídeo. Con este tipo de contenido, la marca logró generar engagement, informar y dar soluciones al usuario sobre el buen uso de aplicaciones de banca. “Con Data Rewards podemos obtener datos importantes sobre el recuerdo del anuncio mediante una pregunta al final del vídeo, para así asegurarnos de que el usuario tiene que ver el vídeo al 100% y de que estamos transmitiendo nuestro principal mensaje de una forma correcta.” Yesenia Delgado, Digital Planner BCP Asimismo, para generar conversiones, combinaron lo anterior con el formato Data Rewards Lead, que permite obtener usuarios interesados en el alta de un servicio a través de la información recogida. Así pues, Data Rewards es el formato que garantiza a las marcas que su mensaje ha sido entregado, entendido y recordado. Además, a través de la segmentación de nuestros clientes en Perú, hemos conseguido llegar de forma efectiva al público objetivo de la campaña, optimizando aún más la inversión. En LUCA Advertising entendemos la necesidad del cliente a través de sus datos. El problema de conexión en Latinoamérica – cerca de 80% de la población consume datos prepago – es una oportunidad para las marcas que eligen el formato de Data Rewards en sus campañas digitales. AI OF THINGS Incrementando la intención de compra con publicidad móvil: caso de éxito de Milpa Real 7 de agosto de 2019 Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
12 de febrero de 2020

Caso de éxito Mahou San Miguel: Inteligencia Artificial para alcanzar objetivos de negocio
Nuestro proyecto para Mahou San Miguel se ha trabajado con dos objetivos principales: Que el departamento de Marketing sea capaz de conocer el impacto digital en términos de imagen de marca y que puedan predecir el mix más adecuado a la hora de alcanzar determinados objetivos. Para una empresa del sector del Gran Consumo como Mahou San Miguel, instaurar una sólida cultura del dato entre sus distintos departamentos es esencial hoy en día para el buen desempeño del negocio, convirtiéndose en un entorno mucho más colaborativo y transversal y equilibrando la transformación digital con la amplia experiencia del sector lograda hasta ahora. En este proceso de transformación digital, el Big Data y la Inteligencia Artificial se vuelven indispensables, y es así cómo surge el proyecto con el área de Marketing de la compañía. Retos del departamento de Marketing antes del proyecto No hay duda, en el ámbito del marketing la tecnología ha hecho que la relación entre las marcas y los consumidores sea mucho más compleja, la comunicación de masas es cada vez menos efectiva y el uso de otras ventanas como el móvil se ha vuelto indispensable para establecer relaciones con el usuario. En un corto espacio de tiempo el panorama de relaciones marca-consumidor ha cambiado mucho. Ahora el juego con el consumidor es mucho más colaborativo y se necesitan más vías para conseguir los objetivos marcados. En este contexto, aparecen entornos nuevos con nuevas oportunidades, pero con el gran reto de saber gobernarlos. A este gran reto se suma la complejidad de la organización del departamento de Marketing en este caso, que trabaja con diversas marcas, diversas geografías y diversos niveles. Soluciones aportadas por Telefónica Tech Las dos barreras detectadas a partir de estas premisas fueron una falta de lenguaje común en el área de Marketing que permitiera una toma de decisiones más eficiente y la complejidad actual a la hora de controlar el customer journeyen los diferentes escenarios que maneja esta compañía. Así pues, el proyecto de Telefónica Tech ha funcionado como una bisagra, que permite resolver esa falta de uniformidad en los lenguajes y ofrece la posibilidad de predecir qué estrategias serán más efectivas para alcanzar determinados objetivos. A través de nuestro servicio de consultoría y analítica ayudamos a las empresas y administraciones públicas de cualquier sector a extraer el valor de los datos en su proceso de transformación digital, para que se adapten al nuevo ecosistema y saquen el máximo partido a los nuevos modelos de negocio y sistemas de toma de decisiones.
28 de enero de 2020

Reto 2020: Enseñar a hablar correcto español a la IA
Gracias a los grandes avances en inteligencia artificial, las máquinas cobran mayor protagonismo introduciéndose de lleno en nuestras vidas. En sólo unas décadas, hemos pasado de aprender los interfaces de las máquinas a que las máquinas aprendan los interfaces humanos, por lo que es de especial importancia enseñar a las máquinas a hablar un correcto español. En este webinar, nuestro AI & Data Ambassador, Richard Benjamins, junto al técnico de comunicación de la Real Academia Española, Juan Romeu, nos hablan del proyecto LEIA, acrónimo de Lengua Española en Inteligencia Artificial. Este proyecto está liderado por la Real Academia Española, en una ambiciosa misión de unir a los humanos con las máquinas y a las humanidades con las ciencias. Enseñar a las máquinas a hablar un correcto español, aprovechar la Inteligencia Artificial para ayudar a las personas a hablar un correcto español y crear un certificado de buen uso del español, son los tres objetivos principales que impulsan este proyecto. https://www.youtube.com/watch?v=rlfzZ3cMqeY Pero la RAE no afronta sola este reto, cuenta con la colaboración de las 23 academias de la lengua española y grandes empresas tecnológicas: Telefónica, Facebook, Google, Microsoft, Twitter y Amazon. Debido al gran impacto que conlleva en el lenguaje español, estas empresas no quieren perder la oportunidad de apostar por este proyecto. Para mantenerte al día sobre nuestros LUCA Talks, visita nuestra página web o síguenos en YouTube, Twitter o LinkedIn.
21 de enero de 2020

Caso de éxito: Big Data para mejorar la calidad de vida en las favelas
Aunque estas poblaciones urbanas son difíciles de medir y monitorear, según datos oficiales del Instituto Brasileño de Geografía y Estadística (IBGE), aproximadamente 11.4 millones de personas (6% de la población) viven en 6329 favelas en todo Brasil. Como era de esperar, muchas de estas personas trabajan en empleos de bajos ingresos, con horarios irregulares y múltiples ubicaciones de trabajo, lo que dificulta a los gobiernos locales encontrar los conjuntos de datos adecuados para apoyar su planificación urbana en torno al transporte público y la infraestructura. Nuestro equipo de LUCA en Brasil ha trabajado junto con el Banco Mundial y la Universidad de São Paulo para ver cómo gracias a nuestros servicios de Business Insights, permite a los perfiles decisores de este caso obtener resultados de un análisis mucho más exhaustivo, de una manera más eficiente, utilizando Big Data para el bien social. Al extraer insights de datos de una variedad de operadores de telecomunicaciones, y combinándola con otras fuentes de información como datos de la tarjeta de transporte inteligente o de aplicaciones móviles, por ejemplo, este equipo multidisciplinario en colaboración, ha podido detectar tendencias globales de grupos de personas (siempre basados en datos anonimizados y agregados), que viven en Paraisópolis , un área de favelas con aproximadamente 55000 habitantes en la ciudad de São Paulo. Figura 1: Nuestra asociación con el Banco Mundial y la Universidad de São Paulo. Durante el proyecto realizado con productos de Crowd Analytics, se analizó durante un total de 2 meses, la población a nivel municipal para el área metropolitana de São Paulo y a nivel intramunicipal para los 96 distritos de la ciudad de São Paulo. En el distrito de Vila Andrade dividimos el área geográfica entre Paraisópolis y el resto del distrito. El principal objetivo fue crear una matriz de viajes Origen-Destino (OD) entre Paraisópolis y estas otras áreas de la ciudad, utilizando datos de eventos móviles anónimos y agregados para comprender cómo se mueven las personas de acuerdo con la hora y el día de la semana, así como proporcionar información sobre su perfil demográfico y el propósito de su viaje. La dificultad de acceso y la falta de seguridad siempre ha sido un desafío para la investigación de campo, especialmente en comunidades que sufren pobreza y delincuencia. Proyectos como este muestran cómo la tecnología puede ayudarnos a superar esta barrera, proporcionando datos de calidad que permitan una planificación urbana de calidad para toda la ciudad. Proyectos como este nos brindan información sin precedentes sobre cómo las personas se mueven dentro y alrededor de las ciudades. Este proyecto fue una oportunidad importante para colaborar con el Banco Mundial y la USP para comprender mejor las demandas únicas de movilidad urbana en Paraisópolis, proporcionando ideas que pueden mejorar la calidad de vida de los residentes de la comunidad.
16 de enero de 2020

Caso de éxito: Optimizando el plan de carreteras de Highways England
La industria del transporte es una industria muy permeable a la aplicación de estrategias de Big Data e Inteligencia Artificial, ya que existen casos de uso claros para maximizar la eficiencia de las empresas y mejorar la planificación de infraestructuras. En este post, analizaremos el caso de éxito de Highways England y veremos cómo esta compañía está sacando partido a sus datos. Highways England es la empresa responsable de la operación, mantenimiento y mejora de las autopistas inglesas. En total, Highways England supervisa más de 6900 km de carreteras. Estas carreteras juegan un papel crucial en la producción económica del país. Gracias al análisis avanzado de los datos, Highways England ha mejorado su eficiencia y es capaz de obtener datos de mayor calidad. El tiempo dedicado a la recogida de datos se ha reducido de 6 meses a 7 días, lo cual supone un ahorro masivo en horas de trabajo. El resultado ha sido un ahorro anual de millones de libras en los costes de recolección de datos. Proyecto de optimización del plan de transporte de Highways England Para poder garantizar la operatividad de las carreteras, Highways England necesita recopilar una gran cantidad de datos. Anteriormente, este proceso era arduo y costoso en tiempo y en dinero. LUCA ha trabajado estrechamente con Highways England para obtener datos de forma más precisa, segura y barata, usando para ello datos móviles. Gracias a nuestra tecnología de última generación LUCA Transit, Highways England tiene acceso a nuestra base de datos anonimizados, que contiene más de 4.000 millones de eventos de red generados cada día por los clientes de O2. Estos datos permiten extraer valiosos insights para el modelado y planificación de las infraestructuras. En el vídeo que aparece a continuación, Dave Sweeney, responsable comercial de LUCA para Sector Público y Transportes en Reino Unido, explica cómo el uso de Big Data e Inteligencia Artificial ayuda a Highways England y otras organizaciones de los sectores de turismo y transporte: https://www.youtube.com/watch?v=mhGgCuzruDE&feature=youtu.be&t=4m9s Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
11 de diciembre de 2019
Podcast: Hablamos de Sports Analytics con Fernando Rivas, entrenador de Carolina Marín
En este nuevo podcast, os contamos cómo la tecnología ha pasado a formar parte del ámbito deportivo y está presente en la rutina y dinámica de disciplinas como baloncesto, ciclismo, atletismo e incluso bádminton. ¿Sorprendido? Aunque no lo creas, Inteligencia Artificial y Big Data son elementos imprescindibles en la preparación y mejora del rendimiento de los deportistas. ¿No tienes en tu muñeca un smartwatch o una pulsera que, además de darte tus constantes vitales te muestra tu progreso e incluso te reta? Hoy vamos a descubrir cómo el análisis avanzado de los datos ayuda a la súper campeona de bádminton Carolina Marín en su rutina profesional. Para ello, conversamos con Pedro de Alarcón, Head of Sports Analytics y Big Data for Social Good de LUCA (la unidad de datos de Telefónica) y Fernando Rivas, entrenador de Carolina Marín. Juntos nos responden a preguntas muy interesantes: ¿Con qué disciplinas se trabaja desde el área de Sports Analytics de LUCA? ¿Cómo se trabaja con los equipos deportivos: modelos predefinidos o diseñados ad hoc? ¿Cómo se aplica el Big Data en el bádminton y desde cuándo lo utilizan en la estrategia de Carolina Marín? ¿Cómo integra Carolina Marín esta tecnología en su día a día? ¿Dónde creen que llegará la aplicación de Inteligencia Artificial en el campo deportivo? Dale al play para escuchar esta interesante lección sobre analítica deportiva: AI OF THINGS Podcast : ¿Cómo se puede usar el Big Data para el bien común? 4 de julio de 2019
5 de diciembre de 2019

El Data Science ayuda a convertir a atletas en súper atletas
¿Sabías que el Big Data y la Inteligencia Artificial se puede aplicar al ámbito del deporte para obtener mejores resultados y mejorar el rendimiento de los deportistas profesionales? Hoy en día no contamos con atletas, los deportistas son súper-atletas. Remontándonos a los Juegos Olímpicos de Estocolmo 1912, la maratón se corrió en 2 horas 36 minutos. En los Juegos Olímpicos de 2018, en cambio, se batió el récord mundial en 2 horas 01 minutos. Es decir, los atletas consiguen correr la maratón en 35 minutos menos que hace cien años. ¿Qué ha pasado para que en tan poco tiempo se mejore tanto una marca? Lo que hay detrás es tecnología y mucho Data Science. En ocasiones la competitividad es tal, que una victoria lo marcan unos minutos o, incluso, unos pocos segundos. En el caso del ciclismo, recordando las tres grandes vueltas en las que ha participado el equipo Movistar Team por ejemplo, la diferencia entre el ganador y el cuarto puesto, que queda fuera del pódium, son solamente 2 o 3 minutos, menos del 0.1% de su rendimiento. Cualquier diferencia, cualquier ganancia por marginal que sea, hace que un deportista consiga el pódium. Todo cuenta. Desde LUCA colaboramos con varios equipos deportivos, como parte de una estrategia conjunta con los equipos de patrocinios de Telefónica en un patrocinio tecnológico, añadiendo una capa de inteligencia artificial y Big Data. Gracias a los algoritmos y últimas herramientas que desarrollamos, trabajamos para extraer el valor de los datos para las organizaciones ayudando a mejorar el rendimiento de los deportistas. Igualmente, las marcas o clubes deportivos han encontrado nuevos modelos de ingresos, activando canales que no tenían activos, incluso activando su audiencia y engagement en redes sociales. En el pasado LUCA Innovation Day 2019, Pedro A. de Alarcón, Head of Big Data for Social Good y Sports Analytics de LUCA, lideró el panel de Analítica Deportiva junto con Miguel Ortega, Director de Operaciones y Desarrollo de Negocio de Movistar Estudiantes y Jorge Sanz, Director equipo femenino de Movistar Team. Durante el panel. De izquierda a derecha: Pedro A. de Alarcón, Miguel Ortega y Jorge Sanz en el Panel de Analítica Deportiva durante el LUCA Innovation Day 2019 Durante el panel, comentaron cómo los ciclistas en particular, gracias al IoT, han disparado la cantidad de datos que se generan gracias las muchas variables obtenidas de los sensores de cadencia, potencia, velocidad, frecuencia cardiaca, GPS, oxígeno muscular… Incluso cuando el deportista no tiene capacidad o no puede llevar sensores, la pista está sensorizada. Esto ocurre en el caso del tennis, donde se sensoriza desde la colocación del jugador, hasta la velocidad de la pelota, obteniendo en una gran cantidad de datos que ofrece muchos insights para mejorar el rendimiento de los deportistas. Estos avances se deben a que, por un lado, la innovación se ha democratizado, casi todas las organizaciones están ya dentro de un ciclo de innovación como parte de supervivencia u oportunidad. Por otro lado, han surgido las tecnologías exponenciales como el Big Data, la Inteligencia Artificial o el Blockchain. Como indica Pedro A. de Alarcón, Head of Big Data for Social Good y Sports Analytics de LUCA en su ponencia, “estos avances generan una oportunidad de disrupción en la industria del deporte. No solo en los atletas, sino en la industria como tal. El desafío ahora es cómo ayudar y equipar a estas organizaciones para que se suban a la ola de la transformación”. En el caso de los atletas, ya pueden tomar decisiones basadas en datos gracias al análisis del rendimiento y los insights obtenidos, mejorando su performance, aumentando su carrera deportiva gracias al control de la fatiga y recuperación… incluso monetizar oportunidades que antes no podían. Pedro A. de Alarcón, Head of Big Data for Social Good y Sports Analytics de LUCA Disfruta de la ponencia del evento, en el que nuestros expertos hablan sobre los proyectos más relevantes del área Sports Analytics de LUCA, contando con Movistar Estudiantes y Movistar Team, entre otros, para mostrar cómo están transformando su organización deportiva. Para conocer más sobre analítica deportiva, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
27 de noviembre de 2019

Incorporación de Big Data en el sector público: caso de éxito Navantia
¿Cuáles son los ingredientes principales para una transformación digital exitosa? La transformación digital se ha hecho indispensable en casi todos los sectores, también en la administración pública y, como hoy vamos a demostrar, en la industria naval. Navantia, protagonista de esta historia con datos, es la empresa pública española referente en el diseño y la construcción de buques militares y buques civiles de alta tecnología. Actualmente, está inmersa en un profundo proceso de transformación orientado a la sostenibilidad de la empresa en el mercado del siglo XXI, donde la innovación tecnológica y la digitalización son dos factores esenciales para activar el cambio. Su necesidad en esta fase del proceso era descubrir casos de uso de analítica avanzada y Big Data para aportar valor a todas las áreas, con el objetivo de obtener un valor diferencial. Dentro de este proyecto se identificaron diferentes casos de uso relacionados con mantenimiento predictivo en buques y astilleros, análisis exploratorio de datos del SICP (Sistema Integrado de Control de Plataforma) y optimización de la gestión de la cadena logística y de suministro. Gracias a los insights extraídos en este proyecto llevado a cabo por LUCA, Navantia cuenta ahora con una hoja de ruta a corto y medio plazo para la incorporación de Big Data dentro de su proceso de transformación digital. Otros resultados más detallados también salieron a la luz. AI OF THINGS Caso de éxito SMASSA: servicios de estacionamiento inteligentes 22 de octubre de 2019 Para la ejecución de este proyecto, se seleccionó a LUCA por su liderazgo en el sector y por su equipo de expertos en todas las disciplinas de Big Data, con amplia experiencia y conocimiento en proyectos de datos tanto del sector público como del privado. A través del servicio de consultoría de LUCA, ayudamos a las empresas públicas y privadas a extraer el valor de los datos, para que se adapten al nuevo ecosistema y saquen el máximo partido a los nuevos modelos de negocio y sistemas de toma de decisiones. Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
25 de noviembre de 2019

¿Cómo extraer el valor de los datos para tu negocio?
La combinación de Big Data e Inteligencia Artificial está transformando la manera de operar de las empresas abriendo un sinfín de nuevas posibilidades. En el anterior blog post Acercando la Inteligencia Artificial a tu negocio hablamos sobre cómo cualquier empresa, sea cual sea su línea de actividad y sector, pueden integrar soluciones de Big Data e Inteligencia Artificial. Pero ¿cómo extraer el valor de los datos para tu negocio? Carlos Martínez, Director Global de Big Data & AI Business de LUCA, nos da las claves para ser exitosos a la hora de extraer el valor de los datos de un negocio. Es decir, utilizar los datos en favor de la actividad y negocio con un impacto positivo en la organización. Partiendo de las prioridades estratégicas que tiene la empresa, sus preguntas de negocio, lo más relevante es saber identificar qué fuentes internas y externas utilizar para tener más información y tomar mejores decisiones. Como destaca Carlos Martínez en su ponencia, “Al combinar fuentes su valor se multiplica. La fusión de datos permite crecer la capacidad de gestión, siendo imprescindible conectar esas respuestas a las preguntas de negocio, a través de acciones que desencadenen en un impacto positivo en la organización”. "Al combinar fuentes su valor se multiplica. La fusión de datos permite crecer la capacidad de gestión de la empresa de manera exponencial" Carlos Martínez, Director Global Big Data & AI Business de LUCA En LUCA llevamos mucho tiempo trabajando entorno a los datos de Telefónica, para poder extraer insights de negocio siempre con un principio de privacidad que pone, como prioridad absoluta, la confidencialidad y la privacidad de los datos de nuestros clientes. Para garantizar esta confidencialidad, no solo aplicamos el Reglamento General de Protección de Datos, sino que, además, incorporamos los mecanismos de seguridad más robustos y avanzados. Carlos Martínez, durante su ponencia en el LUCA Innovation Day 2019, cuenta las diferentes formas en las que trabajamos para la extracción de datos y posterior desarrollo de herramientas y soluciones para cada negocio y línea de actividad. Las soluciones de Crowd Analytics, que trabajamos de manera anonimizada y agregada; las soluciones de Consent-based data en los casos de datos individuales, siendo imprescindible contar siempre con el consentimiento explícito y previo del cliente. Por otro lado, desarrollamos soluciones a partir de datos procedentes del Internet de las Cosas, a través de dispositivos y sensores de IoT que permiten digitalizar procesos, pudiendo medirlos y saber cómo optimizarlos. Marisa Urquía, Directora de Empresas de Telefónica España, puso en relieve en el LUCA Innovation Day 2019 del crecimiento exponencial de empresas que han implementado dispositivos y sensores IoT y sus beneficios. "Como Telefónica aportamos la conectividad, pero vamos más allá, con una propuesta de valor para todos los segmentos: con propuestas de Smart Cities y casos de éxito, propuestas para entorno médico, de tracking de flotas... siendo reconocidos como líderes en el cuadrante de analistas Gartner durante 5 años consecutivos". Maria Urquía, Directora de Empresas de Telefónica España Trabajamos, además, con las comunicaciones empresariales, con los servicios que consumen los clientes internamente y que os prestamos para que los empleados se comuniquen mejor entre ellos, y para que tengan una relación mucho más fructífera con los clientes finales y aliados. Una vez más, en esta tercera edición hemos querido mostrar cómo en LUCA desarrollamos soluciones para ir evolucionando nuestra oferta de servicios e incorporando nuevos avances, siempre con el objetivo de acelerar la transformación de nuestros clientes corporativos y ayudarles en ser competitivos en esta nueva era digital.
19 de noviembre de 2019
10 buenas prácticas para evitar el fraude en SMS
Escrito por Felipe Castillo Todas las empresas son susceptibles a ser víctimas de fraude, ya sea interno o externo, siempre habrá alguien buscando una oportunidad para aprovechar una vulnerabilidad. El mundo de las telecomunicaciones no es la excepción, desde hace varios años los operadores móviles luchan contra personas que han encontrado en los SMS una ventana de oportunidad que puede poner en riesgo incluso la seguridad y privacidad de los usuarios móviles. Mediante instalaciones ‘artesanales’, personas que no cuentan con los permisos o infraestructura necesaria comercializan mensajería masiva a todas las empresas que requieren comunicación con sus clientes (inclusive entidades financieras), es posible que, a través de estas rutas no autorizadas, esté siendo enviada una contraseña de autenticación bancaria sin ninguna consideración de seguridad o confidencialidad. Figura 1: Instalación "artesanal" A partir del análisis de datos los operadores móviles han evolucionado las técnicas de control de este tipo de fraude, sin embargo, en el otro extremo también existe un análisis amplio para evadir las barreras del operador. Todo este escenario se convierte en un juego de ‘Golpea al topo’, ambos soportados por el análisis de datos y comportamiento. Cada vez que el operador cierre un agujero, el topo (defraudador) intentará ingresar por otro. Cada día billones de SMS son cursados por las redes móviles de los operadores, y muchos de estos SMS están compromentiendo seriamente la privacidad de los usuarios. Por tanto el control de este fenómeno es de vital relevancia para los operadores móviles. Estas son las 10 mejores prácticas que un operador puede aplicar para proteger a sus usuarios: 1. Herramienta de control automático Es una plataforma que durante las 24 horas se encuentra analizando el comportamiento de los usuarios, determinando patrones y mediante técnicas de Machine Learning identificando cuales poseen un comportamiento fraudulento. 2. Aplicar Herramienta anti-fraude tanto en tráfico propio como en interconexión Tener una herramienta de control es el primer paso, sin embargo, no es suficiente controlar únicamente el fraude que se genera en la red propia del operador, muchas veces la amenaza viene de agentes externos, si controlamos solo un agujero, el topo saltará por el siguiente. 3. Cuidar la brecha que se puede abrir por interconexión El operador debe cerrar cualquier ventana al defraudador que le permita evadir los controles de la herramienta anti-fraude. Muchas veces acuerdos antiguos o tecnología obsoleta permiten estas brechas. 4. Todo tráfico fraudulento a pesar de ser bloqueado debería ser cobrado Aún si el operador afina sus controles y logra bloquear el tráfico fraudulento que está afectando a sus usuarios, el intento de envío de cada uno de dichos mensajes debe ser cobrado con el único objetivo de desmotivar este tipo de prácticas no autorizadas. 5. Igualar tarifas de terminación internacional masiva y personal Algunas veces los defraudadores utilizan rutas de comunicación personal para transportar mensajería masiva. Esto implica que una persona puede recibir mensajes de un número internacional cualquiera con información publicitaria, notificaciones o incluso información personal y sensible. Es muy probable que en el extranjero el número que envió el mensaje fue obtenido ilegalmente. Una buena práctica que el operador puede ejecutar para prevenir este caso de uso es igualar el valor de terminación de sus tarifas. Esto evitará que la ruta de mensajería personal sea atractiva para fraude. 6. Condiciones claras en contratos La mejor forma de controlar el fraude es prevenirlo. Si se revisan continuamente los contratos con todos los jugadores del negocio podremos evitar que las malas prácticas empiecen dentro de casa. 7. Limitar el enmascaramiento de números origen Muchos defraudadores intentan esconder sus acciones detrás de la identidad de otras personas o empresas. Es fundamental para un negocio sano que los operadores técnicamente limiten en sus plataformas este tipo de comportamiento. 8. Utilizar una herramienta de prueba para identificar rutas sospechosas Disparar SMS desde múltiples orígenes a través de un partner permitirá evaluar el estado de penetración de fraude en un país, así como también trazará el camino a seguir. Gracias a este tipo de pruebas es posible conocer el estado de cada país. 9. Estudiar y analizar la información recopilada Hacer un análisis fino y constante de la información disponible permitirá al operador optimizar todas las herramientas que tenga a su disposición. El comportamiento de los defraudadores es dinámico y se ajusta a las necesidades del negocio irregular, entender esas necesidades y ese comportamiento es clave para lograr neutralizarlos. 10. Cuestionar y actualizar los métodos de control constantemente Sin importar que tan eficientes o precisos sean los controles del operador es necesario siempre cuestionar todos los procedimientos, el análisis de la información permite entender lo que es necesario hacer y cuando hacerlo, sin embargo, en un mundo tan cambiante asumir que todo está bajo control es la forma más sencilla de abrir nuevos agujeros. Siempre existirán personas dispuestas a intentar cometer fraude, esto es inevitable, pero si se utiliza el análisis avanzado de datos podremos entender el comportamiento de defraudadores para detenerlos y eventualmente predecirlos. El Big Data puede ayudar a cerrar todos los agujeros del topo. Para mantenerte al día con LUCA, visita nuestra .
18 de noviembre de 2019

Caso de éxito: Big Data para aumentar el impacto en el turista, con Iberostar
En esta historia con datos, hablamos sobre una de las principales aplicaciones que el Big Data y la Inteligencia Artificial pueden tener en el sector turismo. En este caso, Iberostar, la cadena hotelera, ha podido resolver una necesidad de negocio gracias a nuevas fuentes de datos: conocer mejor el perfil de su cliente y cliente objetivo en sus zonas de influencia. Con los insights que ofrece Telefónica Tech, es posible extraer información valiosa sobre los flujos de personas que transitan alrededor de las propiedades de la compañía, como perfil psicográfico, lugar de residencia o lugares más visitados. Iberostar pretende utilizar esta información en dos vertientes: geomarketing, para que los equipos comerciales puedan detectar en qué áreas están las agencias de viaje que tiene una mayor proximidad con este cliente potencial detectado y así afianzar los mensajes; y en segundo lugar, en el ecommerce, personalizando aún más la experiencia. “La actividad con Telefónica Tech ha sido muy provechosa, estamos muy satisfechos y creemos que es una muy buena aplicación del Big Data dentro del mundo turístico.” Óscar Luis González, Global Marketing Director en Iberostar Hotels & Resorts Con las soluciones de analítica de Telefónica Tech, conseguimos conocer y entender al público objetivo de nuestros clientes también fuera de Internet, siempre asegurando la privacidad y la seguridad del dato y respetando las normas de cada país en el que trabajamos. Estos insights, junto con los ya obtenidos por el cliente en el canal online, consiguen optimizar al máximo el impacto de la marca. AI of Things Caso de éxito: Big Data, la clave en la estrategia de expansión de Benjamin a Padaria 14 de abril de 2020
11 de noviembre de 2019

Acercando la Inteligencia Artificial a tu negocio
¿Es posible integrar soluciones de Inteligencia Artificial en cualquier sector? El pasado LUCA Innovation Day 2019 mostramos nuestra vocación: hacer accesible la Inteligencia Artificial a las empresas, pretendiendo que la adaptación que está viviendo Telefónica la viva de igual manera cualquier cliente sin importar su línea de actividad. En su ponencia, Elena Gil contaba que “hemos alcanzado un momento en el que no se cuestiona el poder transformador del Big Data y la Inteligencia Artificial para que las empresas tomen mejores decisiones, para que mejoren también sus modelos operativos o impulsen e incrementen la productividad”. La IA incluye muchos ámbitos y disciplinas pero, a día de hoy, la gran parte la utilizan para tomar mejores decisiones y hacer mejores recomendaciones utilizando el aprendizaje automático; la automatización de procesos y tareas, por ejemplo en su cadena de produccon, logistica o transporte; y para transformar la relacion con los clientes tanto para atender como para ofrecer una oferta más adaptada, a través de asistentes virtuales y utilizando el lenguaje natural. Elena Gil. CEO de LUCA, en la ponencia de la 3ª edición LUCA Innovation Day 2019 Durante estos tres años hemos acompañado a varias empresas y hemos visto la rápida evolución de la adopción de estas tecnologías. Por ello, un año más, en esta edición de LUCA Innovation Day 2019, bajo el lema "Artificial is Natural" hemos querido mostrar todas las novedades del último año y cómo hemos evolucionado nuestra oferta multisectorial. Porque, como destaca nuestra CEO Elena Gil, "la IA cada vez es mas natural en nuestro día a día, y lo que ambicionamos es que también lo sea en nuestras empresas". Por ello, en LUCA ayudamos a nuestros clientes a desarrollar y acelerar todo este proceso, buscamos hacer accesible la IA a las empresas, ponienido a disposición de nuestros clientes herramientas y soluciones que desarrollamos internamente. Ejemplo de ello es el lanzamiento de Living Apps, que nos abre el ecosistema del hogar para las distintas empresas, o la solución LUCA AI Wizard para poder hacer de una manera muy sencilla un bot para mejorar la relacion entre la compañía y los cilentes. LUCA Suite es también otra de las herramientas que hemos lanzado este año y que nos permite acercar el Machine Learning al cliente, para simplicifar la tarea de los profesionales técnicos de la compañía y también para mejorar la comunicación entre los perfiles técnicos y los de negocios. Mikel Coira, Global Head of Big Data Solutions de LUCA, comenta cómo " la mayor parte de las herramientas que hay en el mercado, se centran en la automatización de tareas técnicas. Muchas veces se pierde la dualidad entre acelerar el proyecto técnico y vincularlo al negocio: se capaces de interpretar el modelo y ser capaces de explotarlo de manera natural. Ahí es donde LUCA Suite ofrece un valor adicional, además de que permite que puedas usar la herramienta con cualquier herramienta de datos que se utilice en la compañía". Para conocer más sobre la herramienta LUCA Suite accede al webinar "LUCA Suite for AI: la herramienta que democratiza el Machine Learning" con nuestros expertos.
5 de noviembre de 2019

Canciones "a medida" gracias a la Inteligencia Artificial
Este año, con motivo del tercer cumpleaños de LUCA nos planteamos un reto interesante. ¿Podría generarse "la canción ideal", en este caso, de cumpleaños, alimentando un algoritmo con nuestras canciones favoritas? Como lo mejor en estos casos es ponerse manos a la obra, lanzamos el reto en redes sociales, para recopilar las canciones, reclutamos voluntariosos cantantes amateurs entre los compañeros (por aquello de los derechos), y nos pusimos a trabajar. El proceso ha resultado apasionante, pero complejo. Por ello, Alfonso Ibáñez y Alberto Granero nos los irán explicando poco a poco en una nueva mini-serie de nuestro blog. Empezamos con este post sobre el estado del arte de la Inteligencia Artificial en el ámbito de la creación musical. Esperamos que os guste. La Inteligencia Artificial, el nuevo artista El arte se entiende como aquella actividad o producto que se realiza con una finalidad estética o comunicativa y que expresa emociones e ideas a través de diversos recursos. Desde un punto de vista más pragmático, se puede decir que es toda forma de expresión (sentimientos, emociones…) de carácter creativo, que puede tener un ser humano. El arte se compone de artes visuales (arquitectura, cinematografía, fotografía, pintura...), las artes escénicas (danza, teatro…), las artes literarias (poesía, drama…) y, por último, las artes musicales (canto, música...). Sin embargo, gracias al avance de la tecnología, se han creado nuevas formas de arte como la composición algorítmica, la cual crea música a través de los algoritmos. ¿Pueden las máquinas generar nuevas canciones exitosas? La mayoría de las canciones musicales y todos sus aspectos (notas, tempo, acordes, ritmos...) se pueden explicar a través de la inteligencia artificial. En los últimos años, estas técnicas han generado avances que permiten eliminar las barreras diferenciadoras respecto a la música producida por los seres humanos. Daddy’s Car se considera la primera canción compuesta íntegramente por la Inteligencia Artificial. Los investigadores de SONY CSL Research Lab desarrollaron FlowMachines en 2016. Este sistema aprende estilos de música a partir de una enorme base de datos y compone nuevas canciones basadas en los estilos musicales analizados. Otro caso de reciente éxito es la plataforma Artificial Intelligence Virtual Artist. Este sistema ha sido entrenado con miles de producciones de autores como Beethoven, Mozart y Chopin, y es capaz de realizar composiciones de temas clásicos como The Golden Age. ¿Qué algoritmos son los más utilizados? Las redes neuronales proporcionan numerosas aplicaciones artísticas como la generación de textos literarios, la modificación de estilos en ciertas imágenes y, por supuesto, la composición de nuevas piezas musicales. En el contexto musical, las recurrent neural networks (RNNs) adquieren un especial interés. Las redes recurrentes se aplican cuando la información disponible es secuencial o temporal. Una de las técnicas más utilizadas de esta tipología son las redes long short-term memory (LSTM). Estas redes son extremadamente útiles para resolver problemas en los que se tiene que recordar información durante un largo periodo de tiempo, como es el caso de la generación de música. Otra posible opción es la utilización de las generative adversarial networks (GANs). En este enfoque, los adversarios pueden ser dos redes neuronales recurrentes diferentes: una red generadora y una red discriminadora. El adversario generador está diseñado para generar datos que no se puedan distinguir de los datos reales, mientras que el adversario discriminador está diseñado para identificar aquellos datos que son reales. El entrenamiento de los modelos se afina iteración a iteración y finaliza cuando el adversario generador produce datos que el adversario discriminador no puede distinguir de los datos reales. Figura 1: Estructura de un modelo basado en las técnicas RNNs+GANs Nuevos paradigmas en el sector Klauss Schwab (fundador y Executive Chairman del foro económico mundial) mencionó que, en la nueva era de los datos en la que vivimos, no es el pez grande el que se come al pez pequeño, si no el pez rápido el que se come al lento. Esta frase hace referencia a la necesidad de adaptación de las empresas. Aquellas que no sepan o no quieran adaptarse a los nuevos cambios tecnológicos desaparecerán. En este contexto, la discográfica Warner Music ha contratado los servicios de la empresa Endel para que, basándose en la Inteligencia Artificial, componga nuevos géneros de música durante el 2019. Esta empresa capta miles de sonidos que provienen de la climatología, la ubicación, la hora o el ritmo cardíaco, entre otros, para producir música personalizada a los usuarios. Desde Warner Music afirman que estos nuevos géneros son capaces de mejorar el estado de ánimo e incluso reducir la ansiedad. Aprovechando las capacidades de la Inteligencia Artificial, Huawei ha conseguido finalizar la inacabada composición de Schubert, la Sinfonía núm. 8, D.759, empezada en 1822. A través de su Smartphone Mate 20 Pro, esta empresa ha analizado, recientemente, el timbre, el tono y demás características de los dos primeros movimientos y ha generado una melodía para los dos últimos movimientos inacabados. Finalmente, los ingenieros de Huawei acudieron al compositor Lucas Cantor, ganador de dos premios Emmy, para dar los retoques finales y conseguir una partitura que pudieran calificar de fiel al estilo original. Hoy en día, no es necesario que los artistas tengan que estar vivos ni presentes para actuar en los escenarios. Un ejemplo perfecto es diva japonesa Hatsune Miku. Esta artista virtual es una cantante humanoide generada mediante holografía y cuenta con miles de seguidores que la acompaña durante sus conciertos de estilo j-pop. Como hemos podido observar, no hay dudas de que, gracias al avance tecnológico, junto con las novedosas técnicas de Inteligencia Artificial y el procesamiento de miles de millones de datos, las máquinas ya son capaces de componer automáticamente nuevas canciones, de transformar las discográficas y de generar nuevas experiencias en conciertos, entre otras muchas opciones. ¿Esta la sociedad preparada para ello? Post escrito por Alfonso Ibáñez y Alberto Granero Para mantenerte al día con LUCA, visita nuestra .
24 de octubre de 2019

Caso de éxito SMASSA: servicios de estacionamiento inteligentes
Hoy traemos otra historia de éxito en el sector público: el caso de SMASSA, Sociedad Municipal de Aparcamientos que tiene como misión solucionar los problemas de estacionamiento que existen en la ciudad de Málaga. La empresa pública ha conseguido hacer uso del análisis de datos para aumentar su eficiencia operativa y de negocio en todas sus líneas de actuación. Este proyecto está alineado con el proceso de transformación de la ciudad de Málaga hacia una Smart City y pretende contribuir a la mejora de la gestión del tráfico urbano y las soluciones de aparcamiento en la ciudad, utilizando soluciones Big Data. El reto del que se partía era convertir a SMASSA en una organización orientada al dato que pudiera aprovechar las sinergias actuales de una ciudad inteligente y activar las 4 palancas de la estrategia: digitalización, eficiencia operativa, sostenibilidad y monetización externa. La solución propuesta por LUCA se desarrolló a través de un proyecto de consultoría que ha construido la visión sobre la que SMASSA debería articular su estrategia de datos durante los próximos cuatro años. El proceso de evolución gradual y progresivo hacia una organización data-driven incluye la definición de diferentes iniciativas a corto, medio y largo plazo, como la visualización avanzada para reporting de KPIs, la segmentación avanzada para el offering de nuevos servicios al usuario o la gestión circular de residuos de vehículos. A través del servicio de consultoría de LUCA, ayudamos a las empresas y administraciones públicas a extraer el valor de los datos en su proceso de transformación digital, para que se adapten al nuevo ecosistema y saquen el máximo partido a los nuevos modelos de negocio y sistemas de toma de decisiones. Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
22 de octubre de 2019

Caso de éxito: segmentación avanzada para publicidad exterior con Clear Channel
Esta historia de éxito comienza con un reto: revolucionar la vía pública y ofrecer una plataforma de publicidad exterior que permita identificar y conocer cualitativamente a las audiencias que transitan por las calles de la ciudad, con una precisión similar a lo que ocurre en el canal online. Pero, ¿es posible? Este es precisamente el enfoque que ha utilizado la empresa de soportes publicitarios Clear Channel Perú para diferenciarse de sus competidores y optimizar sus ingresos en publicidad OOH, creando una herramienta única para que el anunciante conozca el perfil de la audiencia que transita por los soportes y para mejorar su experiencia durante el proceso de la campaña: Clear Targets. "Clear Targets es una herramienta de identificación de audiencias que nos permite entender la demográfica de los transeúntes y con la que conseguimos segmentar al público urbano según industria, según preferencia o según la afinidad que está buscando cada uno de nuestros anunciantes", Tommy Muhvic-Pintar, gerente comercial de Clear Channel Perú. Gracias a la potencia de nuestra solución LUCA Audience, Clear Targets se sitúa un paso por delante y ofrece varios beneficios a sus clientes: identificar movimientos y tendencias, entender el perfil sociodemográfico de los flujos de personas (edad, nivel económico, género, lugar de residencia o de trabajo…), hacer segmentaciones por industria, preferencia o afinidad de compra, e incluso obtener información sobre impactos, alcance y frecuencia, haciendo así más eficiente la inversión, tal y como si estuviéramos lanzando una campaña online. Con las soluciones de crowd analytics de LUCA, como LUCA Audience, conseguimos conocer y entender al público objetivo de nuestros clientes también fuera de Internet, siempre asegurando la privacidad y la seguridad del dato y respetando las normas de cada país en el que trabajamos. Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
8 de octubre de 2019

Datos e Inteligencia Artificial: clave en la estrategia deportiva
A partir del análisis de datos procedentes de deportistas y equipos en su conjunto, las entidades y clubes deportivos pueden adaptar y optimizar sus estrategias deportivas. La famosa película “Moneyball: Rompiendo las reglas” -nominada a 6 Óscars, incluido el de mejor película-, ya mostraba el valor de la estadística en la estrategia deportiva. Basada en la historia real de Billy Beane, gerente general del equipo Oakland Athletics, quien utilizaba las estadísticas avanzadas para fichar jugadores, la película es un claro ejemplo de cómo el análisis avanzado de datos consigue reunir y seleccionar un equipo de jugadores que cada jornada consiguen ganar partidos y llegar a la final. Hoy en día los entrenadores y cuerpo técnico pueden optimizar el rendimiento deportivo de sus equipos gracias a estrategias de planificación de entrenamientos donde se aplican los últimos avances en Ciencias del Deporte, Big Data, Inteligencia Artificial y Machine Learning, con la creación de herramientas analíticas que aportan conocimiento adicional del desempeño del equipo en competición. Son múltiples los ejemplos del uso de Big Data e IA en algunos de los principales deportes en todo el mundo. En el ciclismo profesional, por ejemplo, un ciclista genera 3 millones de datos en una gran vuelta. Alejandro Valverde, ciclista profesional con cientos de victorias y el ciclista con más medallas conseguidas en la historia de los mundiales en ruta, cuenta que “ni mucho menos imaginaba, cuando yo empecé, que podía llevar casi un ordenador en la bicicleta, porque llevamos una cantidad de datos impresionate: la altura, el desnivel de la subida, los vatios, el pulsómetro, la velocidad, vatios máximos… Lo llevamos todo incorporado y se generan una cantidad de datos e información sobre rendimiento, alucinante”. Esta aplicación del Big Data y la Inteligencia Artificial en el ciclismo trae consigo una revolución en el mundo deportivo, pudiendo usar los propios datos del deportista que hasta ahora no se estaban midiendo, ni se estaban recogiendo durante el propio deporte, para dar feedback al deportista en tiempo real sobre su rendimiento y tomar decisiones más adecuadas a cada situación. El baloncesto es otro de los deportes donde más datos se recogen, y desde hace unos años la estadística avanzada es cada vez es más predictiva. A través del desarrollo de estos dashboard, a partir de algoritmos del análisis avanzado de estadísticas históricas de los jugadores y de los equipos, los cuadros de mando permiten al personal del equipo tomar mejores decisiones durante los partidos. Estas herramientas desarrolladas a través de Machine Learning e IA nos permiten, entender cuáles son las variables más influyentes en los resultados de los partidos para ir más allá de la generación de indicadores. Por ejemplo, permite ir más allá en la generación de informes, reduciendo hasta un 95% el tiempo en la extracción de datos y generación de estos. Así se consigue detectar automáticamente variables determinantes en las victorias, así como otros aspectos de mejora competitiva a partir del análisis de temporadas completas y las estadísticas históricas de un gran número de jugadores. Antonio Pérez Caínzos, segundo entrenador del Movistar Estudiantes, explica cómo “gracias a la estadística avanzada del clutchtime, podemos tomar decisiones de equilibrios en los quintetos, y para quién jugar en esos últimos minutos. Un caso se dio, por ejemplo, en el partido de Movistar Estudiantes contra Obradoiro cuando decidimos desde dirección de partido que Dario fuera el jugador que jugase esos últimos balones de cluthtime, porque era nuestro mejor jugador en esos tres últimos minutos. Y salió bien”. https://www.youtube.com/watch?v=k6Q5zF0YeU8&feature=youtu.be Proyecto de Sports Analytics que estamos desarrollando con el equipo Movistar Estudiantes Siempre hay un componente humano, subjetivo, desde seleccionar qué datos escoger hasta las preguntas que nos llegamos a hacer delante del resumen de datos. Estos datos complementan las intuiciones personales para tomar las decisiones adecuadas, y es ahí donde el Big Data y la IA se vuelven una verdadera revelación dentro del sector deportivo, y ayuda a los deportistas a mejorar su rendimiento y superarse cada día. La IA y el análisis avanzado de datos han llegado al deporte para quedarse y sumarse al esfuerzo que día a día realizan los deportistas.
7 de octubre de 2019

“Artificial is Natural”: El evento de Inteligencia Artificial para empresas
Llega el LUCA Innovation Day 2019, la tercera edición de nuestro evento anual de innovación donde tendrás que poner los cinco sentidos. Es un hecho: la Inteligencia Artificial es cada vez más alcanzable y necesaria, tanto en nuestro entorno personal como en el mundo corporativo. El próximo 16 de octubre queremos mostrarte la IA que hemos descubierto durante este último año: una IA natural, accesible para cualquier compañía u organización de cualquier sector y para cualquier objetivo o necesidad de negocio, que te ayudará a optimizar tu propuesta de valor y a afianzar la relación con tus clientes, de persona a persona y al alcance de tu mano. LUCA Innovation Day 2019: Artificial is natural. Durante la jornada te propondremos un juego de percepciones: Verás los usos y aplicaciones más innovadores desarrollados en este último año en LUCA para dar respuestas a las necesidades de tu negocio. Escucharás de primera mano la experiencia de nuestros clientes y las ponencias de nuestros expertos, para para que puedas percibir las próximas tendencias y tecnologías que transformarán tu compañía. Tocarás y experimentarás con nuestras soluciones de Inteligencia Artificial y multisector en directo junto a nuestros expertos. Además, vivirás el lanzamiento al mercado español de Movistar Living Apps, nuestro nuevo canal inteligente que lleva tu negocio directamente al hogar de los millones de clientes de Telefónica, a través de nuevas experiencias a una sola frase de distancia gracias a Aura y la voz. La tecnología maximiza las capacidades de nuestros negocios, pero somos las personas las que tomamos las decisiones. ¿Nos acompañas? El LUCA Innovation Day 2019 tendrá lugar el 16 de octubre a las 16:00 h en el Auditorio Central de Distrito Telefónica (Madrid). Puedes registrarte haciendo clic aquí. AI OF THINGS Lo más destacado de LUCA Innovation Day 2018 ¡Gracias por acompañarnos! 10 de octubre de 2018
25 de septiembre de 2019

Caso de éxito: proyecto pionero para el desarrollo económico y social
En un artículo anterior ya hablábamos sobre lo importante que es llevar a cabo una transformación cultural, es decir, de las personas, al mismo tiempo que una compañía o sector emprende la transformación digital de sus procesos y herramientas. Hoy os contamos el caso de éxito del Banco Interamericano de Desarrollo (BID), organización financiera internacional cuyo objetivo es fomentar el crecimiento comercial sostenible y responsable en América Latina y Caribe. Esta historia comienza cuando la organización detecta un problema en su zona de influencia: las técnicas de análisis avanzado de datos que ofrecen el Big Data y la Inteligencia Artificial no se aprovechaban plenamente en los países de América Latina y el Caribe, especialmente en términos de crecimiento y competitividad para el sector privado y de eficiencia para el sector público. Con el objetivo de reducir estas limitaciones y contribuir a la consolidación de los perfiles demandados en este ámbito, el BID confió en el área de LUCA Academy, desde donde se diseñó y produjo un MOOC en español, pionero en su formato y extensión y con una fuerte orientación a la mejora del capital humano y a la gestión de la información en entornos digitales. La acogida de la primera edición del MOOC fue muy relevante, con más de 17.000 alumnos inscritos en 17 países. En la actualidad y debido a este éxito, ya se ha lanzado la segunda edición del curso. Porque toda transformación comienza desde la educación. Para la ejecución de este proyecto, se seleccionó a LUCA por su liderazgo en el sector y por su equipo de expertos en todas las disciplinas de Big Data e Inteligencia Artificial, con amplia experiencia y conocimiento en proyectos de datos tanto del sector público como del privado. Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
23 de septiembre de 2019

Inteligencia Artificial en el sector industrial: el caso de éxito de Repsol
Aunque ha sido el gran olvidado en estos últimos años de avances tecnológicos, el sector industrial presenta muchas oportunidades en el ámbito de los datos y la Inteligencia Artificial, y también en términos de eficiencia y nuevas fuentes de ingresos. En esta historia con datos, hablamos del caso de éxito de Repsol, una empresa global e integrada del sector energético presente en toda la cadena de valor y que ha apostado por la transformación digital integral de toda la compañía como palanca de su plan estratégico. "En una compañía como Repsol, el impacto de la aplicación masiva y escalada de Big Data e Inteligencia Artificial es muy importante y, además, tiene una incidencia directa en la cuenta de resultados." Juan José Casado, Data Analytics & AI Director de Repsol Así es cómo Repsol apuesta por crecer de forma rentable y liderar el proceso de transición energética. Es en este punto donde cobra especial relevancia el trabajo de consultoría y analítica que para ello se realizó desde Telefónica Tech. En el contexto de digitalización que experimenta la compañía actualmente, la aplicabilidad de Big Data e Inteligencia Artificial ha servido para afrontar el gran reto de explotar los miles de datos recogidos durante años en sus procesos productivos. Esto se ha hecho a través de modelos analíticos desarrollados por Telefónica Tech, que cubren las necesidades que se han ido detectando en cada una de las áreas de negocio. Gracias a los resultados e insights extraídos de los distintos proyectos llevados a cabo, se ha enriquecido la toma de decisiones de Repsol para que sus procesos sean más ágiles y eficaces, las planificaciones más ajustadas y la satisfacción de sus clientes finales más elevada. Estos proyectos son solo el inicio de sucesivos esfuerzos encaminados a facilitar la consecución de la excelencia operativa, optimizando los recursos y materias primas, haciendo más eficientes las paradas no productivas en planta y mejorando la calidad del producto final, evitando fabricaciones de producto de segundas calidades, así como aumentando cada vez más la satisfacción de los clientes gracias a un óptimo conocimiento de los mismos. Cloud AI of Things Cómo XaaS está transformando los servicios Cloud (y la relación entre empresas y clientes) 4 de septiembre de 2023
11 de septiembre de 2019

Incrementando la intención de compra con publicidad móvil: caso de éxito de Milpa Real
El Estudio de Kantar Millward Brown demuestra la efectividad del formato de publicidad móvil Data Rewards El objetivo de un estudio de Brand Lift es medir la efectividad de una campaña de publicidad, identificar si contribuye al conocimiento de marca, evaluar si es memorable y comunica las asociaciones más relevantes de la marca y, finalmente, determinar si la campaña muestra una intención de compra. Movistar Ads México decidió hacer el Brand Lift Insights Estudio junto con una de las marcas más conocidas de tostadas en México, Milpa Real del Grupo Bimbo, a través de una campaña que contenía el formato estrella de LUCA Advertising Data Rewards en su versión vídeo. Y con el objetivo de asociar la cultura mexicana con su marca de tostadas. https://www.youtube.com/watch?v=mofUTCXj2Ls Vídeo de Milpa Real para la campaña de Data Rewards Los resultados entregados por Kantar Millward Brown respecto a la variable conocimiento de marca fueron realmente asombrosos: el grupo expuesto se posicionó 5.5 p.p. por encima del grupo que no vio la campaña, lo que significa que el grupo que visualizó la campaña a través del formato Data Rewards reconoce haber escuchado sobre la marca en mayor medida que quien no la vio. Figura 1: Conocimiento de marca. Uno de los indicadores que más le interesaba a la marca era la asociación del mensaje de la campaña/su producto con la cultura azteca. El resultado fue excelente: el grupo expuesto tuvo casi 11 p.p. de diferencia con respecto al grupo de control que no visualizó la campaña de tostadas. Figura 2: Identificación del mensaje. Kantar Millward Brown afirmó en el estudio que la campaña de Milpa Real lograba explotar el conocimiento de marca para así motivar a las personas a incrementar su intención de compra de esta marca de tostadas, lo que se vio reflejado en los 4,8 p.p. por encima del grupo expuesto respecto al grupo control. Figura 3: Intención de compra Por último, merece la pena mencionar cómo se posiciona la efectividad de las campañas a través del formato Data Rewards con respecto a otras plataformas digitales de gran peso y las más conocidas del mercado publicitario. En este caso, los resultados fueron nuevamente favorables para el formato Data Rewards, con respecto a cualquiera de las plataformas comparadas. Como muestra de ello, en las campañas lanzadas en una de estas importantes plataformas, la diferencia entre los grupos expuesto y control es mucho menor en este tipo de plataformas (2,8 p.p en la variable de asociación del mensaje) con respecto a la diferencia entre los grupos de las campañas lanzadas a través de Data Rewards (10,8 p.p. en la variable de asociación del mensaje). Figura 4: El mensaje de marca ha sido entendido y recordado por la audiencia escogida. Con todos los datos analizados y presentados en el estudio, se puede afirmar que el formato de LUCA Data Rewards, es el formato de publicidad móvil que asegura al 100% que el mensaje de marca ha sido entendido y recordado por la audiencia escogida por la marca. Para conocer más casos de éxito de LUCA, visita nuestra página web, contacta con nosotros o síguenos en Twitter, LinkedIn o YouTube.
7 de agosto de 2019

La aceleración del sector asegurador en Big Data
De todas las aplicaciones que Big Data tiene, las aseguradoras demandan explotar el valor de sus datos para potenciar su relación con el cliente desde la captación a la fidelización. En el sector asegurador son pocos los momentos en los que se interactúa con el cliente y por ende aquellos en los que se puede obtener información del mismo, haciendo que sea muy importante ofrecer un servicio personalizado y ágil al mismo. Para ello, los datos son fundamentales como materia prima para la inteligencia de negocio, que lejos de ser una herramienta complementaria, como es vista aún en otros sectores, se trata de un activo a ser explotado en un sector altamente competitivo y centrado en el cliente. Actualmente, prácticamente todas las empresas del sector están contratando expertos para impulsar el proceso de transformación digital, careciendo muchas de ellas de objetivos claros de negocio que marquen su hoja de ruta. El volumen de facturación de una empresa no siempre está ligado al grado de madurez Big Data y son pocas las compañías que han conseguido explotar con éxito el valor de los datos. Las empresas aseguradoras disponen de una cantidad ingente de datos generada a lo largo de los años y uno de los principales problemas que tienen que afrontar es precisamente saber cómo gestionar su propia información. Dicha información es de vital importancia para la organización, ya que el perfilado del cliente en sí mismo es la esencia del seguro y del sector, por lo que analizando tanto el perfil de los mismos como cuál ha sido su comportamiento en el pasado, es decir cómo ha interactuado con la marca, con sus productos y el uso que ha hecho de las pólizas, podremos descubrir patrones que permitan predecir su comportamiento futuro. De esta manera, un mayor conocimiento del cliente servirá como base para el desarrollo de iniciativas en la organización basadas en el valor aportado por los datos y que se traducen en generación de nuevos ingresos, en mejora de la eficiencia operativa y de procesos o en la detección de fraude y riesgo. Big Data aplicado al ciclo de vida del cliente en el sector asegurador Los datos que las empresas aseguradoras poseen de forma natural son los relativos a las distintas fases del ciclo de vida del cliente, por lo que surgen áreas de trabajo evidentes en las que la explotación de datos juega un valor diferencial: Captación: un caso de uso típico sería el pricing dinámico, que permite calcular en tiempo real y con los datos que el potencial cliente facilita el índice de riesgo para la compañía. En base a dicho riesgo se determina el perfil del cliente (en función de su valor potencial) y se calcula la prima idónea. Fidelización: mediante acciones de cross-selling y up-selling se puede alargar la vida del cliente y maximizar la relación comercial con él. Una vez identificado el valor del cliente, los datos de la propia aseguradora se pueden cruzar con datos externos. Por ejemplo: datos y estadísticas del INE, del Catastro, de meteorología, así como datos de tráfico y el tipo de desplazamientos en coche (en el caso de seguros de automóvil). A día de hoy, el tratamiento de los datos externos es un plus, pero en un futuro, quien no lo haga estará en desventaja. Predicción de riesgo: Big Data permite también predecir los posibles impagos e incluso el riesgo de fuga de un cliente hacia otra compañía aseguradora antes de que este tome la decisión. Esto es posible gracias a la recopilación de información de insatisfacción del cliente y la búsqueda de correlaciones que identifiquen variables o hechos que alarmen y permitan predecir qué clientes tienen un riesgo de fuga elevado o inminente. Detección de fraude: Por último, Big Data ayuda en un punto clave de toda organización, y tiene que ver con la gestión de anomalías que pueden ocurrir durante un siniestro. El análisis de todas las fuentes de información permite identificar patrones de comportamientos irregulares de los clientes pero también permite optimizar la gestión con proveedores (grúas, flotas, etc.) ajustando calidad y coste del servicio que la aseguradora recibe de sus proveedores ante el siniestro de un cliente. Asimismo, el análisis de los datos puede servir para detectar irregularidades en el equipo comercial de la compañía o en la red agencial. Primeros pasos para convertirse en una aseguradora data-driven La principal barrera de las compañías aseguradoras suele ser la desorganización de la información de la que disponen. Normalmente, los datos se encuentran distribuidos en silos independientes en función del departamento de donde provienen, sin homogeneidad ni conexión alguna entre ellos. Uno de los principales retos es precisamente recopilar y compartir todos esos datos a nivel corporativo para que pasen a formar parte de un repositorio unificado que sirva como punto de partida para su posterior análisis. Conocer la preparación y formación de la que disponen las personas en la empresa, el trabajo realizado en la identificación de iniciativas de negocio, las características de las bases de datos existentes, así como la infraestructura y tecnologías disponibles permitirá determinar el estado de madurez Big Data actual y definir objetivos futuros. La estrategia Big Data de una empresa debe venir liderada por negocio. No se trata de cuestiones técnicas y de implantación de tecnologías, sino que tiene que venir asociada a unos objetivos de negocio claros donde los datos darán respuesta a problemáticas concretas, siendo clave para la dirección de la estrategia departamental o global. Escrito por Alfredo Martínez, Insurance/Go to Market LUCA Para mantenerte al día con LUCA, visita nuestra .
31 de julio de 2019

Debate: ¿Y hacia dónde se dirigirá el CDO 3.0?
Tal y como se señaló en anteriores reuniones del Club, la comunidad se ha convertido en una voz de referencia: la de los CDO. Por ello, el debate ocupó una vez más una importante parte de la sesión. Durante su transcurso, como es habitual, surgieron multitud de cuestiones. Por ejemplo, tal y como apunta Mariano Muñoz, CDO de Acciona, muchos equipos de IT se preguntan si se gobierna (o, si se debería gobernar) el dato igual que el proceso analítico. “Hemos tratado muchos temas, como el data ethics, cuyo debate es el inicio para convertirse en una organización data centric. Hoy, muchos más directivos conocen lo que es un modelo prescriptivo y pocos dudan de que toda la información debe ser gestionada y gobernada. En cualquier caso, debemos seguir haciendo pedagogía para que el dato se comparta de manera centralizada”. “Gobernar el dato es ordenarlo. El CDO debe verse a sí mismo como el facilitador que haga posible la transición de un mundo de soluciones artesanales a uno escalable, industrializado” “Efectivamente, el dato y los modelos analíticos deben estar gobernados”, subraya Ana Gadea, partner de Management Solutions, a lo que Lluis Esteban añade que “el CDO también tiene responsabilidad sobre la labor de ejecución y gobierno. Claramente, será quien tenga que rendir cuentas si algo falla, por lo que es una labor que ha de acometer”. Precisamente, por ello es muy importante poner el énfasis en la cultura, que todo el mundo esté familiarizado con el proceso analítico y que hable el lenguaje de los datos. Ángel Galán, Director de Business Intelligence y Data Analytics de Correos, destaca la importancia de compatibilizar la labor analítica con modelos tradicionales de gestión de la demanda. Para ello, es importante tener una visión cross. Por su parte, Angel Sánchez, CEO de Global Strategy Solutions, advierte del peligro de coartar la creatividad, un símbolo de identidad en startups que en ocasiones no es aprovechada eficazmente en la gran empresa: “la gobernanza de los modelos analíticos puede parecer una camisa de fuerza en empresas medianas y startups. La cultura de la creación es positiva. Hay que fomentar la gobernanza, pero sin que coarte la creatividad y las nuevas ideas que ayuden a mejorar el negocio”. Una manera de fomentar tanto la creatividad como la gobernanza es disponer de zonas de pruebas, a modo de sandbox, que estén específicamente diseñadas para permitir pensar nuevas ideas que, si funcionan, puedas aprovecharse de manera escalable. Durante el debate, se hizo patente la necesidad de que el mensaje llegue hasta el nivel máximo de decisión. El CEO debe impregnarse de la cultura del dato y debe creer y fomentar la labor del CDO. “Efectivamente, el CEO debe implicarse”, indica Silvina Arce, CDO de Banco de Chile, “mientras que, cuando hablamos de gobernar, debemos tener en mente que es para permitir la reutilización y la creación. Gobernar también es poner orden para, precisamente, permitir la creación. Por ejemplo, no es efectivo que una misma compañía cuente con una decena de herramientas de visualización. Probar es positivo, y seguro que muchas tienen cosas positivas, pero si al final todas se usan con el mismo fin, es contraproducente. Gobernar también es prescribir tecnología”. La palabra “gobierno” puede producir rechazo. Por eso, el CDO debe comunicar muy bien su labor, hacer ver que gobernar es ordenar y que dicha labor permite que las soluciones sean escalables. Debe ser el facilitador que haga posible la transición de un mundo del dato artesanal a uno industrializado. Por otro lado, Manuel Ferro, CDO de Abanca, advierte que en función del sector en el que nos encontremos, incluso se puede interpretar qué es un modelo de manera distinta. “En banca, veo que el desarrollo de modelos está muy estandarizado según qué áreas: los de entorno macroeconómico, los de riesgos, inteligencia de clientes… Por eso, aquí es muy importante la labor de velar por la calidad del dato del CDO y, sobre todo, abogar por el uso de repositorios comunes que derriben los silos de información”. Asimismo, Esteban recalcó que es importante saber dónde empieza y dónde acaba un proyecto de datos, así como el margen de error permisible. “Debemos desmitificar la calidad del dato: la realidad es mucho más flexible de lo que pensamos y hay cierto margen de error que en determinadas situaciones nos podemos permitir”. Si bien es necesario buscar la calidad del dato, lo perfecto no debe ser enemigo de lo bueno. “Como CDO, debemos hacer un ejercicio interno para determinar nuestro nivel de tolerancia. Ante todo, debemos utilizar el sentido común”. Paula Álvarez, CDO de VidaCaixa, opina que “es esencial potenciar el uso y la capacidad analítica de la compañía, y eso pasa también por la cultura: 'cuando un área usuaria desarrolla todo su potencial analítico, es cuando sus necesidades informacionales aportan el máximo valor a la organización. El CDO puede y debe actuar como punto de entrada; cada área tiene distintos grados de madurez: unos solo necesitan self-service, otros precisan una guía más detallada… Es importante establecer planes de formación acordes a las necesidades de los equipos”. Francisco Torres, CDO de Prosegur, indica que “debemos romper un cliché del CDO, relacionado con la manera en la que visibilizamos nuestra labor. Muchas veces, nuestro entregable llega sobre el papel y tenemos que formar parte de la solución, ser ejecutores de determinados procesos. La manera de hacerlo puede pasar por la aportación de un producto tangible. Si no, puede mantenerse la idea de que no aportamos un valor real. Personalmente, mi experiencia anterior en banca me ha hecho darme cuenta de que fuera de sectores altamente regulados, cuesta mucho más poner en valor nuestra función. Con productos que nos identifiquen como ‘marca’, es más fácil compartir nuestra aportación”. También hubo tiempo para abordar un reto esencial: cómo atraer y retener el talento. Es una tarea muy difícil de acometer ya que la retribución no es el único elemento en juego. Los profesionales del dato quieren formar parte de un proyecto atractivo. Por ello, en el momento del reclutamiento, la honestidad es esencial a la hora de describir las labores que se ejecutarán. Hay que buscar apasionados y alimentar esa pasión con proyectos afines y la libertad para que creen soluciones que aporten valor añadido a la empresa. El talento tiene que sentirse libre para contribuir y aportar. Son recetas útiles, como señaló Galán, teniendo en cuenta que “el mundo del dato es amplísimo. Ingenieros, arquitectos, científicos… Es difícil dar con perfiles tan concretos cuando la oferta es tan limitada”. Para Fernando Lipúzcoa, CDO de ING, “el aprendizaje es clave. Además de la falta de talento cualificado, existen pocas alternativas formativas. Y es importante tener a los mejores y preocuparse porque sigan siendo los mejores, porque el talento atrae al talento”. Antonio Pita, Director de Consulting & Analytics en Luca, Telefónica, incide en ese punto: “tras buscar y no encontrar la formación adecuada a nuestras necesidades, apostamos por aprovechar recursos internos. En nuestro caso, destinamos numerosos esfuerzos a esta labor: incentivamos que los empleados se ofrezcan como formadores, preguntamos al resto de quién querrían aprender dentro de la casa, financiamos estudios de posgrado… La autoformación es una tendencia que ayudará a retener el talento”. Retener el talento no solo posibilita la ejecución de proyectos. Mantener una rotación baja es importante para el equipo del CDO porque “si se producen errores, es más sencillo arreglarlos si contamos con el equipo original. De lo contrario, si tiene que subsanarlo un profesional que trabaja con una metodología distinta, será más complicado”, señala Pita. “Por eso, quizás también sea recomendable estandarizar determinadas prácticas y herramientas. No significa que se prohíba la experimentación, ésta debería tener su momento y su lugar, pero la normalización permite subsanar errores, así como replicar modelos exitosos y mejorarlos”. Asimismo, “los salarios han sido la manera más común en la lucha por el talento, pero esto ha creado un problema adicional: trabajamos en equipo y debemos preocuparnos por crear equipo, no estrellas. Por eso, las fórmulas que fomentan la colaboración, como tiempo para trabajar en proyectos en el extranjero con equipos diversos, son beneficiosas”. “Es recomendable estandarizar determinadas prácticas y herramientas. No significa que se prohíba la experimentación, que debe tener su momento y su lugar, pero la normalización permite replicar modelos exitosos y mejorarlos” Por otro lado, Rafael Fernández, CDO de Bankia, destaca que la estandarización “puede levantar muchas ampollas, especialmente en los comienzos. Hablamos de controles calidad del dato, de metodología, de propiedad del dato… Obviamente, el conflicto viene con el cargo, y precisamente por eso nuestra labor es más importante, y gestionar correctamente los datos más necesario”. En este sentido, Silvina Arce, CDO de Banco de Chile, concluyó la sesión compartiendo su experiencia en el mercado financiero latinoamericano: “efectivamente, en un mercado altamente regulado como el europeo, el CDO se ha hecho muy popular en muy poco tiempo; no quiero decir que tenga una connotación positiva o negativa, sino que, por ejemplo, el GDPR ha impulsado un debate que nos ha puesto el foco sobre nosotros. En Chile, donde la presión regulatoria ha sido tradicionalmente menor, partimos en cierta manera con ventaja: el mercado ya ha tenido tiempo para asimilar, desde la distancia, lo que supone trabajar y gobernar el dato; es decir, que mientras que unos mercados han tenido que ir aprendiendo sobre la marcha, otros pueden fijarse en ellos”. En cualquier caso, tal y como se desprendió durante el debate, la figura del CDO está cada vez más afianzada en la empresa. No obstante, sigue en continuo desarrollo y, a la vez, impulsa nuevas evoluciones para empresas de todo tamaño y sector. Por ello, es importante que los CDO mantengan la innovación constante como un elemento nuclear de su manera de pensar y trabajar. Solo así tendrán la capacidad de liderar e impulsar la toma de decisiones de sus organizaciones en la economía analítica. Post escrito por el Club Chief Data Officer Spain
5 de julio de 2019

Cómo solucionar tu problema de negocio con Big Data
El Big Data es una realidad imperante en la mayoría de negocios y procesos en la actualidad, pero ¿conocemos realmente cómo aplicarlo en nuestro día a día? En este webinar, mostramos a través de un caso práctico cómo tomar decisiones basadas en datos en el entorno corporativo. Como si estuviéramos resolviendo una situación real en una empresa, partimos de un problema de negocio que debemos solventar. En este caso, ese problema es, precisamente, lograr maximizar la audiencia y aceptación del webinar. Para ello, nuestros expertos en estrategia y Data Science Álvaro Alegría y Santiago Morante han diseñado y emulado el mismo proceso que debería poner en práctica cualquier empresa cuyo objetivo sea tomar decisiones en base a datos. https://www.youtube.com/watch?v=-2EP_sueDOE Al final de la emisión, tuvimos una sesión Q&A con los ponentes en directo para resolver algunas de las dudas y preguntas comentadas en el chat live. Algunas están ya incluidas en el vídeo, pero dejamos abajo otras que no dio tiempo a responder durante la sesión: ¿Cuál es el volumen mínimo para que una muestra sea representativa? Esta es una pregunta interesante. Es cierto que, para los métodos estadísticos clásicos, existen unas fórmulas para calcular el tamaño mínimo de la muestra para un margen de error y un nivel de confianza determinados (más información). Sin embargo, cuando hablamos de Machine Learning, y especialmente cuando hablamos de Big Data, no es tan habitual encontrar cálculos asociados al tamaño de la muestra, porque se asume que tienes suficientes datos, o por desconocimiento de quién lo hace. Lo que sí se hace para evaluar si la muestra es adecuada es dividir tus datos en varias partes, algunas de las cuales se usan para entrenar el modelo (set de entrenamiento) y otras para evaluar el modelo (set de validación). Si el modelo entrenado obtiene, en el set de validación, unos resultados adecuados desde el punto de vista de negocio que, además, para tu realidad concreta tiene un error aceptable, la muestra habrá sido suficiente para que el modelo aprenda con rigor. Y si dentro de un mes se demuestra que el algoritmo no tiene razón… ¿qué hacemos? Bueno, es cierto que esperamos que los resultados sean mejores que la media de los videos anteriores, si bien hay que tener en cuenta que no hemos podido seguir los resultados del modelo completamente, debido a las limitaciones que no podíamos evitar (fecha del webinar, somos 2 hombres, etc.). Cruzaremos los dedos ;-) ¿Te parece interesante este webinar? Visita la sección LUCA Talks en nuestra web para ver nuestros anteriores webinars.
2 de julio de 2019

No te pierdas la IV edición de los Data Science Awards Spain
Telefónica cree en el gran potencial del Big Data y la Inteligencia Artificial y por eso, a través de su unidad de Big Data e Inteligencia Artificial; LUCA, convoca, la cuarta edición de los esperados Data Science Awards. Tras el éxito de las primeras tres ediciones, emprendemos de nuevo la búsqueda del mejor talento y las iniciativas más innovadoras que descubran las últimas tendencias dentro del mundo de Data Science. El objetivo de los Data Science Awards es dar visibilidad y premiar el talento analítico en España. También, medir la madurez de las tecnologías Big Data e Inteligencia Artificial analizando la evolución de aspectos tales como el número de participantes que llegan al final de los retos, y el carácter innovador de las soluciones aportadas. Los Data Science Awards son gran oportunidad para que los consursantes pongan en valor sus conocimientos y talento aportando soluciones a problemas reales. ¿Qué categorías se van a premiar? Los premios se dividen en tres categorías para abarcar diversos ámbitos del sector: I Premio Mejor Iniciativa Empresarial o de Administración Pública Big Data Queremos reconocer el trabajo de las empresas y administraciones públicas en adoptar el Big Data o la Inteligencia Artificial, mediante iniciativas o proyectos que ayuden a la organización a convertirse en “Data-Driven”. Se evaluarán las iniciativas más destacadas y se premiará la innovación con mejor equilibrio entre el uso de nuevas tecnologías y la generación de valor de negocio o de interés público. Este premio se adjudicará mediante la evaluación de la candidatura por un jurado especializado. Dicho proyecto se presentará mediante un formulario en el que se recogerán las siguientes cuestiones: estado del arte, datos y tecnologías, metodología, descripción del proyecto y aplicabilidad empresarial o administración pública. II Premio Mejor Trabajo Periodístico de Datos Este premio reconoce la labor de los periodistas pioneros en la comunicación basada en datos dónde la importancia de las fuentes, el tratamiento de datos, su análisis mediante herramientas (Big) Data, la claridad en la exposición y la visualización de los mismos es clave. Este premio se adjudicará mediante la evaluación de la candidatura por un jurado especializado. Dicha candidatura se presentará mediante un formulario en el que se recogerá las siguientes cuestiones: estado del arte, fuentes, metodología, trabajo periodístico y repercusión. III Premio Mejor Data Scientist Buscamos premiar el talento en IA y Big Data en todas las especialidades de la ciencia de datos: Data Science, Data Engineering & Data Visualization. Se premiará la originalidad, la metodología, la calidad de la solución y la aplicabilidad en el desarrollo de los retos. En esta categoría se participa en dos fases: La 1ª fase consiste en un Quiz de 20 preguntas mediante el cual se obtiene una puntuación por tiempo de respuesta y nº de aciertos. ¡Se podrá ver la clasificación en un ranking con el resto de jugadores! Y superada la puntuación exigida, se accede a la 2ª fase dónde planteamos varios retos a elegir uno. ¿Entre qué retos se podrá escoger? GO Green: Salvando el plantea, un paso a la vez El principal pulmón de nuestro planeta, la selva amazónica, se desvanece a pasos alarmantes poniendo en jaque la seguridad de un aire limpio para las próximas generaciones. Una parte importante de ello ocurre en Colombia. ¿Eres capaz de trasladar tus capacidades en el primer vuelo virtual Madrid – Amazonia y ayudar a salvar el planeta? Para ello cuentas con datos de Telefónica Colombia y Open Data. Data Scientist, ¡El medio ambiente te necesita! GO Transparent : Detectando Fake News para fortalecer nuestras democracias Cada día vemos cómo somos sujetos de bombardeos informativos; a través de la televisión, prensa, redes sociales e Internet en general. Las instituciones democráticas están siendo desafiadas por el surgimiento de informaciones incorrectas o fake news que se hacen sorprendentemente virales. ¿Podemos crear herramientas para detectar a tiempo posibles fake news para que los gobiernos y otras instituciones puedan desmontarlas antes de que se propaguen? Si crees que tenemos derecho a la información abierta y veraz ¡Emprende este reto! GO Health: Entendiendo cómo los algoritmos son capaces de detectar enfermedades Gracias a algoritmos de Machine Learning somos capaces de transformar diagnósticos médicos a través de la detección temprana de enfermedades que hoy llegan a un 90% de precisión. Sabemos que somos capaces de predecir, pero ¿Somos capaces de entender por qué los modelos algorítmicos han llegado a esas conclusiones? Si crees que puedes desafiar la máquina ¡Interrógala y cuéntanos que te dice! Reto Strong: Transformando el mundo del baloncesto a través de Sports Analytics ¿Quién no ha visto la película MoneyBall? En el que el entrenador (Brad Pitt) se esfuerza por combatir el método tradicional de entrenamiento usando analítica de datos y transformando así el mundo del béisbol. Tú puedes ser ese entrenador o entrenadora pero del baloncesto. ¡Muéstranos de que estas hech@ Márcate un triple! ¿En qué consisten los premios? Se premiará a un ganador por categoría. Además, el jurado se reserva el derecho de otorgar otras menciones de honor a los trabajos que, sin ser ganadores, destaquen por algún aspecto innovador. Los premios se otorgarán por parte del Comité de Organización de los Data Science Awards Spain durante la Ceremonia de Entrega de Premios en diciembre. Además del reconocimiento público y la repercusión mediática, todos los ganadores tendrán la oportunidad de presentar su proyecto durante el evento. Adicionalmente, la categoría ‘Premio al Mejor Data Scientist’ contará con un premio complementario, que consiste en una estancia de una semana en el Connection Science Group del Massachusetts Institute of Technology (MIT) en Boston, USA. El premio cubre el viaje de ida y vuelta, así como el alojamiento de hasta cinco noches de hotel. ¿Cómo participar? Los participantes tienen hasta el 21 de julio para inscribirse, y dispondrán de un plazo de 2 meses para resolver el reto. Los últimos inscritos tendrán el mes de septiembre como límite para entregar los proyectos. Éstos serán posteriormente evaluados por un jurado experto y especializado formado por profesionales del mundo Data Science & Big Data, teniendo en cuenta ámbitos de negocio, académicos, de comunicación e innovación. El jurado se dividirá según las tres categorías: técnico, de negocio, y periodístico, con el fin de evaluar correctamente todos los proyectos presentados . El fallo del jurado se anunciará entre octubre y noviembre de 2019, cuando nos pondremos en contacto con los ganadores. Una vez que se acepte el premio, se publicará el listado de ganadores en la web www.dscienceawards.com y se procederá a la organización de la Ceremonia de Entrega de Premios. No lo dejes mañana, ¡Inscríbete ya!
25 de junio de 2019

Aplicabilidad de GANs y Autoencoders en la Ciberseguridad
El proceso de transformación digital de la sociedad y de las organizaciones es hoy día una realidad que se asienta sobre dos pilares fundamentales: la inteligencia artificial y la ciberseguridad. Este proceso, que ha supuesto un cambio radical en la forma en la que el ser humano se comunica, se relaciona, trabaja y vive, pasa por conocer los riesgos que las nuevas tecnologías traen consigo. Los beneficios que puede proporcionar la inteligencia artificial son claros, pero ¿y los riegos? Debemos ser cautos porque, aunque facilitar la vida de las personas puede ser uno de sus objetivos, también es posible hacer un mal uso de ellos. Uno de los ejemplos más claros es la proliferación de Fake News apoyadas en vídeos generados por una IA que parecen ser lo que no son. También es posible generar de forma artificial voces que encajan perfectamente con las de personas reales. En este artículo, tras una breve introducción de conceptos básicos sobre Machine Learning y Deep Learning (modelos simples de ML, VAEs, GANs, Redes Neuronales Convolucionales y Recurrentes), se revisa el estado del arte y los casos de uso más populares de estas tecnologías que permiten generar ataques de phising o Fake News; pero también pueden ser utilizadas para protegernos de los mismos. Lee el artículo en este enlace.
20 de junio de 2019

Cómo vender más entradas de cine con nuevas fuentes de datos y un móvil
¿Es posible utilizar publicidad móvil para llevar a más gente a los cines o museos? ¡Definitivamente sí! En nuestra historia con datos de hoy te contamos el caso de éxito del estudio de animación Illumination Mac Guff y su campaña de lanzamiento en Brasil de la película "Mascotas", en la que emplearon nuevas fuentes de datos. El objetivo de la campaña era generar awareness y llevar más tráfico a los cines físicos, algo que cada vez es más complicado debido a la gran oferta de entretenimiento simultánea a la que nos vemos expuestos cada día. A pesar del desafío, los resultados de la campaña fueron muy positivos, obteniendo un resultado 32 veces más alto que la media en publicidad online. Pero, ¿cómo lo hicieron exactamente? Para conseguirlo, se utilizó una estrategia cross en canal móvil, basándose en nuestra solución Data Rewards, una solución que ofrece al cliente una recompensa en forma de pequeños paquetes de datos por interactuar con la marca: en primer lugar, se difundió el vídeo del tráiler a una base de potenciales clientes con un perfil afín a la película. Para reforzar el impacto, se enviaron notificaciones push el día del estreno a todos aquellos que habían visto el tráiler, invitándolos en el mensaje a comprar entradas online. En tercer lugar, se utilizaron datos de geolocalización que ayudaron a impactar nuevamente a todos aquellos que habían visto el tráiler y además pasaban cerca de las salas de cine. Al final, se obtuvieron 500 mil visualizaciones en vídeo y un alcance de más de 165 mil personas, lo que nos demuestra que la combinación de datos y publicidad móvil nos abre un mundo de posibilidades en nuestras campañas. https://www.youtube.com/watch?v=itradnkadGs Así fue la campaña de Data Rewards para el lanzamiento de la película "Mascotas" en Brasil
19 de junio de 2019

Data Rewards: conectando la marca con sus clientes
La multinacional Mondeléz International apostó por la solución Data Rewards en su versión offline a través de su marca global de snacks Social Club, presente en más de 5 países. Durante su campaña “Perdeu, parou” la marca ofreció una conectividad extra a quienes compraban un paquete de sus galletas y se registraban en la página web de la promoción a través del código de activación que encontraban en los envoltorios. En total, más de 48.000 personas fueron premiadas con un promedio de 660 personas beneficiadas al día. [embed]https://www.youtube.com/watch?v=jBvGu_ykrzs[/embed] Club Social es una marca de galletas saladas de Mondelez. El objetivo de la campaña era aumentar la conexión entre la marca y el público joven y encontraron, a través del formato Data Rewards Offline de LUCA, una forma de acercarse de sus clientes solucionando su problema de navegación. Debido a su contexto, muchos de los jóvenes -cerca del 80% de los jóvenes brasileños- tienen sus megas agotados. De este modo, a cambio de la compra de un paquete de galletas Club Social, los jóvenes obtienen en el producto un código para activación de sus megas. Así, la marca de snacks, consigue ofrecer un valor agregado al producto, megas de navegación gratis en este caso, a través de la campaña realizada con el formato Data Rewards Offline. Con más de 48.000 personas premiadas, con un promedio de 660 personas beneficiadas al día, como resultado de la campaña.
27 de mayo de 2019

Cómo PepsiCo optimiza la distribución con segmentación avanzada
"En los puntos de venta donde se aplicó la estrategia Big Data se está creciendo 10 puntos por encima, por lo que el crecimiento potencial es espectacular." Con esta cita queremos introducir nuestra “Historia con datos” de hoy: os contamos el caso de éxito de PepsiCo, una de las principales empresas del sector FMCG (por sus siglas en inglés Fast Moving Consumer Goods), es decir, bienes de consumo de alta rotación. PepsiCo es una empresa internacional líder en su sector, que cuenta con un porfolio de marcas reconocidas resultado de una cuidada respuesta a las necesidades de los consumidores. Sostenibilidad, responsabilidad o innovación se encuentran entre los valores que definen a la compañía. Fuente: Statista / OC&C vía Lebensmittel Zeitung En el marco de esta personalidad de marca y con un fin de negocio claro, incrementar el rendimiento de unos de sus canales de distribución clave en España, PepsiCo decide apostar por el Big Data y por LUCA como partner estratégico. Pero ¿cómo iba a ayudarles el Big Data y la inteligencia artificial a conseguir su objetivo de negocio? Conscientes de sus fortalezas y debilidades a la hora de aplicar su estrategia (tenían muchos datos que no eran capaces de analizar), comienzan un proyecto de consultoría y analítica avanzada con LUCA con el fin de entender mejor tanto a sus clientes como a los consumidores, para poder de este modo responder mejor a sus características y necesidades. En este vídeo, Nuria Bombardó (Nutrition, FB and FR Innovation Commercialisation Director en PepsiCo) nos cuenta más detalles sobre los inicios y desarrollo del proyecto: [embed]https://www.youtube.com/watch?v=6_CM4CA63bY[/embed] En resumen, la colaboración entre PepsiCo y LUCA fue todo un éxito, mejorando tangiblemente los resultados de la compañía en los canales donde se aplicó la estrategia, y este éxito reside principalmente en haber sido capaces de lograr identificar insights o aprendizajes ejecutables para el negocio. Estos insights o resultados se obtienen a través del desarrollo de modelos analíticos avanzados que combinan fuentes de datos del cliente, datos de Telefónica (LUCA Insights) y otras fuentes externas. Esto nos permite ofrecer una propuesta de valor diferencial en el sector del Gran Consumo en general y en compañías líderes como PepsiCo, en particular. Diferenciarse y liderar es hoy posible si apoyamos nuestras estrategias en decisiones inteligentes basadas en Big Data e Inteligencia Artificial. Para mantenerte al día con LUCA visita nuestra página web o síguenos en Twitter, LinkedIn o YouTube.
14 de mayo de 2019

De caballero a diplomático, y de diplomático a estratega: la evolución del CDO
Para comprender una realidad compleja, es necesario observarla desde distintos puntos de vista. Por eso, Adolf Hernández, Director de Data & Analytics en everis, y Lluis Esteban, CDO de CaixaBank, ofrecieron una visión sobre la evolución del rol del CDO desde el punto de vista de la consultoría y del cliente. Tal y como señaló Hernández,“hace 5 años podíamos hablar del CDO como el ‘caballero del dato’. Tenía que luchar por promover una correcta gobernanza y calidad del dato. No es que ahora esa batalla no se produzca”, subrayó, “sino que se ha ganado terreno y ahora la labor de pedagogía es mayor. Por eso, ahora podemos hablar de un CDO 2.0 o ‘diplomático del dato’ como mediador entre IT y negocio en un entorno marcado por una mayor regulación, más expectativas en cuanto a valor añadido proporcionado por los datos y con una falta de talento cualificado”. Asimismo, hubo tiempo para vislumbrar lo que podemos esperar el CDO 3.0, “si bien algunos de sus retos ya se están produciendo”, matiza Hernández. “El CDO 3.0 o ‘estratega del dato’ tiene como misión de llevar la cultura del dato a todos los rincones de la organización, que el dato esté detrás de toda decisión estratégica, mediante una gobernanza sólida, la implementación del data ethics y el despliegue de nuevas tecnologías”. Estamos transitando, por tanto, de un escenario de evangelización y divulgación a uno de negociación, para acabar llegando al centro de la toma de decisiones estratégicas dentro de la empresa. La evolución es patente, pero los retos, también. “Sin duda, hay muchas más compañías con CDO hoy que hace 5 años, pero en muchos casos, su figura no ha evolucionado lo suficiente. Muchos profesionales aún tienen un perfil marcadamente técnico propio del ‘caballero del dato’, que lucha por la calidad de la información y es impulsado o frenado en función de la necesidad de los proyectos”, concluyó Hernández. Según Lluis Esteban, CDO de CaixaBank, “efectivamente, estamos afrontando nuevos retos más relacionados con negocio, y menos con tecnología: valor y monetización, regulación... Por ello, tenemos que cruzar la barrera del tecnicismo, ir más allá, dejando atrás silos de información y compartir y colaborar con un enfoque de producto. Dejar de hablar del dato de marketing o finanzas para hablar del dato a secas de la compañía. Fomentar el ímpetu creativo y despertar el interés de las distintas áreas de negocio para que aprendan a usar los datos”. En este sentido, Esteban destacó que “el CEO debe preocuparse por saber de dónde proceden los insights que impulsan su negocio. Y, cuando se preocupe, debe contar con la seguridad de que los datos son de calidad. En otras palabras, debemos ser capaces de hacer ver a la alta dirección la aportación del CDO. Y, para ello, debemos promover los servicios que busquen proporcionar el máximo valor añadido posible. Parece obvio, pero aún es difícil de entender en España, si bien ya se tiene más curiosidad por el ROI y los KPI, los niveles de satisfacción y la eficiencia”. Esteban señaló otro reto acuciante: “debemos repensar nuestras estructuras organizativas, algo de capital importancia en un contexto marcado por la falta de recursos y la dispersión de herramientas. Las empresas deben hablar un mismo lenguaje y tener clara la definición de los conceptos básicos”. “La alta dirección debe preocuparse por saber de dónde proceden los insights que impulsan su negocio. Para ello, debemos promover los servicios que busquen proporcionar el máximo valor añadido posible” Esta unificación de procesos y herramientas es especialmente importante si la empresa afronta problemas para encontrar y retener el talento. Para abordar este otro desafío, deben motivar a los empleados con proyectos interesantes, más allá de una retribución atractiva. Asimismo, tal y como apuntó Esteban, algunos de los retos del CDO 3.0 ya se están produciendo. “Por ejemplo, el desarrollo tecnológico está propiciando que ya no hablemos solo de visualización de información, sino de un consumo más amplio que puede pasar por la conversación y la búsqueda por voz. En resumidas cuentas, de lo que hablamos es de democratización de la información, y esto va a cambiar la manera en la que trabajamos, nos comunicamos y colaboramos”. ¿QUÉ LE ESPERA AL CDO EN LOS PRÓXIMOS AÑOS? (II) Muchas empresas ya cuentan con un CDO, pero la mayoría aún no ha desarrollado prácticas consolidadas de gestión del dato. Si bien el número de Chief Data Officers crece progresivamente, muchas organizaciones aún no relacionan el dato y su análisis como un elemento clave para el desempeño económico de la organización. Los datos aún no se reconocen de facto como un activo empresarial, pero se están comenzando a implementar estrategias de monetización, que serán más comunes a medida que las empresas comprendan la importancia de ser data driven. Post escrito por el Club Chief Data Officer Spain
13 de mayo de 2019

Las Matemáticas del Machine Learning: Ejemplos de Regresión Lineal (II) y Multilineal
En el anterior artículo vimos el concepto de recta de Regresión Lineal , y cómo obtener sus parámetros o coeficientes estadísticos. Vamos a ver ahora un ejemplo práctico donde podemos aplicarla. 1. Regresión lineal: La siguiente tabla muestra el índice de mortalidad (Y) y el consumo medio diario de cigarrillos (X) para poblaciones distintas: Figura 1: tabla de datos mortalidad por consumo tabaco. ¿Qué índice de mortalidad se podría predecir para una población que consume una media de 32 cigarrillos diarios? Buscamos nuestra expresión, Y=b0 + b1X, para ello necesitaremos calcular b0 y b1, para calcular nuestros coeficientes estadísticos obtendremos las medias, varianzas y covarianzas muestrales: Figura 2: Medias, varianzas y covarianzas muestrales. Por lo tanto, nuestra recta de regresión queda determinada por la siguiente ecuación: Figura 3: Ecuación de la recta de regresión. Veamos el coeficiente de correlación, para determinar la “proximidad” de nuestra recta: Figura 4: Coeficiente de correlación. Es un valor muy próximo a 1, por lo que la dependencia de las variables es muy directa: A mayor consumo medio diario de cigarrillos diarios, mayor índice de mortalidad. Por último calculemos el índice mortal de nuestra población: Figura 5: Índice de mortalidad. 2. Regresión Multilineal: Hasta ahora hemos considerado el método lineal, es decir, una variable dependiente y otra independiente, pero ¿qué pasaría si encontramos que una variable depende de más de una variable? Pues bien, cuando tenemos una extensión del modelo lineal, es decir, cuando tenemos más de una variable independiente o explicativa, estaremos hablando del modelo de Regresión Lineal Múltiple, o Multilineal. Nuestro modelo sigue de la siguiente relación entre las variables explicativas o independientes (x1,x2,x3,…xn) y la variable respuesta o dependiente (y): Figura 6: Fórmula de regresión multivariable. Donde ϵi, sigue una distribución Normal N(0 , σ^2 ), es el error de observación, β0 es el término independiente. Es el valor esperado de y cuando x1,…,xp son cero, βi mide el cambio en y por cada cambio unitario en xi, manteniendo el resto de variables constantes. ¿Qué información muestral tenemos? Figura 7: Información muestral. Por lo que el valor que el modelo estimado predice para la observación i-ésima es: Figura 8: Valor estimado para la observación i-ésima. Y el error cometido en nuestra predicción será: Figura 9: Error en la predicción. Donde: Figura 10: Valores estimados. nos muestra los valores estimados del modelo. El criterio de mínimos cuadrados asignado valores a nuestros valores estimados, tales que minimiza el valor de la suma de los errores al cuadrado de las observaciones. Podemos plantear el modelo en forma matricial de la siguiente forma: Figura 11: Ecuación matricial. o bien: Figura 12: Ecuación matricial extendida. Para estimar el vector de parámetros β, aplicaremos el método de mínimos cuadrados de manera análoga al modelo lineal simple. El criterio de mínimos cuadrados asigna a los parámetros del modelo el valor que minimiza la suma de errores al cuadrado de todas las observaciones. Así pues sea S la suma de los errores al cuadrado: Figua 13: Ecuación cálculo suma errores cuadrados. Para calcular el mínimo de S, lo que hacemos es primero derivar S con respecto a los parámetros, luego igualar a cero cada derivada (quedándonos un sistema de ecuaciones en el que cada incógnita viene dada por los parámetros que queremos estimar), y por último resolver el sistema de ecuaciones. En términos matriciales: Figura 14: Cálculo de la derivada de S respecto a los parámetros. Siendo X^T la matriz traspuesta e igualando a 0 obtenemos: Figura 14: Valores de los parámetros que minimizan S. Ejemplo: Veamos a continuación un ejemplo de un estudio sobre la abundancia (Recuento) de un parásito en 15 localizaciones diferentes en función de su temperatura y la humedad. Los datos obtenidos son los siguientes: Figura 15: Tabla de datos sobre presencia de un parásito según CC temperatura/humedad. Figura 16: Representación gráfica de la tabla anterior. Al parecer tanto la temperatura como la humedad influyen en el recuento: Figura 17: Aplicación de la fórmula de regresión multilineal. Sean: Figura 18: Expresión matricial. Si aplicamos los cálculos anteriores obtenemos: Figura 19: Valores obtenidos. En el siguiente artículo, veremos qué conclusiones obtenemos a partir de la muestra, así como la coolinealidad de las variables independientes y cómo estas pueden afectar a nuestro modelo. Por último hablaremos de los contrastes de hipótesis y de los intervalos de confianza. Esto es todo por hoy ;), hasta el próximo capítulo de nuestra serie de las Matemáticas del Machine Learning. Cualquier duda podéis publicarla como comentario en este mismo artículo. No te pierdas los artículos anteriores: Las Matemáticas del Machine Learning ¿Qué debo saber? Las Matemáticas del Machine Learning: explicando la Regresión Lineal (I) Escrito por Fran Fenoll (@ffenoll16), Fran Ramírez (@cyberhadesblog y @cybercaronte) y Enrique Blanco (@eblanco_h) ambos del equipo de Ideas Locas CDO de Telefónica.
25 de abril de 2019

Innovación constante: la fórmula para competir en la economía analítica
Post escrito por el Club Chief Data Officer Spain Pocos discuten ya el papel del dato y la analítica como elemento transformador de las organizaciones. Su auge ha supuesto la popularización de conceptos como la transformación digital, el data ethics, cultura data driven, inteligencia aumentada etc. Pero como señaló en su ponencia Mariola Lobato, Executive Partner de Gartner, muchas empresas no saben relacionarlos. “ Era necesario identificar una nueva mentalidad digital que relacione distintas maneras de trabajar. Porque, sin ambición digital, las empresas solo tienen una colección de proyectos y la digitalización se queda en una simple mejora de sus servicios, pero no una transformación. Y es que la digitalización es ambas: mejorar e innovar. Por eso creímos necesario acuñar un nuevo concepto de mentalidad 100% digital, lo que conocemos como ContinuousNext”. Para Lobato, la digitalización “no es un asunto tecnológico, sino cultural. Por eso, los CDO deben sentirse parte del área de negocio tanto como de IT”, recomienda la experta. “ Cuando un directivo quiere utilizar datos, la primera pregunta que debe plantearle el CDO es ¿para qué?”. Pensar de manera estratégica es esencial, teniendo siempre en mente la monetización del dato y situando la tecnología al servicio del negocio, y no al revés. “Tradicionalmente, los departamentos de IT se han caracterizado por realizar tareas se soporte, pero deben reivindicar su papel estratégico y facilitador de optimización del negocio”. La experta de Gartner hizo un repaso a algunas de las principales tendencias del sector durante los últimos años: “En 2014 hablamos mucho de automatización. En 2016, de algoritmos. En 2017, los ecosistemas digitales, como herramientas de colaboración, cobraron protagonismo. 2019 será el año de lo que en Gartner hemos definido como ContinuousNext, una mentalidad que destaca por la capacidad de innovación constante y la incorporación progresiva de nuevos conceptos, como el data ethics o la inteligencia aumentada, dentro de un mismo universo”. Esta nueva manera de pensar es que las empresas analógicas sean capaces de desarrollar su ‘gemelo digital’. En España”, señala Lobato, “ya hay buenos ejemplos de organizaciones que han desarrollado exitosamente su gemelo digital, como el caso de uno de los mayores puertos del país, hoy segundo de Europa, introduciendo un proceso de innovación escalable”. “Cerca de la mitad de los CIO considera que la cultura es la principal barrera para desarrollar un modelo de empresa data driven” Este año, hemos sido testigos de importantes caídas en bolsa en determinadas empresas por no ser capaces de gestionar la privacidad de sus usuarios correctamente. La relevancia de las temáticas en torno al dato varía y evoluciona en función de hitos como este. Años atrás, los clientes regalaban sus datos porque desconocían su valor, mientras que ahora son más cautos. Hoy, un gran porcentaje de profesionales cree que la inteligencia artificial supone una amenaza directa para su trabajo, pero quien le ha podido sacar partido sabe que le ayudará a trabajar mejor. En este contexto de cambio, una de las temáticas protagonistas es la cultura corporativa. El CDO sabe que es importante, pero aún pocos directivos comparten su preocupación. Según Lobato, “es posible realizar grandes avances si se introducen ‘hackeos’ culturales. Por ejemplo, es esencial que en las reuniones de IT se hable más de negocio, y menos de tecnología. Ese es un gran cambio cultural y una señal de que las cosas funcionan. Contar con un CEO innovador también es de ayuda y, sin duda, es importante crear una cultura del “Sí”, que premie el probar y experimentar, generar ideas y participar. Esto es importante para que pasemos de realizar proyectos a productos: los top performers entienden que se trata de entregar resultados, no herramientas. El dato debe estar al servicio del negocio para ser útil”. “Es importante que los CDO hablen más de producto. Que empiecen los proyectos hablando de negocio y que los terminen ofreciendo resultados” Volviendo con el ejemplo del puerto español, sus gestores hacían frente a un sinfín de barreras para desplegar una cultura data driven, como la falta de habilidades digitales o la resistencia al cambio. Pero tenían un gran activo en forma de datos de tránsito y tráfico de visitantes. Simplemente explotando esos datos correctamente, ahorraron hasta 3 millones de euros en un año optimizando entradas y salidas. Y, redistribuyendo digitalmente su espacio, multiplicaron por 3 su capacidad de almacenamiento. Son dos proyectos que han abierto la vía a otras innovaciones y cuyo éxito ha dependido de la naturaleza innovadora del CIO. Con mente abierta, trasladó modelos de otros sectores como el retail y capacitó a su equipo para pensar en grande y crear nuevos productos de manera constante. Una cultura que facilite la creación es una cultura exitosa. Se trata de aquella que promueve la innovación y otorga autoridad para probar, equivocarse y que la organización se permita el error que, por otra parte, es inevitable. Pero también es importante, tal y como concluyó Lobato, “que los CDO hablen más de producto. Que empiecen los proyectos hablando de negocio y que los terminen dando resultados de negocio”. El Club de Chief Data Officer Spain es la primera comunidad de CDOs en España. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
24 de abril de 2019

¿Cómo se mueven los trabajadores de Distrito Telefónica?
Telefónica opera en 17 países y tiene presencia en 24, sin embargo sus oficinas centrales se encuentran en Madrid, en un complejo empresarial llamado Distrito Telefónica. El complejo se compone de 140.000 metros cuadrados en los que trabajan cada día más de 13.000 personas entre visitantes y trabajadores. Pero, ¿cómo llegan los trabajadores en este complejo y desde dónde nos visitan? ¿Usan el transporte público o privado en su mayoría? ¿Cuáles son las horas pico de llegada y salida del recinto? Este tipo de cuestiones son muy relevantes a la hora de diseñar estrategias de movilidad sostenibles que reduzcan el impacto ambiental de los desplazamientos, a la vez que resulten convenientes para las personas. El área global de Medioambiente de Telefónica está diseñando un plan de movilidad sostenible para Distrito T. Los científicos de datos del área de Big Data de Telefónica Tech colaboraron con el mismo, aportando análisis de datos que arrojen conocimiento objetivo sobre cómo se desplazan a diario los trabajadores de Distrito Telefónica. Los datos en los que se basa el estudio representan el movimiento de personas hacia Distrito T durante mes de Noviembre de 2017, la gran mayoría siendo trabajadores ubicados en Distrito T. Todos los datos tienen un carácter anónimo y se han alojado en servidores propios de la empresa con los correspondientes controles de seguridad. Dichos datos provienen de tres fuentes distintas con una altísima calidad: por un lado de nuestra plataforma de datos de movilidad de Telefónica Tech, Smart Steps, por otro lado de un dataset del Consorcio de transportes de Madrid, compuesto por todos los eventos de paso de tarjeta por tornos en la red pública de transporte (bus, metro, tren de cercanías) que finalizan en la parada de metro Ronda de la Comunicación y por último de otro dataset del volumen agregado de accesos a Distrito, con el volumen diario de acceso de personal ajeno y propio a cualquiera de los edificios, así como al parking subterráneo. Volumetría de trayectos y dinámica horaria de llegada y salida de Distrito Telefónica Para este análisis utilizamos las tres fuentes de datos. Para la selección de trayectos en la plataforma Smart Steps se seleccionaron aquellos que durante el mes de noviembre de 2017 tuvieron destino en la zona sombreada en rojo de la figura. Figura 1: En Smart Steps se seleccionaron trayectos con destino en las áreas señaladas en rojo. El no poder hacer una delimitación exacta de la zona se debe a la topología de las celdas de telefonía móvil. Estimamos que el impacto es de un 6% de trayectos que fueron incluidos en el análisis pero que realmente no se dirigieron a Distrito, sino a zonas aledañas. El gráfico que integra volumetría trayectos de medidos por red móvil y metro desvela un número medio de 11.738 trayectos diarios (excluyendo festivos y puentes) de los cuales 1.750 fueron realizados en transporte público (referido a aquellos que usaron metro en el último tramo). Figura 2: Volumen de trayectos únicos según Smart Steps y Red Pública de transporte, Comparamos estos datos con las entradas registradas en la entrada a los edificios, cuya media diaria es de 11.102 usuarios (trabajadores), que constituiría el baseline real de afluencia. Figura 3: Usuarios únicos con entrada a un edificio de Distrito. Los datos de uso de parking arrojan una horquilla entre el 40% y el 47% de dicho base line, 20% se estima que acude en coche privado aparcando en superficie y el 19.5% usa el transporte público. Es decir, si analizamos los medios de transporte utilizados tenemos un conocimiento bastante preciso para un 86.5% del total de trabajadores. Es importante destacar que en el estudio no tiene en cuenta el impacto que haya podido suponer la apertura del nuevo parking subterráneo cercano a las plazas Este-Sur de Distrito T. Figura 4: Volumen de personas según medio de transporte utilizado. Otro aspecto que analizamos es la dinámica de horarios de entrada y salida, que impacta directamente en la congestión de la zona en torno a las horas punta. Análisis de origen y tiempos de desplazamiento. Dos factores esenciales a la hora de optar por un medio de transporte, y por tanto a considerar en la propuesta de alternativas más sostenibles, son la ubicación de la residencia del trabajador y el tiempo total de desplazamiento. Utilizando Smart Steps (trayectos inferidos a partir de los movimientos de líneas móviles), extrajimos las ubicaciones en toda la Comunidad de Madrid de donde partían los trayectos diarios con término en el área de Distrito. Seguidamente presentamos un mapa análogo, esta vez usando la volumetría de entradas registradas en la red de transporte público (bus, metro y cercanías) con final en la parada de metro Ronda de la Comunicación. Figura 5: Volumetría de entradas registradas en la red de transporte público con final en la parada Ronda de la Comunicación. En ambos mapas se observa coherencia respecto a las zonas con gran densidad de trayectos de origen (Noreste de la ciudad, eje central de Castellana y Alcobendas), pero al mismo tiempo observamos zonas de origen con gran volumen de trayectos que no tienen reflejo en transporte público, quizás por motivos de conveniencia en cuanto a tiempo de desplazamiento. En la siguiente figura (derecha) hemos marcado dichas zonas en línea punteada. Estas zonas serían idóneas para proponer el uso de coche compartido por situarse lejos de Distrito, tener una orientación radial, y existir pocas alternativas al vehículo privado. Los tiempos de desplazamiento en transporte público se pudieron medir con precisión al disponerse del tiempo transcurrido entre la validación del billete/abono y la salida por torno en la estación Ronda de la Comunicación. Sin embargo, la medición de tiempos en vehículo privado es más compleja. Por ello hemos recurrido al uso del API pública de Google Maps. Dicha API nos proporciona una estimación de tiempo de desplazamiento entre dos puntos a una hora determinada y un modo de transporte. Por ejemplo, en el caso de interrogar el tiempo de desplazamiento entre Chamartín y Distrito, nos devuelve una estimación de trayecto en coche entre 12 y 26 minutos. Figura 6: Estimación de la duración del trayecto usando Google Maps. Por otro lado, sí disponemos de un mapa interactivo propio de los tiempos de desplazamiento en transporte público. Dichos viajeros son de dos tipos: Multimodales: Aquellos que usan bus o cercanías y conmutan a la red de metro para llegar a Distrito T. Unimodales: Aquellos que realizan todo el trayecto hasta Distrito Telefónica en metro. El siguiente mapa ilustra la demanda de uso de las diferentes estaciones de metro, donde el tamaño del circulo y el color oscuro está asociado a mayor demanda. Figura 7: Demanda de uso de las estaciones de metro, mayor a mayor tamaño y color más oscuro. Claramente la estación de Chamartín es la más usada pero la mayoría de usuarios que llegan a Distrito a través de esta estación son de tipo multimodal (92.7%), es decir, de ubicaciones mucho más lejanas. Las estaciones que registran mayores tasas de multimodalidad, son Chamartín (92.7%), Príncipe Pio (76%), Conde de Casal (62%), Moncloa (53%) y Nuevos Ministerios (42%). Esta consideración es relevante debido a las diferencias significativas de tiempos de desplazamiento entre usuarios de tipo multimodal frente a los unimodales. En el caso de Chamartín, los usuarios multimodales emplean un tiempo medio de desplazamiento de 61 minutos frente a los 22 que emplea un usuario de metro. Figura 8: Porcentaje de uso multimodal de la estación. A continuación, obtuvimos un mapa de tiempo medio de desplazamiento en transporte público a nivel de código postal, que puede ser orientativo para aquellas personas que se planteen usar este modo de transporte: Figura 9: Duración media de trayecto en metro por código postal. Además, obtuvimos una versión granular (en la rejilla hexagonal) del tiempo de desplazamiento en transporte público Figura 10: Tiempo de desplazamiento en minutos, metro y multimodal. Si comparamos este mapa con el obtenido a través de las estimaciones de Google sobre desplazamiento en coche, obtenemos un nuevo mapa en el que identificamos las zonas según la diferencia de tiempos frente al transporte público. Verde: El desplazamiento en transporte público supone una demora de hasta 10 minutos respecto al transporte en coche. Verde claro: El desplazamiento en transporte público supone una demora de hasta 20 minutos respecto al transporte en coche. Naranja: El desplazamiento en transporte público supone una demora de hasta 30 minutos respecto al transporte en coche. Rojo: El desplazamiento en transporte público supone una demora de más de 30 minutos respecto al transporte en coche. Figura 11: Intervalos de diferencia en minutos: transporte público versus coche. Como conclusión, podemos destacar a la hora de recomendar usar transporte público o privado para llegar a Distrito lo siguiente: todas las zonas marcadas en verde (especialmente aquellas en verde oscuro) serían las más recomendables para plantear el uso de transporte publico frente al privado ya que no suponen una demora significativa de tiempo y presenta numerosas ventajas (sostenibilidad, impacto ambiental, economía, etc.) Esperamos que os haya resultado interesante el estudio y os animamos a seguir nuestro blog para conocer más historias detrás de los datos.
23 de abril de 2019

DataOps: Del laboratorio a producción de manera ágil
Hace un año, en uno de los workshops tecnológicos que solemos hacer con nuestros clientes, salió a colación la estrategia para implantar advanced analytics. Este cliente ya estaba realizando desarrollos, probando casos de uso y percibiendo un retorno en la inversión realizada. En este caso, nuestro cliente ya había contratado a un equipo de data scientists con una formación y experiencia en matemáticas o estadística, y había empezado a desarrollar los primeros modelos analíticos con Python y R. La principal dificultad a la que se enfrentaba era al intentar pasar a producción los modelos que estaba desarrollando. Le estaba costando alcanzar una velocidad equiparable a la que solía tener un proyecto de desarrollo tradicional. Este es un ejemplo más de los que demuestran que los proyectos de analytics en las grandes empresas tienen un grado de complejidad añadido: tienen una organización y una arquitectura tecnológica bien definida, pero adaptada a los proyectos de desarrollo de software tradicional. En el siguiente gráfico podemos ver el ciclo de vida habitual de un proyecto de analytics: Figura 1: Analytics Lifecycle. Analytics Life Cycle En este ciclo de vida, los equipos de analytics se encuentran con los siguientes retos: Tienen una gran dependencia de los equipos de analistas de datos, al ser estas personas las que conocen dónde está el origen de la información necesaria para desarrollar modelos analíticos No tienen conocimiento de las herramientas tradicionalmente utilizadas para desarrollar aplicaciones en las arquitecturas empresariales, por lo que, a la hora de desplegar estos modelos en una aplicación, surgen problemas de compatibilidad. No tienen las herramientas para monitorizar el rendimiento de los modelos analíticos ni para detectar posibles degradaciones en su funcionamiento. Para poder ayudar a afrontar estos retos, surgió hace tiempo el concepto de DataOps. Primero fue definido por Gartner, un cambio cultural derivado de DevOps, pero centrado en el dato. Más adelante, surgió el Manifiesto DataOps, en el que se incluye también el proceso de desarrollo de aplicaciones analíticas. A partir de este manifiesto, es posible definir un marco de trabajo conceptual con las piezas necesarias para poder agilizar y reducir el time to market de los proyectos de analítica avanzada. Estos componentes pueden ser las herramientas y metodologías necesarias que tendrían que existir en cualquier compañía para disponer de un ciclo de vida de analytics ágil y completamente automatizado. Este ejercicio permite disponer una visión end-to-end que permita definir la estrategia de implantación de analytics dentro de una gran compañía, evaluando el estado actual, y decidiendo qué componentes evolucionar o implantar para conseguir este objetivo. Figura 2: DataOps Framework. Los proyectos de analítica avanzada están demostrando retorno de inversión y aportado de manera incremental valor a negocio. Va a ser necesario gestionar cada vez más aplicaciones productivas que contengan modelos analíticos, por lo que agilizar y automatizar lo máximo posible este tipo de desarrollos será una prioridad en todas las empresas. Una estrategia DataOps es el driver necesario para conseguirlo. Por Angel Llosa Guillen, Digital Architecture Manager en everis Visita la web del Club en este enlace: http://clubcdo.com/ y puedes contactar para más información en clubcdospain@outlook.es
16 de abril de 2019

Runnig y Big Data en la Movistar Media Maratón de Madrid 2019
Vive el running como nunca, en el Medio Maratón más multitudinario, espectacular y conectado de España, gracias a la tecnología IoT de Telefónica y LUCA. Conoce cuáles cómo se pueden utilizar las analíticas avanzadas Big Data para la mejora del rendimiento de los deportistas. El próximo 7 de abril llega la XIX edición del “Movistar Medio Maratón de Madrid”, organizada por la Agrupación Deportiva Marathon, Atresmedia y Motorpress ibérica organizan, junto con la colaboración del Excmo. Ayuntamiento de Madrid, con salida y llegada en el Paseo del Prado. Abierto a todas las personas que lo deseen, mayores de edad, estén federadas o no y sin distinción de sexo o nacionalidad, siempre y cuando estén correctamente inscritas, tanto en tiempo como en forma. También se celebrará, sobre el mismo trazado del medio maratón, la modalidad de discapacitados en silla de ruedas. Entre el Movistar Medio Maratón de Madrid y la carrera solidaria de 5 km ProFuturo, unos 20.000 corredores tomarán parte de esta gran cita del deporte el domingo a partir de las 9:00 AM. Entre los favoritos luchando por la victoria, tenemos a Javi Guerra y Azucena Díaz. Tecnología para los corredores Desde LUCA, se analizará toda la información de los corredores, que será de gran utilidad para estudios posteriores orientados a la mejora del rendimiento deportivo. Una carrera de lo más conectada, en la que el principal objetivo de Movistar es poner a disposición de los corredores todas sus capacidades tecnológicas. 5 Km de Carrera solidaria con ProFuturo Este año, la carrera 5K de la Media Maratón de Madrid volverá a ponerse el dorsal de Profuturo, en la IV Edición de la Carrera Profuturo. La nueva meta es lograr que los niños y niñas de Latinoamérica, África y Asia tengan acceso a una educación de calidad gracias al uso de las nuevas tecnologías. ¡Ayúdanos a favorecer la educación digital en los entornos más desfavorables!. ProFuturo es una iniciativa impulsada por Fundación Telefónica y Fundación Bancaria “la Caixa” que tiene como misión reducir la brecha educativa en el mundo proporcionando una educación digital de calidad a niños y niñas de entornos vulnerables de África, América Latina y Asia.
4 de abril de 2019

Generación automática de textos mediante Deep Learning
Las posibilidades que la aplicación de la Inteligencia Artificial ha traído consigo permiten el avance exponencial que estamos viviendo hoy en día en cuanto a sistemas de voz (asistentes virtuales, chabots, etc.). En este webinar hablamos sobre el potencial de utilizar la Inteligencia Artificial en tareas tales como la escritura automática de poemas o la predicción de la siguiente palabra que escribirás en tu teléfono. En este LUCA Talk hablamos sobre la creación de sistemas inteligentes que nos permitan entender y procesar aquello que, justamente, nos hace humanos - el lenguaje - es hoy más que nunca una realidad gracias al uso de técnicas como el Deep Learning. Más concretamente, el modelado del lenguaje, el procesado del lenguaje natural, permite asignar una probabilidad a una determinada secuencia de palabras. Carlos Rodríguez Abellán, Data Scientist en Aura, impartió el webinar sobre cómo crear, entrenar y probar algunos de estos modelos. Además, al final de la emisión dedicamos un espacio a la sesión Q&A con el experto para responder todas aquellas dudas y preguntas que surgieron y compartisteis a través del chat en directo. Compartimos en el blog algunas de las dudas que quedaron pendientes de contestar: ¿Cómo puede mejorar esto AutoKeras?, ¿Está suficientemente desarrollado para mejorar las decisiones de un data scientist? Entiendo que uno de los retos al afrontar este tipo de problemas es la elección del modelo y de los hiperparámetros asociados. "La elección del modelo, la elección de la arquitectura (si el modelo escogido es una red neuronal) y, por supuesto, la elección de los hiperparámetros óptimos son decisiones críticas a la hora de conseguir la mejor solución. En general, el ajuste de los hiperparámetros es una tarea compleja y laboriosa que, si atendemos solo a modelos de redes neuronales es, si cabe aún más laboriosa (decidir número de capas y de neuronas, tipo de capas, funciones de activación, etc.). Auto Keras, como software que asiste en la elección de muchos de estos hiperparámetros, es una gran herramienta para personas con no demasiado expertise en el mundo del Deep Learning. Pese a ser una herramienta muy potente - y con un potencial de evolución enorme a corto/medio plazo - mi opinión personal es que, dado un determinado reto, es más eficiente en cuanto a recursos (potencia de cómputo, de tiempo y mayor conocimiento de la solución) investigar cuál es el estado del arte para dicho reto e implementar las arquitecturas (o configuraciones de modelos) propuestas arrojará resultados muy similares a los obtenidos usand Auto Keras, si no mejores. Aunque esto es, por supuesto, mi opinión personal", comenta Carlos. ¿Hay un corpus de análisis de sentimiento Open Source? Reviews de Amazon: http://jmcauley.ucsd.edu/data/amazon/ Reviews de IMDB: http://ai.stanford.edu/~amaas/data/sentiment/ Tweets extraídos con su API: http://cs.stanford.edu/people/alecmgo/trainingandtestdata.zip Pero como imagino que preguntas por corpus en español, desgraciadamente los recursos disponibles en español son muchísimo más excasos (tanto de datasets como de modelos preentrenados). Te incluyo algunos ejemplos: Reviews de papers: https://archive.ics.uci.edu/ml/datasets/Paper+Reviews Reviews de Muchocine: http://www.lsi.us.es/~fermin/corpusCine.zip Tweets en español: http://www.sepln.org/workshops/tass/2012/corpus.php Una posibilidad es el uso de lexicons (como este de Kaggle). Pero, como verás, requieren de una revisión puesto que en general no son precisos y, posiblemente, no se adapten del todo al dominio sobre el que quieras entrenar el modelo. En cualquier caso son recursos muy útiles como punto de partida. ¿Conoces nuestros webinars? Visita la sección LUCA Talks en nuestra web
3 de abril de 2019

Debate Club CDO Spain: Poniendo el “Data” en el “Ethics”
Actualmente, tenemos más preguntas que respuestas. Ante la falta de un marco ético global que sirva de guía, el CDO debe ser consciente no solo del potencial beneficio de los datos, sino de todos los posibles efectos en terceros Asier Gochicoa, CDO de Grupo Kutxabank, señala un dilema que surge en este sentido: “No utilizar los datos para discriminar, por ejemplo, es especialmente desafiante en sectores como la banca, donde, para poder prestar un buen servicio con garantías, debemos estudiar muy bien índices de morosidad”. Como en cualquier otro campo de la actividad humana, debemos tener clara la diferencia entre ley y ética. No todo lo que es legal es moral y viceversa. En este sentido, Gochicoa advierte que “Es difícil de imaginar que todo el peso de lo que los CDO entendemos como data ethics llegue a las empresas: el GPDR obliga, la ética del dato, no (más allá del nivel personal)”. “El principal reto del CDO es cultural: como profesionales del dato, debemos llevar a cabo una gran labor pedagógica”. En cualquier caso, el análisis de datos y la IA, bien utilizados, conllevan más beneficios que riesgos. Proporcionan un contexto más detallado sobre los clientes. Pero, ¿qué sucede cuando escapan a nuestro control o entendimiento, cuando tratamos con los conocidos como algoritmos “de caja negra”? Según David Martín, CEO de Damavis, este es un claro ejemplo de la labor pedagogía que aún es necesario realizar: “Realmente, no son cajas negras. Debemos hacer entender que son funciones matemáticas que obedecen directrices lógicas. Su complejidad puede aumentar exponencialmente, pero si las reducimos a sus elementos más básicos, podemos explicar su comportamiento. Es difícil, pero no imposible”. Tenemos la responsabilidad de entrenar a los modelos de aprendizaje automático para que funcionen cada vez mejor. Puede ser que incurran en decisiones discriminatorias, como denegar el derecho de compra de personas en función de su nacionalidad, porque detecten muchos casos de fraude procedentes de determinado país, pero es una responsabilidad humana enseñar a la máquina a discernir. El modelo hace su trabajo (discriminar en base a datos), pero no debemos pedirle que desempeñe la labor de un humano: pensar de manera crítica. “Como CDO, hemos de establecer un protocolo que asegure la calidad de nuestros modelos, por ejemplo, poniéndolos a prueba en entornos acotados. Esto podría hacerse proporcionándoles una muestra real, pero sin llevar el resultado a producción. Como profesionales del dato, debemos velar para que los modelos imperfectos no lleguen a producción hasta que tengan determinada calidad”, indica Martín. Por su parte, Lipúzcoa indica que: “La abundancia de datos ha puesto de manifiesto que existen más dilemas de los que antes nos planteábamos. Para el CDO, el principal reto es cultural: debemos explicar estos dilemas, por qué existen y por qué debemos abordarlos. Por otro lado, debemos enfrentar la eficacia a la ética y encontrar un equilibrio adecuado entre ambas, definiendo modelos con incentivos y contrapesos”. Durante el debate, asimismo surgió la idea de que el problema de la ética del dato es, sobre todo, corporativo porque, si no hubiera “data”, ¿habría “ethics”? ¿Reflexionan lo suficiente las compañías sobre el impacto de sus acciones en la sociedad? Ya existían dilemas morales y comportamientos cuestionables. Ahora, simplemente, tenemos más datos y las compañías están más expuestas. Durante la discusión, Daniel Martínez, CDO de Caja Rural, se preguntó: “Si los datos son realmente discriminatorios. Los prejuicios humanos juegan un papel importante a la hora de definir un algoritmo de machine learning. Por tanto, debemos enseñar a tomar decisiones a la máquina y procurar que no ‘herede’ prejuicios inútiles y perjudiciales”. Por su parte, Francisco Escalona, Big Data Manager de Orange, destacó que: “En ocasiones, el big data también nos ayuda a eliminar viejos dilemas. Por ejemplo, si queremos evitar discriminar por zona residencial, por las posibles implicaciones sobre la renta que pudiera tener, hoy tenemos infinidad de datos de clientes que nos dan una visión más rica y complementaria que si utilizásemos solo el código postal, del que incluso podemos prescindir según qué casos. El big data nos ayuda a acertar más, a conocer mejor los matices del cliente y, por tanto, ser más eficaces a la hora de promocionar nuestra oferta comercial”. Juan Manuel López, como CDO de CUNEF, se enfrenta a retos muy particulares por el sector al que se dirige y a sus potenciales clientes, tanto alumnos como padres de alumnos. “Debemos, en cierto modo, discriminar para asegurarnos que aceptamos buenos estudiantes y que nuestra oferta es competitiva, ya que tenemos más demanda que oferta de plazas. Si no discriminásemos, ofreceríamos un mal servicio y una mala experiencia educativa. El análisis de datos y las técnicas de aprendizaje automático nos ayudan, ciertamente, a resolver problemas que ya teníamos, utilizando nuevas técnicas. Ahora, el dilema es ser transparente y explicar razonablemente nuestras decisiones a las personas afectadas, tanto alumnos como padres”. Las empresas toman muchas decisiones en base a datos diversos y deben ser capaces de explicar la razón de dichas decisiones a sus stakeholders. Por supuesto, el análisis de datos también conlleva nuevos retos que el CDO, como profesional, debe abordar: ¿estamos analizando los correctos? ¿tienen la calidad suficiente? Sin embargo, durante la discusión también quedó claro que no debemos perder la perspectiva de que, en el conjunto del amplio tejido empresarial español, gran parte compuesto de pymes, la mayor parte de las empresas carece de CDO. En otras palabras, el 90% de las empresas españolas no entiende la importancia de analizar datos, sus matices y terminología, cómo hacerlo y los riesgos e implicaciones asociadas. Sin cultura del dato, existe un gran problema por resolver. Para Carlos Zorita, director de tecnología de Ediciones Condé Nast: “La regulación europea ha supuesto un gran empuje para las empresas, para que nos esforcemos en adaptarnos a un nuevo marco y, a la vez, definirlo. En cualquier caso, dado que la ética no es global y depende en gran medida de la educación recibida, me atrevo a aventurar que encontraremos fricciones. Unos países son más laxos con la gestión del dato, en otros, directamente no preocupa y un tercer grupo es más estricto. No en vano, ya se han comenzado a aplicar las primeras grandes multas por incumplimiento del RGPD”. En opinión de Ángel Galán, responsable de Business Intelligence de Correos: “Estamos evolucionando como usuarios y entendiendo mejor el valor del consentimiento. En general, hemos tendido a recolectar datos en exceso (de padecer el ‘síndrome de la dispersión del data lake’) a solicitar su recogida para un uso concreto y claramente comunicado, lo que es un gran paso”. En este sentido, Martín matiza que: “Es importante defender que efectivamente no todas las empresas hacen un uso incorrecto de los datos. Muchas están haciendo una importante labor divulgativa, que sin duda es la clave. Es esencial comunicar claramente al usuario que, si nos permite X datos, podremos hacer Y con ellos”. Por tanto, el usuario también tiene su parte de responsabilidad: “Debe valorar qué le aporta una oferta comercial y si está dispuesto a proporcionar la contraprestación que supone. Últimamente, se escucha mucho aquello de que, si te ofrecen algo gratis, el servicio eres tú”. Daniel Martínez incide en este punto: “El principal reto es pedagógico. Una vez entendemos el impacto del dato en la empresa, sin duda debemos establecer ciertas líneas rojas, pero, en todo lo demás, hemos de fomentar el uso de los datos todo cuanto sea posible, porque sus beneficios son enormes”. En muchas ocasiones, la empresa percibe la regulación como algo costoso y que ralentiza el desarrollo del negocio. No obstante, puede ayudar a avanzar de manera ordenada. En este contexto, ¿cuál debe ser el papel del CDO? Para Javier Marqués, CDO de Grupo Generali España: “La respuesta es compleja, pero sin duda, podemos afirmar que es un rol muy cambiante, según la compañía de la que se trate. En algunas tiene más peso la gobernanza, en otras la analítica… No está definido al 100% para todos por igual. Lo que sí está claro es que su papel está muy ligado a la capacidad empresarial para extraer valor de los datos, con garantías y de manera correcta. El CDO no tiene por qué liderar todo el ciclo de vida del dato, puede compartir la carga. Máxime cuando el efecto, beneficios y desafíos asociados a los datos son transversales a todos los departamentos y, por tanto, la decisión ética está cada vez más colegiada”. ¿Estamos preparados para cumplir con la ética del dato? Gochicoa destaca que muchos sectores se han encontrado muchos más dilemas éticos en comparación con la industria del dato. Gil coincide: “Aún estamos definiendo la ética del dato. Primero debemos identificar y definir los problemas para poder abordarlos” Tras el debate, como era de esperar, surgieron pocas respuestas categóricas y muchas nuevas preguntas. Nos encontramos en una fase previa de descubrimiento. Por ello, es más importante mantener viva la curiosidad, para poder plantearnos nuevos dilemas que nos permitan avanzar. Post escrito por el Club Chief Data Officer Spain El Club de Chief Data Officer Spain es la comunidad de los CDOs en España y el próximo martes 2 de abril celebrará un nuevo evento en el que tratará acerca de Democratización de Datos y de cómo transicionar de un modelo de gestión y explotación del Data de soluciones artesanales a uno más escalable e industrializable. Visita la web del Club en este enlace: http://clubcdo.com/ y puedes contactar para más información en clubcdospain@outlook.es
28 de marzo de 2019

CDO busca talento: ¿Por qué no tú?
La unidad Chief Data Office de Telefónica, liderada por Chema Alonso, busca incorporar jóvenes con talento y ganas de afrontar nuevos retos profesionales a sus equipos en Madrid. Si te apasiona la tecnología, no dejes pasar esta oportunidad. En la actualidad, buscamos dos perfiles: QA Analyst: tu labor consistirá en coordinar el proyecto QA y el developer Test Framework. Definirás casos de uso a partir de requerimientos dados, desarrollarás test cases, y desarrollarás un QA continuous integration environment. En el siguiente vídeo, Elena Ruíz, Q&A en CDO te explica en qué consiste su trabajo. Si eres licenciad@ en Ingeniería en Informática o Telecomunicaciones, has trabajado con herramientas de QA y Testing, y tienes conocimientos de Python u otro lenguaje de programación, ¡esta oferta te interesa!. ¡ENVÍA TU CANDIDATURA! El segundo perfil que buscamos es Python Backend Developer (puedes ver la descripción aquí) En Telefónica te ofrecemos, no sólo 100 años de historia, y un equipo de 106 nacionalidades presente en más de 35 países. Te ofrecemos formar parte de un equipo de personas, cuya misión es "conectar personas, dondequiera que estén", liderar la revolución digital en todos nuestros negocios y crear el mejor ecosistema digital para nuestros clientes: red, IoT, nube, seguridad, innovación etc. Acompáñanos en el apasionante reto de construir la Telefónica del mañana. Para mantenerte al día con LUCA visita nuestra .
25 de marzo de 2019

Cómo desarrollar modelos que faciliten la toma de decisiones morales
Post escrito por el Club Chief Data Officer SpainUna aseguradora quiere obtener datos de velocidad de los conductores de una determinada marca de coches. ¿Es moralmente correcto que el fabricante venda esa información? Un banco puede identificar en tiempo real una compra en una farmacia y enviar un SMS al cliente diciendo: “¡recupérate pronto!” ¿Es invasivo? Una persona ha publicado un mensaje de odio en sus redes sociales, ¿debe usarse esa información en su contra en una entrevista de trabajo? Es posible crear modelos y marcos de trabajo que faciliten a los CDO la resolución de dilemas éticos como estos, cada vez más comunes. De hecho, ya existe una oferta comercial con ese propósito. Las más exitosas son las que más cerca están del CDO y de los problemas y situaciones concretos a los que se enfrentan las empresas. “ La cercanía a las decisiones es esencial para no crear herramientas excesivamente teóricas que los CDO no puedan utilizar en la práctica”, subrayó durante su ponencia Javier Ballesteros, consultor de la firma Management Solutions. La firma mostró un caso real durante la reunión del Club. Concretamente, cómo ING Direct ha podido definir un modelo de decisión sobre Data Ethics de la mano de su CDO, Fernando Lipúzcoa. “El GDPR no cubre todos los problemas, pero nos ha marcado una hoja ruta que seguir y, por tanto, nos permite avanzar. Al principio la clave es, sobre todo, saber quién ha de estar involucrado, a qué nivel y qué decisiones hay que tomar”. A la hora de elaborar un modelo de decisión como este, es muy útil realizarse muchas preguntas: cuál es el posible riesgo reputacional que estamos dispuestos a asumir, qué percepción puede llegar a tener el cliente, por qué queremos tomar una decisión o a quién puede afectar… Puede parecer una obviedad, pero es frecuente pasar por alto un análisis necesario cuando se trata de cuestiones que afectan a usos cotidianos, y aportar una metodología para su resolución de manera objetiva y consensuada con la organización. Figura 1: Data Ethics: uso responsable de los datos en distintos ámbitos para beneficio de la sociedad En una multinacional, la implementación de la ética del dato puede ser complicada por la diversidad de opciones y las distintas culturas implicadas. Según Fernando Lipúzcoa, CDO de ING en España y Portugal, “El reto es ‘picar’ a los miembros del equipo para que empiecen a plantearse sus propias preguntas. El proceso de autoevaluación y descubrimiento personal es muy importante; debemos aprender a identificar a nuestros stakeholders y a plantearnos nuevos dilemas”. En cifras: Menos del 20% de la población se siente cómodo compartiendo datos como búsquedas, ingresos, localización… A más del 75% le incomoda que los datos de sus compras se cedan a terceros El 63% considera que es intrusivo que un servicio de taxis compre datos de geolocalización para, por ejemplo, ofrecer trayectos cuando un viajero se baja del tren (Fuente: KMPG) El Club de Chief Data Officer Spain es la primera comunidad de CDOs en España. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
18 de marzo de 2019

Novedades del MWC2019:¿Conoces Movistar Living Apps?
¿Conoces Movistar Living Apps?. La semana pasada, en el marco del MWC2019, Chema Alonso presentó la línea de producto que, en un futuro próximo, enriquecerá la experiencia de consumo de los clientes Movistar en el hogar en colaboración con empresas tan importantes como El Corte Inglés, Atlético de Madrid, y Air Europa. Si quieres saber cómo, te lo explicamos en nuestro blog. ¿Qué son las Movistar Living Apps? Se trata de aplicaciones desarrolladas por terceros y posteriormente integradas en el Ecosistema Aura con el objetivo de mejorar la experiencia de consumo en el hogar de los clientes Movistar. Estas aplicaciones estarán accesibles a través del canal elegido por el cliente: televisión, Movistar Home o las aplicaciones móviles. Tan sencillo como decir "OK Aura" Los clientes que quieren disfrutar de esta nueva experiencia de consumo de servicios de ocio, entretenimiento o crear una lista de deseos, no tendrán más que decir "OK Aura". Así de fácil. ¿Cómo será esa experiencia en el futuro El Corte Inglés - "OK Aura, lo quiero" Movistar Living Apps te permitirá adquirir productos de El Corte Inglés relacionados con el contenido de Movistar+, y finalizar la compra con tu móvil. Atlético de Madrid - "OK Aura, quiero ceder mi abono” También, permitirá a los socios del Atlético de Madrid que además sean clientes de Movistar, ceder su abono a otra persona para que no quede ningún sitio vacío en el estadio. Air Europa - "OK Aura, quiero hacer el check-in" Y si vas a viajar con Air Europa, con Movistar Living Apps podrás hacer el check-in de un vuelo: seleccionar el asiento, agregar equipaje y enviar la tarjeta de embarque a tu teléfono móvil. Movistar Living Apps también te hará la vida más fácil con los productos y servicios Movistar Smart Wi-Fi - "OK Aura, quiero ver los dispositivos móviles conectados." A través de Aura, podrás controlar la televisión, ver qué dispositivos están conectados en el hogar o la lista de dispositivos en la red Wi-Fi. Movistar Cloud – "OK Aura, quiero ver mis fotos en Movistar Cloud." También, podrás ver en tu televisión todos los vídeos y fotos guardados en Movistar Cloud. Movistar Car - "OK Aura, ¿dónde está el coche?" ¿Tienes coche? Con Movistar Living Apps, podrás pedirle a Aura que te muestre la ruta que está haciendo el coche, o te envíe notificaciones periódicas sobre su estado. Descubre más en: aura.telefonica.com/movistarlivingapps
6 de marzo de 2019

Deep Learning, solo para pilotos profesionales
Escrito por Antonio Pita, Gerente Consulting & Analytics LUCA Si no todos los que cocinan son Chefs y los que conducen no son pilotos, ¿crees que trabajar con datos es suficiente para que alguien sea un Científico de Datos? Deep Learning es el último buzzword de moda en la Ciencia de Datos, impulsado por la proliferación de librerías (Tensorflow, Caffe, Keras, H2O, …) que ponen al alcance de nuestra mano estos potentes algoritmos para entrenar modelos de Deep Learning Podemos entender el Deep Learning con la siguiente analogía para evitar caer en el agujero negro de la moda y la ilusión que suponen estos modelos: “El Deep Learning es elegante y potente como un Ferrari. Pero ¿qué pasa cuando le dejamos un Ferrari a alguien de 17 años? Probablemente se estampe en la primera curva, aunque la sensación de velocidad en la primera recta es impresionante. En mi opinión, los Ferraris (modelos de Deep Learning) deben utilizarse por dos tipologías de personas: los pilotos profesionales en las carreras más exigentes o por pilotos veteranos que van a utilizarlos para lucir palmito a 80 km/h. Un Ferrari no es siempre la mejor alternativa para desplazarse y su elegancia y potencia no suelen justificar su alto precio. De la misma manera los algoritmos de Deep Learning no son los más apropiados para la mayoría de los problemas y su complejidad y necesidad de información no justifica su uso en la mayoría de los casos.” Pero, ¿qué es el Deep Learning? El Deep Learning es un subconjunto de modelos de Redes Neuronales que tratan de aprovechar los entornos distribuidos para poder entrenar Redes Neuronales muy complejas imitando el cerebro humano. En este sentido, las redes neuronales están conformadas por neuronas que se relacionan entre sí para poder llegar a una conclusión. Esta puede ser determinar si en una foto aparece un gato, a qué número corresponde un grafismo o si un cliente abandonará la compañía. Si tratamos de entender qué es una red neuronal sencilla, tenemos que comprender cuáles son sus elementos, las neuronas. Una neurona no es más que un decisor, que recibe varios inputs y los transforma en un output. En el caso del ejemplo del gato, podemos tener decisores que respondan sí o no a las siguientes preguntas: ¿aparecen ojos (en la foto)?, ¿las orejas son puntiagudas?, etc. La combinación de estos decisores junto con otros más complejos, permite predecir si en la foto aparece un gato o no. En teoría es muy potente, pero para poder entrenar/enseñar a una neurona, se necesita una cantidad ingente de datos, de los que normalmente no se dispone. Este suele ser el mayor reto a la hora de utilizar redes neuronales. En uno de los Máster en los que doy clase les pido a los alumnos hacer un modelo de predicción de contratación para un producto financiero. Normalmente les recomiendo hacerlo con modelos sencillos puesto que el objetivo es entender el uso del modelo y su puesta en valor en el negocio. Un alumno me consultó sobre un problema que estaba teniendo, quería explorar modelos más complejos de redes neuronales para tratar de obtener un modelo más fiable. Cuando entrenaba el modelo encontraba patrones inimaginables que le permitían clasificar de forma correcta prácticamente todos los casos de entrenamiento, sin embargo, al ponerlo a trabajar sobre datos nuevos no conseguía acertar de forma acorde. El alumno no sabía el porqué, además, había seguido todas las indicaciones que había encontrado en una página web sobre redes neuronales. Hicimos el siguiente ejercicio, le pregunté por el número de variables, 40, le pregunté por el tamaño de la red neuronal que había considerado. Se trataba de una red neuronal con 3 capas intermedias de 32, 32 y 16 neuronas y un decisor final. Prácticamente era una red neuronal de juguete. Nos pusimos a contar cuántos coeficientes tenía la red neuronal. Cada neurona de la primera capa tiene 40 inputs más el término independiente, por lo que en la primera capa tenemos 41*32=1.312 coeficientes, la segunda capa 33*32=1.056 coeficientes, la tercera capa 33*16= 528 coeficientes y la última capa 17 coeficientes, en total 2.913 coeficientes. Aquí, la pregunta clave es cuántos registros necesitas para poder entrenar una red de estas características que sea estable y sobre todo generalizable. Si consideramos una aproximación utilizando como número máximo de coeficiente la raíz cuadrada del número de registros (particularmente me parece muy optimista), necesitaríamos 8.485.569 registros de entrenamiento para poder entrenarla (repito, siendo muy optimistas). Muy lejos quedaban nuestros 900.000 registros totales. 9 millones de registros no son muchos, las empresas cuentan con bases de datos mucho más grandes, pero cuando hablamos de tablones de modelado, tener 9 millones de registros es una barbaridad que pocas compañías afrontan. Si cada registro representa a un cliente, una maquinaria, una línea de teléfono, un producto, etc, ¿quién tiene 9 millones de clientes (maquinarias, productos, etc.) a los que les vayas a plantear un modelo analítico? En España, se cuentan con los dedos de una mano. Sirva este ejemplo para mostrar la complejidad que puede tener una red neuronal y la necesidad de datos, incluso aquellas redes neuronales muy pequeñas. Si que es cierto, que se han desarrollado técnicas para poder lidiar con estos casos, pero requieren de un conocimiento muy avanzado en redes neuronales que no se consigue leyendo 2 páginas webs y copiando un código de github. Con esto último es muy sencillo “darle a una tecla” y obtener una red neuronal entrenada/enseñada. Otra cosa es si será generalizable, si extraerá conocimiento que nos ayude a mejorar nuestro negocio y si sabremos utilizarla. Pero esto lo dejamos para los pilotos profesionales, que para eso entrenan tantas horas al día. Como decíamos, para comprender las redes neuronales, la clave son las neuronas, las cuales tenemos que conocer perfectamente, al igual que el piloto profesional se preocupa no sólo de conducir sino en comprender la mecánica y los elementos que la componen. Para ello hay que comprender la neurona desde varios puntos de vista: Desde el punto de vista estadístico, la neurona es una distribución estadística que es combinación lineal de otras distribuciones a través de una función de link. Desde el punto de vista geométrico, la neurona es un hiperplano afín que permite separar o distanciar puntos en el espacio. Desde un punto de vista algebraico, la neurona es una aplicación sobreyectiva representada por una matriz de transición. Desde un punto de vista analítico/topológico es una aplicación continua que transforma las distancias. Gracias a los algoritmos recursivos que nos aporta la informática podemos enseñar a estas neuronas a tomar decisiones. Cada enfoque requiere un conocimiento profundo de las bases científicas, por lo que recomiendo encarecidamente que antes de conducir un Ferrari, aprendamos a gatear, andar, montar en bici y conducir, que no es lo mismo que pilotar. Más adelante, con la experiencia adecuada y el conocimiento consolidado, se podrá competir en carreras de velocidad.
26 de febrero de 2019

Open Data para entender la transformación de los barrios.
Cada vez es más común leer noticias y oir hablar sobre gentrificación de los barrios de las ciudades modernas. En este webinar tratamos este tema de actualidad que afecta a una gran parte de la población, centrándonos en las ciudades de Madrid y Nueva York donde hemos realizado un estudio para analizar la realidad de diferentes barrios en ambas ciudades. La gentrificación (proceso mediante el cual la población original de un sector o barrio, generalmente céntrico y popular, es progresivamente desplazada por otra de un nivel adquisitivo mayor) es un fenómeno que se está dando en muchas grandes ciudades, y aunque su existencia es evidente cuando se da, no existe un consenso sobre cuáles son sus causas. Es precisamente esta dificultad para acotar los ejes principales que la motivan, y para aislar los parámetros más relevantes para su desarrollo, lo que la convierten en una materia muy interesante para su consideración. Sin entrar en un estudio formal sobre la definición de lo que es la gentrificación, hemos aprovechado datos publicados por el Ayuntamiento de Madrid y por diferentes organismos de la ciudad de Nueva York para analizar la realidad de diferentes barrios en ambas ciudades. Hemos buscado relaciones entre actividades comerciales, magnitudes socioeconómicas y otros factores, para identificar algunos indicadores sólidos de transformación en los barrios. El trabajo comenzó de manera individual en la ciudad de Madrid, y gracias a la colaboración con la Universidad de Columbia se convirtió en un Capstone Project que desarrollaron un grupo de alumnos en Nueva York. [embed]https://youtu.be/gZN9ZAZ-NP0[/embed] Como en todos los webinars, al terminar la sesión dedicamos unos minutos a la sesión Q&A donde el ponente Luis Nadal, Senior Business Consultant en LUCA, contestó algunas de las preguntas que surgieron en el chat de la emisión. En el blog de hoy compartimos algunas de las preguntas que recibimos: ¿De cuándo son los datos de renta y de alquiler/m2 de Madrid? Los datos de renta y locales son del año 2017, y los datos de alquiler del año 2016. El dato de alquiler por metro cuadrado en Madrid exigió un proceso más elaborado para poderlo conseguir porque no hay datos públicos. El estudio se basó en datos que publicar el portal idealista.es, que publican sus informes, aunque hay que procesar los datos. ¿El modelo de clustering a Coney Island como High Gentrification? El modelo utilizado considera Coney Island como un barrio altamente gentrificado. Es cierto que no se corresponde con el análisis exploratorio realizado, pero son conclusiones que no se pueden llegar a extrapolar a otras ciudades. Y sí que existe un paralelismo entre los distritos en proceso de gentrificación y los que no. Se muestra una tendencia de que Coney Island puede tener una tendencia a la gentrificación. ¿Se podría aplicar el mismo modelo para dos ciudades del mismo país? Teóricamente se podría aplicar el modelo a otra ciudad, aunque debería analizarse muy detalladamente esta posibilidad y caso a caso. ¿Crees que se podría utilizar el mismo modelo para ciudades, países con un mismo estilo o cultura o modo de vida? En principio se podría utilizar el mismo modelo, pero lo cierto es que, el “modo de vida” viene determinado por la realidad en esas ciudades. Pero lo que modifica más el poder trabajar con unos datos u otros es la propia recogida de esos datos. Aunque sean dos ciudades muy parecidas (mismo país o región, por ejemplo), si los datos disponibles no son equiparables, no se va a poder utilizar el mismo modelo. Es muy posible que se llegue a conclusiones muy parecidas, pero no se podría replicar el modelo para aplicarlo en otra ciudad. ¿El modelo entonces no es extrapolable en NY?, ¿Qué variables encontraron similares en NY vs MAD? Efectivamente, el estudio no llevó a un modelo extrapolable. No al menos en el desarrollo, que no deja de ser limitado en el tiempo. Si se pudiera seguir procesando y desarrollando el estudio, probablemente se podría llegar a algo que, al tratarse de variables normalizadas, podría extrapolar. ¿Se puede acceder al estudio de Nueva York? Por ahora no es posible acceder al estudio de Nueva York. Esperamos poder publicar algún whitepaper al respecto próximamente. ¿Qué herramienta habéis utilizado para realizar el clustering? El clustering se realizó tanto por K-Means como por Agrupamiento Jerárquico, obteniéndose los mejores resultados con este último, aunque las diferencias fueron pequeñas. ¿Por qué no usasteis la estructura de población?, Los barrios más envejecidos pueden tener más riego de sufrir gentrificación, ¿no? En Nueva York sí se emplearon datos demográficos, en el clustering se tuvo en cuenta, aunque el estudio posterior sobre las variables más relevantes no lo resaltó como una de las componentes principales. Aunque no siempre mayor edad significa más vulnerabilidad, estoy de acuerdo en que es una variable muy interesante a monitorizar para detectar movimientos. ¿Podrias facilitarnos los links o accesos a fuentes de opendata? Para Madrid, como os comentaba, la fuente principal utilizada fue https://datos.madrid.es En Nueva York se utilizaron conjuntos de datos de diversas fuentes, como pudieron ser: Oficina del censo: https://usa.ipums.org/usa/ Portal de datos abiertos de la ciudad de Nueva York: https://opendata.cityofnewyork.us/ Departamento de Finanzas del ayuntamiento de NY: http://www.nyc.gov/finance Comisión del Taxi de la ciudad de Nueva York: http://www.nyc.gov/tlc ¿No se podría inferir con otros datos como las pernoctaciones, su precio y las duraciones de las mismas en cada uno de los barrios? Efectivamente, este sería un análisis super interesante, sin embargo no es nada fácil conseguir información al respecto. En Madrid no fui capaz de encontrar nada relevante al respecto, y en Nueva York el modelo de alquiler vacacional está directamente prohibido desde el pasado verano (aunque parece que recientemente se ha bloqueado la ley). En cualquier caso, los propietarios de estos datos son los propios gestores de las plataformas (como Airbnb) y hasta la fecha no los han hecho accesibles. Estaría bien incluir datos y evolución de Apartamentos Turísticos Desde luego, en esto estamos completamente de acuerdo. En muchos casos, aunque podamos discutir si el florecimiento de los alojamientos turísticos es la raíz del problema o no, es innegable que su influencia sobre la evolución de los barrios y el estilo de vida que es posible desarrollar en ellos es evidente. Sin embargo, como comentaba antes, estos datos no son de dominio público, y precisamente porque es una actividad que no está adecuadamente regulada o porque directamente se hace fuera de la ley, no existen estadísticas públicas. Así, ahora mismo dependemos de la voluntad de las empresas que gestionan los alquileres turísticos para poder analizar sus datos. Siendo que este tipo de alquileres condicionan importantemente la vida de los barrios, es muy urgente regular la actividad (teniendo en cuenta a todos los interesados) precisamente para que no resulte transparente y no escape a los análisis que se puedan hacer. ¿Te has perdido alguno de nuestros webinars? Entra en la sección LUCA Talks de nuestra web y accede a todos los que quieras. ¡Hasta el próximo webinar! Para mantenerte al día con LUCA visita nuestra página web, y no olvides seguirnos en Twitter, LinkedIn y YouTube.
15 de febrero de 2019

Retos sociales y éticos de la Inteligencia Artificial
Post escrito por Elena Gil, CEO de LUCA para el Club Chief Data Officer Spain Hablar de ética del dato puede resultar vertiginoso. Los retos no han hecho más que aparecer y, por tanto, por el momento tenemos más interrogantes que respuestas. Existe mucha incertidumbre y cualquier ponente que exprese demasiada confianza en su conocimiento sobre el tema corre el riesgo de equivocarse. Sin embargo, Elena Gil, CEO de LUCA, está en una posición privilegiada para explorar los dilemas morales más comunes que nos puede plantear hoy el uso de los datos en la empresa. “Es importante que los CDO tengan la mente puesta no ya en los retos actuales, sino en los que están por venir”, destacó Gil. “Vivimos un momento muy especial por la integración de la inteligencia artificial (IA) -que, como sabemos, no es nueva, aunque esté de moda- con el big data. La mayor capacidad de gestión y almacenamiento de datos ha hecho posible esta combinación, dando una nueva vida a la IA”. Agilidad en la toma de decisiones, recomendaciones más afinadas, asistencia en tiempo real… La combinación de la IA y el big data están favoreciendo la rapidez de adopción de soluciones como estas. Dicha rapidez dependerá de del uso intensivo que cada sector haga de la IA, pero sin duda llegará a todos y cada uno de ellos. Figura 1: ¿Hacia dónde nos dirigimos an analítica?. Desde su incorporación a Telefónica, Gil ha sido testigo, en paralelo, de la evolución de la compañía y de la del mercado de los datos. “Almacenarlos y procesarlos ya no es tan costoso como hace unos años. Las empresas con un gran patrimonio en datos, como las de telecomunicaciones, tienen muchas más facilidades para monetizarlos y darles nuevos usos. El big data, simplemente, ha transformado radicalmente la visión que tenemos de los clientes: podemos segmentar mejor y ofrecer mejores servicios. Conocer con más detalle a nuestros clientes”. “Tradicionalmente, hemos usado más tecnología en casa que en la oficina, pero el análisis de datos, la IA y los dilemas que conllevan son una realidad en la empresa. Hemos pasado rápidamente de la ciencia ficción a la realidad empresarial”. La transformación de Telefónica ha sido una historia de exploración. “Cuando el big data no era una moda había un gran camino que recorrer en cuanto a su divulgación. Incluso hoy, ese reto permanece. Debemos demostrar su valor, dar razones y hechos para apostar por ello, mostrando casos de uso práctico. Hacer pedagogía y la democratización del dato son dos tareas más importantes que nunca, hay que hacer entender que big data no es cualquier Excel un poco largo. El CDO debe estar más cerca que nunca de la alta dirección, debe reportar directamente”. En opinión de Gil, estamos avanzando hacia una nueva etapa, la del poder cognitivo. El uso de la IA no solo transformará las operaciones de las compañías, pero hay que tener en cuenta que, a corto plazo, los retos éticos de la gestión del dato pueden llegar a definir el éxito o el fracaso de esta tecnología. De las numerosas áreas que se verán afectadas por la ética del dato, Gil destaca 4 por su urgencia e impacto inmediatos: privacidad, discriminación, responsabilidad y transformación del entorno laboral. Hoy es más urgente que nunca reflexionar sobre ello porque, en este sentido, Gil destaca que “ya tomamos muchas decisiones sin saber que las estamos tomando. Uno de los ejemplos más conocidos que nos hace reflexionar sobre ello es la Moral Machine del MIT. Todos tenemos en mente el dilema sobre a quién debería atropellar un coche autónomo sin frenos en distintos escenarios moralmente desafiantes”. Figura 2: Moral Machine del MIT ¿Quién decide qué es correcto y qué no lo es cuando se trata de la gestión del dato? Esta pregunta es una de las primeras que puede surgirnos cuando abordamos la cuestión, y de las más complejas. La economía es global, pero la ética, no. Volviendo con el experimento del MIT como ejemplo, las respuestas varían en función de las culturas: la occidental favorece a los ciudadanos más jóvenes, mientras que la japonesa da preferencia a sus ancianos; otras, como las nórdicas, son más neutras y respetuosas con la ley (¿cruzó el peatón con el semáforo en rojo?). No existe un marco ético global y estándar para todos los países, por lo que navegar en las turbulentas aguas de las “zonas grises” es especialmente desafiante para las grandes empresas. No obstante, los marcos regulatorios facilitarán la toma de decisiones y proporcionarán un compás moral a las empresas. “Los informes de las consultoras indican que generaremos un volumen de negocio cercano a los 1,2 trillones de dólares gracias a la IA este año, una cifra que se multiplicará por 3 en 2020”. Por otro lado, ¿quién debe asumir la responsabilidad de las decisiones automatizadas? Ya existen ejemplos reales de aplicaciones punteras de la IA, pero para Gil, “cabe preguntarse si somos conscientes de los riesgos que asumimos”. Existe un acrónimo que está ayudando a definir algoritmos que respeten los valores morales más extendidos: FATE (justos, responsables, transparentes y éticos, por sus siglas en inglés). Asimismo, el impacto en el trabajo será notable, especialmente en el más repetitivo. Surgirán nuevos trabajos y otros puestos deberán reciclarse. Colaboraremos más con las máquinas, lo que abre nuevas preguntas: ¿tienen derechos las máquinas? ¿Deben pagar impuestos? Ya existen grupos de trabajo a distintos niveles que tratan de dilucidar (e identificar) cuestiones como estas. Una de las claves para avanzar, señala Gil, es “ asegurarnos de que cualquier avance en IA tenga un diseño responsable. Es decir, que en cada paso que demos, nos aseguremos de que no contradice nuestro marco ético”. El Club de Chief Data Officer Spain es la primera comunidad de CDOs en España. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
8 de febrero de 2019

Las mejores certificaciones profesionales en Big Data
Durante los últimos 10 años, hemos llegado a generar cantidades ingentes de datos. Tanto es así que se predice que para 2020 cada individuo llegará a generar 1,7 MB por segundo, lo que se traduce en 44 trillones de GB de datos en todo el mundo, lo que conocemos por Big Data. Teniendo en cuenta este escenario, no sorprende que los conocimientos y aptitudes en torno al Big Data se hayan convertido en competencias muy codiciadas en todos los sectores, por lo que formarse en este ámbito se ha vuelto muy recomendable para mejorar nuestra empleabilidad. En consonancia con lo rápido que crecen los datos, el número de certificaciones en Big Data y Data Science también aumenta día a día, y algunas están muy bien valoradas por los empleadores. Varias plataformas ofrecen estos diplomas: proveedores internacionales, instituciones educativas o incluso organismos de gobierno o independientes. A continuación, te ofrecemos algunas de las certificaciones más prestigiosas: Cursos de fabricantes EdX- Data Science Essentials Este curso, ofrecido por Microsoft, forma parte del Porgrama de Formación Profesional en Data Science. Se requiere tener un conocimiento básico previo en lenguajes de programación como R o Python. Durante el curso se desarrollan capacidades en probabilidad y estadística, visualización, exploración de datos y Machine Learning (a un nivel básico y utilizando Microsoft Azure Framework). El material del curso es gratuito, pero es necesario pagar 90$ para obtener el certificado oficial. IBM- Data Science Fundamentals El rebautizado portal online de IBM Cognitive Class ofrece un programa que cubre data science 101, metodología, programación en R y herramientas de código abierto. Se estima que se necesitan unas 20 horas para completar todos los apartados, dependiendo del nivel inicial de cada estudiante. Dataquest- Become a Data Scientist Dataquest, uno de los pocos proveedores de formación independientes, ofrece acceso gratuito a la mayoría de sus materiales, aunque existe la posibilidad de pagar por un servicio superior, que incluye tutorización de proyectos. Es una buena forma de comprobar si la Ciencia de Datos es lo tuyo o no, ya que ofrece tres diferentes itinerarios profesionales para elegir: data analyst, data scientist y data engineer. Coursera- Programa especializado en Ciencia de Datos Coursera es una de las plataformas que más tiempo lleva ofreciendo formación en Data Science. El programa, ofrecido por la Universidad Johns Hopkins, no es totalmente gratuito, pero existe la posibilidad de financiación para alumnos sin recursos. Se compone de 10 cursos y cubre los siguientes temas: procesamiento de lenguaje natural, análisis de conglomerados, programación en R y aplicaciones del Machine Learning. Además, se potencia la parte práctica y se anima a los alumnos a crear productos que puedan utilizarse para resolver problemas en la vida real. The Open Source Data Masters Este curso se compone de un conjunto de recursos gratuitos de acceso abierto. Se tratan temas como el procesamiento de lenguaje natural de la API de Twitter con Python, Hadoop MapReduce, SQL y n SQL y visualización de datos. Los alumnos que opten por esta formación podrán también desarrollar sus conocimientos en álgebra y estadística, muy necesario para entender los fundamentos de la Ciencia de Datos. Instituciones educativas Professional Certificate in Data Science por Harvard University Este programa cubre los principios clave de Data Science, como R o Machine Learning. Utiliza casos de la vida real para ayudar durante el proceso de aprendizaje y se divide en 9 cursos de inmersión. Es uno de los programas de máster online mejor valorados. El temario incluye, entre muchas otras materias, probabilidad, visualización, modelado de patrones, regresión lineal o Machine Learning. Program in Data Science and Statistics por MIT Compuesto por 5 cursos, este programa ayuda a comprender mejor los fundamentos de la Ciencia de Datos, la Estadística y el Machine Learning. También se adquieren conocimientos sobre análisis con Big Data y se aprenden a realizar predicciones basadas en datos a través de inferencia estadística y modelos probabilísticos. Si quieres seguir explorando, te dejamos una lista con más plataformas interesantes que también ofrecen estas certificaciones: AWS Certified Big Data – Specialty Certificaciones de macrodatos de Hortonworks Micro Focus Vertica MCSE: Data Management and Analytics Introduction to R for Data Science (Microsoft) EMC Data Science and Big Data Analytics Certifications Los post más interesantes de LUCA Data Speaks 2018 organizados por series y temáticas
1 de febrero de 2019

El CDO en la empresa española: ¿Tecnología o estrategia?
El Club Chief de Data Officers Spain es la primera comunidad de CDOs de España y en el debate celebrado en la sesión de septiembre pasado se celebró un debate para dar voz a todos los asistentes en el que intervino Ana Gadea, partner de la firma Management Solutions, que inició un debate sobre el lugar que ocupa el Chief Data Officer en la empresa española. Durante la discusión, quedó patente que la ubicación del CDO no está estandarizada actualmente, pero todo parece indicar a que pivotará desde posiciones más cercanas a IT a otras más estratégicas, próximas a la alta dirección. Este movimiento será natural a medida que la alta dirección pueda constatar, con casos reales, todo el potencial del análisis de datos para el desarrollo del negocio: Como reza el dicho, el camino se demuestra andando”, señala Juan Francisco Riesco, Director de Datos de Mutua Madrileña. “En las etapas iniciales, cuando la estrategia analítica no es aún lo suficientemente madura, es importante seleccionar un ámbito de actuación visible y sencillo para desarrollar casos de uso que demuestren el valor del dato , una opinión con la que coincide Manuel Ferro, CDO de Abanca, quien recomienda: Empezar con objetivos pequeños e ir creciendo de manera escalonada El CDO debe estar sentado en la misma mesa que el resto de tomadores de decisiones, a quienes facilita y debe facilitar su labor mediante el análisis y gobernanza del dato. Esto se debe a que, si bien su rol es tecnológico, su función tiene claras implicaciones para toda la empresa, una realidad que comprenden fácilmente las empresas data driven. En el caso de Inditex, según indica su Head of Data Office, Jesús Salceda, La cultura analítica siempre ha formado parte de nuestra empresa, que es lo más importante. Obviamente, a medida que una empresa crece y gestiona más datos, necesita incorporar nuevas herramientas que posibiliten esta tarea, pero lo que realmente marca la diferencia es el hecho de tomar conciencia de la importancia tomar decisiones en base al análisis de datos. El CDO, como principal impulsor de la cultura analítica, es también quien mayor visión posee para afrontar la gestión del cambio En otro punto del debate, Gadea planteó una duda relativa a la ubicación actual del CDO en el organigrama corporativo: ¿tiene sentido que esté ubicado en áreas de IT? En palabras de Pedro López-Montenegro, CDO de Banco Santander, Estar situado en el entorno de operaciones es algo natural, por el componente tecnológico del cargo, y tiene muchas ventajas, pues ayuda al CDO proporcionándole capacidad de acción y una visión transversal de la compañía. Pero "confinarle" en este área también hace que el CDO pierda poder de negociación frente a la alta dirección. Su rol debe evolucionar para ganar poder de prescripción y ser capaz, en última instancia, de situar el dato como verdadero pilar estratégico de las empresas” Asimismo, durante el debate se destacó una habilidad actualmente muy relevante: la diplomacia y negociación corporativa. El CDO, como principal impulsor de la cultura analítica, es también quien mayor visión posee para afrontar la gestión del cambio. Por otra parte, su capacidad para demostrar el valor de los datos será útil a la hora implantar figuras de gobierno del dato definidas, una prioridad para eliminar posibles zonas grises, como las dudas sobre la responsabilidad sobre el control de calidad de la información, su protección y su arquitectura. La relevancia de la cultura Data Driven Para desarrollar una cultura Data Driven madura, es esencial conocer un lenguaje común, el lenguaje de los datos: todos los miembros del equipo deben moverse en el mismo terreno de juego porque: “El compromiso total de todos los miembros del equipo”, tal y como subraya Francisco Escalona, Big Data Manager de Orange, es muy importante. Según Riesco, “Evangelizar cuesta mucho trabajo y para no menoscabar esta tarea es importante demostrar, mediante casos de uso sencillos, lo que la analítica puede hacer por la empresa”. De esta manera, como apunta David Martín, CDO & Big Data Architect de Damavis Studio, “Se podrán desplegar soluciones cada vez más complejas y útiles, como proyectos basados en machine learning para ofrecer análisis de datos avanzado en tiempo real”. Cada vez será más fácil demostrar a la alta dirección el potencial de la estrategia analítica y cómo puede mejorar el negocio. La clave es escoger un caso de uso sencillo y escalable para que, poco a poco, la analítica forme parte de la naturaleza de las organizaciones. Los datos formarán serán a las empresas lo que el aire es a las personas. Serán una parte esencial de cada proceso y se situarán en el centro de la toma de decisiones estratégicas. Esta realidad será más y más común y la gestión del dato evolucionará a medida que más miembros del equipo hablen su lenguaje. Infografía: El ADN de los CDO 47 años: es la edad media del CDO El 14% son mujeres Permanencia media en el cargo: 3 años El 56% de los CDO son incorporaciones externas para las compañías. De este porcentaje, la mitad procede del mismo sector. Solo un tercio de los CDO está al cargo tanto de la gobernanza del dato como de su análisis Infografía: El ADN de los CDOs (Russel Reynokds Associates) Post escrito por el Club Chief Data Officer Spain El Club de Chief Data Officer Spain es la primera comunidad de CDOs en España y el próximo martes 29 de Enero llevará a cabo un nuevo evento de formación y networking dónde se tratará el tema del rol del CDO 2.0 y las tendencias del 2019 en el área de Data y Analytics. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
21 de enero de 2019

Girls Inspire Tech #GIT2018: el laboratorio tecnológico para hijas de empleados de Telefónica
Una sociedad, para poder competir en la economía global necesita potenciar las habilidades de sus ciudadanos y fomentar lo que se ha llamado carreras del futuro . Nos enfrentamos al hecho de que, aunque niñas y niños muestran las mismas competencias en matemáticas y ciencias, su actitud frente a estas y sus aspiraciones de futuro son muy diferentes. El informe The ABC of gender equality en education elaborado por la OCDE plantea que estas diferencias tienen su origen en características innatas de cada género, y al mismo tiempo de las disciplinas. Los prejuicios y estereotipos que acompañan a estas carreras deben ser combatidos. Desde Telefónica creemos que para crear tecnología hay que tener pasión por hacerlo, y no debe existir ninguna correlación entre género y ocupación. Por eso, el sábado 15 de diciembre celebramos el evento Girls Inspire Tech #GIT2018, una iniciativa liderada por las #MujeresHacker que trabajan en Telefónica. #MujeresHacker es una iniciativa de Telefónica que impulsa la diversidad y apoya el sueño de las niñas que desean ser programadoras, matemáticas e ingenieras, para que sean conscientes de su potencial. Ellas con nuestro apoyo definirán la tecnología del futuro. Gracias a las #MujeresHacker que trabajan en Aura, ElevenPaths, LUCA y la Cuarta Plataforma por inspirar a las más jóvenes en Girls Inspire Tech #GIT2018. También puedes seguirnos en Twitter, YouTube y LinkedIn
19 de diciembre de 2018

Creando un chatbot con Microsoft Bot Framework
Los chatbots cada vez son más populares y se están convirtiendo en herramientas importantes para las empresas de cara a la gestión de sus productos e iteración con sus usuarios. Como hemos hablado antes en el blog, los chatbots son una evolución necesaria pero no son nada nuevo, ¿sabías que en 1950, con el test de Turing, se teorizó por primera vez la posibilidad que una maquina se comunicara con un ser humano a través de texto? Es por eso que dedicamos nuestro último webinar del año a los chatbots. Hablamos sobre su historia, sus ventajas, y finalmente creamos uno. Para crear un chatbot, utilizamos Microsoft Bot Framework. Este incluye las herramientas Bot Builder, que nos ayudarán en el desarrollo de chatbots. Bot Builder es un SDK de código abierto compatible con .NET, Node.js y REST. Haciendo uso de este entorno de desarrollo, el cual destaca por su flexibilidad, creamos el bot en Node.js usando los frameworks Express y Restify. Comenzamos mostrando cómo realizar la instalación de Node.js, el Emulador de Bot Framework y continuamos con la creación de un chatbot sencillo, y finalmente cómo crear un chatbot para la previsión de la calidad del aire en Madrid. Si no pudiste verlo en directo te dejamos el LUCA Talk completo a continuación: https://youtu.be/TFc00raiGms Durante el webinar hubieron muchas dudas durante la sesión de Q&A, a continuación dejamos las preguntas que no nos dio tiempo a responder: ¿Usan Machine Learning los Chatbots para que vaya aprendiendo como responder en caso de tener una respuesta no parametrizada previamente pero similar a alguna establecida? ¿Si tengo un dataset con varias preguntas y sus respuestas es capaz de asimilarlas y encontrar patrones en estos para dar las mejores respuestas? La primera y la segunda pregunta se podría responder a la vez con lo siguiente: Para el procesado de lenguaje natural (NLP) se hace uso de LUIS, un servicio de API basado en algoritmos de aprendizaje automático personalizado a una conversación o un texto introducido por el usuario. LUIS aplica el modelo entrenado al texto en NLP para proporcionar reconocimiento inteligente sobre la entrada del usuario. LUIS devuelve una respuesta con formato JSON con la intención o intent principal con mayor puntuación. También puede extraer datos del texto facilitado. Podemos iniciar una aplicación de LUIS con un modelo de dominio creado previamente, crear el suyo propio o una combinación de ambos. Si queremos hacer un uso rápido de LUIS, podemos hacer uso de uno de los modelos de dominio creados previamente, entre los que se incluyen intenciones, expresiones y entidades. También podemos crear entidades personalizadas para identificar intenciones y entidades personalizadas, como las entidades de aprendizaje automático, las entidades específicas o literales y una combinación de aprendizaje automático y literal. ¿Se debería crear una red neural especializada en esto y que el bot framework la consuma para responder? No es necesario generar un modelo desde cero para el reconocimiento de lenguaje natural. Se podría hacer, sin ninguna duda, y así atacar al modelo entrenado desde nuestro chatbot, pero la performance de los modelos disponibles con LUIS o con Natural Language de Cloud de Google es muy superior a cualquier otro que pudiéramos crear nosotros. ¿Se puede integrar un chatbot a Salesforce? ¡Si! te dejamos este tutorial de Salesforce que explica los pasos a seguir, para poder crear y desplegar un chatbot en Salesforce Con esto, ¡cerramos este año lleno de webinars!
13 de diciembre de 2018

¿El advenimiento del periodismo robot? No será para tanto
Post escrito por Iñaki Hernandez, periodista de datos en EuropaPress y colaborador de Huffington Post. Hace 500 años la reina de Inglaterra Isabel I negó al inventor William Lee una patente para una máquina de coser automática porque, según dijo textualmente: “tengo demasiado afecto por las mujeres pobres y jóvenes doncellas que se ganan el pan cosiendo como para impulsar un invento que, al arrebatarles el trabajo, les va a llevar al hambre”. El miedo de la reina por los efectos de la tecnología no impidió sin embargo que las fábricas adoptarán la máquina. La incertidumbre que causa la tecnología sobre su impacto en el empleo no es, por tanto, cosa nueva. Los periodistas tenemos nuestro propio ‘enemigo tecnológico’: el periodista robot. La aterradora imagen de habitaciones enormes llenas de hileras de mesas con robots idénticos escribiendo noticias en base a una agenda robot desconocida para los humanos y, lo que es peor, quitando el trabajo a los periodistas humanos. ¿Es ese el futuro que nos espera? Lo cierto es que medios de todo el mundo llevan ya un tiempo lanzando herramientas basadas en inteligencia artificial que escriben parte de sus noticias y ayudan a sus periodistas con sus historias: Forbes ha llamado a su asistente de IA ‘Bertie’; Reuters, ‘Lynx Insight’; el Washington Post, ‘Heliograf’ y la agencia china Xinhua, en el marco de la apuesta millonaria que está haciendo China por la Inteligencia Artificial, ha anunciado una importante inversión para renovar su redacción enfatizando la colaboración entre humanos y máquinas. El objetivo manifestado por Xinhua resume más o menos lo que están haciendo los robots para los humanos en las redacciones de todo el mundo: “recolección de información, encontrar patrones en los datos que lleven a historias, mejorar la edición y distribución y, por último, dar un feedback con el análisis de métricas". Es decir, las máquinas van a intervenir en todo el proceso, desde la búsqueda de noticias hasta su publicación, pasando por la redacción y edición. ¿Desde cuándo habitan los robots entre nosotros? Uno de los primeros en introducir la Inteligencia Artificial en una redacción fue la agencia Associated Press. Lo hizo en 2014 como prueba para aumentar el número de noticias que producía sobre resultados empresariales. “Con la automatización, AP ha logrado ofrecer a sus clientes 12 veces más de historias sobre resultados empresariales que antes, más de 3.700, incluidas gran cantidad de empresas pequeñas que antes no recibían mucha atención”, explica en este informe de la propia agencia Lisa Gibbs, editora de negocios de AP. El Washington Post de Jeff Bezos empezó a usar la Inteligencia Artificial para escribir artículos en 2016. Ese año, su plataforma de IA produjo alrededor de 850 artículos propios, incluyendo 500 informaciones sobre las elecciones presidenciales, que generaron más de 500.000 clicks. ¿Significa esto que los robots van a acabar con el trabajo de los periodistas? No será para tanto. Reuters, que como AP y el Washington Post también había usado en el pasado la Inteligencia Artificial para escribir artículos sobre ligas de deportes locales, alertas de terremotos o resultados empresariales, ha anunciado recientemente un cambio de enfoque. El objetivo, según ha afirmado en marzo de este año Reg Chua, editor ejecutivo de operaciones editoriales, datos e innovación en Reuters, es dividir el trabajo editorial entre lo que las máquinas hacen mejor (como bucear en los datos y encontrar patrones) y en lo que los humanos son imbatibles (hacer preguntas, juzgar la importancia y entender el contexto) ‘Lynx Insight’, que es como se llama el sistema de IA de Reuters, está diseñado para buscar patrones interesantes en conjuntos de datos gigantes (cambios de precios rápidos en acciones, patrones escondidos en bases de datos…) y ofrecerlos a la redacción para que sean los periodistas los que juzguen si hay noticia. Es decir, más que sustituir a los humanos, servirles de apoyo para mejorar su trabajo. En un enfoque similar, Forbes ha presentado al mundo este mismo año un asistente de IA llamado ‘Bertie’. El hecho de que le hayan puesto nombre de simpático animal de compañía no es casual. "No se trata de crear un herramienta más sino de crear un asistente que con el tiempo se convierta en un ‘colega’ para los periodistas", ha explicado el medio. ‘Bertie’ aprende de los periodistas que lo usan cada día y ofrece sugerencias, en base al análisis de datos, a la medida de cada autor. Si un reportero solo acepta las sugerencias de ‘Bertie’ sobre las imágenes de sus noticias, ‘Bertie’ sólo le ofrece ese tipo de recomendaciones. Si lo que le interesa al periodista es mejorar su presencia en Facebook, ‘Bertie’ le aconseja cómo hacerlo y si escribe habitualmente sobre Trump, la plataforma le avisa de las últimas noticias y temas de actualidad sobre el presidente. Se trata, según explica la AP, de que la Inteligencia Artificial ayude a mejorar el periodismo, pero nunca a sustituirlo. “La Inteligencia Artificial puede ayudar en el proceso, pero los periodistas siempre tendrán que poner las piezas juntas y construir un relato creativo y ameno para el lector“. ¿Y cómo pueden ayudar entonces los robots? Una de las respuesta posibles a esta pregunta es: tiempo. Ofreciendo a los periodistas uno de los bienes más preciados y escasos en la profesión: tiempo. Tiempo para investigar en profundidad, para hacer trabajos de gran valor añadido. Según la estimación de AP la automatización de algunas noticias sobre resultados empresariales ha liberado el 20% del tiempo de los periodistas que se de dedican a estos asuntos, permitiéndoles invertirlo en asuntos más complejos y con mayor valor. Un ejemplo paradigmático de esta colaboración entre máquinas y periodistas es el caso de los ‘Panama Paper’, que sirvió para sacar a la luz cientos de historias sobre cómo el dinero se esconde en los paraísos fiscales para eludir las legislaciones nacionales en materia tributaria o con fines de blanqueo. Navegar a través de los millones de documentos filtrados que sirvieron de base a la investigación es algo tedioso y hasta cierto punto inalcanzable para un ser humano que, sin embargo, puede ser afrontado con relativa rapidez por una máquina. Por contra, ninguna máquina puede ver una relación entre dos organizaciones y pensar “esto es raro, veamos qué hay ahí”, llamar a una fuente para pedir contexto, pensar con genuina creatividad o escribir una historia comprensible por el público. O dicho de otro modo: no hagamos la guerra, colaboremos.
12 de diciembre de 2018

Inteligencia artificial y robótica autónoma: no hay un Terminator a la vista
Post escrito por José Luis Orihuela, profesor universitario, conferenciante y escritor. Analiza el impacto de las innovaciones tecnológicas sobre los modos y los medios de comunicación. Autor de Los medios después de internet. Una conversación con Ángel Rubio Díaz-Cordovés, profesor de Bioestadística y Bioinformática en la Escuela de Ingenieros de la Universidad de Navarra. ¿Qué es la inteligencia artificial? La inteligencia artificial es el conjunto de metodologías que, utilizando grandes cantidades de datos y ordenadores, permiten extraer conclusiones y abstraer conceptos de esos datos, que no eran evidentes. En algunos aspectos, la inteligencia artificial puede comportarse de forma similar a la de un experto del campo que se está analizando. La inteligencia humana es la capacidad de comprender, de reconocer patrones y de resolver problemas, ¿es esto lo que puede hacer una máquina o un programa de inteligencia artificial? En principio, sí. Por ejemplo, la tecnología de deep learning, aprendizaje profundo, se caracteriza por la capacidad para descubrir patrones. Utilizando deep learning, sobre todo en análisis de imágenes, se están obteniendo resultados 5 veces mejores que hace 10 años. Por oposición a la inteligencia natural, ¿aquí lo que tendríamos es la posibilidad de trabajar con mayor cantidad de información y más rápido? Desde luego, con mayor cantidad de información. La cuestión es que hoy todavía no somos capaces de resolver problemas tan complicados como los que puede resolver una persona. Ahora mismo es difícil tener un robot completamente autónomo en un entorno que desconozca, fuera de un laboratorio. La diferencia sustancial es que los ordenadores pueden utilizar muchísimos más datos y resolver problemas basados en datos que superan la capacidad de una persona para manejarlos. ¿Por qué la ficción tiende a presentar la inteligencia artificial de una forma distópica (desde el ordenador Hal 9000 de Odisea del Espacio hasta la serie Black Mirror)? Lo que creo es que puede ocurrir, más allá de la ficción. Por ejemplo, utilizando big data y técnicas de aprendizaje automático e inteligencia artificial, parece que ha sido posible influir en las elecciones de Estados Unidos. Da la impresión de que utilizando robots es posible influir en las redes sociales y crear un estado de opinión a favor o en contra de algo. Lo distópico no está tan alejado como podría parecer. En el debate público contemporáneo aparecen como temas dominantes los coches autónomos y el futuro del trabajo, ¿qué otros asuntos nos estamos perdiendo? Sobre todo, la ayuda en la toma de decisiones. Por ejemplo, los cuadros de mando de una gran empresa. Eso, ahora mismo, es más importante que los coches autónomos. Sobre los temores acerca del futuro del trabajo por incidencia de la tecnología, la historia lo que muestra es que el progreso lo que hace es facilitarte el trabajo, y hace que los trabajos sean más humanos. ¿Que los robots han quitado puestos a los operarios de fábricas de coches? Pues, bienvenidos sean, para que una persona no tenga que estar poniendo tuercas durante cuarenta años de su vida, 8 horas al día. Los robots y la inteligencia artificial facilitan una mejor calidad del trabajo, no producen un retroceso en el bienestar social, sino al contrario. Hoy sería impensable hacer la contabilidad de unos grandes almacenes sin un ordenador, tal vez hagan faltan menos contables que a principios del siglo pasado, pero no pasa nada. En lugar de dedicarnos a la contabilidad, nos dedicamos a otra cosa. ¿Y qué temas de la inteligencia artificial están ausentes de la conversación pública? El qué sabe quién sobre mí, creo que es algo que es importante, así como evitar las cláusulas abusivas de los proveedores de tecnología. Otro gran tema es el uso del big data en medicina para encontrar nuevos medicamentos contra el cáncer y enfermedades autoinmunes, así como para estudiar el envejecimiento. ¿Hacia dónde van la investigación y las aplicaciones de la inteligencia artificial en tu ámbito? En el campo médico, la búsqueda de nuevos medicamentos (aprovechando, también los datos recogidos por los dispositivos wearables) y el análisis del genoma humano. ¿Los avances en robótica y en inteligencia artificial nos llevan a una progresiva disolución de las fronteras hombre/máquina? ¿Vamos hacia una situación de Test de Turing permanente? Es casi imposible construir una especie de Terminator, necesitarías una batería descomunal para hacer funcionar un robot así. En unos años será posible construir máquinas que pasen el Test de Turing. Máquinas que, sin verlas, no te permitan distinguir si estás hablando con una persona o con una máquina. Donde va a ser más difícil avanzar es en el aspecto mecánico. Los robots están sujetos a las leyes de la mecánica. Ahora bien, ordenadores (no robots) que sean capaces de comportarse como una persona, o que superen el Test de Turing, eso va a ocurrir. Pero, en el tema de robótica autónoma, hay una limitación física que es la propia mecánica.
5 de diciembre de 2018

Nuestros favoritos de Noviembre: 5 post del sector que no debes perderte
¿Qué pueden tener en común los Spyce Boys, mítines políticos, lentillas inteligentes y cerditos agresivos que muerden la cola al cerdito de al lado?. Efectivamente, si están en nuestro blog, es porque hay alguna interesante aplicación de Inteligencia Artificial, Ciencia de Datos o big data de por medio. No te pierdas nuestra selección de noticias del sector que, con estos protagonistas resulta, cuanto menos, entretenida. Nuestros favoritos en la red Nuestra primera noticia nos lleva a un entorno donde quizás jamas se nos hubiera ocurrido ubicar una interesante aplicación de la Inteligencia Artificial: una granja de cerdos. En un post anterior ya vimos una interesante aplicación de de la IA al sector de la ganadería, en forma de "detector de sufrimiento animal", ahora el objetivo es evitar ese sufrimiento y también las consecuencias económicas negativas que tiene para el productor. El caso es que los cerdos tienen el desafortunado hábito de morderse las colas. Los motivos por los que lo hacen son muy diversos. Pero las consecuencias son claras: infecciones que pueden hacer que hasta un 30% de los animales no sean aptos para el consumo. ¿Y qué papel juega la Inteligencia Artificial en este escenario?. Científicos escoceses han desarrollado un sistema que utiliza cámara 3D y algoritmos de visión artificial para detectar automáticamente cuándo erdo podría estar a punto de atacar a otro. Si quieres conocer más detalles, aquí tienes el artículo completo. Scottish Farmers Test Machine Vision to Manage Pig Pugnacity Muchos de nosotros todavía recordamos a las Spyce Girls, pero lo cierto es que hace ya unos años que "son historia". Sin embargo, ahora es el momento de los " Spyce Boys", un grupo formado por cuatro jóvenes ingenieros del Instituto Tecnológico de Massachussets (MIT), que decidieron aplicar sus conocimientos de robótica e ingeniería para fundar Spyce, un restaurante cuyos platos se preparan entre robots y humanos. Durante el primer mes, sirvieron más de 10.000 comidas 'Spyce boys', los ingenieros que crearon la cocina robótica, sana y barata Una campaña electoral reñida, un mitin enardecedor, una muchedumbre... En ocasiones, estos factores pueden ser los detonantes de una tragedia, como ocurrió en 2017 en Charlottesville, Virginia. Un inesperado brote de violencia tras un mitin político, se saldó con una persona muerta y decenas de heridos. Un grupo de investigadores de la Universidad de Zhengzhou ha creado un modelo diseñado para detectar estallidos de violencia en este tipo de situaciones, basándose en un modelo diseñado para estudiar la propagación de enfermedades infecciosas. Curioso, ¿verdad? The Challenges of Predicting Mob Behavior at Political Rallies Por último, os proponemos una interesante visualización de datos. Max Roser, economista de la Universidad de Oxford publicó seis gráficos en su web que muestran cómo en los últimos 200 años hemos mejorado, y mucho, en estos seis asuntos: pobreza extrema, educación básica, alfabetización, personas que viven en democracia, vacunas y mortalidad infantil. Aunque muy poca gente crea que el mundo sea cada vez mejor, los datos están ahí y con ellos podremos responder "de forma informada" al amigo/familiar/compañero pesimista empedernido y cenizo. Una dosis de optimismo nunca viene mal. The short history of global living conditions and why it matters that we know it El último post que nos ha llamado la atención, es sobre algo que nunca habíamos visto acompañado por el adjetivo "smart". Se trata de una aplicación de la IA al campo de la salud, en la que los sensores son lentes de contacto inteligentes. La pasada primavera, se anunció a bombo y platillo una revolucionaria forma no invasiva de controlar los niveles de glucosa en sangre mediante lentes de contacto inteligentes, creadas por un equipo de científicos de la Universidad de Purdue en Indiana. Sin embargo, estos últimos días ha sido noticia el abandono de este proyecto por parte de Google. Nos ha resultado interesante este ejemplo por mostrar que no todas las iniciativas tienen éxito, pero aun así son importantes, porque siempre se aprenden cosas que pueden ser la clave del éxito de proyectos posteriores. Google cancela el proyecto de las lentillas inteligentes para diabéticos Después de nuestra selección de las noticias más interesantes sobre Machine Learning, Inteligencia Artificial y Big Data que hemos encontrado en la red en Noviembre, os dejamos el post más popular en nuestro blog este mes. Atrévete con el Deep Learning: Principios básicos al alcance de todos ¿Es el que más te ha gustado a ti también? No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. También puedes seguirnos en Twitter, YouTube y LinkedIn
3 de diciembre de 2018

Interpretación de modelos predictivos
Escrito por Carlos Gil Bellosta. Se dice que hay dos motivos fundamentales para construir modelos estadísticos: para entender y para predecir. Obviamente, son motivos no necesariamente excluyentes: lo ideal sería poder construir modelos muy predictivos y muy interpretables a la vez. Desafortunadamente, esa combinación ideal ocurre muy raramente. De hecho, interpretación y predicción dividen el mundo del análisis de datos aproximadamente por la misma línea que separa las dos culturas a las que me refería en una entrada anterior: a la estadística tradicional le preocupa mucho más la interpretación, en tanto que el machine learning está mucho más orientado a la predicción. Así que, en la práctica, muchos científicos de datos actuales, con su inquebrantable monocultivo de técnicas tales como los boosted trees (p.e., XGBoost) y las redes neuronales, están prácticamente renunciando de partida a cualquier atisbo de interpretabilidad. Sin embargo, hay muchos motivos para recuperar la interpretabilidad. Algunos son de naturaleza meramente epistémica; por ejemplo, en el estudio de las redes neuronales recurrentes para el análisis de texto, es posible, por ejemplo, descubrir e identificar neuronas que se activan cuando se ha abierto un paréntesis y comprobar cómo presionan a la red para cerrarlo posteriormente (¿y qué pasa cuando alguien abre un paréntesis (anidado) dentro de otro paréntesis?). Existen incluso motivos que podrían calificarse de lúdicos. Por ejemplo, en A Neural Algorithm of Artistic Style se identifican capas de una red neuronal (convolucional esta vez) que contienen información sobre las formas que aparecen en una foto por un lado y de las texturas por otro. Lo cual permite mezclar ambas y generar imágenes tan llamativas como las que aparecen en Ostagram. Figura 1: Imagen creada por una red neuronal convolucional. Pero hay motivos mucho más serios. La creciente desconfianza hacia los algoritmos, las acusaciones de sesgo, de que pueden perpetuar ciertos prejuicios que se pensaban confinados a la subjetividad humana, etc. ha generado una presión creciente, a veces reflejada en la legislación, para que quienes sean evaluados por un algoritmo (p.e., a la hora de solicitar un seguro o una hipoteca) puedan exigir una explicación de cómo se ha llegado a la decisión que los afecta. Así que, aunque el problema no es nuevo, han aparecido algoritmos (e implementaciones) para reinterpretar modelos opacos entre los que cabe citar DALEX, iml, lime (disponibles en R y/o Python). Es sintomático que estas implementaciones sean todas del último par de años y que la literatura sobre la que se apoyan sea toda también reciente: prácticamente toda, de la década actual. Sin embargo, la interpretación de modelos tiene una larga tradición en la estadística tradicional: en los ubicuos modelos lineales (o lineales generalizados), la interpretación es casi directa a partir de los coeficientes que se ajustan en el modelo, incluso cuando existen interacciones: coeficientes grandes corresponden (si las variables están mínimamente normalizadas) a las variables más importantes. De hecho, medir la importancia de variables es uno de los primeros problemas de interpretabilidad al que se enfrentaron los algoritmos de la ciencia de datos: aunque solo sea como mecanismo de validación, es conveniente saber cuáles son las variables que más peso tienen en las predicciones: malo, por ejemplo, que en un modelo de predicción de producción fotovoltaica, la lectura del anemómetro pese más que la del heliómetro. El siguiente gráfico muestra la salida típica de la aplicación de un algoritmo para la estimación de la importancia de las variables de un modelo: Figura 2: Ejemplo de gráfica de estimación de importancia de las variables de un modelo. La importancia de las variables es una medida demasiado gruesa del efecto de las distintas variables en el modelo. Por ejemplo, no da información sobre la dirección de los efectos: p.e., ¿aumenta la mortalidad al aumentar la temperatura? ¿o se reduce? Los gráficos de dependencia parcial, introducidos por J. Friedman en 2001, tratan de solucionar ese problema. Tienen como objetivo estudiar la evolución de la variable dependiente, la predicción, al ir variando una (o dos) de las variables independientes. El siguiente gráfico muestra cómo varía el precio de determinadas viviendas según se modifican algunas de las variables predictoras (una a una en los cuatro primeros subgráficos, y una pareja de ellos en el último): Figura 4: Variación del precio de la vivienda según lo hacen distintas variables predictoras. El problema de este tipo de representaciones es el punto de referencia. Podemos hacer variar una variable (por ejemplo, la antigüedad de la vivienda) y ver observar que el precio tiende a subir. Pero bien puede suceder que ese efecto se de en los apartamentos situados en la zona centro y que el efecto sea el contrario en las afueras. Los gráficos de dependencia parcial recogerían un efecto promedio, que puede ser engañoso y enmascarar efectos contrarios en sujetos (o clases de sujetos) distintos. El problema consiste en que describen qué pasa en general, pero no en un caso de interés concreto. Supongamos que las variables que considera un modelo a la hora de determinar si un individuo merece o no un préstamo están recogidas en el vector x. Se podría en tal caso tomar como referencia ese valor y ver qué ocurre con la predicción al modificar cada variable respecto a ese punto de referencia. Eso es lo que hace, por ejemplo, el paquete ceterisParibus de R, Lime, DALEX o iml son implementaciones disponibles en R y/o Python que extienden esas ideas y permiten cuantificar el aporte de los atributos de un sujeto en la decisión final de un modelo, generando, típicamente, una salida de tipo gráfico del estilo de: Figura 5: Aportación de las distintas variables a la respuesta del modelo. No es difícil encontrar ejemplos del uso de lime para explicar modelos de clasificación de imágenes u otros modelos más clásicos. Para concluir, la existencia de estos algoritmos es prueba concluyente de que existía un problema que urgía resolver (el de la interpretabilidad de los modelos). Lo cual, hasta cierto punto, invalida y obliga a matizar la posición extrema de ciertos científicos de datos que defienden como objetivo único y último de su profesión el predecir con la mayor precisión posible. Eso sí, estos algoritmos, por muy bien que puedan explicar la predicción de cada sujeto (a quien se haya otorgado el derecho a reclamarla) se quedan cortos a la hora de explorar sesgos sistemáticos en los modelos. Pero esa es otra historia.
28 de noviembre de 2018

CDO: Un perfil en auge, pero ¿qué perfil?
Mucho se ha hablado ya sobre el Chief Data Officer, sus responsabilidades y su rol en la empresa. También ha evolucionado mucho su figura desde que, a principios de 2018, el CDO Club Spain (que ya cuenta con más de 60 miembros de todos los sectores) inaugurase su primera reunión. Cuatro citas más tarde, aún permanecen sin respuesta dos de las primeras dudas que nos planteamos: ¿quién es exactamente el CDO? ¿Existe consenso en torno a sus funciones? Es complicado hablar de un modelo único de CDO, porque su naturaleza varía mucho en función del tamaño de la empresa, el sector de actividad y las demandas que debe abordar. Podríamos debatir infinitamente sobre ello, pero hay algo que está claro y que, como profesionales, nos une: tenemos una necesidad común de monetizar el dato y convertirlo en un activo estratégico dentro de nuestras organizaciones. Quienes formamos parte del Club queremos impulsar una cultura Data Driven en nuestras empresas. El cargo puede cambiar (CDO, CTO, Data Governance Manager, BI Manager, Chief Compliance Officer, etcétera), pero todos compartimos como prioridad el impulso de una cultura analítica en nuestras organizaciones. En cada encuentro del Club hablamos, por supuesto, de retos, datos y tecnología. Por ejemplo, Anastasio Molano, Senior VP de tecnología y soluciones de Denodo, señaló en el último de ellos uno de los principales desafíos actuales del CDO: disponer de toda la información de manera ágil y bajo una gobernanza robusta. Para ello, apuesta por arquitecturas lógicas de provisión del dato. Mientras que centralizar los datos en un único repositorio ha sido la solución habitual, la virtualización de datos (que integra datos de fuentes dispersas, en distintas localizaciones y formatos, sin replicar información) permite un acceso más rápido a todos los datos, sin replicarlos. En esta cuarta reunión del Club, hemos querido enfatizar un elemento tan importante o más que la tecnología: las personas. ¿cómo es el perfil del CDO? ¿A qué retos se enfrenta? ¿Cómo retener el talento en su equipo o cómo incorporarlo? Precisamente, la gestión del cambio y la incorporación y retención de los CDO es un desafío especialmente complejo dado que la mayoría de headhunters difícilmente puede seguir el paso a la evolución del rol del CDO. Jesús Arévalo, socio del área de tecnología de Russell Reynolds Associates y experto en la identificación de talento ejecutivo, ofreció una visión panorámica del estado actual del CDO en la empresa española, explicó por qué cuesta hablar de un único modelo de CDO y qué se espera de él por parte de la alta dirección. Conocer mejor nuestro rol, no solo presente, sino futuro, es importante. Solo así seremos capaces de alcanzar un consenso sobre nuestro papel en la economía y desplegar todo el potencial de los datos en nuestras organizaciones. Pasado, presente y futuro del Chief Data Officer Pocas empresas dudan ya de la importancia del CDO, pero, ¿qué significa exactamente la “D”? “Quizás sería más apropiado hablar de CxO”, bromeó durante su ponencia Jesús Arévalo, socio del área de tecnología de Russell Reynolds Associates, “ porque la función varía, pero quien la desempeña mucho más, en función de la empresa, su tamaño y el sector: CTO, CIO, CDO…”. Según Arévalo, la figura del Chief Data Officer está en pleno auge tras haber superado un periodo de altas expectativas. Las empresas afrontan una verdadera revolución del dato que les obliga a contar con especialistas en su gestión, gobernanza y análisis. Contar con un CDO con un papel bien definido ya no es una moda: es una necesidad de negocio. Las empresas no pueden posponer o repartir entre diversos perfiles sus funciones si quieren seguir siendo competitivas. Sin embargo, hasta no hace mucho, la política de datos de las empresas, incluso las de gran tamaño, no estaba muy clara. Y aún existen grandes diferencias de una organización a otra, en función de su naturaleza. “ Muchas empresas llegaban a dudar de la veracidad de sus datos, o de si esto era relevante para su negocio”. Tras esta fase de descubrimiento, “son muy pocos los CEO que dudan del valor de una estrategia analítica sólida, que no entienden que el dato es un activo valioso”. Ahora, los CDO necesitan dar un paso más y educar a los directivos para que entiendan que los datos no solo son valiosos, sino estratégicos. Según una encuesta a altos directivos realizada por Russell Reynolds Associates, el trabajo de evangelización ya ha comenzado: el 96% considera con una estrategia analítica correcta tiene un impacto positivo en el negocio el 79% considera que los datos tendrán un efecto disruptivo en su sector en los próximos 12 meses. Por ello, no es de extrañar que, según Bain & Company, las empresas con buenas prácticas analíticas tengan el doble de posibilidades de situarse en las posiciones de liderazgo dentro de su sector. También existe una falta de consenso en torno a cuáles deberían ser las funciones del CDO, qué demandas debe abordar y qué habilidades son las más valoradas por parte de las empresas. Prueba de ello es la escasa duración de media en el cargo, de 3 años. Actualmente, el conocimiento técnico prima ante otro tipo de capacidades y las soft skills. Pero también son importantes, y lo serán cada vez más, la habilidad para desarrollar alianzas estratégicas y adecuadas con proveedores, la capacidad de convertirse en un agente de cambio para el negocio, y la g estión de stakeholders internos. Las competencias del CDO que serán más importantes en la empresa Stakeholder Management Habilidades de comunicación Visión y capacidad de innovación Capacidad operacional y de ejecución Agudeza comercial Capacidades técnicas --- Fuente: Russell Reynolds Associates Existen tantos modelos de Chief Data Officer como empresas, desde la que cuenta con un CDO puro que reporta al CEO, como en la que el CDO depende del CIO, o incluso otras donde existe un Chief Insights Officer, que sería el caso de un experto más cercano a la vertiente del marketing (indica Arévalo) En este sentido, el experto de Russell Reynolds señaló que hoy existen varios modelos distintos de distribución de insights y análisis, si bien Lo más probable es que estos modelos converjan hacia uno de centralización parcial o hub and spoke, ya que los datos soportarán todas las decisiones estratégicas de las compañías. Modelo hub and spoke, el más común entre las organizaciones con mejores prácticas de análisis de datos. Figura 1: Modelo hub and poke. Post escrito por el Club CDO El Club de Chief Data Officer Spain es la primera comunidad de CDOs en España y el próximo miércoles 28 de noviembre llevará a cabo un nuevo evento de formación y networking dónde se tratará el tema de Data Ethics y los dilemas éticos relativos al Big Data y la Inteligencia Artificial. Elena Gil, CEO de LUCA - Unidad de Big Data de Telefónica será la speaker estrella para hablar de los retos sociales y éticos de la Inteligencia Artificial. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
26 de noviembre de 2018

Data Rewards, La publicidad que engancha
Un estudio ha revelado que el 40 % de adultos mira su teléfono a los cinco minutos de despertarse, y esta cifra sube a un 65 % para aquellos menores de 35 años. Está claro que gran parte de nuestro tiempo lo pasamos viendo el móvil, exactamente un tercio de lo que estamos despiertos a lo largo del día. ¿Sabías que existe una manera de obtener recompensas por el tiempo que pasamos viendo el móvil? Data Rewards, es un producto que ayuda a la publicidad móvil a ser mucho más útil, interesante y beneficiosa para nosotros, los usuarios. Lo que ocurre con la publicidad móvil, es que no nos interesa y es una molestia e interrupción. Este es el punto que nuestro equipo de Advertising quiere abordar, y convertir a la publicidad en algo útil para las marcas y para los usuarios. Esto se logra segmentando la base de usuarios, y obteniendo insights de los datos anonimizados y agregados que estos nos proporcionan. Gracias a la segmentación podemos recibir publicidad que sea acorde a nuestros comportamiento, perfil demográfico y a nuestra localización, siempre respetando la privacidad, y en un entorno libre de fraudes y bots. Si te interesa saber más sobre los Data Rewards, y escuchar un testimonial de un cliente, te dejamos el vídeo completo a continuación: [embed]https://youtu.be/rTkcJeOWmKk[/embed] Es importante mencionar que en América Latina, aunque el 40% de la población tiene un smartphone, el 30% de los usuarios únicamente utiliza los datos para situaciones de emergencia, y es por ello que poder obtener más datos siempre es algo muy llamativo. Tuvimos la interesante intervención de Yessenia Delgado, quien nos contó la experiencia del Banco de Crédito del Perú y cómo la campaña con Data Rewards desarrollada para presentar un nuevo producto digital, les ayudó a entender mejor a sus clientes. La ventaja de este formato fue que les proporcionó información importante acerca de los usuarios, y los usuarios que terminaron de ver el vídeo, fueron recompensados con datos para navegar. Si te interesa conocer aún más sobre los Data Rewards, visita nuestra página donde podrás encontrar más informacion.
22 de noviembre de 2018

Cómo usar los datos para tomar mejores decisiones
Post escrito por Tristán Elósegui , consultor senior de marketing online, conferenciante y profesor en diferentes escuelas de negocios. Es especialista en estrategia digital, analítica web y redes sociales. En mi anterior entrada Cuando la información fluye la empresa se mueve, os contaba los beneficios que la mejora en la calidad del dato y el flujo de la información supusieron para una empresa. En esta ocasión quiero contaros la base metodológica necesaria para sacar mayor partido a los datos. Son pasos sencillos a seguir, para guiar a los responsables de marketing en la toma de decisiones. Figura 1, El marketing siempre se ha basado en datos El marketing siempre se ha basado en datos, pero nunca tan exactos como ahora. Los datos siempre han estado presentes en la toma de decisiones. Forma parte del día a día de las empresas. No deberíamos tomar decisiones sin un dato que las soporte. En este sentido la llegada de Internet y la evolución en la gestión de la información (recogida, filtrado, almacenaje, procesado y análisis), ha hecho que la presencia de los datos en la toma de decisiones haya ganado en importancia y valor aportado. Hemos pasado de un escenario en el que los datos eran escasos (al menos comparados con los que podemos acceder ahora) y su nivel de actualización era escaso. Como resultado las decisiones se tomaban en base a datos que no eran del todo válidos. Al final la intuición o la voluntad de la persona que tomaba las decisiones, tenía mucho peso y no se hacía demasiado caso a los datos. No estoy diciendo que tengamos que tomar las decisiones basándonos exclusivamente en los datos (empezando porque nunca vamos a tener todos los datos necesarios, ni vamos a poder controlar todas las variables para poder predecir lo que va a suceder y tomar la decisión más adecuada), pero si que debemos aprovechar la mayor calidad de los datos a los que podemos acceder, para tomar mejores decisiones. ¿Cuál es la forma correcta de usar los datos en el marketing digital actual? Cómo suele pasar con todo lo que supone una innovación para la empresa (aunque sea a nivel de procesos), hemos pasado de un extremo al otro. Independientemente del nivel en la empresa o del tipo de acción, contamos con muchos datos. El problema es separar aquellos que nos aportan valor del resto. Estamos pasando de medir poco y mal, a querer aplicar big data (sin tener muy claro lo que es y el valor que nos aporta). En cualquiera de los casos, tenemos que usar datos para transformarlos en información y esta en conocimiento. Pero tenemos que saber como hacerlo en cada momento. En esta ‘profesionalización’ de la medición en las empresas, la situación de partida más común es: ‘tengo claro que, si quiero optimizar mi estrategia, tengo que empezar medir correctamente. Pero, ¿por dónde empiezo?’ Mi experiencia de estos casi 20 años dedicados al marketing online, me ha permitido definir una breve guía para dar estos primeros pasos. Claves para sacar el máximo partido de los datos 1. Bases sólidas: correcta definición de objetivos y kpis. Lo primero es olvidarse de los datos e informes que maneja la empresa para poder definir un punto de partida que nos sirva de guía para saber si estamos haciendo bien las cosas. Ese punto de partida es la definición de los objetivos y kpis de la estrategia de marketing. Es decir, debemos empezar por plantearnos cuál es la aportación de valor del marketing a los objetivos de la empresa y por definir cuáles son las métricas que mejor los describen. Por experiencia, la situación inicial con la que me encuentro al hablar sobre la medición en una empresa es una visión limitada de la realidad y centrada en temas específicos: “nuestro problema es con el dato X”, “no conseguimos medir la rentabilidad de las campañas”, etc. Antes de solucionar esos problemas concretos, tenemos que empezar por el principio y fijar el rumbo correcto. 2. Sin los datos correctos no podemos tomar las mejores decisiones El siguiente paso es estar seguros de que los datos que estamos manejando son los correctos. No podemos tomar decisiones si no confiamos en el dato de partida. Esto va a provocar que la empresa avance a trompicones, que tome decisiones erróneas y que pierda tiempo discutiendo sobre que dato es el correcto. Una vez definidos los objetivos y las kpis, tenemos claro que cosas debemos medir y debemos comprobar si los datos recogidos se ajustan a la realidad o no. Tenemos que trabajar en la calidad del dato. 3. Romper los silos de información Es muy común que las empresas que empiezan a medir tengan varias fuentes de información y que los datos no coincidan entre ellas. Para solucionar estos problemas en la toma de decisiones, necesitan integrar las fuentes de datos en una misma herramienta y visualizarlos en un único dashboard. Esto nos va a permitir centrarnos en la toma de decisiones y evitar la parálisis por el análisis. Uno de los problemas más comunes es que las empresas cuentan con informes de diferentes fuentes (normalmente en estrategias multicanal), que no cuadran entre si, en los que invierten mucho tiempo en generar un informe único que les de sentido y que les roba tiempo para lo más importante: pensar y tomar decisiones. Por eso tenemos que centrarnos, eliminar distracciones y actuar. 4. Datos claros, decisiones correctas Nada peor que haber hecho todo el trabajo bien, y que al llegar el dashboard a la persona que tiene que tomar decisiones, esta no lo entienda, tome la decisión equivocada o bien lo archive directamente por que no lo entiende. Para ello es necesario que adaptemos la información y el conocimiento que transmitimos en el dashboard, a nuestro interlocutor (nuestro stakeholder interno). Esta adaptación debe ir en dos líneas: Tipos de datos: a cada decisor le interesa una información concreta. Aquella que le habla y ayuda en el desempeño de su trabajo.Por este motivo el número de dashboards que necesita una organización para funcionar es variable. Se parte de un dashboard estratégico que recoge las KPIs claves, la visión global de negocio, y a partir de ahí se analizan las necesidades de análisis (gestión de la inversión publicitaria, clientes, logística, contenido… las opciones son muy numerosas). Visualización: y no solo basta con tener los datos necesarios, tienen que estar representados de manera que la persona que vaya a usar ese dashboard, sepa entender la situación global y localizar rápidamente de los puntos fuertes/débiles. Por regla general, cuanto más estratégico sea el dashboard y más alto el cargo de la persona a la que va dirigido, los dashboards son más sencillos a nivel gráfico y contienen más texto con las recomendaciones (el conocimiento obtenido) y viceversa. 5. La clave de una buena decisión está en el análisis Las estrategias multicanal, la falta de unificación de métricas y formatos y la propia falta de experiencia, hace que las empresas dediquen la mayor parte del tiempo a la extracción y procesamiento de los datos. Y esto les limita el tiempo a lo más importante, a lo que más valor aporta y a lo que en definitiva es el objetivo de un dashboard: analizar los datos para transformarlos en información y esta en conocimiento. Así que necesitamos aumentar la velocidad de extracción y procesamiento, para dedicar el tiempo necesario para lo más importante (la famosa regla del 90/10 de Avinash Kaushik). En el caso del análisis de dashboards recurrimos a su automatización, pero cuando estamos hablando de análisis ad-hoc y más ahora que el volumen de datos ha crecido tanto, estamos hablando de data science. Es decir, de tener la capacidad de combinar la estadística, la programación y el conocimiento del negocio, para tomar y combinar solo los datos necesarios de la forma más rápida y efectiva, para pasar al análisis y toma de decisiones lo antes posible. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
21 de noviembre de 2018

¿Por qué la Inteligencia Artificial puede mejorar la vida de nuestros mayores?
La Inteligencia Artificial, entendida como el conjunto de técnicas y algoritmos que permiten a una máquina “aprender” y mejorar, juega un papel fundamental ya en la sociedad y, dado que estamos en los albores de su aplicación práctica en nuestra vida cotidiana, lo seguirá haciendo de manera incluso más importante en los próximos años. Curiosamente, su impacto social será mucho mayor en sociedades en las que el envejecimiento de la población es mayor. Es una realidad que ya puede comprobarse en países como Japón, donde existen residencias de ancianos que utilizan la robótica para mejorar la salud de los mayores cada día. Por ejemplo, estas máquinas les ayudan a levantarse de la cama, a transportarse de un sitio a otro… e incluso se han convertido en “alguien” que están constantemente pendiente de ellos, que les da su medicación… y que les explica las cosas en un lenguaje natural que ellos pueden entender. Incluso sirven de medio de comunicación y permiten que estén en contacto continuo con sus familias, que a través de una pantalla pueden ver cómo están sus mayores en todo momento. ¿Qué hacen en otros países? Esto es una realidad ya en una sociedad como la japonesa, muy abierta a aceptar los avances tecnológicos y adoptarlos en su vida cotidiana. En otros países, en los que se da más importancia al contacto físico entre personas y se prima la generación de lazos emocionales, como pueden ser las sociedades latinas, la integración de este tipo de algoritmos y tecnologías es todavía un reto… pero fácilmente superable, como veremos. No hay que olvidar que, a lo largo de la historia, las revoluciones tecnológicas se han ido sucediendo durante periodos largos de tiempo, pero cada vez éstos se acortan más y los cambios tecnológicos revolucionan nuestra vida en menos años. Esta rapidez supone una de las principales limitaciones para los mayores, pues puede costarles adaptarse a las novedades. Hay que tener en cuenta que, en sólo unas décadas, durante su vida, se han tenido que enfrentar al nacimiento de la televisión, de los teléfonos móviles, de Internet… y ahora oyen hablar de avances tan novedosos como la Inteligencia Artificial y a muchos les parece algo relativo a la ciencia ficción. Sin duda, en función de su cultura, esto puede generar cierto recelo. Algunas personas mayores piensan que no son capaces de adaptarse a los cambios tecnológicos, deciden quedarse al margen y esto genera cierto aislamiento. Sin embargo, cada vez más personas mayores ven cómo la tecnología les ofrece grandes ventajas y las irán viendo cada vez más según vayan experimentando sus beneficios. ¿Qué beneficios se pueden obtener? En el caso de la Inteligencia Artificial todavía no se ha experimentado casi nada y es todavía una gran desconocida para muchos, pero en los próximos años no se hablará de otra cosa, puesto que los beneficios son muy claros. Por ejemplo, será común que una persona mayor pueda tener algún mecanismo integrado en su cuerpo que monitorice constantemente su estado de salud, que evalúe el riesgo de que pueda ocurrirle algo físicamente y que sea capaz de avisar a un centro de salud o a sus familias si algo no va bien. Esto será especialmente útil en pacientes como los enfermos de Alzheimer, por ejemplo. Disponer de un robot personal con una Inteligencia Artificial integrada podría servir para que, como si de un amigo se tratase, éste le enseñara juegos de memoria e interactuara con él de forma paciente, algo que a menudo falta a los cuidadores, agotados al tener que enfrentarse a una situación difícil de forma cotidiana. Sin embargo, el robot podría ir ofreciendo actividades personalizadas en función de la respuesta y la experiencia anterior con el anciano. Al producirse beneficios, los robots serán capaces de generar incluso cierta empatía en las personas a las que ayudan. Se dice que los robots no tienen emociones, pero sí que pueden ayudar a generarlas… y esto contribuirá a que los avances tecnológicos sean aceptados de forma natural. Otro de los miedos que a veces produce el avance imparable de la tecnología en este sentido es que las máquinas puedan llegar a “superar a las personas”. Obviamente pensar en una “rebelión de las máquinas” y que pudieran llegar a tomar el control de las sociedades no tiene sentido, pero sí que la Inteligencia Artificial hará que los robots puedan ser “más inteligentes” que los humanos en determinados aspectos, lo que no es malo y, en definitiva, ya ocurre, por ejemplo, con la capacidad de procesamiento de datos e información de los ordenadores, que superan con creces a la mente humana. ¿Cuál es el reto? El reto en este caso es el de lograr la convivencia del hombre y la máquina, que permita una cooperación beneficiosa a cualquier nivel. Por ejemplo, el hecho de que un médico pudiese tener a su disposición un robot físico o una inteligencia artificial aplicada a un objeto (por ejemplo, un bolígrafo) le permitiría analizar un diagnóstico y compararlo automáticamente con el historial clínico de miles de pacientes en todo el mundo. Además, como estaría monitorizando su estado de salud en tiempo real, sin necesidad de realizar análisis, podría llegar a tomar una decisión en cuanto a tratamiento teniendo en cuenta las condiciones específicas de esa persona. Es decir, le permitiría ser más eficiente y ofrecer un diagnostico personalizado capaz de acabar con la enfermedad mucho antes, lo que le llevaría a ahorrar en tiempo, en dinero y en padecimiento a la persona. En definitiva, la visión apocalítica de que “la Inteligencia Artificial nos podría superar” no tiene sentido alguno. Sin embargo, sí que lo tiene pensar que en los próximos años el trabajo conjunto con este tipo de tecnología, la colaboración entre hombres y máquinas en el terreno médico, nos permitirá llegar a un futuro más eficiente y que mejorará considerablemente la vida de los enfermos y las personas mayores. Escrito por Manuel Moreno No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. Para mantenerte al día con LUCA visita nuestra página web, y no olvides seguirnos en Twitter, LinkedIn y YouTube.
14 de noviembre de 2018

Analizamos el perfil de turistas en España en colaboración con el INE
El turismo es uno de los principales sectores de actividad económica en España. Según el Instituto Nacional de Estadística (INE), organismo autónomo dependiente del Ministerio de Economía, España recibió en 2017 el récord de 81,8 millones de turistas extranjeros, un 8.6% más que el año 2016. Ahora, gracias al uso de datos móviles, y los insights obtenidos de estos la información es más precisa, y responde a variables que de otra forma no es posible. ¿Por qué necesita el INE insights obtenidos de datos móviles, además de las encuestas convencionales de opinión? Así aplica técnicas Big Data el INE para completar la información que ya obtienen de fuentes tradicionales: Según el INE, España ocupa el tercer puesto en número de turistas recibido según el ranking de la Organización Mundial del Turismo (OMT), y la aportación del turismo a la economía estatal ha aumentado paulatinamente en los últimos años hasta alcanzar el 10,9% sobre el PIB. Además de haber más de 2,3 millones de personas trabajando en la industria turística, convertiéndose en el sector que emplea a 12,99% de la población ocupada en España.El Instituto Nacional de Estadística (INE), es el organismo autónomo de España encargado de la coordinación general de los servicios estadísticos de la Administración General del Estado y la vigilancia, control y supervisión de los procedimientos técnicos de los mismos. Así, tiene como función ofrecer datos a la población, intentando dar respuesta a necesidades de información relacionadas con la demografía, economía, y sociedad española. En este contexto, Belén González Olmos, Subdirectora General de Estadísticas de Turismo y Ciencia y Tecnología del INE explica que: “Tenemos todos los días peticiones relacionadas con la actividad turística, un sector muy importante económicamente para España, empleando a mucha gente. Y, por tanto, es necesario atender a esas peticiones puntualmente, y con una mayor granularidad. Las encuestas del INE no permiten responder tan inmediatamente a esas peticiones, necesitan al menos un mes para disponer de esa información. En cambio, gracias a soluciones como LUCA Tourism, podemos dar respuesta a esas otras necesidades." Las encuestas tradicionales responden, entre otras, a variables requeridas por los reglamentos por la que se rige el INE, como son las variables cualitativas, pero combinándolos con los insights ofrecidos por parte de LUCA, a través de datos móviles de Telefónica, el valor del dato es mayor. Debido a que ofrece una mayor inmediatez (LUCA ofrece datos en 24 - 48 horas, mientras que el INE demoraría un mes), mejora la eficacia reduciendo costes y aumentando la puntualidad y amplia la información que producen con más detalle y desglose. De esta forma, siendo el turismo una de las principales actividades económicas de España, el INE decidió crear un estudio piloto con técnicas de big data para ayudar y complementar los datos obtenidos a través de las encuestas convencionales y ofrecer un análisis más detallado con LUCA. Figura 2: Turistas mirando mapa de ciudad Sistemas de Estadísticas de Turismo en España Todas las metodologías de las encuestas realizadas con el INE están publicadas en la web del INE, cualquier persona que quiera consultar esos datos puede hacerlo. Desde el lado de la demanda, las tres encuestas de turismo más importantes de las que obtienen datos y se publican, son la Encuesta de Turismo de Residentes; FRONTUR, encuesta que da todos los turistas que entran en España; y EGATUR, la encuesta de Gasto Turístico en España. Mientras que desde el lado de la oferta se realizan encuestas de ocupación en hoteles, apartamentos, camping-es y turismo rural. Necesidad de utilizar big data en estadística oficial: El Big Data puede utilizarse tanto en las encuestas tanto de oferta como demanada, y en este caso los estudios trabajados con LUCA, han sido de parte de la demanda siguiendo las recomendaciones del reglamento europeo, con variables y conceptos que recomienda la organización internacional de turismo. Así, hemos trabajado en un sistema integrado con el INE según los principios de calidady confidencialidad fijados, y ofreciendo datos de relevancia; oportunidad y puntualidad; comparabilidad; coherencia; completitud y transparencia. Compromiso de calidad y confidencialidad de los datos Es importante destacar que el INE está obligado por la Ley de Función Estadística Pública a proteger la confidencialidad de los datos que suministran los informantes. Por lo que, ante una posible colaboración con otras instituciones o empresas que trabajen con datos, como es en este caso la colaboración con LUCA, queda garantizado que todos los datos que se manejan están sometidos a este Secreto Estadístico. Además, los insights obtenidos a través de los datos móviles de LUCA también están anonimizados, agregados y extrapolados para su tratamiento. Por otro lado, las estadísticas oficiales europeas se rigen por los principios, recogidos en el Código de buenas prácticas de las estadísticas europeas (CBP), que buscan asegurar la calidad y la credibilidad de los datos. Estos principios hacen referencia, entre otros aspectos, a la independencia profesional, la protección de la confidencialidad, la fiabilidad de los resultados, su precisión, actualidad, puntualidad, accesibilidad, claridad, comparabilidad y coherencia. De esta forma, a la hora de analizar cómo integrar los insights obtenidos de datos móviles, es necesario garantizar que esa información complementaria que obtienen a través del Big Data cumpla también este código de buenas prácticas. Para mantenerte al día con LUCA visita nuestra página web , y no olvides seguirnos en Twitter , LinkedIn y YouTube
12 de noviembre de 2018

Patrones de Movilidad en Lima y Callao basados en tecnología Big Data
Muchas veces pensamos en el Big Data como algo exclusivo para empresas privadas. Pero una de las aplicaciones más claras es la de organismos públicos que desean mejorar la vida y los servicios de sus ciudadanos. En esta línea, estamos trabajando con el Ministerio de Transportes y Comunicaciones de Perú y AATE en el análisis de movilidad urbana de la ciudad de Lima, con el objetivo de optimizar su línea de metro de Lima y Callao. El crecimiento poblacional de las ciudades es cada vez mayor, conformando un nuevo panorama urbano en el que la gestión de un sistema de transporte eficiente ha transcendido de las instituciones para convertise en una cuestión que tiene un impacto directo en la vida cotidiana de los ciudadanos. En este sentido, el transporte es un factor determinante en el desarrollo de las ciudades y, con el creciente auge de las llamadas Smart Cities, las infraestructuras de transporte deben ir ganando cada vez mayor presencia en las tomas de decisiones sobre la localización o el tipo de transporte a implantar en las ciudades. La Autoridad Autónoma del tren eléctrico de Lima (AATE), entidad que depende del Ministerio de Transportes y Comunicaciones del Perú, es la encargada de planificar, coordinar, supervisar, controlar y ejecutar la puesta en marcha de un sistema de transporte eléctrico masivo y eficaz en el área metropolita de Lima y Callao. Según Carlos Ugaz Montero, Director Ejecutivo de AATE, la ciudad de Lima era una de las pocas ciudades que carecia de un plan de transporte, siendo una de las ciudades del ranking de las 50 ciudades más pobladas de las Naciones Unidas. Por este motivo, la AATE está inmersa en la planificación de las nuevas líneas de metro, planificando un Estudio de Demanda, basado en encuestas, pero que necesitan complementarlo con datos que reflejen el comportamiento y las necesidades reales de la población. Basado en los datos que proporciona los teléfonos móviles, obtenidos por nuestra solución LUCA Transit, se han analizado los desplazamientos que realizan los usuarios de dichos teléfonos, que una vez anonimizados extrapolados y agregados, permitan estimar la cantidad de viajes en todo Lima y Callao. Tras un análsis realizado durante 4 meses, estos viajes se han categorizado en función del origen y el destino de los viajeros, así como en función de variables sociodemográficas, propósito de los viajes y variables de segmentación temporales. Así, hemos podido generar una solución para el cliente que ha constado de distintas etapas: Generación de una base de datos que represente los viajes reales realizados por los usuarios. Desarrollo de un visualizador, que permita hacer análisis en función de necesidades puntuales. Documentación técnica del proyecto, incluyendo tanto la parte metodológica como análisis de resultados, patrones y conclusiones. Sesiones de formación, asesoría y acompañamiento con el objetivo de sacar el mayor beneficio de los puntos detallados anteriormente. El estudio permite ver cómo se mueven los habitantes de la ciudad de Lima, conociendo sus rutas y permitiendo además ver sus diversos patrones de movilidad. Además, la segmentación de los habitantes ayuda a implementar un sistema de transporte más integrado y acorde a las necesidades de la ciudad. Así, podrán optimizar la construcción de la red de metro, fortaleciendo las comunicaciones entre los puntos que mayor demanda tienen y adaptando los horarios. Esto permitirá que los usuarios tengan que realizar menos trasbordos, lo que hará más cómodos y rápidos los viajes De modo que se han podido generar los patrones de comportamiento de los usuarios, y se ha generado una base de datos y un visualizador, que permite a AATE realizar análisis adicionales, en función de diferentes necesidades. Entre los principales resultados obtenidos está: • Identificación de los principales polos tanto generadores como atractores de viajes • Identificación de los días y horas medios con mayor demanda, en función del motivo que origina dichos viajes • Segmentación de los viajeros por variables sociodemográficas • Análisis de las zonas comerc LUCA transt, permite analizar los viajes realizados por la población basándonos en datos reales, no declarados, por lo que permite al cliente conocer las neceisdades reales de la población. Para mantenerte al día con LUCA visita nuestra página web, y no olvides seguirnos en Twitter, LinkedIn y YouTube.
11 de noviembre de 2018

Movistar Ads conecta a los desconectados en Latinoamérica
Escrito por Milena Quintana Pinto, Marketing of Mobile Advertising – LUCA Como promedio el 80% de los usuarios de dispositivos móviles de Movistar en Latinoamérica tienen planes de prepago. Esta realidad, sumada a la necesidad constante de ofrecer soluciones que entregan resultados de performance a las marcas al mismo tiempo que ofrecen un beneficio relevante a sus clientes, ha llevado a Movistar Ads a desarrollar distintas estrategias que ponen el foco de atención en aquello que resulta más importante para las personas en la actualidad: su conectividad. LUCA, la unidad de Big Data de Telefónica, trabaja el negocio de la publicidad en América Latina bajo Movistar Ads. Entre todos los servicios disponibles, el portafolio de productos de datos patrocinados ofrece una gran oportunidad, tanto para el mercado de publicidad móvil, como para el usuario final de la región, utilizando la conexión de las operadoras de Telefónica para entregar servicios de publicidad a cambio de una navegación patrocinada. Teniendo en cuenta que los usuarios cuidan mucho el uso de sus datos de conectividad - 74% del acceso en aplicaciones es realizado por wifi- y que al día el usuario gasta 15 megas aproximadamente solo en aplicaciones de su interés (entretenimiento, redes sociales y correo electrónicos), los servicios de Navegación Patrocinada y Data Rewards son la solución para el problema cuando el usuario se queda sin datos. En Latinoamérica, más de 1 millón de usuarios ya se benefician de los servicios de Navegación Patrocinada, con aproximadamente más de 11.000 gigabytes de conexión consumidos, lo cual es equivalente a ver el catálogo completo de Netflix casi dos veces* (aproximadamente 5.700 títulos*). El rol de las soluciones patrocinadas de Movistar Ads es muy completo y dispone de muchos beneficios al usuario/ cliente. Con Data Rewards, los anunciantes logran resultados muy positivos gracias a la garantía de entrega del mensaje de marca, al contar con una pregunta sobre el contenido de la publicidad al final de la campaña y por el vínculo creado entre marca y usuario por recompensar al consumidor en un momento clave en su navegación. Con la Navegación Patrocinada de Movistar Ads se permite a los usuarios de una marca acceder a su app, siempre que quieran sin consumir sus datos. Movistar Ads genera un doble beneficio, tanto para la marca, como para el usuario, donde la marca aumenta su presencia en el entorno digital móvil con la Navegación Patrocinada y también puede conseguir las mejores tasas de recall con el Data Rewards, mientras el cliente gana en acceso a la conexión. Telefónica tiene un rol convirtiendo problemas de conexión en verdaderas oportunidades de negocio para el mercado y de beneficio para el usuario. * 1 GB/hora de streaming Catalogo Netflix
6 de noviembre de 2018

Roles profesionales en el mundo del Big Data
En el mundo del Big Data y la Inteligencia Artificial, hay muchísimos roles de donde elegir, que requieren distintas habilidades, y es habitual tener muchas dudas si no se trabaja en tecnología. Es por ello, que dedicamos nuestro último LUCATalk, "Roles profesionales en el mundo del Big Data" a resolver estas preguntas, y escuchar las experiencias de tres expertos que trabajan en el sector. Una de las primeras preguntas que tienen los estudiantes o las personas buscando cambiar de carrera es ¿que cualidades son necesarias para trabajar en Big Data?, y la cualidad fundamental es la capacidad de análisis. El análisis es fundamental para sacar información de valor o insights, para luego convertirlos en conclusiones y acciones para mejorar el negocio. Aparte de la capacidad de análisis, conocimientos de matemática y programación siempre te ayudarán a tener éxito en estos roles. Figura 1. De acuerdo a InfoJobs, analista de datos y data scientist están entre los perfiles más buscados Dentro de los roles en Big Data, hay mucha variedad, y aunque las tareas de los Analistas de Datos y Data Scientists suele ser la misma en todas las empresas, va a depender mucho de empresa a empresa cuanto tiempo le dedican a limpieza de datos o modelado de datos. Dentro de los distintos roles analíticos, en Telefónica nos encontramos con distintas categorías que el Data Science y Business Intelligence comparten, tenemos roles más especializados a los datos y roles que son comerciales. Si no pudiste verlo en directo, no te pierdas el webinar completo a continuación: [embed]https://youtu.be/EcnNFy1QzPU[/embed] Durante la sesión de Q&A, nos quedaron un par de preguntas sin responder, que dejamos a continuación: 1. Cuál sería el tamaño mínimo para conformar equipo de Analytics y cuáles de los perfiles que describieron antes serían los más importantes La respuesta depende completamente de la estrategia y prioridades que defina el negocio. Asumiendo, por ejemplo una unidad de negocio básica (e.g. digital marketing, logistica, etc) que requiere de data analytics para efectuar tareas operacionales, de segmentación de productos/clientes, etc. debe ser suficiente con tener un equipo básico (2 personas) con un perfil de data analyst, o para análisis mas avanzado data scientists. Tambien es necesario tener por lo menos 1 data engineer o database administrator que ayude a los analistas a trabajar con los equipos de IT a crear, mantener y optimizar una infraestructura básica para almacenamiento y procesamiento del dato. 2. De todos estos roles analíticos (9 en total) , ¿cuáles deberían estar en áreas tecnológicas y cuales en áreas de negocio dentro de una empresa? Los roles de bid manager, pre-sales support y business analyst es conveniente mantenerlos cerca de las áreas de negocio ya que son ellos los que apoyan a los equipos de ventas en tarea técnicas. Si estos tres roles son lo suficientemente técnicos entonces los demás roles se pueden y es conveniente agruparlos dentro del área tecnológica. De esta manera, los data experts (data scientists, data analyst, etc) pueden trabajar de forma mas integral con equipos completamente técnicos como los son desarrolladores y equipos de operaciones. Sin embargo, muchas empresas deciden mover a los data experts a unidades comerciales y se espera que ellos hagan precisamente el vinculo entre el mundo tecnológico y el comercial. 3. ¿Es valorable como Data Scientist tener un portfolio para buscar trabajo? En ese caso, ¿cómo lo estructuraríais? Más que un portfolio detallado (el que se nos viene a la cabeza, es el que típicamente podría necesitar un arquitecto clásico), lo importante a la hora de buscar trabajo como Data Scientist no es tanto destacar los proyectos concretos en los que has trabajado sino las habilidades que has desarrollado en ellos. Por ejemplo, si trabajaste en un proyecto que involucró el desarrollo de un modelo de predicción cuya características más destacables son que conllevaba trabajar con un gran número de variables y que se resolvió con redes neuronales, lo importante es destacar tu experiencia en entornos con gran número de features y tú experiencia con redes neuronales. Es decir, a la hora de estructurar esto, repasaría las técnicas y entornos en los que has trabajado, más que todos los proyectos por los que has pasado, ya que pueden ser muchos y que las técnicas usadas se repitan. 4. ¿El rol de Big Data Visualization se ubica más en la parte Técnica o en la parte Comercial o depende del Proyecto? El rol de big data visualization es conveniente ubicarlo mas cerca a la parte comercial. La visualización del dato es muchas veces una de las partes mas importantes para resaltar el valor que se le ha encontrado al dato. Ese valor esta directamente vinculado con las prioridades y estrategia del negocio que en la mayor parte de las empresas es definido dentro de la parte comercial. Sin embargo esto no es absoluto, ya que habrá compañías donde la visualización se conceptualice como un producto final, en cuyo caso es mas conveniente ponerlo mas cerca de la parte técnica. En los comentarios de este post, también nos puedes dejar tus preguntas, y aclararemos todas tus dudas.
2 de noviembre de 2018

Las 3 Culturas
Escrito por Carlos Gil Bellosta. En 2001 se publicó la primera edición del muy influyente The Elements of Statistical Learning. En su prefacio, sus autores, T. Hastie, R. Tibshirani y J. Friedman, daban cuenta de la emergencia de una nueva disciplina, la ciencia de datos (entonces conocida como Data Mining o Machine Learning). The field of Statistics is constantly challenged by the problems that science and industry brings to its door. In the early days, these problems often came from agricultural and industrial experiments and were relatively small in scope. With the advent of computers and the information age, statistical problems have exploded both in size and complexity. Challenges in the areas of data storage, organization and searching have led to the new field of “data mining”; statistical and computational problems in biology and medicine have created “bioinformatics.” Vast amounts of data are being generated in many fields, and the statistician’s job is to make sense of it all: to extract important patterns and trends, and understand “what the data says.” We call this learning from data. El título del libro no es para nada inocente: la expresión aprendizaje estadístico es toda una declaración de intenciones. Que no son otras que tender puentes entre las dos disciplinas, la estadística y la ciencia de datos: This book is our attempt to bring together many of the important new ideas in learning, and explain them in a statistical framework. El mismo año, 2001, vio también la publicación de un artículo tan influyente como controvertido, Statistical Modeling: The Two Cultures, de Leo Breiman. Breiman identifica también esas dos disciplinas (o culturas), hasta cierto punto contrapuestas; sin embargo, en lugar de ensayar una síntesis de ambas, toma partido decididamente por una de ellas. No en vano, su artículo sigue citándose y utilizándose para marcar distancias entre la estadística clásica y la nueva disciplina emergente (sobre todo por quienes quieren dar a entender que la estadística tradicional es innecesaria para ser un científico de datos). Breiman describe los problemas del interés de ambas disciplinas como una función desconocida, una caja negra, la naturaleza, que asocia entradas a salidas: Figura 1: Breiman define la naturaleza como "caja negra". La estadística tradicional trata de simular esa caja negra con alguno de los modelos clásicos: Figura 2: En Estadística tradicional la "caja negra" se simula con modelos clásicos Como Hastie y sus coautores reconocen, estos modelos no bastan: gran parte de ellos fueron concebidos como soluciones para determinados problemas muy concretos en ingeniería (agrícola, industrial). Pero estos, pese a su importancia, representan un conjunto muy pequeño dentro del universo de los problemas que se plantea la ciencia de datos. La estadística clásica, simplemente, no sabe qué responder cuando se le plantean ese tipo de problemas (o, peor aún, estira esos métodos hasta extremos indefendibles). Breiman encuentra en el Machine Learning el modo de superar esa limitación: Figura 3: Breiman supera la limitación con Machine Learning. La idea no es nueva. Los ingenieros saben desde hace muchos años cómo aproximar funciones arbitrarias (p.e., una onda acústica, una canción) por otra que es una suma de senos y cosenos (mediante la descomposición de Fourier) con una precisión arbitraria. Eso sucede porque, como han probado los matemáticos, los senos y cosenos son densos en el universo de ese tipo de funciones. Los árboles de decisión, los bosques aleatorios, las redes neuronales, los boosted trees (XGBoost, etc.) son igualmente densos en el espacio de funciones que plantea la naturaleza y que interesan a los científicos de datos. Si queremos aproximar cualquier función, podemos usarlos y obtener predicciones razonables. Tal es el programa explícito de Breiman y también, más o menos implícitamente, el de toda una generación de científicos de datos. Sin embargo, este programa se queda igualmente corto en muchas aplicaciones reales. Pensemos, a modo de ejemplo, en el llamado filtro de Kalman, que se usa para mejorar la precisión de la ubicación de un móvil (p.e., un dron) que dispone de un GPS: lo hace corrigiendo estadísticamente la posición que indica el GPS en el momento t con la que se deduciría de su posición en el momento t-1 aplicando las leyes de la dinámica. Si quisiésemos reemplazar el filtro de Kalman por un sistema basado en, p.e., redes neuronales, estas tendrían que aprender por si mismas las leyes de la dinámica. Lo cual es un derroche manifiesto: las leyes de la dinámica son sobradamente conocidas y pueden modelarse explícitamente. La pregunta que uno puede entonces plantearse es: ¿podemos construir una caja alternativa a las dos que propone Breiman que incluya todo lo que ya sabemos del sistema de interés (y, en particular, las leyes de Newton)? La respuesta es positiva y hoy en día podemos modelar este tipo de sistemas (y muchos otros) en los que gran parte de lo que la caja negra hace es conocido y esa información previa puede introducirse explícitamente. Solo en algunos casos particulares esos modelos podrían reducirse a los de la estadística clásica, por lo que esta queda de nuevo superada. Y, habida cuenta de todo lo que sabemos sobre la naturaleza, nuestros modelos superarán también a los propuestos por cajas negras puras (por supuesto, siempre que exista información previa del tipo que se describe más arriba). Esta de la que aquí se da noticia podría considerarse una tercera cultura alternativa a las dos que distingue Breiman y su emergencia en estos años ha venido de la mano de avances teóricos y computaciones muy notables. ¿Has oído hablar de Stan, de Markov Chain Monte Carlo, de expectation propagation, de large scale Bayesian inference, de...? Pues es la tercera cultura que pide paso.
31 de octubre de 2018

Digitalizando las tiendas físicas
Como muchos otros sectores, el sector de Retail también esta pasando por una gran transformación. Gracias a los avances de la tecnología, hay muchas maneras de llegar a los clientes, promocionar productos y de hacer una compra. Agregando una capa de Big Data, los retail managers pueden asegurarse que todas sus decisiones están basadas en datos, y así, están reduciendo el riesgo de malas inversiones y malas decisiones. Pero con todos estos avances también llegan muchos retos, como ¿cual es el perfil de los clientes? y ¿que tipo de publicidad prefieren? En nuestro webinar "LUCA Store: Digitalizando las tiendas físicas" explicamos la situación actual del sector retail. Este sector se encuentra en una fase de transformación, que surge debido a distintos retos, entre ellos las nuevas necesidades de los clientes y las tecnologías disruptivas que están cambiando el mercado. Dentro de los retos en el retail, también se encuentran los clientes y el rol que juegan a la hora de decidir cuando y cómo comprar. 91% de las compras todavía se hacen en tiendas físicas, pero para 2020 se estima que un 50% de ventas serán de canales online. Cada vez más, los clientes prefieren experiencias cuando visitan una tienda, y quisieran una experiencia similar en tiendas físicas a la que tienen en tienda online, es decir, disfrutar de la compra y pasar de un canal a otro de manera más fluida. En una encuesta mundial, 4 de 10 consumidores han dicho que ir a una tienda física se ha vuelto una tarea y no una actividad de la que puedan disfrutar. Esto es importante, pues la decisión de compra se solía hacer dentro de la tienda física, y hoy en día tomamos esta decisión antes de llegar a la tienda, con previo conocimiento del producto (por redes sociales, recomendaciones de amigos o familia y páginas web). LUCA Store ayuda a retailers a mejorar las tomas de decisiones y mejorar los resultados de negocio con las herramientas que el Big Data puede aportar, mejorando el conocimiento del cliente, y su comportamiento.Con la ayuda de datos anonimizados y agregados, esta herramienta puede generar insights de mucho valor y sacarle el mayor provecho a las campañas publicitarias habiendo antes identificado el perfil de los clientes y las zonas de mayor impacto. Si no pudiste verlo en directo, puedes encontrarlo completo aquí: [embed]https://youtu.be/SPf2W1kvGwY[/embed] Esta herramienta cuenta con tres fuentes de datos anonimizados y agregados: red móvil, dispositivos in-store y datos transaccionales, y proporciona insights fuera y dentro de los puntos de venta. Fuera de la tienda, se pueden conocer los perfiles de los clientes que normalmente se encuentran en los alrededores de los negocios, analizar la mejor ubicación para nuevos puntos de venta y observar las áreas en las que hay más de una tienda que ofrece el mismo producto o servicio y está compitiendo varias por el mismo target. Dentro de la tienda, los principales insights son conocer el perfil del cliente y compararlo con los perfiles de los clientes potenciales que frecuentan el área alrededor del punto de venta, averiguar el comportamiento de los clientes en el establecimiento e identificar el perfil de los clientes más leales o beneficiosos y establecer el ratio de numero de clientes en comparación con número de personas cerca del punto de venta. LUCA Store también ayuda a los retailers con campañas de marketing y benchmarking. Para obtener los datos con los que trabaja LUCA Store, hay 4 pasos a seguir. El primer paso es la extracción de los datos, donde se recaba información de la localización de los usuarios de Telefónica directamente de los sistemas. El segundo paso es la anonimización de los datos, los datos personales se eliminan y se reemplazan por un identificador "hash" no reversible, con la eliminación de datos personales, se protege completamente a los usuarios. En el tercer paso se extrapolan los datos, de modo que se pueden establecer conclusiones sobre la población total y finalmente se agregan, el paso de agregación garantiza trabajar siempre con conjuntos de individuos y refuerza la privacidad y protección de los datos de los clientes. El diferencial de LUCA Store es de contar con datos de calidad, una mejor plataforma y una implementación "end to end". LUCA Store utiliza también la plataforma Smart Steps, una plataforma pionera a nivel mundial en extracción de insights de movilidad. Al final del webinar, tuvimos una sesión de Q&A, y podrás encontrar todas las respuestas en nuestro canal de YouTube.
19 de octubre de 2018

Movistar Home ya está aquí para transformar tu hogar...¡resérvalo!
En su proceso de transformación digital, Telefónica anunció en el pasado Mobile World Congress el lanzamiento comercial en España de Movistar Home, un dispositivo cuyo objetivo es reinventar el hogar y que tiene integrado Aura, la inteligencia artificial de la Compañía. Pues bien, lo prometido es deuda y Movistar Home ya está aquí para revolucionar la forma de comunicarse y consumir la TV en el hogar y para celebrar su lanzamiento, Movistar ha lanzado una promoción para que sus clientes puedan reservarlo a un precio exclusivo hasta el 16 de octubre (solo para las primeras 5.000 unidades). ¿Qué se puede hacer con Movistar Home? Movistar Home reinventa el teléfono fijo y lo convierte en un dispositivo inteligente, de forma que mediante el comando de voz “OK Aura”, realiza llamadas y video llamadas (esta última sólo si el destinatario de la llamada tiene también Movistar Home). Ya no tienes que elegir entre tu madre o el sofá. Sigue tumbado y llámala con el comando: "OK Aura, llama a mamá” Movistar Home también cambia tu manera de ver la televisión. Puedes, por ejemplo, ver tu serie favorita, subir el volumen o pedir la recomendación de una película, solo con decir "OK Aura, quiero ver La Peste", "OK Aura, sube el volumen” u "OK Aura recomiéndame una peli”. Otra de las funcionalidades más populares de Movistar Home es aquella que te ayuda a relacionarte con la tecnología en tu hogar, facilitándote tu conectividad. Por ejemplo, recuerda fácilmente tu clave Wifi con el comando “OK Aura dime la clave de la WiFi”. ¿Qué necesito para poder adquirir un Movistar Home? Para poder adquirir un Movistar Home solo necesitas ser cliente de Fusión con fibra , tener un Router Smart Wifi y tener contratado Movistar+ (no válido para clientes de Satélite). Haz tu reserva antes del 16 de Octubre, y podrás adquirirlo por 49 euros solo para las primeras 5.000 unidades. Características técnicas Es un dispositivo que se ha definido y construido tanto a nivel hardware como a nivel software en Telefónica, lo que nos ha permitido incorporar los componentes clave para el uso de los servicios. A alto nivel, las características del dispositivo incorporan: - Tecnología de reconocimiento de voz - Cámara para ver en condiciones de baja luminosidad - Pantalla de 8" - Privacidad (mute y mirilla) - 2 Gb de RAM y 16 de Flash Sigue nuestras noticias en Telegram
12 de octubre de 2018

Los datos y la fe
Post escrito por Enrique Dans, experto en tecnología y profesor de innovación en IE Business School. A medida que se desarrolla el panorama del machine learning, su evolución ofrece una perspectiva que, para muchos, puede resultar desconcertante. Cuando hablamos de la posibilidad de enseñar a una máquina a aprender y de cambiar, por tanto, el concepto que hemos tenido desde hace muchas décadas sobre lo que es un ordenador, hablamos, seguramente, de una de las mayores revoluciones que ha vivido la humanidad en su conjunto a lo largo de toda su historia, comparable seguramente, como dijo Sundar Pichai, CEO de Google, al impacto que tuvo el descubrimiento del fuego o de la electricidad. Y sin embargo, a pesar de su magnitud, hablamos de un campo que parece tener mucho más de evolución lenta que de revolución, y que periódicamente, además, parece sufrir crisis de fe y vaivenes de todo tipo asociados con su desarrollo. Figura 1. El machine learning recibe hoy más atención gracias al incremento de potencia de la computación, a la progresiva disminución de su coste, y a la abundancia y disponibilidad de datos. Desde que Arthur Samuel acuñó el término machine learning en 1959 y desarrolló un algoritmo capaz de jugar a las damas, la disciplina ha combinado décadas de avances febriles con otras de total abandono y desilusión. En la práctica, el pico de atención que hoy vivimos, con un número creciente de compañías haciendo referencia al término en su planificación estratégica, corresponde únicamente a la aplicación de técnicas con décadas de antigüedad convertidas en viables gracias al incremento de potencia de la computación, a la progresiva disminución de su coste, y a la abundancia y disponibilidad de datos. Sin embargo, la ignorancia de muchos medios a la hora de cubrir el fenómeno, la confusión en torno al mismo y la tendencia sensacionalista a ilustrar cada noticia sobre el tema con al menos una imagen de un robot Terminator están contribuyendo a crear una peligrosa inflación de expectativas en torno al asunto que bien podría llegar a generar un nuevo período de escepticismo. El caso de Google y su CEO resulta especialmente paradigmático: en la conferencia inaugural de la edición de 2018 del Google I/O, la conferencia en la que la compañía intenta agasajar a los desarrolladores que utilizan sus herramientas para que continúen haciéndolo, el término machine learning se repitió de manera constante, casi obsesiva, como si fuera un mantra. Algo por otro lado lógico en una empresa que lleva ya varios años poniendo machine learning en todas partes, repensando y reconceptualizando absolutamente todos sus productos para que la incluyan, y dando formación a la práctica totalidad de sus empleados para que sean capaces de conceptualizar sus ideas en ese ámbito. La respuesta ante la impresionante fijación de compañías como Google en la mayoría de las empresas suele ser inmediata: “nosotros no somos Google”. Y en efecto: hablamos de una de las compañías más grandes y con mayor crecimiento del mundo, que desarrolla su actividad en un entorno de innovación radical y que resulta difícilmente comparable o utilizable como ejemplo a seguir. Sus circunstancias y problemáticas, simplemente, son vistas como demasiado lejanas por la inmensa mayoría de los directivos, como tiende a ocurrir también con otras compañías de perfil similar como Apple, Facebook o Amazon. ¿Podemos - o debemos - intentar inspirarnos en ellas y en su estrategia? La respuesta, hoy más que nunca, es un sonoro sí. Hablamos de compañías que son lo que son no porque hayan tenido suerte, sino por la forma que tienen de trabajar cuando se enfrentan a un desafío. Y cuando todas esas compañías consideran el Machine Learning como el actual gran desafío y se organizan para gestionarlo como ventaja competitiva, deberíamos pensar que no es que sean víctimas de algún tipo de alucinación colectiva, sino que, muy posiblemente, sepan de lo que hablan. Tal vez nuestra compañía no sea Google ni se le parezca, pero si no afronta ahora el desafío que implica la adopción del Machine Learning, dentro de pocos años, no existirá, y su hueco en el mercado habrá sido ocupado por compañías que sí supieron verlo. ¿Cómo afrontar el desafío que supone el Machine Learning desde la óptica de una compañía “normal”, no de un gigante de la tecnología? En primer lugar, considerando su aplicación desde una perspectiva abierta, inclusiva y ambiciosa, susceptible de revolucionar completamente el modelo de negocio de la compañía. Cuando comenzamos a pensar en términos de datos y de su análisis, podemos encontrarnos con que terminamos construyendo la ventaja competitiva de la compañía, sus productos o sus servicios en torno a planteamientos completamente distintos a los que históricamente hemos manejado. Una compañía que vende productos podría, por ejemplo, convertirse en una de servicios en función de los datos que el uso de esos productos pueden generar, un reto que la mayoría de los directivos con experiencia en una industria suelen ser incapaces simplemente de imaginar. Figura 2. Una compañía que vende productos podría, por ejemplo, convertirse en una de servicios en función de los datos que el uso de esos productos pueden generar. Pero además, el reto exige entender que todo proyecto de Machine Learning implica arquitecturas de datos que no todas las compañías tienen, que las fases iniciales del proyecto, como ya comentamos en un artículo anterior, consumen muchísimos más recursos que las finales, y que resulta enormemente importante contar con un socio adecuado que sepa realmente lo que está haciendo. Pero además, implica entender que más pronto que tarde, tendremos que transformar completamente nuestra compañía, que rediseñar todos nuestros productos y servicios en torno al Machine Learning (¿no lo hicimos, acaso, en torno a internet?), que formar a la práctica totalidad de nuestro personal para que adquieran familiaridad con el nuevo contexto, y que pasar a ver el Machine Learning, o el que nuestro Machine Learning sea mejor que el Machine Learning de la competencia, como una parte fundamental de nuestra ventaja competitiva. No, no hablamos simplemente de hacer o plantear Machine Learning: hablamos de automatizarlo, de convertirlo en una parte integrante de nuestros procesos empresariales. Todo esto, que parece exceder las dimensiones de la mayoría de los cambios que hemos vivido como directivos, tenemos que afrontarlo con una enorme ambición, no como un proyecto más o como “unas pruebas”, sino como algo que tiene la dimensión suficiente como para transformar completamente nuestra compañía. Y para eso, mucho me temo, hace falta fe. No una fe ciega, porque ya tenemos evidencias suficientes de que hablamos de un cambio que va a transformar ya no nuestra compañía, sino el mundo tal y como lo conocemos, pero fe al fin y al cabo. Si no la tienes, prepárate: vas a necesitarla.
10 de octubre de 2018

Campañas digitales exitosas con Smart Insights
Post escrito por Carlos Vayas, Business Manager Big Data & Advertising La clave para el éxito de las campañas digitales está en tener los datos apropiados en el momento de la toma de decisión y en la capacidad de optimizar acciones basadas en datos en tiempo real. Por esa razón, muchas de las grandes marcas están ejerciendo in house actividades, antes asumidas por la agencia, como la planificación, la gestión del presupuesto, la relación con los medios de comunicación, etc. Este camino elegido por el 60% de los anunciantes asegura, además de ganar agilidad, el tener a un equipo con una mayor capacidad analítica de los datos y una mayor confidencialidad de los mismos. Una vez formado este equipo, capaz de diseñar la mejor estrategia online basada en datos, es imprescindible adoptar la mejor solución para garantizar el buen manejo, el análisis y la optimización de los datos del target de los clientes. Con este objetivo, Movistar Ads ha creado SmartInsights, una herramienta de análisis de datos indoor descriptiva y predictiva. Con esta herramienta, se estudia el perfil del target de los clientes que entran o se acercan al punto de venta, con el objetivo de entregar insights relevantes sobre su comportamiento indoor a través de la plataforma. Los insights son presentados de forma agregada y anonimizada. Sólo los clientes de Movistar que han dado su consentimiento para recibir publicidad, recibirán mensajes de texto con las ofertas. SmartInsights es una potente propuesta que complementa a SmartSteps con diversos casos de uso en retail, supermercados, banca, consumo masivo, etc. De esta manera, la solución apoya la construcción de la estrategia móvil de cualquier empresa. Con acceso real time a los datos, Smart Insights cambiará radicalmente el mercado:
27 de septiembre de 2018

Decisiones cotidianas basadas en datos: data-driven life
Post escrito por José Luis Orihuela, profesor universitario, conferenciante y escritor. Analiza el impacto de las innovaciones tecnológicas sobre los modos y los medios de comunicación. Autor de Los medios después de internet. Una de las consecuencias más fascinantes de la hiperconectividad es que los usuarios de las redes estamos tomando cada vez más decisiones basadas en datos, aunque el proceso quede disimulado por interfaces tan amigables que nos acaba resultando completamente natural. Los algoritmos de los buscadores y de las plataformas sociales que utilizamos a diario se alimentan de nuestros datos y nos devuelven datos agregados, procesados y refinados de tal forma que hemos dejado de verlos como datos. Desde el buscador que corrige nuestra sintaxis y selecciona diez resultados entre cien millones, hasta las contenidos que aparecen en el timeline de nuestras redes sociales favoritas como por arte de magia, todo se basa en datos que nos ayudan a tomar decisiones cotidianas. La música, las películas, las series y los libros que nos sugieren los algoritmos de recomendación de los portales especializados, así como los hoteles y restaurantes que nos proponen las guías de viajes virtuales, se alimentan no solo de nuestro historial y grafo social, sino también de la inteligencia de datos de miles o millones de usuarios. Es la capacidad de recolectar, agregar y refinar datos de modo masivo lo que confiere valor a los servicios “sociales” que las redes y los móviles nos acercan de forma permanente. Sobre esos datos vamos tomando decisiones todos los días por lo que nuestra vida, al decir de la revista del New York Times, se ha convertido en "The Data-Driven Life". Aunque en los entornos corporativos ya resulta habitual hablar de gestión, toma de decisiones y marketing basado en datos, todavía no terminamos de hacernos cargo que también en los ámbitos personales los procesos de toma de decisiones están cada vez más condicionados y enriquecidos por datos, incluso cuando “dialogamos” con un altavoz inteligente. A medida que la internet de las cosas se extiende a dispositivos de uso cotidiano como los relojes inteligentes y los medidores de actividad física, las métricas personales de cada usuario entran en una escala de datos masivos cuyo procesamiento y visualización orientan la toma de decisiones sobre aspectos como las horas de sueño, el consumo de calorías, el control del peso, el ritmo cardíaco y las distancias a recorrer. Las estadísticas que rodean toda nuestra actividad en las redes sociales, a veces hasta extremos obsesivos, también son datos sobre los que tomamos decisiones. Hemos aprendido a golpe de likes, qué fotos funcionan mejor, con qué filtros y palabras clave y a qué hora hay que publicarlas… Aunque seguiremos tomando decisiones personales a partir de la experiencia, el razonamiento y las emociones, es bueno reconocer que los datos (revestidos con interfaces amigables) ya forman parte del modo en el que la tecnología nos ha impulsado a relacionarnos con nuestro entorno. Si aprender a leer y a escribir mediante enlaces de hipertexto fue la alfabetización requerida para vivir en el mundo que creó la Web, aprender a leer, visualizar e interpretar datos serán las destrezas necesarias para vivir en un mundo hiperconectado. También puedes seguirnos en Twitter, YouTube y LinkedIn
26 de septiembre de 2018

Los 6 tipos de historias que pueden contar tus datos
Los datos son uno de los activos principales de un negocio, y las analíticas de datos son una de las fuentes principales de ventaja competitiva para una organización o empresa. De la misma manera que una película o un relato nos cuenta algo nuevo e interesante, los datos también nos pueden contar historias. En nuestro último webinar, hablamos sobre la técnica de “Historias de datos”, también conocida como “Data Storytelling” o “Analytical Stories” y cómo esta técnica nos puede ayudar a convertir los insights que se obtienen a través de los datos, en acciones. En el libro “Keeping Up with the Quants”, los autores Thomas H. Davenport y Jinho Kim, proponen utilizar esta técnica de storytelling desde el principio, al definir el problema, y no al final del proceso de análisis. El proceso de análisis normalment e tiene 3 fases: Definición del problema, Resolución del problema, y Comunicar y Actuar. En la primera fase, una vez sabemos cual es el problema que queremos resolver, también definimos que tipo de historia queremos contar. Antes de entrar en detalle sobre las 6 historias de datos, es importante entender las 4 dimensiones de las historias: tiempo, enfoque, método y profundidad del análisis. Por ejemplo, una encuesta cae dentro de la dimensión de tiempo, pues se estamos hablando de datos recolectados en el presente. Puedes ver el webinar completo a continuación: Brevemente, repasaremos las 6 historias y para qué sirve cada una. 1. Historia CSI Las historias CSI, tienen como objetivo mejorar la eficiencia de un proceso. En este tipo de historias no se hacen cambios en el modelo de negocio. Los datos se utilizan para investigar la naturaleza del problema. Un ejemplo que vimos en el webinar fue el caso de Expedia y su proceso de pagos. La empresa notó que muchos procesos de compra no llegaban a completarse, y después de mucha investigación descubrieron que esto se debía a uno de los campos a rellenar. El campo "Empresa" estaba generando confusión para los compradores, pues ellos pensaban que tenían que poner el nombre del banco donde tenían su cuenta y no era así. Después de contar con estos datos, Expedia eliminó este campo de su formulario de pagos, y solucionó el problema. 2. Historia "Eureka, lo encontré" Las historias Eureka están orientadas a un problema muy concreto cuya solución puede suponer un cambio importante en la estrategia o modelo de negocio. Estas historias suelen ser más largas, analíticas y complejas. 3. Historia "Científico Loco" Las historias Científico loco, son experimentos reales y científicamente validos. Estas historias permiten estudiar la relación causa y efecto. Este estilo de historias se puede utilizar en negocios con diferentes sucursales, o en páginas web, para hacer comparaciones entre A y B. 4. Encuesta De todas estas historias, las encuestas son las que probablemente te suenen más conocidas. Las encuestas son un método clásico de investigación cuantitativa, cuyo objetivo no es manipular el resultado si no observarlo, codificarlo y analizarlo. 5. Historias Predictivas Las historias predictivas se basan en analizar y comprender datos del pasado para extrapolar y predecir comportamientos futuros. Un ejemplo de una historia predictiva es determinar que oferta será mas atractiva para el cliente. 6.Historia "Y esto fué lo que pasó" Finalmente, las historias "y esto fué lo que pasó" proporcionan los hechos y cuentan lo que sucedió mediante los datos. Son historias creadas para informar. Estas historias no requieren análisis, pero es importante elaborar visualizaciones de datos efectivas y atractivas que den un soporte a la historia. ¿Y tus datos, en cual de estas historias encajan?
20 de septiembre de 2018

Tres maneras en que el Big Data y la Inteligencia Artificial están transformando el sector de los medios de comunicación
En junio de 2017 el New York Times puso a prueba uno de sus rediseños más ambiciosos desde 2014. Sin embargo, el cambio más profundo no se veía a simple vista.. De la noche a la mañana, el periódico que tú leías desde el móvil era distinto al que leía yo. Igual que los resultados de búsqueda de Google son distintos para una persona que para otra. El NYT de hace varias décadas llevaba en sus páginas cada mañana a los quioscos las noticias que los editores consideraban más importantes; el periódico digital actual también lo hace, pero al criterio de los editores han añadido un condimento: tu opinión. En palabras de Caroline Que, editora del diario: "Producimos una gran cantidad de buen periodismo; simplemente, no queremos desperdiciarlo" Este nivel de personalización no sería posible si el New York Times, como están haciendo la mayoría de empresas que quieren competir en el terreno digital, no estuviera recopilando, procesando y analizando gran cantidad de datos de sus lectores. Los experimentos realizados por el NYT son muchos y variados: mostrar noticias diferentes en la portada según el lugar desde el que el lector se conecta, cambiar la velocidad de actualización de las historias en función de la frecuencia con la que el usuario accede (a lectores más 'adictos' a la información', mayor velocidad de actualización) o proponer al lector historias sobre temas por los que haya demostrado interés en el pasado. ¿Qué sentido tiene todo esto? ¿por qué no "dejar las cosas como están"? Qué ganas de enredar en algo que funciona perfectamente, después de todo. Bueno, la mala noticia para el periodismo es que hace tiempo que "la cosa" no funciona perfectamente. La irrupción de las nuevas tecnologías ha reducido los ingresos publicitarios que solían financiar el trabajo periodístico y ha lanzado a los medios --lo quieran o no-- a competir por lo atención de los lectores en un entorno, el de Internet, muy distinto al que estaban acostumbrados. He aquí tres verdades incómodas para el periodismo que justifican, y ejemplifican, cómo el NYT, que "no enreda" a lo tonto, esté invirtiendo en análisis de datos e inteligencia artificial para prosperar en esta nueva realidad: 1. El periodismo compite por el tiempo de personas que tienen ofertas más atractivas (o cómo el análisis de datos puede ayudar a mejorar la distribución). El mercado de Internet se ha convertido en una lucha por un bien escaso: el tiempo. El limitado tiempo que alguien tiene a lo largo del día para conectarse a Internet desde su móvil y pinchar en un enlace. En ese mercado del tiempo los periodistas estamos compitiendo --no seamos ingenuos-- con ofertas más atractivas: el atractivo de cotillear en lo que está haciendo el vecino en Facebook, el atractivo de ver una serie en Netflix de la que todo el mundo habla o de consultar cualquier aspecto del conocimiento humano escribiendo unas pocas palabras en un buscador, todo a golpe de un click. Por eso no podemos permitirnos renunciar a tratar de llegar a los lectores allá dónde estén, mejorando la distribución de las noticias todo lo que se pueda. En 2015 el NYT producía alrededor de 300 noticias cada día, de las cuales sólo unas 50 llegaban a publicarse en Facebook, incluso menos en fin de semana. Llegaron a la conclusión de que no podían permitirse el lujo de perder ninguna de esas 50 oportunidades diarias de captar lectores. El equipo de Data Science del periódico creó un "bot" para Slack llamado "Blossom" capaz de predecir, a partir de datos históricos, cuál de esas 300 noticias tenía más posibilidad de funcionar en Facebook. A la vista de los resultados, lo consiguieron: un post de Facebook "típico" recomendado por Blossom tiene 380 más clicks que uno no recomendado. 2. A la gente no le gusta ver anuncios ni pagar por ser informada (o cómo los datos pueden ayudar a tomar mejores decisiones de negocio). Que a la gente no le gusta pagar es tan cierto como que el trabajo de los periodistas, sobre todo si queremos que sea de calidad, hay que pagarlo bien y que el dinero no brota de los árboles. ¿Entonces qué hacemos? No hay una solución fácil, pero las tendencias más prometedoras pasan otra vez por el análisis de datos. La primera gran vía es tratar de mejorar la efectividad de la publicidad mostrando menos anuncios, pero más relevantes y menos molestos para el que los ve. En este sentido, el NYT acaba de anunciar la creación de un grupo llamado nytDEMO encargado de adaptar para los anunciantes las herramientas de análisis de datos que ya usaban internamente. Una de esas herramientas, Project Feels, utiliza el análisis de datos para prever la reacción emocional de los usuarios ante una noticia. La intención del periódico es usar esa herramienta en lo que han llamado "perspective targeting": relacionar anuncios con artículos que vayan a producir una determinada emoción en los lectores. Es decir, ya no sólo se muestran anuncios pensando en la ubicación, el tipo de lector o el tema, sino incluso en la reacción esperada a la noticia. Todo para que el anuncio tenga el mayor efecto y la publicidad sea relevante para la persona. La segunda gran alternativa es conseguir que la gente pague por el periodismo que lee. Y la mejor forma de hacerlo es conseguir que tus lectores sean "fans"; no simplemente que les guste leer tu periódico, sino que sean "frikis" de él, que te reivindiquen, que se sientan identificados como un seguidor de "Juego de Tronos" se define con la HBO. Un nivel de compromiso que es difícil conseguir y que se alcanza, en parte, dando a los lectores la sensación de que forman parte de un selecto club reservado para unos privilegiados. Los comentarios en las noticias son uno de los ingredientes en esta receta. ¿Qué mejor para sentir que formas parte de una familia que poder dar tu opinión en las reuniones familiares? El "pero", y no es un "pero" menor, es que moderar los comentarios de las noticias es caro. Un periódico como el NYT tiene un equipo de 14 personas a tiempo completo expulsando a "trolls", eliminando insultos y asegurándose de que en su sección de comentarios se respeta un ambiente sano para el diálogo. 14 personas: un lujo no al alcance de todo el mundo. Y aún así ese equipo sólo permitía hasta hace poco al NYT moderar los comentarios en el 10% de sus noticias. Muchos medios se han visto en la obligación de sacrificar el "engagement" que conseguían con los comentarios para ahorrar costes. El Times, sin embargo, que se toma muy en serio lo de aumentar su base de suscriptores, ha encontrado, gracias a la inteligencia artificial, una alternativa. En junio de 2017 puso en marcha una sistema llamado Moderator, desarrollado con Jigsaw, el incubador tecnológico de Google, para filtrar automáticamente los comentarios que se envía a su equipo de moderadores. Con ese sistema, el número de artículos con comentarios ha pasado del 10 al 80%. Los comentarios es sólo un ejemplo de cómo el NYT aplica modelos matemáticos para aumentar el número de suscriptores: tratar de predecir qué suscriptor está a punto de darse de baja, antes incluso de de que lo haga o basar en el análisis de datos las campañas de marketing online para aumentar los suscriptores en momentos y lugares concretos son otros ejemplos. 3 - Hacer buen periodismo es caro (o cómo los datos pueden ayudar a hacer mejor contenido). Es un hecho que tanto los lectores como algunos periodistas parecen ignorar, pero es cierto. Enviar alguien a un país lejano para cubrir un conflicto es caro; dejar que un reportero investigue una historia durante un mes o dos, es caro; el mal periodismo es barato, pero el bueno suele resultar caro. En un mundo de "fake news", queremos que el buen periodismo sobreviva. Por ese motivo no podemos permitirnos que nuestro orgullo nos impida usar todos los recursos a nuestro alcance para hacer el mejor contenido posible. Un medio digital como BuzzFeed cuenta con más de 20 herramientas internas para que cualquiera dentro de la organización pueda obtener respuestas de los datos. Cuestiones como: ¿qué es lo que interesa a nuestra audiencia? ¿de qué se está hablando ahora mismo en las redes sociales? ¿qué tema preocupa en este país concreto o, incluso, en esta ciudad concreta? ¿qué información necesita recibir la gente para estar mejor informada sobre ese tema? ¿qué fotografía puede funcionar con esta historia? ¿qué titular va a conseguir que este tema importante sea leído por más personas? No se trata de trocar el criterio periodístico de un profesional por un algoritmo, se trata de dotar a ese profesional de todas las herramientas posibles para que su trabajo tenga una repercusión real en la sociedad. Desde luego que hay riesgos, pero también oportunidades. Nunca antes los periodistas supieron tanto de sus lectores. Aprovechémoslo. Post escrito por Iñaki Hernandez, Periodista de datos en EuropaPress y colaborador de Huffington Post . También puedes seguirnos en Twitter, YouTube y LinkedIn
19 de septiembre de 2018

¿Cuál es tu obra de arte? Descubre tu copia con Inteligencia Artificial y Machine Learning
Imagínate visitar un museo y descubrir que tienes un gran parecido a La Mona Lisa, La joven de La Perla, Frida Kahlo o quizás a El Grito de Munch, ¿conoces a tu doble artístico? La nueva característica de Google Arts & Culture ha resultado ser un auténtico éxito en España. Una aplicación que permite, a todas aquellas personas que hayan instalado la última actualización en sus teléfonos móviles, descubrir en qué obra de arte aparecen rostros similares al tuyo a través de un simple "selfi" y sistemas de reconocimiento facial e Inteligencia Artificial. La fiebre por el autorretrato, o el actual "fenómeno selfi" no es cuestión del siglo XXI o el boom de los smartphones. Lo más parecido al primer autorretrato data de la Edad Antigua, cuando alrededor del año 1300 a. C. en Egipto, un escultor de nombre Bek esculpió un autorretrato sobre piedra. De todos modos, se dice que el género del autorretrato nació en el Renacimiento, cuando la Historia del Arte se comenzaba a convertir en la historia misma de los artistas, y fueron muchos los pintores como Leonardo da Vinci, Van Gogh, Francisco de Goya o Diego Velázquez que convirtieron su propia imagen en modelo para sus creaciones. Hoy en día el autorretrato no es solo privilegio de dioses, personajes poderosos o grandes artistas como antes, cualquiera puede sacarse un "selfi", incluso conocer su copia en obra de arte. Figura 2: selfie con la obra de un museo Hasta ahora, Google & Arts destacaba por ser e l museo virtual más importante de Internet, gracias a la colaboración de la compañía con más de 1200 museos, galerías e instituciones de 70 países, haciendo que sus exposiciones y obras de arte más relevantes estén disponibles online. Ahora, la aplicación llega a un nuevo nivel gracias a su nueva característica, que se lanzó en enero de este año en Estados Unidos y ya está disponible también en España, haciéndose viral y arrasando en las redes sociales. Tras más de 78 millones de "Art Selfis" y la colaboración de instituciones procedentes de todo el mundo, el número de obras de arte disponibles en la app ha aumentado el doble, creando un archivo digital muy variado. El programa utiliza un sistema de Inteligencia Artificial y reconocimiento facial que relaciona los rasgos de la fotografía con el archivo digitalizado de obras de los museos colaboradores. Así, a través de la te cnología por visión por ordenador basada en Machine Learning, el selfi se compara con todas esas obras en las bases de datos y muestra un porcentaje para estimar el parecido entre el cuadro y la foto del usuario. Además, si pinchas sobre el retrato al que te pareces, ofrece información adicional sobre la obra y artista que ha aparecido. especifica en qué museo se encuentra la obra para que los usuarios puedan visitar a su copia en directo, apoyando el objetivo de Google de fomentar el conocimiento y el gusto por el arte. Una manera más basada en tecnologías de Machine Learning e Inteligencia Artificial que ayuda a los usuarios a conocer más sobre la historia del arte y fomentar el interés por los museos y exposiciones.
17 de septiembre de 2018

Tendencias de datos que debes saber. Contra la posverdad, la alfabetización
Parece contradictorio que, en un mundo con cada vez más información y digitalización, las organizaciones se consideren peores que nunca en la toma de decisiones basadas en datos. Para Dan Sommer, líder de Market Intelligence de Qlik, esta afirmación no sólo es cierta, sino que es resultado de un escenario tan cambiante que está conduciendo a una ignorancia en el manejo e interpretación de datos. “Tenemos acceso a más datos que nunca, pero están más fragmentados, con naturalezas y formatos muy diferentes”. Según este experto, a la fragmentación se le suma una “explosión” en el desarrollo de tecnologías analíticas. IoT, Machine Learning… nacen bajo nuevos ecosistemas de proveedores, herramientas y plataformas. Ya no hay un único estándar, ahora diversos modelos conviven, compiten, se complementan, aportan y evolucionan. En esta misma línea opina Gustavo Loewe, Country Manager de Mongo DB : “El 80% de los datos que se generan son desestructurados. Han aumentado los riesgos, el tiempo y los costes de la gestión de datos. Las bases no siempre están optimizadas para las apps de hoy” De acuerdo con la visión de Dan Sommer, “No podemos adaptarnos a la misma velocidad con que lo hace la tecnología, lo que genera un ‘data gap’ o brecha de datos”. Esta brecha contamina la información y convierte la toma de decisiones en un proceso complejo y agotador hasta dar con información válida y de interés. Redes como Facebook o Twitter funcionan como filtros, pero con una visión limitada. Proporcionan generalmente opiniones afines, creando una burbuja de la realidad que impide ver más allá. Sommer recordó los escándalos del Brexit, Cambridge Analytica o el auge de las noticias falsas. “Es posible manipular incluso la voz para que una máquina diga por ti algo que nunca has dicho. Es una mezcla de noticias falsas y machine learning”. Vivimos en la era de la posverdad. La realidad se modela hasta lograr más relevancia que la verdad en sí misma. 45% de los profesionales tienen dificultades para diferenciar un dato real de otro que no lo es. 65% de las organizaciones tomaría decisiones guiadas por la intuición antes que los datos cuando éstos contradicen sus opiniones previas. 23% de las compañías comprueban de forma habitual los resultados que consiguen con sus decisiones de negocio. (Fuente: “Data Equality Survey 2017”, estudio realizado por Qlik y Censuswide entre 5.291 profesionales en Reino Unido, Francia, Alemania, España y Suecia en 2017) La alfabetización de datos como respuesta Sommer expone que sólo conseguiremos superar la era de la posverdad gracias a la alfabetización de datos. Al igual que las capacidades de leer o escribir fueron revolucionarias hace años y hoy son básicas, llegará el momento en que la alfabetización en datos será imprescindible para abarcar la información que nos rodea, no sólo en las organizaciones sino en la vida diaria. “La alfabetización de datos es la capacidad de interpretar datos, trabajar con ellos, analizarlos y argumentarlos. Ser críticos y cuestionarlos, pero también la habilidad de crear historias con datos y ser persuasivos cuando los exponemos” 85% de los alfabetizados en datos asegura que se desenvuelve muy bien en el trabajo, en comparación con apenas el 54% entre los usuarios que no se consideran alfabetizados en datos. 87% de los profesionales españoles querrían invertir más tiempo en mejorar sus habilidades en datos si tuvieran la oportunidad. (Fuente: “Data Equality Survey 2017”) La alfabetización de datos en publicidad. ¿Qué es mejor, 1/4 ó 1/3 de hamburguesa? Como muestra del impacto de la alfabetización de datos en el día a día, Sommer expuso el ejemplo de una franquicia de comida rápida, que lanzó una hamburguesa de 1/3 de libra presumiendo ser más grande que la de su competencia. Sin embargo, tuvo que retirar la campaña porque la hamburguesa de 1/4 de libra era percibida como más grande que la de 1/3. “Esto es un problema de alfabetización de datos”, subrayó. Próximas tendencias en analítica de datos Basándose en la definición de alfabetización de datos como la “capacidad de interpretar, trabajar, analizar y argumentar con datos”, Dan Sommer desgrana las tendencias que se imponen a partir de este año: Interpretar todos tus datos: La combinación de nubes privadas y públicas (híbridas) haciendo uso de las últimas tecnologías que nos proporcionen la capacidad de usar todos los datos. Esto nos conduce a descubrir realmente el Big Data y aportar más valor a la organización. Trabajar y analizar datos haciendo combinaciones. Tecnologías que se interrelacionan y crean nuevos modelos, propiciando la toma de decisiones basadas en datos mediante herramientas self-service. El Blockchain también evolucionará e irá más allá de las criptomonedas para constituir la base del nuevo Internet of Trust. Argumentar con datos y obtener valor. La analítica conversacional está logrando grandes avances que abren nuevas posibilidades analíticas. Por otro lado, se imponen nuevos modelos de informes que contextualizan toda la información disponible para una visión más completa. También emerge la llamada analítica inmersiva, que tanto evolucionó en 2016 gracias a Pokémon Go, y que en 2018 sigue progresando con servicios como Amazon Go, llevando la analítica a entornos reales que permiten a las compañías capturar y medir en tiempo real muchas más variables. Un modelo para construir empresas “conducidas por datos” La alfabetización de datos es uno de los pilares en los que se sustentan las empresas “Data driven”. Es decir, aquellas que convierten el dato en verdadero conocimiento, para ser más competitivas y eficientes en la toma de decisiones a todos los niveles. Sommer propone el modelo “DALAI lama”, que se explica por sus siglas. Un enfoque necesario para construir estos pilares que conducen a las empresas tradicionales a convertirse en empresas “conducidas por datos”. Figura 2: Modelo DALAI. “Todos somos inteligentes, pero no hay nadie más inteligente que todos nosotros juntos” Figura 3: Componentes de un plan de Alfabetización de datos en la empresa. El Club de Chief Data Officers Spain es el grupo exclusivo de CDOs mas importantes de España y celebra una nuevo evento de formación y networking en el que tratará de la evolución del CDO en la industria y las diferentes responsabilidades y funciones de la posición en cada sector el próximo lunes 24 de septiembre. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
14 de septiembre de 2018

El directivo analítico
Post escrito por Enrique Dans, experto en tecnología y profesor de innovación en IE Business School. La dirección de empresas, entendida como los procesos de toma de decisiones que dirigen las acciones de una compañía, es una disciplina que, tradicionalmente, se ha tratado de desarrollar mediante el entrenamiento del sentido común, de la experiencia. Un directivo con experiencia se supone habitualmente más valioso que uno carente de ella sobre todo por esa supuesta capacidad de aplicar una intuición más desarrollada, más rodada en situaciones similares, en muchos casos reforzada mediante estudios que recurren al llamado método del caso , especialmente popular en las escuelas de negocio, para simular esas situaciones. Figura 1. Aunque la inteligencia artificial no sustituya a los directivos, los directivos que utilicen inteligencia artificial sí sustituirán a los que no lo hacen El llamado gut feeling , esa intuición o instinto, es una cualidad muy valorada en un directivo. El mítico jugador de golf sudafricano Gary Player utilizaba una frase de autoría muy disputada , “the harder I practice, the luckier I get” , cuando alguien hacía referencia a la suerte como supuesto ingrediente de sus golpes más exitosos: suerte, sí, pero si quieres tenerla a menudo, desarróllala con la práctica y el entrenamiento. Otros, como Malcolm Gladwell en su libro “Outliers” , afirman que son necesarias diez mil horas de práctica para convertir a alguien en un experto de clase mundial. Esa glorificación y prestigio de la experiencia han dotado a la dirección de empresas de un mítico halo similar al de los magos, capaces de generar importantes beneficios con un supuesto movimiento de su varita. Sin embargo, la gran verdad es que por cada decisión acertada que convierte a una compañía en una referencia citada en los libros de management, hay infinidad de historias menos conocidas de otras compañías que han fracasado estrepitosamente con otras decisiones - o a menudo, decisiones similares - tomadas con la misma intuición o instinto. En gran medida, y lo dice alguien que lleva veintiocho años trabajando en una de las mejores escuelas de negocio del mundo, el management sigue teniendo pendiente una revolución que lo convierta en una disciplina razonablemente científica. ¿Podemos esperar que la tecnología convierta en obsoletos esos procesos de toma de decisiones, y termine relegando el trabajo directivo al ámbito de los algoritmos y las máquinas? No, nada indica que sea así. El trabajo directivo se compone, en general, de un número suficientemente elevado de habilidades, circunstancias y contextos como para situarlo dentro de eso que denominamos “inteligencia general”, no susceptible - al menos todavía - de ser encuadrada en una serie de reglas fijas que proporcionen resultados razonablemente repetibles. Sin embargo, como bien afirman Erik Brynjolfsson y Andrew McAfee en “The business of artificial intelligence”, lo previsible es que, a lo largo de la próxima década, aunque la inteligencia artificial no sustituya a los directivos, los directivos que utilicen inteligencia artificial sí sustituyan a los que no lo hacen. Plantearse un proyecto de machine learning implica, en gran medida, ser capaz de avanzar en ese camino. Los proyectos comienzan con la definición de sus objetivos: queremos que un algoritmo sea capaz de llevar a cabo predicciones lo más correctas y certeras posibles, que detecte patrones de posibles anomalías o fraudes, que analice grandes cantidades de datos como los producidos, por ejemplo, en redes sociales, o un cada vez más largo y prolijo etcétera. Para muchos directivos, el primer problema empieza realmente ahí: no son capaces de imaginarse un proyecto de machine learning, simplemente porque no entienden lo que este tipo de tecnología es capaz de hacer. Pero tras la definición de objetivos, comienza la verdadera travesía del desierto de este tipo de proyectos: la compilación de datos, que habitualmente no fueron recopilados o lo fueron en bases de datos relacionales, la transformación de esos datos para hacerlos compatibles con la explotación analítica que pretendemos utilizar, y la ingeniería necesaria para definir atributos o contextos relativos a esos datos. Si la definición de objetivos puede suponer en torno a un 10% del esfuerzo dedicado a la mayoría de los proyectos de machine learning, esta segunda fase llega a suponer hasta un 80% de ese esfuerzo. A partir de ahí, la fase de creación de modelos y obtención de predicciones resulta mucho más accesible y sencilla: las herramientas para ello se están haciendo cada vez más visuales, sencillas y fáciles de manejar. La fase que antes era característica de los científicos de datos, de perfiles difíciles de atraer y retener, ha reducido su complejidad hasta representar aproximadamente un 5% del esfuerzo de un proyecto. Finalmente, la fase final, la de evaluación de los resultados obtenidos, tiende a consumir el 5% restante. Para una compañía y para sus directivos, invertir en este tipo de proyectos supone familiarizarse con lo que va a constituir la arquitectura de los negocios en un futuro que se ve cada día más cercano. Cuando se dice que los directivos que sean capaces de manejarse con herramientas y proyectos de machine learning sustituirán a los que no sepan hacerlo, se está afirmando también que las compañías que adopten esa tecnología, superarán en competitividad y terminarán echando fuera de sus mercados a aquellas que pretendan seguir gestionándose con herramientas de management tradicionales, con las que se utilizaban antes de que el management cambiase de era. Esa es la verdadera dimensión del cambio, la que es cada vez más apremiante entender. Si aún no está preparado para pasar de directivo intuitivo o instintivo a ser capaz de suplementar esas capacidades con la analítica, a convertirse en directivo analítico, ándese con cuidado. Los tiempos han cambiado ya. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. También puedes seguirnos en Twitter, YouTube y LinkedIn
5 de septiembre de 2018

4 ciudades brasileñas que utilizan Big Data para planes de movilidad
Contar con un Plan de Movilidad Urbana Sostenible es fundamental para los gobiernos y ayuntamientos locales en todo el mundo. En la Unión Europea, por ejemplo, las ciudades representan casi las tres cuartas partes de la población total y desde 2013, los Planes de Movilidad Urbana Sostenibles han sido un requisito indispensable que cumplir. Aún así, además de en Europa, también en el resto de países es importante contar con un plan de movilidad adecuada. En este blog post presentaremos el caso de 4 ciudades brasileñas donde se ha utilizado Big Data para desarrollar planes de movilidad que no solo mejoran la calidad de los ciudadanos, sino que también han conseguido cumplir con los Objetivos de Planificación de Movilidad federal establecidos por la Gobierno brasileño. Antes de presentar los 4 casos de uso brasileños, es importante conocer la tecnología aplicada detrás de cada uno de los casos. La clave está en el uso de matrices de origen y destino (matriz O-D), creadas mediante el análisis de los datos generados por los teléfonos móviles a medida que las personas viajan por la ciudad. Estos datos se agregan, se anonimizan y se extrapolan, para después extraer la información sobre los flujos de población. Para una explicación más detallada de nuestras tecnologías de Smart Steps, compartimos uno de nuestros webinars 'Using Mobile Data in the Transport Sector', de la mano de dos de nuestros analistas de datos, quienes explican la tecnología en la que se basa nuestra solución LUCA Transit. El municipio de Guarujá, en el estado de Sao Paulo, Brasil, fue la primera en aplicar nuestra solución Big Data para su plan de movilidad urbana. Esta región tiene una población de alrededor de 300.000 personas y cubre un área de aproximadamente 55.44 millas cuadradas. Dada la importancia del turismo en este área, muy popular entre turistas de la ciudad de Sao Paulo sobre todo, se necesitaba un nuevo plan de movilidad urbana. Mediante el uso de CDR móviles (registros de detalles de llamadas), LUCA desarrolló una matriz O-D y mapas georeferenciados de Guarujá, en el que se trabajó conjuntamente con Sistran Engenharia para construir el plan de movilidad. Los beneficios de este proyecto son muchos. La matriz O-D se elaboró en tan solo 2 meses (mientras que los métodos tradicionales duran entre 6 y 12 meses, aproximadamente) y su coste fue 1/3 de la media habitual. Además, la muestra de datos utilizada fue mucho más extensa, lo que genera una mayor fiabilidad, así como la capacidad de diferenciar entre flujos de población internos y externos. Este mismo proceso se utilizó también en las ciudades de São Luís y Jandira, siendo la diferencia más notable entre estas su tamaño. La ciudad propiamente dicha de São Luís tiene una población de alrededor de 1 millón de personas, con 300,000 personas adicionales en el área metropolitana. Esto hace que la ciudad sea tres veces más grande que Guarujá y es la 16ª ciudad más grande de Brasil. En el municipio de Jandira, trabajamos junto a Tranzum, una consultora brasileña de transporte, para proporcionar al Ayuntamiento de Jandira las herramientas necesaria para coordinar su Planificación de Movilidad Urbana. Jandira forma parte de la región más amplia de São Paulo y tiene una población de 120,000 habitantes. El hecho de que una matriz O-D sea tan efectiva en una ciudad de un millón de personas como en una de poco más de 100,000 muestra que la escala no es un problema. De hecho, en las ciudades más grandes, donde se crean más datos, el poder de las tecnologías Big Data es aún mayor. El último estudio de caso refuerza la naturaleza adaptable de una matriz O-D, ya que la ciudad de Votuporanga tiene una población diez veces más pequeña que São Paulo. Votuporanga es conocida como la "ciudad de las brisas suaves" y tiene una larga historia con el comercio brasileño del café, pero el 73.85% del PIB de la ciudad se genera gracias al tercer sector. Usando la misma metodología de uso de CDR móviles, LUCA desarrolló una matriz O-D para el gobierno contribuyendo en el diseño de un nuevo Plan de Movilidad Urbana más eficiente. "Con el conjunto de datos de este proyecto, podemos tener listo nuestro Plan de Movilidad Urbana. Es importante recordar que esta es una forma muy avanzada de obtener la información necesaria con la misma precisión. Este sistema reemplaza al antiguo que, de forma manual, haríamos contando personas y su desplazamiento". - Antonio Alberto Casali, Secretario de Transporte de Votuporanga Los beneficios de un Plan de Movilidad Sostenible son muchos. Si se implementa con éxito, mejorará la accesibilidad de los sistemas de transporte, conducirá a un entorno urbano más atractivo, mejorará la seguridad y reducirá la contaminación. En LUCA, creemos firmemente en nuestras tecnologías Smart Steps y en el poder que el uso de los datos puede tener en el desarrollo de planes de movilidad exitosos. Para conocer más casos de uso como este, suscríbete a nuestra newsletter mensual. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. También puedes seguirnos en Twitter, YouTube y LinkedIn
27 de agosto de 2018

Machine Learning y el auge del “Big Fast Data”
Si bien el perfil del CDO aún está pendiente de armonización, ya existen casos de éxito en los que su figura ha sido la base para el desarrollo de soluciones punteras a desafíos de negocio concretos. Logitravel y Caja Rural son dos ejemplos destacados en la aplicación de estrategias de Machine Learning, compartidos respectivamente por David Martín, CDO en Bluekiri, y Daniel Martínez, IT Strategic Projects Director, Rural Servicios Informáticos. Ambos casos son experiencias recientes sobre cómo el Machine Learning permite tomar mejores decisiones de negocio. En este sentido, la analítica predictiva y el entrenamiento de modelos de Deep Learning permiten microsegmentar servicios para mejorar la tasa de retención de clientes. Para Martínez, una de sus tareas más importantes es la “gestión de la frustración interna”. A la vez que los CDO tienen que hacer frente a unas altas expectativas, aún difusas, sobre lo que el Machine Learning es capaz de proporcionar a la empresa, deben utilizar recursos internos que en muchos casos aún no están preparados para hacer frente a las últimas disrupciones tecnológicas de las grandes empresas tecnológicas, los “dragones digitales”. En su opinión, cabe preguntarse “si estamos en una época de cambios o en un cambio de época”, dado que estamos atravesando un cambio de paradigma, sustituyendo la inteligencia de negocio por el negocio inteligente , un modelo en el que las empresas impulsadas por datos o “data driven” juegan un papel determinante, con los últimos avances en inteligencia artificial como pilar. "Mediante el Machine Learning, podemos maximizar el valor del dato gracias a niveles de microsegmentación de los clientes antes impensables. Les conocemos mejor y por tanto podemos ofrecerles servicios más personalizados basándonos en sus datos (comportamiento, interacción, datos demográficos, de transacciones…). Por otro lado, la analítica prescriptiva nos permite, por ejemplo, detectar cuándo es más probable que un cliente abandone nuestros servicios y actuar en consecuencia para mejorar nuestra oferta y rentabilidad. Las técnicas de deep learning avanzadas y el diseño de redes neuronales de clasificación de clientes, entre otros, nos permite mejorar la rentabilidad de las entidades del Grupo Caja Rural", señaló Martínez, para quien es clave “ errar pronto y a bajo coste, lo que nos permite, llegada la hora de la verdad, conocer mejor nuestro negocio y tomar mejores decisiones”. Su equipo, compuesto por analistas, compliance officers y data scientists tiene que hacer frente a un reto adicional: compartir y divulgar una cultura analítica común, de manera que los expertos en datos no sean vistos como elementos externos, sino profesionales integrados en todos los procesos de la compañía que aportan un alto valor añadido a la totalidad del equipo. Asimismo, las empresas deben pensar en los datos no solo como un mero recurso, sino como un activo estratégico y, por tanto, plantearse cuál es la mejor manera de recopilarlos, analizarlos y explotarlos. En palabras de Nate Silver, “las cifras no pueden hablar por sí solas: nosotros debemos darles voz. Antes de pedir más a nuestros datos, debemos exigirnos más a nosotros mismos”. Por su parte, Martín destaca que: Hemos llegado a la era del Big Fast Data. Gracias al Machine Learning, somos capaces de automatizar tareas de manera inteligente, con el consecuente ahorro millonario gracias a, por ejemplo, un análisis predictivo y certero de las ventas El CDO de Bluekiri destaca la dificultad de ofrecer información sobre la disponibilidad de hoteles (que incluye un gran volumen de datos técnicos, como fecha de entrada, noches de estancia o el número de adultos, entre otros) mediante un sistema síncrono, con baja escalabilidad y que suponía un freno tecnológico. Un nuevo flujo de disponibilidad asíncrona conllevó, en el caso de Logitravel, un crecimiento del 2.200% en la capacidad de respuesta a peticiones, mostrando más de 4.200 disponibilidades por segundo. Este nuevo escenario y el éxito obtenido han abierto nuevas preguntas y retos, tanto a nivel de sistemas, como de arquitectura y especialmente de negocio: una vez confirmado el impacto de una estrategia data driven, ¿por qué no continuar en esta línea y utilizar y analizar aún más información? En este sentido, la aplicación del Machine Learning ha permitido a Logitravel responder a desafíos concretos. Por ejemplo, es capaz de predecir cuándo va a recibir una petición de información sobre la disponibilidad de un hotel, permitiendo optimizar el caché y descartar el ruido. También le es posible conocer cuál es la probabilidad de que dicha disposición se transforme en una reserva. Finalmente, el mapeo automático de hoteles y habitaciones permite integrar los datos de los proveedores de manera dinámica. Esto supone, por un lado, obtener un time to market muy reducido en la puesta en marcha de nuevas contrataciones y, por otro, poder mantener la calidad del producto en las activas.En definitiva, el Machine Learning no es una panacea para la transformación digital de cualquier empresa. Es una herramienta que soluciona problemas concretos, que solamente serán identificados cuando el dato funcione como activo estratégico de la organización. Escrito por el Chief Data Officer Club Spain. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
31 de julio de 2018
Predicciones para un mundo inteligente: así será la industria en 2025
El informe Global Industry Vision 2025, desarrollado por Huawei, recoge una visión prospectiva, con predicciones tanto cualitativas como cuantitativas, sobre el futuro de la industria y de la sociedad. Utiliza su propia metodología de investigación única, actuando sobre una combinación de análisis de datos y tendencias mundiales de las TIC para determinar así cuáles son las directrices de evolución del sector. Los datos utilizados pertenecen a más de 170 países y regiones. Además, el informe cubre tres dimensiones (conexión, conciencia propia e inteligencia) y 37 métricas, incluyendo la cantidad de datos generados, el porcentaje de empresas que adoptan inteligencia artificial y el número de dispositivos inteligentes. Figura 1. El informe ayuda a visualizar un mundo totalmente conectado e inteligente (Fuente: Global Industry Vision 2015) Como líneas generales, el informe determina que todas las cosas tendrán conciencia propia y estarán conectadas en 2025, lo que nos lleva a un mundo donde todo a nuestro alrededor aplica inteligencia. El estudio predice también que para 2025 el número de dispositivos inteligentes llegará a los 40 mil millones y el número total de conexiones en el mundo alcanzará los 100 mil millones, generando una economía digital con un valor de 23 trillones de dólares. En este sentido, William Xu, director del consejo ejecutivo y director de Estrategia de Marketing de Huawei, ha explicado que “esta es la primera vez que Huawei lanza el informe GIV. Basándonos en datos y predicciones de futuro, pretendemos desarrollar el modelo de la industria del mundo inteligente impulsado por las tecnologías de la información y la comunicación (TIC). Nuestro objetivo es construir hoy los cimientos que permitirán que el ecosistema de la industria de las TIC se transforme en un mundo inteligente” El informe Global Industry Vision 2025 describe tres visiones de futuro Visión 1: Nueva era – Conciencia, conexión e inteligencia Según el estudio, el mundo inteligente llegará a serlo de verdad cuando todas las cosas sean capaces de tener conciencia propia y cuando todas estén conectadas entre sí. Para 2025, habrá 40 mil millones de dispositivos inteligentes y 100 mil millones de conexiones en el mundo. La ingente cantidad de datos generados por los dispositivos se irán integrando de forma extensiva en todos los sectores de la economía, generando a su vez sectores nuevos, como el Internet industrial de las cosas y los vehículos conectados. Figura 2. 100 mil millones de conexiones eliminarán los silos digitales y allanarán el camino hacia el mundo inteligente (Fuente: Global Industry Vision 2025) Con más y mejores conexiones, el tráfico de datos crecerá de forma exponencial y la mayoría provendrá del vídeo. Por ejemplo, se estima que el mercado Cloud VR alcance los 292 mil millones de dólares en 2025. Así pues, GIV 2025 describe un futuro donde el papel de los dispositivos y robots inteligentes evoluciona de ser una simple herramienta a convertirse en un asistente. La tasa de penetración de los asistentes inteligentes será del 90% en 2025, al tiempo que el 12% de los hogares habrá incorporado robots de servicio inteligente. Estos avances permitirán mejorar la vida diaria de millones de personas con visión o movilidad reducida. Visión 2: Nuevas especies – Nuevos tipos de negocio con +Intelligence De acuerdo con las conclusiones del informe, las conexiones de alta velocidad, el Internet de las cosas y la IA basada en Cloud permitirán que las plataformas +Intelligence ayuden a las diferentes industrias a avanzar hacia el análisis inteligente, la toma de decisiones y la asistencia. Figura 3. Las empresas que carecen de capacidades de nube pueden no sobrevivir incluso en la víspera de un mundo inteligente (Fuente: Global Industry Vision 2025) En 2025, se aplicará tecnología inteligente de forma extensiva en el sector del transporte, con más de 60 millones de vehículos conectados a redes 5G y el 100% de los vehículos nuevos conectados a Internet. Cuando la inteligencia se incorpore al sector industrial, las TIC convergerán rápidamente con tecnología operativa (OT).. Esto proporcionará beneficios positivos a la innovación, la industria, la cadena de valor y el ecosistema en su conjunto. Al incorporar la inteligencia en las ciudades, los responsables de urbanismo serán capaces de crear nuevos planes para el desarrollo sostenible en la gestión de la seguridad, planificaciones de transporte y otros aspectos, haciendo que los ciudadanos disfruten de la seguridad, comodidad y del alto nivel de vida que la vertiente digital puede ofrecer. Visión 3: Nueva economía – Innovación masiva Huawei predice que la economía digital llegará a tener un valor de 23 trillones de dólares. El valor de +Intelligence estará a disposición de los sectores industriales, servicios, transporte y muchos más. Los resultados de la innovación en el mundo inteligente podrán apreciarse en todas partes; el mundo inteligente reformulará las industrias y dará paso a nuevos sectores inteligentes. También provocará que las empresas vayan más allá de sus trayectorias de crecimiento actuales y que consigan un desarrollo acelerado a la vez que impulsan masivamente la innovación. Para obtener más detalles o descargar el informe completo, puedes visitar la página del GIV. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. También puedes seguirnos en Twitter, YouTube y LinkedIn
27 de julio de 2018

Cuando la información fluye la empresa se mueve
Cuando nos enfrentamos a la gestión de un proyecto, tenemos que estar atentos a múltiples aspectos y se hace complicado priorizar. Entran en juego diferentes aspectos: diferenciar entre lo urgente y lo importante, optimizar los procesos internos, definir e implementar la estrategia de marketing, gestionar personas y proyectos… la lista es interminable. Esto provoca que la dirección del proyecto sea muchas veces caótica. Esta es una situación que me encuentro en muchas ocasiones a la hora de definir e implementar estrategias de marketing con mis clientes. Por este motivo, tras un análisis inicial más heurístico, siempre empiezo por los datos. Es la forma de priorizar en base a datos objetivos y no a opiniones o creencias internas.Os voy a contar a modo de breve historia, el proceso de transformación que viven los clientes cuando optimizan la toma de decisiones. “No te preocupes, los datos los tenemos muy controlados” Cuando empiezo a investigar sobre la toma de decisiones, y más desde mi rol de especialista en marketing digital, debo tratar el tema desde el valor que los datos aportan a la estrategia y al negocio en particular. El caso que os voy a contar es el de una empresa que está transformando su negocio. Parten de un modelo de negocio B2B y han lanzado la parte B2C. El negocio B2B funciona bien desde hace años y existe una gran oportunidad en el cliente final. Más allá de su sector (lo omito por cuestiones de confidencialidad), vamos a centrarnos en el cambio que la calidad del dato genera dentro de una organización. A las pocas semanas de empezar el proyecto, plantee la necesidad de reorganizar el proceso completo de recogida, procesamiento e interpretación de los datos. Aproveché esos primeros días para ir recabando opiniones y recopilar fuentes de información (desde su herramienta de analítica digital, a informes, accesos al back office y otras herramientas). Así que ya tenía una idea bastante clara de la situación. La reunión inicial empezó con el siguiente enfoque: “En cuestión de datos no vas a tener ningún problema. Somos conscientes de la importancia de medir y disponemos de la información. Tenemos puntos de mejora, pero creemos tener bastante avanzado”. Y en parte era cierto, medir medían muchas cosas. Eso sí, otra cosa es que lo hiciesen correctamente y/o estuviesen sacando partido de los datos. Muchos datos sí, pero sin conexión entre ellos La medición era un pequeño caos. Me encontré silos de datos tanto a nivel del análisis del proceso de contratación, como por departamento. Cada departamento y casi cada responsable tenía sus propios informes y estos salían de hasta seis fuentes de datos diferentes. Y los informes se hacían manualmente. Ya os podéis imaginar el caos que suponía la toma decisiones. Su reflejo más palpable eran las reuniones mensuales. Además de tomar pocas decisiones, se dedicaba al menos la mitad de la reunión, para decidir cuál era del dato correcto o si el dato mostrado estaba midiendo lo mismo o no, que el resto de departamentos (en fechas, forma de contabilizar el dato, etc.). Cuando trabajaban en el día a día, cada departamento tomaba decisiones en base a sus datos, pero la coordinación de todos se hacía muy difícil. Un mismo dato era diferente en función del departamento que lo mostrase y además no existía la seguridad de si el dato era correcto o no. Por ejemplo, el dato de las ventas de un periodo variaba en función del departamento o herramienta. Cada herramienta tomaba en cuenta unas fechas, contabilizaba a su manera,y no conseguían ponerse de acuerdo en el dato más básico. ¿Qué problemas tenían? (los más importantes) Demasiadas fuentes de datos y sin conexión entre ellas. Falta de definición de métricas: cómo se llama lo que mido (nomenclatura), qué mide exactamente y cuáles son las métricas más relevantes para el negocio y para cada departamento. Falta de criterio en el análisis: esto hacía que no estuviesen claras cuáles eran las KPI más importantes para la empresa y para cada departamento, por lo que había análisis irrelevantes y poca aportación de valor. Errores en la recogida de datos: o no recogían bien los datos o directamente no lo hacían. Falta de herramientas de decisión: no habían dashboards definidos para la gerencia, ni para los diferentes departamentos. Además, los informes que había se hacían a mano, lo que suponía invertir más tiempo del necesario en el procesamiento de datos, y no dejaba lugar al análisis y toma de decisiones ágiles. La falta de datos y su baja calidad hacía que la empresa estuviese paralizada Por eso pensé que lo mejor era contar con la ayuda de una consultora especializada en analítica digital, para que, partiendo de mi análisis y definición estratégica, llevasen a cabo el proyecto. Cuando la información fluye la empresa se mueve Los cambios fueron bastante radicales y rápidos. Primero pequeñas mejoras y poco a poco grandes cambios en la empresa y sus procesos. Disponer de una única fuente de información y con datos fiables afectó al funcionamiento de la empresa. Pasaron de tener una visión parcial y en ocasiones equivocada, a ver con claridad la situación y ser capaces de tomar las mejores decisiones. En este contexto, los cambios fueron muchos, pero por resumir los más destacados: 1. Mejora generalizada de las principales métricas (KPIs): al disponer de un dashboard bien definido y con los datos correctos, hizo que se detectasen mejoras de aplicación inmediata. En el primer mes: Mejoró la tasa de conversión de los principales canales, por lo que se redujeron los costes de captación. Se optimizó la inversión en adwords, display y social ads, por lo que aumentó el volumen y calidad del tráfico captado. Y lo que es mejor, como consecuencia de todo lo anterior, aumentaron las ventas y el ticket medio. 2. Toma de decisiones ágil: al tener la información adecuada, cada departamento pudo priorizar sus tareas y centrarse en aquello que más valor aportaba al negocio. Esto hizo que se desbloqueasen proyectos y que avanzasen con mayor velocidad. 3. Optimización de procesos vitales del negocio: la correcta priorización de tareas hizo que el funcionamiento de los procesos (tanto el proceso de venta web, como su gestión interna) mejorase notablemente. Dentro de un proceso de contratación relativamente complejo, se obtuvieron mejoras del 12% en la tasa conversión web y del 17% en la interna. 4. Dirección de empresa y coordinación interdepartamental: el flujo dinámico de información tanto horizontal como vertical, hizo que la gestión de la empresa, sus procesos, comités de gerentes, etc. fuesen mucho más ágiles. 5. Cambios estratégicos: el tener la información y el análisis adecuados hizo que se detectasen oportunidades de crecimiento e innovaciones a nivel de producto. Post escrito por Tristán Elósegui, consultor senior de marketing online, conferenciante y profesor en diferentes escuelas de negocios. Es especialista en estrategia digital, analítica web y redes sociales.
24 de julio de 2018

Conoce Movistar Home, el dispositivo inteligente que integra Aura y revolucionará las comunicaciones
El pasado mes de febrero durante la edición 2018 del Mobile World Congress, Telefónica anunció Movistar Home, el dispositivo inteligente que incorpora Aura, su asistente virtual con inteligencia artificial. Aura pretende transformar la forma en que los clientes se relacionan con la compañía y cómo gestionan su vida digital. Se trata de una tecnología fácil, al servicio de las personas y entendible, que tomará vida en los hogares españoles a través de esta nueva plataforma. Con Aura, Telefónica lidera la integración de la IA en sus redes y en la atención al cliente, además de revolucionar las comunicaciones y la televisión en el hogar, haciendo más fácil, interactivo y accesible para todos el acceso y gestión a los contenidos. “OK Aura” es el comando de voz que te permitirá empezar a hablar con Aura a través de Movistar Home, de una forma natural y sencilla. Porque Movistar Home es mucho más que un teléfono fijo y busca convertirse en el centro de conexión de todos los dispositivos en el hogar, desde el que los usuarios gestionen sus servicios. El dispositivo tiene capacidades de edge computing para procesar y analizar datos y presenta una segunda pantalla, que permite hacer llamadas y videollamadas, que pueden proyectarse en la televisión; gestionar la conectividad del router, además de controlar con la voz la televisión. Hablando con Aura, los clientes de Telefónica pueden encender la tele, ver o cambiar de canal, poner subtítulos, programar una grabación o pedir una recomendación, todo ello con la voz, olvidándose del mando a distancia. El usuario disfrutará de una nueva experiencia de entretenimiento. Aunque Movistar Home se lanzará en España este otoño, ya podemos experimentar con Aura a través de este device: de julio a septiembre, los usuarios que se acerquen a una de las 6 tiendas Movistar de Madrid y Barcelona, donde se ha puesto en marcha la campaña #MeetMovistarHome, pueden jugar al “OK Aura” como ya lo han hecho Sergio Ramos o Mikel, Nairo y Alejandro, del Movistar Team. Con Movistar Home la tecnología en el hogar se simplifica, liberándote del smartphone o del mando a distancia, ya que solo necesitas articular un sencillo comando de voz, “OK Aura”. Se de los primeros en probar una nueva forma de comunicarte, ver la televisión o gestionar la conectividad de tu hogar solo con tu voz. Estas son solo algunas de las funcionalidades que Aura puede hacer por ti a través de Movistar Home. En otoño, dispondrá de nuevas capacidades sorprendentes. Acércate este verano y conoce a Aura en #MeetMovistarHome en una de las tiendas seleccionadas de Madrid y Barcelona. Más información aquí. También puedes seguirnos en Twitter, YouTube y LinkedIn
19 de julio de 2018
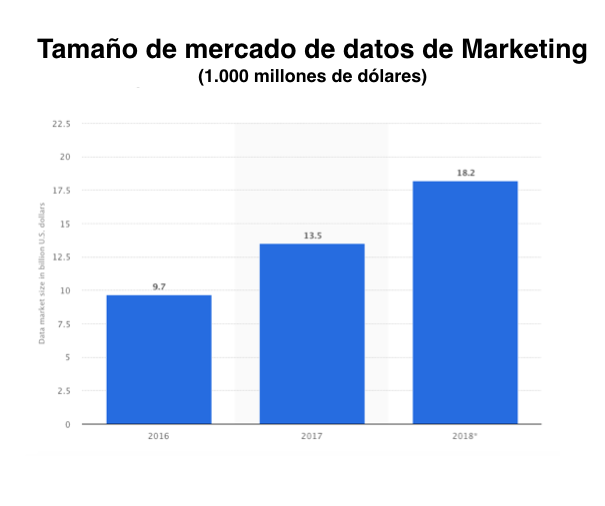
Cómo la Inteligencia Artificial influye en nuestro trabajo sin que nos demos cuenta
Hablamos tanto de Inteligencia Artificial como la “next big thing” que a veces cuesta pensar que vaya a materializarse de verdad (es decir, que lo tengamos en nuestro día a día). ¿Cuándo? ¿Cómo? ¿Qué será de nuestras vidas cuándo las máquinas tomen el control? Lo malo que tiene vivir relativamente cerca de las tendencias (me refiero a leer blogs de tecnología y futurismos varios, no a vivir en Silicon Valley) es que anticipamos tanto el cambio que cuando llega, no tiene la misma gracia. Como anécdota, me gusta recordar como hace unos cuantos años (¿en 2010? ¿11?) en medio de una reunión en la que estábamos hablando de tendencias tecnológicas, un compañero empezó a hacer aspavientos y fibrilar cuando oyó que le tocaba el turno a mobile: ”Lleva siendo el año del mobile desde que yo andaba en tacatá, y nunca termina de llegar”. Por supuesto, llegó, y es posible que leas tranquilamente esto desde el móvil, sin darte cuenta de que hace unos cuantos años el uso que haces (hacemos) de ese aparato se habría considerado ciencia ficción. Al fin y al cabo, no estamos hechos para predecir el cambio Cuando la revolución llega, se convierte en algo tan cotidiano que no merece la pena hablar de ello. Como decía Benedict Evans, prueba a ver ahora la presentación del iPhone: lo que hace 11 años levantaba aplausos, hoy provocaría bostezos. Lo damos por hecho. Y creo que con la Inteligencia Artificial está pasando algo parecido: poco a poco se va colando en nuestra vida personal y profesional. Más allá de los vídeos con súper hype, como la llamada que realizaba Google Duplex en el último I/O (que merece la pena ver), hay casos mucho más pequeños que se están colando en nuestro día a día casi sin que nos enteremos (obviando el hecho de que el auténtico potencial de esto llegará cuando al otro lado conteste también una máquina). IA en Gmail: este tipo no te ha respondido en 3 días, recuérdaselo Figura 1. Gmail ya no te permite ignorar emails Fuente: Blog de Gmail El último rediseño de Gmail vino con unas cuantas novedades. Si lo has activado, te encontrarás con pequeñas píldoras en las que te sugiere o bien responder a un correo que te has dejado sin contestar o bien que hagas un recordatorio a la persona que no te ha contestado. Sin que tengamos que configurar nada, la magia está en que el sistema detecta aquellas cosas que probablemente se te habrían olvidado. Y aunque esto es nuevo, los que usamos Inbox, hace unos pocos años que tenemos “respuestas automáticas”. No, no son cartas de amor, pero personalmente, cada vez las uso más para situaciones que sólo requieren una respuesta rápida. PowerPoint soluciona tu mal gusto Los que hemos trabajado mucho con PowerPoint o Keynote tenemos clara una cosa: se pierde mucho tiempo con los detalles más tontos de diseño. Después del mensaje, el análisis de datos y todo el trabajo sesudo que hay detrás, siempre hay una fase (en la que opina casi todo el mundo) de maquetación que devora el tiempo. Figura 2. Un ejemplo real de tiempo invertido en esta herramienta Desde hace un tiempo, PowerPoint incorpora “Designer” que funciona, una vez más, como si fuera magia. Ya en 2015 algunas startups como Haiku Deck (con Zuru) o Slidebot empezaban a ofrecer la creación de presentaciones con el uso de Inteligencia Artificial, pero ahora que está en PowerPoint, millones de personas empezarán a usar la inteligencia artificial sin darse cuenta. Puede que todavía tengamos granjas de humanos explotados para simular ser IA y algunos estén convencidos de que Skynet se aproxima (que podría ser), pero ya tenemos muchos casos tangibles en los que la máquina nos está ayudando en nuestro trabajo del día a día: las predicciones de Google que te avisan de que vas a llegar tarde si no sales ya porque hay atasco, los asistentes de voz, las recomendaciones de música o series… Pero por supuesto, no nos vamos a quedar ahí Mientras los asistentes de voz se convierten poco a poco en algo medianamente mainstream y leemos noticias catastrofistas de empleos destruidos (McKinsey habla de unos 800 millones de puestos de trabajo perdidos en todo el mundo) en prácticamente cualquier sector (algunos que parecían tan intocables como la publicidad o el trading,…), los pequeños ejemplos de IA en nuestra vida se vuelven cada vez más cotidianos. Pero el auténtico cambio llegará cuando empecemos a hacer cosas completamente nuevas. Lo que se nos ocurría hacer en la prehistoria del smartphone eran pobres réplicas de lo que ya había: noticias, alertas de la bolsa y aplicaciones raras que probábamos emocionados (¿alguien recuerda la locura que desataba la brújula del iPhone?). Con la IA es probable que pase algo parecido: las mejores ideas de hoy nos parecerán simplonas dentro de unos pocos años. Y quizá traigan nuevos empleos bajo el brazo. Post escrito por Iván Fanego, experto en marketing digital, innovación y nuevas tecnologías.
18 de julio de 2018

¡Así fue el Tour de Francia en Distrito Telefónica!
Este pasado viernes 29 de junio, los empleados de Telefónica tuvieron la oportunidad de escalar la etapa de Alpe D'Huez del Tour de Francia, ¡sin salir de Distrito Telefónica! Perico Delgado, el reconocido ciclista, animó a los participantes en esta dinámica mientras celebraba el 30º aniversario de su maillot amarillo. Como toda acción de Sports Analytics de LUCA, los datos no pudieron faltar. Con rodillos conectados, los 22 participantes pudieron conocer sus métricas en tiempo real, y medir su desempeño en comparación con las métricas de Nairo Quintana, en esta misma etapa en 2015. Un poco de presión competitiva nunca le sienta mal a un atleta, ¿verdad? Figura 1. Perico Delgado, Chema Alonso y Pedro de Alarcón ¡que bien lo pasamos en LUCA! A media mañana, Distrito estaba lleno de compañeros animando, y dimos inicio a la acción. Como nos gustan tanto los retos, elegimos una de las etapas más duras: el Alpe D'Huez. Con sus significativas 21 curvas de herradura, da poco descanso a los ciclistas, ¡se dice que el primer kilómetro es uno de los más difíciles! La primera sesión fue un éxito, entre la música, los animadores, y Perico liderando con muchísimas ganas. A pocos minutos de haber terminado, le tocó el turno a los ciclistas más avanzados, que sudaron igual o más que los anteriores. En ambas sesiones, la demo de LUCA Sports Analytics mostró los datos de cada participante en tiempo real, y el equipo realizó un pequeño análisis al finalizar, para mostrarle a cada ciclista su desempeño a lo largo de la carrera. Figura 2. Listos para la segunda ronda No hay esfuerzo sin recompensa. Al finalizar la acción llegó el turno de sortear una de las bicicletas CANYON con un rodillo conectado. La bicicleta iba firmada por estrellas del Movistar Team: Nairo Quintana, Alejandro Valverde y Mikel Landa. ¡Enhorabuena a todos los que formaron parte de esta gran actividad! Figura 3. La afortunada ganadora de la bicicleta y rodillo Te dejamos este vídeo a continuación con todos los momentos más destacados: No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. También puedes seguirnos en nuestras redes sociales: @Telefonica , @LUCA_D3 , @ElevenPaths
4 de julio de 2018

Dando sentido al Big Data
El Big Data es algo muy importante para las empresas – específicamente, si pueden usarlo para generar insights de valor. Y la investigación muestra que la mayoría no puede. De hecho, solo el 39 % de las empresas invirtió en una plataforma de análisis de big data, según una encuesta de Tech Pro Research en el cuarto trimestre de 2017. El Dr. Craig Brown, experto en Big Data, autor y consultor, comparte sus consejos sobre cómo las empresas pueden convertir los datos en oro en lugar de kryptonita. Una cuestión de calidad “Cuando te estás moviendo hacia una solución data driven, la pregunta que debes hacerte inicialmente es sobre la calidad de tus datos ". dice Brown. “¿Los datos te permitirán tomar decisiones claras en un sistema basado en ellos?" Si no estás respondiendo estas preguntas en un contexto estratégico claro, tus planes de Big Data pueden fallar. En noviembre de 2017, Nick Heudecker de Gartner tuiteó que la estimación de 2017 de la compañía, que el 60 % de los proyectos de Big Data fracasan fue de hecho "demasiado conservador”. El porcentaje de fracasos está, de hecho, más cerca del 85 %. Y el problema no es la tecnología ". Los problemas más urgentes vienen de una combinación de factores como no contar con las estrategias correctas, las herramientas adecuadas y el apoyo directivo necesario . Se necesita más infraestructura Según Brown, definir la calidad, respuestas y tipos de decisiones que quieres extraer de los datos – tu estrategia – va a ayudar a identificar cuáles son las fuentes de datos relevantes, un primer paso que es crucial hacer bien. Algunos ejemplos de fuentes de datos son datos archivados, documentos, reportes, emails, redes sociales, imágenes, aplicaciones de negocio, motores de análisis, sensores, “click-streams”, aplicaciones, APIs y sitios web públicos. Los minoristas, por ejemplo, pueden aplicar técnicas sencillas como asignar una identificación de invitado a tarjetas de crédito para rastrear preferencias y hábitos de compra, monitorizar la actividad de las redes sociales para dar mayor visibilidad a promociones, optimizar el diseño en la tienda para aumentar el tráfico y administrar el inventario de manera más efectiva, para que los artículos agotados dejen de ser un problema. McKinsey informa que el retorno de la inversión a cinco años es del 15 % al 20 % para los minoristas que invierten en Big Data. A su vez, las empresas de telecomunicaciones se pueden beneficiar de las fuentes que producen grandes cantidades de datos, incluyendo registros de detalles de llamadas, uso de teléfonos móviles, equipos de red, registros de servidores, facturación y redes sociales, que se pueden aplicar a cosas como predecir el tráfico, evitar la fuga de clientes y recuperar facturas. La analítica es más fácil en el caso de los datos estructurados, es decir, cuando existen un registro predefinido, están organizados y pueden almacenarse en una base de datos relacional (RDB) para facilitar la búsqueda y el análisis. Los datos estructurados pueden generarse de forma automática, como etiquetas RFID de sensores en dispositivos como medidores inteligentes y collares para ganado, o ser generados por humanos, por ejemplo, el rastro de datos de un “click-stream” que dejaste la última vez que hiciste una compra online. Sin embargo, se estima que el 80 % de todos los datos están parcialmente estructurados o desestructurados, incluyendo publicaciones en redes sociales, artículos, correos electrónicos y archivos multimedia, lo que significa que no están organizados ni almacenados en un RDB. Este tipo de datos - la forma en que se crean - tiene un matiz típicamente humano, por lo que es más difícil para los algoritmos realizar análisis sintácticos o la visión de la computadora para dar sentido al discurso natural, el texto o las imágenes. Los programas de análisis tradicionales tienden a usar etiquetas para datos estructurados y palabras clave para datos no estructurados, que son imprecisos y pueden crear una brecha de conocimiento. Según Brown, queda mucho camino por recorrer en el campo del análisis de datos no estructurados, siendo la IA y el 5G los puntos clave. "La inteligencia de red puede actuar en redes 5G, recogiendo datos de sensores y llevando esa información no estructurada a nuevas tecnologías que proporcionan análisis ", dice refiriéndose a la arquitectura de gestión de la información no estructurada (UIMA). El problema del personal Otra cuestión que Brown cree que deben plantearse las empresas es "la calidad de la colaboración entre sus administradores de datos y los que toman las decisiones". Una encuesta realizada por Tata Consulting, sobre el análisis de Big Data en la fabricación, identificó que la creación de una relación de confianza entre los científicos de datos y los gerentes funcionales, es una de las principales preocupaciones de las empresas. Esta falta de confianza crea una brecha entre los datos y cómo y qué estrategias comerciales se ejecutan. Estos resultados fueron respaldados por una encuesta realizada por Forrester para Consultoría KPMG, que encontró que solo el 38 % de los encuestados tiene un alto nivel de confianza en las perspectivas de los clientes, solo un tercio parece confiar en los análisis que generan de sus operaciones comerciales y solo El 51 % de los ejecutivos alto nivel tienen plena confianza en su política de datos y análisis. De acuerdo a un reporte de 2017 realizado por McKinsey, sobre la analítica avanzada de las empresas de telecomunicaciones, “Dado el volumen y el ritmo a que suceden los cambios dentro de la industria, los líderes [de empresas de telecomunicaciones] no están bien posicionados para mover sus empresas tan rápido o tan lejos como es necesario para prosperar.” Sin embargo, para que los datos tengan valor en la cadena de toma de decisiones, dice Brown, "debe haber una comprensión clara y concisa sobre cuáles deberían ser esas decisiones, qué se espera confirmar de ellas, y qué datos los datos tienen el valor necesario para cubrir esas expectativas ". Ese impulso debe venir desde los niveles más altos de una empresa. Las herramientas correctas para el trabajo Una faceta clave para superar la resistencia de los ejecutivos de alto nivel, es conocer los beneficios que tienen para las empresas las analíticas Big Data y elegir la herramienta adecuada para recopilar, organizar, almacenar y acceder a esos datos. Los problemas más comunes a la hora de elegir soluciones analíticas suelen ser el hacerlo sin antes haber definido correctamente qué problemas quieren resolver, el implementar una solución que no es ágil y no puede escalar, y el olvidarse de los sistemas legacy y cómo integrarlos. FusionInsight-Universe Analytics de Huawei recibió el premio a la Solución de gobierno de datos más innovadora en la conferencia Telco Big Data Analytics Summit Euro 2017. Optimizada tanto para empresas como para operadoras de telecomunicaciones, la solución reduce de forma muy significativa las cargas de trabajo de integración de datos y proporciona capacidades de administración de la información en almacenes de datos heterogéneos, auditorías de calidad integradas, gestión del ciclo de vida y análisis de linaje de datos. Su solución de gobierno de Big Data proporciona datos de alta calidad para IA y aplicaciones de Big Data, acortando el ciclo de preparación de datos de meses a horas, incrementando en más del 40 % la eficiencia del gobierno de datos, y en un 40 % la cantidad de datos de alta calidad. Junto con Informatica PowerCenter, una solución de integración de datos basada en Hadoop, la solución proporciona capacidades de integración, conversión y limpieza de datos, características clave porque, como dice Brown, "En el futuro, habrá cada vez más datos y, por lo tanto, necesitaremos sistemas más rápidos y una capacidad de procesamiento mayor para convertir esos datos en información útil para el negocio". Los datos pueden ser una mina de oro, pero su valor permanecerá enterrado sin las estrategias, herramientas y personal adecuados. Post original escrito por Gary Maidment, periodista de tecnología y tendencias de negocio para Huawei
3 de julio de 2018

El gobierno del dato: ¿Chief Data Officer o Chief Diplomatic Officer?
¿Cuál es la frontera del gobierno del dato? ¿Hasta dónde llega y debe llegar? “ Nos encontramos en un escenario en el que muchos profesionales ejecutan tareas distintas bajo el mismo cargo”, destaca Rafael Fernández, CDO en Bankia. Esta falta de armonización de responsabilidades en la empresa española causa confusión, tanto interna como externamente. Los CDO tienen que afrontar peticiones de naturaleza diversa según del área de negocio del que proceda. Los requisitos son cambiantes según el sector, la empresa y su madurez digital. En este contexto heterogéneo, el CDO tiene la tarea extra de consensuar expectativas y peticiones de diversas áreas corporativas, por lo que, bromea Fernández: " a veces pienso en mi cargo como el de Chief Diplomatic Officer ”. Por ello, los CDO tienen uno de los puestos directivos más exigentes. Además, su rol está evolucionando rápidamente. Es probable que, a medida que su figura, su regulación, la industria y el gobierno del dato maduren y estén más definidos, el CDO podrá prestar más atención a uno de sus principales cometidos: actuar como catalizador de la innovación en sus empresas. Según datos de Gartner, la función del CDO será tan esencial en 2021 como las de finanzas o recursos humanos para el 75% de las grandes compañías. El CDO, un rol en evolución: La posición del CDO es relativamente nueva en la mayoría de las empresas españolas que cuentan con esta figura. Sin embargo, ya ha experimentado cambios de calado desde su aparición en el mercado. En los próximos años, su incorporación será más y más común, pero pocas compañías verán grandes avances en el corto plazo. Para poder explotar sus capacidades, será necesario desarrollar una estructura sólida en torno al CDO, delimitando su cometido y necesidades. El profesional del dato se enfrenta ahora a limitaciones (p.ej. de personal a su disposición) que se irán reduciendo en muchos casos, a medida que se identifiquen prioridades y necesidades de negocio concretas Existe una gran necesidad de que los CDO cuenten con “una visión de conjunto de todo el proyecto, tanto la de IT como la de negocio”, señala Daniel Escuder, Data Manager y responsable de BI y Big Data en Oney Servicios Financieros. En su opinión, el CDO ha de estar al corriente de todos los procesos que abordan las distintas áreas de la organización, porque “ a partir del 25 de mayo, ya no vale todo”. La aplicación del RGPD está cada vez más cerca, y no todas las empresas están preparadas de la misma manera. El RGPD está obligando a las empresas a abordar un cambio de mentalidad, y a los empleados y directivos a mejorar su alfabetización de datos, es decir, la capacidad para leer, gestionar y compartir datos. “En los próximos 3 años, el rol del CDO será tan esencial como el del área de finanzas o recursos humanos, entre otros, para el 75% de las grandes compañías" Adoptar un marco regulatorio internacional, al modo de los Acuerdos de Basilea III en la banca, puede conllevar beneficios para el sector, según Javier Marqués, CDO en Grupo Generali España. Pero, además de confiar en el regulador, el cambio ha de proceder del fuero interno de las organizaciones. “Se ha promovido la “ingeniería inversa” en el gobierno del dato: una vez desarrollada y recopilada la información, se han llevado a cabo los esfuerzos en compliance y gestión. Pero debemos darle la vuelta a esta realidad: debemos promover un modelo de gobierno del dato que esté presente en todo el ciclo de vida de los proyectos; en otras palabras, impulsar políticas ‘data driven’”. El hecho de que el regulador imponga un criterio y unas bases, si bien de manera rígida, ayuda a impulsar y establecer consenso sobre el que trabajar, proporcionando guías de actuación claras. En este sentido, es importante que las empresas establezcan políticas sólidas, especialmente en lo relativo a los roles y funciones del CDO, subrayan Ramón Morote y Beatriz Moreno, CDOs en Gas Natural. “ Las necesidades y urgencias de los negocios avanzan a una velocidad vertiginosa. Debemos ser consecuentes a la hora de definir nuestro rol, necesidades y qué objetivos perseguir, sin perder el pulso de la realidad de la empresa”, destaca Morote. Para ello es necesario transmitir el valor que el CDO aporta: desde su capacidad de asesoría tecnológica, su conocimiento de los retos digitales existentes en el entorno de la organización o el desarrollo de nuevas soluciones analíticas que respondan a necesidades de negocio concretas. Hoy, los CDO llevan a cabo una labor diplomática para tender puentes entre IT y negocio. Esta tarea es especialmente compleja si tenemos en cuenta que existen tantos perfiles de CDO como empresas, con roles y requisitos distintos. No obstante, este perfil irá convergiendo y, progresivamente, será más homogéneo. La especialización seguirá existiendo, pero de manera más ordenada. Por otro lado, las métricas clave también serán más uniformes conforme pase el tiempo, a medida que se vaya comprendiendo de manera generalizada cuáles son los beneficios reales de una estrategia analítica. La “sombra” del RGPD: A partir del 25 de mayo, comenzará a aplicarse el Reglamento General de Protección de Datos (RGPD). Según datos de Gartner, más del 50% de las empresas no cumplirán con sus requisitos antes de que finalice el año 2018. Entre los consejos de la consultora, destacan las labores de preparación para afectados por el RGPD y empleados, así como la necesidad de designar a un Data Protection Officer, figura que será clave en la gestión de los datos Escrito por el Chief Data Officer Club Spain. Si quieres conocer más sobre el Club, escribe a: clubcdospain@outlook.es
26 de junio de 2018

¡Traemos el Tour de Francia a Distrito Telefónica!
Los empleados de la compañía tendrán la oportunidad de escalar la etapa de Alpe D'Huez con Perico Delgado y ganar una bicicleta profesional como las del equipo Movistar Team firmada por ellos. Como ya os hemos contado en varias ocasiones, desde LUCA colaboramos con el equipo técnico de Movistar Team y el equipo global de Patrocinios de Telefónica para impulsar al equipo ciclista en su estrategia de decisiones basadas en datos. Mediante el análisis avanzado, ayudamos a mejorar el rendimiento de los ciclistas y los resultados del equipo, colaborando en la planificación de los entrenamientos y en la creación de herramientas analíticas que aporten conocimiento adicional del desempeño del equipo en competición. Con el fin de mostrar todo el poder que la analítica de datos y el Machine Learning tiene en el sector deportivo, hemos realizado varias acciones como la demo del pasado Febrero para los clientes de la tienda flagship Movistar de Barcelona, o una demo en la que podías competir con nuestro CDO Chema Alonso en la Feria OpenExpo de la pasada semana. Siguiendo esta dinámica, el próximo Viernes 29 de Junio a partir de las 11 de la mañana, el área de Sports Analytics de LUCA realizará una simulación de la subida del Alpe D'Huez del Tour de Francia de 2015, etapa en la que Nairo Quintana, corredor del Movistar Team, hizo una tremenda exhibición de fuerza que puso al límite al mismo Chris Froome. De entre todos los registrados, 16 empleados de la compañía serán elegidos por sorteo para realizar esta experiencia. La experiencia consiste en competir con el resto de participantes durante un tramo de esa etapa mítica de Alpe D’Huez. Para ello, los participantes se subirán en grupos a bicicletas conectadas a rodillos que envían los datos de potencia y velocidad en tiempo real. Esto nos permite poner en marcha un simulador de competición en el que ganará aquel o aquella que consiga completar el tramo en el menor tiempo (estimamos que la duración de la prueba se sitúa en torno a los 35 minutos). Una vez finalizada la prueba publicaremos el ranking de llegada y mostraremos las principales variables de rendimiento comparadas con las obtenidas por Nairo Quintana en 2015. Figura 2: Perico Delgado, uno de los ciclistas españoles más reconocidos liderará la acción. La acción será liderada por el conocido ciclista Perico Delgado, el mismísimo vencedor de esta etapa hace 30 años coincidiendo con su aniversario. Delgado es uno de los ciclistas españoles más reconocidos después de lograr 49 victorias en su trayectoria, y será el que animará a los empleados a terminar la simulación con éxito. Como broche final a esta mañana de datos, entre todos los participantes se sorteará una de las bicicletas CANYON, patrocinador del Movistar Team, firmada por Nairo Quintana, Alejandro Valverde y Mikel Landa. La bicicleta irá acompañada del rodillo conectado que usan los corredores para entrenar. No te pierdas nuestras redes sociales el día 29 para seguir nuestra “trayectoria ciclista” de cerca!
15 de junio de 2018

Todos los detalles de la OpenExpo Europe 2018
Este 6 y 7 de junio se celebró la OpenExpo Europe en Madrid, el mayor Congreso y Feria sobre Open Source & Software Libre y Open World Economy (Open Data y Open Innovation) de Europa, donde LUCA participó presentando tres demos interactivas del portfolio: LUCA Comms, Big Data en el ciclismo con LUCA Sports Analytics y SafePost. Además de dos ponencias impartidas por nuestro CDO Chema Alonso y Richard Benjamins, Data & IA Ambassador de Telefónica. Figura 1. OpenExpo Europe, el punto de encuentro donde las empresas amplían su red de contactos, generan negocios y promueven sus servicios Chema Alonso, Chief Data Officer (CDO) de Telefónica, abrió el evento con “Un beso a un sappo y te quedas en silencio,“ donde habló de los sistemas de seguridad y de la herramienta Sappo, que permite atacar el ámbito digital. Chema mencionó que “durante años hemos entrenado al usuario para detectar solo un tipo de ataque y, a su vez, para que pase por alto el resto de ataques”, y resaltó la importancia de la cyberseguridad en las empresas y por qué es importante entender cómo funciona la tecnología, para evitar ataques de seguridad. Para hacer énfasis en esto, tomo el control de una cuenta de Twitter en directo, mostrando lo fácil que es entrar cuando las medidas no son las ideales. La segunda ponencia, impartida por Richard Benjamins, AI Ambassador de CDO, trató de Big Data for Social Good y la aplicación de los datos para ayudar a la sociedad, mostrando distintos proyectos como la predicción de la calidad del aire y prevención de desastres naturales. El movimiento de Big Data for Social Good es un movimiento en crecimiento y las empresas privadas tienen la responsabilidad de llenar esos huecos de datos abiertos para contribuir. Richard, además, hizo gran enfásis en que "estos proyectos deben ser sostenibles a largo plazo". La demo de Big Data en el Ciclismo y Sports Analytics fue un éxito, sorprendiendo a los visitantes con una de las bicicletas del Movistar Team. Mostrando una simulación de la Vuelta Ciclista España, en la etapa de los Lagos de Covadonga, los participantes pudieron disfrutar de una demo sobre riesgo de fuga, que calcula la distancia y tiempo estimado para alcanzar a Chema Alonso, cabeza de carrera en la demo. En la demo de LUCA Comms se mostró cómo utiliza l os algoritmos de aprendizaje automático para permitir a las empresas predecir y comprender el comportamiento de las comunicaciones mundiales, mediante una herramienta de visualización. Y, finalmente, SafePost: la app que facilita la comunicación en áreas sin internet, pudiendo publicar en RRSS y enviar corresos electrónicos sin conexión. Los visitantes al stand de LUCA pudieron probar enviar mensajes de SMS cifrado como si estuvieran en una de esas áreas. El objetivo del OpenExpo Europe ha sido ayudar a todos aquellos que buscan invertir e implementar una estrategia de Open Source (código abierto), o mejorar la estrategia que tienen en la actualidad y llegar a conocer nuevas propuestas en el mercado. Compartimos en un video de un minuto los momentos destacados de la feria, ¡míralo! Para mantenerte al día con LUCA visita nuestra página web, y no olvides seguirnos en Twitter, LinkedIn y YouTube. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
8 de junio de 2018

Ready for a Wild World: El Big Data es la clave para cuestiones humanitarias
El evento Big Data for Social Good: Ready for a Wild World, organizado por LUCA y que tuvo lugar el pasado 24 de mayo en Madrid, ha reunido a expertos de relevantes organismos globales como FAO, Unicef, el Ministerio español de Agricultura y Pesca, Alimentación y Medio Ambiente (MAPAMA), la GSMA o empresas como Data-Pop Alliance y Digital Globe, que demostraron con sus intervenciones la importancia del uso de los datos a la hora de desarrollar planes de prevención eficientes para la preparación ante desastres naturales y el cambio climático. En la nueva era digital, la toma de decisiones basadas en datos es un pilar fundamental para el éxito de las organizaciones. Según palabras de Kyla Reid, Directora de Servicios Móviles para Identidad Digital e Innovación Humanitaria de GSMA, "el Big Data es clave para la innovación digital en cuestiones humanitarias". En esta línea, el departamento de Big Data for Social Good de LUCA ya está trabajado en proyectos de organizaciones como FAO o UNICEF. De hecho, recientemente se ha firmado un acuerdo con FAO, del que también habló en el evento Natalia Winder Rossi, su Responsable de Protección Social: “FAO y Telefónica están trabajando juntas para aprovechar el uso de tecnologías digitales de vanguardia para el desarrollo agrícola, la seguridad alimentaria y la nutrición y específicamente, preparar y fortalecer a los agricultores frente a los fenómenos meteorológicos extremos relacionados con el cambio climático”. Otro debate que se abrió durante la jornada fue el de la protección y la cesión de los datos. Isabel Bombal, asesora de la Dirección General de Desarrollo Rural y Política Forestal-MAPAMA, resumió muy bien cómo superar las barreras que surgen cuando se plantea el hecho de compartir la información: “El primer incentivo para hacer posible el intercambio de datos es explicar los beneficios de por qué es importante". Sea cual sea el objetivo que se persiga al trabajar con los datos, filantrópico o de negocio, Elena Gil, CEO de LUCA, nos recordó que “la privacidad es un derecho y debemos ser muy protectores con eso." Además de presentar herramientas y proyectos reales en directo, como OPAL, una plataforma que busca liberar el potencial de los datos privados para el bien social, la aplicación de datos geoespaciales como los ofrecidos por DigitalGlobe para predecir eventos de toda clase, también medioambientales, o la iniciativa SafePost, herramienta que envía mensajes en situaciones de emergencia sin necesidad de conexión a Internet, también se habló de la necesidad de que todas estas iniciativas sean sostenibles en el medio-largo plazo y accesibles para los actores que principalmente hacen uso de estas herramientas, es decir, organizaciones de ayuda humanitaria y administraciones públicas. Si quieres entrar en detalle, visita la web del evento donde publicaremos lo más destacado de la jornada.
30 de mayo de 2018

¡Se aproxima la OpenExpo 2018!
Este 6 y 7 de junio se celebra la OpenExpo Europe en Madrid, el mayor congreso y feria sobre Open Source & Software Libre y Open World Economy (Open Data y Open Innovation) de Europa. En el centro tecnológico La Nave se reunirán profesionales y empresas nacionales e internacionales del sector, con desarrolladores y expertos del mundo de los datos. Figura 1. OpenExpo Europe es el punto de encuentro donde las empresas amplían su red de contactos, generan negocios y promueven sus servicios LUCA tendrá dos ponencias el 6 de junio, la primera impartida por Chema Alonso, Chief Data Officer (CDO) de Telefónica se titula “Un beso a un sappo y te quedas en silencio,“ y la segunda tratará de Big Data for Social Good, impartida por Richard Benjamins, AI Ambassador de CDO. Richard explicará la importancia de los datos para crear una sociedad mejor, utilizando los datos para crear proyectos que pueden ayudar a la sociedad, como gestión de desastres naturales, calidad del aire y monitorización de epidemias; y el compromiso de LUCA y Telefónica al negocio responsable. Para más detalles sobre los horarios puedes consultar la agenda completa aquí . LUCA también participará en la Feria con un stand (64) donde se estarán presentando tres demos interactivas del portfolio, LUCA Comms, Big Data en el ciclismo (Sports Analytics) y SafePost. LUCA Comms mostrará como utiliza los algoritmos de aprendizaje automático para permitir a las empresas predecir y comprender el comportamiento de las comunicaciones mundiales, mediante una herramienta de visualización. La demo de Big Data en el Ciclismo será una simulación de la Vuelta Ciclista España, en la etapa de los Lagos de Covadonga, donde los participantes podrán ver sus métricas y rendimiento en tiempo real mientras prueban una de las bicicletas del Movistar Team. Y finalmente en la demo de SafePost, que facilita la comunicación en áreas sin internet, los visitantes al stand de LUCA podrán probar enviar mensajes de SMS cifrado como si estuvieran en una de esas áreas. El objetivo del OpenExpo Europe es ayudar a todos aquellos que buscan invertir e implementar una estrategia de Open Source (código abierto), o mejorar la estrategia que tienen en la actualidad y llegar a conocer nuevas propuestas en el mercado. Si te interesan las nuevas tendencias OpenSource no olvides inscribirte aquí, y visitar el stand de LUCA. ¡Te esperamos! Para mantenerte al día con LUCA visita nuestra página web, y no olvides seguirnos en Twitter, LinkedIn y YouTube. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
29 de mayo de 2018

Telefónica celebra el Network Innovation Day: La red del futuro ya está aquí
Cada vez mas, necesitamos una red mas flexible y basada en software. Es por eso que este año queremos compartir contigo nuestra visión de como será la red del futuro. Telefónica celebra el próximo 14 de junio el evento más importante del año de innovación en la red: Network Innovation Day. We are in. El crecimiento exponencial de los datos continuará sobrecargando todos los tipos de infraestructuras de redes de que disponemos hoy en día. Junto con la revisión de los procesos de servicio y de negocio actuales, habrá que crear e implementar una nueva infraestructura de IT y de red. Las nuevas infraestructuras y servicios tendrán que mejorar la capacidad, la flexibilidad, el conocimiento de las aplicaciones, la seguridad y la eficiencia en costes de las soluciones existentes. E Estas son las nuevas normas del mundo digital. Para tomar mejores decisiones comerciales y tener una comprensión más profunda de los clientes, ser data-driven es esencial. En LUCA, la unidad de datos de Telefónica, entendemos que hablar el lenguaje de los datos es fundamental para las empresas del futuro. Chema Alonso, Chief Data Officer, dará una ponencia sobre " Planificación y operación de redes Data-Driven" donde hará énfasis en el Machine Learning, y en las últimas técnicas que ayudan a mejorar la experiencia de los usuarios y crear herramientas que también ayudan a mejorar las redes, y prepararlas para el futuro. El lema para nuestro evento de innovación en la red es: We are in. Desde dentro. Desde el corazón. Desde el centro neurálgico de Telefónica llega la verdadera transformación de la red. Gracias a la Inteligencia Artificial (IA), el Big Data, el 5G y la Seguridad recorremos un camino innovador revolucionando todos los procesos e infraestructuras técnicas hacia el futuro digital de nuestros clientes. Reserva ya tu sitio y Regístrate aquí Conoce de la mano de nuestros expertos las líneas de innovación tecnológica de Telefónica para responder a los nuevos desafíos que plantea la industria. Intervienen: Chema Alonso, Chief Data Officer de Telefónica; Enrique Blanco, Global CTIO de Telefónica y destacados expertos del sector. ¡No dejes pasar esta oportunidad! Te esperamos el próximo 14 de junio a las 9:30h en el Auditorio de Telefónica. Consulta los contenidos de la agenda que se presentarán en la agenda del evento Network Innovation Day 2018: 9:30 Acreditación 10:00 La innovación en el core. Guillermo Ansaldo 10:30 Planificación y operación de redes Data-Driven. Chema Alonso La información de nuestras redes y las últimas técnicas de Machine Learning permiten crear una herramienta de referencia en la industria para el desarrollo de redes cada vez mejores y así enriquecer la experiencia de usuario. 11:00 Virtualizando la red extremo a extremo. Enrique Blanco Telefónica a través del programa UNICA, agiliza el despliegue y la provisión de servicios con el objetivo de alcanzar la extrema automatización de la red. 11:45 Café 12:15 Seguridad desde la red. Chema Alonso y Pedro Pablo Pérez El mercado actual demanda un replanteamiento radical de la seguridad de la red. Para ello, profundizaremos en cómo estamos definiendo una estrategia de seguridad desde la red proporcionando un modelo mucho más flexible y simplificado . 12:35 Ordenadores cuánticos y la seguridad de las redes. Ignacio Cirac (invitado especial) Los ordenadores cuánticos supondrán una amenaza para los protocolos criptográficos en uso. Uno de los expertos más reconocidos en la materia explicará los desafíos para la seguridad de las redes y los procedimientos para restaurarla. 13:00 Hacia redes dinámicas basadas en Inteligencia Artificial. Juan Carlos García Nuestras redes auto-organizadas y su evolución hacia mecanismos cognitivos nos permiten facilitar los despliegues de las redes móviles, así como ofrecer servicios basados en técnicas de IA para abordar la complejidad de las futuras redes 5G. 13:30 Cierre institucional. Chema Alonso y Enrique Blanco Si no puedes asistir presencialmente al evento, puedes conectarte via streaming aquí. ¡No te pierdas ningún detalle! Síguenos también en la web del evento y redes sociales con el hashtag #NID2018
29 de mayo de 2018

Se inaugura la Cátedra Telefónica ProFuturo-UPSA
La Universidad Pontificia de Salamanca, Telefónica y la Fundación ProFuturo han firmado un convenio para crear la Cátedra Telefónica ProFuturo-UPSA. La cátedra UPSA: 'Analítica de datos de proyectos educativos en entorno vulnerable' tiene como objetivo revolucionar la educación digital. ProFuturo nace con la vocación de transformar la educación de 10 millones de niños en 2020, y tiene como misión reducir la brecha educativa con su proyecto de educación digital. Este proyecto se desarrolla en África, Latinoamérica y Asia y podrá ser potenciado con la ayuda del análisis de datos, y el impulso de Fundación Telefónica y Fundación Bancaria “la Caixa”. ProFuturo quiere detectar el talento, poder personalizar la educación con el feedback continuo que los datos proporcionan y se centra en las siguientes características: online, modular, adaptable, integral, y de apoyo local. En la firma del acuerdo estuvieron presentes la rectora de la Universidad, Mirian de las Mercedes Cortés Diéguez; la directora general de ProFuturo, Sofía Fernández de Mesa, y el director de Grandes Clientes de Telefónica y Territorio Centro, Adrián García Nevado. Cortés Diéguez ha considerado fundamental esta colaboración y ha mencionado que el compromiso social de la Universidad y que los alumnos puedan poner su conocimiento el servicio a los desfavorecidos son dos elementos fundamentales de este proyecto. Para incentivar la creatividad de los alumnos, y ayudarlos a proponer ideas para solucionar los problemas planteados, se organizarán competiciones, conferencias y otros eventos que inspiren a los alumnos a intercambiar propuestas. También se fomentará la investigación de los estudiantes de tesis doctorales que desarrollen nuevos modelos, métodos, algoritmos, o herramientas específicas, sobre los desafíos que propongan Telefónica y ProFuturo. Con el asesoramiento de LUCA, la unidad de datos de Telefónica, ProFuturo podrá potenciar sus soluciones detectando dificultades operativas, descubrir patrones de uso y medir la calidad de la enseñanza. Figura 2. Antonio Bengoa Crespo, Jacinto Núñez Regodón, Sofía Fernández de Mesa y Alfonso J. López Rivero Previamente a la firma institucional, las entidades han organizado una jornada en la que se ha detallado el proyecto en el que la UPSA va a colaborar. Esta jornada contó con la presencia de Jacinto Núñez Regodón (vicerrector de Relaciones Institucionales y Comunidad Universitaria), Antonio Bengoa Crespo (director de Relaciones Institucionales de Telefónica España),Sofía Fernández de Mesa Echeverría (directora general de la Fundación ProFuturo), Alfonso J. López Rivero (decano de la Facultad de Informática). Tras la inauguración, se desarrollaron una serie de conferencias: 'El estado del arte de la analítica y Big Data aplicado a la educación', a cargo de Head of Big Data for Social Good (LUCA Telefónica), Pedro Antonio de Alarcón, 'ProFuturo: mejorando la enseñanza y el aprendizaje a través de la analítica de datos', a cargo de Head of Product & Innovation ProFuturo, Paula Valverde y 'Analítica de datos de proyectos educativos en entorno vulnerable', por el director de la nueva Cátedra, Manuel Martín-Merino. Bengoa Crespo destacó que en la Red de Cátedras se está creando un think tank de muy alto nivel, y con esto, la educación digital logrará ayudar a todos los estudiantes entornos vulnerables a poder impulsar sus conocimientos. Otro ejemplo de cómo los datos contribuyen a hacer de este mundo, un mundo mejor. También puedes seguirnos en nuestras redes sociales: @Telefonica , @LUCA_D3 , @ElevenPaths
21 de mayo de 2018

El foro con las últimas innovaciones tecnológicas y mucho deporte
Creemos en que la vida digital es la vida, y la tecnología es parte esencial del ser humano. Por ello, en el pasado Foro de Tecnología y Deporte de Telefónica, disfrutamos de la presencia de estrellas del deporte y entre todos quisimos trasladar un mensaje muy importante para nosotros: "Las nuevas tecnologías apoyan a los deportistas tanto en competición como en sus entrenamientos, poniendo al servicio del deporte los dispositivos inteligentes, la gestión de los datos con Big Data, la Inteligencia Artificial o el Internet de las Cosas (IoT).Hace unos meses presentamos nuestra acción Ven a hacer deporte con Telefónica durante el Mobile World Congress de Barcelona, y seguimos demostrando los beneficios de la tecnología y el Big Data en el deporte con colaboraciones de nuestro área Sports Analytics, como el equipo ciclista Movistar Team y de eSports, Movistar Riders. El foro comenzó con la intervención del Presidente de Telefónica, José María Álvarez-Pallete, quién subrayó el compromiso de la compañía que lleva apoyando el deporte y compartiendo sus valores durante 25 años, "los valores del deporte nos contaminan positivamente como personas, como compañía y como país. Es el momento de que el esfuerzo deportivo se vea acompañado y apoyado por el esfuerzo tecnológico". El famoso tenista Rafa Nadal y su "Rafa Nadal Academy by Movistar" fue el primer caso que se mostró en el Foro, detallando el funcionamiento de su academia y la aplicación de la tecnología para el seguimiento de los alumnos o la digitalización de la pista de tenis. Quien explicó en primera persona que "aunque yo he crecido sin tecnología y sigo entrenando como siempre, disponer de los datos, las estadísticas, el poder grabarme y visualizarlo en el momento, son, sin duda, herramientas claves para saber en qué debemos mejorar". Figura 2: Chema Alonso presentando la colaboración entre Movistar Team y LUCA Chema Alonso, CDO de Telefónica, no podía faltar en esta jornada. En este caso junto con Movistar Team, el equipo ciclista representado por los ciclistas Alejandro Valverde y Lourdes Oyarbide, y Mikel Zabala, responsable de innovación del equipo. Una presentación para mostrar c ómo aplicamos los últimos avances en Ciencias del Deporte, Big Data y Machine Learning en la planificación de los entrenamientos y en la creación de herramientas analíticas que aporten conocimiento adicional del desempeño del equipo en competición. Todo ello gracias al análisis avanzado de datos, con el objetivo de mejorar el rendimiento de los ciclistas y, por ende, los resultados. Alejandro Valverde, además, se animó a realizar una demo que simula una de las etapas de la Vuelta Ciclista España, en los Lagos de Covadonga, y que ponía a prueba las capacidades predictivas de la inteligencia artificial. Figura 3: Visualizació de la demo realizada por Alejandro Valverde, demostrando cómo se aplica el Big Data en el cicilsmo El encuentro dio visibilidad a deportes como los eSports menos conocidos a primera vista, pero que cada vez tienen más seguidores. En este caso, se presentó a Movistar Riders, el equipo de eSports patrocinado por la compañía, y que también hace uso desde hace tiempo del Big Data para mejorar el rendimiento de sus profesionales, en una colaboración con LUCA. En esta presentación se dio especial importancia de la conectividad y la seguridad para asegurar el éxito del equipo, de la mano de Enrique Blanco, CTIO de Telefónica, y Fernando Piquer, CEO de Movistar Riders. Cambiando de escenario, Carme Artigas, CEO de Synergic Partners, junto con Mª José López, CEO de Sierra Nevada, explicaron el enorme potencial del uso del Big Data para entender, predecir y promocionar la demanda de los deportistas aficionados al esquí de estaciones como la de Sierra Nevada. Durante la ponencia, además, se realizó un breve análisis del centro deportivo con datos cruzados de los remontes y redes móviles a modo de caso de uso. Mostrando la aplicación real del Big Data en deportes como el equí, garantizando siempre la seguridad y privacidad de los datos, utilizándolos de forma anónima y agregada. Figura 4: Carme Artigas, CEO de Synergic Partners, en el Foro Tecnología y Deporte de Telefónica La jornada contó también con la presentación de proyectos como el caso del Wanda Metropolitano, el primer estadio 100% IP del mundo, con Telefónica como socio tecnológico, presentado por Miguel Ángel Gil, consejero delegado del Atlético de Madrid y Emilio Gayo, presidente de Telefónica España. Seguido de la presentación de Xtreamer, una tecnología desarrollada por Telefónica que permite generar contenidos en calidad para la emisión en directo a través de dispositivos móviles. Una tecnología ya utilizada por medios de comunicación como la BBC, y con la que se realizó una conexión en directo con el Gran Premio de Jerez de MotoGP. Un encuentro que puso de manifiesto, una vez más, cómo las nuevas tecnologías apoyan a los deportistas profesionales en la mejora de su rendimiento, con la participación de grandes deportistas que pudieron contar en primera persona cómo incorporan estas tecnologías en su día a día y los beneficios que ello les aporta. Porque la tecnología va a cambiarlo todo, y también el deporte. Si no pudiste asistir al encuentro, puedes ver el v ideo completo sobre el Foro de Tecnología y Deporte y t ambién puedes seguirnos en nuestras redes sociales: @Telefonica , @LUCA_D3 , @ElevenPaths No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
8 de mayo de 2018

Domina los videojuegos clásicos con OpenAI y Machine Learning
Para muchos de nosotros, pensar en videojuegos es recordar la infancia. Nos acordamos de todas esas horas que pasamos intentando pasar al siguiente nivel, y hasta podemos escuchar la música de nuestro juego favorito. Hoy en día, con la ayuda de la tecnología hay nuevas maneras de superar cada prueba, y hasta podemos entrar a un agente AI. ¿Quieres saber como? Figura 1. La mejor manera de aprender, ¡es la práctica! En el primer capítulo del webinar (serie de dos episodios), Fran Ramírez y Enrique Blanco nos explicaron la instalación y las bases de funcionamiento del entorno OpenAI Gym. El framework de videojuegos OpenAI Gym nos ofrece un entorno ideal para aprender técnicas de Inteligencia Artificial (IA) y en concreto de Machine Learning. La mejor forma de hacerlo es construyendo nuestra propia IA que sea capaz de desenvolverse en esos entornos y llegar a dominar juegos clásicos como Breakout, Pong, Pac-Man o incluso DOOM. Si te perdiste del webinar, encuentra el vídeo a continuación. Recuerda que para aún más información sobre este tema puedes consultar este post .
26 de abril de 2018

Primeros resultados del proyecto Mapa OOH en Brasil
El pasado 26 de marzo Clear Channel, JCDecaux y Otima presentaron los resultados de la campaña de mapas OOH en Rio de Janeiro y São Paulo realizado conjuntamente con LUCA, la unidad de datos de Telefónica. La iniciativa se implementó en abril de 2017, con el objetivo de comprobar la eficacia de la publicidad exterior con soluciones como LUCA OOH Audience, a través de la fusión de gran variedad de datos de Telefónica, capaces de aportar una visión más en profundidad de distintas localizaciones. Comprobar la eficacia del sector de publicidad Out Of Home ha sido uno de los principales objetivos de las grandes empresas del sector de publicidad y marketing. Así, con ese objetivo en común, las empresas Clear Channel, JCDecaux y Otima se asociaron para crear el Mapa OOH, el proyecto que ofrece métricas y herramientas que permiten a las agencias y anunciantes la planificación y evaluación de campañas de publicidad exterior con datos de alcance y frecuencia, gracias a el análisis avanzado de datos ofrecido por LUCA. Ahora, tras el l anzamiento del proyecto en Brasil el segundo semestre de 2017, se han publicado los primeros resultados del proyecto en el que se han invertido más de 2 millones R$ para su implantación inicial en Rio de Janeiro y São Paulo. El proyecto ha contado con el expertise de LUCA junto con Ipsos Brasil, Ipsos Reino Unido, MGE Data y Logit. Gracias a las más de 17 mil entrevistas realizadas y los más de 80 mil trayectos analizados en las ciudades de estudio, se ha realizado una estimación muy fiable y segura de los datos de la audiencia. Sergio Viriato, gerente de Conmark, indica que "según los datos registrados, los ciudadanos de São Paulo son impactados por publicidad exterior de media 86 veces por semana, y 173 veces los ciudadanos de Rio de Janeiro. Lo que se traduce en 490 millones y 495 millones de impactos a la semana, respectivamente". Un modelo de publicidad que cada vez tiene más presencia en las grandes ciudades, y el motivo: su gran impacto. Según estos primeros resultados, durante una campaña semanal con una instalación de 300 implantaciones en cada ciudad, el alcance en São Paulo es del 29% entre jóvenes mayores de 15 años de edad; llegando hasta el 38% en el caso de los jóvenes de Rio de Jainero. Traduciendose en una frecuencia media de 5,1 y 10,1 impactos por persona, respectivamente. "Si la publicidad exterior fuese un programa de televisión, estaría entre los cinco principales programas en términos de audiencia", afirma Sergio Viriato, coordinador del proyecto. El gerente asegura que los buenos resultados pueden elevar la inversión en el sector en un futuro, como ocurre ya en países como Japón, Francia o Reino Unido. Este proyecto de publicidad OOH estará disponible con acceso gratuito para aquellas personas que registren su email en la plataforma del proyecto. De este modo, Ipsos realizará simulacros del proyecto con agencias y anunciantes registrados, y la organización del proyecto realizará un road show de las agencias para presentar las conclusiones del estudio. Para las próximas aplicaciones del software utilizado, el proyecto contará con la información anónima de 410 millones de trayectos identificados por los datos de telefonía móvil y, a finales de este año, el número de instalaciones publicitarias aumentará, incluso en medios de transporte. Una vez adaptada la metodología, además, se aplicará el proyecto también a municipios a las afueras de Rio de Janeiro y São Paulo. El estudio sigue directrices de Esomar y fue resuelta por un consorcio formado por Ipsos Brasil, Ipsos Reino Unido, MGE Data, Telefónica y Logit, y financiado por las empresas fundadoras.
19 de abril de 2018

Prediciendo el crimen en Nueva York con Big Data
¿Recuerdas Minority Report, la película de Steven Spielberg y Tom Cruise? Trataba de una división de la policía llamada PreCrimen, que con la ayuda de tres mutantes tenía visiones del futuro y la habilidad de detener un crimen antes de que este ocurriera. Aunque la realidad no es igual que en las películas, hoy en día con el uso del Big Data, también se pueden predecir crímenes en ciudades grandes. La ciudad de Nueva York siempre ha llamado mucho la atención, no solo por ser centro de negocios, moda y cultura, sino también por ser bastante innovadora. Por esta razón, es la ciudad idónea para este proyecto tan interesante liderado por Santiago Gónzalez, el Director de Tecnologías e Innovación de Synergic Partners, el área de consultoría estratégica y tecnológica de LUCA y desarrollado en colaboración con la Columbia University y el Ayuntamiento de Nueva York. El webinar de este pasado 10 de abril fue todo un éxito y con la presentación interactiva de Santiago González se pudieron ver los modelos analíticos utilizados en el proyecto, y qué factores se tomaban en cuenta para obtener resultados. El clima, la hora del día y el tráfico, por ejemplo, marcaban una diferencia en cuanto al nivel de crimen. En días de mucho tráfico, el NYPD se encuentra controlando ciertas calles, y hay menos posibilidades de que puedan llegar con rapidez a la escena de un robo. También se mostró un mapa interactivo de la ciudad, donde destacaba Brooklyn como la zona donde se observa más actividad criminal y Staten Island por ser la más segura. A continuación, Santiago González responde las preguntas que nos dejaron en el chat del webinar, y que, debido al gran volumen, no se pudieron responder en directo. ¿Podría ser un factor de delito a tener en cuenta la apertura o cierre de negocios donde se suele robar? ¿Esto alteraría las estadísticas de delitos de esa zona concreta? Ese tipo de delitos no está contemplado dentro del estudio de crímenes, y creo que las fuentes asociadas a este crimen son diferentes a las que hemos usado. Hemos intentado usar las fuentes que, de alguna manera, tienen relación causa-efecto con el comportamiento humano ante un crimen (¡y faltan muchas otras fuentes! sobre todo para crímenes pasionales). Pero para el caso de cierre de negocios, habría que analizar movimientos de shopping, competencias, interés público, blanqueo de capitales, etc. ¿Qué posibilidad hay de aplicar este modelo en otras ciudades? Como tal, el modelo puede ser directamente aplicable si y solo si existe en esa ciudad el concepto de precinto policial (zona controlada por una estación de policía). En caso contrario, habría que modificar el modelo y analizar la granularidad de los datos, para ver cómo enfocar la posible predicción. ¿Las bases de datos sólo las habéis obtenido del Data Open Source de New York? ¿Habéis tenido en cuenta el factor cultural a la hora de la clasificación de las variables? Open Data New York (http://opendata.cityofnewyork.us/), es el origen de la gran mayoría de fuentes. Otras fuentes (como el NY Times) se saca directamente del servicio Open. Pero todas son Open Data. Si como factor cultural te refieres a cómo influye la información sociodemográfica al resto de variables, sí. Es algo muy interesante de analizar, ya que afecta directa e indirectamente sobre la clasificación de "crimen" y de "no crimen". Cosas como que, por ejemplo, un criminal de una determinada característica étnica, racial o social no actúa sobre otros iguales en zonas de su clase social. En la comparación de todos los modelos ¿cuál es el modelo que se eligió para entrenarlo con los datos? El mejor, con diferencia, tanto en estabilidad a lo largo del tiempo como en resultados, es el XGBoost. Pensaba que las series temporales ARIMA & family iban a dar buenos resultados, pero me equivoqué... ¿Cuál es la "resolución" en tiempo y espacio para la predicción del crimen? En espacio es un precinto policial (aproximadamente 1,3km de radio a la redonda) y en cuanto al tiempo, es periodos de una hora (por ej. de 12 a 13). Para asegurar calidad en el modelo, recomendamos desde Synergic que no se predigan ventanas de tiempo de más de 1 mes. ¿Los datos con los que habéis entrenado el modelo son oficiales de la policía de New York? ¿Y qué tipo de datos os han proporcionado? Si, son totalmente oficiales. Es más, al principio los datos los sacamos del portal Open Data. Pero como tardaban en subir datos, luego directamente nos pasaba la propia Policía cada mes. Tal cual lo que viene en el portal Open Data es lo que teníamos, echad un vistazo a este enlace. ¿Qué opinas de la realización de perfiles psicográficos a través de Big Data (Cambridge Analytica) para la prevención de conductas violentas? Siempre que seamos capaces de generar perfiles tipo que representen los patrones de conducta de criminales a partir de redes sociales, y NOSOTROS no seamos (o no queramos ser) capaces de inferir que personas son las que representan dichos patrones, estoy de acuerdo con utilizar este enfoque. Quiero decir que, nuestro objetivo no es inferir las personas, sino ayudar a la policía a que los infieran ellos. Para nosotros, TODOS los datos deben ser anónimos, agregado y el modelo de inferencia, a poder ser, basarse en Sistemas Basados en el Conocimiento (KBS) de clasificación heurística o jerárquica con procesos de abstracción. Fuera de esto, mi opinión es que el creador del dato (cada persona que genera la información sobre su vida) es el propietario del mismo y el que debe dar permiso o no de usarse para terceros.
12 de abril de 2018

El Big Data se suma a la Movistar Media Maratón de Madrid
Llega la XVIII edición del Movistar Media Maratón, l a carrera más conectada gracias a la tecnología IoT de Telefónica y LUCA, realizando estudios e informes posteriores, con el análisis de los datos recabados de los corredores, gracias a la app por aquellos que lo descarguen, y los dispositivos instalados. Una manera más de mostrar cuáles son los beneficios del análisis avanzado de Big Data en el deporte, contribuyendo en la mejora del rendimiento de los deportistas. Este domingo, 8 de abril, más de 25.000 atletas se reunirán para correr la Movistar Media Maratón en las calles madrileñas con el patrocinio de Movistar. La prueba recorre la parte noreste de la ciudad, desde el Paseo del Prado (cerca del palacio de Cibeles) hasta las Cuatro Torres Business area, con la meta final en el Paseo del Prado, enfrente del Real Jardín Botánico. Tecnología para los corredores Telefónica regresa al patrocinio de las carreras con la implantacion las últimas innovaciones tecnológicas gracias a Telefónica IoT, que instalará un millar de trackers a lo largo del recorrido y la posibilidad de descargarse una app desarrollada por Movistar, que permite estar al día de todas las novedades y consultar toda la información sobre la carrera. La App Movistar Medio Maratón es la principal novedad de este año. Los corredores y su entorno podrán e star al día de toda la información del evento (consultar los dorsales, la clasificación, ver vídeos y fotos de la carrera), y conocer en tiempo real por GPS la posición de otros corredores que participen en la prueba y señalados previamente, lo que permite la competición entre grupos de amigos y aumentar la motivación. Además, para aquellos que eviten llevar el móvil durante la prueba, s e han diseñado unos dispositivos ligeros que transmiten en tiempo real su ubicación en el recorrido y la velocidad a la que se mueven. Estos mismos dispositivos IoT se implantarán en las bicicletas que acompañan a los líderes, en las liebres de la carrera y en determinados grupos de corredores, con el objetivo de completar la información que ofrezca la app. Esto mejorará el seguimiento de los atletas y ofrecerá información muy relevante para que desde LUCA, la unidad de datos de Telefónica, se pueda analizar toda la información de los corredores y realizar estudios posteriores. Así, a través de un dashboard diseñado para la ocasión y que se dará a conocer tras la carrera, los participantes podrán conocer la posición absoluta en la carrera y la clasificación respecto a los corredores de su mismo segmento (definido según rango de edad y género) en una comparativa por puntos de control y estadística agregada de datos, entre otras informaciones relevantes para cualquier deportista que quiera conocer su desempeño. Una carrera de lo más conectada, en la que el principal objetivo de Movistar es poner a disposición de los corredores todas sus capacidades tecnológicas. 5 Km de Carrera con ProFuturo La carrera 5K de la Media Maratón de Madrid se pondrá el dorsal solidario y se convierte en la Carrera ProFuturo 2018, con el objetivo de recaudar fondos para el proyecto. ProFuturo es una iniciativa impulsada por Fundación Telefónica y Fundación Bancaria “la Caixa” que tiene como misión reducir la brecha educativa en el mundo proporcionando una educación digital de calidad a niños y niñas de entornos vulnerables de África, América Latina y Asia. La Carrera ProFuturo, que el año pasado contó con más de 3.000 corredores y logró una recaudación de 13.000 euros, celebrará su tercera edición este año. En esta ocasión, la carrera pasa de celebrarse alrededor del Distrito Telefónica en Las Tablas al centro de Madrid y los fondos se destinarán a la implementación del proyecto ProFuturo en las zonas más desfavorecidas del mundo.
5 de abril de 2018

Los 5 errores de concepto más habituales sobre Data Science
Introducción Hoy vamos a hablar de datos y de Ciencia de Datos. Como ocurre en tantos aspectos relacionados con la innovación y la tecnología se impone la terminología en inglés, así que, por claridad, nosotros también la adoptaremos. Por tanto, hablaremos de Data Science. Los datos han invadido prácticamente todas las facetas de nuestra vida, personal y profesional. En la parte personal, por ejemplo, en las áreas relativas al ocio, la salud, el deporte, medio ambiente, incluso en las relaciones humanas. En la parte profesional o de negocio, los datos están en el corazón de las actividades de comercio, finanzas, marketing, seguridad, investigación, educación, turismo etc. En realidad, cualquier actividad humana o fenómeno natural observable y medible genera datos. Y en la actualidad disponemos de tecnologías que nos permiten captarlos, depurarlos, procesarlos, almacenarlos y analizarlos para “exprimir” su potencial. Ese jugo que le sacamos a los datos es el que revoluciona cómo trabajan las empresas de cualquier sector que han abrazado la revolución digital, y que han dejado de basar sus decisiones de negocio en la experiencia y en la intuición, para hacerlo de forma más “informada”, basándose en los Insights obtenidos a partir de sus datos. Sin embargo, aunque el Data Science parece hoy en día la panacea, el bálsamo de Fierabrás que resuelve cualquier problema, y de hecho, es cierto que los resultados son tangibles, están ahí, conviene hacer algunas matizaciones. Es necesario aclarar algunos errores de concepto que están muy extendidos y ajustar las expectativas a la realidad. Eso es precisamente el objetivo de este webminar. 1 Data Science, Big Data… es lo mismo Hablemos con precisión Mucha gente utiliza estos conceptos de forma intercambiable, como si fueran lo mismo. Sin embargo, son dos conceptos que, aunque efectivamente están muy relacionados, tienen distinto significado. Es indudable que el Big data ha sido uno de los principales aceleradores del Data Science, sumado al abaratamiento y cada vez mayor complejidad de los circuitos integrados en la infinidad de sensores que constituyen el corazón del IoT. Cuando hablamos de Big data, hablamos de captación, depuración, gestión y procesamiento de cantidades ingentes de datos (volúmenes mínimos de terabytes). Pero se trata de algo más que un gran número de “0” y de “1”s. Lo que caracteriza al Big Data es lo que se conoce como las 3Vs: Volumen, Variedad y Velocidad. Sobre el Volumen, ya hemos dicho que son grandes no, enormes. Pero es que además son diferentes (y aquí entra el factor Variedad). Porque tenemos datos estructurados, no estructurados o semi-estructurados. Datos numéricos, imágenes, sonidos, vídeos, texto etc. Y son datos que se están generando continuamente, a gran velocidad. Un solo tuit no supone más que unos pocos cientos de bytes, pero si consideramos que, en un minuto, en promedio, se generan unos 350.000, no es difícil identificar que estamos ante un caso claro de Big Data. Sin embargo, el Data Science es un concepto mucho más amplio, que abarca tanto las tareas que hemos comentado antes de captura de datos, transformación, modelado, almacenamiento, como el análisis exploratorio, la construcción de modelos y algoritmos adaptados a cada problemática concreta y la visualización e interpretación de los resultados. Podríamos decir que el Big Data es un aspecto particular de Data Science en el que los datos sobre los que se trabajan se pueden caracterizar por alguna de las 3Vs. Muchas veces el problema de las empresas no viene por el volumen de sus datos (no es habitual manejar petabytes de información), sino más bien por su variedad. El desafío es ser capaces de extraer información dºe fuentes online y mobile, integrar conjuntos de información dispares, dispersos, a veces inconsistentes e incompletos y transformarlos en información útil para el negocio. 2. Las máquinas aprenden solas ¿Pero cómo aparende una máquina? Muchas personas piensan que sólo hay que introducir los datos y la magia del machine Learning dará las respuestas. Pero no hay magia que valga. Las máquinas aprenden de los datos por medio de algoritmos. Si entrenamos el algoritmo ofreciéndole preguntas y respuestas correctas, podemos construir un modelo que le permita predecir las respuestas para nuevas preguntas. Algoritmos hay muchos, más o menos complejos, basados en distintos campos de las matemáticas (estadísticos,probabilísticos, geométricos etc.). Según el problema, serán más adecuados unos u otros. Pero siempre, lo fundamental, es que la máquina debe aprender de los datos que le facilitemos para entrenamiento. Es como preparar un examen. Al estudiar, nos “entrenamos” con situaciones para las que tenemos la solución correcta. Trabajamos con problemas resueltos para “aprender” a resolver los que nos planteen en el examen, que nos son desconocidos (qué más quisiéramos ¿no?). De la misma forma que nosotros nos entrenamos para el examen resolviendo problemas conocidos, el algoritmo aprende a partir de esos datos de entrenamiento. Va ajustando sus parámetros, y si los datos son bastantes y de calidad suficiente, será capaz de predecir una respuesta adecuada cuando le planteemos una situación nueva. Es decir, será capaz de resolver el problema, parecido, pero nuevo, que nos pongan en el examen. Esta es la forma de aprender conocida como “Aprendizaje Supervisado”. Cuando no se dispone de “datos etiquetados” para entrenar el algoritmo, sólo se puede describir la estructura de los datos para encontrar algún tipo de organización o patrón que simplifique el análisis (exploratorio). Este tipo de ataque es lo que se conoce como “Aprendizaje no supervisado”. ¿Y cómo han de ser esos datos? Vamos a ver un ejemplo. Si quisiéramos enseñar aritmética básica a un niño de 7 años, ¿Con cuál de estas dos pizarras tendría más posibilidades de aprender? (...) Está claro que con el primero, lo tendría muy complicado. Con el segundo, al menos, podría memorizar los resultados y sabría responder correctamente a alguna pregunta. La idea con la que nos tenemos que quedar es que para poder desarrollar un modelo que funcione, lo primero será tener claro el objetivo que buscamos, pero después necesitamos disponer de un conjunto suficiente de datos con el que entrenar. El entrenamiento en realidad consiste en encontrar qué relación existe entre esos datos de entrada, los inputs y los resultados, los outputs. Y si no encontramos esa relación, probablemente habrá que transformar o agregar los datos de alguna forma que nos permita encontrarla. Por ejemplo, en vez de trabajar con palabras de un texto, trabajar con el número de veces que aparece determinada palabra. 3. Todos los datos valen ¿Qué quieres decir con que “estos datos no tienen suficiente poder predictivo? Está claro que el uso de analíticas de datos ha cambiado las reglas del juego. Pero los datos, por si solos no pueden resolver los problemas o los desafíos a los que se enfrenta la empresa. No es cuestión de coger los datos, coger un data scientist y decirle, “Hala, encuentra algo interesante”. Esta estrategia “exploratoria” de los datos no es que sea mala, incluso puede sacar a la luz temas que merezca la pena investigar con data science. Pero lo ideal es empezar a trabajar a partir de preguntas bien planteadas. Porque, además, muchas veces, la información que necesitamos está oculta, o es difícil de extraer, o hace falta combinar datos de distintas fuentes, Existe una infinidad de herramientas con las que un buen analista puede obtener la información más relevante de los datos…. si es que la hay. Porque a veces la respuesta que buscamos no está en nuestros datos. Por ejemplo, si lo que queremos es medir lo que se conoce como “customer sentiment”, la percepción, el aprecio que tienen los clientes por nuestra marca, los datos de la línea de atención al cliente pueden no ser la mejor fuente de información para este análisis. ¿Por qué? Porque normalmente, cuando los clientes llaman a soporte es porque tienen un problema, y por tanto, suelen estar si no enfadados, cuanto menos molestos, incómodos. Si medimos su “sentimiento” a partir de estos datos, el resultado va a tener un sesgo hacia los sentimientos negativos. Por tanto, estos datos no nos sirven para responder a esta pregunta concreta. Habría que trabajar con datos de valoraciones del producto en la web del fabricante y otras externas, con referencias al producto en otras webs, con tuits que mencionan al fabricante etc. Todos los datos son valiosos. Si, pero a lo mejor no lo son para lo que necesitamos en un momento dado. La clave es determinar qué le queremos preguntar a los datos, cuáles nos hacen falta, dónde encontrarlos y cuál es la mejor forma de explotarlos. 4. El "Data Scientist" ¿Quién es el científico de datos? Según como lo mires… Hace unos años, en 2012, se proclamó la profesión de Data Scientist como la más sexy del momento y hoy, en 2017, aunque puede que ya no tenga tanto glamour, sigue siendo una de las profesiones más demandadas del mercado. Sin embargo, definir las áreas de conocimiento que hay que dominar para ser un científico de datos no es tarea fácil. De hecho, dio origen a una curiosa, colorida e incruenta “batalla de diagramas de Venn”. Desde el original, creado en 2010 por Drew Conway,: Pasando por versiones más elaboradas como la de Michael Malak de 2014:(...) O esta otra versión del original anotada por Gartner:(...) Lo que está claro es que un perfil de Data Scientist requiere una compleja combinación de habilidades, conocimientos y experiencia que ha ido evolucionando con el tiempo. Hace unos años, los perfiles más buscados solicitaban experiencia en Hadoop, HDFS, Big Data y Map Reduce (es decir, más orientado a ingeniería). En nuestro blog tenemos una miniserie sobre estos conceptos, por si alguien tiene interés. Sin embargo, hoy en día las palabras clave son “ Deep Learning”, Analíticas en tiempo real, y Blockchain. Seguramente, en unos años, serán sustituidas por otros términos que hoy día no existen. ¿Y entonces, quienes son los data scientist de hoy?. Pues son analistas, programadores en R o Python, expertos en machine Learning, ingenieros de datos … Da igual cómo les llamemos. La descripción del perfil es como la cara de los Reyes Magos (el unicornio morado, en EEUU). Es muy difícil encontrar individuos que reúnan todas los conocimientos, habilidades y experiencias necesarios. Así que lo más habitual es trabajar con equipos formados por personas expertas en varios de estos campos para así, entre todos, emular al perfecto Data Scientist. 5. Data Science es una ciencia, pero… Pero también es un arte Al hablar de ciencia de datos, de algoritmos, de modelos, de lenguajes de programación etc., parece que estamos hablando de una ciencia exacta, donde no hay cabida para la subjetividad. Pero veremos que no es así. La ciencia de datos, es una ciencia, sí, pero también es un arte. Todo el proceso, desde plantearse las preguntas adecuadas, decidir qué datos hacen falta para responderlas, capturar esos datos, tratarlos, modelarlos, reducirlos, analizarlos, desarrollar modelos a partir de ellos, valorar esos modelos, inferir resultados, sacar conclusiones, visualizarlas, presentárselas a otros… En todos estos pasos hay cabida a un punto de subjetividad que dependerá de nuestra experiencia, de nuestro criterio, o incluso de nuestra inspiración. Puede haber muchas soluciones distintas para un mismo problema, lo difícil es dar con la óptima. Incluso definir cuál sería la óptima Es importante ser conscientes de ello ya que, aunque lleva tiempo desarrollar la experiencia y la intuición necesarias, “el mejor escribano echa un borrón”, Como nuestra, un ejemplo de correlación espuria de la web de Tyler Vigen, que nos muestra la aparentemente ajustada correlación entre en consumo de queso por persona y el número de personas que murieron enredadas en sus sábanas. (...) Está claro que, el Data Scientist es el que debe estar ahí para preguntarse ¿Tiene sentido este resultado?, por muy bien que se ajusten los datos al modelo o muy ajustada que sea la precisión. Y con esto, terminamos. Esperamos haber aclarado algunos errores habituales sobre ciencia de datos, pero somos conscientes que la vertiginosa evolución tecnológica en este campo traerá de la mano muchas más. En cualquier caso, es un tema complejo, pero apasionante, que, queramos o no, ya se ha hecho un hueco en nuestras vidas. Publicaremos el vídeo y el post, este jueves (hoy). También podéis enviar vuestras preguntas a través de este canal. Estad atentos a nuestros canales (Página de Eventos, blog, y redes sociales) para la convocatoria de nuestro weminar de abril.
22 de marzo de 2018

II Encuentro Big Data Talent Madrid 2018
Según Peter Sondergaard “ La información es la gasolina del siglo XXI y la analítica de datos el motor de combustión”. El valor del Big Data reside en encontrar patrones que ayuden a predecir el futuro, ofreciendo ventajas competitivas porque la información es poder. El Big Data ha tomado un rol importante en el desarrollo de las empresas, y ha abierto una infinidad de posibilidades profesionales para aquellos buscando ampliar sus conocimientos o hacer un cambio profesional. El próximo 15 de marzo, se celebrará en la Facultad de Matemáticas de la Universidad Complutense, el II Encuentro Big Data Talent Madrid 2018, que tendrá como tema la situación actual del universo del Big Data. Este evento reunirá a profesionales de distintas compañías del sector que compartirán conocimientos y experiencias, nuevas tendencias y darán a conocer las oportunidades profesionales y perfiles más demandados para las compañías Data-Driven. Figura 1 : Las compañias pueden usar Big Data para encontrar nuevo talento. De parte de Telefónica, Antonio Guzmán, Head de Discovery & Innovation de AURA, estará impartiendo una conferencia. AURA es la nueva división de Inteligencia Artificial de Telefónica, que acaba de ser introducida al público en el Mobile World Congress 2018 en Barcelona. Esta unidad, junto con ElevenPaths y LUCA forman parte del Chief Data Office (CDO) liderado por Chema Alonso. El evento contará con una Talent Zone, donde los participantes podrán consultar con responsables de los equipos de RRHH y Gestión del Talento de las empresas participantes y estos explicarán sus necesidades reales dentro de sus equipos de trabajo de las áreas de Big Data de sus compañías. La inscripción al Encuentro Big Data Talent es totalmente gratuita y accesible para todo aquel que muestre interés en el mundo de los datos, busca nuevas salidas profesionales o, simplemente quiere una introducción al Big Data. Solo tienes que entrar en www.campusbigdata.com/big-data-talent-madrid e inscribirte. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
12 de marzo de 2018

Semana Sports Analytics de LUCA en Movistar Centre Barcelona
La semana pasada se celebró el Mobile World Congress en Barcelona y, aprovechando ese momento, el Movistar Centre acogió una acción dinamizadora organizada por LUCA, en colaboración con los equipos Movistar Team y Movistar Riders. Una acción creada ad hoc de la que pudieron disfrutar los asistentes al centro, montando en las bicicletas del equipo ciclista y jugando a eSports, mientras conocían sus métricas con Big Data como auténticos profesionales. Descubre cómo transcurrió la semana con LUCA y nuestra área Sports Analytics en Barcelona. Figura 1: Chema Alonso (CDO Telefónica), Elena Gil (CEO LUCA) y el equipo de LUCA en Movistar Centre Barcelona Durante la semana del Mobile World Congress, LUCA organizó esta acción dinamizadora con el fin de mostrar cómo la aplicación de los datos contribuye en la mejora del rendimiento y resultados de los equipos deportivos. Una acción organizada bajo el lema Sports Analytics y en colaboración con Movistar Team y Movistar Riders. La acción en colaboración con el equipo ciclista tuvo gran acogida en la ciudad condal, con más de 115 participantes que se animaron a montar en las bicicletas oficiales del equipo y conocer su rendimiento gracias a los insights obtenidos a través de los datos. La demo que reflejaba variables como la velocidad y la potencia de cada participante, representaba la etapa de los Lagos de Covadonga con las métricas obtenidas por Alejandro Valverde en La Vuelta España 2016. Una acción que motivó a todos los asistentes en el centro a participar, incluso al propio Mikel Landa, ciclista profesional del equipo Movistar Team, quien se animó junto con Chema Alonso, CDO de Telefónica, a participar y conocer sus métricas en las bicicletas del equipo. Además, el participante con mejores métricas obtenidas durante la primera jornada de la acción, recibió como premio un maillot oficial del equipo Movistar Team firmado por Mikel Landa. Figura 2: Chema Alonso y Mikel Landa, ciclista profesional, participante en la acción de LUCA en Movistar Centre La aplicación de los datos en los eSports también obtuvieron gran expectación. Esta vez, los registrados previamente para la acción, pudieron disfrutar de una partida online de League of Legends con los profesionales del equipo Movistar Riders, mientras conocían su performance a través de la demo diseñada ad hoc para ello, y con la que podían comparar su rendimiento con los de los profesionales. Una manera de conocer cómo el equipo de eSports profesional colabora con LUCA para mejorar la potenciación de la preparación física y mental de los jugadores, a través de una herramienta analítica que aporte insights únicos sobre los jugadores, las competiciones y los rivales a los que se enfrentan. Además, algunos de ellos también pudieron probar una de las diademas que utiliza el equipo para monitorizar las ondas cerebrales de los jugadores mientras compiten, lo que permite conocer los niveles de estrés o concentración, por ejemplo, según factores externos que influyen en su rendimiento. Figura 3: El equipo Movistar Riders en directo en la pantalla, y participantes listos para competir en los ordenadores Una semana de jornadas deportivas en el Movistar Centre de Barcelona, en la que una vez más, LUCA demostró cómo la tecnología y la aplicación de los datos, permiten mejorar diferentes ámbitos de nuestras vidas, como el deporte, para tomar decisiones más acertadas y mejorar los resultados. ¿Quieres conocer más? Mira el video a continuación, con todos los detalles de la acción.
8 de marzo de 2018

Selección de audiencia para datos patrocinados: la precisión es poder
Los datos patrocinados, que ya son un poderoso mecanismo de participación móvil, están por dispararse gracias a la adición de la segmentación precisa de los consumidores. La fuerza sólo se vuelve realmente efectiva cuando está bien dirigida. Una enorme potencia puede haber elevado las misiones lunares del Apolo al espacio, pero fue un objetivo preciso lo que las llevó a la luna. Aquí en la Tierra, se puede aplicar la misma regla casi universalmente. Figura 1 - En el mundo del marketing móvil, los datos patrocinados – usados por las marcas B2C para cubrir el costo de los datos móviles generados por los clientes al usar las aplicaciones de sus teléfonos inteligentes – se han convertido en un mecanismo de participación muy poderoso. Las principales marcas bancarias y marcas minoristas han utilizado los datos patrocinados con gran efecto como medio para impulsar las descargas y el uso de sus aplicaciones, generando aumentos en las instalaciones y la participación que van desde el 10% hasta el 37%. Pero las descargas son sólo la fase de despegue – indispensable para que una aplicación llegue a su destino – pero no son el destino en sí. En cambio, el objetivo para la mayoría de las aplicaciones es impulsar comportamientos clave constantes que de alguna manera sean beneficiosos para el propietario de la aplicación, a menudo en términos de generación de ingresos o ahorro de costos. Esto plantea una pregunta importante para las marcas B2C que patrocinan los datos generados por sus aplicaciones: Una vez que se ha descargado la aplicación, ¿cómo pueden obtener un rendimiento continuo sobre su inversión en datos patrocinados? Uno de los inconvenientes de las aplicaciones de calificación cero es que las marcas se ven obligadas a abordarlas como un proceso binario; o bien todas las instalaciones de aplicaciones están patrocinadas, o ninguna de ellas. Por lo tanto, si usted tiene una aplicación de comercio electrónico en la que el 50% de sus usuarios activos navegan regularmente pero nunca hacen una compra, gran parte del poder de los datos patrocinados (sin mencionar su presupuesto) está desapareciendo en el espacio. En otras palabras, se trata de una situación donde la energía se está usando sin dirección. La capacidad de identificar y dirigirse a consumidores específicos ha sido fundamental para los mecanismos de participación empleados tan exitosamente por empresas como Amazon, Facebook y Google – y los datos patrocinados no son diferentes en este respecto. Lo que realmente necesitan los propietarios de aplicaciones es poder dirigir su patrocinio de datos hacia individuos y grupos de usuarios que están participando en esos comportamientos clave continuos. Esto es lo que nos han dicho nuestros clientes, y lo que ha impulsado el desarrollo de nuestra solución de Selección de Audiencia, que lanzamos esta semana. En una primera fase, una marca puede optar por ofrecer un período de patrocinio de datos con todas las nuevas descargas de aplicaciones. Pero más allá de este período, la capacidad de dirigirse a usuarios específicos con la herramienta de Selección de Audiencia ofrece un nuevo nivel de flexibilidad. Se puede ofrecer sólo a los usuarios de aplicaciones que mantienen las notificaciones activadas, por ejemplo, o que crean una cuenta, comparten datos demográficos o personales, o que han realizado algún tipo de transacción en los últimos 30 días. Las marcas también pueden simplemente proporcionar datos patrocinados exclusivamente a aquellas personas que demuestren la demanda por ellos, al inscribirse para recibirlos. Independientemente de la manera en que se use, la Selección de Audiencia agrega precisión al poder de los datos patrocinados. Permite a los propietarios de aplicaciones identificar y recompensar sólo a sus más valiosos clientes, al mismo tiempo que anima a otros usuarios a obtener datos patrocinados mediante su participación en un comportamiento de alto valor. Las marcas y empresas que adoptan los datos patrocinados hoy día dependen cada vez más de una efectiva segmentación y personalización en sus actividades principales orientadas al cliente. Los datos patrocinados pronto se convertirán en un mecanismo esencial para la captación del cliente, lo que significa que el mismo nivel de flexibilidad y dinamismo no sólo es deseable sino que es un requisito fundamental. La precisión es la clave de la efectividad del poder. Independientemente de lo que dicen los memes de Internet sobre apuntar hacia lo más alto, la realidad es que -si estás apuntando a la luna- quieres poder alcanzar la luna. No hace falta ser un genio. Contenido original de David Nowicki CMO y Director de Desarrollo de Negocio en Datami and published through LinkedIn. "Los retailers online líderes utilizan los datos patrocinados obteniendo efectos notables en su actividad: los consumidores pasan más tiempo utilizando su apps y comprando online. Antes, "buscar" lo que quieres comprar consistía en trasladarse hasta el establecimiento físico. Un perfecto descriptor de lo que consiste navegar en la web, convertiéndose en una búsqueda exploratoria y de amplio espectro, más que algo específico".
7 de marzo de 2018

¿Cómo se relacionan Big Data y Ciberseguridad?
Escrito por Santigo Hernández, Investigador de Seguridad en Telefónica. Big Data y Ciberseguridad: dos conceptos que no dejan de sonar. Pero, ¿cómo se relacionan? En este artículo vamos a tratar la importancia que tiene el Big Data en el mundo de la Ciberseguridad, de la mano de Santiago Hernández. Para los que no estéis muy puestos sobre el concepto de Big Data, empezaremos por realizar una pequeñísima introducción sobre lo que significa. Lo primero de todo, vamos a formularnos un par de preguntas sencillas como, ¿ qué es Big Data? De manera muy resumida, el Big Data es una forma de describir grandes cantidades de datos (estructurados, no estructurados y semi-estructurados), pero, ¿esto no lo hacen ya las bases de datos y otras tecnologías tradicionales? Si, sin embargo, el concepto de Big Data se aplica a todos aquellos conjuntos de datos que, por su tamaño, complejidad o velocidad de crecimiento, por ejemplo, no pueden ser procesados o analizados utilizando procesos o herramientas tradicionales, como, pueden ser, bases de datos relacionales. Una vez introducido de manera muy general el concepto de Big Data, vamos a ver qué cabida tiene en el mundo de la ciberseguridad. Probablemente muchos de los que os dediquéis a la seguridad informática hayáis oído que la seguridad de la información es un proceso y no un fin. Esto quiere decir, que, para poder garantizarla, hay que estar constantemente iterando sobre un conjunto de fases. A pesar de que la ciberseguridad puede tener muchos tipos de actividades o estrategias, es muy común ver agrupadas las fases sobre las que se debe iterar en las siguientes tres: prevención, detección y respuesta. Entendiendo esto, vamos a ver como el Big Data no sólo nos ayuda a mejorar cada una de las fases anteriores, sino que, además, nos ayuda a mejorar el proceso completo proporcionándonos la capacidad de añadir nuevas fases, como por ejemplo la predicción. Vamos a empezar por analizar cómo el Big Data ayuda al proceso de prevención de una amenaza en términos de seguridad de la información. Tener la capacidad de tratar grandes volúmenes de información no solamente nos permite saber que es lo que está pasando en este instante, también nos permite trazar patrones a lo largo del tiempo. Muchas veces es fácil pasar por alto algunos indicadores cuando analizamos información en tiempo real, sin embargo, si analizamos esa información en otros contextos y a lo largo del tiempo, quizá podamos encontrarle otros significados. Gracias a estos patrones que extraemos del análisis de la información de otros ataques o amenazas a lo largo del tiempo, tenemos la posibilidad de tomar medidas de prevención que nos ayuden a reducir el riesgo de que esos mismos sucesos nos ocurran a nosotros. La detección de un sistema que se encuentra infectado es una parte crítica del ciclo de aseguramiento de la información del que hablábamos anteriormente. Probablemente la parte más importante del proceso de detección sea el instante temporal en el que se produce. No es lo mismo la detección de un ataque en sus primeras fases de ejecución (detección temprana) que, en las últimas fases, cuando la mayor parte del daño ha sido ocasionado. El Big Data nos posibilita la automatización de tareas de recogida de datos a gran escala y realización de su análisis en tiempos de procesamiento bajos, lo que nos permite disponer de información sobre el estado del sistema en tiempo real y proporcionar conclusiones de manera muy rápida cuando el sistema se encuentra en un estado anómalo, de tal forma que se pueda llegar a detectar una amenaza de forma temprana. Aunque aparentemente parece que el Big Data no tiene demasiada relación con la fase de respuesta ante una amenaza, lo cierto es que también puede ayudar a mejorarla. La fase de respuesta es probablemente una de las más críticas y la que más interacción humana requiere. Para poder llevar a cabo un manejo de riesgos adecuado, es fundamental disponer de toda la información posible sobre el incidente y aplicarle la inteligencia suficiente como para extraer conclusiones que nos permitan tomar mejores decisiones, y esto es justo lo que nos proporciona el Big Data. De esta forma, no solo nos permitirá el procesamiento de toda esta información y la aplicación de inteligencia para obtener resultados concretos, sino que nos permitirá realizarlo con el mínimo retraso de tiempo posible de forma que esta información no sea irrelevante para las personas que lo reciben durante un ataque y puedan tomar decisiones rápidas. Por último, nos gustaría hablar de algunas fases que no se encuentran dentro del ciclo de aseguramiento tradicional del que hemos hablado anteriormente, pero que gracias a tecnologías como el Big Data cada vez están más presentes, este es el caso, por ejemplo, de la fase de predicción. Gracias al gran volumen de información que somos capaces de procesar a lo largo del tiempo utilizando nuevas tecnologías como el Big Data unidas a otras tecnologías de procesamiento avanzado de información como Machine Learning, podemos generar modelos de predicción suficientemente precisos como para saber de forma aproximada cuando sufriremos un determinado ciberataque o que tipo de ciberataques es probable que suframos próximamente. Esto facilita la fase de prevención y alimenta todo el ciclo de aseguramiento de la información en general. Como podemos ver, el Big Data aporta muchas ventajas dentro del mundo de la ciberseguridad. Es por ello que muchas de las grandes empresas ya incorporan este tipo de tecnologías en sus procesos de aseguramiento de la información. Por lo tanto, y teniendo todo esto en cuenta, es importante que aquel que vaya a definir uno de estos procesos tenga en cuenta esta tecnología y estudie las formas en las que le puede ser útil para su caso de uso particular. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks. También puedes seguirnos en nuestras redes sociales: @Telefonica , @LUCA_D3 , @ElevenPaths
1 de marzo de 2018

En Marzo, nuevo hackatón LUCA "HackForGood"
Conceptos como “ cambio climático, contaminación o desastres naturales” entran ya en la agenda de trabajo de LUCA (la unidad de servicios Big Data de Telefónica), permitiéndole a esta contribuir al desarrollo de la sociedad mediante el establecimiento de patrones de alerta temprana en cualquier país donde está presente Telefónica, y todo ello gracias a los beneficios del Big data y la analítica de datos. En este sentido, LUCA planteará dos nuevos retos ante los más de 1500 hackers “ForGood” y las 20 universidades que participarán los días 8, 9 y 10 de marzo en este hackathón: el primero de ellos, “ Preparación ante el cambio climático en Latinoamérica ”; y el segundo, “ ¿Cómo mejoramos la calidad del aire en nuestras ciudades? ”. Se valorará la creatividad e innovación de las soluciones propuestas, el grado de acabado conseguido durante el hackathón y el impacto social de las mismas. Figura 1 : El calentamiento global es un problema enorme. El cambio climático está agravando la magnitud y el impacto de los desastres naturales, especialmente en los países más vulnerables a los mismos. ¿Podría diseñarse un servicio de vigilancia y alerta temprana con datos abiertos? ¿Pueden medirse sus efectos en términos de desastres naturales y migraciones? Por otra parte, la contaminación atmosférica ya está identificada por la WHO como una de las amenazas más importantes para la salud pública en los núcleos urbanos. ¿Cuáles son las variables que más influyen en la elevación súbita de los niveles de contaminación? ¿Podremos usar el análisis de datos para predecir cuándo se producirá el próximo pico de contaminación que active las restricciones de movilidad? Figura 2 : La comtaminación es una amenaza para la salud de los ciudadanos de grandes ciudades. Así, LUCA se suma al compromiso de Telefónica con el negocio responsable y los Objetivos de Desarrollo Sostenible de la ONU, sumándose a iniciativas como HackForGood en las que los datos suponen un elemento transformador de la sociedad. Para más información: www.hackforgood.net No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
26 de febrero de 2018

Cómo gestionar mejor las flotas de vehículos con herramientas Big Data
¿Has pensado alguna vez en cómo se puede aplicar los datos en una flota de vehículos? En el pasado webinar del martes 20 de febrero, presentaremos una herramienta de analítica y Big Data asociada a los activos de compañías de alquiler de vehículos, organizaciones con flota propia, de empresas de mensajería y logística, o fabricantes de automóviles. Conoce LUCA Fleet. El pasado martes, 20 de febrero, presentaremos uno de nuestros webinars de la mano de nuestros expertos, " LUCA Fleet: cómo el Big Data transforma el negocio de las flotas de vehículos". En esta ocasión, la sesión fue impartida por Agustín Alarcón Ortiz, jefe de producto de Smart Mobility en el área global de IoT, y Marta García Moreno, responsable del producto LUCA Fleet dentro de LUCA, la unidad de datos de Telefónica. Además, al final del webinar se ofreció una sesión Q&A en directo con los expertos para resolver cualquier duda de los espectadores. Pero, ¿ en qué consiste esta herramienta y qué beneficio puede aportar a estas empresas? LUCA Fleet es una h erramienta digital que agrega y analiza los datos de su flota basados en rutas frecuentes, consumos, comportamientos de conducción, POIs (puntos de interés visitados) o mantenimiento, a través de una plataforma cloud. Esto facilita su análisis de manera completa, sencilla e intuitiva, incluyendo un sistema de alertas, predicciones, tendencias y recomendaciones, dando además autonomía al cliente para su utilización, consulta e interpretación. El valor añadido de este servicio es que complementa a los productos de gestión de flotas y movilidad que forman parte del portfolio de productos IoT, ofreciendo una capa superior de analítica y de visualización de los datos que impactan directamente en la toma de decisiones y en la fijación de nuevos objetivos. De esta manera, trata de un servicio con grandes beneficios para empresas como compañías de alquiler de automóviles, empresas con flota de vehículos propia, distribuidoras de mensajería y logística, empresas de leasing, fabricantes del sector de automoción, así como organizaciones de transporte público y privado. Entre esos beneficios, los principales son: La mejora de la productividad: posibilita optimizar rutas y evitar posibles situaciones de fatiga o incidencias (hábitos de conducción). La reducción de costes, tanto de operación, como por consumo de gasolina. La mejora de la eficiencia y la seguridad, al optimizar tiempos de entrega, consumo de gasolina, gastos de mantenimiento o tiempos de inactividad. La predicción de futuras averías o desgastes de componentes, al mejorar la planificación de las tareas de mantenimiento. La detección de posibles causas de fraude, al tener conocimiento agregado la localización de los vehículos de la flota y su actividad. ¿Quieres conocer más sobre LUCA Fleet y sus beneficios? Aquí puedes ver el video del webinar con nuestros expertos: [embed]https://youtu.be/wsCwmmvVsDc[/embed]
22 de febrero de 2018

Somos la Telco que mejor protege los datos en España
Telefónica lidera el ranking de empresas analizadas en la primera edición española del estudio "¿Quién defiende tus datos" en el que además de las Telco aparecen portales de vivienda. Nuestra compañía ha obtenido 6 estrellas y puntuación en 10 criterios, de un total de 12. El análisis, realizado por ETICAS Foundation, se ha basado en 5 criterios de evaluación, cada uno de los cuales está dividido en distintos subcriterios. Protección e datos (4) Cumplimiento de la Ley (2) Notificación al usuario (1) Transparencia (2) Promoción de la privacidad de los usuarios (2) En la siguiente imagen se puede ver la tabla de resultados del informe y el desglose de criterios. [caption id="attachment_38062" align="alignnone" ] Figura 1: Tabla de resultados del informe ¿Quién defiende tus datos (España)?.[/caption] La entidad destaca que “Telefónica es la única empresa, hasta el momento, que ofrece información sobre peticiones rechazadas de accesos a datos personales de sus usuarios”. También señala que publicamos un informe anual de transparencia y nos ajustamos a los dos criterios de cumplimiento de la ley examinados: información del marco legal y entrega de datos conforme a la ley. Por el lado de los puntos de mejora, ETICAS apunta que es importante notificar los cambios que recojamos en nuestra Política de Privacidad. En general, según ETICAS, Las empresas en España aún tienen un largo camino por recorrer para proteger completamente los datos personales de sus clientes y ser transparentes sobre quién tiene acceso a ellos "¿Quién Defiende Tus Datos, España?" es un proyecto de ETICAS Foundation, y forma parte de una iniciativa regional de importantes grupos de derechos digitales para arrojar luz sobre las prácticas de privacidad. El informe se basa en la publicación anual de ‘Who's Your Back?’, que ha sido adaptado a las leyes y realidades locales. Descubre aquí el estudio "¿Quién Defiende Tus Datos?" y los Centros de Privacidad de Telefónica y Movistar. Si quieres leer más sobre privacidad de datos en nuestro blog: Big Data con Privacidad. También puedes seguirnos en nuestras redes sociales: @Telefonica, @LUCA_D3, @ElevenPaths
8 de febrero de 2018

Convierte datos complejos de tu empresa en insights accionables con LUCA Comms
En un mundo cada vez más digital, son muchos los datos que una empresa genera a raíz del uso de los servicios de comunicaciones que tiene contratados con su operador (ya sean comunicaciones móviles, fijas, a través de la red corporativa, …). Aún así, la mayoría de estos datos no están siendo explotados aún por las empresas. Por ello, en el último webinar presentamos LUCA Comms, la herramienta de visualización avanzada de comunicaciones globales. La principal razón por la que las empresas no explotan aún todos esos datos que generan es porque muchos de ellos no están a su disposición, ya que se encuentran únicamente en las plataformas de los operadores, y también porque muchas empresas no cuentan con las tecnologías y herramientas necesarias para procesar y explotar tal cantidad de información. Desde Telefónica trabajamos con el compromiso de transparencia y queremos poner los datos que navegan por nuestra infraestructura a disposición de nuestros clientes. Con LUCA Comms lo que hacemos es ofrecer una herramienta analítica que permita a las empresas explotar los datos que generan con el uso de las comunicaciones. También la empresa puede incorporar información interna de estructura para hacer más ad-hoc la información que luego se muestra. A partir de toda esta información, LUCA Comms la r ecopila en una única plataforma, la limpia, la ordena y la muestra en visualizaciones avanzadas, sin olvidar lo más importante, la anonimización y agregación de todos esos datos, con el fin de mantener la confidencialidad del usuario de dicho servicio. En pocas palabras, con LUCA Comms convertimos datos complejos de las empresas en insights accionables para su negocio. Por un lado, los CIOS y responsables de los servicios de comunicaciones de la empresa, van a tener información de sus necesidades reales para así ajustar los planes y servicios de comunicaciones a dichas necesidades y, por tanto, optimizar los costes. También les va a permitir detectar malas prácticas en el uso de las comunicaciones y, por tanto, definir políticas para mejorar tal uso. Con los algoritmos predictivos que utiliza LUCA Comms, va a ofrecer información a la empresa que le va a permitir anticiparse a futuras necesidades de servicio. Y, yendo más allá, la empresa va a conocer c ómo se comunica y relaciona su organización y sus departamentos con el objetivo de detectar posibles mejoras y eficiencias a nivel organizativo. Y, por supuesto, dispondrá de más información sobre sus clientes, al conocer cómo éstos se comunican con la empresa, lo que les permitirá tomar decisiones que mejoren directamente los resultados de campañas o acciones sobre su propio negocio. En el video a continuación presentamos el webinar sobre LUCA Comms del pasado martes 30 de enero, presentado por Pedro Alonso Baigorri, responsable de Productos de Big Data para Empresas en el área de LUCA, y Raquel Crespo, Product Manager de Big Data para empresas en el área de LUCA.
5 de febrero de 2018
¡Conoce los resultados de #CDOChallenge!
El pasado 29 de diciembre, a través de la unidad de Chief Data Office (CDO) de Telefónica, liderada por Chema Alonso, lanzamos la convocatoria CDO Challenge en busca de nuevos talentos apasionados por la tecnología aplicada a la inteligencia artificial en entornos de desarrollo Android. ¿Eres uno de los participantes? ¡Ya tenemos los resultados! En esta ocasión, decidimos innovar en los procesos tradicionales de reclutamiento para nuestras áreas de CDO compuesto por Aura -Inteligencia Cognitiva-, ElevenPaths -Ciberseguridad-, LUCA -Big Data- y la Cuarta Plataforma. Por eso, en lugar de seleccionar candidatos como en procesos tradicionales, valorando sus currículums, d esarrollamos un reto de programación, integrado en la app CDO Challenge, creada ad-hoc. Durante todo el mes de enero, los candidatos debían descargarse la app y descifrar un challenge de programación y, de este modo, conseguir una entrevista personal con nuestros expertos en las oficinas Distrito C de Telefónica en Madrid. La respuesta a esta iniciativa ha sido muy buena y queremos compartiros, a través de la siguiente infografía, l os resultados obtenidos en nuestro CDO Challenge: Muchas gracias a todos los que habéis participado en el reto y también por la difusión y los mensajes recibidos en estas semanas. En los próximos días nos pondremos en contacto con los candidatos seleccionados. ¡Mucha suerte a todos! Síguenos en nuestras redes sociales: @Telefonica, @LUCA_D3, @ElevenPaths ¡Nos vemos pronto con nuevas iniciativas!
1 de febrero de 2018

Publica en Gmail con SafePost hasta en las situaciones más difíciles
SafePost es un nuevo servicio lanzado por la unidad de datos de Telefónica que permite realizar publicaciones en tus redes sociales o enviar emails a través de un SMS, algo para lo que no se requiere conexión a internet. Esta herramienta puede ser de gran utilidad en situaciones críticas como puede ser tras un terremoto o un huracán, ya que en esas circunstancias las redes de internet fallan o pueden estar colapsadas, en cambio se pueden seguir enviando SMS. 1 ¿Cómo configuro la aplicación? Para comenzar a utilizar SafePost tendrás que configurar tu cuenta desde la página web y proporcionar permisos para que publique en ella, También deberás descargar su aplicación de móvil . SafePost es un servicio seguro que genera tokens de un solo uso en cada SMS, haciendo que nadie pueda publicar en tu nombre, además todo el contenido de tus mensajes irá cifrado , algo que incrementa la longitud del mensaje pero que sin duda ofrece una seguridad más robusta. Al acceder a su página principal, encontraremos un campo en el que deberemos introducir nuestro teléfono móvil precedido del prefijo correspondiente a nuestro país. A continuación, pulsaremos en “entrar”. Al hacer esto automáticamente recibiremos una solicitud de acceso en nuestro móvil, la cual se realiza a través de Mobile Connect. Deberemos pulsar “Si”. Figura 1: Paso 1, descargar la aplicación. Una vez hayamos aceptado la solicitud de Mobile Connect accederemos a una página que nos indica que deberemos vincular la aplicación de móvil con nuestra cuenta web, esta aplicación es necesaria ya que sin ella no podríamos acceder al servicio sin conexión a internet. Pulsaremos sobre “vincular SafePost app”. Hecho esto seremos redirigidos a una página donde nos explica como adquirir la aplicación y nos facilita un acceso directo a ella en la Tienda de Google. Una vez hayamos adquirido la aplicación pulsaremos en “siguiente”. Figura 2: Paso 2, vincular la aplicación. En este momento hemos llegado al punto más importante de la configuración, la página nos mostrará un código QR que deberemos escanear desde nuestra aplicación móvil. Para ello solo tenemos que abrir nuestra aplicación de SafePost y pulsar sobre “Escanear Código QR”. En caso de no funcionar este método también podremos copiar la clave que se nos proporciona y utilizar la opción “introducir clave manualmente”. Figura 3: Recibimos un pin temporal para la vinculación. Al capturar el código QR desde la aplicación nos generará un código de 6 dígitos de un solo uso, tras memorizar o acopiar el código deberemos pulsar en siguiente para acceder al tercer y último paso de la configuración, en esta página deberemos introducir el código que tenemos en la pantalla de nuestro móvil y pulsar en “enviar”, hecho esto podremos pulsar finalizar en nuestro móvil. Figura 4: Paso 3, confirmar. Introducimos en la web de SafePost el pin recibido en nuestro móvil. Una vez tenemos nuestra aplicación y cuenta de SafePost vinculadas, el siguiente paso para poder publicar sin conexión es añadir los servicios dándoles acceso a nuestras cuentas para que puedan publicar en nuestro nombre (esto deberemos hacerlo desde la web). Figura 5: Añadimos los servicios con los que queramos publicar mediante SMS. 2 ¿Cómo publico en gmail? En este caso realizaremos la configuración para añadir nuestra cuenta de Gmail. Lo primero que debemos hacer es a cceder a la página web de SafePost. En ella pincharemos en el icono de Gmail. A continuación nos solicitará que introduzcamos nuestro usuario y contraseña. Hecho esto podremos ver los permisos que solicita SafePost para poder publicar en nuestro nombre, pulsaremos sobre “Allow”. Figura 6: Introducimos usuario y contraseña de gmail. Para publicar solo tendremos que entrar en nuestra aplicación, seleccionar la opción de Gmail. En el campo de destinatario deberemos introducir el correo de la persona a la que queramos escribir. Para terminar rellenaremos el siguiente campo con el asunto del mensaje y redactaremos nuestro correo. Antes de que nuestro mensaje se envíe, la aplicación nos marcará el número de mensajes requeridos para enviar tu publicación. En caso de que el correo sea demasiado largo se enviará en distintos SMS. Figura 7: Al redactar el mensaje te indica cuántos SMS son necesarios para enviarlo. Para comprobar que los mensajes enviados por la aplicación están cifrados solo tendremos que acceder a nuestro registro de mensajes e ir a la carpeta de enviados, ahí podremos observar que todos los mensajes cuyo destinatario es el número del servicio de SafePost están cifrados y son ilegibles. Regístrate al próximo LUCA Talk sobre SafePost el 16 de enero a las 16h, ¡te esperamos! También te puede interesar: SafePost: La tecnología al servicio del usuario en cualquier instante ¿Cómo puedo utilizar SafePost? Configuración e implantación en Twitter Equipo SafePost – Telefónica CDO No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
28 de diciembre de 2017
"El corredor verde" más data driven de Cali
El poder de los datos ha traspasado la frontera de las empresas y startups para llegar a esferas públicas y, sobre todo, a las ciudades. Cada vez más ayuntamientos se suman a las técnicas del Big Data para poder entender y planificar mejor sus ciudades. En este ámbito, publicábamos hace unas semanas el caso de la Municipalidad de Neuquén y su proyecto de diseño del nuevo sistema de transporte público. De Argentina nos movemos ahora a Colombia, concretamente a la ciudad de Santiago de Cali. Cali tiene cerca de 2,5 millones de habitantes, siendo la tercera ciudad más poblada de Colombia. Esto se debe, en gran medida, a la antigua vía del tren por dónde pasaba el ferrocarril del Pacífico, clave para el desarrollo industrial de la ciudad. La ciudad se formó alrededor de las vías del tren, pero éste dejo de ser el medio de transporte principal con la llegada del automóvil. Con la finalidad de renacer el poder del corredor, el “Corredor Verde de Cali”, como se nombró el proyecto, es el plan de renovación urbana más ambicioso que ha tenido la ciudad. Su misión es reconvertir el corredor en el pulmón de la ciudad, uniéndola en vez de separarla. El proyecto, planeado sobre un tramo de 22 kilómetros, incluye una enorme ciclorruta, lugares para la recreación y sobre todo, un sistema de transporte masivo, no motorizado, como el tranvía, que contribuye a la protección del medio ambiente del cual está rodeado. El proyecto fue fruto de una asociación internacional entre el Ministerio de Asuntos Exteriores del Reino Unido, la consultora ATKINS, FDI Pacífico, la ciudad de Cali y Telefónica Móviles Colombia. En el caso de Telefónica, participó en la planificación urbana a través del uso de los datos móviles como instrumentos para la evaluación e identificación de oportunidades. Concretamente, se analizaron datos obtenidos por LUCA Transit, incluyendo entre otros la cantidad de viajes generados entre las áreas de análisis y la distribución de los desplazamientos por hora y el propósito. Las técnicas de Big Data permitieron así planificar de manera mucho más acertada el proyecto, entendiendo mejor los patrones de movilidad de la ciudad de Cali y aquellos puntos críticos donde se concentraba la población, dividiendo el proyecto en fases y con una amplia perspectiva de las necesidades. Actualmente, el corredor está en fase de implementación y se espera conseguir la renovación de la ciudad en los próximos años.
20 de diciembre de 2017

¿Quieres multiplicar la tasa de conversión?: Data Rewards
Contenido escrito por Félix Sanz Justel , Marketing Effectiveness Manager, Mobile Advertising Los servicios de recompensa de datos o “Data Rewards” son una poderosa herramienta a disposición de las marcas para incentivar la relación con sus clientes, tanto actuales como potenciales. Estos servicios buscan un intercambio de valor en la que la marca ofrece al consumidor un pequeño paquete de datos de datos (25MB, 50MB, 100MB) a cambio de interactuar con ella. Esta interacción puede ser de distintos tipos. Desde ver un vídeo a descargar una app pasando por contestar una encuesta. [caption id="attachment_37433" align="aligncenter" ] Figura 1: Experiencia de usuario en campañas Data Rewards.[/caption] Para poder comprender mejor el alcance de estos servicios, Aquto, especialista en el ámbito de recompensas y patrocinio de datos y proveedor tecnológico de Telefónica, ha querido mostrar las bondades de estos servicios lanzando junto a Coca-Cola una campaña de vídeo enriquecida. La campaña que tuvo lugar durante la segunda mitad de septiembre, tenía como principal objetivo comprobar la eficacia de los servicios de recompensa de datos basados en la tecnología que Aquto pone a disposición de los clientes de Telefónica. Dicha campaña contó con un grupo de control de más de 4,5 millones de impresiones en cientos de páginas web repartidas por todo México (MXDF, Monterrey, Guadalajara, Baja California, Durango, Puebla, Campeche, Chiapas, Oaxaca, Puebla, etc….). La " Campaña A" fue recibida por un grupo de prueba de 625.836 impresiones (ver imagen inferior), donde a cambio de hacer clic en el banner y ver un video se ofrecía una recompensa de datos móviles por valor de 10MB. El resto de usuarios recibieron la " Campaña B", donde no había promoción alguna de recompensa de datos (4.168.000 impresiones). Figura 2: Comparativa de Campañas con promoción de recompensa de datos y sin ella. Una vez finalizada la acción publicitaria se analizaron los resultados y observamos que un 0,017% de las personas impactadas por la " Campaña B" vieron el vídeo hasta el final, mientras que de las personas impactadas por la " Campaña A" las visualizaciones completas alcanzaron el 0,21% lo que multiplica por 12 el porcentaje total de visualizaciones. El gran éxito obtenido con dicha prueba demuestra que los servicios de recompensa de datos no solamente mejoran la interacción con la marca por parte del consumidor, sino que además la conversión de la campaña publicitaria es muy superior a la conversión ofrecida por una campaña tradicional. Hay 4 importantes drivers que son los que orientan todas las decisiones de los consumidores: la seguridad, el bienestar, la gratificación y la libertad. Si conjugamos la seguridad que ofrece una gran marca, con la gratificación ofrecida por los servicios de recompensa de datos, dotamos al consumidor de la libertad para navegar desde cualquier lugar sin consumir su tarifa de datos, lo que provoca una mayor satisfacción al interactuar con la marca.
12 de diciembre de 2017

Lo más destacado del BDID2017 (VI): como crear el mejor equipo de eSports del mundo, Pedro de Alarcón y Fernando Piquer
El Big Data Innovation Day 2017 cerró la agenda del evento con un tema de gran interés para un gran público: los eSports. Una ponencia de la mano de Pedro Antonio de Alarcón, responsable del área Big Data for Social Good de LUCA, y Antonio Piquer, CEO de Movistar Riders, en el que anunciaron el nuevo proyecto de colaboración entre Movistar Riders y LUCA, en el que se estudiará el comportamiento de los jugadores del equipo utilizando Big Data. La última ponencia del pasado BDID2017 de LUCA, la unidad de datos de Telefónica, fue uno de los momentos más esperados para el público fan de los eSports. La charla empezó con Fernando Piquer hablando del fenómeno eSports, definiéndolo como el deporte de la era digital que ha crecido gracias al crecimiento de la conectividad y es un buen ejemplo de transformación digital y de cómo está creciendo la industria con roles profesionales que hasta hace poco no existía. Movistar Riders es un club que cuenta con 35 jugadores profesionales de deporte electrónico, en 7 equipos diferentes y 6 juegos distintos; y participan en distintas competiciones profesionales o semiprofesionales donde se enfrentan dos o más jugadores o equipos en un videojuego. Según explicó Fernando Piquer los eSports implican concentración, superación, esfuerzo, saber comunicarse con el resto del equipo y una vida saludable. Habilidades se precisan en los jugadores para luchar cada día por estar al máximo nivel, y que son difíciles de encontrar. "Sabemos todo lo que son capaces de hacer nuestros jugadores, pero no somos capaces de medirlo. Por eso, todo lo que nos propuso LUCA para empezar a utilizar el Big Data y poder encontrar un modelo que optimizara el rendimiento de nuestros jugadores nos pareció interesante. Sobre todo para saber cuándo nuestros jugadores obtienen un mayor rendimiento o son más competitivos y por qué" - Fernando Piquer, CEO Movistar Riders Figura 2: Pedro A. Alarcón y Fernando Piquer durante su presentación en el BDID2017 Y, ¿ cómo mejorar un equipo de eSports con Big Data? Pedro A. Alarcón mostró el reto de este proyecto: y es que no solo contamos con los datos de Movistar Riders, sino de todos los competidores. Lo que se traduce en una escala de 30 millones de jugadores a nivel europeo. Lo primero, por tanto, es monitorizar el estado físico y mental de los jugadores, estableciendo patrones de influencia en el juego, apoyados en dispositivos wearables. Esto permite capturar variables del electroencefalograma (EEG) simplificadas, capturando la información necesaria en este caso. Así, se determina qué variables inducen al estrés o a la falta de concentración de un jugador. De este modo, se accede a los servidores de partida, donde todo queda registrado, y construimos una herramienta analítica. ¿Quieres saber más detalles sobre esta iniciativa? Mira la ponencia completa del Big Data Innovation Day 2017 sobre Cómo crear el mejor equipo de eSports del mundo en nuestro canal. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
5 de diciembre de 2017

SafePost: La tecnología al servicio del usuario en cualquier instante
Hoy nace SafePost, un nuevo servicio que permite la publicación en redes sociales y el envío de correo electrónico a través del uso del SMS. La tecnología móvil construye un mundo mejor y podemos ir más allá, por ejemplo, ayudándonos en situaciones de emergencia. Si te encuentras en una situación de riesgo y tienes la necesidad de hacer llegar mensajes al resto del mundo puedes utilizar SafePost para notificar la emergencia a través de tus perfiles en Facebook o Twitter. Además, si tienes la necesidad de enviar un correo electrónico, pero no dispones de cobertura de datos, puedes utilizar SafePost para hacer llegar estas notificaciones a través de Gmail u Outlook. La aplicación de SafePost, disponible en Google Play, utiliza los SMS para poder publicar y enviar correos electrónicos. Los SMS que se envían desde la aplicación de SafePost se encuentran cifrados mediante una clave temporal, generalmente denominada de un solo uso. Esto hace que la privacidad de lo que el usuario envía esté garantizada. Para utilizar el servicio puedes registrarte en el sitio web de SafePost. El registro se hace de forma sencilla mediante Mobile Connect. Una vez realizada la vinculación se podrá utilizar la aplicación de SafePost para realizar las publicaciones y envíos de correo electrónicos en las cuentas dónde se haya autorizado. En el siguiente video te enseñamos los pasos a seguir para configurar SafePost y su uso básico: ¿Dónde usar SafePost? A continuación, os dejamos una serie de casos de uso de SafePost: Si te encuentras en una catástrofe natural, como por ejemplo un terremoto o un huracán, y no dispones de Internet, puedes notificar a través de la aplicación de SafePost. Si te encuentras en un escenario en el que no dispones de datos y necesitas comunicarte con el resto del mundo, puedes utilizar la aplicación de SafePost. Si te encuentras ante la necesidad de comunicar información con el resto del mundo y no dispones de una conexión mínima a Internet por algún tipo de escenario, puedes utilizar la aplicación de SafePost para no dejar de decir, lo que tienes que decir. En los próximos días os iremos mostrando de forma práctica cómo sacar el máximo rendimiento a SafePost y las posibilidades que éste aporta como solución de notificación de emergencia. SafePost, la tecnología en manos de todos para construir un mundo mejor. Regístrate al próximo LUCA Talk sobre SafePost el 16 de enero a las 16h, ¡te esperamos! También te puede interesar: ¿Cómo puedo utilizar SafePost? Configuración e implantación en Twitter Publica en Gmail con SafePost hasta en las situaciones más difíciles Equipo SafePost – Telefónica CDO
28 de noviembre de 2017

Diseñando el mapa de publicidad OOH en Brasil gracias a los datos
Es imprescindible que una empresa maximice el alcance de sus clientes, y una manera de conseguirlo es hacer uso del poder y valor que ofrece la publicidad. Hoy en día existen infinitas maneras de difundir un mensaje; siendo la Publicidad OOH (Out-Of-Home) el estilo publicitario que más exposición tiene entre la población. Por ello, en este post compartimos proyecto llevado a cabo en Brasil, con el objetivo de crear un mapa OOH llevado a cabo en las ciudades de Sao Paulo y Rio de Janeiro. Pero, ¿en qué consiste la publicidad OOH? Es un estilo de publicidad que consiste en crear campañas de publicidad al aire libre, a través de vallas publicitarias, muppies, publicidad en transporte público como autobuses o tranvías, por ejemplo. De hecho, es una manera excelente para alcanzar el mayor número de gente e influencia. Solo hace falta pensar con cuántos carteles publicitarios se cruza cada ciudadano en un día, nada más salir de casa. Además, este tipo de publicidad suele ser muy llamativa; el anunciante tiene más o menos 3 segundos para captar la atención de su target, de modo que los colores vivos y eslóganes cortos y directos suelen ser recursos muy comunes. Últimamente, además es muy común incorporar innovaciones tecnológicas en la publicidad como los códigos QR o el uso de NFC, para descubrir más sobre un producto a través del dispositivo móvil, dirigiéndonos a su página web, por ejemplo. LUCA OOH Audience trabaja junto con Clear Channel, JCDecaux y Otima con el fin de crear un mapa de OOH en Brasil. El objetivo de este mapa es ofrecer métricas y herramientas útiles para que las agencias de comunicación y publicidad, y los propios anunciantes, puedan planificar y evaluar sus campañas de Publicidad OOH. El enfoque del estudio se ha centrado en las ciudades de Sao Paulo y Rio de Janeiro, en Brasil. Así, haciendo uso de los datos que recopilan las empresas, incluso el número de usuarios, su localización geográfica, cada uno de los viajes querealizan y el modo de transporte utilizado. Todos estos puntos aportan un mejor conocimiento sobre cómo aplicar la Publicidad OOH. El reto del estudio es elevar Brasil al mismo nivel que los líderes mundiales en OOH (Reino Unido, Francia y Japón). ¿Por qué invertir en la Publicidad OOH, en lugar de otras maneras de publicidad como Internet que, a simple vista, parecen más modernas? Gracias a la Publicidad OOH se puede alcanzar gente de cualquier edad y grupo demográfico. Además, gracias a la aplicación del mapa OOH diseñado, entre las ciudades de Sao Paulo y Rio de Janeiro, se acumulan un total de 400 millones de viajes a la semana , lo que permite una gran exposición a los anuncios OOH entre sus habitantes. Figura 2: Bahía de Río de Janeiro. LUCA OOH Audience, usando la tecnología de Smart Steps, es capaz de aportar una visión en profundidad de distintas localizaciones; ofrece una muestra incomparable. La solución permite a las empresas tomar mejores decisiones en cuanto a la publicidad externa.
23 de noviembre de 2017

Lo más destacado del BDID2017 (IV): Transformando los puntos de venta y atención del sector retail
¿Qué más podemos destacar del Big Data Innovation Day 2017? A día de hoy la mayoría de transacciones se realizan a través de un canal presencial, es decir, nos encontramos en un entorno en el que el canal físico es el principal para las ventas. En este contexto, el Big Data está contribuyendo también en la transformación de puntos físicos de venta y atención en el sector retail. ¿Cómo? Lourdes Cubero, Retail Business Developer en Telefónica España, y Elena Díaz, Senior Analytical Consultant en LUCA, mostraron en su ponencia cómo aprovechar los beneficios que aportan los datos en el sector retail. Sigue leyendo, porque te lo contamos en este post. El Big Data Innovation Day 2017 comenzó con la ponencia de Chema Alonso , CDO de Telefónica, y continuó con la ponencia de Elena Gil Lizasoain , CEO de LUCA , la unidad de datos de Telefónica, tal y como resumimos también en el post de agradecimiento por la buena acogida que recibimos. Durante su ponencia, Lourdes Cubero y Elena Díaz presentaron los beneficios que ofrecen los datos en el sector retail con servicios como LUCA Store. Teniendo en cuenta que partimos de un contexto completamente omnicanal, el usuario actúa e interactúa con las organizaciones, marcas y tiendas con la libertad de decidir cuándo y cómo quiere realizar su compra. Lo cual hace muy necesario tener las mismas medidas en un contexto y en otro, estando preparados para c ombinar los diferentes canales. Lourdes Cubero quiso precisar además que esta transformación de los puntos de venta y atención "es aplicable a todos los sectores, como pueden ser: moda, farmacéuticas, gasolineras, centros de atención al cliente, universidades, centros de alimentación... En definitiva, todo lugar donde se crea una relación con los consumidores o ciudadanos". El objetivo es recopilar la misma información que aporta el e-commerce de forma directa, en la tienda física, respondiendo a necesidades como; quién visita el establecimiento, cómo es el entorno, a quién se consigue atraer y de entre ellos quién consigo que compre el producto... y hacer ratios de conversión de todos esos datos. Todo ello a través del análisis de comportamiento analógicos que se producen en la tienda física, que no están digitalizados, pero se pueden digitalizar, almacenar esos datos y así tomar las medidas necesarias para cumplir los objetivos deseados: aumentar los ingresos, reducir gastos o mejorar la experiencia de cliente, por ejemplo. "Debemos dejar de actuar a través de la intuición y hacerlo en base a los datos y medidas concretas, del mismo modo que se hace online" Lourdes Cubero R etail Business Developer en Telefónica España Para mostrar todo lo contado, se dio paso a Jesús Hernández, subdirector Centro Comercial La Vaguada, junto con Elena Díaz, Senior Analytical Consultant en LUCA, para compartir con la audiencia la colaboración realizada con el centro comercial La Vaguada y los beneficios que, gracias al valor que aportan los datos y soluciones desarrolladas por LUCA, han podido percibir. Figura 2: Jesús Hernández hablando sobre la colaboración con LUCA en el Big Data Innovation Day 2017 Según Jesús Hernández, "gracias a las soluciones ofrecidas por LUCA pueden obtener datos sobre su centro comercial en comparación con dos de sus mayores competidores de la zona". De modo que pueden obtener datos demográficos, de niveles de renta o poder adquisitivo de los visitantes, que antes no podían obtener, tanto de su centro comercial como de los competidores. Concluyendo que, "desde que en La Vaguada hemos empezado a implementar este tipo de técnicas, basándose en los datos para tomar decisiones, poniendo foco sobre ellos, y estamos observando muy buenos resultados". "Vamos a intentar obtener datos, y vamos a intentar sobre esos datos" Jesús Hernández Subdirector del Centro Comercial La Vaguada Para conocer más sobre la ponencia y los beneficios que pueden aportar los datos en el sector retail, transformando los puntos de venta y atención físicos, mira el vídeo a continuación: No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
20 de noviembre de 2017

Diseño de plan de movilidad y transporte para Neuquén gracias al Big Data e Inteligencia Artificial
Cada vez son más las ciudades que, gracias a la tecnología y el uso de los datos, buscan mejorar la calidad de vida de los ciudadanos llevando a cabo planes de movilidad u otras muchas iniciativas. En este post presentamos el proyecto realizado por LUCA junto con la Municipalidad de Neuquén; donde se ha aplicado el valor de los datos para diseñar un nuevo sistema de transporte público de pasajeros y la traza del nuevo Metrobus Inteligente, convirtiéndose en una oportunidad para mejorar la movilidad urbana y el transporte público. La Ciudad de Neuquén cuenta con una población de 245.000 ciudadanos formando, junto a los municipios de Plotter y Cipolletti, el área de concentración poblacional mas grande de la Patagonia Argentina con 341.300 habitantes. Teniendo en cuenta estas características, el municipio está a la vanguardia en la innovación buscando utilizar las tecnologías disponibles para mejorar la calidad de vida de los ciudadanos. El objetivo de la Municipalidad de Neuquén es aprovechar la información con la que contamos en LUCA y nuestras soluciones para poder diseñar un mapa de movilidad con datos fehacientes y actuales. Además de utilizar esta información para una planificación organizada del transporte, apuntando a crear el primer Metrobus del Interior del país. La Ciudad de Neuquén no contaba con ninguna fuente de información para recopilar datos sobre los flujos de movimiento de las personas en la ciudad, principalmente en los horarios pico, como horarios bancarios o escolares. De modo que LUCA ofreció a la ciudad una solución que se adaptara perfectamente a la idea de Smart City anhelada por el Municipio. Utilizando herramientas de Big Data e Inteligencia Artificial, LUCA analiza las tendencias y patrones de datos de tráfico para poder saber más sobre el comportamiento de los consumidores. Los datos de tráfico se enriquecen con información demográfica y de comportamiento e incluyen la ubicación sociodemográfica, residencial y laboral, la información sobre los objetivos de los visitantes, el grupo de edad, género y otros atributos que permiten una evaluación por perfil y una segmentación sofisticadas. Así, gracias a la aplicación de LUCA Transit basada en Smart Steps (una solución de insight que utiliza datos móviles anónimos y agregados), se consigue recabar los datos necesarios y estimar el movimiento de grupos de personas en la ciudad. Esta solución permite a las organizaciones tanto públicas como privadas tomar mejores decisiones de negocio basadas en comportamientos reales. Y, sustentado por la fidelidad de los datos, respaldará tanto el trayecto del transporte como la ubicación de estaciones y paradas. De modo que se consigue organizar también la planificación de transporte público en la ciudad como desea la Municipalidad. Además de permitir que el Municipio pueda medir y caracterizar el flujo de viajes dentro de la Ciudad de Neuquén, conocer las zonas de atracción de tránsito, obtener tendencias sobre movimientos de masas, respaldar el trayecto del nuevo servicio de Metrobus y, en definitiva, generar una ciudad más habitable. [embed]https://www.youtube.com/watch?v=V1ptoNPLBUg&t[/embed] No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
13 de noviembre de 2017

Analizando a los visitantes del Museo Reina Sofía
Cualquier organización necesita conocer cuál es su target para saber a quién va dirigida su actividad, y definir así su estrategia y líneas de actuación. En el caso concreto de los museos, el análisis de sus visitantes y su comportamiento, gustos y preferencias es muy importante, ya que sirve para conocer los perfiles e intereses de éstos y ayuda a definir su actividad. El caso del Reina Sofía. Con motivo del 80 aniversario de la creación de Guernica (1937), de Pablo Ruiz Picasso, y de la llegada a sus salas hace 25 años, la exposición “Piedad y terror en Picasso. El camino a Guernica” ha podido visitarse en el museo Reina Sofía durante un periodo de 5 meses. Normalmente cuando compramos la entrada de un museo o de una exposición como ésta, nos preguntan de dónde venimos, si ya hemos visitado el museo u otras exposiciones antes o el motivo de nuestra visita. Todo ello para después elaborar estadísticas internas y conocer a los asistentes. El Museo de Reina Sofia en Madrid, en cambio, ha querido ir más allá y ha sido el primer museo de España en aplicar un estudio usando analíticas Big Data para realizar un análisis más exhaustivo. Las tecnologías Big Data permiten procesar grandes volúmenes de datos, analizarlos y extraer de ellos patrones de comportamiento que permitan predecir comportamientos futuros. Un análisis que en este caso ha generado ingente cantidad de 157 gigabytes de información. De esta forma, gracias a esa gran volumen de datos, el Museo Reina Sofía ha podido analizar el comportamiento del público que ha visitado la exposición. Para ello, ha manejando diferentes fuentes de información, tanto de carácter interno, derivadas de la propia actividad del Museo, como externas y totalmente independientes a su actividad (meteorológica, escucha activa de medios y redes sociales, calendario de festividades o datos de movilidad etc). La solución empleada en esta ocación ha sido Smart Steps. Esta plataforma, sirve para la explotación de datos de movilidad. “es importante conocer estos datos para hacer que la visita sea lo más satisfactoria posible Manuel Borja-Villel, Director del museo. Datos relevantes del estudio Estos son algunos datos facilitados por el proyecto de colaboración entre el Museo Reina Sofía y LUCA, para aplicar esta tecnología con grandes capacidades de cómputo y almacenamiento: Figura 2: Datos sobre perfiles y patrones de comportamiento de los visitantes de la exposición Para el estudio se han tenido en cuenta muchos factores, como por ejemplo, el volumen de turistas que visitaron Madrid durante esos meses , los eventos que tuvieron lugar en esas fechas en la capital, la actividad en las redes sociales, la climatología e incluso las transacciones bancarias efectuadas. El estudio realizado por los servicios de consultoría y analítica de LUCA, ha revelado que la exposición ha sido visitada por más de 680.000 personas procedentes de 189 países, con una media de 4.800 personas diarias. También se ha podido concluir, que un 11,5% de los turistas que recibió Madrid en esos meses, visitó el Museo Reina Sofía. Las horas de mayor afluencia de visitantes fueron las comprendidas entre las 10 y 12, siendo los miércoles el día con mayor afluencia y el lunes los de menor. Respecto a la procecencia de los visitantes, más del 60% han sido extranjeros, y entre ese porcentaje los que predominan son los procedentes de Italia (17% del total), seguido por Francia (11%), Alemania (7%), Estados Unidos (7%), Gran Bretaña (5,6%), Japón (1,4%) y Portugal (1,3%). También resulta interesante conocer los patrones de comportamiento de estos visitantes. Una de las conclusiones extraídas del estudio es el efecto positivo de la climatología extrema sobre el número de visitas. Tanto las precipitaciones como las bajadas repentinas de temperatura en los meses de calor, se traducen en incrementos del número de visitantes. Por ejemplo, los días 4 y 5 de junio, una bajada significativa de los termómetros, supuso aumento del 33% en las visitas. También se extrajeron conclusiones interesantes sobre el proceso de compra de entradas y el impacto económico en el área circundante. Así, se determinó que el 79% de los visitantes adquieren la entrada el mismo día de la visita, y que cada visitante genera un gasto adicional de 5 euros de media en la zona próxima del museo, por lo que la exposición se convirtió en uno de los catalizadores de la actividad económica de las inmediaciones, con un aumento del 18% respecto al trimestre anterior.
7 de noviembre de 2017

Lo más destacado del BDID2017 (I): ¡Gracias por disfrutar de este día con nosotros!
El pasado martes 31 de octubre celebramos el Big Data Innovation Day 2017 y disfrutamos de una tarde excepcional. El Auditorio de Telefónica estaba repleto de asistentes y muchos otros siguieron el evento vía streaming desde varios países. Por ello, y para agradeceros la buena acogida que recibimos, queremos compartir los momentos más destacados del BDID2017 y de las ponencias de nuestros expertos. Y es que queremos seguir creciendo contigo en este apasionado viaje Data Driven. ¿Comenzamos? El Big Data Innovation Day 2017 recibió a un total de 467 asistentes en el evento, consiguiendo el aforo completo tanto del Auditorio Central de Telefónica como del Centro de Innovación. También conectamos vía streaming con más de 800 usuarios en más de 20 países, y se convocaron reuniones con clientes para que siguieran desde diferentes salas el minuto a minuto del evento, lo que hizo del evento un encuentro mundial. La jornada comenzó con la bienvenida de Javier Magdalena, Director de Negocios Digitales y TSOL en Telefónica de España, y dio paso a la ponencia de Chema Alonso, CDO de Telefónica, que acompañado por uno de los hackers de LUCA, hizo especial hincapié en la competitividad que aportan los datos a las empresas en su transformación digital y desarrollo de negocio. Presentó las novedades en los productos LUCA Transit, LUCA Comms, LUCA Fleet y LUCA Verify, y compartió con el auditorio el deseo de devolver a los usuarios el valor de los datos para que su vida digital sea más fácil y segura. Elena Gil Lizasoain, CEO de LUCA, nos hizo ver que el Big Data es una realidad y que seguiremos creciendo contigo, ya que el valor del Big Data está en combinar los datos con los insights para tomar decisiones data-driven. Presentó las nuevas soluciones e integraciones tecnológicas que hemos desarrollado en LUCA en este primer año y los diferentes casos de éxito con clientes reconocidos en los sectores tanto retail, turismo, banca, logística o transporte, entre otros. Además de mostrar cómo el Big Data puede transformar el ámbito empresarial, esta tecnología contribuye también en la labor de mejorar la sociedad con proyectos llevados a cabo con diferentes entidades como Unicef, Fundación Profuturo, Fundación Telefónica etc. enfocados a cumplir con los Objetivos de Desarrollo Sostenibles fijados por la ONU para el 2030. Las ponencias siguieron de la mano de Lourdes Cubero, Retail Business Developer en Telefónica España, y Elena Díaz, Senior Analytical Consultant en LUCA. Presentaron los beneficios que ofrecen los datos en el sector retail con LUCA Store y para demostrarlo, dieron paso a Jesús Hernández, subdirector Centro Comercial La Vaguada para compartir con la audiencia la colaboración realizada con el centro comercial y los beneficios que, gracias al valor que aportan los datos y soluciones desarrolladas por LUCA, han podido percibir. Carme Artigas, CEO y Co-fundadora de Synergic Partners, el área de analítica y consultoría de LUCA, presentó su ponencia "Big Data: Show Me The Money!" enfocado en cómo gracias a los datos y al buen uso de ellos combinándolo con insights, las empresas pueden aumentar sus beneficios económicos de manera destacada. Para terminar, se presentó la colaboración de LUCA y Movistar Riders con la presentación de Pedro de Alarcón, responsable de Big Data for Social Good en LUCA, y Fernando Piquer, CEO de Movistar Riders. En la ponencia " ¿Cómo crear el mejor equipo de eSports con Big Data?" se presentó la colaboración entre LUCA y Movistar Riders basada en un doble objetivo: analizar cómo la preparación física y mental influye en el desempeño de los jugadores de deportes electrónicos, así como diseñar una herramienta de análisis que permita aprovechar todos los datos que se generan para extraer conclusiones que ayuden a la toma de decisiones deportivas. Todo ello con una demostración en real time que mostró cómo se realiza el análisis de esta relación entre desempeño del jugador y el Big Data. Tras las ponencias el evento concluyó con un cóctel donde los asistentes pudieron visitar también los cuatro córners Imagine, Build, Grow y Dream en los que se pusieron a disposición del público varias demos de productos de LUCA, así como presentaciones de nuestros partners Qlik y Pindrop. No te pierdas el vídeo Recap del BDID2017 y disfruta de las ponencias y recuerda que si quieres seguir informado de nuestras novedades puedes suscribirte a nuestra newsletter de LUCA. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
3 de noviembre de 2017

LUCA marca tendencia en Mobile Advertising en Perú
Esta semana, nuestro departamento de LUCA Advertising en Perú, a través de su marca Movistar, ha anunciado el lanzamiento del nuevo servicio de Navegación Patrocinada, con su primera campaña al lado de Interbank, uno de los principales bancos del país. La Navegación Patrocinada es una herramienta comercial por la cual las empresas pueden patrocinar la navegación de sus apps o websites a sus clientes. Con esto logran que los clientes tengan libertad de acceder a sus canales digitales sin consumir sus planes o paquetes de datos móviles. Gonzalo Manceñido, gerente de Productos y Servicios en Telefónica Perú, afirma que este servicio ofrecerá la posibilidad a las marcas de esponsorizar la conectividad a sus clientes, mejorando así la relación cliente-marca y fomentando la cercanía entre ellos. Se trata de un modelo en el que todos ganan: El usuario obtiene conectividad que no consume de su plan de datos contratado, para disfrutar de aquellas apps/webs que sean esponsorizadas por empresas. Las empresas incentivan el uso de sus canales digitales, generando nuevas oportunidades de ingresos por compras online y optimizando los costos asociados a la atención presencial y/o telefónica. Figura 1: Jason Pareja, responsable del equipo LUCA Advertising en Perú. Jason Pareja, responsable de Proyectos de Innovación y Desarrollo de Negocios Digitales en Telefónica Perú, explica que el cliente local es muy precavido con relación al uso de sus datos, priorizando siempre su navegación en redes sociales y apps de entretenimiento (80% de su actividad digital) sobre otro tipo de contenido más corporativo. El contexto no puede ser más favorable, ya que en Perú, las barreras para realizar transacciones por Internet disminuyen día a día, al tiempo que se incrementa velozmente la penetración de smartphones. Es más, cerca del 30% de los clientes de Telefónica con smartphones prefieren esperar a conectarse a una red WiFi para disfrutar de algún contenido que ofrece Internet, alargando así la vida de los datos de su plan o paquete contratado; y que el porcentaje es aún mayor cuando se trata de clientes de prepago. A esto se suma el hecho de que nueve de cada diez peruanos conectados a Internet lo hacen desde un smartphone y el uso de apps abarca más del 80% del tiempo gastado en el mundo digital. Tal es el caso de la banca móvil, cuya adopción se ha duplicado en los últimos cinco años, debido a que los usuarios ya no están dispuestos a realizar largas filas en los bancos para realizar una transacción sino que aprovechan este canal alternativo para interactuar con sus bancos. Es por esto que, como parte de las acciones de Interbank para facilitar a sus clientes digitales el acceso a su app de banca móvil, a partir del 23 de agosto el costo por el uso de datos que generan las transacciones y consultas a través de este canal -a los más de 500 mil usuarios digitales- será asumido por la entidad financiera. Por tanto, Telefónica espera que así como Interbank, apuesta por acelerar la adopción digital de sus servicios financieros a través de la tecnología, empresas de diferentes sectores se sumen a la navegación patrocinada como nueva estrategia de atención y relacionamiento con el cliente. Con este anuncio, Telefónica Perú marca la pauta como el primer operador en ofrecer datos patrocinados en el país, esperando replicar el éxito comercial ya alcanzado en la operación de Vivo en Brasil. Si quieres conocer más en detalle cómo funcionan los servicios de Navegación Patrocinada, no dejes de leer este otro post (en inglés) de nuestro Blog.
22 de septiembre de 2017

¿Cómo ha afectado a los usuarios de Metro de Madrid el cierre temporal de la Línea 5?
Metro de Madrid está acometiendo importantes mejoras en su red de transporte. Este año, la Línea 5 que une las zonas de Sudoeste-Noreste de la capital, ha sido la tercera en colgar el letrero de "Cerrado por obras de mejora en las instalaciones" Para que los responsables públicos del sector puedan tomar mejores decisiones sobre cómo y cuándo acometer este tipo de obras de mejora de forma informada y transparente, se hace imprescindible comprender el impacto que estas actuaciones causan en los ciudadanos y sus repercusiones económicas. Hoy día, gracias a los datos de localización generados por dispositivos tecnológicos, como los sensores IoT ("Internet de las cosas") y los teléfonos inteligentes sí es posible medir cómo afectan a la población estos proyectos de mantenimiento. Por ello, decidimos investigar qué tipo de respuestas podíamos obtener de los sistemas de inteligencia de localización, combinando datos abiertos con insights de datos sobre telefonía móvil. Figura 1: Visualización del efecto de las obras en la Línea 5 del Metro de Madrid. Un cierre veraniego de 62 días Como ya hizo en la Línea 8 a principios de este año, Metro de Madrid trabaja para ofrecer un mejor servicio a los ciudadanos, llevando a cabo obras de mantenimiento y mejora de los sistemas de señalización y alumbrado. Pero tomar la decisión de cerrar una infraestructura como esta en un área urbana tan poblada nunca es fácil. En este caso, la decisión sobre cuál era el momento más adecuado para acometer las obras tomó basándose en criterios de estacionalidad. Por ello, el cierra de la línea ha tenido lugar en los meses de verano, ya que debido a las vacaciones estivales la demanda es menor. Sin embargo, ¿Cómo pueden los responsables de la toma de decisiones de la ciudad saber realmente cuál es el mejor momento para el cierre? ¿Cómo pueden aprovechar la experiencia de otros cierres anteriores en otras líneas para optimizar los trabajos de mantenimiento futuros? Tomar decisiones basadas en datos de Inteligencia de Localización es el primer paso seguro para minimizar el impacto negativo sobre el sistema público de transportes. Los habitantes de la periferia, los más afectados La Línea 5 de Metro es la cuarta línea más utilizada por los madrileños, trasladando pasajeros desde zonas de la periferia de la ciudad como Carabanchel y Ciudad Lineal al centro de la ciudad. Los residentes en éstas zonas son los más perjudicados por el cierre de la línea, ya que los que viven en zonas más céntricas disponen de mayor variedad de opciones de transporte alternativas. Para analizar los patrones de desplazamiento en una ciudad es fundamental conocer dónde viven y trabajan las personas que se desplazan. Estos datos se puede averiguar de distintas formas. Por ejemplo, según el "Atlas de la Movilidad", en el distrito de Carabanchel reside un mayor número de trabajadores que en otros distritos (seguido por Vallecas, Latina, Fuenlabrada y Móstoles, todos ellos en la zona sur). Sin embargo, el área de Julián Camarillo (también en la Línea 5, en la estación de Sauces) es la zona de oficinas/trabajo más habitual (después de AZCA, Barajas, Gran Vía y Valportillo en Alcobendas). Esto demuestra que, la mayoría de los trabajadores reside en el sur de la ciudad, pero tiene su lugar de trabajo en la zona norte. Por ello, los trabajadores de la zona de Julián Camarillo serán de los más afectados por el cierre de la línea. Sin embargo, para ofrecer una Inteligencia de Localización de calidad, nuestro partner Carto decidió ir un paso más allá y contactar con uno de sus partners, nosotros. Desde LUCA pudimos aportar una mayor granularidad y conocimiento, gracias a nuestra plataforma LUCA Transit, la cual utiliza datos agregados y anonimizados de clientes de telefonía móvil que permiten comprender mejor cómo se desplazan los grupos de personas. La tecnología Smart Steps permite identificar determinados “puntos de interés”, basándose en las localizaciones recurrentes de los teléfonos móviles (ofreciendo tendencias de movilidad que cubren aproximadamente un 40% de la población española). En este caso particular, los puntos de interés a estudiar eran el lugar de residencia y el lugar de trabajo. Uno de los Insights más relevantes que reflejaron los datos (como se puede ver abajo) es que los trayectos de la Línea 5 que cubren áreas fuera del anillo de la M30, transportan más del 50% de los pasajeros que usan esta línea. Este dato pone de relieve el hecho de que los habitantes de las zonas periféricas son los que sufren un mayor impacto por el cierre de la línea. Figura 2: Efecto sobre los habitantes de la periferia. Campañas de geomarketing e incentivación del uso compartido de vehículos. Una vez superado el primer desafío de usar datos de localización para generar Insights, para los responsables públicos resulta fundamental aprovechar la inversión en proyectos basados en datos, para tomar mejores decisiones por el bien de la ciudad. Por ejemplo, esta información se puede usar para decidir las rutas y frecuencias más adecuadas para el servicio de autobuses de sustitución. Los pasajeros que viven en el centro pueden tener 2 o 3 rutas de autobús que pueden usar como alternativa. Sin embargo, los pasajeros de la periferia de la ciudad que analizamos en este estudio no tienen tantas opciones. Las autoridades locales también pueden decidir lanzar campañas de geomarketing para dar a conocer las alternativas del transporte disponibles durante las obras, o para incentivar el uso de vehículos compartidos en áreas suburbanas, con el objeto de aliviar el impacto negativo en el transporte durante las obras. En resumen, está claro que usar datos de localización para optimizar las decisiones sobre infraestructuras y movilidad, es de gran valor para las autoridades que quieren aportar transparencia a la toma de decisiones. Los ciudadanos quieren vivir en ciudades más inteligentes y eficientes. La Inteligencia de Localización es una poderosa herramienta para los líderes que quieren hacer de los datos la piedra angular de su estrategia y servicio al público. Si quiere saber más sobre este tema, visita la web de LUCA.
21 de septiembre de 2017

Big Data y Deportes: excelentes catalizadores para el desarrollo
Día a día, vemos cómo el Big Data va abriendo camino en sus innumerables campos de aplicación, y uniendo mundos que a primera vista no parecen tener mucho que ver. La Tecnología, el Deporte, y el Desarrollo fueron los protagonistas en el evento “Deporte y Big Data como catalizadores del Desarrollo” que tuvo lugar ayer martes, en el evento del BID, en Washington DC. Desde su creación, en 1959, el Banco Interamericano de Desarrollo (BID), trabaja para mejorar la calidad de vida en América Latina y Caribe, a través de tres retos principales de desarrollo: Inclusión social e igualdad, Productividad e innovación Integración económica. Para lograr la consecución de estos retos, ofrece apoyo financiero y técnico a los países que trabajan para reducir la pobreza y la desigualdad, siendo de hecho, la principal fuente de financiación para el desarrollo en América Latina y el Caribe. Hace ya tiempo que el deporte se ha convertido en una poderosa herramienta para el desarrollo. Numerosas organizaciones sociales lo utilizan por su gran potencial para empoderar personas en riesgo de exclusión, y por cómo aquéllas que consiguen salir de esas situaciones de riesgo a través del deporte, se convierten en motivadores ejemplos para otras que viven circunstancias similares. La aplicación del Big Data es uno de los motores de cambio de nuestra Sociedad y ciertamente puede actuar como motor para el desarrollo. En este sentido tanto el BID como LUCA comparten la visión del uso de datos para planificar, tomar decisiones y medir el impacto de sus proyectos. Esta visión es aplicable a casi todos los ámbitos de nuestra Sociedad, como lo es el deporte LUCA, a través de la iniciativa "Big Data for Social Good", plantea cómo se pueden aplicar técnicas de analíticas avanzadas al deporte para mejorar los entrenamientos y, trabajar así también en aras de conseguir el segundo objetivo del BID, mejorar la productividad por medio de la innovación. Figura 1: Elena Gil, Nairo Quintana y Luis Alberto Moreno Elena Gil Lizasoín, Global Big Data Director de Telefónica y CEO de LUCA, presentó la ponencia “Deporte y Big Data como catalizadores del Desarrollo” , en la que se plantea cómo se puede poner a trabajar juntos deporte, tecnología y análisis de datos para crear sociedades más activas e inclusivas. Cada ciclista lleva durante los entrenamientos un dispositivo que recoge datos físicos (por ejemplo, sus pulsaciones), datos del entorno (coordenadas GPS, perfil de la etapa, pendiente del perfil), y de rendimiento (como la potencia de pedalada en vatios). Al finalizar la etapa, el ciclista se conecta a una computadora que descarga los datos recogidos y los sube a la nube. Entonces llega el momento de las analíticas. Primero, las descriptivas: "¿Qué ha pasado en esta etapa?". Después, las predictivas: "¿Qué va a hacer el ciclista en la etapa siguiente?". Y, por último, las prescriptivas: "¿Sobre qué variables podemos actuar para conseguir el resultado deseado?". La revolución es también poder usarlo en tiempo real, haciendo del ciclismo un deporte cada día más eficiente y parecido a la Fórmula 1. A continuación, acompañada por Luis Alberto Moreno, (Presidente, BID) y Nairo Quintana, (Ciclista de Movistar Team, Vencedor Vuelta a España, Giro Italia y tres veces pódium Tour de Francia), dialogaron en un panel sobre la importancia de la tecnología para mejorar el desempeño de los deportistas y, en particular, sobre el gran potencial que supone la aplicación de Big Data al deporte y al ciclismo. Si quieres saber más sobre este tema, no dejes de ver este reportaje o visita nuestra web. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
6 de septiembre de 2017

Descubriendo el poder del Big Data en el mundo energético
Contenido creado por Pedro A. Baigorri, Marta García Moreno, Henar Muñoz Frutos y J.Carlos Calvo Martínez, miembros del equipo de producto de LUCA. Ahora más que nunca las técnicas Big Data están ayudando a las empresas a conseguir los estrictos requisitos de eficiencia energética que la legislación les obliga a cumplir. Asimismo, es un importante mecanismo para la reducción de consumo de energía y por lo tanto, el ahorro económico. Pero, ¿en qué consisten realmente las técnicas de Big Data aplicadas al mundo energético? ¿Qué tipos de análisis existen? Figura 1: Nuestra solución LUCA Energy. Un ejemplo de análisis predictivo es nuestra solución LUCA Energy. El procedimiento seguido en la creación del Predictor de Energía de LUCA Energy se ajusta a los pasos que debe seguir un proyecto de analítica predictiva. Impulsado por el equipo de IOT Global, LUCA Energy complementa con la capacidad BigData el Servicio de Eficiencia Energética de Movistar España. 96 Normal 0 21 false false false ES-TRAD X-NONE X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-fareast-language:EN-US;} Como ya se presentó en este blog, el primer módulo de LUCA Energy es el Predictor de Consumo de Energía que detecta desviaciones de consumo de manera que pueda alertar anticipadamente a las empresas de su exceso de consumo para que puedan tratar de reducirlo. Descubrimiento y Preparación de los datos Los datos obtenidos en crudo provenientes de los sensores IoT instalados en la empresa, son filtrados y procesados para obtener un formato común con datos de temperatura interior y exterior y consumo energético. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} Figura 2: Ejemplo resultados predicción consumo sin calendario. Planificación y Construcción del modelo Generar el modelo implica seleccionar las variables más importantes y que más influyen en el consumo energético. La primera versión del algoritmo se centró en los consumos de los días anteriores y los valores de temperaturas. Con esta versión, se obtuvieron resultados de calidad para días de trabajo estándar, pero no para aquellos días que no se ajustaban a ciertos patrones. Por ejemplo, si se trabajaba un domingo de forma extraordinaria, los ajustes de consumo no eran muy precisos al día siguiente, tal y como se muestra en la Figura 1. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} En una segunda iteración, para resolver el problema mencionado anteriormente se abordó una siguiente versión del algoritmo donde se incorporaron al modelo datos de calendarios tanto días festivos en los años y regiones particulares de los clientes, como festivos abiertos. Con ello, el algoritmo obtuvo un ajuste de predicciones mucho mayor en las situaciones que se comentaban anteriormente. Se puede observar la mejoría de la predicción de los resultados en la Figura 2, tratándose del mismo día observado en la gráfica anterior. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} Figura 3: Ejemplo resultados predicción consumo con calendario. Comunicación de los resultados Los resultados obtenidos de los modelos deben ser evaluados y reportados. Para ello, se adoptó la métrica R2Score o coeficiente de determinación de la regresión, cuyo valor oscila entre 0-1 siendo 1. Esta métrica fue usada en un proceso de benchmarking que analizaba la calidad de los resultados de forma automatizada. Esto permitió realizar análisis comparativos probando las distintas opciones de configuración existentes en los algoritmos. Un ejemplo de ello fueron las pruebas para la selección del periodo de histórico de datos necesario para el entrenamiento de los algoritmos. Con este enfoque y realizando un benchmarking global del algoritmo se consiguió llegar en la mayor parte de las oficinas analizadas a unos resultados de predicción con R2Score entre 0.8 y 1. También se pudo determinar el periodo de entrenamiento mínimo y óptimo para llegar al régimen de mayor R2Score, tal y como se visualiza en la Figura 3. Figura 4: R2Score del algoritmo de LUCA Energy en función del tiempo y oficinas. Mejora de la robustez del algoritmo Tras analizar más detalladamente el benchmarking realizado, se detectó que anomalías o desviación en el consumo enérgico típico afectaban en la predicción de los días que dependía y bajaban la calidad del algoritmo. Para mejorar el R2score del algoritmo, se aplicó técnica de detección de valores atípicos en la entrada de los datos. El objetivo es mejorar la robustez del algoritmo a posibles problemas ocasionales en la calidad de los datos de entrada. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} La Figura 3 muestra en azul los datos obtenidos a partir de los sensores de la Plataforma de Eficiencia Energética de Telefónica. Dichos datos se compararon con datos de consumo de días similares y se consideró que eran valores atípicos, es decir datos que distaban mucho de los demás correspondientes al mismo tipo de día, procediendo a la sustitución de dichos valores. Esto dio lugar a los valores de input “limpiados” representados por la línea naranja de la Figura 4. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} Figura 5: Input original (azul) vs Input sin valores atípicos. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} Con los nuevos datos limpiados de input, el algoritmo de predicción mejoró tanto los valores de R2Score como el número de días y minutos desviados, tal y como se muestra en la Tabla 1. Normal 0 21 false false false EN-GB JA X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-name:"Tabla normal"; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:""; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:12.0pt; font-family:Calibri; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-ansi-language:EN-GB; mso-fareast-language:EN-US;} Tabla 1: Resultados Benchmarking Con Valores Atípicos vs Sin Valores Atípicos. Otro caso relativamente frecuente e importante es que los sensores no puedan enviar los valores de consumo y se reciban valores nulos como entrada al Predictor. En ese caso también debe hacerse una eliminación de los valores atípicos. Llegados a este punto y dada la robustez del algoritmo, el Predictor de Energía está listo para ser usado como parte del Servicio de Eficiencia Energética de Telefónica España. Inicialmente arrancará como Piloto que servirá para obtener un feedback importante de los clientes. Próximos pasos La evolución del servicio LUCA Energy empieza a afrontar otros casos de uso como la “Simulación de Cambios” que tratará de dar respuesta a preguntas como “¿Cuánto consumiré de más si abro una hora antes al público entre semana?”, “¿Cuánto ahorraré si disminuyo la temperatura 1 grado en invierno durante el horario de trabajo?”. Además de esto, LUCA Energy abordará otros casos de uso aún más complejos tales como el “Mantenimiento Predictivo” que permitirá alertar sobre futuras averías antes de que se produzcan y el caso “Gestor de Diseño” que se encargará de proporcionar un diseño de oficinas óptimo desde el punto de vista de eficiencia energética. La respuesta a estas preguntas y todos estos avances demuestran el poder que puede ofrecernos el Big Data y su correcta aplicación y análisis en el mundo de la eficiencia energética. No te pierdas ninguno de nuestros post. Suscríbete a LUCA Data Speaks.
5 de septiembre de 2017

Case study: Como está usando Jacobs LUCA Transit para mejorar el sistema de transportes en UK
Escrito por Dave Sweeney, Head of Smart Steps (Public & Transport) en O2. El transporte público se compone de viajes diarios alrededor de todo el mundo. No importa si se trata de un viaje de trabajo o de unas vacaciones familiares, es importante que esos trayectos sean tan fluidos como sea posible. Sin embargo, las necesidades de transporte cambian constantemente. Por este motivo, la planificación y previsión estratégica del transporte es crucial para mantenerlo libre de complicaciones. Jacobs, una de las compañías de servicios de transporte más grandes, tiene un papel importante en el desarrollo de planes de transporte en UK. Recientemente, Jacobs firmó un acuerdo con 02 y LUCA Transit para ayudarles a que su planificación estratégica fuera más data driven. Jacobs siempre ha confiado en los datos para tomar decisiones informadas de planificación. Sin embargo, los procesos de recolección de datos tradicionales implican entrevistas tradicionales a pie de calle. Este método requiere la asistencia de policía local y conductora que estén dispuestos a contestar a una serie de preguntas sobre su origen, destino y propósito del viaje. Para ser un método tan trabajosos y costoso, los resultados son muy limitados. Están sujetos al nivel de veracidad de las respuestas de los conductores y solo incluyen conductores de coches, sin contar autobuses, bicicletas y otro tipo de viajeros. Debido a las limitaciones de este tipo de encuestas, Jacobs buscaba una fuente de datos más robusta para dar fundamento a las estrategias de planificación de sus clientes. Jacobs se ha convertido se ha unido a 02 y LUCA Transit para intentar resolver este problema. A través de LUCA Transit, Jacobs tiene disponibles los datos de movilidad de todos los consumidores de 02 agregados y anonimizados. Como 02 cuenta con aproximadamente el 33% de la cuota de mercado de Inglaterra, esto significa que Jacobs cuenta con datos en tiempo real de casi 25 millones de teléfonos. Figure 2: Jacobs helps with forecasts and strategy development for key transit clients in the UK. LUCA Transit no solo permite a Jacobs tomar decisiones basadas en bases de datos mucho más grandes, sino que también soluciona otros problemas de la recolección de datos tradicional. Desde que los usuarios de teléfono no están solo limitados a conductores, esta base de datos incluye hábitos de transporte de ciclistas, conductores de autobús, viandantes y más. A su vez elimina las complicaciones de coordinación local, y supone un ahorro de tiempo y dinero. LUCA Transit ha permitido a Jacobs tener acceso a datos de movilidad históricos, desde el 2013 al presente. Jacobs por lo tanto tiene una nueva base de datos mucho más amplia y profunda. Los resultados de usar LUCA Transit hablan por si solos. En comparación con los métodos tradicionales, LUCA Transit ha ayudado a Jacobs a mejorar sus bases de datos en todos los frentes: Figura 3: LUCA Transit enabled Jacobs to save money and gather better data faster. Echa un vistazo a este video para conocer más sobre esta unión: El equipo de Jacobs esta agradecido a LUCA Transit porque le ha permitido ofrecer un servicio mejor y más preciso a sus clientes. Darren Martin, Director de soluciones digitales en Jacobs: "Usar buenas fuentes de datos nos permite crear estrategias más eficientes, sugiriendo a nuestros clientes que caminos deben seguir, tanto en la parte de la oferta como en la de la demanda, haciendo que las ciudades sean un mejor sitio donde vivir." Para conocer más sobre LUCA Transit y el resto de productos de LUCA visita nuestra página.
26 de julio de 2017

Quito, la primera ciudad inteligente de America Latina
¿Cuántas personas cogen el metro al día? ¿En que paradas se bajan? ¿Cuánto tiempo tardan en llegar a su destino? Todas estas preguntas podrán ser respondidas gracias a la alianza entre el Municipio de Quito, el Banco Interamericano de Desarrollo (BID) y LUCA para conocer los comportamientos y movimientos de los usuarios del Metro de Quito. Conocer estos datos será posible gracias a la solución tecnológica LUCA Transit un sistema que utiliza datos móviles anónimos para estimar el movimiento de grupos de personas en las ciudades. Este sistema recopila tendencias y agrega datos móviles de la red de Telefónica para entender cómo se comportan los segmentos de la población en conjunto. En concreto, Telefónica cuenta con 4,4 millones de clientes a escala nacional mientras que en Quito, el número de usuarios es de aproximadamente 1,4 millones. Todos estos datos son agregados y anonimizados respetando la seguridad y privacidad de los usuarios. Para la aplicación de esta tecnología se dividió a Quito en 673 zonas urbanas y 30 rurales, con lo cual se determinarán los flujos de movilidad entre todas las zonas del Distrito. Con esta información, el Municipio podrá desarrollar estudios exactos sobre los usuarios del futuro sistema de transporte. Esa información incluye datos tan relevantes como datos de flujos de paradas, numero de viajeros en una linea, cuanto tiempo pasa una persona en el metro y de donde viene. Figura 2: En Quito existen 700 zonas con más de 180.000 usuarios que comparten datos a través de radios base. Este tipo de soluciones ya han sido implementadas con éxito en otros países como España, Brasil, Colombia, Perú, Chile, México, varios países de Centroamérica y Argentina. Un caso de éxito ha sido el de la municipalidad de Neuquén donde se analizó la movilidad urbana a través de los datos obtenidos por LUCA transit, incluyendo la cantidad de viajes generados entre las áreas de análisis y la distribución de los desplazamientos por hora y propósito. La gestión de la movilidad no es un aspecto fácil de tratar para los organismos públicos de las ciudades. Sin embargo, gracias al Big Data y a iniciativas como la de LUCA Transit ciudades como la de Quito serán capaces de mejorar sus condiciones de movilidad.
17 de julio de 2017
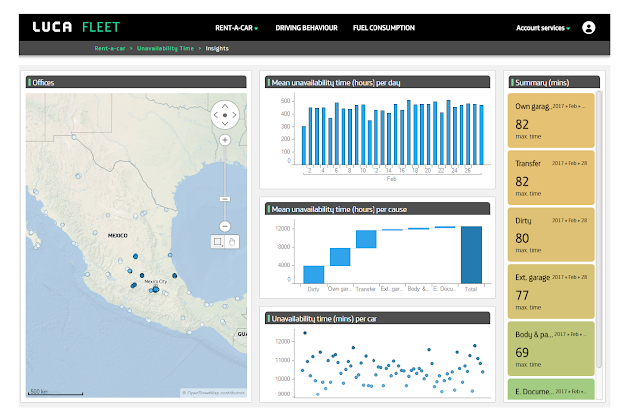
¿Qué datos se esconden tras los vehículos de una flota?
Contenido creado por Raquel Crespo Crisenti, Pedro A. Baigorri, María Luisa Rivero y Marta García Moreno, miembros del equipo de producto de LUCA. Son muchos los datos que se generan cada día en una empresa, y sin embargo no siempre esos datos son tratados, analizados y utilizados de la manera más eficiente posible. El mercado cada vez es más competitivo y por este motivo surge la necesidad de tomar decisiones basadas en un mayor conocimiento del negocio. Si nos centramos en el sector automovilístico y de gestión de flotas, conocer la actividad que está llevando a cabo cada uno de los vehículos es algo esencial. Por este motivo surge LUCA Fleet, una capa de analítica que usa tecnologías avanzadas de Big Data sobre el servicio de Gestión de Flotas que ofrece actualmente Telefónica. Conocer donde se localizan los vehículos de una flota y cuales han sido sus movimientos es posible gracias a un dispositivo llamado GeoTab (Go7). En esta plataforma todos la información de los vehículos se almacena y se adapta a la necesidades específicas de los usuarios. Además se hace cada vez más necesario presentar las analíticas de los datos de una manera más transparente y fácil de interpretar por lo que la usabilidad y experiencia de usuario se hace más notorio y presente en este tipo de soluciones. Figura 1: Demo LUCA Fleet sobre un caso de uso real en México. Gracias a un mayor conocimiento de sus principales activos, las empresas que utilizan esta herramienta sn capaces de ofrecer una mayor seguridad del conductor y de los pasajeros o carga. También son capaces de mejorar la productividad y de disminuir los costes tanto de operación como de gasolina siendo más eficientes. Por otro lado, las empresas de este sector pueden predecir futuras averías o desgastes de componentes así como detectar posibles causas de fraudes. Para conocer en profundidad como funciona esta herramienta, no te pierdas esta demo sobre un caso de uso real en Cancún (México): Queda demostrado que las decisiones basadas en datos reales, analizados y tratados correctamente hacen que la toma de decisiones sea mucho más eficiente. El Big Data se ha convertido en un activo muy importante para las empresas y en concreto para el sector automovilístico y de gestión de flotas.
14 de julio de 2017

La nueva España: Redibujando el país con los datos de movilidad
Uno de los campos más apasionantes que nos abre el uso de datos es el estudio de redes. Nuestras sociedades, comunicaciones, infraestructuras, negocios y muchos otros ámbitos de la vida pueden representarse como una serie de elementos interconectados o redes, alimentadas constantemente con datos. El nacimiento de plataformas como Facebook, Twitter o Instagram ha convertido a las redes sociales en un elemento habitual en la vida diaria de todos los ciudadanos, con el consecuente crecimiento de los datos que se generan asociados a ellas, que son de gran interés. El análisis de estas redes nos permite establecer quienes son las personas más relevantes de la red, comunidades de usuarios, las personas que unen las diferentes agrupaciones...Por ejemplo, en la Figura 1 puede verse un análisis de mi red de actividad en Twitter. Figura 1: Ejemplo de mi red de seguidores y seguidos en Twitter con la herramienta Gephi. Pero estas técnicas no están reservadas solo a redes sociales. Cualquier red puede ser sujeto de este análisis, llegando a ejemplos tan diversos como una red de interacción de diferentes proteínas o una red que representa las interconexiones exactas de las neuronas del cerebro de un insecto. Con los datos que disponemos en LUCA, podemos realizar un estudio similar utilizando datos de movilidad real. Llevados por la curiosidad nos propusimos construir un mapa de comunidades basado en cómo nos movemos, obviando las divisiones administrativas de comunidades autónomas o provincias. Obtención de datos En LUCA y gracias a la plataforma Smart Steps disponemos de forma sencilla de los datos de movilidad que necesitamos. En el caso de este estudio, usamos datos de Enero de 2016 de España tanto a nivel de provincias como a nivel de municipios. A partir de aquí construimos una red en la que los vértices son las provincias o municipios y los arcos que los conectan se les atribuye un peso proporcional al número de personas que han viajado entre los dos puntos (Figura 2). Figura 2: Red representativa de desplazamientos entre Madrid y Toledo (500 personas en sentido Madrid - Toledo y 200 personas en sentido inverso). La representación visual de la red construida puede hacerse con herramientas de libre disposición como Gephi o igraph. Tras esto, decidimos aplicar un algoritmo de detección de comunidades. Estos algoritmos detectan grupos naturales de nodos (en nuestro caso provincias o municipios) basándose en la interconectividad de los mismos, de tal modo que nodos muy conectados entre sí tenderán a aparecer en la misma comunidad. Hemos usado el algoritmo “Infomap”. Lo interesante además, es que el algoritmo decide cuántas comunidades deben generarse. Con esta información ya podemos visualizar los datos, colocándolos en un mapa para que resulte más sencillo y natural su análisis. Análisis En primer lugar ejecutamos el algoritmo sobre una red de movilidad entre provincias. Las provincias están coloreadas por el color de la comunidad a la que han sido asignadas y la provincia resaltada de cada comunidad es la provincia con más movilidad. Los resultados del cálculo de comunidades es el siguiente: Figura 3: Comunidades a nivel de provincias. Lo primero que apreciamos es que el país queda representado en 7 comunidades compactas y con una estructura radial (quizás influenciado por la estructura de carreteras primarias), es decir, una comunidad central y luego comunidades que la rodean. Salvo en el caso de Extremadura, ninguna comunidad de movilidad coincide exactamente con los límites administrativos conocidos, dándose uniones (Aragón y Cataluña) y separaciones (Castilla La Mancha). El siguiente paso es mejorar la resolución del mapa a un nivel mucho más local para obtener información sobre el comportamiento de los municipios. Los datos obtenidos nos permiten sin problemas esa precisión. Del mismo modo que en el mapa anterior, colorearemos los municipios según su comunidad y marcamos el municipio con más movilidad como el más importante. Figura 4: Comunidades a nivel de municipio. Podemos extraer varias conclusiones de este mapa. La primera es que muchas comunidades se forman en torno a grandes municipios, capitales de provincia en su mayoría. Se podría entender la comunidad como el área de influencia de dichos municipios principales. También podemos apreciar que la comunidades se ven fuertemente influenciadas por la red de carreteras. Los municipios más importantes de todas las regiones se encuentran en el cruce de carreteras principales (autovías y autopistas) y esta cualidad ayuda a que se desarrollen y tengan una importancia creciente en la zona. También es curioso observar que estas comunidades respetan en su mayoría los límites de las provincias y comarcas, lo que nos indica que, pese a que puedan ir a una ciudad más cercana, la población suele moverse dentro de su provincia o comarca. No obstante, es habitual que una misma provincia quede fragmentada internamente en varias comunidades, principalmente debido a la existencia de varios núcleos importantes de población. Aplicaciones Los conocimientos extraídos del análisis pueden servir para un múltiples propósitos: Transporte e Infraestructuras: Ya que es un mapa obtenido con la información de la movilidad, es evidente que éste sea el primer punto. Conocer la distribución de estas comunidades puede permitirnos replanificar la red de carreteras. Por ejemplo, sería interesante tener buenas conexiones entre todos los municipios que son capitales de su región, o entre los municipios de una comunidad y su “capital”. Sería interesante también estudiar las fronteras de las comunidades: al indicarnos que dos municipios están separados el algoritmo nos indica que hay un bajo tráfico entre ambas lo que nos puede informar de pobres infraestructuras entre los municipios que fuerce a la población a utilizar otras rutas. También podemos usar el análisis para estudiar el impacto en movilidad antes y después de la construcción de una nueva carretera. Edificios institucionales: Estos mapas apunta a las capitales de las comunidades como localizaciones perfectas para albergar edificios institucionales, desde una delegación de Hacienda hasta policía. Esto tendría como resultado un mejor servicio al ciudadano, una reducción de la necesidad de tráfico y una descarga de la saturación de estos servicios en las capitales de provincia o comunidad autónoma. Servicios de Salud y Emergencias: Dentro de los edificios institucionales, destacamos el caso de los servicios médicos. Por su necesidad de acción rápida, una distribución geográfica es más que necesaria. Utilizar esta información puede ayudar a localizar estos servicios no solo en las zonas entorno a las que se organizan las poblaciones, sino que además estas zonas aportan varios beneficios a nivel de movilidad pues los usuarios no solo estarán más cerca de su hospital de referencia sino que además conocerán mejor la zona, al ser un municipio al que están más acostumbrados a visitar. Turismo: Se puede adoptar una estrategia de publicitar los municipios de la zona de influencia de una comunidad, sabiendo que a posteriori los turistas probablemente viajarán para hacer noche en la capital de la comunidad, mejorando los ingresos generales en la región pues los turistas tendrán más sitios que visitar y se quedarán más tiempo en la zona. Comercio: La zona de influencia de un municipio nos informa de los municipios que potencialmente serán clientes de un nuevo comercio, permitiendo un estudio más preciso de su clientela. En resumen, el análisis de datos de movilidad usando redes nos ofrece una novedosa visión sobre nuestro concepto de comunidades y provincias, dando una visión complementaria de las dinámicas de nuestra sociedad. Aparte de satisfacer nuestra curiosidad, nos ayuda a entender el comportamiento de la población, las agrupaciones de regiones que se forman con los desplazamientos, conocer la provincia y el municipio de referencia… Esto permite actuar de manera más inteligente, maximizando el beneficio para la población. Y tú, ¿qué ves en los mapas?
22 de junio de 2017

A un click de Changing the Game with Big Data
¡Por fin llego el día! Hoy tiene lugar nuestro evento Changing the Game with Big Data en el espacio Fundación Telefónica. Si no te es posible asistir, no te preocupes, todo el evento será retransmitido en vivo y podrás seguir las ponencias de nuestros speakers desde cualquier lugar. Figura 1: No te pierdas nuestro evento #ChangingTheGame with Big Data. A continuación puedes encontrar un pequeño resumen de la agenda del evento: 11.00- Bienvenida: Chema Alonso, CDO de Telefónica y Jose Luis Gilpérez, Director Ejecutivo Administraciones Públicas, Defensa Seguridad y Big Data Telefónica. 11:05- Elena Gil, CEO de LUCA: La propuesta de LUCA para ayudarte a transformar tu sector 11:20-12:00- Case Studies: LUCA Store & LUCA Transit Exposición de casos de uso presentados por nuestros clientes. En primer lugar, comenzaremos con LUCA Store y cómo realizar un conocimiento efectivo de tu cliente para incrementar las ventas. A continuación, LUCA Transit versará sobre la innovación en la planificación de la movilidad. 12:20- Pausa café 12:50- Synergic Partners: Big Data en los negocios 13:20- Case Studies: LUCA Tourism Los asistentes tendrán la oportunidad de conocer como se puede utilizar el Big Data para optimizar la oferta turística. 13:50- Q&A y cierre El streaming comenzará a las 11 de la mañana y podrás acceder a él haciendo click aquí. A su vez os animamos a participar en el evento mandando vuestras preguntas por twitter con el hashtag #LUCA. ¡Te esperamos!
15 de junio de 2017

Usos inverosímiles del Open Data: dónde aterrizar con tu paracaídas
Escrito por Antonio Sanchez Chinchón, Data Scientist en Telefónica España y fundador de Fronkonstin, un blog de experimentos, matemáticas y ciencia de datos en R. No es ningún secreto que Internet guarda datos muy interesantes esperando a ser analizados y desbloquear así toda las posibilidades infinitas de información que llevan dentro. Sin embargo, aún no hemos conseguido que la explotación de estos datos se haga “mainstream”, en otras palabras, hay mucha gente que todavía desconoce las posibilidades de los datos abiertos. En este post analizaremos qué encontraría a su alrededor un paracaidista que aterrizara en un punto cualquiera de ciertos países. Aunque no lo necesites para tu día a día, este experimento te valdrá para conocer la riqueza de los datos de Google Places y saber si te pueden ayudar en tus propios proyectos. Figura 1: ¿Donde es el mejor lugar para realizar un aterrizaje de paracaidismo en función de los lugares que rodean al punto de aterrizaje? Sacar los datos La primera incógnita que te debes de estar preguntado es ¿de dónde sacas los datos? Lo cierto es que existen multitud de sitios web de dónde puedes obtener datos de todo tipo. Además, muchos de estos sitios web te lo ponen aún más fácil para que descargues paquetes de datos, pues disponen de las famosas APIs. Éstas facilitan mucho el trabajo de programación ya que te permiten utilizar funciones ya predefinidas y no tengas que empezar a escribir códigos desde cero. Ya no tienes excusa si quieres utilizar sus datos para algo. Algunos de mis sitios favoritos donde encontrar datos interesantes son los siguientes: Enigma, un sitio alucinante que contiene más de 100.000 datasets acerca de gobiernos, empresas, universidades y organizaciones de diversos tipos. Puedes encontrar desde el registro de visitantes a la Casa Blanca hasta datos diarios de la temperatura registrada en las estaciones meteorológicas de todo el planeta durante los últimos 10 años o la ubicación de todas las cárceles de Estados Unidos. Twitter, para analizar de qué habla un tuitero en particular, qué opina gente de algún tema, o de qué se habla en algún sitio concreto del mundo. Si quieres entrenarte con algoritmos de text mining, éste es tu sitio. Yo lo he usado para este caso de uso., Genderize permite determinar el género (masculino o femenino) de un nombre propio. Actualmente su base de datos contiene más de 215.000 nombres de 79 países y 89 idiomas distintos. Su versión gratuita permite hasta 1.000 consultas al día y el resultado de la búsqueda viene acompañado de medidas de certeza muy útiles. El siguiente ejemplo te puede ayudar a comprender para qué nos sirve esta información. UN Data reúne datos de 35 organismos dependientes de Naciones Unidas y está mantenido por el Departamento de Asuntos Económicos y Sociales de la propia Organización. Es una web perfecta para conocer un poco mejor el mundo en que vivimos. Wikipedia comparte estadísticas sobre el número de visitas a sus páginas. Con esos datos se puede medir el efecto colateral que tiene algún hecho relevante sobre la notoriedad de sus protagonistas. Por ejemplo, ¿tuvo impacto la aprobación de la Ley Turing en el número de visitas a la página de wikipedia de Alan Turing? La respuesta, aquí. Google, sobre el que hablaré en detalle a continuación. Estas APIs casi siempre tienen un límite de uso, bien en el número de consultas o en el volumen de datos que puedes descargar durante un periodo de tiempo. Por ejemplo, Google no te deja geolocalizar más de 2.500 direcciones al día en la opción gratuita. Por supuesto, siempre existe la opción de pago para aumentar el límite. A veces, incluso existen paquetes específicos para R o Python, que hacen más fácil la consulta y el trabajo posterior con los datos. Es el caso por ejemplo de Enigma, Twitter o Genderize. Además, Google pone a tu disposición mucha información interesante, como las tendencias de búsquedas a través de su buscador, la posibilidad de geolocalizar una dirección o la de saber qué hay alrededor de unas coordenadas cualesquiera de la tierra. Para consultar esto último pone a nuestra disposición el API de Google Places. Esta es la que vamos a utilizar para jugar a ser paracaidistas. Nuestro experimento de paracaidismo Imagina que te lanzas sobre un país cualquiera de la tierra: ¿qué probabilidad hay de que encuentres un bar a menos de 10 kilómetros de distancia de tu punto de aterrizaje? ¿Y un gimnasio? Con Google Places es muy fácil de calcular. Sin embargo, antes de ponernos manos a la obra, hay que tener a contar con una serie de premisas: He elegido seis países: Brasil, Alemania, España, Gran Bretaña, Perú y Estados Unidos. Fijaremos el radio de búsqueda a 10 km por ser un equilibrio razonable entre distancia que puede recorrer un paracaidista y número de aterrizajes a simular, que serán 1.100 para cada país. Los lugares de alrededor se clasifican en seis categorías: Salud y belleza: salón de belleza, dentista, doctor, gimnasio, peluquería, salud, hospital, farmacia, fisioterapia y spa. Comida y bebida: panadería, bar, cafetería, tienda de conveniencia, alimentación, tienda de comestibles o supermercado, licorería, reparto de comida, comida para llevar, club nocturno y restaurante. Cultura y educación: acuario, galería de arte, librería, biblioteca, museo, escuela, universidad y zoo. Transporte: aeropuerto, estación de autobuses, venta de coches, alquiler de coches, gasolinera, estación de metro, parada de taxis y estación de tren. Alojamiento: sólo contiene el tipo del mismo nombre. Establecimiento: al igual que el anterior sólo contiene el tipo homónimo. Para generar coordenadas aleatorias de un país he utilizado el paquete rworldmap de R, que contiene datos espaciales de las fronteras de los países del mundo de Natural Earth, otro sitio web con datos abiertos muy útiles, esta vez cartográficos. Después de generar una coordenada (o lo que es lo mismo, simular un aterrizaje), hago una llamada al API de Google Places para ver qué hay en un radio de 10 kilómetros alrededor. Los resultados ¿Qué probabilidad hay de encontrar algún lugar a 10 km en un aterrizaje azar? El siguiente gráfico lo muestra: Si nuestro paracaidista aterrizara en España, Alemania o Gran Bretaña, siempre encuentra algún sitio alrededor. Uno de cada cuatro aterrizajes en EEUU serían en áreas sin ningún lugar registrado en Google Places. Este número sube aproximadamente a dos de cada cuatro aterrizajes en el caso de Brasil y Perú. Es fácil suponer que esto depende en gran medida de la densidad de población en el país, y así parece pero con una excepción a la norma: España. Su densidad es notablemente inferior a la de Alemania y Gran Bretaña pero nuestro paracaidista siempre encuentra lugares alrededor en los tres países. Una posible explicación es que España aprovecha bien su territorio y su población no se concentra excesivamente en grandes ciudades a expensas de las zonas rurales. Es interesante también el caso de Perú y Estados Unidos, con densidades de población similares pero con muy diferentes probabilidades de éxito en los aterrizajes. Ahora que sabemos qué opciones tenemos de aterrizar en un sitio no desértico, ¿cuántos sitios encontraríamos alrededor? Este gráfico muestra el número de sitios alrededor de un aterrizaje exitoso (es decir, descartando los aterrizajes sin sitios alrededor): Los resultados de Alemania son verdaderamente impresionantes, donde nuestro paracaidista encontraría cerca de 200 sitios alrededor de su punto de aterrizaje. En el otro extremo está Perú, donde sólo encontraría unos 20. Por otro lado, la densidad de población explica la diferencia de sitios entre Gran Bretaña y España. Es también interesante ver el tipo de sitios que encontraríamos en un aterrizaje exitoso como muestra el siguiente gráfico: Es muy interesante el caso de Perú, donde los pocos sitios que encontraría nuestro paracaidista estarían la mayoría categorizados como establishment, un tipo genérico que Google utiliza hasta que reúne datos suficientes del sitio para saber de qué tipo de lugar es. Por el contrario, en Alemania encontraríamos siempre de todo. Si aterrizamos con hambre, habrá un restaurante cerca. Si aterrizamos con sueño, habrá un hotel. España y Gran Bretaña también son buenos lugares donde aterrizar. Comparando ambos países, en España nuestro paracaidista quizás tendría alguna dificultad más para encontrar un sitio de la categoría transportes que en Gran Bretaña. Brasil y Estados Unidos presentan similitudes aunque nuestro paracaidista tendría más fácil encontrar hotel y transporte en éste último. Conclusion Internet ofrece infinitas posibilidades al usuario y programar te da las herramientas necesarias para dar rienda suelta a tu imaginación: jugar a ser paracaidista por el mundo y ver qué hay alrededor es sólo cuestión de un poco de entrenamiento (en mi caso, con R), de curiosidad, y de un poco de paciencia. No hace mucho hacer algo así sería prácticamente imposible pero cada vez tenemos más información al alcance de nuestra mano. Por ejemplo, hará un tiempo utilicé Google Places para crear esta aplicación que ayuda a encontrar un lugar para quedar a tomar algo con alguien. Como ya hemos dicho, las posibilidades son infinitas. Los datos abiertos nos ayudan a conocer mucho más nuestro mundo y con ello estoy seguro de que nos permitirá mejorarlo con el tiempo.
25 de abril de 2017

Telefónica Tech y Sierra Nevada utilizan el Big Data para mejorar la experiencia de los esquiadores
Con motivo de la celebración de los Campeonatos del mundo de FreestyleSki y Snowboard en Sierra Nevada (del 8 al 19 de marzo), se ha lanzado una nueva solución basada en los estudios analíticos que permiten mejorar la experiencia de los esquiadores a través del Big Data. Synergic Partners, que forma parte de Telefónica Tech, son los autores de este proyecto analítico sobre las posibilidades que tiene el análisis de datos en la mejora de la experiencia de los esquiadores en Sierra Nevada. El proyecto ha permitido explorar desde el comportamiento de los usuarios de la estación, el perfil del esquiador, patrones de compra de forfaits, edad, procedencia y frecuencia de uso de los remontadores hasta el tiempo total de su estancia en la estación de esquí. Tal y como ha declarado Carme Artigas, CEO de Synergic Partners, “sólo estudiando los datos de los últimos meses ya podemos prever cómo será el comportamiento de los usuarios, y esto permite realizar recomendaciones personalizadas que pueden mejorar enormemente la experiencia del usuario”. En opinión de Carme, la incorporación del análisis del Big Data es un elemento clave para potenciar los resultados de cualquier persona de empresa. Sierra Nevada, pionera en la incorporación de Big Data Sobre la base del estudio en Big Data, Telefónica Tech y Synergic Partners han presentado también una nueva caracterización de los usuarios a partir de su nivel de experiencia y la identificación de patrones de uso de los diferentes remontes de la estación de esquí, permitiendo así conocer en profundidad el perfil de los usuarios y la utilización de las pistas de Sierra Nevada con el objetivo de realizar propuestas personalizadas que se ajusten a las necesidades de cada esquiador. En ese sentido, se ha detectado que existen cuatro tipos de usuarios: principiante, intermedio, risklover y experto. Y que los clientes de Sierra Nevada se pueden clasificar también en esquiadores de larga estancia y de corta estancia. La duración media de las horas que pasan los esquiadores en la estación es de 4,5. Otros datos interesantes extraídos del análisis tienen que ver con que el 80% de los forfaits se usan el día de la compra; y un 4% de ellos son comprados con una antelación de entre 2 y 7 días. Además, también se han presentado novedades que podría incorporar Sierra Nevada como servicio, por ejemplo, ver a tiempo real la ocupación de todas las pistas o la fila de espera en los distintos remontadores, o generar recomendaciones personalizadas para cada uno de los usuarios en función de su perfil. “Con esta iniciativa, Sierra Nevada se posiciona como estación pionera en adoptar Big Data para mejorar la experiencia de los esquiadores”, añade Artigas. Sierra Nevada, de la mano de Synergic Partners y Telefónica Tech, se posiciona, por tanto, como pionera en el uso del Big Data y se convierte en la primera estación de esquí inteligente de España.
5 de abril de 2017
Open Data y APIs en Videojuegos: el caso de League of Legends
Escrito por David Heras, becario en LUCA, y Javier Carro, Data Scientist en LUCA. Cuando en LUCA nos hemos enterado del próximo estreno de Movistar eSports hemos querido hacer un guiño a todos los fans de juegos como LOL y CSGO. Con la ayuda de David Heras, que colabora con nosotros en una beca y tiene una dilatada experiencia en LOL (tanto de juego como de uso de las APIs que ofrece), hemos hecho una pequeña representación de 3 equipos europeos que participarán en el Intel Extreme Masters Katowice de este fin de semana. Para hacer una valoración correcta evidentemente habría que utilizar sobre todo más histórico y más métricas, pero queríamos centrarnos en mostrar el potencial de Open Data vía APIs. De hecho, existen más sitios donde hacen uso de estas APIs para presentar estadísticas de forma muy atractiva, como champion.gg, web que recoge estadísticas de uso de los campeones del juego para mostrar unas estadísticas globales y así poder saber qué se juega más o menos, cómo y cómo jugar en contra o league-analytics.com, especializada en recoger gráficas y estadísticas de las competiciones importantes del juego. Figura 1: Imagen de la ceremonia de inauguración del IEM Katowice del pasado 2016. Efectivamente, multiplicar el valor de tus datos es una de las mayores ventajas de exponerlos vía API, ya sea para consumo interno para agilizar y sistematizar el flujo y procesamiento de datos dentro de una compañía, como para crear un ecosistema de negocio en torno a ellos. Idealmente este flujo, que comienza en las fuentes de datos, actúa en dos vertientes, por un lado facilita acciones intra e inter sistemas de la compañía (gestión de clientes, de productos, de procesos) y, por otro lado, alimenta herramientas de visualización (descripción, patrones, alertas, predicciones, etc.) que ayudan a la toma de decisiones de negocio. Un buen ejemplo de ecosistema de negocio en torno a los datos de una compañía accesibles mediante APIs es el API Market de BBVA. Sin olvidar nunca que algunos de los retos que mencionábamos para el uso de datos para el bien social también están vigentes en estos casos: privacidad, seguridad, y legislación. Esperamos que esta aproximación al mundo de los videojuegos os haya resultado entretenido e inspirador. A seguir jugando!
24 de febrero de 2017
Movistar Team: Los mejores ciclistas, el mejor cuerpo técnico, la mejor estrategia … y Big Data
By Mikel Zabala, PhD (Sport Scientist, Profesor Titular de la Universidad de Granada y miembro del equipo de entrenadores de Movistar Team), Javier Carro (Data Scientist en LUCA) y Pedro A. de Alarcón, PhD (Data Scientist en LUCA). Los mejores ciclistas, el mejor cuerpo técnico, la mejor estrategia...y Big Data. Cómo el Movistar Team seguirá siendo el mejor equipo en 2017. 29 de Agosto de 2016, 10ª etapa de La Vuelta a España en la que se subía a los lagos de Covadonga. A 40km de meta, el Mirador del Fito, un puerto de 1ª Categoría en el que el equipo Movistar tira del grupo con fuerza, evitando que un grupo de escapados se hagan con la etapa. La sorpresa espera a 7 kilómetros de meta, Alberto Contador lanza un fuerte ataque el cual es respondido por Nairo Quintana y juntos empiezan a alcanzar a fugados, y finalmente a 3.6km de meta, Nairo atrapa al primer fugado para marchar en solitario a meta. Esta es la belleza del ciclismo, protagonizada por unos deportistas de altísimo rendimiento, gran capacidad de sufrimiento y coordinados estratégicamente para que uno de ellos se alce con el triunfo. Detrás de ellos hay un cuerpo técnico que se encarga de planificar los entrenamientos, las recuperaciones, de cuidar el estado físico y anímico de los corredores, de tener a punto las bicis… tanto trabajo que al final merece la pena cuando vemos etapas como esta. En 2017 el equipo Movistar dirigido por Eusebio Unzué volverá a contar con Nairo Quintana y Alejandro Valverde como grandes líderes de un plantel que mezcla veteranía y juventud (10 ciclistas menores de 26 años) … pero lo queremos todo, queremos que nuestros ciclistas usen los datos que generan tanto en entrenamientos como en carrera para mejorar individualmente y mejorar en equipo. Por hacernos una idea del volumen de datos, sólo en La Vuelta a España contamos con más de 25 millones de muestras generadas por los 8 corredores del equipo. La revolución del Big Data también llega al ciclismo y en LUCA la queremos poner en práctica. Las grandes competiciones de ciclismo, como La Vuelta a España, el Giro de Italia o el Tour de Francia se desarrollan en cientos de kilómetros, decenas de horas de esfuerzo y al final, son unos pocos segundos lo que separan al ganador del segundo clasificado. Por tanto, en un deporte tan competitivo y “tecnificado” como el ciclismo profesional, es clave encontrar herramientas que ayuden a conseguir mejoras marginales que sumadas dan la victoria. Según este artículo de Harvard Business Review, sólo un 1% de mejora sobre determinadas variables que afectan al rendimiento es lo que está detrás del espectacular aumento del palmarés olímpico del equipo de ciclismo en pista de Reino Unido. Se trata de analizar cuidadosamente todos los aspectos que pueden afectar al ciclista y su rendimiento (desde la aerodinámica del casco hasta el tiempo de traslado desde la villa olímpica a la pista…) y actuar sobre ellas aunque sea de forma mínima… y la suma de diferencias marginales produce la victoria. Desde LUCA, nuestra portación, será aplicar la potencia del Big Data y la Ciencia de Datos para identificar las variables donde actuar y mejorar. Durante la presentación del equipo Movistar para latemporada 2017, Chema Alonso, Chief Data Officer de Telefónica ha avanzado parte del trabajo que estamos realizando junto a Mikel Zabala profesor de la universidad de Granada con una larga trayectoria académica y profesional en Sport Science y queforma parte del Staff Técnico de entrenadores del equipo. Mikel usa los datos generados por los computadores de los ciclistas del equipo tanto en entrenamiento como en carrera así como otras variables asociadas al corredor (test de esfuerzo, alimentación…). Estos datos sirven a Mikel como base para generar una serie de variables complejas y modelos matemáticos que permiten analizar el rendimiento y desgaste físico del ciclista, lo cual es un input crítico para la planificación y personalización de los entrenamientos. El objetivo último es que el ciclista llegue en un estado óptimo de forma a la competición, y que durante la misma pueda cumplir perfectamente su rol dentro del equipo y recuperarse adecuadamente. Para analizar los datos extraídos del computador de la bici podemos encontrar software gratuito y compatible con la mayoría de formatos de archivos como GoldenCheetah o TrainingPeaks. Ambas plataformas proporcionan información muy técnica y valiosa, sin embargo, nosotros nos proponemos llegar un poco más lejos, creando una herramienta de análisis adaptada a las necesidades específicas del equipo y que use los últimos modelos estadísticos y técnicas de Machine Learning de forma que podamos proporcionar al equipo conocimiento diferencial tanto en los entrenamientos como en competición. Algunas de las líneas de trabajo que estamos desarrollando son: Modelización temporal del pico de forma de cada corredor de forma que podamos predecirlo y ajustarlo con entrenamiento al tiempo donde ocurre la competición. Determinación de las variables del contexto de entrenamiento (perfil de altitud, meteorología...), del entrenamiento y del corredor que más impactan en el rendimiento y sus sensaciones subjetivas. Contrastar los roles adoptados en carrera por los ciclistas con variables de rendimiento y fatiga para alimentar la estrategia de siguientes etapas y planificar la recuperación de los corredores. Empezamos a pedalear fuerte, nos espera un 2017 ¡ lleno de victorias!
26 de enero de 2017

Próposito de este 2017: Cambiar el Mundo
By Javier Carro and Pedro de Alarcón PhD, Data Scientists at LUCA. ¿Ya has hecho tu lista de propósitos para el año nuevo? ¿Qué te parece que esta vez uno de ellos sea cambiar el mundo? Fuimos millones los que hace tres noches tomamos las 12 uvas con el deseo de que el año 2017 sea mejor que el anterior. Con la Figura 2 te puedes hacer una idea de las proporciones de hombres y mujeres que se congregaron en el lugar emblemático de la Nochevieja, la Puerta del Sol. También puedes ver su lugar de residencia habitual durante el resto del año y sus edades. Figura 2: Distribución de los que celebraron el cambio de año en la Puerta del Sol por edades, género y lugar de residencia habitual. El rango de edades que más participa en la Puerta del Sol es el de los que se encuentran en la cuarentena, seguidos de los treintañeros y de los veinteañeros. También hay unos cuantos representantes de nuestros menores (menos de 20 años) y de nuestros mayores (más de 70 años). Como lugares de origen destacados vuelven los que ya mencionamos en este post: Barcelona, Valencia, Alicante, Toledo, ... pero emergen ante nosotros las Islas Canarias, quizá con ganas de añadir una hora a su año habitual. Por cierto, gran parte de los mayores de 70 vienen precisamente de estas islas. Todos ellos, como el resto de nosotros, celebraron el cambio de año con los mejores deseos. Naciones Unidas nos propone sus particulares deseos: acabar con la pobreza extrema, luchar contra desigualdades e injusticias, y parar el cambio climático. En este post y en este otro mencionamos estos objetivos y el compromiso de Telefónica con ellos, y seguro que éste es buen momento para incluirlos entre nuestros propósitos personales de año nuevo. Casi nada. "¿Qué puedo hacer yo?". Echa un vistazo a su propuesta para perezosos en la que se exponen bastantes ejemplos de acciones sencillas que todos podemos realizar para contribuir a los tres grupos de objetivos desglosados en la Figura 3. Figura 3: Objetivos de Naciones Unidas para el desarrollo sostenible: acabar con la pobreza extrema, luchar contra desigualdades e injusticias, y parar el cambio climático. Algunas de estas acciones se pueden llevar a cabo prácticamente desde el sofá, y otras sólo implican variaciones en los hábitos diarios: uso razonable de la energía (luces, electrodomésticos, calefacción, ...), del agua, del papel, del transporte, sensibilidad a injusticias o desigualdades en el día a día dentro nuestro ámbito más cercano, aprovechamiento de los alimentos, reciclar, reutilizar (donar lo que ya no utilices), hacerte eco (redes sociales, ...), etc. Así que todos podemos contribuir a cambiar el mundo desde este preciso momento. Empezando por ese grupo de mayores de 70 años que aparece en la Figura 2 y que no tuvieron pereza a la hora de recibir al 2017 en la Puerta del Sol, hasta los más pequeños para los que puede haber incluso iniciativas más divertidas como ésta. Desde el equipo de LUCA, te deseamos un muy feliz 2017!
3 de enero de 2017

Lo que se mueve en tu país vecino, y más allá
El valor de las llamadas telefónicas internacionales para entender nuestra sociedad Telefónica dispone de una amplia infraestructura global de red que es ofrecida a otras operadoras para transportar su tráfico internacional de voz y datos. Éste y otros muchos servicios son comercializados por Telefonica Business Solutions (negocio de "wholesale"). El servicio que nos ocupa en este caso consiste básicamente en recoger tráfico de voz y datos en un país (proporcionado por una operadora de telecomunicaciones), transportarlo y entregarlo en otra operadora y país. Hace pocos días tuvimos la ocasión de procesar algunos meses de datos de este servicio con la intención de encontrar insights asociados a algunas hipótesis que conocemos y descubrimos algunas cosas interesantes con relativo poco esfuerzo de análisis. Toda la información con la que se trabaja se proporciona anonimizada y se almacena y procesa en nuestra infraestructura de Big Data Global. En el caso de llamadas de voz, las características de cada "evento" del dataset se pueden resumir en un número de teléfono origen, un número de teléfono destino, un timestamp y la duración de la llamada. Hay además una serie de parámetros adicionales de la llamada proporcionados por la red en los que no nos detendremos en esta ocasión. Aunque los números de teléfono se encuentran anonimizados, disponemos de código de país y, en algunos casos, región/provincia del número llamante y llamado. Se trata, pues, de un dataset con limitaciones en cuanto a variables disponibles, pero muy rico en cuanto a volumen. En cuanto a estructura tiene gran similitud con algunos datos abiertos muy populares sobre tráfico aéreo (ver este ejemplo). De hecho esta similitud nos permitiría reutilizar fácilmente algunas visualizaciones como ésta tan espectacular generada con la herramienta Carto. Empezamos a escuchar lo que dicen los datos Dada la información básica que nos proporciona este dataset, la primera exploración que nos planteamos es la evolución del número total de llamadas que se cursan. La siguiente gráfica es una representación diaria del tráfico total cursado. Figura 2: Representación de un caso específico de volumen de llamadas gestionadas por Telefónica. Se observa el evidente patrón semanal y los curiosos comportamientos intra semanales Se comprueba un evidente patrón semanal con valles durante los fines de semana. Pero lo que llama la atención son las variaciones intra-semanales y, por supuesto, los casos en los que estas variaciones son muy pronunciadas. Los datos están empezando a hablar. ¿Qué están intentando decirnos? La respuesta empieza a descubrirse al viajar por los países. Por ejemplo, en la siguiente gráfica se ve la evolución diaria del número de llamadas con destino Italia desde varios países. Los grandes picos que se aprecian en la parte derecha de las gráficas corresponden al día 24 de agosto de 2016, fecha en el que hubo un importante terremoto en Italia. Figura 3: Representación del volumen de llamadas desde diferentes países hacia Itaila donde se observa el pico correspondiente al terremoto en Italia del 24 de agosto de 2016 Cabe pensar entonces que los datos van a hablar sobre eventos de orden internacional que al menos afecten a una pareja de países. De hecho, empieza a entreverse información más sutil: ¿Por qué la respuesta de Ecuador o Argentina es más pronunciada que la de otros países?. Cualquiera nos animaríamos a explicarlo con un par de argumentos razonables, pero queremos que sean los datos los que lo digan. Google nos ofrece una herramienta muy útil para ayudarnos a interpretar estos eventos que estamos encontrando. Se trata del proyecto GDELT, que monitoriza en tiempo real lo que sucede en el mundo y el impacto que tiene, considerando el idioma y el lugar donde sucede. De esta forma podemos empezar a enriquecer lo que encontramos en nuestros datos con información local en cada caso. Esta herramienta está disponible en la plataforma BigQuery de Google, por lo que puede consultarse libremente o usar ciertas herramientas analíticas preconfiguradas (que, por cierto, no siempre devuelven los resultados de forma inmediata). Por ejemplo, en Junio de 2016, Reino Unido votaba su permanencia en la Unión Europea. ¿Hablarán nuestros datos sobre esto?. En efecto lo hacen. Y no sólo hablan del impacto puntual, sino de su impacto durante las semanas siguientes. Se puede comprobar en la siguiente gráfica de llamadas entre Reino Unido y Bélgica (sede de la Comisión Europea). La primera fecha marcada (rojo) es el día de la votación (jueves 23 de junio). Pero se aprecia también el impacto que tuvo durante las semanas siguientes. La segunda fecha marcada, justo un mes después, coincide con la primera publicación de un índice económico (índice Markit) que apuntaba a la contracción económica en Reino Unido. Figura 4: Representación del volumen de llamadas entre UK y Bélgica alrededor del evento de la votación del Brexit en UK Estas exploraciones iniciales ayudan a plantearse un modelado más formal de las entidades que se están abordando. Estas entidades podrían ser tanto los números de teléfono anonimizados como las regiones geográficas de origen y destino. Y, por otro lado, se pueden tratar como elementos individuales sobre los cuales generamos una serie de indicadores (volumen de minutos de entrada o salida), o bien se pueden tratar en forma de pares de manera que se estaría hablando de una red o grafo dirigido en la que los nodos son las entidades y los arcos conectan aquellos nodos entre los cuales hubo tráfico. Tipo de entidad considerada Análisis sugeridos Números de teléfono anonimizados Detección de outliers potencialmente asociados a números que actúan de forma fraudulenta Análisis de comunidades de números basados en llamadas ("Social Network Análisis") Geografías (país, provincia...) Predicción de tráfico y alertas basados en modelos de series temporales Caracterización de patrones de actividad según variables temporales (laborables/festivos, horario diurno...) Medición de impacto de acontecimientos globales Caracterización de comunidades de países/regiones según el volumen de tráfico entre los mismos Establecer correlaciones con otros datasets (abiertos o disponibles internamente) tales como movilidad, información sociodemográfica, etc. La siguiente figura muestra un ejemplo de grafo representado sobre un mapa y reflejando las conexiones existentes entre España y el resto de países. En concreto los datos corresponden al 7 de julio de 2016, y llaman la atención las conexiones con países islámicos ya que es la fecha del final del Ramadán, conexiones con países que aportan turistas en verano, etc. En un vídeo más abajo podéis ver la evolución diaria animada de este mapa. Figura 5: Grafo de conexiones entre España y resto de países para el 7 de julio de 2016 (fin del Ramadán) Series Temporales La naturaleza secuencial y temporal de los datos nos permiten modelarlos como series temporales. El Análisis de Series Temporales es una disciplina de la estadística muy consolidada y para la que se han generado librerías de funciones en prácticamente todos los lenguajes habituales en el análisis de datos ( R, Python, Matlab...). Incluso hay herramientas gratuitas, como INZight, que permiten hacer análisis (no muy sofisticados) sin programar una sola línea. Como primer paso antes de hacer cualquier análisis, es importante comprobar que nuestra serie de datos es estacionaria (la media, varianza y covarianza de sus valores no depende del tiempo) y, si no lo es, hacer que lo sea. Nuestras series de datos en el dataset de llamadas no suelen ser estacionarias, así que nos toca trabajar un poco. Simplificando, una serie temporal como la que observamos en los datos de tráfico de llamadas, se puede dividir en tres componentes que, sumadas o multiplicadas, producen la serie original: Tendencia. En nuestro caso depende del volumen de tráfico que Telefónica esté enrutando para un país determinado. Es decir, está principalmente vinculado al crecimiento o contracción del negocio generado. Estacionalidad: Claramente existen ciclos semanales, en los que se aprecia un descenso significativo de llamadas en fines de semana. Residuales. Son las diferencias de valores entre la serie de datos original y los valores generados a partir de "tendencia + estacionalidad". Este componente es muy interesante ya que la identificación de picos y valles pueden estar asociados a incidencias técnicas, eventos internacionales, días festivos... En definitiva, el análisis de residuales es el lugar donde mirar si queremos analizar qué pasó fuera de la normalidad de la serie. Cualquier librería de series temporales (como zoo, xts o timeSeries de R) nos permite extraer fácilmente estas tres componentes. Figura 6. Descomposición en tendencia, estacionalidad y residuales de la serie temporal de volumen de minutos enrutados para un país determinado El interés habitual en hacer análisis de series temporales es poder generar un modelo predictivo (como los modelos de suavizado exponencial o los modelos ARIMA) que nos anticipe, por ejemplo, cuánto tráfico tendremos en los próximos días. O nos ayude a encontrar verdaderos outliers en la serie (aquellos valores que salen de los intervalos de confianza de la predicción), lo cual es bastante sencillo de hacer en R. Por su fiabilidad para hacer predicciones a corto plazo, la familia de tests de suavizado exponencial a la cual pertenece el test de Holt-Winters se han popularizado y están disponibles en herramientas de análisis comerciales como Tableau o TIBCO Spotfire. Los modelos ARIMA son un poco más complejos de aplicar, pero mejoran en muchos casos la predicción de los anteriores ya que tienen en cuenta la dependencia existente entre los datos, es decir, cada punto en un momento dado es modelado en función de valores anteriores. Figura 7: Predicción de tráfico generada con el suavizado exponencial (Holt-Winters) "Redes sociales telefónicas" inter-país La información que subyace en el uso de las redes sociales es un valor que ya se utiliza intensivamente en los negocios. El objetivo principal que persiguen las empresas al explotar esta información es segmentar a los clientes para llegar a ellos de forma más eficaz aumentando la probabilidad de que consuman sus productos. Sin embargo, los principales obstáculos para las empresas a la hora de explotar estas fuentes son la complejidad y el coste. Telefónica dispone de experiencia y conocimiento diferencial sobre la construcción de modelos de redes sociales o SNA (Social Network Analysis) usando por ejemplo patrones de llamadas. En esta ocasión, inspirados en iniciativas con un enfoque más social (por ejemplo Combating global epidemics with big mobile data y Behavioral insights for the 2030 agenda), nos planteamos contribuir a explicar las relaciones existentes entre los países adentrándonos en las redes sociales internacionales que surgen de las comunicaciones telefónicas. La siguiente figura nos ofrece un primer acercamiento a los datos bajo este tipo de perspectivas. Teniendo en cuenta únicamente los volúmenes relativos de llamadas vemos confirmado, más allá del mero sentido común, el alineamiento con datos socioeconómicos globales. Figura 8: Volúmenes de llamadas entre parejas de países origen y destino en agosto de 2016. Sólo se representan los países con mayores volúmenes generados y los principales volúmenes de destino para cada uno de ellos Hay buenas fuentes con datos socioeconómicos internacionales para poder contrastar y complementar lo que se observa en los datos propios. Por ejemplo, se pueden encontrar gran cantidad de datos económicos en el Observatorio económico del MIT, en el Databank del Banco Mundial, o en Eurostat. Y datos de tipo más social (y también económicos) en el banco de datos de Naciones Unidas o en el de UNICEF. Este tipo de datos son muy útiles aunque la granularidad temporal, espacial, o la frecuencia con que se publican, no siempre son ideales. Antes de continuar adentrándonos en cómo se relacionan los países, nos detenemos un momento en un detalle relativo a cómo se comportan las personas a la hora de llamar. En la Figura 9 hemos representado las llamadas que hacen cada día cuatro grupos diferentes de usuarios: los propensos a llamar en horario laboral (verde), en su tiempo libre (azul), los fines de semana (rojo), o por la noche (morado). Esta separación, aunque sencilla, permite una primera segmentación social en usuarios que llaman por "motivos personales" y los que llaman por "motivos profesionales". Podemos destacar, por ejemplo, que el nivel de llamadas en fin de semana prácticamente supera al que se alcanza de lunes a viernes y, además, ninguno de los dos grupos "invade" los días del otro. ¿Previsible?. Insistimos en que no es lo mismo intuirlo que escuchar cómo los datos nos lo dicen y cuantifican. Figura 9: Un caso de evolución diaria de llamadas de usuarios que suelen llamar en horario de oficina (verde), por las tardes de lunes a viernes (azul), en fines de semana (rojo) y por las noches (morado) Volviendo a la perspectiva inter-país, en la siguiente gráfica vemos una representación geográfica que nos ayuda a entender aún mejor los flujos de comunicación. Los datos originales han sido simplificados y escalados convenientemente para facilitar la legibilidad del mapa. Se pueden observar los aumentos correspondientes a las fechas del final del Ramadán (7/7/2016, tal y como se veía en la Figura 5) y del terremoto en Italia (24/8/2016). Vídeo 1: Representación animada de las conexiones entre España y resto de países en los meses de junio, julio y agosto de 2016. Se pueden observar los aumentos correspondientes a las fechas del final del Ramadán (6/7/2016) y del terremoto en Italia (24/8/2016). Estas representaciones vienen a confirmar los lazos personales (sociales) y profesionales (económicos) que más arriba mencionábamos refiriéndonos a datos socioeconómicos. En la siguiente gráfica profundizamos un poco más mostrando, a modo de zoom del vídeo anterior, las comunicaciones entre regiones más específicas de una zona concreta de Centro Europa. Figura 10: Representación geográfica de comunicaciones en una región acotada de Europa entre provincias Recapitulando los factores observados hasta aquí, donde hemos separado tipos de llamadas basándonos en sus hábitos y tenemos información más precisa sobre la localización, podemos empezar a plantearnos de forma más fundamentada la relación entre los datos de las llamadas y diferentes indicadores socioeconómicos, eventos, relaciones comerciales entre regiones, relaciones entre comunidades de personas, etc. Por ejemplo: Podríamos caracterizar las comunicaciones entre zonas eminentemente industriales y comprobar casos como la relación entre puertos marítimos comerciales relacionados mediante líneas de transporte de mercancías entre ellos. Caracterizar la comunicación entre zonas origen y destino de emigración y compararlos con datos históricos de emigración internacional viendo que son coherentes con los datos de llamadas de perfil "residencial". Hemos podido contrastar esta coherencia entre, por ejemplo, Argentina e Italia, algo que cabría esperar. Y también cabe esperarlo de España y Alemania. ¿Pueden entonces las llamadas convertirse en un indicador de emigración en tiempo real?. ¿Se pueden inferir los destinos actuales de emigración?. Obviamente, nuestras comunicaciones nos describen. Por Pedro de Alarcón y Javier Carro, Data Scientists en LUCA.
30 de noviembre de 2016

Smart Energy: predecir el consumo para detectar desviaciones
No han pasado ni 150 años desde que Thomas Alva Edison patentó su bombilla. Sin embargo, en un mundo donde el avance tecnológico es tan rápido en unas décadas hemos pasado de sorprendernos por poder tener luz por la noche a un consumo masivo de energía: ya no solo no nos maravillamos por esto, sino que damos por supuesto que en nuestros edificios tendremos la iluminación correcta para cada hora del día y que en nuestra oficina habrá unos agradables 22º. Figure 1: Smart Energy: utilizar algoritmos para predecir desviaciones Cada vez somos más conscientes del coste implicado, no solo económico, sino también para el Planeta. Por eso, cada día aparecen equipos más eficientes e inteligentes para reducir el gasto de energía y normativas que obligan a racionalizar el consumo. Telefónica dispone ya de productos de eficiencia energética que ayudan a las empresas a hacer una mejor gestión de sus instalaciones y recursos, disminuyendo el consumo energético…pero ¿podemos conformarnos solo con esto? La respuesta de un ingeniero va a ser siempre un rotundo ¡NO! Desde LUCA hemos estado hablando con los responsables de los productos, para conocer cuáles son esas preguntas a las que, con las herramientas actuales, no pueden darles respuesta, y hemos encontrado que unas de las cosas mas preocupantes son los ‘Expedientes X’: ¿Por qué en una oficina aparece un pico de consumo que no sabemos explicar? ¿Por qué hay días que gasto más que otros similares? Una vez conocimos estas preguntas, nos pusimos manos a la obra para construir un sistema que permita predecir cuál va a ser el consumo de energía y avisar, casi en tiempo real, de las desviaciones en este para poder analizarlas. Video: Javier Magdalena explica la visualización de Smart Energy en su presentación en nuestro evento de lanzamiento. Empezamos construyendo nuestro algoritmo de predicción usando datos de consumo energético como series temporales. Además de saber que necesitábamos datos de más de un año para poder detectar variaciones estacionales (diferencias de comportamiento que se repiten en determinados meses), hemos visto que los datos de consumo únicamente no nos son suficientes, necesitamos más fuentes de datos: información de temperatura dentro y fuera de las oficinas, ya que el aire acondicionado suele ser uno de los sistemas de mayor consumo; datos sobre el calendario laboral de las ciudades, conocimiento sobre el número de personas en cada momento en los edificios…y un largo etcétera de datos que iremos filtrando y refinando en sucesivas versiones del algoritmo. Todos estos datos están convenientemente anonimizados y protegidos, para que la privacidad de nuestros clientes quede siempre garantizada. Un buen algoritmo, necesita una herramienta de visualización que permita la interpretación de sus resultados por los usuarios. En nuestro caso se optó por hacer uso de Spotfire, que permite representar información de forma interactiva e intuitiva. Para su desarrollo se hicieron uso de datos de distintas oficinas dentro de España. La interfaz se divide en dos zonas: filtrado de datos y visualización. Figure 2: Nuestra herramienta de Smart Energy El filtrado de datos permite seleccionar ciudad, oficina y sensor que queremos analizar, de modo que el usuario puede acceder rápidamente a los datos que le son útiles. En cuanto a la visualización, se le muestra al usuario la diferencia existente entre el consumo de energía previsto y el real, para que pueda analizar y actuar sobre los puntos conflictivos. Con esto damos herramientas para controlar el consumo energético en base a predicciones, pudiendo detectar algún tipo de anomalía que se salga del comportamiento esperado, para poder tomar medidas de forma inmediata para hacer un uso eficiente de la energía, reduciendo costes e impacto medioambiental. Desde LUCA estamos trabajando para incorporar este producto a la gestión energética de Telefónica y esté disponible para los clientes lo antes posible.
14 de noviembre de 2016